展开查看详情
1 .Cnn architectures ImageNet Large Scale Visual Recognition Challenge Gene Olafsen
2 .Cnn architectures ImageNet Large Scale Visual Recognition Challenge Gene Olafsen
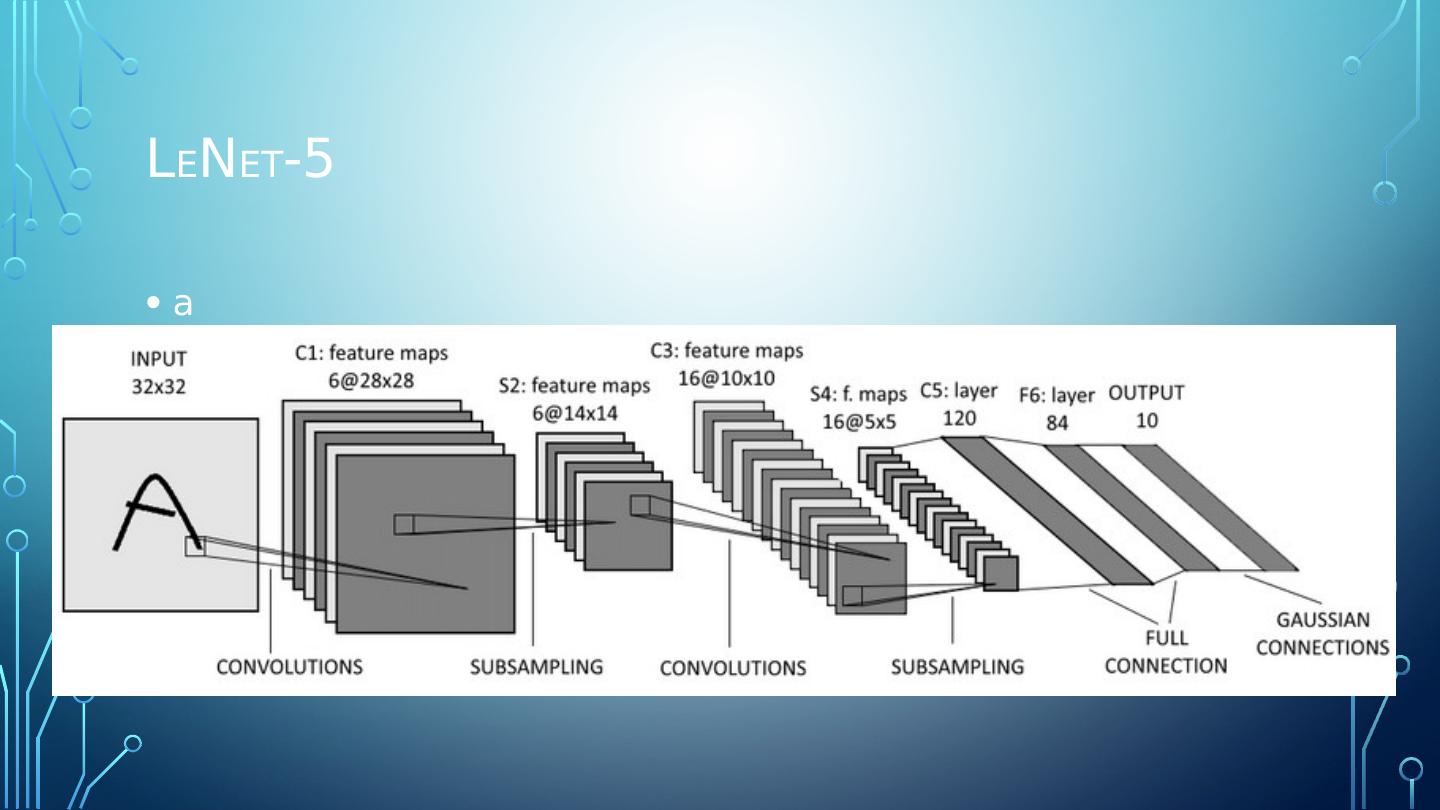
3 .L e N et -5 Output layer The output layer computes the dot product of the inputs and the weight vector, each neuron outputs the square of the Euclidian distance between its input vector and its weight vector. Each output measures how much the image belongs to a particular digit class. The cross entropy cost function is now preferred, as it penalizes bad predictions, producing larger gradients and thus faster convergence. http://ml-cheatsheet.readthedocs.io/en/latest/loss_functions.html (Cost function cheat sheet)
5 .I mage N et The ImageNet project is a large visual database designed for use in visual object recognition software research. The ImageNet project runs an annual software contest, the ImageNet Large Scale Visual Recognition Challenge (ILSVRC).
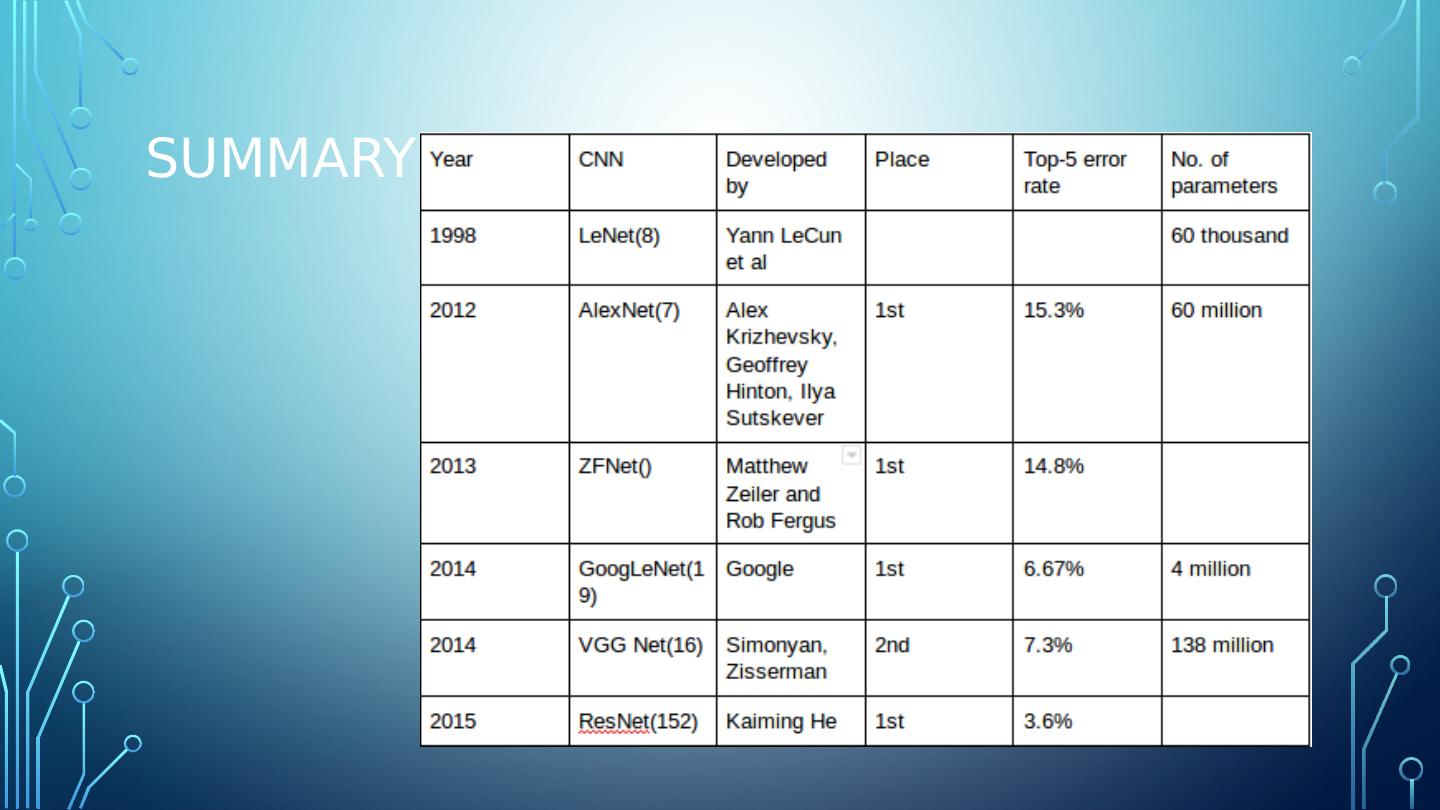
6 .A lex n et AlexNet – won the 2012 ImageNet ILSVRC challenge. Developed by Alex Krizhevsky , IIya Sutskever and Geoffrey Hinton. Similar to LeNet-5 only larger and deeper First to stack convolution layers (instead of inserting pooling layers) Used two regularizers (see slide deck on Regularizers ) Dropout of 50% Data augmentation of images
7 .Local Response Normalization AlexNet utilizes a competitive normalization step after the ReLU step in layers C1 and C3. Similar to biological neurons, this form of normalization makes the neurons that most strongly activate inhibit neurons at the same location but in neighboring feature maps. This encourages different feature maps to specialize, pushing them further apart and forcing them to explore a wider range of features- ultimately improving generalization. For example: If a neuraon has strong activation, it will inhibit activation of the neurons located in the feature maps immediately above and below its own.
9 .A LEX N ET Pipelines AlexNet was trained simultaneously on two Nvidia Geforce GTX 580 GPUs which is the reason for why their network is split into two pipelines
10 .g oog l e n et /Inception GoogLeNet developed by Christian Szegedy winning ILSVRC in 2014. Pushed the top-5 error rate below 7% using a much deeper CNN network. Utilized sub-networks, called inception modules, permitting the more efficient use of parameters. GoogLeNet has 10 times fewer parameters than AlexNet . (6 million vs 60 million)
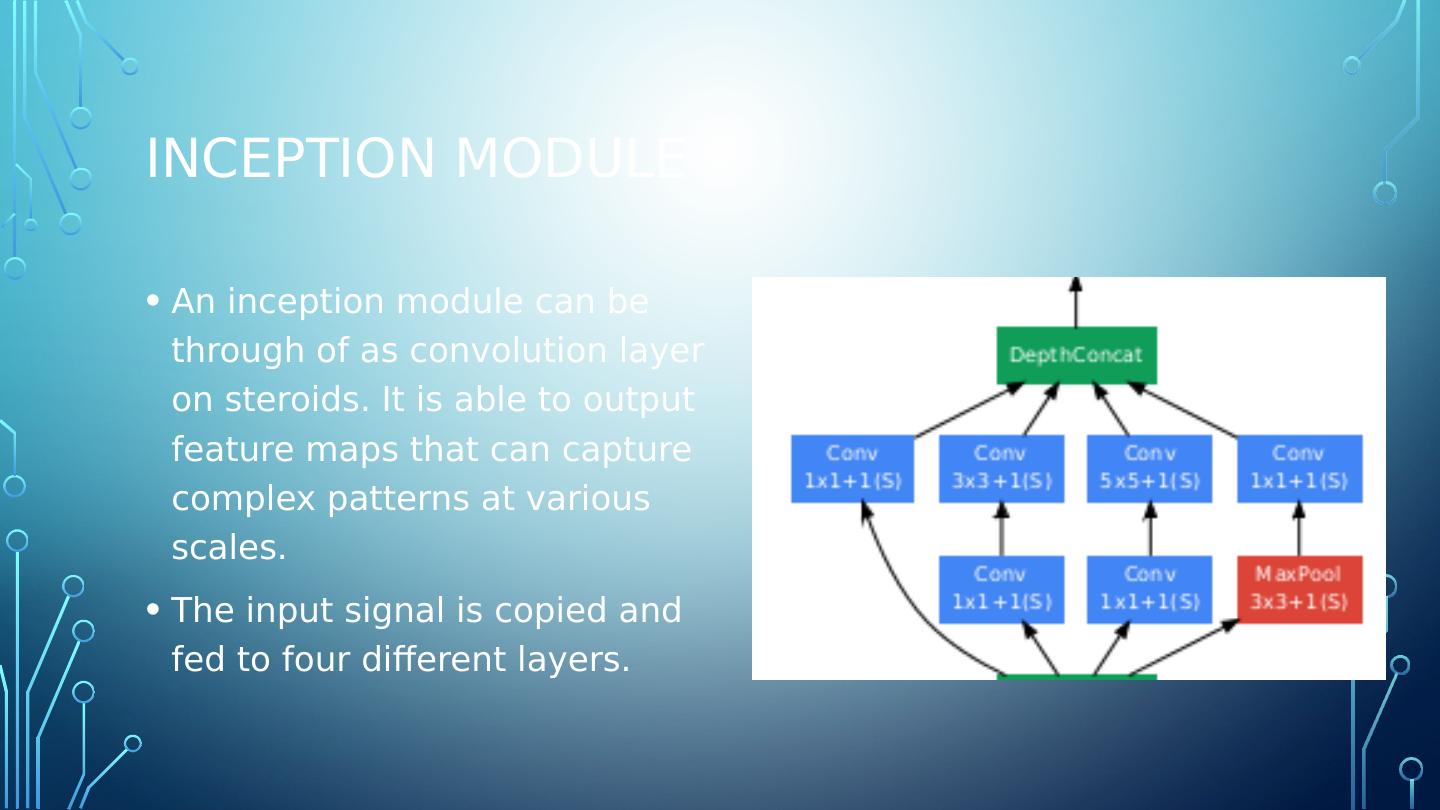
11 .Inception Module An inception module can be through of as convolution layer on steroids. It is able to output feature maps that can capture complex patterns at various scales. The input signal is copied and fed to four different layers.
12 .Inception Module All the convolution layers utilize ReLU activation. All layers use: Stride =1 SAME padding (even for the MaxPool layer) thus outputs have same width/height as inputs- making it possible to concatenate all outputs along the same depth dimension in DeptConcat Layer There are three different kernel sizes: 1x1, 3x3 and 5x5. The different size kernels allow the model to capture patterns at different scales.
13 .1x1 convolution layer explained Reduce dimensionality and act as bottleneck layers . They are placed before the 3x3 and 5x5 convolutions. Each pair of convolution layers ([1x1,3x3] and [1x1,5x5]) act as a single powerful convolution layer- capturing more complex patterns.
15 .R es n et Residual Neural Network (ResNet) by Kaiming He et al introduced a novel architecture with “skip connections” and features heavy batch normalization. ResNet delivered top-5 error rage under 3.6% in 2015, utilizing 152 layers.
16 .Skip connections and residual learning In Skip (or Shortcut) Connections, the input connection to a layer is also added to the output layer located a bit higher up the stack. A regular neural network initializes its weights close to zero. Skip connections output a copy of its inputs. Adding many skip connections results in the network making progress even if several layers have not started learning yet.
17 .Residual units A deep residual network can be seen as a stack of residual units , where each residual unit is a small neural network with a skip connection. Layer Layer + Layer Layer +
18 .Residual units A deep residual network can be seen as a stack of residual units , where each residual unit is a small neural network with a skip connection. Layer Layer + Layer Layer + Residual Unit Residual Unit
21 .Resnet and beyond The ResNet architecture is both the most powerful and arguably the simplest- to it is highly recommended as the one to use right now. In 2016 Trimps-Soushen team from China achieved a 2.99% error rate at the ILSVRC challenge. This feat was achieved joining new and previous trained combination models into an ensemble.