展开查看详情
1 .Attention-based models Up and coming Recurrent neural network alternative Gene Olafsen
2 .Time for a change "We fell for Recurrent neural networks (RNN), Long-short term memory (LSTM), and all their variants. Now it is time to drop them! " https://towardsdatascience.com/the-fall-of-rnn-lstm-2d1594c74ce0
3 .Attention please! Google, Facebook, Salesforce have replaced RNN and variants for attention based models. RNN may have their days numbered, because they require more resources to train and run than attention-based models.
4 .Rnn weakness Think of an unrolled RNN. Long-term information has to sequentially travel through all cells before getting to the present processing cell. This information can be easily corrupted by being multiplied many time by small numbers < 0. (this is the cause of vanishing gradient!)
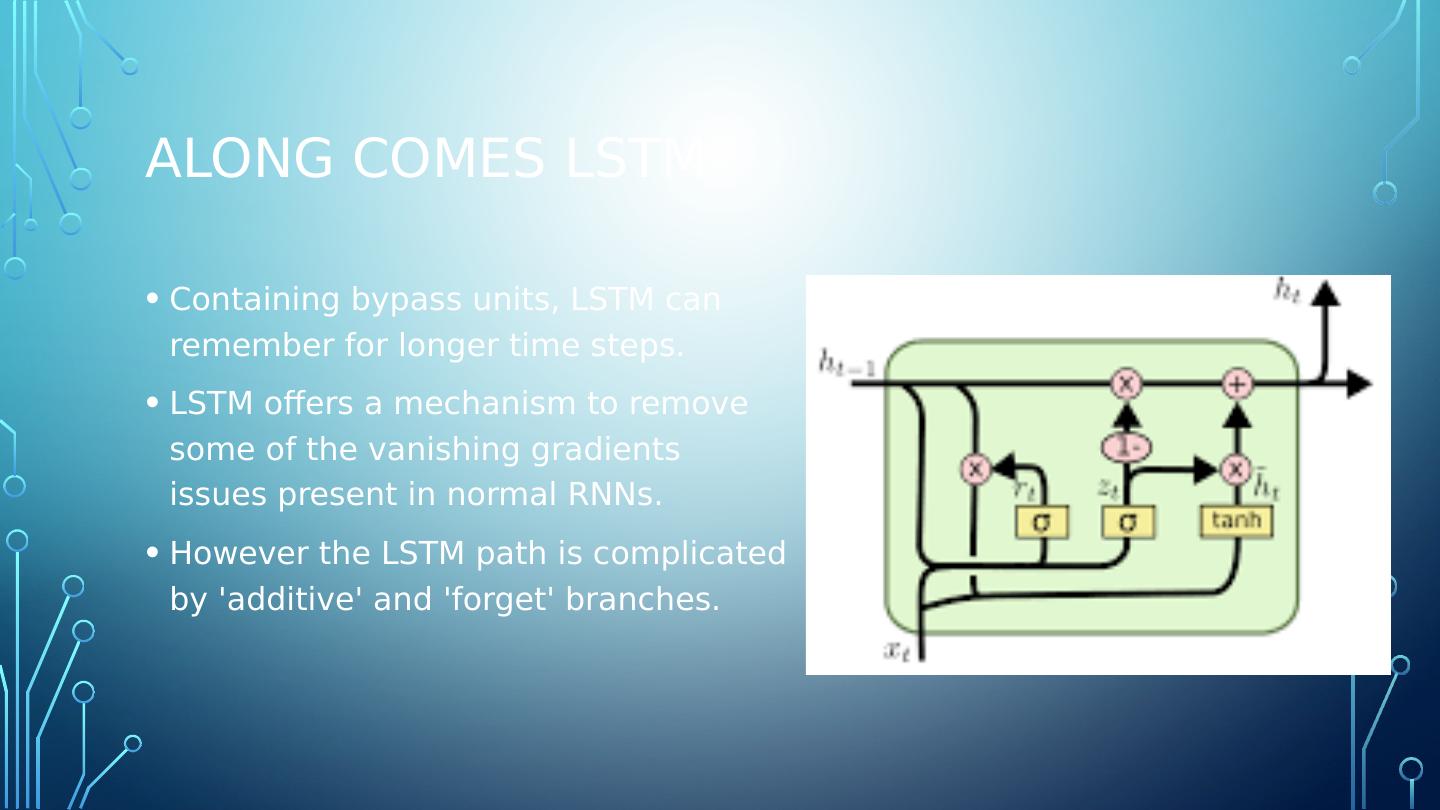
5 .Along comes LSTM Containing bypass units, LSTM can remember for longer time steps. LSTM offers a mechanism to remove some of the vanishing gradients issues present in normal RNNs. However the LSTM path is complicated by additive and forget branches.
6 .Typical Image captioning The image captioning system encodes the image, using a pre-trained Convolutional Neural Network that produces a hidden state h. It decodes this hidden state by using a Recurrent Neural Network (RNN), and recursively generates each word of the caption. https://blog.heuritech.com/2016/01/20/attention-mechanism/
7 .Inefficient captioning When the model is trying to generate the next word of the caption, that word usually only describes a part of the image. Using the whole representation of the image h to condition the generation of each word cannot efficiently produce different words for different parts of the image. This is exactly where an attention mechanism is helpful.
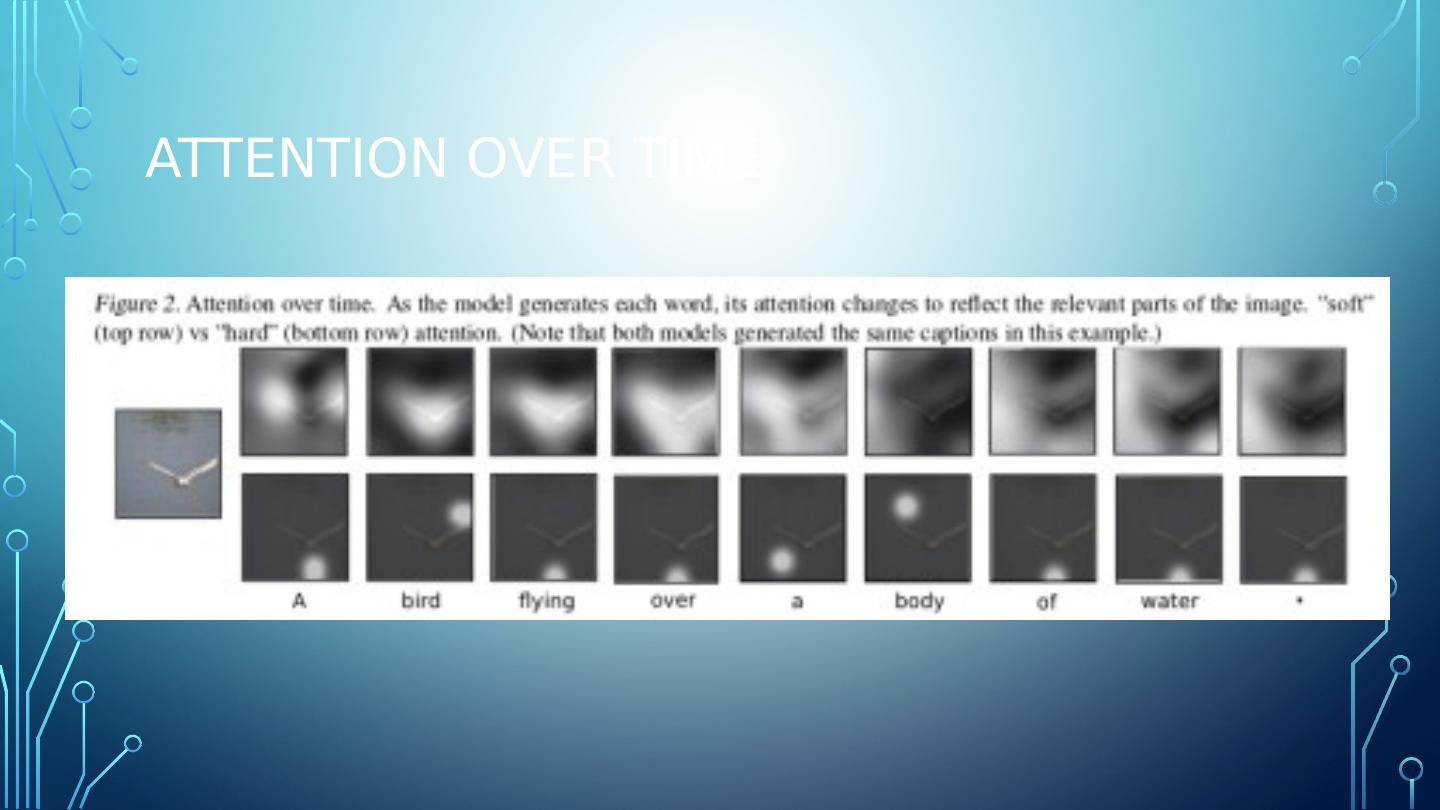
8 .Attention mechanism for captioning With an attention mechanism, the image is first divided into n parts, and then computes (via a Convolutional Neural Network) representations of each part h_1, ..., h_n . When the RNN is generating a new word, the attention mechanism focuses on the relevant part of the image, so the decoder only uses specific parts of the image.
10 .Attention to static images
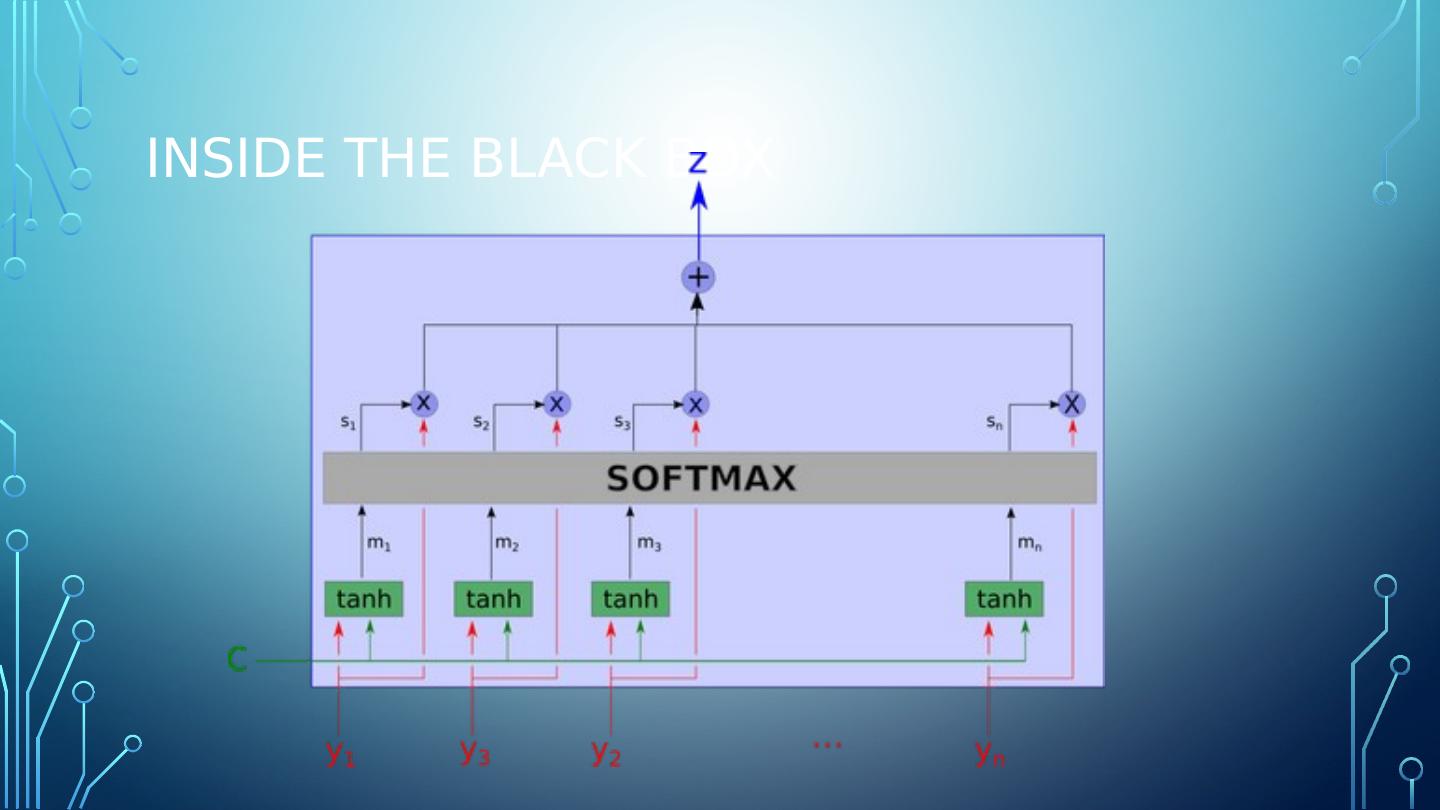
11 .An attention model is a method that takes n arguments y_1 … y_n and a context c. It returns a vector z which is the summary of the y_i focusing on the information linked to context c. More formally, it returns a weighted arithmetic mean of the y_i and the weights are chosen according the relevance of each y_i given the context c. https://blog.heuritech.com/2016/01/20/attention-mechanism/
12 .An attention model is a method that takes n arguments y_1 … y_n and a context c. It returns a vector z which is the summary of the y_i focusing on the information linked to context c. More formally, it returns a weighted arithmetic mean of the y_i and the weights are chosen according the relevance of each y_i given the context c. https://blog.heuritech.com/2016/01/20/attention-mechanism/
14 .Attention – part 1 C is the context. Y_i is the data we are looking at.
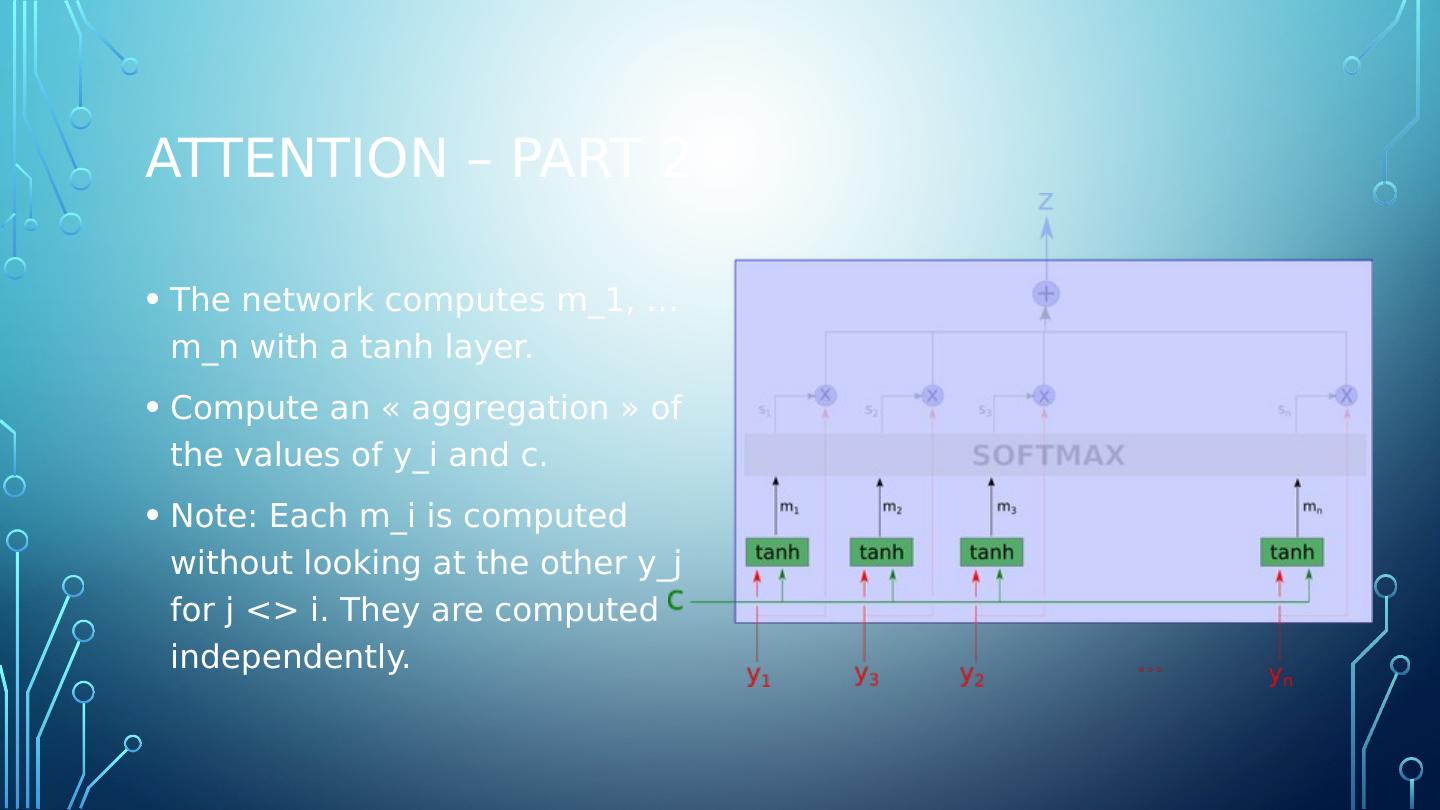
15 .Attention – Part 2 The network computes m_1, … m_n with a tanh layer. Compute an « aggregation » of the values of y_i and c. Note: Each m_i is computed without looking at the other y_j for j <> i . They are computed independently.
16 .Attention – part 3 Compute each weight using a softmax .
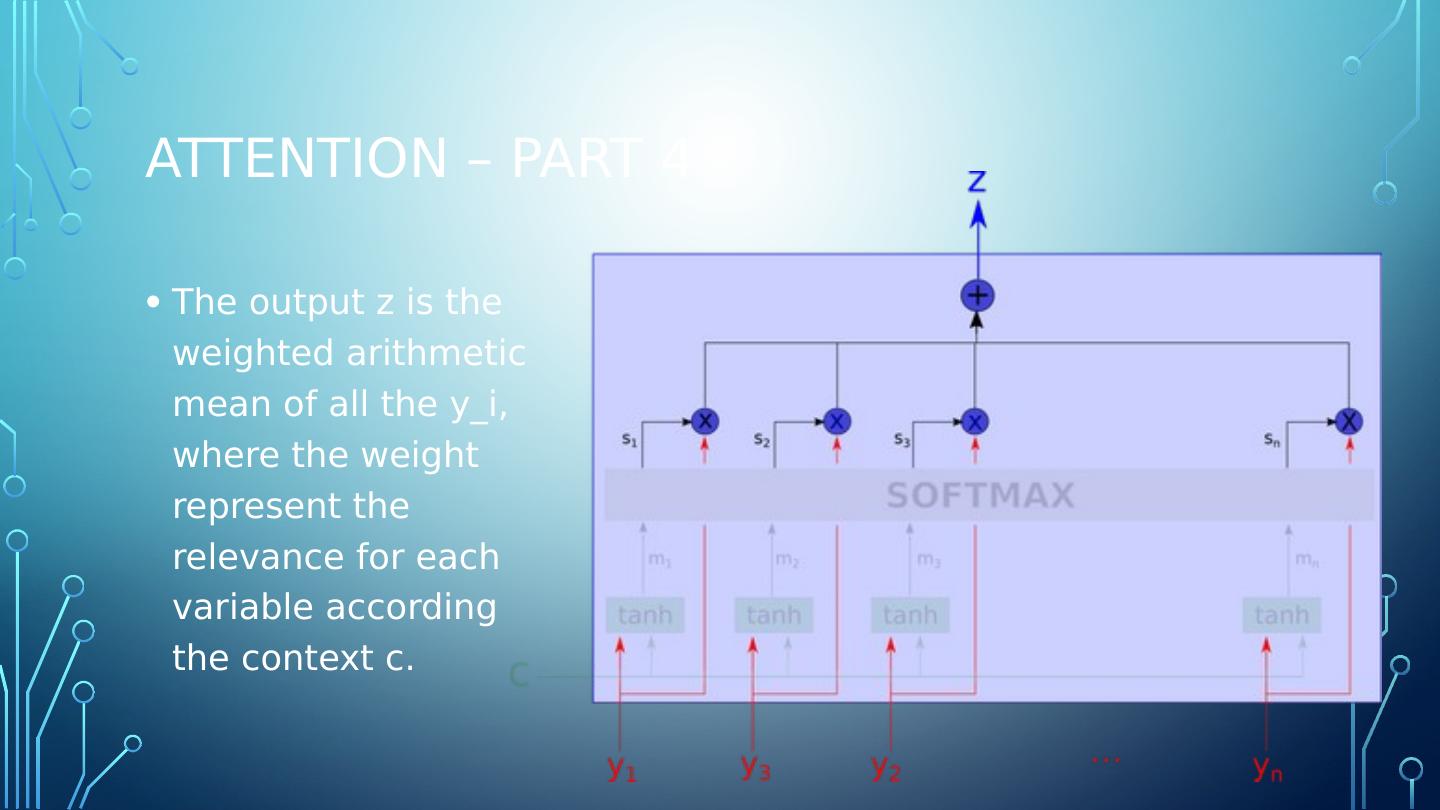
17 .Attention – part 4 The output z is the weighted arithmetic mean of all the y_i , where the weight represent the relevance for each variable according the context c.
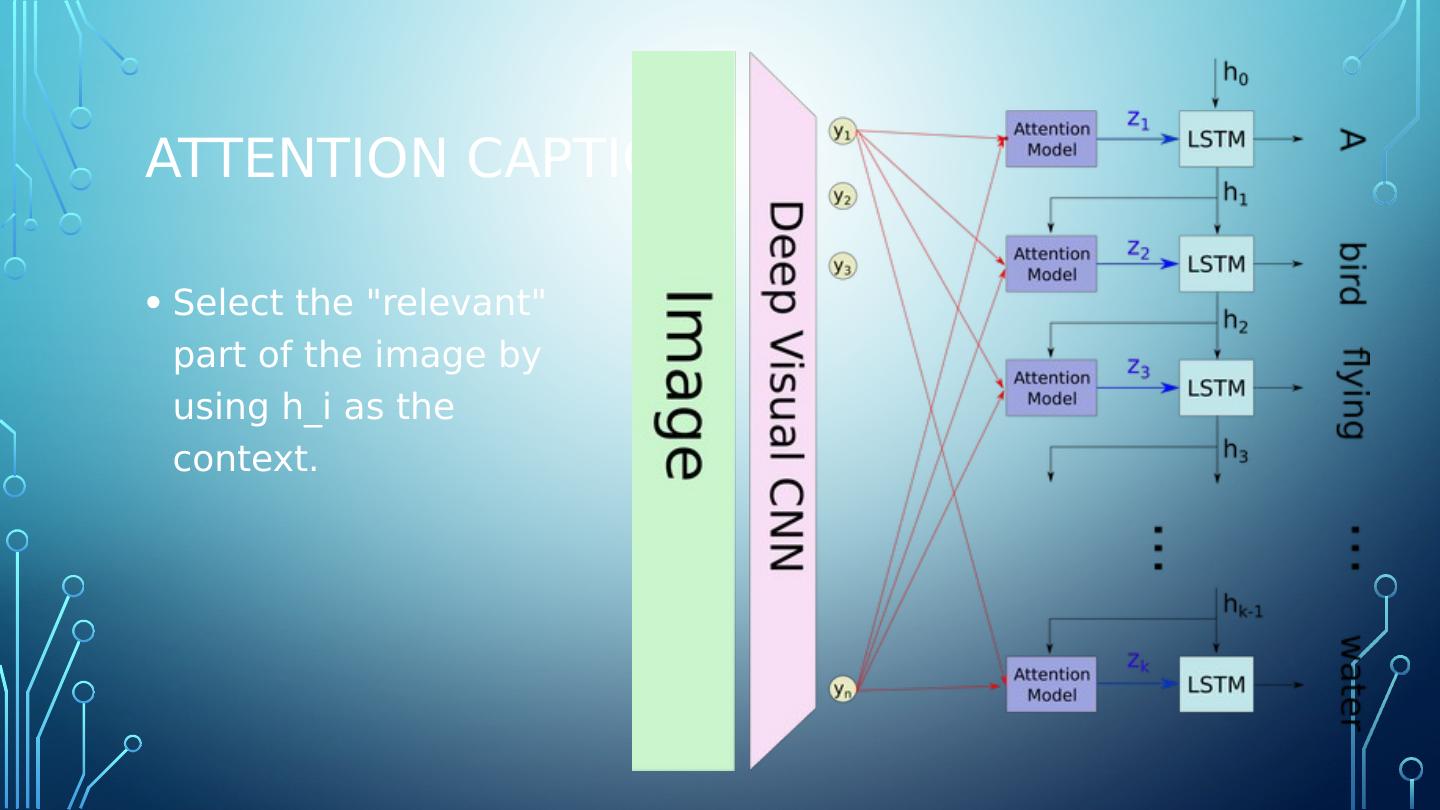
18 .Attention Caption Select the "relevant" part of the image by using h_i as the context.
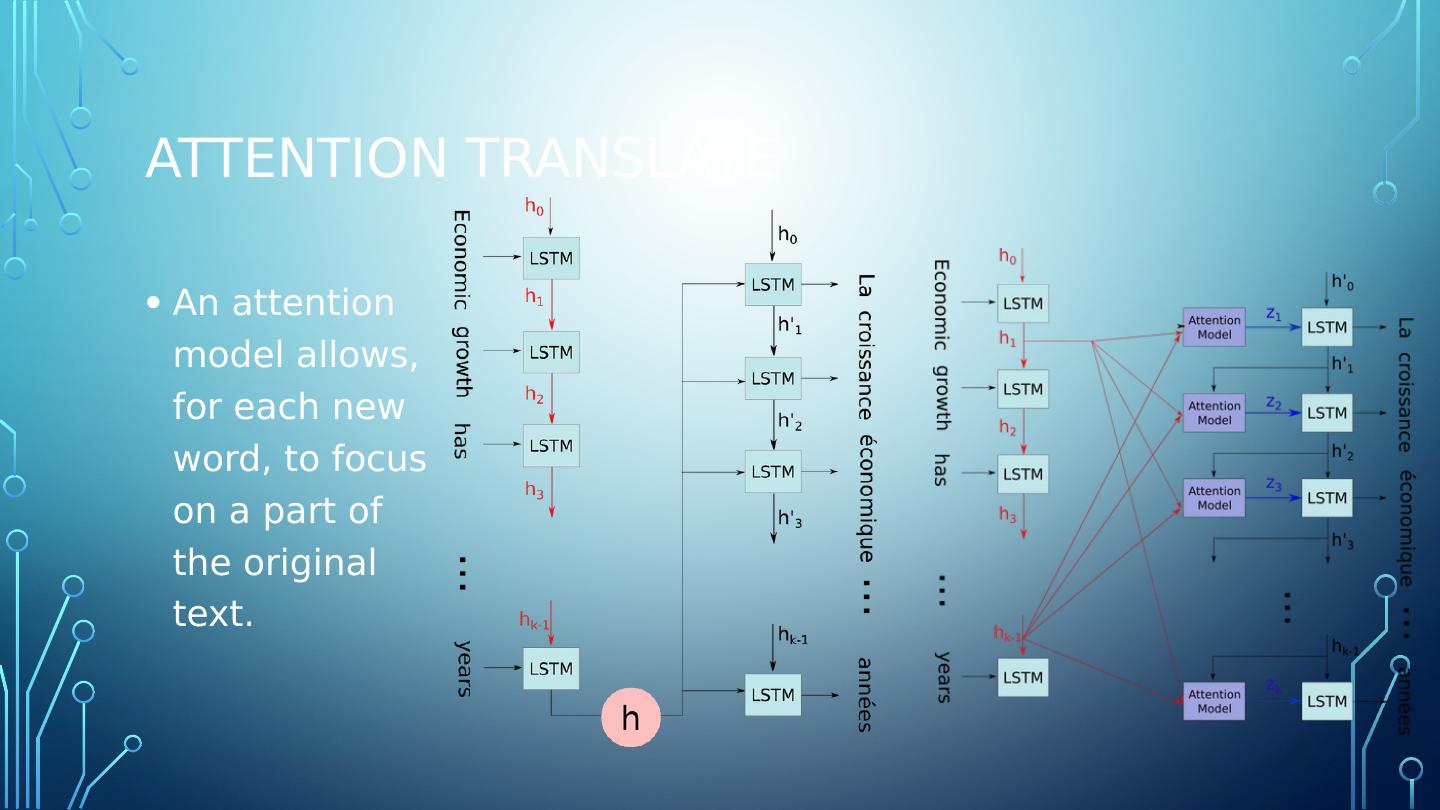
19 .Attention translate An attention model allows, for each new word, to focus on a part of the original text.
20 .Word alignment in translation The network usually learns to focus on a single input word each time it produces an output word. This means that most of the attention weights are 0 (black) while a single one is activated (white).
21 .Not hardware friendly Memory bandwidth for recurrent neural networks is one of the highest. https://medium.com/@culurciello/computation-and-memory-bandwidth-in-deep-neural-networks-16cbac63ebd5 RNN and LSTM are difficult to train because they require memory-bandwidth-bound computation. Many times RNN inputs need to be processed right at the edge device. Think Amazon Echo.
22 .attention "Attention is then one of the most important components of neural networks adept to understand sequences, be it a video sequence, an action sequence in real life, or a sequence of inputs, like voice or text or any other data." https://towardsdatascience.com/memory-attention-sequences-37456d271992
23 .hierarchical neural attention encoder A better way to look into the past is to use attention modules to summarize all past encoded vectors into a context vector Ct.
24 .Hierarchy is key The layering of attention modules allows this technique to look back 10,000 past vectors or more. The length of the path needed to propagate a representation vector to the output of the network: in hierarchical networks it is proportional to log(N). Where in a typically RNN of T steps, a representation vector must survive T hops to reach the network output.
25 .Learn more Hierarchical neural attention is similar to the ideas in WaveNet . WaveNet : https://deepmind.com/blog/wavenet-generative-model-raw-audio/