展开查看详情
1 .What does an artificial neuron do? Understanding activation functions Gene Olafsen
2 .Questions: Why are there so many activation functions? Does one activation function work better than another? What is the process of selecting an activation function?
3 .Questions: Why are there so many activation functions? Does one activation function work better than another? What is the process of selecting an activation function?
4 .Math at the heart of a neuron The value of Y can be anything ranging from -infinity to +infinity. Something must decide whether to fire the neuron, without knowing the bounds of Y.
5 .Activation function wraps the basic neuron The activation function checks the Y value produced by a neuron and decides if it exceeds a threshold such that outside connections should consider this neuron as fired or not-fired . ACTIVATION FUNCTION
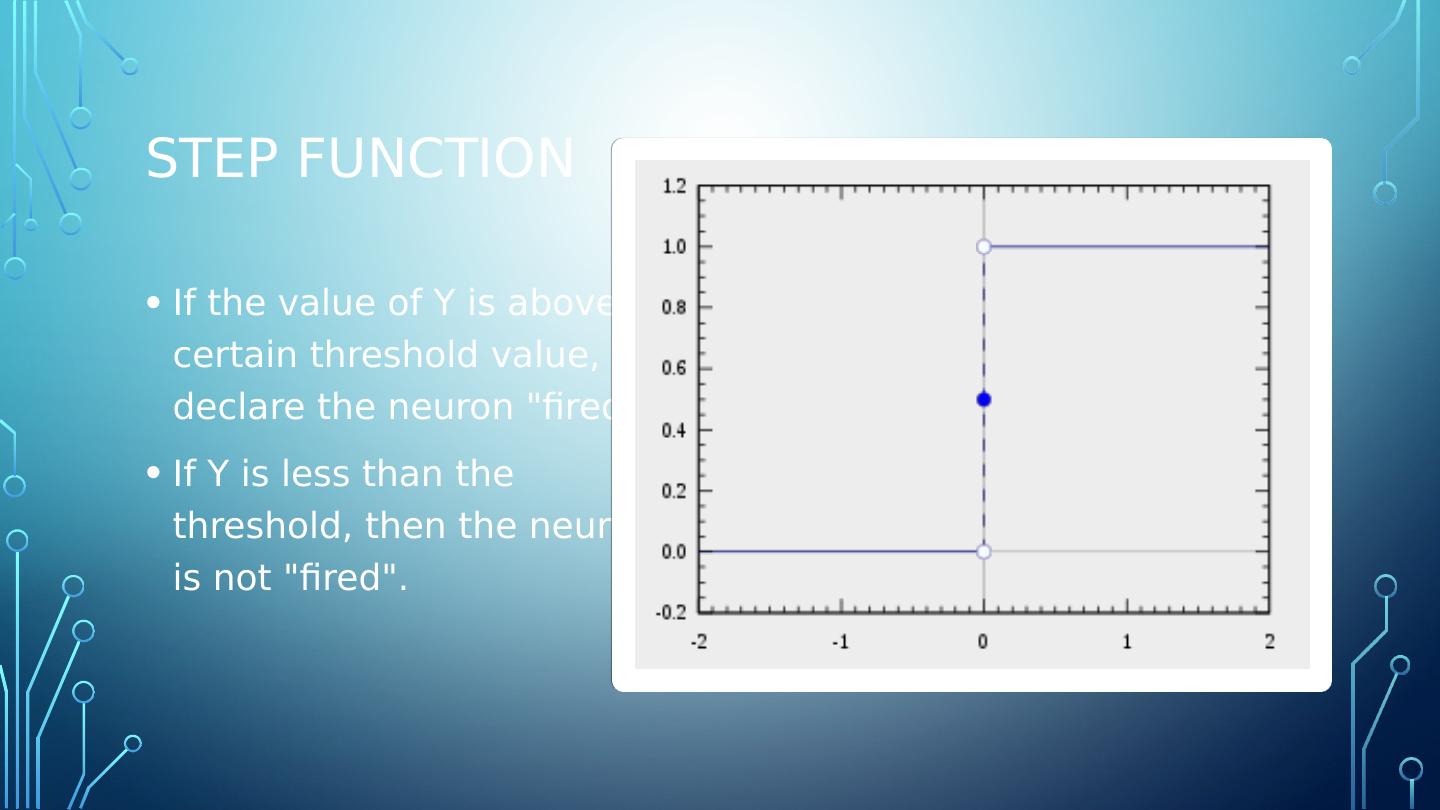
6 .step function If the value of Y is above a certain threshold value, declare the neuron "fired". If Y is less than the threshold, then the neuron is not "fired".
7 .step function If the value of Y is above a certain threshold value, declare the neuron "fired". If Y is less than the threshold, then the neuron is not "fired".
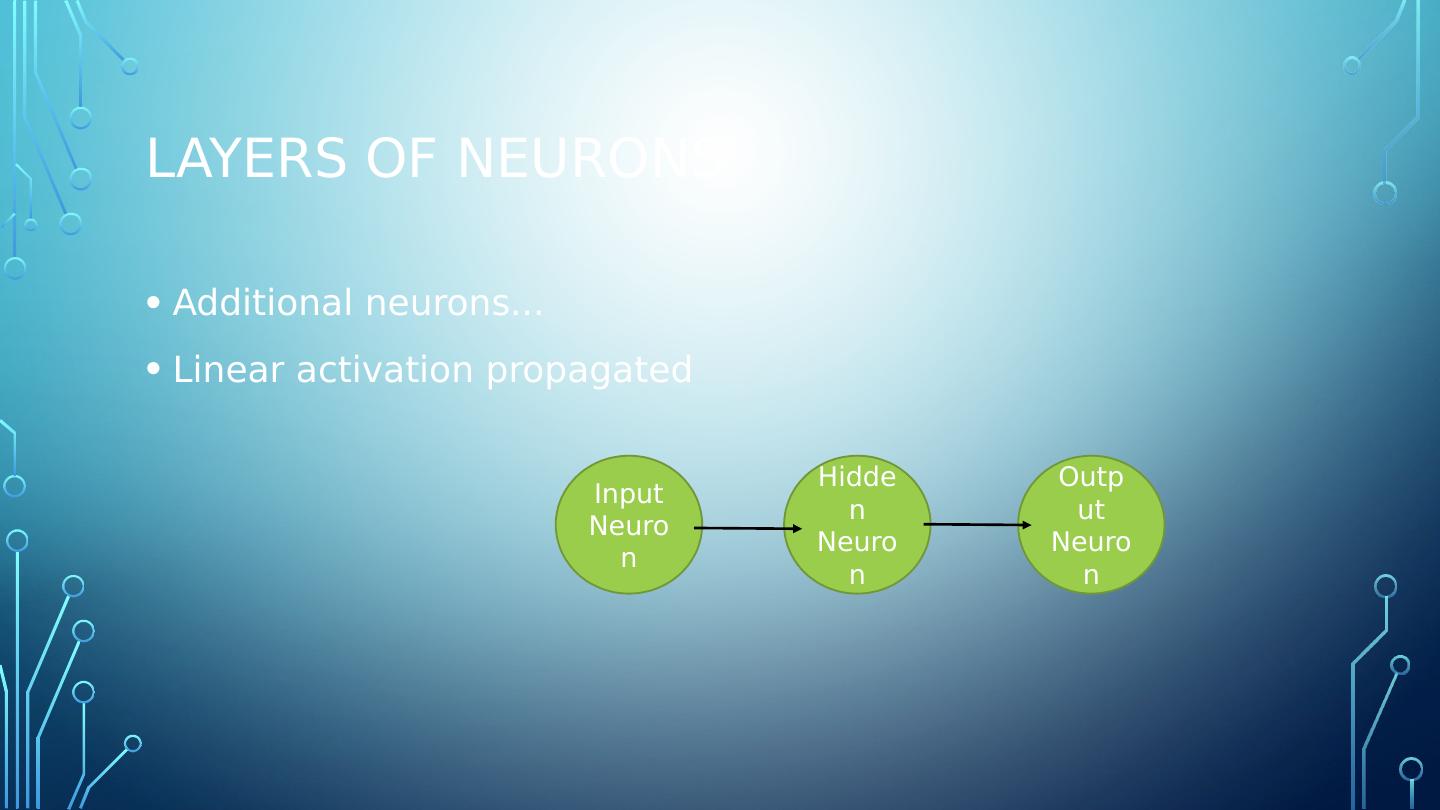
8 .Layers of Neurons Additional neurons... Linear activation propagated Input Neuron Hidden Neuron Output Neuron
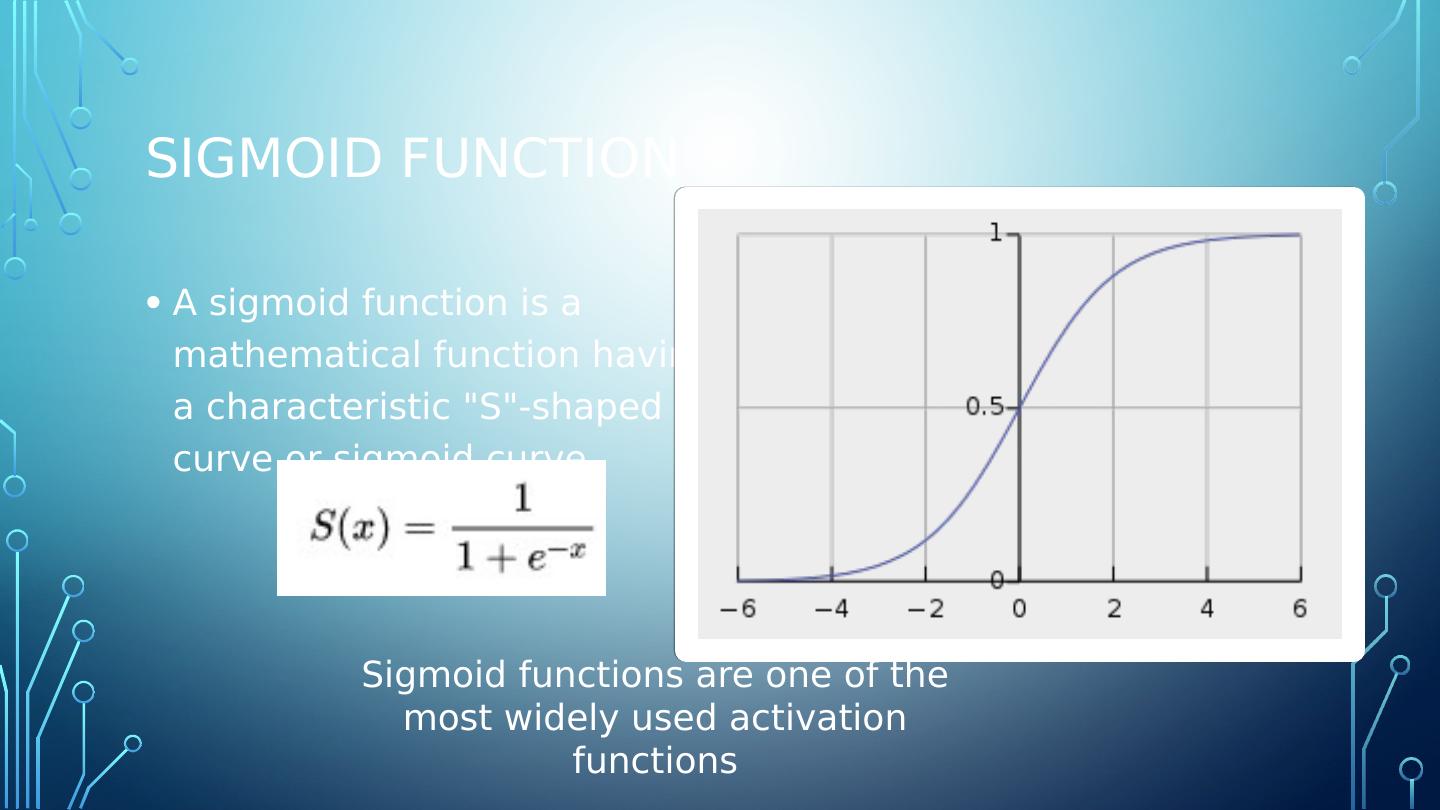
9 .Sigmoid function A sigmoid function is a mathematical function having a characteristic "S"-shaped curve or sigmoid curve. Sigmoid functions are one of the most widely used activation functions
10 .Sigmoid function A sigmoid function is a mathematical function having a characteristic "S"-shaped curve or sigmoid curve. Sigmoid functions are one of the most widely used activation functions
11 .Vanishing gradients Take note, towards either end of the sigmoid function, the Y values tend to respond less and less to changes in X. This means that the gradient at that region is going to be small toward either end of the function—giving rise to what is known as "vanishing gradients". When the gradient is small and cannot make a significant change it is said to have "vanished". The outcome is the network refuses to learn further or is drastically slow in any progress it makes.
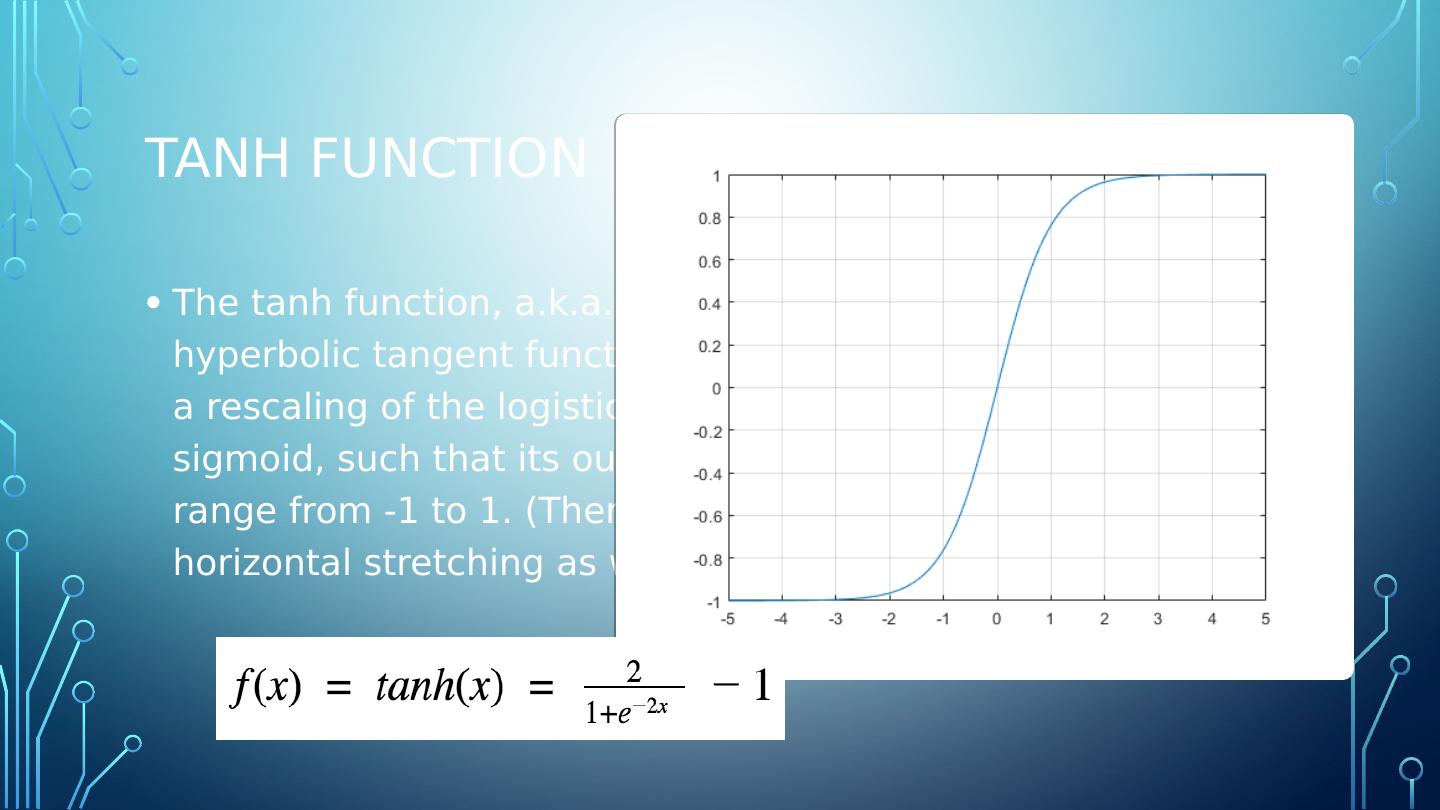
12 .Tanh function The tanh function, a.k.a. hyperbolic tangent function, is a rescaling of the logistic sigmoid, such that its outputs range from -1 to 1. (There’s horizontal stretching as well.)
13 .Tanh function The tanh function, a.k.a. hyperbolic tangent function, is a rescaling of the logistic sigmoid, such that its outputs range from -1 to 1. (There’s horizontal stretching as well.)
14 .Relu : rectified linear unit First introduced by Hahnloser et al. In a paper in Nature in 2000 it is backed by strong biological motivations and mathematical justifications ReLU was demonstrated for the first time in 2011 to enable better training of deeper networks and compared to the widely used activation functions prior to 2011. ReLU is also known as a ramp function and is analogous to half-wave rectification in electrical engineering.
15 .Advantage: Relu The ReLU gives an output x if x is positive and 0 otherwise. This gets us closer to what biology seems to be doing when deciding whether or not inputs should pass through the neuron and throughout the rest of the network. Nonlinear and combinations of ReLU are nonlinear- which means it can be used in stacked layers! Less computationally expensive than tanh and sigmoid because it involves simpler mathematical operations.
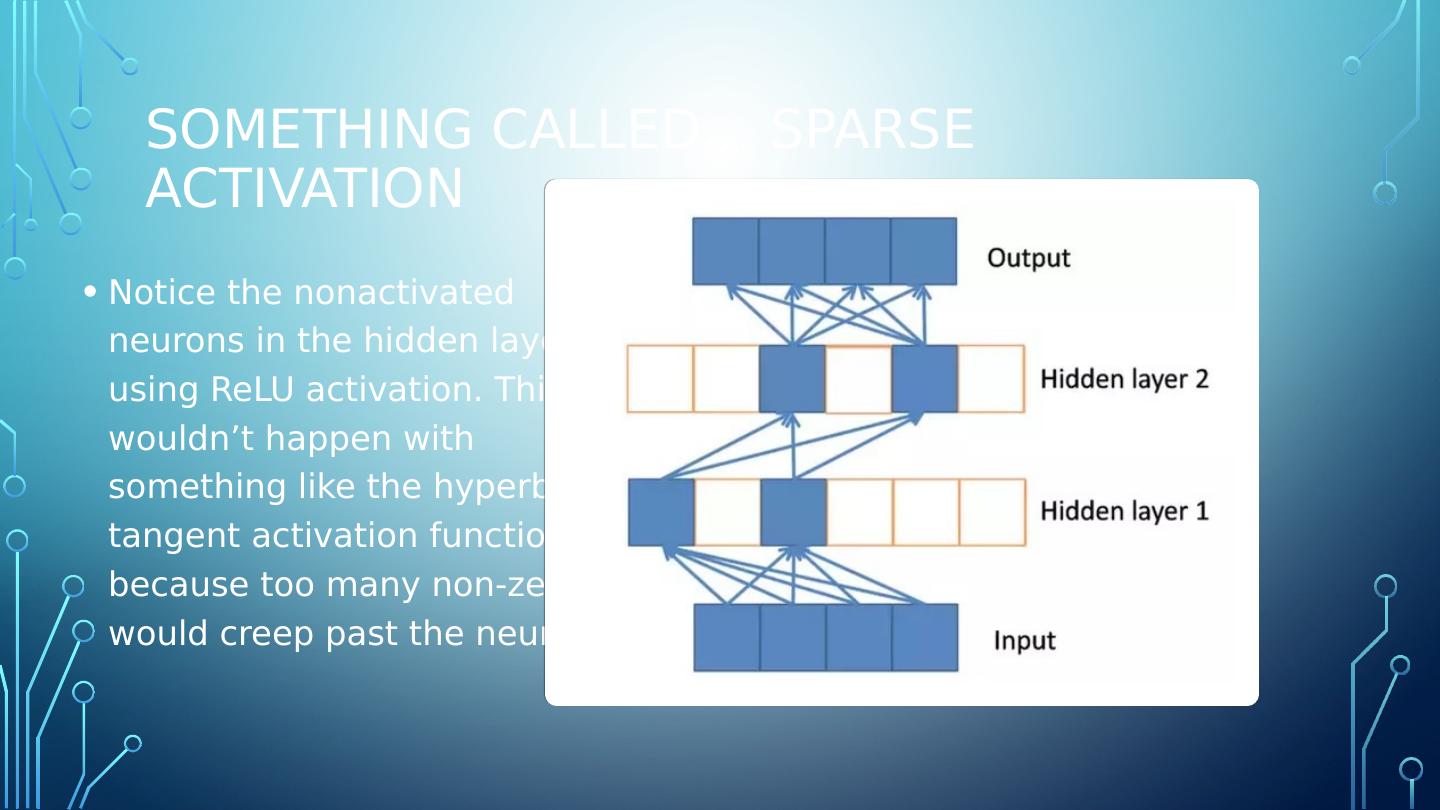
16 .Something called... sparse activation Notice the nonactivated neurons in the hidden layers using ReLU activation. This wouldn’t happen with something like the hyperbolic tangent activation function because too many non-zeros would creep past the neurons.
17 .Sparse activation and the brain Studies conducted on ‘brain energy expenditure’ suggest that biological neurons encode information in a ‘sparse and distributed way.’ This means that the percentage of neurons that are active at the same time are very low: in the range of 1–4%.
18 .Sparse activation and the brain Studies conducted on ‘brain energy expenditure’ suggest that biological neurons encode information in a ‘sparse and distributed way.’ This means that the percentage of neurons that are active at the same time are very low: in the range of 1–4%.
19 .Leaky ReLU Leaky ReLU is a variation of ReLU mitigate the "dying ReLU " issue by simply making the horizontal line into non-horizontal component. For example: y = 0.01x for x<0 will make it a slightly inclined line rather than horizontal line.