





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Data Lake Acceleration through next-gen Platform - North Texas ...
Torch. IBMCaffe. DL4J. TensorFlow. OpenBLAS. Theano. Deep Learning Framework. Accelerated Service and Infrastructure for Scaling. Spectrum Scale ESS:.
展开查看详情
1 .Data Lake Acceleration through next-gen Platform Pijush Chatterjee IBM Big Data Technical Architect
2 .AGENDA Data Lake Emerges Changes in the wind - Distributed computing, Machine & Deep Learning Next-Gen Platform evolves
3 .Business scenarios we see S ubject matter experts want access to their organization’s data to explore the content, select, control, annotate and access information using their terminology with an underpinning of protection and governance. Data Scientists seeking data for new analytics models. Marketeer seeking data for new campaigns. Fraud investigator seeking data to understand the details of suspicious activity. Day-to-day activity. Requiring ad hoc access to a wide variety of data sources. Supporting analysis and decision making. Using the subject matter experts terminology . Providing the flexibility of spreadsheets that can scale to large volumes, a wide variety of information types whilst protecting sensitive information and optimizing data storage and provisioning.
4 .SOA The broadening scope of analytics – Data Lake emerges Master Data Management Hub Applications Data Warehouse Pattern Discovery for Analytics Operational Data Store Adding in a business desire for real-time analytics, self service data and increasing regulations relating to individual privacy, it becomes necessary to have a well- defined, managed and governed approach to information architecture. We call this IBM’s data Lake. Sand boxes Analyze Values Search For Data Reporting Data Lake Hadoop
5 .How many data lakes do you need? Two valid approaches … Data Lake Data Lake Data Lake Zoned Data Lake Public Partners Private Public Partners Private Enables selective sharing of data. Each group gets access to a different subsets of data, formatted for their needs Requires greater care in curation as the catalog definitions define access. Physically separate systems. Access to similar data achieved through copying. Suitable when each group needs different types of data.
6 .The Data Lake subsystems Data Lake (System of Insight) Information Management and Governance Fabric Catalogue Self-Service Access Enterprise IT Data Exchange Self-Service Access Analytics Teams Governance, Risk and Compliance Team Information Curator Line of Business Teams Data Lake Operations Enterprise IT Other Data Lakes Systems of Engagement Data Lake Repositories Systems of Automation Systems of Record New Sources
7 .Considerations for a well-managed and governed data lake No direct access to repositories Business-led information governance and management Catalog of data, ownership, meaning and permitted usage Moderated, view-based self-service access to data and analytics for line of business. Access to raw data to develop new production analytics. Effective interchange of data and insight with other systems. Data-centric Security Multiple repositories organized based on source and usage; hosted on appropriate data platforms for workload. Curation of all data to define meaning and classifications Active monitoring and management of data 1 10 9 8 7 6 4 3 5 2
8 .Data repositories support multiple zones Line of Business Applications Information Service Calls Search Requests Report Requests Deploy Decision Models Information Service Calls Data Access Data Lake Deploy Real-time Decision Models Data Lake Operations Curation Interaction Management Data Access Data Deposit Data Deposit Decision Model Management Deploy Real-time Decision Models Consumers of Insight Analytics Tools Simple, ad hoc Discovery and Analysis Reporting Analytical Insight Applications Events to Evaluate Information Service Calls Data Out Data In Notifications Data Lake Repositories Descriptive Data Context Data Deposited Data Historical Data Harvested Data Published Data Enterprise IT New Sources Third Party Feeds Third Party APIs Internal Sources Other Systems Of Insight Other Data Lakes System of Record Applications Enterprise Service Bus Systems of Engagement Systems of Automation
9 .Enterprise IT New Sources Third Party Feeds Third Party APIs Internal Sources Other Systems Of Insight Other Data Lakes System of Record Applications Enterprise Service Bus Systems of Engagement Systems of Automation Big data needs a variety of repositories for cost, access and performance reasons Line of Business Applications Information Service Calls Search Requests Report Requests Deploy Decision Models Information Service Calls Data Access Data Lake Deploy Real-time Decision Models Data Lake Operations Curation Interaction Management Data Access Data Deposit Data Deposit Decision Model Management Deploy Real-time Decision Models Consumers of Insight Analytics Tools Simple, ad hoc Discovery and Analysis Reporting Analytical Insight Applications Events to Evaluate Information Service Calls Data Out Data In Notifications Data Lake Repositories Descriptive Data Information Views Catalog Context Data Asset Hub Activity Hub Code Hub Content Hub Deposited Data Historical Data Harvested Data Information Warehouse Deep Data Audit Data Operational History Search Index Log Data Published Data Data Marts Object Cache Export Area All types of data Structured and Optimized System-level Data (Pre-Archive) Master and Reference Data
10 .Appropriate Data is In the Eye of the Consumer Information Virtualization Report on Values View related Values Search Values Browse Sources Analyze Values Provision Information Provisioning Information Delivery Data Access APIs Semantic/Business Objects 10001 01010 01010 Data Scientist Line of Business Provision and prepare data for modeling
11 .Data lake logical architecture Line of Business Applications Information Service Calls Search Requests Report Requests Deploy Decision Models Data Access Data Lake Deploy Real-time Decision Models Data Lake Operations Curation Interaction Management Data Access Data Deposit Data Deposit Decision Model Management Events to Evaluate Information Service Calls Data Out Data In Notifications Deploy Real-time Decision Models Understand Information Sources Understand Information Sources Understand Compliance Report Compliance Advertise Information Source Governance, Risk and Compliance Team Information Curator Catalog Interfaces Information Service Calls Raw Data Interaction Enterprise IT Interaction APIs Data Ingestion Publishing Feeds Continuous Analytics Streaming Analytics Consumers of Insight Simple, ad hoc Discovery and Analysis Reporting Analytical Insight Applications Analytics Tools View-based Interaction Secure Access Sand boxes Event Correlation Data Lake Repositories Descriptive Data Information Views Catalog Context Data Asset Hub Activity Hub Code Hub Content Hub Deposited Data Historical Data Harvested Data Information Warehouse Deep Data Audit Data Operational History Search Index Information Integration & Governance Information Broker Operational Governance Hub Broker Code Hub Workflow Staging Areas Guards Monitor Offline Archive Log Data Published Data Data Marts Object Cache Export Area Search Access Feedback Refine Sand boxes Secure Access Secure Access Enterprise IT New Sources Third Party Feeds Third Party APIs Internal Sources Other Systems Of Insight Other Data Lakes System of Record Applications Enterprise Service Bus Systems of Engagement Systems of Automation
12 .Changes in the wind - Distributed computing, Machine & Deep Learning
13 .Transactions b Conventional Data Platform RDBMS OLTP ACID Systems of Record Systems of Insight Data Warehouse/Marts Structured Data Structured Data The Conventional Data Platform
14 .Client value Lower cost, greater scale, speed Open source, Dev Ops model Reduce vendor lock-in Flexible Data Models New data sources Social Location Sensors b 14 Mobile New Data Models Hadoop/Spark Unstructured Data / Text The Modern Data Platform Emerges New Data Models NoSQL Document, Column, Key Value, Graph, SQL PostgreSQL compatible SQL MySQL compatible “New” Relational Open Source SQL New Analytics – ML/DL, In-memory + GPU Data Services
15 .Artificial Intelligence and Cognitive Applications Machine Learning Deep Learning (Neural Networks) The deeper you go, the more value you gain, and the more you know
16 .requires different skills DEPLOY & INFER experience all that pain again MAINTAIN ACCURACY Iterate faster and do it again Single click to deploy most time spent here DATA PREPARATION u p and running over a quick lunch time spent drops from 80% to 30% very iterative BUILD, TRAIN, OPTIMIZE 9 days work becomes 4 hours … more models weeks to months UP & RUNNING Realizing business value comes with its challenges
17 .Building cognitive apps using deep learning requires multiple skillsets . Data Science is a Team Sport Biz Analyst Dev Ops Data Engineer App Developer Dev Ops Data Scientist
18 .GPU Aware Scheduling in Spectrum Conductor with Spark Conductor scheduler interfaces with Spark scheduler to ensure that GPU resources are assigned to the applications that can use them Workload Management Spark Application Session Scheduler GPU resources CPU resources
19 .GPU Spark Machine Learning Predictive Analytics Example: Adverse Drug Reaction Prediction built on Spark 25X Speed up for Building Model stage (using Spark Mllib Logistic Regression) Transparent to the Spark Application Game changer for Personalized Medicine Without GPU With GPU
20 .PowerAI: 3 CLs for deployment PowerAI Support: L1-L3 across stack Discovery Workshops Lab Services CwS : Multi Tenancy, Shared Services DL Impact: Distributed data processing & transformation DL Impact: Single click REST API CwS : Integrated SPARK for data management & ETL PowerAI: Distributed DL, Large Model Support DL Impact: Visualization, Hyper- paramer , Accuracy monitoring Enabling Deep Learning workflows with PowerAI, Conductor for SPARK and DL Impact DL Impact: Model management & accuracy monitoring
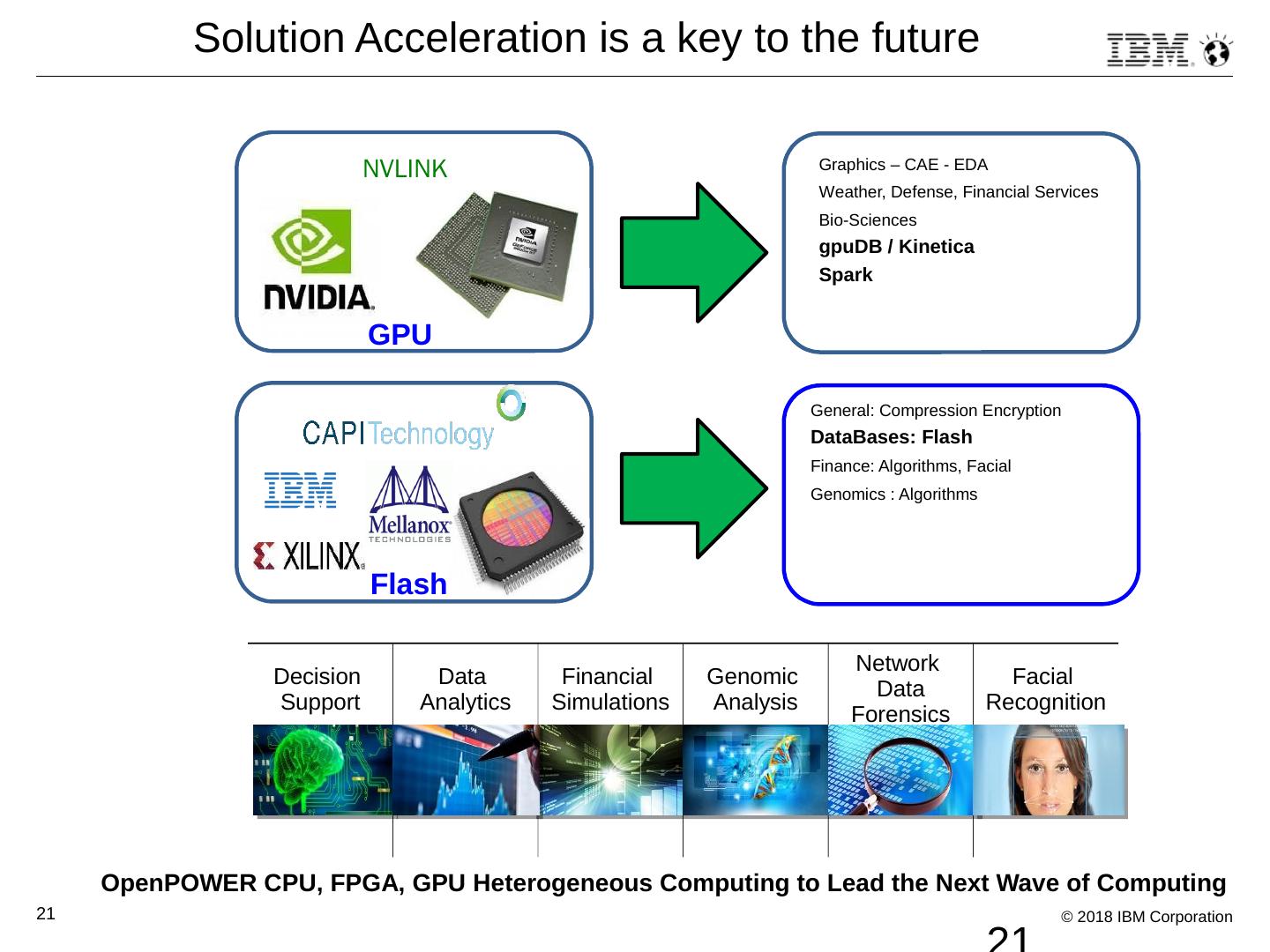
21 .21 Solution Acceleration is a key to the future NVLINK GPU Flash Graphics – CAE - EDA Weather, Defense, Financial Services Bio-Sciences gpuDB / Kinetica Spark General: Compression Encryption DataBases : Flash Finance: Algorithms, Facial Genomics : Algorithms Decision Support Data Analytics Financial Simulations Genomic Analysis Network Data Forensics Facial Recognition OpenPOWER CPU, FPGA, GPU Heterogeneous Computing to Lead the Next Wave of Computing
22 .Next-Gen Platform evolves
23 .P8 P9 P10 Open Frameworks Partnerships Industry Alignment Dev Ecosystem Accelerator Roadmaps Open Accelerator Interfaces Not Just About Hardware Design hardware software + It’s about co-optimized which just work for Machine Learning, Deep Learning, and AI IBM Software Cognitive Systems are built with optimized HW & SW
24 .High Performance Cores Fast & Large Memory System Fast PowerAccel Interconnects for Accelerators >2X vs. Intel 4-5X Memory Bandwidth 3X Cache vs. Intel NVLink 1.0 5x vs. Intel CAPI NVLink PCIe Gen3 P8 Faster PowerAccel Interconnect for Accelerators OpenCAPI / NVLink 2.0 7-10x vs. Intel OpenCAPI NVLink 2.0 PCIe Gen4 P9 Power partnerships with accelerator industry players: Nvidia GPU, Xilinx, AMD GPU, open to other options P8 Balanced Systems Designed for Cognitive Power high-performance core, bandwidth, accelerator differentiation
25 .High performance Self-Service environment for compute and memory intensive workload Spark in memory analytics to support real time/ad-hoc query/analysis and batch reporting De-Coupled compute/storage infrastructure ; Independent scaling of compute and storage True multi-tenant platform supporting many LOBs/Users, resource plan, & application SLA Multiple Spark version , multiple notebook version support GPU acceleration for ML , Shared RDD optimization, and new innovations around ML/DL Support Spark as well as traditional batch, micro-service application frameworks in the same environment ML /DL for Machine Learning/Deep Learning with IBM Minsky GPU/AI Data Scientists Via Spark notebook, analyze data to develop new apps Geo-Spatial Intelligence Customer Entity Relationship Customer Sentiment Models Smarter Payments… Fraud Detection Teams Run third party ML Counter Fraud reporting Risk & Quant Teams Develop risk models, train ML/DL models High Performance Next-Gen Platform | A Spark centric environment Load data from Hadoop data lake(On-Premise/Cloud) or other enterprise data sources Spark In -memory cache Cluster management Other data sources, DB2… Analytics Grid – May host Hadoop too !! … Data Lake Hadoop Cloud Based Data Providers IOT AI Deep Learning Data Engineering Consume ETL as service Bring Analytics to Data Virtual Data Lake Global Name Space
26 .CAFFE NVCaffe Torch IBMCaffe DL4J TensorFlow OpenBLAS Theano Deep Learning Framework Accelerated Service and Infrastructure for Scaling Spectrum Scale ESS: High-Speed Parallel File System Scale to Cloud Cluster of NVLink Servers Bazel DIGITS NCCL Distributed Frameworks Supported Libraries Deep Learning Module of Conductor with Spark Deep Learning Platform Data Science Experience, developer productivity tooling Distributed training capacity cross nodes and GPU Hyper-parameter search capacity to improve the accuracy Model fine tuning capacity and suggestion for customized model design Data preparation capacity to fit real case requirement Value for PowerAI Enterprise Pro Solution
27 .PowerAI Enterprise Pro Deep Learning Software Stack DL Frameworks (TF, Caffe , etc ) Data Prep & ETL via Spectrum Conductor with Spark Input Data Deep Learning GUI Data & Model Management, ETL Tools, Monitor, Visualize, Advise DL Insight Tuning Engine AI Vision Computer Vision App Development Toolkit IBM Spectrum Conductor with Spark System Mgmt , Distributed ETL, Distributed Training , Hyper-Parameter Optimization Distributed Training New Data preparation & transformation tools for deep learning Cluster Orchestration, Virtualization & Distribution with Apache Spark Tools to enhance developer experience for data scientists Faster training times by distributing deep learning across a cluster DSX Tooling & Collaboration for Data Scientists
28 .
3秒后跳转登录页面
去登陆

