




































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
05_Speech Recognition
Recognition procedures
Dynamic programming
展开查看详情
1 .Ch. 5: Speech Recognition An example of a speech recognition system using dynamic programming Speech recognition techniques, v.8b 1
2 .Overview (A) Recognition procedures (B) Dynamic programming Speech recognition techniques, v.8b 2
3 .(A) Recognition Procedures Preprocessing for recognition endpoint detection Pre-emphasis Frame blocking and windowing distortion measure methods Comparison methods Vector quantization Dynamic programming Hidden Markov Model Speech recognition techniques, v.8b 3
4 .LPC processor for a 10-word isolated speech recognition system Steps End-point detection Pre-emphasis -- high pass filtering (3a) Frame blocking and (3b) Windowing Feature extraction Find cepstral cofficients by LPC Auto-correlation analysis LPC analysis, Find Cepstral coefficients, or find cepstral coefficients directly Distortion measure calculations Speech recognition techniques, v.8b 4
5 .Example of speech signal analysis Frame size is 20ms, separated by 10 ms, S is sampled at 44.1 KHz Calculate: n and m. Speech recognition techniques, v.8b 5 One frame =n samples 1 st frame 2 nd frame 3 rd frame 4 th frame 5 th frame Separated by m samples ( one set of LPC -> code word) ( one set of LPC -> code word) ( one set of LPC -> code word) ( one set of LPC -> code word) Speech signal S E.g. whole duration about is 1 second Answer: n=20ms/(1/44100)=882, m=10ms/(1/44100)=441
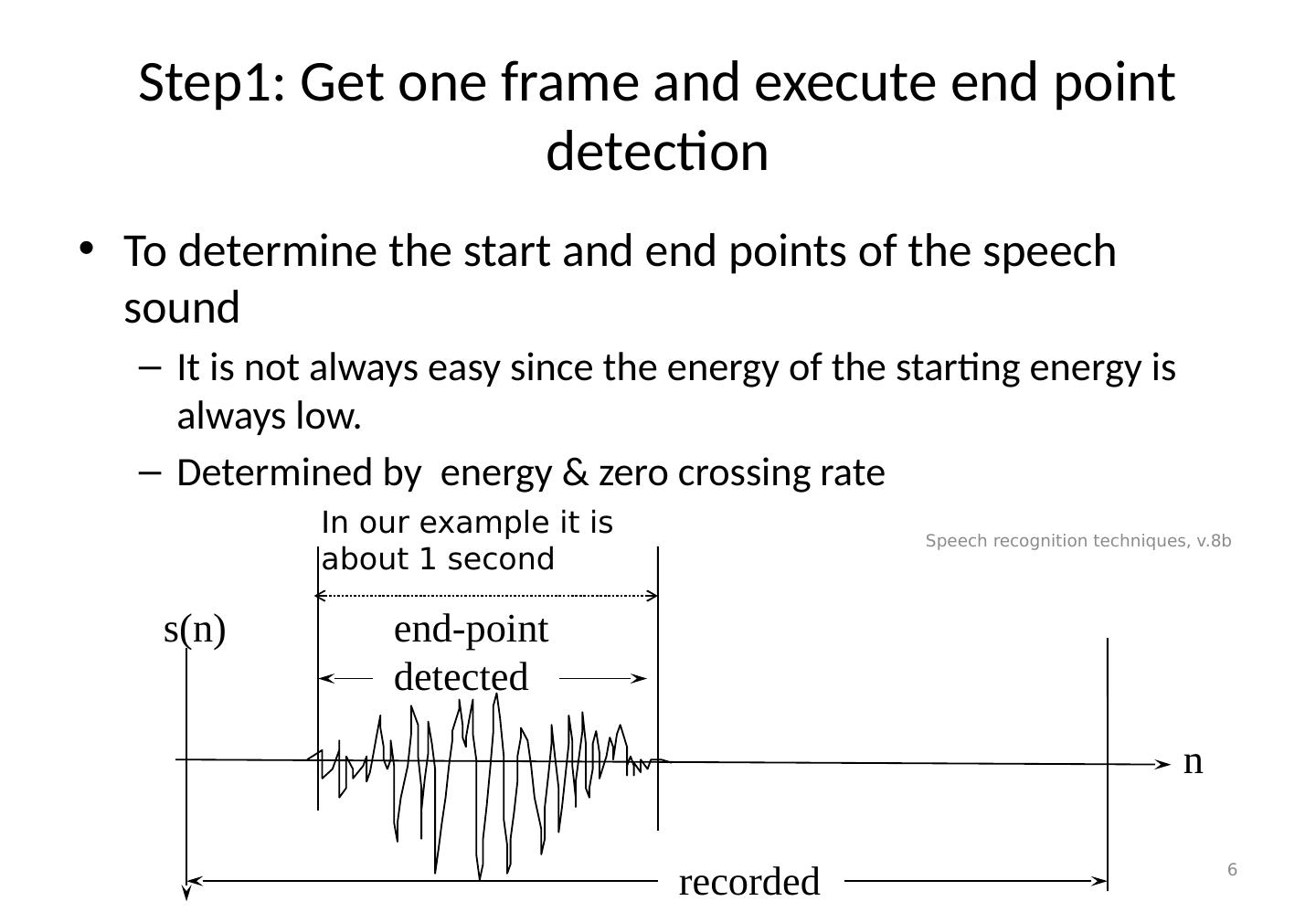
6 .Step1: Get one frame and execute end point detection To determine the start and end points of the speech sound It is not always easy since the energy of the starting energy is always low. Determined by energy & zero crossing rate Speech recognition techniques, v.8b 6 recorded end-point detected n s(n) In our example it is about 1 second
7 .A simple End point detection algorithm At the beginning the energy level is low. If the energy level and zero-crossing rate of 3 successive frames is high it is a starting point. After the starting point if the energy and zero-crossing rate for 5 successive frames are low it is the end point. Speech recognition techniques, v.8b 7
8 .Energy calculation E(n) = s(n).s(n) For a frame of size N, The program to calculate the energy level: for(n=0;n< N;n ++) { Energy(n)=s(n) s(n); } Speech recognition techniques, v.8b 8
9 .Energy plot Speech recognition techniques, v.8b 9
10 .Zero crossing calculation A zero-crossing point is obtained when sign[s(n)] != sign[s(n-1)] (=at change of sign) The zero-crossing points of s(n)= 6 (you may exclude n=0 and n=N-1. Speech recognition techniques, v.8b 10 n s(n) 1 2 3 4 5 6 n =N-1 n=0
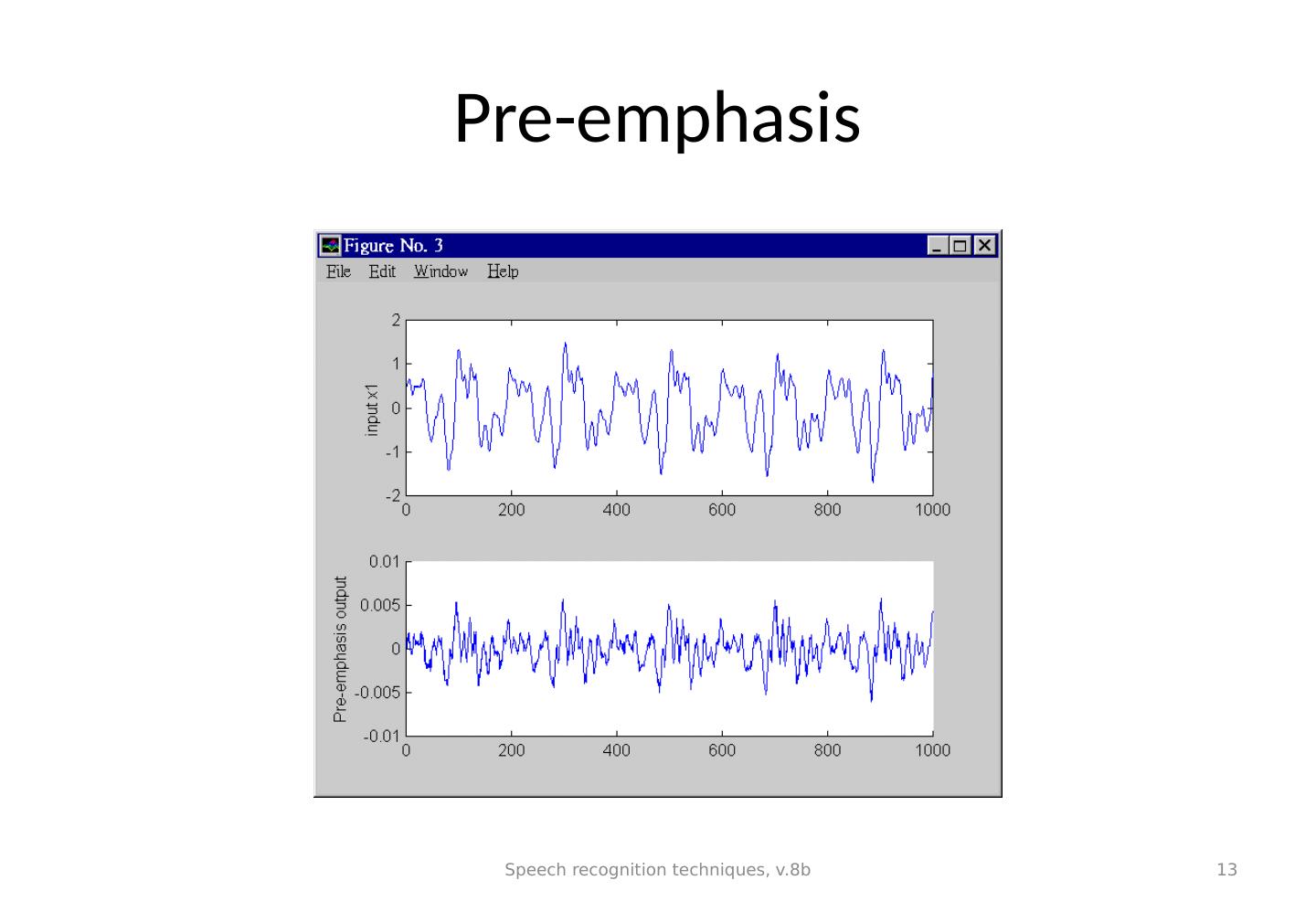
11 .Step2: Pre-emphasis -- high pass filtering To reduce noise, average transmission conditions and to average signal spectrum. Tutorial: write a program segment to perform pre-emphasis to a speech frame stored in an array int s[1000]. Speech recognition techniques, v.8b 11
12 .Pre-emphasis program segment input=sig1, output=sig2 void pre_emphasize (char far *sig1, float *sig2) { int j; sig2[0]=(float)sig1[0]; for (j=1;j< WINDOW;j ++) sig2[j]=(float)sig1[j] - 0.95*(float)sig1[j-1]; } Speech recognition techniques, v.8b 12
13 .Pre-emphasis Speech recognition techniques, v.8b 13
14 .Step3(a): Frame blocking and Windowing To choose the frame size (N samples )and adjacent frames separated by m samples. I.e.. a 16KHz sampling signal, a 10ms window has N=160 samples, m=40 samples. Speech recognition techniques, v.8b 14 m N N n s n l =2 window, length = N l =1 window, length = N
15 .Step3(b): Windowing To smooth out the discontinuities at the beginning and end. Hamming or Hanning windows can be used. Hamming window Tutorial: write a program segment to find the result of passing a speech frame, stored in an array int s[1000], into the Hamming window. Speech recognition techniques, v.8b 15
16 .Effect of Hamming window (For Hanning window See http://en.wikipedia.org/wiki/Window_function ) Speech recognition techniques, v.8b 16
17 .Matlab code segment x1=wavread( violin3.wav ); for i=1:N hamming_window(i)= abs(0.54-0.46*cos(i*(2*pi/N))); y1(i)=hamming_window(i)*x1(i); end Speech recognition techniques, v.8b 17
18 .Cepstrum Vs spectrum The spectrum is sensitive to glottal excitation (E). But we only interested in the filter H In frequency domain Speech wave (X)= Excitation (E) . Filter (H) Log (X) = Log (E) + Log (H) Cepstrum =Fourier transform of log of the signal’s power spectrum In Cepstrum, the Log(E) term can easily be isolated and removed. Speech recognition techniques, v.8b 18
19 .Step4 a: Auto-correlation analysis Auto-correlation of every frame ( l =1,2,..)of a windowed signal is calculated. If the required output is p-th ordered LPC Auto-correlation for the l-th frame is Speech recognition techniques, v.8b 19
20 .Step 4a : LPC calculation (if you use LPC as features, less accurate than MFCC) Recall: To calculate LPC a[ ] from auto-correlation matrix * coef using Durbin’s Method (solve equation 2) void lpc_coeff (float * coeff ) { int i , j; float sum,E,K,a [ORDER+1][ORDER+1]; if( coeff [0]==0.0) coeff [0]=1.0E-30; E= coeff [0]; for ( i =1;i<= ORDER;i ++) { sum=0.0; for (j=1;j< i;j ++) sum+= a[j][i-1]* coeff [ i -j]; K=( coeff [ i ]-sum)/E; a[ i ][ i ]=K; E*=(1-K*K); for (j=1;j< i;j ++) a[j][ i ]=a[j][i-1]-K*a[ i -j][i-1]; } for ( i =1;i<= ORDER;i ++) coeff [ i ]=a[ i ][ORDER];} Speech recognition techniques, v.8b 20
21 .Step 4 b : Cepstral coefficients calculation (more accurate) If Cepstral coefficients are weight by the Mel scale, it is called MFCC (Mel scale Cepstral coefficients) C(n)=IDFT[log 10 |S(w)|]= IDFT[ log 10 {|E(w)|} + log 10 {|H(w)|} ] In C(n), you can see E(n) and H(n) at two different positions Application: useful for ( i ) glottal excitation removal (ii) vocal tract filter analysis Speech recognition techniques, v.8b 21 windowing DFT Log|x(w)| IDFT X(N) X(w) Log|x(w)| N=time index w=frequency I-DFT=Inverse-discrete Fourier transform S(N) C(n)
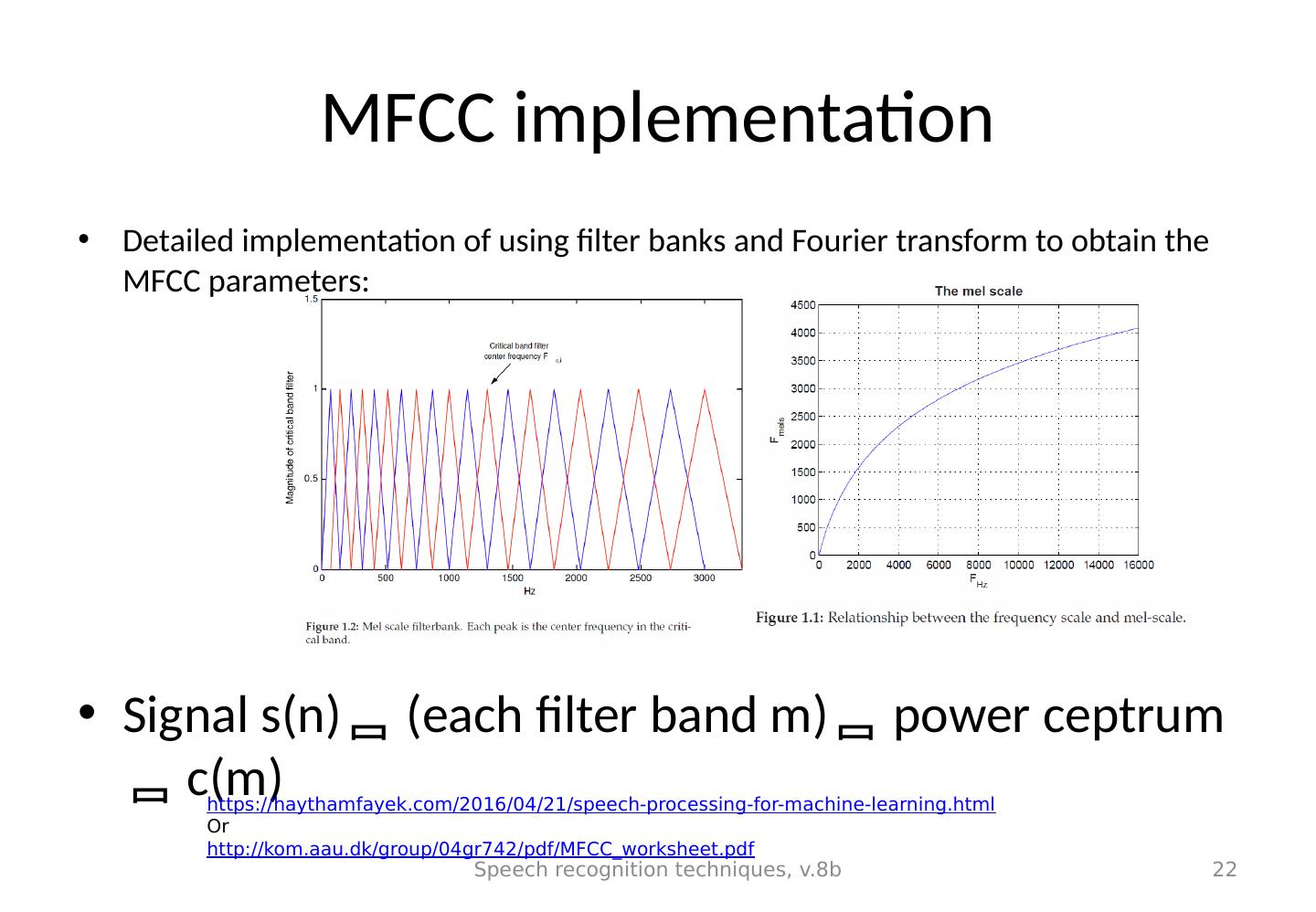
22 .MFCC implementation Detailed implementation of using filter banks and Fourier transform to obtain the MFCC parameters: Signal s(n) (each filter band m) power ceptrum c(m) Speech recognition techniques, v.8b 22 https:// haythamfayek.com/2016/04/21/speech-processing-for-machine-learning.html Or http:// kom.aau.dk/group/04gr742/pdf/MFCC_worksheet.pdf
23 .Step 5: Distortion measure - difference between two signals measure how different two signals is: Cepstral distances between a frame (described by cepstral coeffs (c 1 ,c 2 … c p )and the other frame (c’ 1 ,c’ 2 … c’ p ) is MFCC ( Mel scale Cepstral coefficients) : Weighted Cepstral distances to give different weighting to different cepstral coefficients( more accurate) Speech recognition techniques, v.8b 23
24 .Matching method: Dynamic programming DP Correlation is a simple method for pattern matching BUT: The most difficult problem in speech recognition is time alignment. No two speech sounds are exactly the same even produced by the same person. Align the speech features by an elastic matching method -- DP. Speech recognition techniques, v.8b 24
25 .Example: A 10 words speech recognizer Small Vocabulary (10 words) DP speech recognition system Store 10 templates of standard sounds : such as sounds of one , two, three ,… Unknown input –>Compare (using DP) with each sound. Each comparison generates an error The one with the smallest error is result. Speech recognition techniques, v.8b 25
26 .(B) Dynamic programming algo. Step 1: calculate the distortion matrix for dist ( i,j ) Step 2: calculate the accumulated matrix for D( i,j ) by using Speech recognition techniques, v.8b 26 D( i , j) D( i-1, j) D( i , j-1) D( i-1, j-1)
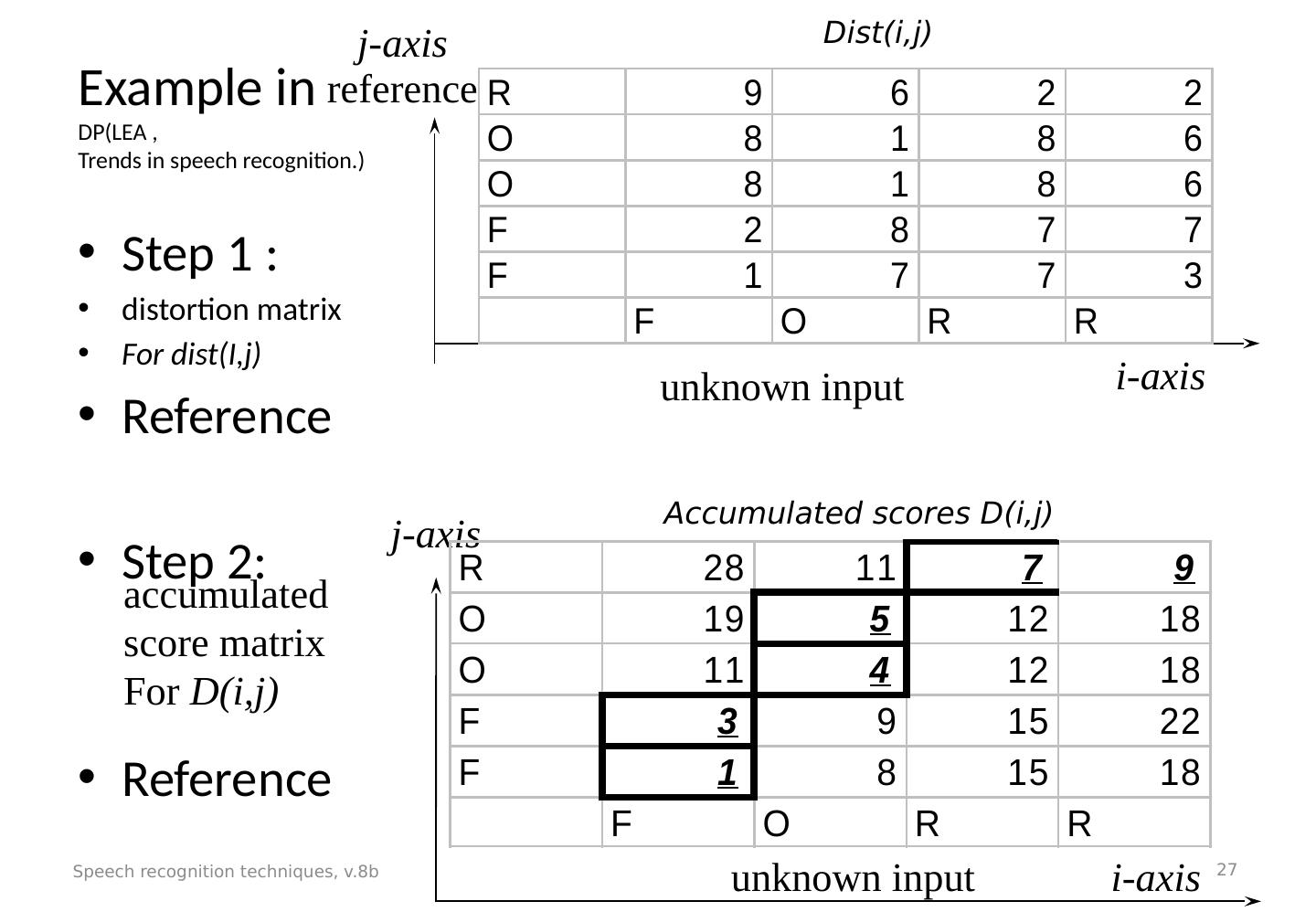
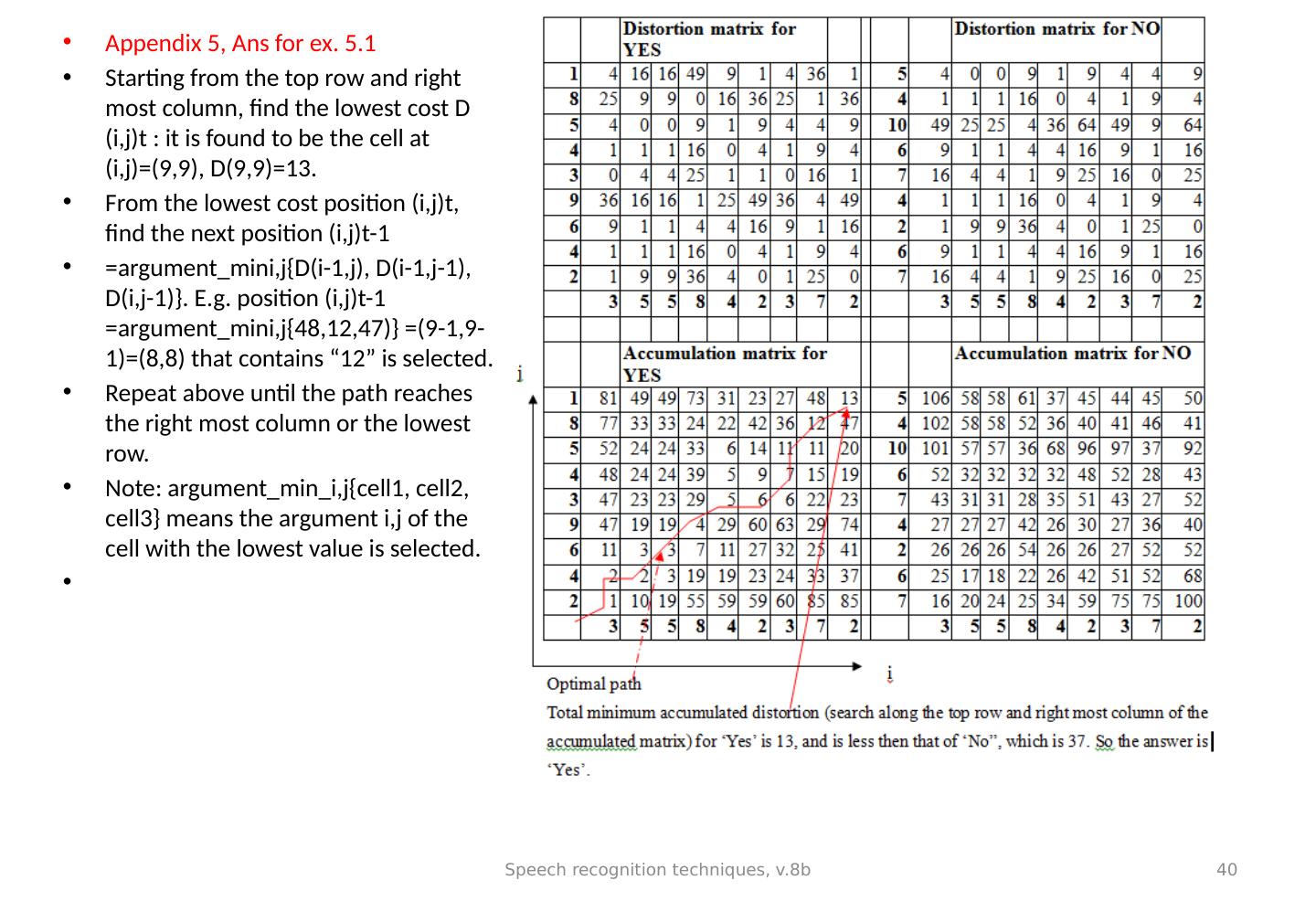
27 .Example in DP(LEA , Trends in speech recognition.) Step 1 : distortion matrix For dist(I,j) Reference Step 2: Reference Speech recognition techniques, v.8b 27 unknown input accumulated score matrix For D(i,j) j-axis i -axis unknown input reference Dist(i,j) Accumulated scores D(i,j) i-axis j-axis
28 .To find the optimal path in the accumulated matrix (and the minimum accumulated distortion/ distance) (updated) Starting from the top row and right most column, find the lowest cost D (i,j) t : it is found to be the cell at (i,j)=(3,5), D(3,5)=7 in the top row. *(this cost is called the “ minimum accumulated distance” , or “minimum accumulated distortion” ) From the lowest cost position p(i,j) t , find the next position (i,j) t-1 =argument_min_i,j{D(i-1,j), D(i-1,j-1), D(i,j-1)}. E.g. p(i,j) t-1 =argument_min i,j {11,5,12)} = 5 is selected. Repeat above until the path reaches the left most column or the lowest row. Note: argument_min_i,j{cell1, cell2, cell3} means the argument i,j of the cell with the lowest value is selected. Speech recognition techniques, v.8b 28
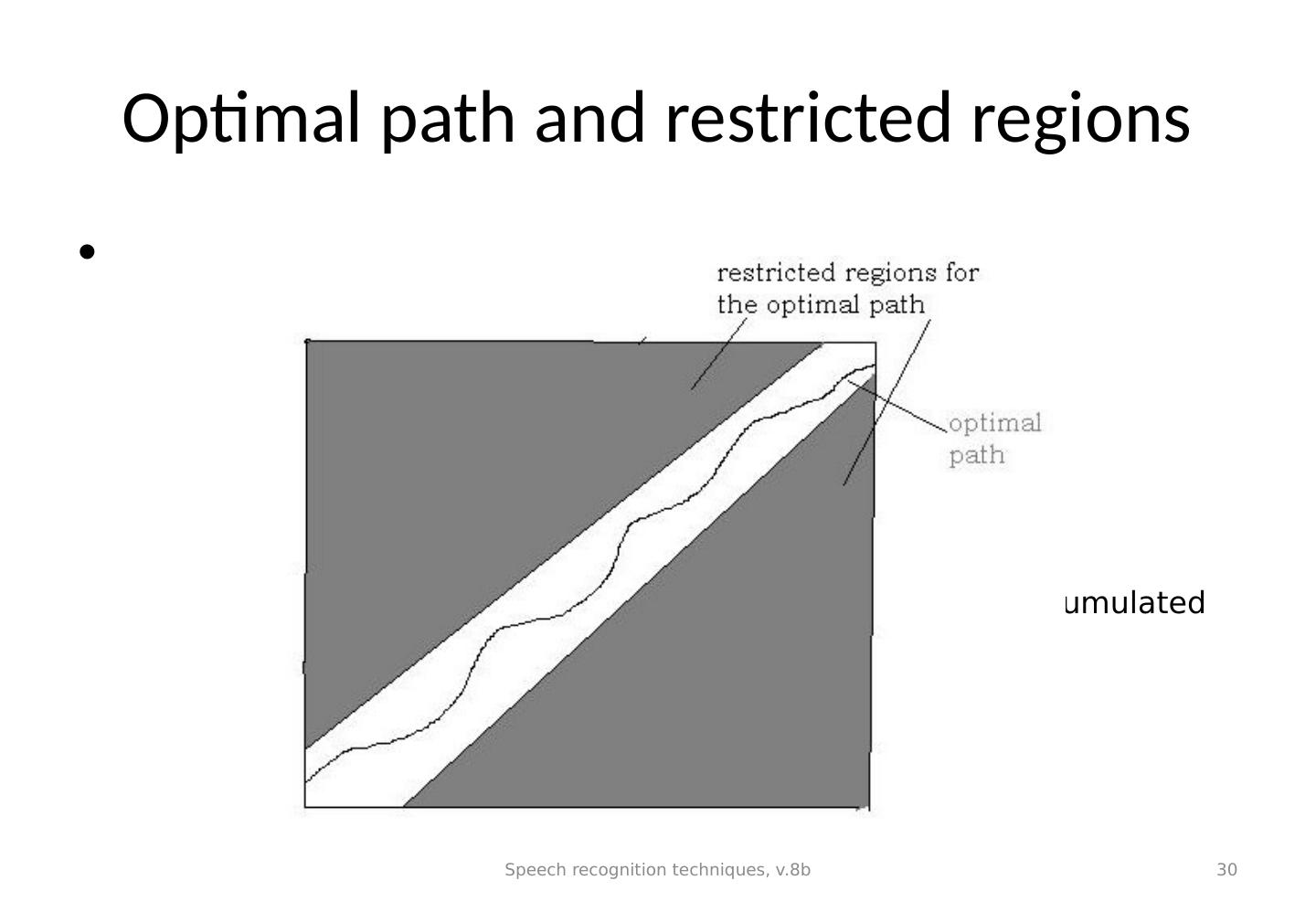
29 .Optimal path It should be from any element in the top row or right most column to any element in the bottom row or left most column. The reason is noise may be corrupting elements at the beginning or the end of the input sequence. However, in fact, in actual processing the path should be restrained near the 45 degree diagonal (from bottom left to top right), see the attached diagram, the path cannot passes the restricted regions. The user can set this regions manually. That is a way to prohibit unrecognizable matches. See next page. Speech recognition techniques, v.8b 29
3秒后跳转登录页面
去登陆

