
























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
03_Feature extraction from audio signals
Filtering
Linear predictive coding LPC
Cepstrum
展开查看详情
1 .Ch. 3: Feature extraction from audi o signals Filtering Linear predictive coding LPC Cepstrum Feature extraction, v.8a 1 week2
2 .(A) Filtering Ways to find the spectral envelope Filter banks: uniform Filter banks can also be non-uniform LPC and Cepstral LPC parameters Vector quantization method to represent data more efficiently Feature extraction, v.8a 2 freq.. filter1 output filter2 output filter3 output filter4 output spectral envelop Spectral envelop energy
3 .You can see the filter band output using windows-media-player for a frame Try to look at it Run windows-media-player To play music Right-click, select Visualization / bar and waves Video Demo Feature extraction, v.8a 3 Spectral envelop Frequency energy
4 .Speech recognition idea using 4 linear filters, each bandwidth is 2.5KHz Two sounds with two Spectral Envelopes SE ar ,SE ei ,E.g. Spectral Envelop (SE) “ar”, Spectral envelop “ei” Feature extraction, v.8a 4 Spectral envelope SE ar =“ar” energy energy Freq. Freq. Spectrum A Spectrum B filter 1 2 3 4 filter 1 2 3 4 v1 v2 v3 v4 w1 w2 w3 w4 Spectral envelope SE ei =“ei” Filter out Filter out 10KHz 10KHz 0 0
5 .Difference between two sounds (or spectral envelopes SE SE’) Difference between two sounds, E.g. SE ar ={v1,v2,v3,v4}=“ar”, SE ei ={w1,w2,w3,w4}=“ei” A simple measure of the difference is Dist =sqrt(|v1-w1| 2 +|v2-w2| 2 +|v3-w3| 2 +|v4-w4| 2 ) Where |x|=magnitude of x Feature extraction, v.8a 5
6 .Filtering method For each frame (10 - 30 ms), a set of filter outputs will be calculated. (frame overlap 5ms) There are many different methods for setting the filter bandwidths -- uniform or non-uniform Feature extraction, v.8a 6 Time frame i Time frame i+1 Time frame i+2 Input waveform 30ms 30ms 30ms 5ms Filter outputs (v1,v2,…) Filter outputs (v’1,v’2,…) Filter outputs (v’’1,v’’2,…)
7 .How to determine filter band ranges The pervious example of using 4 linear filters is too simple and primitive. We will discuss Uniform filter banks Log frequency banks Mel filter bands Feature extraction, v.8a 7
8 .Uniform Filter Banks Uniform filter banks bandwidth B= Sampling Freq... (Fs)/no. of banks (N) For example Fs=10Kz, N=20 then B=500Hz Simple to implement but not too useful Feature extraction, v.8a 8 ... freq.. 1 2 3 4 5 .... Q 500 1 K 1.5 K 2 K 2.5 K 3 K ... ( Hz) V Filter output v1 v2 v3
9 .Non-uniform filter banks : Log frequency Log. Freq... scale : close to human ear Feature extraction, v.8a 9 200 400 800 1600 3200 freq.. (Hz) v1 v2 v3 V Filter output
10 .Inner ear and the cochlea (human also has filter bands) Ear and cochlea Feature extraction, v.8a 10 http://universe-review.ca/I10-85-cochlea2.jpg http://www.edu.ipa.go.jp/chiyo/HuBEd/HTML1/en/3D/ear.html
11 .Mel filter bands (found by psychological and instrumentation experiments) Freq. lower than 1 KHz has narrower bands (and in linear scale) Higher frequencies have larger bands (and in log scale) More filter below 1KHz Less filters above 1KHz Feature extraction, v.8a 11 http://instruct1.cit.cornell.edu/courses/ece576/FinalProjects/f2008/pae26_jsc59/pae26_jsc59/images/melfilt.png Filter output
12 .Mel filter bands (found by psychological and instrumentation experiments) Freq. lower than 1 KHz has narrower bands (and in linear scale) Higher frequencies have larger bands (and in log scale) More filter below 1KHz Less filters above 1KHz Feature extraction, v.8a 11 http://instruct1.cit.cornell.edu/courses/ece576/FinalProjects/f2008/pae26_jsc59/pae26_jsc59/images/melfilt.png Filter output
13 .Critical band scale: Mel scale Based on perceptual studies Log. scale when freq. is above 1KHz Linear scale when freq. is below 1KHz Popular scales are the “Mel” (stands for melody) or “Bark” scales Feature extraction, v.8a 13 (f) Freq in hz Mel Scale (m) http://en.wikipedia.org/wiki/Mel_scale m=150 f=7000-6000 Below 1KHz, f m , linear Above 1KHz, f> m , log scale
14 .E xercise 3.0: Exercise ( i ): When the input frequency ranges from 200 to 800 Hz ( f=600Hz), what is the delta Mel ( m) in the Mel scale? Exercise (ii): When the input frequency ranges from 6000 to 7000 Hz ( f=1000Hz), what is the delta Mel ( m) in the Mel scale? Feature extraction, v.8a 14
15 .Matlab program to plot the mel scale Matlab code %plot mel scale, f=1:10000 %input frequency range mel=(2595* log10(1+f/700)); figure(1) clf plot(f,mel) grid on xlabel(freqeuncy in HZ) ylabel(freqeuncy Mel scale) title(Plot of Frequency to Mel scale) Plot Feature extraction, v.8a 15
16 .(B) Use Linear Predictive coding LPC to implement filters Linear Predictive coding LPC methods Feature extraction, v.8a 16
17 .Motivation Fourier transform is a frequency method for finding the parameters of an audio signal, it is the formal method to implement filter. However, there is an alternative, which is a time domain method, and it works faster. It is called Linear Predicted Coding LPC coding method. The next slide shows the procedure for finding the filter output. The procedures are: (i) Pre-emphasis, (ii) autocorrelation, (iii) LPC calculation, (iv) Cepstral coefficient calculation to find the representations the filter output. Feature extraction, v.8a 17
18 .Feature extraction data flow - The LPC (Liner predictive coding) method based method Signal preprocess -> autocorrelation-> LPC ---->cepstral coef (pre-emphasis) r 0 ,r 1 ,.., r p a 1 ,.., a p c 1 ,.., c p (windowing) (Durbin alog.) Feature extraction, v.8a 18
19 .Pre-emphasis “ The high concentration of energy in the low frequency range observed for most speech spectra is considered a nuisance because it makes less relevant the energy of the signal at middle and high frequencies in many speech analysis algorithms. ” From Vergin, R. etal. ,“ "Compensated mel frequency cepstrum coefficients ", IEEE, ICASSP-96. 1996 . Feature extraction, v.8a 19
20 .Pre-emphasis -- high pass filtering (the effect is to suppress low frequency) To reduce noise, average transmission conditions and to average signal spectrum. Feature extraction, v.8a 20
21 .Class exercise 3.1 A speech waveform S has the values s0,s1,s2,s3,s4,s5,s6,s7,s8= [1,3,2,1,4,1,2,4,3]. Find the pre-emphasized wave if the pre-emphasis constant is 0.98. Feature extraction, v.8a 21
22 .The Linear Predictive Coding LPC method Linear Predictive Coding LPC method Time domain Easy to implement Achieve data compression Feature extraction, v.8a 22
23 .The LPC speech production model Speech synthesis model: Impulse train generator governed by pitch period-- glottis Random noise generator for consonant. Vocal tract parameters = LPC parameters Feature extraction, v.8a 23 X Time-varying digital filter output Impulse train Generator Voice/unvoiced switch Gain Noise Generator (Consonant) LPC parameters Time varying digital filter Glottal excitation for vowel http://home.hib.no/al/engelsk/seksjon/SOFF-MASTER/ill061.gif
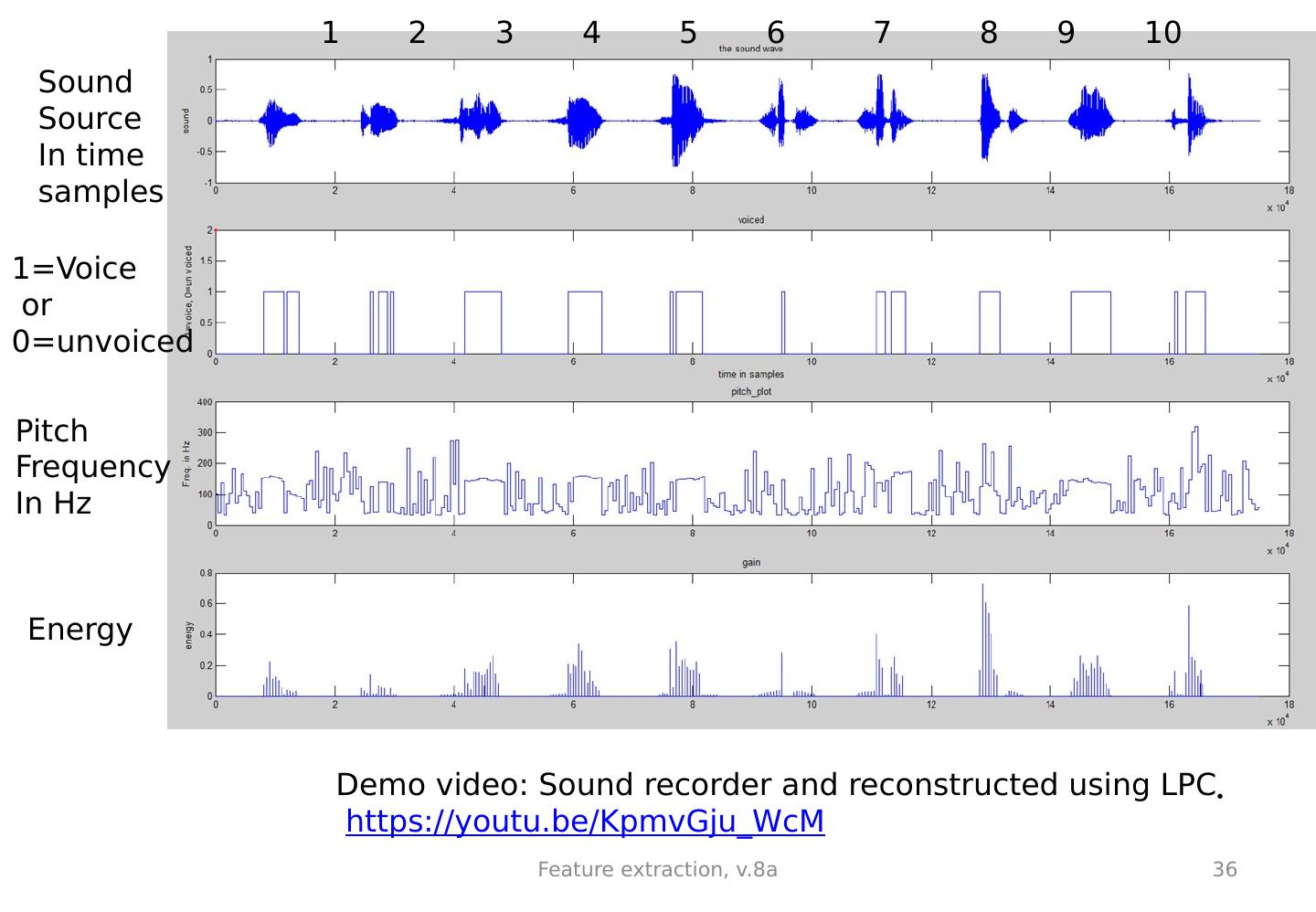
24 .Example of a Consonant and Vowel Sound file : http://www.cse.cuhk.edu.hk/~khwong/www2/cmsc5707/sar1.wav The sound of ‘sar’ (沙) in Cantonese The sampling frequency is 22050 Hz, so the duration is 2x10 4 x(1/22050)=0.9070 seconds. By inspection, the consonant ‘s’ is roughly from 0.2x10 4 samples to 0.6 x10 4 samples. The vowel ‘ar’ is from 0.62 x10 4 samples to 1.2 2x10 4 samples. The lower diagram shows a 20ms (which is (20/1000)/(1/22050)=441=samples) segment (vowel sound ‘ar’) taken from the middle (from the location at the 1x10 4 th sample) of the sound. %Sound source is from http://www.cse.cuhk.edu.hk/~khwong/www2/cmsc5707/sar1.wav [x,fs]=wavread(sar1.wav); %Matlab source to produce plots fs % so period =1/fs, during of 20ms is 20/1000 %for 20ms you need to have n20ms=(20/1000)/(1/fs) n20ms=(20/1000)/(1/fs) %20 ms samples len=length(x) figure(1),clf, subplot(2,1,1),plot(x) subplot(2,1,2),T1=round(len/2); %starting point plot(x(T1:T1+n20ms)) Consonant (s), Vowel(ar) Feature extraction, v.8a 24 The vowel wave is periodic
25 .For vowels (voiced sound), use LPC to represent the signal The concept is to find a set of parameters ie. 1 , 2 , 3 , 4 ,.. p=8 to represent the same waveform (typical values of p=8->13) Feature extraction, v.8a 25 1, 2, 3, 4,.. 8 Each time frame y=512 samples ( S 0 ,S 1 ,S 2 ,. S n ,S N-1=511 ) 512 integer numbers (16-bit each) Each set has 8 floating point numbers (data compressed) ’1, ’2, ’3, ’4,.. ’8 ’’1, ’’2, ’’3, ’’4,.. ’’8 : Can reconstruct the waveform from these LPC codes Time frame y Time frame y+1 Time frame y+2 Input waveform 30ms 30ms 30ms For example
26 .Class Exercise 3.2 Concept: we want to find a set of a1,a2,..,a8, so when applied to all Sn in this frame (n=0,1,..N-1), the total error E (n=0 N-1) is minimum Feature extraction, v.8a 26 0 N-1=511 Exercise 2.2 Write the error function e n at n=130, draw it on the graph Write the error function at n=288 Why e 0 = s 0 ? Write E for n=1,..N-1, (showing n=1, 8, 130,288,511) S n-2 S n-4 S n-3 S n-1 S n S Signal level Time n n
27 .LPC idea and procedure The idea: from all samples s 0 ,s 1 ,s 2 ,s N-1=511 , we want to find a p (p=1,2,..,8), so that E is a minimum. The periodicity of the input signal provides information for finding the result. Procedures For a speech signal, we first get the signal frame of size N =512 by windowing(will discuss later). Sampling at 25.6KHz, it is equal to a period of 20ms. The signal frame is ( S 0 ,S 1 ,S 2 ,. S n ..,S N-1=511 ) total 512 samples. Ignore the effect of outside elements by setting them to zero, I.e. S - ..=S -2 = S -1 =S 512 =S 513 =…= S =0 etc. We want to calculate LPC parameters of order p=8 , i.e. 1 , 2 , 3 , 4 ,.. p=8 . Feature extraction, v.8a 27 Week3
28 .For each 30ms time frame Feature extraction, v.8a 28 Time frame y Input waveform 30ms 1, 2, 3, 4,.. 8
29 . Solve for a 1,2,…,p Feature extraction, v.8a 29 Time frame y Input waveform 30ms 1, 2, 3, 4,.. 8 Derivations can be found at http://www.cslu.ogi.edu/people/hosom/cs552/lecture07_features.ppt Use Durbin’s equation to solve this From the literature (https://en.wikipedia.org/wiki/Linear_prediction) , it says a0 is -1, why? One explanation is: in equation 1 of slide 29 (chapter 3) , put s_Tilda(n) (the current guessed signal value ) on the left hand side to the right, and assume it is multiplied by a constant a0. So a0 must be -1 .
3秒后跳转登录页面
去登陆

