展开查看详情
1 .CSC2/458 Parallel and Distributed Systems
Checkpointing and Recovery
Sreepathi Pai
April 17, 2018
URCS
�
2 .Outline
Checkpointing and Recovery
Independent Checkpointing
Coordinated Checkpointing
Message Logging
�
3 .Outline
Checkpointing and Recovery
Independent Checkpointing
Coordinated Checkpointing
Message Logging
�
4 .Errors happen
• Errors happen
• How do we recover from them (say, for message loss)?
• (before information theory): ?
• (after information theory): ?
�
5 .Checkpointing and Recovery
To checkpoint is to save the state of a computation so that you
can “rollback” to it
• Examples:
• Save games
• Virtual machine snapshots
Recovery is then “simply” restoring the checkpoint
�
6 .Distributed Checkpointing: The Challenge
• Processes only know:
• which messages they have received
• which messages they have sent
• what their local state is
• Checkpointing ideally should not require everybody to
“pause”
• Must run concurrently with computation
�
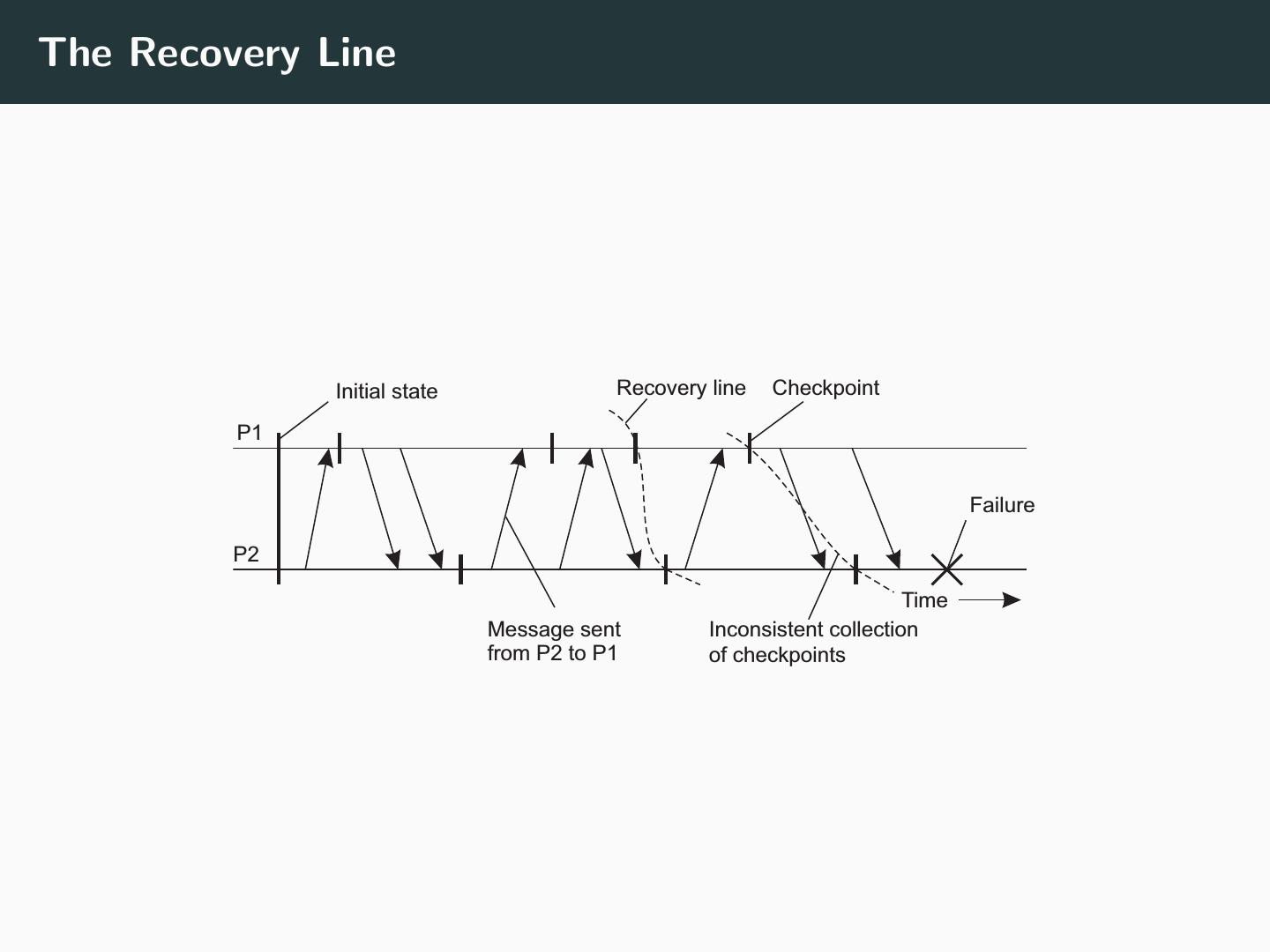
7 .The Recovery Line
Initial state Recovery line Checkpoint
P1
Failure
P2
Time
Message sent Inconsistent collection
from P2 to P1 of checkpoints
�
8 .Outline
Checkpointing and Recovery
Independent Checkpointing
Coordinated Checkpointing
Message Logging
�
9 .Algorithm
• A process records its local state independently
• messages sent/received included
• A recovery for a process entails going back to its most recent
checkpoint
• Unfortunately, this can’t be done independently
�
10 .Rollbacks
Initial state Checkpoint
P1
m* m Failure
P2
Time
Assume P2 fails. How far we do need to rollback to achieve a
consistent worldview?
�
11 .Detecting dependencies
• For a process Pi , let INTi (m) be the interval between the
m − 1 and m checkpoints.
• All messages sent in INTi (m) contain (i, m)
• When process Pj receives this message, it may be in INTj (n)
• records dependency INTi (m) → INTj (n)
• saves dependency with checkpoint
�
12 .Rolling back: Consistency
• If Pi rolls back to checkpoint m − 1, no messages from
INTi (m) were ever sent
• All checkpoints dependent on INTi (m) are invalid
• Rollbacks need to continue until consistency is reached
�
13 .Outline
Checkpointing and Recovery
Independent Checkpointing
Coordinated Checkpointing
Message Logging
�
14 .Algorithm
• Coordinator broadcasts CHECKPOINT-REQUEST message to
all processes
• When this request is received,
• Process checkpoints local state
• Acknowledges to coordinator that it has taken checkpoint and
waits
• When coordinator receives acknowledgements from all
processes, it sends CHECKPOINT-DONE
• Processes resume computation
• What about messages?
�
15 .Message handling
• All incoming messages received after
CHECKPOINT-REQUEST are not considered part of the
checkpoint
• All outgoing messages are held back until
CHECKPOINT-DONE is received
• This results in a “globally consistent state”
• How?
�
16 .Outline
Checkpointing and Recovery
Independent Checkpointing
Coordinated Checkpointing
Message Logging
�
17 .Basic idea
• Computations are deterministic and rely only on messages
transmitted
• Save messages from a checkpoint and replay them during
recovery
�
18 .Piecewise deterministic execution
• A piecewise deterministic computation interval:
• starts with a non-deterministic event (e.g. receipt of a
message)
• continues in a completely deterministic fashion
• ends just before another non-deterministic event
This implies that only non-deterministic events need to be logged.
�
19 .Who should save the messages?
Q crashes and recovers
P
m1 m1 m2 is never replayed,
so neither will m3
Q
m3 m2 m3
m2
R
Unlogged message Time
Logged message
�
20 .Orphan processes
• Let DEP(m) represent processes that depend on message m
• Let COPY (m) represent processes that contain a copy of m
• but may not have logged it
• Note, m contains all details necessary to retransmit it
A process Q is orphaned if and only if:
• Q depends on m (i.e. Q ∈ DEP(m))
• All processes in COPY (m) have failed
• So m cannot be played back
�
21 .Pessimistically avoiding orphan processes
• Orphan processes can be avoided by ensuring that
• A non-deterministic message is sent only to one process
• That process cannot send another message without logging m
�
22 .Further reading
Chandy and Lamport, “Distributed Snapshots: Determining Global
States of Distributed Systems”, ACM TOCS 1985
�
23 .Acknowledgments
All figures from Van Steen and Tanenbaum, Distributed Systems,
3rd Edition, Chapter 8.
�