





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
20-Distribute Computing – Other Programming Models
Abstractions for Distributed Computing
Spark’s Abstractions
The Spark Runtime
Layering on top of Spark
展开查看详情
1 .CSC2/458 Parallel and Distributed Systems Distribute Computing – Other Programming Models Sreepathi Pai April 03, 2018 URCS
2 .Outline Abstractions for Distributed Computing Spark’s Abstractions The Spark Runtime Layering on top of Spark
3 .Outline Abstractions for Distributed Computing Spark’s Abstractions The Spark Runtime Layering on top of Spark
4 .Abstractions for Shared Memory Programming • Shared address space • One Address, One Value • Shared memory • Disk • RAM • Coherent Caches • Disk Cache (OS) • Processor Cache (Processor) • Locking • Libraries • Hardware Atomics • Resilience • ECC (Hardware)
5 .Abstractions for Distributed Computing • Distributed Name Space • e.g. ? • Distributed Shared Memory • Distributed File Systems • Distributed Caching • e.g. memcached • Distributed Concurrency Control • i.e. locking and consistency • Data Distribution and Marshalling • e.g. ntoh, hton • Distributed Execution • Resilience • e.g. ?
6 .Provided by most OS • Sockets
7 .Provided by MPI • Distributed Name Space (Ranks) • Send/Recv • Communication Primitives • Distributed Execution (SPMD) • No: • distributed shared memory • distributed file system • caching • locking and consistency • resilience • marshalling
8 .Erlang/Elixir What is Erlang? Maybe, now, we should ask what is Elixir?
9 .What is Erlang? Part I Verbatim from the Erlang FAQ: Introduction • Erlang provides a simple and powerful model for error containment and fault tolerance (supervised processes). • Concurrency and message passing are a fundamental to the language. Applications written in Erlang are often composed of hundreds or thousands of lightweight processes. Context switching between Erlang processes is typically one or two orders of magnitude cheaper than switching between threads in a C program.
10 .What is Erlang? Part II Verbatim from the Erlang FAQ: Introduction • Writing applications which are made of parts which execute on different machines (i.e. distributed applications) is easy. Erlang’s distribution mechanisms are transparent: programs need not be aware that they are distributed. • The Erlang runtime environment (a virtual machine, much like the Java virtual machine) means that code compiled on one architecture runs anywhere. The runtime system also allows code in a running system to be updated without interrupting the program.
11 .Hadoop What is Hadoop?
12 .What does Hadoop give us? • Distributed File System • HDFS • MapReduce programming model • distributed execution • marshalling • caching • Resilience • Always writes to stable storage • Reruns failed jobs • No need for: • distributed name space • distributed shared memory • concurrency control
13 .Perspective MapReduce ? Erlang/Elixir MPI Sockets
14 .Outline Abstractions for Distributed Computing Spark’s Abstractions The Spark Runtime Layering on top of Spark
15 .A Spark of an idea • Apache Spark • “fast and general engine for large-scale data processing.” • Translation: Write more than MapReduce programs easily • Compared to MPI • 100x faster than Hadoop • “In-memory” • You can write your own data processing engine on top of Spark
16 .What Spark Provides • Distributed File system • Reuses HDFS • Distributed Execution • Data Partitioning • Marshalling • Resilience • Distributed Caching • No coherence required (or supported) • No: • Distributed Concurrency Control (not supported) • Distributed Shared Memory (fine-grained)
17 .Spark Programming Model: 10000ft overview • Spark is a limited programming model • Built on observation that: • “Many parallel applications naturally apply the same operations to multiple data items” • i.e. data-parallel model, e.g. SIMD, SPMD, etc. • Provides a distributed data structure • Resilient Distributed Datasets (RDDs) • Like a huge table, but could be anything really • Programs (you write) operate on RDDs in a coarse-grained fashion • They always operate on entire RDDs • I.e. on all elements in a RDD • Constrast with DSM which allows fine-grained accesses • Java/Python/Scala
18 .Resilient Distributed Datasets (RDD) • A RDD is a • “read-only, partitioned set of records” • Can only be built by “deterministic operations” (transformations) on: • data in stable storage • or other RDDs • RDDs “remember” the operations that were used to create them • paper calls this “lineage” • RDDs exist “lazily” in memory • the operations are only applied when needed (database lingo: materialized) • can be stored on disk too • Why are these properties important?
19 .Comparison to DSM
20 .Spark Example lines = spark.textFile("hdfs://...") errors = lines.filter(_.startsWith("ERROR")) errors.persist() errors.count()
21 .Spark Transformations
22 .Spark Actions
23 .Outline Abstractions for Distributed Computing Spark’s Abstractions The Spark Runtime Layering on top of Spark
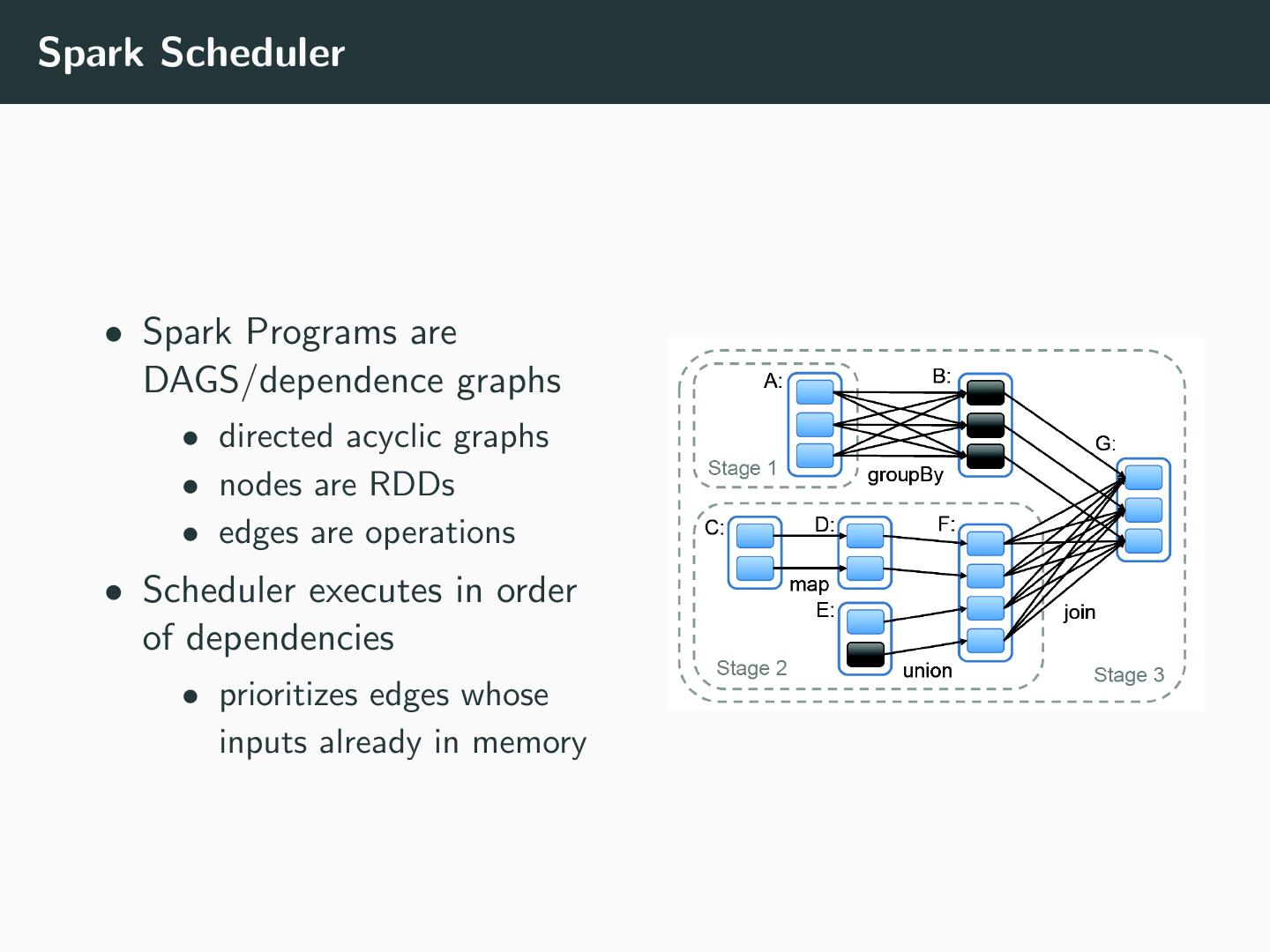
24 .Spark Scheduler • Spark Programs are DAGS/dependence graphs • directed acyclic graphs • nodes are RDDs • edges are operations • Scheduler executes in order of dependencies • prioritizes edges whose inputs already in memory
25 .Scheduler Optimizations • Narrow operations pipelined • i.e. loop coalescing for(r in RDD) for(r in RDD) { out1 = op1(r) out1 = op1(r) out2 = op2(r) for(r in RDD) } out2 = op2(r) • Operations scheduled on machines based on locality • similar to “owner-computes”
26 .Handling Failure • Each RDD knows how to recreate itself • Ultimately from stable storage • Recreation may use RDDs from other machines • “Wide” operations • e.g. join • Or from the same machine • “Narrow” operations • e.g. map • Can run in parallel • RDDs are immutable
27 .Outline Abstractions for Distributed Computing Spark’s Abstractions The Spark Runtime Layering on top of Spark
28 .MapReduce • RDD.map() • RDD.reduceByKey()
29 .DryadLINQ and SQL • RDD.select() • RDD.groupby() • etc.
3秒后跳转登录页面
去登陆

