展开查看详情
1 .CSC2/458 Parallel and Distributed Systems
PPMI: Synchronization Preliminaries
Sreepathi Pai
February 15, 2018
URCS
�
2 .Outline
Synchronization Primitives
Transactional Memory
Mutual Exclusion Implementation Strategies
Mutual Exclusion Implementations
�
3 .Outline
Synchronization Primitives
Transactional Memory
Mutual Exclusion Implementation Strategies
Mutual Exclusion Implementations
�
4 .Embarrassingly Parallel Programs
What are the characteristics of programs that scale linearly?
�
5 .Embarrassingly Parallel Programs
No serial portion.
I.e., no communication and synchronization.
�
6 .Critical Sections
Why should critical sections be short?
[A critical section is a region of code that must be executed by a
single thread at a time.]
�
7 .Locks
tail_lock.lock() // returns only when lock is obtained
tail = tail + 1
list[tail] = newdata
tail_lock.unlock()
�
8 .Outline
Synchronization Primitives
Transactional Memory
Mutual Exclusion Implementation Strategies
Mutual Exclusion Implementations
�
9 .The Promise of Transactional Memory
transaction {
tail += 1;
list[tail] = data;
}
• Wrap critical sections with transaction markers
• Transactions succeed when no conflicts are detected
• Conflicts cause transactions to fail
• Policy differs on who fails and what happens on a failure
�
10 .Implementation (High-level)
• Track reads and writes
• inside transactions (weak atomicity)
• everywhere (strong atomicity)
• Conflict when
• reads and writes “shared” between transactions
• these may not correspond to programmer-level reads/writes
• Eager conflict detection
• every read and write checked for conflict
• aborts transaction immediately on conflict
• Lazy conflict detection
• check conflicts when transaction end
• May provide abort path
• taken when transactions fail
�
11 .Actual Implementations
How can we use cache coherence protocols to implement
transactional memory?
�
12 .Outline
Synchronization Primitives
Transactional Memory
Mutual Exclusion Implementation Strategies
Mutual Exclusion Implementations
�
13 .Mutual Exclusion
How do n processes co-ordinate to achieve exclusive access to one
or more resources for themselves?
�
14 .Some strategies
• Take turns
• Tokens
• Time-based
• Queue
• Assume you have exclusive access and detect and resolve
conflicts
�
15 .Evaluating Strategies: Correctness
Show that mutual exclusion is achieved (under all possible
orderings).
• Does strategy deadlock?
• What are the conditions for deadlock?
• Does strategy create priority inversions?
• What is a priority inversion?
�
16 .Evaluation: Performance
How do we evaluate performance of, say, a particular
implementation strategy for locks?
• Use execution time for locking and unlocking?
�
17 .Evaluation: Performance
• Use throughput: Operations/Second
• Vary degree of contention
• I.e. change number of parallel workers
• “Low contention” vs “High contention”
• Operations can either be:
• Application-level operations
• Lock/Unlock operations
�
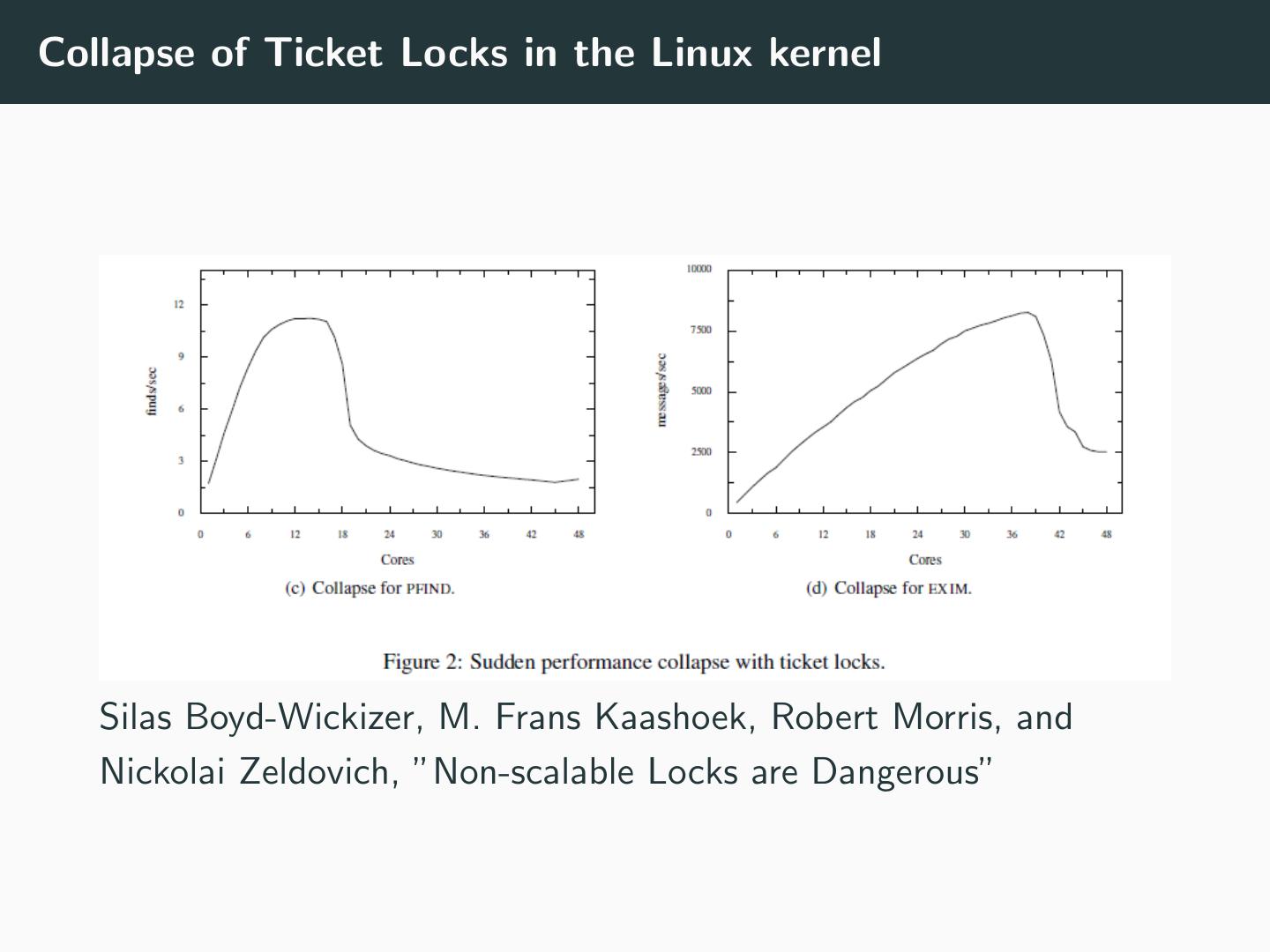
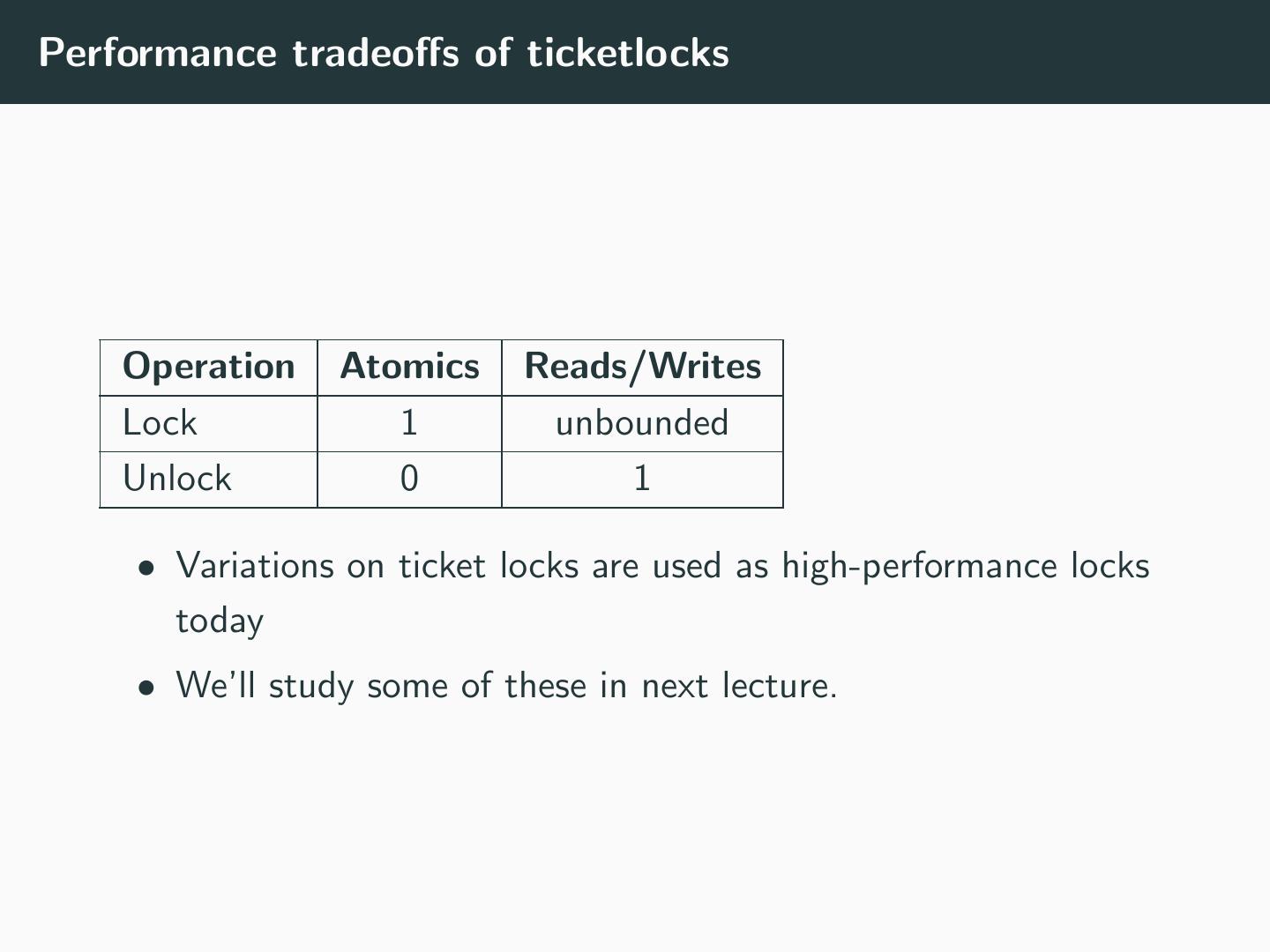
18 .Collapse of Ticket Locks in the Linux kernel
Silas Boyd-Wickizer, M. Frans Kaashoek, Robert Morris, and
Nickolai Zeldovich, ”Non-scalable Locks are Dangerous”
�
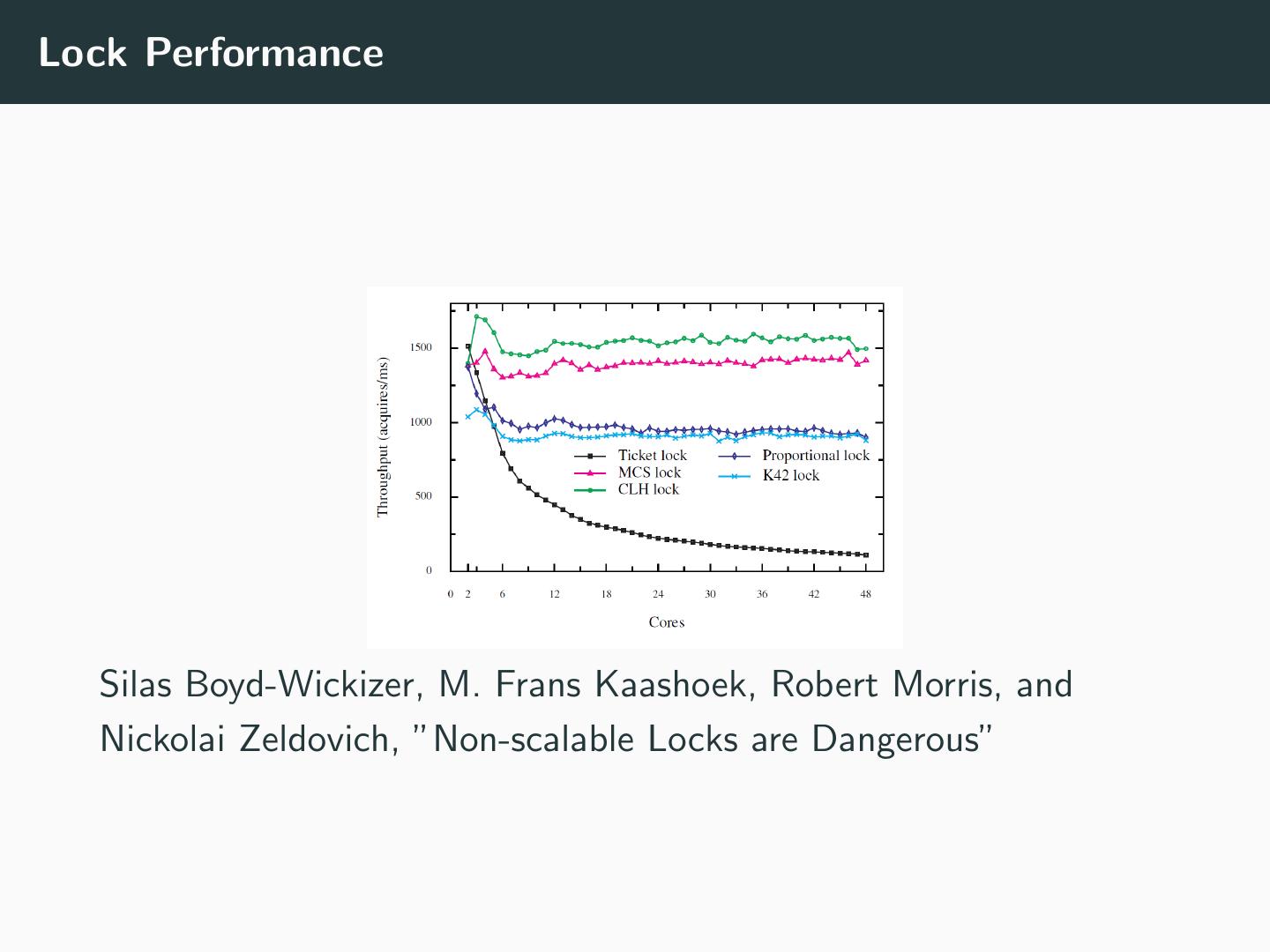
19 .Lock Performance
Silas Boyd-Wickizer, M. Frans Kaashoek, Robert Morris, and
Nickolai Zeldovich, ”Non-scalable Locks are Dangerous”
�
20 .Evaluation: Fairness/Starvation
Will all workers that need access to a resource get it?
Consider scheduler queues with shortest-job-first scheduling.
�
21 .Evaluation: Efficiency
• How much storage is required?
• How many operations are used?
• How much do those operations cost?
• Should you yield or should you spin?
�
22 .Evaluation: Other Notions
We will examine these notions in more detail in next two lectures:
• Progress
• System-wide progress (“lock-free”)
• Per-thread (“wait-free”)
• Resistance to failure of workers
�
23 .Outline
Synchronization Primitives
Transactional Memory
Mutual Exclusion Implementation Strategies
Mutual Exclusion Implementations
�
24 .Can this happen?
T0 T1
a = -5 a = 10
A later read of a returns −10.
�
25 .Implementation of Locks
All of the below algorithms require only read/write instructions(?):
• Peterson’s Algorithm (for n = 2 threads)
• Filter Algorithm (> 2 threads)
• Lamport’s Bakery Algorithm
�
26 .Limitations
• for n threads, require n memory locations
• between a write and a read, another thread may have changed
values
�
27 .Atomic Read–Modify–Write Instructions
• Combine a read–modify–write into a single “atomic” action
• Unconditional
• type sync fetch and add (type *ptr, type value,
...)
• Conditional
• bool sync bool compare and swap (type *ptr, type
oldval, type newval, ...)
• type sync val compare and swap (type *ptr, type
oldval, type newval, ...)
• See GCC documentation
• sync functions are replaced by atomic functions
�
28 .AtomicCAS
• (Generic) Compare and Swap
• atomic cas(ptr, old, new)
• writes new to ptr if ptr contains old
• returns old
• Only atomic primitive really required
atomic_add(ptr, addend) {
do {
old = *ptr;
} while(atomic_cas(ptr, old, old + addend) != old);
}
�
29 .Locks that spin/Busy-waiting locks
• Locks are initialized to UNLOCKED
lock(l):
while(atomic_cas(l, UNLOCKED, LOCKED) != UNLOCKED);
unlock(l):
l = UNLOCKED;
• This is a poor design
• Why?
• Suitable only for very short lock holds
• Use random backoff otherwise (e.g. sleep or PAUSE)
�