






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
06-Parallel Memory Systems: Coherence
Introduction to Parallel Memory Systems
Memory Systems in Parallel Processors
Coherence
Implementations in Hardware
Implications for Parallel Programs
展开查看详情
1 .CSC2/458 Parallel and Distributed Systems Parallel Memory Systems: Coherence Sreepathi Pai February 06, 2018 URCS
2 .Outline Introduction to Parallel Memory Systems Memory Systems in Parallel Processors Coherence Implementations in Hardware Implications for Parallel Programs
3 .Outline Introduction to Parallel Memory Systems Memory Systems in Parallel Processors Coherence Implementations in Hardware Implications for Parallel Programs
4 .Traditional View of Memory • Memory is accessed through loads/stores CPU • Memory contents have addresses • Smallest unit of access varies across machines • Usually 8 bits (i.e. 1 byte) • Some machines have other correctness constraints Memory • e.g. alignment • x86 has very few correctness constraints
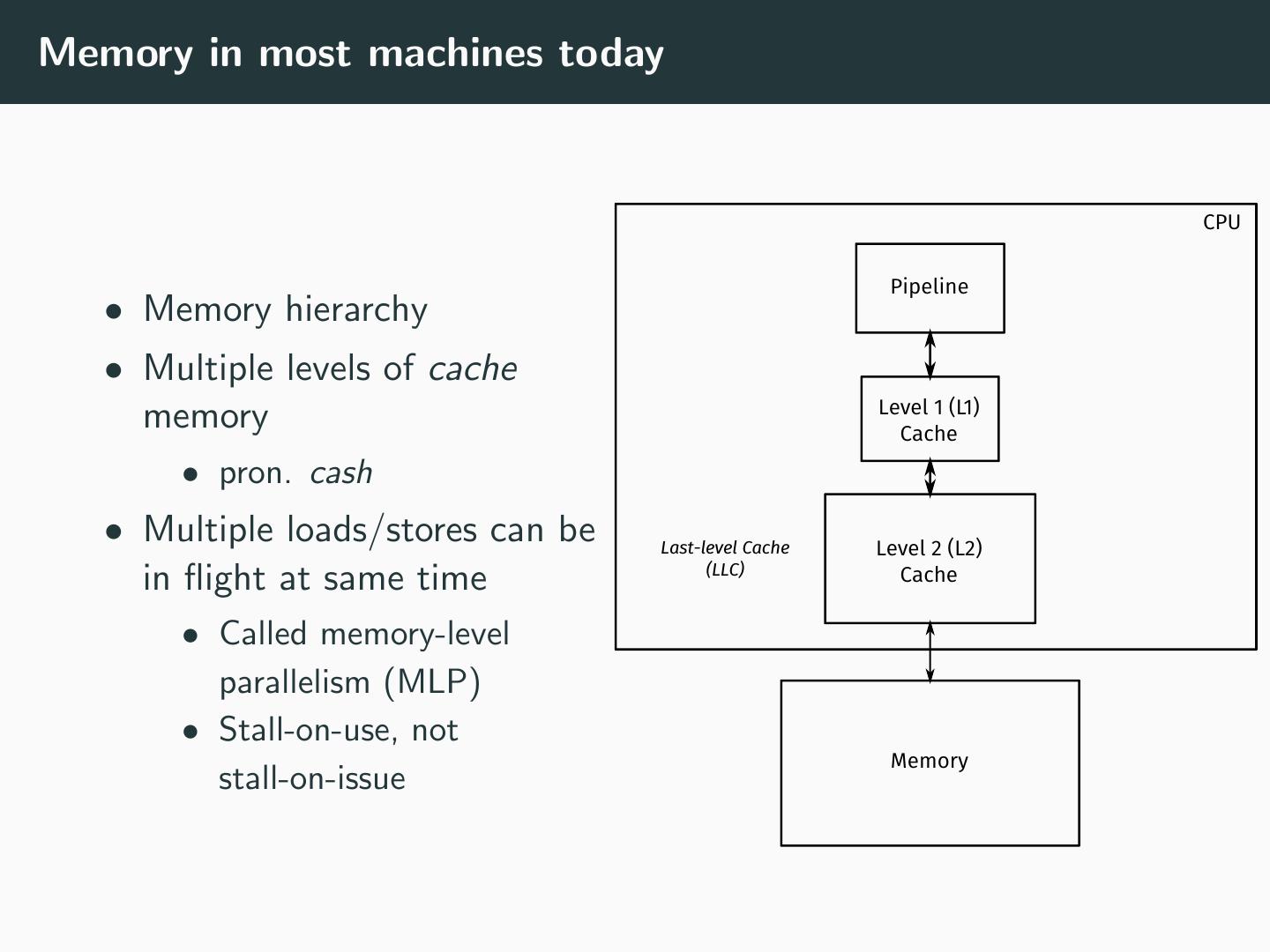
5 .Memory in most machines today CPU Pipeline • Memory hierarchy • Multiple levels of cache Level 1 (L1) memory Cache • pron. cash • Multiple loads/stores can be Last-level Cache Level 2 (L2) (LLC) Cache in flight at same time • Called memory-level parallelism (MLP) • Stall-on-use, not Memory stall-on-issue
6 .Caches • Caches are faster than main memory • Closer to pipeline • Smaller than main memory • Usually, SRAM instead of DRAM (main memory) • Caches contain copies of data in main memory • If address requested by load/store exists in cache: hit • If address does not exist in cache: miss • Addresses that hit can be satisfied from the cache • Addresses that miss are forwarded to next level of memory hierarchy • Forwarding continues until found • What is the last level?
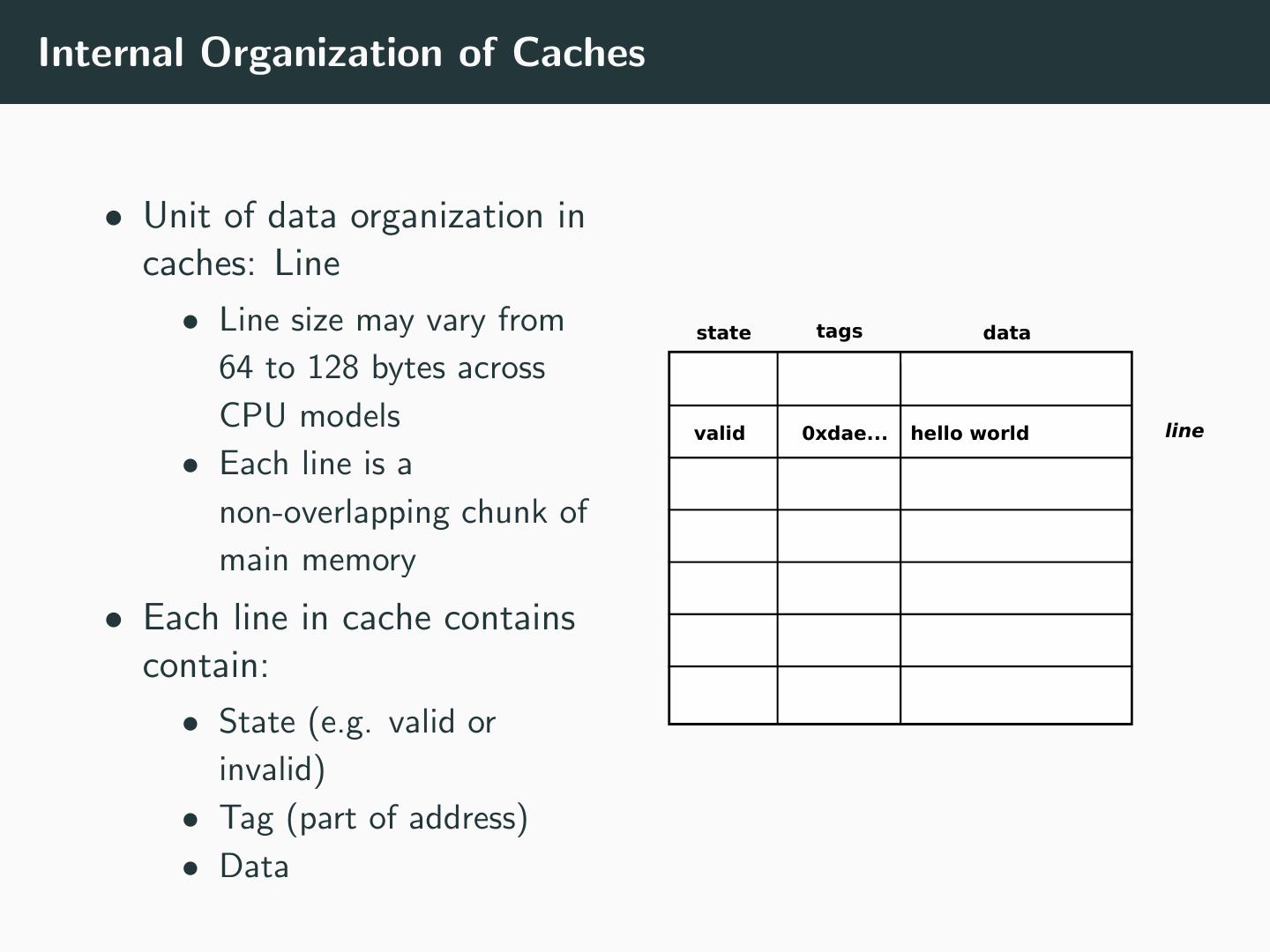
7 .Internal Organization of Caches • Unit of data organization in caches: Line • Line size may vary from state tags data 64 to 128 bytes across CPU models valid 0xdae... hello world line • Each line is a non-overlapping chunk of main memory • Each line in cache contains contain: • State (e.g. valid or invalid) • Tag (part of address) • Data
8 .Outline Introduction to Parallel Memory Systems Memory Systems in Parallel Processors Coherence Implementations in Hardware Implications for Parallel Programs
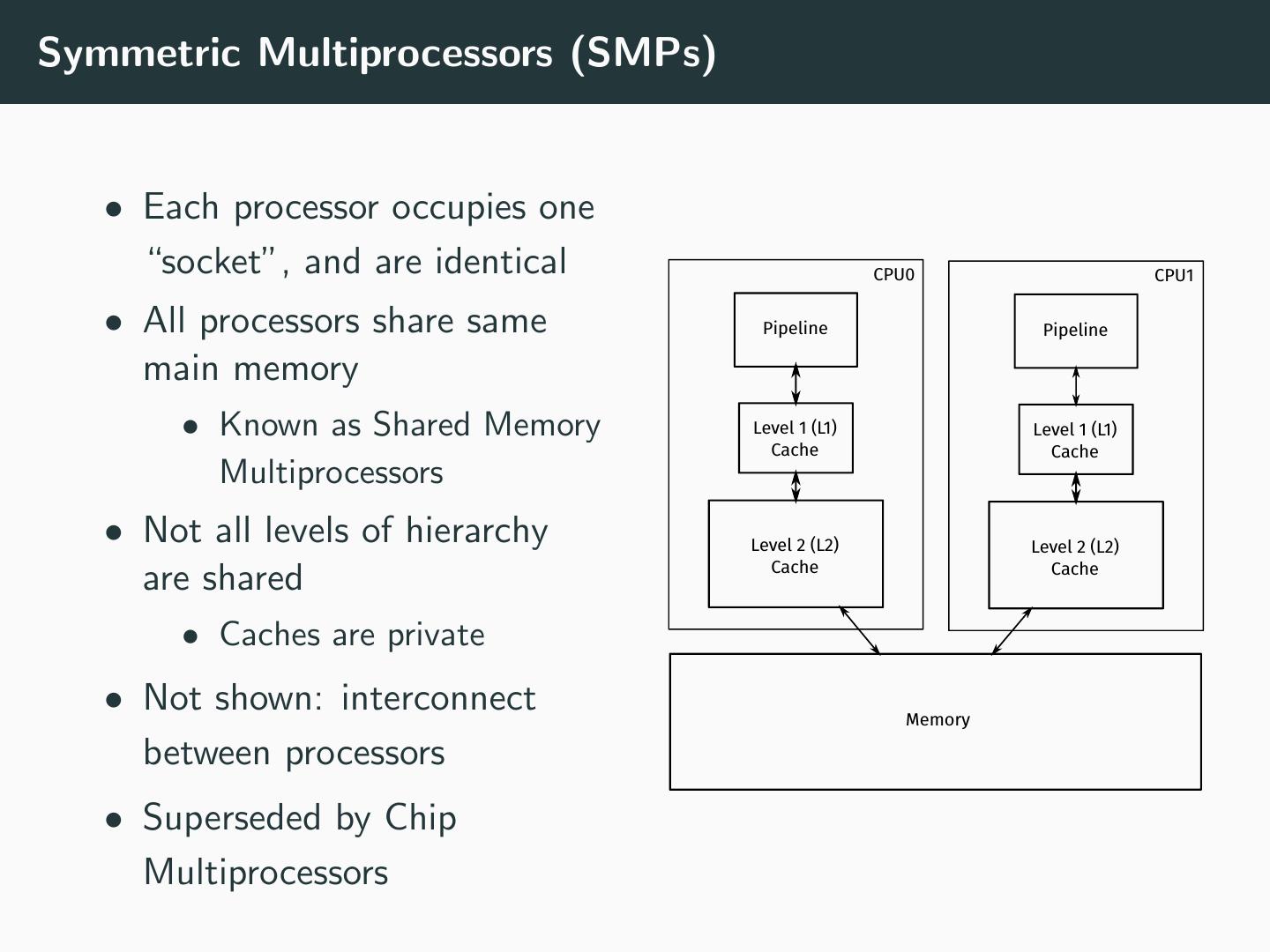
9 .Symmetric Multiprocessors (SMPs) • Each processor occupies one “socket”, and are identical CPU0 CPU1 • All processors share same Pipeline Pipeline main memory • Known as Shared Memory Level 1 (L1) Level 1 (L1) Cache Cache Multiprocessors • Not all levels of hierarchy Level 2 (L2) Level 2 (L2) Cache Cache are shared • Caches are private • Not shown: interconnect Memory between processors • Superseded by Chip Multiprocessors
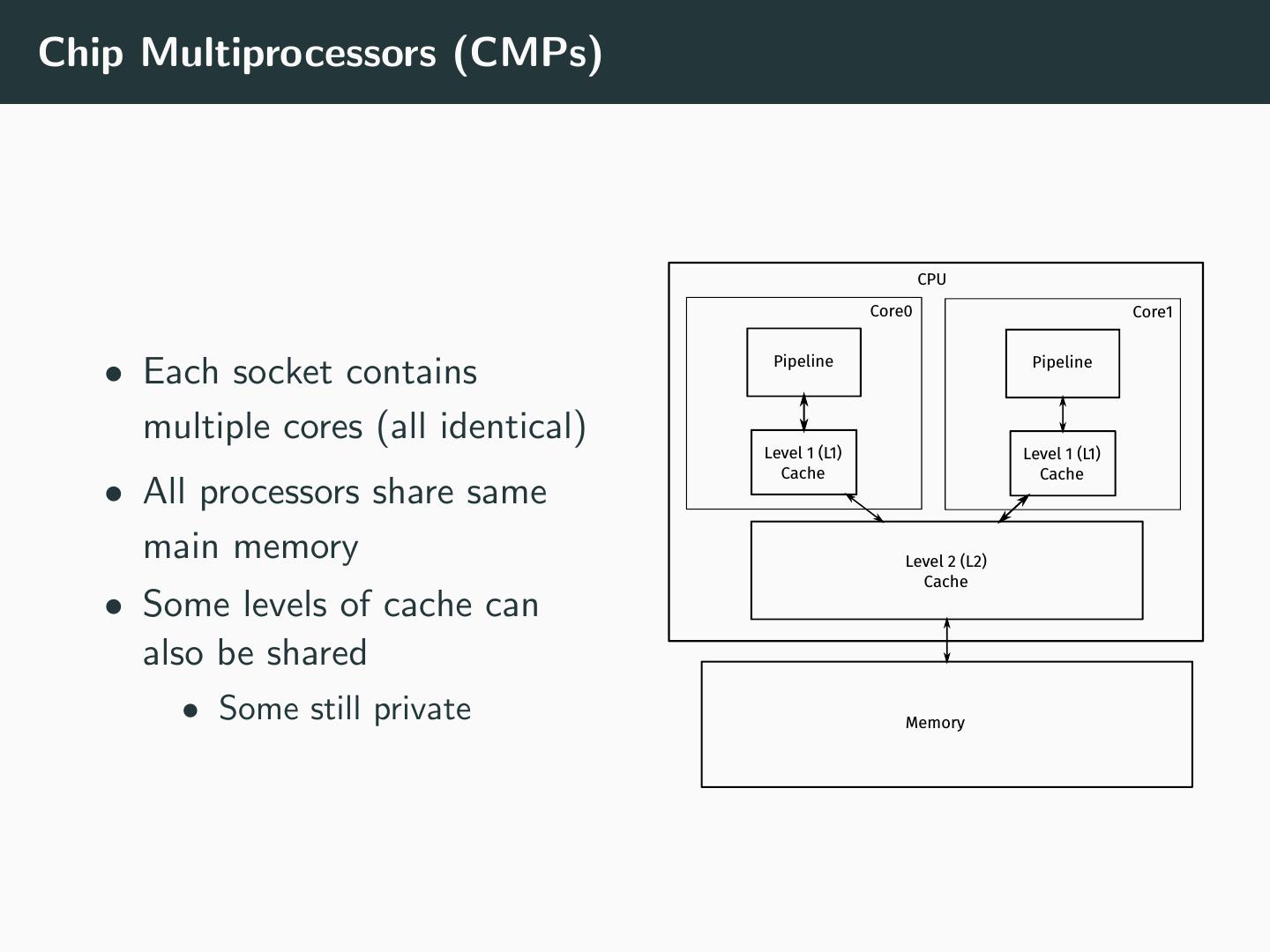
10 .Chip Multiprocessors (CMPs) CPU Core0 Core1 Pipeline Pipeline • Each socket contains multiple cores (all identical) Level 1 (L1) Level 1 (L1) Cache Cache • All processors share same main memory Level 2 (L2) Cache • Some levels of cache can also be shared • Some still private Memory
11 .Reads and writes in xMPs - reads/reads processor/core processor/core READ 0xdae... cc tags data cc tags data 0xdae... X Memory 0xdae... X
12 .Reads and writes in xMPs - reads/reads processor/core processor/core cc tags data cc tags data 0xdae... X 0xdae... X Memory 0xdae... X
13 .Reads and writes in xMPs - read/writes processor/core processor/core WRITE Y to 0xdae... cc tags data cc tags data 0xdae... X 0xdae... X Memory 0xdae... X
14 .Reads and writes in xMPs - write/write processor/core processor/core WRITE Z to 0xdae... WRITE Y to 0xdae... cc tags data cc tags data 0xdae... X 0xdae... X Memory 0xdae... X
15 .Outline Introduction to Parallel Memory Systems Memory Systems in Parallel Processors Coherence Implementations in Hardware Implications for Parallel Programs
16 .The problem of coherence • Multiple copies of same address exist in the memory hierarchy • How do we keep all the copies the same? • How do we resolve ordering of writes to the same address? Usually resolved through a coherence protocol.
17 .Coherence Protocols • Can be transparent (in hardware) • You might need to implement one in software • if you’re creating your own caches • Basic idea: every read and write needs to participate in a “coherence protocol” • Usually a finite state machine (FSM) • Each line in the cache has a state associated with it • Reads, writes and cache evictions in the coherence domain may change the line’s coherence state • Coherence domain can consist other CPUs, I/O devices, etc. • State determines which actions (reads/writes/evictions) are valid • Validity conditions?
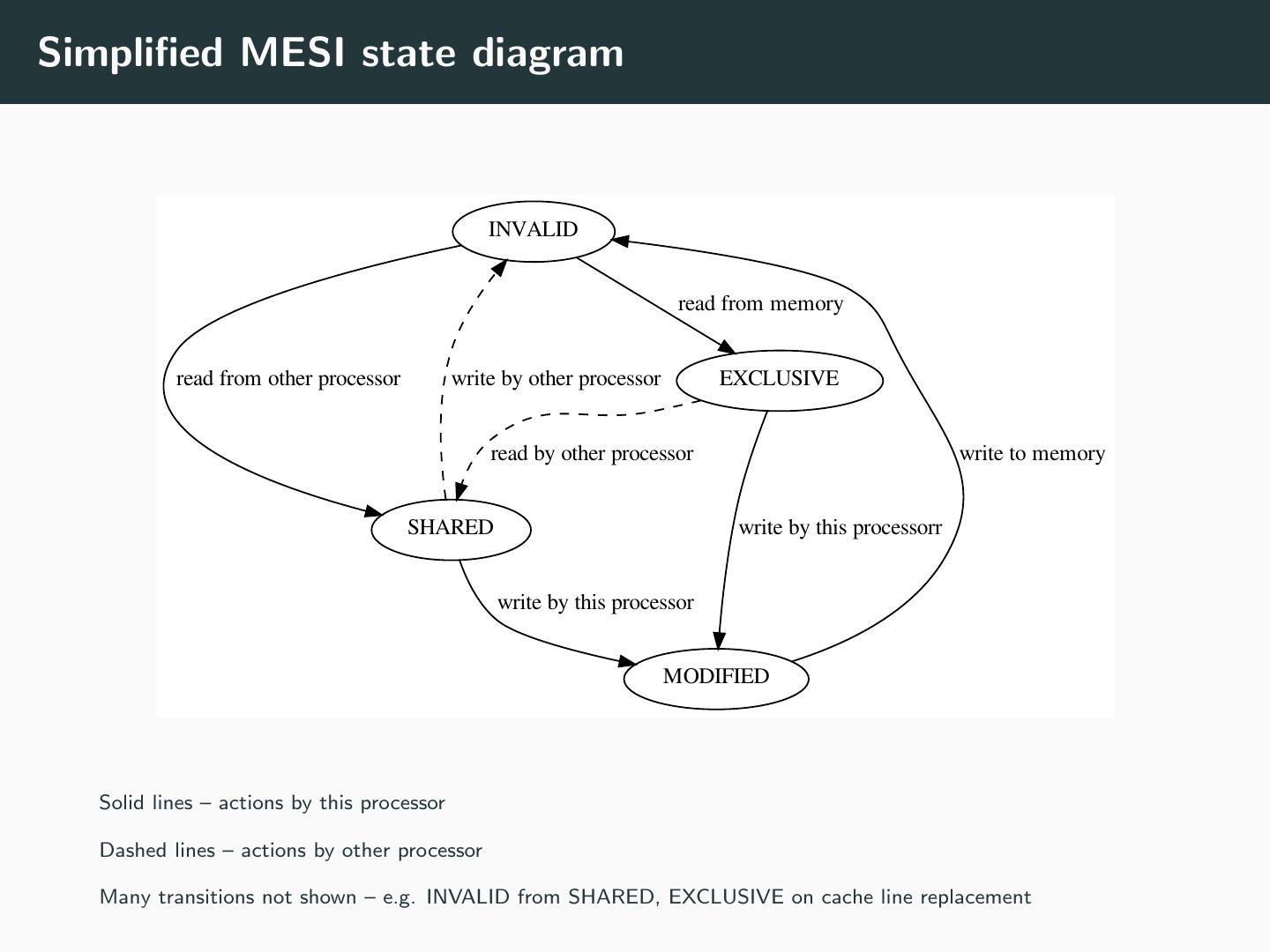
18 .MESI coherence protocol • States in MESI • Modified: line contains modified data • Exclusive: line is not shared • Shared: line is shared read-only • Invalid: line contains no data
19 .Simplified MESI state diagram INVALID read from memory read from other processor write by other processor EXCLUSIVE read by other processor write to memory SHARED write by this processorr write by this processor MODIFIED Solid lines – actions by this processor Dashed lines – actions by other processor Many transitions not shown – e.g. INVALID from SHARED, EXCLUSIVE on cache line replacement
20 .The MESI Protocol (Simplified) • Every cache line begins in INVALID state • On a read, the cache line is put into: • EXCLUSIVE: if it was read from memory • SHARED: if it was read from another copy • On a write, line is moved to MODIFIED state • If it was previously SHARED, all other copies are INVALIDATED • It will eventually be written back to memory
21 .MESI protocol test • How many concurrent readers does MESI allow? • How many concurrent writers does MESI allow?
22 .MESI protocol test 2 • How does the MESI protocol order concurrent writers?
23 .Outline Introduction to Parallel Memory Systems Memory Systems in Parallel Processors Coherence Implementations in Hardware Implications for Parallel Programs
24 .Snoop Protocols • Requires a shared bus among all processors • All requests to read/write are broadcast on the bus • All processors “snoop”/listen to memory requests • If a processor has a copy in EXCLUSIVE/SHARED/MODIFIED state: • It responds with a copy of its data • Moves its line to SHARED • Processors broadcast “INVALIDATE” to all processors before writing • Must wait for acknowledgements
25 .Directory-based Protocols • Requires a shared structure called “directory” • Directory tracks contents of every cache in the system • Addresses only • Caches talk to directory only • Directory send messages only to caches that contain affected data • Used in systems with large number of processors • >8 • Implementation need NOT be a centralized structure
26 .Summary of Cache Coherence • Reads and writes to shared data involve communication with other processors • Expensive • Possible Serialization bottleneck
27 .Outline Introduction to Parallel Memory Systems Memory Systems in Parallel Processors Coherence Implementations in Hardware Implications for Parallel Programs
28 .Shared Variables Variables that are read/written by multiple threads are called shared variables.
29 .Compilers and Cache Coherence int *a; T0 T1 while(*a < 1000) while(1) *a = *a + 1; printf("%d\n", *a);
3秒后跳转登录页面
去登陆

