


























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
02-Machines and Models
What is the goal of parallel programming?
展开查看详情
1 .CSC2/458 Parallel and Distributed Systems Machines and Models Sreepathi Pai January 23, 2018 URCS
2 .Outline Recap Scalability Taxonomy of Parallel Machines Performance Metrics
3 .Outline Recap Scalability Taxonomy of Parallel Machines Performance Metrics
4 .Goals What is the goal of parallel programming?
5 .Scalability Why is scalability important?
6 .Outline Recap Scalability Taxonomy of Parallel Machines Performance Metrics
7 .Speedup T1 Speedup(n) = Tn • T1 is time on one processor • Tn is time on n processors
8 .Amdahl’s Law Let: • T1 be Tserial + Tparallelizable Tparallelizable • Tn is then Tserial + n , assuming perfect scalability Divide both terms T1 and Tn by T1 to obtain serial and parallelizable ratios. 1 Speedup(n) = rparallelizable rserial + n
9 .Amdahl’s Law – In the limit 1 Speedup(∞) = rserial This is also known as strong scalability – work is fixed and number of processors is varied. What are the implications of this?
10 .Scalability Limits Assuming infinite processors, what is the speedup if: • serial ratio rserial is 0.5 (i.e. 50%) • serial ratio is 0.1 (i.e. 10%) • serial ratio is 0.01 (i.e. 1%)
11 .Current Top 5 supercomputers • Sunway TaihuLight (10.6M cores) • Tianhe 2 (3.1M cores) • Piz Daint (361K cores) • Gyoukou (19.8M cores) • Titan (560K cores) Source: Top 500
12 .Weak Scalability • Work increases as number of processors increase • Parallel work should increase linearly with processors • Work W = αW + (1 − α)W • α is serial fraction of work • Scaled Work W = αW + n(1 − α)W • Empirical observation • Usually referred to as Gustafson’s Law Source: http://www.johngustafson.net/pubs/pub13/amdahl.htm
13 .Outline Recap Scalability Taxonomy of Parallel Machines Performance Metrics
14 .Organization of Parallel Computers Components of parallel machines: • Processing Elements • Memories • Interconnect • how processors, memories are connnected to each other
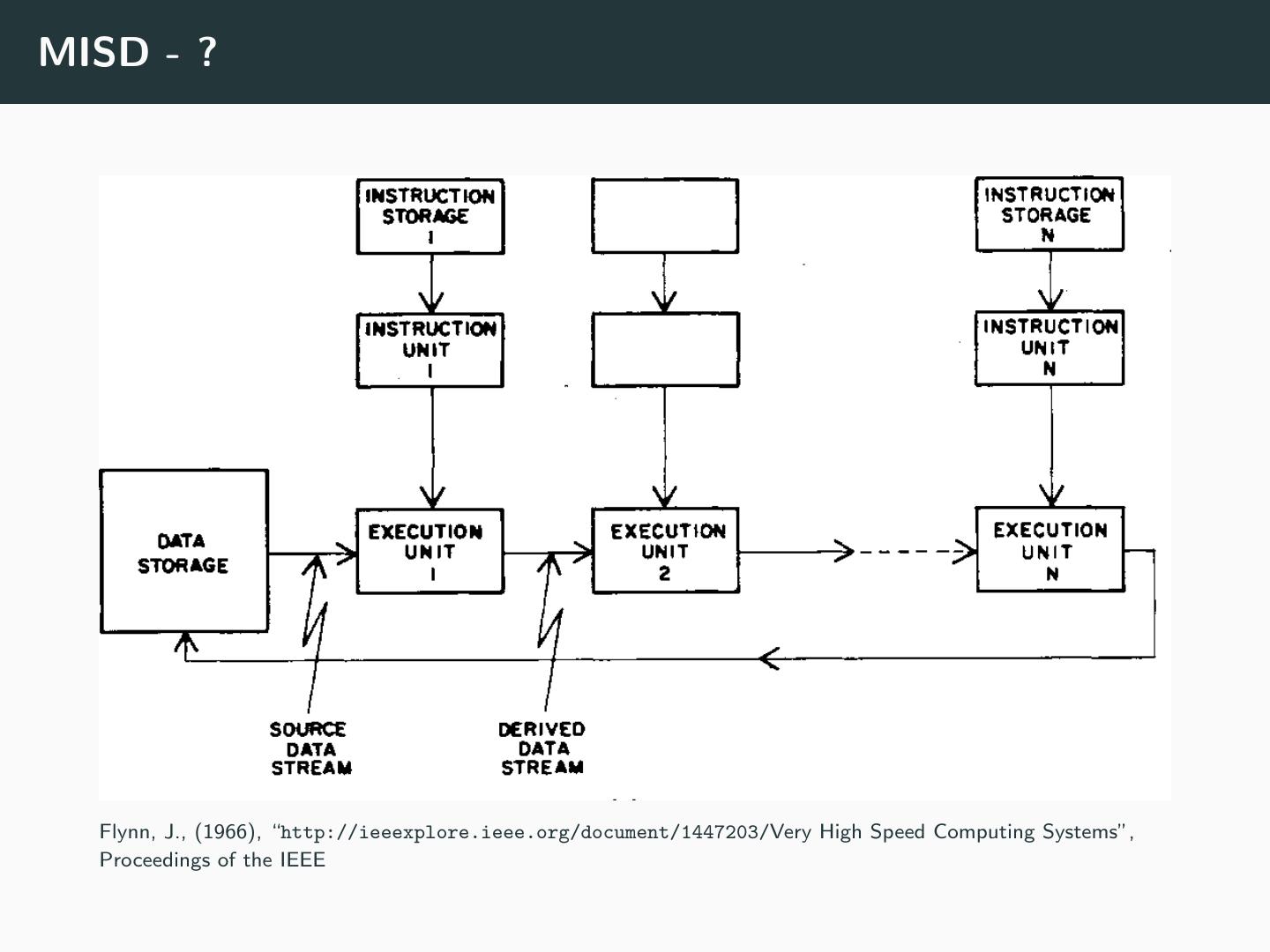
15 .Flynn’s Taxonomy • Based on notion of “streams” • Instruction stream • Data stream • Taxonomy based on number of each type of streams • Single Instruction - Single Data (SISD) • Single Instruction - Multiple Data (SIMD) • Multiple Instruction - Single Data (MISD) • Multiple Instruction - Multiple Data (MIMD) Flynn, J., (1966), “http://ieeexplore.ieee.org/document/1447203/Very High Speed Computing Systems”, Proceedings of the IEEE
16 .SIMD Implementations: Vector Machines The Cray-1 (circa 1977): • Vx – vector registers • 64 elements • 64-bits per element • Vector length register (Vlen) • Vector mask register Richard Russell, “The Cray-1 Computer System”, Comm. ACM 21,1 (Jan 1978), 63-72
17 .Vector Instructions – Vertical 1 2 3 4 + 5 6 2 3 = 6 8 5 7 For 0 < i < Vlen: dst[i] = src1[i] + src2[i] • Most arithmetic instructions
18 .Vector Instructions – Horizontal 1 = min( 1 2 3 4 ) For 0 < i < Vlen: dst = min(src1[i], dst) Note that dst is a scalar. • Mostly reductions (min, max, sum, etc.) • Not well supported • Cray-1 did not have this
19 .Vector Instructions – Shuffle/Permute src 1 2 3 4 mask 0 3 1 1 dst 1 4 2 2 dst = shuffle(src1, mask) • Poor support on older implementations • Reasonably well-supported on recent implementations
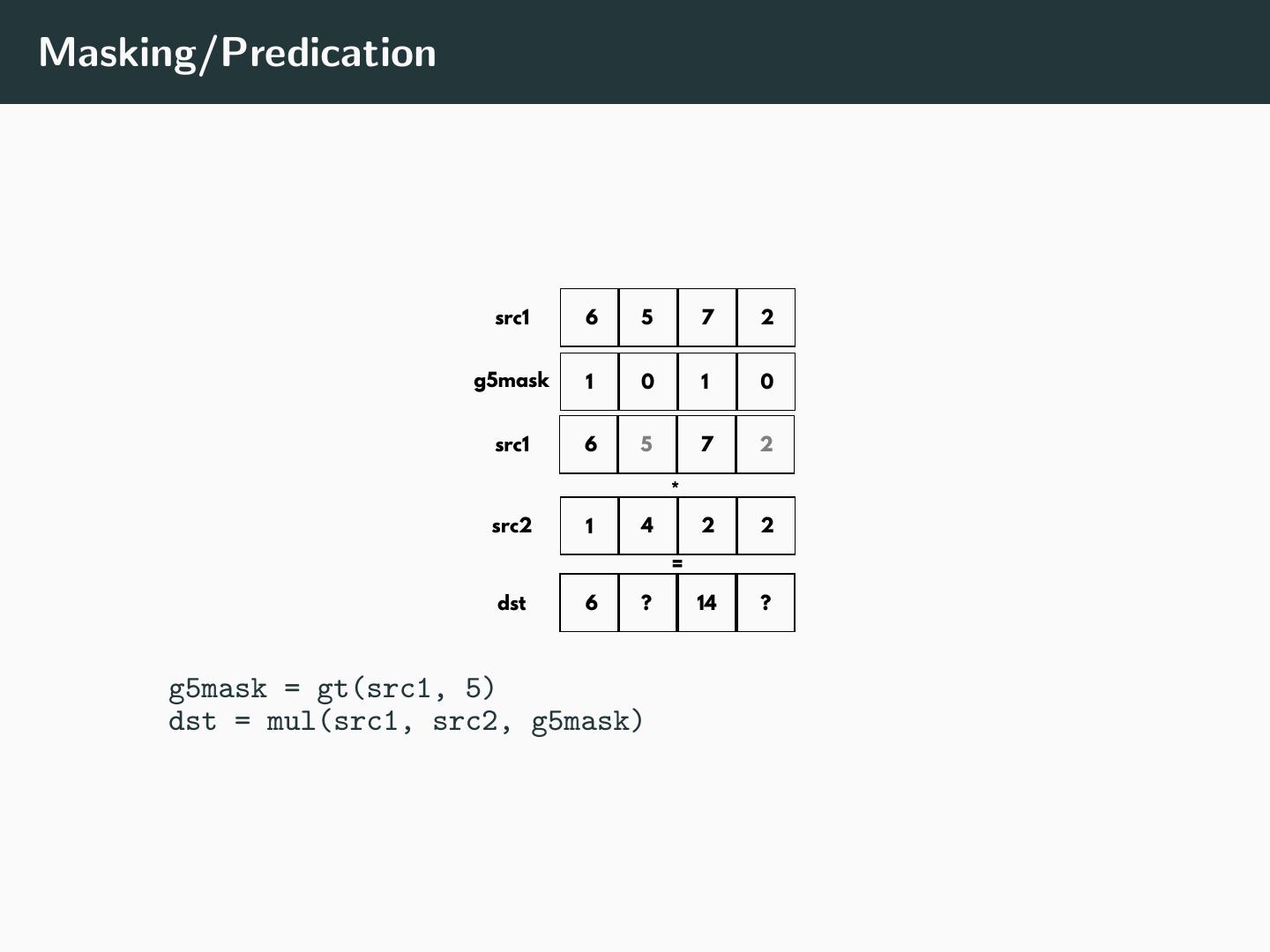
20 .Masking/Predication src1 6 5 7 2 g5mask 1 0 1 0 src1 6 5 7 2 * src2 1 4 2 2 = dst 6 ? 14 ? g5mask = gt(src1, 5) dst = mul(src1, src2, g5mask)
21 .MISD - ? Flynn, J., (1966), “http://ieeexplore.ieee.org/document/1447203/Very High Speed Computing Systems”, Proceedings of the IEEE
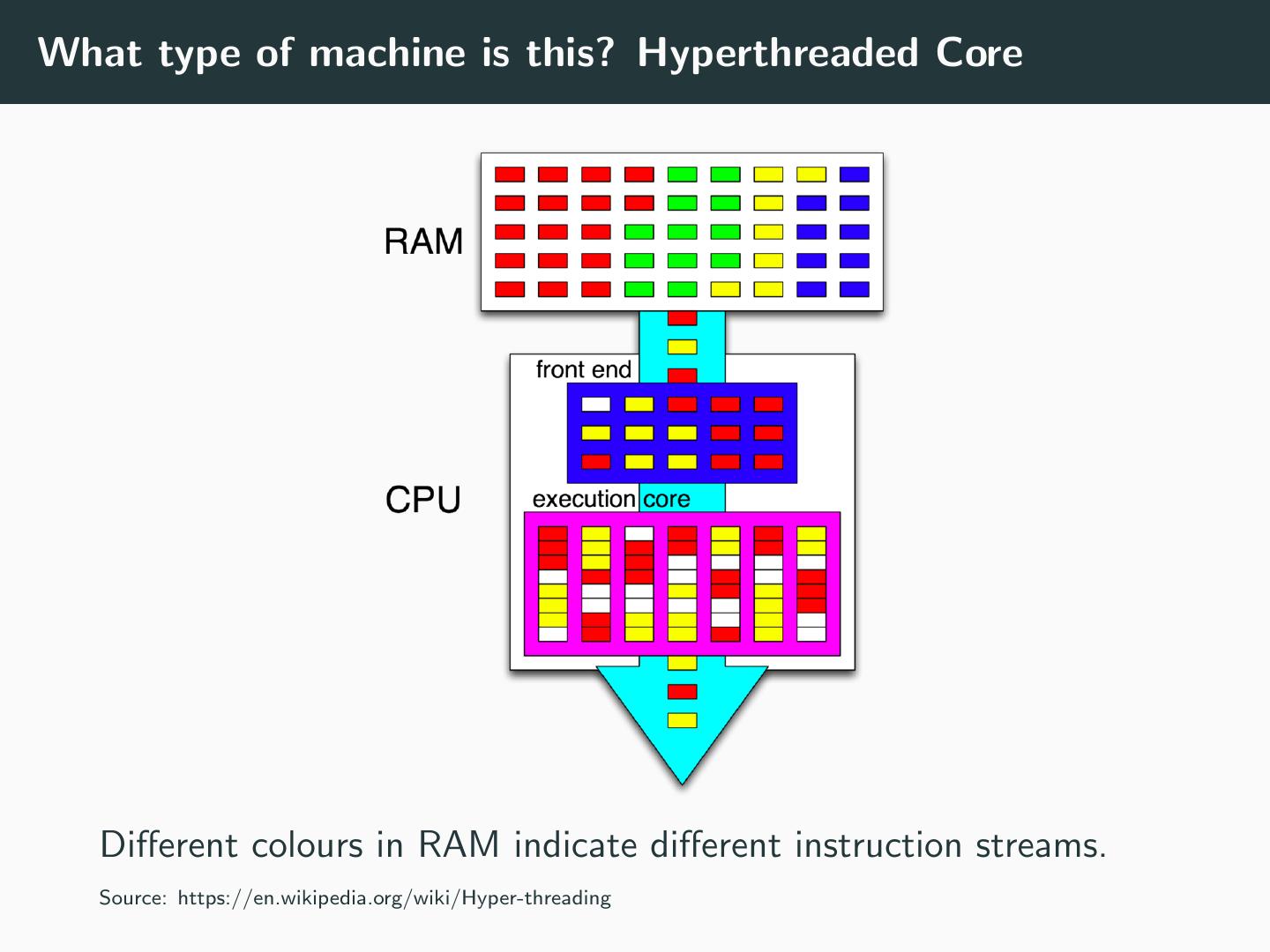
22 .What type of machine is this? Hyperthreaded Core Different colours in RAM indicate different instruction streams. Source: https://en.wikipedia.org/wiki/Hyper-threading
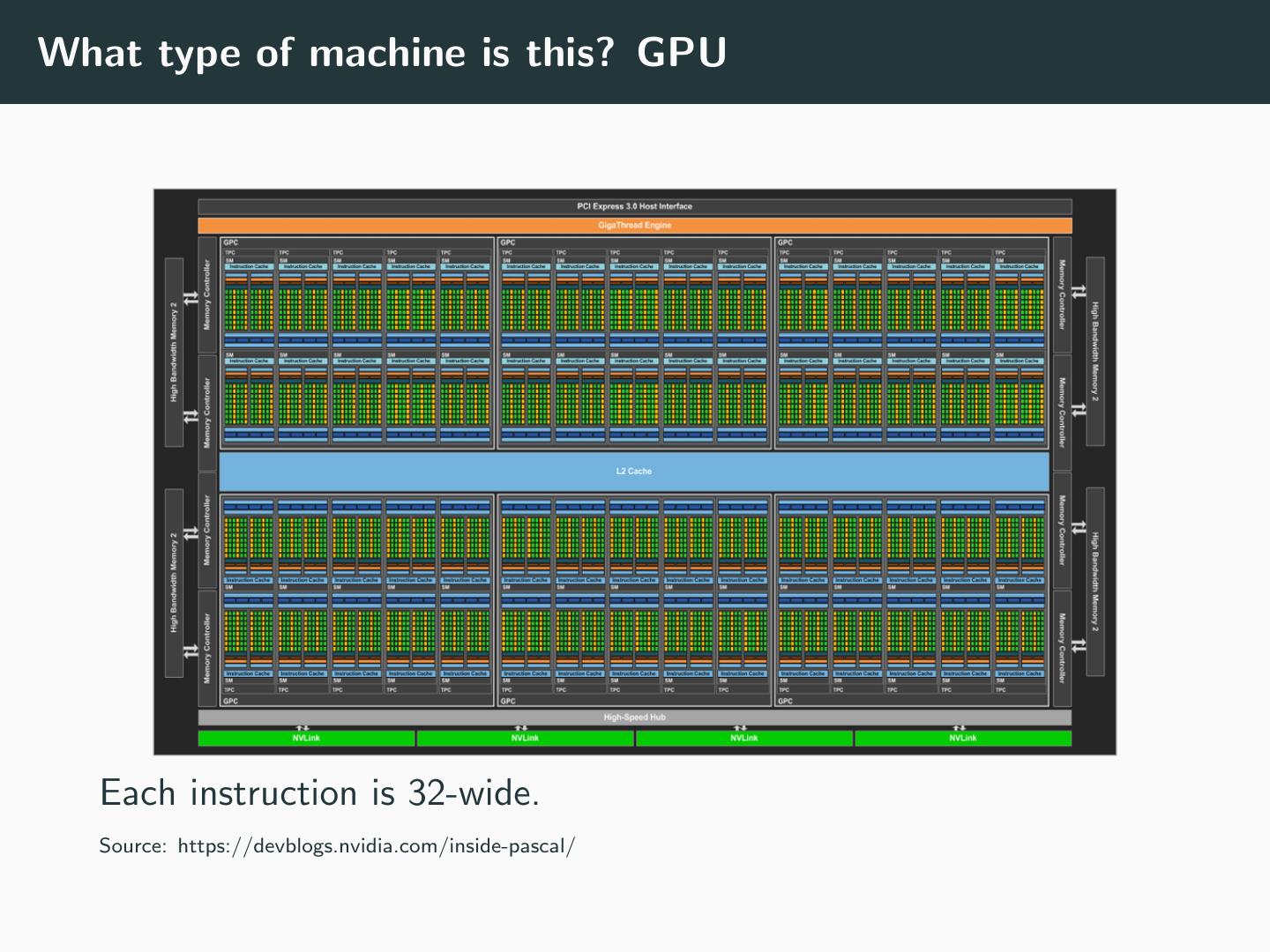
23 .What type of machine is this? GPU Each instruction is 32-wide. Source: https://devblogs.nvidia.com/inside-pascal/
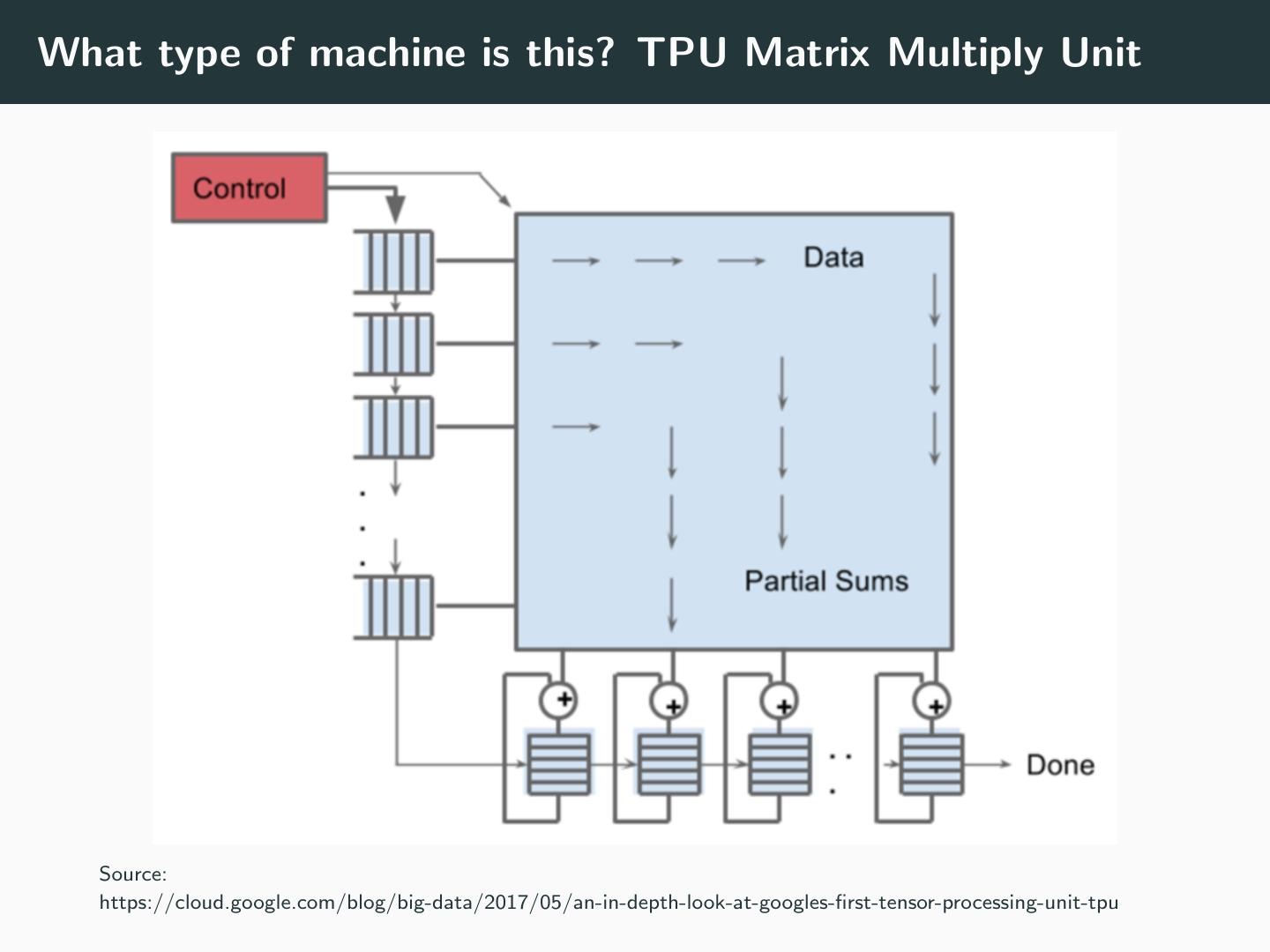
24 .What type of machine is this? TPU Matrix Multiply Unit Source: https://cloud.google.com/blog/big-data/2017/05/an-in-depth-look-at-googles-first-tensor-processing-unit-tpu
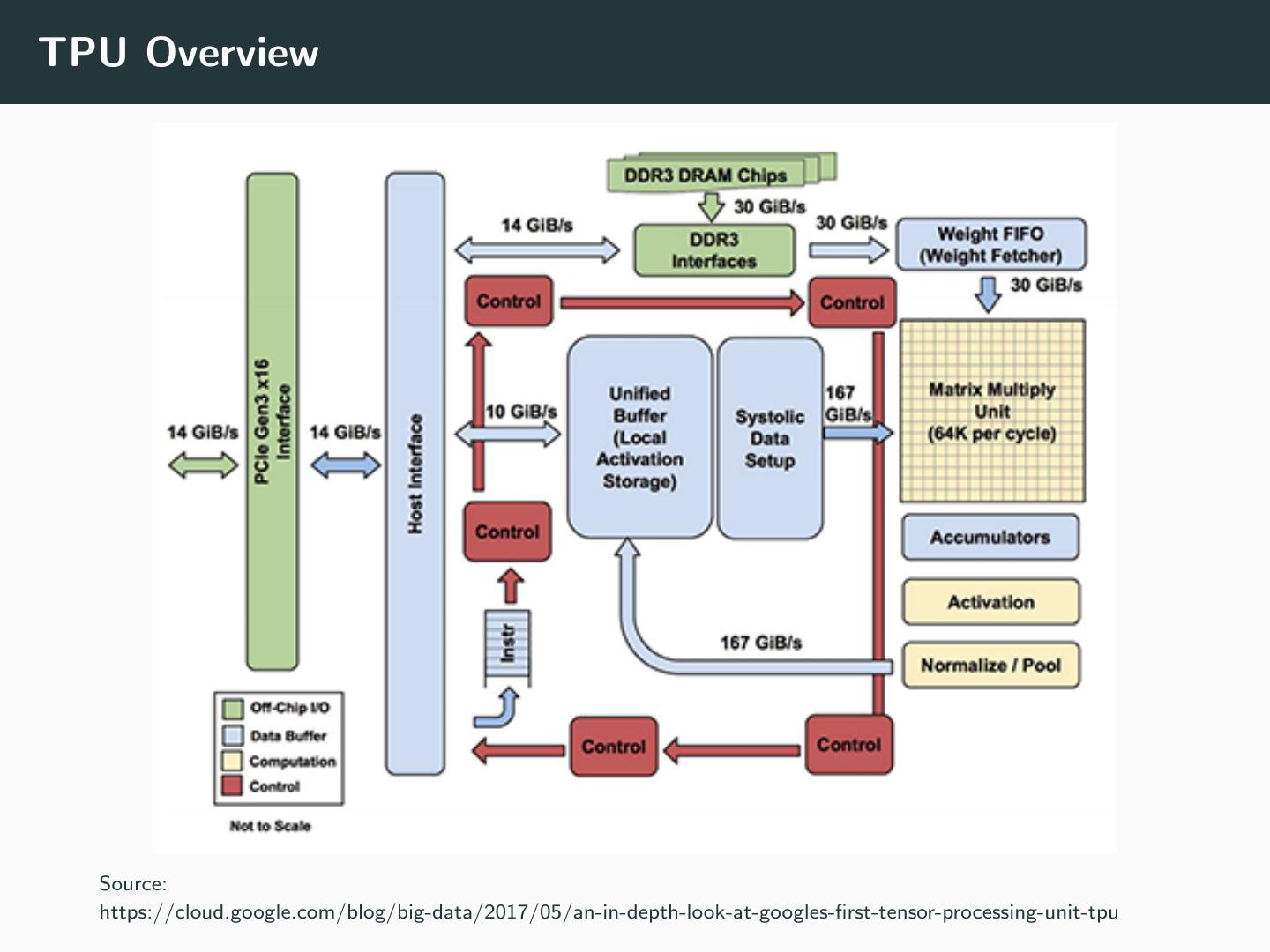
25 .TPU Overview Source: https://cloud.google.com/blog/big-data/2017/05/an-in-depth-look-at-googles-first-tensor-processing-unit-tpu
26 .Modern Multicores • Multiple Cores (MIMD) • (Short) Vector Instruction Sets (SIMD) • MMX, SSE, AVX (Intel) • 3DNow (AMD) • NEON (ARM)
27 .Outline Recap Scalability Taxonomy of Parallel Machines Performance Metrics
28 .Metrics we care about • Latency • Time to complete task • Lower is better • Throughput • Rate of completing tasks • Higher is better • Utilization • Time “worker” (processor, unit) is busy • Higher is better • Speedup • Higher is better
29 .Reducing Latency • Use cheap operations • Which of these operations are expensive? • Bitshift • Integer Divide • Integer Multiply • Latency fundamentally bounded by physics
3秒后跳转登录页面
去登陆

