

























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
05-Group Communication and MPI
Outline
Reliability of group communication
--IP multicast
--Atomic multicast
Ordering of group communication
--Absolute ordering
--Total ordering
--Causal ordering
--FIFO ordering
MPI Java
--Programming, compilation and invocation
--Major group communication functions: Bcast( ), Reduce( ), Allreduce( )
展开查看详情
1 .CSS434 Group Communication and MPI Textbook Ch4.4-5 and 15.4 Professor: Munehiro Fukuda CSS434 MPI 1
2 .Outline Reliability of group communication IP multicast Atomic multicast Ordering of group communication Absolute ordering Total ordering Causal ordering FIFO ordering MPI Java Programming, compilation and invocation Major group communication functions: Bcast( ), Reduce( ), Allreduce( ) CSS434 MPI 2
3 . Group Communication Communication types One-to-many: broadcast Many-to-one: synchronization, collective communication Many-to-many: gather and scatter Applications Fault tolerance based on replicated services (type: one-to-ma ny) Finding the discovery servers in spontaneous networking (typ e: a one-to-many request, a many-to-one response) Better performance through replicated data (type: one-to-ma ny, many-to-one) Propagation of event notification (type: one-to-many) CSS434 MPI 3
4 . IP (Unreliable) Multicast import java.net.*; import java.io.*; Using a special network address: IP Class D and UD public class MulticastPeer{ public static void main(String args[]){ // args give message contents & destination multicast group (e.g. "228.5.6.7") MulticastSocket s =null; try { InetAddress group = InetAddress.getByName(args[1]); s = new MulticastSocket(6789); s.joinGroup(group); byte [] m = args[0].getBytes(); DatagramPacket messageOut = new DatagramPacket(m, m.length, group, 6789); s.send(messageOut); // get messages from others in group byte[] buffer = new byte[1000]; for(int i=0; i< 3; i++) { DatagramPacket messageIn = new DatagramPacket(buffer, buffer.length); s.receive(messageIn); System.out.println("Received:" + new String(messageIn.getData())); } s.leaveGroup(group); }catch (SocketException e){System.out.println("Socket: " + e.getMessage()); }catch (IOException e){System.out.println("IO: " + e.getMessage());} }finally {if(s != null) s.close();} } } CSS434 MPI 4
5 .Reliability and Ordering Fault tolerance based on replicated services Send-to-all and all-reliable semantics Finding the discovery servers in spontaneous networking 1-reliable semantics Better performance through replicated data Semantics depend on applications. (send-to-all a nd all- or m-out-of-n reliable semantics) Propagation of event notifications In general, send-to-all and all-reliable semantics CSS434 MPI 5
6 . Atomic Multicast Send-to-all semantics and all-reliable Simple emulation: A repetition of one-to-one communication with acknowledgment What if a receiver fails Time-out retransmission What if a sender fails before all receivers receive a message All receivers forward the message to the same group and thereafter deliver it to themselves. A receiver discard the 2nd or the following messages. CSS434 MPI 6
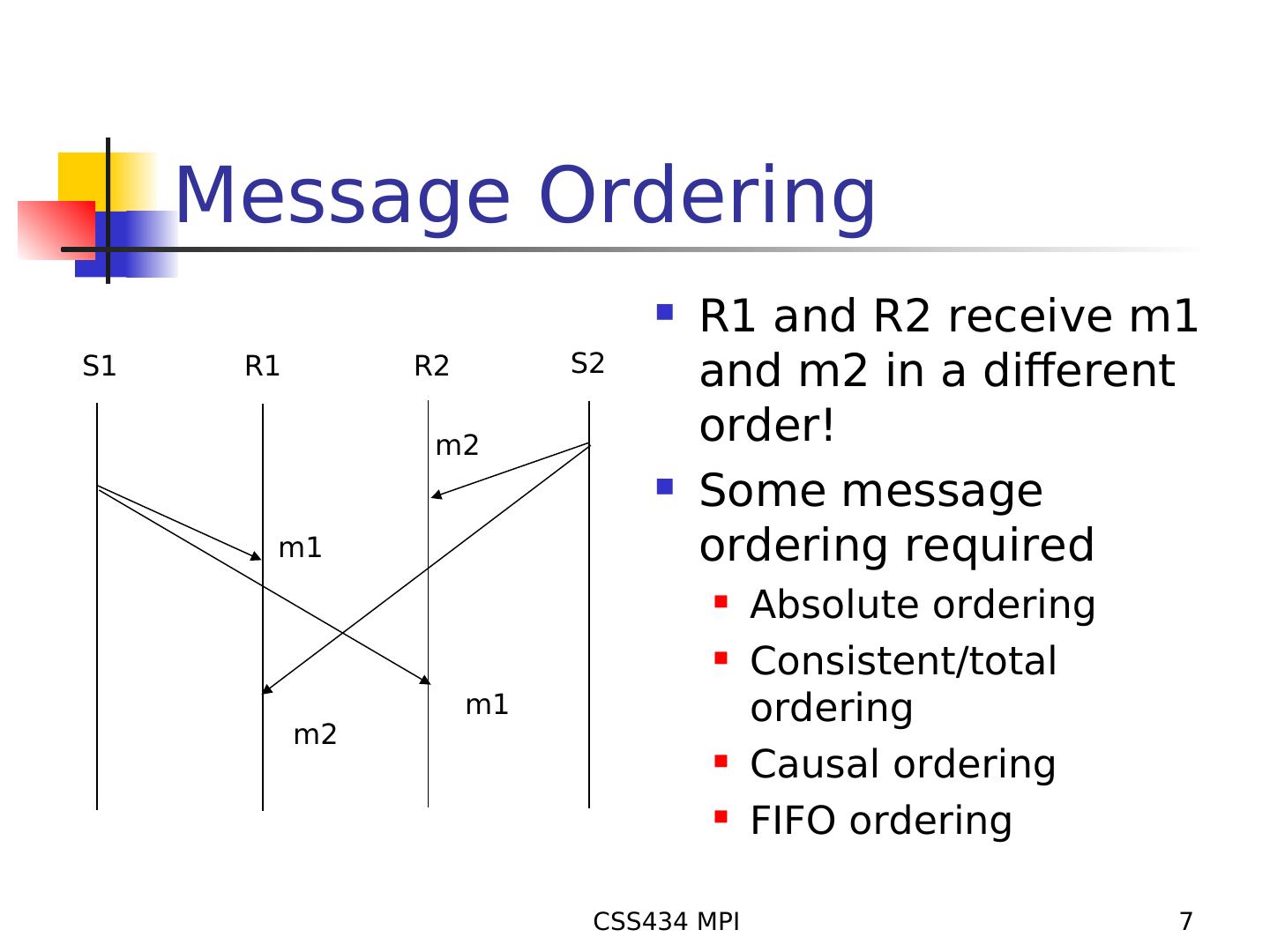
7 . Message Ordering R1 and R2 receive m1 S1 R1 R2 S2 and m2 in a different m2 order! Some message m1 ordering required Absolute ordering Consistent/total m1 ordering m2 Causal ordering FIFO ordering CSS434 MPI 7
8 . Absolute Ordering Rule: Ti < Tj Mi must be delivered before mj if Ti < Tj Implementation: Ti A clock synchronized among machines mi A sliding time window used to commit Tj message delivery whose timestamp is in this window. mi Example: Distributed simulation mj Drawback mj Too strict constraint No absolute synchronized clock No guarantee to catch all tardy messages CSS434 MPI 8
9 . Consistent/Total Ordering Rule: Ti < Tj Messages received in the same Ti order (regardless of their timestamp). Tj Implementation: mj A message sent to a sequencer, assigned a sequence number, and mj finally multicast to receivers A message retrieved in incremental mi order at a receiver mi Example: Replicated database updates Drawback: A centralized algorithm CSS434 MPI 9
10 .Total Ordering Using A Sequencer Message sent to all group members and a sequencer Receive an incoming message in a temporary queue Receive a sequence number message from the sequen Reorder the incoming message with this sequence #, a Deliver it if my local counter reaches this number. Receive a message, associate it with a sequence numbe multicast it to all group members, and increments the sequence number CSS434 MPI 10
11 . The ISIS System for Total Ordering Ap4 Proposed Seq Pp4= max(Ap4, Pp4) + 1 Pp4 P2 Receiver 1 Message 3 Receiver 22 d S eq P4 A p4 e o pos Pp4 1 2 Pr Ap4= max(Ap4, a) 3 Agreed Seq 1 a = max(Pp1, Pp2, P ,P p3 ) p4 2 P1 Sender 3 Receiver Ap4 P 3 Pp4 CSS434 MPI 11
12 . Causal Ordering Rule: S1 R1 R2 R3 S2 Happened-before relation • If ek , el ∈h and k < l, then ek → el , i i i i • If e = send(m) and e = receive(m), t i j m4 m1 hen ei → ej, • If e → e’ and e’ → e”, then e → e” m1 m4 Implementation: Use of a vector message m2 Example: Distributed file system m2 Drawback: Vector as an overhead m3 Broadcast assumed From R2’s view point m1 →m2 CSS434 MPI 12
13 . Causal Ordering Using A Vector Stamps Each process maintains a vector. Increment my vector element, and Send a messge with a vector Make sure J’s element of J’s vector reaches J’s element of my vector. (All J’s previous message ha been delivered.) Make sure all elements of J’s vector <= all elements of my vector. (I’ve delivered all messages that J has delivered. Increment the sender’s vector element CSS434 MPI 13
14 . Vector Stamps Site A Site B Site C Site D 2, 1, 1, 0 1, 1, 1, 0 2, 1, 0, 0 2, 1, 1, 0 3,1,1,0 delayed delayed delivered S[i] = R[i] + 1 where i is the source id S[j] ≤ R[j] where i≠j CSS434 MPI 14
15 . FIFO Ordering S Rule: R Messages received in the m1 same order as they were Router m2 1 sent. m3 m1 Implementation: m2 Messages assigned a m4 sequence number m3 Example: Router 2 TCP m4 This is the weakest ordering. CSS434 MPI 15
16 . Why High-Level Message Passing Tools? Data formatting Data formatted into appropriate types at user level Non-blocking communication Polling and interrupt handled at system call level Process addressing Inflexible hardwired addressing with machine id + local id Group communication Group server implemented at user level Broadcasting simulated by a repetition of one-to- one communication CSS434 MPI 16
17 . PVM and MPI PVM: Parallel Virtual Machine Developed in 80’s The pioneer library to provide high-level message passing functions The PVM daemon process taking care of message transfer for user processes in background MPI: Message Passing Interface Defined in 90’s The specification of high-level message passing functions Several implementations available: mpich, mpi-lam Library functions directly linked to user programs (no background d aemons) The detailed difference is shown by: PVMvsMPI.pdf CSS434 MPI 17
18 . Getting Started with MPI Java Website: http://www.hpjava.org/courses/arl/lectures/mpi.ppt http://www.hpjava.org/reports/mpiJava-spec/mpiJava-spec.pdf Creating a machines file: [mfukuda@UW1-320-00 mfukuda]$ vi machines uw1-320-00 uw1-320-01 uw1-320-02 uw1-320-03 Compile a source program: [mfukuda@UW1-320-00 mfukuda]$ javac MyProg.java Run the executable file: [mfukuda@UW1-320-00 mfukuda]$ prunjava 4 MyProg args CSS434 MPI 18
19 . Program Using MPI import mpi.*; class MyProg { public static void main( String[] args ) { MPI.Init( args ); // Start MPI computation int rank = MPI.COMM_WORLD.Rank( ); // Process ID (from 0 to #processes – 1) int size = MPI.COMM_WORLD.Size( ); // # participating processes System.out.println( "Hello World! I am " + rank + " of " + size ); MPI.Finalize(); // Finish MPI computation } } CSS434 MPI 19
20 . MPI_Send and MPI_Recv void MPI.COMM_WORLD.Send( Object[] message /* in */, int offset /* in */, int count /* in */, MPI.Datatype datatype /* in */, int dest /* in */, int tag /* in */) Status MPI.COMM_WORLD.Recv( Object[] message /* in */, int offset /* in */, int count /* in */, MPI.Datatype datatype /* in */, int source /* in */, int tag /* in */) int Status.Get_count( MPI.Datatype, datatype ) /* #objects received */ MPI.Datatype = BYTE, CHAR, SHORT, INT, LONG, FLOAT, DOUBLE, OBJECT CSS434 MPI 20
21 . MPI.Send and MPI.Recv import mpi.*; class myProg { public static void main( String[] args ) { int tag0 = 0; MPI.Init( args ); // Start MPI computation if ( MPI.COMM_WORLD.rank() == 0 ) { // rank 0…sender int loop[1]; loop[0] = 3; MPI.COMM_WORLD.Send( "Hello World!", 12, MPI.CHAR, 1, tag0 ); MPI.COMM_WORLD.Send( loop, 1, MPI.INT, 1, tag0 ); } else { // rank 1…receiver int loop[1]; char msg[12]; MPI::COMM_WORLD.Recv( msg, 12, MPI.CHAR, 0, tag0 ); MPI::COMM_WORLD.Recv( loop, 1, MPI.INT, 0, tag0 ); for ( int i = 0; i < loop[0]; i++ ) System.out.println( msg ); } MPI.Finalize( ); // Finish MPI computation } } CSS434 MPI 21
22 . Message Ordering in MPI Source Destination FIFO Ordering in each data type Source Destination Messages tag = 1 reordered with a tag = 3 tag in each data tag = 2 type CSS434 MPI 22
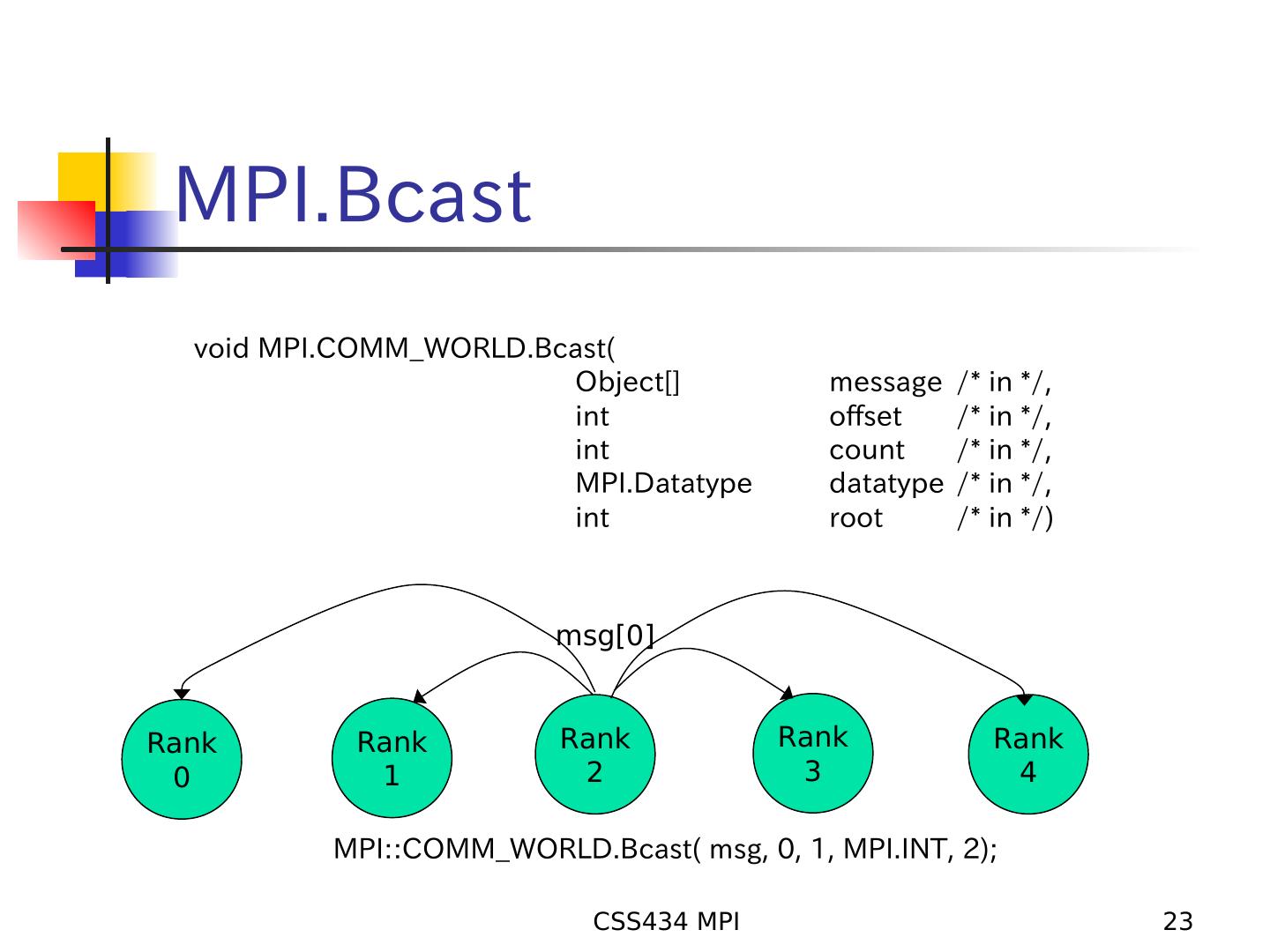
23 . MPI.Bcast void MPI.COMM_WORLD.Bcast( Object[] message /* in */, int offset /* in */, int count /* in */, MPI.Datatype datatype /* in */, int root /* in */) msg[0] Rank Rank Rank Rank Rank 0 1 2 3 4 MPI::COMM_WORLD.Bcast( msg, 0, 1, MPI.INT, 2); CSS434 MPI 23
24 . MPI_Reduce void MPI.COMM_WORLD.Reduce( Object[] sendbuf /* in */, int sendoffset /* in */, Object[] recvbuf /* out */, int recvoffset /* in */, int count /* in */, MPI.Datatype datatype /* in */, MPI.Op operator /* in */, int root /* in */ ) MPI.Op = MPI.MAX (Maximum), MPI.MIN (Minimum), MPI.SUM (Sum), MPI.PROD (Product), MPI.LAND (Logical and), MPI.BAND (Bitwise and), MPI.LOR (Logical or), MPI.BOR (Bitwise or), MPI.LXOR (logical xor), MPI.BXOR(Bitwise xor), MPI.MAXLOC (MAX location) MPI.MINLOC (MIN loc.) Rank0 Rank1 Rank2 Rank3 Rank4 15 10 12 8 4 49 MPI::COMM_WORLD.Reduce( msg, 0, result, 0, 1, MPI.INT, MPI.SUM, 2); CSS434 MPI 24
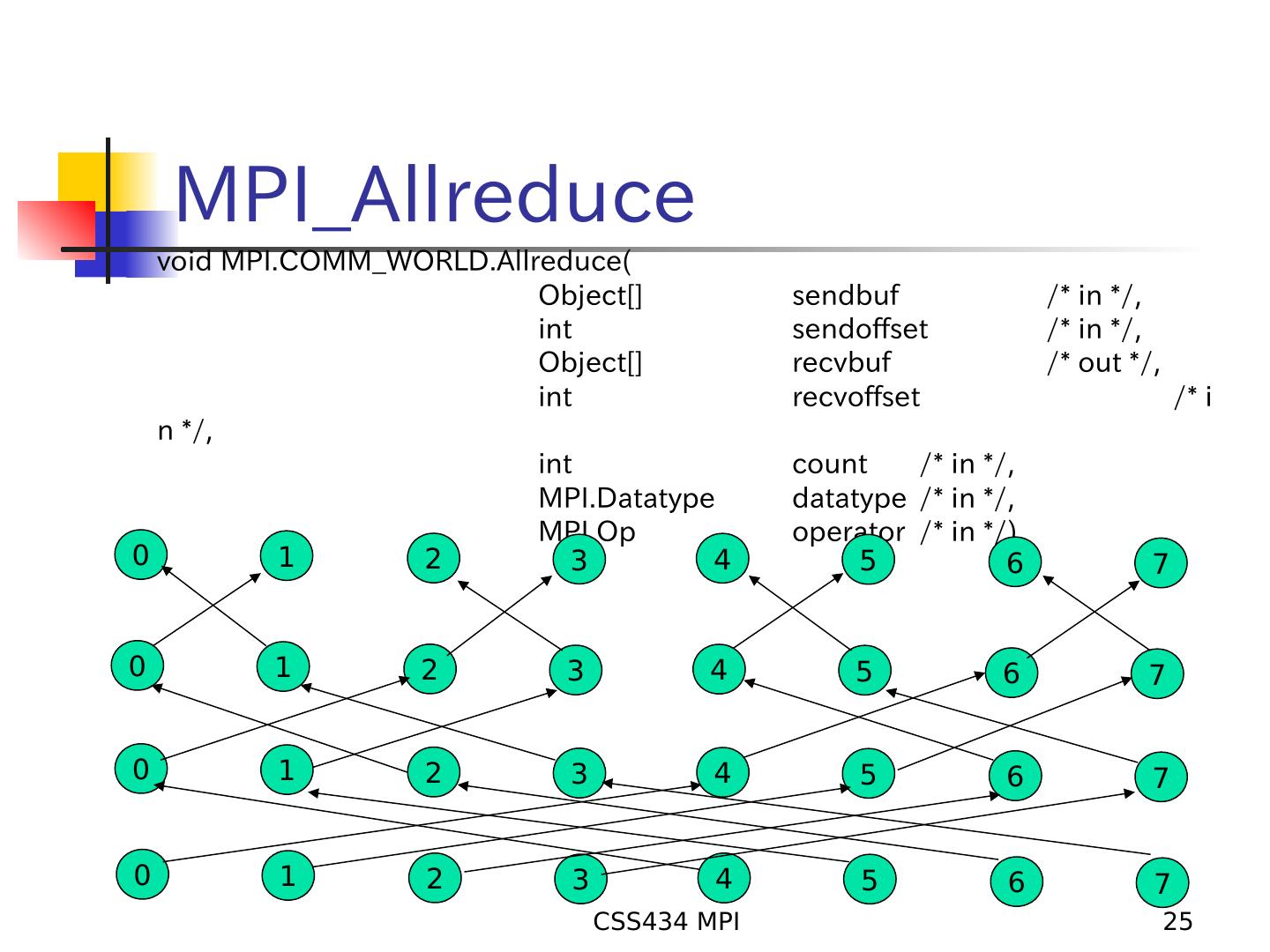
25 . MPI_Allreduce void MPI.COMM_WORLD.Allreduce( Object[] sendbuf /* in */, int sendoffset /* in */, Object[] recvbuf /* out */, int recvoffset /* i n */, int count /* in */, MPI.Datatype datatype /* in */, MPI.Op operator /* in */) 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 0 1 2 3 4 5 6 7 CSS434 MPI 25
26 . Exercises (No turn-in) 1. Explain, in atomic multicast on page 6, why reversing the order of operations “all receivers forward the message to the same group and thereafter deliver it to themselves” makes the multicast no longer atomic. 2. Assume that four processes communicate with one another in causal ordering. Their current vectors are show below. If Process A sends a message, which processes can receive it immediately? Process A Process B Process C Process D 3, 5, 2, 1 2, 5, 2, 1 3, 5, 2, 1 3, 4, 2, 1 3. Show that, if the basic multicast that we use in the algorithm of P9 is also FIFO-ordered, then the resultant totally-ordered multicast is also causally ordered. 4. Consider pros and cons of PVM’s daemon-based and MPI’s library linking-based message passing. 5. Why can MPI maintain FIFO ordering? CSS434 MPI 26
3秒后跳转登录页面
去登陆

