



















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
10--Distributed Shared Memory
Simpler abstraction
--Underlying tedious communication primitives are all shielded by memory accesses
Better portability of distributed application programs
--Natural transition from sequential to distributed application
Better performance of some applications
--Data locality, one-demand data movement, and large memory space reduce network traffic and paging/swapping activities.
Flexible communication environment
--Sender and receiver have no need to know each other. They even need not coexist.
Ease of process migration
--Migration is completed only by transferring the corresponding PCB to the destination.
展开查看详情
1 .CSS434 Distributed Shared Memory Textbook Ch18 Professor: Munehiro Fukuda CSS434 DSM 1
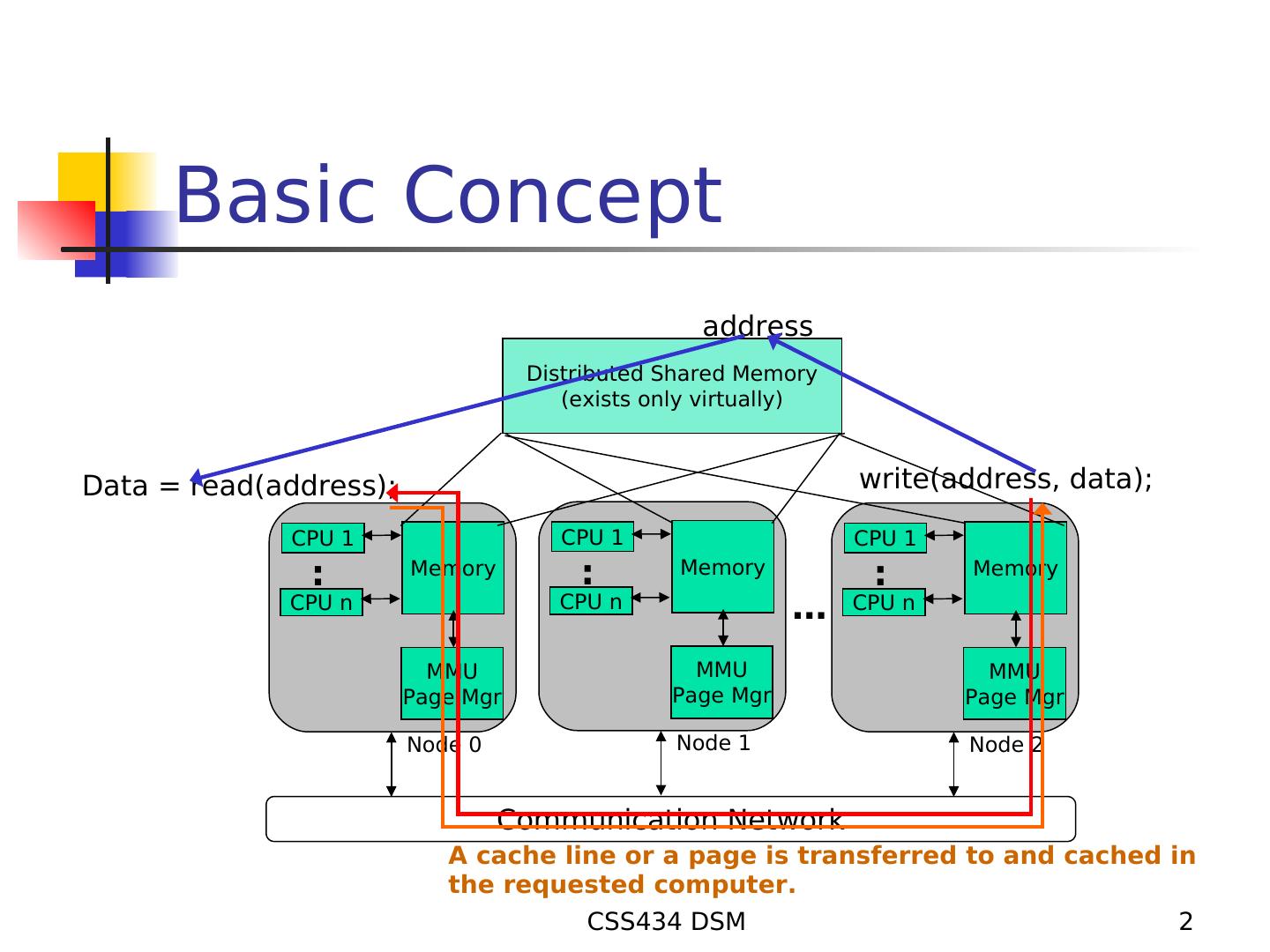
2 . Basic Concept address Distributed Shared Memory (exists only virtually) Data = read(address); write(address, data); CPU 1 CPU 1 CPU 1 : Memory : Memory : Memory CPU n CPU n … CPU n MMU MMU MMU Page Mgr Page Mgr Page Mgr Node 0 Node 1 Node 2 Communication Network A cache line or a page is transferred to and cached in the requested computer. CSS434 DSM 2
3 . Writer Process on DSM #include "world.h" struct shared { int a,b; }; Program Writer: main() { int x; struct shared *p; methersetup(); /* Initialize the Mether run-time */ p = (struct shared *)METHERBASE; /* overlay structure on METHER segment */ p->a = p->b = 0; /* initialize fields to zero */ while(TRUE) { /* continuously update structure fields */ p –>a = p –>a + 1; p –>b = p –>b - 1; } } CSS434 DSM 3
4 .Reader Process on DSM Program Reader: main() { struct shared *p; methersetup(); p = (struct shared *)METHERBASE; while(TRUE) { /* read the fields once every second */ printf("a = %d, b = %d\n", p –>a, p –>b); sleep(1); } } CSS434 DSM 4
5 . Why DSM? Simpler abstraction Underlying tedious communication primitives are all shielded by memory accesses Better portability of distributed application programs Natural transition from sequential to distributed application Better performance of some applications Data locality, one-demand data movement, and large memory space reduce network traffic and paging/swapping activities. Flexible communication environment Sender and receiver have no need to know each other. They even need not coexist. Ease of process migration Migration is completed only by transferring the corresponding PCB to the destination. CSS434 DSM 5
6 . Main Issues Granularity Fine (less false sharing but more network traffic) Cache line (e.g. Da sh and Alewife), Object (e.g. Orca and Linda), Page (e.g. Ivy) Coarse (more false sharing but less network traffice) Memory coherence and access synchronization Strict, Sequential, Causal, Weak, and Release Consistency models Data location and access Broadcasting, centralized data locator, fixed distributed data locator, and dynamic distributed data locator Replacement strategy LRU or FIFO (The same issue as OS virtual memory) Thrashing How to prevent a block from being exchanged back and forth betwee n two nodes. Heterogeneity CSS434 DSM 6
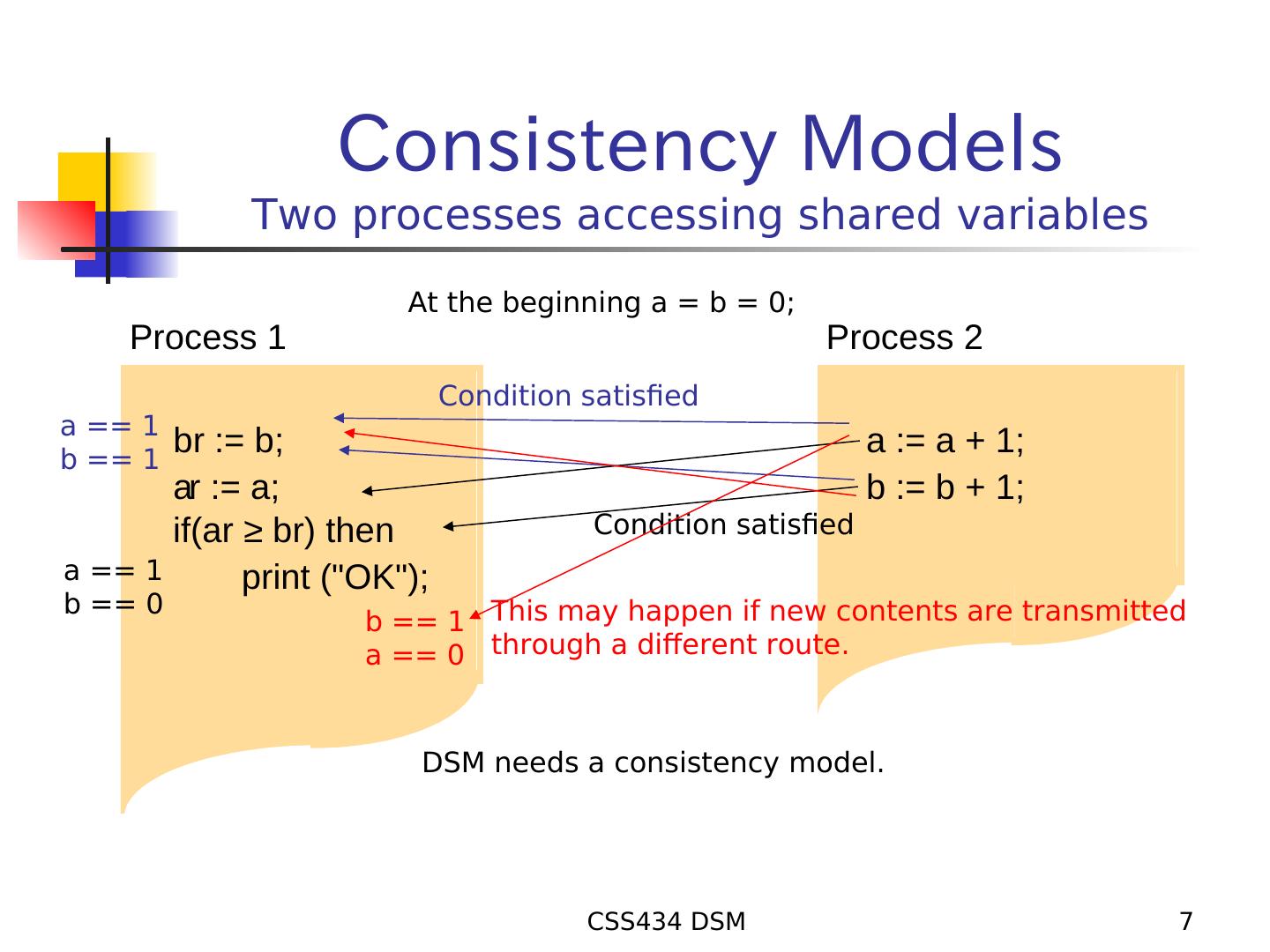
7 . Consistency Models Two processes accessing shared variables At the beginning a = b = 0; Process 1 Process 2 Condition satisfied a == 1 b == 1 br := b; a := a + 1; ar := a; b := b + 1; if(ar ≥ br) then Condition satisfied a == 1 print ("OK"); b == 0 b == 1 This may happen if new contents are transmitted a == 0 through a different route. DSM needs a consistency model. CSS434 DSM 7
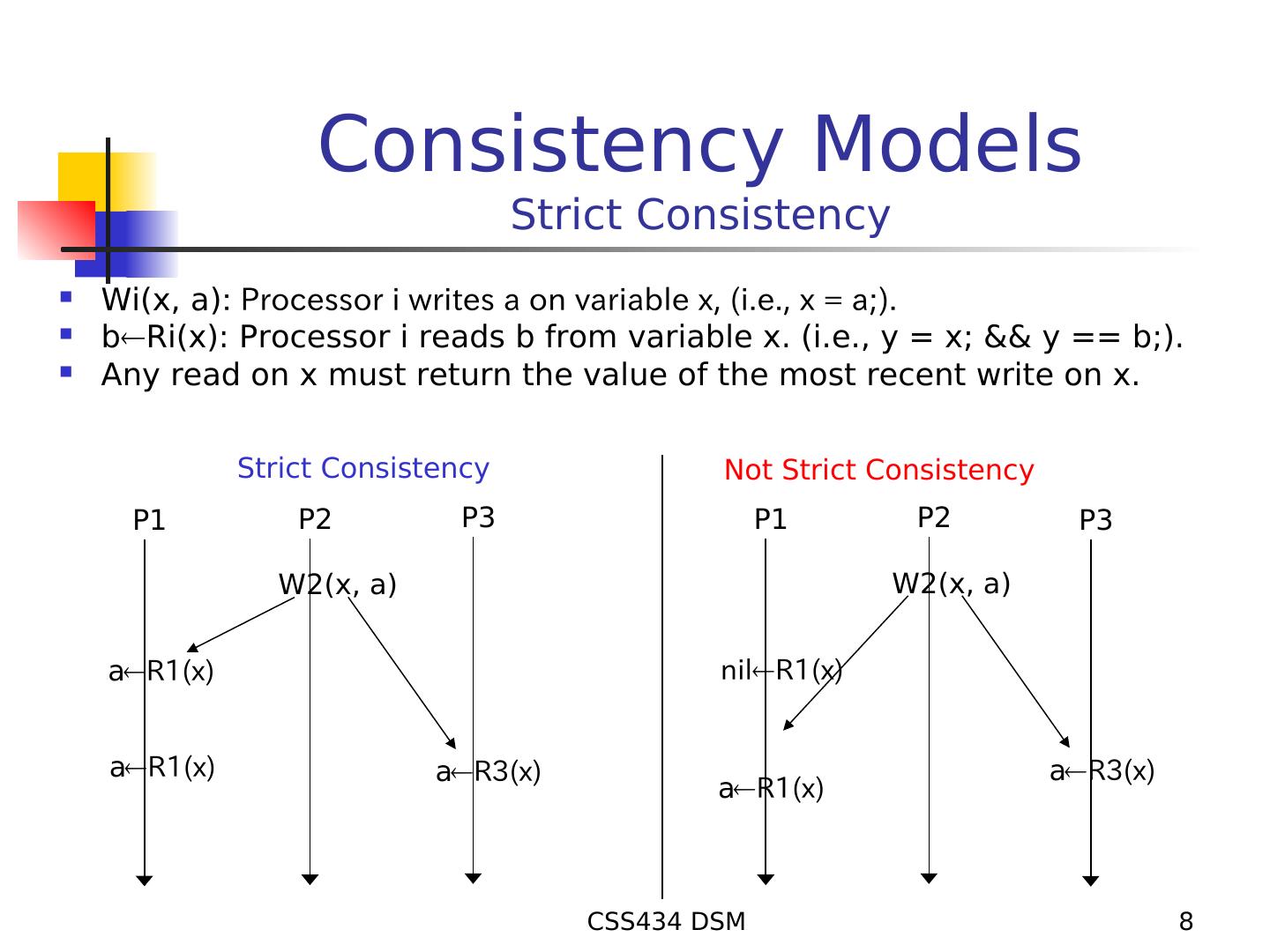
8 . Consistency Models Strict Consistency Wi(x, a): Processor i writes a on variable x, (i.e., x = a;). bRi(x): Processor i reads b from variable x. (i.e., y = x; && y == b;). Any read on x must return the value of the most recent write on x. Strict Consistency Not Strict Consistency P1 P2 P3 P1 P2 P3 W2(x, a) W2(x, a) aR1(x) nilR1(x) aR1(x) aR3(x) aR3(x) aR1(x) CSS434 DSM 8
9 . Consistency Models Linearizability and Sequential Consistency Linearlizability: Operations of each individual process appear to all processes in the same order as they happen. Sequential Consistency: Operations of each individual process appear in the same order to all processes. Linearlizability Sequential Consistency P1 P2 P3 P4 P4 P1 P2 P3 W2(x, a) W2(x, a) Nil <-R1(x) W3(x, b) W3(x, b) aR1(x) bR1(x) aR4(x) bR4(x) bR1(x) bR4(x) aR4(x) aR1(x) CSS434 DSM 9
10 . Consistency Models FIFO and Processor Consistency FIFO Consistency: writes by a single process are visible to all other processes in the order in which they were issued. Processor Consistency: FIFO Consistency + all write to the same memory location must be visible in the same order. FIFO Consistency Processor Consistency P1 P2 P3 P P1 P2 P3 P4 W2(x, a) 4 W2(x, a) W2(x, b) W3(x, 0) aR1(x) aR1(x) W2(x, b) W3(y, 0) W3(x, 1) 0R1(x) aR1(x) 0R1(y) aR1(x) W3(y, 1) 0R1(x) bR1(x) 0R1(y) 1R1(y) 1R1(y) W3(z, 1) 1R1(x) W2(y, a) W3(z, a) 1R1(x) W2(y, a) bR1(x) bR1(x) bR1(x) 1R1(z) 1R1(z) aR1(y) aR1(y) 1R1(z) aR1(y) 1R1(z) aR1(y) CSS434 DSM 10
11 . Consistency Models Causal Consistency Causally related write must be visible to all processes in the same order. Concurrent writes may be propagated in a different order. Causal Consistency Not Causal Consistency P1 P2 P3 P4 P4 P1 P2 P3 W2(x, a) W2(x, a) aR3(x) aR4(x) aR3(x) aR3(x) W2(x, c) W3(x, b) W3(x, b) bR4(x) cR1(x) aR1(x) bR4(x) bR1(x) cR4(x) bR1(x) aR4(x) CSS434 DSM 11
12 . Consistency Models Weak Consistency Accesses to synchronization variables must obey sequential consistency. All previous writes must be completed before an access to a synchronization variable. All previous accesses to synchronization variables must be completed before access to non-synchronization variable. Weak Consistency Not Weak Consistency P1 P2 P3 P1 P2 P3 W2(x, a) W2(x, a) W2(x, b) W2(y, c) bR4(x) W2(y, c) aR4(x) W2(x, b) NilR4(y) S3 S3 S1 S1 S2 S2 cR4(y) bR4(x) bR4(x) aR4(x) cR4(y) cR4(y) cR4(y) bR4(x) CSS434 DSM 12
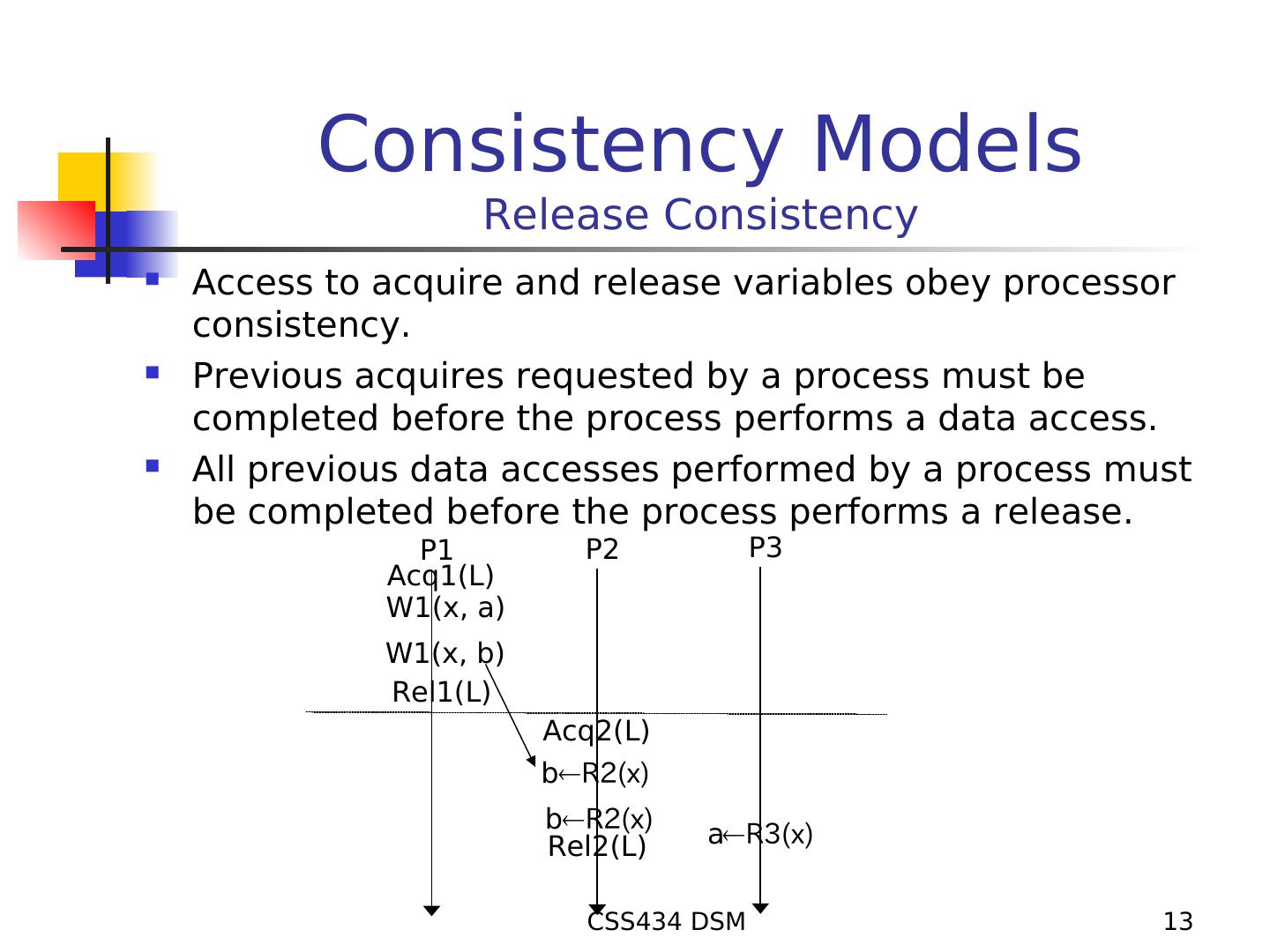
13 . Consistency Models Release Consistency Access to acquire and release variables obey processor consistency. Previous acquires requested by a process must be completed before the process performs a data access. All previous data accesses performed by a process must be completed before the process performs a release. P1 P2 P3 Acq1(L) W1(x, a) W1(x, b) Rel1(L) Acq2(L) bR2(x) bR2(x) Rel2(L) aR3(x) CSS434 DSM 13
14 . Consistency Models Release Consistency (Example) Process 1: acquireLock(); // enter critical section a := a + 1; b := b + 1; releaseLock(); // leave critical section Process 2: acquireLock(); // enter critical section print ("The values of a and b are: ", a, b); releaseLock(); // leave critical section CSS434 DSM 14
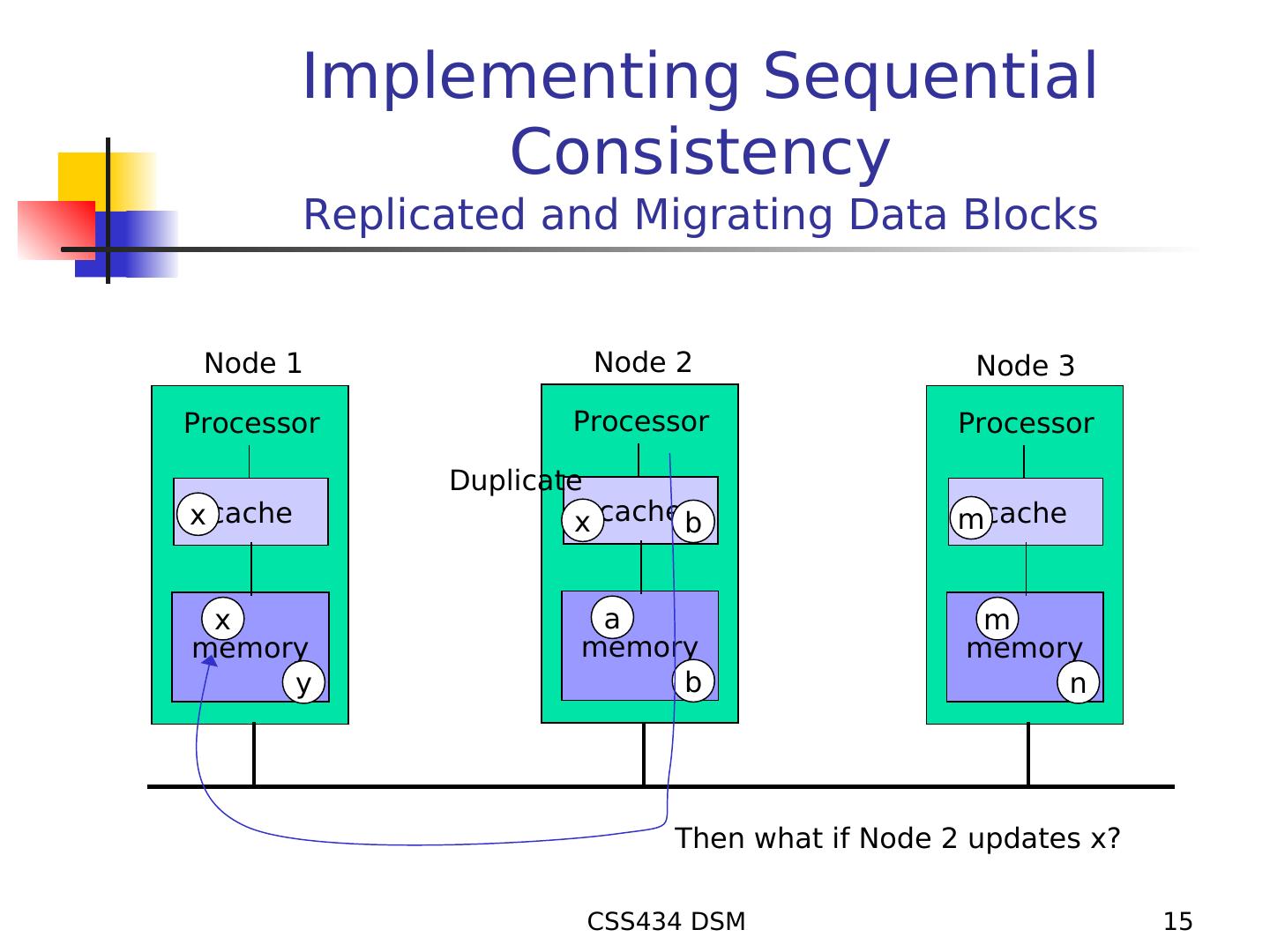
15 . Implementing Sequential Consistency Replicated and Migrating Data Blocks Node 1 Node 2 Node 3 Processor Processor Processor Duplicate x cache x cache b mcache x a m memory memory memory y b n Then what if Node 2 updates x? CSS434 DSM 15
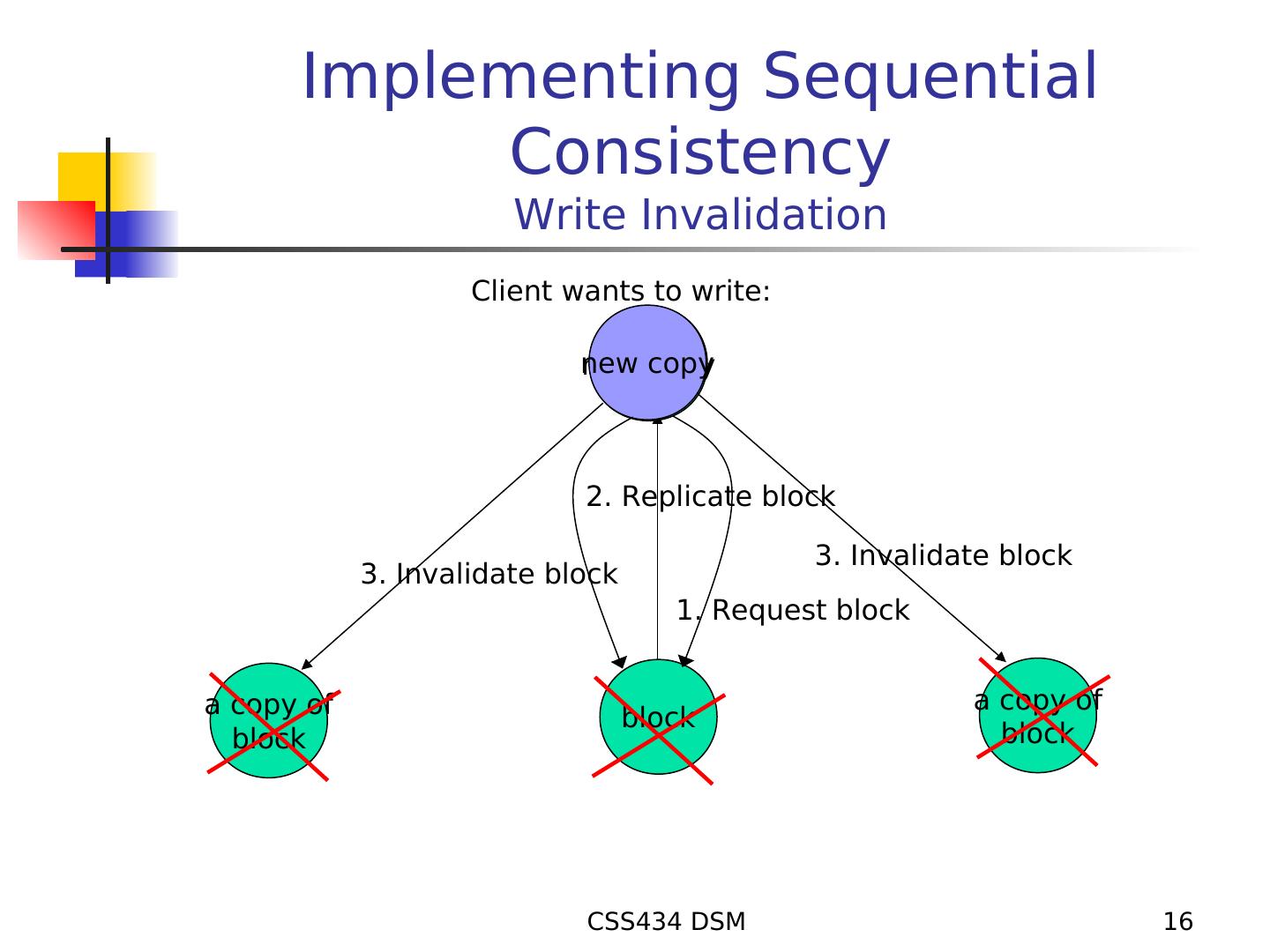
16 . Implementing Sequential Consistency Write Invalidation Client wants to write: new copy 2. Replicate block 3. Invalidate block 3. Invalidate block 1. Request block a copy of a copy of block block block CSS434 DSM 16
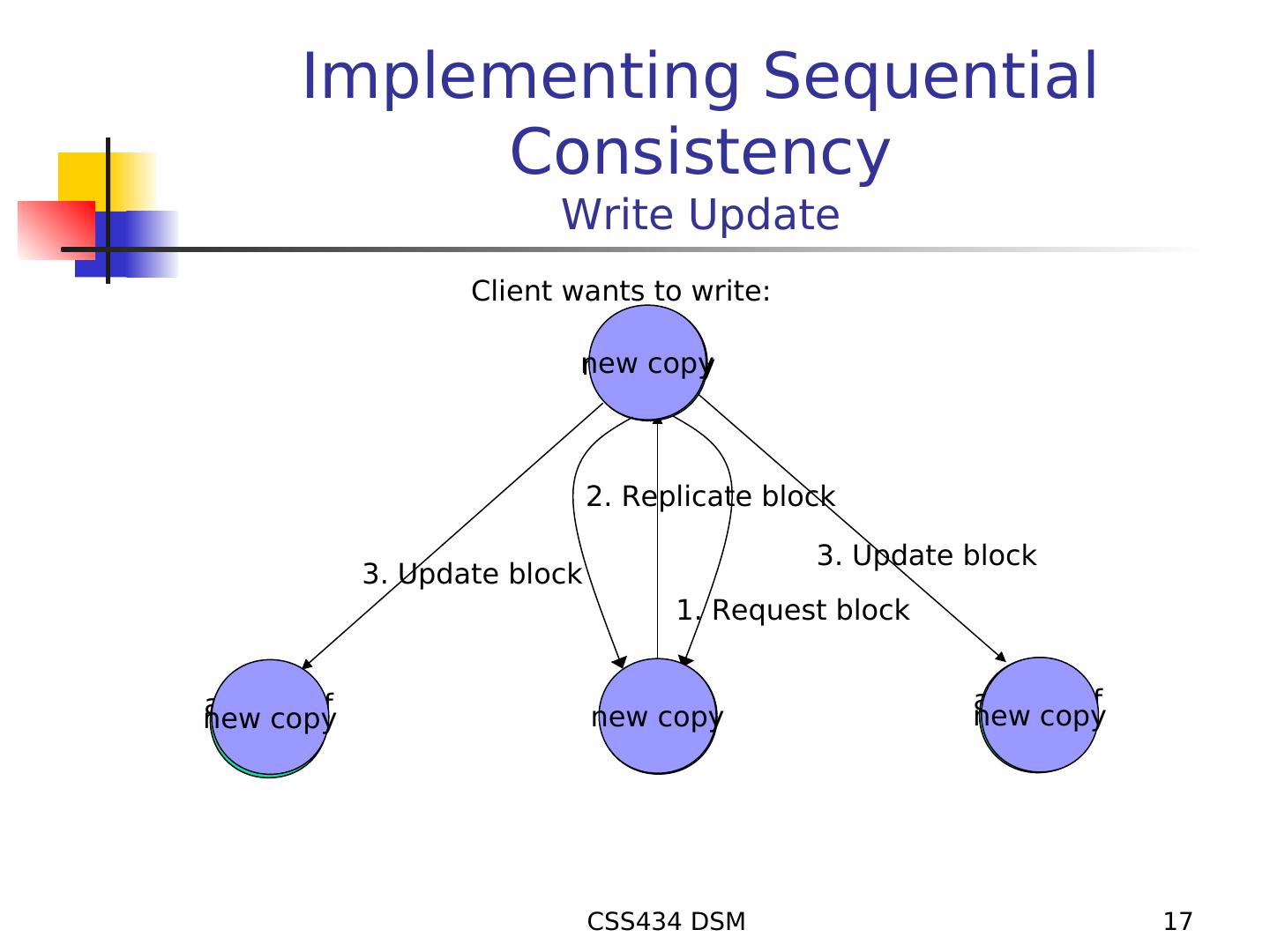
17 . Implementing Sequential Consistency Write Update Client wants to write: new copy 2. Replicate block 3. Update block 3. Update block 1. Request block a copy of a copy of new copy new copy block new copy block block CSS434 DSM 17
18 . Implementing Sequential Consistency Read/Write Request Unused Read (Read a copy from the onwer) Replacement Replacement Replacement Replacement Write invalidate Nil Read only Read (Read from memory and get an ownership) Write Write invalidate Write (invalidate others if they have a copy (invalidate others if they have a copy and get an ownership) and get an ownership) Write invalidate Read-owned Write Writable (invalidate others if they have a copy) CSS434 DSM 18
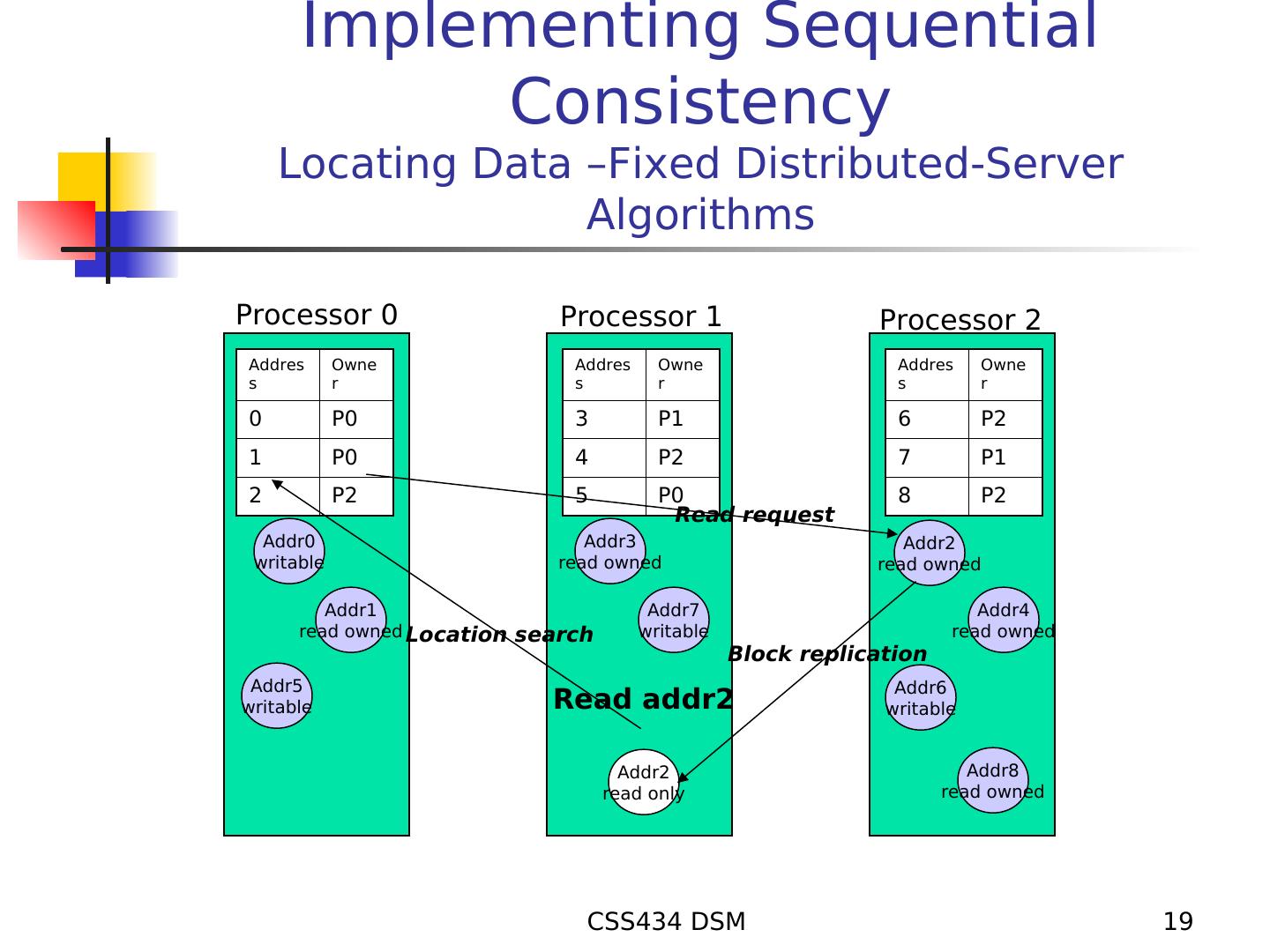
19 . Implementing Sequential Consistency Locating Data –Fixed Distributed-Server Algorithms Processor 0 Processor 1 Processor 2 Addres Owne Addres Owne Addres Owne s r s r s r 0 P0 3 P1 6 P2 1 P0 4 P2 7 P1 2 P2 5 P0 8 P2 Read request Addr0 Addr3 Addr2 writable read owned read owned Addr1 Addr7 Addr4 read owned Location search writable read owned Block replication Addr5 Addr6 writable Read addr2 writable Addr2 Addr8 read only read owned CSS434 DSM 19
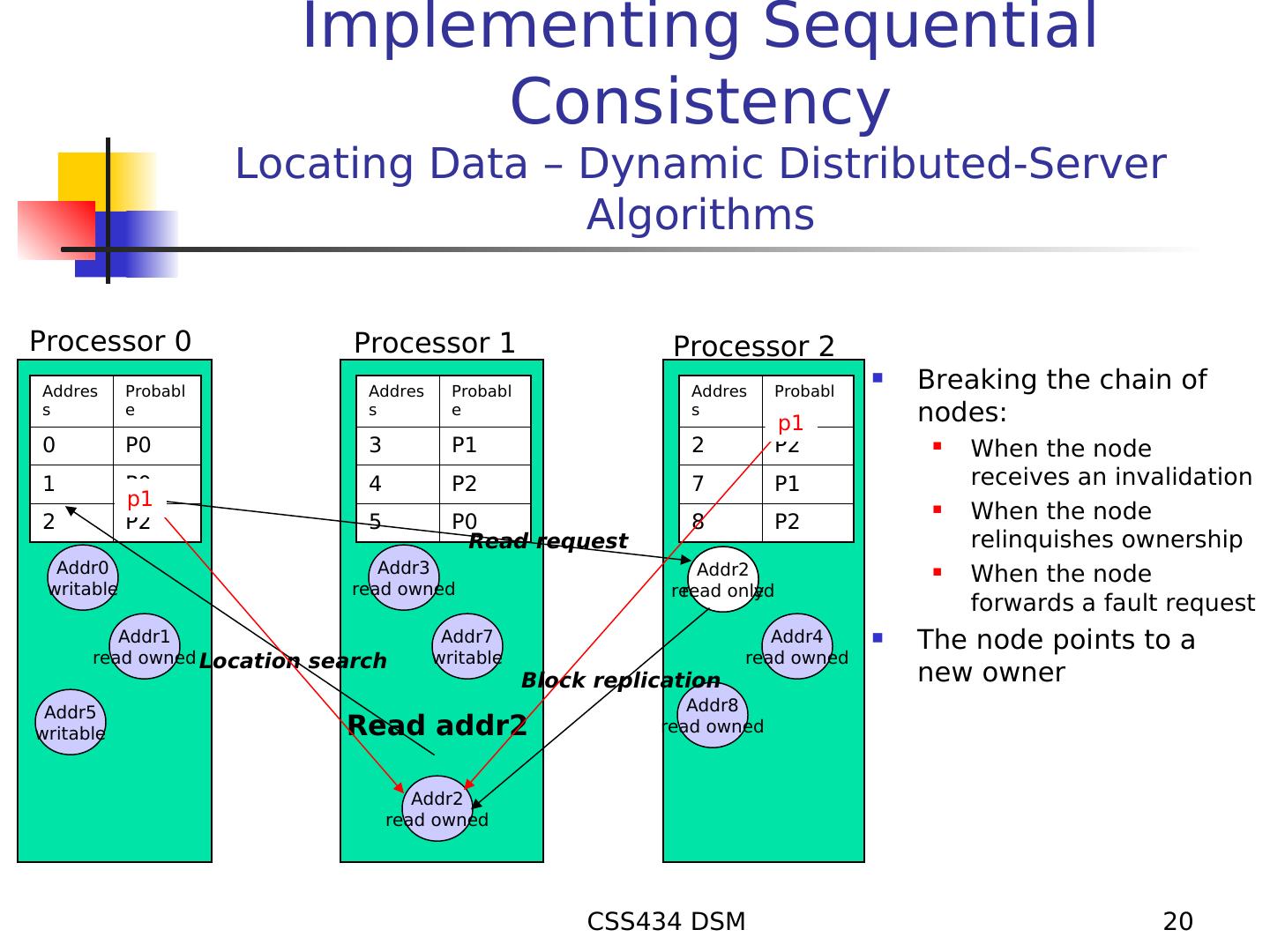
20 . Implementing Sequential Consistency Locating Data – Dynamic Distributed-Server Algorithms Processor 0 Processor 1 Processor 2 Addres Probabl Addres Probabl Addres Probabl Breaking the chain of s e s e s e p1 nodes: 0 P0 3 P1 2 P2 When the node 1 P0 4 P2 7 P1 receives an invalidation p1 2 P2 5 P0 8 P2 When the node Read request relinquishes ownership Addr0 Addr3 Addr2 When the node writable read owned read readowned only forwards a fault request Addr1 Addr7 Addr4 The node points to a read owned Location search writable read owned Block replication new owner Addr5 Addr8 writable Read addr2 read owned Addr2 read owned CSS434 DSM 20
21 .Replacement Strategy Which block to replace Non-usage based (e.g. FIFO) Usage based (e.g. LRU) Mixed of those (e.g. Ivy ) Unused/Nil: replaced with the highest priority Read-only: the second priority Read-owned: the third priority Writable: the lowest priority and LRU used. Where to place a replaced block Invalidating a block if other nodes have a copy. Using secondary store Using the memory space of other nodes CSS434 DSM 21
22 .Thrashing Thrashing: Two or more processes try to write the same shared block. An owner keeps writing its block shared by two or more reader processes. The larger a block, the more chances of false sharing that causes thrashing. Solutions: Allow a process to prevent a block from accessed from the others, using a lock. Allow a process to hold a block for a certain amount of time. Apply a different coherence algorithm to each block. What do those solutions require users to do? Are there any perfect solutions? CSS434 DSM 22
23 .Paper Review by Students IVY Dash Munin Linda/Jini/JavaSpace Discussions: Classify which system is based on sequential consistency, release consistency, and lazy release consistency. Classify the shared data granularity of these systems: cache-line based, page-based, and object-based. Classify the implementation of these systems: hardware implementation, OS implementation, and User-level implementation. CSS434 DSM 23
24 .Non-Turn-In Exercises 1. Is the memory underlying the following execution of two processes sequentially consistent (assuming that, initially, all variables are set to zero)? P1: R(x)1; R(x)2; W(y)1 1. P2: W(x)1; R(y)1; W(x)2 2. Show that the following history is not causally consistent. 1. P1: W(a)0; W(a)1 2. P2: R(a)1; W(b)2 3. P3: R(b)2; R(a)0 3. Explain the relationship between false sharing and data granularity in DSM. CSS434 DSM 24
25 . Non-Turn-In Exercises Processor 1 Processor 2 Processor 3 ownership table ownership table ownership table addr owner shared addr owner shared addr owner shared 0 4 P0 3 P2 6 P3 1 P0 P3 4 P3 7 P2 2 P3 5 P0 8 P2 data items data items data items addr addr addr addr 2 addr 0 addr 3 7 4 1 addr addr eve 6 copy 8 addr1 nt 4. There is a DSM system that is based on the write-invalidation protocol, uses a fixed distributed-server algorithm for locating a given data item, and consists of three processors such as 1, 2, and 3. Each processor has the following data items and an ownership/sharing-processor table. CSS434 DSM 25
26 . Non-Turn-In Exercises Given the following sequence of memory accesses, draw additional arrows and circles in the above figure as instructed. To distinguish which arrow corresponds to which operation, add the operation number 1 – 8 to each arrow. Also, update the corresponding ownership table entries. (1) Memory access #1: Processor 2 reads data from address 2. Add arrows in the above figure to indicate operations required for the memory access #1. 1. Send a query to search for the address 2 2. Send a request to read from the address 2 3. Read data from the address 2 to Processor 2 Update the corresponding ownership table entry. (Just add P2 in the “share” field.) Draw a circle to indicate that a copy of address 2 was created on Processor 2. (2) Memory access #2: Processor 1 reads data from address 2. Add arrows in the above figure to indicate operations required for the memory access #2. 4. Send a query to search for the address 2 5. Send a request to read from the address 2 6. Read data from the address 1 to Processor 2 Update the corresponding ownership table entry. (Just add P1 in the “share” field.) Draw a circle to indicate that a copy of address 2 was created on Processor 1. (3) Memory access #3: Processor 2 writes data to address 2. Add arrows in the above figure to indicate operations required for the memory access #3. 7. Send a request to update the ownership information on the address 2 8. Send a write invalidation to all non-owner processors sharing the address 2 Update the corresponding ownership table entry. (Make Processor 2 a new owner of address 2 and cross out all other processor Ids in the entry.) Cross out all circles to indicate that old copies of address 2 were all invalidated. CSS434 DSM 26
3秒后跳转登录页面
去登陆

