






























































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Go在Grab地理服务中的实践
本章介绍什么是 Grab--东南亚最大的出行平台
● 一个典型的派单流程
● 一个核心地理服务系统演进历程
为什么选择go语言
● 压测与调优
展开查看详情
1 .Go在Grab地理服务中的实践 张志印
2 .大纲 ● What’s Grab ● 一个典型的派单流程 ● 一个核心地理服务系统演进历程 ● Why go ● 压测与调优 ● QA 2
3 .What’s Grab 3
4 .东南亚最大的出行平台 4
5 .连接供(Supply,司机)需(Demand,乘客) 5
6 .从派单流程说起 6
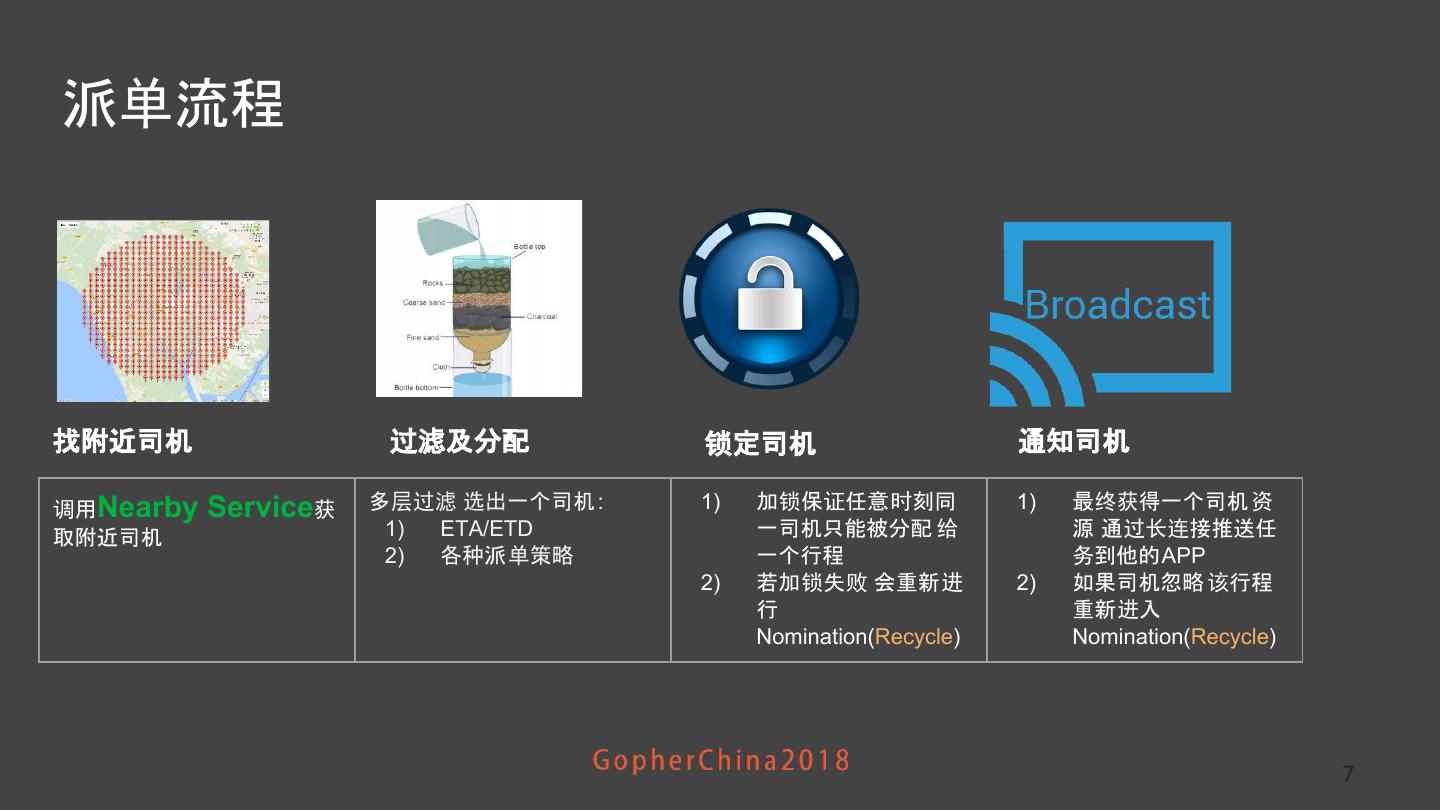
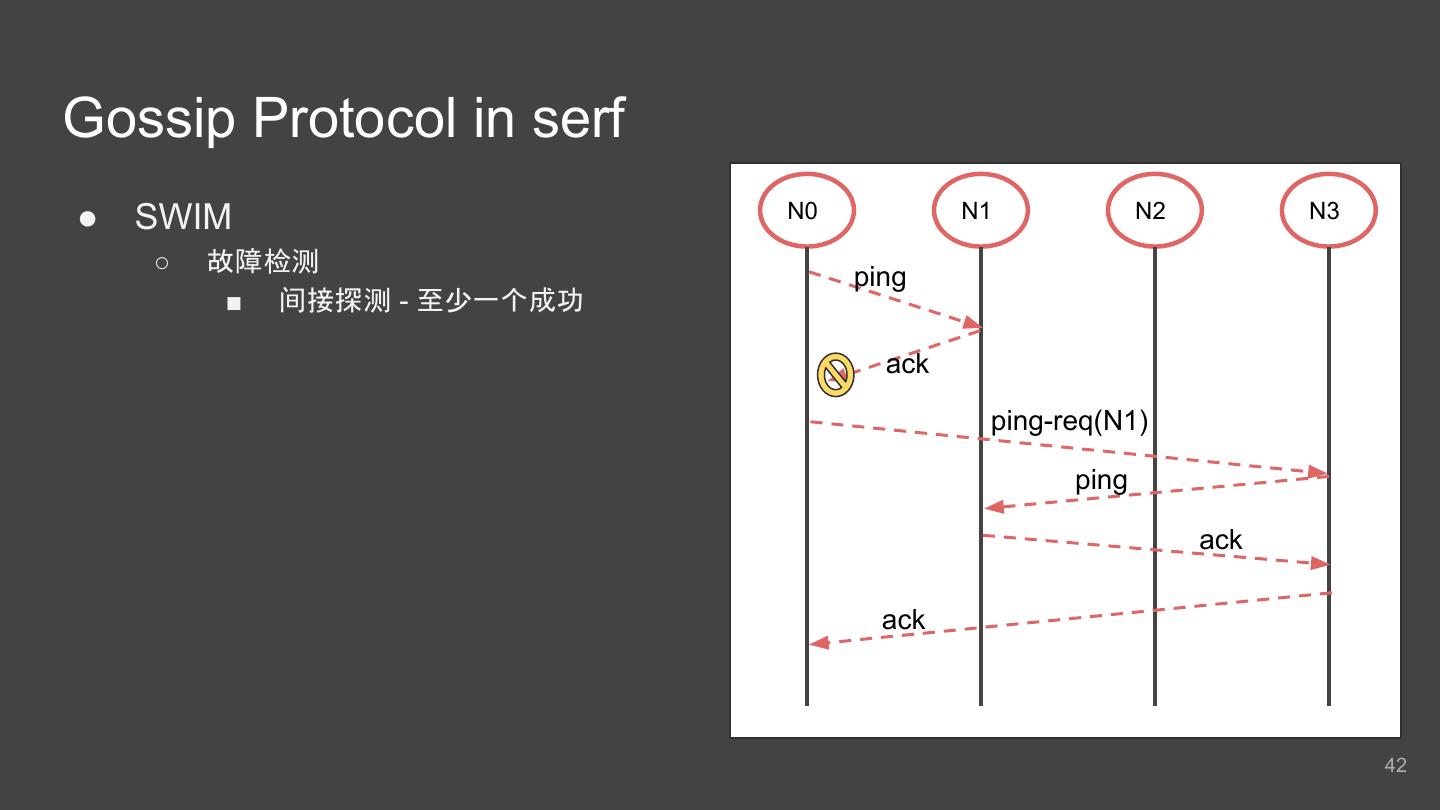
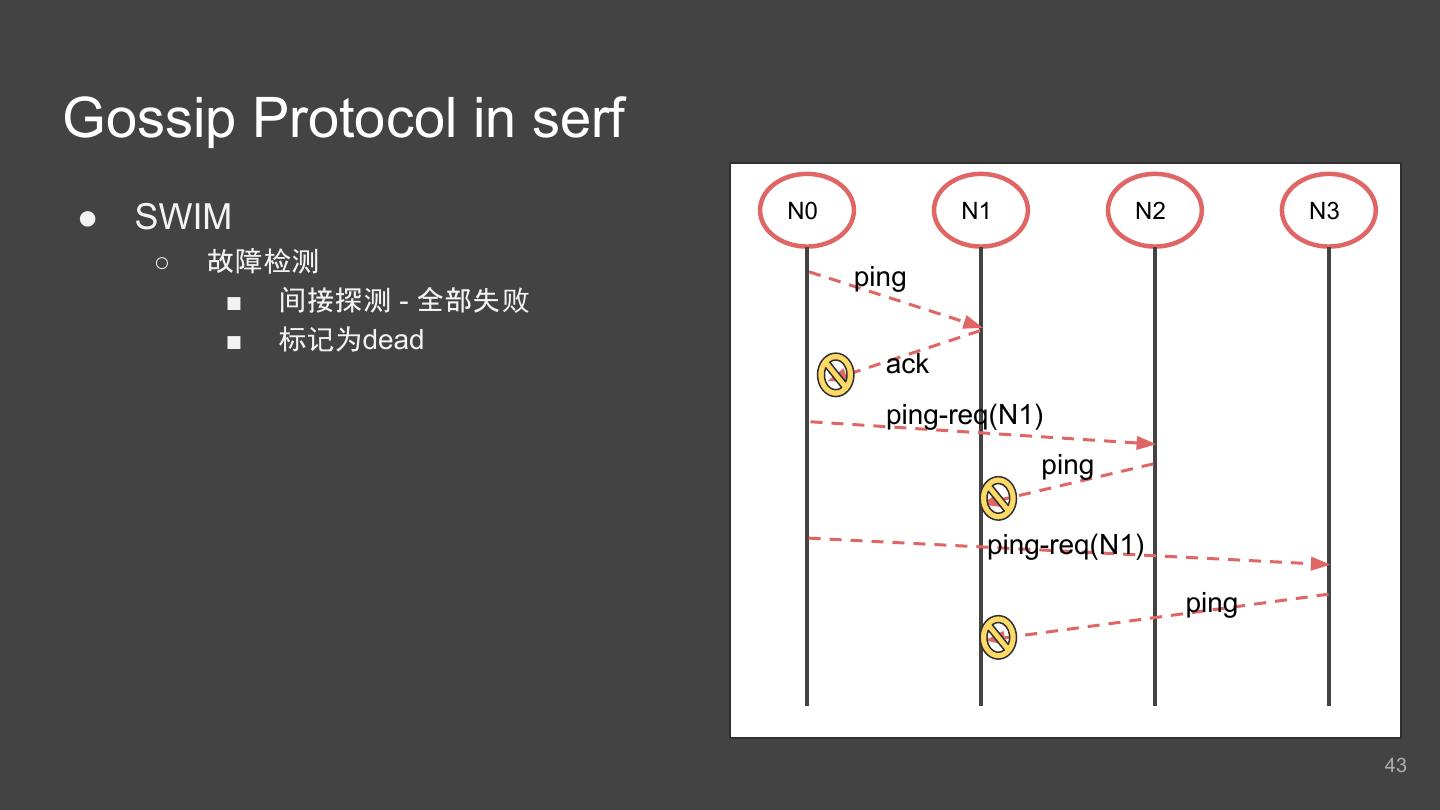
7 .派单流程 找附近司机 过滤及分配 锁定司机 通知司机 调用Nearby Service获 多层过滤 选出一个司机 : 1) 加锁保证任意时刻同 1) 最终获得一个司机 资 取附近司机 1) ETA/ETD 一司机只能被分配 给 源 通过长连接推送任 2) 各种派单策略 一个行程 务到他的APP 2) 若加锁失败 会重新进 2) 如果司机忽略 该行程 行 重新进入 Nomination(Recycle) Nomination(Recycle) 7
8 .如何构建一个高可用Nearby服务? 8
9 .要解决的问题 ● 写(Update Location) ○ 司机坐标秒级实时上传 高并发写 ○ 司机坐标动态变化 ● 读(Nearby Search) ○ 查找附近的司机 ○ 司机坐标具有时效性 ● 可用性要求高 ○ 不能宕机 ● 性能要好 ○ 读写都要低延时 9
10 .Nearby服务的演进历程 10
11 .我们的目标 11
12 .我们从这里起步 12
13 .NearbyV1 - 最初版本 ● Node.js + PostGIS ● 缺点 ○ 写性能低 ■ 约几百毫秒 ■ 基于R-Tree ● 空间数据存储 一种平衡树 ● 高频写 触发频繁再平衡 ○ 可用性低 ■ 高峰时服务经常崩掉 可用性完全不可接受 13
14 .有节操的程序猿都是在造轮子
15 .NearbyV2 - Astrolabe ● 脱胎于我们内部的一次Hackathon ○ R-Tree => Geohash ○ Node.js => Golang ○ PostGIS => Redis ● Geohash特点 ○ http://geohash.org/wtw6j89guz9y ■ 坐标: 31.292494, 121.533371 ○ 使用一维字符串表示二 维坐标数据 ○ 具有相同前缀的Geohash字符串地理位置相近 ■ 邻近搜索(Nearby) How to make one Astrolabe ● 基于SortedSet作Range查询 15
16 .NearbyV2 - Astrolabe ● 写 ○ 计算Geohash ○ 按城市将Geohash存储到Redis的zset中 ● 读 ○ 计算MBR(最小外接矩形 ) 获取左下/右上两个位置的 Geohash ○ 基于Redis zset range粗略获取一批司机 ○ 计算距离找到附近的司机 ● 解决了哪些问题 ○ 写性能提高了 How to make one Astrolabe ■ ~10ms ○ 可用性更高了 很少宕机 16
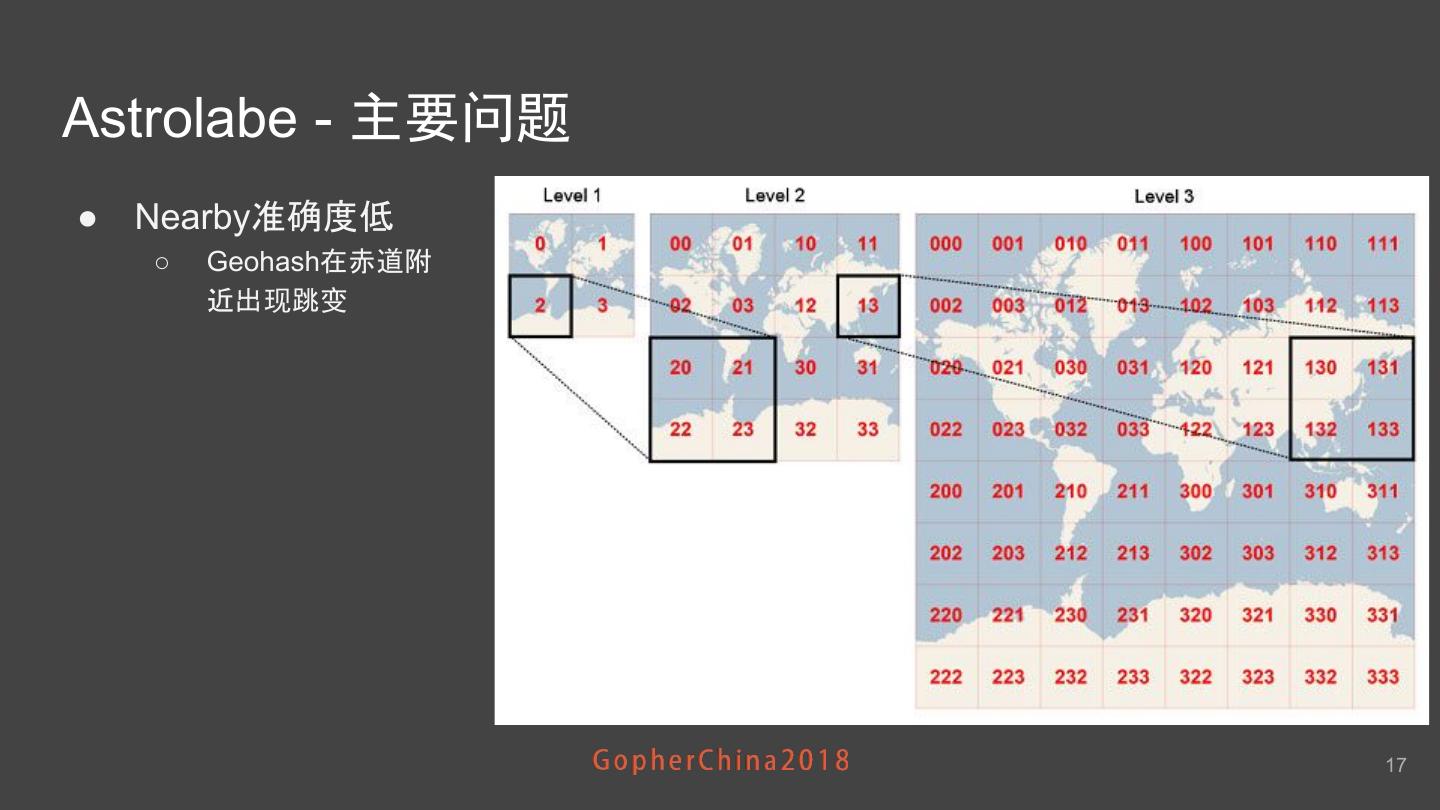
17 .Astrolabe - 主要问题 ● Nearby准确度低 ○ Geohash在赤道附 近出现跳变 17
18 .Astrolabe - 主要问题 ● 准确度低 ○ Geohash在赤道附近出 现跳变 ● 很难横向扩展 ○ 基于Geohash有序性的Range查询决定了每个城市属于一个独立 SortedSet ○ 但司机人数在不快速增 长 瓶颈日益显现 ● CPU/IO非常高 内存非常低 不能横向扩展 成为业务发展的主要瓶颈 18
19 .造一个更好的轮子 19
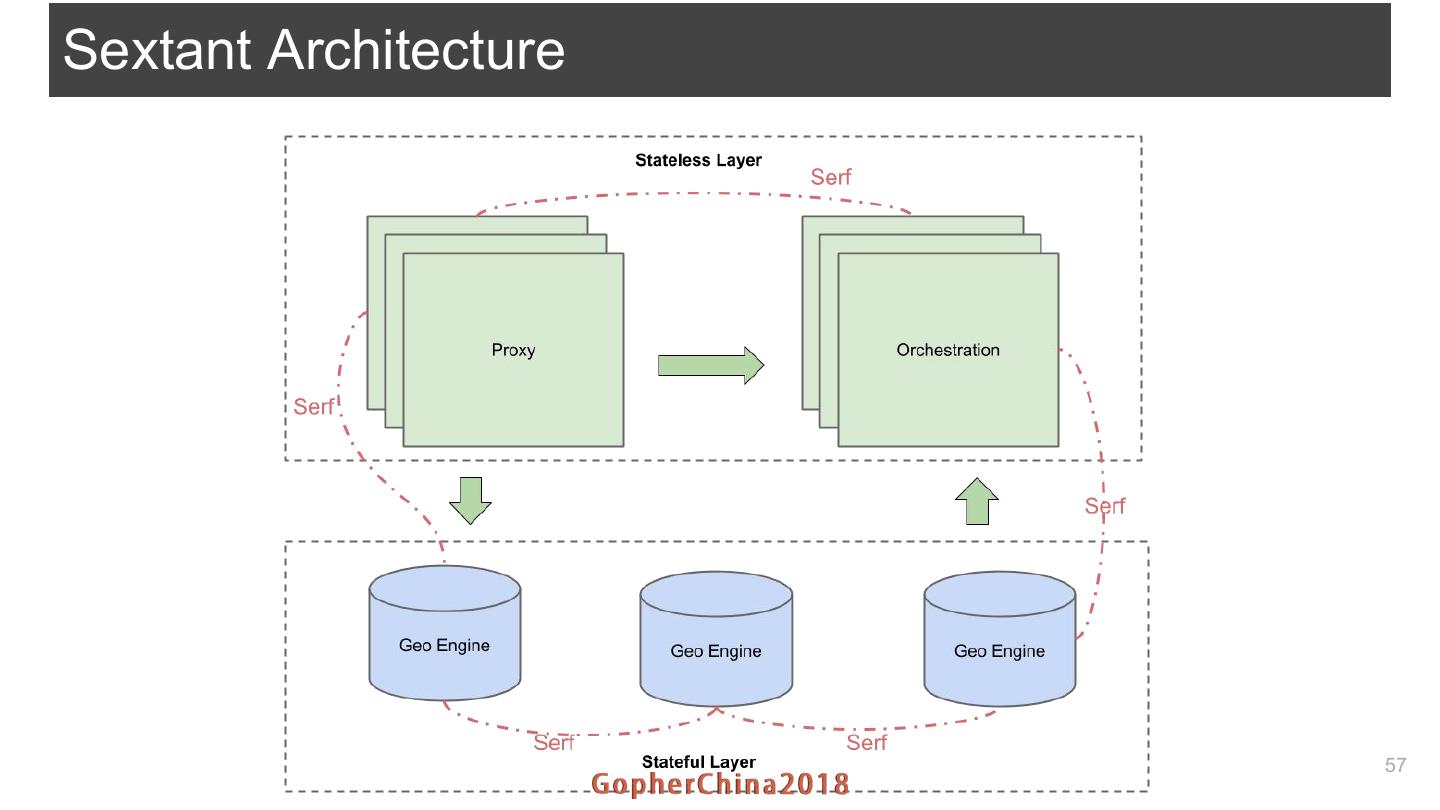
20 .NearbyV3 - Sextant 20
21 .回顾 - 要解决的问题 ● 业务高速增长 ○ 快速横向扩容 ● 写(Update Location) ○ 上百万司机坐 标秒级实时上传 ○ 司机坐标动态变化 ● 读(Nearby Search) ○ 查找附近司机 ● 可用性要求高 ○ 不能宕机 ● 性能要好 ○ 读写都要低延时 即使在流量高峰 21
22 .从扩容说起
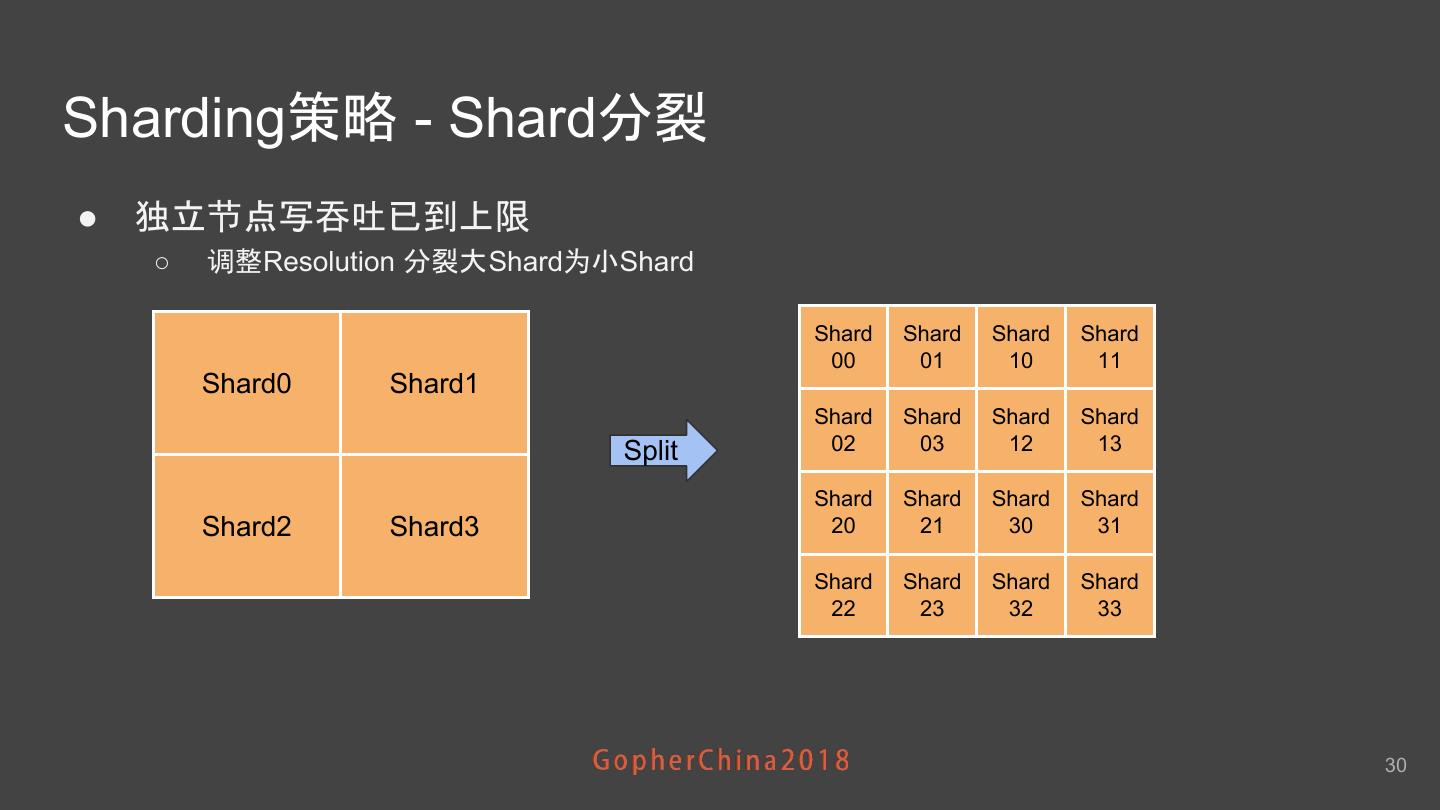
23 .要扩容 先Sharding ● Sharding就是基于空间索引将不同的司机分布到不同的服务器节点上 Sharding 分配 司机 Shard 节点 位置 空间索引 ● 司机位置通过空间索引映射到某一个Shard里 最终被分配到服务器节点上 ● Shard完全在内存中 ● 每个Shard运行在至少2个节点上 23
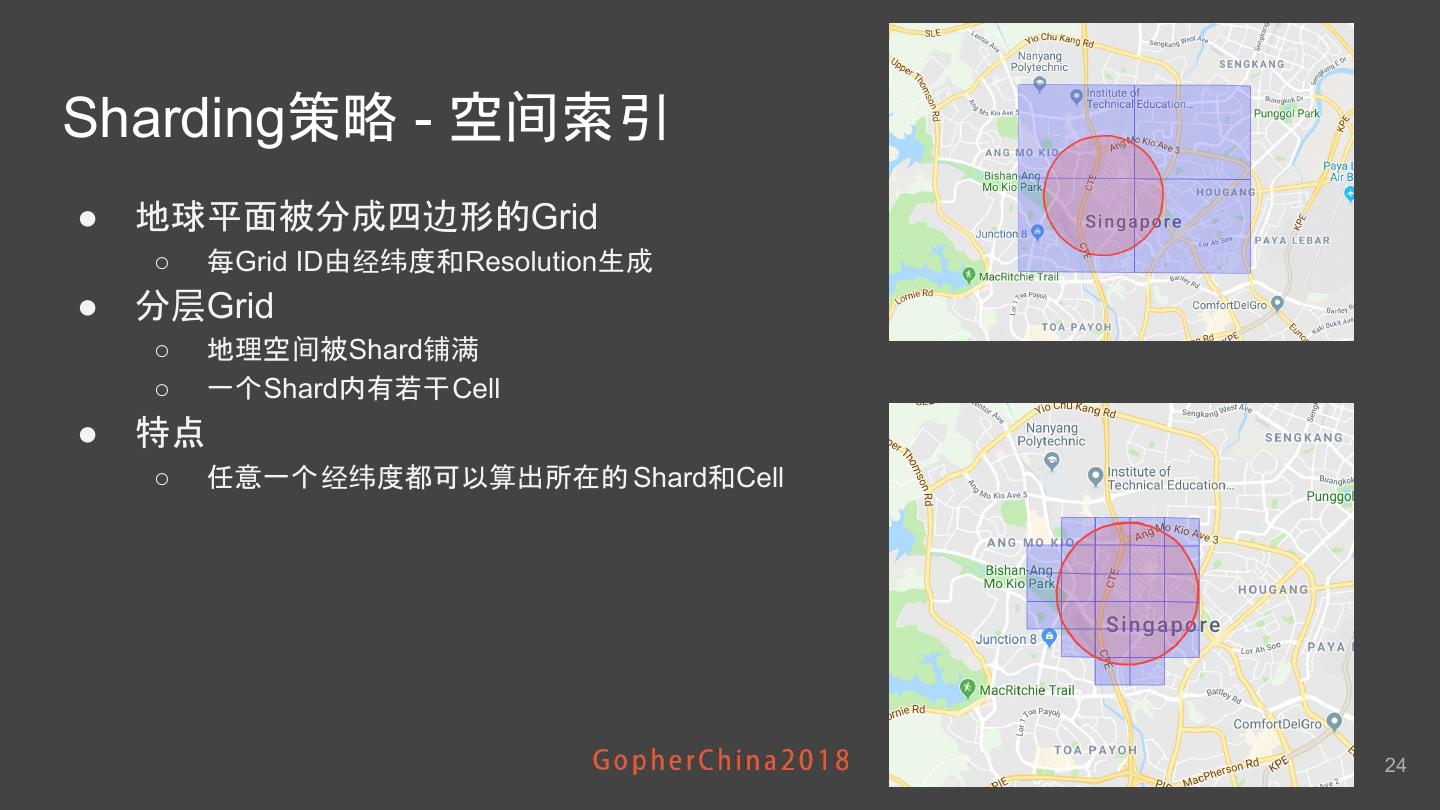
24 .Sharding策略 - 空间索引 ● 地球平面被分成四边形的Grid ○ 每Grid ID由经纬度和Resolution生成 ● 分层Grid ○ 地理空间被Shard铺满 ○ 一个Shard内有若干Cell ● 特点 ○ 任意一个经纬度都可以算出所在的 Shard和Cell 24
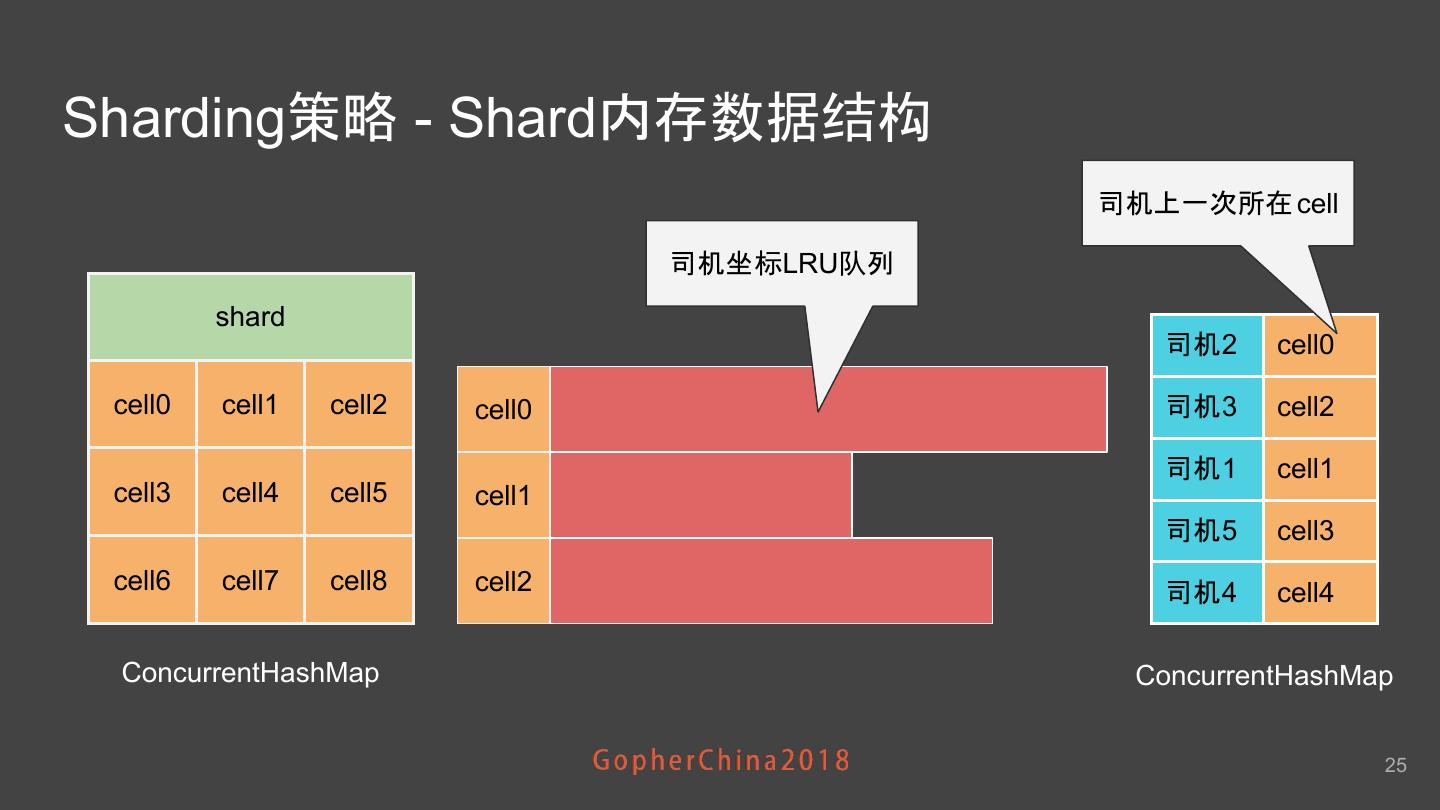
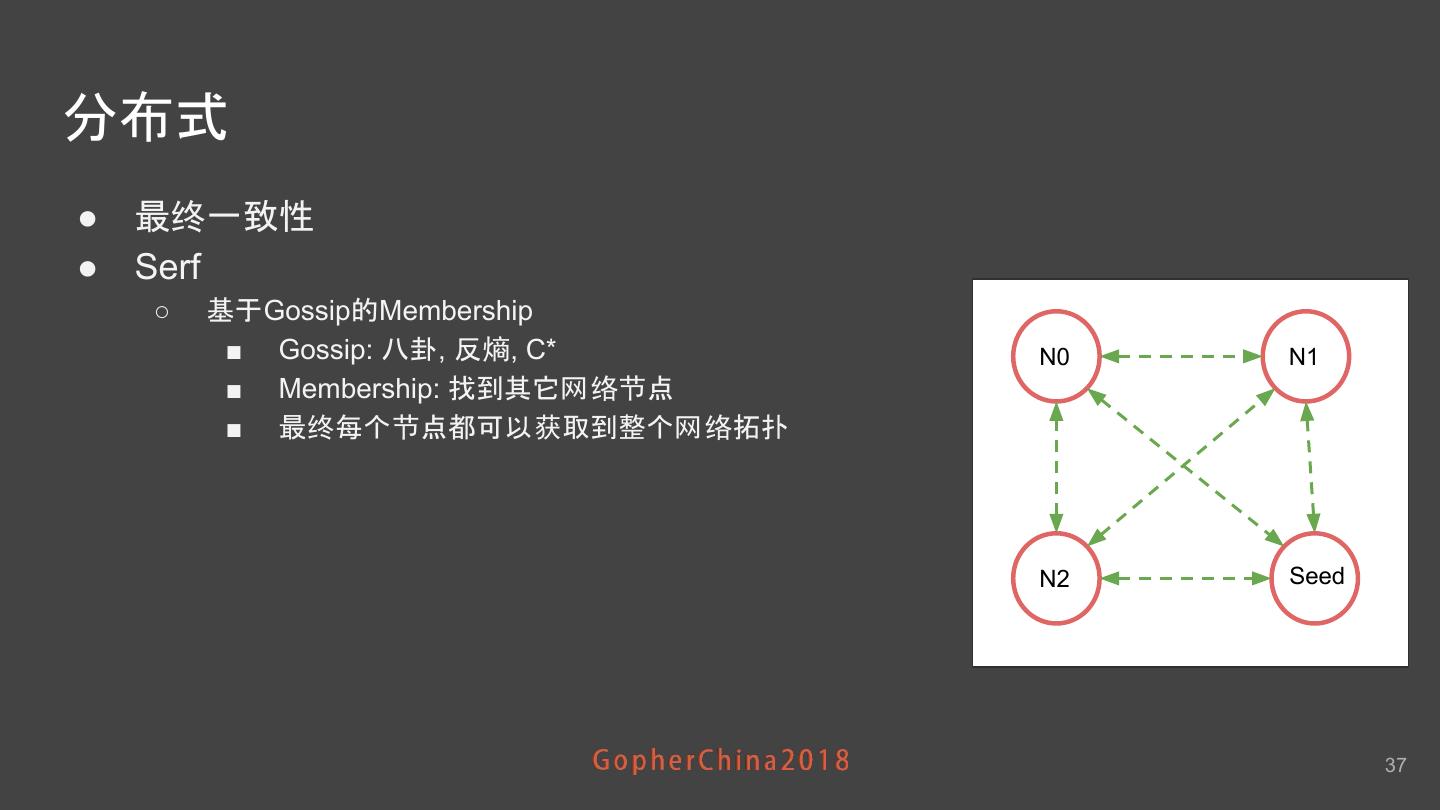
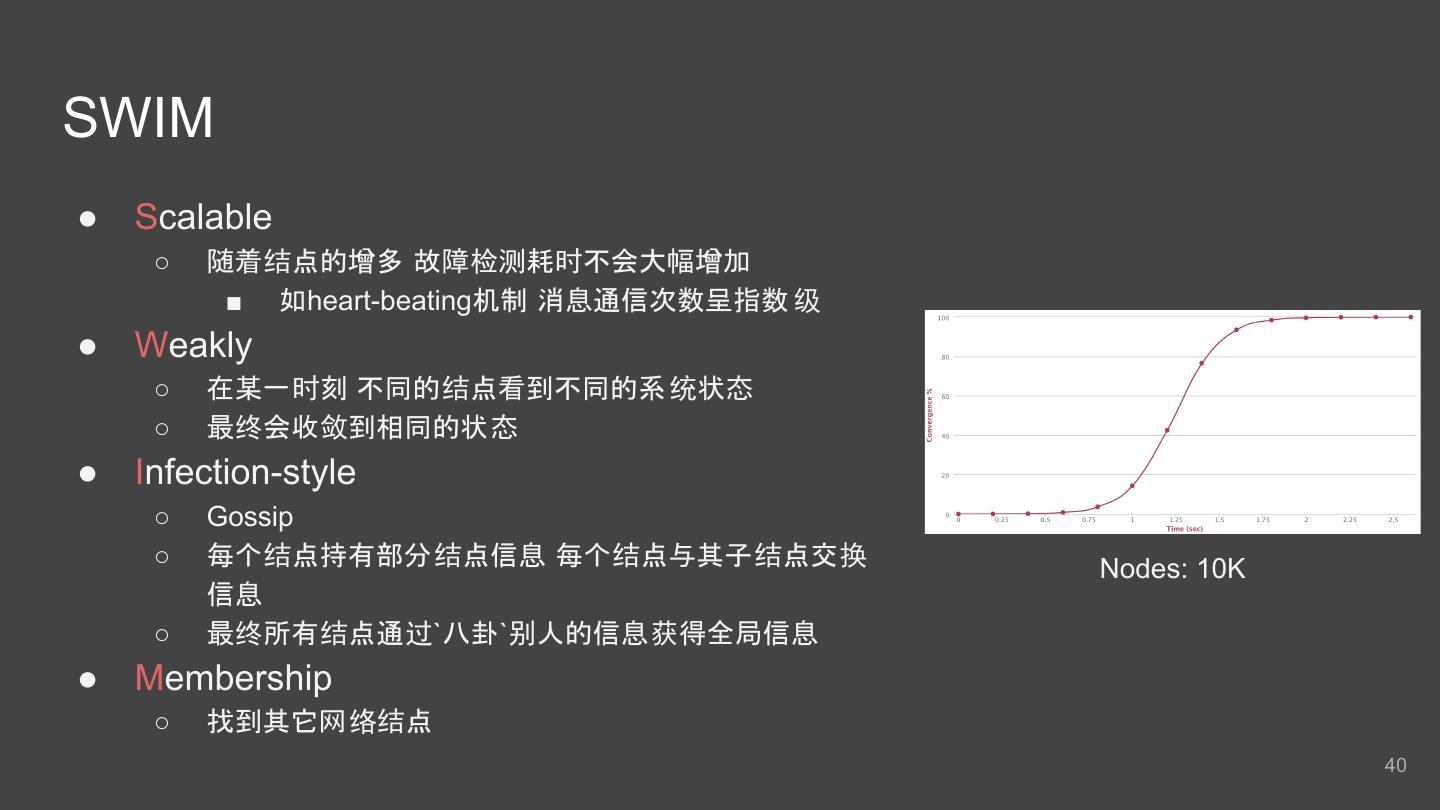
25 .Sharding策略 - Shard内存数据结构 司机上一次所在 cell 司机坐标LRU队列 shard 司机2 cell0 cell0 cell1 cell2 cell0 司机3 cell2 司机1 cell1 cell3 cell4 cell5 cell1 司机5 cell3 cell6 cell7 cell8 cell2 司机4 cell4 ConcurrentHashMap ConcurrentHashMap 25
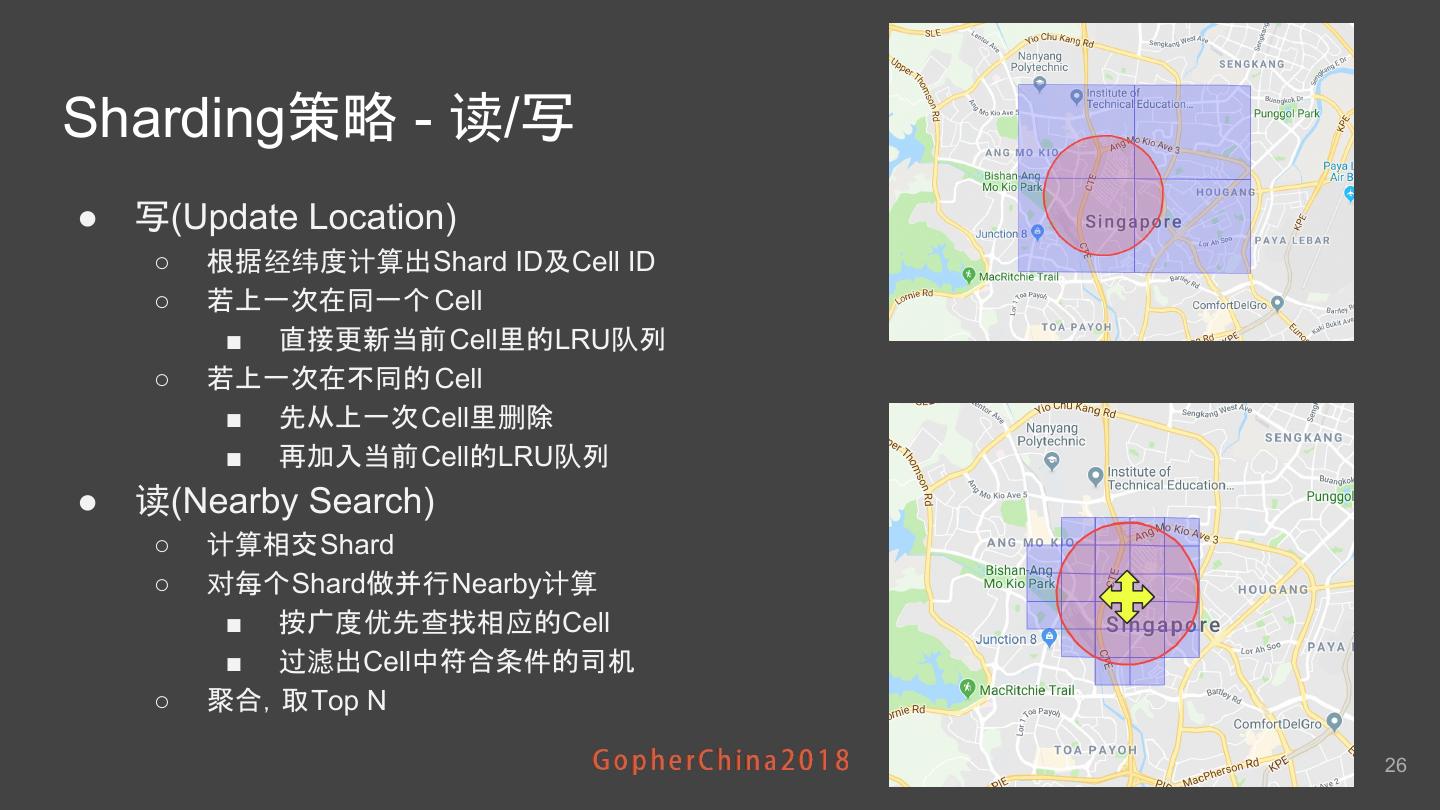
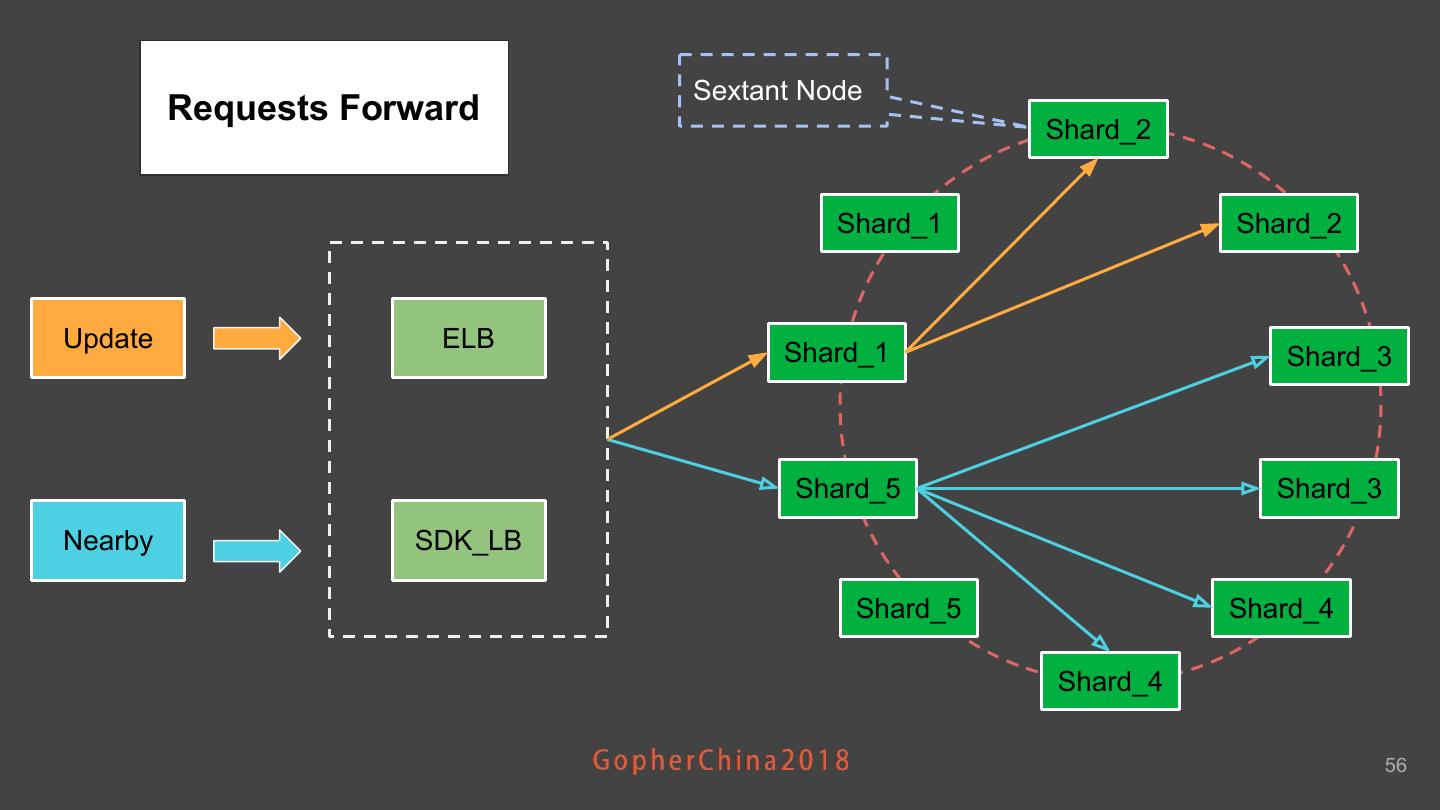
26 .Sharding策略 - 读/写 ● 写(Update Location) ○ 根据经纬度计算出Shard ID及Cell ID ○ 若上一次在同一个 Cell ■ 直接更新当前 Cell里的LRU队列 ○ 若上一次在不同的 Cell ■ 先从上一次Cell里删除 ■ 再加入当前Cell的LRU队列 ● 读(Nearby Search) ○ 计算相交Shard ○ 对每个Shard做并行Nearby计算 ■ 按广度优先查找相应的Cell ■ 过滤出Cell中符合条件的司机 ○ 聚合,取Top N 26
27 .Sharding策略 - 清理 ● 清理过期数据 ○ 各种原因如网 络问题 司机可能会 遗留一个过期坐标在某个Cell里 ○ 专有的Goroutine去清理Cell里过期 数据 27
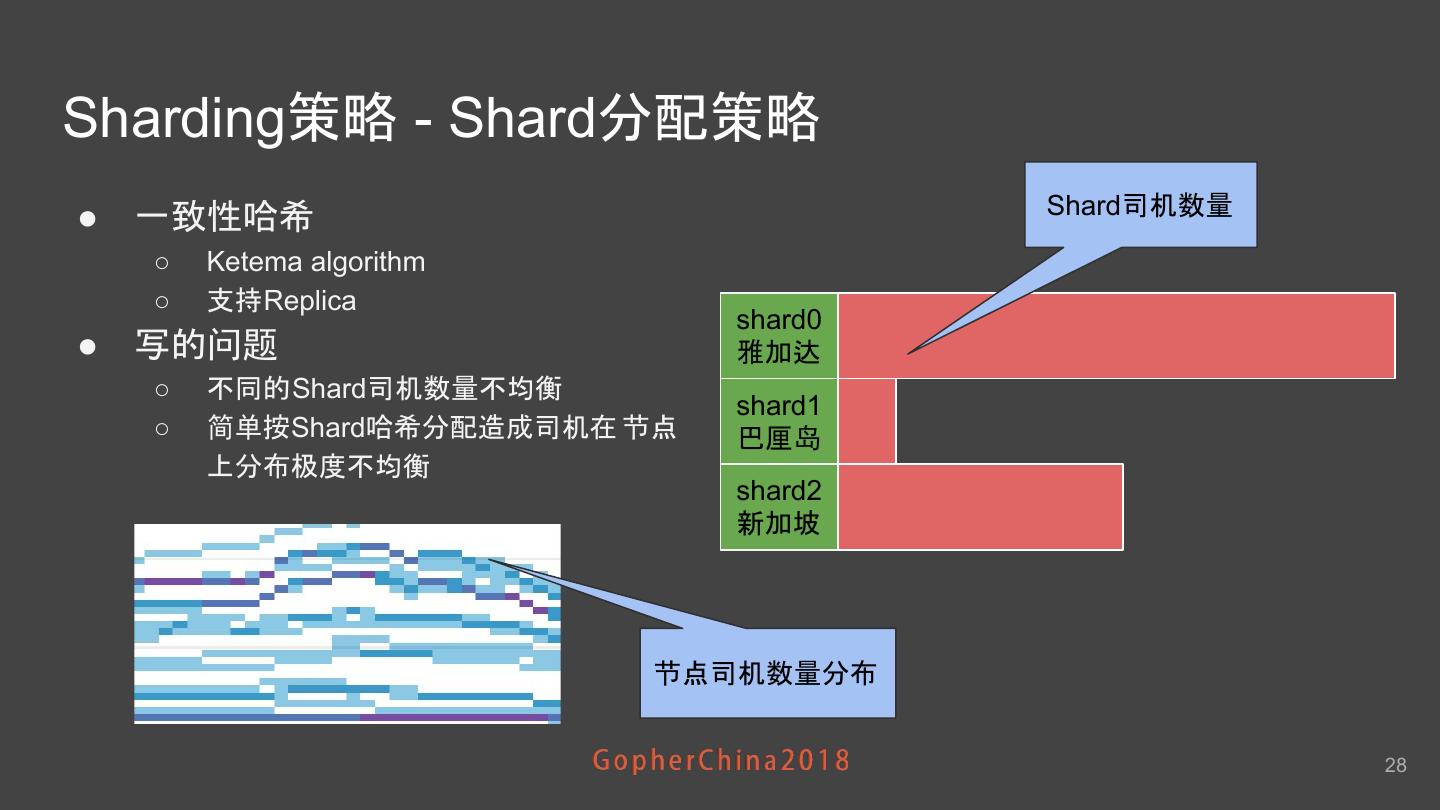
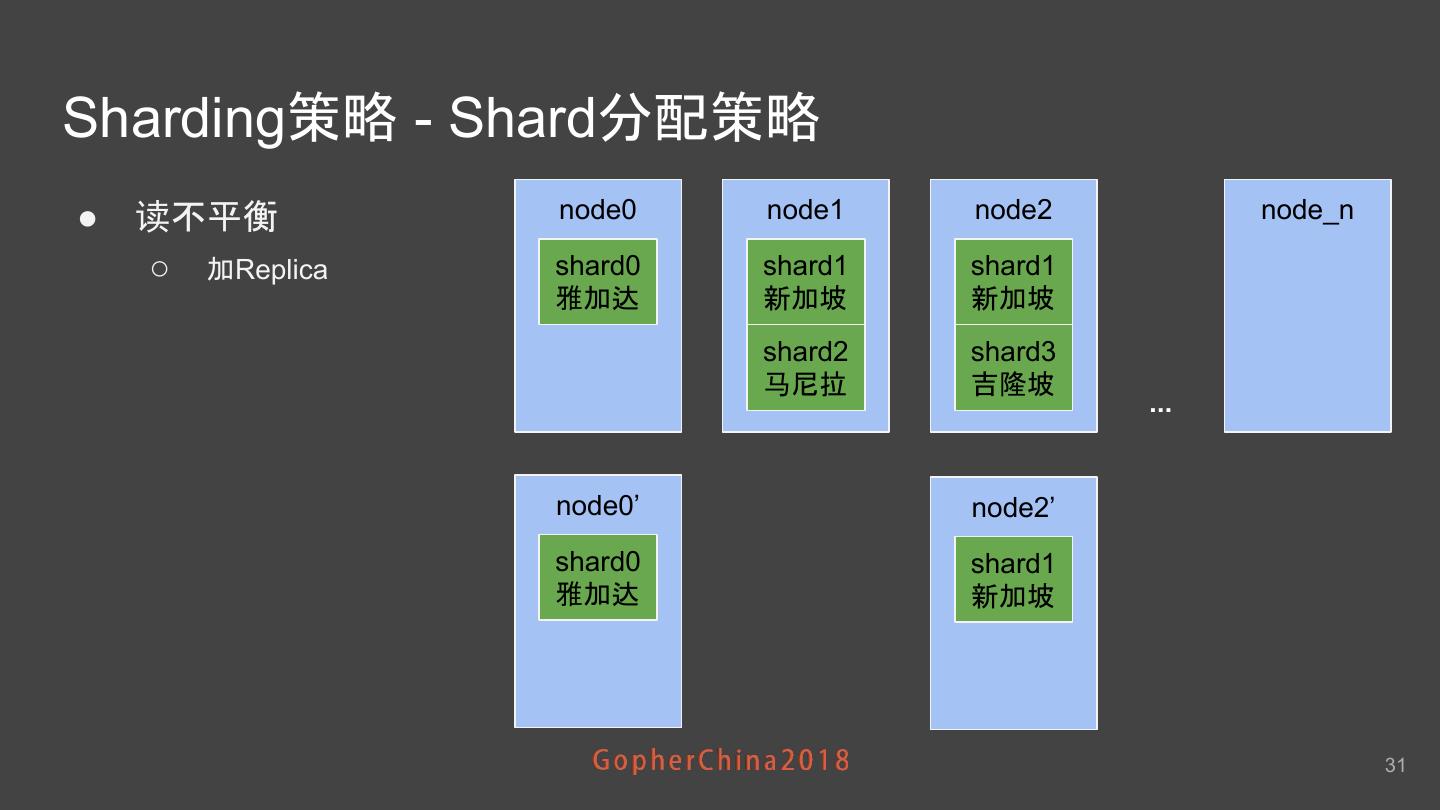
28 .Sharding策略 - Shard分配策略 Shard司机数量 ● 一致性哈希 ○ Ketema algorithm ○ 支持Replica shard0 ● 写的问题 雅加达 ○ 不同的Shard司机数量不均衡 shard1 ○ 简单按Shard哈希分配造成司机在 节点 巴厘岛 上分布极度不均衡 shard2 新加坡 节点司机数量分布 28
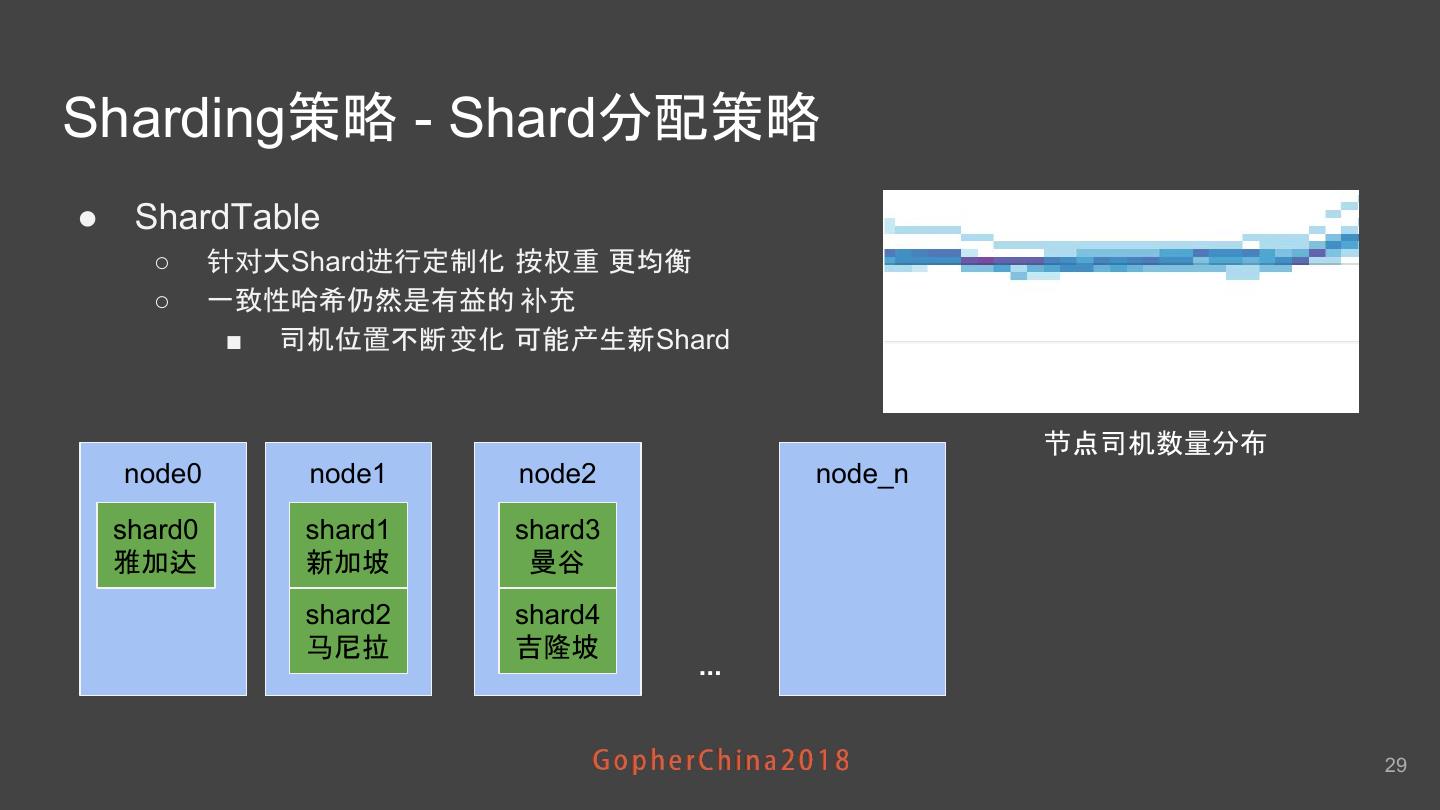
29 .Sharding策略 - Shard分配策略 ● ShardTable ○ 针对大Shard进行定制化 按权重 更均衡 ○ 一致性哈希仍然是有益的 补充 ■ 司机位置不断 变化 可能产生新Shard 节点司机数量分布 node0 node1 node2 node_n shard0 shard1 shard3 雅加达 新加坡 曼谷 shard2 shard4 马尼拉 吉隆坡 ... 29
3秒后跳转登录页面
去登陆

