











- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Incremental Visualization Lets Analysts Explore Large Datasets
Queries over large scale (petabyte) data bases often mean waiting overnight for a result to come back. Scale costs time. Such time also means that potential avenues of exploration are ignored because the costs are perceived to be too high to run or even propose them. With sampleAction we have explored whether interaction techniques to present query results running over only incremental samples can be presented as sufficiently trustworthy for analysts both to make closer to real time decisions about their queries and to be more exploratory in their questions of the data. Our work with three teams of analysts suggests that we can indeed accelerate and open up the query process with such incremental visualizations.
展开查看详情
1 . Trust Me, I’m Partially Right: Incremental Visualization Lets Analysts Explore Large Datasets Faster Danyel Fisher*, Igor Popov†, Steven M. Drucker*, mc schraefel† * † Microsoft Research Electronics and Computer Science 1 Microsoft Way, University of Southampton Redmond, WA USA Southampton, Hampshire, UK SO17 1BJ {danyelf, sdrucker}@microsoft.com {mc+w, ip2go9}@ecs.soton.ac.uk ABSTRACT query costs in a variety of ways. Strategies to accelerate Queries over large scale (petabyte) data bases often mean large scale data processing are represented in systems like waiting overnight for a result to come back. Scale costs Dremel [9] and C-Store [18] that churn through large time. Such time also means that potential avenues of collections of data by pre-structuring the data and moving exploration are ignored because the costs are perceived to the computation closer to the data. be too high to run or even propose them. With sampleAction we have explored whether interaction So while computational and storage approaches make large techniques to present query results running over only scale queries possible, they still often restrict either the incremental samples can be presented as sufficiently number and types of queries that might be run, or avenues trustworthy for analysts both to make closer to real time that might be explored because the queries must be decisions about their queries and to be more exploratory in designed with such care to be worth the wait and the cost of their questions of the data. Our work with three teams of queuing for the resource. analysts suggests that we can indeed accelerate and open up One possible technique, proposed by Hellerstein and others the query process with such incremental visualizations. [7], is to query databases incrementally, looking at ever- Author Keywords larger segments of the dataset. These samples can be used Incremental visualizations, large data, exploratory data to extrapolate estimated final values and the degree of analysis, online aggregation. certainty of the estimate. The analyst would get a response quickly by considering a large, initially unclear range of ACM Classification Keywords values that rapidly converge to more precise values. This H.5.2. Information interfaces and presentation: approach may let an analyst iterate on a query with Miscellaneous. H.2.8. Database Applications: Data mining. substantially decreased delay and increased flexibility: if General Terms the way forward is sufficiently clear from the samples, they Experimentation, Human Factors can quickly refine queries or explore new parameters. INTRODUCTION There is an important interaction issue here. Analysts are The increased capacity to capture data from systems and accustomed to seeing precise figures, rather than sensors that generate it, from social networks to highway probabilistic results, and may not be willing to act on partial traffic flows, gives us an unprecedented opportunity to information. Confidence intervals add a degree of interrogate behavior from the individual to the complex complexity to a visualization, and may simply be confusing. system. Unfortunately, the speed at which this data can be In order for incremental analysis to be a viable technique, it explored, and the richness of the questions we might ask are will be important to understand how analysts interact with currently compromised by the cost in time and resources of incremental data. running our queries over such vast arrays of data. We have Most research in incremental queries has gone into the reverted to a batch-job era, where users formulate a query, technical aspects of the back-end [3,6]; we complement that wait for some time, and evaluate the results—a step technical agenda with an investigation of the interaction backwards from the interactive querying that we expect in design challenges involved. Our exploration presented in exploratory data analysis. this paper is two-fold: the production of an application with Of course the database community has attempted to reduce sufficient fidelity that will allow users to experience converging iterative estimates of their own data, and, in particular, to understand how this interaction enables an Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are exploratory analysis process. not made or distributed for profit or commercial advantage and that copies In this paper, we present sampleAction, a tool that allows us bear this notice and the full citation on the first page. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior to simulate the effects of interacting with very large specific permission and/or a fee. datasets while supporting an iterative query interaction for CHI ‘12, May 5-10, 2012, Austin, Texas, USA. large aggregates. Our simulator allows us to examine how Copyright 2012 ACM 978-1-4503-1015-4/12/05...$10.00.
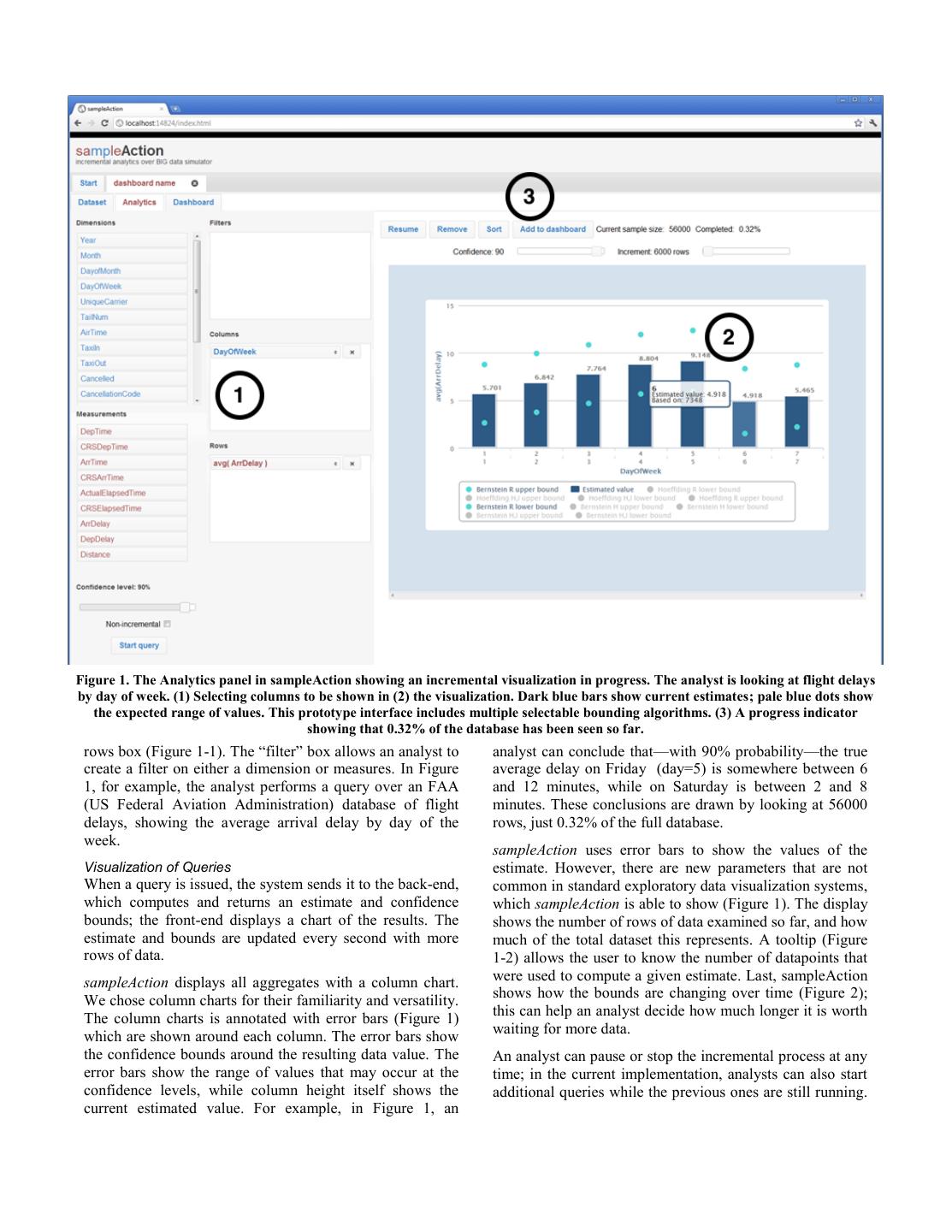
2 .both user interfaces and data storage concepts may be In a very large dataset, exploratory visualization becomes effectively redesigned to be amenable to our incremental onerous: each query can take hours or days to compute interaction approach. In our evaluation, we carried out in- before a result is ready to be seen on screen. There are depth interviews with members of three different teams of several ways to deal with visualizing very large datasets. data analysts, working in three different areas. The analysts The simplest technique is to wait through a long processing reconstructed a series of queries from their own data in our job, allowing the job to run overnight. This has the virtue of system. We found that, after they had examined only a precision, but loses out on speed. In particular, by waiting small fraction of the database with our interface, they for hours for each query, a user writes off the possibility of overall found our representations of the incremental query iteratively exploring their dataset. results sufficiently robust that they were prepared either to Dremel [9] and other scale-out architectures have massively abandon that query, refine it further, or create new ones increased the speed of accessing data rows. These previously unconsidered. Significantly, they were able to architectures are expensive, though, both in money and make these iterations rapidly, in real time. energy. An incremental database can help save computation We contribute, first, a methodology for simulating costs by looking at fewer rows and spinning fewer disks. In aggregate queries against large data back-ends; we hope addition, even large-scale architectures can be that this will allow researchers to more broadly explore the overwhelmed by ever-larger datasets, and datasets where it interaction issues that arise in this area. Second, we is expensive to access rows. contribute observations of expert analyst behavior in The user can save computation time on queries by building interacting with approximate queries. an OLAP (Online Analytical Processing) cube [1]. An Our paper draws on past research about incremental, OLAP cube pre-aggregates a database by specifying approximate queries [4], as well as visualizations of dimensions and measures in advance. This allows users to uncertainty [15]. We present past work, followed by a explore those aggregated dimensions, at the cost of another rationale for the design and implementation approach and long processing job. The results also limit flexibility, as an overview and analysis of our sessions with the analysts. users cannot easily add new dimensions after the cube has We discuss how our system enables analysts to make their been built. decisions on incremental samples and the implications of If the dataset is well-organized as tabular data, a user might our design approach for enhancing flexible data take a fixed-size sample and use exploratory visualization exploration. on the sample, using off-the-shelf software like Tableau1. BACKGROUND AND RELATED WORK Indeed, Tableau has an ability to handle samples from a In this project, we visualize estimates on incremental data. large dataset, selected randomly. Tableau then allows rapid Incremental analysis is an alternative to other techniques queries against the in-memory portion of the dataset. These that are more familiar, but have disadvantages compared to queries can be interactive, but, as they are based on a our method. In this section, we first discuss these sample, they cannot be precise—and the system does not techniques in order to motivate incremental data analysis. provide a way for the user to know how good an We then discuss techniques for visualizing uncertainty, approximation is the sample of the full dataset. Extending which we adapt for our visualization. the idea of samples, Infobright [16], has explored the idea Background on Handling Large Data for Visualization of using approximate SQL to allow for more responsive Information visualization is a popular way to help analysts queries, although the estimates do not improve make sense of large datasets. It allows an analyst to incrementally. overview data quickly by seeing summary statistics, With incremental, approximate analysis we avoid the compared easily, through a selection of charts. difficulties of these approaches. Incremental analysis Many visualizations are based on aggregate queries against collects ever-larger samples in the back-end, and uses them of datasets. A dataset can be thought of as a table of data, to estimate the true value of a query. In addition, made up of measures—the values being visualized—and approximate queries can present confidence bounds: the dimensions, the categories into which the measures are region in which the final value is likely to fall. divided. For example, in a sales database, an analysts might The system can respond quickly and flexibly as it acts on choose to create a bar chart (the visualization) showing samples; over time it gains accuracy. Because the system is average sales per customer (the measure) divided by based around samples, it computes estimated values, rather different products (a dimension). In exploratory data than definitive results. In addition to the estimate, the visualization, it is common to rapidly iterate through system can compute a confidence interval for many types of different views and queries about a data-sets. In contrast, visualizations for reporting or presentations are usually prepared in advance and allow limited interaction. 1 http://www.tableausoftware.com/
3 .aggregate queries. This interval predicts the possible range allow them to act rapidly on their queries. Last, we of the true value. hypothesize that incremental results will allow users to carry out exploratory queries. The CONTROL project initiated the area of online incremental data analysis; in the course of a series of papers Experimentation [3,4,5], the project laid out an agenda for incremental To interrogate our hypotheses, we do not need to implement analysis and laid out a technical infrastructure. Later an incremental database system at full scale. Rather, we projects by Jermaine and colleagues further explored need to produce a realistic experience that allows users to incremental database queries [6,7]. All of these projects understand what using an incremental database would be produce output including estimates and confidence like. The system must, of course, incrementally update intervals; several have prototyped possible visualizations, samples, showing ever-larger portions of the dataset and the although none of them evaluate these visualizations. estimates that emerge from them. In order to maintain ecological validity, the system should work with data that is Incremental Visualization familiar to the analyst, and should allow the analyst to This project uses uncertainty visualization techniques to experiment with a broad assortment of queries. monitor estimates on incremental data. Neither of these component ideas are new individually: both Olston and To that end, we have created a tool that allows us to Mackinlay [11] and Fisher [2] argue that uncertainty simulate the experience of using a very large dataset. visualization would be a valuable output for incremental Analysts provide us with a table of data. In turn, we enable techniques. Neither paper on this work, however, offers an the analysts to execute a variety of queries, while implementation nor examines how users would respond to incrementally displaying results based on ever-larger the combined system. portions of the dataset. This allows users to work with their own data while exploring our interface. We called this Uncertainty Visualization The research community has had a standing interest in system sampleAction. sampleAction allows a user to visualizing uncertain data: researchers have addressed data formulate a query visually. The system responds with a that is uncertain in its values, quality, provenance, and even partial result, displaying a bar chart with confidence in its structure [15,20]. Researchers have experimented with bounds; as the analyst waits, the system increases its sample a number of different visualizations of uncertainty, size, narrowing the confidence intervals and producing including error bars, translucency and fuzzy regions [8,18]. more precise results (Figure 1). However, several evaluations [14,20,21] have found that sampleAction uses estimators that produce error bounds to more exotic schemes can be difficult for users to interpret. predict the final values; these estimators base their results The most applicable approach from this work is on the size of the sample, rather than the size of the ‘statistically uncertain visualization.’ Both Olston and database, and so can scale up with the data. Mackinlay [11] and Sanyal et al [14] refer specifically to System Implementation uncertain data values that have known properties, such as In the following sections we first describe the front end bounds or probability ranges. In an original CONTROL interaction that drives the queries and represents the paper [4], the authors suggest both a bar chart with error incremental responses. We next describe the statistical bars, and a “cloud” plot to represent multidimensional data. reasoning used to present the confidence in the samples We leverage these past approaches by representing presented and close this section with the description of the confidence intervals as error bars: both confidence intervals database implementation supporting the simulation. and error bars refer to an expected range of values, and Interface for Formulating Queries error bars are familiar representations in statistics. The front-end interface of sampleAction allows users to METHOD execute basic aggregate queries (averages, sums, counting) The purpose of the work we present here has been to typically used in exploratory data analysis, in an understand whether data-intensive users would be willing to environment that resembles analytics tools like Tableau. make decisions on the fly using incremental visualizations The user can connect to arbitrary database tables, and, in order to engage in exploratory data analysis. We wanted without any knowledge of the underlying query language, to understand whether they found the concept of dealing use the graphical user interface to create visual summaries with confidence bounds confusing, and at what point a of database queries with filters, sorting, and groups. visualization’s bounds are “good enough” to act upon. We An initial screen allows users to connect to an SQL server, also wanted to understand whether providing an interactive select a table from that database and open a dashboard over exploratory front-end encouraged them to learn about their which analytics over the data in the table can be performed. datasets in new ways. The major screen in sampleAction is the Analytics panel Our hypothesis is that users working with incremental (Figure 1), which allows users to compose aggregate visualizations will be able to interpret the confidence queries over the data table. An analyst can drop one or more intervals comfortably. We further hypothesize that this will dimensions onto the column box, and a measure onto the
4 .Figure 1. The Analytics panel in sampleAction showing an incremental visualization in progress. The analyst is looking at flight delays by day of week. (1) Selecting columns to be shown in (2) the visualization. Dark blue bars show current estimates; pale blue dots show the expected range of values. This prototype interface includes multiple selectable bounding algorithms. (3) A progress indicator showing that 0.32% of the database has been seen so far. rows box (Figure 1-1). The “filter” box allows an analyst to analyst can conclude that—with 90% probability—the true create a filter on either a dimension or measures. In Figure average delay on Friday (day=5) is somewhere between 6 1, for example, the analyst performs a query over an FAA and 12 minutes, while on Saturday is between 2 and 8 (US Federal Aviation Administration) database of flight minutes. These conclusions are drawn by looking at 56000 delays, showing the average arrival delay by day of the rows, just 0.32% of the full database. week. sampleAction uses error bars to show the values of the Visualization of Queries estimate. However, there are new parameters that are not When a query is issued, the system sends it to the back-end, common in standard exploratory data visualization systems, which computes and returns an estimate and confidence which sampleAction is able to show (Figure 1). The display bounds; the front-end displays a chart of the results. The shows the number of rows of data examined so far, and how estimate and bounds are updated every second with more much of the total dataset this represents. A tooltip (Figure rows of data. 1-2) allows the user to know the number of datapoints that sampleAction displays all aggregates with a column chart. were used to compute a given estimate. Last, sampleAction We chose column charts for their familiarity and versatility. shows how the bounds are changing over time (Figure 2); The column charts is annotated with error bars (Figure 1) this can help an analyst decide how much longer it is worth which are shown around each column. The error bars show waiting for more data. the confidence bounds around the resulting data value. The An analyst can pause or stop the incremental process at any error bars show the range of values that may occur at the time; in the current implementation, analysts can also start confidence levels, while column height itself shows the additional queries while the previous ones are still running. current estimated value. For example, in Figure 1, an
5 . Figure 2. Convergence of confidence bounds for a given column as the database reads in more columns based on two different formulae. We experimented with different bounds in order to better understand convergence behavior. All queries will continue to add samples and slowly separate. For example, if we are querying for total sales, converge. grouped by state, then sampleAction will estimate fifty different values. The tool attempts to estimate the true value Bounded uncertainty based on samples The back-end of sampleAction computes responses based of all rows that match the query (Figure 3-2); however, it on queries from the front-end. In order to supply the has only seen a subset of rows (Figure 3-4). The estimate is information in the UI, the responses that it sends back are based therefore on those rows which it has seen already and somewhat more complex than standard SQL query result that match the query (Figure 3-3), which can be a much sets: in addition to returning a set of values, queries also smaller subset. In a fixed-size sample, this fraction could return confidence bounds and the number of rows seen. mean that the estimated values might be very inaccurate; in an incremental system, it means that the user interested in a The choice of appropriate bounds is at the heart of the rare phenomenon can choose to wait for more samples. sampleAction system. Bounds should appropriately bound the data—that is, they need to represent the highest and For a tool like sampleAction to work against very large lowest likely values of the true value. If the bounds are too datasets we want the formula that provides the confidence wide, users will gain little information about the estimate. If bounds to be scalable. In particular, even for very large bounds converge too slowly, incremental visualization will databases (that is, where (Figure 3-1) is large), we would be little better than waiting overnight for a precise value. not want that size to generate very broad confidence bounds. We also want an estimator in which the confidence Computing statistically accurate bounds requires random bounds narrow monotonically as the sample size increases: samples from the dataset in order to ensure that the sample as the number of rows that the stream has processed (Figure is unbiased. As a result, incremental results need to be 3-3) grows, we expect the bounds to tighten. selected from a randomly-ordered stream. The efficient computation of random samples from a database is a well- The computation of appropriate bounds is an active area of known problem (Olken and Rotem [10] survey techniques research in probability theory, and different bounds are from 1990). This sampling can be accomplished by appropriate under different circumstances. In general, selecting randomly from the table, which is computationally though, some estimators gain their strength by using expensive. Alternately, we can randomly order the additional information from the dataset beyond the sampled database, which potentially interferes with index structures values. For example, it is common to examine the minimum or requires a redundant copy of the data. These tradeoffs are and maximum values in the data column. The pace at which active areas of research in the database community. For the bounds shrink is determined by the size and variance of the goals of this project, we randomly ordered the dataset. sample: the bounds expand with the variance of the sample, and tighten in proportion to the square root of the number Given its stream of samples, sampleAction computes an of samples. As a result, the choice of estimators, combined estimate of the expected value of an aggregate of the with the distribution in the results can produce very stream. The tool uses the rows processed so far in order to different bounds, changing at very different speeds. make an estimate of the value based on the full dataset, as illustrated in Figure 3. For the purposes of estimating a In the sampleAction protoype, we computed several value, we treat each category of a group-by query as different sets of bounds in order to learn about their
6 .convergence properties. These bounds are displayed in the We note that our sample is far from using SQL to its captions of Figures 1 and 2, and were selectable by the user. capacity: we would expect that in a production system, We do not expect that this variety of bounds would be users might see updates of millions of rows at a time. available, or desirable, in a final product; our user study did USER STUDY not emphasize multiple bound types. To evaluate the effectiveness of our technique, we recruited three sets of experts who analyze data on a regular basis. All three work for a large, data-intensive corporation. We selected three very different groups of analysts, with very different types of data to see how they would respond to incremental visualization in their work. One team runs system operations on a large network, looking for network and server errors. The second team is part of a marketing organization looking at the marketing and use of network- connected games. The third participant is a researcher, studying social behavior on Twitter. To create a familiar, real-world data experience with sampleAction, we collected sample data from each of the Figure 3. Schematic view of sampling against filters. A expert teams; they provided us with recent selections of restrictive query, joined with a small sample, can make for a their datasets. We asked them to provide us around a very small set of rows to inform estimates. million rows of data in order to have a reasonably large The Back-End Database dataset. We wished to ensure that the session asked real Industrial database management systems do not currently questions that the analysts might have encountered. support incremental queries of the type required to test our Therefore, in preparation for the session, we asked them to hypotheses. Therefore, we constrained this initial evaluation recall a recent data exploration session, or to think of the to deploying sampleAction on a database small enough to sorts of questions that they frequently ask of their data. query interactively: sampleAction takes samples from a Because of the iterative query services facilitated by our database with several millions of records. We used a interface, we expected our sessions to diverge from their standard SQL database system to store the data. While these usual queries, but this structure allowed us to start from a datasets are still relatively small in comparison with “big familiar place. data” systems, they are nevertheless sufficiently large for After introducing the system to the teams, we had the our purposes: it is possible to extract samples, run aggregate experts reconstruct the questions that they had encountered statistics, and compute probability bounds over them. These in the past. During this series, we asked them to think aloud smaller databases have the virtue that they are easy to query through the charts they were seeing on screen, and asked and return rapid results. Therefore, sampleAction is able to them to describe points at which they would be able to interactively run complete queries over the entire dataset, make a decision. Periodically, we paused computation to collect metadata, and compare estimates with ground truth ask them about how they would interpret the interrupted results. session. While the session with the Twitter researcher took sampleAction stores data in its back-end SQL database in a place in person, the other sessions were carried out by randomized order. Putting the data in random order allows remote conversation with a shared desktop session running sampleAction to perform collection of random samples, the application. Voice and screen interactions for all merely by querying for the first few thousand rows. To sessions were recorded. simulate incremental results, we simply executed repeated Bob: Server Operations queries of increasing size. For example, the first initial Bob is on a team that manages operations for a handful of query requests results based on the first 5000 records; the servers. Their group has a logging infrastructure that is second query based on the top 10000, and so on. Each of periodically uploaded into an SQL server; nightly, the these queries could be resolved quickly and returned to the server’s results are produced into a static report, generated user. This scheme allows us to prototype the effects of an by Microsoft SQL Reporting Services. Bob’s team both incremental query against a randomized dataset. monitors the performance of a set of servers, and diagnoses We note that because the queries for different groups are error conditions that may occur. The report is not drawn from the same sample, the estimates are not fully interactive; as a result, the team has created an interactive independent. For the experiments we conducted, we found custom application that shows some results that the report the sample sizes were typically large enough for these cannot. However, they complain that the custom application effects to be negligible. has a very limited set of queries.
7 .Bob was able to provide 200,000 rows in each of two Allan: Online Game Reporting tables: one that was oriented around error conditions; the Allan is in charge of maintaining the database reporting other around successful interactions. Bob’s dataset is fairly system for a large online gaming system. The core database uniform: the back-end server behaves reliably, and the records every session by every player logged into the range of data is small. Therefore, he was able to get rapid system, as well as their purchasing history. Allan is and accurate estimates, and the confidence intervals regularly asked to prepare tremendously varying reports for converged very rapidly. a variety of stakeholders, ranging from marketing teams as well as game designers. In order to present these reports, Bob started off by looking at number of errors divided by Allan often creates an OLAP cube which summarizes datacenter. After seeing the first set of results, he realized relevant answers. Allan, therefore, is accustomed to having that the errors he was investigating were all in one to clearly specify queries and is unused to exploring his datacenter: “Ok, we’ll stop that, and we’ll change over to data. the right variable this time.” Allan suggested that we examine player session information. The player session table has the locations of players (on a national level), statistics about the players (such as their age), and which games they played on any given day. Allan provided two billion player records. Allan had recently run an interesting statistic: the average age of a game player on the system. He began by looking at the sum of ages. After a moment, he realized that he wanted to see the average age, and stopped the query in order to correct it and issue a new one. Reassured that the data was showing the same result he had seen before, he terminated the query after a few seconds (looking at just thirty thousand rows) and began to explore new queries. Figure 4. Consistent error behavior across three servers of one He looked at average age by country, before deciding that type, and two other servers of another. the many categories caused the error values to converge too slowly; cancelled the query, and instead looked at average After changing to a display by server, he let it run for a age by region. For some regions where there are fairly few moment (Figure 4). “What we’re not seeing is any players, the system found few examples, and so generated particular outliers. What this is telling me is that all the very broad confidence intervals for those regions. Other machines are performing about the same. The errors are regions, such as the United States and the UK, had very high, but consistent. The pile of errors we’re seeing is a precise error bars due to the high number of players. In the site-wide issue, not a machine issue.” current sampleAction implementation, the scale broadened He then wished to drill down into the types of errors. He to show the large confidence intervals which swamped the filtered down to just two servers and added the error type as values. Consequently Allan turned off confidence intervals, a measure along the X axis. In these machines, most records feeling he now knew which columns he could trust. were of the same error type. A very small number of rows He then wanted to see whether sports games have a were of other error types; these other types had few different distribution then war games. He added a filter to samples, and so displayed very wide confidence intervals. the previous query, specifying only war games, and started Bob was interested in incremental visualization as an it. He changed the filter again, and started another query, alternative to their current, index-heavy implementation of specifying only sports games. He scrolled back and forth, data management. As his team has attempted to scale comparing the results to each other. A few moments later, upward, they have spent a great deal of effort optimizing he added another query, comparing the numbers of war- their data, queries, and indices to be able to diagnose errors gamers to sports players by region. within a few minutes of their occurring. Finding these rare Allan, accustomed to running reports, had not been able to errors will not be helped by sample-based methods: explore his dataset before; he enjoyed exploring the dataset sampling cannot find outliers. in ways that had not been accessible to him before. Bob’s team currently archives all data after a day in order to Sam: Twitter Analytics focus on new data—and infrequently carries out the costly Sam is analyzing Twitter data to understand relationships queries that would be required to access their archive. He between the use of vocabulary and sentiment. He works felt that incremental systems might help them explore their with Twitter data that is saved to a high-capacity distributed archives, understanding how system performance is system. New data constantly streams into its ever-growing gradually changing over time. archive, which has stored several years’ worth of data.
8 .Sam’s queries require several sets of keyword filters, which X axis would be wider than he wanted, and changed his he frequently tunes. Sam provided us with a single day query to narrow his results. Bob’s data was uniform enough worth of data, with annotations labeling which filters would that even the first view had a good confidence interval, and have affected which tweets. The result was approximately so he was able to draw conclusions from it. 10 million records. New Behaviors around Data Sam sometimes uses visualization: “I’ve generated my own All three of our analysts were accustomed to seeing their charts in R, but it’s based on small samples.” data in a static, non-interactive form: they formulate a query (or cube), wait a period of time, and can explore the results. During Sam’s interview, he created a series of bar charts, Most visibly with Sam, the opportunity to interact with the tweaking variables. He frequently made small errors, data without waiting was freeing: it changed the sorts of realizing that he had placed the wrong variable in the query queries that he was able to make, as well as the results of or had failed to filter out ‘null’ values. In each of those those queries. Allan was excited to have the opportunity to cases, he observed this within the first few iterations, when ask new questions of his dataset without delay. we had seen less than 0.1% of the full dataset. Using his usual batch tools, he would not have caught this error until We observed real exploration of the dataset using our after the computation was done, several hours later. system. Sam was able to play with a hypothesis that he had not previously explored, in part because it required several In using sampleAction, Sam moved rapidly from query to different permutations of his query in order to find the query, exploring and testing different variations. Once, for interesting result. Allan was able to try a handful of example, he wanted to compare the relative frequency of different variations, exploring questions in depth. Bob was keywords having to deal with emotions. When he generated able to clean his queries on the fly, removing special cases the column chart, he was able to stop the iteration after and exploring the types of results returned. None of these 150,000 samples (about 30 seconds) and explore it. By the were possible in the non-interactive case. time he was at that phase, the differences were vivid. For this keyword, at least, the error margins were tight: “I didn’t At the same time, the incremental aspects were helpful to actually know before that ‘hate’ was so dominant.” the analysts. If the first few samples had not converged, they would decide whether it was worth the trade-off of He was aware of the limitations of looking at a sample: “the waiting longer, sometimes checking the convergence view statistician in me is saying, I want to let this run a little (Figure 2) to decide. In cases where the system seemed longer before I make a total judgment call on these two unlikely to converge, they would decide which columns of sets.” Nonetheless, the partial result was enough for him to data to regard. continue to explore. Difficulties with Error Bar Convergence He decided to figure out why the keyword was so large. To We did not anticipate the tremendous variance in do so, he needed to compare the word list under two confidence interval sizes. While Bob never saw a different conditions. He created two filters—one for each confidence interval much larger than his largest data point, condition—and started two queries. He compared the two Allan often could not see his data without hiding the runs to each other: “See how much bigger ‘angry’ was in confidence intervals. Past literature on visualizing the other one? These are hugely different.” uncertainty [11] has emphasized visualizations that fit the Because his X axis had so many different keywords, some entire uncertainty range on screen; these were not sufficient of which were rare, the results were distributed across a for some of these preliminary bounds. It would be very large confidence interval. As happened for Allan, this worthwhile investigating visualizations that can show the large confidence interval distorted the scale on the rest of size of the interval even past screen borders. the image. He found the distortion to be too large to In Allan’s sample, some data points had noisy values: for interpret the chart, and often distracting; he would turn example, the minimum ‘age’ listed was -100, while the them off to examine the values, then turn them back on to oldest was 284. This threw off the “minimum” and check how confident he could be in any value. “maximum” values; as the computation we used included ANALYSIS these values, the bounds converged slowly. Incremental In this section, we collect some of the major insights from systems can be slowed by datasets that are not clean. Using the three different user studies. additional domain knowledge during the execution—such as discarding values that fall outside meaningful The value of seeing a first record fast constraints—would improve convergence, and would show In all three studies, users found value in getting a quick more meaningful results. response to their queries. Sam and Allan realized they had entered an incorrect query, and were able to repair it Non-Expert Views of Confidence Intervals quickly by adding appropriate filters. Ordinarily, While error bars are familiar indications of confidence, discovering and repairing these errors would have been a some of the users found them confusing. It was not initially costly, even overnight process. Allan also realized that his
9 .obvious to Allan, for example, that the interval would incremental joins. As with outliers, some types of joins can shrink toward a converged value. be very difficult for incremental sampling techniques; in some cases, such as joins against a rare or unique key, using The confidence interval is a complex indicator: it carries samples from joining tables may not work at all. information about both the number of samples seen so far, and the variance of a column. As a result, two very different Future Work adjacent columns might have identical confidence intervals: The experience of exposing users to incremental queries one has a small variance but is fairly rare in the database; and approximate visualizations motivates several lines of the one next to it is common, but has a high variance. future work. First, it has highlighted the importance of Helping users distinguish these would be useful. exploring representations of confidence. While error bars are conventional, they are not necessarily easily In all three cases, users had data that was unevenly comprehensible. In addition, they can only highlight one distributed across the X-axis, with some categories having a probability value at a time. The downsides of error bars, great many entries, and others having very few. For such as the difficulties they raise with scaling, argue that example, in Allan’s situation, countries with few players there could be an opportunity to find new ways to represent converged very slowly, causing estimates to be very large. confidence intervals. Sam and Allan were able to adapt to the error bars, Our users also asked for more types of visualizations: regarding the numbers that converged faster as more certain clustered bar charts showing more than one measure; a line than the ones that took longer. chart; and two-dimensional histograms. Each of these Implications visualizations will raise new issues in presenting confidence Our work shows both that users seem to be able to interpret intervals. It is worthwhile to explore new visualizations in confidence intervals, and that this finding opens order to enable rapid refinement for these more opportunities for using uncertainty visualization tied to sophisticated query types. probabilistic datasets. Creating sampleAction has allowed Last, we would like to explore more types of data analysis, us to have a concrete feel for the experience of watching such as machine learning techniques. We believe that bounds shrink at different rates, which in turn is applying incremental techniques to a broad range of illuminating for visualization design of confidence algorithms might help users anticipate their algorithm’s intervals. progress before it comes out with its final result. The major step that stands between simulators like Conclusions sampleAction and true interactive techniques are limitations While the concept of approximate queries has been known to databases. Currently, Big Data systems do not support for some time, the visualization implications have not been the callbacks or partial results that would allow incremental explored with users. In particular, it has been an open results to be computed. Similarly, SQL tables allow question whether data analysts would be comfortable sampling, but do not allow the user to progressively interacting with confidence intervals. We hope that showing increase the size of their sample. Allowing these is a the utility of these approximations will encourage further necessary back-end for future interactions. research on both the front- and back-ends of these systems. Limitations of Incremental Visualization HCI researchers have also been limited in their ability to sampleAction has helped us interpret how users interact explore these concepts; our model for simulating large data with incomplete and incremental data. Even in a complete systems may help them explore realistic front-ends without incremental system, however, there some genres of queries needing to build full-scale computation back-ends. that are structurally going to be difficult. These are not limitations of our prototype, but are fundamental to the We have shown that it is both tractable and desirable to approach. support incremental query interactions for data analysts. With such mechanisms in place, analysts can take Outlier Values This system only works for meaningful, aggregate queries. advantage of the immediate feedback afforded by Thus, operations that depend on single items, such as incremental queries by rapidly refining their queries, and outlier queries, cannot be supported. There is no more importantly, exploring new avenues which they would probabilistic answer to “which item has the highest value”. not have done before. However, there might be ways to rephrase queries: for Our approach has validated the concept of incremental example, it might be possible to use order statistics in this queries. We have shown that it is possible to use interaction context. strategies that analysts have desired, but not been able to Table Joins pursue given the time required to complete queries of large Joins are an important part of database interaction; past scale databases. As our interviews show, even relatively database projects like CONTROL [4] and others [6] have simple representations of uncertainty using error bars looked at the statistical and technical issues involved in progressively updating over time, allowed analysts to trust
10 .their decision points, potentially saving days or weeks of 11. C. Olston and J. Mackinlay. Visualizing data with effort, and exploring unimagined routes through their data bounded uncertainty. In Proceedings of IEEE for new discoveries and insights. Symposium on Information Visualization, pp. 37-40. 2002. ACKNOWLEDGEMENTS We thank our participants for their time and enthusiasm in 12. C. Olston, B. Reed, U. Srivastava, R. Kumar, and A. working with our prototype. This project has benefitted Tomkins. Pig Latin: A Not-So-Foreign Language for from the expert advice of Christian Konig, who has Data Processing. In Proceedings of the 2008 ACM provided us with valuable references, design, and sanity; SIGMOD international conference on Management of and from the comments of the anonymous reviewers. data (SIGMOD '08). ACM, New York, NY, USA, 1099-1110. REFERENCES 1. S. Chaudhuri and U. Dayal. An overview of data 13. R. Pike, S. Dorward, R. Griesemer, and S. Quinlan. warehousing and OLAP technology. SIGMOD Record. 2005. Interpreting the data: Parallel analysis with 26(1):65-74. March 1997. Sawzall. Sci. Program. 13, 4 (October 2005), 277-298. 2. D. Fisher. Incremental, Approximate Database Queries 14. J. Sanyal, S. Zhang, G. Bhattacharya, P. Amburn, and R. and Uncertainty for Exploratory Visualization. In Moorhead. 2009. A User Study to Compare Four Proceedings of 1st IEEE Symposium on Large-Scale Uncertainty Visualization Methods for 1D and 2D Data Analysis and Visualization. 2011. Datasets. IEEE Transactions on Visualization and Computer Graphics 15(6): 1209-1218. November 2009. 3. P. Haas, J. Hellerstein. Ripple Joins for Online Aggregation. In Proceedings of ACM SIGMOD 15. M. Skeels, B. Lee, G. Smith, and G. Robertson. International Conference on Management of Data. Revealing Uncertainty for Information Visualization. In 1999. Proceedings of the Working Conference on Advanced Visual Interfaces. ACM, New York, NY, USA. 2008, 4. J. Hellerstein, R. Avnur, A. Chou, C. Olston, V. Raman, 376-379 T. Roth, C. Hidber, P. Haas. Interactive Data Analysis with CONTROL. IEEE Computer, 32(8). August, 1999. 16. D. Ślęzak and M. Kowalski. Towards Approximate SQL – Infobright’s Approach. In M. Szczuka et al (Eds.): 5. J. Hellerstein, P. Haas, and H. Wang. Online Rough Sets and Current Trends in Computing (RSCTC). aggregation. In Proceedings of the 1997 ACM SIGMOD LNAI 6086, pp. 630-639. Springer-Verlag. 2010. International Conference on Management of data (SIGMOD '97), J. Peckman, S. Ram, and M. Franklin 17. A. Streit, B. Pham, and R. Brown. A Spreadsheet (Eds.). ACM, New York, NY, USA, 171-182. Approach to Facilitate Visualization of Uncertainty in Information. IEEE Transactions on Visualization and 6. C. Jermaine, A. Dobra, S. Arumugam, S. Joshi, and A. Computer Graphics 14(1): 61-72. January 2008. Pol. The Sort-Merge-Shrink Join. ACM Transactions on Database Systems 31(4): 1382-1416. December 2006. 18. M. Stonebraker, D. Abadi, A. Batkin, X. Chen, M. Cherniack, M. Ferreira, E. Lau, A. Lin, S. Madden, E. 7. S. Joshi and C. Jermaine. Materialized Sample Views O'Neil, P. O'Neil, A. Rasin, N. Tran, and S. Zdonik. for Database Approximation. IEEE Transactions on 2005. C-store: a column-oriented DBMS. In Knowledge and Data Engineering. 20(3): 337-351. Proceedings of the 31st International Conference on March 2008. Very Large Data Bases (VLDB '05). VLDB Endowment 8. R. Kosara, S. Miksch, and H. Hauser. Semantic Depth 553-564. of Field. In Proceedings of the IEEE Symposium on 19. J. Thomson, E. Hetzler, A. MacEachren, M. Gahegan Information Visualization 2001 (INFOVIS'01). IEEE and M. Pavel, A typology for visualizing uncertainty. In Computer Society. 2001. Proceedings of SPIE & IS&T Conference on Electronic 9. S. Melnik, A. Gubarev, J. Long, G. Romer, S. Imaging, Visualization and Data Analysis 2005, 5669: Shivakumar, M. Tolton, and T. Vassilakis. 2010. 146-157. 2005. Dremel: interactive analysis of web-scale datasets. Proc. 20. C. Wittenbrink, A. Pang, and S. Lodha. Glyphs for VLDB Endow. 3, 1-2 (September 2010), 330-339. Visualizing Uncertainty in Vector Fields. IEEE 10. F. Olken and D. Rotem. 1990. Random sampling from Transactions on Visualization and Computer Graphics. database files: a survey. In Proc.of the 5th international 2(3):266-279. September 1996. conference on Statistical and Scientific Database 21. T. Zuk and S. Carpendale. Visualization of Uncertainty Management (SSDBM'1990), Zbigniew Michalewicz and Reasoning. In Proceedings of the 8th international (Ed.). Springer-Verlag, London, UK, 92-111. 1990. symposium on Smart Graphics (SG '07). Springer- Verlag, Berlin, Heidelberg. 2007.
3秒后跳转登录页面
去登陆

