













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spark SQL: Relational Data Processing in Spark
Spark SQL: Relational Data Processing in Spark
展开查看详情
1 . Spark SQL: Relational Data Processing in Spark Michael Armbrust† , Reynold S. Xin† , Cheng Lian† , Yin Huai† , Davies Liu† , Joseph K. Bradley† , Xiangrui Meng† , Tomer Kaftan‡ , Michael J. Franklin†‡ , Ali Ghodsi† , Matei Zaharia†∗ † ∗ ‡ Databricks Inc. MIT CSAIL AMPLab, UC Berkeley ABSTRACT While the popularity of relational systems shows that users often prefer writing declarative queries, the relational approach is insuffi- Spark SQL is a new module in Apache Spark that integrates rela- cient for many big data applications. First, users want to perform tional processing with Spark’s functional programming API. Built ETL to and from various data sources that might be semi- or un- on our experience with Shark, Spark SQL lets Spark program- structured, requiring custom code. Second, users want to perform mers leverage the benefits of relational processing (e.g., declarative advanced analytics, such as machine learning and graph processing, queries and optimized storage), and lets SQL users call complex that are challenging to express in relational systems. In practice, analytics libraries in Spark (e.g., machine learning). Compared to we have observed that most data pipelines would ideally be ex- previous systems, Spark SQL makes two main additions. First, it pressed with a combination of both relational queries and complex offers much tighter integration between relational and procedural procedural algorithms. Unfortunately, these two classes of systems— processing, through a declarative DataFrame API that integrates relational and procedural—have until now remained largely disjoint, with procedural Spark code. Second, it includes a highly extensible forcing users to choose one paradigm or the other. optimizer, Catalyst, built using features of the Scala programming language, that makes it easy to add composable rules, control code This paper describes our effort to combine both models in Spark generation, and define extension points. Using Catalyst, we have SQL, a major new component in Apache Spark [39]. Spark SQL built a variety of features (e.g., schema inference for JSON, machine builds on our earlier SQL-on-Spark effort, called Shark. Rather learning types, and query federation to external databases) tailored than forcing users to pick between a relational or a procedural API, for the complex needs of modern data analysis. We see Spark SQL however, Spark SQL lets users seamlessly intermix the two. as an evolution of both SQL-on-Spark and of Spark itself, offering Spark SQL bridges the gap between the two models through two richer APIs and optimizations while keeping the benefits of the contributions. First, Spark SQL provides a DataFrame API that Spark programming model. can perform relational operations on both external data sources and Spark’s built-in distributed collections. This API is similar to the Categories and Subject Descriptors widely used data frame concept in R [32], but evaluates operations H.2 [Database Management]: Systems lazily so that it can perform relational optimizations. Second, to support the wide range of data sources and algorithms in big data, Keywords Spark SQL introduces a novel extensible optimizer called Catalyst. Catalyst makes it easy to add data sources, optimization rules, and Databases; Data Warehouse; Machine Learning; Spark; Hadoop data types for domains such as machine learning. 1 Introduction The DataFrame API offers rich relational/procedural integration within Spark programs. DataFrames are collections of structured Big data applications require a mix of processing techniques, data records that can be manipulated using Spark’s procedural API, or sources and storage formats. The earliest systems designed for using new relational APIs that allow richer optimizations. They can these workloads, such as MapReduce, gave users a powerful, but be created directly from Spark’s built-in distributed collections of low-level, procedural programming interface. Programming such Java/Python objects, enabling relational processing in existing Spark systems was onerous and required manual optimization by the user programs. Other Spark components, such as the machine learning to achieve high performance. As a result, multiple new systems library, take and produce DataFrames as well. DataFrames are more sought to provide a more productive user experience by offering convenient and more efficient than Spark’s procedural API in many relational interfaces to big data. Systems like Pig, Hive, Dremel and common situations. For example, they make it easy to compute Shark [29, 36, 25, 38] all take advantage of declarative queries to multiple aggregates in one pass using a SQL statement, something provide richer automatic optimizations. that is difficult to express in traditional functional APIs. They also Permission to make digital or hard copies of all or part of this work for personal or automatically store data in a columnar format that is significantly classroom use is granted without fee provided that copies are not made or distributed more compact than Java/Python objects. Finally, unlike existing for profit or commercial advantage and that copies bear this notice and the full cita- data frame APIs in R and Python, DataFrame operations in Spark tion on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is permitted. To copy otherwise, or re- SQL go through a relational optimizer, Catalyst. publish, to post on servers or to redistribute to lists, requires prior specific permission To support a wide variety of data sources and analytics workloads and/or a fee. Request permissions from permissions@acm.org. in Spark SQL, we designed an extensible query optimizer called SIGMOD’15, May 31–June 4, 2015, Melbourne, Victoria, Australia. Catalyst. Catalyst uses features of the Scala programming language, Copyright is held by the owner/author(s). Publication rights licensed to ACM. ACM 978-1-4503-2758-9/15/05 ...$15.00. such as pattern-matching, to express composable rules in a Turing- http://dx.doi.org/10.1145/2723372.2742797. complete language. It offers a general framework for transforming
2 .trees, which we use to perform analysis, planning, and runtime This code creates an RDD of strings called lines by reading an code generation. Through this framework, Catalyst can also be HDFS file, then transforms it using filter to obtain another RDD, extended with new data sources, including semi-structured data errors. It then performs a count on this data. such as JSON and “smart” data stores to which one can push filters RDDs are fault-tolerant, in that the system can recover lost data (e.g., HBase); with user-defined functions; and with user-defined using the lineage graph of the RDDs (by rerunning operations such types for domains such as machine learning. Functional languages as the filter above to rebuild missing partitions). They can also are known to be well-suited for building compilers [37], so it is explicitly be cached in memory or on disk to support iteration [39]. perhaps no surprise that they made it easy to build an extensible One final note about the API is that RDDs are evaluated lazily. optimizer. We indeed have found Catalyst effective in enabling us Each RDD represents a “logical plan” to compute a dataset, but to quickly add capabilities to Spark SQL, and since its release we Spark waits until certain output operations, such as count, to launch have seen external contributors easily add them as well. a computation. This allows the engine to do some simple query Spark SQL was released in May 2014, and is now one of the optimization, such as pipelining operations. For instance, in the most actively developed components in Spark. As of this writing, example above, Spark will pipeline reading lines from the HDFS Apache Spark is the most active open source project for big data file with applying the filter and computing a running count, so that processing, with over 400 contributors in the past year. Spark SQL it never needs to materialize the intermediate lines and errors has already been deployed in very large scale environments. For results. While such optimization is extremely useful, it is also example, a large Internet company uses Spark SQL to build data limited because the engine does not understand the structure of pipelines and run queries on an 8000-node cluster with over 100 the data in RDDs (which is arbitrary Java/Python objects) or the PB of data. Each individual query regularly operates on tens of semantics of user functions (which contain arbitrary code). terabytes. In addition, many users adopt Spark SQL not just for SQL queries, but in programs that combine it with procedural processing. 2.2 Previous Relational Systems on Spark For example, 2/3 of customers of Databricks Cloud, a hosted service running Spark, use Spark SQL within other programming languages. Our first effort to build a relational interface on Spark was Shark [38], Performance-wise, we find that Spark SQL is competitive with which modified the Apache Hive system to run on Spark and im- SQL-only systems on Hadoop for relational queries. It is also up plemented traditional RDBMS optimizations, such as columnar to 10× faster and more memory-efficient than naive Spark code in processing, over the Spark engine. While Shark showed good perfor- computations expressible in SQL. mance and good opportunities for integration with Spark programs, More generally, we see Spark SQL as an important evolution of it had three important challenges. First, Shark could only be used the core Spark API. While Spark’s original functional programming to query external data stored in the Hive catalog, and was thus not API was quite general, it offered only limited opportunities for useful for relational queries on data inside a Spark program (e.g., on automatic optimization. Spark SQL simultaneously makes Spark the errors RDD created manually above). Second, the only way accessible to more users and improves optimizations for existing to call Shark from Spark programs was to put together a SQL string, ones. Within Spark, the community is now incorporating Spark SQL which is inconvenient and error-prone to work with in a modular into more APIs: DataFrames are the standard data representation program. Finally, the Hive optimizer was tailored for MapReduce in a new “ML pipeline” API for machine learning, and we hope to and difficult to extend, making it hard to build new features such as expand this to other components, such as GraphX and streaming. data types for machine learning or support for new data sources. We start this paper with a background on Spark and the goals of Spark SQL (§2). We then describe the DataFrame API (§3), the 2.3 Goals for Spark SQL Catalyst optimizer (§4), and advanced features we have built on Catalyst (§5). We evaluate Spark SQL in §6. We describe external With the experience from Shark, we wanted to extend relational research built on Catalyst in §7. Finally, §8 covers related work. processing to cover native RDDs in Spark and a much wider range of data sources. We set the following goals for Spark SQL: 2 Background and Goals 1. Support relational processing both within Spark programs (on 2.1 Spark Overview native RDDs) and on external data sources using a programmer- friendly API. Apache Spark is a general-purpose cluster computing engine with 2. Provide high performance using established DBMS techniques. APIs in Scala, Java and Python and libraries for streaming, graph processing and machine learning [6]. Released in 2010, it is to our 3. Easily support new data sources, including semi-structured data knowledge one of the most widely-used systems with a “language- and external databases amenable to query federation. integrated” API similar to DryadLINQ [20], and the most active 4. Enable extension with advanced analytics algorithms such as open source project for big data processing. Spark had over 400 graph processing and machine learning. contributors in 2014, and is packaged by multiple vendors. Spark offers a functional programming API similar to other recent systems [20, 11], where users manipulate distributed collections 3 Programming Interface called Resilient Distributed Datasets (RDDs) [39]. Each RDD is Spark SQL runs as a library on top of Spark, as shown in Fig- a collection of Java or Python objects partitioned across a cluster. ure 1. It exposes SQL interfaces, which can be accessed through RDDs can be manipulated through operations like map, filter, JDBC/ODBC or through a command-line console, as well as the and reduce, which take functions in the programming language DataFrame API integrated into Spark’s supported programming lan- and ship them to nodes on the cluster. For example, the Scala code guages. We start by covering the DataFrame API, which lets users below counts lines starting with “ERROR” in a text file: intermix procedural and relational code. However, advanced func- lines = spark . textFile (" hdfs ://...") tions can also be exposed in SQL through UDFs, allowing them to errors = lines . filter (s => s. contains (" ERROR ")) be invoked, for example, by business intelligence tools. We discuss println ( errors . count ()) UDFs in Section 3.7.
3 . well as complex (i.e., non-atomic) data types: structs, arrays, maps User Programs JDBC Console and unions. Complex data types can also be nested together to (Java, Scala, Python) create more powerful types. Unlike many traditional DBMSes, Spark SQL provides first-class support for complex data types in the Spark SQL DataFrame API query language and the API. In addition, Spark SQL also supports user-defined types, as described in Section 4.4.2. Catalyst Optimizer Using this type system, we have been able to accurately model data from a variety of sources and formats, including Hive, relational Spark databases, JSON, and native objects in Java/Scala/Python. Resilient Distributed Datasets 3.3 DataFrame Operations Users can perform relational operations on DataFrames using a domain-specific language (DSL) similar to R data frames [32] and Figure 1: Interfaces to Spark SQL, and interaction with Spark. Python Pandas [30]. DataFrames support all common relational operators, including projection (select), filter (where), join, and aggregations (groupBy). These operators all take expression objects 3.1 DataFrame API in a limited DSL that lets Spark capture the structure of the expres- The main abstraction in Spark SQL’s API is a DataFrame, a dis- sion. For example, the following code computes the number of tributed collection of rows with the same schema. A DataFrame female employees in each department. is equivalent to a table in a relational database, and can also be employees manipulated in similar ways to the “native” distributed collections .join(dept , employees (" deptId ") === dept (" id ")) in Spark (RDDs).1 Unlike RDDs, DataFrames keep track of their . where ( employees (" gender ") === " female ") schema and support various relational operations that lead to more . groupBy (dept (" id"), dept (" name ")) optimized execution. .agg( count (" name ")) DataFrames can be constructed from tables in a system catalog Here, employees is a DataFrame, and employees("deptId") is (based on external data sources) or from existing RDDs of native an expression representing the deptId column. Expression objects Java/Python objects (Section 3.5). Once constructed, they can be have many operators that return new expressions, including the usual manipulated with various relational operators, such as where and comparison operators (e.g., === for equality test, > for greater than) groupBy, which take expressions in a domain-specific language and arithmetic ones (+, -, etc). They also support aggregates, such (DSL) similar to data frames in R and Python [32, 30]. Each as count("name"). All of these operators build up an abstract syntax DataFrame can also be viewed as an RDD of Row objects, allowing tree (AST) of the expression, which is then passed to Catalyst for users to call procedural Spark APIs such as map.2 optimization. This is unlike the native Spark API that takes functions Finally, unlike traditional data frame APIs, Spark DataFrames containing arbitrary Scala/Java/Python code, which are then opaque are lazy, in that each DataFrame object represents a logical plan to to the runtime engine. For a detailed listing of the API, we refer compute a dataset, but no execution occurs until the user calls a spe- readers to Spark’s official documentation [6]. cial “output operation” such as save. This enables rich optimization Apart from the relational DSL, DataFrames can be registered as across all operations that were used to build the DataFrame. temporary tables in the system catalog and queried using SQL. The To illustrate, the Scala code below defines a DataFrame from a code below shows an example: table in Hive, derives another based on it, and prints a result: users . where ( users (" age ") < 21) ctx = new HiveContext () . registerTempTable (" young ") users = ctx. table (" users ") ctx.sql (" SELECT count (*) , avg(age) FROM young ") young = users . where ( users (" age ") < 21) println ( young . count ()) SQL is sometimes convenient for computing multiple aggregates concisely, and also allows programs to expose datasets through In this code, users and young are DataFrames. The snippet JDBC/ODBC. The DataFrames registered in the catalog are still users("age") < 21 is an expression in the data frame DSL, which unmaterialized views, so that optimizations can happen across SQL is captured as an abstract syntax tree rather than representing a Scala and the original DataFrame expressions. However, DataFrames can function as in the traditional Spark API. Finally, each DataFrame also be materialized, as we discuss in Section 3.6. simply represents a logical plan (i.e., read the users table and filter 3.4 DataFrames versus Relational Query Languages for age < 21). When the user calls count, which is an output opera- tion, Spark SQL builds a physical plan to compute the final result. While on the surface, DataFrames provide the same operations as This might include optimizations such as only scanning the “age” relational query languages like SQL and Pig [29], we found that column of the data if its storage format is columnar, or even using they can be significantly easier for users to work with thanks to their an index in the data source to count the matching rows. integration in a full programming language. For example, users We next cover the details of the DataFrame API. can break up their code into Scala, Java or Python functions that pass DataFrames between them to build a logical plan, and will still 3.2 Data Model benefit from optimizations across the whole plan when they run an Spark SQL uses a nested data model based on Hive [19] for tables output operation. Likewise, developers can use control structures and DataFrames. It supports all major SQL data types, including like if statements and loops to structure their work. One user said boolean, integer, double, decimal, string, date, and timestamp, as that the DataFrame API is “concise and declarative like SQL, except 1 We chose the name DataFrame because it is similar to structured data I can name intermediate results,” referring to how it is easier to libraries in R and Python, and designed our API to resemble those. structure computations and debug intermediate steps. 2 These Row objects are constructed on the fly and do not necessarily repre- To simplify programming in DataFrames, we also made API sent the internal storage format of the data, which is typically columnar. analyze logical plans eagerly (i.e., to identify whether the column
4 .names used in expressions exist in the underlying tables, and whether in other database systems. This feature has proven crucial for the their data types are appropriate), even though query results are adoption of the API. computed lazily. Thus, Spark SQL reports an error as soon as user In Spark SQL, UDFs can be registered inline by passing Scala, types an invalid line of code instead of waiting until execution. This Java or Python functions, which may use the full Spark API inter- is again easier to work with than a large SQL statement. nally. For example, given a model object for a machine learning 3.5 Querying Native Datasets model, we could register its prediction function as a UDF: Real-world pipelines often extract data from heterogeneous sources val model : LogisticRegressionModel = ... and run a wide variety of algorithms from different programming ctx.udf. register (" predict ", libraries. To interoperate with procedural Spark code, Spark SQL al- (x: Float , y: Float ) => model . predict ( Vector (x, y))) lows users to construct DataFrames directly against RDDs of objects ctx.sql (" SELECT predict (age , weight ) FROM users ") native to the programming language. Spark SQL can automatically infer the schema of these objects using reflection. In Scala and Java, Once registered, the UDF can also be used via the JDBC/ODBC the type information is extracted from the language’s type system interface by business intelligence tools. In addition to UDFs that (from JavaBeans and Scala case classes). In Python, Spark SQL operate on scalar values like the one here, one can define UDFs that samples the dataset to perform schema inference due to the dynamic operate on an entire table by taking its name, as in MADLib [12], and type system. use the distributed Spark API within them, thus exposing advanced For example, the Scala code below defines a DataFrame from an analytics functions to SQL users. Finally, because UDF definitions RDD of User objects. Spark SQL automatically detects the names and query execution are expressed using the same general-purpose (“name” and “age”) and data types (string and int) of the columns. language (e.g., Scala or Python), users can debug or profile the entire case class User(name: String , age: Int) program using standard tools. The example above demonstrates a common use case in many // Create an RDD of User objects pipelines, i.e., one that employs both relational operators and ad- usersRDD = spark . parallelize ( vanced analytics methods that are cumbersome to express in SQL. List(User (" Alice ", 22) , User (" Bob", 19))) The DataFrame API lets developers seamlessly mix these methods. // View the RDD as a DataFrame usersDF = usersRDD .toDF 4 Catalyst Optimizer Internally, Spark SQL creates a logical data scan operator that To implement Spark SQL, we designed a new extensible optimizer, points to the RDD. This is compiled into a physical operator that Catalyst, based on functional programming constructs in Scala. accesses fields of the native objects. It is important to note that this Catalyst’s extensible design had two purposes. First, we wanted to is very different from traditional object-relational mapping (ORM). make it easy to add new optimization techniques and features to ORMs often incur expensive conversions that translate an entire Spark SQL, especially to tackle various problems we were seeing object into a different format. In contrast, Spark SQL accesses the specifically with “big data” (e.g., semistructured data and advanced native objects in-place, extracting only the fields used in each query. analytics). Second, we wanted to enable external developers to The ability to query native datasets lets users run optimized re- extend the optimizer—for example, by adding data source specific lational operations within existing Spark programs. In addition, it rules that can push filtering or aggregation into external storage makes it simple to combine RDDs with external structured data. For systems, or support for new data types. Catalyst supports both example, we could join the users RDD with a table in Hive: rule-based and cost-based optimization. While extensible optimizers have been proposed in the past, they views = ctx.table (" pageviews ") usersDF .join(views , usersDF (" name ") === views (" user ")) have typically required a complex domain specific language to spec- ify rules, and an “optimizer compiler” to translate the rules into executable code [17, 16]. This leads to a significant learning curve 3.6 In-Memory Caching and maintenance burden. In contrast, Catalyst uses standard features Like Shark before it, Spark SQL can materialize (often referred to of the Scala programming language, such as pattern-matching [14], as “cache") hot data in memory using columnar storage. Compared to let developers use the full programming language while still mak- with Spark’s native cache, which simply stores data as JVM objects, ing rules easy to specify. Functional languages were designed in the columnar cache can reduce memory footprint by an order of part to build compilers, so we found Scala well-suited to this task. magnitude because it applies columnar compression schemes such Nonetheless, Catalyst is, to our knowledge, the first production- as dictionary encoding and run-length encoding. Caching is particu- quality query optimizer built on such a language. larly useful for interactive queries and for the iterative algorithms At its core, Catalyst contains a general library for representing common in machine learning. It can be invoked by calling cache() trees and applying rules to manipulate them.3 On top of this frame- on a DataFrame. work, we have built libraries specific to relational query processing 3.7 User-Defined Functions (e.g., expressions, logical query plans), and several sets of rules that handle different phases of query execution: analysis, logical User-defined functions (UDFs) have been an important extension optimization, physical planning, and code generation to compile point for database systems. For example, MySQL relies on UDFs to parts of queries to Java bytecode. For the latter, we use another provide basic support for JSON data. A more advanced example is Scala feature, quasiquotes [34], that makes it easy to generate code MADLib’s use of UDFs to implement machine learning algorithms at runtime from composable expressions. Finally, Catalyst offers for Postgres and other database systems [12]. However, database several public extension points, including external data sources and systems often require UDFs to be defined in a separate programming user-defined types. environment that is different from the primary query interfaces. Spark SQL’s DataFrame API supports inline definition of UDFs, 3 Cost-based optimization is performed by generating multiple plans using without the complicated packaging and registration process found rules, and then computing their costs.
5 . Add Rules (and Scala pattern matching in general) can match multi- ple patterns in the same transform call, making it very concise to implement multiple transformations at once: Attribute(x) Add tree. transform { case Add( Literal (c1), Literal (c2 )) => Literal (c1+c2) case Add(left , Literal (0)) => left case Add( Literal (0) , right ) => right Literal(1) Literal(2) } In practice, rules may need to execute multiple times to fully Figure 2: Catalyst tree for the expression x+(1+2). transform a tree. Catalyst groups rules into batches, and executes each batch until it reaches a fixed point, that is, until the tree stops changing after applying its rules. Running rules to fixed point 4.1 Trees means that each rule can be simple and self-contained, and yet still eventually have larger global effects on a tree. In the example The main data type in Catalyst is a tree composed of node objects. above, repeated application would constant-fold larger trees, such Each node has a node type and zero or more children. New node as (x+0)+(3+3). As another example, a first batch might analyze types are defined in Scala as subclasses of the TreeNode class. These an expression to assign types to all of the attributes, while a second objects are immutable and can be manipulated using functional batch might use these types to do constant folding. After each transformations, as discussed in the next subsection. batch, developers can also run sanity checks on the new tree (e.g., to As a simple example, suppose we have the following three node see that all attributes were assigned types), often also written via classes for a very simple expression language:4 recursive matching. • Literal(value: Int): a constant value Finally, rule conditions and their bodies can contain arbitrary • Attribute(name: String): an attribute from an input row, e.g., “x” Scala code. This gives Catalyst more power than domain specific languages for optimizers, while keeping it concise for simple rules. • Add(left: TreeNode, right: TreeNode): sum of two expres- In our experience, functional transformations on immutable trees sions. make the whole optimizer very easy to reason about and debug. These classes can be used to build up trees; for example, the tree They also enable parallelization in the optimizer, although we do for the expression x+(1+2), shown in Figure 2, would be represented not yet exploit this. in Scala code as follows: 4.3 Using Catalyst in Spark SQL Add( Attribute (x), Add( Literal (1) , Literal (2))) We use Catalyst’s general tree transformation framework in four phases, shown in Figure 3: (1) analyzing a logical plan to resolve 4.2 Rules references, (2) logical plan optimization, (3) physical planning, and Trees can be manipulated using rules, which are functions from a (4) code generation to compile parts of the query to Java bytecode. tree to another tree. While a rule can run arbitrary code on its input In the physical planning phase, Catalyst may generate multiple tree (given that this tree is just a Scala object), the most common plans and compare them based on cost. All other phases are purely approach is to use a set of pattern matching functions that find and rule-based. Each phase uses different types of tree nodes; Catalyst replace subtrees with a specific structure. includes libraries of nodes for expressions, data types, and logical Pattern matching is a feature of many functional languages that and physical operators. We now describe each of these phases. allows extracting values from potentially nested structures of al- 4.3.1 Analysis gebraic data types. In Catalyst, trees offer a transform method that applies a pattern matching function recursively on all nodes of Spark SQL begins with a relation to be computed, either from an the tree, transforming the ones that match each pattern to a result. abstract syntax tree (AST) returned by a SQL parser, or from a For example, we could implement a rule that folds Add operations DataFrame object constructed using the API. In both cases, the between constants as follows: relation may contain unresolved attribute references or relations: for example, in the SQL query SELECT col FROM sales, the type of tree. transform { case Add( Literal (c1), Literal (c2 )) => Literal (c1+c2) col, or even whether it is a valid column name, is not known until } we look up the table sales. An attribute is called unresolved if we do not know its type or have not matched it to an input table (or Applying this to the tree for x+(1+2), in Figure 2, would yield an alias). Spark SQL uses Catalyst rules and a Catalog object that the new tree x+3. The case keyword here is Scala’s standard pattern tracks the tables in all data sources to resolve these attributes. It matching syntax [14], and can be used to match on the type of an starts by building an “unresolved logical plan” tree with unbound object as well as give names to extracted values (c1 and c2 here). attributes and data types, then applies rules that do the following: The pattern matching expression that is passed to transform is a • Looking up relations by name from the catalog. partial function, meaning that it only needs to match to a subset of all possible input trees. Catalyst will tests which parts of a tree a • Mapping named attributes, such as col, to the input provided given rule applies to, automatically skipping over and descending given operator’s children. into subtrees that do not match. This ability means that rules only • Determining which attributes refer to the same value to give need to reason about the trees where a given optimization applies them a unique ID (which later allows optimization of expressions and not those that do not match. Thus, rules do not need to be such as col = col). modified as new types of operators are added to the system. • Propagating and coercing types through expressions: for exam- 4 We use Scala syntax for classes here, where each class’s fields are defined ple, we cannot know the type of 1 + col until we have resolved in parentheses, with their types given using a colon. col and possibly cast its subexpressions to compatible types.
6 . Logical Physical Code Analysis Optimization Planning Generation SQL Query Cost Model Physical Selected Unresolved Optimized Physical Physical Logical Plan Plans Physical RDDs Logical Plan Logical Plan Plans Plans Plan DataFrame Catalog Figure 3: Phases of query planning in Spark SQL. Rounded rectangles represent Catalyst trees. In total, the rules for the analyzer are about 1000 lines of code. 4.3.4 Code Generation 4.3.2 Logical Optimization The final phase of query optimization involves generating Java The logical optimization phase applies standard rule-based optimiza- bytecode to run on each machine. Because Spark SQL often operates tions to the logical plan. These include constant folding, predicate on in-memory datasets, where processing is CPU-bound, we wanted pushdown, projection pruning, null propagation, Boolean expres- to support code generation to speed up execution. Nonetheless, sion simplification, and other rules. In general, we have found it code generation engines are often complicated to build, amounting extremely simple to add rules for a wide variety of situations. For essentially to a compiler. Catalyst relies on a special feature of the example, when we added the fixed-precision DECIMAL type to Spark Scala language, quasiquotes [34], to make code generation simpler. SQL, we wanted to optimize aggregations such as sums and aver- Quasiquotes allow the programmatic construction of abstract syntax ages on DECIMALs with small precisions; it took 12 lines of code to trees (ASTs) in the Scala language, which can then be fed to the write a rule that finds such decimals in SUM and AVG expressions, and Scala compiler at runtime to generate bytecode. We use Catalyst to casts them to unscaled 64-bit LONGs, does the aggregation on that, transform a tree representing an expression in SQL to an AST for then converts the result back. A simplified version of this rule that Scala code to evaluate that expression, and then compile and run the only optimizes SUM expressions is reproduced below: generated code. As a simple example, consider the Add, Attribute and Literal tree object DecimalAggregates extends Rule[ LogicalPlan ] { /** Maximum number of decimal digits in a Long */ nodes introduced in Section 4.2, which allowed us to write expres- val MAX_LONG_DIGITS = 18 sions such as (x+y)+1. Without code generation, such expressions would have to be interpreted for each row of data, by walking down def apply(plan: LogicalPlan ): LogicalPlan = { a tree of Add, Attribute and Literal nodes. This introduces large plan transformAllExpressions { case Sum(e @ DecimalType . Expression (prec , scale )) amounts of branches and virtual function calls that slow down exe- if prec + 10 <= MAX_LONG_DIGITS => cution. With code generation, we can write a function to translate a MakeDecimal (Sum( LongValue (e)), prec + 10, scale ) specific expression tree to a Scala AST as follows: } } def compile (node: Node ): AST = node match { case Literal ( value ) => q" $value " As another example, a 12-line rule optimizes LIKE expressions case Attribute (name) => q"row.get( $name )" with simple regular expressions into String.startsWith or case Add(left , right ) => q"${ compile (left )} + ${ compile ( right )}" String.contains calls. The freedom to use arbitrary Scala code in } rules made these kinds of optimizations, which go beyond pattern- matching the structure of a subtree, easy to express. In total, the The strings beginning with q are quasiquotes, meaning that al- logical optimization rules are 800 lines of code. though they look like strings, they are parsed by the Scala compiler 4.3.3 Physical Planning at compile time and represent ASTs for the code within. Quasiquotes can have variables or other ASTs spliced into them, indicated using In the physical planning phase, Spark SQL takes a logical plan and $ notation. For example, Literal(1) would become the Scala AST generates one or more physical plans, using physical operators that for 1, while Attribute("x") becomes row.get("x"). In the end, a match the Spark execution engine. It then selects a plan using a tree like Add(Literal(1), Attribute("x")) becomes an AST for cost model. At the moment, cost-based optimization is only used to a Scala expression like 1+row.get("x"). select join algorithms: for relations that are known to be small, Spark Quasiquotes are type-checked at compile time to ensure that only SQL uses a broadcast join, using a peer-to-peer broadcast facility appropriate ASTs or literals are substituted in, making them sig- available in Spark.5 The framework supports broader use of cost- nificantly more useable than string concatenation, and they result based optimization, however, as costs can be estimated recursively directly in a Scala AST instead of running the Scala parser at runtime. for a whole tree using a rule. We thus intend to implement richer Moreover, they are highly composable, as the code generation rule cost-based optimization in the future. for each node does not need to know how the trees returned by its The physical planner also performs rule-based physical optimiza- children were built. Finally, the resulting code is further optimized tions, such as pipelining projections or filters into one Spark map by the Scala compiler in case there are expression-level optimiza- operation. In addition, it can push operations from the logical plan tions that Catalyst missed. Figure 4 shows that quasiquotes let us into data sources that support predicate or projection pushdown. We generate code with performance similar to hand-tuned programs. will describe the API for these data sources in Section 4.4.1. We have found quasiquotes very straightforward to use for code In total, the physical planning rules are about 500 lines of code. generation, and we observed that even new contributors to Spark 5 Table sizes are estimated if the table is cached in memory or comes from SQL could quickly add rules for new types of expressions. Qua- an external file, or if it is the result of a subquery with a LIMIT. siquotes also work well with our goal of running on native Java
7 . simple data sources of virtually any type. We and others have used Intepreted the interface to implement the following data sources: • CSV files, which simply scan the whole file, but allow users to Hand-written specify a schema. Generated • Avro [4], a self-describing binary format for nested data. 0 10 20 30 40 • Parquet [5], a columnar file format for which we support column pruning as well as filters. Runtime (seconds) • A JDBC data source that scans ranges of a table from an RDBMS in parallel and pushes filters into the RDBMS to minimize com- Figure 4: A comparision of the performance evaluating the ex- munication. presion x+x+x, where x is an integer, 1 billion times. To use these data sources, programmers specify their package names in SQL statements, passing key-value pairs for configuration objects: when accessing fields from these objects, we can code- options. For example, the Avro data source takes a path to the file: generate a direct access to the required field, instead of having to CREATE TEMPORARY TABLE messages copy the object into a Spark SQL Row and use the Row’s accessor USING com. databricks . spark .avro methods. Finally, it was straightforward to combine code-generated OPTIONS (path " messages .avro ") evaluation with interpreted evaluation for expressions we do not yet All data sources can also expose network locality information, generate code for, since the Scala code we compile can directly call i.e., which machines each partition of the data is most efficient to into our expression interpreter. read from. This is exposed through the RDD objects they return, as In total, Catalyst’s code generator is about 700 lines of code. RDDs have a built-in API for data locality [39]. 4.4 Extension Points Finally, similar interfaces exist for writing data to an existing or new table. These are simpler because Spark SQL just provides an Catalyst’s design around composable rules makes it easy for users RDD of Row objects to be written. and third-party libraries to extend. Developers can add batches of rules to each phase of query optimization at runtime, as long 4.4.2 User-Defined Types (UDTs) as they adhere to the contract of each phase (e.g., ensuring that One feature we wanted to allow advanced analytics in Spark SQL analysis resolves all attributes). However, to make it even simpler to was user-defined types. For example, machine learning applications add some types of extensions without understanding Catalyst rules, may need a vector type, and graph algorithms may need types for we have also defined two narrower public extension points: data representing a graph, which is possible over relational tables [15]. sources and user-defined types. These still rely on facilities in the Adding new types can be challenging, however, as data types per- core engine to interact with the rest of the rest of the optimizer. vade all aspects of the execution engine. For example, in Spark SQL, 4.4.1 Data Sources the built-in data types are stored in a columnar, compressed format for in-memory caching (Section 3.6), and in the data source API Developers can define a new data source for Spark SQL using several from the previous section, we need to expose all possible data types APIs, which expose varying degrees of possible optimization. All to data source authors. data sources must implement a createRelation function that takes In Catalyst, we solve this issue by mapping user-defined types a set of key-value parameters and returns a BaseRelation object for to structures composed of Catalyst’s built-in types, described in that relation, if one can be successfully loaded. Each BaseRelation Section 3.2. To register a Scala type as a UDT, users provide a contains a schema and an optional estimated size in bytes.6 For mapping from an object of their class to a Catalyst Row of built-in instance, a data source representing MySQL may take a table name types, and an inverse mapping back. In user code, they can now use as a parameter, and ask MySQL for an estimate of the table size. the Scala type in objects that they query with Spark SQL, and it will To let Spark SQL read the data, a BaseRelation can implement be converted to built-in types under the hood. Likewise, they can one of several interfaces that let them expose varying degrees of register UDFs (see Section 3.7) that operate directly on their type. sophistication. The simplest, TableScan, requires the relation to As a short example, suppose we want to register two-dimensional return an RDD of Row objects for all of the data in the table. A more points (x, y) as a UDT. We can represent such vectors as two DOUBLE advanced PrunedScan takes an array of column names to read, and values. To register the UDT, we write the following: should return Rows containing only those columns. A third interface, class PointUDT extends UserDefinedType [ Point ] { PrunedFilteredScan, takes both desired column names and an array def dataType = StructType (Seq( // Our native structure of Filter objects, which are a subset of Catalyst’s expression syntax, StructField ("x", DoubleType ), allowing predicate pushdown.7 The filters are advisory, i.e., the data StructField ("y", DoubleType ) )) source should attempt to return only rows passing each filter, but it def serialize (p: Point ) = Row(p.x, p.y) is allowed to return false positives in the case of filters that it cannot def deserialize (r: Row) = evaluate. Finally, a CatalystScan interface is given a complete Point (r. getDouble (0) , r. getDouble (1)) } sequence of Catalyst expression trees to use in predicate pushdown, though they are again advisory. After registering this type, Points will be recognized within native These interfaces allow data sources to implement various degrees objects that Spark SQL is asked to convert to DataFrames, and will of optimization, while still making it easy for developers to add be passed to UDFs defined on Points. In addition, Spark SQL will 6 Unstructured data sources can also take a desired schema as a parameter; store Points in a columnar format when caching data (compressing x and y as separate columns), and Points will be writable to all of for example, there is a CSV file data source that lets users specify column names and types. Spark SQL’s data sources, which will see them as pairs of DOUBLEs. 7 At the moment, Filters include equality, comparisons against a constant, We use this capability in Spark’s machine learning library, as we and IN clauses, each on one attribute. describe in Section 5.2.
8 .{ each field defined by a distinct path from the root JSON object "text ": "This is a tweet about # Spark ", (e.g., tweet.loc.latitude), the algorithm finds the most specific "tags ": ["# Spark "], Spark SQL data type that matches observed instances of the field. "loc ": {" lat ": 45.1 , "long ": 90} } For example, if all occurrences of that field are integers that fit into 32 bits, it will infer INT; if they are larger, it will use LONG (64-bit) { or DECIMAL (arbitrary precision); if there are also fractional values, "text ": "This is another tweet ", "tags ": [], it will use FLOAT. For fields that display multiple types, Spark SQL "loc ": {" lat ": 39, "long ": 88.5} uses STRING as the most generic type, preserving the original JSON } representation. And for fields that contain arrays, it uses the same { “most specific supertype" logic to determine an element type from all "text ": "A #tweet without # location ", the observed elements. We implement this algorithm using a single "tags ": ["# tweet ", "# location "] reduce operation over the data, which starts with schemata (i.e., trees } of types) from each individual record and merges them using an associative “most specific supertype" function that generalizes the Figure 5: A sample set of JSON records, representing tweets. types of each field. This makes the algorithm both single-pass and communication-efficient, as a high degree of reduction happens locally on each node. text STRING NOT NULL , tags ARRAY < STRING NOT NULL > NOT NULL , As a short example, note how in Figures 5 and 6, the algorithm loc STRUCT <lat FLOAT NOT NULL , long FLOAT NOT NULL > generalized the types of loc.lat and loc.long. Each field appears as an integer in one record and a floating-point number in another, so the algorithm returns FLOAT. Note also how for the tags field, the Figure 6: Schema inferred for the tweets in Figure 5. algorithm inferred an array of strings that cannot be null. In practice, we have found this algorithm to work well with 5 Advanced Analytics Features real-world JSON datasets. For example, it correctly identifies a usable schema for JSON tweets from Twitter’s firehose, which In this section, we describe three features we added to Spark SQL contain around 100 distinct fields and a high degree of nesting. specifically to handle challenges in “big data" environments. First, Multiple Databricks customers have also successfully applied it to in these environments, data is often unstructured or semistructured. their internal JSON formats. While parsing such data procedurally is possible, it leads to lengthy In Spark SQL, we also use the same algorithm for inferring boilerplate code. To let users query the data right away, Spark schemas of RDDs of Python objects (see Section 3), as Python is SQL includes a schema inference algorithm for JSON and other not statically typed so an RDD can contain multiple object types. In semistructured data. Second, large-scale processing often goes the future, we plan to add similar inference for CSV files and XML. beyond aggregation and joins to machine learning on the data. We Developers have found the ability to view these types of datasets describe how Spark SQL is being incorporated into a new high-level as tables and immediately query them or join them with other data API for Spark’s machine learning library [26]. Last, data pipelines extremely valuable for their productivity. often combine data from disparate storage systems. Building on the data sources API in Section 4.4.1, Spark SQL supports query 5.2 Integration with Spark’s Machine Learning Library federation, allowing a single program to efficiently query disparate As an example of Spark SQL’s utility in other Spark modules, ML- sources. These features all build on the Catalyst framework. lib, Spark’s machine learning library, introduced a new high-level 5.1 Schema Inference for Semistructured Data API that uses DataFrames [26]. This new API is based on the Semistructured data is common in large-scale environments be- concept of machine learning pipelines, an abstraction in other high- cause it is easy to produce and to add fields to over time. Among level ML libraries like SciKit-Learn [33]. A pipeline is a graph Spark users, we have seen very high usage of JSON for input data. of transformations on data, such as feature extraction, normaliza- Unfortunately, JSON is cumbersome to work with in a procedu- tion, dimensionality reduction, and model training, each of which ral environment like Spark or MapReduce: most users resorted to exchange datasets. Pipelines are a useful abstraction because ML ORM-like libraries (e.g., Jackson [21]) to map JSON structures to workflows have many steps; representing these steps as composable Java objects, or some tried parsing each input record directly with elements makes it easy to change parts of the pipeline or to search lower-level libraries. for tuning parameters at the level of the whole workflow. In Spark SQL, we added a JSON data source that automatically To exchange data between pipeline stages, MLlib’s developers infers a schema from a set of records. For example, given the JSON needed a format that was compact (as datasets can be large) yet objects in Figure 5, the library infers the schema shown in Figure 6. flexible, allowing multiple types of fields to be stored for each Users can simply register a JSON file as a table and query it with record. For example, a user may start with records that contain text syntax that accesses fields by their path, such as: fields as well as numeric ones, then run a featurization algorithm such as TF-IDF on the text to turn it into a vector, normalize one of SELECT loc.lat , loc.long FROM tweets the other fields, perform dimensionality reduction on the whole set WHERE text LIKE ’% Spark %’ AND tags IS NOT NULL of features, etc. To represent datasets, the new API uses DataFrames, Our schema inference algorithm works in one pass over the data, where each column represents a feature of the data. All algorithms and can also be run on a sample of the data if desired. It is related to that can be called in pipelines take a name for the input column(s) prior work on schema inference for XML and object databases [9, and output column(s), and can thus be called on any subset of the 18, 27], but simpler because it only infers a static tree structure, fields and produce new ones. This makes it easy for developers to without allowing recursive nesting of elements at arbitrary depths. build complex pipelines while retaining the original data for each Specifically, the algorithm attempts to infer a tree of STRUCT types, record. To illustrate the API, Figure 7 shows a short pipeline and each of which may contain atoms, arrays, or other STRUCTs. For the schemas of DataFrames created.
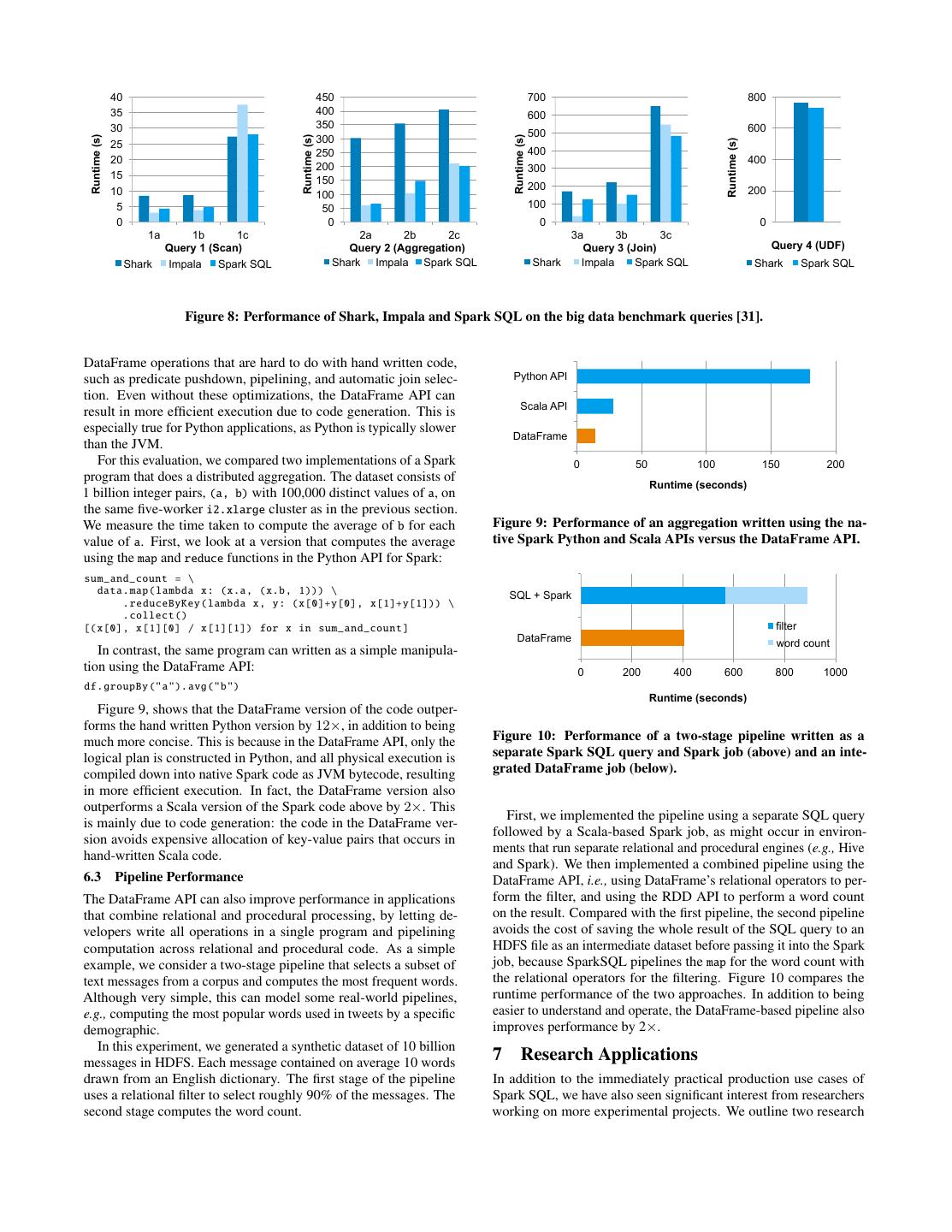
9 . model CREATE TEMPORARY TABLE logs USING json OPTIONS (path "logs.json ") tokenizer tf lr SELECT users .id , users .name , logs. message FROM users JOIN logs WHERE users .id = logs. userId (text, label) (text, label, (text, label, AND users . registrationDate > "2015 -01 -01" words) words, features) Under the hood, the JDBC data source uses the PrunedFiltered- data = <DataFrame of (text , label ) records > Scan interface in Section 4.4.1, which gives it both the names of the columns requested and simple predicates (equality, comparison and tokenizer = Tokenizer () IN clauses) on these columns. In this case, the JDBC data source . setInputCol (" text "). setOutputCol (" words ") tf = HashingTF () will run the following query on MySQL:8 . setInputCol (" words "). setOutputCol (" features ") lr = LogisticRegression () SELECT users .id , users .name FROM users . setInputCol (" features ") WHERE users . registrationDate > "2015 -01 -01" pipeline = Pipeline (). setStages ([ tokenizer , tf , lr ]) In future Spark SQL releases, we are also looking to add predicate model = pipeline .fit(data) pushdown for key-value stores such as HBase and Cassandra, which support limited forms of filtering. Figure 7: A short MLlib pipeline and the Python code to run it. 6 Evaluation We start with a DataFrame of (text, label) records, tokenize the text into words, run a term frequency featurizer (HashingTF) to We evaluate the performance of Spark SQL on two dimensions: SQL get a feature vector, then train logistic regression. query processing performance and Spark program performance. In particular, we demonstrate that Spark SQL’s extensible architecture not only enables a richer set of functionalities, but brings substantial The main piece of work MLlib had to do to use Spark SQL was performance improvements over previous Spark-based SQL engines. to create a user-defined type for vectors. This vector UDT can store In addition, for Spark application developers, the DataFrame API both sparse and dense vectors, and represents them as four primi- can bring substantial speedups over the native Spark API while tive fields: a boolean for the type (dense or sparse), a size for the making Spark programs more concise and easier to understand. vector, an array of indices (for sparse coordinates), and an array of Finally, applications that combine relational and procedural queries double values (either the non-zero coordinates for sparse vectors run faster on the integrated Spark SQL engine than by running SQL or all coordinates otherwise). Apart from DataFrames’ utility for and procedural code as separate parallel jobs. tracking and manipulating columns, we also found them useful for 6.1 SQL Performance another reason: they made it much easier to expose MLlib’s new API in all of Spark’s supported programming languages. Previously, We compared the performance of Spark SQL against Shark and each algorithm in MLlib took objects for domain-specific concepts Impala [23] using the AMPLab big data benchmark [3], which (e.g., a labeled point for classification, or a (user, product) rating for uses a web analytics workload developed by Pavlo et al. [31]. The recommendation), and each of these classes had to be implemented benchmark contains four types of queries with different parameters in the various languages (e.g., copied from Scala to Python). Using performing scans, aggregation, joins and a UDF-based MapReduce DataFrames everywhere made it much simpler to expose all algo- job. We used a cluster of six EC2 i2.xlarge machines (one master, rithms in all languages, as we only need data conversions in Spark five workers) each with 4 cores, 30 GB memory and an 800 GB SSD, SQL, where they already exist. This is especially important as Spark running HDFS 2.4, Spark 1.3, Shark 0.9.1 and Impala 2.1.1. The adds bindings for new programming languages. dataset was 110 GB of data after compression using the columnar Finally, using DataFrames for storage in MLlib also makes it very Parquet format [5]. easy to expose all its algorithms in SQL. We can simply define a Figure 8 shows the results for each query, grouping by the query MADlib-style UDF, as described in Section 3.7, which will inter- type. Queries 1–3 have different parameters varying their selectivity, nally call the algorithm on a table. We are also exploring APIs to with 1a, 2a, etc being the most selective and 1c, 2c, etc being the expose pipeline construction in SQL. least selective and processing more data. Query 4 uses a Python- based Hive UDF that was not directly supported in Impala, but was 5.3 Query Federation to External Databases largely bound by the CPU cost of the UDF. Data pipelines often combine data from heterogeneous sources. For We see that in all queries, Spark SQL is substantially faster than example, a recommendation pipeline might combine traffic logs Shark and generally competitive with Impala. The main reason with a user profile database and users’ social media streams. As for the difference with Shark is code generation in Catalyst (Sec- these data sources often reside in different machines or geographic tion 4.3.4), which reduces CPU overhead. This feature makes Spark locations, naively querying them can be prohibitively expensive. SQL competitive with the C++ and LLVM based Impala engine in Spark SQL data sources leverage Catalyst to push predicates down many of these queries. The largest gap from Impala is in query 3a into the data sources whenever possible. where Impala chooses a better join plan because the selectivity of For example, the following uses the JDBC data source and the the queries makes one of the tables very small. JSON data source to join two tables together to find the traffic log for 6.2 DataFrames vs. Native Spark Code the most recently registered users. Conveniently, both data sources can automatically infer the schema without users having to define it. In addition to running SQL queries, Spark SQL can also help The JDBC data source will also push the filter predicate down into non-SQL developers write simpler and more efficient Spark code MySQL to reduce the amount of data transferred. through the DataFrame API. Catalyst can perform optimizations on 8 The JDBC data source also supports “sharding” a source table by a particu- CREATE TEMPORARY TABLE users USING jdbc OPTIONS ( driver "mysql " url "jdbc: mysql :// userDB / users ") lar column and reading different ranges of it in parallel.
10 . 40 450 700 800 35 400 600 30 350 600 500 300 Runtime (s) Runtime (s) Runtime (s) Runtime (s) 25 250 400 20 400 200 300 15 150 10 200 200 100 5 50 100 0 0 0 0 1a 1b 1c 2a 2b 2c 3a 3b 3c Query 1 (Scan) Query 2 (Aggregation) Query 3 (Join) Query 4 (UDF) Shark Impala Spark SQL Shark Impala Spark SQL Shark Impala Spark SQL Shark Spark SQL Figure 8: Performance of Shark, Impala and Spark SQL on the big data benchmark queries [31]. DataFrame operations that are hard to do with hand written code, such as predicate pushdown, pipelining, and automatic join selec- Python API tion. Even without these optimizations, the DataFrame API can Scala API result in more efficient execution due to code generation. This is especially true for Python applications, as Python is typically slower DataFrame than the JVM. For this evaluation, we compared two implementations of a Spark 0 50 100 150 200 program that does a distributed aggregation. The dataset consists of Runtime (seconds) 1 billion integer pairs, (a, b) with 100,000 distinct values of a, on the same five-worker i2.xlarge cluster as in the previous section. We measure the time taken to compute the average of b for each Figure 9: Performance of an aggregation written using the na- value of a. First, we look at a version that computes the average tive Spark Python and Scala APIs versus the DataFrame API. using the map and reduce functions in the Python API for Spark: sum_and_count = \ data.map( lambda x: (x.a, (x.b, 1))) \ SQL + Spark . reduceByKey ( lambda x, y: (x[0]+y[0] , x[1]+y [1])) \ . collect () [(x[0], x [1][0] / x [1][1]) for x in sum_and_count ] filter DataFrame word count In contrast, the same program can written as a simple manipula- tion using the DataFrame API: 0 200 400 600 800 1000 df. groupBy ("a"). avg ("b") Runtime (seconds) Figure 9, shows that the DataFrame version of the code outper- forms the hand written Python version by 12×, in addition to being much more concise. This is because in the DataFrame API, only the Figure 10: Performance of a two-stage pipeline written as a logical plan is constructed in Python, and all physical execution is separate Spark SQL query and Spark job (above) and an inte- compiled down into native Spark code as JVM bytecode, resulting grated DataFrame job (below). in more efficient execution. In fact, the DataFrame version also outperforms a Scala version of the Spark code above by 2×. This First, we implemented the pipeline using a separate SQL query is mainly due to code generation: the code in the DataFrame ver- followed by a Scala-based Spark job, as might occur in environ- sion avoids expensive allocation of key-value pairs that occurs in ments that run separate relational and procedural engines (e.g., Hive hand-written Scala code. and Spark). We then implemented a combined pipeline using the 6.3 Pipeline Performance DataFrame API, i.e., using DataFrame’s relational operators to per- The DataFrame API can also improve performance in applications form the filter, and using the RDD API to perform a word count that combine relational and procedural processing, by letting de- on the result. Compared with the first pipeline, the second pipeline velopers write all operations in a single program and pipelining avoids the cost of saving the whole result of the SQL query to an computation across relational and procedural code. As a simple HDFS file as an intermediate dataset before passing it into the Spark example, we consider a two-stage pipeline that selects a subset of job, because SparkSQL pipelines the map for the word count with text messages from a corpus and computes the most frequent words. the relational operators for the filtering. Figure 10 compares the Although very simple, this can model some real-world pipelines, runtime performance of the two approaches. In addition to being e.g., computing the most popular words used in tweets by a specific easier to understand and operate, the DataFrame-based pipeline also demographic. improves performance by 2×. In this experiment, we generated a synthetic dataset of 10 billion messages in HDFS. Each message contained on average 10 words 7 Research Applications drawn from an English dictionary. The first stage of the pipeline In addition to the immediately practical production use cases of uses a relational filter to select roughly 90% of the messages. The Spark SQL, we have also seen significant interest from researchers second stage computes the word count. working on more experimental projects. We outline two research
11 .projects that leverage the extensibility of Catalyst: one in approxi- One system that inspired Spark SQL’s design was DryadLINQ [20], mate query processing and one in genomics. which compiles language-integrated queries in C# to a distributed DAG execution engine. LINQ queries are also relational but can 7.1 Generalized Online Aggregation operate directly on C# objects. Spark SQL goes beyond DryadLINQ Zeng et al. have used Catalyst in their work on improving the gener- by also providing a DataFrame interface similar to common data ality of online aggregation [40]. This work generalizes the execution science libraries [32, 30], an API for data sources and types, and of online aggregation to support arbitrarily nested aggregate queries. support for iterative algorithms through execution on Spark. It allows users to view the progress of executing queries by seeing Other systems use only a relational data model internally and results computed over a fraction of the total data. These partial re- relegate procedural code to UDFs. For example, Hive and Pig [36, sults also include accuracy measures, letting the user stop the query 29] offer relational query languages but have widely used UDF in- when sufficient accuracy has been reached. terfaces. ASTERIX [8] has a semi-structured data model internally. In order to implement this system inside of Spark SQL, the au- Stratosphere [2] also has a semi-structured model, but offers APIs thors add a new operator to represent a relation that has been broken in Scala and Java that let users easily call UDFs. PIQL [7] likewise up into sampled batches. During query planning a call to transform provides a Scala DSL. Compared to these systems, Spark SQL in- is used to replace the original full query with several queries, each tegrates more closely with native Spark applications by being able of which operates on a successive sample of the data. to directly query data in user-defined classes (native Java/Python However, simply replacing the full dataset with samples is not objects), and lets developers mix procedural and relational APIs sufficient to compute the correct answer in an online fashion. Oper- in the same language. In addition, through the Catalyst optimizer, ations such as standard aggregation must be replaced with stateful Spark SQL implements both optimizations (e.g., code generation) counterparts that take into account both the current sample and the and other functionality (e.g., schema inference for JSON and ma- results of previous batches. Furthermore, operations that might filter chine learning data types) that are not present in most large-scale out tuples based on approximate answers must be replaced with computing frameworks. We believe that these features are essential versions that can take into account the current estimated errors. to offering an integrated, easy-to-use environment for big data. Each of these transformations can be expressed as Catalyst rules Finally, data frame APIs have been built both for single ma- that modify the operator tree until it produces correct online answers. chines [32, 30] and clusters [13, 10]. Unlike previous APIs, Spark Tree fragments that are not based on sampled data are ignored by SQL optimizes DataFrame computations with a relational optimizer. these rules and can execute using the standard code path. By using Extensible Optimizers The Catalyst optimizer shares similar goals Spark SQL as a basis, the authors were able to implement a fairly with extensible optimizer frameworks such as EXODUS [17] and complete prototype in approximately 2000 lines of code. Cascades [16]. Traditionally, however, optimizer frameworks have 7.2 Computational Genomics required a domain-specific language to write rules in, as well as an “optimizer compiler” to translate them to runnable code. Our major A common operation in computational genomics involves inspecting improvement here is to build our optimizer using standard features overlapping regions based on a numerical offsets. This problem can of a functional programming language, which provide the same (and be represented as a join with inequality predicates. Consider two often greater) expressivity while decreasing the maintenance burden datasets, a and b, with a schema of (start LONG, end LONG). The and learning curve. Advanced language features helped with many range join operation can be expressed in SQL as follows: areas of Catalyst—for example, our approach to code generation SELECT * FROM a JOIN b using quasiquotes (Section 4.3.4) is one of the simplest and most WHERE a. start < a.end composable approaches to this task that we know. While extensi- AND b. start < b.end bility is hard to measure quantitatively, one promising indication AND a. start < b. start is that Spark SQL had over 50 external contributors in the first 8 AND b. start < a.end months after its release. For code generation, LegoBase [22] recently proposed an ap- Without special optimization, the preceding query would be ex- proach using generative programming in Scala, which would be ecuted by many systems using an inefficient algorithm such as a possible to use instead of quasiquotes in Catalyst. nested loop join. In contrast, a specialized system could compute the answer to this join using an interval tree. Researchers in the Advanced Analytics Spark SQL builds on recent work to run ad- ADAM project [28] were able to build a special planning rule into vanced analytics algorithms on large clusters, including platforms a version of Spark SQL to perform such computations efficiently, for iterative algorithms [39] and graph analytics [15, 24]. The de- allowing them to leverage the standard data manipulation abilities sire to expose analytics functions is also shared with MADlib [12], alongside specialized processing code. The changes required were though the approach there is different, as MADlib had to use the approximately 100 lines of code. limited interface of Postgres UDFs, while Spark SQL’s UDFs can be full-fledged Spark programs. Finally, techniques including Sinew 8 Related Work and Invisible Loading [35, 1] have sought to provide and optimize Programming Model Several systems have sought to combine re- queries over semi-structured data such as JSON. We hope to apply lational processing with the procedural processing engines initially some of these techniques in our JSON data source. used for large clusters. Of these, Shark [38] is the closest to Spark SQL, running on the same engine and offering the same combi- 9 Conclusion nation of relational queries and advanced analytics. Spark SQL We have presented Spark SQL, a new module in Apache Spark improves on Shark through a richer and more programmer-friendly providing rich integration with relational processing. Spark SQL API, DataFrames, where queries can be combined in a modular way extends Spark with a declarative DataFrame API to allow relational using constructs in the host programming language (see Section 3.4). processing, offering benefits such as automatic optimization, and It also allows running relational queries directly on native RDDs, letting users write complex pipelines that mix relational and complex and supports a wide range of data sources beyond Hive. analytics. It supports a wide range of features tailored to large-scale
12 .data analysis, including semi-structured data, query federation, and [18] J. Hegewald, F. Naumann, and M. Weis. XStruct: efficient data types for machine learning. To enable these features, Spark schema extraction from multiple and large XML documents. SQL is based on an extensible optimizer called Catalyst that makes In ICDE Workshops, 2006. it easy to add optimization rules, data sources and data types by [19] Hive data definition language. embedding into the Scala programming language. User feedback https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL. and benchmarks show that Spark SQL makes it significantly simpler [20] M. Isard and Y. Yu. Distributed data-parallel computing using and more efficient to write data pipelines that mix relational and a high-level programming language. In SIGMOD, 2009. procedural processing, while offering substantial speedups over [21] Jackson JSON processor. http://jackson.codehaus.org. previous SQL-on-Spark engines. [22] Y. Klonatos, C. Koch, T. Rompf, and H. Chafi. Building Spark SQL is open source at http://spark.apache.org. efficient query engines in a high-level language. PVLDB, 10 Acknowledgments 7(10):853–864, 2014. [23] M. Kornacker et al. Impala: A modern, open-source SQL We would like to thank Cheng Hao, Tayuka Ueshin, Tor Myklebust, engine for Hadoop. In CIDR, 2015. Daoyuan Wang, and the rest of the Spark SQL contributors so far. [24] Y. Low et al. Distributed GraphLab: a framework for machine We would also like to thank John Cieslewicz and the other members learning and data mining in the cloud. VLDB, 2012. of the F1 team at Google for early discussions on the Catalyst [25] S. Melnik et al. Dremel: interactive analysis of web-scale optimizer. The work of authors Franklin and Kaftan was supported datasets. Proc. VLDB Endow., 3:330–339, Sept 2010. in part by: NSF CISE Expeditions Award CCF-1139158, LBNL [26] X. Meng, J. Bradley, E. Sparks, and S. Venkataraman. ML Award 7076018, and DARPA XData Award FA8750-12-2-0331, pipelines: a new high-level API for MLlib. and gifts from Amazon Web Services, Google, SAP, The Thomas https://databricks.com/blog/2015/01/07/ml-pipelines-a-new- and Stacey Siebel Foundation, Adatao, Adobe, Apple, Inc., Blue high-level-api-for-mllib.html. Goji, Bosch, C3Energy, Cisco, Cray, Cloudera, EMC2, Ericsson, Facebook, Guavus, Huawei, Informatica, Intel, Microsoft, NetApp, [27] S. Nestorov, S. Abiteboul, and R. Motwani. Extracting Pivotal, Samsung, Schlumberger, Splunk, Virdata and VMware. schema from semistructured data. In ICDM, 1998. [28] F. A. Nothaft, M. Massie, T. Danford, Z. Zhang, U. Laserson, 11 References C. Yeksigian, J. Kottalam, A. Ahuja, J. Hammerbacher, M. Linderman, M. J. Franklin, A. D. Joseph, and D. A. [1] A. Abouzied, D. J. Abadi, and A. Silberschatz. Invisible Patterson. Rethinking data-intensive science using scalable loading: Access-driven data transfer from raw files into analytics systems. In SIGMOD, 2015. database systems. In EDBT, 2013. [29] C. Olston, B. Reed, U. Srivastava, R. Kumar, and A. Tomkins. [2] A. Alexandrov et al. The Stratosphere platform for big data Pig Latin: a not-so-foreign language for data processing. In analytics. The VLDB Journal, 23(6):939–964, Dec. 2014. SIGMOD, 2008. [3] AMPLab big data benchmark. [30] pandas Python data analysis library. http://pandas.pydata.org. https://amplab.cs.berkeley.edu/benchmark. [31] A. Pavlo et al. A comparison of approaches to large-scale data [4] Apache Avro project. http://avro.apache.org. analysis. In SIGMOD, 2009. [5] Apache Parquet project. http://parquet.incubator.apache.org. [32] R project for statistical computing. http://www.r-project.org. [6] Apache Spark project. http://spark.apache.org. [33] scikit-learn: machine learning in Python. [7] M. Armbrust, N. Lanham, S. Tu, A. Fox, M. J. Franklin, and http://scikit-learn.org. D. A. Patterson. The case for PIQL: a performance insightful [34] D. Shabalin, E. Burmako, and M. Odersky. Quasiquotes for query language. In SOCC, 2010. Scala, a technical report. Technical Report 185242, École [8] A. Behm et al. Asterix: towards a scalable, semistructured Polytechnique Fédérale de Lausanne, 2013. data platform for evolving-world models. Distributed and [35] D. Tahara, T. Diamond, and D. J. Abadi. Sinew: A SQL Parallel Databases, 29(3):185–216, 2011. system for multi-structured data. In SIGMOD, 2014. [9] G. J. Bex, F. Neven, and S. Vansummeren. Inferring XML [36] A. Thusoo et al. Hive–a petabyte scale data warehouse using schema definitions from XML data. In VLDB, 2007. Hadoop. In ICDE, 2010. [10] BigDF project. https://github.com/AyasdiOpenSource/bigdf. [37] P. Wadler. Monads for functional programming. In Advanced [11] C. Chambers, A. Raniwala, F. Perry, S. Adams, R. R. Henry, Functional Programming, pages 24–52. Springer, 1995. R. Bradshaw, and N. Weizenbaum. FlumeJava: Easy, efficient [38] R. S. Xin, J. Rosen, M. Zaharia, M. J. Franklin, S. Shenker, data-parallel pipelines. In PLDI, 2010. and I. Stoica. Shark: SQL and rich analytics at scale. In [12] J. Cohen, B. Dolan, M. Dunlap, J. Hellerstein, and C. Welton. SIGMOD, 2013. MAD skills: new analysis practices for big data. VLDB, 2009. [39] M. Zaharia et al. Resilient distributed datasets: a fault-tolerant [13] DDF project. http://ddf.io. abstraction for in-memory cluster computing. In NSDI, 2012. [14] B. Emir, M. Odersky, and J. Williams. Matching objects with [40] K. Zeng et al. G-OLA: Generalized online aggregation for patterns. In ECOOP 2007 – Object-Oriented Programming, interactive analysis on big data. In SIGMOD, 2015. volume 4609 of LNCS, pages 273–298. Springer, 2007. [15] J. E. Gonzalez, R. S. Xin, A. Dave, D. Crankshaw, M. J. Franklin, and I. Stoica. GraphX: Graph processing in a distributed dataflow framework. In OSDI, 2014. [16] G. Graefe. The Cascades framework for query optimization. IEEE Data Engineering Bulletin, 18(3), 1995. [17] G. Graefe and D. DeWitt. The EXODUS optimizer generator. In SIGMOD, 1987.
3秒后跳转登录页面
去登陆

