













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
SnipSuggest: Context-Aware Autocompletion for SQL
In this paper, we present SnipSuggest, a system that provides onthe-go, context-aware assistance in the SQL composition process.SnipSuggest aims to help the increasing population of non-expert database users, who need to perform complex analysis on their large-scale datasets, but have difficulty writing SQL queries.
展开查看详情
1 . SnipSuggest: Context-Aware Autocompletion for SQL Nodira Khoussainova, YongChul Kwon, Magdalena Balazinska, and Dan Suciu Department of Computer Science and Engineering, University of Washington, Seattle, WA, USA {nodira, yongchul, magda, suciu}@cs.washington.edu ABSTRACT SQL [1]. To date, astronomers and others have submitted over 20.7 In this paper, we present SnipSuggest, a system that provides on- million SQL queries to the SDSS database; most queries are sub- the-go, context-aware assistance in the SQL composition process. mitted through web forms but many forms enable users to modify SnipSuggest aims to help the increasing population of non-expert the submitted queries or even author queries from scratch [23]. database users, who need to perform complex analysis on their There are many more examples of SQL use in science. The SQL- large-scale datasets, but have difficulty writing SQL queries. As a Share system [14], developed by the eScience institute [25] at the user types a query, SnipSuggest recommends possible additions to University of Washington (UW), allows scientists to upload their various clauses in the query using relevant snippets collected from data (e.g., in Excel files), and immediately query it using SQL. Our a log of past queries. SnipSuggest’s current capabilities include own small survey of UW scientists revealed that respondents across suggesting tables, views, and table-valued functions in the FROM the sciences are using SQL on a weekly or even daily basis. clause, columns in the SELECT clause, predicates in the WHERE SQL is thus having a transformative effect on science. Author- clause, columns in the GROUP BY clause, aggregates, and some ing SQL queries, however, remains a challenge for the vast ma- support for sub-queries. SnipSuggest adjusts its recommendations jority of scientists. Scientists are highly-trained professionals, and according to the context: as the user writes more of the query, it is can easily grasp the basic select-from-where paradigm; but to con- able to provide more accurate suggestions. duct advanced scientific research, they need to use advanced query We evaluate SnipSuggest over two query logs: one from an un- features, including group-by’s , outer-joins, user defined functions, dergraduate database class and another from the Sloan Digital Sky functions returning tables, or spatial database operators, which are Survey database. We show that SnipSuggest is able to recom- critical in formulating their complex queries. At the same time, mend useful snippets with up to 93.7% average precision, at in- they have to cope with complex database schemas. For example the teractive speed. We also show that SnipSuggest outperforms na¨ıve SDSS schema has 88 tables, 51 views, 204 user-defined functions, approaches, such as recommending popular snippets. and 3440 columns [22]. One of the most commonly used views, PhotoPrimary, has 454 attributes! The learning curve to becoming an expert SQL user on a specific scientific database is steep. 1. INTRODUCTION As a result, many scientists today leverage database manage- Recent advances in technology, especially in sensing and high- ment systems (DBMSs) only with the help of computer scientists. performance computing, are fundamentally changing many fields Alternatively, they compose their SQL queries by sharing and re- of science. By increasing the amount of data collected by orders using sample queries: the SDSS website provides a selection of of magnitude, a new method for scientific discovery is emerging: 57 sample queries, corresponding to popular questions posed by testing hypotheses by evaluating queries over massive datasets. its users [1]. Similarly, SQLShare provides a “starter kit” of SQL In this setting, spreadsheets and hand-written scripts are insuffi- queries, translated from English questions provided by researchers. cient. Consequently, despite the belief still held by many database Scientists who write complex SQL today do this through cut and researchers, scientists today are increasingly using databases and paste. The challenge with sample SQL queries is that users either SQL to meet their new data analysis needs [13, 23, 24]. have access to a small sample, which may not contain the infor- The Sloan Digital Sky Survey (SDSS) [22] is a famous exam- mation that they need, or they must search through massive logs of ple of this shift toward data-intensive scientific analytics and SQL. past queries (if available), which can be overwhelming. SDSS has mapped 25% of the sky, collecting over 30 TB of data Assisting users in formulating complex SQL queries is difficult. (images and catalogs), on about 350 million celestial objects [22]. Several commercial products include visual query building tools [4, SDSS has had a transformative effect in Astronomy not only due 7, 15, 19], but these are mostly targeted to novice users who strug- to the value of its data, but because it made that data accessible via gle with the basic select-from-where paradigm, and are not used by scientists. More recent work [26] has proposed a method for Permission to make digital or hard copies of all or part of this work for clustering and ranking relations in a complex schema by their im- personal or classroom use is granted without fee provided that copies are portance. This can be used by an automated tool to recommend not made or distributed for profit or commercial advantage and that copies tables and attributes to SQL users, but it is limited only to the most bear this notice and the full citation on the first page. To copy otherwise, to important tables/attributes. Scientists are experts in their domain, republish, to post on servers or to redistribute to lists, requires prior specific they learn quickly the most important tables. Where they truly need permission and/or a fee. Articles from this volume were invited to present help are precisely the “advanced” features, the rarely-used tables their results at The 37th International Conference on Very Large Data Bases, August 29th - September 3rd 2011, Seattle, Washington. and attributes, the complex domain-specific predicates, etc. Some Proceedings of the VLDB Endowment, Vol. 4, No. 1 new systems, such as QueRIE [8], recommend entire queries au- Copyright 2010 VLDB Endowment 2150-8097/10/10... $ 10.00. 22
2 .thored by other users with similar query patterns. These, however, table’s schema fails to reveal any useful attributes over which to are designed for users who have already written multiple queries, specify this condition. Joe suspects that he needs to join PhotoPri- and wish to see past queries that touch a similar set of tuples. mary with some other table, but he does not know which one. Joe In this paper, we take a radically different approach to the prob- thus turns to SnipSuggest for help and asks for a recommendation lem. We introduce SnipSuggest, a new SQL autocomplete system, of a table to add to his FROM clause. which works as follows. As a user types a query, she can ask Snip- SnipSuggest suggests the five most-relevant snippets Suggest for recommendations of what to add to a specific clause of for this clause: SpecObj, Field, fGetNearbyObjEq(?,?,?), her query. In response, SnipSuggest recommends small SQL snip- fGetObjFromRect(?, ?, ?, ?), and RunQA. (All the suggestions in pets, such as a list of k relevant predicates for the WHERE clause, this section are real suggestions from SnipSuggest.) k table names for the FROM clause, etc. The key contribution is in In this example, fGetNearbyObjEq is what Joe needs. There are computing these recommendations. Instead of simply recommend- several challenges with showing such a recommendation. First, the ing valid or generally popular tables/attributes, SnipSuggest pro- recommended snippet is not a table, it is a user-defined function. duces context-aware suggestions. That is, SnipSuggest considers Second, the desired tables, views, or UDFs are not necessarily pop- the partial query that the user has typed so far, when generating its ular by themselves. They are just frequently used in the context of recommendations. Our key hypothesis is that, as a user articulates the query that the user wrote so far. Finally, all recommendations an increasingly larger fragment of a query, SnipSuggest has more must be done at interactive speed for the user to remain focused. information on what to recommend. SnipSuggest draws its recom- Additionally, upon seeing a recommendation, a user can be con- mendations from similar past queries authored by other users, thus fused as to how to use the recommended snippet. To address this leveraging a growing, shared, body of experience. challenge, SnipSuggest can show, upon request, either documenta- This simple idea has dramatic impact in practice. By narrow- tion related to the suggested snippet, or real queries that use it. ing down the scope of the recommendation, SnipSuggest is able After this first step, Joe’s query thus looks as follows: to suggest rarely-used tables, attributes, user-defined functions, or SELECT * predicates, which make sense only in the current context of the par- FROM PhotoPrimary P, tially formulated query. In our experimental section, we show an fGetNearbyObjEq(145.622,0.0346249,2) n increase in average precision of up to 144% over the state-of-the-art WHERE (Figure 5(c)), which is recommendation based on popularity. Joe would now like to restrict the objects to include only those with More specifically, our paper makes the following contributions: a certain redness value. Encouraged by his early success with Snip- Suggest, instead of browsing through documentation again, he di- 1. We introduce query snippets and the Workload DAG, two rectly asks SnipSuggest for recommendations for his WHERE clause. new abstractions that enable us to formalize the context- First is the missing foreign-key join p.objId = n.objId. Once aware SQL autocomplete problem. Using these abstractions, added, SnipSuggest’s next recommendations become: p.dec<#, we define two metrics for assessing the quality of recommen- p.ra>#, p.dec>#, p.ra<#, and p.r≤#. These predicates are the most dations: accuracy and coverage (Section 3.2). popular predicates appearing in similar past queries. After a quick 2. We describe two algorithms SSAccuracy and SSCoverage for glance at p.r’s documentation, Joe picks the last option, and adds recommending query snippets based on a query log, which the following predicate to his query: p.r < 18 AND p.r > 15. This maximize either accuracy or coverage (Sections 3.2.4, 3.2.5). example demonstrates the need for the query log. With the excep- 3. We devise an approach that effectively distinguishes between tion of foreign-key joins, it is not possible to determine useful pred- potentially high-quality and low-quality queries in a log. We icates for the WHERE clause using the database schema alone. Past use this technique to trim the query log, which drastically re- queries enable SnipSuggest to select the relevant predicates among duces the recommendation time while maintaining and often the large space of all possible predicates. increasing recommendation quality (Section 3.3). Now, his query looks as follows: 4. We implement the above ideas in a SnipSuggest prototype SELECT * and evaluate them on two real datasets (Section 4). We FROM PhotoPrimary P, fGetNearbyObjEq(145.622,0.0346249,2) n find that SnipSuggest makes recommendations with up to WHERE p.objID = n.objID AND p.r < 18 AND p.r > 15 93.7% average precision, and at interactive speeds, achiev- ing a mean response time of 14ms per query. In a similar fashion, SnipSuggest can help Joe to add a second predicate (i.e., keep only objects that are stars: p.type = 6), and to write the SELECT and GROUP BY clauses. 2. MOTIVATING EXAMPLE In summary, the challenges for SnipSuggest are to (1) recom- In this section, we present an overview of the SnipSuggest sys- mend relevant features without knowledge of the user’s intended tem through a motivating scenario based on the SDSS query log. query, (2) leverage the current query context to improve the recom- Astronomer Joe wants to write a SQL query to find all the stars mendation quality, and (3) produce recommendations efficiently. 1 of a certain brightness in the r-band within 2 arc minutes (i.e., 30 th ◦ of 1 ) of a known star. The star’s coordinates are 145.622 (ra), 0.0346249 (dec). He wants to group the resulting stars by their right 3. SnipSuggest ascensions (i.e., longitudes). This is a real query that we found in SnipSuggest is a middleware-layer on top of a standard rela- the SDSS query log. Joe is familiar with the domain (i.e., astron- tional DBMS as shown in Figure 1. While users submit queries omy), but is not familiar with the SDSS schema. He knows a bit of against the database, SnipSuggest’s Query Logger component logs SQL, and is able to write simple select-from-where queries. these queries in a Query Repository. Upon request, SnipSug- It is well known that PhotoPrimary is the core SkyServer view gest’s Snippet Recommender uses this query repository to pro- holding all the primary survey objects. So, Joe starts off as follows: duce SQL-autocomplete recommendations. Finally, SnipSuggest’s SELECT * FROM PhotoPrimary. Query Eliminator periodically prunes the query log to improve rec- Joe is interested in only those objects that are near his coordi- ommendation performance by shrinking the Query Repository. We nates. Browsing through the 454 attributes of the PhotoPrimary now present these three components and SnipSuggest’s algorithms. 23
3 . New Partial Query Some FROM examples are fPhotoPrimary , representing if the Other applications Suggest Snippets PhotoPrimary table appears in the query’s FROM clause, Snippet Recommender WHERE fPhotoPrimary.objID=SpecObj.objID , representing whether the pred- Traditional DB Usage Snippet Lookup Query Logger Query Eliminator icate PhotoPrimary.objID = SpecObj.objID appears in the WHERE Log Eliminate clause, or fdistinct representing whether the distinct keyword ap- Database queries Query Repository queries pears anywhere in the query. A feature can have a clause associated FROM with it, denoted clause(f ). For example, clause(fPhotoPrimary )= Figure 1: SnipSuggest System Architecture c FROM. Through this paper, we use the notation fs to denote the 3.1 Query Logger and Repository feature that string s appears in clause c. When the Query Logger logs queries, it extracts various features D EFINITION 2. The feature set of a query q, is defined as: from these queries. Informally, a feature is a specific fragment of SQL such as a table name in the FROM clause (or view name or f eatures(q) = {f |f (q) = true} table-valued function name), or a predicate in the WHERE clause. The Query Repository comprises three relations: Queries, When SnipSuggest ‘recommends a snippet’, it is recommending Features, and QueryFeatures. Queries contains metadata about that the user modify the query so that the snippet evaluates to true FROM the query (e.g., id, timestamp, query text) and is populated using the for the query. For example, when it recommends fPhotoPrimary , it is existing infrastructure for query logging offered by most DBMSs. recommending that the user add PhotoPrimary to the FROM clause. The Features table lists each feature (i.e., SQL fragment) and the clause from which it was extracted. The QueryFeatures table lists D EFINITION 3. The dependencies of a feature f , which features appear in which queries. Appendix B outlines these dependencies(f ), is the set of features that must be in the tables’ schemas, and the features that are currently supported. query so that no syntactic error is raised when one adds f . 3.2 Snippet Recommendation e.g., dependencies(fPhotoPrimary.objID=SpecObj.objID WHERE FROM )={fPhotoPrimary FROM , fSpecObj } While a user composes a query, she can, at any time, select a SnipSuggest only suggests a feature f for a partial query q if clause, and ask SnipSuggest for recommendations in this clause. dependencies(f ) ⊆ f eatures(q). In the workload DAG, feature At this point, SnipSuggest’s goal is to recommend k features that sets have parent-child relationships defined as follows: are most likely to appear in that clause in the user’s intended query. D EFINITION 4. A feature set F2 is a successor of a feature set To produce its recommendations, SnipSuggest views the space F1 , if ∃ f where F2 =F1 ∪{f } and dependencies(f )⊆F1 . of queries as a directed acyclic graph (DAG) 1 such as that shown in Figure 2 (which we return to later). For this, it models each query as A successor of a feature set F1 is thus a feature set F2 that can a set of features and every possible set of features becomes a vertex be reached by adding a single, valid feature. in the DAG. When a user asks for a recommendation, SnipSuggest, Additionally, recommendations are based on feature popularity similarly, transforms the user’s partially written query into a set of that is captured by either marginal or conditional probabilities. features, which maps onto a node in the DAG. Each edge in the DAG represents the addition of a feature (i.e., it links together sets D EFINITION 5. Within a workload W , the marginal probabil- of features that differ by only one element). The recommendation ity of a set of features F is defined as problem translates to that of ranking the outgoing edges for the vertex that corresponds to the user’s partially written query, since |{q ∈ W |F ⊆ f eatures(q)}| P (F ) = this corresponds to ranking the addition of different features. |W | The query that the user intends to write is somewhere below the i.e. the fraction of queries which are supersets of F . As shorthand, current vertex in the DAG, but SnipSuggest does not know which we use P (Q) for P (f eatures(Q)), and P (f ) for P ({f }). query it is. It approximates the intended query with the set of all queries in the Query Repository that are descendants of the current D EFINITION 6. The conditional probability of a feature f vertex in the DAG. We refer to such queries as the potential goals given a feature set F is defined as for the partial query. For now, we assume that the set is not empty P ({f } ∪ F ) (and discuss the alternative at the end of Section 3.2.4). Given this P (f |F ) = set of potential goals, there are several ways to rank the features P (F ) that could possibly be added to the user query. We investigate two We are now ready to define the workload DAG. Let F be the set of them in this paper. The first approach is simply to recommend of all features (including those that do not appear in workload). the most popular features among all those queries. The problem with this approach is that it can easily lead to k recommendations D EFINITION 7. The workload DAG T = (V, E, w, χ) for a all leading to a single, extremely popular query. An alternate ap- query workload W is constructed as follows: proach is thus to recommend k features that cover a maximal num- ber of queries in the potential goals set. 1. Add to V , a vertex for every syntactically-valid subset of F . We now describe the problem and our approach more formally. We refer to each vertex by the subset that it represents. 2. Add an edge (F1 , F2 ) to E, if F2 is a succes- 3.2.1 Definitions sor of F1 . Denote the additional feature of F2 by We begin with the definition of features. addlFeature((F1 , F2 )) = f, where F2 = F1 ∪ {f }. D EFINITION 1. A feature f is a function that takes a query as 3. w : E → [0, 1] is the weight of each edge. The weights input, and returns true or false depending on whether a certain are set as: w((X, Y )) = P (addlF eature((X, Y ))|X). If property holds on that query. P (X) = 0, then set to unknown. 1 Note that the DAG is purely a conceptual model underlying Snip- 4. χ : V → {blue, white} is the color of each vertex. The Suggest. The user never interacts with it directly. colors are set as: χ(q) = blue if q ∈ W , otherwise white. 24
4 . {} 3.2.3 Context-Aware Algorithms 0.33 0.07 1.0 0.33 In this section, we introduce the two algorithms that SnipSuggest {fGN} v {PP} {SO} {PO} uses to recommend suggestions based on the current context (i.e., 1.0 0.0 7 1.0 1. 0 1.0 the current partial query). First, we need one more notion, and a 0.0 0.2 0.33 1.0 0.33 u 0.0 precise definition of the problem that each algorithm aims to solve. 7 {fGN,SO} {fGN,PP} {PP,PP.objID=#} {PP,SO} {PP,PO} {SO,PO} un n kn w ow 1.0 o 1.0 D EFINITION 8. Given a workload DAG and a vertex q, define: 1.0 kn n 1.0 un {fGN,SO, {fGN, PP, fGN.objID=#} fGN.objID = PP.objID} {PP,SO,PO} potential goals(q) = {v|v is blue and reachable f rom q}. ... 1.0 1.0 !"#$$$$SELECT * FROM PP %#$$$$$$SELECT * FROM PP WHERE objID=# {PP, SO, PO, {PP, SO, PO, The potential goals of q is the set of queries that could poten- &#$ $$$SELECT * FROM PP, fGN() PP.objID=SO.objID} SO.objID=PO.objID} tially be the user’s intended query, if it appears in the workload. $ $$$WHERE PP.objID = fGN.objID 1.0 !"#$$$$SELECT * FROM PP, SO, PO 1.0 Sometimes, potential goals(q) is the empty set. {PP, SO, PO, $ $$$WHERE PP.objID = SO.objID PP.objID = SO.objID, We consider two variations of the Snippet Suggestion Problem. $ $$$AND SO.objID = PO.objID SO.objID = PO.objID} Given a workload DAG G, and a partial query q, recommend a set $$$$$$$$$$$$$$$$$$$$$$$$$ Figure 2: Example of a workload DAG. of k outgoing edges, e1 , . . . , ek , from q that: Figure 2 shows an example workload DAG for 30 queries. The 1. Max-Accuracy Problem: maximizes k queries correspond to the blue nodes, and are summarized at the P (addlF eature(ei )|q) bottom. Ten are of the form SELECT * FROM PhotoPrimary, eight i=1 are SELECT * FROM PhotoPrimary WHERE objID = #, etc. For sim- 2. Max-Query-Coverage Problem: maximizes plicity, we exclude, from the figure, features in the SELECT clause, P (addlF eature(e1 ) ∨ . . . ∨ addlF eature(ek )|q) and nodes that are not reachable from the root along edges of Max-Accuracy aims to maximize the number of features in the top- weight > 0, with the exception of node u. We use the acronyms FROM FROM k that are helpful (i.e., appear in the intended query), whereas Max- fGN, PP, SO, and PO to represent ffGetNearbyObjEq , fPhotoPrimary , FROM FROM Query-Coverage aims to maximize the probability that at least one fSpecObjAll , and fPhotoObjAll , respectively. The edge ({P P }, feature in the top-k is helpful. {P P, SO}) indicates that if a query contains PhotoPrimary, there Consider the earlier example. Suppose SnipSuggest recom- is 33% chance that it also contains SpecObjAll. mends the top-2 snippets to add to the FROM clause. If the goal Every syntactically-correct partial query appears in the workload is Max-Accuracy, then it suggests SO and PO. This corresponds to DAG since there is a vertex for every valid subset of F . Consider the two outgoing edges from q, with the highest conditional prob- a partial query, and its corresponding vertex q. Given q, SnipSug- abilities. If the aim is Max-Query-Coverage, then it suggests SO gest’s goal is to lead the user towards their intended query q∗ (also a and fGN. The reasoning is as follows: if Anna’s intention is the vertex in the DAG), one snippet at a time. We assume that there is a rightmost blue query, then suggesting SO covers this case. If her path from q to q∗, i.e., that the user can reach q∗ by adding snippets intention is not that query, then rather than PO, it is better to suggest to their query. Since SnipSuggest suggests one snippet at a time, fGN because it increases the number of potential goals covered. the recommendation problem becomes that of ranking the outgo- It is infeasible to build the workload DAG as it can have up to ing edges of q. Note that recommending an edge e corresponds to 2n vertices, where n = |F |. Thus, SnipSuggest implements two recommending addlF eature(e). algorithms, which simulate traversing parts of the DAG, without For example, suppose Anna has written: SELECT * FROM ever constructing it: SSAccuracy and SSCoverage. PhotoPrimary. This puts her at vertex v in Figure 2. Then, she re- quests snippets to add to the FROM clause. At v, we see that she can 3.2.4 SSAccuracy add fGetNearbyObjEq(), SpecObjAll, or PhotoObjAll. Re- Given a partial query q and a query workload W , the goal of member, Figure 2 is not showing the whole DAG. In fact, the full the SSAccuracy algorithm is to suggest the k features with the workload DAG contains an outgoing edge from v for each of the highest conditional probabilities given q. If q’s features have ap- 342 tables, views, and table-valued functions in the SDSS schema. peared together in past queries, SSAccuracy is able to efficiently The job of SnipSuggest is to recommend the edges that are most identify the features with the highest conditional probabilities, with likely to lead Anna towards her intended query. a single SQL query over the QueryF eatures table, as shown in Figure 3. By setting m to |f eatures(q)|, the first half of the query 3.2.2 Na¨ıve Algorithms finds potential goals(q), i.e. the queries which have all the fea- We present three techniques that we compare against Snip- tures of q. It then orders all the features which appear in these Suggest in Section 4. The most na¨ıve, the Random recom- SimilarQueries, by their frequencies within this set of queries. mender, ranks the outgoing edges randomly. The second ap- Note that each qf.feature f corresponds to one outgoing edge proach, Foreign-key-based, used only for suggesting snippets from q (i.e. the edge e where addlF eature(e) = f ). Additionally, in the WHERE clause, exploits the schema information to rank if we divided count(s.query) by |potential goals(q)|, we would the features. It suggests predicates for foreign-key joins before find P (f |q). Thus, this query returns a list of edges, ordered by other predicates. The third approach, the Popularity-based tech- weight (i.e., the conditional probability of the feature given q). nique actually leverages the past workload. It considers f = What if the partial query q does not appear in the work- addlF eature(e) for each outgoing edge from q, and ranks them load? Every partial query q appears in the DAG, but it can by P (f ), the marginal probability of f . Even this simple tech- happen that all incoming edges have weight 0, and all outgoing nique, outperforms the above two algorithms by up to 449%. edges are unknown. This happens when potential goals(q) = The problem with these approaches is that they do not exploit ∅. e.g., if Bob has written q = SELECT * FROM SpecObjAll, the rich information available in the workload DAG; the weighted fGetNearbyObjEq(143.6,0.021,3), and requests suggestions in the edges can tell us which features are likely to appear in the intended FROM clause (which is represented by vertex u in Figure 2). query, given the current partial query. SnipSuggest’s algorithms In this case, SnipSuggest traverses up the DAG from q un- aim to better recommend snippets by leveraging such information. til it reaches the vertices whose marginal probability is not zero 25
5 . WITH SimilarQueries (query) AS --finds potential_goals that the problem is NP-hard. Instead of an exact solution, we pro- (SELECT query pose an approximation algorithm, SSCoverage, which is a greedy, FROM QueryFeature approximation algorithm for Max-Query-Coverage. We prove in WHERE feature IN features(q) Appendix D that Max-Query-Coverage is NP-hard and that SSCov- [AND NOT EXISTS ( --used only by SSCoverage select * from QueryFeature q erage is the best possible approximation for it. We show this by where q.query=query and q.feature in( previous))] proving that Max-Query-Coverage is equivalent to the well-known GROUP BY query Maximum Coverage problem [12]. Given a set of elements U and HAVING count(feature) = m) SELECT qf.feature --popular features among SimilarQueries a set of sets S = S1 , . . . , Sn , where each Si ∈ U , the Maximum FROM QueryFeature qf, SimilarQueries s Coverage problem is to find a subset of S of size k (fixed) such that WHERE qf.query = s.query AND qf.feature NOT IN features(q) a maximal number of elements in U are ‘covered’. Our equivalence GROUP BY qf.feature ORDER BY count(s.query) DESC proof is sufficient because it is known that the Maximum Coverage problem is NP-hard, and that the best possible approximation is the Figure 3: Finds the most popular features among queries that share greedy algorithm [12], achieving an approximation factor of 1 − 1e . m features with partial query q. NOT EXISTS clause is included for The SSCoverage algorithm proceeds as follows. To compute SSCoverage, but omitted for SSAccuracy. the first recommendation f1 , it executes the SQL query in Figure 3, with the NOT EXISTS clause and previous ← ∅. This is equiv- Algorithm 1 SnipSuggest’s Suggestion Algorithm alent to SSAccuracy’s first recommendation because the Max- Input: query q, number of suggestions k, clause c, technique t Accuracy and Max-Query-Coverage formulas are equivalent when Output: a ranked list of snippet features k = 1. For its second suggestion, SSCoverage executes the Fig- 1: i ← |f eatures(q)| ure 3 query again, but with previous ← {f1 }. This effectively 2: suggestions ← [] removes all the queries covered by f1 (i.e., potential goals(q ∪ 3: while |suggestions| < k : do {f1 })), and finds the feature with the highest coverage (i.e., condi- 4: if t = SSAcc then tional probability) in the remaining set. In terms of the workload 5: S ← execute Figure 3 SQL (m←i, exclude NOT EXISTS clause) 6: else if t = SSCov then DAG, this step discards the whole subgraph rooted at f1 , and then 7: S ← execute Figure 3 SQL (m←i, previous ← suggestions) finds the best feature among the remaining DAG. It repeats this pro- 8: end if cess k times in order to collect k features. Algorithm 1 describes 9: for all s ∈ S do SSCoverage in detail (if we pass it t = SSCov). 10: if s ∈ / suggestions and clause(s) = c then 11: suggestions ← suggestions, s 3.3 Query Elimination 12: end if All queries, correct or incorrect, are logged by the Query Logger. 13: end for This is problematic for SnipSuggest because a large workload can 14: i ← i − 1 deteriorate its response time. The Query Eliminator addresses this 15: end while 16: return suggestions problem; it periodically analyzes the most recent queries and drops some of them. The goal is to reduce the workload size, and the recommendation time, while maintaining recommendation quality. (i.e., there exists an incoming edge with weight > 0). This cor- For the Query Eliminator, we introduce the notion of a query ses- responds to finding the largest subsets of f eatures(q) that ap- sion. A query session is a sequence of queries written by the same pear in the workload. In the above example, SnipSuggest tra- user as part of a single task. The Query Eliminator eliminates all verses up to the vertices {SO} and {fGN}. Then, it suggests queries, except those that appear at the end of a session. Intuitively, the most popular features among the queries under these vertices. queries that appear near the end of the session are of higher quality, This can be achieved by executing the SQL query shown in Fig- since the user has been working on them for longer. Since many ure 3. First, SnipSuggest sets m to |f eatures(q)|, thus looking at users write a handful of queries before reaching their intended one, potential goals(q). If fewer than k features are returned, then it this technique eliminates a large fraction of the workload. We show sets m to |f eatures(q)| − 1, thus considering queries that share in Section 4.3 that the Query Eliminator reduces the response time, |f eatures(q)| − 1 features with q. It repeatedly decrements m while maintaining, and often improving, the average precision. until k features are returned. Note that SnipSuggest executes the SnipSuggest extracts query sessions in two phases (as shown in query in Figure 3 at most |f eatures(q)| times. In other words, Figure 4). First, SnipSuggest segments the incoming query log. SnipSuggest will not iterate through every subset of f eatures(q). It does so by monitoring changes between consecutive queries in Instead, it considers all subsets of size m all at once, and it does order to detect starts of new revision cycles. A revision cycle is this for m = n, n − 1, n − 2, . . . , 0, where n = |f eatures(q)|. the iterative process of refining and resubmitting queries until a This process can cause some ambiguity of how to rank features. desired task is complete. When it detects a new cycle, SnipSuggest For example, if P (f1 |{SO, f GN }) = 0.8 and P (f2 |{SO}) = labels, as query segment, the set of all queries since the beginning 0.9, it is not clear whether f1 or f2 should be ranked first. Heuristi- of the previous cycle. We call this phase segmentation. Second, cally, SnipSuggest picks f1 , because it always ranks recommenda- SnipSuggest stitches multiple segments together, if they are part of tions based on more similar queries first. Algorithm 1 outlines the a single, larger revision cycle. For example, when a user is stuck full SSAccuracy algorithm (if we pass it t = SSAcc). In Section 4, on a difficult task A, they often move to a different task B and we show that SSAccuracy achieves high average precision, and in later return to A. In this scenario, A will produce multiple query Appendix C, we describe two simple optimizations. segments, because the queries for task B will separate the later queries of A from the earlier ones. Via stitching, the segments are 3.2.5 SSCoverage concatenated together to create a large session for A. The Max-Query-Coverage problem is to suggest the features Both phases require an expert to provide some training data, in f1 , . . . , fk that maximize the probability that at least one sugges- the form of a query log with labeled sessions. SnipSuggest lever- tion is helpful. The goal is to diversify the suggestions, to avoid ages machine learning techniques to learn the appropriate thresh- making suggestions that all lead toward the same query. It turns out olds for the segmentation and stitching. We present a more detailed 26
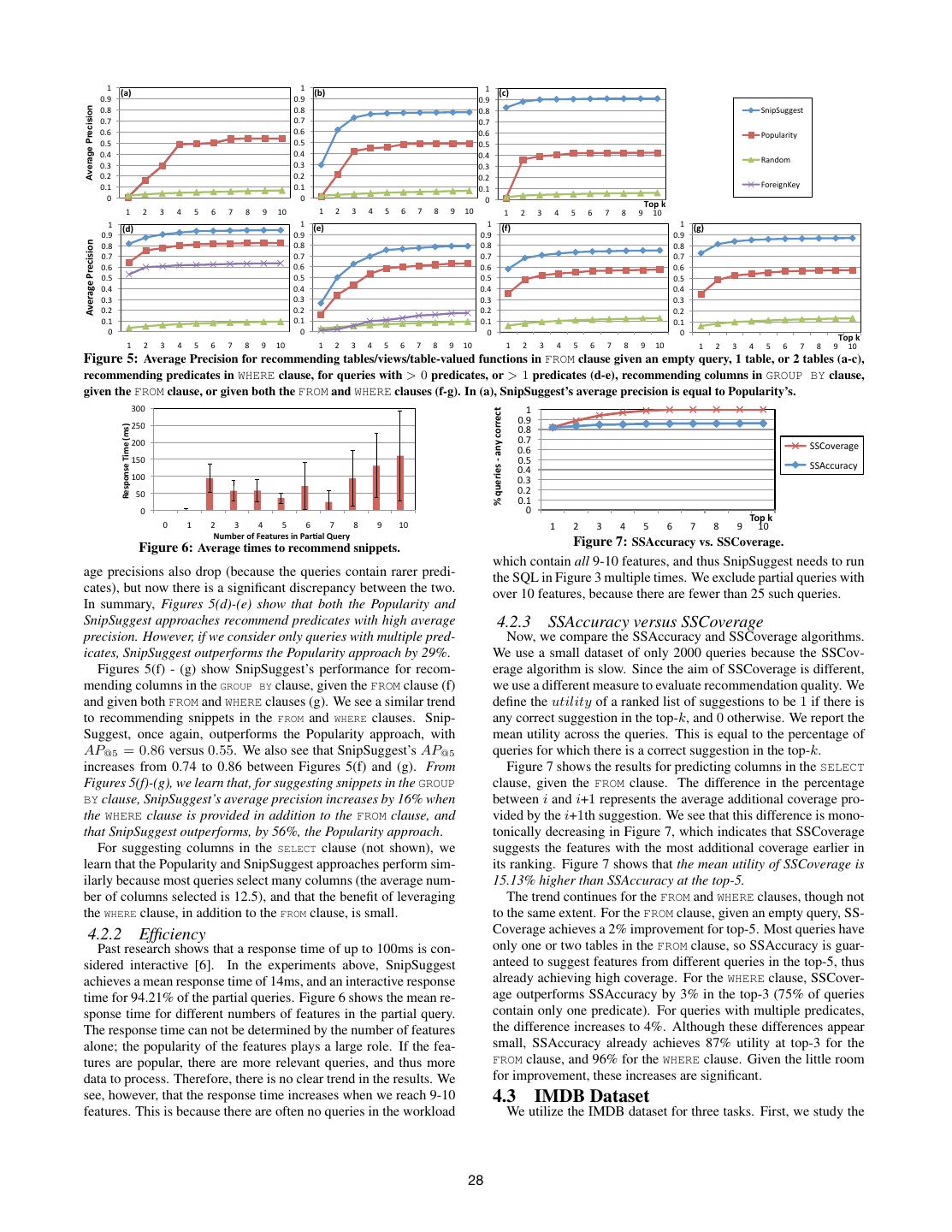
6 . (a) Query log This measure looks at the precision after each correct snippet is Segmentation included, and then takes their average. If a correct snippet is not included in the top-k, it contributes a precision of zero. The ben- (b) Session segments efit of using this approach, instead of recall or precision, is that it Stitching rewards the techniques that put the correct snippets near the top of the list. For an example, we refer the reader to Appendix G. (c) Query sessions 4.2 SDSS Dataset Figure 4: Extracting query sessions from the query log. We first evaluate SnipSuggest on the real SDSS dataset. description of the two algorithms in Appendix E. We also show 4.2.1 Quality of Recommendations that our technique is able to more accurately segment a query log We evaluate several aspects of SnipSuggest: its ability to rec- into sessions, in comparison to a time-interval-based technique. ommend relations, views and tables-valued functions in the FROM clause, predicates in the WHERE clause, columns and aggregates in 4. EVALUATION the SELECT clause, and columns in the GROUP BY clause. We evalu- We evaluate SnipSuggest over two datasets. The first consists ate only the SSAccuracy algorithm here because it is able to achieve of queries from the Sloan Digital Sky Survey. The SDSS database an interactive response time, and it is the algorithm that aims to logs all queries submitted through public interfaces including web solve the Max-Accuracy problem, which corresponds to achieving pages, query forms, and a web services API. Thus, query authors high average precision. We compare the SSAccuracy and SSCov- vary from bots, to the general public, and real scientists. We down- erage algorithms in Section 4.2.3. loaded 106 million queries from 2002 to 2009. Removing queries We do a 10-fold cross-validation, with the queries ordered ran- from bots, ill-formed queries, and queries with procedural SQL or domly; we use 90% of the queries as the past query workload and proprietary features, left us with approximately 93 million queries. test on the remaining 10%. We repeat the experiment 10 times, For our evaluation, we use a random sample of 10,000 queries, in each time selecting a different set of test queries, so that all queries which there are 49 features for tables, views and table-valued func- are part of the test set exactly once. We measure the mean average tions, 1835 columns and aggregates, and 395 predicates. precision for each of the ten experiments at top-1 through top-10. The second dataset consists of SQL queries written by stu- Figures 5(a) - (c) show the results for predicting snippets in the dents in an undergraduate database class, which were automati- FROM clause. For this experiment, we consider queries with at least cally logged as they worked on nine different problems for one three tables, views or table-valued functions in the FROM clause. Fig- assignment. All queries are over a local copy of the Internet Movie ure 5(a) shows how accurately SnipSuggest recommends snippets, Database (IMDB), consisting of five tables and 21 columns. To if an empty query is presented. It achieves the same average pre- evaluate, we use a sample consisting of ten students’ queries, which cision as the Popularity-based algorithm (and thus, SnipSuggest’s results in a total of 1679 queries. For each student, we manually la- points are not visible in the graph). This is expected, because with bel each query with the assignment problem number that it was no information, SnipSuggest recommends the most popular snip- written for, which gives us ground truth information about query pets across all queries. As soon as the user adds one table to the sessions and thus serves as training data for the Query Eliminator. query (out of three), SnipSuggest’s AP@5 jumps from 0.49 to 0.77 We aim to answer four questions: Is SnipSuggest able to ef- (nearly a 60% increase). In contrast, the other two techniques’ aver- fectively recommend relevant snippets? Does its recommendation age precisions degrade, because once we add one table to the query, quality improve as the user adds more information to a query? Can the number of correct snippets has decreased from 3 snippets per it make suggestions at interactive speeds? Is the Query Elimina- query, to only 2 snippets per query. The Popularity approach’s av- tor effective at reducing response times, while maintaining recom- erage precision, for example, drops from 0.49 to 0.46. This trend mendation quality? We evaluate the first three questions on both continues when we add two tables to the FROM clause. SnipSug- datasets. The fourth is answered on only the IMDB dataset because gest’s average precision jumps to 0.90 (an 84% increase from 0 we do not have the ground truth for the SDSS query sessions. tables), and Popularity drops to 0.42 (a 16% decrease from 0 ta- 4.1 Evaluation Technique bles). In brief, Figures 5(a)-(c) show that SnipSuggest’s average Neither query log includes “partial queries”; they only include precision improves greatly as the user makes progress in writing full SQL queries that were submitted for execution. Therefore, in the SQL query, whereas the other two techniques degrade. order to evaluate SnipSuggest on a given query, we remove some Figures 5(d) - (e) show how accurately SnipSuggest recommends portion of the query, and the task is to recommend snippets to add predicates in the WHERE clause, for queries with at least one predi- to this new partial query. We denote by f ullQuery(q), the full cate (d), and with at least two predicates (e). In our sample, 75% SQL query from which the partial query q was generated. For this of the queries have exactly one predicate, and 23% have more. We setting, we define correctness for a partial query q, and feature f . see that the Popularity approach performs well (AP@5 = 0.81). D EFINITION 9. A suggestion f is correct for partial query q if This is because all the techniques recommend only valid snippets, and only if f ∈f / eatures(q) and f ∈f eatures(f ullQuery(q)). and so the Popularity approach restricts its recommended predi- To measure the recommendation quality of SnipSuggest, we use a cates to only those which reference tables that are already in the measure called average precision [3]. It is a widely-used measure partial query, and then suggests them in popularity order. Many in Information Retrieval for evaluating ranking techniques. Snip- predicates are join predicates, but the ForeignKey approach still Suggest returns a ranked list of snippets, Lq , for query q. lags because many of the join predicates involve table-valued func- D EFINITION 10. Average precision at k for suggestions Lq is tions, and thus are not across foreign-key connections. SnipSuggest k · rel(q, Lq [i])) remains the top approach, achieving an average precision (AP@5 ) i=1 (P (q, Lq , i) AP@k (q, Lq ) = of 0.94. Once we consider the less common case, when the query |f eatures(f ullQuery(q)) − f eatures(q)| has multiple predicates, Figure 5(e) shows a larger difference be- where P (q, Lq , k) is the precision of the top-k recommendations tween the techniques. The ForeignKey technique’s performance in Lq and rel(q, Lq [i]) = 1 if Lq [i] is correct, and 0 otherwise. degrades drastically because we are now looking at mostly non- k i=1 rel(q,Lq [i]) Precision is defined as P (q, Lq , k) = k join predicates. The Popularity approach and SnipSuggest’s aver- 27
7 . $" $" $" 1)2' 1%2' 132' !#," !#," !#," !#+" !#+" Average Precision !#+" -./0-122345" !#*" !#*" !#*" !#)" !#)" !#)" 670189:/5;" !#(" !#(" !#(" !#'" !#'" !#'" <9.=7>" !#&" !#&" !#&" !#%" !#%" !#%" !#$" !#$" !#$" ?7:3/2.@3;" !" !" !" .,/'0' $" %" &" '" (" )" *" +" ," $!" $" %" &" '" (" )" *" +" ," $!" $" %" &" '" (" )" *" +" ," $!" $" $" $" $" 142' 1#2' 152' 1&2' !#," !#," !#," !#," !"#$%&#'($#)*+*,-' !#+" !#+" !#+" !#+" !#*" !#*" !#*" !#*" !#)" !#)" !#)" !#)" !#(" !#(" !#(" !#(" !#'" !#'" !#'" !#'" !#&" !#&" !#&" !#&" !#%" !#%" !#%" !#%" !#$" !#$" !#$" !#$" !" !" !" !" .,/'0' $" %" &" '" (" )" *" +" ," $!" $" %" &" '" (" )" *" +" ," $!" $" %" &" '" (" )" *" +" ," $!" $" %" &" '" (" )" *" +" ," $!" Figure 5: Average Precision for recommending tables/views/table-valued functions in FROM clause given an empty query, 1 table, or 2 tables (a-c), recommending predicates in WHERE clause, for queries with > 0 predicates, or > 1 predicates (d-e), recommending columns in GROUP BY clause, given the FROM clause, or given both the FROM and WHERE clauses (f-g). In (a), SnipSuggest’s average precision is equal to Popularity’s. &!!" !"#$%&'%(")"*+,"-.&&%-/"" $" %#!" !#," !"#$%&#"'()*"'+*#,' !#+" %!!" !#*" !#)" "--./012341" $#!" !#(" "--56672368" !#'" $!!" !#&" #!" !#%" !#$" !" !" 0.1"2" !" $" %" &" '" #" (" )" *" +" $!" $" %" &" '" (" )" *" +" ," $!" -.*/"0'%1'2"34.0"#')&'530637'8."09' Figure 6: Average times to recommend snippets. Figure 7: SSAccuracy vs. SSCoverage. which contain all 9-10 features, and thus SnipSuggest needs to run age precisions also drop (because the queries contain rarer predi- the SQL in Figure 3 multiple times. We exclude partial queries with cates), but now there is a significant discrepancy between the two. over 10 features, because there are fewer than 25 such queries. In summary, Figures 5(d)-(e) show that both the Popularity and SnipSuggest approaches recommend predicates with high average 4.2.3 SSAccuracy versus SSCoverage precision. However, if we consider only queries with multiple pred- Now, we compare the SSAccuracy and SSCoverage algorithms. icates, SnipSuggest outperforms the Popularity approach by 29%. We use a small dataset of only 2000 queries because the SSCov- Figures 5(f) - (g) show SnipSuggest’s performance for recom- erage algorithm is slow. Since the aim of SSCoverage is different, mending columns in the GROUP BY clause, given the FROM clause (f) we use a different measure to evaluate recommendation quality. We and given both FROM and WHERE clauses (g). We see a similar trend define the utility of a ranked list of suggestions to be 1 if there is to recommending snippets in the FROM and WHERE clauses. Snip- any correct suggestion in the top-k, and 0 otherwise. We report the Suggest, once again, outperforms the Popularity approach, with mean utility across the queries. This is equal to the percentage of AP@5 = 0.86 versus 0.55. We also see that SnipSuggest’s AP@5 queries for which there is a correct suggestion in the top-k. increases from 0.74 to 0.86 between Figures 5(f) and (g). From Figure 7 shows the results for predicting columns in the SELECT Figures 5(f)-(g), we learn that, for suggesting snippets in the GROUP clause, given the FROM clause. The difference in the percentage BY clause, SnipSuggest’s average precision increases by 16% when between i and i+1 represents the average additional coverage pro- the WHERE clause is provided in addition to the FROM clause, and vided by the i+1th suggestion. We see that this difference is mono- that SnipSuggest outperforms, by 56%, the Popularity approach. tonically decreasing in Figure 7, which indicates that SSCoverage For suggesting columns in the SELECT clause (not shown), we suggests the features with the most additional coverage earlier in learn that the Popularity and SnipSuggest approaches perform sim- its ranking. Figure 7 shows that the mean utility of SSCoverage is ilarly because most queries select many columns (the average num- 15.13% higher than SSAccuracy at the top-5. ber of columns selected is 12.5), and that the benefit of leveraging The trend continues for the FROM and WHERE clauses, though not the WHERE clause, in addition to the FROM clause, is small. to the same extent. For the FROM clause, given an empty query, SS- 4.2.2 Efficiency Coverage achieves a 2% improvement for top-5. Most queries have Past research shows that a response time of up to 100ms is con- only one or two tables in the FROM clause, so SSAccuracy is guar- sidered interactive [6]. In the experiments above, SnipSuggest anteed to suggest features from different queries in the top-5, thus achieves a mean response time of 14ms, and an interactive response already achieving high coverage. For the WHERE clause, SSCover- time for 94.21% of the partial queries. Figure 6 shows the mean re- age outperforms SSAccuracy by 3% in the top-3 (75% of queries sponse time for different numbers of features in the partial query. contain only one predicate). For queries with multiple predicates, The response time can not be determined by the number of features the difference increases to 4%. Although these differences appear alone; the popularity of the features plays a large role. If the fea- small, SSAccuracy already achieves 87% utility at top-3 for the tures are popular, there are more relevant queries, and thus more FROM clause, and 96% for the WHERE clause. Given the little room data to process. Therefore, there is no clear trend in the results. We for improvement, these increases are significant. see, however, that the response time increases when we reach 9-10 4.3 IMDB Dataset features. This is because there are often no queries in the workload We utilize the IMDB dataset for three tasks. First, we study the 28
8 . Task Decrease in Time Increase in AP@3 6. CONCLUSION In this paper, we presented SnipSuggest, a context-aware, SQL- FROM → WHERE 74.49% 8.12% ∅ → FROM 9.17% 4.67% autocomplete system. SnipSuggest is motivated by the growing 1 table in FROM → FROM 79.76% 0.74% population of non-expert database users, who need to perform com- 2 tables in FROM → FROM 79.47% -0.71% plex analysis on their large-scale datasets, but have difficulty with FROM → SELECT 88.87% 15.80% FROM, WHERE → SELECT 79.37% 2.72% SQL. SnipSuggest aims to ease query composition by suggesting FROM → GROUP BY 77.04% 7.11% relevant SQL snippets, based on what the user has typed so far. We FROM, WHERE → SELECT 60.91% 5.37% have shown that SnipSuggest is able to make helpful suggestions, at Table 1: The benefits and drawbacks of the Query Eliminator. interactive speeds for two different datasets. We view SnipSuggest as an important step toward making databases more usable. Query Eliminator’s effect on the response time and average pre- cision. Second, we evaluate SnipSuggest over a second dataset. 7. ACKNOWLEDGMENTS Third, we measure the Query Eliminator’s ability to correctly de- This work is partially supported by NSF Grants IIS-0627585, tect end-of-session queries. We present the results of the first task IIS-0713576, NSF CAREER award IIS-0845397, NSF CRI grant here, and the remaining two are discussed in Appendix F.2. CNS-0454425, gifts from Microsoft Research, as well as Balazin- We summarize the benefits and drawbacks of the Query Elimina- ska’s Microsoft Research New Faculty Fellowship. The authors tor in Table 1. From 1679 queries, the Query Eliminator maintains would also like to thank the reviewers for their helpful feedback. only 7%, or a total of 117 queries. The goal here is to decrease the response time, while maintaining a similar average precision. 8. REFERENCES [1] SkyServer. http://cas.sdss.org/dr6/en/. Table 1 shows that the technique decreases the response time by [2] Aqua Data Studio. http://www.aquafold.com/. up to 89%. For this dataset, it also increases the average precision [3] R. Baeza-Yates and B. Riberio-Neto. Modern Information Retrieval. (AP@3 ) for all tasks but one. Even in the worst case, the average Addison-Wesley Longman Publishing, Boston, MA, 1999. precision decreases by less than 1%! [4] BaseNow. About SQL Query Builder. www.basenow.com/help/About_SQL_Query_Builder.asp. 5. RELATED WORK [5] A. Broder. A taxonomy of web search. SIGIR Forum, 2002. There are various efforts toward making databases easier to use. [6] S. K. Card, G. G. Robertson, and J. D. Mackinlay. The information Jagadish et al. [16] present six challenges in using databases today. visualizer, an information workspace. In Proc. SIGCHI, 1991. Nandi et al. [21] present a technique for phrase autocomple- [7] T. Catarci, M. F. Costabile, S. Levialdi, and C. Batini. Visual query tion for keyword search over structured databases. Another similar systems for databases: A survey. J. of Visual Languages & tool [20] allows users to construct search queries without knowl- Computing, 8(2):215–260, 1997. [8] G. Chatzopoulou, M. Eirinaki, and N. Polyzotis. Query edge of the underlying schema. As the user types in the search recommendations for interactive database exploration. In SSDBM box, the tool starts suggesting elements of the schema, followed 2009. by fragments of text from the database content. This tool supports [9] S. Chaudhuri, G. Das, V. Hristidis, and G. Weikum. Probabilistic standard conjunctive attribute-value queries. Although both papers ranking of database query results. In Proc. VLDB, 2004. are related to SnipSuggest, they focus on keyword and key-value [10] D. Downey, S. Dumais, D. Liebling, and E. Horvitz. Understanding queries, which make the problems different from suggesting rele- the relationship between searchers’ queries and information goals. In vant snippets for a structured SQL query. CIKM, 2008. QueRIE [8] analyzes a user’s query log, finds other users who [11] D. Downey, S. T. Dumais, and E. Horvitz. Models of searching and browsing: Languages, studies, and application. In IJCAI, 2007. have executed queries over similar parts of the database, and rec- [12] U. Feige. A threshold of ln n for approximating set cover. Journal of ommends new queries to retrieve relevant data. SnipSuggest differs the ACM, 45:314–318, 1998. in several aspects. It provides assistance based on the user’s partial [13] UCSC Genome Browser. http://genome.ucsc.edu/. query, does not require the user to have written previous queries, [14] B. Howe and G. Cole. SQL Is Dead; Long Live SQL: Lightweight and only recommends small snippets at a time. Query Services for Ad Hoc Research Data. In Microsoft eScience Annotating a query with a description can increase its under- Workshop, 2010. standability, but users can not be expected to annotate every query [15] IBM. Cognos software. http://cognos.com/. they write. Koutrika et al. [17] present methods for automatically [16] H. V. Jagadish, A. Chapman, A. Elkiss, M. Jayapandian, Y. Li, translating SQL into natural language. This work is complementary A. Nandi, and C. Yu. Making database systems usable. In Proc. to ours, and we hope to extend SnipSuggest with this capability. SIGMOD, 2007. [17] G. Koutrika, A. Simitsis, and Y. Ioannidis. Explaining structured Several commercial tools aim to ease the SQL composition pro- queries in natural language. In Proc. of the 26th ICDE Conf. cess, through autocomplete for tables and columns [2], and visual [18] T. Lau and E. Horvitz. Patterns of search: analyzing and modeling querying [4, 7, 15, 19]. Similarly, SnipSuggest also supports au- web query refinement. In Proc. UM, pages 119–128, 1999. tocomplete. However, it supports autocomplete for snippets (ver- [19] MicroStrategy 9. Microstrategy. http://www.microstrategy.com. sus only table and column names [2]), and provides suggestions [20] A. Nandi and H. V. Jagadish. Assisted querying using that are context-aware. We view the visual query building work instant-response interfaces. In Proc. SIGMOD, 2007. as complementary to ours. Extending SnipSuggest with these vi- [21] A. Nandi and H. V. Jagadish. Effective phrase prediction. In Proc. sual techniques would enrich its usability. To enable such features, VLDB, pages 219–230, 2007. SnipSuggest would need the capability to map a SQL query to a [22] Sloan Digital Sky Survey. http://www.sdss.org/. state of visual query composition. [23] V. Singh, J. Gray, and A. T. A. S. Szalay. Skyserver traffic report - the first five years, 2006. Many projects mine past query logs. Most focus on keyword [24] A. Szalay and J. Gray. Science in an exponential world. Nature, search logs [5, 10, 11, 18], for goals ranging from predicting the March 23 2006. next user action to designing a taxonomy of searches. One paper [25] University of Washington eScience Institute. mines SQL query logs [9], in order to rank the result tuples of a www.escience.washington.edu. query. Though these projects are similar to SnipSuggest since they [26] X. Yang, C. M. Procopiuc, and D. Srivastava. Summarizing relational leverage query workloads, they do so for a different goal. databases. Proc. VLDB Endow., 2(1):634–645, 2009. 29
9 .APPENDIX In addition to these two tables, for the optimization of SSAc- curacy, SnipSuggest’s Query Logger also maintains the following A. SMALL-SCALE SURVEY tables: To better understand how scientists use DBMSs today and, in 1. MarginalProbs(featureID, probability) particular, how they query these databases, we carried out a small- scale, informal, online survey. Our survey included 37 questions, 2. CondProbs(feature1, feature2, probability) mostly multiple-choice ones and took about 20 minutes to com- The first table stores the marginal probability for each feature plete. We paid respondents $10 for their time. Seven scientists from across the whole workload. The second contains the conditional three domains responded to our survey (four graduate students, one probability of feature1 given feature2, for every pair of fea- postdoc, and two research scientists); these scientists have worked tures that have ever appeared together. We discuss how these tables with either astronomical, biological, or clinical databases. are used below, in Appendix C. Of interest to this paper, through this survey, we learned the fol- lowing facts. All respondents had at least one year experience us- B.2 Features Supported ing DBMSs, while some had more than three years. Three scien- The current implementation of SnipSuggest supports the follow- tists took a database course, whereas the other four were self-taught ing classes of features: DBMS users. Four participants have been working with the same 1. FTf rom for every table, view and table-valued function T dataset for over a year, while three of them acquired new datasets in the database, representing whether T appears in the FROM in the past six months. The data sets ranged in size from less than clause of the query. one gigabyte (one user), to somewhere between one gigabyte and 2. FCselect , FCwhere , and FCgroupby , for every column C in the one terabyte (five users), to over a terabyte (one user). The reported database, representing whether this column appears in the database schemas include 3, 5, 7, 10, 30, and 100 tables. One re- SELECT, WHERE, or GROUP BY clause of the query, respectively. spondent did not report the number of tables in his/her database. All select respondents reported using a relational DBMS (some used other al- 3. Faggr(C 1 ,...Cn ) , for every aggregate function and list of ternatives in addition). columns, representing whether this aggregate and list of More interestingly, three of the participants reported writing columns appear in the SELECT clause. SQL queries longer than 10 lines, with one user reporting queries 4. FCwhere 1 op C2 for every pair of columns C1 , C2 , and every oper- of over 100 lines! All users reported experiencing difficulties in ator which appears in the database, representing whether this authoring SQL queries. Two participants even reported often not predicate appears in the WHERE clause of the query. knowing which tables held their desired data. 5. FCwhere op for every column C in the database, and for every Five respondents reported asking others for assistance in com- operator, representing whether there is a predicate of the form posing SQL queries. All but one reported looking at other users’ C op constant in the WHERE clause of the query. queries. Five participants reported looking “often” or even “al- subquery subquery subquery subquery 6. FALL , FAN Y , FSOM E , FIN , and ways” at others’ queries, whereas all participants either “often” or subquery “always” look for sample queries online. Three participants men- FEXIST S representing whether there is a subquery in the WHERE clause, of the form ALL(subquery), ANY(subquery), tioned sharing their queries on a weekly to monthly basis. Finally, SOME(subquery), IN(subquery), EXISTS(subquery), respec- all but one user save their own queries/scripts/programs primarily in text files and reuse them again to write new queries or analyze tively. different data. The findings of this informal survey thus indicate that many sci- C. SSACCURACY OPTIMIZATIONS entists could potentially benefit from tools to share and reuse past SnipSuggest materializes two relations to improve the SSAccu- queries. racy algorithm’s recommendation time. The first is M arginalP robs, which contains P (f ) for every B. QUERY REPOSITORY DETAILS feature f . When the user’s partial query q is the empty query (i.e., f eatures(q) = ∅), or if q consists of only features that have never before appeared in the workload, SnipSuggest can execute B.1 Repository Schema an order by query over M arginalP robs, instead of the more The Query Repository component stores the details of all the complex SQL in Figure 3. (When q contains only unseen features, queries logged by the Query Logger, along with the features which SnipSuggest traverses up to the root vertex since it is the largest appear in each query. The Query Repository contains the following subset of q that appears in the workload. So, SnipSuggest makes three relations: its suggestions for ∅, and thus exploits M arginalP robs.) 1. Queries(id, timestamp, user, database name, query The second is CondP robs, which contains the conditional prob- text, running time, output size) ability P (f1 |f2 ) for every pair of features f1 , f2 . It is indexed on the f2 column. It is leveraged when the user’s partial query q con- 2. Features (id, feature description, clause) tains just one feature f , or it contains multiple features, but only 3. QueryFeatures(query, feature) one feature f has appeared in the workload. In these cases, Snip- Suggest can execute a simple query over CondP robs with filter The first relation, named Queries, stores the details of each logged f2 = f , and order by the conditional probability, instead of execut- query. The second relation, Features, consists of all the fea- ing the slower SQL in Figure 3. tures that have been extracted from these queries. Note that fea- ture descriptions are parameterized if there is some constant in- volved (e.g., the predicate PhotoPrimary.objID = 55 is trans- D. Max-Query-Coverage PROBLEM lated into the parameterized predicate PhotoPrimary.objID = In this section, we show that the Max-Query-Coverage problem #). Finally, the third table, QueryFeatures, maintains the infor- is NP-hard, and that the SSCoverage algorithm is the best possible mation about which feature appears in which query. approximation algorithm for it (up to lower order terms). 30
10 . Remember, the Max-Query-Coverage problem, as presented in mapped to an instance of the Max-Query-Coverage problem, and Section 3.2.3, is defined as follows. Given a workload DAG G and that there is a bijection between the set of solutions to each. Second, a partial query q, recommend a set of k outgoing edges, e1 , . . . , ek , we show the reverse. from q that maximizes Consider an instance I1 of the Maximum Coverage Problem, where U is the set of elements and S = S1 , . . . , Sm is the col- P (addlF eature(e1 ) ∨ . . . ∨ addlF eature(ek )|q) lection of sets. We translate I1 into an instance I2 of the Max- For shorthand, denote by fi the feature addlF eature(ei ). To make Query-Coverage problem as follows. U is the set of queries, S is our next step easier, we want to show that the features f1 , . . . , fk the set of features. Denote by fT the feature that corresponds to the that maximize the formula above are the ones that maximize the set T . T represents the set of queries which contain the feature fT . number of queries covered, under the q vertex. For a given element/query q ∈ U , f eatures(q) = {fT : q ∈ T }. Consider P (f1 ∨ . . . ∨ fk |q). If we select some random query The input partial query is the empty query, and so the problem is to whose feature set is a superset of f eatures(q) (i.e. any query in suggest the top-k features given the empty query. Next, we show potential goals(q)), then this is the probability that it also has that there is a bijection between the solutions for I1 and I2 . feature f1 , f2 , . . ., or fk . So, P (f1 ∨ . . . ∨ fk |q) can be written as: Given any solution S = {S1 , . . . , Sk } to I1 (not necessar- ily an optimal solution), the equivalent solution in I2 is to sug- gest the features F = {fS1 , . . . , fSk }. Of course, conversely, P r(f1 ∨ . . . ∨ fk |q ∧ u) · P r(u|q) given a solution F = {f1 , . . . , fk } to I2 , the equivalent in I1 is u∈potential goals(q) S = {Si : fSi ∈ F }. Clearly, the number of elements of U P r(f1 ∨ . . . ∨ fk |q ∧ u) is 1 if u contains f1 , f2 , . . ., or fk , and covered by S is the same as the number of queries covered by F 0 otherwise (because q does not contain any of f1 , . . . , fk either). (which is the mass covered by F multiplied by |W |). Hence this is equal to: Now, consider an instance I1 of the Max-Query-Coverage prob- lem, where the query workload is W , the set of all features is P r(u|q) F , and the partial query is q. We translate this into the Maxi- u∈potential goals(q):(f1 ∈u∨...∨fk ∈u) mum Coverage Problem as follows. First, scan through W to find potential goals(q) (i.e., all the blue vertices under q). For each Therefore, we can now rewrite the Max-Query-Coverage prob- potential goal q , if it is a leaf node, add P (q ) × |W | elements to lem to maximize: U . If it is not a leaf, add (P (q ) − f ∈F P (q ∪ {f })) × |W | el- k ements. This represents the number of queries in the workload that P (v|q), where U = potential goals(q ∪ {fi }) have exactly this set of features. Note that the number of elements v∈ U i=1 added to U is at most the number of queries in W . Add to S, one Next, we define the Maximum Coverage Problem. The problem set per feature f ∈ F , consisting of all queries that contain f . Let’s is known to be NP-hard [12]. denote this by queries(f ). Given any solution F = {f1 , . . . , fk } to I1 (not necessar- D EFINITION 11. Given a set of elements U , a number k and a ily optimal), the equivalent solution in I2 is to select the sets set of sets S = S1 , . . . Sn , where each Si ⊆ U , the maximum S = {queries(f1 ), . . . , queries(fk )}. Conversely, a solution coverage problem is to find a subset of sets S ⊆ S such that S = {S1 , . . . , Sk } to I2 can be translated to the following solu- |S | ≤ k and the following is maximized: tion for I1 : F = {fi : queries(fi ) = Si }. If we consider the number of queries covered by F , this is equal to the number of | Si | elements of U covered by S . Si ∈S We have successfully shown that we can translate an instance i.e., the number of elements covered is maximized. of the Maximum Coverage Problem into an instance of the Max- Query-Coverage problem, and the reverse, in time polynomial in In his paper [12], Feige proves the following theorem. |W |. We’ve also shown that given an instance of one problem, and its corresponding instance in the other, there is a bijection between T HEOREM D.1. The maximum coverage problem is NP-hard to the solutions for the two instances. approximate within a factor of 1 − 1e + , for any > 0. Moreover, the greedy algorithm achieves an approximation factor of 1 − 1e . The analysis of the greedy algorithm was well-known, E. QUERY ELIMINATION: DETAILS and is reproved in Feige’s paper [12]. In this section, we describe the segmentation and stitching al- We prove our results by showing Max-Query-Coverage’s equiv- gorithms in more detail. The two algorithms extract query ses- alence to the Maximum Coverage Problem. sions from the query log, then the Query Eliminator eliminates all queries except those that appear at the end of a session. Using this T HEOREM D.2. The Max-Query-Coverage is equivalent to the technique, the Eliminator aims to dispose of a large fraction of the Maximum Coverage problem. queries, while maintaining the high-quality ones. The goal of the segmentation phase is to take a pair of consecu- In particular, there are polynomial time reductions between the tive queries P , Q, and decide whether the two queries belong to the two problems, which preserve the values of all solutions. With this same query session or not. The algorithm proceeds in three steps. theorem, and the known results described above, we can conclude First, it constructs the Abstract Syntax Tree (AST) for each query that Max-Query-Coverage is NP-hard to approximate within any and transforms it into canonical form, which includes, for exam- factor substantively better than 1− 1e , and that SnipSuggest’s greedy ple, removing any constants, and alphabetically ordering the list of algorithm, SSCoverage, achieves this bound. tables in the FROM clause (this process is also used by the Query P ROOF OF T HEOREM D.2. We show two mappings. First, we Logger). Second, it extracts a set of segmentation features from P show that an instance of the Maximum Coverage Problem can be and Q as well as extra information such as timestamps of queries 31
11 .and the query output of the preceding query P . Unlike SnipSuggest 1.0 features, the segmentation features capture the difference between two queries. Some examples include the time interval between the 0.8 queries, the cosine similarities between their different clauses, and the relationship between ASTs. In the third step, using these seg- 0.6 Precision mentation features, our technique uses a perceptron-based classifi- cation algorithm to decide whether the queries belong in the same 0.4 segment. For this final step, as training data, SnipSuggest requires some labeled data in the form of queries labeled with the identifier 0.2 SnipSuggest of the task that the queries are intended for. Time-‐interval The most significant segmentation feature is AST inclusion type. 0.0 This feature represents whether the relationship between the two 0.0 0.1 0.2 0.3 0.4 0.5 0.6 Recall 0.7 0.8 0.9 1.0 queries’ ASTs is the Same, Add, Delete, Merge, Extract or None. This feature captures the following intuition. Within a query seg- Figure 8: Average precision-recall for the Query Eliminator algorithm ment, the user incrementally adds or removes terms from the query versus the time interval based algorithm. after seeing the query result of the previous query. Such incremen- tal edits are captured by the values Same, Add, or Delete. Oc- casionally, the user may introduce a subquery written in the past or copied from some sample query to compose a more complex F. EVALUATION OVER IMDB DATASET query. The user may also pull-out a subquery to debug or analyze unexpected results. In both these cases, the user may start to work F.1 Recommendation Quality towards a different purpose when the change involves subqueries; First, for SnipSuggest’s recommendation quality over this this signals a new query segment. Merge and Extract captures dataset, we saw similar patterns to the SDSS dataset. Namely, the such changes involving subqueries. Table 2 summarizes these five SnipSuggest approach outperforms the other approaches (e.g., by AST inclusion types. 5 to 20% in average precision in the top-3, in comparison to the Although the AST inclusion type may be a strong indicator of Popularity approach), and the recommendation quality improves as continuing or breaking a query segment, it does not capture the the user gives more information (e.g., if there are no tables in the amount of change. Thus, the other segmentation features that we FROM clause, SnipSuggest is able to recommend a correct table with described above, which capture the degree of change, are necessary 0.62 average precision in the top 2, which increases to 0.91 after a for better accuracy. table is added). Although, the general trends still hold, the benefit of the SnipSuggest approach is less significant in the IMDB dataset simply due to the magnitude difference in the schema size (and thus Label Description Expect a new segment? the number of possible features). This schema consists of only five Same Q is canonically the same as Q No tables and 21 columns. Add Q is based on P and has more terms No Delete Q is based on P and has fewer terms No Merge P is a subquery of Q Yes F.2 Query Eliminator Accuracy Extract Q is a subquery of P Yes We study the session extraction accuracy for only the IMDB None All other types of changes Unknown dataset. We were able to manually label the session information for this dataset because we have the ground truth in the form of Table 2: Summary of AST inclusion type. Each feature value has problem numbers from the course assignment. In other words, we an expected decision on segmentation discussed in the text. P and Q can determine which problems (from the assignment) that queries denote preceding query and following query, respectively. are written for. Query segments are useful because of the coherency among the F.2.0.1 Segmentation. queries in the same segment. However, in order to extract more To quantify the segmentation algorithm’s performance, we mea- complete query sessions, SnipSuggest often needs to stitch together sure the precision and recall with which it identifies segment multiple segments. boundaries. We compare its performance against using only the The stitching phase tests whether two segments create a single time interval between queries. The time interval technique is a revision cycle, smooth transitions via small changes, when they are common method for extracting sessions from web search logs [5, concatenated in time order. To perform stitching, SnipSuggest iter- 10, 11, 18]. The procedure is to set a threshold for the time inter- ates over each segment s in the input and all its time-wise successor val, say 30 minutes, and consider a query to be part of a new session segments. It runs the core of the segmentation algorithm between if the time interval between it and the last query is more than the the last query of s and the first query of a time-wise successor seg- threshold. ment t, with a modification. Since SnipSuggest is now considering Figure 8 shows the average precision-recall for the two different segments that are separated by multiple segments, the time interval segmentation algorithms. We show the average results across 10- between the queries becomes less meaningful. Thus, the algorithm fold cross validation. Overall, for SnipSuggest’s approach, the area treats the time interval as a missing attribute. Then, if the segmenta- under the curve is 0.930. It is only 0.580 for the time-interval based tion algorithm outputs that the last query of s and the first query of technique. Our approach significantly outperforms the time-based t belong in the same segment and this does not contradict to value segmentation technique. of AST inclusion type, SnipSuggest concatenates the two segments. In Appendix F.2, we show that the Query Eliminator is able to F.2.0.2 Stitching. accurately perform segmentation and stitching for a workload of As mentioned above, the most significant segmentation feature queries written over the movie database. for session extraction, is what we call the AST inclusion type. 32
12 . Threshold µ µ+σ µ + 2σ ∞ gested the following snippets, in this order: PhotoPrimary, Precision 0.707 0.656 0.628 0.578 SpecObjAll, fGetNearbyObjEq(), PhotoObjAll, Columns. Recall 0.801 0.893 0.934 1.000 Consider the following table, which will help us calculate the F-measure 0.751 0.756 0.751 0.733 Average Precision of these suggestions. # of Edges 714 896 993 1165 Table 3: Precision-recall of stitched edges for different thresholds. Rank Suggestion Correct? Precision 1 PhotoPrimary true 1.0 2 SpecObjAll false 0.5 This feature represents whether the relationship between the two 3 fGetNearbyObjEq() true 0.67 queries’ ASTs is the Same, Add, Delete, Merge, Extract or None 4 PhotoObjAll false 0.5 (as defined in Table 2). We said that two queries are in the same 5 Columns false 0.4 session if this feature has a value of Same, Add, or Delete, with some threshold on the amount of change. We examine how this The P recision column at rank i indicates the precision of the threshold can affect the performance of the stitching algorithm. Ta- first i snippet recommendations. With this table, we collect the ble 3 shows the results. µ is the mean difference amount in the ranks where the suggestion is correct. In this example, these are training data, among those queries that lie on a session boundary, ranks 1 and 3. Then, we take the sum of the precisions at these while σ is the standard deviation. We see that, as expected, smaller ranks and divide by two (i.e., the number of ground truth features). thresholds yield better precision while larger thresholds yield bet- For this example, the Average Precision is (1.0+0.67) 2 = 0.83. ter recall. The F-measure, however, remains approximately con- Note how this measure rewards correct suggestions that appear stant. The mean threshold already recalls 80% of session bound- early in the ranking more than those that appear later. For exam- aries, while achieving a precision of 70.7%. ple, if fGetNearbyObjEq() had appeared second in the ranking, then the average precision would be (1.0+1.0) 2 = 1.0. Whereas if G. EXAMPLE OF AVERAGE PRECISION fGetNearbyObjEq() appeared fourth in the ranking, the Average In this section, we present a toy example of the Average Pre- Precision would be (1.0+0.5) 2 = 0.75. cision measure in action. The aim is to give the reader a better Now, suppose Carol’s intended query also includes the RunQA ta- understanding of Average Precision. ble, but that SnipSuggest still suggests the same recommendations Suppose that Carol has an empty query, and has requested the as listed above. In this case, the Average Precision drops down top-5 suggestions for the FROM clause. Her intended query in- to (1.0+0.67) = 0.56. We divide by 3 (instead of 2) because the 3 cludes two snippet features in the FROM clause: PhotoPrimary number of ground truth features is now 3. and fGetNearbyObjEq(). Suppose that SnipSuggest has sug- 33
3秒后跳转登录页面
去登陆

