















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Approximating Aggregates with Distribution Precision Guarantee
In many cases analysts require the distribution of (group, aggvalue) pairs in the estimated answer to be guaranteed within a certain error threshold of the exact distribution. Existing AQP techniques are inadequate for two main reasons. First, users cannot express such guarantees. Second, sampling techniques used in traditional AQP can produce arbitrarily large errors even for SUM queries. To address those limitations, we first introduce a new precision metric, called distribution precision, to express such error guarantees. We then study how to provide fast approximate answers to aggregation queries with distribution precision guaranteed within a user specified error bound.
展开查看详情
1 . Sample + Seek: Approximating Aggregates with Distribution Precision Guarantee ∗ Bolin Ding1 Silu Huang2 Surajit Chaudhuri1 Kaushik Chakrabarti1 Chi Wang1 1 Microsoft Research, Redmond, WA 2 University of Illinois, Urbana-Champaign, IL {bolind, surajitc, kaushik, chiw}@microsoft.com, shuang86@illinois.edu ABSTRACT example, data analysts in a retail enterprise slice and dice their sales Data volumes are growing exponentially for our decision-support data to understand the sales performance along different dimen- systems making it challenging to ensure interactive response time sions like product and geographic location with a varying set of fil- for ad-hoc queries without increasing cost of hardware. Aggrega- tering conditions. Interactive query response time is critical in such tion queries with Group By that produce an aggregate value for data exploration; studies in human-computer interaction show that every combination of values in the grouping columns are the most the analyst typically loses the analysis context if the response time important class of ad-hoc queries. As small errors are usually tol- is above one second [26]. Unfortunately, as data volume (i.e., num- erable for such queries, approximate query processing (AQP) has ber of rows) and complexity of filtering conditions increase (e.g., the potential to answer them over very large datasets much faster. arbitrary user-given logical expression on multiple dimensions), the In many cases analysts require the distribution of (group, aggvalue) response time to answer such queries becomes longer unless addi- pairs in the estimated answer to be guaranteed within a certain er- tional hardware resources are leveraged. Is it possible to fend off ror threshold of the exact distribution. Existing AQP techniques the need for additional resources by leveraging the fact that “small” are inadequate for two main reasons. First, users cannot express errors are acceptable for such exploratory queries? such guarantees. Second, sampling techniques used in traditional For arbitrary SQL queries, it is hard to take advantage of the AQP can produce arbitrarily large errors even for SUM queries. To flexibility of answering queries with “small” errors, because of the address those limitations, we first introduce a new precision met- difficulty of defining “error” in an easy-to-understand manner. For- ric, called distribution precision, to express such error guarantees. tunately, there is a very important class of queries for which we can We then study how to provide fast approximate answers to aggre- both crisply formalize the notion of “small” errors and take advan- gation queries with distribution precision guaranteed within a user- tage of this flexibility in bringing down response time using approx- specified error bound. The main challenges are to provide rigorous imate query processing (AQP) techniques. A query in this class is a error guarantees and to handle arbitrary highly selective predicates SQL query with aggregation on a few measure attributes (e.g., sales without maintaining large-sized samples. We propose a novel sam- and population) along with a filter predicate and a group-by oper- pling scheme called measure-biased sampling to address the former ator (see Section 2.1). Such aggregation queries are very common challenge. For the latter, we propose two new indexes to augment in OLAP and many business intelligence (BI) applications. in-memory samples. Like other sampling-based AQP techniques, Limitations of existing AQP systems. For many tasks, analysts our solution supports any aggregate that can be estimated from ran- require the returned distribution of (group, aggvalue) pairs to be dom samples. In addition to deriving theoretical guarantees, we within a certain error threshold of the exact distribution. Suppose conduct experimental study to compare our system with state-of- the analyst wants to visualize the (group, aggvalue) pairs using a the-art AQP techniques and a commercial column-store database pie-chart. She would require the error between the two distributions system on both synthetic and real enterprise datasets. Our system to be small such that the pie-chart based on the returned answer is provides a median speed-up of more than 100x with around 5% similar to that based on the exact answer in terms of relative areas distribution error compared with the commercial database. for the different groups. Existing sampling-based AQP systems, e.g., in [3, 12, 7, 5], fall short in such tasks for two main reasons: • Inadequate semantics of precision metrics: Confidence inter- 1. INTRODUCTION val (CI) [3, 5] used by existing AQP systems are inadequate to Enterprises are collecting large volumes of data and are increas- express the above guarantees. A 90% confidence interval CI = ingly relying on analysis of the data to drive their businesses. For [est − w, est + w] means that, informally, with 90% probability (pre-sampling), the resulting CI covers the true value, where est is ∗Work done while visiting Microsoft Research the estimated value for a group [22]. CI-based techniques measure the error for each group independently, but not for the entire distri- Permission to make digital or hard copies of all or part of this work for personal or classroom use is granted without fee provided that copies are not made or distributed bution: a 90% CI for every group does not mean they are correct for profit or commercial advantage and that copies bear this notice and the full citation for all groups at the same time with 90% probability. What we on the first page. Copyrights for components of this work owned by others than the seek is a precision metric that captures errors across groups. While author(s) must be honored. Abstracting with credit is permitted. To copy otherwise, or republish, to post on servers or to redistribute to lists, requires prior specific permission mean squared (relative) error (MSE) [12, 7] provides another alter- and/or a fee. Request permissions from permissions@acm.org. native to measure precision, MSE can be estimated after the query SIGMOD’16, June 26-July 01, 2016, San Francisco, CA, USA has been evaluated but cannot be guaranteed in advance. c 2016 Copyright held by the owner/author(s). Publication rights licensed to ACM. • Unbounded (data-dependent) errors: Consider a SUM query. For ISBN 978-1-4503-3531-7/16/06. . . $15.00 a sample Sm of m rows drawn from n rows (in one group) on the DOI: http://dx.doi.org/10.1145/2882903.2915249 679
2 . ID C1 C2 C3 M C1 = 0 aggregates, which are central to many BI tasks. We also describe 1 0 0 0 1 how our techniques are extended for queries with foreign-key joins ... 0 0 0 1 39% on multiple tables, and a large class of predicates and aggregates. 90 0 0 0 1 61% Our approach, referred to as sample+seek is driven by several 91 0 1 0 10 key insights. First, we want to find a way to capture precision of ... 0 1 0 10 C1 = 1 the entire distribution across groups. To address this issue, we in- 100 0 1 0 10 troduce the notion of distribution precision. Second, we assert that 101 1 0 0 1 (b) Distribution answer AQP is not effective with unbounded data-dependent errors, as il- ... 1 0 0 1 lustrated in Example 1.1. Therefore, we must look beyond tradi- 198 1 0 0 1 tional uniform/stratified sampling-based techniques to find an ef- 15% 66% 199 1 0 0 100 85% fective sampling schema aided by indexes if necessary, which is 200 1 0 1 100 34% not subject to unbounded errors and able to deal with a large class (a) Example table T : rows 1- of queries, including those with highly selective predicates. To ad- 90 / 91-100 / 101-198 have the (c) Case I (d) Case II dress the second issue, we introduce a combination of novel sam- same dimension values pling strategy (measure-biased sampling) and indexes (measure- Figure 1: Table and Answer to aggregation query augmented inverted index and low-frequency group index). We de- √ scribe these three key aspects of our framework below. measure attribute, the CI width is proportional to std(Sm )/ m • Precision metric. We propose to use, distribution precision, to [16, 5] for uniform sampling and stratified sampling – std(Sm ) is measure the precision of the entire distribution over all groups (as the sample standard deviation on the measure attribute. In√particu- opposed to the precision of individual groups) and to allow the ana- lar, for SUM, the 90% CI width is w ≈ 1.65n · std(Sm )/ m (the lyst to express the desired guarantees. Distribution precision is de- constant 1.65 is determined by the confidence level 90% and cen- fined to be the L2 distance between normalized distributions of the tral limit theorem). This result has a profound implication. Since approximate answer and the exact one. In Example 1.1, the distri- std(Sm ) depends on data and can be arbitrarily large, the CI width bution answer x = 0.39, 0.61 . And if we give an can be arbitrarily large. As a consequence, it is not possible to √approximation ˆ = 0.40, 0.60 , their L2 distance is x− x x ˆ 2 = 0.012 + 0.012 support AQP with a user-specified error bound in many situations. = 0.014. The analyst specifies the value of a single parameter, We illustrate the above drawbacks using an example. error upper bound , and our system guarantees to produce an ap- proximation x ˆ s.t. with high probability (e.g., 0.9), x − x ˆ 2≤ . E XAMPLE 1.1. Consider a table T with C1 (state), C2 (prod- • Measure-biased sampling. We address the challenge of avoid- uct), C3 (customer group), a measure M (sales), and 200 rows, in ing data-dependent error bound by developing a novel sampling Figure 1(a). An analyst wants to find sales number per state with scheme called measure-biased sampling. The insight is to pick Q: SELECT C1 , SUM(M ) FROM T GROUP BY C1 . a row with probability proportional to its value on the measure The answer is a set of (group, aggvalue)-pairs: {(C1 = 0, 190), attribute. For SUM-queries without predicates, we show that a (C1 = 1, 298)}. We can normalize the answer as a distribution x measure-biased sample of O 1/ 2 rows suffices to give answers = 190/488, 298/488 = 0.39, 0.61 (pie-chart in Figure 1(b)). under our distribution precision guarantee with errors independent Suppose a sample of 20 rows are drawn uniformly from T to an- of the (sample) standard deviation of measure values. swer Q. With high chance, 9 rows from rows 1-90 with M = 1 and • Indexes for selective predicates. Large samples have to be main- 1 row from rows 91-100 with M = 10 are picked for the first group tained to handle queries with highly selective predicates. We ad- (C1 = 0). For the second group (C1 = 1), there are two cases with dress this challenge by building two auxiliary indexes, measure- high probability. Case I: when exactly one of rows 199 and 200 is augmented inverted index and low-frequency group index, to aid in the sample, the answer is estimated as {(C1 = 0, 19/0.1), (C1 = in-memory samples. For selective predicates, we identify rows that 1, 109/0.1)}, which can be normalized as 19/128, 109/128 = satisfy the predicate by looking up these two indexes instead of 0.15, 0.85 (pie-chart in Figure 1(c)). Case II: when neither of maintaining prohibitively large samples in memory. The insight is rows 199 and 200 is taken, the answer is estimated as {(0, 19/0.1), that since we need to lookup rows only for highly selective predi- (1, 10/0.1)} and normalized as 19/29, 10/29 = 0.66, 0.34 cates, we need very few data accesses to guarantee the distribution (pie-chart in Figure 1(d)). This shows that uniform sampling can precision. In particular, we need at most O 1/ 2 random I/O’s to produce large errors. Stratified sampling in [5, 3] and small group answer selective queries under our precision guarantee. sampling in [7] cannot help here. They use different sampling rates Extensibility. Our solution enjoys the same degree of extensibility for groups of different sizes. But the two groups in the answer to Q as other sampling-based AQP techniques (e.g. [7, 5]) do and thus have the same size. These techniques end up with drawing uniform supports a range of aggregate functions like AVG, STDEV, and samples from each group, and suffer from the same issue. COUNT(DISTINCT ·). Specialized summaries like views [6], As mentioned √ above, for SUM, we have the CI width w = 1.65n· data cube [18], and histograms [17] do not have such extensibil- std(Sm )/ m. For the second group in the above (C1 = 1), the ity. Our solution can be easily extended for foreign key joins in a true value is 298. In Case I, we have est = 1090, and w ≈ 1470 star/snowflake schema. The predicates we can handle range from – CI correctly covers the true value but is too wide as std(Sm ) is (dis)conjunctions of constraints on categorical dimensions to range large. In Case II, we have est = 100, and w = 0 (as std(Sm ) = constraints and arbitrary AND-OR logical expressions of them. 0), which does not cover the true value. In both cases, it is difficult Our experiments show that compared to the state of the art AQP to guarantee the error to be within a user-given threshold. systems, our sample+seek solution provides answers with equal or less error in orders of magnitude faster response time. Contributions. In this paper, we build an AQP system to answer aggregation queries with interactive speed that addresses the above Organization. Section 2 introduces the class of aggregation queries two limitations. It processes aggregation queries with precision our system can handle and formalizes our distribution precision of answers guaranteed within a user-given error bound. We first guarantee. Section 3 overviews our sample+seek approach and focus on queries on single table with predicates and COUNT/SUM system architecture. Details about the “sample” part, i.e., how to 680
3 .construct and utilize uniform and measure-biased samples, is intro- distribution answer xˆ= x ˆ1 , . . . , x ˆr . We propose to measure the duced in Section 4, and the “seek” part, i.e., auxiliary indexes, is in ˆ using the L2 (Euclidean)-distance between x and x error in x ˆ , i.e., r Section 5. Section 6 discusses extensions of our approach. Exper- x−x ˆ 2 = i=1 (xi − x ˆi )2 . For the ease of understanding, imental study is reported in Section 7, followed by related work in we can rephrase x − x ˆ 2 in words as follows: Section 8 and conclusion in Section 9. Proofs of most non-trivial group i’s value estimated group i’s value 2 theorems and additional experiments are in the appendix. − . (2) total group value total est. group value group i 2. PRELIMINARIES Our system allows users to specify an error bound which is We first define the class of queries that we focus on, and formal- independent on both the query Q and the data distribution in table ize the precision guarantee our system offers for query answers. T . The estimated answer x ˆ is called an -approximate answer or -approximation of the true distribution answer x if x − x ˆ 2≤ . 2.1 Single-Block Aggregation Queries System task and precision guarantee. Our AQP system processes T (D1 , . . . , DdC , M1 , . . . , MdM ) is a table with dC + dM dimen- single-block aggregation queries and promises -distribution preci- sions. D1 , . . . , DdC are group-by and predicate dimensions and sion guarantee: that is, for a user-specified error bound , our sys- M1 , . . . , MdM are measure attributes. Types of dimensions are de- tem can produce an estimated answer x ˆ for any given single-block fined by data owner. A column can be both a group-by/predicate aggregation query Q, s.t. xˆ must be an -approximation of the exact dimension and a measure at the same time in different queries. answer x to Q, i.e., x − x ˆ 2 ≤ , with high probability. For a row t ∈ T , let tD and tM be the values of dimension D As discussed in Section 1, compared to CI, our distribution pre- and measure M on this row, respectively, and tID denote the ID of cision guarantee based on L2 -distance is more rigorous, easier to a row. Let |T | = n be the number of rows in T . be interpreted, and has only one parameter that consistently mea- Table aggregation queries. For the ease of explanation, we first sures how two answers differentiate globally. focus on queries in the form of Q(G, F (M ), P), called table ag- Another good property of our guarantee is: maxi |xi − x ˆi | ≤ gregation queries, on a single table T to introduce our techniques: x−x ˆ 2 ≤ . It says that, when -distribution precision guarantee holds, the max of errors |xi − x ˆi | for all groups is also bounded by SELECT G, F (M ) FROM T WHERE P GROUP BY G. (1) , with high probability. It implies that the order of groups or the • Group-by dimensions G ⊆ {D1 , . . . , DdC } are a subset of di- top-k groups derived from x ˆ can be wrong by at most . mensions of T on which rows are aggregated on. • Aggregate measure F (M ) is COUNT(∗) or SUM(M ) where 3. SYSTEM OVERVIEW M ∈ {M1 , . . . , Mm } is a measure attribute. We give an overview of our solution in Section 3.1, including • Predicate P consists of equality constraints on categorical di- sample/index building and aggregation query processing, and sum- mensions {D1 , . . . , DdC }, in the form of “Di = vi ”. P is an marize the main theoretical results we obtain. In Section 3.2, we AND-OR expression of multiple such constraints. introduce the architecture of our system. For simplicity of discussion, we assume that values of a measure M 3.1 Overview of Our Approach are non-negative when presenting our techniques. How to handle To tackle the inherent deficiency of sampling-based approach measures with negative values will be introduced in Section 6.1 . when handling queries with very selective predicates, we propose Single-block aggregation queries. Our techniques can be extended a novel sample+seek framework. We classify queries into large for a more general class, single-block aggregation queries, which queries and small queries based on how many rows satisfy the generalizes the class of table aggregation queries in three aspects: i) predicates. For large queries, with many rows satisfying their pred- (schema) to support foreign key joins on a star/snowflake schema; icates, we are able to collect enough number of rows satisfying ii) (predicates) to support range constraints on numeric dimen- their predicates from a uniform sample or a new sample designed sions and arbitrary AND-OR logical expressions P of equality con- for SUM aggregates, called measure-biased sample, to obtain - straints and range constraints; iii) (aggregates) support more ag- approximate answers. For small queries, random samples are not gregates, e.g., AVG(M ), STDEV(M ), and COUNT(Distinct M ). sufficient, so we propose two new index structures, called measure- We introduce how our system handles the above extensions in Sec- augmented inverted index and low-frequency group index, to eval- tion 6.2. The class of aggregates supported by us is the same as the uate them for -approximations using index seeks. class supported by state of the art AQP systems like BlinkDB [5]. Answers and distributions. An output to an aggregation query Q 3.1.1 Classification of Queries is a set of (group, value)-pairs, {(g1 , z1 ), (g2 , z2 ), . . . , (gr , zr )}, We classify queries using (measure) selectivity into large queries where r is the number of distinct values on the product of group-by and small queries, based on the hardness of being answered. dimensions G = {G1 , . . . , Gl }. Each gi ∈ G1 × G2 × . . . Gl is D EFINITION 1. (Selectivity and Measure selectivity) The se- said to be a group, and zi is the corresponding aggregate value. We lectivity of predicate P in a query Q against a table T is s(P) = can present the output to be an r-dim vector z = z1 , . . . , zr . |TP |/|T | where |T | is the number of rows in T and TP ⊆ T is the The query output z can be normalized as a distribution on all set of rows that satisfy the predicates P in T . groups G1 × . . . × Gl : let xi ← zi / rj=1 zj , for i = 1, 2, . . . , r. The measure selectivity of predicate P in a query Q against The vector x = x1 , . . . , xr is said to be a distribution answer (or a table T on measure M is sM (P) = M (TP )/M (T ), where answer for short) to the query Q. Our guarantee about precision M (TP ) = t∈TP tM and M (T ) = t∈T tM . introduced next is w.r.t. the distribution answer with the goal of preserving the relative ratio/order of groups in the query output. D EFINITION 2. (Large queries and small queries) For a selec- tivity threshold s0 , a query Q with COUNT aggregate is a s0 -large 2.2 Distribution Precision Guarantee query iff s(P) ≥ s0 and otherwise a s0 -small query. Computing the exact output or distribution answer x to a query Q Similarly, a query Q with SUM(M ) is a s0 -large query iff we can be expensive on large tables. Our system produces an estimated have sM (P) ≥ s0 , and otherwise a s0 -small query. 681
4 . Input: aggregation query Q(G, F (M ), P) collect enough number of rows satisfying the predicate from the Output: -approximate answer distribution samples, it continues to use the other two deterministic auxiliary 1: If F = COUNT then indexes to evaluate the query for -approximation. 2: x, supxˆ ) ← ProcessWithDataBubble(Q, T 0 ); (ˆ Our query processing algorithm is outlined in Algorithm 1. We 3: Else If F = SUM then process a query with the data bubble samples first (lines 1-4). Let 4: x, supxˆ ) ← ProcessWithDataBubble(Q, T M ). (ˆ ˆ be the estimated distribution answer, and supxˆ be the number of x 5: If supxˆ ≥ 1/ 2 then sample rows satisfying the predicate P (those used to calculate x ˆ ). 6: Output x ˆ; If supxˆ ≥ 1/ 2 , we can terminate with an -approximate answer x ˆ 7: Else ˆ is not accurate enough, so we will continue (lines 5-6); otherwise, x 8: If the low-frequency group index is usable to check whether the low-frequency group index is usable (lines 8- 9: ˆ ← ProcessWithLFIndex(Q); x 9), or refer to the measure-augmented inverted index (lines 10-11). 10: Else Section 4 introduces how to create and utilize data bubble sam- 11: ˆ ← ProcessWithMAIndex(Q); x ples. Section 5 presents how to build and process queries with 12: Output x ˆ. measure-augmented inverted index and low-frequency group index. Algorithm 1: Processing Aggregation Queries 3.1.4 A Summary of Theoretical Guarantees We now present the performance guarantees of our system for √ producing -approximations, in an informal way. We set s0 to be 1/ n, where n is the number of rows in T , in Main results. For a table T with dC group-by/predicate dimen- most of discussion and analysis later on. We simply√call the two √ sions, dM measures, and n rows. We need to keep O n/ 2 rows classes large queries and small queries when s0 = 1/ n. in each of the dM +1 data bubbles. For any aggregation query Q(G, F (M ), P), we need to scan one of the data√bubbles to compute - 3.1.2 Offline Sampling and Index Building approximate answer in linear time O |G| · n/ 2 . If Q is a large For a table T with dC group-by and predicate dimensions, dM query, we can terminate with an -approximation with high proba- measures, and n rows, we build three types of samples/indexes. bility. If Q is a small query and the low-frequency group index can √ The first one is called data bubble. Each data bubble is a random be used to answer it, we scan at most n rows in the index to get sample of rows drawn √ from T . We draw a uniform sample T 0 ⊆ its answer. If the low-frequency group index cannot be used, we T containing O n/ 2 rows to answer COUNT-queries, and a can always use the measure-augmented inverted index to perform √ measure-biased sample containing O n/ 2 rows T M used to O 1/ 2 random I/O’s for an -approximation. answer SUM(M )-queries for each measure dimension M . So there Parameters. Both the error bound and the selectivity threshold are a total of dM +1 data bubbles. The basic idea of measure-biased s0 are tunable. Our theoretical results and system can be extended sampling is to pick a row t in T with replacement with probabil- for general parameter settings. The precision parameter can be ity proportional to tM , to get -approximate answers to SUM(M )- specified by users or administrators to trade-off between precision queries using a minimum number of sample rows. As their sizes and√indexing/processing cost. The selectivity threshold s0 is set as are sublinear in n, we load them into memory in pre-processing. 1/ n by default. Generally, the size of each sample needs to be The second one is called measure-augmented inverted index. For O (1/s0 ) · (1/ 2 ) to get -approximations for s0 -large queries. each value of a categorical dimension, we keep a postings list of Error bound and accuracy probability in big O notations. All row IDs where this value appears in the corresponding dimension. the theoretical results about obtaining -approximation in this pa- Up until now, it is similar to an inverted index in IR systems. We per hold with high probability (“w.h.p.” for short) – we mean that, then augment each postings list with rough values of measures. For with probability at least 1 − δ (e.g., 0.95) for some constant δ example, if tM = 28 + 10, we store 8 (i.e., apx(tM ) = 28 ) for (e.g., 0.05), our estimation is an -approximation. For a fixed er- tM in the index to save space. Similar to measure-biased sampling, ror bound , there is a tradeoff between the sample sizes/processing these rough values apx(tM )’s will be used to guide our online sam- costs (those in “main results” above) and the accuracy probability pling when processing SUM-aggregation queries. We keep this in- 1−δ: theoretically, for an accuracy probability 1−δ, there is an ad- dex on disk if we do not have enough memory, but each postings ditional factor log(1/δ) behind the O(·) notations about the sample list is stored sequentially s.t. it can be efficiently read when needed. sizes/processing costs. However, since δ does not have to be arbi- The third one is called low-frequency group index. In this index, trarily small, we can treat log(1/δ) as a constant for simplicity of for each value that is infrequent in a categorical√dimension, i.e., the presentation. So in all O(·) or Ω(·) notations in the main body of number of rows containing it is no more than n, we materialize this paper, we omit all the small logarithmic terms like log(1/δ) these rows sequentially on disk. The motivation of this index is and log(1/ ) when presenting theoretical results. These terms will that, if an infrequent value appears in the predicate of a query as be found in the proofs of our theorems in the appendix. part of a conjunction, we can simply scan these rows sequentially on disk to calculate the answer. For example, consider the table T 3.2 System Architecture in Figure 1(a) and a predicate “C2 = 1 AND C3 = 0”. Only 10 The architecture of our system is in Figure 2. Our system can be rows satisfy C2 = 1, so we can simply scan them for the answer. attached to a database with its independent storage and query pro- cessing engine. It connects to a data source in the column-based 3.1.3 Sample+Seek Processing of Queries format using a component called data connector, which can be Our system does not estimate queries’ selectivities. For every in- customized for different database systems. In the index building coming query, we first proceed with our uniform sample or measure- stage, the three of indexes, data bubbles, measure-augmented in- biased samples. If enough number (1/ 2 ) of rows satisfying its verted index, and low-frequency group index, are created from the predicate are collected from the samples, an -approximation can column-based storage. After index building is finished, our query be produced. For large queries, the processing can be terminated processor needs to access the data bubbles (in memory) and the at this point with high probability. Only when our system does not other two indexes (on disk) to process aggregation queries. 682
5 . Query Processing Query of Theorem 3 generalizes it extensively from two aspects: i) to Aggregation query Estimated answer processor distribution show E x − x ˆ 22 ≤ O 2 , we need to utilize the fact that the number of sample rows satisfying P, denoted as mP , concentrates Index Building on Ω 1/ 2 (w.h.p.); and ii) we need to generalize McDiarmid’s Data bubbles: √samples Measure-augmented Low-frequency inverted index group index inequality to complete the proof for x − x ˆ 2 ≤ (w.h.p.). with sizes O 2n C OROLLARY 4. (Without Predicate [1]) We use uniform sam- Meta data Data pling to draw O 1/ 2 rows T 0 from a table T of n rows. For any Columnizer Column-based Data source storage connector aggregation query Q with COUNT aggregate on T and no predi- (n rows) Dictionary cate, let x be the exact answer to Q. We can use T 0 to calculate an estimated answer x ˆ s.t. with high probability, x − x ˆ 2≤ . Figure 2: System Architecture Input: aggregation query Q(G, F (M ), P) and sample T Optimality. The information-theoretic lower bound in [1] also im- Output: -approximate answer x ˆ and support supxˆ plies the optimal sampling size for COUNT, i.e., at least Ω 1/ 2 sample rows are needed to obtain an -approximate answer (with ˆ ← 0; supxˆ ← 0; 1: x probability at least 1 − δ) for a COUNT-query with no predicate. 2: For each sample row t ∈ T : 3: If t satisfies P then Early termination. We can derive an early termination condition 4: Let i be the group t belonging to on G; for Algorithm 2 from Corollary 4. In order to be an -approximate 5: ˆi ← x x ˆi + 1; supxˆ ← supxˆ +1; distribution answer to a query Q, x ˆ needs a sample of O 1/ 2 6: Normalize x ˆ to be a distribution on all groups on G; rows among all rows that satisfy Q’s predicate. So we can track the 7: Output (ˆ x, supxˆ ). size of this sample using supxˆ in Algorithm 2. When supxˆ ≥ 2/ 2 , we can exit the loop of lines 2-5 and output the normalized x ˆ. Algorithm 2: ProcessWithDataBubble(Q, T ): processing ag- We have integrated this early termination condition in our imple- gregation queries with a data bubble (sample) mentation. It offers significant performance gain for √ large queries whose selectivities s(P)’s are much larger than 1/ √n, as for those queries, only a small portion of rows in the O n/ 2 -sample 4. SAMPLE: UNIFORM OR BIASED need to be scanned to get a sample of 2/ 2 rows satisfying P. We now introduce the two sampling schemes, uniform sampling and measure-biased sampling, and how to use them to answer large 4.2 Measure-biased Sampling COUNT and SUM-queries with -approximation, respectively. To extend the uniform sampling schema for queries with SUM aggregates on any measure dimension M , a naive way is to change 4.1 Uniform Sampling xi ← x “ˆ ˆi + 1” to “ˆ xi ← x ˆi + tM ” on line 5 of Algorithm 2 Uniform sampling is a very natural idea to approximate the an- (recall that tM is the value of measure M on a row t). This simple swer distribution x for an aggregation query Q. The sampling pro- extension, however, is not accurate enough. We can show that using cess can be formally described as follows. For a given sample size √ a uniform sample with size m = O n/ 2 , the expected squared m, we repeat drawing a row with replacement from a table T for error E x − x ˆ 22 for large queries is no less than Var [M ] · 2 , m times – each row t ∈ T is chosen into T 0 with equal probability ¯ − 1)2 and M ¯ is the average where Var [M ] = n1 t∈T (tM /M Pr [t is picked] = 1/n. (3) value of measure M . Later in Proposition 7, we will also prove 0 that E x − x ˆ 22 is upper bounded by O ∆3 · 2 with the same The resulting m sample rows in T are stored in memory for pro- sample size, if measure M takes value in [1, ∆]. Both Var [M ] cessing √queries. We show that a pre-drawn uniform sample with and ∆ could be very large for a general data distribution on M . size O n/ 2 suffices for all large COUNT-queries against T . Recall cases I and II in Example 1.1. If we use the above naive Algorithm 2 shows how the uniform sample T 0 can be used to adaption of uniform sampling to process query Q, we will get an estimate answers to aggregation queries. When Q(G, COUNT(∗), estimated answer either in Figure 1(c) or in 1(d) with high proba- P) comes, we process it with T 0 using one scan. For each row t ∈ bility. Both are far away from the true answer. T 0 , we check whether t satisfies P (line 3); if yes and t belongs to We now introduce a new sampling schema called measure-biased the ith group on group-by columns G, we increase x ˆi by 1 (lines 4- sampling. For each measure M , we first need to construct (ran- 5). Finally, we normalize x ˆ = x ˆ1 , . . . , x ˆr as a distribution and domly) a measure-biased sample T M in preprocessing, which will also report the number of rows satisfying P as supxˆ (lines 6-7). be used to estimate answers for SUM-queries with high accuracy. The follow √ theorem formally shows that why T 0 with sample Constructing measure-biased samples. To construct T M with 2 size O n/ suffices for all large COUNT-queries. a given sample size m, we repeat drawing a row with replacement from T for m times – each row t is picked into T M with probability T HEOREM 3. (Precision of Uniform Sampling) We use uniform proportional to its value tM on measure M , i.e., sampling to draw O (1/s0 ) · (1/ 2 ) rows to form a sample T 0 from a table T of n rows. For any COUNT-aggregation query on tM Pr [t is picked] = ∼ tM ; (4) T , Q(G, COUNT(∗), P), let x be the exact answer to Q. If the t ∈T tM selectivity of predicates P is no less than s0 , s(P) ≥ s0 , Algo- rithm 2 uses T 0 to calculate an estimated answer x ˆ s.t. with high All the rows drawn are kept in T M . Note that each row may appear probability, x − ˆ x 2 ≤ . In particular, if the selectivity threshold multiple times in T M , i.e., T M could be a multi-set. We will show √ √ s0 = 1/ n, a uniform sample of O n/ 2 rows suffices. a table T with n rows, a measure-biased sample T M with that for √ size O n/ 2 suffices for all large SUM(M )-queries. A special case of Theorem 3 with selectivity threshold s0 = 1 If there are d measure attributes, we need to maintain d measure- has been studied in [1], as stated in Corollary 4 below. Our proof biased samples, each for one measure. We can construct all the 683
6 .measure-biased samples together with the uniform sample in two 5.1 Measure-Augmented Inverted Index scans of the table T . Please refer to Appendix B for details. As we first focus on aggregation queries with categorical dimen- Estimating using measure-biased samples. When using T M to sions in their predicates, it is a natural idea to apply inverted indexes estimate the answer for a SUM(M )-query Q, it is a bit surprising from IR systems in our problem. For each value v of each dimen- that we can reuse Algorithm 2 – we only need to call the procedure sion Di , we can keep a postings list of rows that have value v on ProcessWithDataBubble(Q, T M ). Readers may wonder why in dimension Di . Then for a query Q(G, F (M ), P), there have been line 5, x ˆi is increased by 1 instead of the measure value tM for a extensive studies on how to efficiently retrieve all rows satisfying sample row t. The reason is, informally, that since the sampling P using those postings lists, such as [8]. For a predicate that is a probability of t is proportional to tM (as in (4)), we need to cali- conjunction (with only ANDs) of equi-constraints, it is equivalent ˆ with t−1 brate row t’s contribution to the estimation x M . This idea is to computing the intersection of postings lists. After that, we only similar to Horvitz-Thompson estimator (which is for single-point need to scan the retrieved rows once for aggregation. estimation), but here we are estimating a distribution x. Refer to There are, however, at least two optimizations we can do in the the following example for more intuition. scenario of aggregation queries processing. First, we cannot keep full rows in the postings list, as each row could be wide (in terms E XAMPLE 4.1. (Continue Example 1.1) Let’s look at the query of the number of bits), especially if the number of dimensions is Q in Example 1.1, for which uniform sample fails. We draw a non-trivial (e.g., 30). We can keep only the IDs of those rows, and measure-biased sample T M with rows 1, 26, 51, 76, 92, 94, 96, later seek their dimension/measure values in the original table. 98, 111, 136, 161, and 186 each appearing once, and 199 and 200 Secondly, of course, random seek based on row ID is expensive. each appearing four times (considering their values on M – refer to Our basic idea is that, after we get the IDs of rows that satisfy the Example B.1 and Figure 9 in Appendix B on how they were drawn). predicate P, we draw a random sample from these IDs, and per- Reusing Algorithm 2, call ProcessWithDataBubble(Q, T M ) – the form random seeks only for the sample IDs. The two sampling ˆ = 8/20, 12/20 = 0.40, 0.60 , which is estimation it gives is x schemes introduced in Section 4 can be applied here online to draw very close to the exact answer x = 0.39, 0.61 . proper samples to achieve our -approximation precision guaran- tee. To this end, besides row IDs, we need approximate measure The following theorem formally shows that, values to guide our online measure-biased sampling. √ for each measure We introduce how to construct and utilize measure-augmented M , a measure-biased sample T M with size O n/ 2 suffices for all large SUM(M )-queries to give -approximation. inverted index in this subsection. 5.1.1 Construction T HEOREM 5. (Precision of Measure-Biased Sampling) We ap- Our measure-augmented inverted index is described in Figure 3. ply measure-biased sampling on measure attribute M and draw For each value v of a categorical dimension D, we maintain a O (1/s0 ) · (1/ 2 ) rows T M from a table T of n rows. For any measure-augmented postings list inv(D, v). Each of our measure- aggregation query, Q(G, SUM(M ), P), with aggregate SUM(M ) augmented postings lists consists of two parts. on T , let x be the exact answer to Q. If the measure selectiv- First, inv(D, v) maintains IDs of rows that have value v on D ity of predicates P, sM (P), is no less than s0 , Algorithm 2 uses just as in an IR-style postings list. This part is depicted in the left T M to calculate an estimated answer x ˆ s.t. with high probability, √ of Figure 3. From the ID of a row t, denoted as tID , we can access x−ˆx 2 ≤ . In particular, if the √selectivity threshold s0 = 1/ n, the value of each the dimension or measure of t from our column- 2 a measure-biased sample of O n/ rows suffices. based storage, using one random seek (I/O). Second, let’s use inv(D, v) also to denote the set of rows that Optimality of measure-biased sampling. Our measure-biased have value v on D. For each row t ∈ inv(D, v), we maintain the sampling for SUM-queries draws the same number of sample rows values of measures M1 , . . . , MdM on this row. Note that keeping all as the uniform sampling does for COUNT-queries. Since COUNT the exact measure values is still too expensive (e.g., for ten 64-bit is a special case of SUM (when the measure attribute is a constant integers). So we only keep an approximation apx(tMi ) of measure 1), the low-bound result in [1] also implies that for SUM-queries tMi in order to save the space as well as to speedup the access of with no predicate (s0 = 1), we need at least Ω 1/ 2 sample rows inv(D, v). apx(tMi ) only needs to be an 2-approximation of tMi : to obtain an -approximate answer with high probability. apx(tMi ) ≤ tMi < 2 · apx(tMi ). (5) Early termination. The same early termination condition intro- duced in Section 4.1 for the uniform samples can be applied here So the number of bits we need is at most log log ∆(Mi ) + 1, where for measure-biased samples. When we collect supxˆ ≥ 2/ 2 sam- ∆(Mi ) is the range of values in measure Mi . ples rows that satisfy the predicate in Q, we can exit the loop of The construction of measure-augmented inverted index is similar lines 2-5 of Algorithm 2 and output the normalized x ˆ . This condi- to constructing traditional IR inverted index, which can be done tion is also integrated in our implementation and offers significant within one scan of all the rows in linear time. performance gain for queries with high measure selectivities. E XAMPLE 5.1. (Continue Example 1.1) For the example ta- ble T with 200 rows in Figure 1(a), Figure 4(a)-4(b) shows the 5. SEEK: RANDOM OR SEQUENTIAL measure-augmented postings lists inv(C2 , 0) and inv(C3 , 0), re- Large √ queries with (measure) selectivity no smaller than s0 (= spectively. Values on measure M , i.e., tM , are rounded to apx(tM ) 1/ n by default) have been handled by uniform and measure- as 20 , 21 , 22 , . . ., so that (5) is satisfied. For example, tM for row biased samples. So what left here are small queries with (measure) 100 is rounded to 8 from 10 in inv(C3 , 0) and tM for row 200 is selectivity smaller than s0 . For example, for such a small COUNT rounded to 64 from 100 in inv(C2 , 0). The number of bits needed aggregation query, we know √ that the number of rows satisfying its for each apx(tM ) is log2 log2 ∆(M ) + 1. In this example, the predicate is no more than n. We will keep this property in mind range of M is ∆(M ) = 100, so we need only log2 log2 100 + 1 = when designing the two indexes to handle small queries. log2 6 + 1 = 3 bits, as apx(tM ) can only be 20 , 21 , . . . , 26 . 684
7 . Postings Approximate log log ∆(Mi ) + 1 bits list inv(D, v) measures Input: aggregation query Q(G, F (M ), P) and table T (1) (1) (1) Index: measure-augmented inverted index inv (D, v) tID apx(tM1 ) ... ... apx(tMi ) ... ... Output: -approximate answer distribution x ˆ ... ... ... ... ... ... ... ... ... number of rows ˆ ← 0; 1: x (j) tID (j) apx(tM1 ) ... ... (j) apx(tMi ) ... ... containing v 2: Compute TPID ← {tID | rows t that satisfy P} using inv; 3: Repeat min{1/ 2 , |TPID |} times: ... ... ... 4: Randomly pick tID ∈ TPID : for each tID ∈ TPID , Figure 3: Measure-Augmented Inverted Index apx(tM ) ID apx(M ) Pr [tID is picked] = ∼ apx(tM ); (6) t ∈T apx(tM ) ID apx(M ) 1 1 ID apx(M ) 1 1 ... 1 5: t ← seeking T using tID for other dimensions; 1 1 6: Let i be the group t belonging to on G; ... 1 90 1 ... 1 90 1 91 8 7: ˆi ← x x ˆi + tM /apx(tM ); 90 1 101 1 ... 8 8: Normalize xˆ to be a distribution and output x ˆ. 101 1 ... 1 100 8 ... 1 Algorithm 3: ProcessWithMAIndex(Q): online approximate 198 1 101 1 198 1 measure-biased sampling and processing 199 64 ... 1 199 64 200 64 198 1 199 64 (c) inv(C2 , 0) ∩ inv(C3 , 0) (a) inv(C2 , 0) (b) inv(C3 , 0) measure M are within range [1, ∆]. For a SUM aggregation query Q with predicate P, let x be the exact answer to Q. We can use TP Figure 4: Two Measure-Augmented Postings Lists ˆ s.t. E [ x − x to get an estimation x ˆ 2] ≤ . Size of index. Our measure-augmented inverted index is composed How to process a query using the approximate measure-biased of row IDs and approximate measures. Suppose a table has n rows sampling technique is described in Algorithm 3. Inspired by the and dC dimensions. Each row ID needs O(log n) bits and is stored idea of measure-biased sampling (recall (4)), the sample size can dC times in the index, one time for each dimension. For each row be reduced tremendously to O 1/ 2 if rows in TP can be sam- ID and each measure Mi , we need O(log log ∆(Mi )) bits to store pled with probability proportional to tM . In measure-augmented the approximate measure apx(tMi ). So the index size is: inverted index, tM is not available, but an approximation to tM , T HEOREM 6. For a table with n rows, dC dimensions, and dM apx(tM ), is available. A row t in TP is drawn into sample TP measures, the measure-augmented inverted index needs a total of with probability proportional to apx(tM ) (line 4). If t is picked, we dM retrieve its dimension and measure values by seeking our column- O n · dC · (log n + Σi=1 log log ∆(Mi )) bits. based storage (line 5), and let i be the group it belongs to (lines 6). Each postings list inv(D, v) can be compressed using standard Let tM = tM /apx(tM ) be the weight of t in the estimation x ˆi techniques as it will only be accessed sequentially. We will report ˆ is normalized and output (line 8). We know (line 7). Finally, x the actual size of such indexes in our experiments. that, for any t, 1 ≤ tM < 2, from how apx(·M ) is chosen as in (5). The reduction in sampling complexity is achieved by shrink- 5.1.2 Processing Queries ing ∆ in Proposition 7. Intuitively, from Proposition 7, if ∆ = 2, To process a query Q(G, F (M ), P) using measure-augmented which is true for tM , a sample of size O 1/ 2 should suffice. Be- inverted index, we first retrieve IDs of all rows that satisfy P. Let fore proving the formal result in Theorem 8, we use an example to TP be the set of all such rows, and TPID be the set of their IDs. For demonstrate the online approximate measure-biased sampling. a predicate expression with AND, OR, and NOT operators on equi- E XAMPLE 5.2. (Continue Example 5.1) For the table T with constraints in the form of “Di = vi ”, this is equivalent to comput- 200 rows in Figure 1(a), consider such a query Q: ing set intersection, union, and minus of postings lists inv(Di , vi ), SELECT C1 , SUM(M ) FROM T and we only need one scan of those lists. WHERE C2 = 0 AND C3 = 0 GROUP BY C1 . After we get IDs of rows in TPID , we can seek the original table The answer x = 90/288, 198/288 = 0.31, 0.69 . Using our T for their dimension and measure values to finish the aggregation. measure-augmented postings lists in Figures 4(a)-4(b), we can first But |TPID | random seeks are expensive. compute the IDs of rows that satisfy “C2 = 0 AND C3 = 0”. A very natural idea is to draw a random sample from TPID , and We get TPID = {1, . . . , 90, 101, . . . , 198, 199} as in Figure 4(c). perform random seeks only for the sample rows. There are 188 rows in TPID with apx(tM ) = 1, and 1 row (199) For COUNT aggregates, from Corollary 4, a uniform sample of with apx(tM ) = 64. So if we draw 20 rows with probability pro- O 1/ 2 rows suffice for an -approximate answer x ˆ. portional to apx(tM ) from TPID , with high likelihood, we will get 7 For SUM aggregates, we propose approximate measure-biased rows from {1, . . . , 90}, 8 rows from {101, . . . , 198}, 5 copies of sampling to estimate an -approximate answer. row 199. From line 7 in Algorithm 3, we can estimate x ˆ= Online approximate measure-biased sampling. We start with a 7×1 8 × 1 + 5 × 100/64 proposition about the sample size needed for an -approximation if , = 0.30, 0.70 . uniform sampling is used. We prove that, with uniform sampling, 7 + 8 + 5 × 100/64 7 + 8 + 5 × 100/64 it suffices to seek O ∆3 / 2 sample rows, where ∆ is the range of measure values. This result itself is discouraging as ∆3 is large. T HEOREM 8. (Sample using Approximate Measures) We can Our approximate measure-biased sampling scheme will improve draw O 1/ 2 rows TP from TP biased on approximate measure the sample size to O 1/ 2 using approximate measures apx(·M ). apx(·M ) of M (in (6)). For an aggregation query Q(G, SUM(M ), P), let x be the exact answer to Q. We can use the measure- P ROPOSITION 7. (Uniform Sample for SUM) We draw a uni- biased sample TP to calculate an approximate answer x ˆ (as in form sample of O ∆3 / 2 rows TP from TP , assuming values of Algorithm 3) s.t. with high probability, we have x − x ˆ 2≤ . 685
8 .Query processing cost. We observe the bottleneck in cost lies on Input: aggregation query Q(G, F (M ), P) and sample T the second step, because the first step only involves sequential scans 1: Sˆi ← ∅ for all groups i’s; sup ← 0; of postings lists, but the second step needs random seeks. The num- 2: For each sample row t ∈ T : ber of random seeks, however, is bounded by min{1/ 2 , |TPID |} for 3: If t satisfies P then each dimension in the query to get an -approximation. 4: Let i be the group t belonging to on G; T HEOREM 9. A query Q with predicate P can be processed 5: Sˆi ← Sˆi ∪ {t}; w(t) ← Pr [t ∈ T ]; sup ← sup +1; using our measure-augmented inverted index (with Algorithm 3) to 6: For each group i: x ˆ i ← Estimator(Sˆi , w(·), F ); get an -approximation. Let TP be the set of rows satisfying P. The 7: Output (ˆ x, sup). total number of random seeks to our index and the column-based Algorithm 4: ProcessWithDataBubble(Q, T ): extended for storage is O min{1/ 2 , |TP |} · dQ , where dQ is the number of general measure F on uniform/measure-based sample dimensions and measures in the query Q. 5.2 Low-Frequency Group Index Input: aggregation query Q(G, F (M ), P) and table T Low-frequency group index is designed to benefit a special class Index: measure-augmented index MAInd of predicates in the form of 1: Sˆi ← ∅ for all groups i’s; 2: Compute TPID ← {tID | rows t that satisfy P} using MAInd; P : D1 = v1 AND . . . AND Dl = vl AND (. . .), (7) 3: Repeat min{1/ 2 , |TPID |} times: 4: Randomly pick tID ∈ TPID : for each tID ∈ TPID , i.e., a conjunction of one or more equi-constraints and some other 5: If MeasureBiased = true: Pr [tID ] ∼ apx(tM ); constraints. For example, for table T in Figure 1(a), “C2 = 1 AND 6: Else (uniform sampling): Pr [tID ] = 1/|TPID |; (C3 = 0 OR C3 = 1)” is such a predicate. 7: t ← seeking T using tID for other dimensions; The construction and processing using low-frequency √ group in- 8: Let i be the group t belonging to on G; dex is quite straightforward. If there is less than n rows (out of 9: Sˆi ← Sˆi ∪ {t}; w(t) ← Pr [tID ]; all the n rows in the table T ) with value v on a dimension D, we simply store these rows sequentially in the index. Any query in the 10: For each group i: x ˆ i ← Estimator(Sˆi , w(·), F ); form (7) with “D = v” in its predicate is a small query and cannot 11: Output x ˆ. be handled by our samples. Processing such queries using√the low- Algorithm 5: ProcessWithMAIndex(Q, MeasureBiased): ex- frequency group index is easy: we only need to scan the n rows tended for general measure F on uniform/measure-based sample sequentially in the index. More details are in Appendix C. Not all small queries can be processed using this index.√For ex- ample, when TD1 =v1 and TD2 =v2 are both large (with > n rows natively, we can estimate M (TP ) as M (T )·mP /m, and therefore, and thus not in the index), their intersection TD1 =v1 ∩ TD2 =v2 could be small. We still rely on our measure-augmented inverted in- zˆi = M (T ) · mi /m = x ˆi · M (T ) · mP /m. dex to answer the query with predicate “D1 = v1 AND D2 = v2 ”. Negative values on measures. For a measure attribute M with both positive values and negative values, we can create two versions 6. EXTENSIONS of M : M + takes only positive values and is set to 0 if the row has a negative value on M ; and similarly, M − takes only negative values 6.1 From Distributions to Absolute Answers and is set to 0 if the row has a positive value on M . Using the above We now introduce how to convert a distribution answer x ˆ to an tricks, we can get estimated answers for both M + and M − . The absolute answer z ˆ. For the distribution answer obtained from low- estimation for M can be obtained from the difference between the frequency group index, since it is exact, the conversion is trivial. So estimated M + and M − on each group. In this way, we can at least let’s focus on SUM-queries with estimated distribution obtained handle negative values for both SUM and AVG. from measure-biased sampling. Measure-augmented inverted in- dex also relies on (approximate) measure-biased sampling, so it is 6.2 Extensibility of Our Techniques similar. And COUNT is a special case of SUM. Foreign key joins and star schema. In order for our system to Consider a SUM(M )-query Q with predicate P against a table support aggregate queries with foreign key joins in a star schema, T . Suppose its output is z = z1 , . . . , zr , where zi is the aggre- our samples and indexes can be extended as follows. gate value of the ith group. z can be normalized to a distribution Uniform/measure-biased samples are drawn from the fact table x = x1 , . . . , xr as in Section 2.1. Let TP ⊆ T be the set of rows in the same way as introduced in Section 4. But for each dimen- satisfying P and Ti ⊆ TP be the set of rows in the ith group of the sion table, we have two options. i) We can join it with the sam- output to Q. For a set of rows S, let M (S) = t∈S tM . So we ples from the fact table in the offline sampling stage and attach the can easily derive that xi = M (Ti )/M (TP ) = zi /M (TP ). additional dimensions to the samples; or ii) we can perform the In the measure-biased sample T M , let m be the number of sam- join when processing aggregation queries using samples, if one or ple rows in T M , mP be the number of sample rows satisfying P more of its dimensions appear in the query. Option ii) is feasible in T M , and mi be the be the number of rows belonging to the ith when the dimension table is small enough to be fit into the mem- group in T M . So from Algorithm 2, we have x ˆi = mi /mP . ory. In our implementation, we choose option i). For the complex Since |ˆ xi − xi | ≤ (implied by our distribution precision guar- schema in TPC-H, Table 1 shows the space overhead of all uniform antee x − x ˆ 2 ≤ ), informally, we have and measure-biased samples, which is affordable in memory even xi = zi /M (TP ) ≈ mi /mP = x ˆi . though samples are attached with dimensions from all tables. For the measure-augmented inverted index and the low-frequency So it is intuitive to estimate zˆi = M (TP ) · mi /mP . Both mi and group index, we construct them in the view that joins the fact table mP are known from Algorithm 2, but M (TP ) is unknown. Alter- with all the dimensions. For TPC-H, Table 1 shows their total sizes. 686
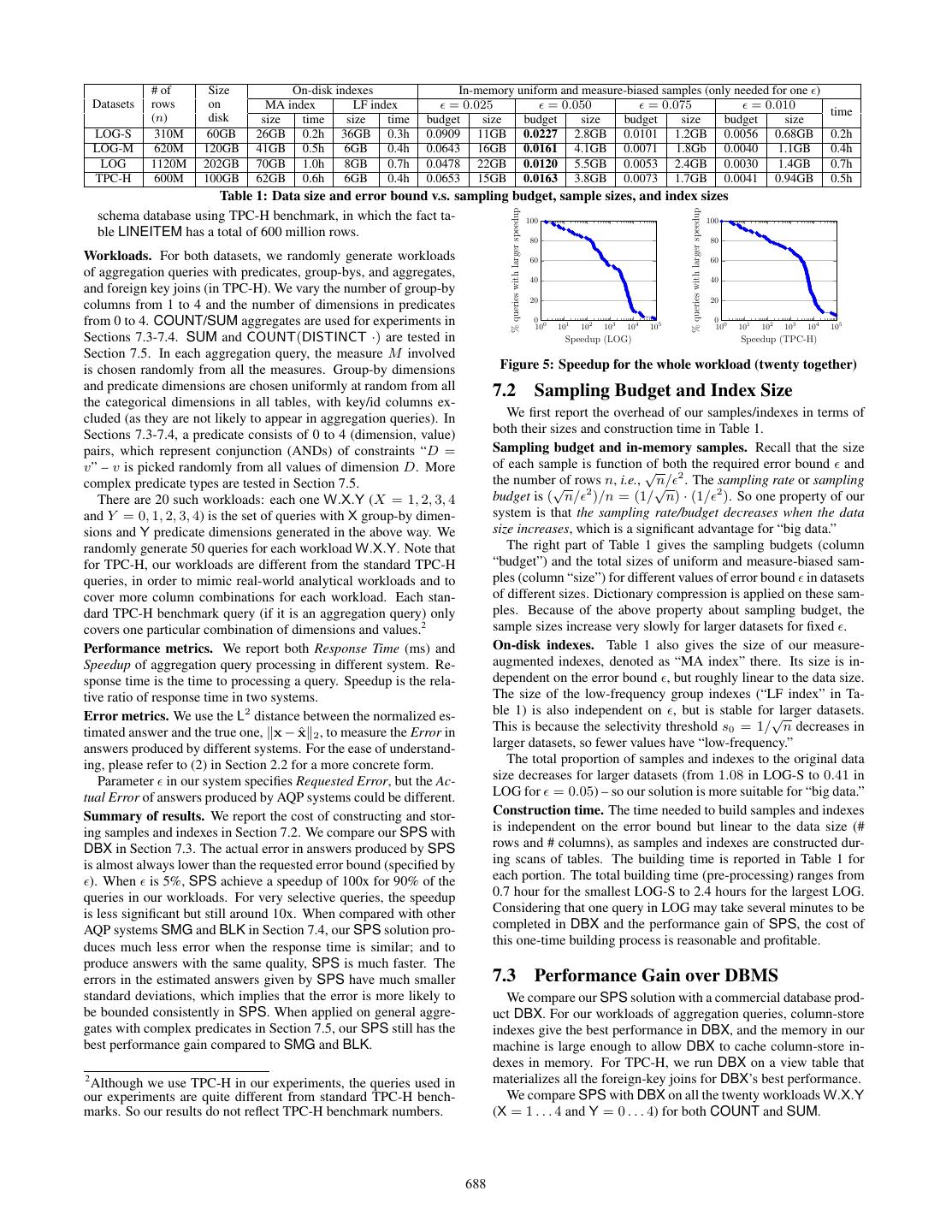
9 . In a snowflake schema with multiple fact tables and multi-level 7. EVALUATION dimensions, the above extensions can still be applied. We compare our system with a commercial RDB and two state Range predicates. Our samples can already be used to handle any of the art AQP solutions with stratified sampling: Babcock et al. predicate that is based on existing dimensions. To handle range [7] (workload-independent) and BlinkDB [5] (workload-aware). predicates like “D ≥ s AND D ≤ t” for small queries, we intro- • SPS: Our sample+seek solution introduced in this paper. duce the following measure-augmented B+ tree index. • DBX: A standard commercial database system with column-store • Measure-augmented B+ tree. In a B+ tree built on a numerical indexes built for all tables on all columns.1 dimension D, each leaf node is associated with a list of D’s values • SMG: Small group sampling introduced in [7]. within certain range. In our measure-augmented B+ tree, for each • BLK: BlinkDB with multi-dim stratified sampling [5]. D’s value at each leaf, we associate it with IDs (pointers) of the More implementation details of SPS. rows with this value on D and also approximate measure apx(tM ) • Parameters. Our √ SPS has two parameters. The selectivity thresh- for each measure (as in (5)) of these rows – recall that these approx- old s0 is set to 1/ n, where n is the total number of rows in a imate measures need much less bits than the exact measure values. table. The requested error bound varies from 0.025 to 0.1, and is When a range constraint s ≤ D ≤ t is in the predicate, we set as 0.05 if not specified. We use constants 1 behind all O(·)’s in can use this measure-augmented B+ tree to retrieve IDs of rows our theoretical results. √For uniform/measure-biased sampling, our with s ≤ tD ≤ t as well as their approximate measures. Our analysis shows that O n/ 2 rows in each sample suffice – we approximate measure-biased sampling introduced in Section 5.1.2 √ pick exactly n/ 2 rows for each sample. Similarly, from Theo- can then be used to pick O 1/ 2 row IDs and seek their dimension rem 8, we pick exactly 1/ 2 rows to perform random seeks. values in the original table to answer a query with -approximation. • Independent storage. We implement our storage/index and query Extension for other aggregates. We now focus on how to extend execution engine in SPS using C# from sketch. Our custom imple- our sample+seek solution to a wide range of aggregates. mentation (of all the components in Figure 2 except “data source”) • Simple extensions. We can convert both estimated distributions does not reply on other database systems. In our system architec- for SUM and COUNT to absolute answers using the way intro- ture in Figure 2, we have the original data kept in a column-based duced in Section 6.1. Then some measure like AVG can be easily storage with dictionary compression on disk. Our samples/indexes supported as it is nothing but the ratio of SUM to COUNT. are constructed from it, with samples loaded into memory and the • Generic aggregates. To support a generic range of aggregates in other two types of indexes maintained on disk. DBX has a better Algorithm 1, we extend processing with uniform/measure-biased optimized column-based storage engine – we do not utilize it for samples (Algorithm 2) and processing with measure-augmented in- SPS, as we want to highlight the speedups brought by our sam- dex (Algorithm 3) to Algorithm 4 and Algorithm 5, respectively. ples/indexes and processing algorithms with early termination. Processing with low-frequency group index is trivial: one can get • Column-store v.s. row-store. Our sample+seek framework is the exact value of any aggregate by scanning rows in the index. independent on the actual data storage of tables, but we choose The main idea behind Algorithms 4-5 is that, no matter with column-store for uniform/measure-biased samples, and row-store i) uniform/measure-biased samples or ii) with measure-augmented for low-frequency group indexes based on the ways they are ac- indexes, our estimations are made based on a set of sample rows cessed. For in-memory samples, a query may touch only a few di- with different sampling probabilities. For each group in the answer, mensions of sample rows and only data on these dimensions need with i), sample rows have been pre-drawn and kept in memory, so to be read. So to take the best advantage of data locality and cache, Algorithm 2 can directly use them. With ii), Algorithm 3 does it is more efficient to store the data column by column. For on- online sampling/seeking in lines 4-5, and make use of the sample √ disk low-frequency group indexes, since at most n rows need to rows for estimation in lines 6-7. So it is intuitive to replace the spe- be scanned to answer a query, it is more efficient to store the data cific estimation methods in Algorithm 2 (lines 4-5) and Algorithm 3 row by row so that only one random access is required per query. (lines 6-7) with generic estimators to handle other aggregates. Dictionary compression is applied on both types of storages. In Algorithm 4, when scanning rows in a (uniform or measure- SMG and BLK are implemented on the same storage engine (to biased) sample T , we keep rows from each group i in Sˆi as well as store data and samples) as SPS, and all the samples from SMG the probability of seeing each row t in w(t) (line 5). After the scan, and BLK are pre-loaded into memory for fair comparison. for each group i, a point estimation of its aggregate F can be made based on the set of sample rows Sˆi from group i and their weights 7.1 Experiment Settings and Summary w(·), using a generic estimator Estimator(Sˆi , w(·), F ) (line 6). All of our experiments are conducted on a Windows server with The extension in Algorithm 5 is similar, but the sampling is 8 core 2.27GHz CPUs and 64 GB memory. DBX is given 4 cores conducted online, either uniformly (line 6) or biased on measure for better performance, and each of the rest uses one core. (line 5). Again, rows collected from sampling are kept in Sˆi for group i together with sampling probabilities in w(·) (line 9). Af- Datasets. We use two datasets (a real one and a benchmark): ter enough number of rows are collected, estimation of aggregate • LOG: This is a real dataset about service logs in a Fortune 500 value F for each group can be made using Estimator(Sˆi , w(·), F ). company. It is a single table with 29 columns – 19 of them are Estimator is a customizable component and any sample-based categorical dimensions (for group-by), and the rest 10 are numer- point estimator for the aggregate F can be applied. It takes a set of ical dimensions/measures. The numbers of distinct values in the sample rows S,ˆ their sampling weights w(·), and F as the input, but categorical dimensions range from 2 to 3000. The whole table does not rely on other components of our system. So our solution has 1.12 billion rows. To test the scalability of different systems, enjoys the same extensibility as other sampling-based AQP tech- we extract two sub-tables from LOG, LOG-S with 310 million niques (e.g. [7, 5]) do to support a generic range of aggregates. For rows and LOG-M with 620 million rows. example, if F is STDEV(M ), the sample standard deviation esti- • TPC-H: With a scaling factor 100, we produce a 100 GB star- mator can be used as Estimator; if F is COUNT(DISTINCT M ), the estimator GEE proposed in [10] can be used as Estimator. 1 We tried different types of indexes. Column-store indexes turn out We will evaluate such extensions in experiments. to be the best option for our aggregation query workloads. 687
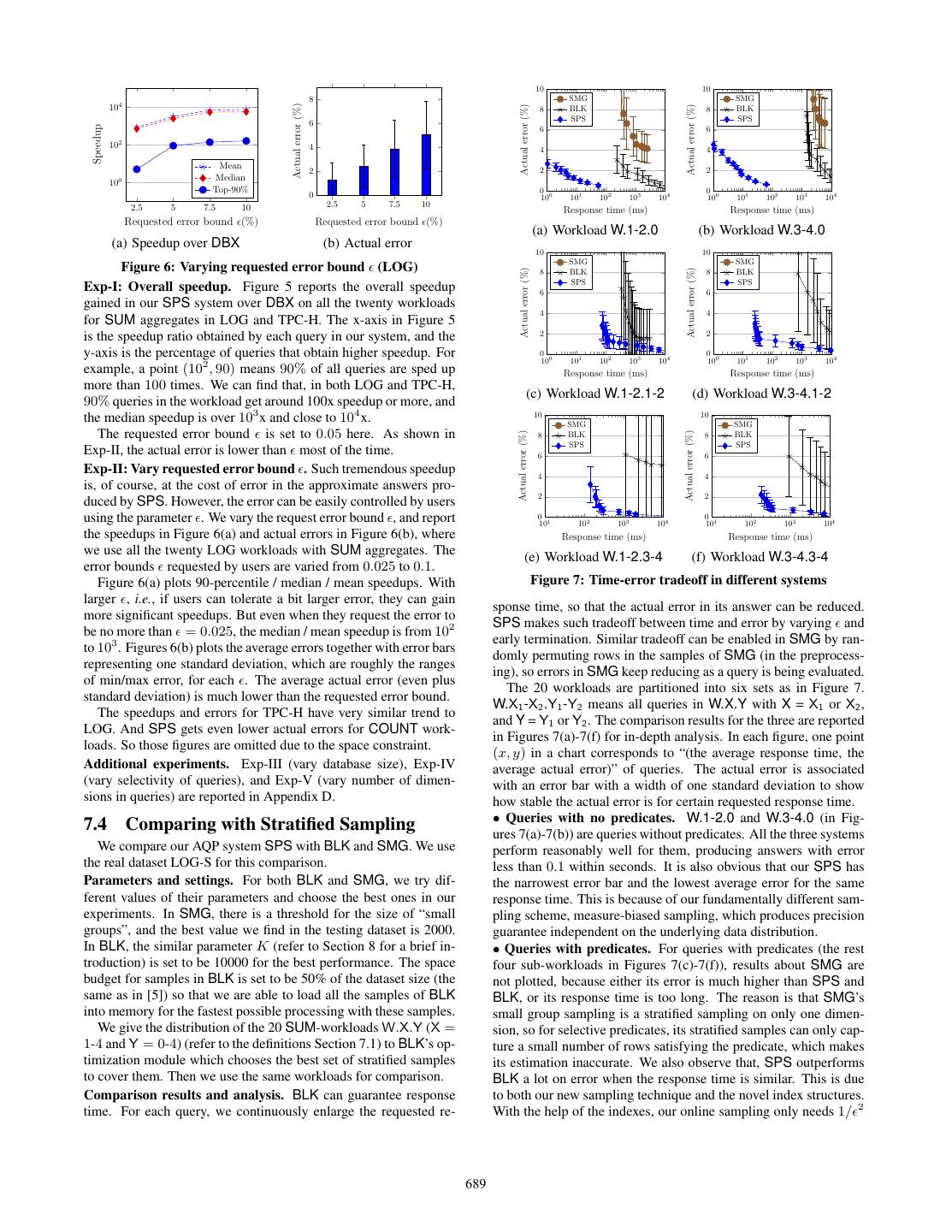
10 . # of Size On-disk indexes In-memory uniform and measure-biased samples (only needed for one ) Datasets rows on MA index LF index = 0.025 = 0.050 = 0.075 = 0.010 time (n) disk size time size time budget size budget size budget size budget size LOG-S 310M 60GB 26GB 0.2h 36GB 0.3h 0.0909 11GB 0.0227 2.8GB 0.0101 1.2GB 0.0056 0.68GB 0.2h LOG-M 620M 120GB 41GB 0.5h 6GB 0.4h 0.0643 16GB 0.0161 4.1GB 0.0071 1.8Gb 0.0040 1.1GB 0.4h LOG 1120M 202GB 70GB 1.0h 8GB 0.7h 0.0478 22GB 0.0120 5.5GB 0.0053 2.4GB 0.0030 1.4GB 0.7h TPC-H 600M 100GB 62GB 0.6h 6GB 0.4h 0.0653 15GB 0.0163 3.8GB 0.0073 1.7GB 0.0041 0.94GB 0.5h Table 1: Data size and error bound v.s. sampling budget, sample sizes, and index sizes % queries with larger speedup % queries with larger speedup schema database using TPC-H benchmark, in which the fact ta- 100 100 ble LINEITEM has a total of 600 million rows. 80 80 Workloads. For both datasets, we randomly generate workloads 60 60 of aggregation queries with predicates, group-bys, and aggregates, 40 40 and foreign key joins (in TPC-H). We vary the number of group-by 20 20 columns from 1 to 4 and the number of dimensions in predicates from 0 to 4. COUNT/SUM aggregates are used for experiments in 0 0 10 101 102 103 104 105 0 0 10 101 102 103 104 105 Sections 7.3-7.4. SUM and COUNT(DISTINCT ·) are tested in Speedup (LOG) Speedup (TPC-H) Section 7.5. In each aggregation query, the measure M involved is chosen randomly from all the measures. Group-by dimensions Figure 5: Speedup for the whole workload (twenty together) and predicate dimensions are chosen uniformly at random from all 7.2 Sampling Budget and Index Size the categorical dimensions in all tables, with key/id columns ex- cluded (as they are not likely to appear in aggregation queries). In We first report the overhead of our samples/indexes in terms of Sections 7.3-7.4, a predicate consists of 0 to 4 (dimension, value) both their sizes and construction time in Table 1. pairs, which represent conjunction (ANDs) of constraints “D = Sampling budget and in-memory samples. Recall that the size v” – v is picked randomly from all values of dimension D. More of each sample is function √ of both the required error bound and complex predicate types are tested in Section 7.5. the number√of rows n, i.e., √ n/ 2 . The sampling rate or sampling There are 20 such workloads: each one W.X.Y (X = 1, 2, 3, 4 budget is ( n/ )/n = (1/ n) · (1/ 2 ). So one property of our 2 and Y = 0, 1, 2, 3, 4) is the set of queries with X group-by dimen- system is that the sampling rate/budget decreases when the data sions and Y predicate dimensions generated in the above way. We size increases, which is a significant advantage for “big data.” randomly generate 50 queries for each workload W.X.Y. Note that The right part of Table 1 gives the sampling budgets (column for TPC-H, our workloads are different from the standard TPC-H “budget”) and the total sizes of uniform and measure-biased sam- queries, in order to mimic real-world analytical workloads and to ples (column “size”) for different values of error bound in datasets cover more column combinations for each workload. Each stan- of different sizes. Dictionary compression is applied on these sam- dard TPC-H benchmark query (if it is an aggregation query) only ples. Because of the above property about sampling budget, the covers one particular combination of dimensions and values.2 sample sizes increase very slowly for larger datasets for fixed . Performance metrics. We report both Response Time (ms) and On-disk indexes. Table 1 also gives the size of our measure- Speedup of aggregation query processing in different system. Re- augmented indexes, denoted as “MA index” there. Its size is in- sponse time is the time to processing a query. Speedup is the rela- dependent on the error bound , but roughly linear to the data size. tive ratio of response time in two systems. The size of the low-frequency group indexes (“LF index” in Ta- Error metrics. We use the L2 distance between the normalized es- ble 1) is also independent on , but is stable for√larger datasets. timated answer and the true one, x − x ˆ 2 , to measure the Error in This is because the selectivity threshold s0 = 1/ n decreases in answers produced by different systems. For the ease of understand- larger datasets, so fewer values have “low-frequency.” ing, please refer to (2) in Section 2.2 for a more concrete form. The total proportion of samples and indexes to the original data Parameter in our system specifies Requested Error, but the Ac- size decreases for larger datasets (from 1.08 in LOG-S to 0.41 in tual Error of answers produced by AQP systems could be different. LOG for = 0.05) – so our solution is more suitable for “big data.” Summary of results. We report the cost of constructing and stor- Construction time. The time needed to build samples and indexes ing samples and indexes in Section 7.2. We compare our SPS with is independent on the error bound but linear to the data size (# DBX in Section 7.3. The actual error in answers produced by SPS rows and # columns), as samples and indexes are constructed dur- is almost always lower than the requested error bound (specified by ing scans of tables. The building time is reported in Table 1 for ). When is 5%, SPS achieve a speedup of 100x for 90% of the each portion. The total building time (pre-processing) ranges from queries in our workloads. For very selective queries, the speedup 0.7 hour for the smallest LOG-S to 2.4 hours for the largest LOG. is less significant but still around 10x. When compared with other Considering that one query in LOG may take several minutes to be AQP systems SMG and BLK in Section 7.4, our SPS solution pro- completed in DBX and the performance gain of SPS, the cost of duces much less error when the response time is similar; and to this one-time building process is reasonable and profitable. produce answers with the same quality, SPS is much faster. The errors in the estimated answers given by SPS have much smaller 7.3 Performance Gain over DBMS standard deviations, which implies that the error is more likely to We compare our SPS solution with a commercial database prod- be bounded consistently in SPS. When applied on general aggre- uct DBX. For our workloads of aggregation queries, column-store gates with complex predicates in Section 7.5, our SPS still has the indexes give the best performance in DBX, and the memory in our best performance gain compared to SMG and BLK. machine is large enough to allow DBX to cache column-store in- dexes in memory. For TPC-H, we run DBX on a view table that 2 Although we use TPC-H in our experiments, the queries used in materializes all the foreign-key joins for DBX’s best performance. our experiments are quite different from standard TPC-H bench- We compare SPS with DBX on all the twenty workloads W.X.Y marks. So our results do not reflect TPC-H benchmark numbers. (X = 1 . . . 4 and Y = 0 . . . 4) for both COUNT and SUM. 688
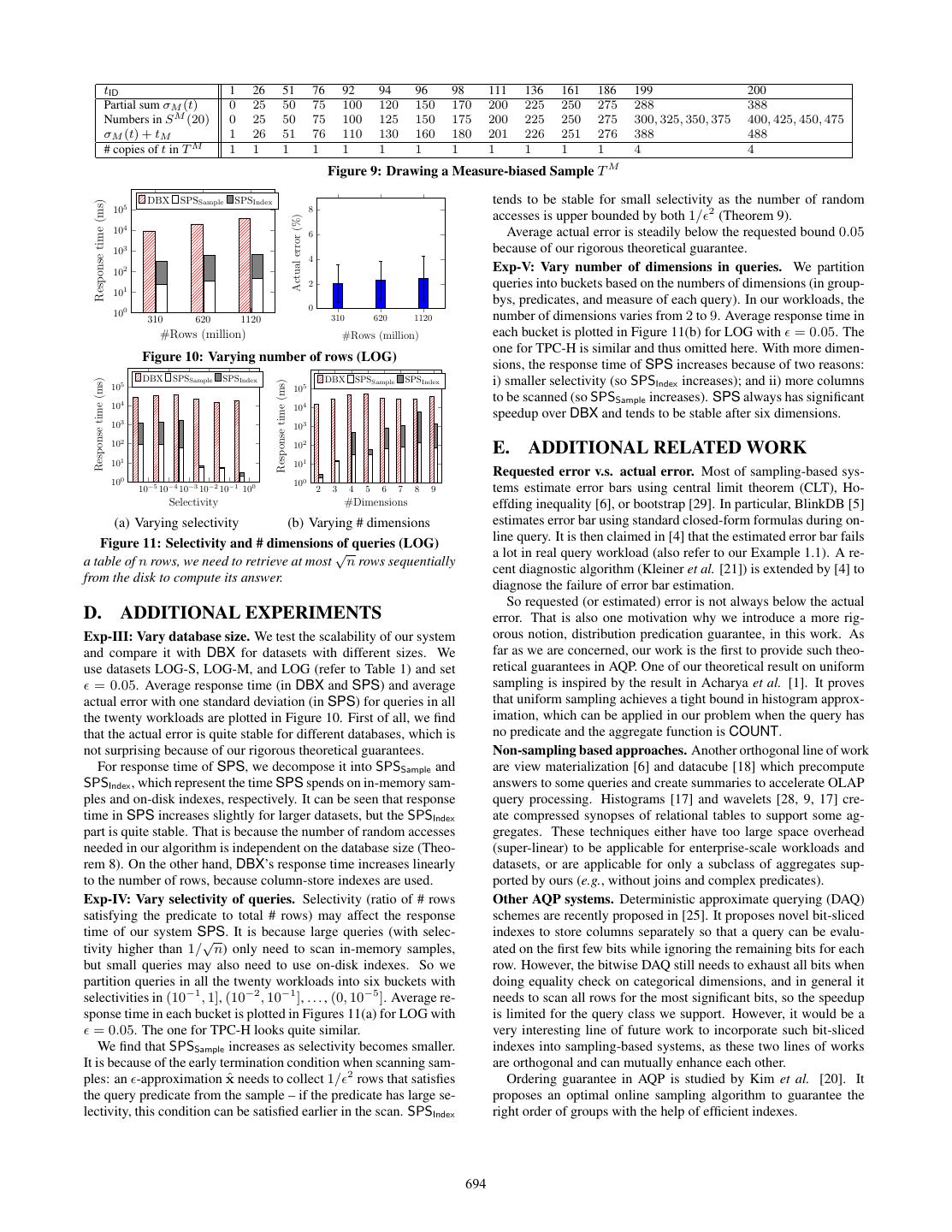
11 . 10 10 8 SMG SMG 104 Actual error (%) Actual error (%) Actual error (%) 8 BLK 8 BLK SPS SPS 6 Speedup 6 6 102 4 4 4 Mean 2 2 2 Median 100 Top-90% 0 0 0 0 0 10 101 102 103 104 10 101 102 103 104 2.5 5 7.5 10 2.5 5 7.5 10 Response time (ms) Response time (ms) Requested error bound (%) Requested error bound (%) (a) Workload W.1-2.0 (b) Workload W.3-4.0 (a) Speedup over DBX (b) Actual error 10 10 SMG SMG Figure 6: Varying requested error bound (LOG) Actual error (%) Actual error (%) 8 BLK 8 BLK SPS SPS Exp-I: Overall speedup. Figure 5 reports the overall speedup 6 6 gained in our SPS system over DBX on all the twenty workloads 4 4 for SUM aggregates in LOG and TPC-H. The x-axis in Figure 5 2 2 is the speedup ratio obtained by each query in our system, and the y-axis is the percentage of queries that obtain higher speedup. For 0 0 10 101 102 10 3 104 0 0 10 101 102 103 104 example, a point (102 , 90) means 90% of all queries are sped up Response time (ms) Response time (ms) more than 100 times. We can find that, in both LOG and TPC-H, (c) Workload W.1-2.1-2 (d) Workload W.3-4.1-2 90% queries in the workload get around 100x speedup or more, and the median speedup is over 103 x and close to 104 x. 10 SMG 10 SMG The requested error bound is set to 0.05 here. As shown in Actual error (%) Actual error (%) 8 BLK 8 BLK SPS SPS Exp-II, the actual error is lower than most of the time. 6 6 Exp-II: Vary requested error bound . Such tremendous speedup 4 4 is, of course, at the cost of error in the approximate answers pro- 2 2 duced by SPS. However, the error can be easily controlled by users using the parameter . We vary the request error bound , and report 0 1 10 102 103 104 0 1 10 102 103 104 the speedups in Figure 6(a) and actual errors in Figure 6(b), where Response time (ms) Response time (ms) we use all the twenty LOG workloads with SUM aggregates. The (e) Workload W.1-2.3-4 (f) Workload W.3-4.3-4 error bounds requested by users are varied from 0.025 to 0.1. Figure 6(a) plots 90-percentile / median / mean speedups. With Figure 7: Time-error tradeoff in different systems larger , i.e., if users can tolerate a bit larger error, they can gain sponse time, so that the actual error in its answer can be reduced. more significant speedups. But even when they request the error to SPS makes such tradeoff between time and error by varying and be no more than = 0.025, the median / mean speedup is from 102 early termination. Similar tradeoff can be enabled in SMG by ran- to 103 . Figures 6(b) plots the average errors together with error bars domly permuting rows in the samples of SMG (in the preprocess- representing one standard deviation, which are roughly the ranges ing), so errors in SMG keep reducing as a query is being evaluated. of min/max error, for each . The average actual error (even plus The 20 workloads are partitioned into six sets as in Figure 7. standard deviation) is much lower than the requested error bound. W.X1 -X2 .Y1 -Y2 means all queries in W.X.Y with X = X1 or X2 , The speedups and errors for TPC-H have very similar trend to and Y = Y1 or Y2 . The comparison results for the three are reported LOG. And SPS gets even lower actual errors for COUNT work- in Figures 7(a)-7(f) for in-depth analysis. In each figure, one point loads. So those figures are omitted due to the space constraint. (x, y) in a chart corresponds to “(the average response time, the Additional experiments. Exp-III (vary database size), Exp-IV average actual error)” of queries. The actual error is associated (vary selectivity of queries), and Exp-V (vary number of dimen- with an error bar with a width of one standard deviation to show sions in queries) are reported in Appendix D. how stable the actual error is for certain requested response time. • Queries with no predicates. W.1-2.0 and W.3-4.0 (in Fig- 7.4 Comparing with Stratified Sampling ures 7(a)-7(b)) are queries without predicates. All the three systems We compare our AQP system SPS with BLK and SMG. We use perform reasonably well for them, producing answers with error the real dataset LOG-S for this comparison. less than 0.1 within seconds. It is also obvious that our SPS has Parameters and settings. For both BLK and SMG, we try dif- the narrowest error bar and the lowest average error for the same ferent values of their parameters and choose the best ones in our response time. This is because of our fundamentally different sam- experiments. In SMG, there is a threshold for the size of “small pling scheme, measure-biased sampling, which produces precision groups”, and the best value we find in the testing dataset is 2000. guarantee independent on the underlying data distribution. In BLK, the similar parameter K (refer to Section 8 for a brief in- • Queries with predicates. For queries with predicates (the rest troduction) is set to be 10000 for the best performance. The space four sub-workloads in Figures 7(c)-7(f)), results about SMG are budget for samples in BLK is set to be 50% of the dataset size (the not plotted, because either its error is much higher than SPS and same as in [5]) so that we are able to load all the samples of BLK BLK, or its response time is too long. The reason is that SMG’s into memory for the fastest possible processing with these samples. small group sampling is a stratified sampling on only one dimen- We give the distribution of the 20 SUM-workloads W.X.Y (X = sion, so for selective predicates, its stratified samples can only cap- 1-4 and Y = 0-4) (refer to the definitions Section 7.1) to BLK’s op- ture a small number of rows satisfying the predicate, which makes timization module which chooses the best set of stratified samples its estimation inaccurate. We also observe that, SPS outperforms to cover them. Then we use the same workloads for comparison. BLK a lot on error when the response time is similar. This is due Comparison results and analysis. BLK can guarantee response to both our new sampling technique and the novel index structures. time. For each query, we continuously enlarge the requested re- With the help of the indexes, our online sampling only needs 1/ 2 689
12 . 105 105 DBX SPS BLK DBX SPS BLK Offline sampling. This line of work is especially relevant to ours. Response time (ms) Response time (ms) 104 104 The idea is to create random samples before queries come, and calibrate their sampling rates carefully using stratified (or impor- 3 10 103 tance) sampling [22] to reduce variance when using them to an- swer queries. There are two types of offline sampling techniques: 102 102 one calibrates sampling rates without the knowledge of workload; 101 0 0.5 1 3 5 7 101 0 1 2 3 4 5 and the other utilizes historical workload distribution. Actual error (%) Actual error (%) • Workload-independent sampling. Aqua [3, 2] proposes con- gressional sampling. For all possible queries, consider combina- (a) SUM(M ) (b) COUNT(DISTINCT M ) tions of group-by dimensions. For each combination, the sampling Figure 8: With complex predicates and general aggregates rate is set based on a weighting function that considers the group sizes for all subsets of the group-by dimensions in this combina- random seeks to produce an -approximation for any small query. tion. For d possible group-by dimensions, there are 2d combina- On the other hand, when only very few rows satisfy a small query’s tions, which renders it impractical for datasets with dozens or hun- predicate, if the predicate’s column set is not covered exactly by dreds of possible group-by columns. In addition, Aqua operates on the columns of any stratified sample selected by BLK’s optimiza- a single sample which has to be very general-purpose in nature but tion module, BLK will suffer from the same problem as SMG (al- only loosely appropriate for any particular query [7]. though it happens less frequently than in SMG). To overcome such shortcomings, Babcock et al. [7] proposes 7.5 Extensibility small group sampling, a stratified sampling technique that builds a biased sample on each single column. Uniform sampling does We conduct experiments on more general workloads (generic ag- a satisfactory job at providing good estimates for the large groups gregates with range constraints and complex logical expressions as in a group-by query. A group here is the set of all rows with cer- predicates) to evaluate the extensibility of SPS as introduced in tain (the same) value on a group-by dimension. For small groups, Section 6.2. SPS still outperforms the others on such workloads. uniform sampling fails to draw enough number of rows for each. The workloads are generated on LOG-S with 1-4 group-by di- So all the rows from the small groups are included in the biased mensions, and complex logical expressions on 4 dimensions as sample on their dimension. A query is executed on the union of the predicates, such as “(C1 = v1 OR v2 ≤ C2 ≤ v2 ) AND (C3 = uniform sample and all biased samples whose dimensions appear v3 OR v4 ≤ C4 ≤ v4 )”. We generate two such workloads with in the query for an estimated answer. Using similar heuristics, out- aggregates SUM(M ) and COUNT(DISTINCT M ), respectively. lier indexing [11] is proposed to include rows with outlier values in We always include 2 equality constraints on categorical dimensions additional samples to improve estimation accuracy. and 2 range constraints on numerical dimensions in a predicate. For • Workload-aware sampling. Workload information can be used each of such workloads, dimensions, values, and logical expres- to optimize samples’ constitution. For example, Aqua [2] can be sions are randomly picked to form 200 queries. adapted to workloads. Workloads are also used in [15] to construct Results for the two workloads are reported in Figure 8. We plot “self-tuning” biased samples. STRAT [12, 13] aims to minimize the average response time of SPS and BLK when achieving certain the expected relative error of workloads. [23] requires building a actual error, and compare them with DBX (we ignore SMG as it new sample for each query template. SciBORQ [27] targets scien- is dominated by the other two). Overall, our SPS provides much tific analysis and creates samples based on past query results with better tradeoff between time and error than BLK does, and is always no guarantees on error margin. However, the assumption of these faster than BLK when with the same error. works that workloads are stable can easily be wrong in practice. The performance gain of SPS over BLK and DBX on SUM is BlinkDB [5] abstracts workload to query column set (QCS), i.e., significant (Figure 8(a)) because of the strong theoretical guarantee. the set of columns that appear in a query, allowing it to tolerate SPS can benefit from measure-biased samples on other aggregates moderate workload change. A group is the set of all rows with AVG and STDEV as well even though the theoretical guarantees the same values on a QCS. A stratified sample can be created for are weaker for them. It benefits from our samples and indexes also each QCS by sampling K rows for each group on this QCS – if a on COUNT(DISTINCT M ) (Figure 8(b)). So when the error is group has less than K rows, all of its rows are put in the sample. above 2% or 1%, SPS is still the best option with significant per- BlinkDB formulates an optimization problem to decides how to formance gain and smooth tradeoff between time and accuracy. In allocate space budget across QCSs based on previous workloads. It particular, SPS still gets 100x speedup when the error is 5%. provides either time guarantee or CI-based error guarantee. Related work on requested error v.s. actual error, non-sampling 8. RELATED WORK approaches, and other AQP systems is discussed in Appendix E. AQP has been studied extensively during last few decades. There are three related lines, including i) online sampling – drawing sam- 9. CONCLUSIONS ples after each query comes, ii) offline sampling – drawing samples We propose an AQP system based on a novel sample+seek frame- before queries come; and iii) non-sampling based approaches. work. Distribution precision is guaranteed in answers to aggre- Online sampling/aggregation. Online aggregation [19, 14, 24] gation queries. A new measure-biased sampling technique is in- streams data in a random order or assumes that sample rows can troduced to approximately process SUM aggregation queries with be randomly drawn from the underlying database, and uses them less selective predicates and achieve this precision guarantee. For to estimated query answers. The disadvantage is that drawing rows queries with more selective predicates, sampling is not enough, and randomly from the table for each query means many random I/O we propose two novel indexes to aid in-memory samples. The num- accesses, which are costly at query time, resulting in high latency. ber of random seeks using our indexes can be bounded to achieve Such techniques are orthogonal to our ideas of sampling and build- the same precision guarantee. Thus, our system is efficient for ing indexes before queries come, and can be integrated into our queries with various selectivities. Our system can extend to sup- system to provide estimations before index building is finished. port a generic range of aggregates with complex predicates. 690
13 .10. REFERENCES bootstrap: a new method for fast error estimation in approximate [1] J. Acharya, I. Diakonikolas, C. Hegde, J. Z. Li, and L. Schmidt. Fast query processing. In SIGMOD, 2014. and near-optimal algorithms for approximating distributions by histograms. In PODS, 2015. [2] S. Acharya, P. B. Gibbons, and V. Poosala. Congressional samples APPENDIX for approximate answering of group-by queries. In SIGMOD, 2000. [3] S. Acharya, P. B. Gibbons, V. Poosala, and S. Ramaswamy. The aqua A. PROOFS approximate query answering system. In SIGMOD, 1999. Proof of Theorem 3. Suppose there are r groups in the answer [4] S. Agarwal, H. Milner, A. Kleiner, A. Talwalkar, M. Jordan, x to Q. For each group i ∈ {1, . . . , r}, let ni be the number S. Madden, B. Mozafari, and I. Stoica. Knowing when you’re wrong: of rows belonging to the ith group and satisfying the predicate P, building fast and reliable approximate query processing systems. In SIGMOD, 2014. and nP be the total number of rows satisfying P. So of course, r [5] S. Agarwal, B. Mozafari, A. Panda, H. Milner, S. Madden, and i=1 ni = nP and s(P) = nP /n. I. Stoica. Blinkdb: queries with bounded errors and bounded We draw a uniform sample of m rows T 0 from T . Similarly, response times on very large data. In Eurosys, 2013. in the sample T 0 , let mi be the number of rows belonging to the [6] S. Agrawal, S. Chaudhuri, and V. R. Narasayya. Automated selection ith group and satisfying the predicate P, and mP be the number of of materialized views and indexes in sql databases. In VLDB, 2000. rows satisfying P. [7] B. Babcock, S. Chaudhuri, and G. Das. Dynamic sample selection Consider the answer x to Q and the estimated answer xˆ , we have for approximate query processing. In SIGMOD, 2003. xi = ni /nP and x ˆi = mi /mP . So, [8] P. Bille, A. Pagh, and R. Pagh. Fast evaluation of union-intersection expressions. In ISAAC, 2007. r 2 2 ni mi [9] K. Chakrabarti, M. Garofalakis, R. Rastogi, and K. Shim. E x−x ˆ 2 =E − (8) Approximate query processing using wavelets. VLDBJ, 10(2-3), i=1 nP mP 2001. r 2 [10] M. Charikar, S. Chaudhuri, R. Motwani, and V. R. Narasayya. n2 ni nP m i =E m· −m· · . (9) Towards estimation error guarantees for distinct values. In PODS, m2 n2P i=1 n n mP 2000. [11] S. Chaudhuri, G. Das, M. Datar, R. Motwani, and V. Narasayya. mP can be interpreted as the number of successes in m indepen- Overcoming limitations of sampling for aggregation queries. In dent Bernoulli trials with success probability nP /n. So E [mP ] = ICDE, 2001. m · nP /n m ¯ P . Similarly, mi can be interpreted as the number [12] S. Chaudhuri, G. Das, and V. Narasayya. A robust, of successes in m independent Bernoulli trials with success proba- optimization-based approach for approximate answering of aggregate bility ni /n. So E [mi ] = m · ni /n m ¯ i . From Chernoff bound, queries. In SIGMOD, 2001. [13] S. Chaudhuri, G. Das, and V. Narasayya. Optimized stratified for 0 < < 1, we have sampling for approximate query processing. TODS, 32(2), 2007. 2 ¯ P ] ≤ e− Pr [mP ≥ (1 + )m m ¯ P /3 , (10) [14] T. Condie, N. Conway, P. Alvaro, J. M. Hellerstein, K. Elmeleegy, and R. Sears. Mapreduce online. In NSDI, 2010. − 2m ¯ P /2 and Pr [mP ≤ (1 − )m ¯ P] ≤ e . (11) [15] V. Ganti, M.-L. Lee, and R. Ramakrishnan. Icicles: Self-tuning samples for approximate query answering. In VLDB, 2000. Consider two events: Ein = [(1 − )m ¯ P < mP < (1 + )m ¯ P ] and [16] M. N. Garofalakis and P. B. Gibbons. Approximate query processing: Eout = [mP ≥ (1 + )m ¯ P ∨ mP ≤ (1 − )m ¯ P ]. We can then Taming the terabytes. In VLDB, 2001. rewrite (9) using conditional probability: [17] A. C. Gilbert, Y. Kotidis, S. Muthukrishnan, and M. J. Strauss. r 2 Optimal and approximate computation of summary statistics for 2 1 mi range aggregates. In PODS, 2001. E x−x ˆ 2 =E ¯i −m m ¯P · = (12) ¯ 2P m i=1 mP [18] J. Gray, S. Chaudhuri, A. Bosworth, A. Layman, D. Reichart, M. Venkatrao, F. Pellow, and H. Pirahesh. Data cube: A relational r 2 1 mi aggregation operator generalizing group-by, cross-tab, and sub-totals. E ¯i −m m ¯P · Ein · Pr [Ein ] (13) Data Min. Knowl. Discov., 1(1), 1997. ¯ 2P m i=1 mP [19] J. M. Hellerstein, P. J. Haas, and H. J. Wang. Online aggregation. r 2 SIGMOD, 1997. 1 mi +E ¯i −m m ¯P · Eout · Pr [Eout ] . (14) [20] A. Kim, E. Blais, A. G. Parameswaran, P. Indyk, S. Madden, and ¯ 2P m i=1 mP R. Rubinfeld. Rapid sampling for visualizations with ordering guarantees. PVLDB, 8(5), 2015. Let mP /m ¯ P = α. (13) can be upper bounded as: [21] A. Kleiner, A. Talwalkar, S. Agarwal, I. Stoica, and M. I. Jordan. A r general bootstrap performance diagnostic. In KDD, 2013. 1 mi 2 [22] S. L. Lohr. Sampling: Design and Analysis. Thomson, 2009. (13) ≤ E ¯i − m 1− <α<1+ (15) ¯ 2P m i=1 α [23] C. Olston, E. Bortnikov, K. Elmeleegy, F. Junqueira, and B. Reed. r Interactive analysis of web-scale data. In CIDR, 2009. 1 mi 2 [24] N. Pansare, V. R. Borkar, C. Jermaine, and T. Condie. Online ≤ max E ¯i − m (16) 1− <α<1+ ¯ 2P m i=1 α aggregation for large mapreduce jobs. PVLDB, 4(11), 2011. [25] N. Potti and J. M. Patel. Daq: a new paradigm for approximate query r 1 1 (α − 1)2 2 processing. PVLDB, 8(9), 2015. = max Var [mi ] + m ¯i (17) [26] B. Shneiderman. Response time and display rate in human 1− <α<1+ ¯ 2P m i=1 α 2 α2 performance with computers. ACM Computing Surveys, 1984. r r 2 2 [27] L. Sidirourgos, M. L. Kersten, and P. A. Boncz. Sciborq: Scientific ≤ Var [mi ] + ¯ 2i m ( ≤ 0.5 is small). (18) data management with bounds on runtime and quality. In CIDR, ¯ 2P m i=1 i=1 2011. [28] J. S. Vitter and M. Wang. Approximate computation of Since mi is the number of successes in m Bernoulli trials, multidimensional aggregates of sparse data using wavelets. In r r SIGMOD, 1999. ni ni m · nP Var [mi ] = m· · 1− ≤ =m ¯ P . (19) [29] K. Zeng, S. Gao, B. Mozafari, and C. Zaniolo. The analytical i=1 i=1 n n n 691
14 .From Cauchy-Schwarz inequality, we have T M . Recall that, in our estimated answer x ˆ = x ˆ1 , . . . , x ˆr , we 2 have xˆi = mi /m. So we can rewrite r r 2 ¯ 2i ≤ m 2 m ¯i = 2 ¯ 2P ·m (20) 1 r M (Ti ) 2 2 i=1 i=1 E x−x ˆ 2 = E · m − mi . (30) m2 i=1 M (T ) Putting (19) and (20) back to (18), we have 2 In our measure-biased sampling, a row in the ith group Ti is (13) ≤ + 2 2. (21) drawn into T M with probability pMi = M (Ti )/M (T ). So mi is m ¯P the number of successes of in m independent Bernoulli trials with Now we upper bound (14). From (10) and (11), success probability pM M i . We have E [mi ] = mpi and Var [mi ] = M M 2 2 2 mpi (1 − pi ). (30) can be rewritten as Pr [Eout ] ≤ e− m ¯ P /3 + e− m ¯ P /2 ≤ 2e− m ¯ P /3 . (22) r r 2 1 1 1 For the values of mP /m ¯ P = α in event Eout , we have E x−x ˆ 2 = Var [mi ] = pM M i (1−pi ) ≤ . m2 i=1 m i=1 m r 2 1 mi E ¯i −m m ¯P · Eout (23) The rest part is similar to the proof of Theorem 3. Let m = ¯ 2P m mP i=1 Ω (1/ 2 ) · log(1/δ) . Using Jensen’s inequality, we could have √ 1 r r mi 2 E[ x − x ˆ 2 ] ≤ 1/ m ≤ . As replacing one row in T M changes ≤ 2 E ¯ 2i + m ¯P · m ≤ 2. (24) x−x ˆ 2 at most by 1/m, using McDiarmid’s inequality, x − m ¯P i=1 i=1 mP ˆ 2 ≤ 2 with probability at most 1 − δ. x where the second inequality of (24) is from Cauchy-Schwarz in- Now consider the general case with 0 < s0 ≤ 1 and a query equality and linearity of expectation. Putting (22) and (24) back to Q(G, SUM(M ), P) with measure selectivity sM (P) ≥ s0 . The (14), together with (13) and (21), we have idea is identical to the proof of Theorem 3 so we only sketch it in the following part. 2 2 2 2 E x−x ˆ 2 ≤ +2 + 4e− m ¯ P /3 ≤ 6 2, (25) Let TP ⊆ T be the set of rows satisfying P in T , and Ti ⊆ TP m ¯P be the set of rows satisfying P and belonging to the ith group in if m ¯P = Ω 1 2 log 1 2 , and from Jensen’s inequality, T . Also, let mP be the number of rows satisfying P in the sample T M , and mi be the number of rows satisfying P and belonging to E[ x − x ˆ 2] ≤ ˆ 22 ] ≤ 3 . E[ x − x (26) the ithe group in T M . In our measure-biased sampling, it is not hard to see E [mP ] = We can conclude the proof using a generalized McDiarmid’s in- m · M (TP )/M (T ) m¯ P . Similar to the proof of Theorem 3, equality. Rewrite φ(t1 , . . . , tm ) x−x ˆ 2 , where ti is a sample consider two events: Ein = [(1 − )m ¯ P < mP < (1 + )m ¯ P ] and row from the table T and {ti | i = 1, . . . , m} are mutually inde- Eout = [mP ≥ (1 + )m ¯ P ∨ mP ≤ (1 − )m ¯ P ]. Decompose pendent. Consider a different estimation x ˆ = x ˆ1 , . . . , x ˆr , where E x−x ˆ 22 as in (13)-(14) into x ˆi = mi /m ¯ P (and truncate x ˆi at 1). Note that m ¯ P is unknown 2 2 ˆ is only conceptually feasible. Similarly, let φ (t1 , . . . , tm ) so x E x−x ˆ 2 =E x−x ˆ 2 | Ein · Pr [Ein ] (31) x−x ˆ 2 . Using Chernoff bound as (10), if m ¯ P = Ω 12 log 1δ , +E x−x ˆ 2 2 | Eout · Pr [Eout ] . (32) x−x ˆ 2 We can show that Pr [Eout ] is small enough so that (32) only adds a Pr 1 − ≤ ≤1+ ≥ 1 − δ. (27) x−x ˆ 2 term . On the other hand, in the event Ein , E x − x ˆ 22 | Ein can be upper bounded similarly as in the above special case by 1/m ¯P For any two random samples {t1 , . . . , ti , . . . , tm } and {t1 , . . . , ti , with high probability. Putting them together with a generalized . . . , tm } differing at only one pair of tuples ti and ti , the function argument using McDiarmid’s inequality completes the proof. ✷ φ satisfies the Lipschitz property that Proof of Proposition 7. In the answer x = x1 , . . . , xr to Q, |φ (t1 , . . . , ti , . . . , tm ) − φ (t1 , . . . , ti , . . . , tm )| = ci ≤ 2/m ¯ P. there are r groups. Let Ti ⊆ TP be the set of rows belonging m to the ith group for i = 1, . . . , r. For a set T of rows, recall and c2i ≤ 4/m ¯ P . So using McDiarmid’s inequality, M (T ) = t∈T tM . So we have xi = M (Ti )/M (TP ). Let m i=1 2 be the number of rows in TP and Ti be the set of rows belonging Pr x−x ˆ 2 >E x−x ˆ 2 + ≤ e−8 m ¯P = δ. (28) to the ith group in TP . We estmate xˆi = M (Ti )/M (TP ). Thus, from (26), (27), and (28), we have We rewrite E x − x ˆ 22 = r Pr [ x − x ˆ 2 ≤ ] ≥ 1 − δ, (29) 1 2 = E xi · M (TP ) − M (Ti ) (33) M (TP )2 if m = Ω 1 s0 · 1 2 · log 1 2 + log 1 δ ¯ P = m · s0 ). (note m ✷ i=1 r Proof of Theorem 5. Let’s first focus on a special case where 1 2 ≤ E xi · M (TP ) − M (Ti ) . (34) s0 = 1 and the query Q(G, SUM(M ), ∅) has no predicate. m2 i=1 Suppose there are r groups in the answer x = x1 , . . . , xr to Q. Let Ti ⊆ T be the set of rows belonging to the ith group for Now focus on the ith group. Consider one random draw of a i = 1, . . . , r. Recall that, for a set T of rows, M (T ) = t∈T tM row t in TP . Let It,i be indicator variable of the event that t ∈ Ti is the sum of values of measure M over all rows in T . So we have (i.e., It,i = 1 if t ∈ Ti and It,i = 0 otherwise). Define random xi = M (Ti )/M (T ). variable Zt,i = xi · tM − tM · It,i . We can rewrite the term in Let m be the number of rows in the measure-biased sample T M , (34) as xi · M (TP ) − M (Ti ) = t∈TP Zt,i . It is not hard to and let mi be the number of rows belonging to the ith group in see that Et [Zt,i ] = 0. And because the m rows in TP are drawn 692
15 .independently, we have of measure values when scanning rows; more specifically, for each 2 row t, we maintain the sum of tM for all rows t that were scanned 2 E Σt∈TP Zt,i = mEt Zt,i . before arriving at t, denoted as σM (t). We add one copy of t into T M if there exists s ∈ S M (m) s.t. σM (t) ≤ s < σM (t) + tM , Putting it back to (34), we have and k copies of t if there are k such samples s in S M (m). The intuition behind the above implementation is that a row t r 2 1 2 occupies an interval [σM (t), σM (t) + tM ) with width tM on the E x−x ˆ 2 ≤ Et Zt,i . (35) m whole range [0, M (T )), so a uniformly picked number from the i=1 range falls into the interval of t with probability exactly propor- 2 We upper bound Et Zt,i in the rest part. tional to tM (as required in (4) by measure-biased sampling). A 2 simplified version can be used for generating uniform samples. Et Zt,i = Et x2i · t2M − 2xi · t2M · It,i + t2M · I2t,i . (36) We illustrate this sampling procedure using an example. Let n = |TP | and ni = |Ti |. Using the fact that tM ∈ [1, ∆] for any row t, we have E XAMPLE B.1. (Continue Example 1.1) Let’s use the table T with 200 rows in Figure 1(a) and measure M to demonstrate how t2M n∆2 to implement measure-biased sampling in two scans. To draw a Et x2i · t2M = x2i · ≤ x2i · = x2i ∆2 . n n measure-biased sample T M with 20 rows, in the first scan, we cal- t∈TP culate M (T ) = t tM = 488. We draw 20 random numbers And similarly, from ni /n ≤ xi ∆, we have S M (20) uniformly from the range [0, 488]. For example, we could have S M (20) = {0, 25, 50, . . . , 450, 475}. t2M ni ∆ 2 Et t2M · I2t,i = ≤ ≤ xi ∆3 , We maintain partial sums on M during the second scan of rows t∈Ti n n from 1 to 200. For row 26, the partial sum is 25 and we have 25 in S M (20), so row 26 is put into T M . For row 199, the partial sum Putting them back to (36), we have is 288 and {300, 325, 350, 375} ⊆ S M (20) falling into the range 2 Et Zt,i ≤ x2i ∆2 + xi ∆3 ≤ (∆3 + ∆2 ) · xi . (37) [288, 388), so 4 copies of row 199 are put into T M . Figure 9 shows how the measure-biased sample T M is constructed from random And putting (37) back to (35), we have numbers in S M (20). When there are multiple measures, the second r scans for all of them can be easily merged (by maintaining partial 2 1 ∆3 + ∆ 2 E x−x ˆ 2 ≤ (∆3 + ∆2 ) · xi = . sums on all the measures simultaneously). m i=1 m Let m = Ω ∆ / 3 2 and then we have E x − x ˆ 22 ≤ 2 , and C. LOW-FREQUENCY GROUP INDEX from Jessen’s inequality, we complete the proof. ✷ Construction. For a dimension D and a value v, let TD=v be Proof of Theorem 8. In the answer x = x1 , . . . , xr to Q, there the set of rows with value v on dimension D. In a table of n are r groups. Let Ti ⊆ TP be the set of rows belonging to the ith rows, it is obvious that if there is an√equi-constraint Di = vi in group. Let n = |TP | and ni = |Ti |. For a set T of rows, recall the predicate of Q with |TDi =vi | ≤ n (or n · s0 ), then Q must M (T ) = t∈T tM . So we have xi = M (Ti )/M (TP ). Let m be the number of rows in the approximate measure-biased √ query. For each (dimension,value)-pair (D, v), iff be a (s0 -)small |TD=v | ≤ n, the low-frequency group index materializes TD=v , sample TP , and let Ti be the set of rows belonging to the ith group i.e., explicitly stores rows in TD=v sequentially. Note that in our in TP . Recall that we estimate xi as xˆi = M (Ti )/M (TP ). We measure-augmented inverted index, inv(D, v) points to the same can rewrite E x − x ˆ 22 = set of rows as TD=v does. But inv(D, v) keeps only row IDs and r approximate measures, while in our low-frequency group index, 1 2 TD=v , if presents, keeps these rows with all dimensions and mea- = E xi · M (TP ) − M (Ti ) . (38) M (TP )2 i=1 sure attributes in a row-oriented format. We cannot get a tight theoretical bound √ of the size of this index (38) is analogous to (33). The probability of drawing a row from Ti as the set of pairs (D, v) with |TD=v | ≤ n is dependent √ on the is pi = t∈Ti apx(tM )/ t∈TP apx(tM ). It is not hard to show frequency distribution of dimension D. But since n is small, in pi ≤ 2xi . Similar to (33)-(37), we can show both benchmark and real datasets, we observe that its size is usually 2 12 very small (see “LF index” in Table 1). We store it on disk. When E x−x ˆ 2 ≤ , m the disk space budget is a problem, we can choose to not build it, as measure-augmented inverted index suffices for all small queries. with ∆ = 2. So with m = Ω 1/ 2 , we have E x − x ˆ 22 ≤ 2 , and from Jessen’s inequality, we have E [ x − x ˆ 2] ≤ . Processing queries. For a query Q, we check two conditions: Finally, replace one row in TP changes x − x ˆ 2 at most by whether i) its predicate P is in the form of (7) and ii) P contains an 2/m (because 1 ≤ tM < 2). So, using McDiarmid’s inequality, equi-constraint “Di = vi ” with√TDi =vi stored in the index. If yes, we have that x − x ˆ 2 ≤ 2 , with probability at most 1 − δ, if we simply need to scan up to n rows in TDi =vi sequentially to m = Ω (1/ 2 ) · log(1/δ) . ✷ get the exact answer. It corresponds to ProcessWithLFIndex(Q) in lines 8-9 of Algorithm 1. For example, the following query SELECT C1 , SUM(M ) FROM T GROUP BY C1 B. DRAWING SAMPLES EFFICIENTLY WHERE C2 = 1 AND (C3 = 0 OR C3 = 1) In the first scan, for each measure M , we compute M (T ) = can be answered by scanning rows TC2 =1 . t∈T tM , i.e., the sum of values on M over all rows in T . We gen- erate m random real numbers S M (m) uniformly from the range T HEOREM 10. If a query Q satisfies the above conditions i) [0, M (T )). Then in the second scan, we maintain a partial sum and ii), the low-frequency group index can be used to answer Q. On 693
16 . tID 1 26 51 76 92 94 96 98 111 136 161 186 199 200 Partial sum σM (t) 0 25 50 75 100 120 150 170 200 225 250 275 288 388 Numbers in S M (20) 0 25 50 75 100 125 150 175 200 225 250 275 300, 325, 350, 375 400, 425, 450, 475 σM (t) + tM 1 26 51 76 110 130 160 180 201 226 251 276 388 488 # copies of t in T M 1 1 1 1 1 1 1 1 1 1 1 1 4 4 Figure 9: Drawing a Measure-biased Sample T M DBX SPSSample SPSIndex tends to be stable for small selectivity as the number of random Response time (ms) 105 8 accesses is upper bounded by both 1/ 2 (Theorem 9). Actual error (%) 104 6 Average actual error is steadily below the requested bound 0.05 103 because of our rigorous theoretical guarantee. 4 102 Exp-V: Vary number of dimensions in queries. We partition 2 queries into buckets based on the numbers of dimensions (in group- 101 bys, predicates, and measure of each query). In our workloads, the 0 100 310 620 1120 number of dimensions varies from 2 to 9. Average response time in 310 620 1120 #Rows (million) #Rows (million) each bucket is plotted in Figure 11(b) for LOG with = 0.05. The one for TPC-H is similar and thus omitted here. With more dimen- Figure 10: Varying number of rows (LOG) sions, the response time of SPS increases because of two reasons: DBX SPSSample SPSIndex DBX SPSSample SPSIndex i) smaller selectivity (so SPSIndex increases); and ii) more columns Response time (ms) Response time (ms) 105 105 to be scanned (so SPSSample increases). SPS always has significant 104 104 speedup over DBX and tends to be stable after six dimensions. 103 103 102 102 E. ADDITIONAL RELATED WORK 101 101 Requested error v.s. actual error. Most of sampling-based sys- 100 100 10−5 10−4 10−3 10−2 10−1 100 2 3 4 5 6 7 8 9 tems estimate error bars using central limit theorem (CLT), Ho- Selectivity #Dimensions effding inequality [6], or bootstrap [29]. In particular, BlinkDB [5] (a) Varying selectivity (b) Varying # dimensions estimates error bar using standard closed-form formulas during on- Figure 11: Selectivity and # dimensions of queries (LOG) line query. It is then claimed in [4] that the estimated error bar fails √ a lot in real query workload (also refer to our Example 1.1). A re- a table of n rows, we need to retrieve at most n rows sequentially cent diagnostic algorithm (Kleiner et al. [21]) is extended by [4] to from the disk to compute its answer. diagnose the failure of error bar estimation. So requested (or estimated) error is not always below the actual D. ADDITIONAL EXPERIMENTS error. That is also one motivation why we introduce a more rig- Exp-III: Vary database size. We test the scalability of our system orous notion, distribution predication guarantee, in this work. As and compare it with DBX for datasets with different sizes. We far as we are concerned, our work is the first to provide such theo- use datasets LOG-S, LOG-M, and LOG (refer to Table 1) and set retical guarantees in AQP. One of our theoretical result on uniform = 0.05. Average response time (in DBX and SPS) and average sampling is inspired by the result in Acharya et al. [1]. It proves actual error with one standard deviation (in SPS) for queries in all that uniform sampling achieves a tight bound in histogram approx- the twenty workloads are plotted in Figure 10. First of all, we find imation, which can be applied in our problem when the query has that the actual error is quite stable for different databases, which is no predicate and the aggregate function is COUNT. not surprising because of our rigorous theoretical guarantees. Non-sampling based approaches. Another orthogonal line of work For response time of SPS, we decompose it into SPSSample and are view materialization [6] and datacube [18] which precompute SPSIndex , which represent the time SPS spends on in-memory sam- answers to some queries and create summaries to accelerate OLAP ples and on-disk indexes, respectively. It can be seen that response query processing. Histograms [17] and wavelets [28, 9, 17] cre- time in SPS increases slightly for larger datasets, but the SPSIndex ate compressed synopses of relational tables to support some ag- part is quite stable. That is because the number of random accesses gregates. These techniques either have too large space overhead needed in our algorithm is independent on the database size (Theo- (super-linear) to be applicable for enterprise-scale workloads and rem 8). On the other hand, DBX’s response time increases linearly datasets, or are applicable for only a subclass of aggregates sup- to the number of rows, because column-store indexes are used. ported by ours (e.g., without joins and complex predicates). Exp-IV: Vary selectivity of queries. Selectivity (ratio of # rows Other AQP systems. Deterministic approximate querying (DAQ) satisfying the predicate to total # rows) may affect the response schemes are recently proposed in [25]. It proposes novel bit-sliced time of our system SPS. √ It is because large queries (with selec- indexes to store columns separately so that a query can be evalu- tivity higher than 1/ n) only need to scan in-memory samples, ated on the first few bits while ignoring the remaining bits for each but small queries may also need to use on-disk indexes. So we row. However, the bitwise DAQ still needs to exhaust all bits when partition queries in all the twenty workloads into six buckets with doing equality check on categorical dimensions, and in general it selectivities in (10−1 , 1], (10−2 , 10−1 ], . . . , (0, 10−5 ]. Average re- needs to scan all rows for the most significant bits, so the speedup sponse time in each bucket is plotted in Figures 11(a) for LOG with is limited for the query class we support. However, it would be a = 0.05. The one for TPC-H looks quite similar. very interesting line of future work to incorporate such bit-sliced We find that SPSSample increases as selectivity becomes smaller. indexes into sampling-based systems, as these two lines of works It is because of the early termination condition when scanning sam- are orthogonal and can mutually enhance each other. ples: an -approximation x ˆ needs to collect 1/ 2 rows that satisfies Ordering guarantee in AQP is studied by Kim et al. [20]. It the query predicate from the sample – if the predicate has large se- proposes an optimal online sampling algorithm to guarantee the lectivity, this condition can be satisfied earlier in the scan. SPSIndex right order of groups with the help of efficient indexes. 694
3秒后跳转登录页面
去登陆

