







- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
MLbase: A Distributed Machine-learning System
In this work, we present our vision for MLbase,a novel system harnessing the power of machine learning for
both end-users and ML researchers. MLbase provides
(1) a simple declarative way to specify ML tasks,
(2) a novel optimizer to select and dynamically adapt the choice of learning algorithm,
(3) a set of high-level operators to enable ML researchers to scalably implement a wide range of ML methodswithout deep systems knowledge,
(4) a new run-time optimized for the data-access patterns of these high-level operators.
展开查看详情
1 . MLbase: A Distributed Machine-learning System Tim Kraska† Ameet Talwalkar† John Duchi Brown University AMPLab, UC Berkeley AMPLab, UC Berkeley kraskat@cs.brown.edu ameet@cs.berkeley.edu jduchi@eecs.berkeley.edu Rean Griffith Michael J. Franklin Michael Jordan VMware AMPLab, UC Berkeley AMPLab, UC Berkeley rean@vmware.com franklin@cs.berkeley.edu jordan@cs.berkeley.edu † These authors contributed equally. ABSTRACT only beginning to appear [7]. The complexity of existing al- Machine learning (ML) and statistical techniques are key to gorithms is (understandably) overwhelming to layman users, transforming big data into actionable knowledge. In spite who may not understand the trade-offs, parameterization, of the modern primacy of data, the complexity of existing and scaling necessary to get good performance from a learn- ML algorithms is often overwhelming—many users do not ing algorithm. Perhaps more importantly, existing systems understand the trade-offs and challenges of parameterizing provide little or no help for applying machine learning on and choosing between different learning techniques. Fur- Big Data. Many systems, such as standard databases and thermore, existing scalable systems that support machine Hadoop, are not designed for the access patterns of machine learning are typically not accessible to ML researchers with- learning, which forces developers to build ad-hoc solutions out a strong background in distributed systems and low-level to extract and analyze data with third party tools. primitives. In this work, we present our vision for MLbase, With MLbase we aim to make machine learning accessi- a novel system harnessing the power of machine learning for ble to a broad audience of users and applicable to various both end-users and ML researchers. MLbase provides (1) a data corpora, ranging from small to very large data sets. simple declarative way to specify ML tasks, (2) a novel opti- To achieve this goal, we provide here a design for MLbase mizer to select and dynamically adapt the choice of learning along the lines of a database system, with four major foci. algorithm, (3) a set of high-level operators to enable ML re- First, MLbase encompasses a new Pig Latin-like [22] declar- searchers to scalably implement a wide range of ML methods ative language to specify machine learning tasks. Although without deep systems knowledge, and (4) a new run-time MLbase cannot optimally support every machine learning optimized for the data-access patterns of these high-level scenario, it provides reasonable performance for a broad operators. range of use cases. This is similar to a traditional DBMS: highly optimized C++ solutions are stronger, but the DBMS achieves good performance with significantly lower develop- 1. INTRODUCTION ment time and expert knowledge [28]. Second, MLbase uses Mobile sensors, social media services, genomic sequencing, a novel optimizer to select machine learning algorithms— and astronomy are among a multitude of applications that rather than relational operators as in a standard DBMS— have generated an explosion of abundant data. Data is no where we leverage best practices in ML and build a sophis- longer confined to just a handful of academic researchers or ticated cost-based model. Third, we aim to provide answers large internet companies. Extracting value from such Big early and improve them in the background, continuously re- Data is a growing concern, and machine learning techniques fining the model and re-optimizing the plan. Fourth, we enable users to extract underlying structure and make pre- design a distributed run-time optimized for the data-access dictions from large datasets. In spite of this, even within patterns of machine learning. statistical machine learning, an understanding of computa- In the remainder, we outline our main contributions: tional techniques for algorithm selection and application is • We describe a set of typical MLbase use cases, and we sketch how to express them in our high-level language • We show the optimization pipeline and describe the opti- mizer’s model selection, parameter selection, and valida- tion strategies This article is published under a Creative Commons Attribution License • We sketch how the optimizer iteratively improves the model (http://creativecommons.org/licenses/by/3.0/), which permits distribution in the background and reproduction in any medium as well allowing derivative works, pro- • We describe the MLbase run-time and show how it differs vided that you attribute the original work to the author(s) and CIDR 2013. from traditional database pipelines. 6th Biennial Conference on Innovative Data Systems Research (CIDR’13) January 6-9, 2013, Asilomar, California, USA.
2 .2. USE CASES The semantics of doCollabFilter are identical to doClassify, MLbase will ultimately provide functionality to end users with the obvious distinction of returning a model fn-model for a wide variety of common machine learning tasks: classi- to predict song ratings. fication, regression, collaborative filtering, and more general exploratory data analysis techniques such as dimensionality 2.3 Twitter Analysis reduction, feature selection, and data visualization. More- Equipped with snapshots of the Twitter network and as- over, MLbase provides a natural platform for ML researchers sociated tweets [19, 26], one may wish to perform a variety to develop novel methods to these tasks. We now illustrate of unsupervised exploratory analyses to better understand a few of the many use cases that MLbase will provide and the data. For instance, advertisers may want to find features along the way, we describe MLbase’s declarative language that best describe “hubs,” people with the most followers or for tackling these problems. the most retweeted tweets. MLbase provides facilities for graph-structured data, and finding relevant features can be 2.1 ALS Prediction expressed as follows: Amyotrophic Lateral Sclerosis (ALS), commonly known as Lou Gehrig’s disease, is a progressive fatal neurodegener- var G = loadGraph("twitter_network") ative illness. Although most patients suffer from a rapidly var hubs-nodes = findTopKDegreeNodes(G, k = 1000) progressing disease course, some patients (Stephen Hawking, var T = textFeaturize(load("twitter_tweet_data")) for example) display delayed disease progression. Leverag- var T-hub = join(hub-nodes, "u-id", T, "u-id") ing the largest database of clinical data for ALS patients findTopFeatures(T-hub) ever created, the ALS Prediction Prize [5] challenges partic- ipants to develop a binary classifier to predict whether an In this example, the user first loads the twitter graph and ALS patient will display delayed disease progression. applies the findTopKDegreeNodes() function to determine MLbase on its own will not allow one to win the ALS prize, the hubs. Afterwards, the tweets are loaded and featurized but it can help a user get a first impression of standard classi- with textFeaturize(). During this process, every word in a fiers’ performance. Consider the following example “query,” tweet, after stemming, becomes a feature. The result of the which trains a classifier on the ALS dataset: featurization as well as the pre-determined hubs are joined together on the user-id, u-id, and finally, findTopFeatures var X = load("als_clinical", 2 to 10) finds the distinguishing features of the hubs. var y = load("als_clinical", 1) var (fn-model, summary) = doClassify(X, y) 2.4 ML Research Platform The user defines two variables: X for the data (the inde- A key aspect of MLbase is its extensibility to novel ML pendent features/variables stored in columns 2 to 10 in the algorithms. We envision ML experts using MLbase as a dataset) and y for the labels (stored in the first column) to platform to experiment with new ML algorithms. MLbase be predicted via X. The MLbase doClassify() function de- has the advantage that it offers a set of high-level primitives clares that the user wants a classification model. The result to simplify building distributed machine learning algorithms of the expression is a trained model, fn-model, as well as a without knowing the details about data partitioning, mes- model summary, describing key characteristics of the model sage passing, or load balancing. These primitives currently itself, such as its quality assessment and the model’s lineage include efficient implementations of gradient and stochas- (see Section 3). tic gradient descent, mini-batch extensions of map-reduce The language hides two key issues from the user: (i) which that naturally support divide-and-conquer approaches such algorithms and parameters the system should use and (ii) as [21], and graph-parallel primitives as in GraphLab [20]. how the system should test the model or distribute com- We have already mapped several algorithms, including k- putation across machines. Indeed, it is the responsibility means clustering, LogitBoost [16], various matrix factoriza- of MLbase to find, train and test the model, returning a tion tasks (as described in [21]), and support vector ma- trained classifier function as well as a summary about its chines (SVM) [13] to these primitives. performance to the user.MLbase Furthermore, we allow the ML expert to inspect the execu- tion plan using a database-like explain function and steer 2.2 Music Recommendation the optimizer using hints, making it an ideal platform to The Million Song Dataset Challenge [6] is to predict the easily setup experiments. For example, the hints allow an listening behavior of a set of 110,000 music listeners (i.e., the expert to fix the algorithms, the parameter ranges and/or test-set), deciding which songs of the Million Song Dataset [10] force a full grid-search in order to generate parameter sensi- they will listen to based on partial listening history and the tivity analysis. Even though in this setting, the ML expert listening history of 1M other users (i.e., the training-set). does not use the automatic ML algorithm nor the parameter This is an exemplar of collaborative filtering (or noisy matrix selection, he would still benefit from the run-time optimiza- completion) problem. Specifically, we receive an incomplete tion. observation of a ratings matrix, with columns correspond- ing to users and rows corresponding to songs, and we aim to 3. ARCHITECTURE infer the unobserved entries of this ratings matrix. Under Figure 1 shows the general architecture of MLbase, which this interpretation, we can tackle this collaborative filtering consists of a master and several worker nodes. A user is- task with MLbase’s doCollabFilter expression as follows: sues requests using the MLbase declarative task language to var X = load("user_song_pairs", 1 to 2) the MLbase master. The system parses the request into a var y = load("user_ratings", 1) logical learning plan (LLP), which describes the most gen- var (fn-model, summary) = doCollabFilter(X, y) eral workflow to perform the ML task. The search space for
3 . In contrast to traditional database systems, the task here is not necessarily complete upon return of the first result. Declarative result Instead, we envision that MLbase will further improve the ML Task (e.g., fn-model & summary) model in the background via additional exploration. The User first search therefore stores intermediate steps, including Master Server models trained on subsets of data or processed feature val- ues, and maintains statistics on the underlying data and Meta-Data Parser ML Contract + learning algorithms’ performance. MLbase may then later Code LLP re-issue a better optimized plan to the execution module to Master ML Library improve the results the user receives. Statistics Optimizer This continuous refinement of the model in the background has several advantages. First, the system becomes more PLP interactive, by letting the user experiment with an initial Executor/Monitoring model early on. Second, it makes it very easy to create ML Developer progress bars, which allow the user to decide on the fly when the quality is sufficient to use the model. Third, it reduces the risk of stopping too early. For example, the user might DMX DMX DMX DMX find, that in the first 10 minutes, the system was not able to Slaves Runtime Runtime Runtime Runtime …. create a model with sufficient quality and he is now consid- ering other options. However, instead of letting the system remain idle until the user issues the next request, MLbase continues searching and testing models in the background. If it finds a model with better quality, it informs the user Figure 1: MLbase Architecture about it. Finally, it is very natural for production systems MLbase to continuously improve models with new data. MLbase is designed from the beginning with this use case in mind by making new data one of the dimensions for improving a the LLP consists of the combinations of ML algorithms, fea- model in the background. turization techniques, algorithm parameters, and data sub- Another key aspect of MLbase is its extensibility to novel sampling strategies (among others), and is too huge to be ML algorithms. We envision ML experts constantly adding explored entirely. Therefore, an optimizer tries to prune the new ML techniques to the system, with the requirement that search-space of the LLP to find a strategy that is testable in developers implement new algorithms in MLbase primitives a reasonable time-frame. Although the optimization process and describe their properties using a special contract (see the is significantly harder than in relational database systems, left part of Figure 1). The contract specifies the type of al- we can leverage many existing techniques. For example, gorithm (e.g., binary classification), the algorithm’s parame- the optimizer can consider the current data layout, mate- ters, run-time complexity (e.g., O(n)) and possible run-time rialized intermediate results (pre-processed data) as well as optimizations (e.g., synchronous vs. asynchronous learning; general statistics about the data to estimate the model learn- see Section 5). The easy extensibility of MLbase will simul- ing time. However, in contrast to a DBMS, the optimizer taneously make it an attractive platform for ML experts and also needs to estimate the expected quality for each of the allow users to benefit from recent developments in statistical model configurations to focus on the most promising candi- machine learning. dates. After constructing the optimized logical plan, MLbase transforms it into a physical learning plan (PLP) to be exe- 4. QUERY OPTIMIZATION cuted. A PLP consists of a set of executable ML operations, Having described our architecture, we now turn to a deeper such as filtering and scaling feature values, as well as syn- description of our query optimization techniques and ideas. chronous and asynchronous MapReduce-like operations. In Similar to approaches in traditional database systems, we contrast to an LLP, a PLP specifies exactly the parameters transform the declarative ML task into a logical plan, op- to be tested as well as the data (sub)sets to be used. The timize it, and finally translate it into a physical plan; we MLbase master distributes these operations onto the worker describe each of these three below. nodes, which execute them through the MLbase runtime. The result of the execution—as in the examples of the 4.1 Logical Learning Plan previous section—is typically a learned model (fn-model) The first step of optimizing the declarative ML task into or some other representation (relevant features) that the our machine-executable language is the translation into a user may use to make predictions or summarize data. ML- logical learning plan. During this translation many opera- base also returns a summary of the quality assessment of the tions are mapped 1-to-1 to LLP operators (e.g., data load- model and the learning process (the model’s lineage) to allow ing), whereas ML functions are expanded to their best-practice the user to make more informed decisions. In the prototype workflows. we have built, we return the learned model as a higher-order In what follows, we use binary support vector machine function that can be immediately used as a predictive model (SVM) classification (see, e.g., [24]) as our running example on new data.1 throughout. An SVM classifier is based on a kernel function 1 K, where K(x, x ) is a particular type of similarity measure We use the Scala language, which makes it easy to return and serialize functions. between data points x, x . Given a dataset {x1 , . . . , xn }, the
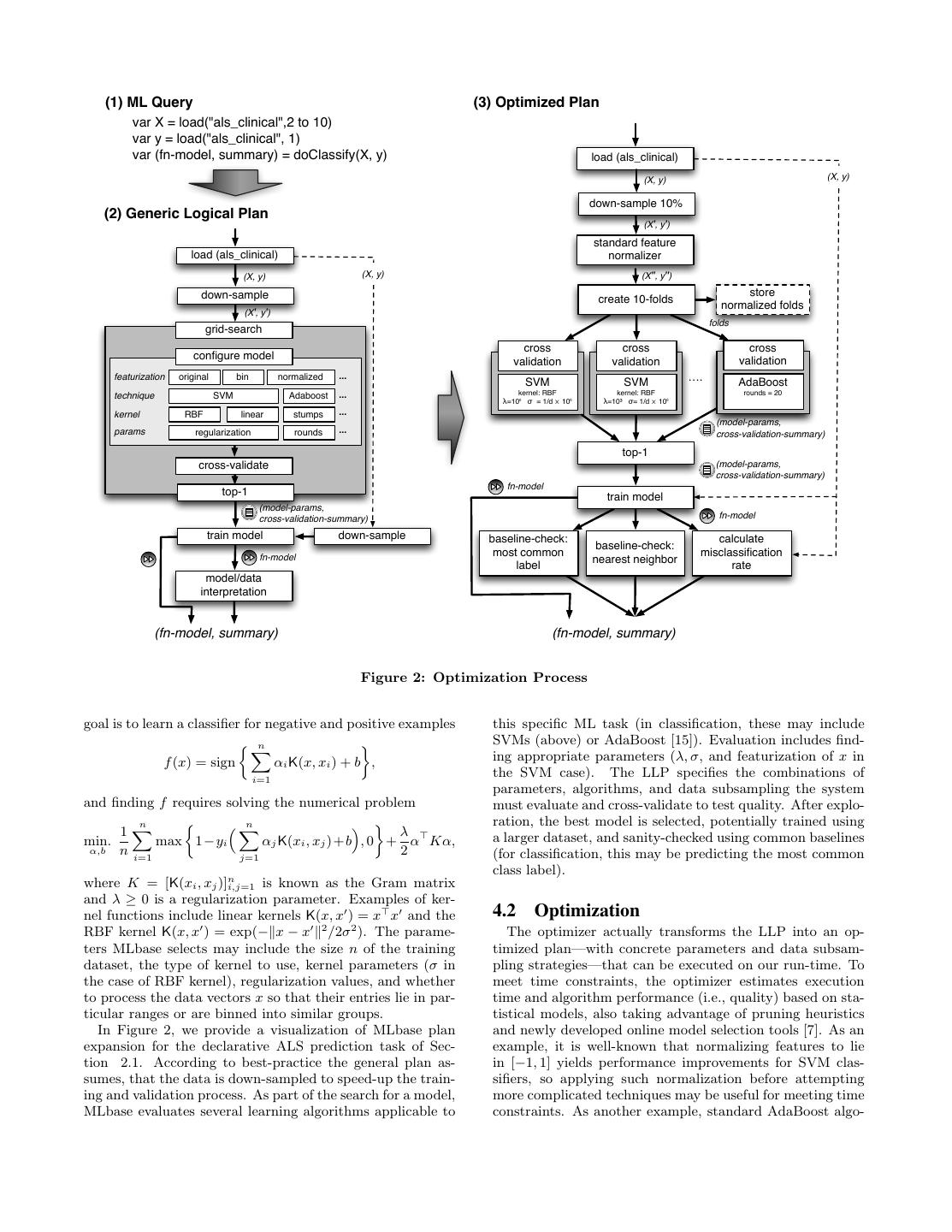
4 . (1) ML Query (3) Optimized Plan var X = load("als_clinical",2 to 10) var y = load("als_clinical", 1) var (fn-model, summary) = doClassify(X, y) load (als_clinical) (X, y) (X, y) down-sample 10% (2) Generic Logical Plan (X', y') standard feature load (als_clinical) normalizer (X, y) (X, y) (X'', y'') down-sample store create 10-folds normalized folds (X', y') folds grid-search cross cross cross configure model validation validation validation featurization original bin normalized ... …. SVM SVM AdaBoost ... kernel: RBF kernel: RBF rounds = 20 technique SVM Adaboost λ=10⁶ σ = 1/d ⨉ 10⁶ λ=10³ σ= 1/d ⨉ 10⁶ kernel RBF linear stumps ... (model-params, params regularization rounds ... cross-validation-summary) top-1 cross-validate (model-params, cross-validation-summary) fn-model top-1 train model (model-params, cross-validation-summary) fn-model train model down-sample baseline-check: calculate baseline-check: fn-model most common misclassification nearest neighbor label rate model/data interpretation (fn-model, summary) (fn-model, summary) Figure 2: Optimization Process goal is to learn a classifier for negative and positive examples this specific ML task (in classification, these may include n SVMs (above) or AdaBoost [15]). Evaluation includes find- f (x) = sign αi K(x, xi ) + b , ing appropriate parameters (λ, σ, and featurization of x in i=1 the SVM case). The LLP specifies the combinations of parameters, algorithms, and data subsampling the system and finding f requires solving the numerical problem must evaluate and cross-validate to test quality. After explo- n n ration, the best model is selected, potentially trained using 1 λ a larger dataset, and sanity-checked using common baselines min. max 1−yi αj K(xi , xj )+b , 0 + α Kα, α,b n i=1 j=1 2 (for classification, this may be predicting the most common class label). where K = [K(xi , xj )]ni,j=1 is known as the Gram matrix and λ ≥ 0 is a regularization parameter. Examples of ker- nel functions include linear kernels K(x, x ) = x x and the 4.2 Optimization RBF kernel K(x, x ) = exp(− x − x 2 /2σ 2 ). The parame- The optimizer actually transforms the LLP into an op- ters MLbase selects may include the size n of the training timized plan—with concrete parameters and data subsam- dataset, the type of kernel to use, kernel parameters (σ in pling strategies—that can be executed on our run-time. To the case of RBF kernel), regularization values, and whether meet time constraints, the optimizer estimates execution to process the data vectors x so that their entries lie in par- time and algorithm performance (i.e., quality) based on sta- ticular ranges or are binned into similar groups. tistical models, also taking advantage of pruning heuristics In Figure 2, we provide a visualization of MLbase plan and newly developed online model selection tools [7]. As an expansion for the declarative ALS prediction task of Sec- example, it is well-known that normalizing features to lie tion 2.1. According to best-practice the general plan as- in [−1, 1] yields performance improvements for SVM clas- sumes, that the data is down-sampled to speed-up the train- sifiers, so applying such normalization before attempting ing and validation process. As part of the search for a model, more complicated techniques may be useful for meeting time MLbase evaluates several learning algorithms applicable to constraints. As another example, standard AdaBoost algo-
5 .rithms, while excellent for choosing features, may be non- SVM AdaBoost robust to data outliers; a dataset known to contain outliers original scaled may render training a classifier using AdaBoost moot. a1a 82.93 82.93 82.87 Figure 2 shows an example optimized plan in step (3). australian 85.22 85.51 86.23 In this example, the optimizer uses standard feature nor- breast 70.13 97.22 96.48 malization and subsamples the data at a 10% rate. Fur- diabetes 76.44 77.61 76.17 thermore, the optimizer uses the best practice of 10-fold fourclass 100.00 99.77 91.19 cross-validation— equally splitting the data in 10 partitions splice 88.00 87.60 91.20 and setting one partition aside for evaluation in each of ten experiments—while the final model is trained using the full Figure 3: Classifier accuracy using SVM with an data set (X, y). The runtime evaluates the model using RBF kernel and using AdaBoost the misclassification rate and against nearest-neighbor and most-common label baselines. Note, that many of the discussed optimization techniques AdaBoost. As shown in Figure 4, the choice of σ in the also apply to unsupervised learning even though it does not SVM problem clearly has a huge impact on quality; auto- allow for automatically evaluating the result with respect matically selecting σ is important. On the other hand, for to quality (e.g., done through the 10-fold cross validation the same datasets, it appears that the number of rounds in in Figure 2). For example, for clustering, very basic statis- AdaBoost is not quite as significant once r ≥ 25 (shown tics about the data can help to determine a good initial in Figure 5). Hence, an optimizer might decide to use Ad- number of seed clusters. Furthermore, the optimizer can aBoost first without scaling and a fixed round parameter to consider building multi-dimensional index structures and/or provide the user quickly with a first classifier. Afterwards, pre-compute distance matrices to speed up the cluster algo- the system might explore SVMs with scaled features to im- rithm. prove the model, before extending the search space to the MLbase allows user-specified hints that can influence the remaining combinations. optimizer, which is similar to user influence in database The general accuracy of algorithms is just one of the as- systems. Experts may also modify training algorithms, in pects an optimizer may take into account. Statistics about essence, the runtime itself, if they desire more control. These the dataset itself, different data layouts, algorithm speed hints, which may include recommended algorithms or fea- and parallel execution strategies (as described in the next turization strategies, makes MLbase a powerful tool even section) are just a few additional dimensions the optimizer for ML experts. may exploit to improve the learning process. 100% 4.3 Optimizer examples 90% To demonstrate the advantages of an optimizer for se- 80% lecting among different ML algorithms, we implemented a 70% 10^-‐6 prototype using two algorithms: SVM and AdaBoost. For Accuracy 60% 10^-‐3 both algorithms, we used publicly available implementa- 50% tions: LIBSVM [12] for SVM and the ML AdaBoost Tool- 1 40% box [1] for AdaBoost. We evaluated the optimizer for a clas- 30% 10^3 sification task similar to the one in Figure 2 with 6 datasets 20% 10^6 from the LIBSVM website: ‘a1a’, ‘australian’, ‘breast-cancer’, 10% ‘diabetes’, ‘fourclass’, and ‘splice’. To better visualize the 0% impact of finding the best ML model, we performed a full a1a australian breast diabetes fourclass splice grid search over a fixed set of algorithm parameters, i.e., number of rounds (r) for AdaBoost and regularization (λ) Figure 4: Impact of different σ = 1 × d and RBF scale (σ) parameters for SVM. Specifically, we −6 −3 3 6 {10 , 10 , 1, 10 , 10 } on the SVM accuracy with an tested r = {25, 50, 100, 200}, λ = {10−6 , 10−3 , 1, 103 , 106 }, RBF kernel and λ = 10−6 on LIBSVM data-sets and σ = d1 × {10−6 , 10−3 , 1, 103 , 106 }, where d is the num- ber of features in the dataset. For each algorithm, set of features and parameter settings, we performed 5-fold cross 100% validation, and report the average results across the held-out 90% fold. 80% Table 3 shows the best accuracy after tuning the param- 70% 25 eters using grid search for the different datasets and algo- 60% Accuracy rithms, with and without scaling the features (the best com- 50% 50 bination is marked in bold). The results show first that there 40% 100 is no clear winning combination for all datasets. Sometimes 30% 200 AdaBoost outperforms SVM, sometimes scaling the features 20% helps, sometimes it does not. 10% Now we turn to understanding the search problem for pa- 0% rameters itself, depicted in Figures 4 and 5. Figure 4 shows, a1a australian breast diabetes fourclass splice for fixed regularization λ the impact of the σ parameter in the RBF kernel on the accuracy, whereas Figure 5 visual- Figure 5: Impact of r = {25, 50, 100, 200} on AdaBoost izes the accuracy for varying the number of rounds r for on LIBSVM data-sets
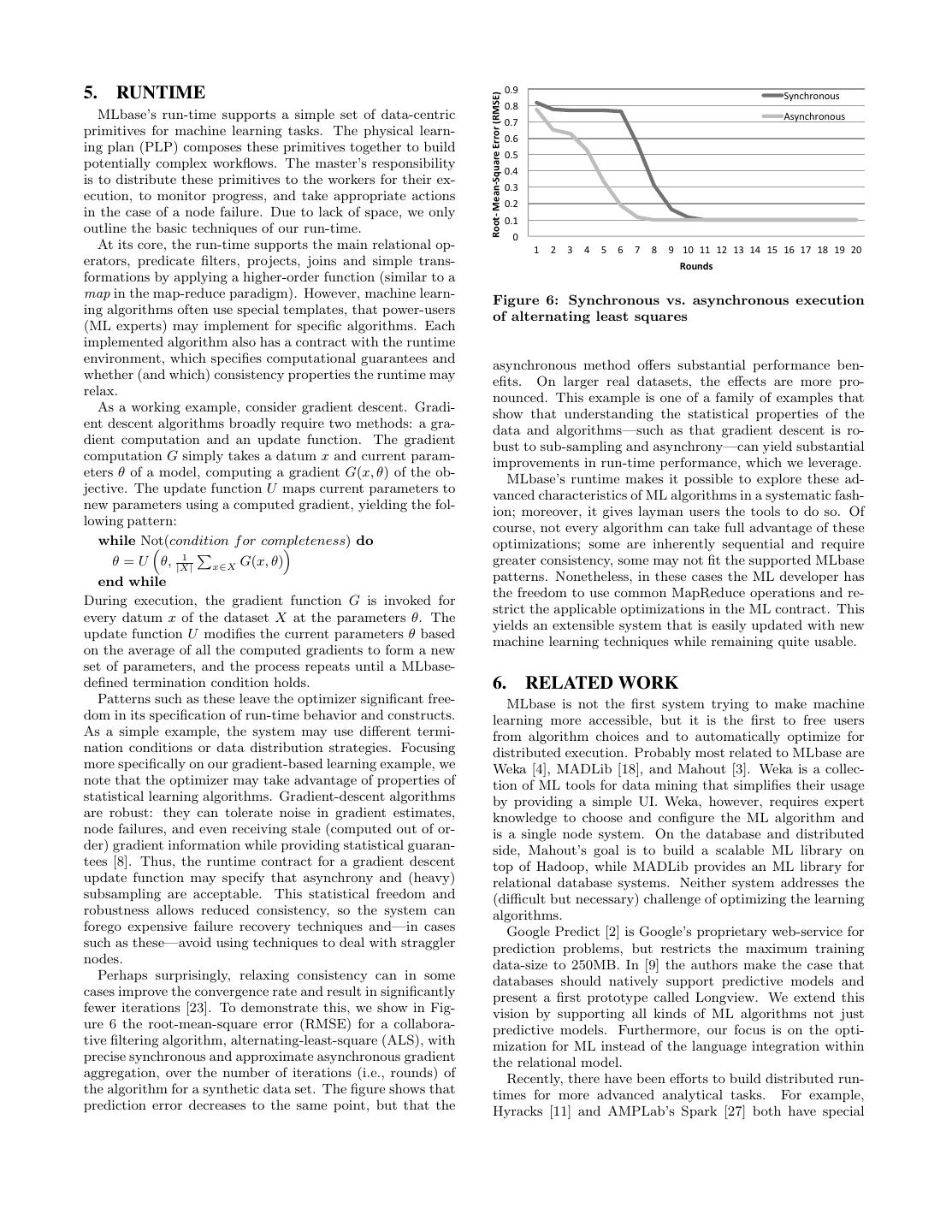
6 . 0.9 5. RUNTIME Synchronous Root-‐ Mean-‐Square Error (RMSE) 0.8 MLbase’s run-time supports a simple set of data-centric 0.7 Asynchronous primitives for machine learning tasks. The physical learn- 0.6 ing plan (PLP) composes these primitives together to build 0.5 potentially complex workflows. The master’s responsibility 0.4 is to distribute these primitives to the workers for their ex- 0.3 ecution, to monitor progress, and take appropriate actions 0.2 in the case of a node failure. Due to lack of space, we only 0.1 outline the basic techniques of our run-time. 0 At its core, the run-time supports the main relational op- 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 erators, predicate filters, projects, joins and simple trans- Rounds formations by applying a higher-order function (similar to a map in the map-reduce paradigm). However, machine learn- Figure 6: Synchronous vs. asynchronous execution ing algorithms often use special templates, that power-users of alternating least squares (ML experts) may implement for specific algorithms. Each implemented algorithm also has a contract with the runtime environment, which specifies computational guarantees and asynchronous method offers substantial performance ben- whether (and which) consistency properties the runtime may efits. On larger real datasets, the effects are more pro- relax. nounced. This example is one of a family of examples that As a working example, consider gradient descent. Gradi- show that understanding the statistical properties of the ent descent algorithms broadly require two methods: a gra- data and algorithms—such as that gradient descent is ro- dient computation and an update function. The gradient bust to sub-sampling and asynchrony—can yield substantial computation G simply takes a datum x and current param- improvements in run-time performance, which we leverage. eters θ of a model, computing a gradient G(x, θ) of the ob- MLbase’s runtime makes it possible to explore these ad- jective. The update function U maps current parameters to vanced characteristics of ML algorithms in a systematic fash- new parameters using a computed gradient, yielding the fol- ion; moreover, it gives layman users the tools to do so. Of lowing pattern: course, not every algorithm can take full advantage of these while Not(condition f or completeness) do optimizations; some are inherently sequential and require 1 θ = U θ, |X| x∈X G(x, θ) greater consistency, some may not fit the supported MLbase end while patterns. Nonetheless, in these cases the ML developer has the freedom to use common MapReduce operations and re- During execution, the gradient function G is invoked for strict the applicable optimizations in the ML contract. This every datum x of the dataset X at the parameters θ. The yields an extensible system that is easily updated with new update function U modifies the current parameters θ based machine learning techniques while remaining quite usable. on the average of all the computed gradients to form a new set of parameters, and the process repeats until a MLbase- defined termination condition holds. 6. RELATED WORK Patterns such as these leave the optimizer significant free- MLbase is not the first system trying to make machine dom in its specification of run-time behavior and constructs. learning more accessible, but it is the first to free users As a simple example, the system may use different termi- from algorithm choices and to automatically optimize for nation conditions or data distribution strategies. Focusing distributed execution. Probably most related to MLbase are more specifically on our gradient-based learning example, we Weka [4], MADLib [18], and Mahout [3]. Weka is a collec- note that the optimizer may take advantage of properties of tion of ML tools for data mining that simplifies their usage statistical learning algorithms. Gradient-descent algorithms by providing a simple UI. Weka, however, requires expert are robust: they can tolerate noise in gradient estimates, knowledge to choose and configure the ML algorithm and node failures, and even receiving stale (computed out of or- is a single node system. On the database and distributed der) gradient information while providing statistical guaran- side, Mahout’s goal is to build a scalable ML library on tees [8]. Thus, the runtime contract for a gradient descent top of Hadoop, while MADLib provides an ML library for update function may specify that asynchrony and (heavy) relational database systems. Neither system addresses the subsampling are acceptable. This statistical freedom and (difficult but necessary) challenge of optimizing the learning robustness allows reduced consistency, so the system can algorithms. forego expensive failure recovery techniques and—in cases Google Predict [2] is Google’s proprietary web-service for such as these—avoid using techniques to deal with straggler prediction problems, but restricts the maximum training nodes. data-size to 250MB. In [9] the authors make the case that Perhaps surprisingly, relaxing consistency can in some databases should natively support predictive models and cases improve the convergence rate and result in significantly present a first prototype called Longview. We extend this fewer iterations [23]. To demonstrate this, we show in Fig- vision by supporting all kinds of ML algorithms not just ure 6 the root-mean-square error (RMSE) for a collabora- predictive models. Furthermore, our focus is on the opti- tive filtering algorithm, alternating-least-square (ALS), with mization for ML instead of the language integration within precise synchronous and approximate asynchronous gradient the relational model. aggregation, over the number of iterations (i.e., rounds) of Recently, there have been efforts to build distributed run- the algorithm for a synthetic data set. The figure shows that times for more advanced analytical tasks. For example, prediction error decreases to the same point, but that the Hyracks [11] and AMPLab’s Spark [27] both have special
7 .iterative in-memory operations to better support ML algo- [9] M. Akdere, U. Cetintemel, ¸ M. Riondato, E. Upfal, and rithms. In contrast to MLbase, however, they do not have S. B. Zdonik. The case for predictive database learning-specific optimizers, nor do they take full advantage systems: Opportunities and challenges. In CIDR, of the characteristics of ML algorithms (e.g., specification of pages 167–174, 2011. contracts allowing relaxed consistency). SystemML [17] pro- [10] T. Bertin-Mahieux, D. P. Ellis, B. Whitman, and poses an R-like language and shows how it can be optimized P. Lamere. The million song dataset. In ISMIR, 2011. and compiled down to MapReduce. However, SystemML [11] V. R. Borkar et al. Hyracks: A flexible and extensible tries to support ML experts to develop efficient distributed foundation for data-intensive computing. In ICDE, algorithms and does not aim at simplifying the use of ML, 2011. for example, by automatically tuning the training step. Still, [12] C.-C. Chang and C.-J. Lin. LIBSVM: A library for the the ideas of SystemML are compelling and we might support vector machines. ACM TIST, 2, 2011. leverage them as part of our physical plan optimization. [13] C. Cortes and V. N. Vapnik. Support-Vector Finally, in [14] the authors show how many ML algorithms Networks. Machine Learning, 20(3):273–297, 1995. can be expressed as a relational-friendly convex-optimization [14] X. Feng et al. Towards a unified architecture for problem, whereas the authors of [25] present techniques to in-RDBMS analytics. In SIGMOD, 2012. optimize inference algorithms in a probabilistic DBMS. We leverage these techniques in our run-time, but our system [15] Y. Freund and R. E. Schapire. A decision-theoretic aims beyond a single machine and extends the presented generalization of on-line learning and an application to optimization techniques. boosting. J. Comput. Syst. Sci., 55(1):119–139, 1997. [16] J. Friedman, T. Hastie, and R. Tibshirani. Additive logistic regression: a statistical view of boosting. 7. CONCLUSION Annals of Statistics, 28:2000, 1998. We described MLbase, a system aiming to make ML more [17] A. Ghoting et al. Systemml: Declarative machine accessible to non-experts. The core of MLbase is its opti- learning on mapreduce. In Proceedings of the 2011 mizer, which transforms a declarative ML task into a so- IEEE 27th International Conference on Data phisticated learning plan. During this process, the optimizer Engineering, ICDE ’11, pages 231–242, Washington, tries to find a plan that quickly returns a first quality answer DC, USA, 2011. IEEE Computer Society. to the user, allowing MLbase to improve the result itera- [18] J. M. Hellerstein et al. The madlib analytics library or tively in the background. Furthermore, MLbase is designed mad skills, the sql. In PVLDB. to be fully distributed, and it offers a run-time able to ex- [19] H. Kwak et al. What is twitter, a social network or a ploit the characteristics of machine learning algorithms. We news media? In WWW, 2010. are currently in the process of building the entire system. [20] Y. Low et al. Graphlab: A new framework for parallel In this paper, we reported first results showing the potential machine learning. In UAI, 2010. of the optimizer as well as the performance advantages of [21] L. Mackey, A. Talwalkar, and M. I. Jordan. algorithm-specific execution strategies. Divide-and-conquer matrix factorization. In NIPS, 2011. 8. ACKNOWLEDGMENTS [22] C. Olston et al. Pig latin: a not-so-foreign language This research is supported in part by NSF CISE Expe- for data processing. In SIGMOD, 2008. ditions award CCF-1139158, gifts from Amazon Web Ser- [23] B. Recht et al. Hogwild: A lock-free approach to vices, Google, SAP, Blue Goji, Cisco, Cloudera, Ericsson, parallelizing stochastic gradient descent. In NIPS, General Electric, Hewlett Packard, Huawei, Intel, Microsoft, 2011. NetApp, Oracle, Quanta, Splunk, VMware and by DARPA [24] J. Shawe-Taylor and N. Christianini. Kernel Methods (contract #FA8650-11-C-7136). for Pattern Analysis. Cambridge University Press, 2004. 9. REFERENCES [25] D. Z. Wang et al. Hybrid in-database inference for [1] GML AdaBoost Toolbox. declarative information extraction. In SIGMOD, 2011. http://www.inf.ethz.ch/personal/vezhneva/Code/ [26] J. Yang and J. Leskovec. Temporal variation in online AdaBoostToolbox_v0.4.zip. media. In WSDM, 2011. [2] Google Prediction API. [27] M. Zaharia et al. Resilient distributed datasets: A https://developers.google.com/prediction/. fault-tolerant abstraction for in-memory cluster [3] Mahout. http://mahout.apache.org/. computing. In NSDI, 2012. [4] Weka. http://www.cs.waikato.ac.nz/ml/weka/. [28] M. Zukowski et al. Monetdb/x100 - a dbms in the cpu [5] ALS Prediction Prize. http://www.prize4life.org/ cache. IEEE Data Eng. Bull., 28(2), 2005. page/prizes/predictionprize, 2012. [6] Million Song Dataset Challenge. http://www.kaggle.com/c/msdchallenge, 2012. [7] A. Agarwal, P. Bartlett, and J. Duchi. Oracle inequalities for computationally adaptive model selection. In Conference on Learning Theory, 2011. [8] A. Agarwal and J. Duchi. Distributed delayed stochastic optimization. In Advances in Neural Information Processing Systems 25, 2011.
3秒后跳转登录页面
去登陆

