














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Deco: Declarative Crowdsourcing
Deco’s data model was designed to be general (it can be instantiated to other proposed models), flexible (it allows methods for data cleansing and external access to be plugged in), and principled (it has a precisely-defined semantics). Syntactically, Deco’s query language is a simple extension to SQL. Based on Deco’s data
model, we define a precise semantics for arbitrary queries involving both stored data and data obtained from the crowd. We then describe the Deco query processor which uses a novel push-pull hybrid execution model to respect the Deco semantics while coping with the unique combination of latency, monetary cost, and uncertainty introduced in the crowdsourcing environment.
展开查看详情
1 . Deco: Declarative Crowdsourcing Aditya Parameswaran Hyunjung Park Hector Garcia-Molina Stanford University Stanford University Stanford University adityagp@cs.stanford.edu hyunjung@cs.stanford.edu hector@cs.stanford.edu Neoklis Polyzotis Jennifer Widom UC Santa Cruz Stanford University alkis@cs.ucsc.edu widom@cs.stanford.edu ABSTRACT hiding many of the complexities of dealing with humans as data Crowdsourcing enables programmers to incorporate “human com- sources (e.g., breaking down large tasks into smaller ones, posting putation” as a building block in algorithms that cannot be fully tasks to a marketplace and pricing them, dealing with latency, and automated, such as text analysis and image recognition. Simi- handling errors and inconsistencies in human-provided data). larly, humans can be used as a building block in data-intensive We describe the Deco data model, the query language and se- applications—providing, comparing, and verifying data used by mantics, and the query processor. applications. Building upon the decades-long success of declara- While the idea of declarative access to crowd data is appealing tive approaches to conventional data management, we use a similar and natural, there are significant challenges to address: approach for data-intensive applications that incorporate humans. • How do we resolve disagreeing human opinions? For in- Specifically, declarative queries are posed over stored relational stance, if we collect five ratings for a movie, we may want data as well as data computed on-demand from the crowd, and the to give the end user the average, but if we collect five phone underlying system orchestrates the computation of query answers. numbers, we may want to instead eliminate duplicates. How We present Deco, a database system for declarative crowdsourc- does the schema designer (or DBA) specify what to do, and ing. We describe Deco’s data model, query language, and our pro- when during query execution do we resolve the opinions? totype. Deco’s data model was designed to be general (it can be • How does the database system interact with the human work- instantiated to other proposed models), flexible (it allows methods ers (the crowd)? For instance, to get restaurant information, for data cleansing and external access to be plugged in), and prin- we may want Deco to give the worker the name of a restau- cipled (it has a precisely-defined semantics). Syntactically, Deco’s rant (e.g., “Bouchon”), and ask for its cuisine. But in other query language is a simple extension to SQL. Based on Deco’s data cases Deco may want to give the worker the cuisine (e.g., model, we define a precise semantics for arbitrary queries involv- “French”), and ask for restaurants serving that cuisine. Or ing both stored data and data obtained from the crowd. We then Deco may ask for cuisine and rating given the name of a describe the Deco query processor which uses a novel push-pull restaurant. How does the schema designer define the avail- hybrid execution model to respect the Deco semantics while coping able options, which we can view as different “access meth- with the unique combination of latency, monetary cost, and uncer- ods”? Are there restrictions on the access methods that can tainty introduced in the crowdsourcing environment. Finally, we be defined? And how does Deco decide what access method describe our current prototype, and we experimentally explore the to use for a given query? How do we enable Deco to use query processing alternatives provided by Deco. external sources in addition to the crowd? For instance, we may want Deco to be able to use an information extraction 1. INTRODUCTION program that, given a restaurant, extracts a phone number from a webpage. Crowdsourcing [12, 31] uses human workers to capture or gen- erate data on demand and/or to classify, rank, label or enhance ex- • What is the right data model and query language for a crowd- isting data. Often, the tasks performed by humans are hard for a sourced database? We already argued for a model and end computer to do, e.g., rating a new restaurant or identifying features user language that are as close as possible to conventional of interest in a video. We can view the human-generated data as ones, but extensions are needed to deal with the uncertain- a data source, so naturally one would like to seamlessly integrate ties and ambiguities of crowd data. For instance, since there the crowd data source with other conventional sources, so the end is an “endless supply” of crowd data, the end user (or the user can interact with a single, unified database. And naturally one schema designer) needs to circumscribe what is needed. For would like a declarative system, where the end user describes the instance, the user may state that five answer tuples are suf- needs, and the system dynamically figures out what and how to ficient, or that five opinions are enough to report an average obtain crowd data, and how it must be integrated with other data. movie rating. How are such constraints/guidelines defined, This overall vision, and the underlying issues and challenges, were and by whom? outlined in our earlier paper [27]. • What data should the crowdsourced database system actually In this paper, we realize our earlier vision to present Deco (short store? Is it cleansed data, or is it the uncleansed data? If it for “declarative crowdsourcing”), a database system that answers is cleansed data, then how do we update it as new opinions declarative queries posed over stored relational data, the collective arrive? If it is uncleansed data, what does the user see, when knowledge of the crowd, as well as other external data sources. Our is it computed, and how can it be stored compactly? Should goal is to make Deco appear to the end user as similar as possible to there be a notion of crowdsourced data becoming stale? a conventional database system (a relational one in our case), while
2 . • How does the query processor execute crowd queries? How AddrInfo(address,city,zip) does it deal with the complexity of having several access methods to the crowd? How does it deal with the latency Here too, we may obtain some or all of the information from exter- of crowdsourcing services? How does it deal with the reso- nal sources in response to queries. We might use human workers lution of disagreement or uncertainty in answer tuples? How for this task, or we might invoke information extraction tools, per- does it ensure that constraints (such as a desired number of haps with results verified by humans. In addition, we may need answer tuples) are met? to coordinate values between our two relations, since queries are Our Deco design addresses these questions, trying to strike a bal- likely to join them on their address fields. ance between too much generality, and achieving an elegant, im- We will see how these logical relations form the conceptual schema plementable system. While it may not be immediately apparent to that is declared by the administrator setting up a Deco database, and the reader, the design of Deco required significant effort as well as they are the relations queried by end users and applications. Under- consideration of many possible alternative designs. In particular, neath, Deco uses a different raw schema. The heart of Deco query we will argue in our related work section (Section 7) that Deco is processing is the significant machinery and algorithms for combin- more principled, general, and flexible than recent approaches for ing stored data with crowdsourced (or other externally-obtained) declarative crowdsourcing [14, 24, 25]. data to answer declarative queries over the conceptual schema. In summary, our contributions are the following: • We present a data model for Deco (Section 2) that is practi- 2. DATA MODEL cal, based on sound semantics, and derived from the familiar There are several components to Deco’s data model: relational data model. We define the precise semantics of the • The conceptual schema. In our running example introduced data model (Section 2.6). We also describe important data in Section 1.1, relations Restaurant and AddrInfo are part of model extensions (Section 2.7). the conceptual schema. These are the relations specified by • We describe the Deco query language (Section 3) that mini- the schema designer, and they are queried by end users and mally departs from SQL, and expresses the constraints nec- applications. The conceptual schema also includes: essary for crowdsourcing. • Partitioning of the attributes in each conceptual relation • We present our design for the query processor (Section 4) into anchor attributes and dependent attribute-groups. which uses a novel push-pull hybrid execution model. Roughly speaking, anchor attributes typically identify • We experimentally analyze queries running on the Deco pro- “entities” while dependent attribute-groups specify prop- totype (Section 6). We show that our Deco prototype sup- erties of the entities, although schema designers could ports a large variety of plans with varying performance, and use attributes differently. we gain some valuable insights in the process. • Fetch rules, specifying how data in the conceptual rela- • We compare Deco’s design with other declarative crowd- tions can be obtained from external sources (including sourcing systems, and survey other related work (Section 7). humans). 1.1 Running Example • Resolution rules, used to reconcile inconsistent or un- certain values obtained from external sources. Throughout the paper we use a running example that is by design simple and a bit contrived, yet serves to illustrate the major chal- • The raw schema. Deco is designed to use a conventional lenges of declarative crowdsourcing, and to motivate our solutions relational DBMS as its back-end. The raw schema is the to these challenges. We (as the users) are interested in querying a one stored in the DBMS. It is derived automatically from (logical) database containing information about restaurants. Each the conceptual schema, and is invisible to both the schema restaurant may have one or more addresses (multiple addresses in- designer and end users. dicate a chain), and each restaurant may serve one or more cuisines. • The data model semantics. We specify the semantics of a We also have ratings, which are associated with restaurant-address Deco schema in terms of conventional relations. Loosely, pairs since different outlets of a chain may be rated differently. We the “valid instances” of a Deco database are those conven- will see that Deco’s conceptual schema encourages denormalized tional databases that can be constructed by executing fetch relations, so our restaurant information can be captured in a single rules to expand the contents of the raw tables, then apply- logical relation: ing resolution rules and joining the raw tables to produce the Restaurant(name,address,rating,cuisine) conceptual relations. The catch is that our database may not contain a full set of in- In the remainder of this section we begin by illustrating each of formation to begin with, in fact it may not contain any information the data model components informally, then we step through each at all! In response to queries, we obtain information from external component formally. sources—including humans—using a set of “fetch rules” (formal- We use the term designer to refer to both the schema designer as ized as part of our data model). For example, given a restaurant and well as the database administrator. We use the term user to refer to an address we might seek ratings, or given a rating and a cuisine we the end user or the application developer. might seek restaurant-address pairs. We will shortly see many more examples of fetch rules, as well as other aspects of Deco relations, 2.1 Example of Data Model Components such as how we deal with the uncertainty resulting from inconsis- Consider the restaurant relation introduced in Section 1.1: Rest- tencies in the information we obtain. aurant (name, address, rating, cuisine). The designer designates We add a second (logical) relation containing address informa- name and address as anchor attributes, and rating and cuisine as tion. We assume a restaurant’s address may be encoded in some dependent attributes. Informally, we can see that the pair of name fashion—perhaps as a string or a geolocation—but we may want to and address attributes together identify the “entities” in our relation pose queries involving, say, cities or zipcodes. Thus we have the while the other two attributes are properties of entities; we will see relation: shortly the specific roles of anchor versus dependent attributes.
3 . name addr rating cuisine Subway SF 3.9 Sandwiches User Subway NY 3.7 Sandwiches view Bouchon LV 3.8 French Bouchon LV 3.8 Continental ••• ••• ••• ••• o resolution resolution ⋈ rule rule RestA RestD1 RestD2 name addr name addr rating name cuisine Subway SF Subway SF 3.9 Subway Sandwiches Subway NY Subway SF 4.1 Bouchon French Bouchon LV Subway SF 3.7 Bouchon French Limon SF Subway NY 3.6 Bouchon Continental ••• ••• Bouchon LV 4.7 Limon ••• Anchor Limon SF ••• ••• French fetch rule Dependent Dependent φ name,addr fetch rule fetch rule fetch rule name,addr rating name cuisine cuisine name Figure 1: Components of the Deco Data Model The raw schema corresponding to this specification of Restau- have inconsistencies or uncertainty in the collected data. One de- rant is shown in the lower half of Figure 1. These relations are the cision we made in Deco is to provide a conceptual schema that ones actually stored as tables in the back-end RDBMS. There is one does not have uncertainty as a first-class component, however meta- anchor table (RestA) containing the anchor attributes, and one de- data in both the raw and conceptual schemas (described later in pendent table for each dependent attribute (RestD1 and RestD2); Section 2.7) can be used to encode information about confidence, dependent tables also contain some anchor attributes. (In general, worker quality, or other aspects of collected data that may be use- both anchor and dependent attributes can be a group of attributes.) ful to applications. To obtain conceptual relations that are “clean” Recall that we associate cuisines with the restaurant name, and rat- from raw tables that may contain inconsistencies, we use resolu- ing with a name-address pair, since different branches of a restau- tion rules, specified by the designer. In Figure 1 we illustrate two rant (such as NY and SF in Figure 1—to save space, we use abbre- resolution rules: viated addresses) can have different ratings, but all branches serve • A resolution rule for attribute rating specifying that the con- the same kind of food. We will see in Section 2.5 how the raw ceptual schema contains one rating for each restaurant name- schema are generated. address pair, namely the average of the ratings stored in the The top of the figure shows the original conceptual relation, which raw schema. is the outerjoin of the raw tables with certain attribute values “re- • A resolution rule for attribute cuisine specifying that the con- solved” (explained shortly). ceptual schema contains all of the cuisines for each restaurant Now let us consider how our database might be populated. Per- name from the raw schema, but with duplicates eliminated. haps we already have some restaurant name-address pairs, with or without ratings and/or cuisines. If so, Deco might ask human work- The semantics of a Deco database is defined based on a Fetch- ers to specify ratings and/or cuisines given a restaurant name and/or Resolve-Join sequence. Every Deco database has a (typically in- address. Alternatively, Deco might ask human workers to specify finite) set of valid instances. A valid instance is obtained by log- restaurant names and addresses given a cuisine and/or rating, or ically: (1) Fetching additional data for the raw tables using fetch to provide restaurant names without regard to ratings or cuisines. rules; this step may be skipped. (2) Resolving inconsistencies using Referring to Figure 1, the designer can specify fetch rules that: resolution rules for each of the raw tables. (3) Outerjoining the re- solved raw tables to produce the conceptual relations. Note that the • Ask for one or more restaurant name-address pairs, inserting “intermediate” relations between steps (2) and (3) are not depicted the obtained values into raw table RestA. in Figure 1; in the figure we resolve and join in one step. Also it • Ask for a rating given a restaurant name and an address (e.g., is critical to understand that the Fetch-Resolve-Join sequence is a (Limon,SF) in the figure), inserting the resulting pair into logical concept only. When Deco queries are executed, not only table RestD1; similarly ask for a cuisine given a restaurant may these steps be interleaved, but typically no conceptual data is name (e.g., Limon in the figure), inserting the resulting pair materialized except the query result. into RestD2. Note that valid instances could contain wildly varying amounts • Ask for a restaurant name given a cuisine, inserting the re- of data, from no tuples at all to several million tuples, and they are sulting restaurant into table RestA, and inserting the restaurant- all valid. So, when a user poses a query to the database, the valid cuisine pair into RestD2 (e.g., French in the figure). instance used to answer his query may be the one with no tuples at These fetch rules are depicted at the bottom of the raw tables in all. We therefore need a mechanism to allow the user to request that Figure 1. There are many more fetch rules that may be used to at least a certain number of tuples are returned, discussed further in populate this database, we return to this point later on. Section 3. Now suppose we’ve obtained values for our raw tables, but we
4 .2.2 Conceptual Relations, Anchor and Depen- • RR3 : The name-address pairs in the conceptual database dent Attributes are a “canonicalized” version of the raw name-address pairs. Now let us begin formalizing the concepts illustrated in Sec- Canonicalization can put the values in a particular form, and tion 2.1. The designer declares two conceptual relations, and des- can perform “entity resolution” to merge differing name- ad- ignates their anchor and dependent attributes. In our example: dress pairs that are judged to refer to the same restaurant. • RR4 : If the raw data contains more than one city-zip pair for Restaurant(name,address,[rating],[cuisine]) a given address, the pair occurring most frequently is the one AddrInfo(address,[city,zip]) present in the conceptual database. We can assume ties are broken arbitrarily. Each attribute is either an anchor attribute or a member of ex- actly one dependent attribute-group. Thus, to partition a relation’s • RR5 : Assuming address values in the AddrInfo relation are attributes, it suffices to enclose dependent attribute-groups within never uncertain or inconsistent, the simple identity resolution square brackets. In our example, the pair of anchor attributes name function is used in this case. and address identify individual restaurants, while rating and cui- As an example, the three tuples corresponding to (Subway,SF,*) sine are dependent attributes that are independent of each other. in raw table RestD1 in Figure 1 are resolved using resolution func- (We assume ratings are not associated with specific cuisines of a tion RR1 into a single tuple (Subway,SF,3.9), which then partici- restaurant.) In relation AddrInfo, address is the anchor attribute; at- pates in the join with RestA and RestD2. tributes city and zip are not independent of each other with respect Readers inclined towards dependency theory may already have to an address, so they form a single dependent attribute-group. The noticed that that resolution rules suggest multivalued dependen- next subsection clarifies the purpose of these designations within cies on the conceptual relations. In relation Restaurant we have the Deco data model. the multivalued dependencies name,address→ →rating and name→ →cuisine. Furthermore, when a resolution rule for a dependent 2.3 Resolution Rules attribute-group is guaranteed to produce exactly one value, we have For each conceptual relation, the schema designer must spec- a functional dependency. For instance, name and address function- ify one resolution rule for each dependent attribute-group, and one ally determine rating, since the resolution rule for rating produces resolution rule for the anchor attributes treated as a group. Thus, a exactly one value. resolution rule takes one of the following two forms, where A, A , and D are sets of attributes and f is a function. 2.4 Fetch Rules The schema designer may specify any number of fetch rules. Un- 1. A → D : f like resolution rules, fetch rules may be added or removed at any where A is a subset of the anchor attributes (A ⊆ A) and time during the lifetime of a database—they are more akin to “ac- D is a dependent attribute-group cess methods” than to part of the permanent schema. A fetch rule takes the following form: 2. ∅ → A : f where A is the set of anchor attributes A1 ⇒ A2 : P where A1 and A2 are sets of attributes from one relation (with In the first form, resolution function f takes as input a tuple of val- A1 = ∅ or A2 = ∅ permitted, but not both), and P is a fetch ues for the anchor (A ) attributes, and a set of tuples with values procedure that implements access to human workers or other exter- for the dependent (D) attributes. It produces as output a new (pos- nal sources. (P might generate HITs (Human Intelligence Tasks) sibly empty, possibly unchanged) set of dependent tuples. The idea to Amazon’s Mechanical Turk [3], for example, but nothing in our is that function f “cleans” the set of dependent values associated model or system is tied to AMT specifically.) The only restriction with specific anchor values, when the dependent values may be in- on fetch rules is that if A1 or A2 includes a dependent attribute D, consistent or uncertain. In the second form, function f “cleans” a then A1 ∪ A2 must include all anchor attributes from the left-hand set of anchor (A) values. In either case, if no cleaning is necessary side of the resolution rule containing D. In other words, if AD is then f can simply be the identity function. the left hand side of a resolution rule containing dependent attribute Let us look at a set of resolution rules for our running example. D, then, if D ⊆ A1 ∪ A2 , then AD ⊆ A1 ∪ A2 . We will see the (Rules RR1 and RR2 are displayed in Figure 1.) reason for this restriction in Section 2.6. [RR1 , relation Restaurant] name,address → rating : avg() Let us look at a set of possible fetch rules for our running ex- [RR2 , relation Restaurant] name → cuisine : dupElim() ample. We use R and A to abbreviate Restaurant and AddrInfo [RR3 , relation Restaurant] ∅ → name,address : canonicalize() respectively. (Rules FR1 , FR2 , FR4 , and FR5 are displayed in Fig- [RR4 , relation AddrInfo] address → city,zip : majority() ure 1.) [RR5 , relation AddrInfo] ∅ → address : identity() [FR1 ] R.name, R.address ⇒ R.rating : P1 [FR2 ] R.name ⇒ R.cuisine : P2 (Note the function specifications here are abstracted; in practice the [FR3 ] A.address ⇒ A.city, A.zip : P3 Deco system requires resolution functions to adhere to a specific [FR4 ] R.cuisine ⇒ R.name : P4 API.) The interpretation of these rules is: [FR5 ] ∅ ⇒ R.name, R.address : P5 • RR1 : The rating for a specific restaurant (name-address [FR6 ] R.name ⇒ R.address : P6 pair) in the conceptual database is the average of the ratings [FR7 ] ∅ ⇒ R.name, R.cuisine : P7 in the raw data. [FR8 ] R.name, R.address ⇒ ∅ : P8 [FR9 ] R.address ⇒ R.name, R.rating, R.cuisine : P9 • RR2 : The cuisines for a restaurant are associated with the restaurant name but not its address (under the assumption all The interpretation of these rules is: outlets in a chain serve the same cuisine). The conceptual • FR1 –FR3 : It is very common—though not required—to have database contains each cuisine for each restaurant in the raw a set of fetch rules that parallel the resolution rules. For ex- data, with duplicates removed. ample, fetch rule FR1 says that procedure P1 takes a specific
5 . restaurant (name-address pair) as input, and it accesses hu- AddrA(address) mans or other external sources to obtain zero or more rating AddrD1(address,city,zip) values for that restaurant. For readers inclined towards dependency theory: Continuing from • FR4 : Another common form is the reverse of a resolution the discussion at the end of Section 2.3, we can see that the raw rule: gather anchor values for given dependent values. For schema is in fact a Fourth Normal Form (4NF) decomposition of example, FR4 says that procedure P4 takes a cuisine as input, the conceptual schema based on the multivalued dependencies im- and accesses humans or other external sources to obtain one plied by the resolution rules. or more restaurant name values for that cuisine. Applications or end users may wish to insert, modify, and/or • FR5 –FR6 : Fetch rules can be used to gather values for an- delete data in the conceptual relations, in a standard database fash- chor attributes, either from scratch or from other anchor at- ion. The mapping from conceptual relations to raw tables is simple tributes. FR5 says restaurant name-address pairs can be ob- enough that all such modifications can be translated directly to cor- tained without any input, while FR6 says that address values responding modifications on the raw tables. More interestingly, if can be obtained given name values. an application has chosen to use Deco, then we expect some of the data stored in the raw tables to be obtained from human workers or • FR7 : Fetch rules can gather anchor and dependent values other external sources over time as part of query processing. How simultaneously. Instead of asking for a cuisine given a name that process works, while properly reflecting our data model and (as in FR2 ) or a name given a cuisine (as in FR4 ), procedure query language semantics, is the topic of much of the remainder of P7 takes no input and asks for name-cuisine pairs. this paper. Next we define the data model semantics, which centers • FR8 : Fetch rule FR8 is the reverse of FR7 and has a quite around the mapping from raw tables to conceptual relations. different function. A fetch rule with ∅ on the right-hand side performs verification: Procedure P8 takes a name-address 2.6 Data Model Semantics pair and accesses humans or other external sources to re- The semantics of a Deco database at a given point in time is de- turn a yes/no verification of the input values. A similar rule fined as a set of valid instances for the conceptual relations. The might be used to verify address-city-zip triples for relation valid instances are determined by the current contents of the raw AddrInfo, for example. tables, the potential of the fetch rules, and the invocation of resolu- • FR9 : Fetch rule FR9 demonstrates a fetch rule that can’t be tion rules before outerjoining the raw data to produce the concep- pigeon-holed into a particular structure. It says that proce- tual relations. Let us consider this Fetch-Resolve-Join sequence in dure P9 will take an address as input, and will obtain zero detail. Note that these three steps may not actually be performed, or more name-rating-cuisine triples for that address. Note but query answers must reflect a valid instance that could have been that this rule would not be allowable if name were omitted: derived by these three steps, as we will discuss in Section 3. The presence of dependent attributes rating and cuisine re- 1. Fetch quires that the anchor attributes from their resolution rules The current contents of the raw tables may be extended by in- (name,address and name respectively) are also present. voking any number of fetch rules any number of times, inserting Invocations of the Fetch Rule FR1 (with (Limon,SF)), FR2 (with the obtained values into the raw database. Consider a fetch rule Limon), FR4 (with French), FR5 (with no input) are depicted in A1 ⇒ A2 : P with A2 = ∅. By definition, procedure P takes Figure 1. Note that these fetch rules affect at most one dependent as input a tuple of values for the attributes in A1 , and produces as raw table; other fetch rules, such as FR9 , affect multiple dependent output zero or more tuples of values for the attributes in A2 . We raw tables. can equivalently think of an invocation of the fetch rule as return- There are many, many more possible fetch rules for our running ing a set T of tuples for A1 ∪ A2 . Note the input values for A1 example. Which fetch rules are used in practice may depend on the may come from the database or from a query (see Section 4), but capabilities (and perhaps costs) of the human workers and other ex- for defining semantics we can assume any input values. ternal data sources, and perhaps the programming burden of imple- The returned tuple set T with schema A1 ∪ A2 may include menting a large number of fetch procedures. Also remember that any number of attributes from any number of raw tables. Consider fetch rules are not set in stone—they can be added, removed, and any of the raw tables T (A), and let B = A ∩ (A1 ∪ A2 ) be the modified as capabilities change or tuning considerations dictate. attributes of T present in T . If B is nonempty, we insert ΠB (T ) into table T , assigning NULL values to the attributes of T that are 2.5 Raw Schema not present in T (i.e., the attributes in B − A). Informally, we can The raw schema—for the tables actually stored in the underlying think of the process as vertically partitioning T and inserting the RDBMS—depends only on the definitions of the conceptual rela- partitions into the corresponding raw tables, with anchor attributes tions, anchor and dependent attributes, and resolution rules. Specif- typically replicated across multiple raw tables. The one guarantee ically, for each relation R in the conceptual schema, the raw schema we have, based on our one fetch rule restriction (Section 2.4), is that contains: no NULL values are inserted into anchor attributes of dependent • One anchor table whose attributes are the anchor attributes tables. This property simplifies the resolution process, discussed of R shortly. As an example, fetch rule FR9 above would insert a tuple • One dependent table for each dependent attribute-group D in all three restaurant raw tables. Note that inserting tuples in this in R, containing the attributes in the resolution rule for D manner may end up proliferating duplicate tuples, especially in the From the conceptual schema in Section 2.2, and the resolution rules anchor raw table. As an example, if we have a name-address pair in Section 2.3, it is straightforward to derive the following raw in RestA, then every time we use the name-address pair in the fetch schema: rule name,address ⇒ rating, we end up adding an extra copy of the same name-address pair to RestA. If duplicates may pose a RestA(name,address) problem, then the origin of the tuples (i.e., the fetch rule invocation RestD1(name,address,rating) that added them) can be recorded in the metadata (Section 2.7) and RestD2(name,cuisine) used by the resolution function.
6 . Lastly, consider a fetch rule A1 ⇒ ∅ : P . In this special case its benefits. However in reality there are several messy aspects where a fetch rule is being used for verification (recall Section 2.4), of using crowdsourced (or other external) data that also must be we proceed with the insertions as described above, but only when P accommodated—pieces of the crowdsourcing puzzle that we have returns a yes value. If the no values are important for resolution, a chosen not to make first-class in our data model, yet are crucial for more general scheme for verification may be used, and is described some applications. Examples include: in Section 2.7 below. • Data expiration: If we store fetched data in the raw tables 2. Resolve for future queries, we may wish to purge it automatically at After gathering additional data via fetch rules, each anchor and some later point in time. dependent table in the raw schema is logically replaced by a “re- • Worker quality: When data is obtained from humans, we solved” table. Consider a dependent table T (A , D) with corre- may have some knowledge of the expected quality, e.g., based sponding resolution rule A → D : f . We logically: (a) group on the crowdsourcing service, or on worker history. the tuples in T based A values; (b) call function f for each group; • Voting: In Section 2.4 we described how fetch rules can be (c) replace each group with the output of f for that group. (Recall used to ask humans or other sources to verify uncertain val- from Section 2.3 that f takes as input a tuple of values for the A ues. If the response of such a fetch rule is a yes/no answer, attributes and a set of tuples with values for the D attributes. It pro- we could record the tally of yes/no votes. This tally can then duces as output a new, possibly empty or unchanged, set of tuples be used for resolution. for D.) Resolving an anchor table T (A) simply involves invoking • Confidence scores: While worker quality and voting are mech- the function f in the resolution rule ∅ → A : f with all tuples in anisms associated with confidence in data values, ultimately T. we may wish to associate explicit confidence scores with our Note that NULL values may appear in anchor tables, and for data. dependent attributes in dependent tables. We assume if NULL val- • Fetch Rule: Since some fetch rules may be more accurate or ues are possible, then the corresponding resolution functions are informative than others, we may wish to record which fetch equipped to deal with them. We need not worry about NULLs rule generated which data. when grouping anchor attribute values (step (a) above), since our fetch-rule restriction (Section 2.4) ensures that all anchor values in All of these examples can be handled by allowing additional dependent tables are non-NULL. metadata columns in the raw tables. Metadata columns can be used In Figure 1, resolution on the three RestD1 tuples correspond- for timeout values, to store information about worker quality, to ing to Subway, SF returns an average rating of 3.9. Since cuisine tally votes, and for confidence values. Metadata attributes can be has a duplicate-elimination resolution function, resolution on the included in the input and/or output of fetch procedures and resolu- three tuples corresponding to Bouchon in RestD2 returns two tu- tion functions. In our examples, data expiration and worker quality ples (one for French, one for Continental). values might be returned by a fetch function; a resolution function might take worker quality and fetch rules as part of its input and re- 3. Join turn confidence scores as part of its output. Metadata columns can The final step is simple: For each conceptual relation R, a left out- be exposed in the conceptual relations too, if their contents may be erjoin of the resolved anchor and dependent tables for R is per- of direct use to applications. formed to obtain the final tuples in R. Note that an outerjoin (as opposed to a regular join) is necessary to retain all resolved values, 3. QUERY LANGUAGE since values for some attributes may not be present. In Figure 1, resolved tuples (Subway,SF) from RestA, (Subway,SF,3.9) from The Deco query language and semantics is straightforward: RestD1 and (Subway,Burgers) from RestD2 join to give the tuple: A Deco query Q is a relational query over the concep- (Subway,SF,3.9,Burgers). tual relations. The answer to Q is the result of eval- The left outerjoin must have the anchor table as its first operand, uating Q over some valid instance of the database as but otherwise the resolved dependent tables may be left outerjoined defined in Section 2.6. in any order; Appendix A proves that all such orders are equivalent. We assume either relational algebra or SQL for posing queries. To recap, a valid instance of a Deco database is obtained by Since the Deco system supports SQL, we use SQL for examples starting with the current contents of the raw tables and logically in this paper. performing the three steps above, resulting in a set of data for the Referring back to Section 2.6, recall that one valid instance of the conceptual relations. Since in step 1 any number of fetch rules may database can be obtained by resolving and joining the current con- be invoked any number of times (including none), we typically have tents of the raw tables, without invoking any fetch rules. Thus, it an infinite number of valid instances. This unboundedness is not a appears a query Q can be always answered correctly without con- problem; as we will see shortly, our goal is to deliver the result of a sulting human workers or other outside sources. The problem is query over some valid instance, not over all valid instances. that often times this “correct” query result will also be empty. For We emphasize again that these three steps are logical—they are example, if our query is: used only to define the semantics of the data model. Of course Select name,address From Restaurant some amount of fetching, resolving, and joining does need to oc- Where cuisine=‘Thai’ and rating > 4 cur in order to answer queries, but not necessarily as “completely” as defined above, and not necessarily in Fetch-Resolve-Join order. and there are currently no highly-rated Thai restaurants in our database, Section 4 describes our query processing strategies that respect the then the query result is empty. semantics while meeting cost, performance, and quality objectives. To retain our straightforward semantics over valid instances while avoiding the empty-answer syndrome, we simply add to our query 2.7 Metadata language an “AtLeast n” clause. This clause says that not only The Deco data model as described so far has precise formal un- must the user receive the answer to Q over some valid instance of derpinnings and relies heavily on the relational model with all of the database, but it must be a valid instance for which the answer
7 .has at least n tuples with non-NULL attributes. Adding “AtLeast and then propagated to the view (the conceptual table in our 5” to the query above, for example, forces the query processor to case). collect additional data using fetch rules until it obtains the name • Asynchronous Pull: We borrow ideas from asynchronous and address values for at least five highly-rated Thai restaurants. iteration to cause messages to flow down the plan to initiate Our basic problem formulation for query processing, discussed multiple new fetches in parallel and feed more tuples back in detail in the next section, thus requires a minimum number of tu- to the plan as soon as any fetches complete. The messages ples in query results, while attempting to optimize other dimensions that flow down the plan are similar to getNext requests in an such as number of fetches, monetary cost, response time, and/or re- iterator model, except that the parent operator does not wait sult quality. These considerations suggest other possibilities at the for a response (due to the inherent latency in crowdsourcing, language level, for example: it would take a very long time to get a response). Without • Specify MaxTime instead of AtLeast, in which case the query these messages, the query processor would only be able to processor must deliver the result within a certain amount of passively apply given changes to the raw tables rather than time, and attempts to return as many tuples as possible. actively drive them. • Specify MaxBudget or MaxFetches instead of MaxTime or • Two Phase: The query processor needs to make sure that AtLeast, in which case the query processor is constrained fetches are issued only if sufficient data is not present in the in how much external data it can obtain (based on monetary raw tables to answer the query. Deco achieves this constraint cost or number of fetch procedures allowed), and attempts to by using a two phase execution model, where the first phase, return as many tuples as possible. termed materialization, tries to answer the query using the There are many interesting variants, but it is important to note that current content of raw tables, and the second phase, termed all of them rely on the same query language semantics: return the accretion, issues fetch rules to obtain more result tuples. relational answer to Q over some valid instance of the conceptual Significant additional details of the Push-Pull Hybrid Execution relations while satisfying any performance-related constraints. Model are given in [30]. 4.2 Alternate Plans 4. QUERY PROCESSING To show the flexibility of our execution model, we present four Having defined the Deco data model and query language, we different query plans for the following query on the Restaurant now consider how to build a query processor that implements the relation from Section 1.1: defined semantics. The query processor must support constraints Q: Select name,address,rating,cuisine such as AtLeast while dealing with the inherent challenges in crowd- From Restaurant Where rating > 4 AtLeast 5 sourcing, such as latency, cost, and uncertainty. We first describe Deco’s execution model, then we present a As resolution functions, we use duplicate elimination for name- space of alternate plans that demonstrate Deco’s flexibility. Plan address, average of 3 (or more) tuples for rating, and majority of 3 costing and selection is a topic of ongoing work. (or more) for cuisine. We will see in Section 6 how these different query plans perform in terms of execution time and monetary cost. 4.1 Execution Model Basic Plan: Figure 2(a) shows a basic query plan that uses the The Deco data model and query semantics gives us some unique fetch rules ∅ ⇒ name,addr (operator 7), name,addr ⇒ rating challenges to address at the execution-model level. (operator 10), and name ⇒ cuisine (operator 13). At a high level, • First, the result tuples may change based on the added data the plan performs an outerjoin (operator 4) of a resolved version of in the raw tables. For example, an additional rating value for RestA (operator 5) and a resolved version of RestD1 (operator 8), a given restaurant may change the output of the resolution followed by a filter on rating (operator 3). Then the result is out- function. A traditional iterator model does not allow us to erjoined (operator 2) with a resolved version of RestD2 (operator modify values in tuples once they are passed up the plan. 11). The root operator (operator 1) stops the execution once five • Second, Deco fetch rules are general enough to provide tu- output tuples are generated. ples spanning multiple raw tables. For example, a fetch rule Predicate Placement: Alternatively, we can place the Filter oper- invocation name,address ⇒ rating,cuisine provides a rat- ator above both of the DLOJoin or Dependent Left Outerjoin oper- ing and a cuisine at the same time. Thus, data can be in- ators 16 and 17 (Figure 2(b)). serted in the raw table for cuisine even if the intent was to Due to the nature of our execution model, this simple transfor- obtain more ratings. The iterator model has no mechanism mation has more significant implication. The plan in Figure 2(a) for operators to signal arrival of new data to parent operators. will fetch cuisine only for the restaurants that satisfy rating>4, so • Finally, since crowdsourcing services have high latency and it may have lower monetary cost. On the other hand, the plan in provide natural parallelism, our execution model needs to in- Figure 2(b) increases the degree of parallelism by fetching rating voke multiple fetch rules in parallel. While asynchronous and cuisine at the same time, while having a higher monetary cost. iteration [15] can solve this problem, it does not solve the Reverse Fetches: Another interesting alternative plan can use re- other problems above. verse fetch rules. For our query Q, suppose the predicate rating > To address these challenges, Deco uses a novel Push-Pull Hybrid 4 is very selective. If we use the query plans in Figure 2, even ob- Execution Model, drawing on a combination of ideas from incre- taining a single answer could be expensive in terms of latency and mental view maintenance [7] and asynchronous iteration (devel- monetary cost, because we are likely to end up fetching a number oped in WSQ-DSQ [15]). It has the following features: of restaurants that do not satisfy the predicate. • Incremental Push: We borrow ideas from incremental view Instead, we can use the reverse fetch rule rating ⇒ name,address maintenance to make sure that the output reflects the current underneath the Resolve operator to start with a restaurant with a cer- state of the raw tables. The result of a fetch rule is handled as tain rating (according to at least one worker) instead of a random an update to one or more base tables (raw tables in our case), restaurant. Figure 3(a) shows a query plan that uses this reverse
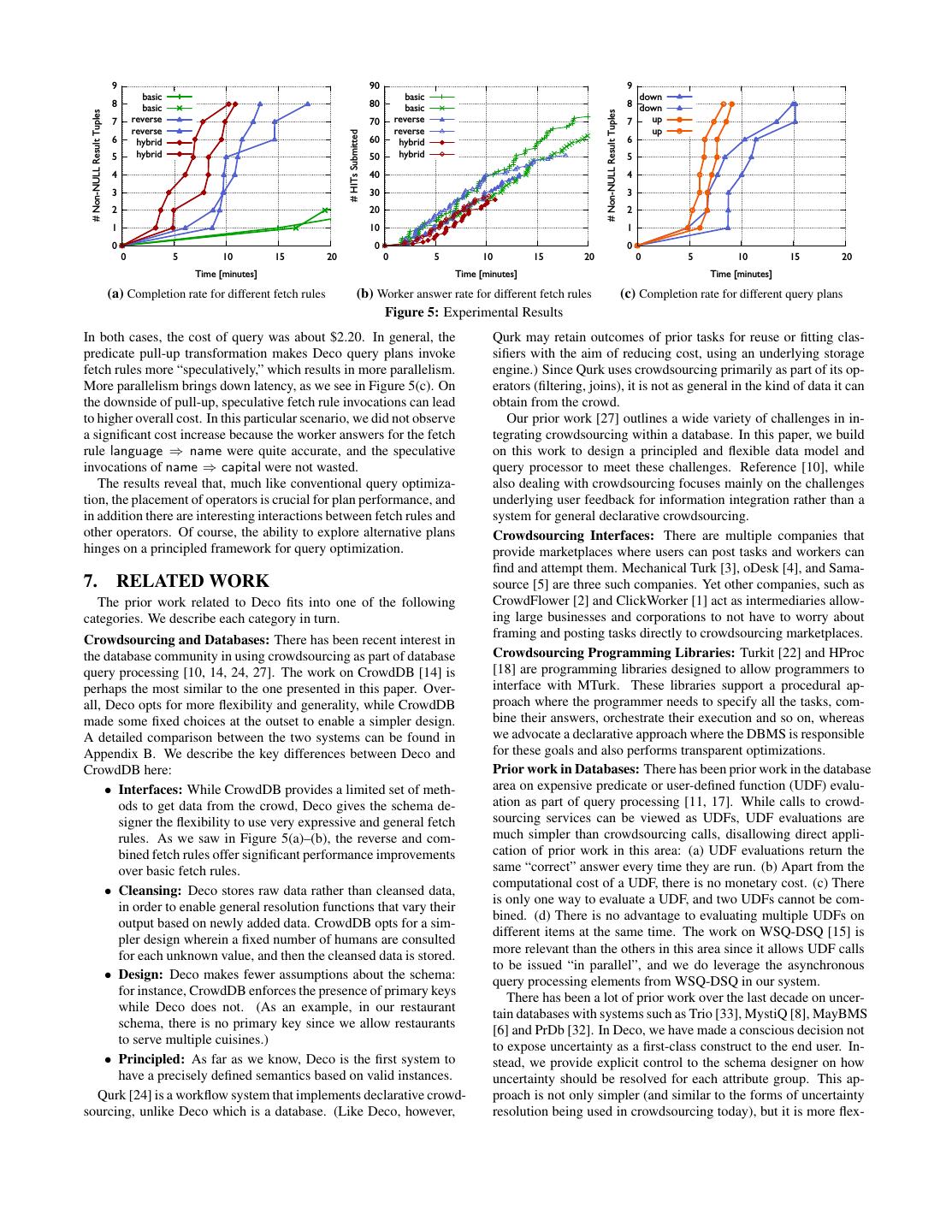
8 . 1 AtLeast[5] 14 AtLeast[5] 2 DLOJoin[name] 15 Filter[rating>4] 3 Filter[rating>4] 11 Resolve[maj3] 16 DLOJoin[name] 4 DLOJoin[name,addr] Scan Fetch 12 13 [RestD2] [nàc] 17 DLOJoin[name,addr] 24 Resolve[maj3] 5 Resolve[dupEli] 8 Resolve[avg3] 18 Resolve[dupEli] 21 Resolve[avg3] Scan Fetch 25 26 [RestD2] [nàc] Scan Fetch Scan Fetch Scan Fetch Scan Fetch 6 7 9 10 19 20 22 23 [RestA] [Φàn,a] [RestD1] [n,aàr] [RestA] [Φàn,a] [RestD1] [n,aàr] Figure 2: (a) Basic Plan (b) Filter Later 1 AtLeast[5] 14 AtLeast[5] 2 DLOJoin[name] 15 DLOJoin[name] 3 Filter[rating>4] 11 Resolve[maj3] 16 Filter[rating>4] 24 Resolve[maj3] 4 DLOJoin[name,addr] Scan Fetch 17 DLOJoin[name,addr] 12 13 [RestD2] [nàc] 5 Resolve[dupEli] 8 Resolve[avg3] 18 Resolve[dupEli] 21 Resolve[avg3] Scan Fetch Scan Fetch Scan Fetch Scan Scan Fetch 6 7 9 10 19 20 22 25 23 [RestA] [ràn,a] [RestD1] [n,aàr] [RestA] [ràn,a] [RestD1] [RestD2] [n,aàr,c] Figure 3: (a) Reverse Fetch (b) Combined Fetch fetch rule. Notice that the Fetch operator 7 “pushes” tuples to both ing the query, choosing the best query plan, and executing the cho- RestA and RestD1 via the Scan operators 6 and 9 (dotted arrows). sen plan is similar to a traditional DBMS. However, the query plan- Combined Fetches: It may be less expensive to use a fetch rule ner translates declarative queries posed over the conceptual schema that gathers multiple dependent attributes at the same time, rather to execution plans over the raw schema, and the query executor is than fetching one attribute at a time. For the example query Q, we not aware of the conceptual schema at all. To obtain data from can use a combined fetch rule name,address ⇒ rating,cuisine in- humans, the query executor invokes fetch procedures, and the raw stead of two fetch rules name,address ⇒ rating and name,address data is cleaned by invoking resolution functions. ⇒ cuisine. Figure 3(b) shows a query plan that uses this combined fetch rule. Notice that both Resolve operators 21 and 24 “pull” 6. EXPERIMENTAL EVALUATION more tuples from the Fetch operator 23. To illustrate the types of performance results that can be obtained from Deco, we present two experiments. One studies how different fetch rule configurations affect query performance, while the sec- 5. SYSTEM ond experiment evaluates different query plans given a particular We implemented our Deco prototype in Python with a SQLite fetch rule configuration. Given our space limitations, it is impossi- back-end. Currently, the system supports some DDL commands ble to present here more comprehensive results. that create tables, resolution functions, and fetch rules as well as a DML command that executes queries. In this section, we describe Experimental Setup: We used the following conceptual relation: Deco’s overall architecture (Figure 4). Country(name,[language],[capital]) Client applications interact with the Deco system using the Deco The anchor attribute name identifies a country, while the two de- API, which implements the standard Python Database API v2.0: pendent attributes language and capital are independent properties connecting to a database, executing a query, and fetching results. of the country. For resolution functions, we used dupElim (du- The Deco API also provides an interface for registering and con- plicate elimination) for name, and majority-of-3 for language and figuring fetch procedures and resolution functions. Using the Deco capital. (We assume one language per country.) The resolution API, we built a command line interface, as well as a web-based function majority-of-3 finds the majority of three or more tuples. graphical user interface that executes queries, visualizes query plans, In addition, we created six fetch rules that use the Mechanical and shows log messages in real-time. Turk fetch procedure to fetch data. Our experiments use one of the When the Deco API receives a query, the overall process of pars- following fetch rule configurations:
9 . End Schema For each set, we ran the query twice and noted similar results. Both User Designer runs are included in our graphs. Figure 5(a) depicts the number of non-NULL result tuples ob- DML Results DDL, Register UDFs tained over time. Since our query specified AtLeast 8, reaching eight output tuples signifies the completion of query. In addition, Deco API Figure 5(b) shows the number of HITs submitted by workers over time. Note that the monetary cost of a query is proportional to the Parser total number of HITs submitted. User Using the hybrid configuration, the query took 10.5 minutes and Defined cost $1.35 for 27 worker answers on average (across two runs). Us- Statistics Resolution Resolution Planner Functions Functions ing the reverse configuration, the query took 15 minutes and cost $2.30 for 46 worker answers on average. In comparison, the ba- Catalogs sic configuration performed very poorly: the query took two hours Executor overall and cost around $12.05. (We ended up collecting 64 coun- Raw Tables tries and their languages.) Thus, we find that it is important to consider a variety of query MTurk User Defined User Defined plans, and the decisions of the query optimizer can significantly Fetch Proc. Fetch Proc. Fetch Proc. impact query performance in terms of latency and total monetary cost. Choosing fetch rules is a significant decision under the con- Amazon Other Other trol of the optimizer. In particular, for this benchmark query, those Mechanical Crowdsourcing External fetch rules that get multiple pieces of information at once (such as Turk Service Source name⇒language,capital), and those that operate in the reverse di- rection (such as language⇒name) offer significant benefits over basic fetch rules. In general, it is important for a declarative crowd- Figure 4: Deco Architecture sourcing system (like Deco) to handle fetch rules of different types, and thus increase the opportunities for finding a good execution • Basic configuration (3 fetch rules): ∅ ⇒ name, plan. (Of course, we depend on the schema designer to take advan- name ⇒ language, and name ⇒ capital tage of the flexibility and provide multiple fetch rules.) • Reverse configuration (3 fetch rules): language ⇒ name, Overall, our findings validate the role of fetch rules as “access name ⇒ language, and name ⇒ capital methods” for the crowd, and reinforce the importance of including • Hybrid configuration (2 fetch rules): them in a principled query optimization framework. language ⇒ name,capital and name ⇒ language,capital We repeated our experiment with the constraint AtLeast 12 in- For attributes name and capital, workers were allowed to enter free stead of AtLeast 8 (graphs not shown). While the relative per- text, but our question server validated this input to ensure that the formance of our configurations was similar, it was interesting to text had no leading or trailing whitespaces and that all letters were observe that AtLeast 12 queries did not take significantly longer uppercase. For language, workers were allowed to select one lan- than AtLeast 8 despite producing more answers, but they did in- guage from a drop-down list of about 90 languages. cur higher cost. This behavior is because our execution model is- On Mechanical Turk, we paid a fixed amount of five cents per sues more fetches (i.e., HITs) in parallel (via bind messages) for HIT (i.e., per fetch rule invocation) as compensation for completed AtLeast 12 than for AtLeast 8, and a larger number of HITs in work. All experiments were conducted on weekends in Feb 2012. the same HIT group attract more workers. We plan to investigate Our benchmark query requested eight Spanish-speaking coun- trading off cost for time by varying the number of bind messages tries along with their capital cities. in future work. In terms of the quality, the results were clean and correct except Select name,capital From Country one typo (“Ddominican Republic”). Not suprisingly, individual an- Where language=’Spanish’ AtLeast 8 swers had several errors that are not exposed in the result. Common For each experiment, we begin with empty raw tables. According errors for capital cities were for Spain and Bolivia. to Wikipedia, there are 20 Spanish-speaking countries in total. Experiment 2: Performance for Different Query Plans: In this Experiment 1: Performance for Different Fetch Configurations: experiment, we evaluated the query performance of different query In our first experiment, we evaluated the query performance of plans under the reverse fetch rule configuration. Specifically, we different fetch rule configurations to study the usefulness of the studied the performance implication of pulling up the (language flexibility of Deco fetch rules. Our fetch configurations are by = ’Spanish’) predicate. Our Deco prototype pushes all predicates default translated into query plans similar to Figure 2(a) (Basic), down as much as possible by default and produces a query plan Figure 3(a) (Reverse), Figure 3(b) (Hybrid), where the raw table similar to Figure 3(a) in the reverse configuration. Under this plan containing names is left outerjoined with the raw table containing (termed “down”), Deco does not invoke the fetch rule name ⇒ cap- names and languages, followed by a filter on language, and then the ital until language is resolved to Spanish. On the other hand, under result is left outerjoined with the raw table containing names and the plan (termed “up”) that is produced by applying the predicate capitals. However, the fetch operators in each of these plans use pull-up transformation (similar to Figure 2(b)), Deco invokes fetch different fetch rules. For instance, for the Hybrid configuration, the rules name ⇒ language and name ⇒ capital simultaneously as fetch operator for the name raw table uses language ⇒ name,capital, soon as a new country name is fetched. while the (shared) fetch operator for language and capital raw ta- We ran the same benchmark query with these two query plans. bles uses name ⇒ language,capital as the fetch rule. Figure 5(c) depicts the number of non-NULL result tuples obtained We ran the same benchmark query with the three sets of fetch over time for two runs each. The completion times for the “up” rules (therefore different query plans) on our Deco prototype [29]. and “down” plans were 9 minutes and 15 minutes, respectively.
10 . �� ��� �� ����� ����� ���� �� ����� ��� ����� �� ���� ������������������������ ������������������������ �� ������� ��� ������� �� �� ������� ������� �� ���������������� �� ������ ��� ������ �� �� ������ ��� ������ �� �� ��� �� �� ��� �� �� ��� �� �� ��� �� �� �� �� �� �� ��� ��� ��� �� �� ��� ��� ��� �� �� ��� ��� ��� �������������� �������������� �������������� (a) Completion rate for different fetch rules (b) Worker answer rate for different fetch rules (c) Completion rate for different query plans Figure 5: Experimental Results In both cases, the cost of query was about $2.20. In general, the Qurk may retain outcomes of prior tasks for reuse or fitting clas- predicate pull-up transformation makes Deco query plans invoke sifiers with the aim of reducing cost, using an underlying storage fetch rules more “speculatively,” which results in more parallelism. engine.) Since Qurk uses crowdsourcing primarily as part of its op- More parallelism brings down latency, as we see in Figure 5(c). On erators (filtering, joins), it is not as general in the kind of data it can the downside of pull-up, speculative fetch rule invocations can lead obtain from the crowd. to higher overall cost. In this particular scenario, we did not observe Our prior work [27] outlines a wide variety of challenges in in- a significant cost increase because the worker answers for the fetch tegrating crowdsourcing within a database. In this paper, we build rule language ⇒ name were quite accurate, and the speculative on this work to design a principled and flexible data model and invocations of name ⇒ capital were not wasted. query processor to meet these challenges. Reference [10], while The results reveal that, much like conventional query optimiza- also dealing with crowdsourcing focuses mainly on the challenges tion, the placement of operators is crucial for plan performance, and underlying user feedback for information integration rather than a in addition there are interesting interactions between fetch rules and system for general declarative crowdsourcing. other operators. Of course, the ability to explore alternative plans Crowdsourcing Interfaces: There are multiple companies that hinges on a principled framework for query optimization. provide marketplaces where users can post tasks and workers can find and attempt them. Mechanical Turk [3], oDesk [4], and Sama- 7. RELATED WORK source [5] are three such companies. Yet other companies, such as The prior work related to Deco fits into one of the following CrowdFlower [2] and ClickWorker [1] act as intermediaries allow- categories. We describe each category in turn. ing large businesses and corporations to not have to worry about framing and posting tasks directly to crowdsourcing marketplaces. Crowdsourcing and Databases: There has been recent interest in the database community in using crowdsourcing as part of database Crowdsourcing Programming Libraries: Turkit [22] and HProc query processing [10, 14, 24, 27]. The work on CrowdDB [14] is [18] are programming libraries designed to allow programmers to perhaps the most similar to the one presented in this paper. Over- interface with MTurk. These libraries support a procedural ap- all, Deco opts for more flexibility and generality, while CrowdDB proach where the programmer needs to specify all the tasks, com- made some fixed choices at the outset to enable a simpler design. bine their answers, orchestrate their execution and so on, whereas A detailed comparison between the two systems can be found in we advocate a declarative approach where the DBMS is responsible Appendix B. We describe the key differences between Deco and for these goals and also performs transparent optimizations. CrowdDB here: Prior work in Databases: There has been prior work in the database • Interfaces: While CrowdDB provides a limited set of meth- area on expensive predicate or user-defined function (UDF) evalu- ods to get data from the crowd, Deco gives the schema de- ation as part of query processing [11, 17]. While calls to crowd- signer the flexibility to use very expressive and general fetch sourcing services can be viewed as UDFs, UDF evaluations are rules. As we saw in Figure 5(a)–(b), the reverse and com- much simpler than crowdsourcing calls, disallowing direct appli- bined fetch rules offer significant performance improvements cation of prior work in this area: (a) UDF evaluations return the over basic fetch rules. same “correct” answer every time they are run. (b) Apart from the • Cleansing: Deco stores raw data rather than cleansed data, computational cost of a UDF, there is no monetary cost. (c) There in order to enable general resolution functions that vary their is only one way to evaluate a UDF, and two UDFs cannot be com- output based on newly added data. CrowdDB opts for a sim- bined. (d) There is no advantage to evaluating multiple UDFs on pler design wherein a fixed number of humans are consulted different items at the same time. The work on WSQ-DSQ [15] is for each unknown value, and then the cleansed data is stored. more relevant than the others in this area since it allows UDF calls to be issued “in parallel”, and we do leverage the asynchronous • Design: Deco makes fewer assumptions about the schema: query processing elements from WSQ-DSQ in our system. for instance, CrowdDB enforces the presence of primary keys There has been a lot of prior work over the last decade on uncer- while Deco does not. (As an example, in our restaurant tain databases with systems such as Trio [33], MystiQ [8], MayBMS schema, there is no primary key since we allow restaurants [6] and PrDb [32]. In Deco, we have made a conscious decision not to serve multiple cuisines.) to expose uncertainty as a first-class construct to the end user. In- • Principled: As far as we know, Deco is the first system to stead, we provide explicit control to the schema designer on how have a precisely defined semantics based on valid instances. uncertainty should be resolved for each attribute group. This ap- Qurk [24] is a workflow system that implements declarative crowd- proach is not only simpler (and similar to the forms of uncertainty sourcing, unlike Deco which is a database. (Like Deco, however, resolution being used in crowdsourcing today), but it is more flex-
11 .ible, and also eliminates the computationally intractable aspects of [10] X. Chai, B. Vuong, A. Doan, and J. F. Naughton. Efficiently dealing with uncertainty correlations between different attributes. incorporating user feedback into information extraction and Intuitively, our intention is less to manage and query uncertain data integration programs. In SIGMOD, 2009. as it is to fetch and clean data. [11] S. Chaudhuri and K. Shim. Query optimization in the Our data model is also related to the field of Global-As-View presence of foreign functions. In VLDB, 1993. (GAV) data integration [19]. In particular, our fetch rules can be [12] A. Doan, R. Ramakrishnan, and A. Halevy. Crowdsourcing viewed as binding patterns or capabilities of sources [13, 20, 21], systems on the world-wide web. CACM, 2011. and the conceptual schema can be viewed as a mediated database. [13] D. Florescu, A. Levy, I. Manolescu, and D. Suciu. Query However, the properties and behavior of humans and sources are optimi- zation in the presence of limited access patterns. In different, necessitating different query processing techniques: First, SIGMOD, 1999. humans, unlike external data sources, need to be compensated mon- [14] M. J. Franklin, D. Kossmann, T. Kraska, S. Ramesh, and etarily. Second, subsequent invocations of the same fetch rule im- R. Xin. Crowddb: answering queries with crowdsourcing. In proves the quality of results since multiple humans would be con- SIGMOD, 2011. sulted, unlike external sources where repeating the same query re- [15] R. Goldman and J. Widom. Wsq/dsq: A practical approach turns the same results. Third, different invocations of fetch rules for combined querying of databases and the web. In can be done in parallel (i.e., many humans may address tasks in SIGMOD, 2000. parallel), while external data sources have a single point of access. [16] S. Guo, A. Parameswaran, and H. Garcia-Molina. So who Crowdsourcing Algorithms: Recently, there has been an effort to won? dynamic max discovery with the crowd. In SIGMOD, design fundamental algorithms for crowdsourcing. In other words, 2012. the algorithms, such as sorting, filtering and searching use human [17] J. M. Hellerstein and M. Stonebraker. Predicate migration: workers to perform basic operations, such as comparisons, evalu- Optimizing queries with expensive predicates. In SIGMOD, ating a predicate on an item, or rating or ranking items. This work 1993. is orthogonal to ours and can be used as part of the query proces- [18] P. Heymann and H. Garcia-Molina. Turkalytics: analytics for sor of our Deco system. So far, there have been papers on filtering human computation. In WWW, 2011. items [26], finding max [16], searching in a graph [28], and sorting and joins [23]. [19] M. Lenzerini. Data integration: a theoretical perspective. In PODS, 2002. 8. CONCLUSIONS [20] A. Levy, A. Rajaraman, and J. Ordille. Querying heterogeneous information sources using source We presented Deco, a system for declarative crowdsourcing. Deco descriptions. In VLDB, 1996. offers a practical and principled approach for accessing crowd data [21] C. Li and E. Chang. Query planning with limited source and integrating it with conventional data. We believe that our no- capabilities. In ICDE, 2000. tions of fetch and resolution rules provide simple but powerful mechanisms for describing crowd access methods. We also believe [22] G. Little, L. B. Chilton, M. Goldman, and R. C. Miller. that our split conceptual/raw data model (top and bottom parts of Turkit: tools for iterative tasks on mechanical turk. In Figure 1), together with our “Fetch-Resolve-Join” semantics, yield HCOMP, 2009. an elegant way to manage the data before and after cleansing. Our [23] A. Marcus, E. Wu, D. Karger, S. Madden, and R. Miller. query processor utilizes a novel push-pull execution model to al- Human-powered sorts and joins. In VLDB, 2012. low worker requests to proceed in parallel, a critical aspect when [24] A. Marcus, E. Wu, S. Madden, and R. Miller. Crowdsourced dealing with humans and other high-latency external data sources. databases: Query processing with people. In CIDR, 2011. While our current Deco prototype does not yet perform sophisti- [25] R. McCann, W. Shen, and A. Doan. Matching schemas in cated query optimization, our design and system do provide a solid online communities: A web 2.0 approach. In ICDE, 2008. foundation to study the cost, latency and accuracy tradeoffs that [26] A. Parameswaran, H. Garcia-Molina, H. Park, N. Polyzotis, make crowdsourced data such an interesting challenge. A. Ramesh, and J. Widom. Crowdscreen: Algorithms for filtering data with humans. In SIGMOD, 2012. Acknowledgements: We thank Richard Pang for helping us run the experiments in this paper. [27] A. Parameswaran and N. Polyzotis. Answering queries using humans, algorithms and databases. In CIDR, 2011. 9. REFERENCES [28] A. Parameswaran, A. D. Sarma, H. Garcia-Molina, N. Polyzotis, and J. Widom. Human-assisted graph search: [1] ClickWorker. http://clickworker.com. it’s okay to ask questions. In VLDB, 2011. [2] CrowdFlower. http://crowdflower.com. [29] H. Park, R. Pang, A. Parameswaran, H. Garcia-Molina, [3] Mechanical Turk. http://mturk.com. N. Polyzotis, and J. Widom. Deco: A system for declarative [4] ODesk. http://odesk.com. crowdsourcing. In VLDB, 2012. [5] Samasource. http://samasource.com. [30] H. Park, A. Parameswaran, and J. Widom. Query processing [6] L. Antova, C. Koch, and D. Olteanu. MayBMS: Managing over crowdsourced data. Technical report, Stanford Infolab, Incomplete Information with Probabilistic World-Set 2012. Decompositions. In ICDE, 2007. [31] A. Quinn and B. Bederson. Human computation: a survey [7] J. A. Blakeley, P. Larson, and F. W. Tompa. Efficiently and taxonomy of a growing field. In CHI, 2011. updating materialized views. In SIGMOD, 1986. [32] P. Sen and A. Deshpande. Representing and Querying [8] J. Boulos, N. Dalvi, B. Mandhani, S. Mathur, C. Re, and Correlated Tuples in Probabilistic Databases. In ICDE, 2007. D. Suciu. Mystiq: a system for finding more answers by [33] J. Widom. Trio: A System for Integrated Management of using probabilities. In SIGMOD, 2005. Data, Accuracy, and Lineage. In CIDR, 2005. [9] S. Ceri and J. Widom. Deriving production rules for incremental view maintenance. In VLDB, 1991.
12 .APPENDIX have fetch rule that adds more tuples, along with another fetch rule that fills in missing values. A CrowdDB table on the other A. JOIN ORDER hand only allows either fetching an entire tuple (CrowdTa- In this section, we show that all left outerjoin orders with the an- bles) or filling in missing values (CrowdColumns). chor table as the first operand followed by the dependent tables (in • Deco allows user-defined resolution functions, for instance, any order) produce identical results. Let denote the left outerjoin average-of-3 for rating. Or, the schema designer could spec- operator. ify a more sophisticated resolution function, such as average T HEOREM A.1. Let A be the anchor table, and let D1 , D2 , . . . , of 3 to 10 values with standard deviation smaller than 1. Also, Dn be the dependent tables. Let π denote a permutation of 1 . . . n. the resolution functions are allowed to output multiple values For all permutations π, the following expression Eπ evaluates to after resolution, for instance, dupElim for cuisine. On the the same result: other hand, CrowdDB only allows a majority vote for each attribute with a fixed maximum number of votes. Eπ = (. . . ((A Dπ(1) ) Dπ(2) ) . . . Dπ(n) ) • Deco retains all crowdsourced data in raw tables, while P ROOF. Let t = (a1 , a2 , . . . , am ) be a tuple in A. Let t(Dπ(i) ) = CrowdDB discards crowdsourced data and populates the re- Πδπ(i) ({t} Dπ(i) ), where δπ(i) is the set of all dependent at- solved values in its relations. If a new resolution function is to tributes in Dπ(i) . Note that none of the t(Dπ(i) ) nor t share any be applied or more crowdsourced data is provided, Deco can attributes. Now, let us consider easily recompute the new resolved value on-demand, while CrowdDB will need to start afresh. Eπt = (. . . (({t} Dπ(1) ) Dπ(2) ) . . . Dπ(n) ) We now show that the CrowdDB data model is an instance of the which is intuitively the contribution of t to Eπ . Note that Deco data model. CrowdDB supports regular relations, however, some relations may be designated as CrowdTables. For those rela- Eπ = Eπt (1) tions that are not CrowdTables, some attributes may be designated t∈A as CrowdColumns. Now, we have: CrowdColumns: The regular relations in CrowdDB that contain CrowdColumns may be expressed in Deco as conceptual relations Eπt = (. . . (({t} Dπ(1) ) Dπ(2) ) . . . Dπ(n) ) with the same schema. We first designate the set of all attributes = (. . . (({t} × t(Dπ(1) )) Dπ(2) ) . . . Dπ(n) ) (2a) that are not CrowdColumns to be the anchor attribute group of that = (. . . ({t} × t(Dπ(1) ) × t(Dπ(2) )) . . . Dπ(n) ) (2b) conceptual relation. (Note that in CrowdDB one of these attributes will be the primary key.) We may then express each CrowdCol- .. umn as a dependent attribute group. Since CrowdDB uses a ma- . jority vote to resolve multiple answers, we use the same majority = {t} × t(Dπ(1) ) × t(Dπ(2) ) × . . . × t(Dπ(n) ) (2c) vote as the resolution function for each dependent attribute. The Equality 2a holds by definition of left outerjoin. Equality 2b holds anchor attribute group has duplicate elimination as the resolution because the left outerjoin is unaffected by the cross-product with function. The fetch rule used in CrowdDB to populate values in t(Dπ(1) ) since no attributes are shared between t(Dπ(1) ) and Dπ(2) . CrowdColumns is a single one from all the anchor attributes to all Thus, ({t} × t(Dπ(1) )) Dπ(2) = ({t} Dπ(2) ) × t(Dπ(1) ) = the dependent attributes. {t} × t(Dπ(2) ) × t(Dπ(1) ). Subsequent equalities hold for similar CrowdTables: We can represent CrowdTables once again as a sin- reasons. gle conceptual relation in Deco. We designate the key attribute as Since × is associative and commutative, Eπt (Expression 2c) is the anchor attribute. Each of the other attributes is designated as a identical, independent of the permutation π. Since this argument separate dependent attribute. As before, the resolution function for applies for each t in A, using Equation 1, the argument holds for each of these dependent attributes is a majority vote. The resolution Eπ itself. In other words, the final result is independent of the function is set to be duplicate elimination for the anchor attribute. permutation π. In CrowdDB, entire tuples may be crowdsourced (which is equiv- alent to a fetch rule ∅ ⇒ all-attributes) or some attributes whose B. COMPARISON WITH CROWDDB majority has already been reached are provided, and the other at- Since the CrowdDB data model is the closest one to ours, in tributes are crowdsourced (which can be captured by a fetch rule this section we perform a more thorough comparison between the D ⇒ D , where D ∪ D = all-attributes). CrowdDB and Deco data models. Specifically, we show that the Thus, the Deco data model captures the CrowdDB data model as an Deco data model is more expressive than the CrowdDB data model instance. We now discuss other issues that differ in the two system as described in [14]. designs. B.1 Data Model B.2 Data Manipulation We first provide some examples of data model constructs Deco Since CrowdDB does not store any of the unresolved raw data supports that CrowdDB does not, and then show that the CrowdDB explicitly, all relations are visible to an end user. CrowdDB thus data model as presented in [14] is an instance of the Deco data allows users to insert new tuples into these relations and to update model. and delete existing tuples. • Unlike CrowdDB, Deco does not require that every (concep- In Deco, conceptual relations may be materialized on demand tual) relation has a primary key. For instance, in our Restau- during query processing. As a result, we only allow updates and rant example, there is no (nontrivial) key, since there could deletes to tuples in the raw tables. Inserts, on the other hand, are be multiple cuisines for each name. permitted on conceptual relations. They are handled just like fetch • Deco allows various kinds of fetch rules, and fetch rules may rules: the raw tables that have attributes mentioned in the insert be added or removed at any time. Thus, a Deco relation can statement are populated with new tuples.
13 . Of course, a schema designer may wish to allow updates and in a CrowdDB relation with all of their values already resolved, deletes to conceptual relations. They would need to be translated to CrowdDB will still only return the number of tuples specified in the raw tables, akin to update and delete rules in standard relational the LIMIT clause (instead of all of them, even though returning all databases [9]. the tuples would not require any further crowdsourcing calls). CrowdDB also supports two constructs CROWDEQUALS (to B.3 Query Language and Semantics allow human-evaluated equality predicates) and CROWDORDER CrowdDB uses standard relational queries with an optional LIMIT (to allow human-based sorting). All comparisons are cached in clause to specify the maximum number of tuples required in the CrowdDB. In Deco, we can support these constructs using a simi- output. CrowdDB ensures that no unresolved values are output lar approach. We create two conceptual relations: CrowdCompare (i.e., all the CrowdColumns of each tuple must be filled in before contains all triples of the form (a, b, V ) such that V corresponds to the tuple is output). the boolean value of the expression a < b, according to a human While LIMIT is related to our AtLeast construct, it has some- worker. CrowdEquals contains all triples of the form (a, b, V ) such what different semantics. AtLeast ensures a lower bound on the that V corresponds to the boolean value of the expression a = b, number of output tuples given budget restrictions, while LIMIT according to a human worker. Resolution rules can be applied on ensures an upper bound on the number of output tuples. Let us these tables to improve the quality of the comparisons. Then, a consider a single-relation query. If there are no current tuples in a query involving CROWDEQUALS can be translated into a query CrowdDB relation, then the query processor will return an empty that joins with the CrowdEquals table. Similarly, a query involving result since the LIMIT clause does not place a lower bound on the CROWDORDER can be translated into one with an operator that number of output tuples. Additionally, if there are many tuples implements the ORDER-BY semantics using CrowdCompare.
3秒后跳转登录页面
去登陆

