










- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Crowdsourced Enumeration Queries
Hybrid human/computer database systems promise to greatly expand the usefulness of query processing by incorporating the crowd for data gathering and other tasks. Such systems raise many implementation questions. Perhaps the most fundamental question is that the closed world assumption underlying relational query semantics does not hold in such systems. As a consequence the meaning of even simple queries can be called
into question. Furthermore, query progress monitoring becomes difficult due to non-uniformities in the arrival of crowdsourced. To address these issues, we develop statistical tools that enable users and systems developers to reason about query completeness. These tools can also help drive query execution and crowdsourcing strategies.
展开查看详情
1 . Crowdsourced Enumeration Queries Beth Trushkowsky, Tim Kraska, Michael J. Franklin, Purnamrita Sarkar AMPLab, UC Berkeley, United States {trush, kraska, franklin, psarkar}@cs.berkeley.edu Abstract— Hybrid human/computer database systems promise mistakes must be fixed, duplicates must be removed, etc. to greatly expand the usefulness of query processing by incorpo- Similar issues arise in data ingest for traditional database rating the crowd for data gathering and other tasks. Such systems systems through ETL (Extract, Transform and Load) and raise many implementation questions. Perhaps the most funda- mental question is that the closed world assumption underlying data integration, but techniques have also been developed relational query semantics does not hold in such systems. As a specifically for crowdsourced input [5], [6], [7], [8]. consequence the meaning of even simple queries can be called The above concerns, while both interesting and important, into question. Furthermore, query progress monitoring becomes are not the focus of this paper. Rather, we believe that there difficult due to non-uniformities in the arrival of crowdsourced are more fundamental issues at play in such hybrid systems. data and peculiarities of how people work in crowdsourcing systems. To address these issues, we develop statistical tools Specifically, when the crowd can augment the data in the that enable users and systems developers to reason about query database to help answer a query, the traditional closed-world completeness. These tools can also help drive query execution assumption on which relational database query processing is and crowdsourcing strategies. We evaluate our techniques using based, no longer holds. This fundamental change calls into experiments on a popular crowdsourcing platform. question the basic meaning of queries and query results in a hybrid human/computer database system. I. I NTRODUCTION Advances in machine learning, natural language processing, B. Can You Really Get it All? image understanding, etc. continue to expand the range of In this paper, we consider one of the most ba- problems that can be addressed by computers. But despite sic RDBMS operation, namely, scanning a single table these advances, people still outperform state-of-the-art algo- with predicates. Consider, for example, a SQL query rithms for many data-intensive tasks. Such tasks typically to list all restaurants in San Francisco serving scal- involve ambiguity, deep understanding of language or context, lops: SELECT * FROM RESTAURANTS WHERE CITY = or subjective reasoning. ‘San Francisco’ and DISH = ‘Scallops’. In a Crowdsourcing has emerged as a paradigm for leverag- traditional RDBMS there is a single correct answer for this ing human intelligence and activity at large scale. Popular query, and it can be obtained by scanning the table, filtering crowdsourcing platforms such as Amazon Mechanical Turk the records, and returning all matching records of the table. (AMT) provide access to hundreds of thousands of human This approach works even for relations that are in reality workers via programmatic interfaces (APIs). These APIs pro- unbounded, because the closed world assumption dictates that vide an intriguing new opportunity, namely, to create hy- any records not present in the database at query execution brid human/computer systems for data-intensive applications. time do not exist. Of course, such limitations can be a source Such systems, could, to quote J.C.R. Licklider’s famous 1960 of frustration for users trying to obtain useful real-world prediction for man-computer symbiosis, “...process data in a information from database systems. way not approached by the information-handling machines we In contrast, in a crowdsourced system like CrowdDB, once know today.” [1]. the records in the stored table are exhausted, jobs can be sent to the crowd asking for additional records. The question then A. Query Processing with Crowds becomes: when is the query result set complete? Crowdsourced Recently, a number of projects have begun to explore queries can be inherently fuzzy or have unbounded result the potential of hybrid human/computer systems for database sets, with tuples scattered over the web or only in human query processing. These include CrowdDB [2], Qurk [3], minds. For example, consider a query for a list of graduating and sCOOP [4]. In these systems, human workers can per- Ph.D. students currently on the job market, or companies in form query operations such as subjective comparisons, fuzzy California interested in green technology. Such queries are matching for predicates and joins, entity resolution, etc. As often considered one of the main use cases for crowd-enabled shown in [2], these simple extensions can greatly extend the database systems, as they reside in the sweet spot between usefulness of a query processing system. too much work for the user but not executed often enough to Of course, many challenges arise when adding people to justify a complex machine learning solution. query processing, due to the peculiarities in latency, cost, In this paper we address the question of “How should quality and predictability of human workers. For example, users think about enumeration queries in the open world data obtained from the crowd must be validated, spelling of a crowdsourced database system?”. We develop statistical
2 . States: unique items 50 CrowdSQL Results 40 avg # unique answers Quality Control/ 30 Parser MetaData Progress Monitor Turker Relationship 20 10 Optimizer Manager Executor UI Manager Statistics 0 0 50 100 150 200 250 300 Files Access Methods HIT Manager # Answers (HITs) Fig. 1. States experiments: average unique vs. total number of answers Disk 1 tools that enable users to reason about tradeoffs between time/cost and completeness, and that can be used to drive Disk 2 query execution and crowdsourcing strategies. C. Counting Species Fig. 2. CrowdDB Architecture The key idea of our technique is to use the arrival rate of environment. We also describe methods to leverage these new answers from the crowd to reason about the completeness techniques to help users make intelligent tradeoffs between of the query. Consider the execution of a “SELECT *” query time/cost and completeness. These techniques extend beyond in a crowdsourced database system where workers are asked to crowdsourced databases and, for example, can help to estimate provide individual records of the table. For example, one could the completeness of deep-web queries. query for the names of the 50 US states using a microtask To summarize, we make the following contributions: crowdsourcing platform like AMT by generating HITs (i.e., • We formalize the process of crowdsourced set enumeration Human Intelligence Tasks) that would have workers provide and describe how it violates statistical fundamental assump- the name of one or more states. As workers return results, tions of existing species estimation techniques. the system collects the answers, keeping a list of the unique • We develop a technique to estimate result cardinality and answers (suitably cleansed) as they arrive. query progress in the presence of crowd-specific behaviors. Figure 1 shows the results of running that query, with the • We devise a pay-as-you-go approach to allow informed number of unique answers received shown on the vertical axis, decisions about the cost/completeness tradeoff, we well as and the total number of answers received on the x-axis. As a technique to determine if data scraping could be applied. would be expected, initially there is a high rate of arrival for • We examine the effectiveness of our techniques via experi- previously unseen answers, but as the query progresses (and ments using Amazon Mechanical Turk (AMT). more answers have been seen) the arrival rate of new answers The paper is organized as follows: In Section II we give back- begins to taper off, until the full population (i.e., the 50 states, ground on the CrowdDB system. Section III describes how in this case) has been identified. crowd-specific behaviors break assumptions on which species This behavior is well-known in fields such as biology and estimation algorithms are based. In Section IV we develop statistics, where this type of figure is known as the Species techniques to improve the estimation in the presence of crowd- Accumulation Curve (SAC) [9]. Imagine you were trying to specific behavior, whereas Section V discusses a heuristic to count the number of unique species of animals on an island detect when alternate data-gathering techniques could be used. by putting out traps overnight, identifying the unique species Section VI introduces a pay-as-you-go technique. Section VII found in the traps the next morning, releasing the animals covers related work and in Section VIII we conclude. and repeating this daily. By observing the rate at which new II. BACKGROUND : C ROWD DB species are identified over time, you can begin to infer how close to the true number of species you are. We can use similar CrowdDB is a hybrid human-machine database system that reasoning to help understand the execution of set enumeration uses human input to process queries. CrowdDB currently queries in a crowdsourced query processor. supports two crowdsourcing platforms: AMT and our own mobile platform [10]. We focus on AMT in this paper, the D. Overview of the Paper leading platform for so-called microtasks. Microtasks, also In this paper, we apply species estimation techniques from called Human Intelligence Tasks (HITs) in AMT, usually do the statistics and biology literature to understand and manage not require any special training and do not take more than the execution of set enumeration queries in crowdsourced a few minutes to complete. AMT provides a marketplace for database systems. We find that while the classical theory microtasks that allows requesters to post HITs and workers to provides the key to understanding the meaning of such queries, search for and work on HITs for a small reward, typically a there are certain peculiarities in the behavior of microtask few cents each. crowdsourcing workers that require us to develop new methods Figure 2 shows the architecture of CrowdDB. CrowdDB to improve the accuracy of cardinality estimation in this incorporates traditional query compilation, optimization and
3 . A. The Problem with Existing Estimators Various techniques have been devised in biology to estimate the number of species [12], [13] as well as in the database community to estimate the number of distinct values in a table [11]. They all operate similarly: a sample is drawn at random from a population (e.g., the entire table) and based on Fig. 3. Ice cream flavors task UI on AMT the frequency of observed items (distinct values), the number of unobserved items (number of missing distinct values) is execution components, which are extended to cope with estimated. The techniques differ most notably in their assump- human-generated input. In addition the system is extended tions, in particular that distinct value estimation techniques with crowd-specific components, such as a user interface (UI) assume that the population (i.e., table) size is known. Unfor- manager and quality control/progress monitor. Users issue tunately, knowledge of the population size is only possible in queries using CrowdSQL, an extension of standard SQL. the closed world; in systems with crowdsourced enumerations, CrowdDB automatically generates UIs as HTML forms based records can be acquired on-demand, thus the table size is on the CROWD annotations and optional free-text annotations potentially infinite. We focus the remaining discussion on of columns and tables in the schema. Figure 3 shows an species estimators suitable for the open world because they example HTML-based UI that would be presented to a worker allow for an infinite population. for the following crowd table definition: To gain an understanding of the crowd’s ability to answer CREATE CROWD TABLE ice_cream_flavor { set enumeration queries and its impact on existing estimation name VARCHAR PRIMARY KEY techniques, we crowdsourced the elements of sets for which } the true cardinality is known, using the UI exemplified in Figure 3. We use the open-world-safe estimator “Chao92” Although CrowdDB supports alternate user interfaces (e.g., [14] as it is widely used in the species estimation literature showing previously received answers), this paper focuses on [15].1 Figure 4 shows the observed Chao92 estimate (“actual”) a pure form of the set enumeration question. The use of evaluated as answers arrive in one AMT experiment in which alternative UIs is the subject of future work. we crowdsourced the names of the 192 United Nations (UN) During query processing, the system automatically posts one member countries and compares it to the expected behavior or more HITs using the AMT web service API and collects the using simulation with the empirical data distribution derived answers as they arrive. After receiving the answers, CrowdDB from all our UN experiment runs. We focus on a single repre- performs simple quality control using quorum votes before it sentative experiment rather than an average over multiple runs passes the answers to the query execution engine. Finally, the to investigate the behavior a user would observe; averaging system continuously updates the query result and estimates can also disguise the effects described next. the quality of the current result based on the new answers. Note in Figure 4 that the value of the estimate begins The user may thus stop the query as soon as the quality is approaching the true value of 192, however it then significantly sufficient or intervene if a problem is detected. More details overestimates the true value for most of the remaining time of about the CrowdDB components and query execution are given the experiment. This is surprising as our simulation shows in [2]. This paper focuses on the quality control and progress that the estimate should become more accurate and stable component that allows the user to continuously reason about as it receives more data (“expected” in Figure 4). As it query completeness and cost. turns out, the way in which crowd workers each provide their answers deeply impacts the behavior of an estimation III. A M ODEL AND A NALYSIS OF P ROGRESS E STIMATION algorithm. For example, in five runs of the UN experiment, FOR C ROWDSOURCED E NUMERATIONS we observed various trends in how the crowd responds to a set enumeration query. A worker could enumerate the To evaluate progress as answers are arriving, the system UN countries by traversing an alphabetical list, starting with needs an estimate of the result set’s cardinality in order to cal- Afghanistan. However, it was not uncommon for workers to culate the percentage complete. Species estimation algorithms begin their answer sequence with a few countries they knew of from statistics and biology literature tackle a similar goal: (e.g., United States, India, Pakistan, China, etc.), or to provide an estimate of the number of distinct species is determined a completely non-alphabetical sequence. We even observed using observations of species in the locale of interest. These alphabetical traversals that began at the end or in the middle techniques are also used in traditional database systems to of the alphabet! In general, people may use different internal inform query optimization of large tables [11]. In this section, biases or techniques for finding items in the set (we discuss full we describe our observations of how the crowd answers set- list traversals in Section V). We also noticed that individual enumeration queries and why existing estimation techniques yield inaccurate estimates. We also present a model for crowd- 1 We experimented with various other estimators for the open-world such as sourced enumerations and list the requirements for human- “Chao84”[16], “Jackknife”[17], and “uniform maximum-likelihood”[14] and tolerant cardinality estimators. also found Chao92 to be superior.
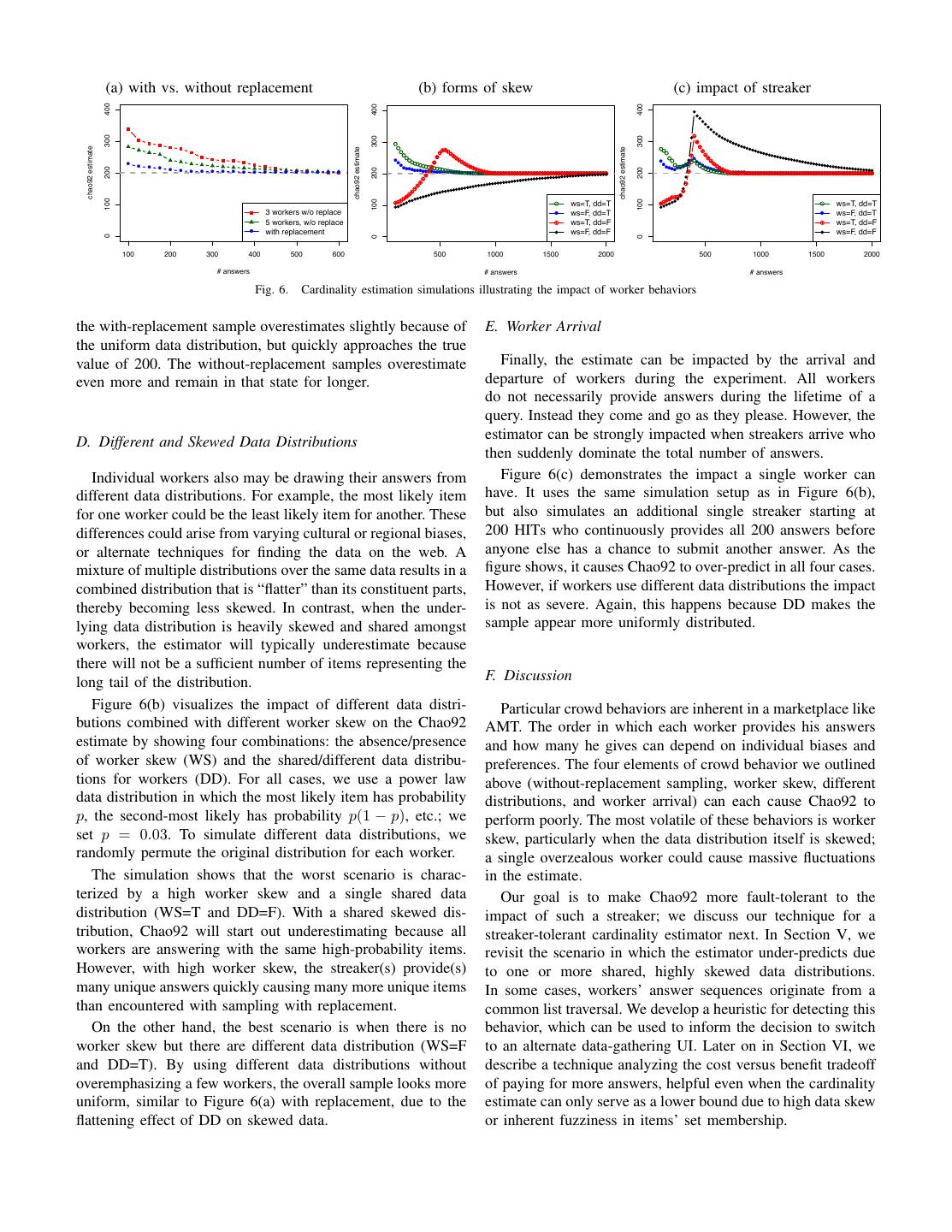
4 . 300 #&= sampling process with replacement !&= sampling process without replacement 250 (A, B, G, H, F, I, A, E, E, K, ….) (A, B, C, D, F, A, G, B, A, ….) 200 chao92 estimate Arrival Process Worker 150 # # 100 Processes !" !$ !% … Worker 50 actual expected 0 200 400 600 800 A B C D E F G H I J K... A B C D E F G H I J K... A B C D E F G H I J K... A B C D E F G H I J K... # answers (a) Database Sampling (B) Crowd Based Sampling Fig. 4. Estimated Cardinality Fig. 5. Sampling Process workers complete different amounts of work and arrive/depart 1) Sampling Without Replacement: When a worker submits from the experiment at different points in time. multiple items for a set enumeration query, each answer is The next subsection formalizes a model of how answers different from his previous ones. In other words, individuals arrive from the crowd in response to a set enumeration query, are sampling without replacement from some underlying dis- as well as a description of how crowd behaviors impact tribution that describes the likelihood of selecting each answer. the sample of answers received. We then use simulation to Of course, this behavior is beneficial with respect to the goal of demonstrate the principles of how these behaviors play off acquiring all the items in the set, as low-probability items be- one another and thereby influence an estimation algorithm. come more likely after the high-probability items have already been provided by that worker (we do not pay for duplicated B. A Model for Human Enumerations work from a single worker). A negative side effect of workers Species estimation algorithms assume a with-replacement sampling without replacement is that the estimation algorithm sample from some unknown distribution describing item likeli- receives less information about the relative frequency of items, hoods (visualized in Figure 5(a)). The order in which elements and thus the skew, of the underlying data distribution; having of the sample arrive is irrelevant in this context. knowledge of the skew is a requirement for a good estimate. After analyzing the crowdsourced enumerations, for exam- 2) Worker skew: On crowdsourcing platforms like AMT, it ple in the previously mentioned UN experiment, we found is common that some workers complete many more HITs than that this assumption does not hold for crowdsourced sets. others. This skew in relative worker HIT completion has been In contrast to with-replacement samples, workers provide labeled the “streakers vs. samplers” effect [18]. In the two- answers from an underlying distribution without replacement. layer sampling process, worker skew dictates which worker Furthermore, workers might sample from different underlying supplies the next answer; streakers are chosen with higher distributions (e.g., one might provide answers alphabetically, frequency. High worker skew can cause the arrival rate of while another worker provides answers in a more random unique answers to be even more rapid than that caused by order). sampling without replacement alone, causing the estimator to This process of sampling significantly differs from what tra- over-predict. The reasoning is intuitive: if one worker gets ditional estimators assume, and it can be represented as a two- to provide a majority of the answers, and he provides only layer sampling process as shown in Figure 5(b). The bottom answers he has not yet given, then a majority of the total layer consists of many sampling processes, each correspond- answer set will be made up of his unique answers. ing to one worker, that sample from some data distribution Furthermore, in an extreme scenario in which one worker without replacement. The top layer processes samples with provides all answers, the two-layer process reduces to one replacement from the set of the bottom-layer processes (i.e., process sampling from one underlying distribution without workers). Thus, the ordered stream of answers from the crowd replacement. In this case, completeness estimation becomes represents a with-replacement sampling amongst workers who impossible because no inference can be made regarding the are each sampling a data distribution without replacement. underlying distribution. Another extreme is if an infinite number of “samplers” would provide one answer each using C. The Impact of Humans the same underlying distribution, the resulting sample would The impact of the two-layer sampling process on the es- correspond to the original scenario of sampling with replace- timation can vary significantly based on the parameterization ment (Figure 5(a)). of the process (e.g., the number of worker processes, different The latter is the reason why it is still possible to make esti- underlying distributions, etc.). In this section, we study the mations even in the presence of human-generated set enumer- impact of different parameterizations, define when it is actually ations. Figure 6(a) shows the impact of having more workers possible to make a completeness estimation as well as the on the averaged Chao92 estimates with 100 simulation runs requirements for an estimator considering human behavior. using a uniform data distribution over 200 items. As expected,
5 . (a) with vs. without replacement (b) forms of skew (c) impact of streaker 400 400 400 ! 300 300 300 ! ! ! ! chao92 estimate chao92 estimate !! chao92 estimate !! ! ! ! !! ! ! ! ! !! ! ! ! ! ! !! !! ! ! !! !! ! ! ! !!! ! !! ! ! !!! !!! ! ! ! ! ! !! !! !!! !!!!!!!!!! !! !!!!!!! !!! !!!!!!! !! 200 !!!!!!! !!!! 200 200 ! ! ! ! ! ! ! ! !!!!!!!!! ! !!!!!! !!!!!! ! ! ! ! ! ! ! ! ! ! ! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! !!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! ! ! ! ! ! ! ! ! ! ! !!!! !! !! 100 100 100 !! ! ws=T, dd=T !! ! ws=T, dd=T 3 workers w/o replace ! ws=F, dd=T ! ws=F, dd=T 5 workers, w/o replace ! ws=T, dd=F ! ws=T, dd=F ! with replacement ws=F, dd=F ws=F, dd=F 0 0 0 100 200 300 400 500 600 500 1000 1500 2000 500 1000 1500 2000 # answers # answers # answers Fig. 6. Cardinality estimation simulations illustrating the impact of worker behaviors the with-replacement sample overestimates slightly because of E. Worker Arrival the uniform data distribution, but quickly approaches the true value of 200. The without-replacement samples overestimate Finally, the estimate can be impacted by the arrival and even more and remain in that state for longer. departure of workers during the experiment. All workers do not necessarily provide answers during the lifetime of a query. Instead they come and go as they please. However, the D. Different and Skewed Data Distributions estimator can be strongly impacted when streakers arrive who then suddenly dominate the total number of answers. Individual workers also may be drawing their answers from Figure 6(c) demonstrates the impact a single worker can different data distributions. For example, the most likely item have. It uses the same simulation setup as in Figure 6(b), for one worker could be the least likely item for another. These but also simulates an additional single streaker starting at differences could arise from varying cultural or regional biases, 200 HITs who continuously provides all 200 answers before or alternate techniques for finding the data on the web. A anyone else has a chance to submit another answer. As the mixture of multiple distributions over the same data results in a figure shows, it causes Chao92 to over-predict in all four cases. combined distribution that is “flatter” than its constituent parts, However, if workers use different data distributions the impact thereby becoming less skewed. In contrast, when the under- is not as severe. Again, this happens because DD makes the lying data distribution is heavily skewed and shared amongst sample appear more uniformly distributed. workers, the estimator will typically underestimate because there will not be a sufficient number of items representing the long tail of the distribution. F. Discussion Figure 6(b) visualizes the impact of different data distri- Particular crowd behaviors are inherent in a marketplace like butions combined with different worker skew on the Chao92 AMT. The order in which each worker provides his answers estimate by showing four combinations: the absence/presence and how many he gives can depend on individual biases and of worker skew (WS) and the shared/different data distribu- preferences. The four elements of crowd behavior we outlined tions for workers (DD). For all cases, we use a power law above (without-replacement sampling, worker skew, different data distribution in which the most likely item has probability distributions, and worker arrival) can each cause Chao92 to p, the second-most likely has probability p(1 − p), etc.; we perform poorly. The most volatile of these behaviors is worker set p = 0.03. To simulate different data distributions, we skew, particularly when the data distribution itself is skewed; randomly permute the original distribution for each worker. a single overzealous worker could cause massive fluctuations The simulation shows that the worst scenario is charac- in the estimate. terized by a high worker skew and a single shared data Our goal is to make Chao92 more fault-tolerant to the distribution (WS=T and DD=F). With a shared skewed dis- impact of such a streaker; we discuss our technique for a tribution, Chao92 will start out underestimating because all streaker-tolerant cardinality estimator next. In Section V, we workers are answering with the same high-probability items. revisit the scenario in which the estimator under-predicts due However, with high worker skew, the streaker(s) provide(s) to one or more shared, highly skewed data distributions. many unique answers quickly causing many more unique items In some cases, workers’ answer sequences originate from a than encountered with sampling with replacement. common list traversal. We develop a heuristic for detecting this On the other hand, the best scenario is when there is no behavior, which can be used to inform the decision to switch worker skew but there are different data distribution (WS=F to an alternate data-gathering UI. Later on in Section VI, we and DD=T). By using different data distributions without describe a technique analyzing the cost versus benefit tradeoff overemphasizing a few workers, the overall sample looks more of paying for more answers, helpful even when the cardinality uniform, similar to Figure 6(a) with replacement, due to the estimate can only serve as a lower bound due to high data skew flattening effect of DD on skewed data. or inherent fuzziness in items’ set membership.
6 . IV. S TREAKER -T OLERANT C OMPLETENESS E STIMATOR Good-Turing estimator [19] using the f -statistic is used: Our goal is to provide the user with a progress estimate Cˆ = 1 − f1 /n (1) for an open-world query based on the answers that have been Furthermore, the Chao92 estimator attempts to explicitly char- gathered so far. However, in the last section we demonstrated acterize and incorporate the skew of the underlying distribution how having a crowd of humans enumerate a set creates a using the coefficient of variance (CV), denoted γ, a metric two-layer sampling process, and that the order in which items that can be used to describe the variance in a probability arrive depends heavily on different worker behaviors—which distribution [14]; we can use the CV to compare the skew of impacts the accuracy of the estimator. different class distributions. The CV is defined as the standard In this section, we extend the Chao92 algorithm to make deviation divided by the mean. Given the pi ’s (p1 · · · pN ) the estimator more robust against the impact of individual that describe the � probability of the ith class being selected, workers. We focus our effort mainly on reducing the impact with mean p¯ = i pi�/N = 1/N , the CV is expressed as of streakers and worker arrival, and exclude for now cases for �� 1/2 2 which we can not make a good prediction, discussed in the γ = i (pi − p ¯) /N / p¯ [14]. A higher CV indicates following subsections in more detail. We first introduce the higher variance amongst the pi ’s, while a CV of 0 indicates basic estimator model and Chao92 more formally before we that each item is equally likely. present our extension that handles streaker impact. Finally, The true CV cannot be calculated without knowledge of the we evaluate our technique by first proposing a new metric pi ’s, so Chao92 uses an estimate γˆ based on the f -statistic: �c � � i i(i − 1)fi that incorporates the notions of estimate stability and fast ˆ 2 convergence to the true cardinality, then applying this metric γˆ = max C − 1, 0 (2) n(n − 1) to measure the effectiveness of our technique using various use cases in addition to the UN. The final estimator is then defined as: ˆ A. Basic Estimator Model and F-Statistic ˆchao92 = c + n(1 − C) γˆ 2 N (3) ˆ C Cˆ Receiving answers from workers is analogous to drawing Note that if γˆ 2 = 0 (i.e., indicating a uniform distribution), samples from some underlying distribution of unknown size ˆ the estimator reduces to c/C. N ; each answer corresponds to one sample from the item distribution. We can rephrase the problem as a species esti- C. An Estimator for Crowdsourced Enumeration mation problem as follows: The set of HITs received from The Chao92 estimator is heavily influenced by the presence AMT is a sample of size n drawn from a population in which of rare items in the sample; the coverage estimate Cˆ is elements can be from N different classes, numbered 1 − N based entirely on the percentage of singleton answers (f1 s). (N , unknown, is what we seek); c is the number of unique Recall from Section III the different crowd behaviors—many classes (species) seen in the sample. Let ni be the number of of them result in rapid arrival of unique answers. When unique elements in the sample that belong to class i, with 1 ≤ i ≤ N . items appear “too quickly”, the estimator interprets this as Of course some ni = 0 because they have not been observed a sign the complete set size is larger than it truly is. We in the sample. Let pi be the probability �N that an element from develop an estimator based on Chao92 that ameliorates some class i is selected by a worker, i=1 pi = 1; such a sample of the overestimation issues caused by an overabundance of is often described as a multinomial sample [12]. f1 answers. One might try to estimate the underlying distribution Most of the dramatic overestimation occurs in the presence {p1 , ..., pN } in order to predict the cardinality N . However, of streakers, i.e., significant skew in the amount of answers Burnham and Overton show in [17] that the aggregated provided by each worker. Notably, problems occur when one “frequency of frequencies”-statistic (hereon f -statistic) is suf- or a few workers contribute substantially more answers than ficient for estimating the number of unobserved species for others, possibly also drawing answers from a different data non-parametric algorithms. The f -statistic captures the relative distribution. As other workers are not given the opportunity frequency of observed classes in the sample. For a population to provide answers that would subsequently increase the f2 s, that can be partitioned into N classes (items), and given a f3 s, etc. in the sample, Chao92 predicts a full set cardinality sample of size n, let fj be the number of classes that have that is too large. Thus our estimator is designed to identify any exactly j members in the sample. Note f1 represents the worker(s) who are outliers with respect to their contribution “singletons” and f2 the “doubletons”. The goal is to estimate of unique answers in the sample (their f1 answers). the cardinality by predicting f0 , the number of unseen classes. The idea behind making the Chao92 estimator more resilient against streakers is to alter the f -statistic. The first step is B. The Chao92 Estimator to identify those workers who are “f1 outliers”. We define Our technique is based on the Chao92 [14] estimator, which outlier in a traditional sense, two standard deviations outside uses sample coverage to predict N . The sample coverage C is the mean of all workers W . To avoid false negatives due to the sum of the probabilities pi of the observed classes. How- a true outlier’s influence on the mean and standard deviation, ever, since the underlying distribution p1 ...pN is unknown, the both statistics are calculated without including the potential
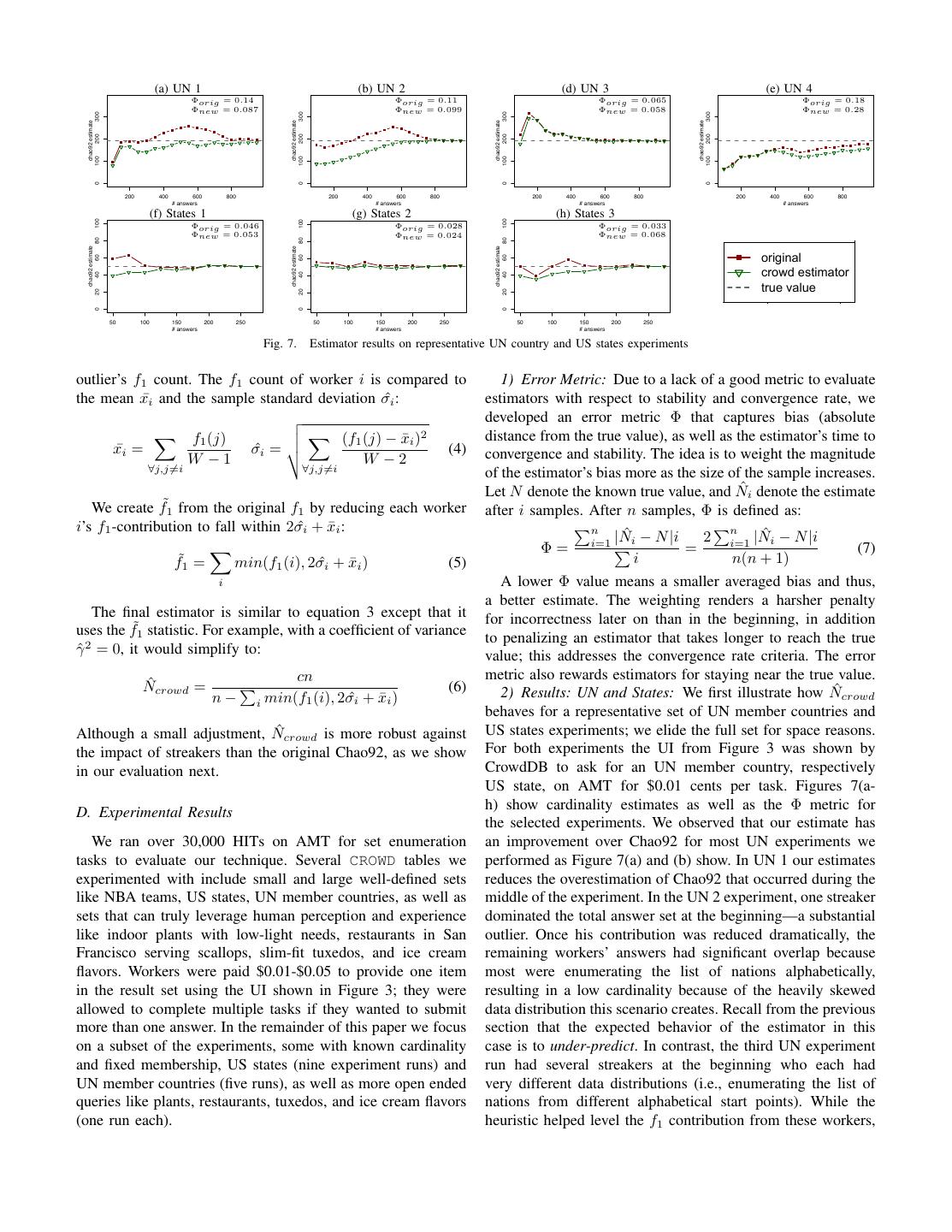
7 . 8 (a) UN 1 (b) UN 2 (d) UN 3 (e) UN 4 Φorig = 0.14 Φorig = 0.11 Φorig = 0.065 Φorig = 0.18 Φnew = 0.087 Φnew = 0.099 Φnew = 0.058 Φnew = 0.28 6 c(1, 10) 300 300 300 300 chao92 estimate chao92 estimate chao92 estimate chao92 estimate 200 200 200 200 100 100 100 100 4 0 0 0 0 200 400 600 800 200 400 600 800 200 400 600 800 200 400 600 800 # answers # answers # answers # answers (f) States 1 (g) States 2 (h) States 3 100 100 100 Φorig = 0.046 Φorig = 0.028 Φorig = 0.033 Φnew = 0.053 Φnew = 0.024 Φnew = 0.068 80 80 80 chao92 estimate chao92 estimate chao92 estimate 2 original 60 60 60 crowd estimator 40 40 40 true value 20 20 20 0 0 0 50 100 150 # answers 200 250 50 100 150 # answers 200 250 0 50 2 100 150 # answers 4 200 250 6 8 10 Fig. 7. Estimator results on representative UN country and US states experiments c(1, 1) outlier’s f1 count. The f1 count of worker i is compared to 1) Error Metric: Due to a lack of a good metric to evaluate the mean x¯i and the sample standard deviation σˆi : estimators with respect to stability and convergence rate, we � developed an error metric Φ that captures bias (absolute � f1 (j) � � � (f1 (j) − x ¯i )2 distance from the true value), as well as the estimator’s time to x¯i = σˆi = � (4) convergence and stability. The idea is to weight the magnitude W −1 W −2 ∀j,j�=i ∀j,j�=i of the estimator’s bias more as the size of the sample increases. Let N denote the known true value, and N ˆi denote the estimate We create f˜1 from the original f1 by reducing each worker after i samples. After n samples, Φ is defined as: i’s f1 -contribution to fall within 2σˆi + x¯i : �n ˆi − N |i �n ˆi − N |i |N 2 i=1 |N � Φ = i=1 � = (7) f˜1 = min(f1 (i), 2σˆi + x ¯i ) (5) i n(n + 1) i A lower Φ value means a smaller averaged bias and thus, a better estimate. The weighting renders a harsher penalty The final estimator is similar to equation 3 except that it for incorrectness later on than in the beginning, in addition uses the f˜1 statistic. For example, with a coefficient of variance to penalizing an estimator that takes longer to reach the true γˆ 2 = 0, it would simplify to: value; this addresses the convergence rate criteria. The error cn metric also rewards estimators for staying near the true value. ˆcrowd = N � (6) ˆcrowd n− min(f1 (i), 2σ ˆi + x ¯i ) 2) Results: UN and States: We first illustrate how N i behaves for a representative set of UN member countries and Although a small adjustment, N ˆcrowd is more robust against US states experiments; we elide the full set for space reasons. the impact of streakers than the original Chao92, as we show For both experiments the UI from Figure 3 was shown by in our evaluation next. CrowdDB to ask for an UN member country, respectively US state, on AMT for $0.01 cents per task. Figures 7(a- h) show cardinality estimates as well as the Φ metric for D. Experimental Results the selected experiments. We observed that our estimate has We ran over 30,000 HITs on AMT for set enumeration an improvement over Chao92 for most UN experiments we tasks to evaluate our technique. Several CROWD tables we performed as Figure 7(a) and (b) show. In UN 1 our estimates experimented with include small and large well-defined sets reduces the overestimation of Chao92 that occurred during the like NBA teams, US states, UN member countries, as well as middle of the experiment. In the UN 2 experiment, one streaker sets that can truly leverage human perception and experience dominated the total answer set at the beginning—a substantial like indoor plants with low-light needs, restaurants in San outlier. Once his contribution was reduced dramatically, the Francisco serving scallops, slim-fit tuxedos, and ice cream remaining workers’ answers had significant overlap because flavors. Workers were paid $0.01-$0.05 to provide one item most were enumerating the list of nations alphabetically, in the result set using the UI shown in Figure 3; they were resulting in a low cardinality because of the heavily skewed allowed to complete multiple tasks if they wanted to submit data distribution this scenario creates. Recall from the previous more than one answer. In the remainder of this paper we focus section that the expected behavior of the estimator in this on a subset of the experiments, some with known cardinality case is to under-predict. In contrast, the third UN experiment and fixed membership, US states (nine experiment runs) and run had several streakers at the beginning who each had UN member countries (five runs), as well as more open ended very different data distributions (i.e., enumerating the list of queries like plants, restaurants, tuxedos, and ice cream flavors nations from different alphabetical start points). While the (one run each). heuristic helped level the f1 contribution from these workers,
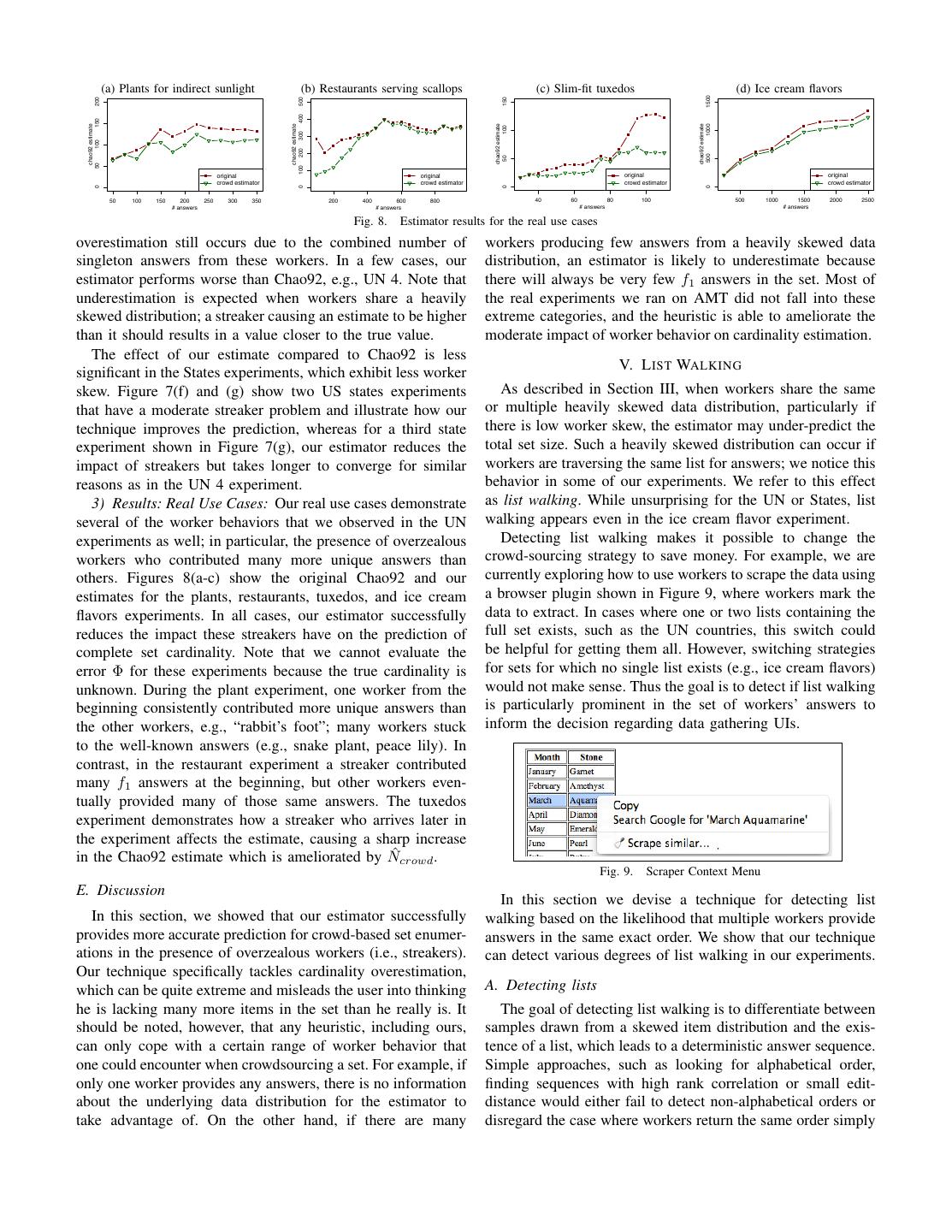
8 . (a) Plants for indirect sunlight (b) Restaurants serving scallops (c) Slim-fit tuxedos (d) Ice cream flavors 1500 150 200 500 200 300 400 150 chao92 estimate chao92 estimate 1000 chao92 estimate chao92 estimate 100 100 500 50 50 100 original original original original crowd estimator crowd estimator crowd estimator crowd estimator 0 0 0 0 50 100 150 200 250 300 350 200 400 600 800 40 60 80 100 500 1000 1500 2000 2500 # answers # answers # answers # answers Fig. 8. Estimator results for the real use cases overestimation still occurs due to the combined number of workers producing few answers from a heavily skewed data singleton answers from these workers. In a few cases, our distribution, an estimator is likely to underestimate because estimator performs worse than Chao92, e.g., UN 4. Note that there will always be very few f1 answers in the set. Most of underestimation is expected when workers share a heavily the real experiments we ran on AMT did not fall into these skewed distribution; a streaker causing an estimate to be higher extreme categories, and the heuristic is able to ameliorate the than it should results in a value closer to the true value. moderate impact of worker behavior on cardinality estimation. The effect of our estimate compared to Chao92 is less V. L IST WALKING significant in the States experiments, which exhibit less worker skew. Figure 7(f) and (g) show two US states experiments As described in Section III, when workers share the same that have a moderate streaker problem and illustrate how our or multiple heavily skewed data distribution, particularly if technique improves the prediction, whereas for a third state there is low worker skew, the estimator may under-predict the experiment shown in Figure 7(g), our estimator reduces the total set size. Such a heavily skewed distribution can occur if impact of streakers but takes longer to converge for similar workers are traversing the same list for answers; we notice this reasons as in the UN 4 experiment. behavior in some of our experiments. We refer to this effect 3) Results: Real Use Cases: Our real use cases demonstrate as list walking. While unsurprising for the UN or States, list several of the worker behaviors that we observed in the UN walking appears even in the ice cream flavor experiment. experiments as well; in particular, the presence of overzealous Detecting list walking makes it possible to change the workers who contributed many more unique answers than crowd-sourcing strategy to save money. For example, we are others. Figures 8(a-c) show the original Chao92 and our currently exploring how to use workers to scrape the data using estimates for the plants, restaurants, tuxedos, and ice cream a browser plugin shown in Figure 9, where workers mark the flavors experiments. In all cases, our estimator successfully data to extract. In cases where one or two lists containing the reduces the impact these streakers have on the prediction of full set exists, such as the UN countries, this switch could complete set cardinality. Note that we cannot evaluate the be helpful for getting them all. However, switching strategies error Φ for these experiments because the true cardinality is for sets for which no single list exists (e.g., ice cream flavors) unknown. During the plant experiment, one worker from the would not make sense. Thus the goal is to detect if list walking beginning consistently contributed more unique answers than is particularly prominent in the set of workers’ answers to the other workers, e.g., “rabbit’s foot”; many workers stuck inform the decision regarding data gathering UIs. to the well-known answers (e.g., snake plant, peace lily). In contrast, in the restaurant experiment a streaker contributed many f1 answers at the beginning, but other workers even- tually provided many of those same answers. The tuxedos experiment demonstrates how a streaker who arrives later in the experiment affects the estimate, causing a sharp increase in the Chao92 estimate which is ameliorated by N ˆcrowd . Fig. 9. Scraper Context Menu E. Discussion In this section we devise a technique for detecting list In this section, we showed that our estimator successfully walking based on the likelihood that multiple workers provide provides more accurate prediction for crowd-based set enumer- answers in the same exact order. We show that our technique ations in the presence of overzealous workers (i.e., streakers). can detect various degrees of list walking in our experiments. Our technique specifically tackles cardinality overestimation, which can be quite extreme and misleads the user into thinking A. Detecting lists he is lacking many more items in the set than he really is. It The goal of detecting list walking is to differentiate between should be noted, however, that any heuristic, including ours, samples drawn from a skewed item distribution and the exis- can only cope with a certain range of worker behavior that tence of a list, which leads to a deterministic answer sequence. one could encounter when crowdsourcing a set. For example, if Simple approaches, such as looking for alphabetical order, only one worker provides any answers, there is no information finding sequences with high rank correlation or small edit- about the underlying data distribution for the estimator to distance would either fail to detect non-alphabetical orders or take advantage of. On the other hand, if there are many disregard the case where workers return the same order simply
9 .by chance. In the rest of this section, we focus on a heuristic Let r(i) be the number of times answer αi appears in the to determine the likelihood that a given number of workers w ith position among all the sequences W being compared, would respond with s answers in the exact same order. pα (i) is defined as ri /W . For example, if the target sequence List walking is similar to extreme skew in the item distri- α starting at offset o is “A,B,C” and the first answers for bution; however even under the most skewed distribution, at four workers are “A”,“A”,“A”, and “B”, respectively, ro+1 /W some point (i.e., large w or large s), providing the exact same would be 3/4. Now the probability of seeing α is a product sequence of answers will be highly unlikely. Our heuristic of the probabilities of observing αo+1 , then αo+2 , etc. determines the probability that multiple workers would give o+s � ri the same answer order if they were really sampling from pα = (10) the same item distribution. Once this probability drops below i=o W a particular threshold (we use 0.01), we conclude that list Relying solely on the data in this manner could lead to walking is likely to be present in the answers. We also consider false negatives in the extreme case where w = W , i.e., cases of list walking with different offsets (i.e., both workers where all workers use the same target sequence. Note that start from the fifth item on the list), but we do not consider in this case pα attains the maximum possible value of 1. approximate matches which may happen if a worker skips As a result, pα will be greater than any threshold we pick. items on the list. Detecting list walking in those scenarios is We need to incorporate both the true data via ri /W as well considered as future work. Furthermore, approximate matches as our most pessimistic belief of the underlying skew. As a in answer order may make the sample more random and hence pessimistic prior, we choose the highly skewed Grays self- more desirable for estimation purposes. similar distribution [20], often used for the 80/20 rule. Only if 1) Preliminary setup: binomial distribution: Let W be the we find a sequence which can not be explained (with more than total number of workers who have provided answer sequences 1% chance) with the 80/20 distribution, we believe we have of length s or more. Among these, let w be the number of encountered list walking. Assuming a high skew distribution is workers who have the same sequence of answers with length conservative because it is more likely that workers will answer s starting at the same offset o in common. We refer to this in the same order if they were truly sampling than with, say, a sequence as the target sequence α of length s, which itself uniform distribution. The self-similar distribution with h = 0.2 is composed of the individual answers αi at every position is beneficial for our analysis because when sampling without i starting with offset o (α = (αo+1 , . . . , αo+s )). If pα is replacement, the most likely item has 80% (1 − h = 0.8) the probability of observing that sequence from some worker, chance of being selected and, once that item is selected and we are interested in the probability that w out of W total removed, the next most likely item has an 80% chance as well. workers would have that sequence. This probability can be As a first step, we assume that the target sequence follows expressed using the binomial distribution: W corresponds to the self-similar distribution exactly by always choosing the the number of trials and w represents the number of successes, most likely sequence. In this case α is simply a concatenation with probability mass function (PMF): of the most likely answer, followed by the second most likely � � answer, and so on. Hence the likelihood of selecting this W w P r(w; W, pα ) = p (1 − pα )W −w (8) sequence under our prior belief is (1 − h)s and the likelihood w α that a set of w workers select this same sequence is: Note that the combinatorial factor captures the likelihood of (1 − h)sw (11) having w workers sharing the given sequence by chance just because there are many workers W . In our scenario, we do Note that this probability does not calculate the probability not necessarily care about the probability of exactly w workers of having any given sequence of length s shared among w providing the same sequence, but rather the probability of w workers; instead it represents the likelihood of having the most or more workers with the same answer sequence: likely sequence in common. Incorporating the probability of all sequences of length s would be the sum of the probabilities � �W � w−1 of each sequence order, i.e., the most likely sequence plus the P r≥ (w; W, pα ) = 1 − piα (1 − pα )W −i (9) i second most likely sequence, etc. However, we found that the i=0 terms after the most likely sequence contribute little and our The probability in equation 9 determines if the target se- implementation of that version had little effect on the results; quence shared among w out of W workers is likely caused by thus do not consider it further. list walking. We now discuss pα , the probability of observing To combine the distribution derived from data and our prior a particular target sequence α of length s. belief in the maximum skew, we use a smoothing factor β 2) Defining the probability of a target sequence: Not all to shift the emphasis from the data to the distribution; higher workers use the same list or use the same order to walk values of β put more emphasis on the data. Using β to combine through the list, so we want pα to reflect the observed equation 10 with equation 11, we yield the probability of answer sequences from workers. We do this by estimating having the target sequence α (of length s) in common: the probability pα (i) of encountering answer αi in the ith s � � � ri position of the target sequence by the fraction of times this pα = β + (1 − β)(1 − h) (12) answer appears in the ith position among all W answers. i=1 W
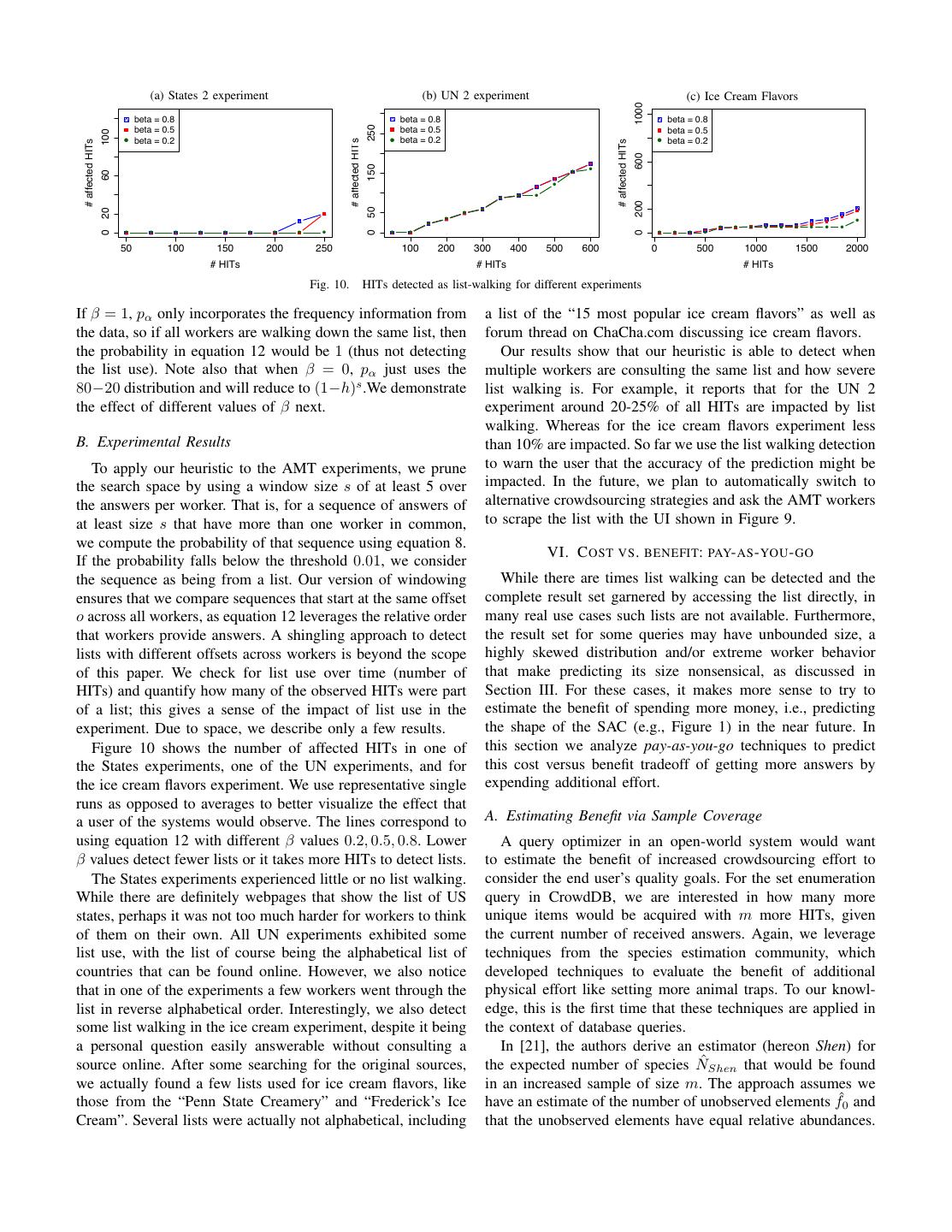
10 . (a)HITs States 2 experiment affected by list use: States 2 (b)HITs UNaffected 2 experiment by list use: UN 2 (c) Ice Cream Flavors HITs affected by list use: Ice Cream 1000 beta = 0.8 beta = 0.8 beta = 0.8 250 beta = 0.5 beta = 0.5 beta = 0.5 100 ! beta = 0.2 ! beta = 0.2 ! beta = 0.2 # affected HITs # affected HITs # affected HITs 600 150 ! ! 60 ! ! ! ! 200 50 ! 20 ! ! ! ! ! ! ! ! ! ! ! ! ! 0 0 0 ! ! ! ! ! ! ! ! ! ! ! ! ! ! ! 50 100 150 200 250 100 200 300 400 500 600 0 500 1000 1500 2000 # HITs # HITs # HITs Fig. 10. HITs detected as list-walking for different experiments If β = 1, pα only incorporates the frequency information from a list of the “15 most popular ice cream flavors” as well as the data, so if all workers are walking down the same list, then forum thread on ChaCha.com discussing ice cream flavors. the probability in equation 12 would be 1 (thus not detecting Our results show that our heuristic is able to detect when the list use). Note also that when β = 0, pα just uses the multiple workers are consulting the same list and how severe 80−20 distribution and will reduce to (1−h)s .We demonstrate list walking is. For example, it reports that for the UN 2 the effect of different values of β next. experiment around 20-25% of all HITs are impacted by list walking. Whereas for the ice cream flavors experiment less B. Experimental Results than 10% are impacted. So far we use the list walking detection To apply our heuristic to the AMT experiments, we prune to warn the user that the accuracy of the prediction might be the search space by using a window size s of at least 5 over impacted. In the future, we plan to automatically switch to the answers per worker. That is, for a sequence of answers of alternative crowdsourcing strategies and ask the AMT workers at least size s that have more than one worker in common, to scrape the list with the UI shown in Figure 9. we compute the probability of that sequence using equation 8. VI. C OST VS . BENEFIT: PAY- AS - YOU - GO If the probability falls below the threshold 0.01, we consider the sequence as being from a list. Our version of windowing While there are times list walking can be detected and the ensures that we compare sequences that start at the same offset complete result set garnered by accessing the list directly, in o across all workers, as equation 12 leverages the relative order many real use cases such lists are not available. Furthermore, that workers provide answers. A shingling approach to detect the result set for some queries may have unbounded size, a lists with different offsets across workers is beyond the scope highly skewed distribution and/or extreme worker behavior of this paper. We check for list use over time (number of that make predicting its size nonsensical, as discussed in HITs) and quantify how many of the observed HITs were part Section III. For these cases, it makes more sense to try to of a list; this gives a sense of the impact of list use in the estimate the benefit of spending more money, i.e., predicting experiment. Due to space, we describe only a few results. the shape of the SAC (e.g., Figure 1) in the near future. In Figure 10 shows the number of affected HITs in one of this section we analyze pay-as-you-go techniques to predict the States experiments, one of the UN experiments, and for this cost versus benefit tradeoff of getting more answers by the ice cream flavors experiment. We use representative single expending additional effort. runs as opposed to averages to better visualize the effect that a user of the systems would observe. The lines correspond to A. Estimating Benefit via Sample Coverage using equation 12 with different β values 0.2, 0.5, 0.8. Lower A query optimizer in an open-world system would want β values detect fewer lists or it takes more HITs to detect lists. to estimate the benefit of increased crowdsourcing effort to The States experiments experienced little or no list walking. consider the end user’s quality goals. For the set enumeration While there are definitely webpages that show the list of US query in CrowdDB, we are interested in how many more states, perhaps it was not too much harder for workers to think unique items would be acquired with m more HITs, given of them on their own. All UN experiments exhibited some the current number of received answers. Again, we leverage list use, with the list of course being the alphabetical list of techniques from the species estimation community, which countries that can be found online. However, we also notice developed techniques to evaluate the benefit of additional that in one of the experiments a few workers went through the physical effort like setting more animal traps. To our knowl- list in reverse alphabetical order. Interestingly, we also detect edge, this is the first time that these techniques are applied in some list walking in the ice cream experiment, despite it being the context of database queries. a personal question easily answerable without consulting a In [21], the authors derive an estimator (hereon Shen) for source online. After some searching for the original sources, the expected number of species N ˆShen that would be found we actually found a few lists used for ice cream flavors, like in an increased sample of size m. The approach assumes we those from the “Penn State Creamery” and “Frederick’s Ice have an estimate of the number of unobserved elements fˆ0 and Cream”. Several lists were actually not alphabetical, including that the unobserved elements have equal relative abundances.
11 . Error: Average UN Experiments Error: Average States Experiments Error: Ice Cream Experiment m n = 200 n = 500 n = 800 m n = 50 n = 150 n = 200 m n = 1K n = 1.5K n = 2K 10 1 0.6 0 10 1 0.67 0.44 10 4 0 0 50 5 1.6 1.6 50 2.6 1.8 0.78 50 9 1 0 100 8.4 3 3 100 5.7 2 - 100 13 1 3 Error: Plant Experiment Error: Restaurant Experiment Error: Tuxedo Experiment m n = 100 n = 200 n = 300 m n = 200 n = 400 n = 800 m n = 30 n = 50 n = 70 10 2 3 0 10 2 0 3 10 3 0 1 50 7 3 2 50 11 5 13 50 8 10 - 100 7 1 - 100 18 3 - 100 - - - Fig. 11. Pay-as-you-go cost-benefit predictions using Shen However, this cardinality estimate fˆ0 can incorporate a coeffi- the user will end up getting more bang for his buck than cient of variance estimate (equation 2) to account for skew, as anticipated. There is also potential to use knowledge of worker shown by Chao92. An estimate of the unique elements found skew and particularly the presence of streakers to inform the in an increased effort of size m is: user when an under-prediction is likely. Thus N ˆshen provides a � � �m � reasonable mechanism for the user to analyze the cost-benefit 1 − ˆ C ˆShen = fˆ0 1 − 1 − N (13) tradeoff of acquiring more answers in the set. fˆ0 VII. R ELATED W ORK We present results based on the Chao92 estimate of fˆ0 . Our estimator is designed to reduce the impact of streakers to yield In this paper we focused on estimating progress towards a more accurate estimate of total set size, i.e., as m → ∞, completion of a query result set, an aspect of query quality. however disregarding the rapid arrival rate of new times can To our knowledge, quality of an open-ended question posed cause local predictions with N ˆshen to under-predict. Thus to the crowd has not been directly addressed in literature. In we use the original Chao92 estimate for the pay-as-you-go contrast, techniques have been proposed for quality control for prediction. individual set elements [5], [8]. Another technique [22] models the “expected mean” SAC Our estimation techniques build on top of existing work on with a binomial mixture model. It performs similarly to the species or class estimation [12], [9], [13]. These techniques coverage approach; we do not discuss it further. have also been used and extended in database literature for distinct value estimation [11], [23]. For example, a hybrid B. Experimental Results approach is proposed in [11], choosing between the Shlosser We evaluated the effectiveness of the N ˆshen estimator in estimator [24] and a version of the Jackknife estimator [17] the determining how many more unique items would arrive if authors modified to suit a finite population (i.e., known table m additional answers were given by workers; this analysis size). This approach is further improved and extended by [23] would be done after having already received n answers (HITs). to derive a lower bound on error. Unfortunately, both the error Accuracy is calculated as the absolute value of the error (bias); bounds and developed estimators for distinct values in a table the absolute value allows for averaging the errors. The tables in explicitly incorporate knowledge of the full table size, possible Figure 11 contain the errors for various queries. For example, only in the closed world. Furthermore, none of the techniques in the UN experiment after n = 500 the average error for the consider the sampling scenario of crowdsourced queries and next m = 50 HITs is 1.6 (i.e., on average the prediction is are therefore not applicable as discussed in Section III. off by 1.6). For some cells, we were not able to evaluate the Species estimation techniques were also explored for search prediction as we did not receive enough answers for at least and meta-search engines. For example, in [25] the authors one of the experiments. These cases are marked with an dash. develop an algorithm to estimate the size of any set of For all experiments, predictions for small m are easier since documents defined by certain conditions based on previously only the near future is considered, thus they tend to be more executed queries. Whereas [26] describes an algorithm to accurate. The larger the m, the further the prediction has to estimate the corpus size for a meta-search engine in order reach and thus the more error-prone the result, particularly if to better direct queries to search engines. Similar techniques m exceeds the current HITs size n [21]). The pay-as-you-go are also used to measure the quality of search engines [27]. results are also aligned with the intuition the SAC provides: at All techniques differ from those described in this paper, as the beginning when there are few worker answers, it is fairly they do not consider the specific worker behavior and assume inexpensive to acquire new unique items. Towards the end, sampling with replacement. more unique items are hard to come by. Recent work also tries to explore species estimation tech- Worker behavior also has an influence on the pay-as-you- niques for the deep web [28], [29]. Again, the proposed tech- go predictions. The Shen estimator tends to under-predict niques have strong assumptions regarding the sample which before the accumulation curve plateaus, as the curve is steeper do not hold in the crowd setting. Some of these assumptions than expected. This happens because workers sample without might not even hold in the context of the deep web. We believe replacement—unique answers appear more quickly than they that our techniques, which are more robust against biased would from a with-replacement sample. While minimizing samples, are applicable in the context of deep web search/data all error is ideal, under-prediction is not catastrophic since integration and consider it future work.
12 . Although this work was done as part of CrowdDB [2], [3] A. Marcus, E. Wu, S. Madden, and R. Miller, “Crowdsourced Databases: it could be applied to other hybrid human-machine database Query Processing with People,” in Proc. of CIDR, 2011. [4] A. Parameswaran and N. Polyzotis, “Answering Queries using Humans, systems, such as Qurk [3] or sCOOP [30]. Both systems allow Algorithms and Databases,” in Proc. of CIDR, 2011. for acquiring sets from the crowd but do not yet provide any [5] P. G. Ipeirotis, F. Provost, and J. Wang, “Quality management on quality control mechanisms for it. Amazon Mechanical Turk,” in Proc. of HCOMP, 2010. [6] D. W. Barowy, E. D. Berger, and A. McGregor, “AUTOMAN: A Plat- There is an array of literature on crowdsourcing in general, form for Integrating Human-Based and Digital Computation,” University addressing issues from improving and controlling latency [31], of Massachusetts, Tech. Rep., 2011. [6] to correcting the impact of worker capabilities [32]. This [7] K.-T. Chen et al., “A crowdsourceable QoE evaluation framework for multimedia content,” in ACM Multimedia, 2009. work is orthogonal to estimating the set quality. [8] A. Doan, M. J. Franklin, D. Kossmann, and T. Kraska, “Crowdsourcing VIII. F UTURE WORK AND C ONCLUSION Applications and Platforms: A Data Management Perspective,” PVLDB, vol. 4, no. 12, 2011. People are particularly well-suited for gathering new infor- [9] R. K. Colwell and J. A. Coddington, “Estimating Terrestrial Biodiversity mation because they have access to both real-life experience through Extrapolation,” Philosophical Trans.: Biological Sciences, vol. and online sources of information. Incorporating crowdsourced 345, no. 1311, 1994. [10] A. Feng et al., “CrowdDB: Query Processing with the VLDB Crowd,” information into a database, however, raises questions regard- PVLDB, vol. 4, no. 12, 2011. ing the meaning of query results without the closed-world [11] P. J. Haas et al., “Sampling-based estimation of the number of distinct assumption – how does one even reason about a simple values of an attribute,” in Proc. of VLDB, 1995. [12] J. Bunge and M. Fitzpatrick, “Estimating the Number of Species: A SELECT * query? We argue that progress estimation allows Review,” Journal of the American Statistical Association, vol. 88, no. the user to make sense of query results in the open world. 421, 1993. We develop techniques for analyzing progress via result set [13] A. Chao, “Species Richness Estimation,” http://viceroy.eeb.uconn.edu/EstimateSPages/ EstSUsers- cardinality estimation that consider crowd behaviors, based on Guide/References/Chao2005.pdf, 2005. species estimation algorithms. [14] A. Chao and S. Lee, “Estimating the Number of Classes via Sample Many future directions exist, ranging from different user Coverage,” Journal of the American Statistical Association, vol. 87, no. 417, pp. 210–217, 1992. interfaces for soliciting worker input to incorporating the [15] J. Bunge, M. Fitzpatrick, and J. Handley, “Comparison of three estima- above techniques into a query optimizer. We have done initial tors of the number of species,” Journal of Applied Statistics, vol. 22, explorations into a “negative suggest” UI that only allows no. 1, pp. 45–59, 1995. [16] A. Chao, “Nonparametric Estimation of the Number of Classes in a workers to enter answers no one has yet provided. A hybrid Population,” SJS, vol. 11, no. 4, 1984. approach with this interface and the current interface could [17] K. P. Burnham and W. S. Overton, “Estimation of the Size of a be used to expand an existing set and/or target rare items. In Closed Population when Capture Probabilities vary Among Animals,” Biometrika, vol. 65, no. 3, 1978. this paper, we assume that workers do not provide incorrect [18] J. Heer and M. Bostock, “Crowdsourcing graphical perception: using answers, as a variety of quality control solutions for single mechanical turk to assess visualization design,” in Proc. of CHI, 2010. answers are proposed already in the literature. However, fuzzy [19] I. J. Good, “The Population Frequencies of Species and the Estimation of Population Parameters,” Biometrika, vol. 40, no. 3/4, 1953. set membership (e.g., is Pizza or Basil a valid ice-cream flavor) [20] J. Gray et al., “Quickly generating billion-record synthetic databases,” imposes interesting new challenges on quality control for sets. in Proc. of SIGMOD, 1994. Techniques developed for crowdsourced queries in databases [21] T. Shen, A. Chao, and C. Lin, “Predicting the Number of New Species in Further Taxonomic Sampling,” Ecology, vol. 84, no. 3, 2003. are readily applicable to deep web queries. Human perception [22] R. K. Colwell, C. X. Mao, and J. Chang, “Interpolating, Extrapolating, is advantageous in answering these queries, and the question and Comparing Incidence-Based Species Accumulation Curves,” Ecol- of query completeness appears in this context as well. ogy, vol. 85, no. 10, 2004. [23] M. Charikar et al., “Towards Estimation Error Guarantees for Distinct Using statistical techniques we enable users to reason about Values,” in Proc. of PODS, 2000. query progress and cost-benefit trade-offs in the open world. [24] A. Shlosser, “On Estimation of the size of the dictionary of a long text on the basis of a sample,” Engrg. Cybernetics, vol. 19, 1981. ACKNOWLEDGMENT [25] A. Broder, M. Fontura, V. Josifovski, R. Kumar, R. Motwani, S. Nabar, This work was inspired by the CrowdDB project, and R. Panigrahy, A. Tomkins, and Y. Xu, “Estimating corpus size via we would like to thank our CrowdDB collaborators Donald queries,” in Proc. of CIKM, 2006. [26] K.-L. Liu, C. Yu, and W. Meng, “Discovering the representative of a Kossmann, Sukriti Ramesh, and Reynold Xin. search engine,” in Proc. of CIKM, 2002. This research is supported in part by a National Science [27] Z. Bar-Yossef and M. Gurevich, “Efficient search engine measurements,” Foundation graduate fellowship, in part by NSF CISE Ex- ACM Trans. Web, vol. 5, no. 4, pp. 18:1–18:48, Oct. 2011. [Online]. Available: http://doi.acm.org/10.1145/2019643.2019645 peditions award CCF-1139158, and gifts from Amazon Web [28] J. Lu and D. Li, “Estimating deep web data source size by Services, Google, SAP, Blue Goji, Cisco, Cloudera, Ericsson, capture—recapture method,” Inf. Retr., vol. 13, no. 1, pp. 70–95, Feb. General Electric, Hewlett Packard, Huawei, Intel, Microsoft, 2010. [Online]. Available: http://dx.doi.org/10.1007/s10791-009-9107-y [29] J. Liang, “Estimation Methods for the Size of Deep Web Textural Data NetApp, Oracle, Quanta, Splunk, VMware and by DARPA Source: A Survey,” cs.uwindsor.ca/richard/cs510/survey jie liang.pdf, (contract #FA8650-11-C-7136). 2008. [30] A. Parameswaran et al., “Deco: Declarative Crowdsourcing,” Stanford R EFERENCES University, Tech. Rep., 2011. [1] J. C. R. Licklider, “Man-Computer Symbiosis,” IRE Trans. of Human [31] M. S. Bernstein et al., “Crowds in Two Seconds: Enabling Realtime Factors in Electronics, vol. 1, 1960. Crowd-Powered Interfaces,” in Proc. of UIST, 2011. [2] M. J. Franklin, D. Kossmann, T. Kraska, S. Ramesh, and R. Xin, [32] P. Welinder et al., “The Multidimensional Wisdom of Crowds,” in Proc. “CrowdDB: Answering Queries with Crowdsourcing,” in Proc. of SIG- of NIPS, 2010. MOD, 2011.
3秒后跳转登录页面
去登陆

