




















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
OrpheusDB: Bolt-on Versioning for Relational Databases
OrpheusDB: Bolt-on Versioning for Relational Databases
展开查看详情
1 .OrpheusDB : Bolt-on Versioning for Relational Databases Silu Huang 1 , Liqi Xu 1 , Jialin Liu 1 , Aaron J. Elmore 2 , Aditya Parameswaran 1 1 University of Illinois (UIUC) 2 University of Chicago 1
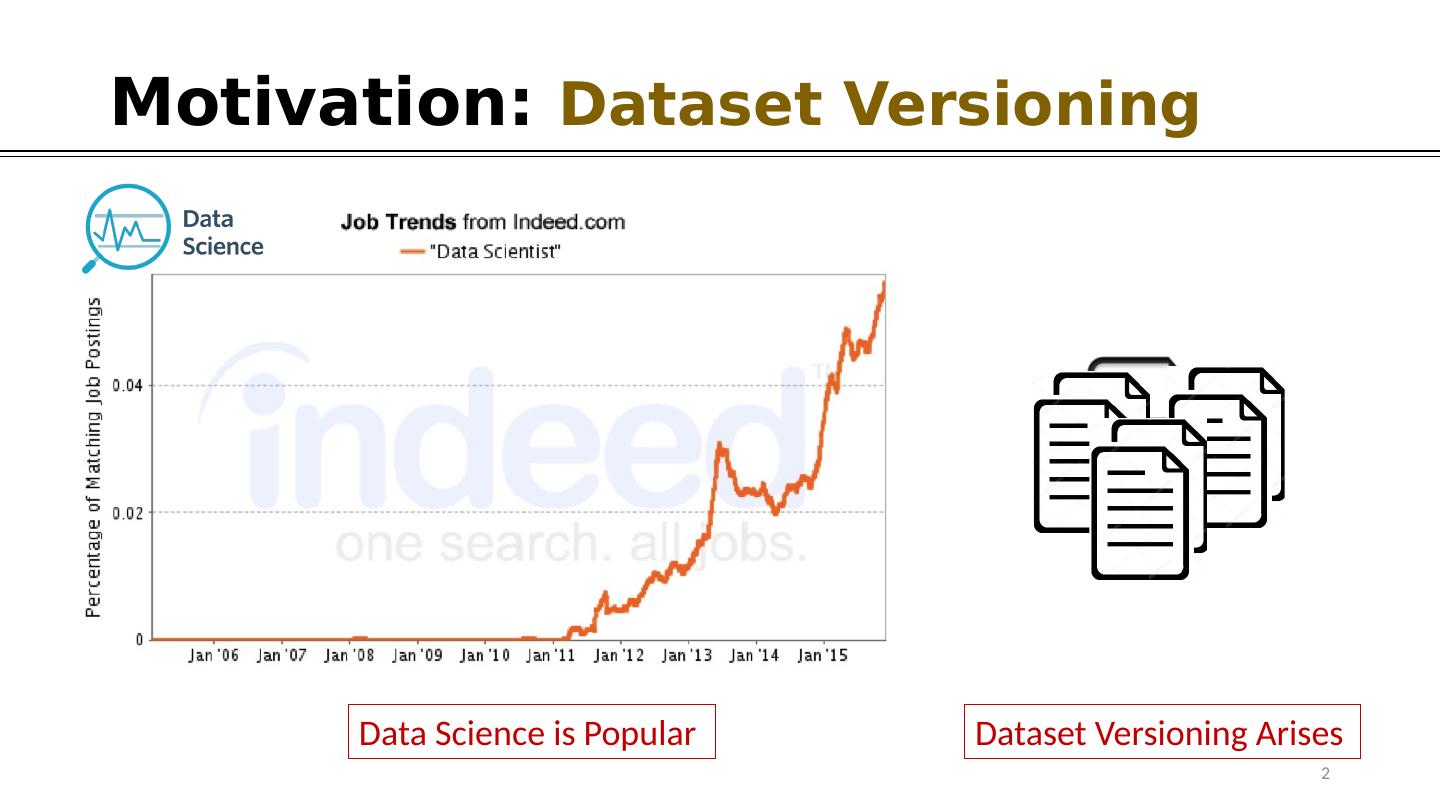
2 .Motivation: Dataset Versioning Data Science is Popular Dataset Versioning Arises 2
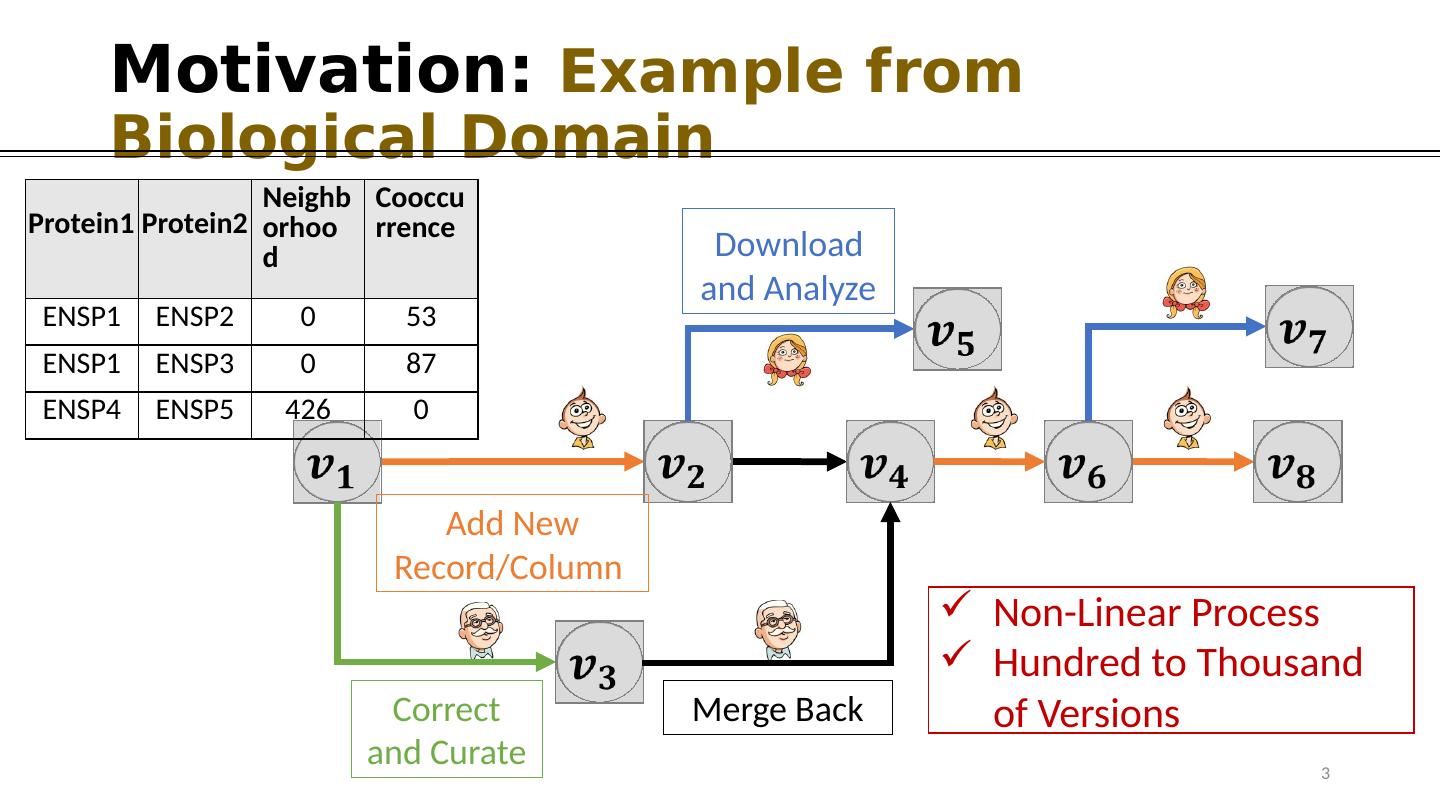
3 .Motivation: Example from Biological Domain Add N ew Record/Column Correct and Curate Merge Back Download and Analyze Neighborhood Cooccurrence ENSP1 ENSP2 0 53 ENSP1 ENSP3 0 87 ENSP4 ENSP5 426 0 Protein1 Protein2 Non-Linear Process Hundred to Thousand of Versions 3
4 .Versioned Dataset Management In the Wild Shared System/Folder: everyone can access Make Private Copies, Modify, Analyze, and Integrate back. 4 Massive Redundancy No True Collaboration N o Querying Capability
5 .Existing Management Systems: Alternatives I . SC-VC, G itHub Cannot scale to large dataset Limited functionalities II. Temporal Databases Only support a linear chain of versions 5 III. Decibel [1], DEX [2] Build “from the ground up” No parser, query optimizer, transaction manager for now [1] Decibel: The relational dataset branching system. PVLDB 2016. [2] DEX: Query Execution in a Delta-based Storage System. SIGMOD 2017 “Bolt-on” Approach ?
6 .How to Support Compact S torage? How to Support True Collaboration? A llow branching, checkout, commit, merge How to Support Advanced Querying? Issue query against versioning provenance Identify versions satisfying some property Show aggregate statistics across versions 6 Version Control Commands SQL Commands Unmodified DBMS Versioning Layer Client Issues to address: Bolt-on Versioning: “Reuse” Relational Databases
7 .How to Support Compact S torage? Data Representation How to Support True Collaboration? A llow branching, checkout, commit, merge How to Support Advanced Querying? Issue query against versioning provenance Identify versions satisfying some property Show aggregate statistics across versions 7 Version Control Commands SQL Commands Unmodified DBMS Versioning Layer Client Issues to address: Bolt-on Versioning: “Reuse” Relational Databases
8 .Outline 8 Strawman Approach Data Representation Access/Storage Optimization
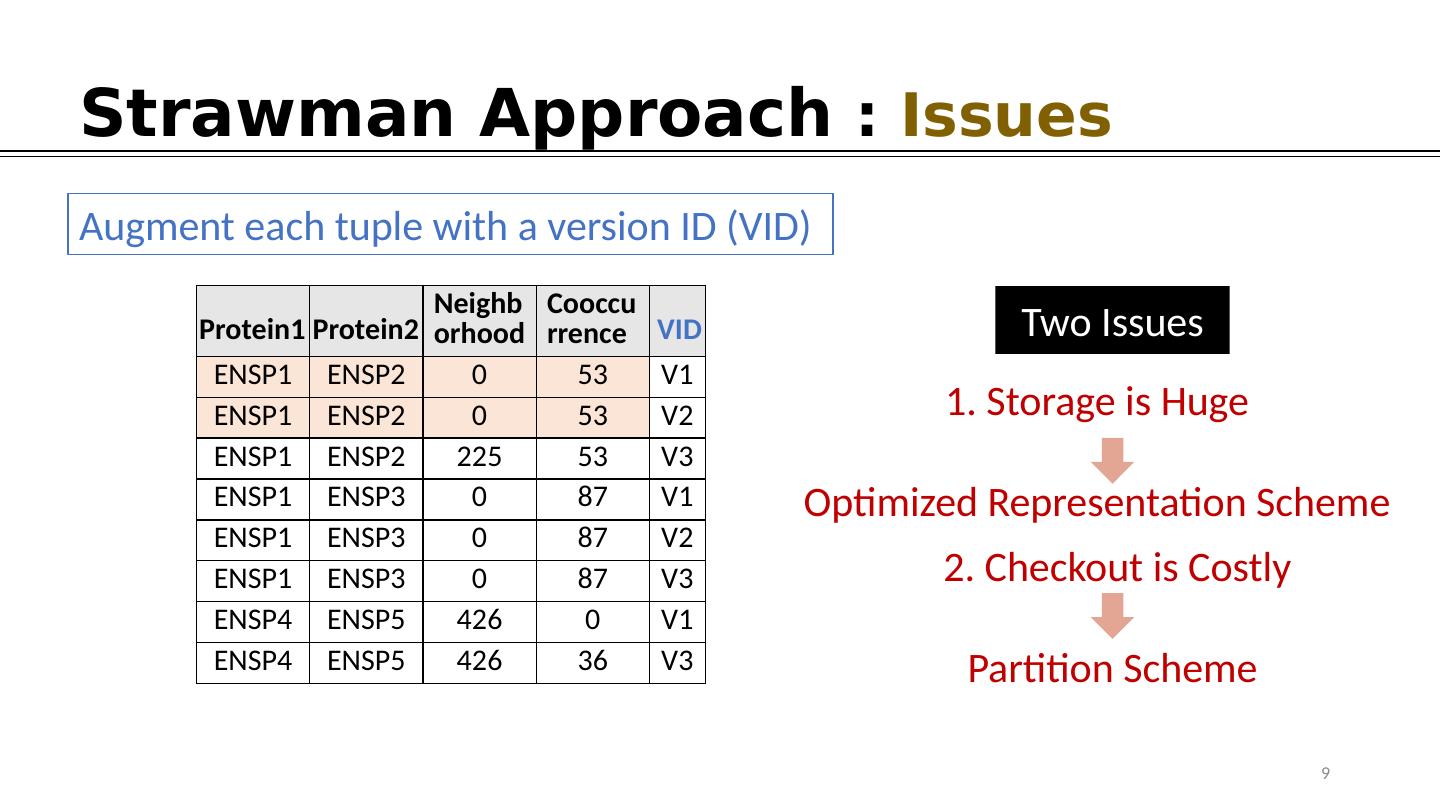
9 .Strawman Approach : Issues Neighborhood Cooccurrence ENSP1 ENSP2 0 53 V1 ENSP1 ENSP2 0 53 V2 ENSP1 ENSP2 225 53 V3 ENSP1 ENSP3 0 87 V1 ENSP1 ENSP3 0 87 V2 ENSP1 ENSP3 0 87 V3 ENSP4 ENSP5 426 0 V1 ENSP4 ENSP5 426 36 V3 Protein1 Protein2 VID Augment each tuple with a version ID (VID) 1. Storage is Huge Optimized Representation Scheme 9 Two Issues 2. Checkout is Costly Partition Scheme
10 .Outline 10 Strawman Approach Data Representation Access/Storage Optimization
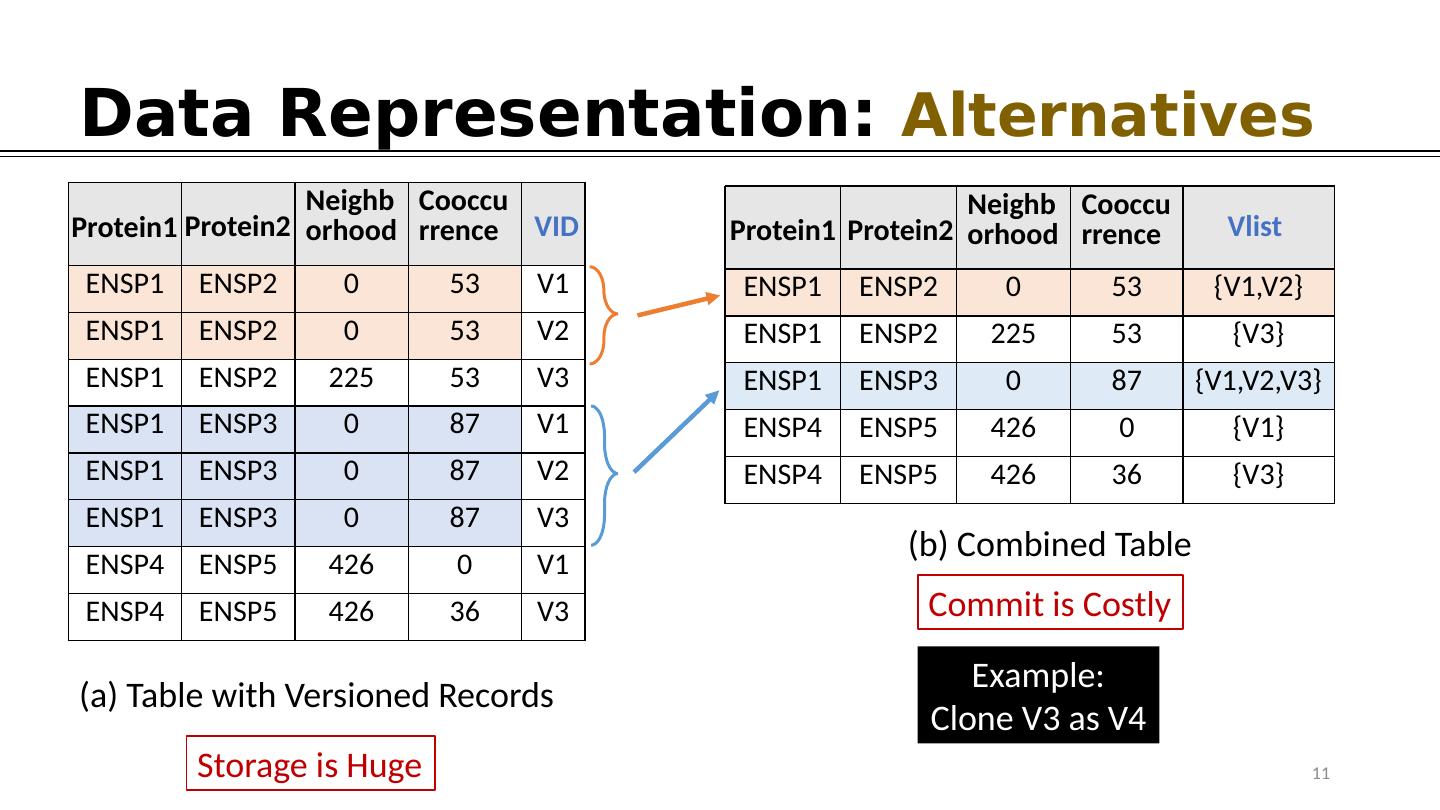
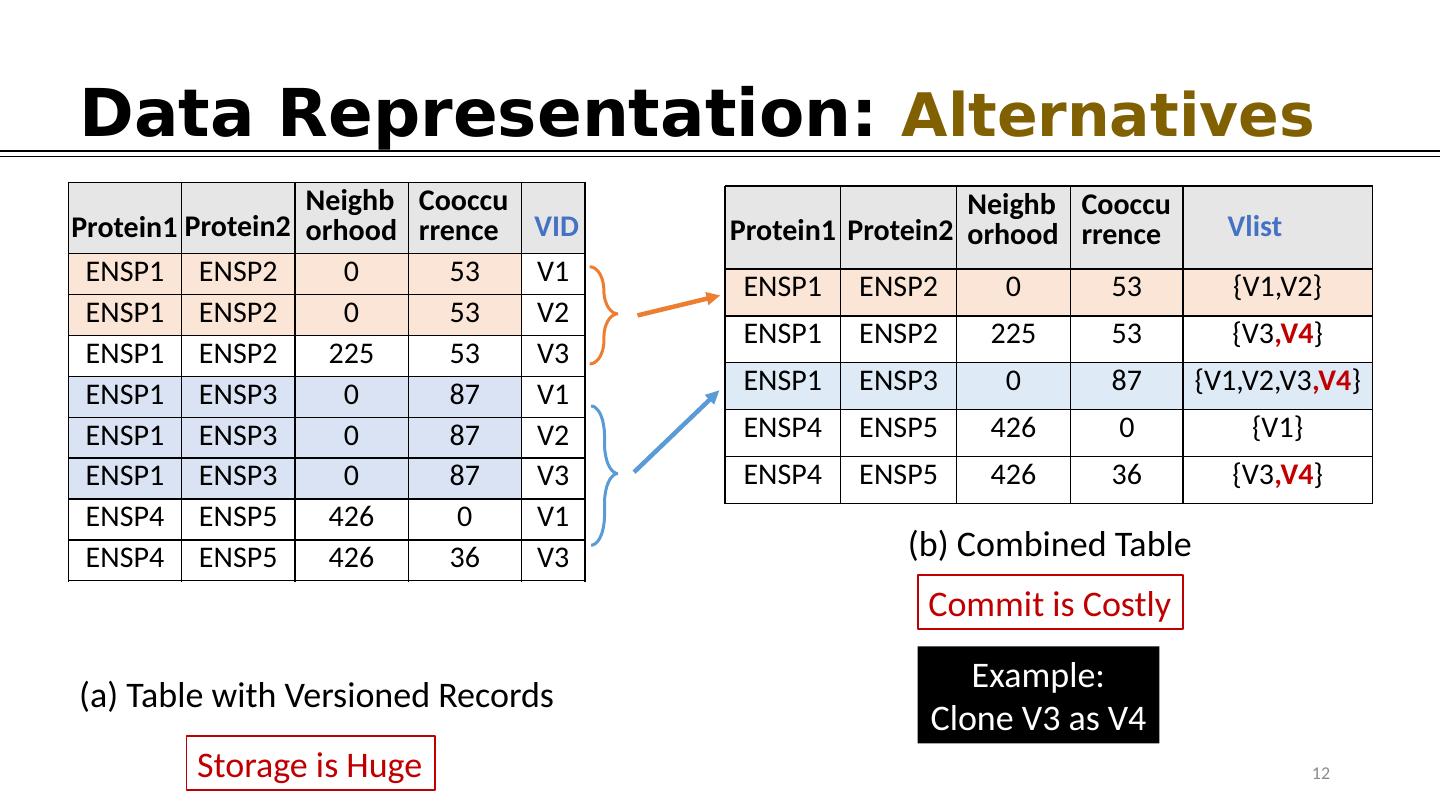
11 .Data Representation: Alternatives Storage is Huge Neighborhood Cooccurrence ENSP1 ENSP2 0 53 V1 ENSP1 ENSP2 0 53 V2 ENSP1 ENSP2 225 53 V3 ENSP1 ENSP3 0 87 V1 ENSP1 ENSP3 0 87 V2 ENSP1 ENSP3 0 87 V3 ENSP4 ENSP5 426 0 V1 ENSP4 ENSP5 426 36 V3 Protein1 Protein2 VID (a) Table with Versioned Records Neighborhood Cooccurrence ENSP1 ENSP2 0 53 {V1,V2} ENSP1 ENSP2 225 53 {V3} ENSP1 ENSP3 0 87 {V1,V2,V3} ENSP4 ENSP5 426 0 {V1} ENSP4 ENSP5 426 36 {V3} Protein1 Protein2 Vlist (b) Combined Table 11 Example: Clone V3 as V4 Commit is Costly
12 .Data Representation: Alternatives Neighborhood Cooccurrence ENSP1 ENSP2 0 53 V1 ENSP1 ENSP2 0 53 V2 ENSP1 ENSP2 225 53 V3 ENSP1 ENSP3 0 87 V1 ENSP1 ENSP3 0 87 V2 ENSP1 ENSP3 0 87 V3 ENSP4 ENSP5 426 0 V1 ENSP4 ENSP5 426 36 V3 Protein1 Protein2 VID (a) Table with Versioned Records Neighborhood Cooccurrence ENSP1 ENSP2 0 53 {V1,V2} ENSP1 ENSP2 225 53 {V3 ,V4 } ENSP1 ENSP3 0 87 {V1,V2,V3 ,V4 } ENSP4 ENSP5 426 0 {V1} ENSP4 ENSP5 426 36 {V3 ,V4 } Protein1 Protein2 Vlist (b) Combined Table 12 Example: Clone V3 as V4 Commit is Costly Storage is Huge
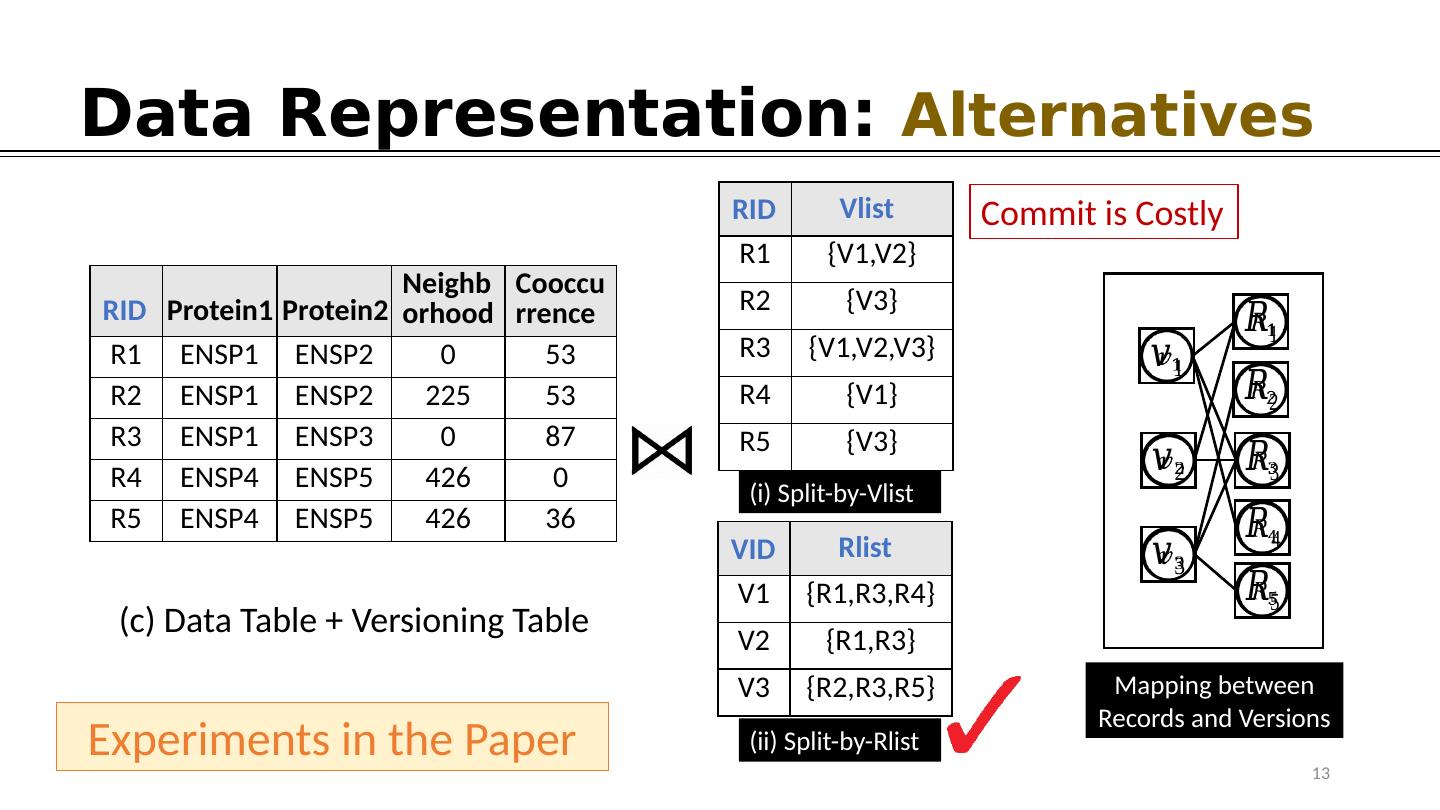
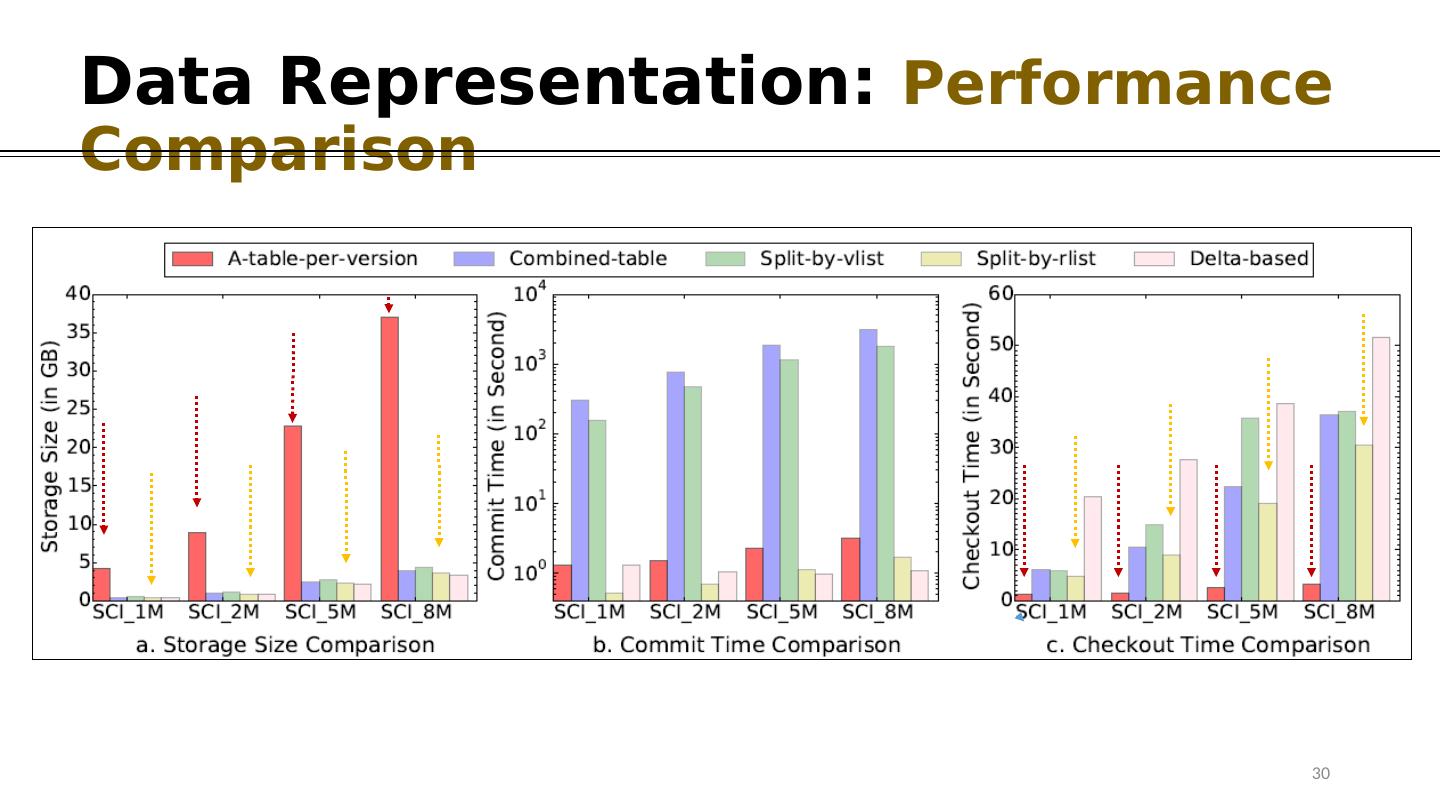
13 .Data Representation: Alternatives Neighborhood Cooccurrence R1 ENSP1 ENSP2 0 53 R2 ENSP1 ENSP2 225 53 R3 ENSP1 ENSP3 0 87 R4 ENSP4 ENSP5 426 0 R5 ENSP4 ENSP5 426 36 (c) Data Table + Versioning Table Protein1 Protein2 RID R1 {V1,V2} R2 {V3} R3 {V1,V2,V3} R4 {V1} R5 {V3} Vlist RID V1 {R1,R3,R4} V2 {R1,R3} V3 {R2,R3,R5} R list V ID ( i ) Split-by- Vlist (ii) Split-by- Rlist Commit is Costly 13 Mapping between Records and Versions Experiments in the Paper
14 .Outline 14 Strawman Approach Data Representation Access/Storage Optimization
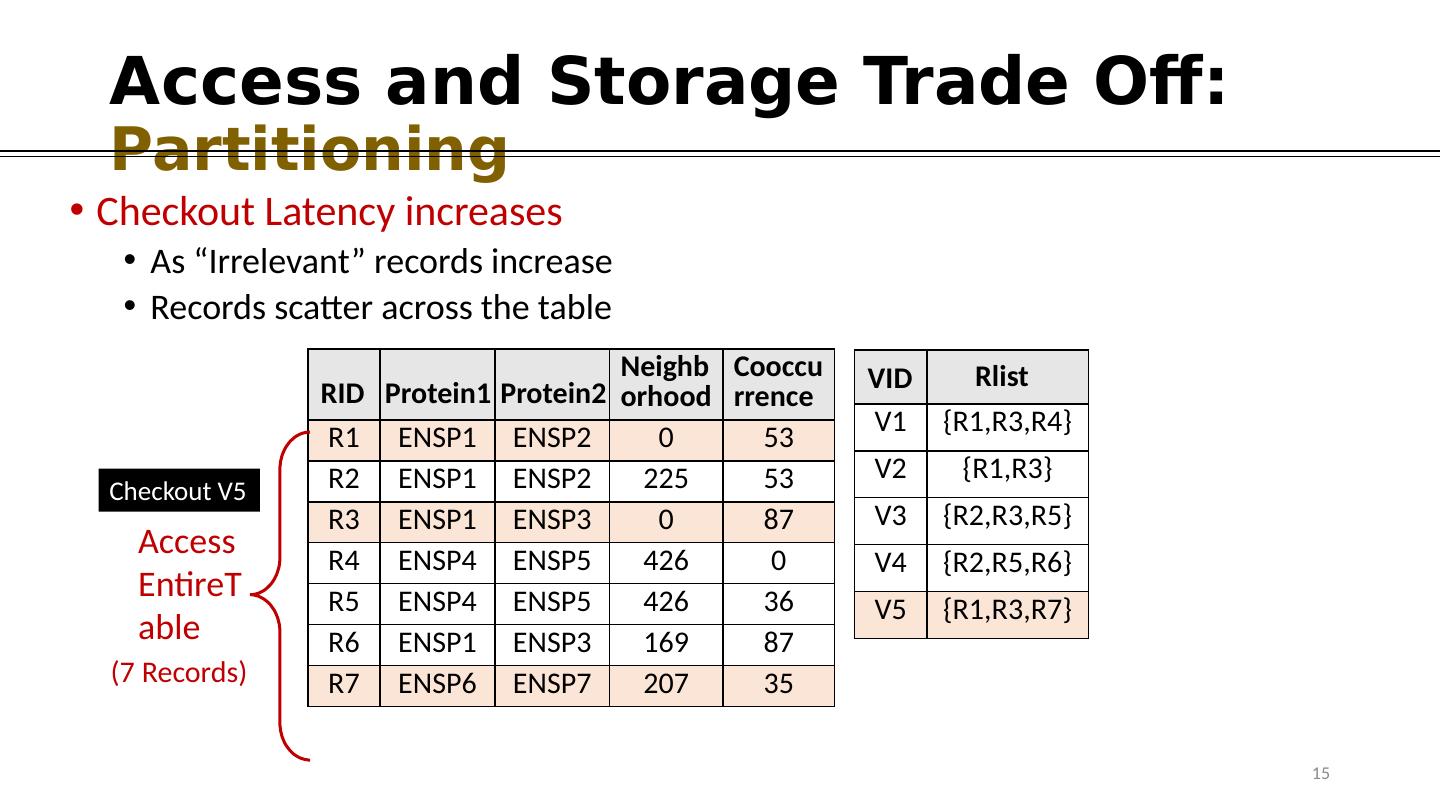
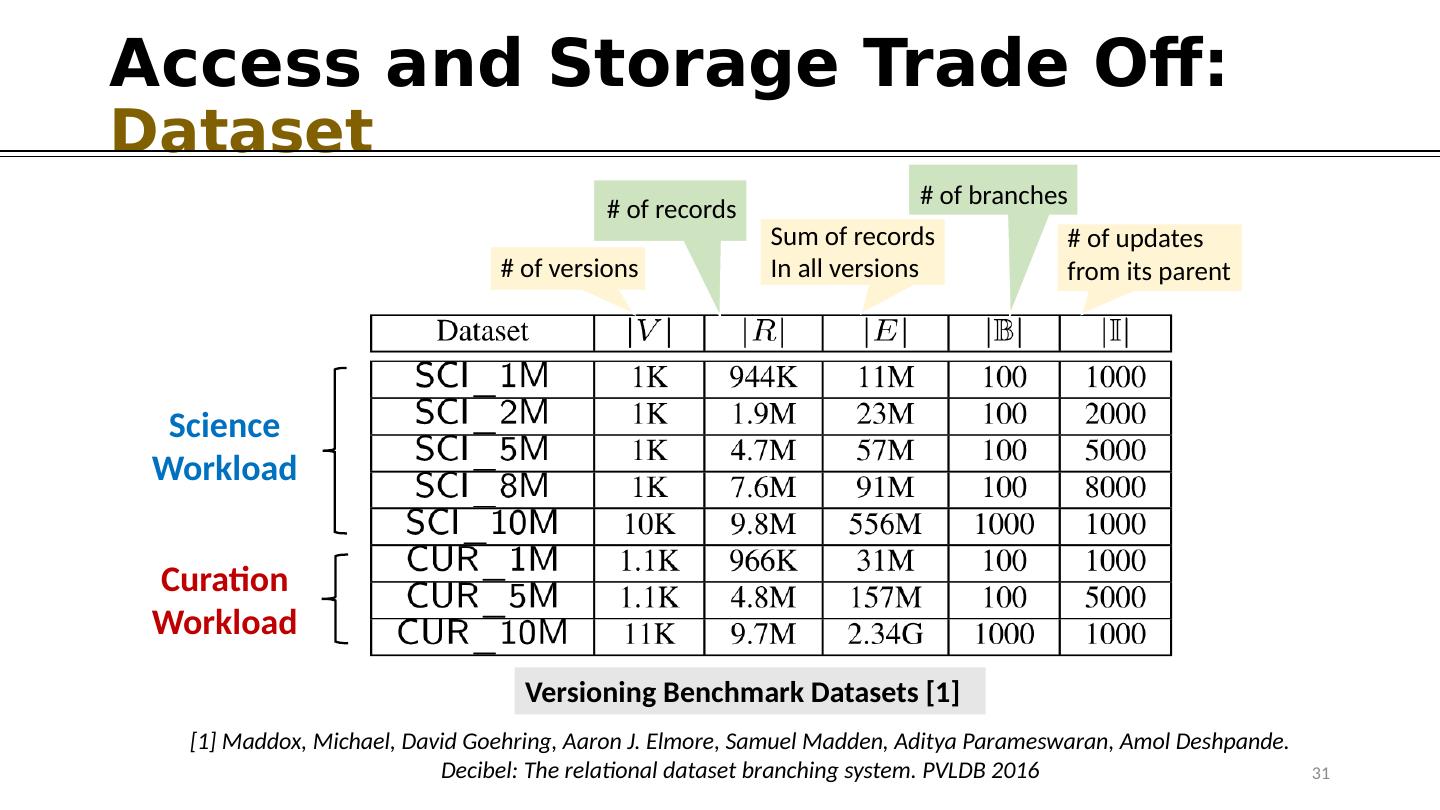
15 .Access and Storage Trade Off: Partitioning Checkout Latency increases As “Irrelevant” records increase Records scatter across the table Neighborhood Cooccurrence R1 ENSP1 ENSP2 0 53 R2 ENSP1 ENSP2 225 53 R3 ENSP1 ENSP3 0 87 R4 ENSP4 ENSP5 426 0 R5 ENSP4 ENSP5 426 36 R6 ENSP1 ENSP3 169 87 R7 ENSP6 ENSP7 207 35 Protein1 Protein2 RID V1 {R1,R3,R4} V2 {R1,R3} V3 {R2,R3,R5} V4 {R2,R5,R6} V5 {R1,R3,R7} R list V ID Checkout V5 15 Access EntireTable (7 Records)
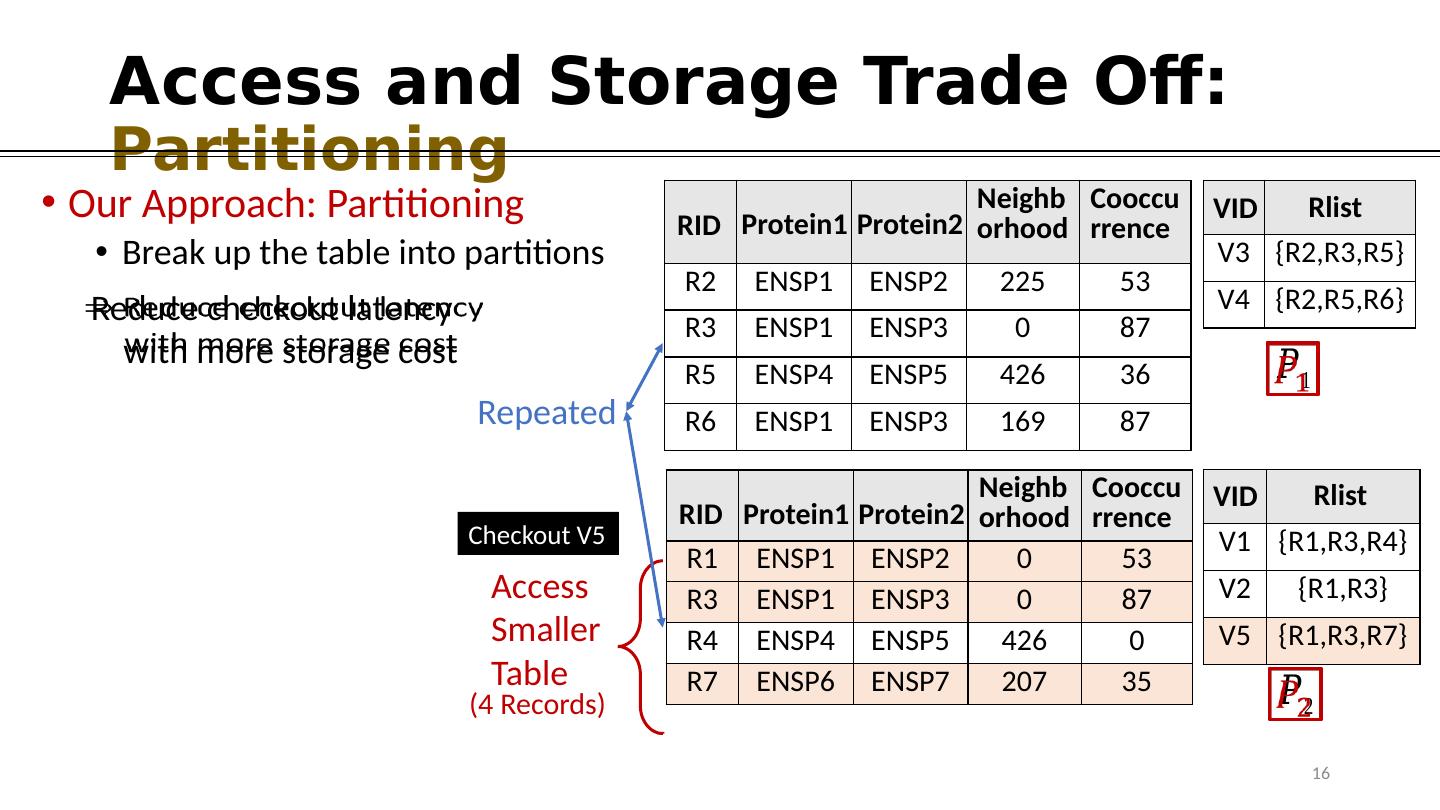
16 .Access and Storage Trade Off: Partitioning Our A pproach : Partitioning Break up the table into partitions Neighborhood Cooccurrence R1 ENSP1 ENSP2 0 53 R3 ENSP1 ENSP3 0 87 R4 ENSP4 ENSP5 426 0 R7 ENSP6 ENSP7 207 35 Protein1 Protein2 RID V1 {R1,R3,R4} V2 {R1,R3} V5 {R1,R3,R7} R list V ID Checkout V5 Neighborhood Cooccurrence R2 ENSP1 ENSP2 225 53 R3 ENSP1 ENSP3 0 87 R5 ENSP4 ENSP5 426 36 R6 ENSP1 ENSP3 169 87 Protein1 Protein2 RID V3 {R2,R3,R5} V4 {R2,R5,R6} R list V ID 16 Access Smaller Table (4 Records) Reduce checkout latency with more storage cost Repeated
17 .Access and Storage Trade Off: Cost Model Average Checkout C ost Checkout cost for version the size of the partition belongs to : checkout cost across all versions, divided by # of versions Storage Cost Total # of records in all partitions Problem Formulation: Given a storage threshold , find a partitioning scheme that minimizes such that NP-Hard! (Reduction from 3-Partition) 17
18 .Access and Storage Trade Off: T wo Extremes All in One Table Smallest S torage Cost Each Version as One Table Smallest Average Checkout Cost 18
19 .Access and Storage Trade Off: T wo Extremes All in One Table Smallest S torage Cost Each Version as One Table Smallest Average Checkout Cost Partition Per Version Single Partition O ptimal Scheme 19 Intuition: Group Similar Versions
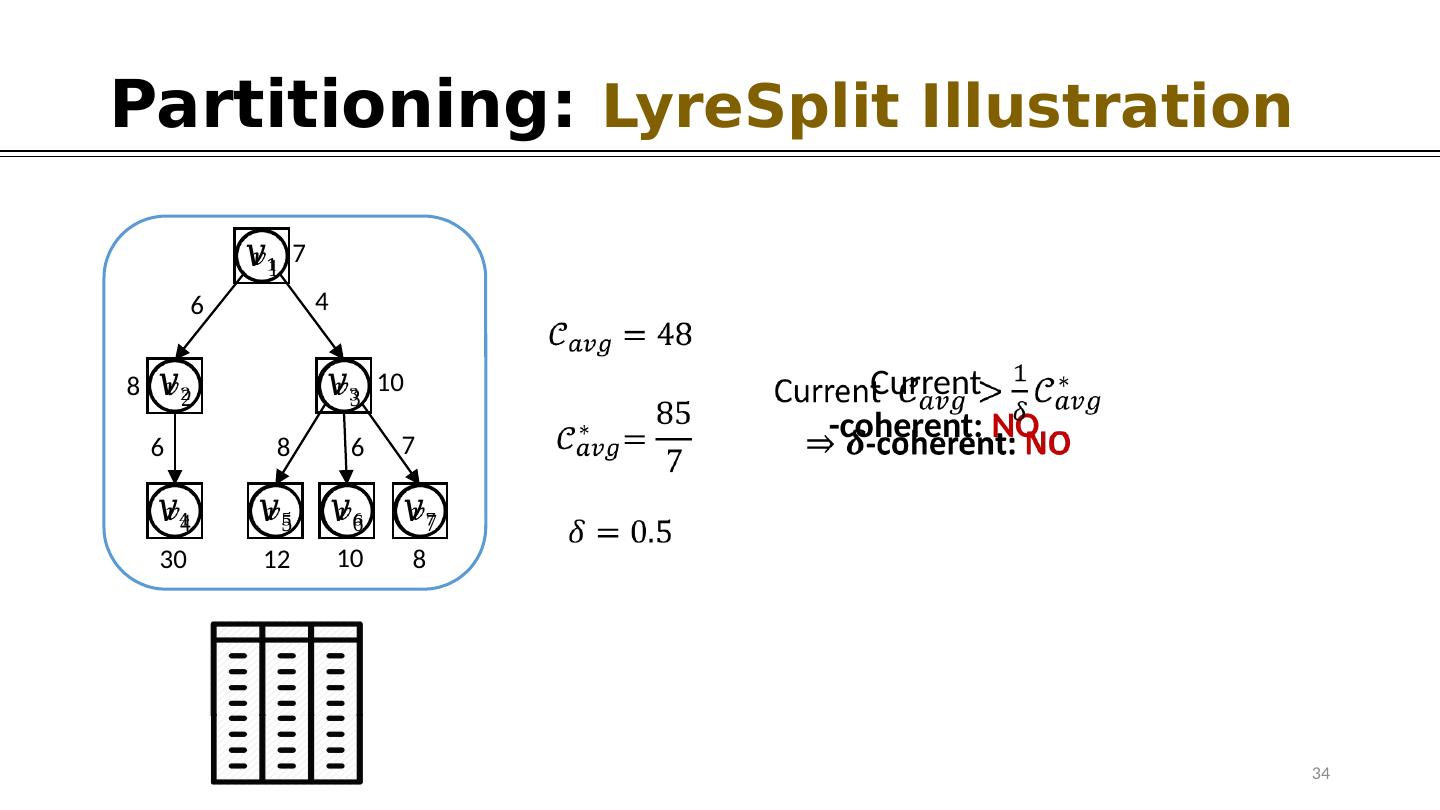
20 .Partitioning: LyreSplit Clustering Approach Group versions with similar records together Need to examine every single record; Costly 7 6 4 8 10 6 8 6 7 8 30 12 10 LyreSplit : Operate on Version Graph Encodes the derivation information Indicates similarity among versions 20 vs. ~1K Versions ~10M Records Light-Weight
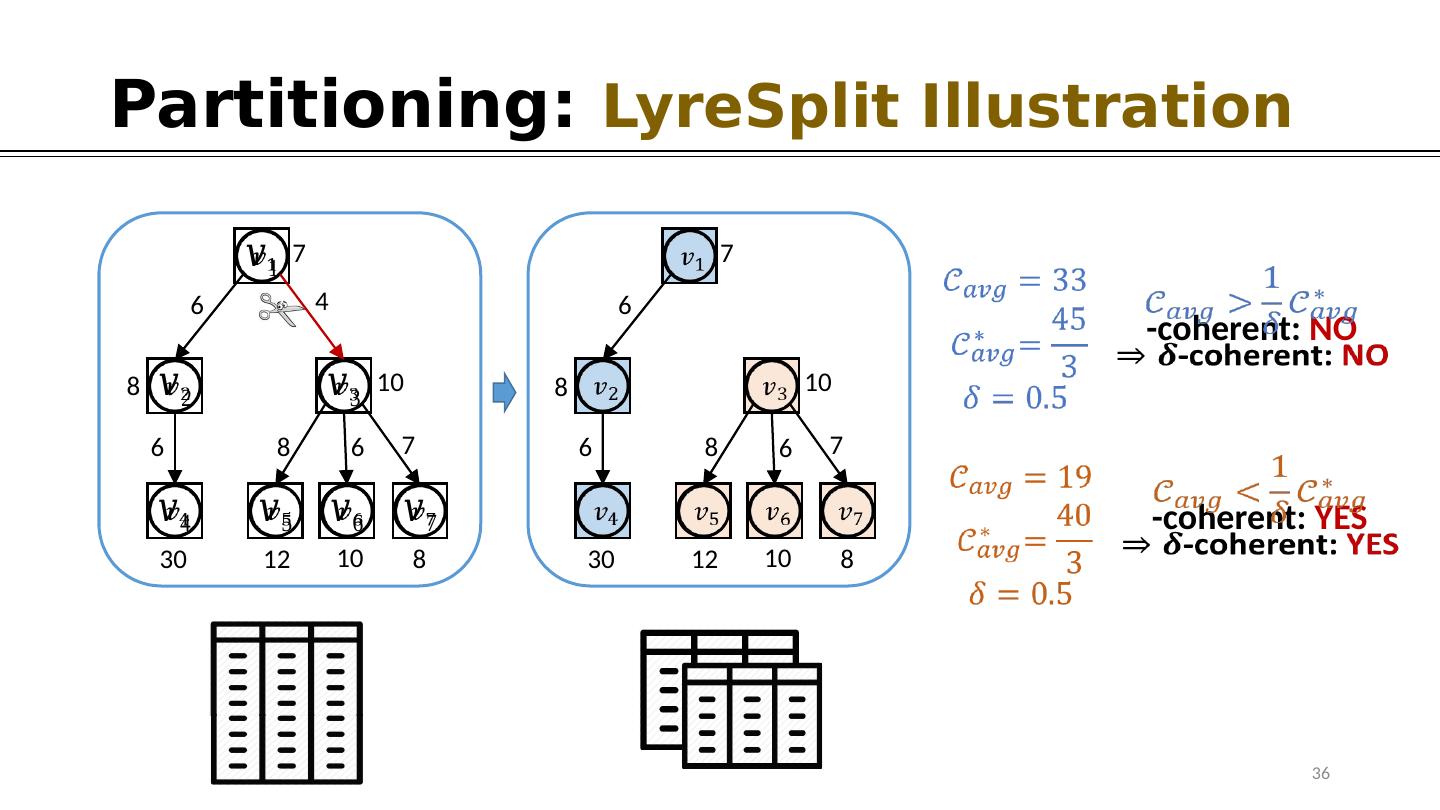
21 .Partitioning: High-level Idea of LyreSplit 7 6 4 8 10 6 8 6 7 8 30 12 10 - coherent: Current Single Partition -coherent ? NO Split ( , )- Approximation G uarantee 21
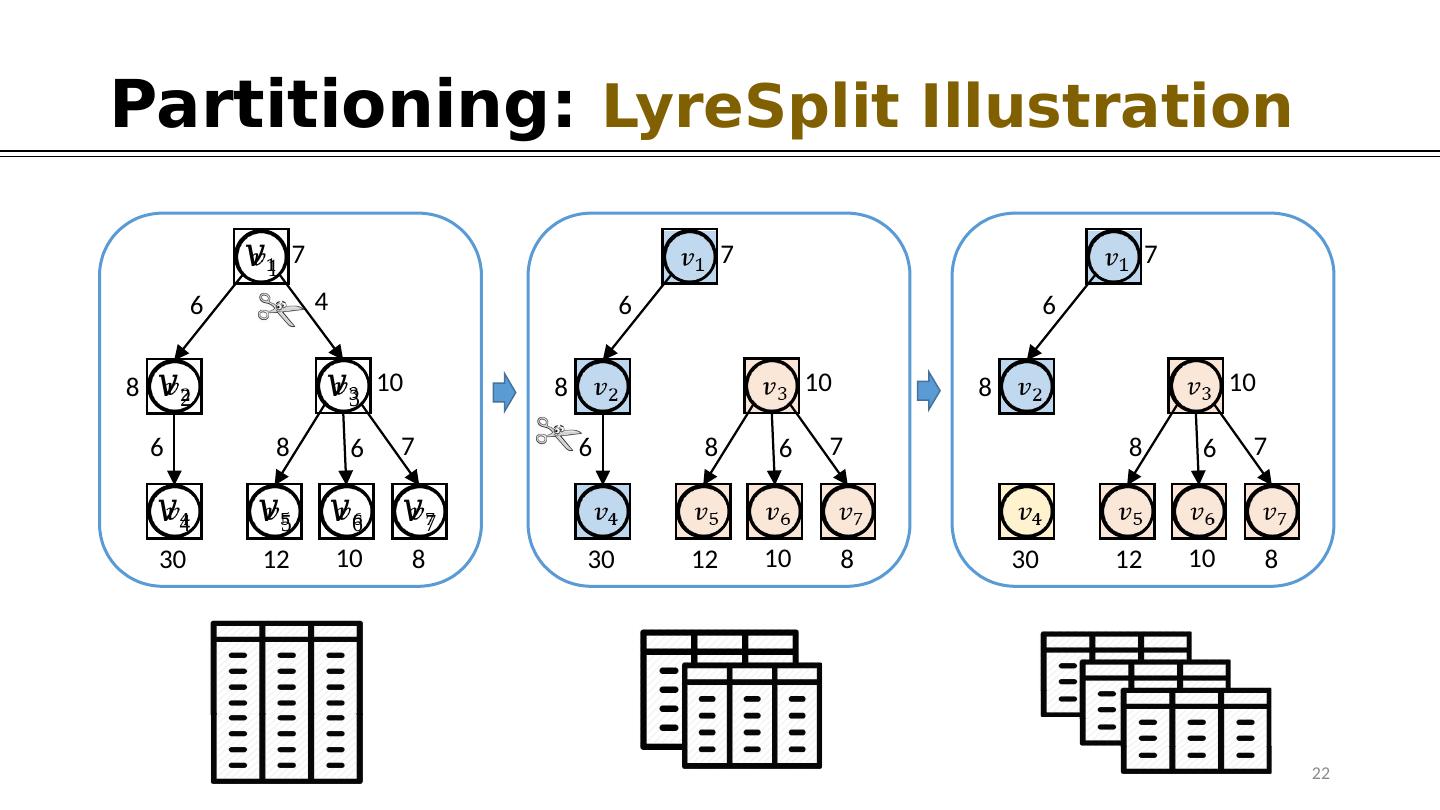
22 . 7 6 4 8 10 6 8 6 7 8 30 12 10 7 6 8 10 6 8 6 7 8 30 12 10 7 6 8 10 8 6 7 8 30 12 10 Partitioning: LyreSplit Illustration 22
23 .Partitioning: Experimental Setting Dataset Versioning workload from Decibel[1] Algorithm Our proposed algorithm – LyreSplit LyreSplit (Varying – coherence parameter) Two clustering-based algorithm from Nscale [2] AGGLO (Varying – partition capacity) KMeans ( Varying – # of partitions) [1] Decibel : The relational dataset branching system. PVLDB 2016 [2] NScale : neighborhood-centric large-scale graph analytics in the cloud . VLDB Journal 2016 23
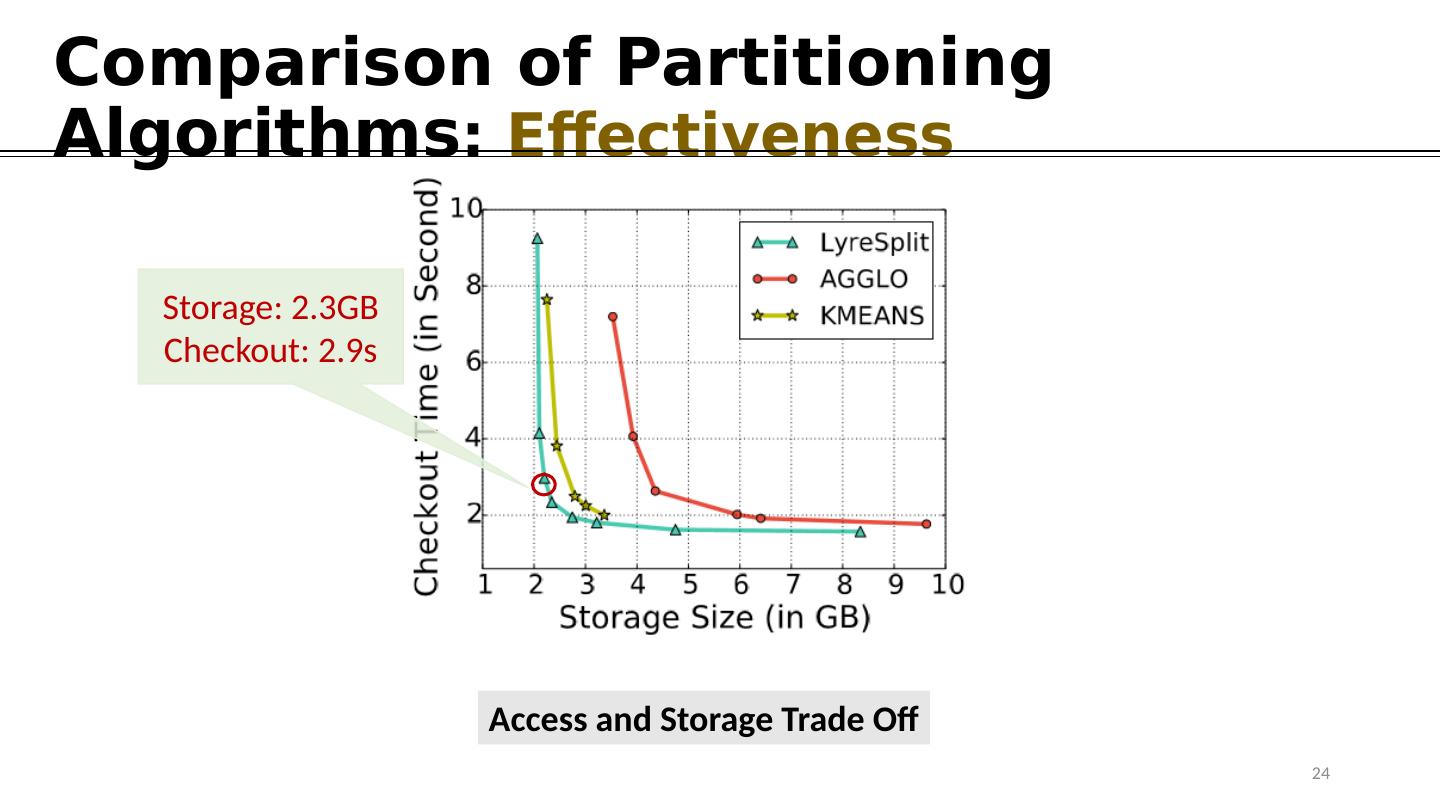
24 .Comparison of Partitioning Algorithms : Effectiveness Access and Storage Trade Off Storage: 2.3GB Checkout: 2.9s 24
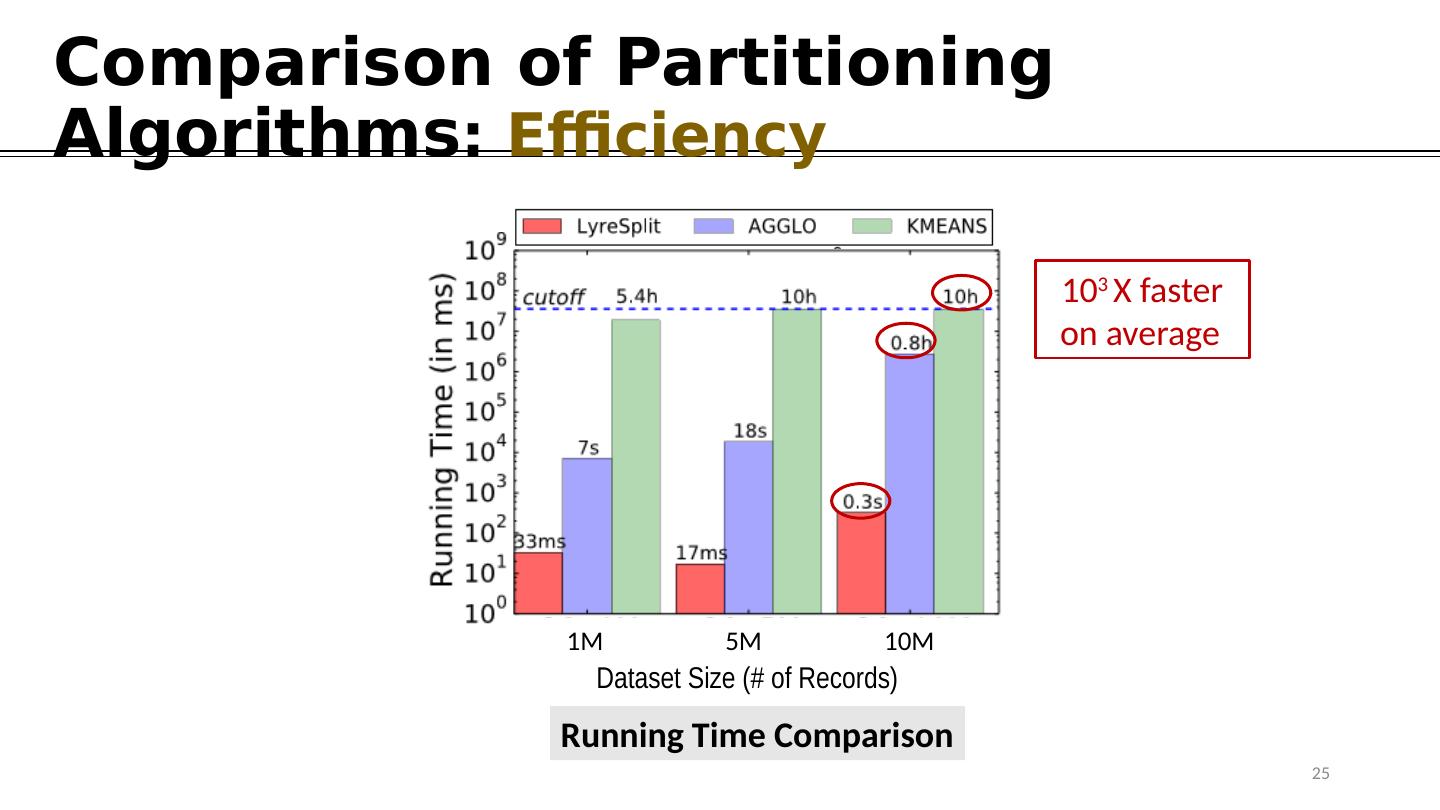
25 .Comparison of Partitioning Algorithms : Efficiency 10 3 X faster on average 25 Running Time Comparison 1M 5M 10M Dataset Size (# of Records)
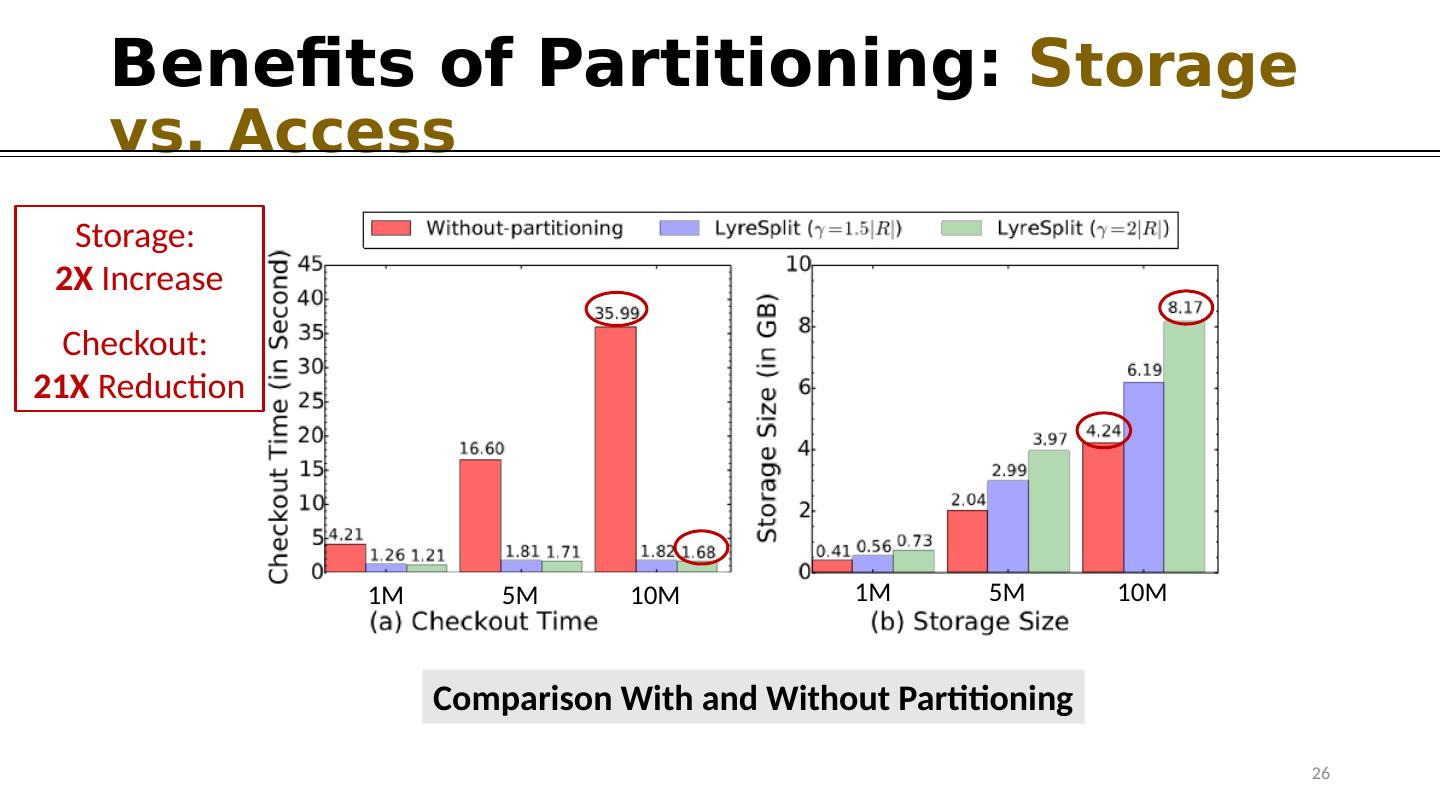
26 .Benefits of Partitioning: S torage vs. Access Comparison With and Without Partitioning Storage: 2X I ncrease Checkout: 21X Reduction 26 1M 5M 10M 1M 5M 10M
27 .Summary 27 Bolt-on versioning for relational databases [ OrpheusDB ] Optimized data representation [Split-by- rlist ] D esigned partition scheme [ LyreSplit ]
28 .http://orpheus-db.github.io/ [Fully Open-Source] 28
29 .Proposal: “Reuse” Relational Database Traditional SQL Identify Version Aggregates Across Versions Checkout Commit Diff Translate and Rewrite Query Optimize Performance H ow data is stored 29
3秒后跳转登录页面
去登陆

