展开查看详情
1 .MAD skills: New Analysis Practices for Big Data 2009 CS598 Yue Sun (yuesun3)
2 .Trend: collect, leverage data in multiple organizational units Data: Fox Audience Network using Greenplum parallel database system Motivation ? Cheap storage Growing number of large-scale databases Value of data analysis Complement statisticians with software skills
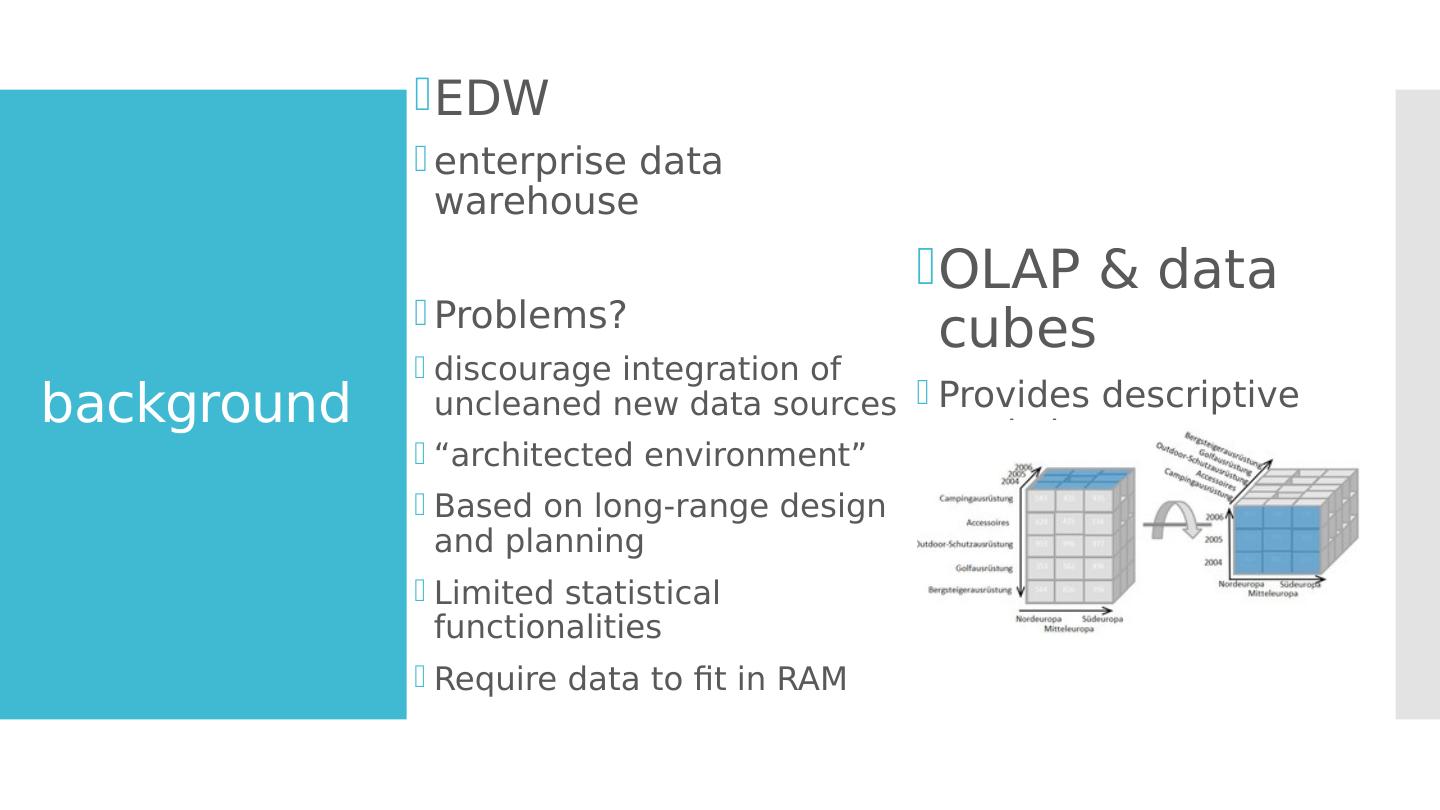
3 .background EDW enterprise data warehouse Problems? discourage integration of uncleaned new data sources “architected environment” Based on long-range design and planning Limited statistical functionalities Require data to fit in RAM OLAP & data cubes Provides descriptive statistics
4 .Background continue… MapReduce and Parallel programming Data-parallel fashion via summations Data mining and Analytics correspond to only statistical libraries that ship with a stat package Statistical packages Spreadsheets
5 .MAD database design Objectives: 1. get the data into the warehouse as soon as possible 2. intelligent cleaning of data 3. intelligent integration of data 3 layer approach 1. staging schema 2. production data warehouse schema 3. reporting schema
6 .Fourth class of schema: S andbox Why sandbox? used for managing experimental processes 1. track and record work and work products 2. materialize query results and reuse the results later
7 .Data parallel statistics Layers of abstraction in traditional SQL database 1. Simple arithmetic 2. Vector arithmetic 3. Functions 4. Functionals
8 .Vectors and Matrices Matrix addition: Matrix transpose: Matrix-matrix multiplication
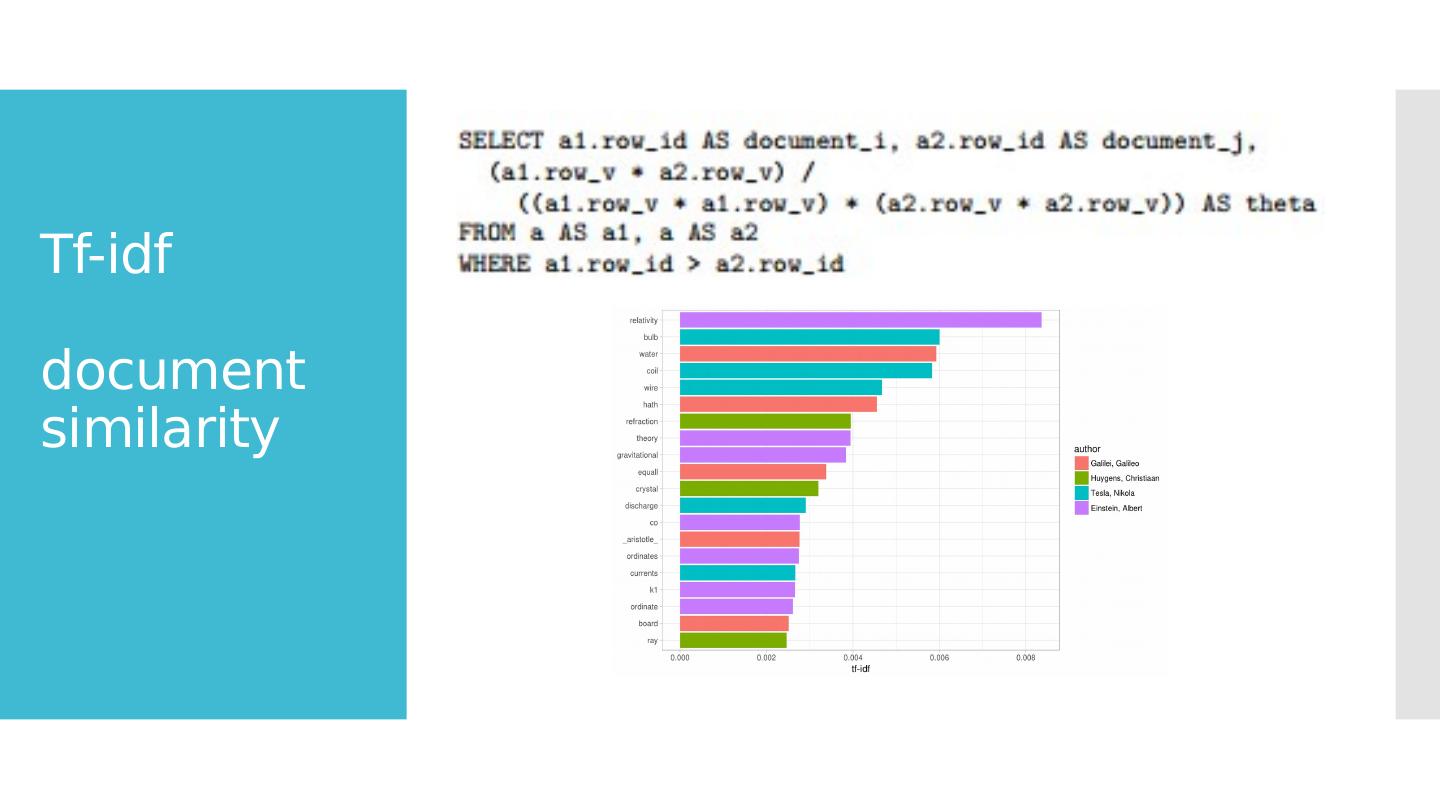
9 .Tf-idf document similarity
10 .Matrix based analytical methods Ordinary least squares
11 .Matrix based analytical methods continue… Conjugate gradient update alpha( r_i , p_i , A ) update x( x_i , alpha_i , v_i ) update r( x_i , alpha_i , v_i , A ) update v( r_i , alpha_i , v_i , A ) Construction of these functions allow user to insert one full row at a time
12 .functional : data-parallel implementations of comparative statistics expressed in SQL Mann-Whitney U Test
13 .Log-likelihood ratios useful for comparing a subpopulation to an overall population on a particular attributed Example: multinomial distribution
14 .Resampling techniques 2 standard resampling techniques: 1 . bootstrap from a population of size N, pick k members randomly, compute statistic; replace subsample with another k random member… 2 . jackknife Repeatedly compute statistic by leaving out one or more data items
15 .MAD DBMS requirements? Easy and efficient to put new data source into the warehouse Make physical storage evolution easy and efficient Provide powerful, flexible programming environment
16 .Storage and partitioning Require multiple storage mechanisms 1. [early stage] iterate over tasks frequently; load databases quickly; allow users to run queries directly against external tables 2. [for “detail tables”] well served by traditional transactional storage techniques 3. [for fact tables] better served by compressed storage because it handles appends and reads more efficiently
17 .MAD DBMS loading & unloading Parallel access for external tables via Scatter/Gather Streaming Require coordination with external processes to “feed” in parallel More Support transformations written in SQL Support MapReduce scripting in DBMS
18 .MAD DBMS Support external tables traditional “heap” storage format for frequent updates data Highly-compressed “append-only” (AO) table feature for data with no updates With compression off: bulk loads run quickly With most aggressive compression: use as little space as possible With medium compression: improved table scan time with slower loads
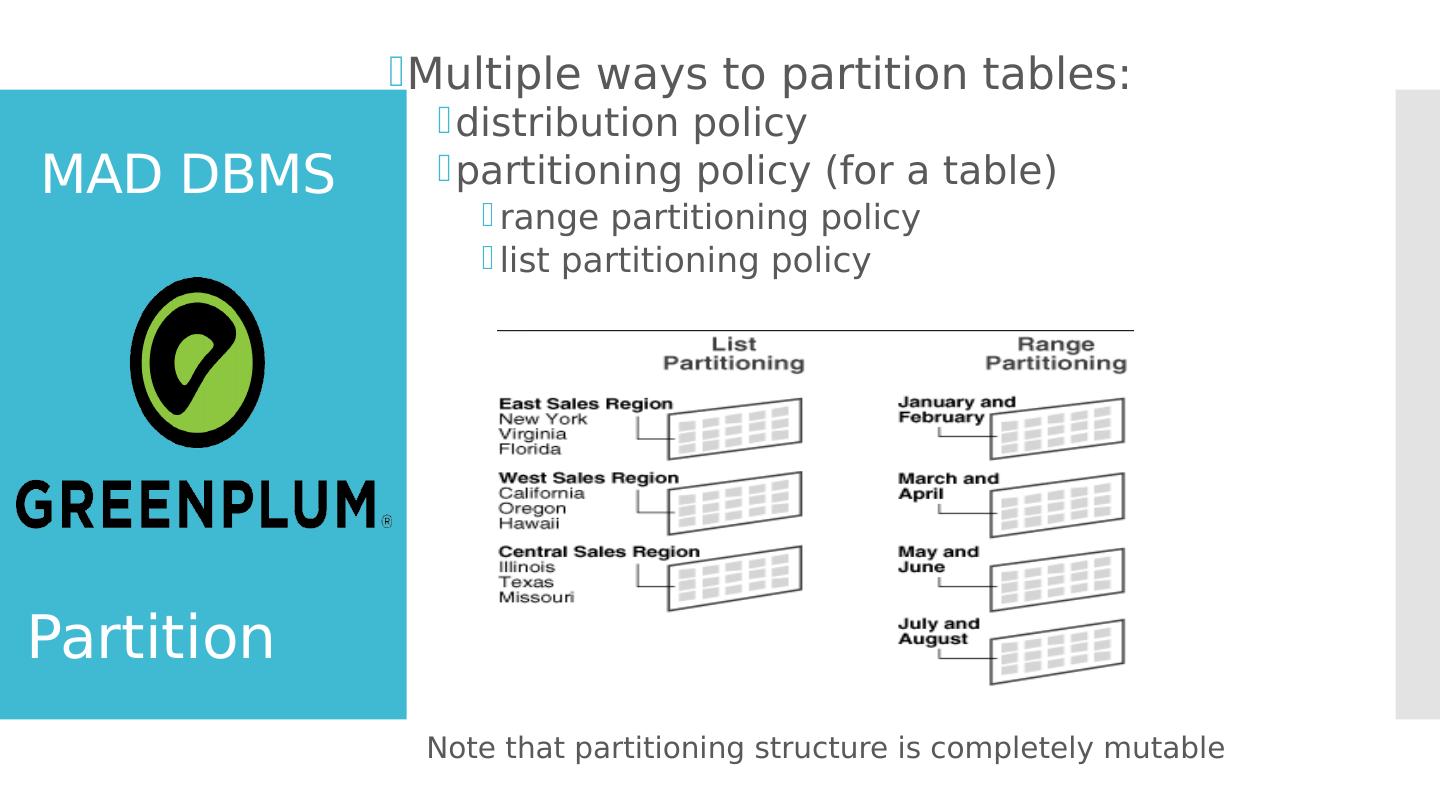
19 .MAD DBMS Multiple ways to partition tables: distribution policy partitioning policy (for a table) range partitioning policy list partitioning policy Note that partitioning structure is completely mutable Partition