展开查看详情
1 .DataSpread : Unifying Databases and Spreadsheets Mangesh Bendre
2 .Data Analytics to the People Most of the people doing ad-hoc data manipulation and analysis use spreadsheets, e.g., Excel Why? Easy to use : direct manipulation of data Built-in visualization capabilities Flexible : no need for a schema
3 .But Spreadsheets are Terrible! Slow s ingle change wait minutes on a 10,000 x 10 spreadsheet can’t even open a spreadsheet with >1M cells speed by itself can prevent analysis Tedious + not Powerful filters via copy-paste only FK joins via VLOOKUPs; others impossible even simple operations are cumbersome B rittle sharing excel sheets around, no collab /recovery using spreadsheets for collaboration is painful and error-prone 3
4 .Let’s turn to Databases Databases are: Slow Scalable Tedious + not Powerful Powerful and expressive (SQL) Brittle Collaboration, recovery, succinct So why not use databases? Well, for the same reason why spreadsheets are so useful: Easy to use Not easy to use Built-in visualization No built-in visualization Flexible Not flexible 4
5 .Combining the benefits of spreadsheets and databases Spreadsheet as a frontend interface Databases as a backend engine Result: retain the benefits of both! But it’s not that simple…
6 .Different Ideologies Databases and spreadsheets have different ideologies that need to be reconciled… Due to this, the integration is not trivial… Feature Databases Spreadsheets Data Model Schema-first Dynamic/No Schema Addressing Tuples with PK Cells, using Row/Col Presentation Set-oriented, no such notion Notion of current window, order Modifications Must correspond to queries Can be done at any granularity Computation Query at a time Value at a time 6
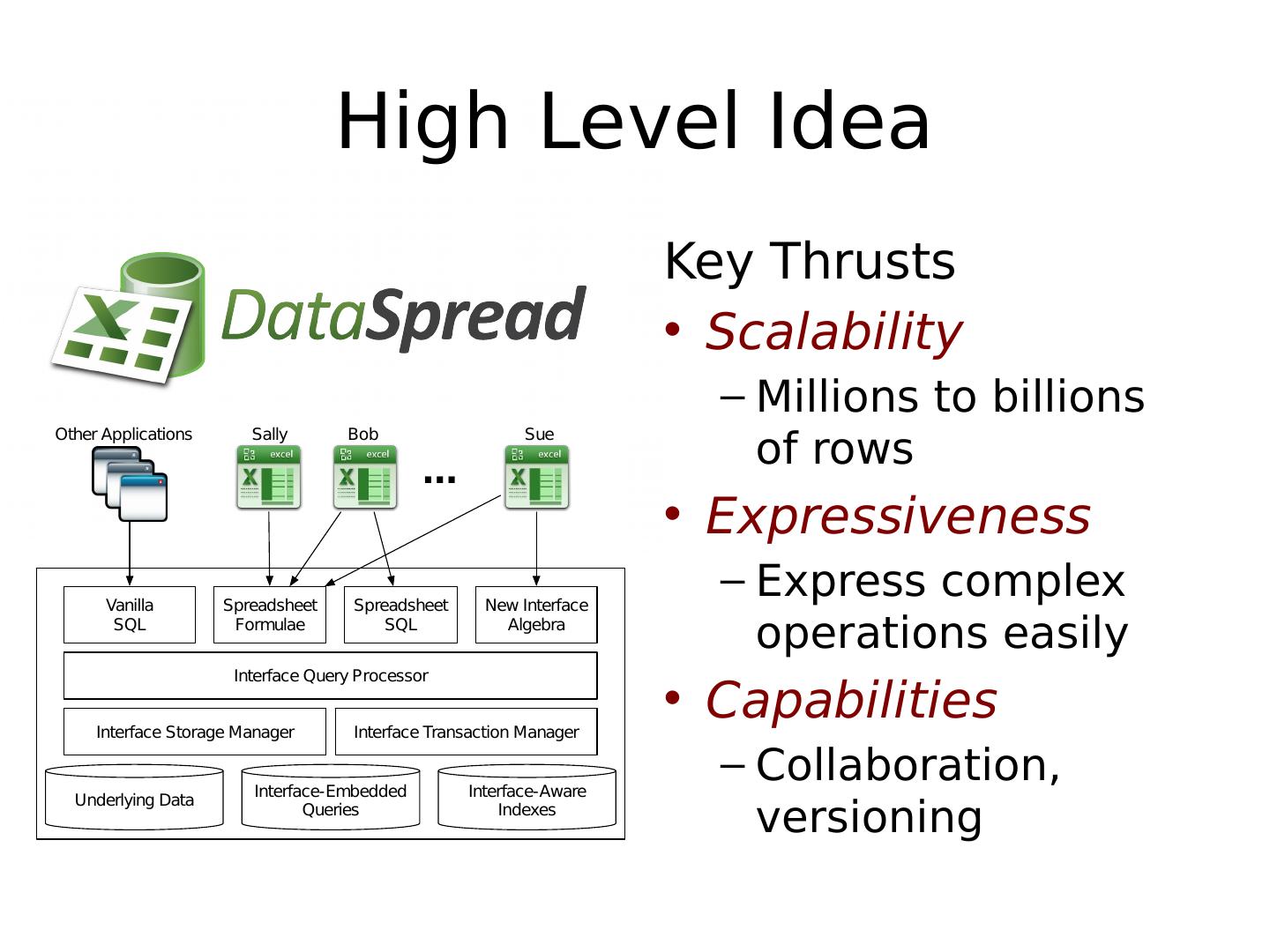
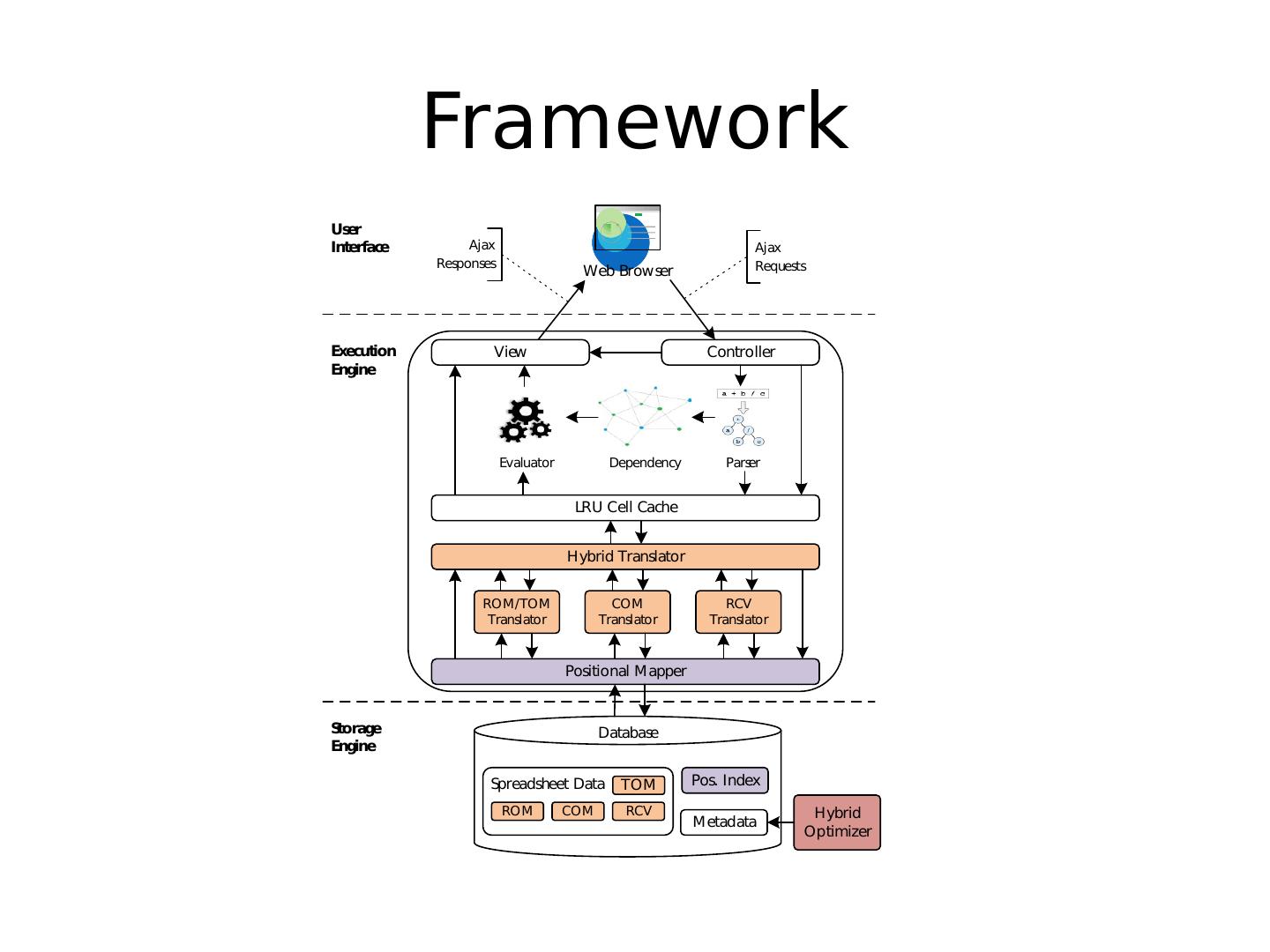
7 .High Level Idea Key Thrusts Scalability Millions to billions of rows Expressiveness Express complex operations easily Capabilities Collaboration, versioning
8 .Current Progress Version 0.1: I ntegration of spreadsheets and databases. Scalable spreadsheets. Version 0.3: Support for tables on a spreadsheet Relational Operators. SQL Asynchronous formula computation. Multi-cell functions. Capture dependency using database.
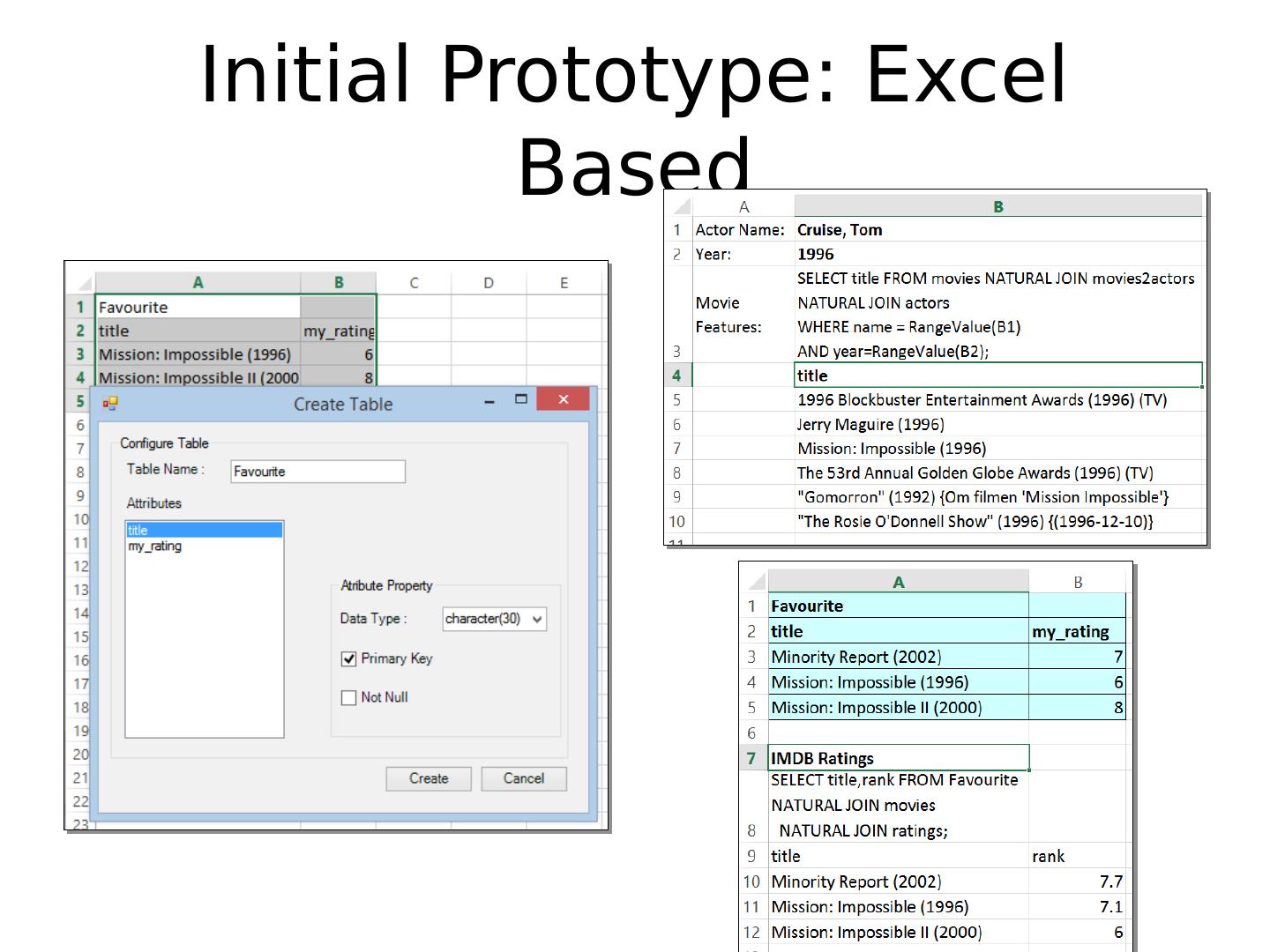
9 .Initial Prototype: Excel Based
10 .Current Prototype: Web Based
11 .Scalability Goal : To effortlessly handle spreadsheets with billions of cells. Problem: How do we represent the data to allow efficient access ? 11
12 .Problem : Representation Q: how do we represent spreadsheet data? Dense spreadsheets: represent as tables (Row #, Col1 val , Col2 val , …) Sparse spreadsheets: represent as triples (Row #, Column #, Value) 12
13 .Problem : Representation However, even if we only use “tables”, carving out the ideal # partitions (min. storage, modif ., access) is NP-Hard Reduction from min. edge-length partition of rectilinear polygons Thankfully, we have a way out … 13
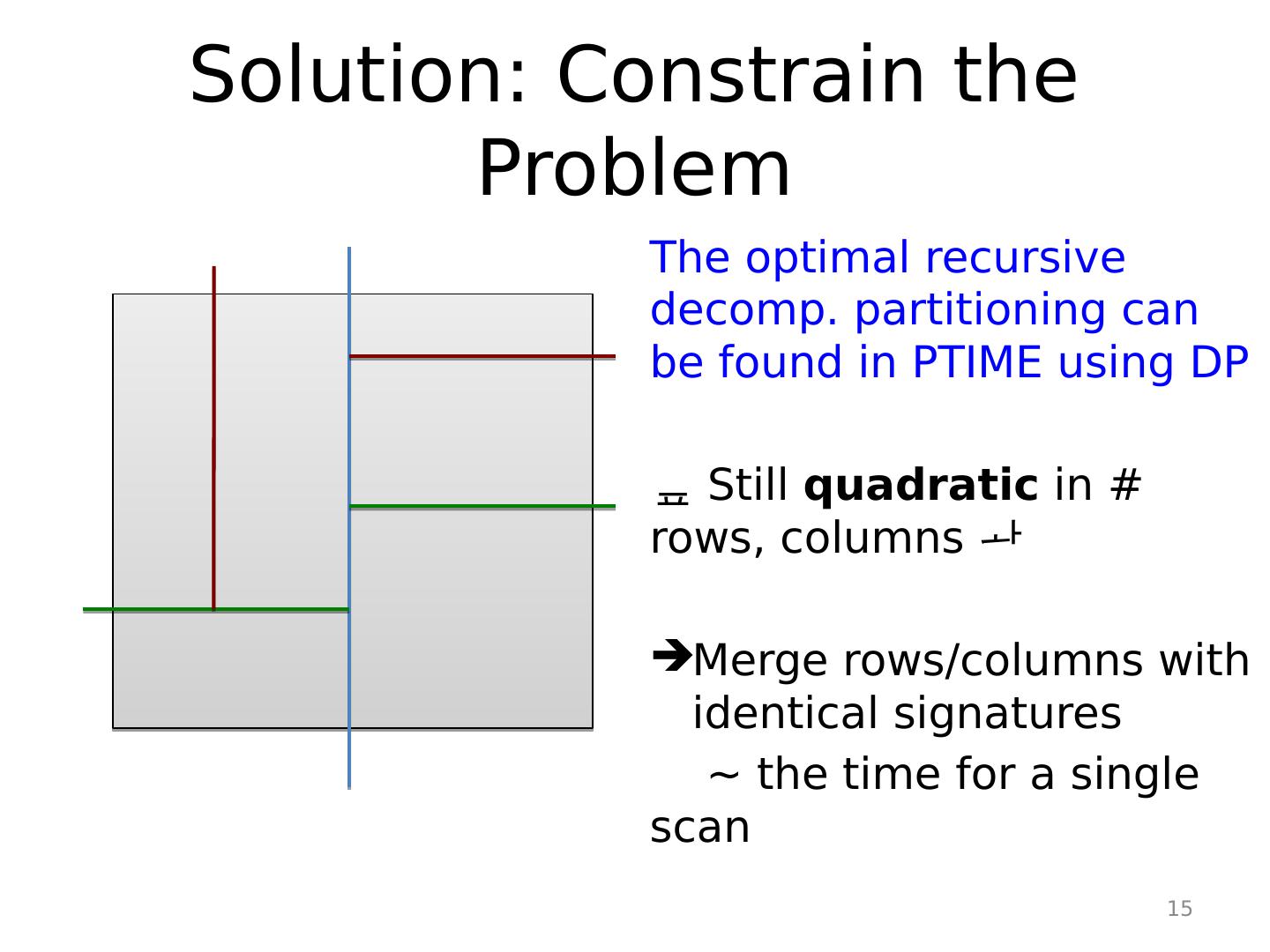
14 .Solution: Constrain the Problem A new class of partitionings : recursive decomp . A very natural class of partitionings ! 14
15 .Solution: Constrain the Problem The optimal recursive decomp . partitioning can be found in PTIME using DP Still quadratic in # rows, columns Merge rows/columns with identical signatures ~ the time for a single scan 15
16 .Problem : Spreadsheet operations Q: how do we support spreadsheet operations like insert/delete row/column? Inserting a row requires updating the row numbers of subsequent rows. 16
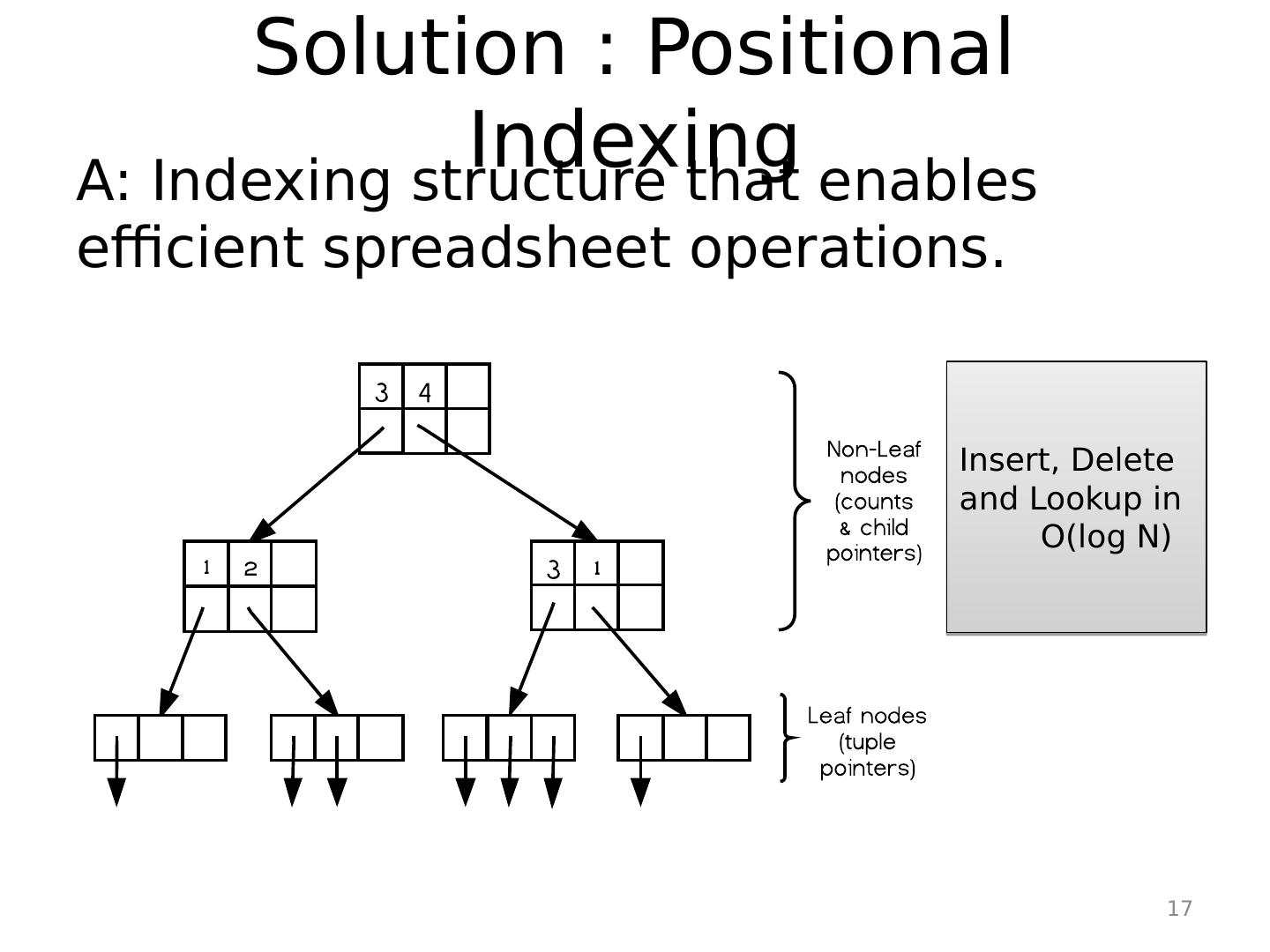
17 .Solution : Positional Indexing A : Indexing structure that enables efficient spreadsheet operations. Insert, Delete and Lookup in O(log N) 17
19 .Current Prototype PostgreSQL backend ZK spreadsheet open-source web frontend Comfortably scales to arbitrarily many rows + additional features. Hopefully bring spreadsheets to the big data age! 19 1224560
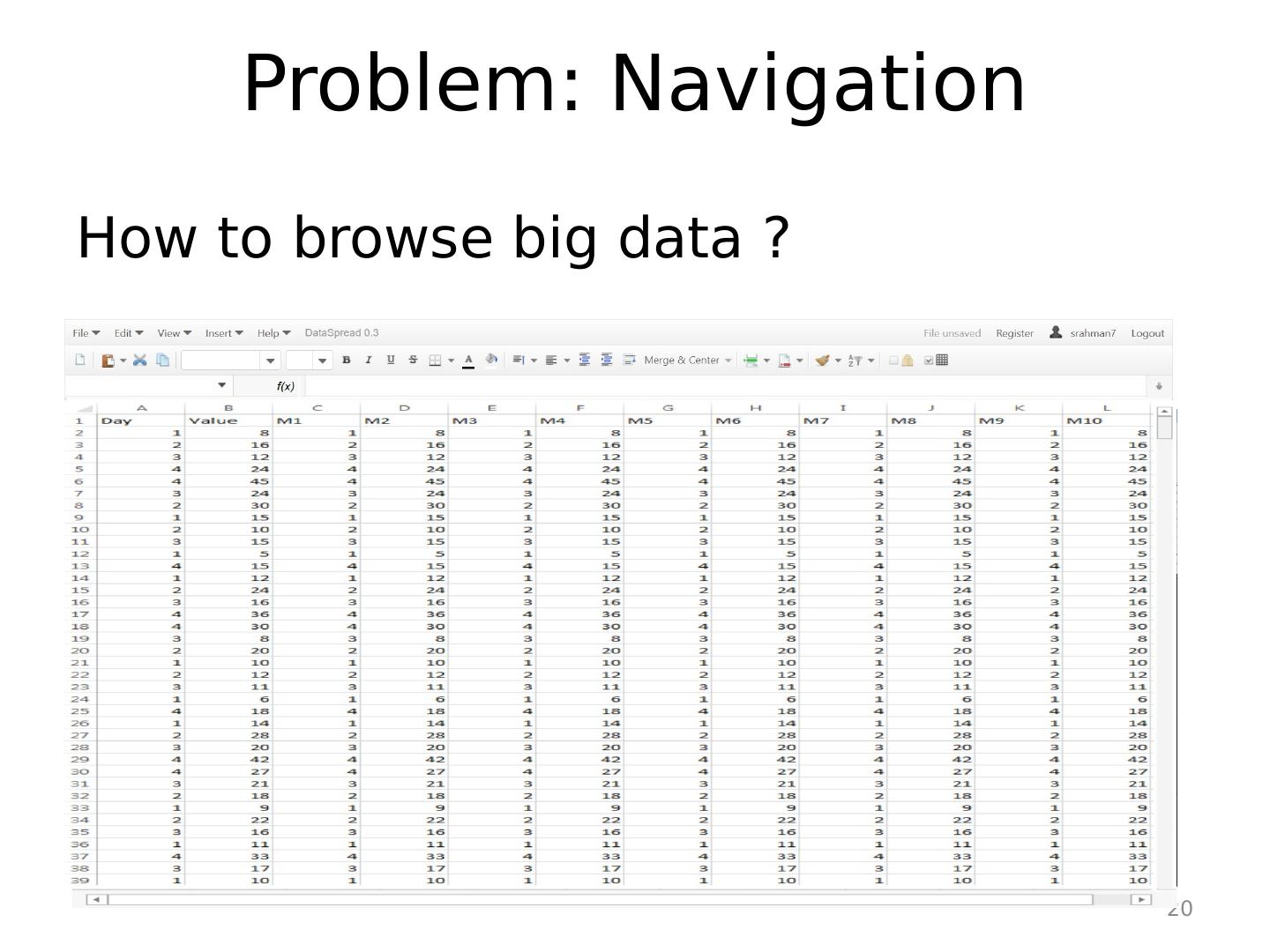
20 .Problem: Navigation 20 How to browse big data ?
21 .Solution: Navigation Support 21
22 .Scalability Goal : To effortlessly handle spreadsheets with billions of cells and formulae . Problem: How do we maintain interactivity while dealing with large and complex formulae ? 22
23 .Interactivity for Formula Computation Observation: A formula that accesses a million cell cannot be executed interactively (<500ms). Solution: Asynchronous formula computation. Challenges: How to present a consistent view of the spreadsheet? 23
24 .Asynchronous formula Computation Consistent view:- Never show incorrect data to users. Identify dependent cells in a constant time. Tolerate False positives. Dependency Graph Compression . Computation Scheduling I/O is a bottleneck. How to fetch cells for efficient computation ? 24
25 .Expressivity Goal : To make spreadsheets more expressive. Inspired from relational databases. S upport the notion of tables on spreadsheets Relational algebra. SQL. 25
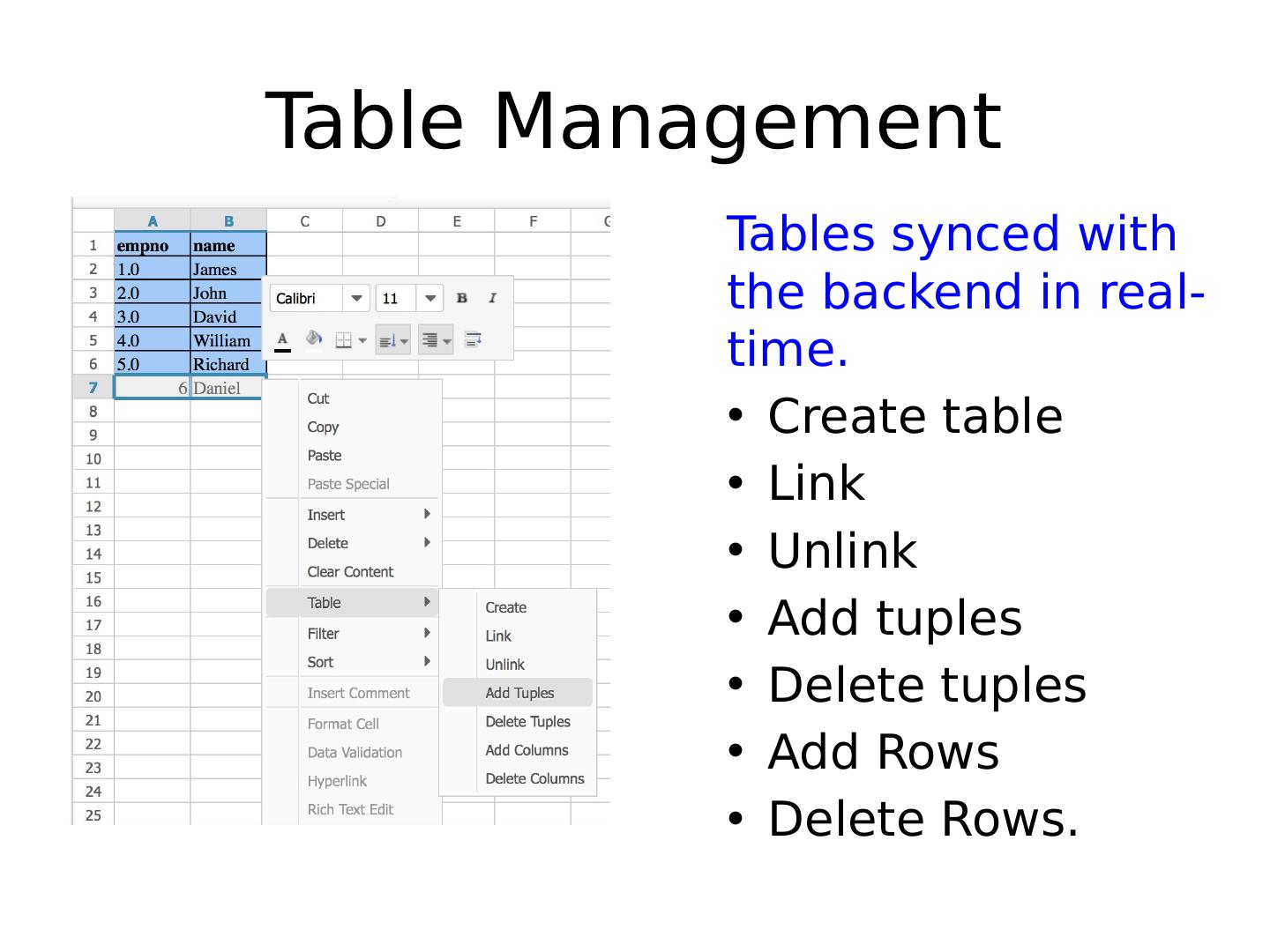
26 .Table Management Tables synced with the backend in real-time . Create table Link Unlink Add tuples Delete tuples Add Rows Delete Rows.
27 .Relational Operators. UNION DIFFERENCE INTERSECTION CROSSPRODUCT SELECT PROJECT RENAME JOIN Input is a table Output is a table cell.
28 .Multi Cell Functions.
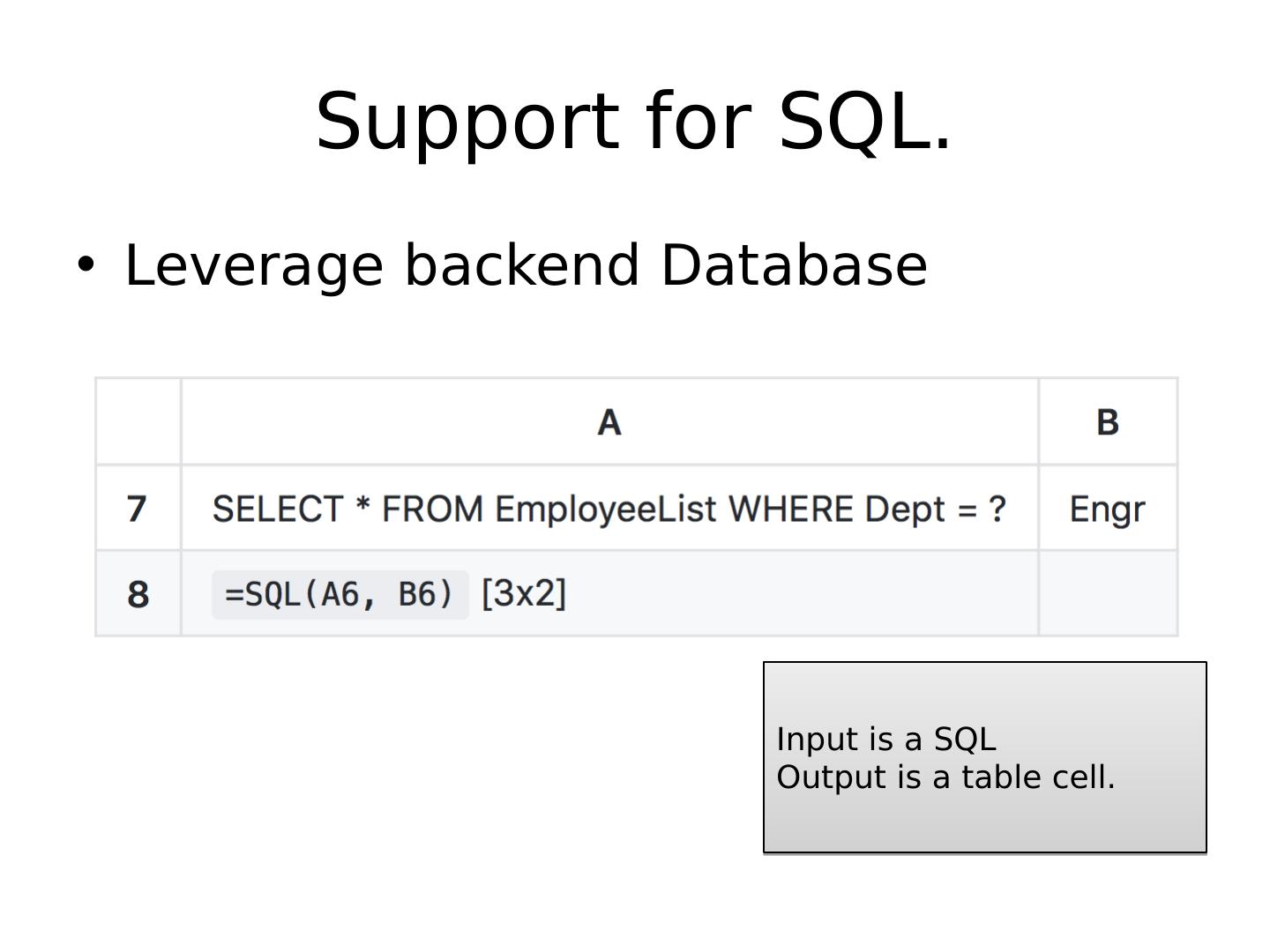
29 .Support for SQL. Leverage backend Database Input is a SQL Output is a table cell.