展开查看详情
1 .BlinkDB: Queries with Bounded Error and Bounded Response Times on Very Large Data Sameer Agarwal, Barzan Mozafari , Aurojit Panda, Henry Milner, Samuel Madden, Ion Stoica Presented By Subham De
2 .Motivation: Huge Data & Real-Time Response Multiple dimensions of data Aggregate Queries over large number of records Sessions : 100 million tuples for ‘New York’ High cost in execution time UsedID City Age SessionTime 2
3 .Main Idea Trade Off : Accuracy vs Latency Approximation Techniques Sampling Sketches Online Aggregation BlinkDB 3
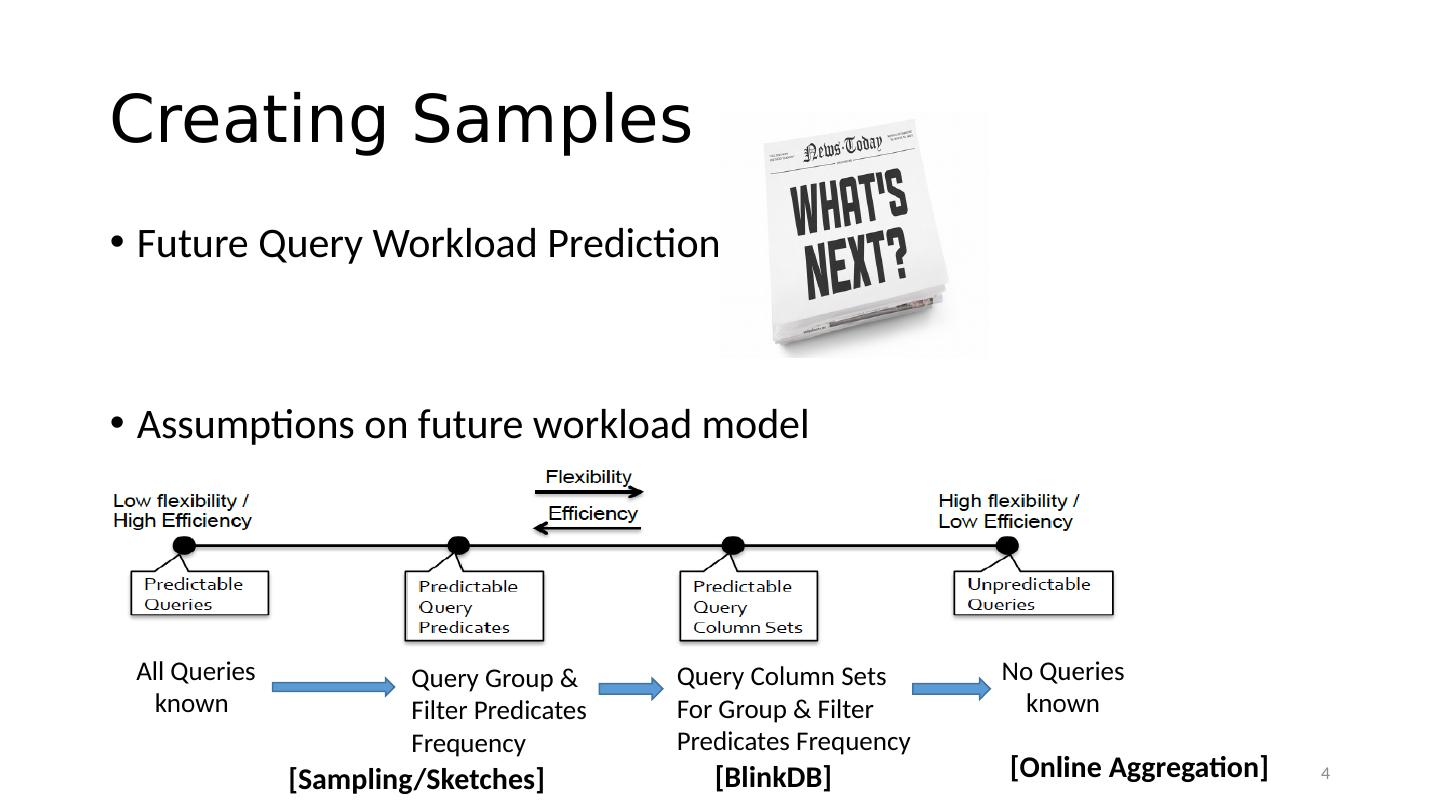
4 .Creating Samples Future Query Workload Prediction Assumptions on future workload model All Queries known No Queries known Query Column Sets For Group & Filter Predicates Frequency Query Group & Filter Predicates Frequency [Sampling/Sketches] [ Online Aggregation] [BlinkDB] 4
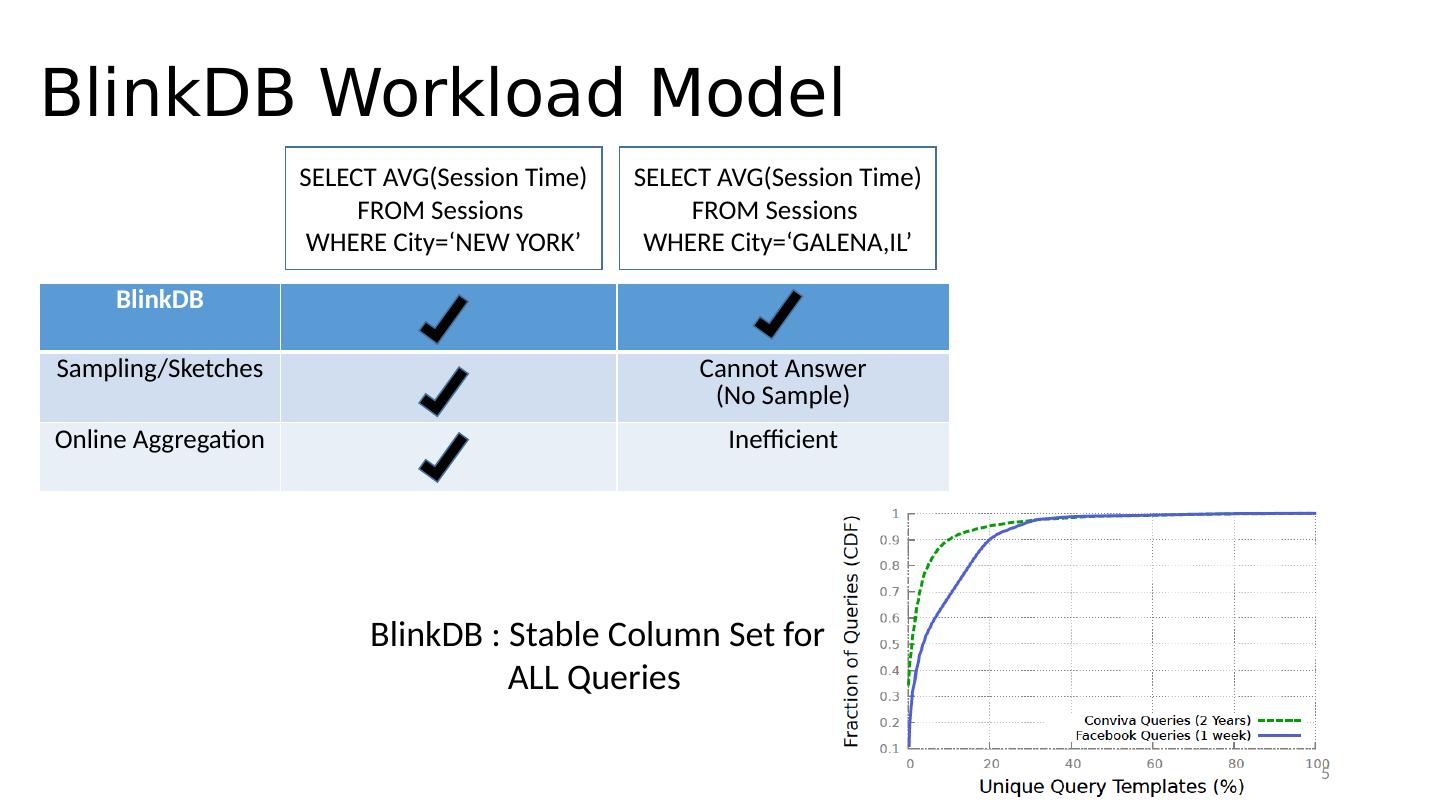
5 .BlinkDB Workload Model SELECT AVG(Session Time) FROM Sessions WHERE City=‘NEW YORK’ SELECT AVG(Session Time) FROM Sessions WHERE City=‘GALENA,IL’ BlinkDB Sampling/Sketches Cannot Answer (No Sample) Online Aggregation Inefficient BlinkDB : Stable Column Set for ALL Queries 5
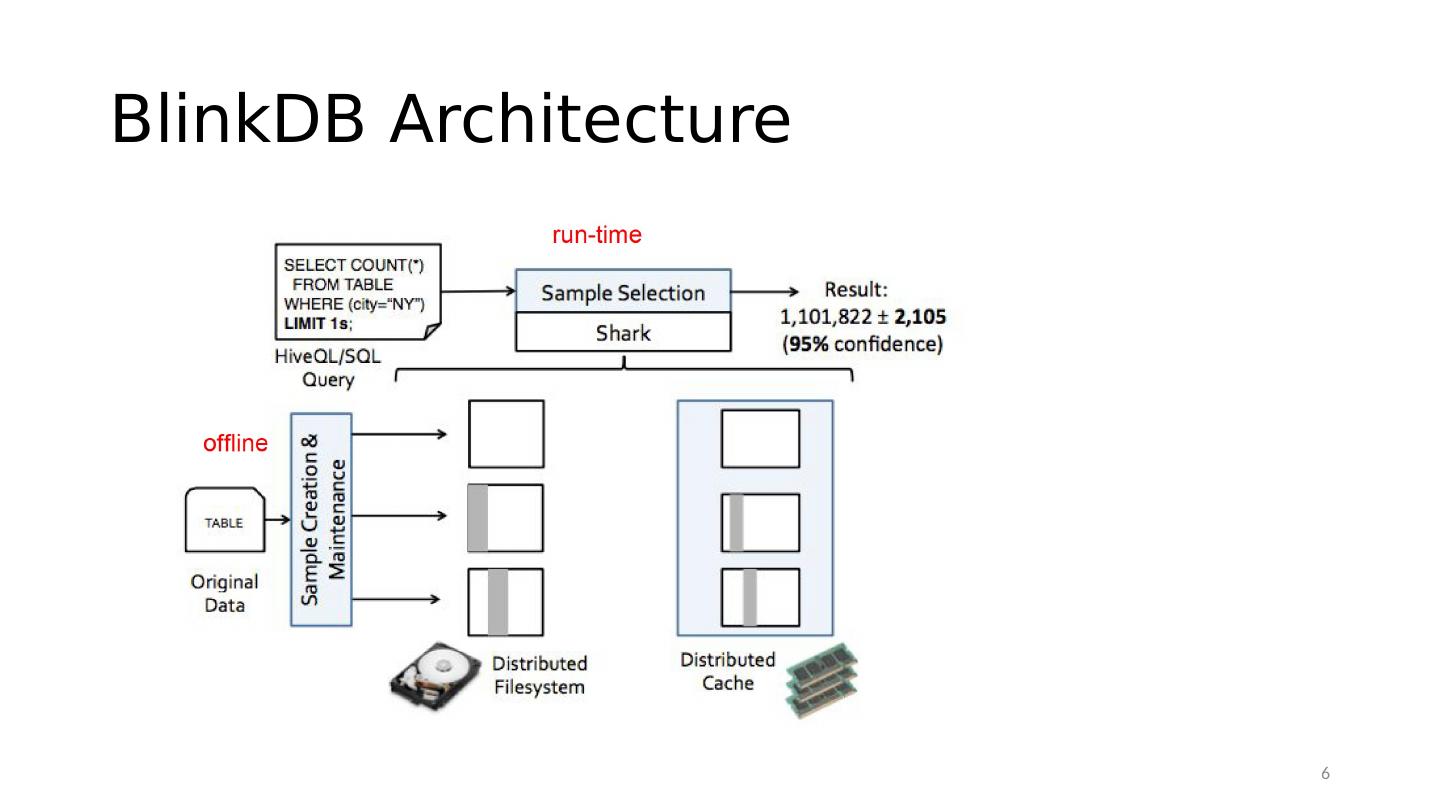
6 .BlinkDB Architecture 6
7 .BlinkDB Query Model SessionID Genre OS City URL Sessions : Constraint in respect of Error or Time 7
8 .Sample Creation Uniform vs Stratified Sampling Query Column Set(QCS) = [‘City’ ] UserID City Age SessionTime 1 New York 25 234 2 Galena,IL 34 432 3 New York 33 456 4 New York 32 574 Uniform Sampling = 1/2 UserID City Age Session Time 1 New York 25 234 3 New York 33 456 Galena,IL missed 8
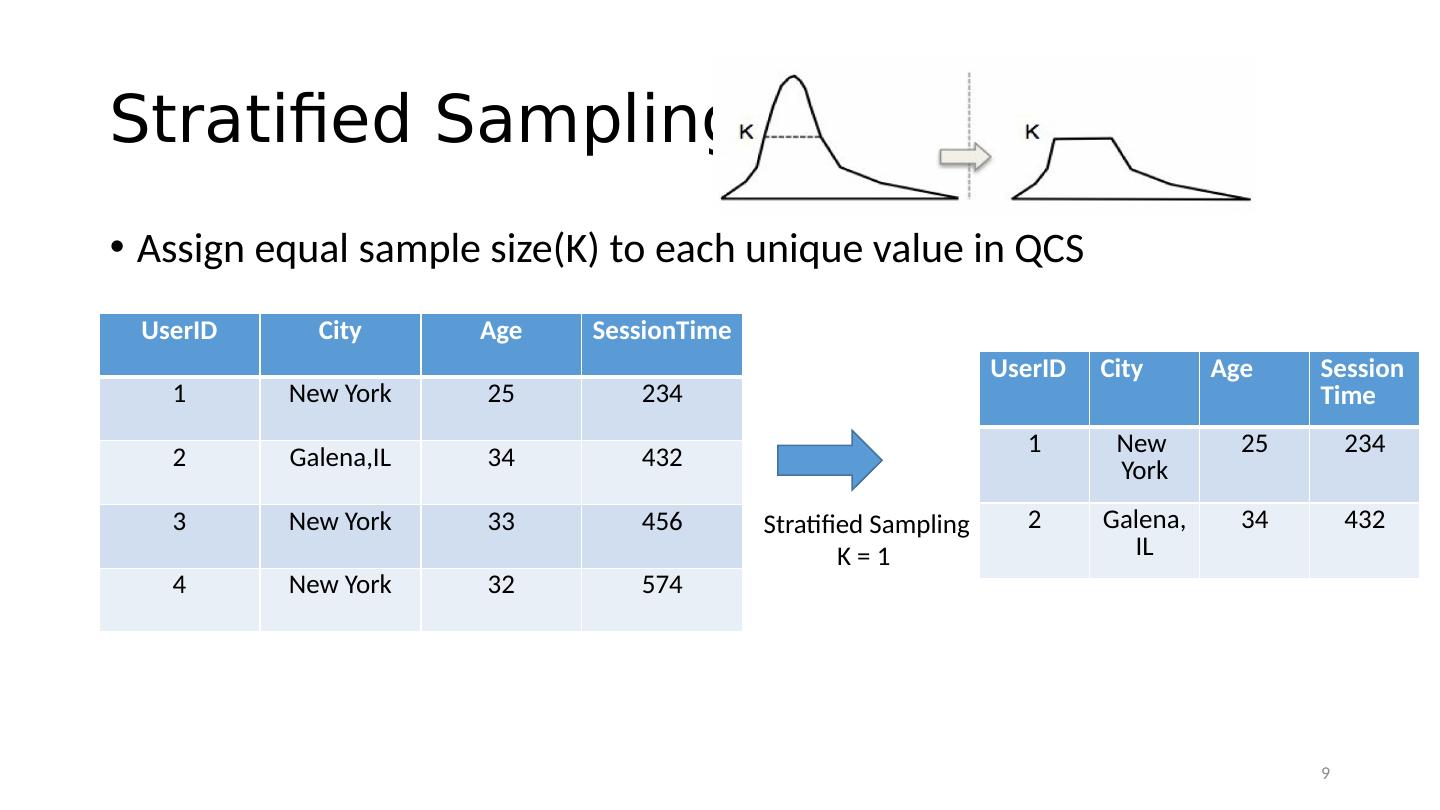
9 .Stratified Sampling Assign equal sample size(K) to each unique value in QCS UserID City Age SessionTime 1 New York 25 234 2 Galena,IL 34 432 3 New York 33 456 4 New York 32 574 Stratified Sampling K = 1 UserID City Age Session Time 1 New York 25 234 2 Galena, IL 34 432 9
10 .Stratified Sampling Strategies Multiple single dimensional samples Too many samples. Inefficiently answer queries with multiple columns Single multi-dimensional sample Too many unique values Storage overhead huge BlinkDB : several multi-dimensional samples [City], [Age], [City,Age], [City,SessionTime] … . many possibilities N Columns -> 2^N possible stratified samples Optimize subset selection 10
11 .Optimization Factors Sparsity : Select column subset that has many rare tuples. Otherwise, Uniform better COUNT( Distinct_Value ) WHERE Freq( Distinct_Value ) <= Threshold Workload : Choose Column subset that occurs more in past query Normalized (Query Count containing target subset) Storage Cost : Restrict total size of all samples to some constraint, C 11
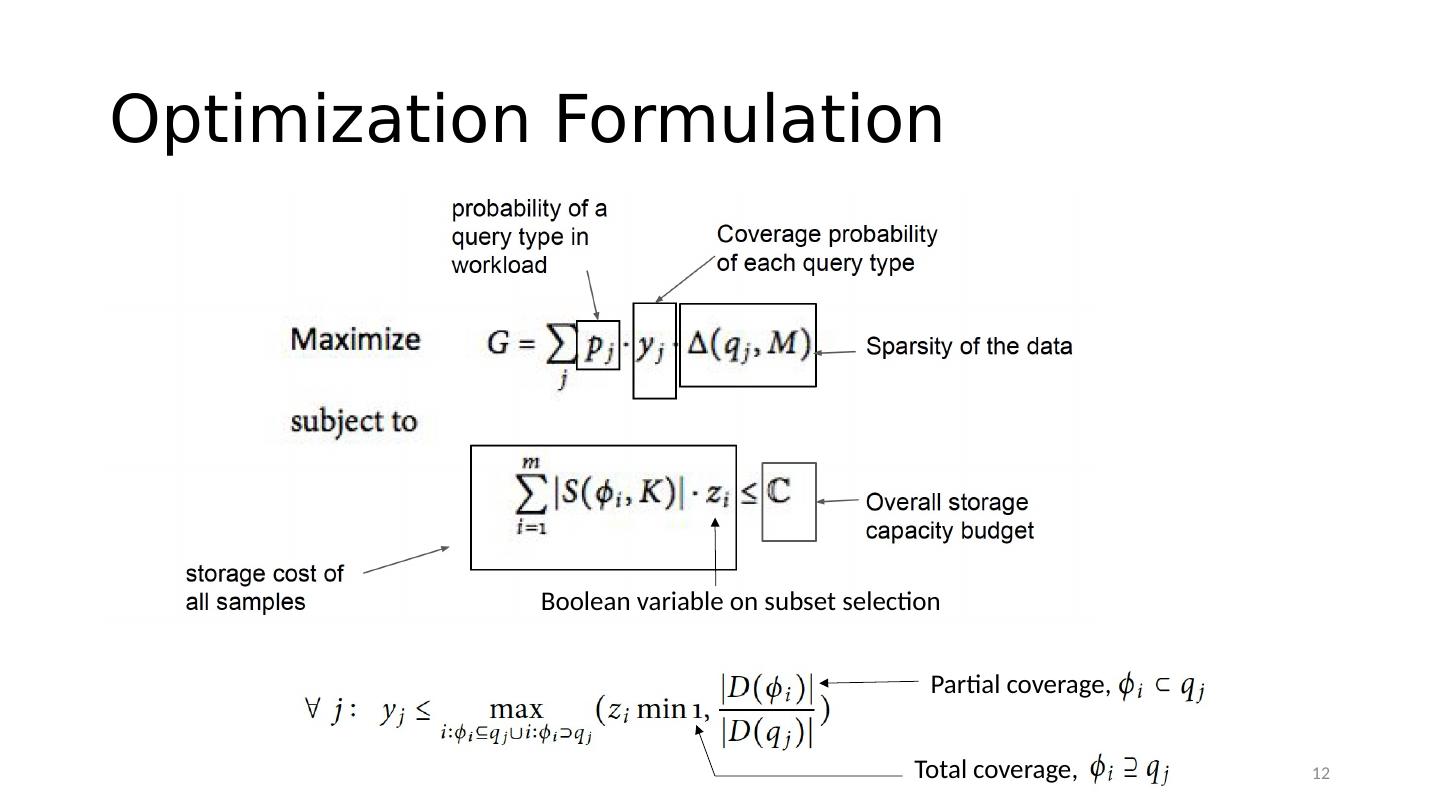
12 .Optimization Formulation Boolean variable on subset selection Partial coverage, Total coverage, 12
13 .Sample Selection Select best sample that satisfies error/time constraints Select best fitted sample 1. Sample with smallest column superset of current query [Full Coverage] 2. Sample with column subset of current query and Highly selective [Partial Coverage] Selectivity = ( Number of rows selected by Q ) / (Number of rows in sample) 13
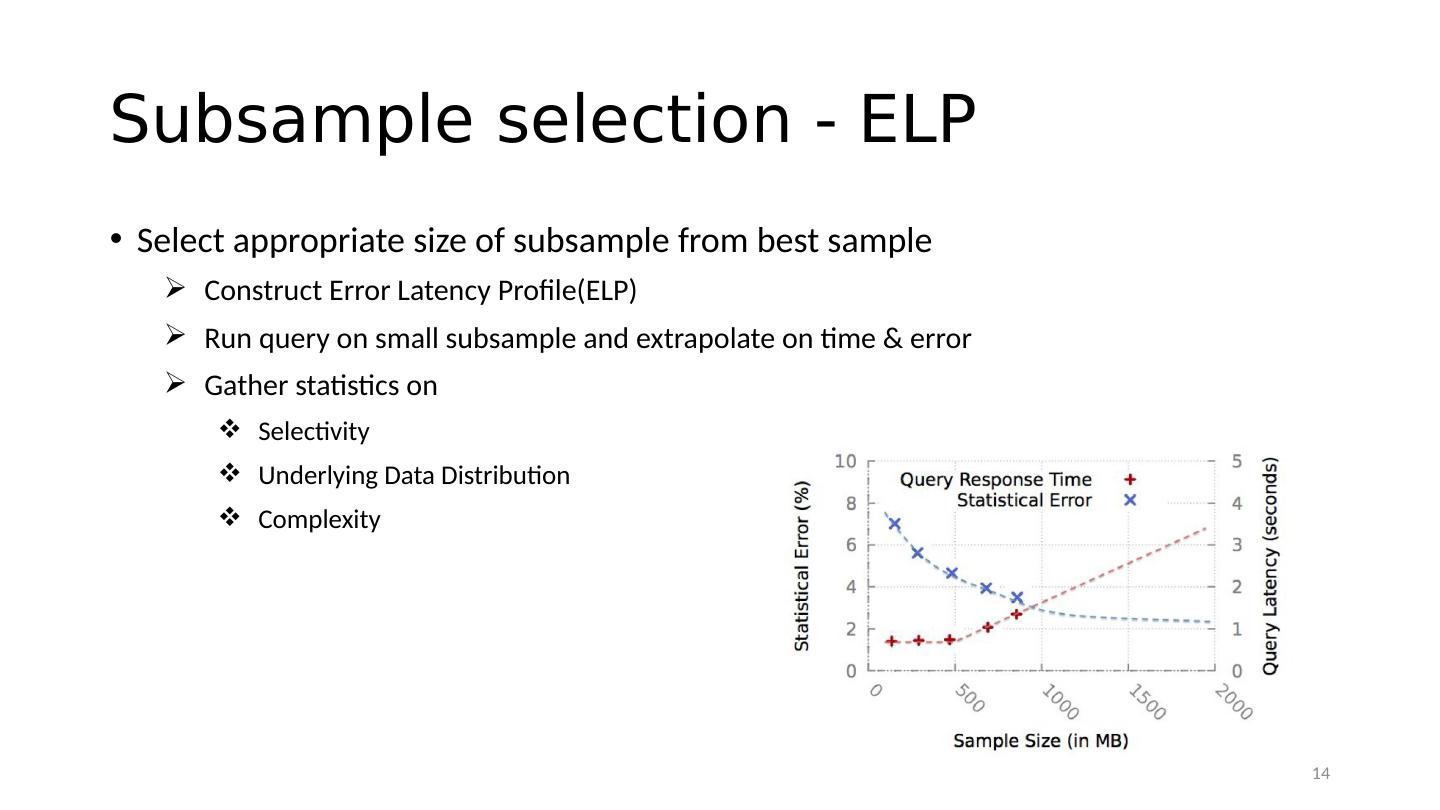
14 .Subsample selection - ELP Select appropriate size of subsample from best sample Construct Error Latency Profile(ELP ) Run query on small subsample and extrapolate on time & error Gather statistics on Selectivity Underlying Data Distribution Complexity 14
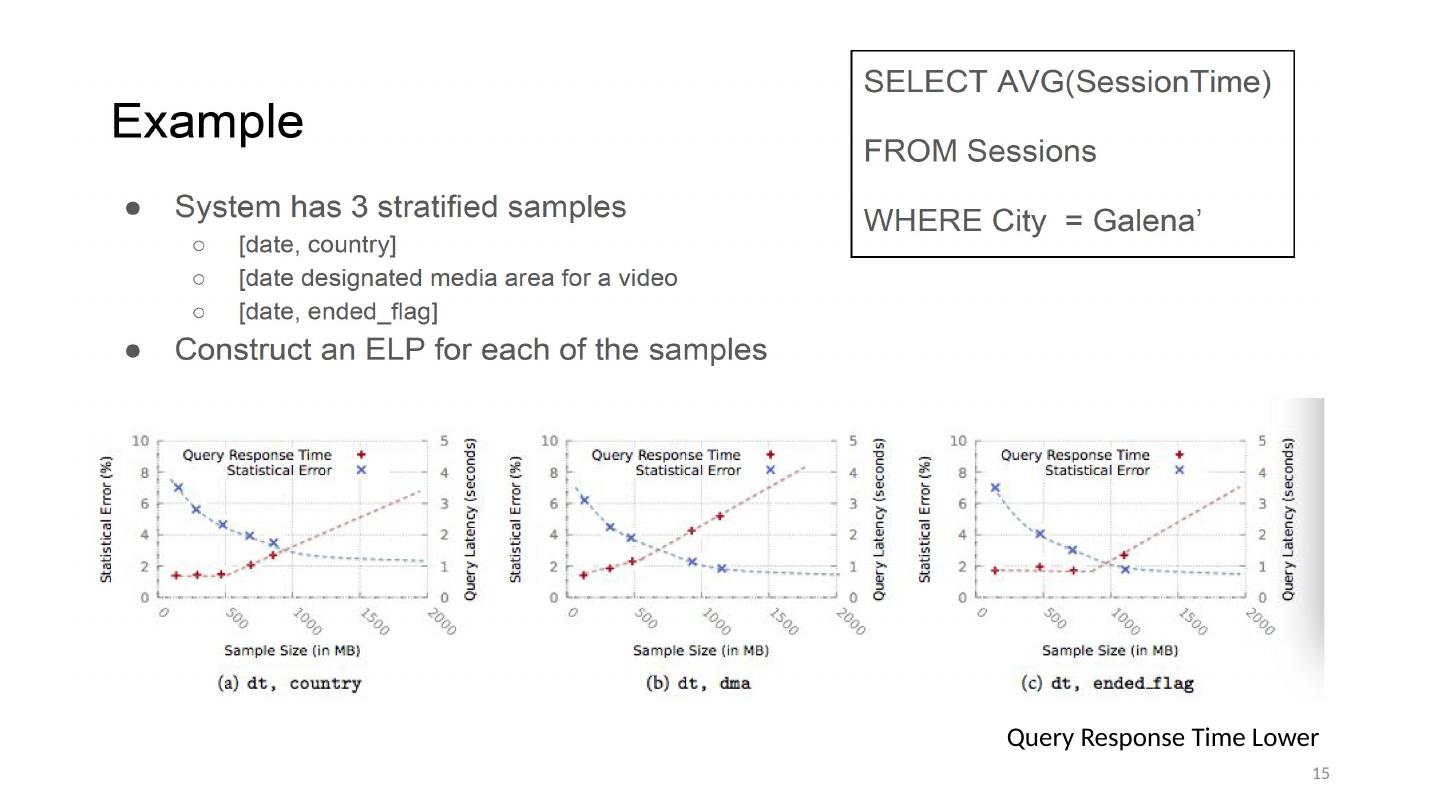
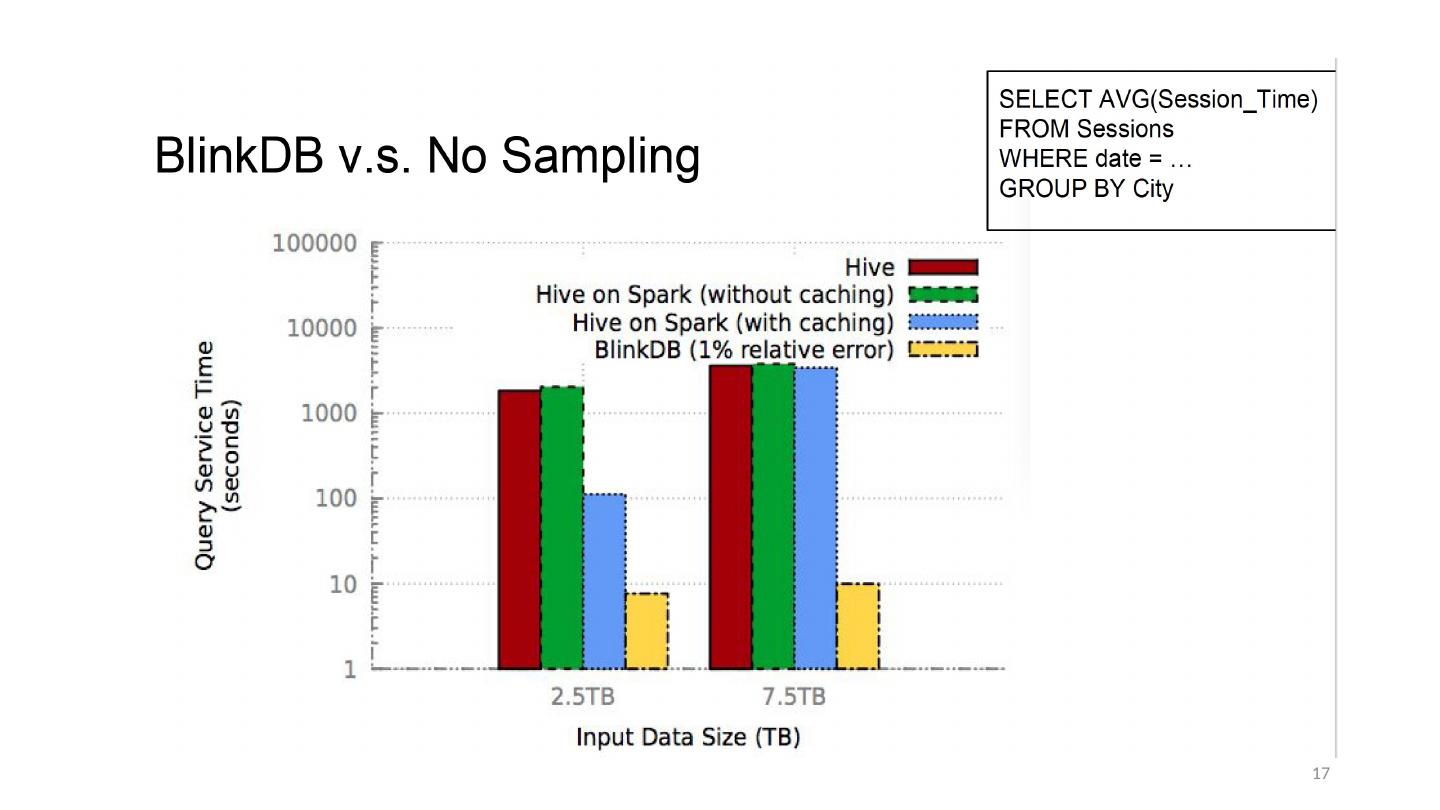
15 .Query Response Time Lower 15
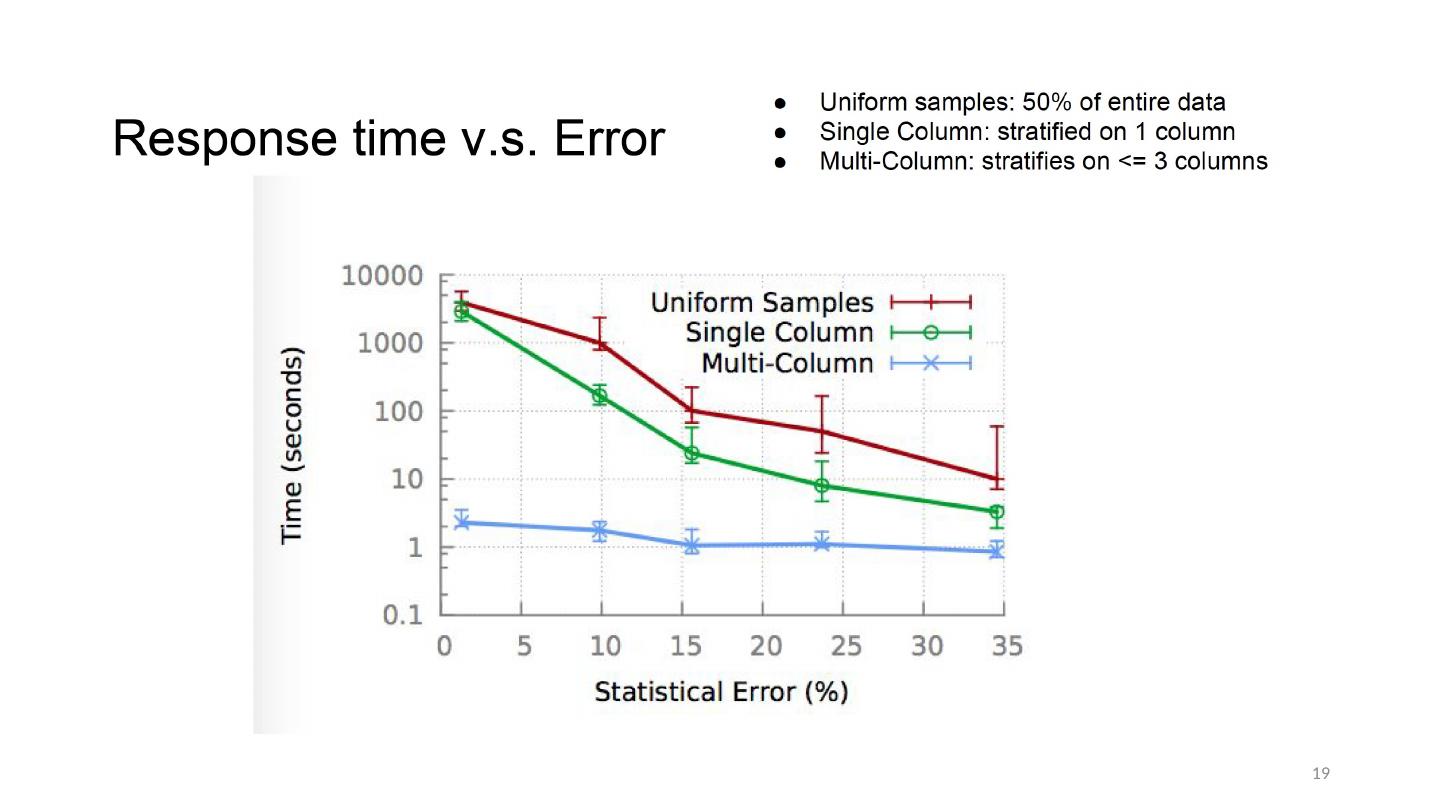
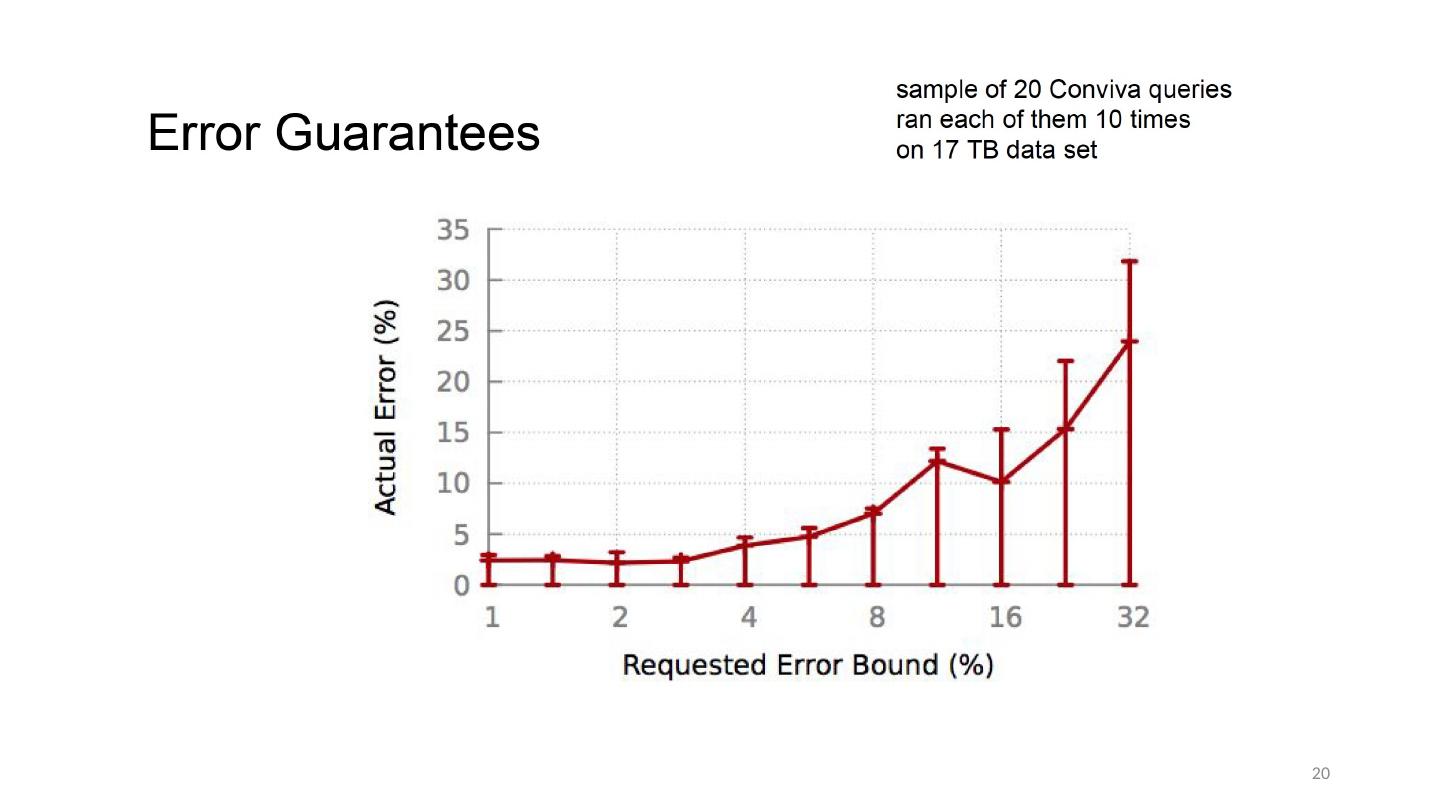
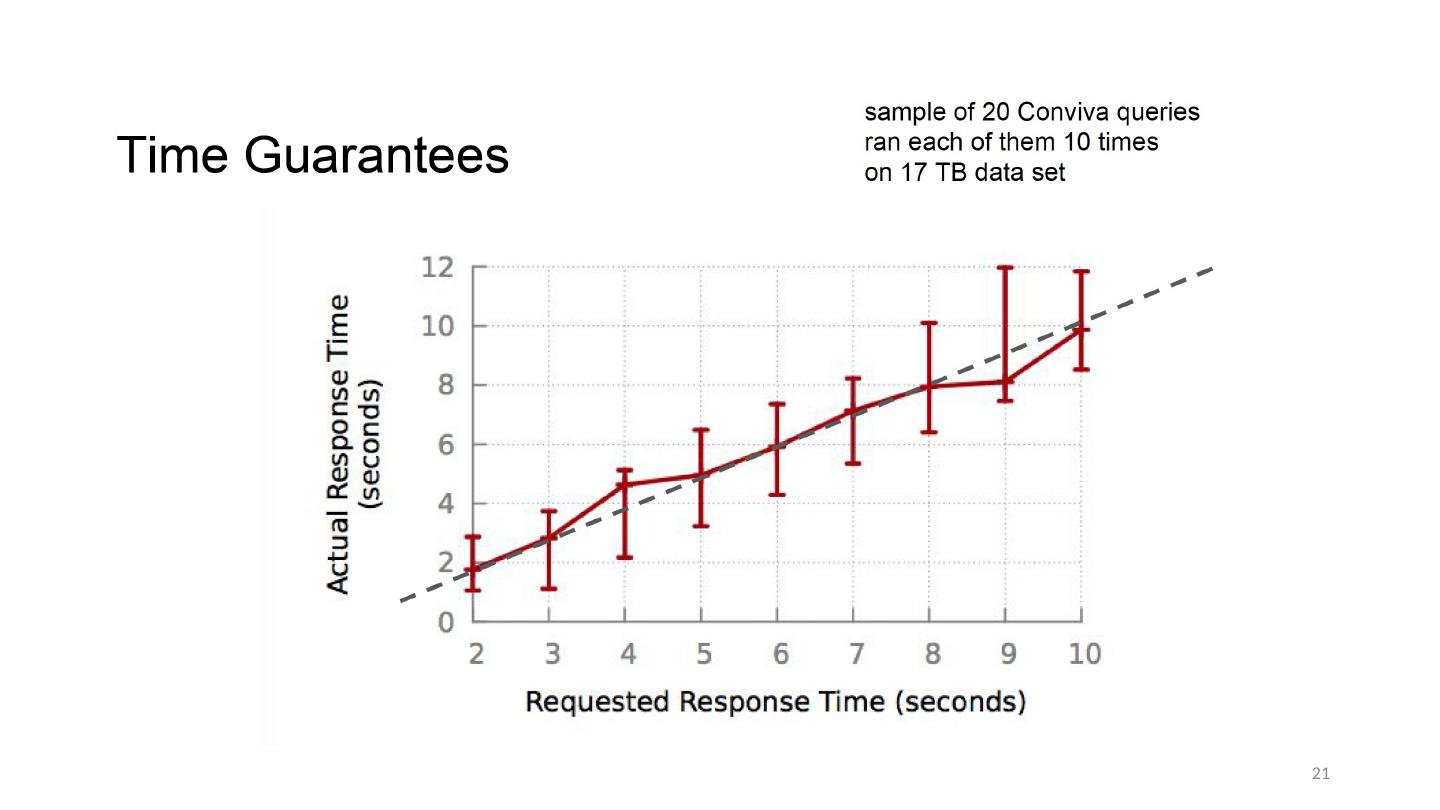
18 .Error Properties with Different Samples All samples of same size Queries run for max 10s BlinkDB samples on QCS1, QCS2 18