



































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
A Deep Dive into Structured Streaming
分享
点赞
0
收藏
0
From Spark PMC
展开查看详情
1 .A Deep Dive into Structured Streaming 范文臣
2 .Complexities in stream processing COMPLEX DATA COMPLEX WORKLOADS COMPLEX SYSTEMS Diverse data formats Combining streaming with Diverse storage systems (json, avro, binary, …) interactive queries (Kafka, S3, Kinesis, RDBMS, …) Data can be dirty, Machine learning System failures late, out-of-order
3 . building robust stream processing apps is hard
4 . Structured Streaming stream processing on Spark SQL engine fast, scalable, fault-tolerant rich, unified, high level APIs deal with complex data and complex workloads rich ecosystem of data sources integrate with many storage systems
5 . you should not have to reason about streaming
6 . you should write simple queries & Spark should continuously update the answer
7 .Structured Streaming Model
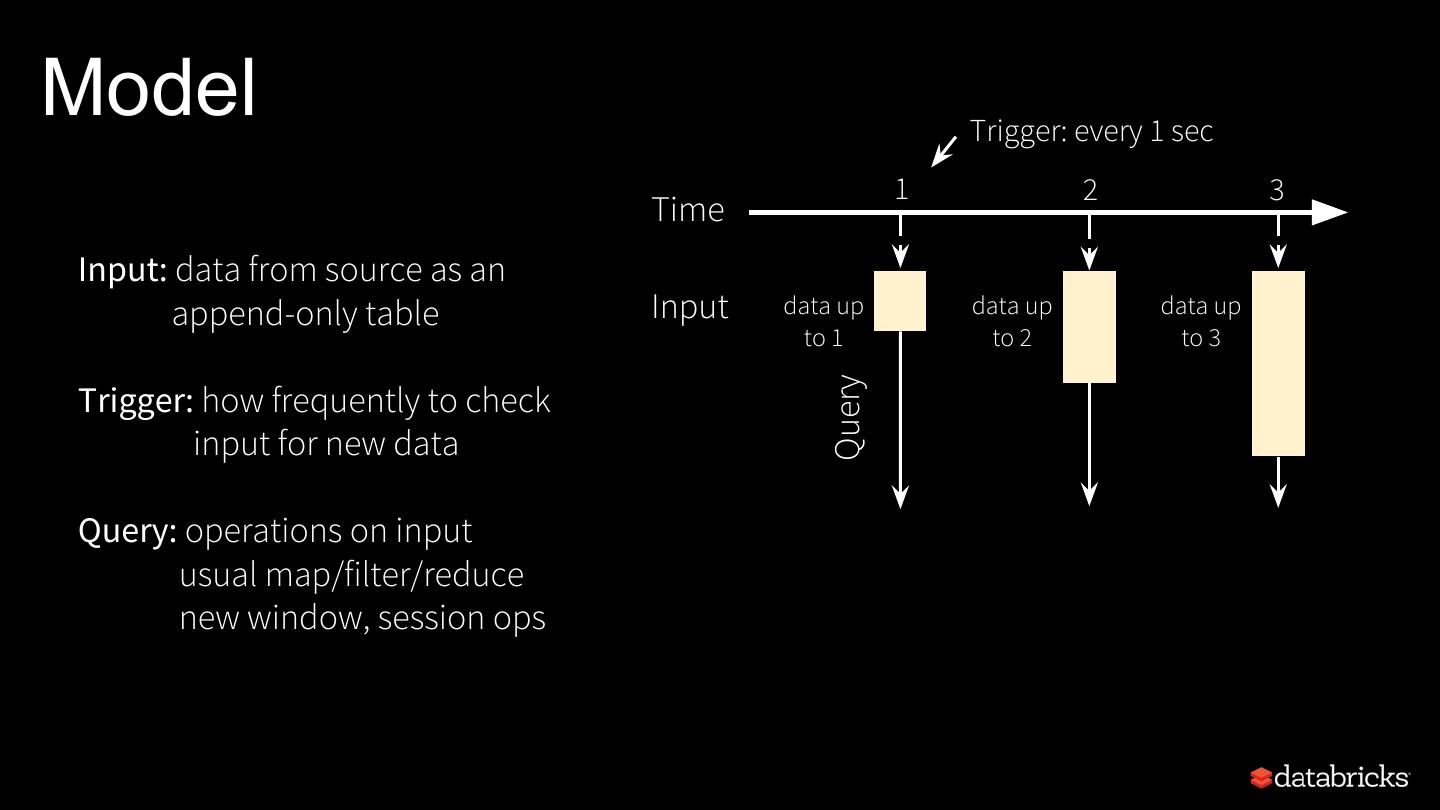
8 .Model Trigger: every 1 sec 1 2 3 Time Input: data from source as an append-only table Input data up data up data up to 1 to 2 to 3 Query Trigger: how frequently to check input for new data Query: operations on input usual map/filter/reduce new window, session ops
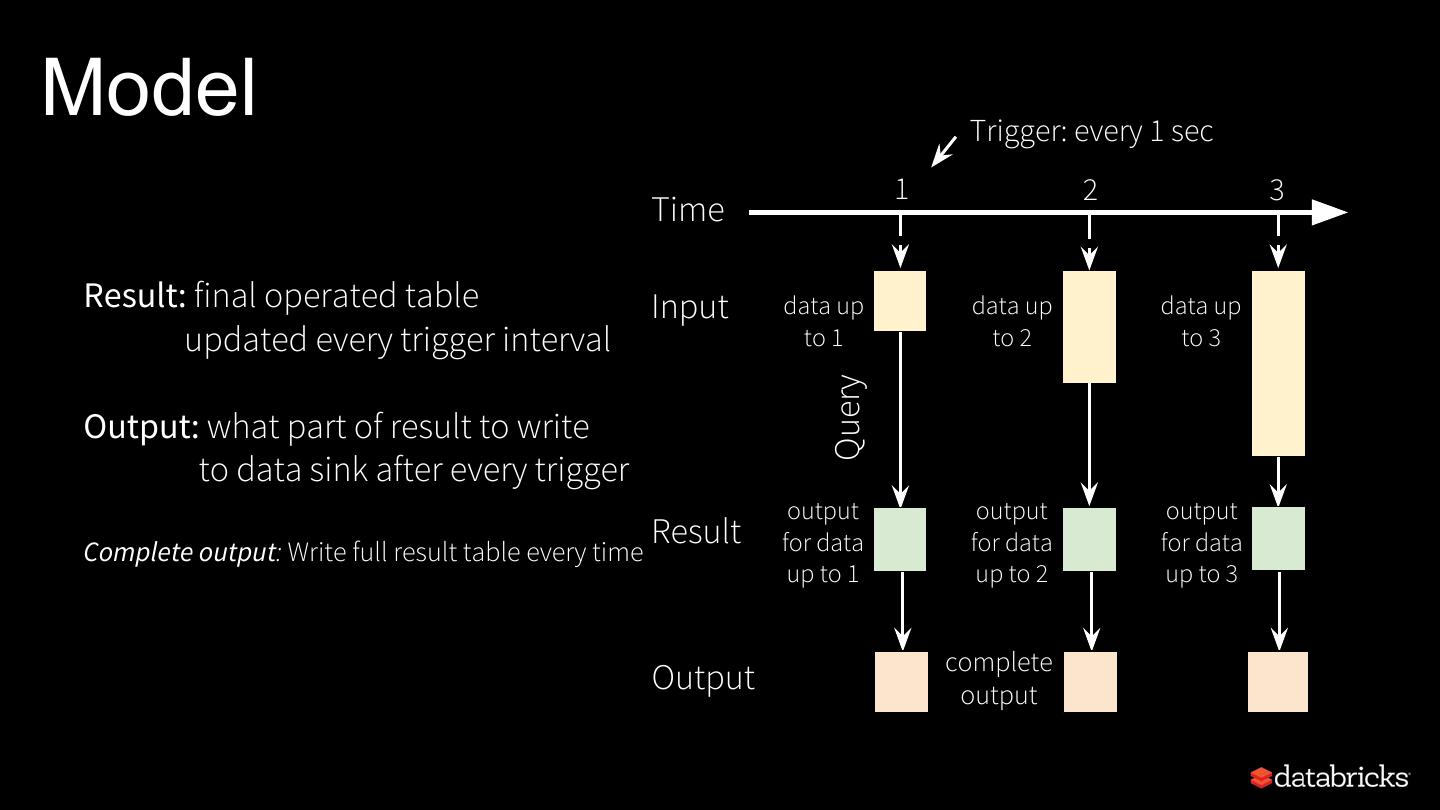
9 .Model Trigger: every 1 sec 1 2 3 Time Result: final operated table Input data up data up data up updated every trigger interval to 1 to 2 to 3 Query Output: what part of result to write to data sink after every trigger output output output Complete output: Write full result table every time Result for data for data for data up to 1 up to 2 up to 3 complete Output output
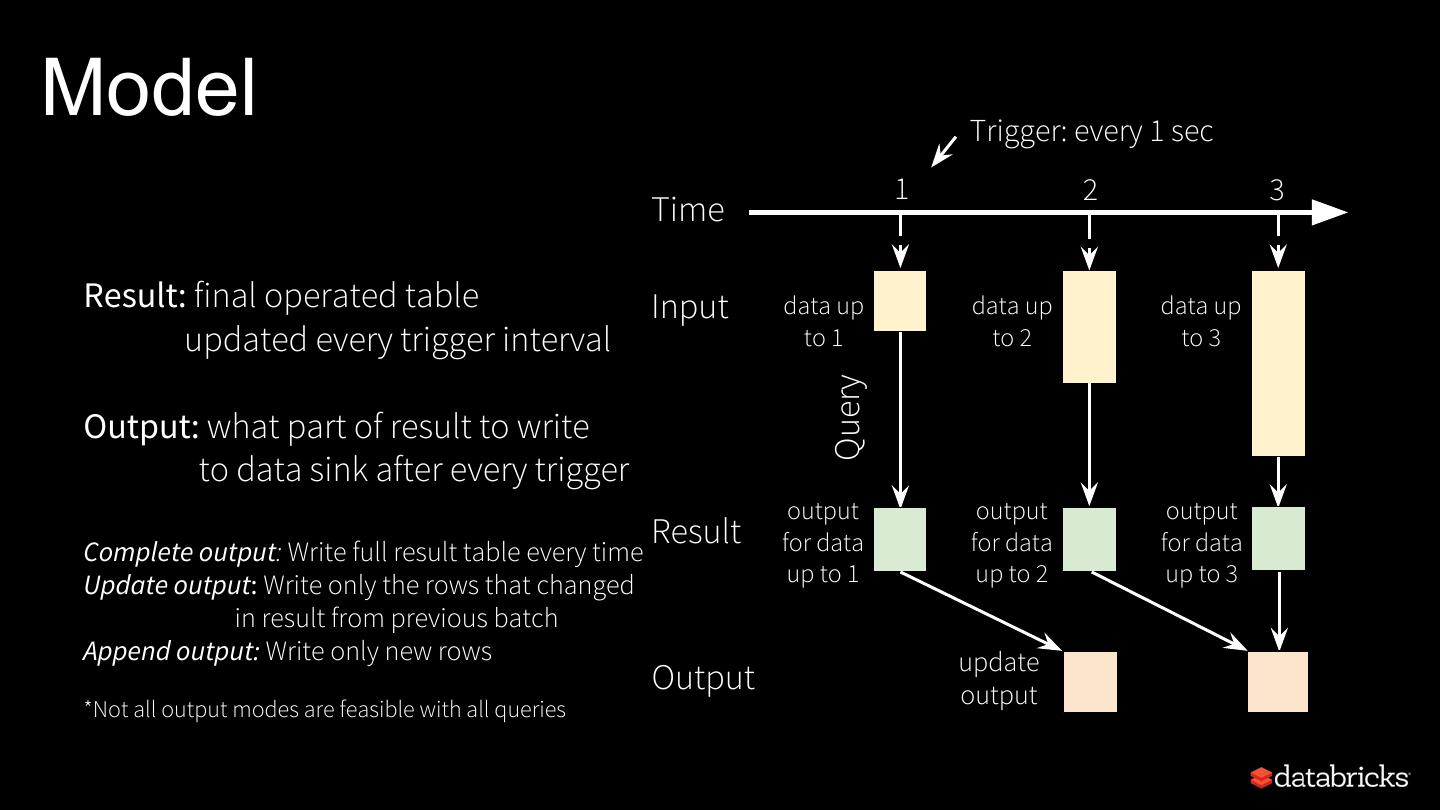
10 .Model Trigger: every 1 sec 1 2 3 Time Result: final operated table Input data up data up data up updated every trigger interval to 1 to 2 to 3 Query Output: what part of result to write to data sink after every trigger output output output Complete output: Write full result table every time Result for data for data for data Update output: Write only the rows that changed up to 1 up to 2 up to 3 in result from previous batch Append output: Write only new rows update Output output *Not all output modes are feasible with all queries
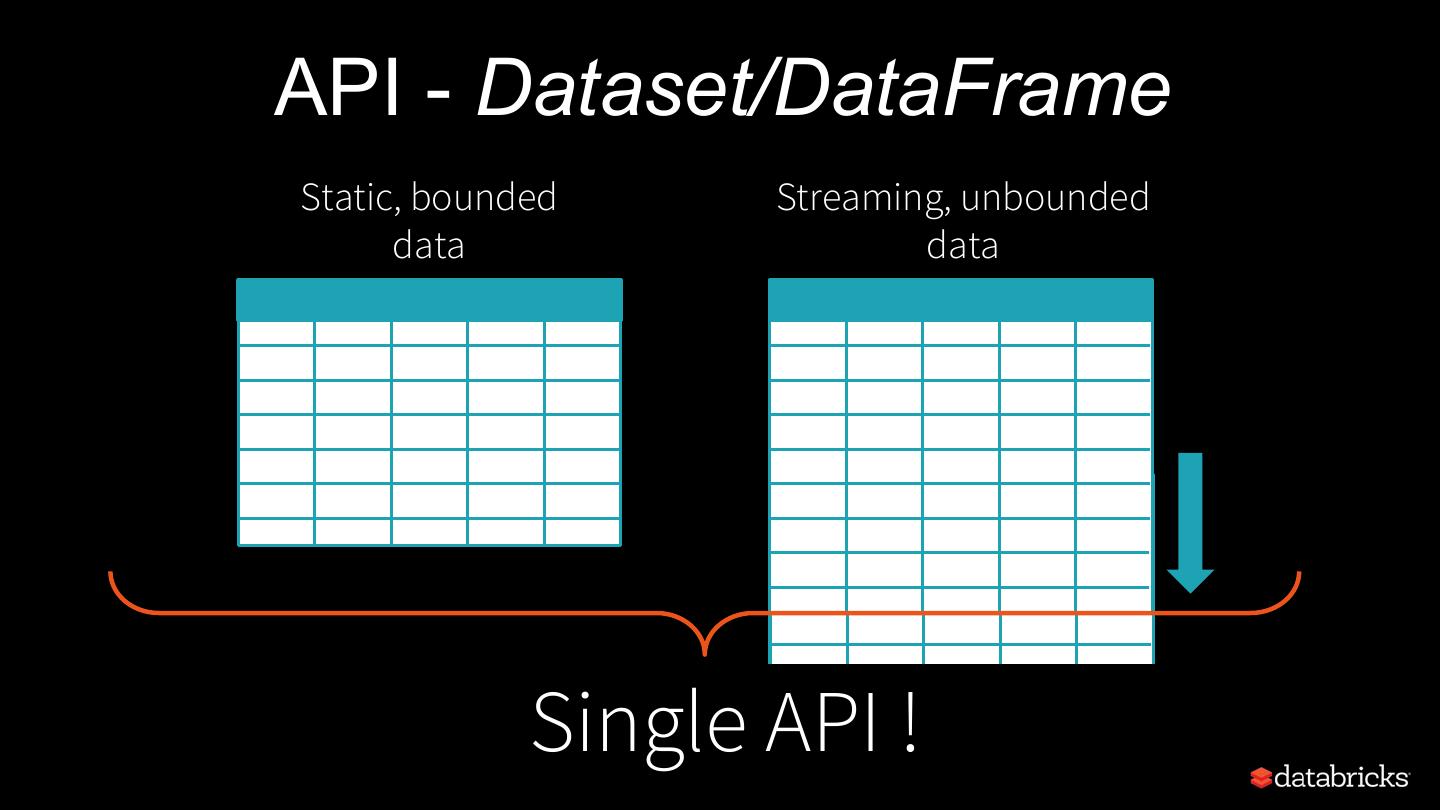
11 .API - Dataset/DataFrame Static, bounded Streaming, unbounded data data Single API !
12 .Streaming word count
13 .Anatomy of a Streaming Word Count spark.readStream .format("kafka") Source .option("subscribe", "input") .load() • Specify one or more locations .groupBy($"value".cast("string")) to read data from .count() .writeStream • Built in support for .format("kafka") .option("topic", "output") Files/Kafka/Socket, .trigger("1 minute") pluggable. .outputMode(OutputMode.Complete()) .option("checkpointLocation", "…") • Can include multiple sources .start() of different types using union()
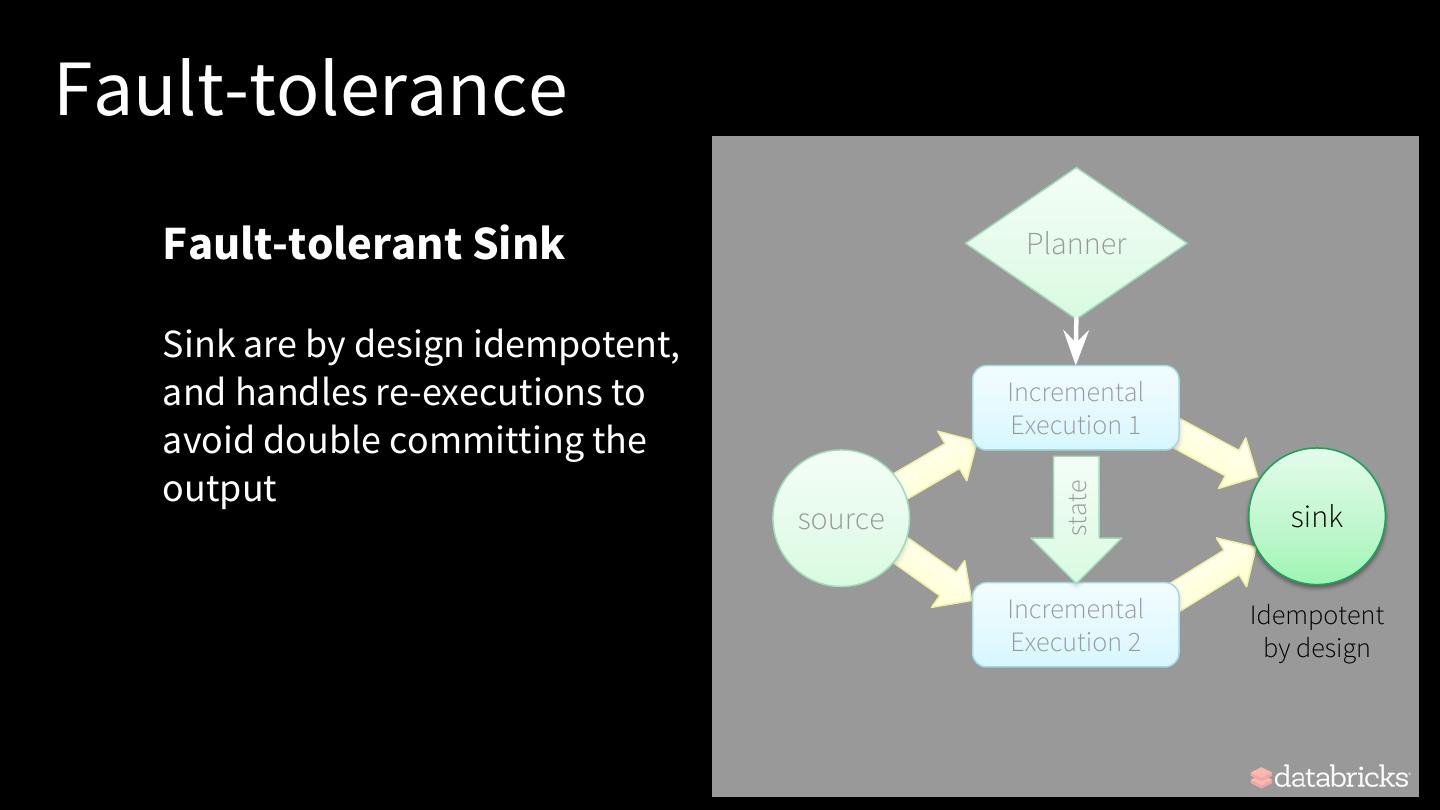
14 .Anatomy of a Streaming Query spark.readStream .format("kafka") Transformation .option("subscribe", "input") .load() • Using DataFrames, .groupBy('value.cast("string") as 'key) .agg(count("*") as 'value) Datasets and/or SQL. .writeStream .format("kafka") • Catalyst figures out how to .option("topic", "output") execute the transformation .trigger("1 minute") .outputMode(OutputMode.Complete()) incrementally. .option("checkpointLocation", "…") .start() • Internal processing always exactly-once.
15 .Anatomy of a Streaming Query spark.readStream .format("kafka") Sink .option("subscribe", "input") .load() • Accepts the output of each .groupBy('value.cast("string") as 'key) .agg(count("*") as 'value) batch. .writeStream .format("kafka") • When supported sinks are .option("topic", "output") transactional and exactly .trigger("1 minute") .outputMode(OutputMode.Complete()) once (Files). .option("checkpointLocation", "…") .start() • Use foreach to execute arbitrary code.
16 .Anatomy of a Streaming Query spark.readStream .format("kafka") Output mode – What's output .option("subscribe", "input") .load() • Complete – Output the whole answer .groupBy('value.cast("string") as 'key) every time .agg(count("*") as 'value) .writeStream • Update – Output changed rows .format("kafka") • Append – Output new rows only .option("topic", "output") .trigger("1 minute") .outputMode("append") Trigger – When to output .option("checkpointLocation", "…") • Specified as a time, eventually .start() supports data size • No trigger means as fast as possible
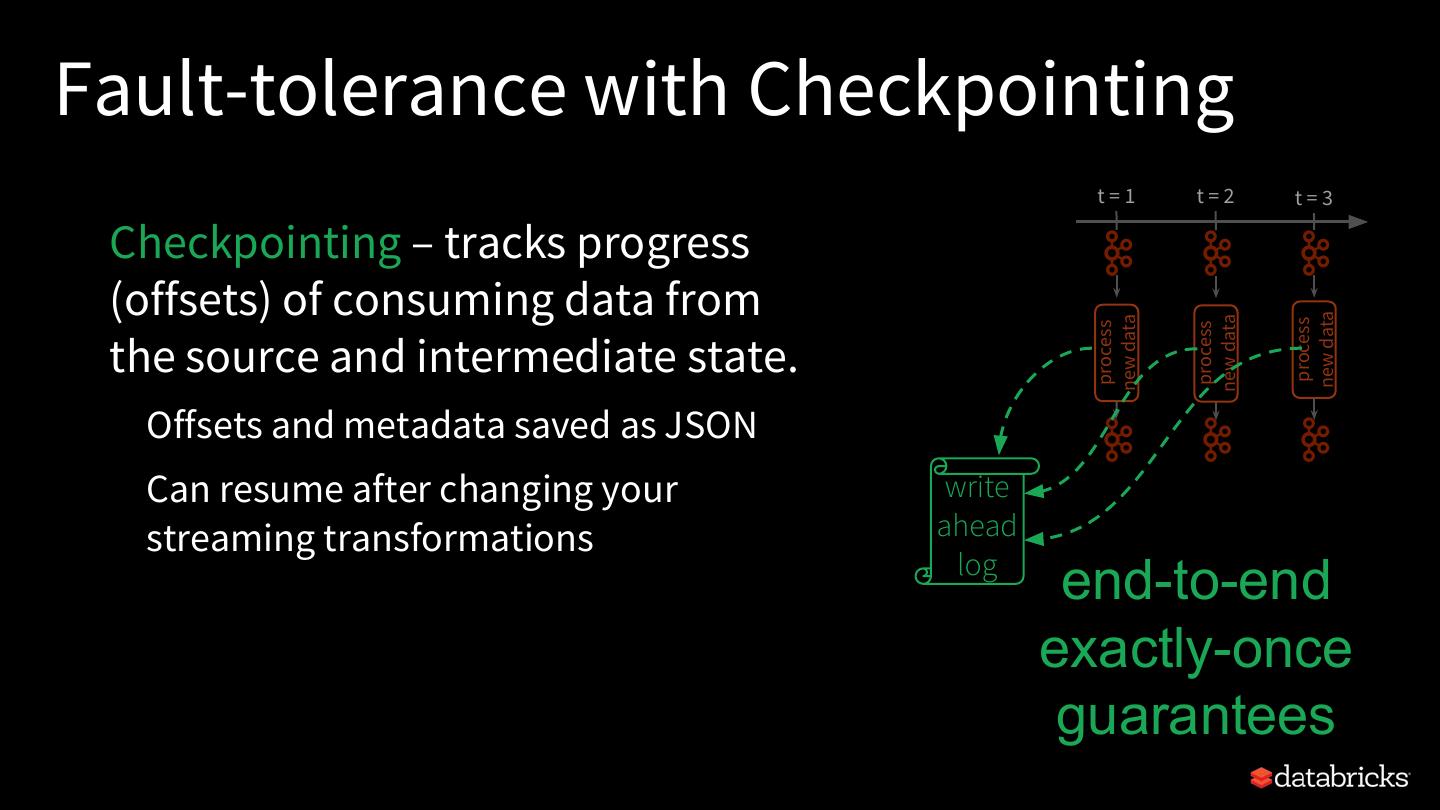
17 .Anatomy of a Streaming Query spark.readStream .format("kafka") Checkpoint .option("subscribe", "input") .load() • Tracks the progress of a .groupBy('value.cast("string") as 'key) .agg(count("*") as 'value) query in persistent storage .writeStream .format("kafka") • Can be used to restart the .option("topic", "output") query if there is a failure .trigger("1 minute") .outputMode("append") .option("checkpointLocation", "…") .start()
18 .Fault-tolerance with Checkpointing t=1 t=2 t=3 Checkpointing – tracks progress (offsets) of consuming data from new data new data new data process process process the source and intermediate state. Offsets and metadata saved as JSON Can resume after changing your write streaming transformations ahead log end-to-end exactly-once guarantees
19 .Underneath the Hood
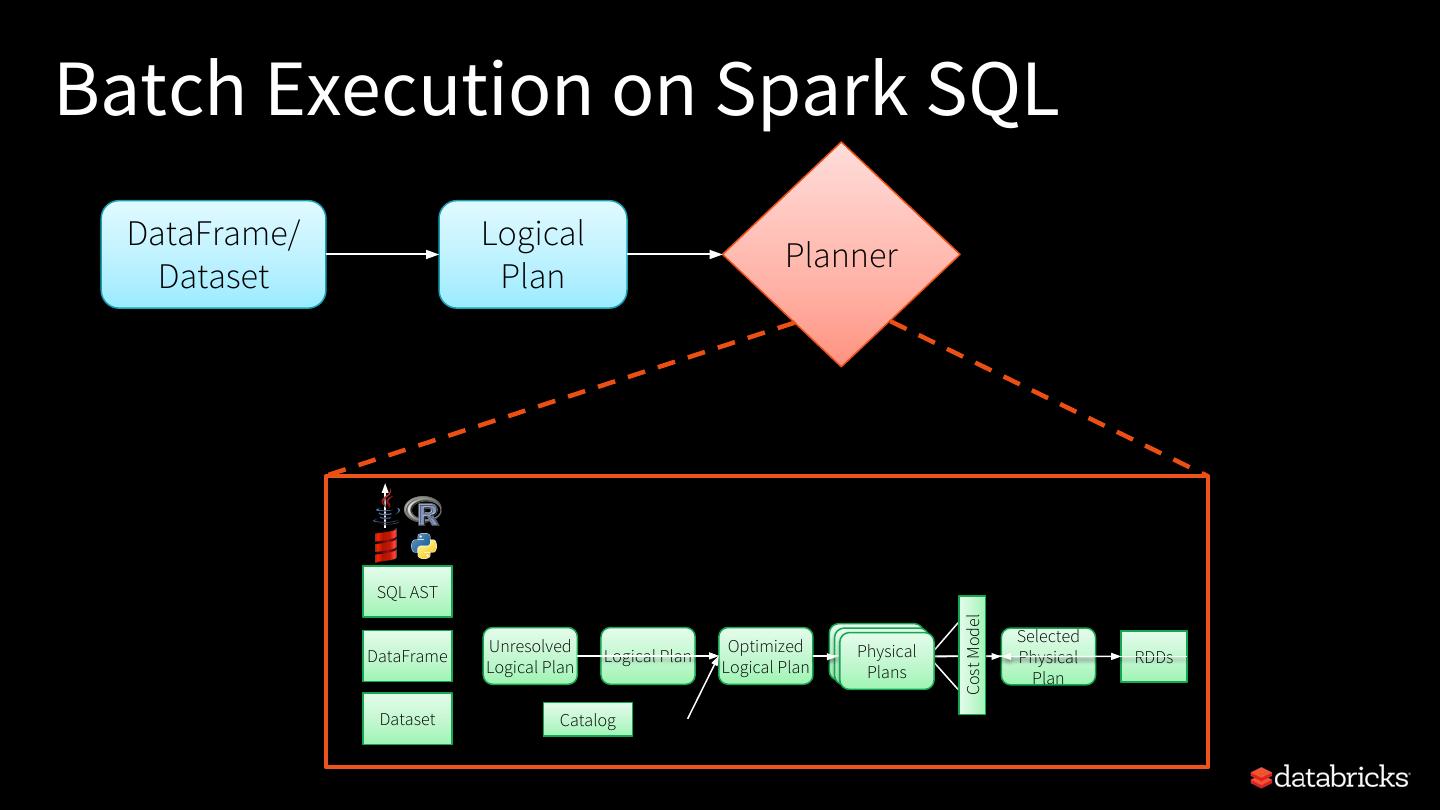
20 .Batch Execution on Spark SQL DataFrame/ Logical Dataset Plan Abstract representation of query
21 .Batch Execution on Spark SQL DataFrame/ Logical Planner Dataset Plan SQL AST Logical Physical Code Analysis Optimization Planning Generation Cost Model Selected Unresolved Optimized Physical DataFrame Logical Plan Physical RDDs Logical Plan Logical Plan Plans Plan Dataset Catalog
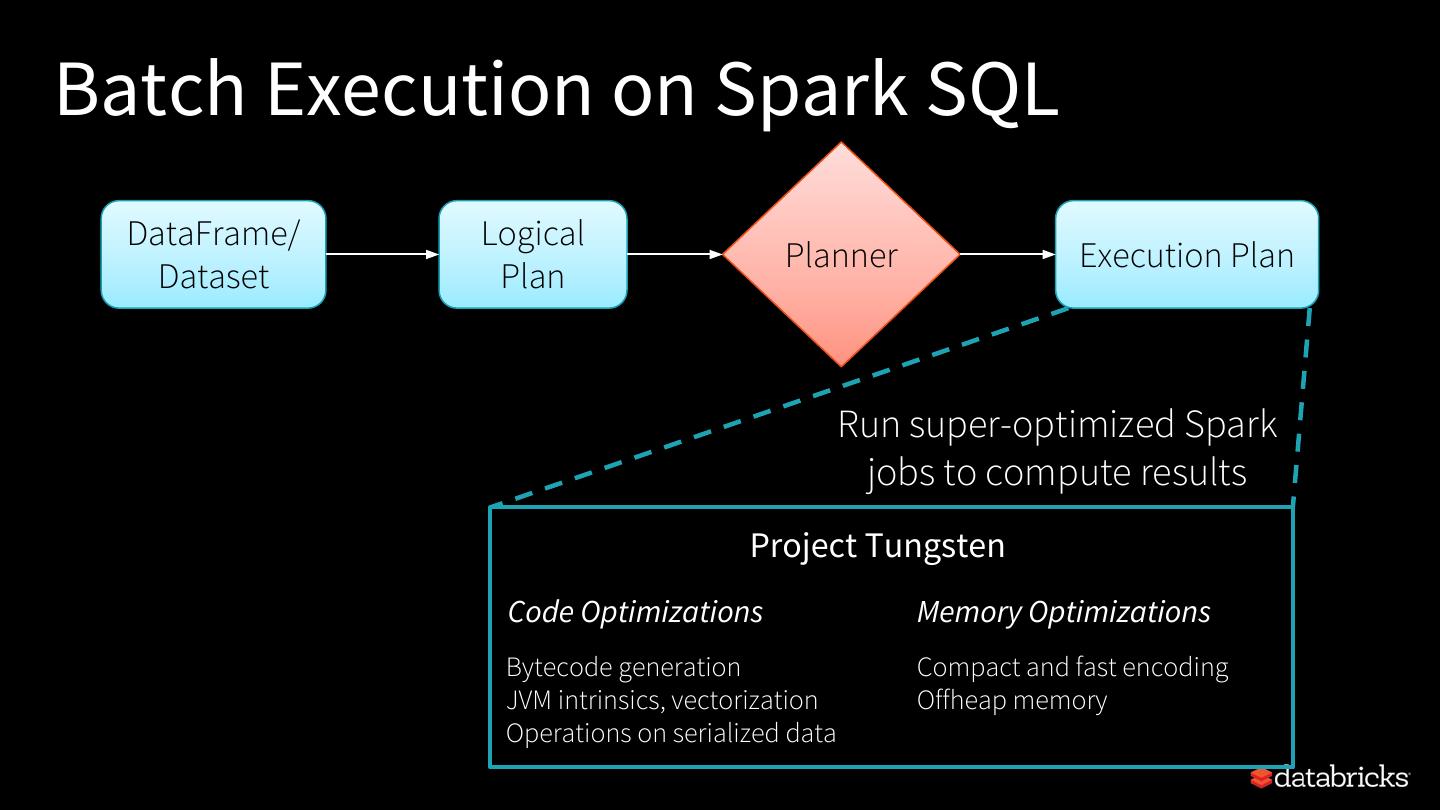
22 .Batch Execution on Spark SQL DataFrame/ Logical Planner Execution Plan Dataset Plan Run super-optimized Spark jobs to compute results Project Tungsten Code Optimizations Memory Optimizations Bytecode generation Compact and fast encoding JVM intrinsics, vectorization Offheap memory Operations on serialized data
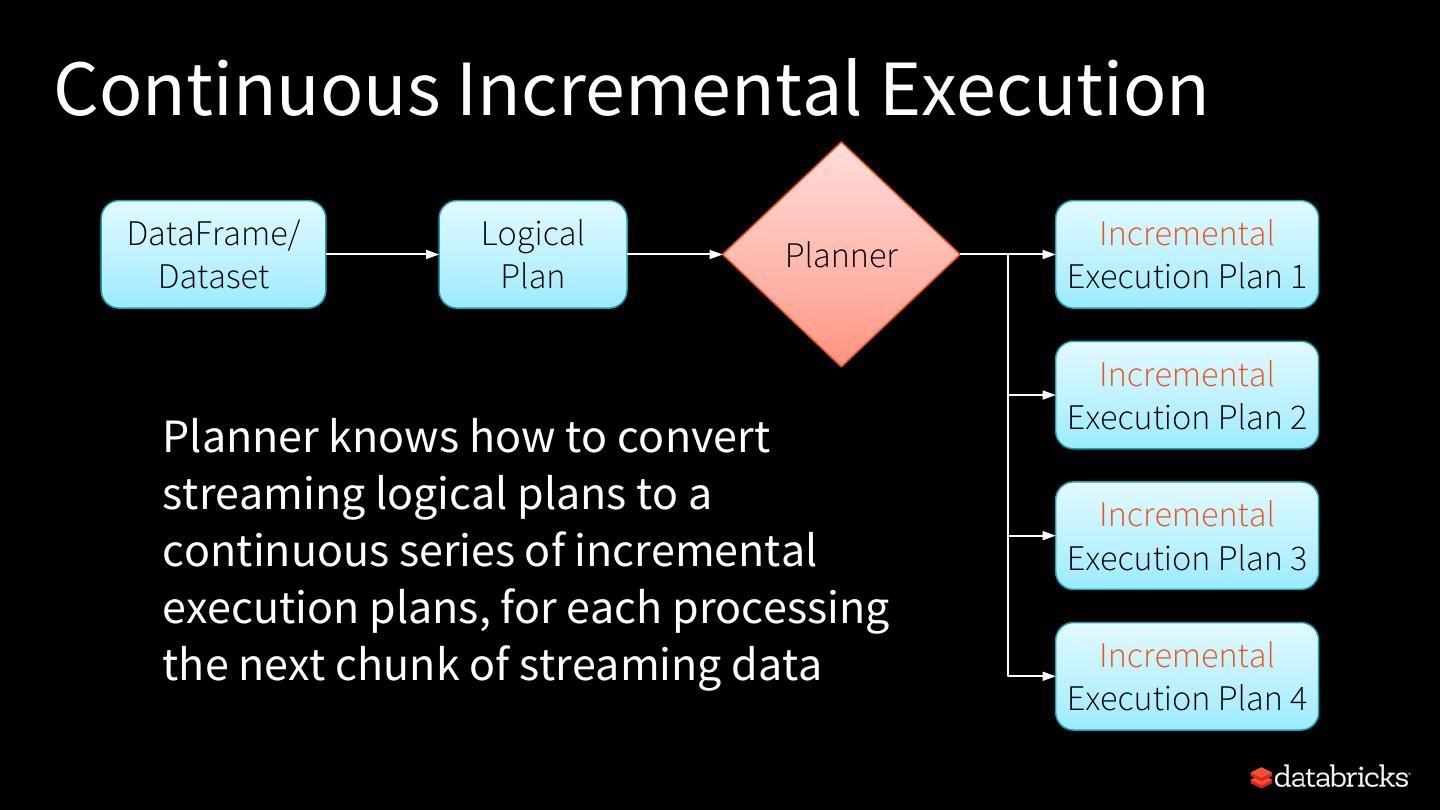
23 .Continuous Incremental Execution DataFrame/ Logical Incremental Planner Dataset Plan Execution Plan 1 Incremental Execution Plan 2 Planner knows how to convert streaming logical plans to a Incremental continuous series of incremental Execution Plan 3 execution plans, for each processing the next chunk of streaming data Incremental Execution Plan 4
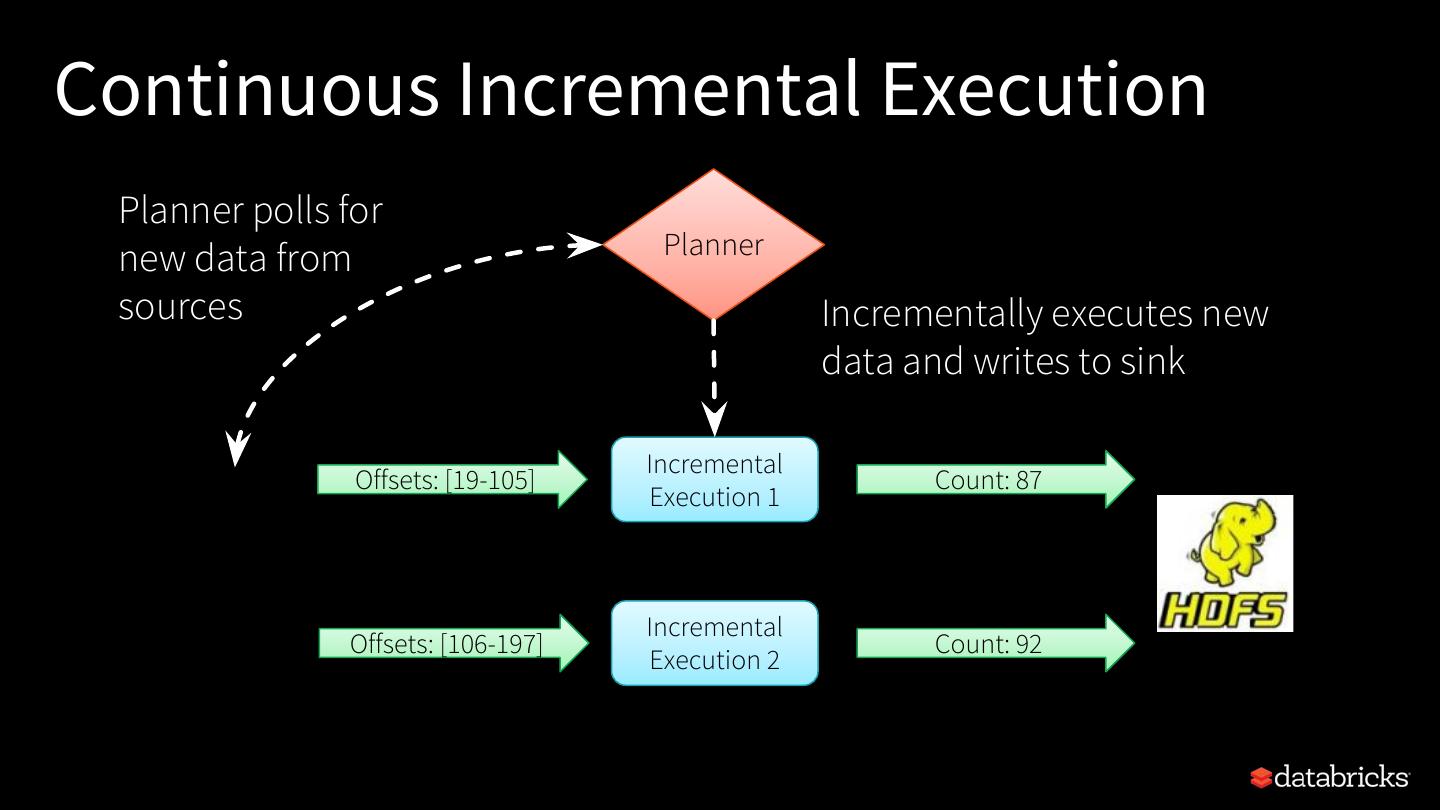
24 .Continuous Incremental Execution Planner polls for new data from Planner sources Incrementally executes new data and writes to sink Incremental Offsets: [19-105] Count: 87 Execution 1 Incremental Offsets: [106-197] Count: 92 Execution 2
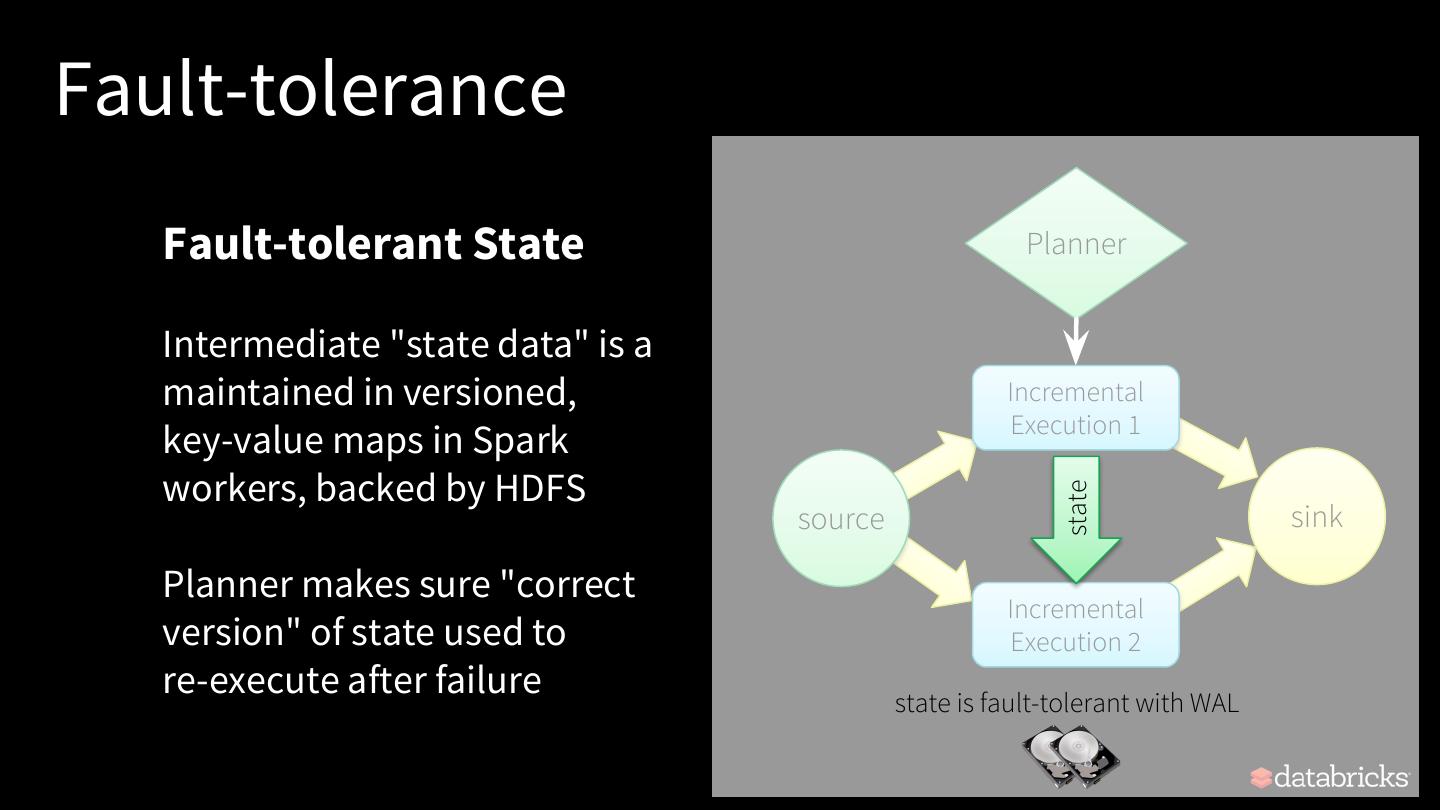
25 .Continuous Aggregations Maintain running aggregate as in-memory state backed by WAL in file system for fault-tolerance Incremental Offsets: [19-105] Running Count: 87 Execution 1 sta te: 87 Incremental Offsets: [106-179] Count: 87+92 = 179 memory 2 Execution sta te: state data generated and used 17 across incremental executions 9
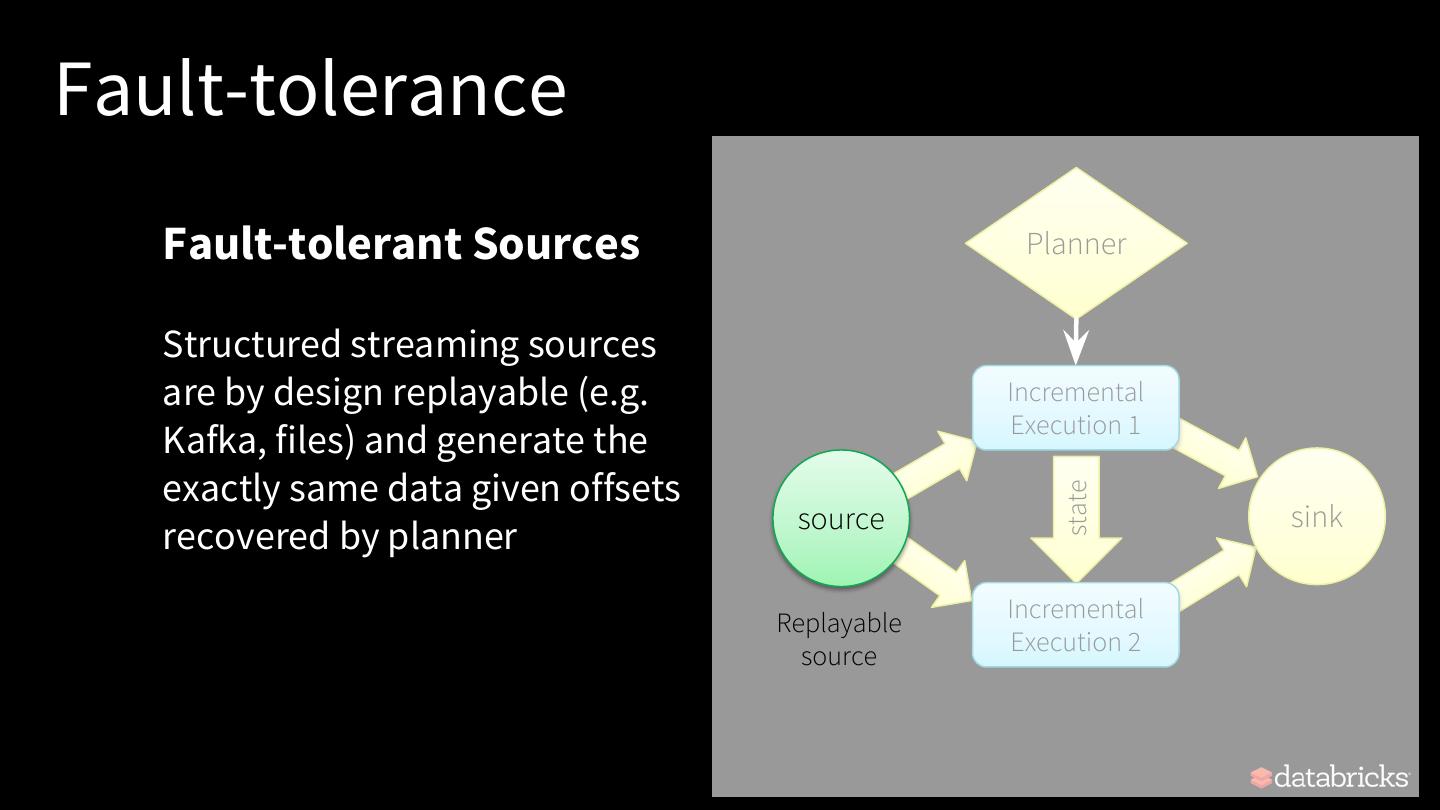
26 .Fault-tolerance Planner All data and metadata in Incremental the system needs to be Execution 1 recoverable / replayable state source sink Incremental Execution 2
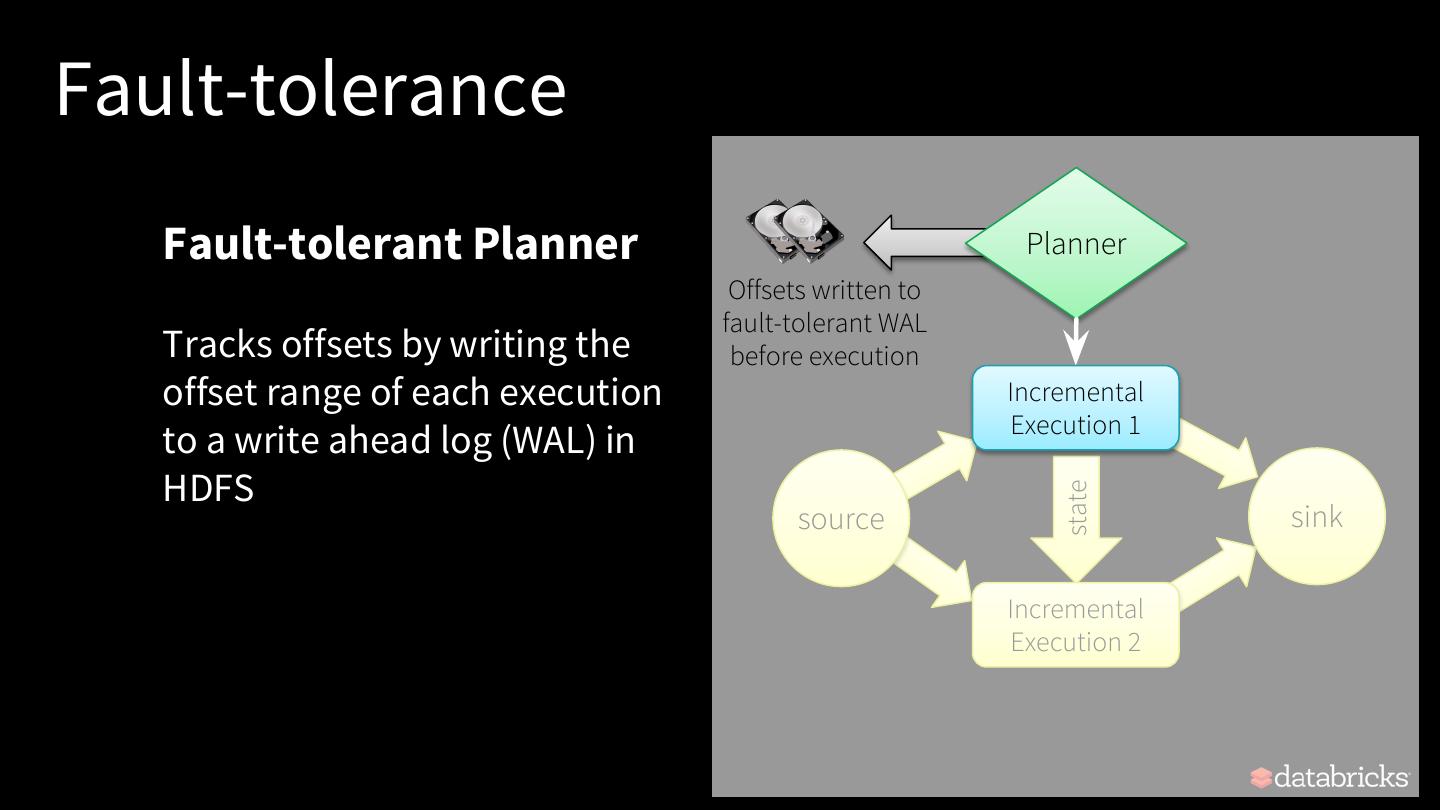
27 .Fault-tolerance Fault-tolerant Planner Planner Offsets written to fault-tolerant WAL Tracks offsets by writing the before execution offset range of each execution Incremental Execution 1 to a write ahead log (WAL) in HDFS state source sink Incremental Execution 2
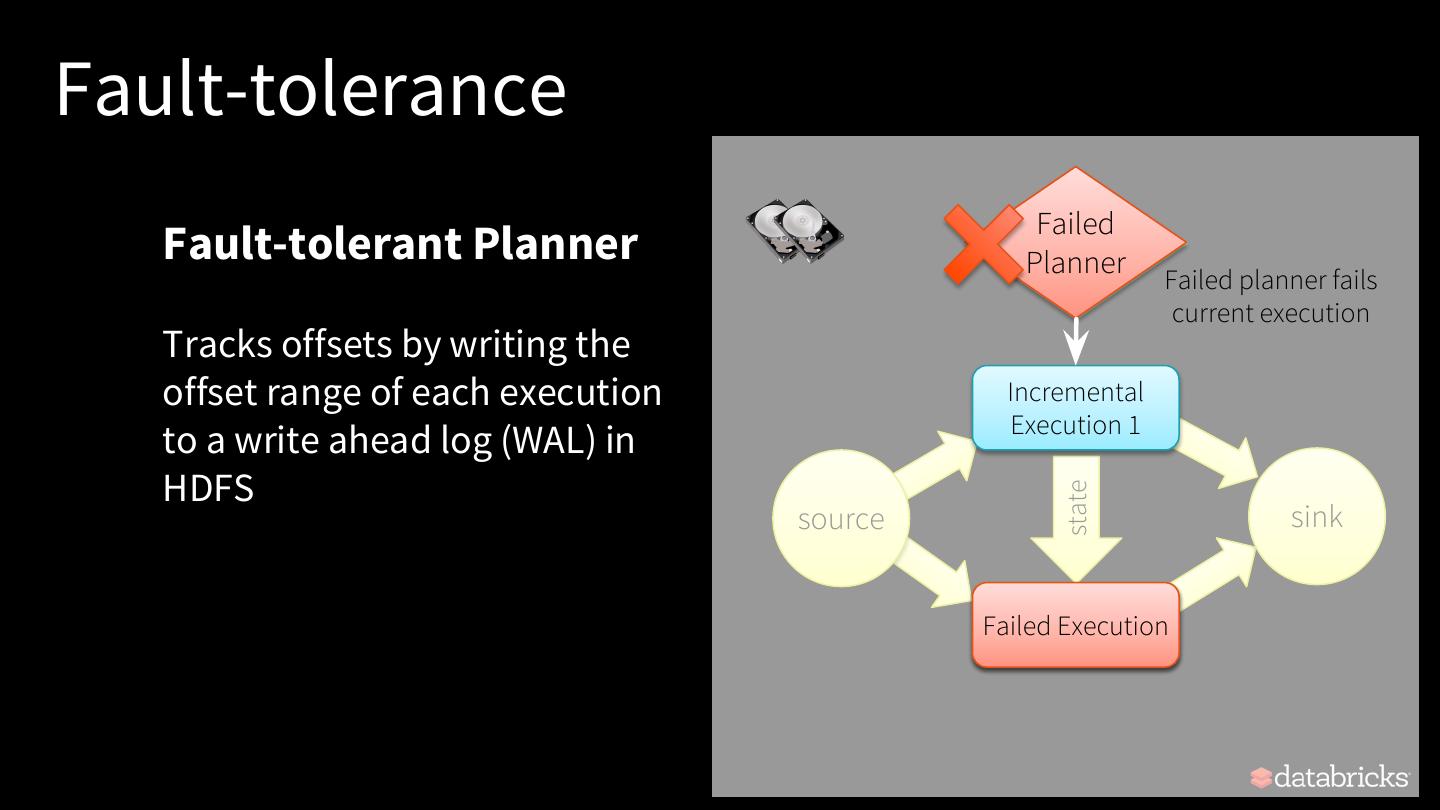
28 .Fault-tolerance Failed Fault-tolerant Planner Planner Planner Failed planner fails current execution Tracks offsets by writing the offset range of each execution Incremental Execution 1 to a write ahead log (WAL) in HDFS state source sink Incremental Failed Execution Execution 2
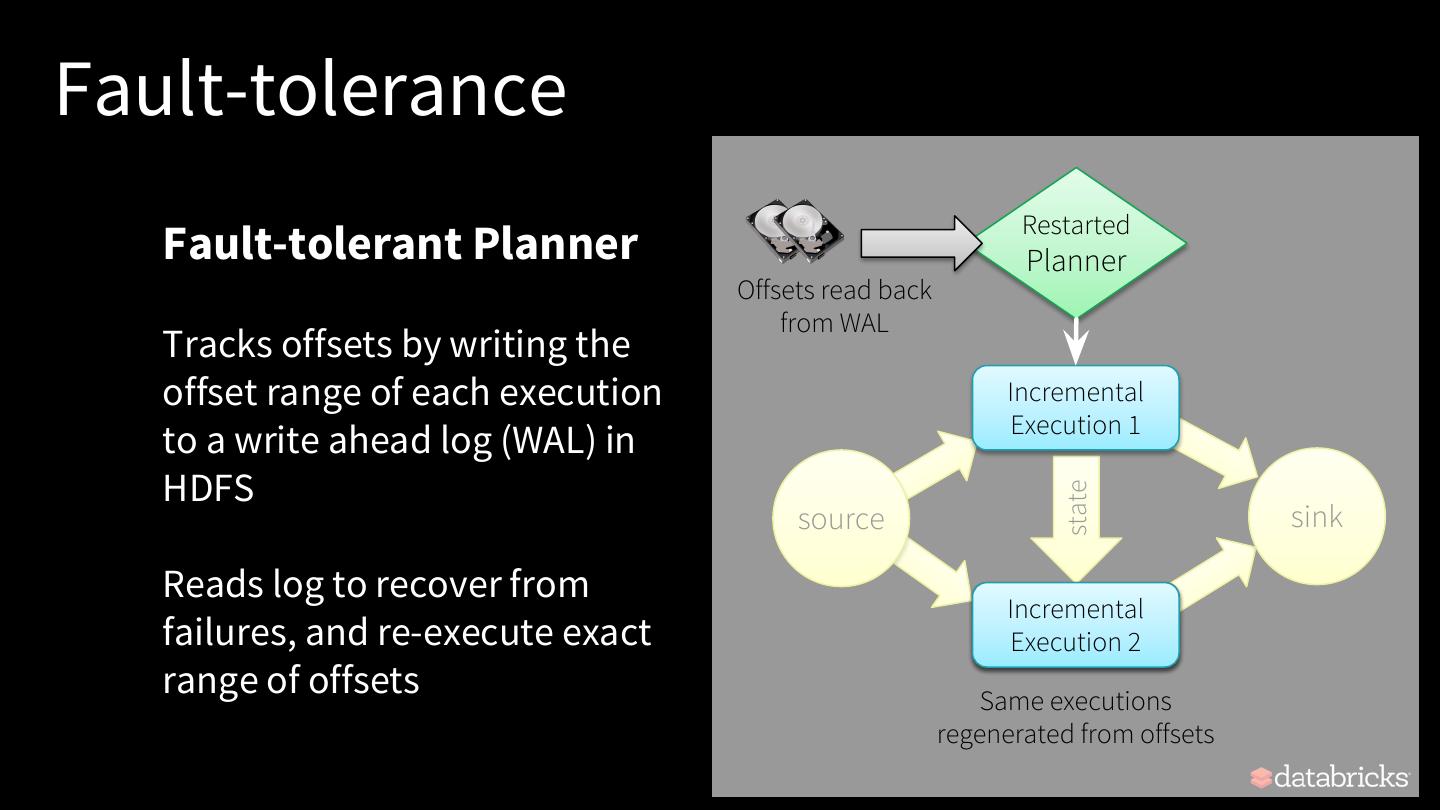
29 .Fault-tolerance Restarted Fault-tolerant Planner Planner Offsets read back from WAL Tracks offsets by writing the offset range of each execution Incremental Execution 1 to a write ahead log (WAL) in HDFS state source sink Reads log to recover from Incremental failures, and re-execute exact Failed Execution Execution 2 range of offsets Same executions regenerated from offsets
0点赞
0收藏
3秒后跳转登录页面
去登陆

