1 .
2 .1 背景介绍 2 Catalyst优化 3 Shuffle优化 4 Spark优化方向探索
3 .
4 .
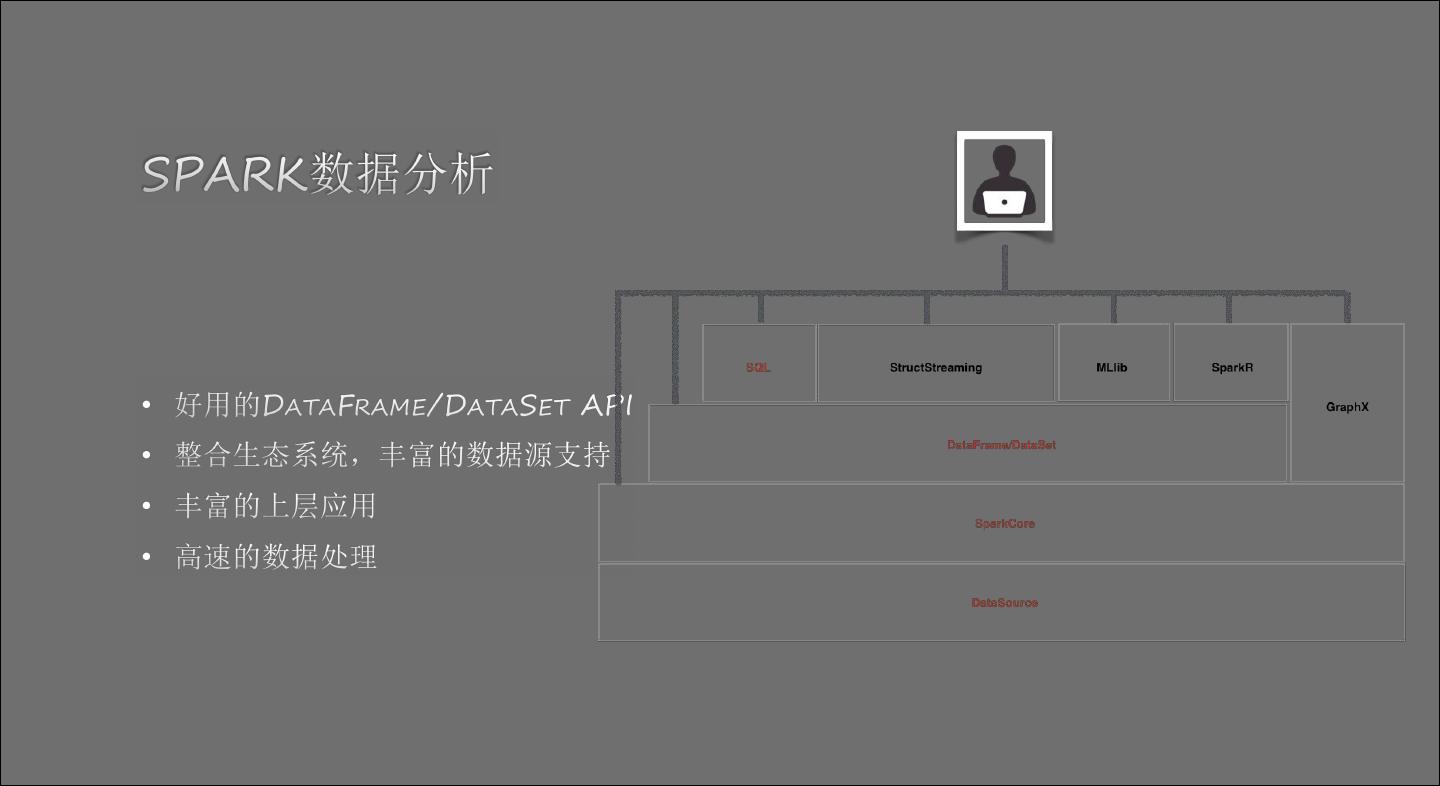
5 .易用 成本 稳定 安全
6 .
7 .
8 . Join Reorder Join表个数多 Query64: 18个表Join 动态规划 动态规划 表个数<=12: 动态规划算法 不做reorder Reorder 算法 杂交 遗传算法 遗传算法 | 表个数 >12: 遗传算法 计算适应度 | 淘汰
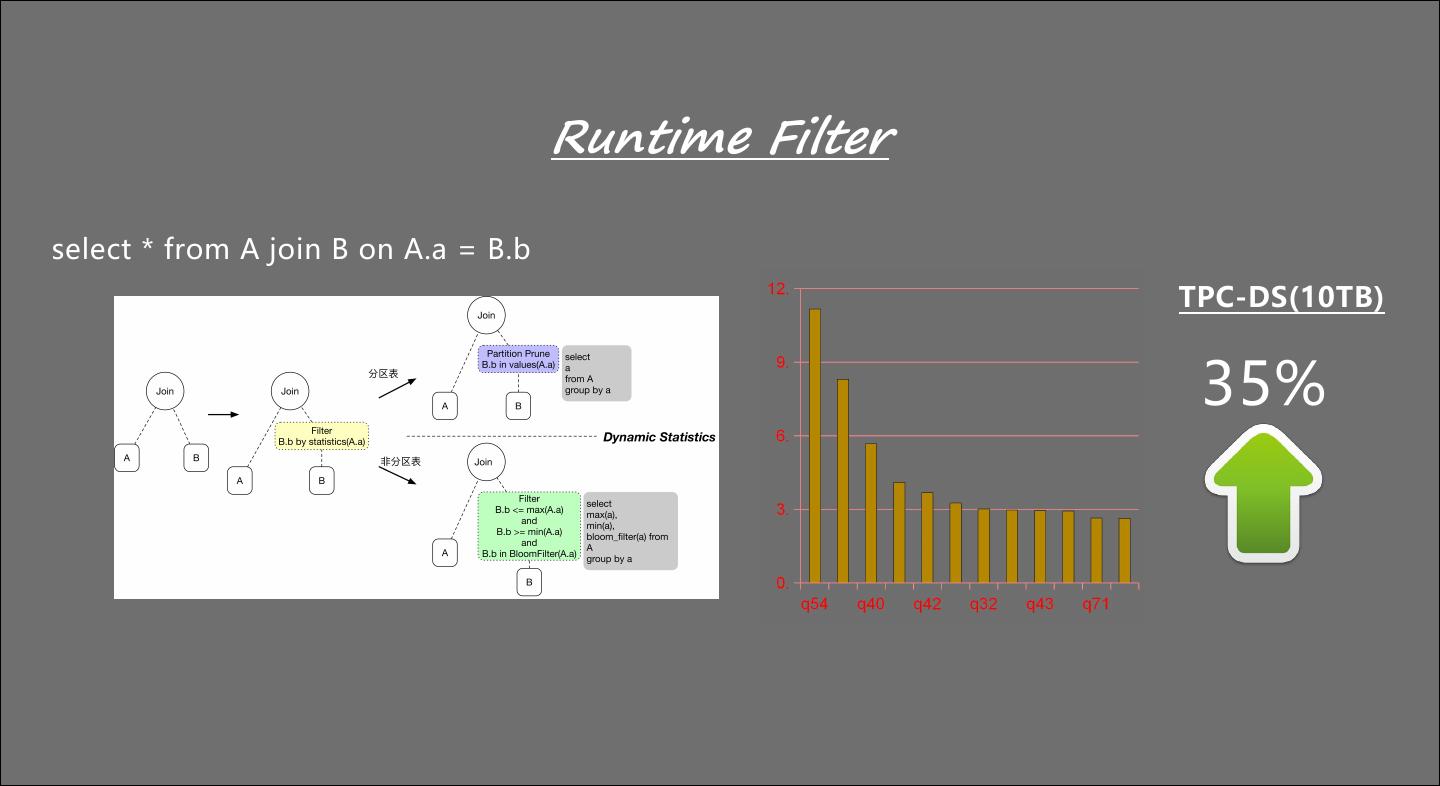
9 . Runtime Filter select * from A join B on A.a = B.b TPC-DS(10TB) 35%
10 .Runtime Filter Query 54 14,327,953,968 分区列裁剪:减少到136,107,053 非分区列过滤: 减少到135,564,763
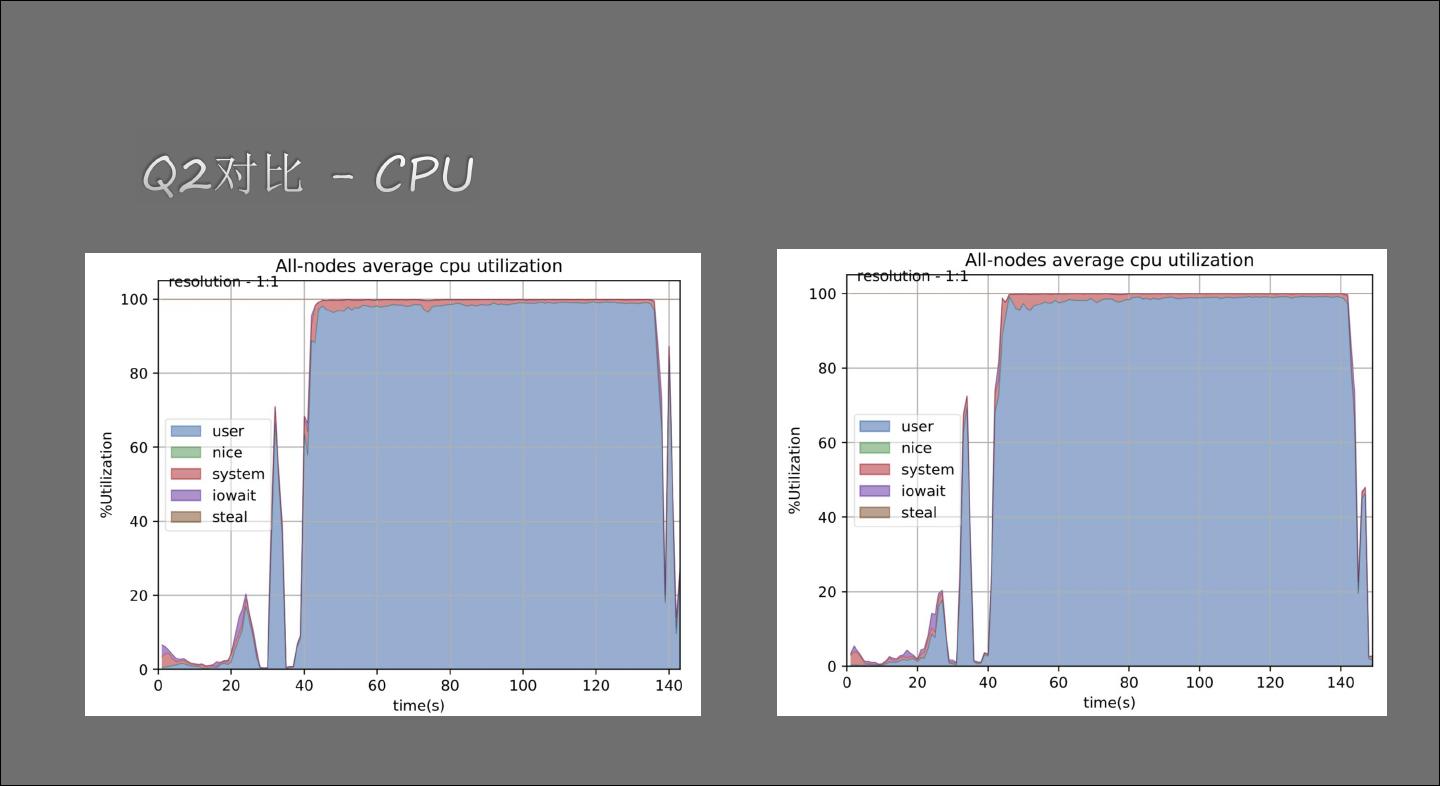
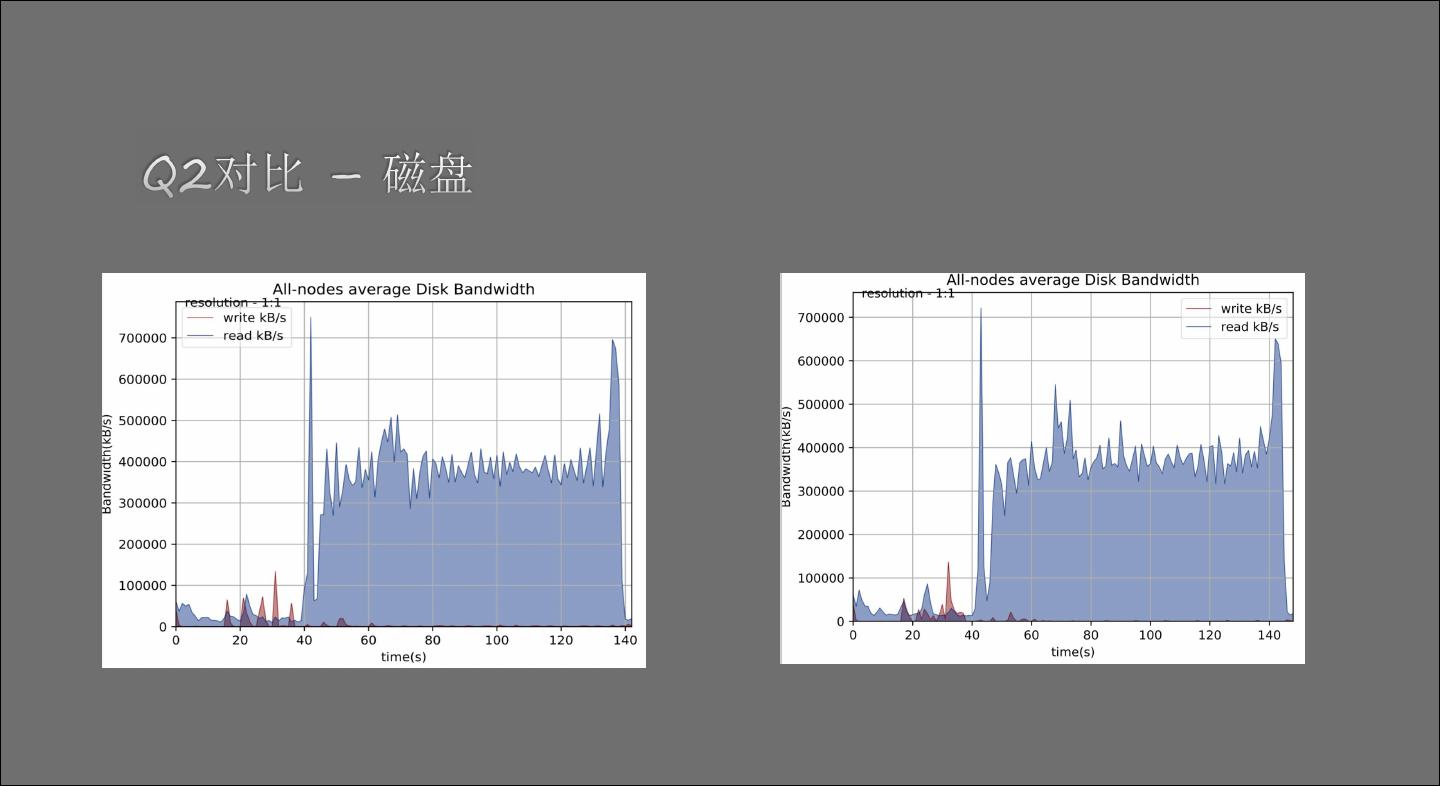
11 . Runtime Filter IO 打开RF 关闭RF 网络
12 .
13 . Spark Shuffle类型 HashTable BypassMergeSortShuffleWriter MergeSort SortShuffleWriter Optimized UnsafeShuffleWriter
14 .Map端: 1. 串行的计算,spill,merge操 作。 2. 多次文件IO。 Reduce端: 1. 随机IO访问。 2. 串行的网络,计算操作。
15 .1. 异步的计算,网络,磁盘IO, 充分利用集群资源。 2. 一次文件读写。 3. 随机文件访问=>顺序读写
16 .
17 .
18 .
19 .
20 .
21 .
22 .
23 .
24 .
25 . 技术 场景 云
26 .
27 . • MR 批处理 • Tez • Impala 交互式 • Presto 查询 • Hive • Flink 流处理 • Storm • TensorFlow... AI • Mahout...
28 .
确定删除吗?