






























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Kylin 2.5更智能、更敏捷、更易用的OLAP引擎-李栋
对比传统企业级架构,kylin将OLAP/DW带回大数据,使其支持云计算,高并发,支持传统建模 。并详细介绍了Apache Kylin 2.5更智能、更敏捷、更易用的OLAP引擎的具体内容与案例分享。
展开查看详情
1 .Apache Kylin 2.5: 更智能、更敏捷、 更易用的OLAP引擎 李栋 dong.li@kyligence.io Kyligence 技术合伙人、生态合作技术总监 Apache Kylin PMC & Committer info@kyligence.io
2 . 传统企业级数据仓库架构 可视化 展现层 ◼ 针对关键业务分析进行了优化 ◼ 千锤百炼的数据模型 OLAP ◼ 行业最佳实践 数据集市 ◼ 丰富的生态系统 企业级 ◼ 大量训练有素的分析师 数据仓库 数据源 © Kyligence Inc. 2018, Confidential.
3 . OLAP: 大数据的缺失部分 可视化 ◼ 太多的SQL on Hadoop 展现层 ◼ 不适合做交互式分析 ◼ 漫长的学习曲线 ◼ 兼容性问题 Hive Impala Spark SQL Drill ◼ 技术 vs 数据 数据湖 MapReduce Spark … 数据源 © Kyligence Inc. 2018, Confidential.
4 . Apache Kylin: 将OLAP/DW带回大数据 ◼ Hadoop上的OLAP/DW 可视化 展现层 ◼ 支持传统建模方式(Kimball) ◼ 为交互式分析进行优化 OLAP ◼ ANSI SQL 数据集市 ◼ 原生Hadoop应用 ◼ 支持云计算 Hive Impala Spark SQL Drill 数据湖 MapReduce Spark … ◼ 支持高并发、关键型应用 数据源 © Kyligence Inc. 2018, Confidential.
5 . Apache Kylin 历史 InfoWorld: Bossie Award InfoWorld: Bossie Award Kyligence公司创建 最佳开源大数据工具奖 最佳开源大数据工具奖 加入Apache 首个来自中国的 Apache Kylin v2.5.1 Apache顶级项目 商业版KAP发布 发布 项目开始 正式开源 孵化器项目 Sep 2013 Oct 2014 Nov 2014 Sep 2015 Nov 2015 Mar 2016 Aug 2016 Sep 2016 Nov 2018 © Kyligence Inc. 2018, Confidential.
6 .1000+ 全球生产用户 解决方案 • 用户行为分析 • 流量日志分析 • 数据集市/数据仓库 • 大数据自助分析平台 • 零售/电商分析 • 资产管理平台 • 广告效果分析 • 数据服务平台 • 实时分析 • 游戏分析 © Kyligence Inc. 2018, Confidential.
7 . 高性能、高并发 By 网易: http://datalab.int-yt.com/archives/1708 © Kyligence Inc. 2018, Confidential.
8 . Apache Kylin vs. SQL-on-Hadoop Query Latency by SQL Query Latency by data scale Star schema benchmark: http://www.cs.umb.edu/~poneil/StarSchemaB.PDF © Kyligence Inc. 2018, Confidential.
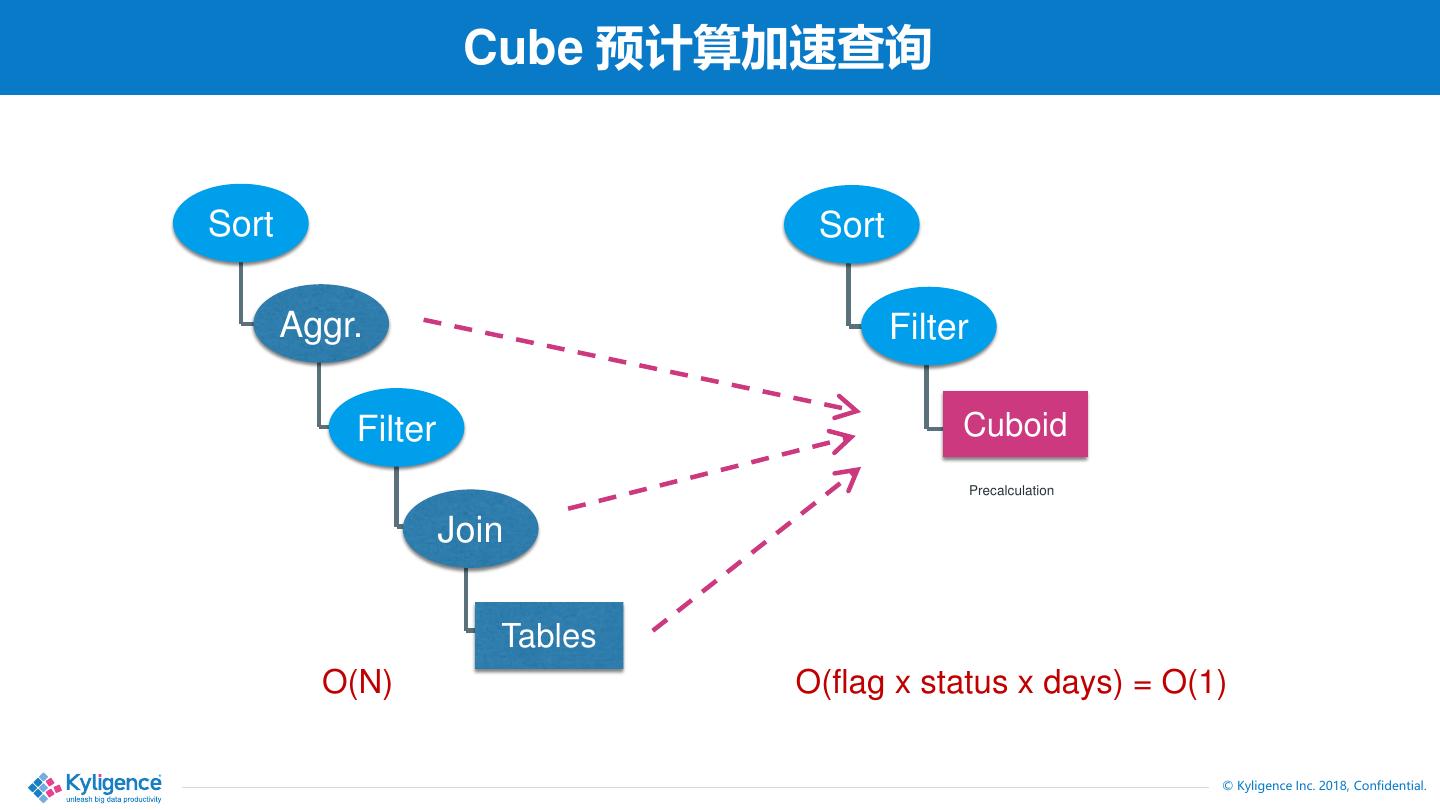
9 . 传统 SQL 执行逻辑 A sample query: Sort Report revenue by “returnflag” and “orderstatus” select l_returnflag, o_orderstatus, Aggr. sum(l_quantity) as sum_qty, sum(l_extendedprice) as sum_base_price … from Filter v_lineitem inner join v_orders on l_orderkey = o_orderkey where Join l_shipdate <= '1998-09-16' group by l_returnflag, o_orderstatus Tables order by l_returnflag, O(N) o_orderstatus; © Kyligence Inc. 2018, Confidential.
10 . Cube 预计算加速查询 Sort Sort Aggr. Filter Filter Cuboid Precalculation Join Tables O(N) O(flag x status x days) = O(1) © Kyligence Inc. 2018, Confidential.
11 . Apache Kylin 关键在于预计算 - OLAP Cube 理论基础 - Model 和 Cube 定义预计算范围 - Build Engine 执行预计算任务 - Query Engine 在预计算结果上完成查询 0-D(apex) cuboid time item location supplier 1-D cuboids time, time, Time, item, item, location, item location supplier location supplier supplier 预计算 2-D cuboids time, location, item, location, supplier supplier 3-D cuboids time, item, time, item, location supplier 4-D(base) cuboid time, item, location, supplier © Kyligence Inc. 2018, Confidential.
12 . 理论基础:O(1) Vs O(N) • 并行计算 响应时间 O(N) • 列式存储 • (倒排)索引 O(1) • 预计算 数据量 All rights reserved ©Kyligence Inc. http://kyligence.io © Kyligence Inc. 2018, Confidential.
13 . Apache Kylin 技术架构 BI Tools, Web App… ANSI SQL JDBC Kylin © Kyligence Inc. 2018, Confidential.
14 . 基于HBase的列式存储 ⚫ 计算结果集保存在HBase中,原有的基于行的关系模型被转换成基于键值对的列式存储 ⚫ 维度组合作为Rowkey,查询访问不再需要昂贵的表扫描,提供高速的扫描性能 ⚫ 维度值通过编码算法(字典、定长、时间戳等)高度压缩 ⚫ 指标通过Column存储,可以灵活、无限制的增加指标数量 ⚫ 预先计算的结果为高速高并发分析带来了可能 © Kyligence Inc. 2018, Confidential.
15 . 统一查询入口 ANSI SQL BI / Apps SQL Query Engine Apache Kylin Query Pushdown: minutes latency Cube Access: sub-second latency Hive / HBase SQL on Hadoop Hadoop Hive Spark … SQL on Hadoop Data Cubes © Kyligence Inc. 2018, Confidential.
16 . 可扩展的部署架构 ◆ Job Server基于ZK高可 靠部署 ◆ Query Server无状态, Kylin Cluster 基于LB进行水平扩展 ◆ 计算集群与查询集群相 分离,隔离不同 workload ◆ Hadoop原生应用,非 侵入式部署 © Kyligence Inc. 2018, Confidential.
17 .支持ODBC/JDBC,实现大数据可视化分析 © Kyligence Inc. 2018, Confidential.
18 . 今日头条:万亿级日志分析平台 海量数据+低延迟+高并发的分析引擎 • 痛点 • 国内最大的新闻客户端之一 • 数据规模大,日志明细每天1000亿+ • 6+亿用户数,8000+万DAU • 维度多,宽表列数300+ • 每天人均使用时长70+分钟 • 要求查询响应时间在秒级 • 解决方案 • 采用Apache Kylin作为多维分析平台,60 HBase region server • 头条用户视频展示分析,最大Cube 4+TB,膨胀率4%(明细数据 3+万亿,100+TB) • APP性能监控及分析,服务研发部门,1000+用户 • 新闻日志分析,100+Cube服务不同产品线 • 收益 • 查询速度快,90%+查询毫秒级(比Hive快上万倍) • 节省计算资源,一次构建,长期受益 Apache Kylin是目前最好的OLAP-on-Hadoop引擎。在头条,我们需要在万亿规模的数据集上 • 丰富的API,通过程序化方式自动创建100+Cube 做多维分析,没有Kylin,这件事几乎不可能 © Kyligence Inc. 2018, Confidential.
19 . 美团:PB级大数据分析平台 Cube Storage: 971TB (almost PB) Supporting all critical Latest updated - 201808 business lines including E- Cube numbers: 973 Cube Takeaways, Hotel, Movie, LBS, Tickets… Data Records: 8.9 Trillion rows 90%ile latency: <1.2s Frequency: 3.8 million queries / day © Kyligence Inc. 2018, Confidential.
20 . 贝壳找房:KPI指标平台 • 800+ Cube,覆盖公司16个业务 线 • Cube 存储总量300T+, 数据行数 1600+亿行,单 Cube 最大60+亿 行 • 日查询量100万+,时延 <500ms(95%), <1s(99%) © Kyligence Inc. 2018, Confidential.
21 . 雅虎日本:跨地域电商报表系统 The most visited website in Japan ▪ Thanks to low latency with Kylin, we become possible to focus on adding functions for users. https://techblog.yahoo.co.jp/oss/apache-kylin/ ▪ We provide a reporting system that show statistics for store owners. - e. g. impressions, clicks and sales. ▪ Our reporting system used Impala as a backend database previously. - It took a long time (about 60 sec) to show Web UI. ▪ In order to lower the latency, we moved to Apache Kylin. - Average latency < 1sec for most cases © Kyligence Inc. 2018, Confidential.
22 . 小米:Lambda 架构 • Serving 18 business lines as the engine for mi’s“data factory” • Daily incremental 17 billion • 95% queries < 500ms. © Kyligence Inc. 2018, Confidential.
23 . Strikingly:网站流量分析服务 A company to provide convenient and one stop website building solutions. The data platform based on Apache Kylin solved the problem of massive user queries excellently. -- Chase Zhang, Data Platform Engineer of Strikingly Performance • Use Apache Kylin to speedup analytics with Keen.io, and support high concurrency Containerizing • Apache Kylin runs on AWS ECS Integration • Developed a scheduler system to manage all kinds of jobs © Kyligence Inc. 2018, Confidential.
24 .最新特性介绍
25 . Cube Planner: make cube smaller • An example with SSB: • Reduce cuboid number from 512 to 152 with only phase I optimization • Storage saved 70% • Cube build improved 25% © Kyligence Inc. 2018, Confidential.
26 . All-in-Spark 构建引擎 • Why move to Spark? • Better performance & resource utilization; • Less dependency on Hadoop; • Kylin 2.0 only moved layer cubing steps to Spark • Now all jobs moved to Spark • Convert to HFile • Merge segments • Fact distinct dimension values Cubing steps improved about 10% than previous version © Kyligence Inc. 2018, Confidential.
27 . Up-coming features • Cache enhancements (KYLIN-2895) • Memcached as query cache • Storage level cache • More Data Source (KYLIN-3552) • SDK for adding new JDBC data sources easily • API for handling dialects • Can do syntax conversion when push down to the data source • New Storage • New columnar storage engine for Apache Kylin © Kyligence Inc. 2018, Confidential.
28 .关于Kyligence 企业级 专业服务 产品 管理 构建领先的 与 自动化 全球开源社区 行业 云计算 解决方案 © Kyligence Inc. 2018, Confidential.
29 .We Are Hiring! Our Contact Apache Kylin Address dev@kylin.apache.org 上海市浦东新区亮秀路112号Y1座405 Telephone 021-61060928 E-mail info@kyligence.io Kyligence Inc Website https://kyligence.io info@kyligence.io
3秒后跳转登录页面
去登陆

