展开查看详情
1 .Spark在智慧图书馆建设中的应用探索 2017年12月22日
2 .目 录 一、Spark研究背景和研究现状 二、Spark平台的相关技术 三、基于Spark平台关联规则的研究 四、阶段目标与展望
3 .一、Spark研究背景和研究现状 (一)背景 大数据时代背景下 ,很多企业和研究机构都在研究挖掘海量数据及利用,将带动一波新的快速增长 。 大数据处理平台生态圈的更新 ,由早期的Apache开源项目Hadoop中的 HadoopHDFS 、 HadoopMapReduce、HBase、Hive 的逐步产生的可扩展分布式处理平台 。 Spark 的诞生是基于内存的计算,处理速度在计算过程中多次迭代优于 MapReduce Apriori算法是关联规则挖掘的经典算法之一,它是基于用户的相关行为数据,通过挖掘频繁项集,找出彼此之间的关系。
5 .01 02 03 04 First one 仅支持Map和Reduce两种操作 Second one 迭代计算效率低(如机器学习、图计算等) Fourth one 不适合交互式处理(数据挖掘) Third one 不适合流式处理(点击日志分析) MapReduce框架局限性
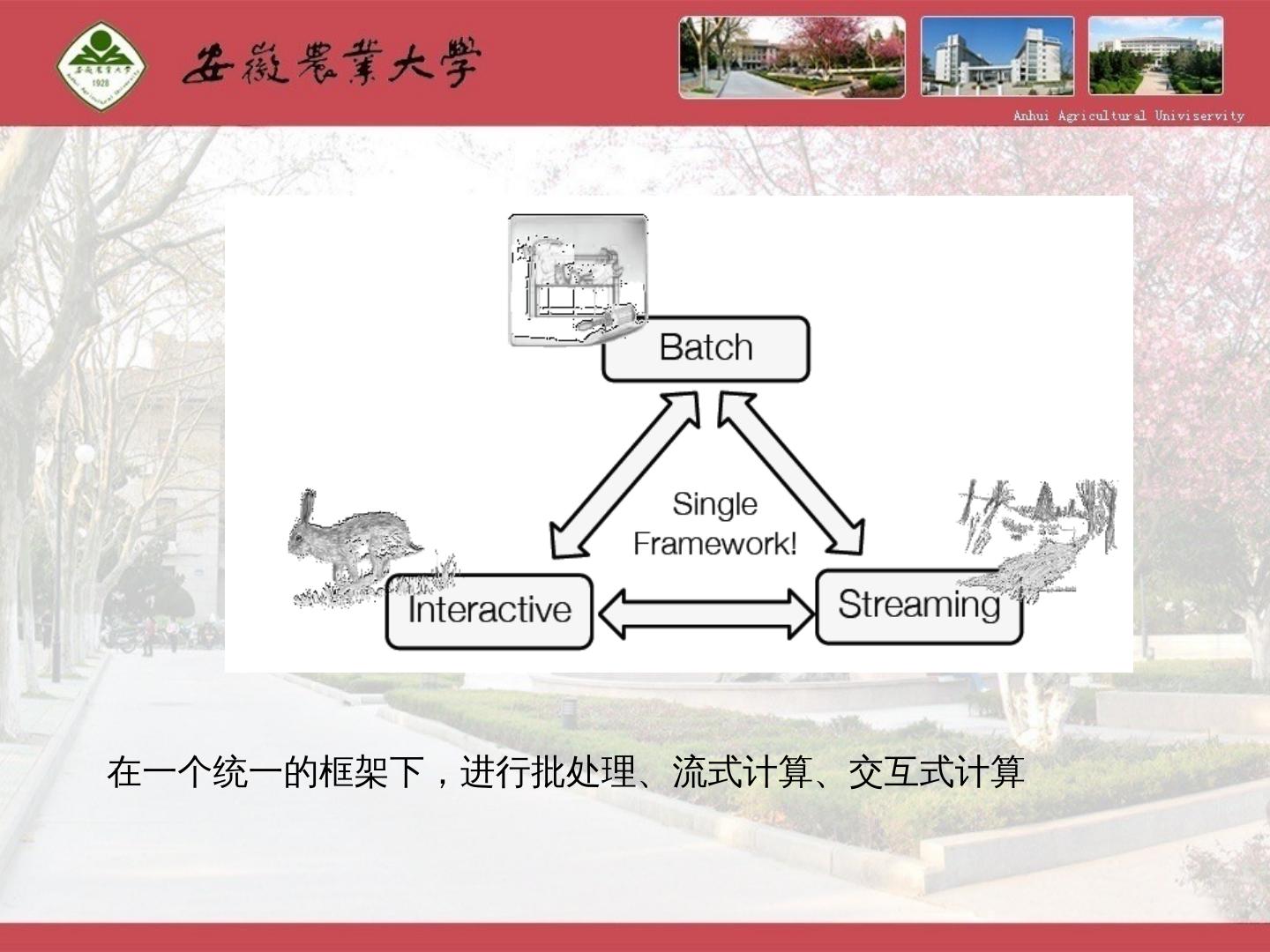
6 .MapReduce编程不够灵活 尝试scala函数式编程语言 现有的各种计算框架各自为战 批处理:MapReduce、Hive、Pig 流式计算:Storm 交互式计算:Impala 能否有一种灵活的框架可同时进行批处理、流式计算、交互式计算等?
7 .在一个统一的框架下,进行批处理、流式计算、交互式计算
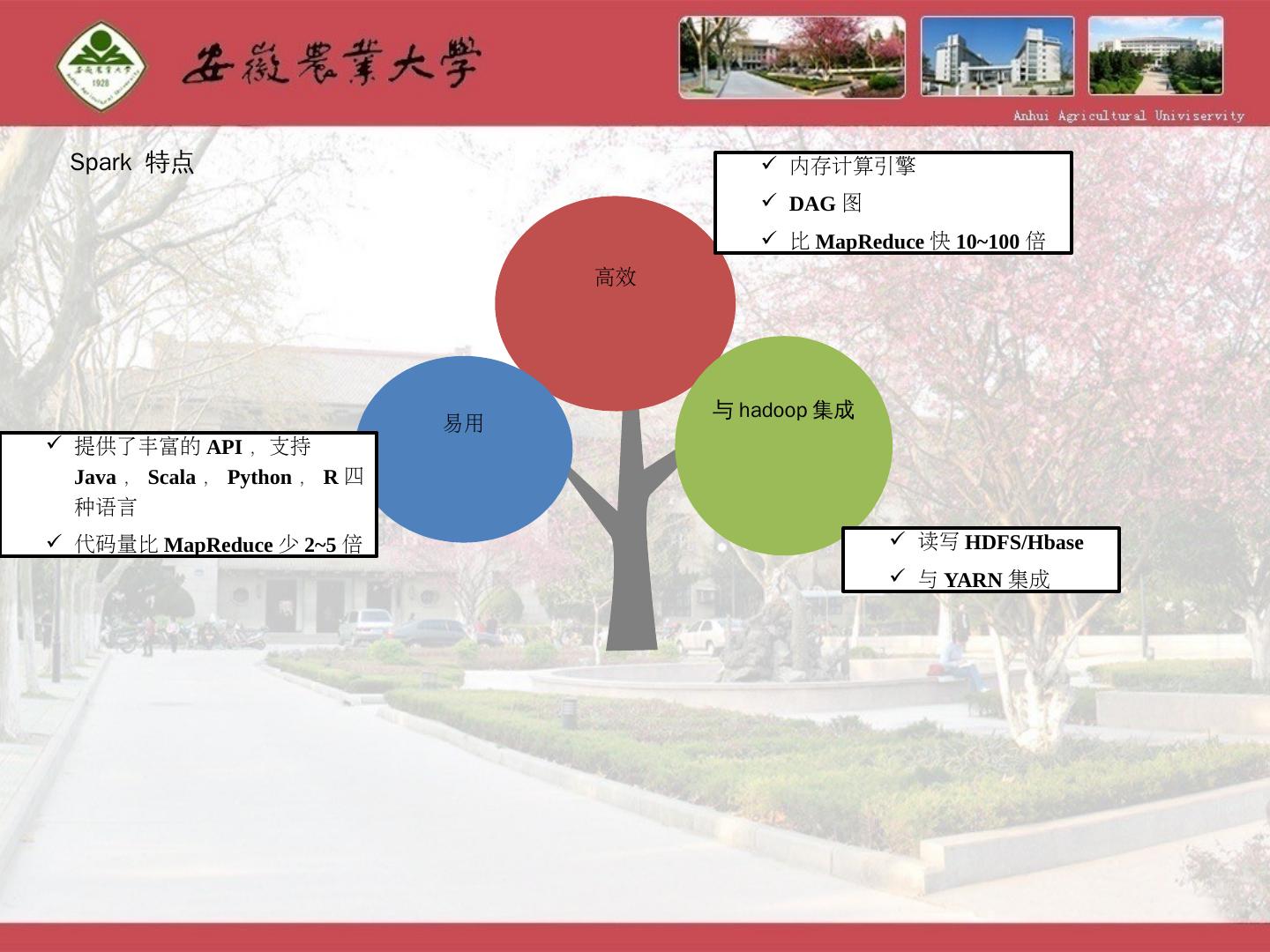
8 .Spark 特点 高效 与hadoop集成 易用 内存计算引擎 DAG 图 比 MapReduce 快 10~100 倍 读写 HDFS/Hbase 与 YARN 集成 提供了丰富的 API ,支持 Java , Scala , Python , R 四种语言 代码量比 MapReduce 少 2~5 倍
9 .(二)Spark研究现状 (1)Spark发展 Spark从2009年诞生,当下进入了快速发展期,国内目前主要集中在一些互联网行业,比如阿里巴巴、百度、搜狐等。例如腾讯公司数据仓库TDW大量使用Spark替代原来的Hadoop MapReduce,使性能得到有效提高,高校现在针对Spark研究相对较少,随着智慧校园的建设模式的提出,更多的高校老师加入到研究Spark如何处理海量没有被深入挖掘出的数据。
10 .(二)Spark研究现状 (2)关联规则模型研究现状 关联分析是Agrawal于1993年提出的,对博客在商店购物零售数量进行分析,从中找出可能同时购买的商品的集合,帮助销售上有目的为顾客推荐商品,有效引导购物。
11 .(二)Spark研究现状 (3)关联规则Apriori算法模型 Apriori算法是挖掘关联规则的频繁项集。 首先定义两个互相独立的集合A和B,假设A和B之间有一定的关联性,存在关联规则。用支持度和置信度来说明:(1)支持度 support(A=>B ) = P(A∪B) 即 P(A∪B) 的同时出现的概率;(2)置信度A和B在一定条件下出现的概率,即confidence = P(B|A),揭示了A出现时,B是否也出现或有多大的概率出现。
12 .(二)Spark研究现状 (3)关联规则Apriori 算法模型
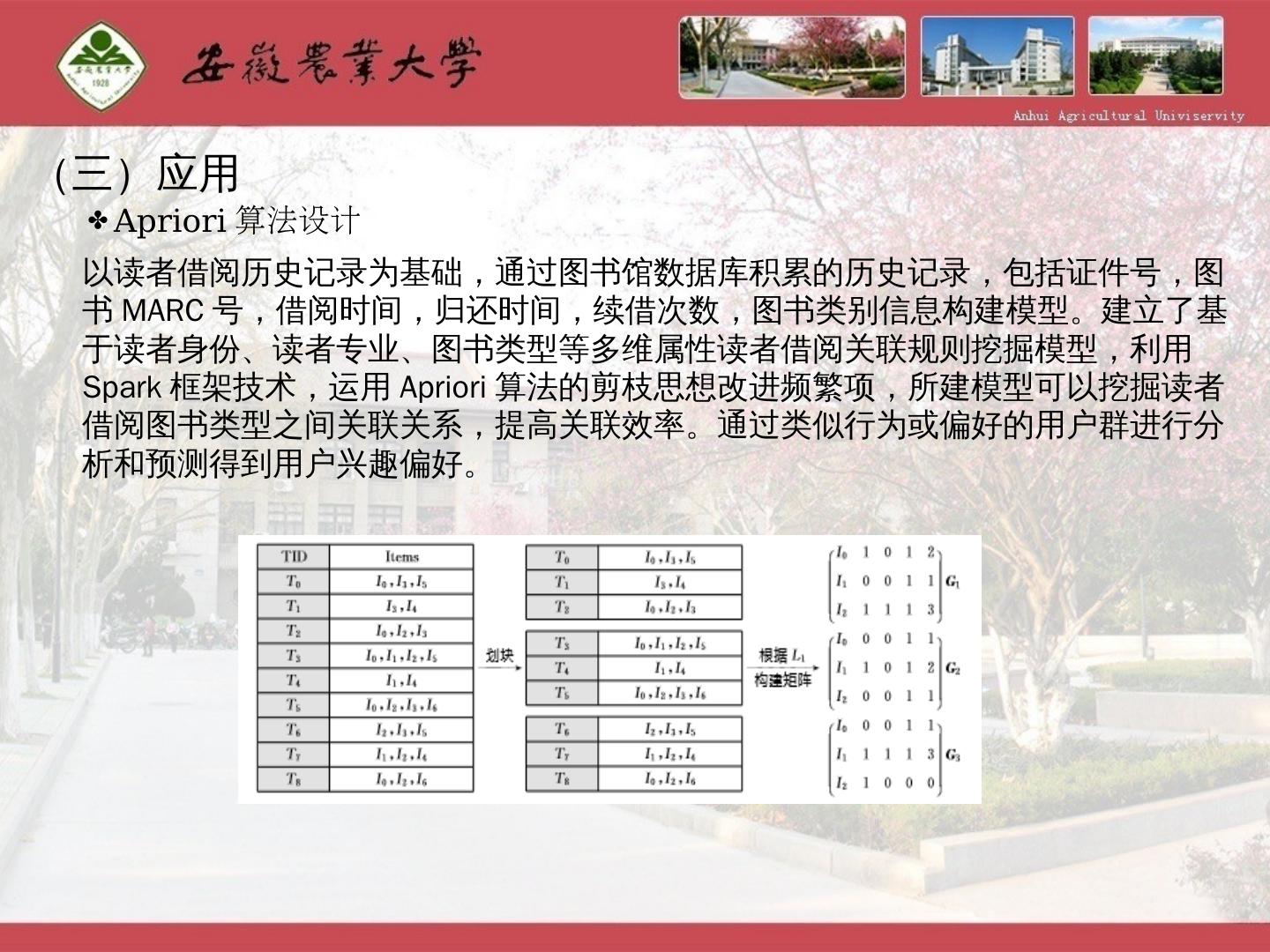
13 .(二)Spark研究现状 (3)关联规则Apriori 算法模型 原始数据中每一行称作一个事务,包含顾客一次购买的全部商品。如 “milk” 就是一个项。包含 0 个或多个项的集合被称作项集。因此每一个事务可以看做一个项集,事物的一个子集也可以看做一个项集。如果一个项集包含 K 个项,则称为 K- 项集。对于一个给定事务集合 T ,可以分为 1- 项集, 2- 项集, … , K- 项集, K 是 T 中最大事务宽度。
14 .(二)Spark研究现状 (4)基于Spark关联规则Apriori算法模型的应用 传统基于Hadoop MapReduce 因为多次迭代,I/O访问次数多,需要处理的时间增长,影响了服务需求,因此借助Spark的基于内存的运算,快速迭代的并行化计算优势,可提高关联规则挖掘的效率。 在挖掘用户产生数据中相关联信息的同时, 及时推送 读者可能感兴 趣 的书籍。 比如学校图书馆个性化图书推荐, 都是基于关联规则的预处理,其中 询问者是学校老师和学生用户, 最终 回答者担任倒角色就是一个推荐系统的作用。
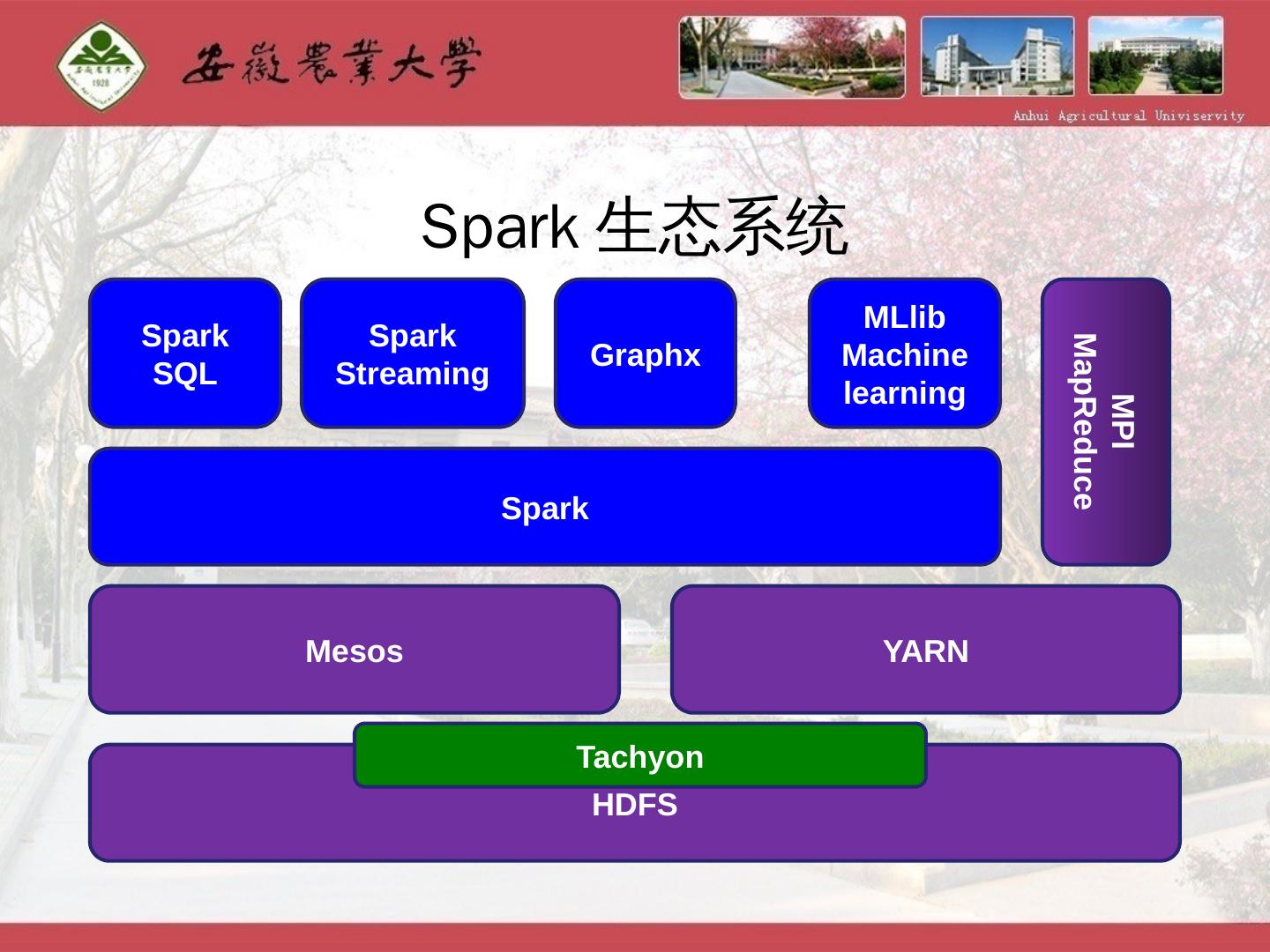
15 .二、Spark平台的相关技术 (一)Spark简介 Spark 是UC Berkeley AMP lab所开源的类Hadoop MapReduce通用并行计算框架,基于内存的快速通用可扩展数据分析引擎。 目前 ,Spark整个生态生态系统中核心框架spark基础上,提供四个范畴计算框架,分别是: Spark streaming 支持流运算 MLbase 底层分布式机器学习库和机器学习功能 Graphx 并形图计算框架 SparkSQL 支持结构化数据的SQL查询及分析查询引擎
16 .Spark生态系统 Spark Streaming Spark SQL Graphx MLlib Machine learning Spark MPI MapReduce Mesos YARN HDFS Tachyon
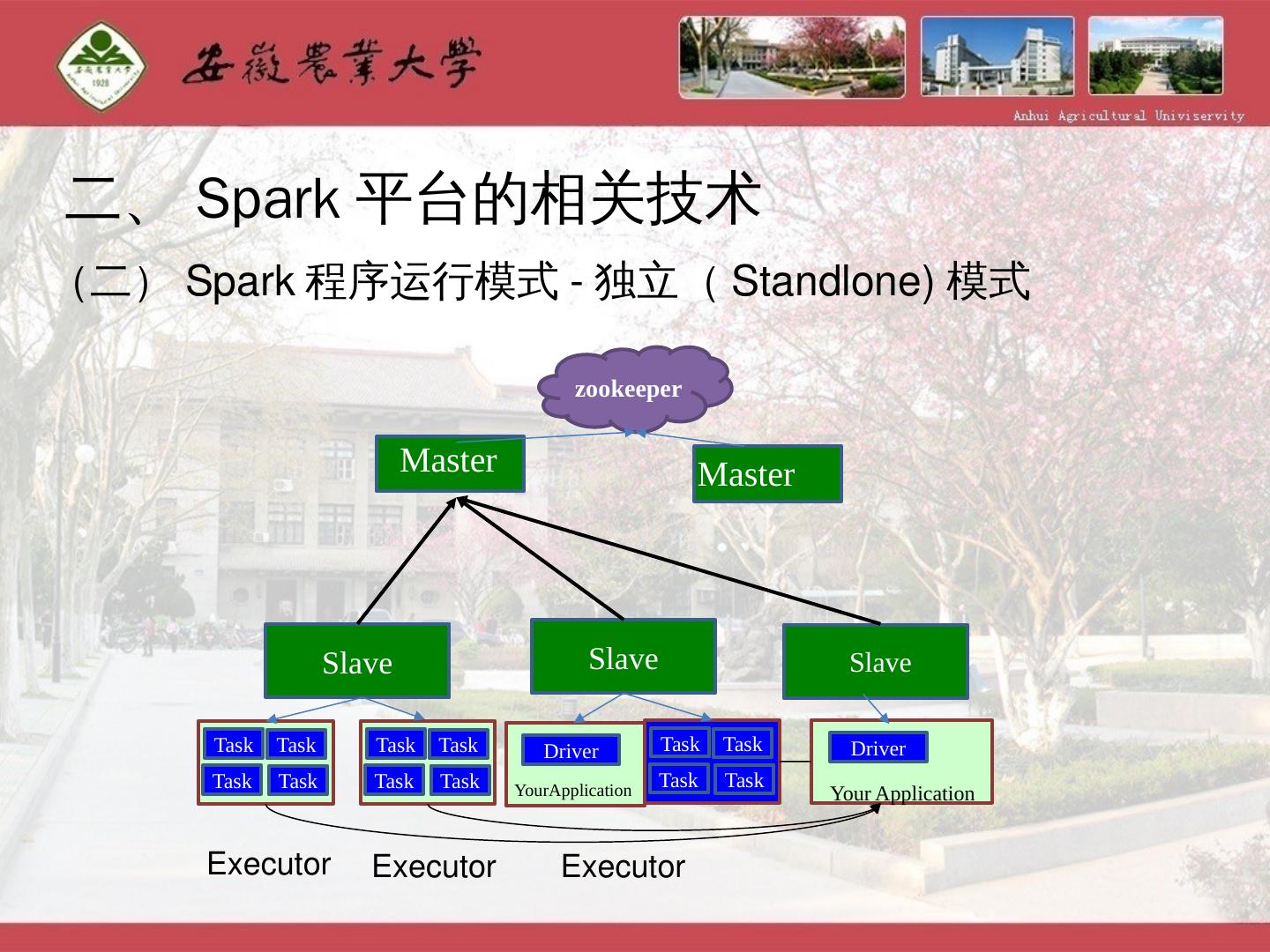
17 .二、Spark平台的相关技术 (二)Spark程序运行模式-独立(Standlone)模式 Master Slave Slave Slave Master zookeeper Task Task Task Task Task Task Task Task Task Task Task Task Executor Executor Executor Driver Driver YourApplication Your Application
18 .二、 Spark 平台的相关技术 (三) Spark 核心概念和基本操作 RDD : Resilient Distributed Datasets , 弹性分布式数据集 分布在集群的只读对象集合(由多个Partition构成) 可以存储在磁盘或内存中(多种存储级别) 通过并行“转换”操作构造 失效后自动重构
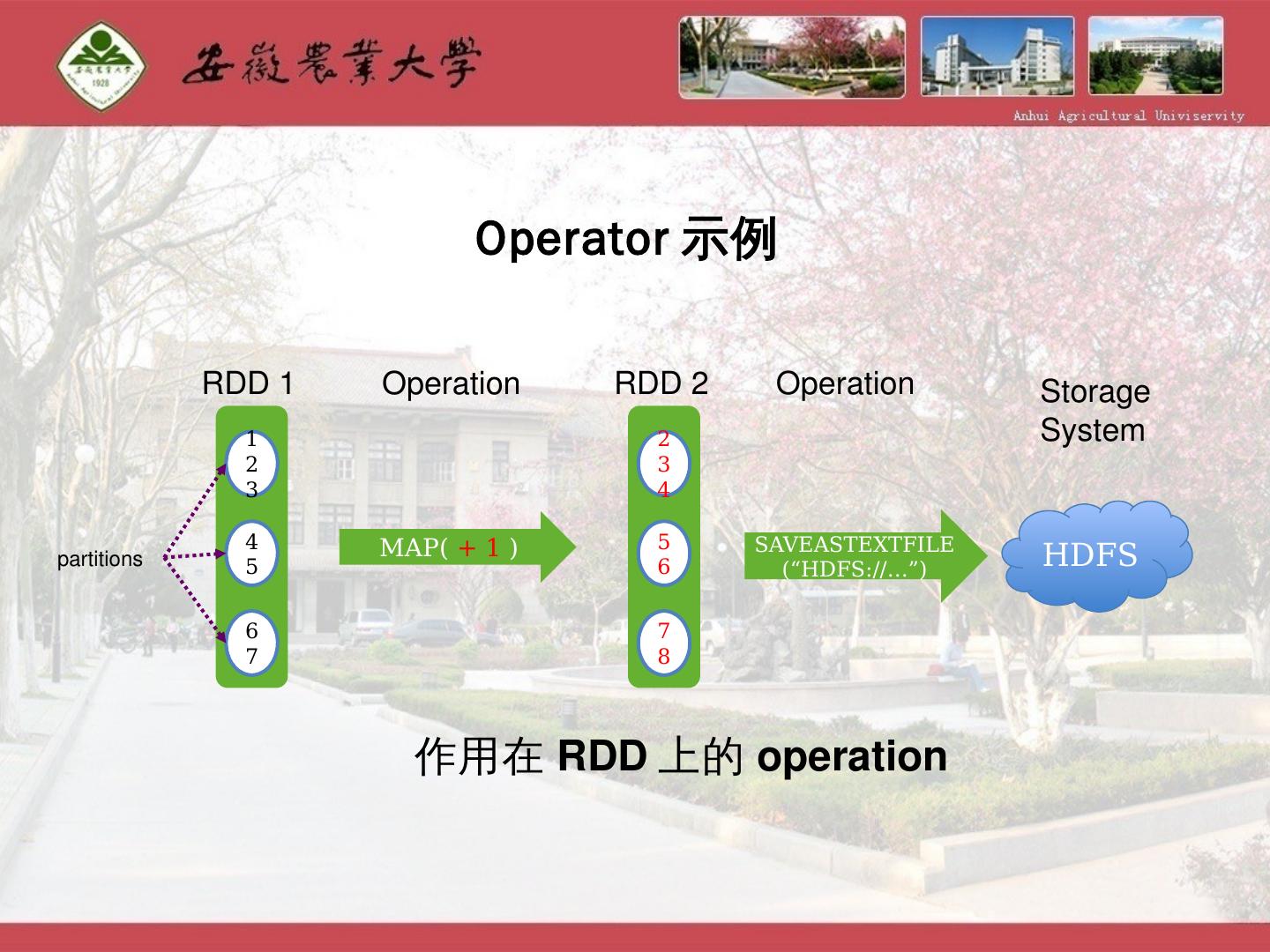
19 .1 2 3 4 5 6 7 RDD 1 partitions 作用在RDD上的operation 2 3 4 5 6 7 8 map( + 1 ) RDD 2 Operation saveASTEXTFILE(“HDFS://…”) HDFS Storage System Operation Operator示例
20 .RDD 基本操作: Transformation (转换) 可通过 Scala 集合或者 Hadoop 数据集构造一个新的 RDD 通过已有的 RDD 产生新的 RDD 举例 : map , filter , groupBy , reduceBy Action (行动) 通过 RDD 计算得到一个或者一组值 举例: count , collect , save
21 .一个完 整 的实例:wordcount import org.apache.spark._ import SparkContext._ object WordCount { def main(args: Array[String]) { if (args.length != 3 ){ println("usage is org.test.WordCount <master> <input> <output>") return } val sc = new SparkContext(args(0), "WordCount", System.getenv("SPARK_HOME"), Seq(System.getenv("SPARK_TEST_JAR"))) val textFile = sc.textFile(args(1)) val result = textFile.flatMap(line => line.split("\s+")) .map(word => (word, 1)).reduceByKey(_ + _) result.saveAsTextFile(args(2)) } } Master 地址 依赖的 jar 包 Spark 安装 目录 作业名称 输入数据所在目录,比如 : hdfs://host:port/input/data 数据输出目录,比如 : hdfs://host:port/output/data
22 .三、基于Spark平台Apriori关联规则算法研究 近年来,随着国内高校图书馆的规模越来越大,业务流程应用数据挖掘技术,对关联规则、聚类分析进行研究,在基于Hadoop平台提出一种MapReduce方式并行处理的Apriori算法,图书推荐服务在理论方面有了一些进展,相关算法被相继的提出和改进,利于从大量数据中找到隐藏的规则,进而挖掘出读者的借阅兴趣。改进和优化频繁项集的产生,在海量数据挖掘中大大提高效率,例如基于Spark框架的Apriori关联规则挖掘算法,提出分布式并行化算法,适用于大数据关联规则的挖掘。
24 . 以安徽农业大学图书馆 2010-2015年的所有图书借阅历史数据为实验数据 , 对前文提出的关联规则兴趣模型进行验证。通过迭代调用 transformation 和 Action 操作,每次迭代中利用上一次迭代结果进行求解。对数据集 D 设置最小支持度阈值 minSup=0.4. 置信度阈值 minConf=0.7
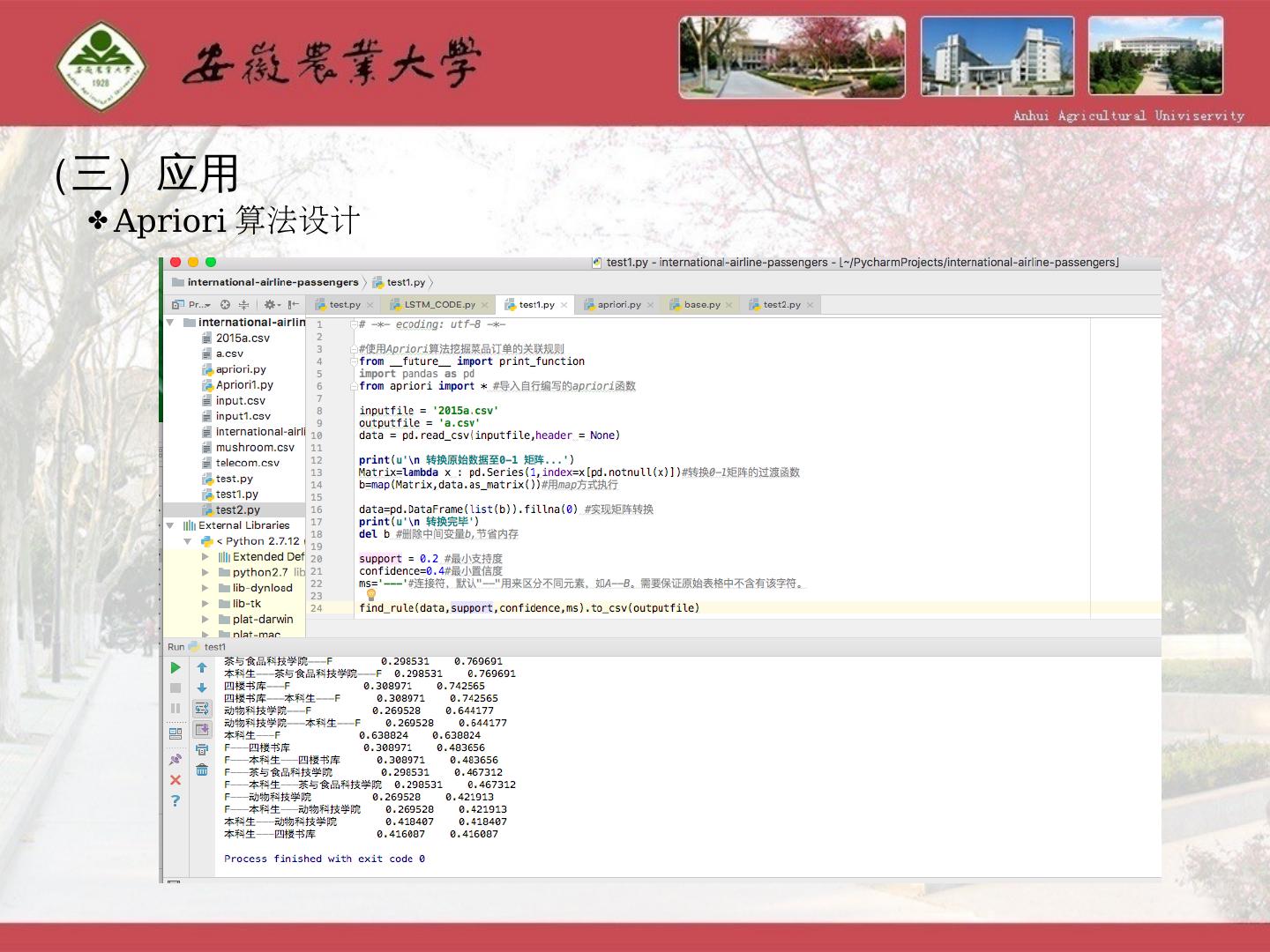
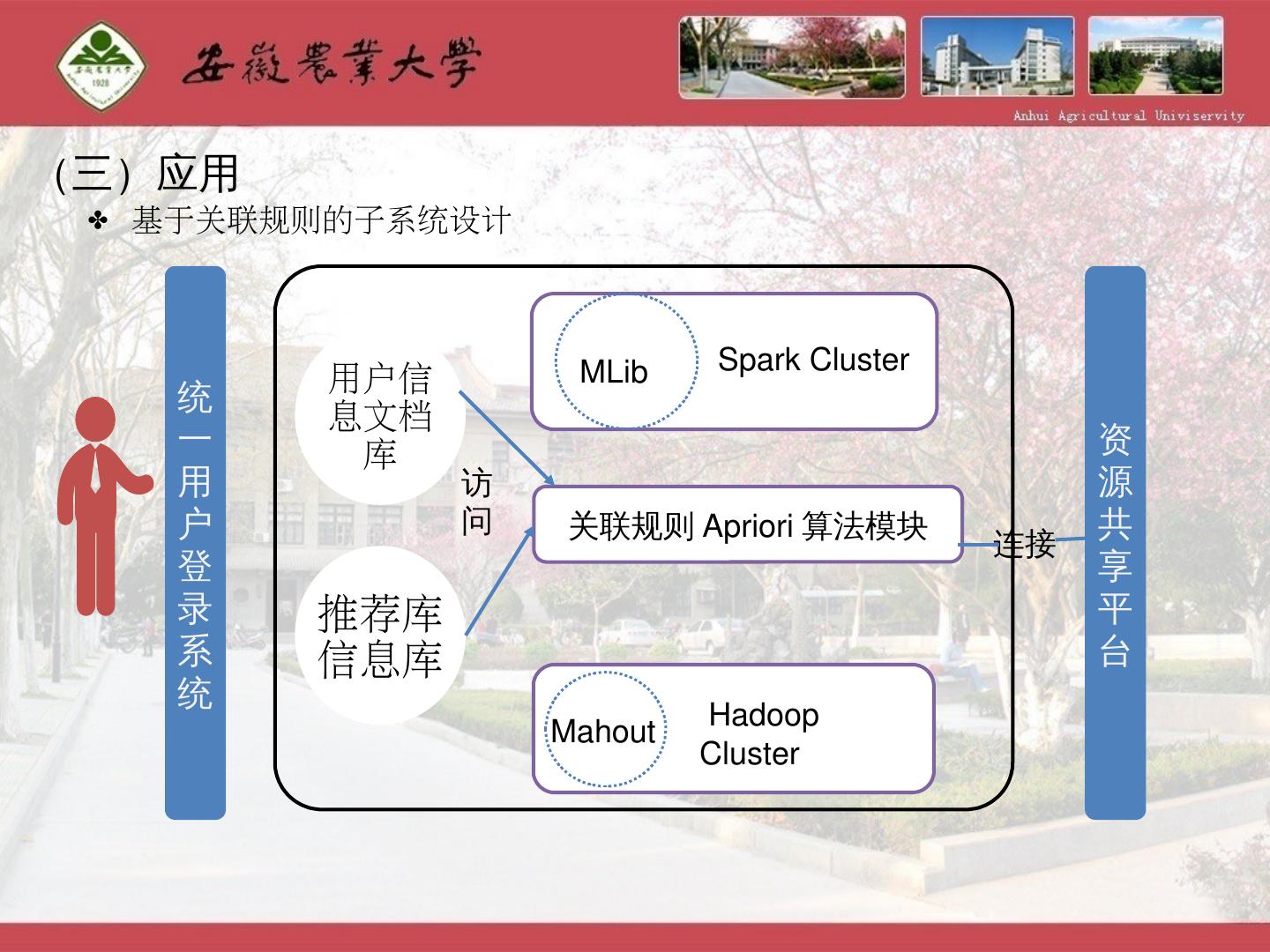
25 .(三)应用 A priori 算法设计 以读者借阅历史记录 为 基础, 通过图书馆数据库积累的历史记录,包括证件号,图书 MARC 号,借阅时间,归还时间,续借次数,图书类别信息构建模型。 建立了基于读者身份、读者专业、图书类型等多维属性读者借阅关联规则挖掘模型,利用 Spark 框架技术,运用 Apriori 算法的剪枝思想改进频繁项,所建模型可以挖掘读者借阅图书类型之间关联关系,提高关联效率。 通过类似行为或偏好的用户群进行分析和预测得到用户兴趣偏好 。
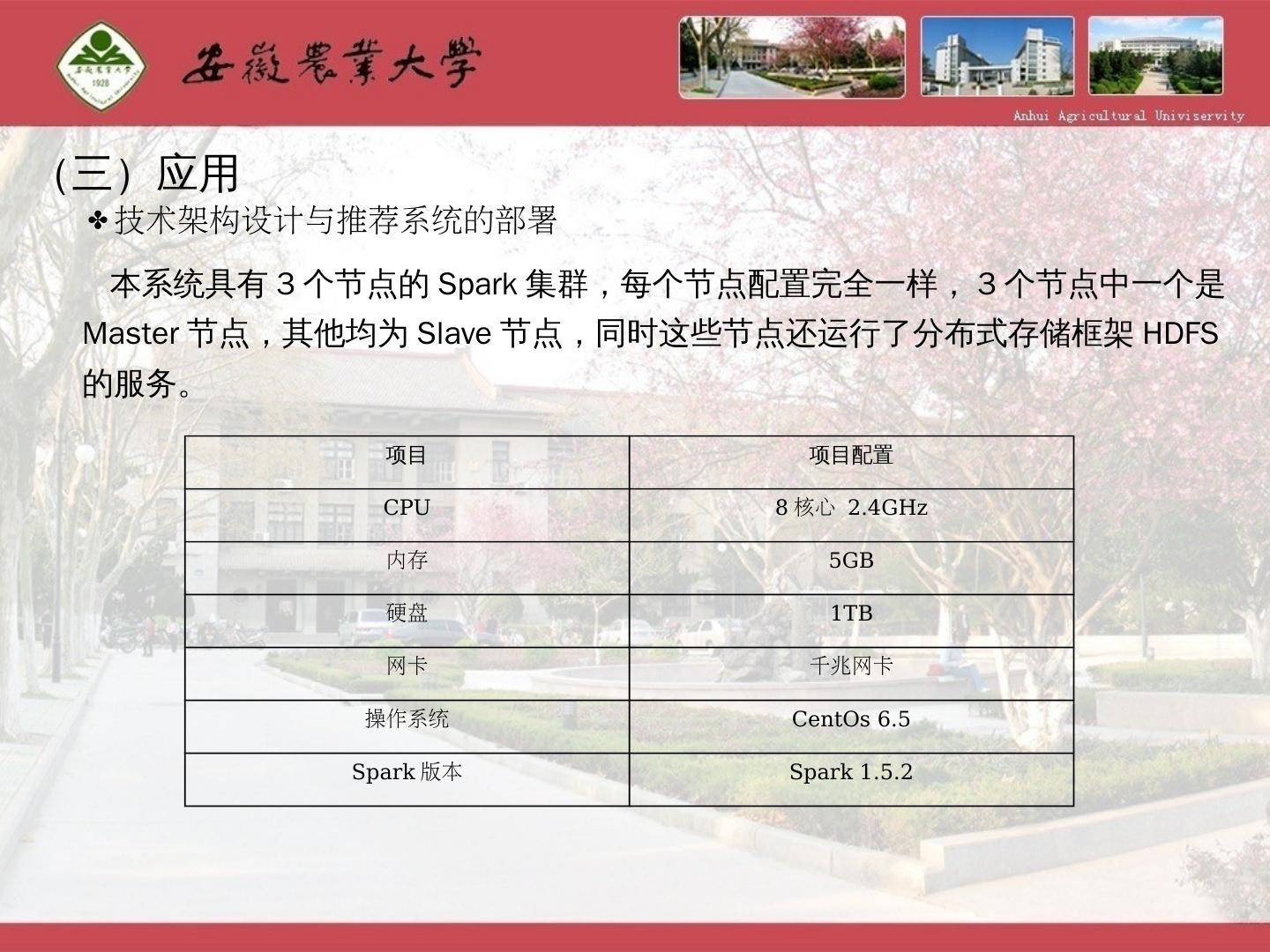
27 .(三)应用 技术架构设计与推荐系统的部署 本系统具有3个节点的Spark集群,每个节点配置完全一样,3个节点中一个是Master节点,其他均为Slave节点,同时这些节点还运行了分布式存储框架HDFS的服务。 项目 项目配置 CPU 8 核心 2.4GHz 内存 5GB 硬盘 1TB 网卡 千兆网卡 操作系统 CentOs 6.5 Spark 版本 Spark 1.5.2
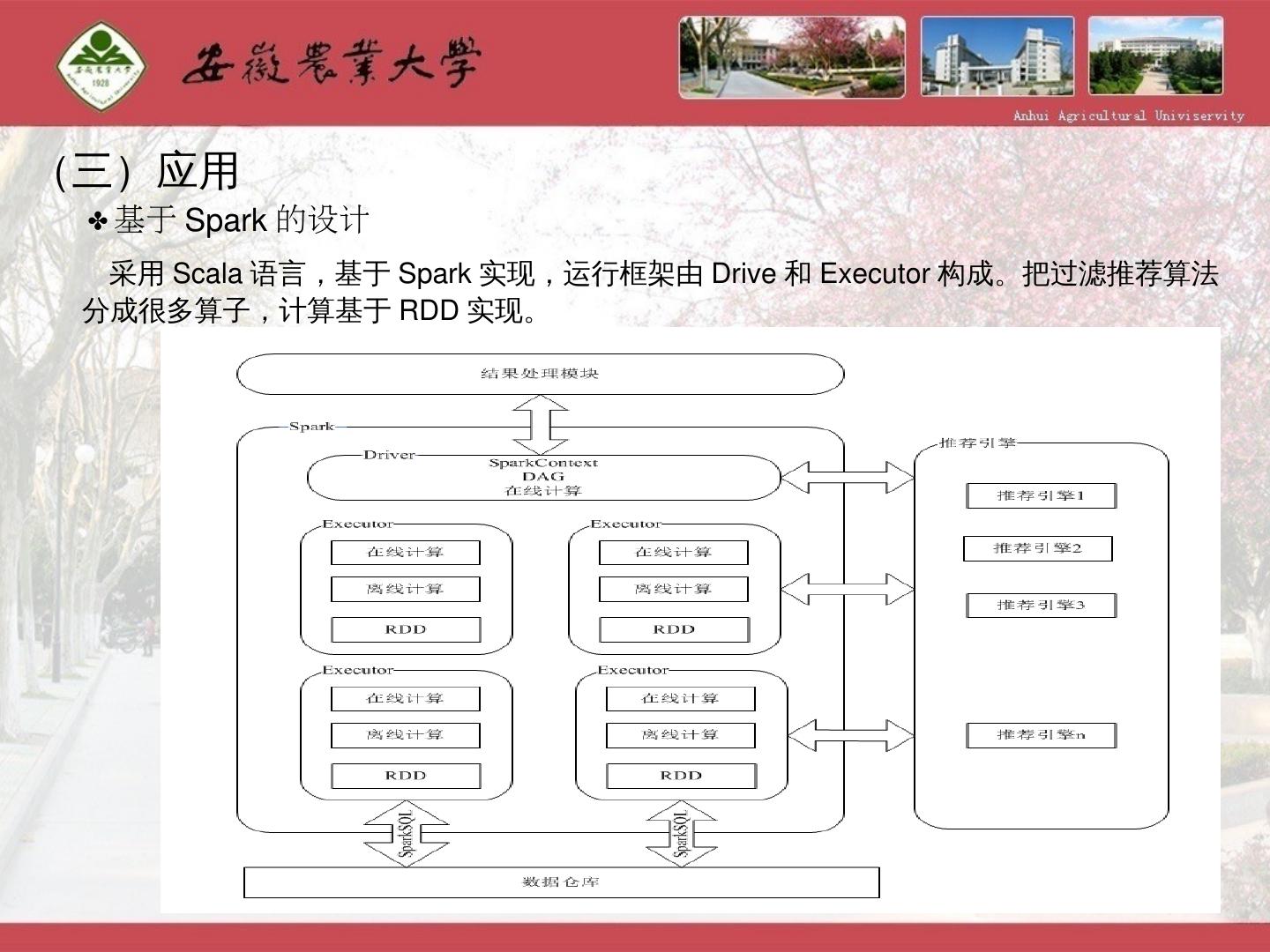
28 .(三)应用 基于Spark的设计 采用Scala语言,基于Spark实现,运行框架由Drive和Executor构成。把过滤推荐算法分成很多算子,计算基于RDD实现。
29 .(三)应用 技术架构和部署架构 类实时处理层 Web Service Spark MVC Logback Map/Reduce Mahout FTP Sqlite HDFS HBase JDBC HDFS 工具 Spark Spark streaming MLLib 实时处理层 数据层访问层 数据层 离线加工层