























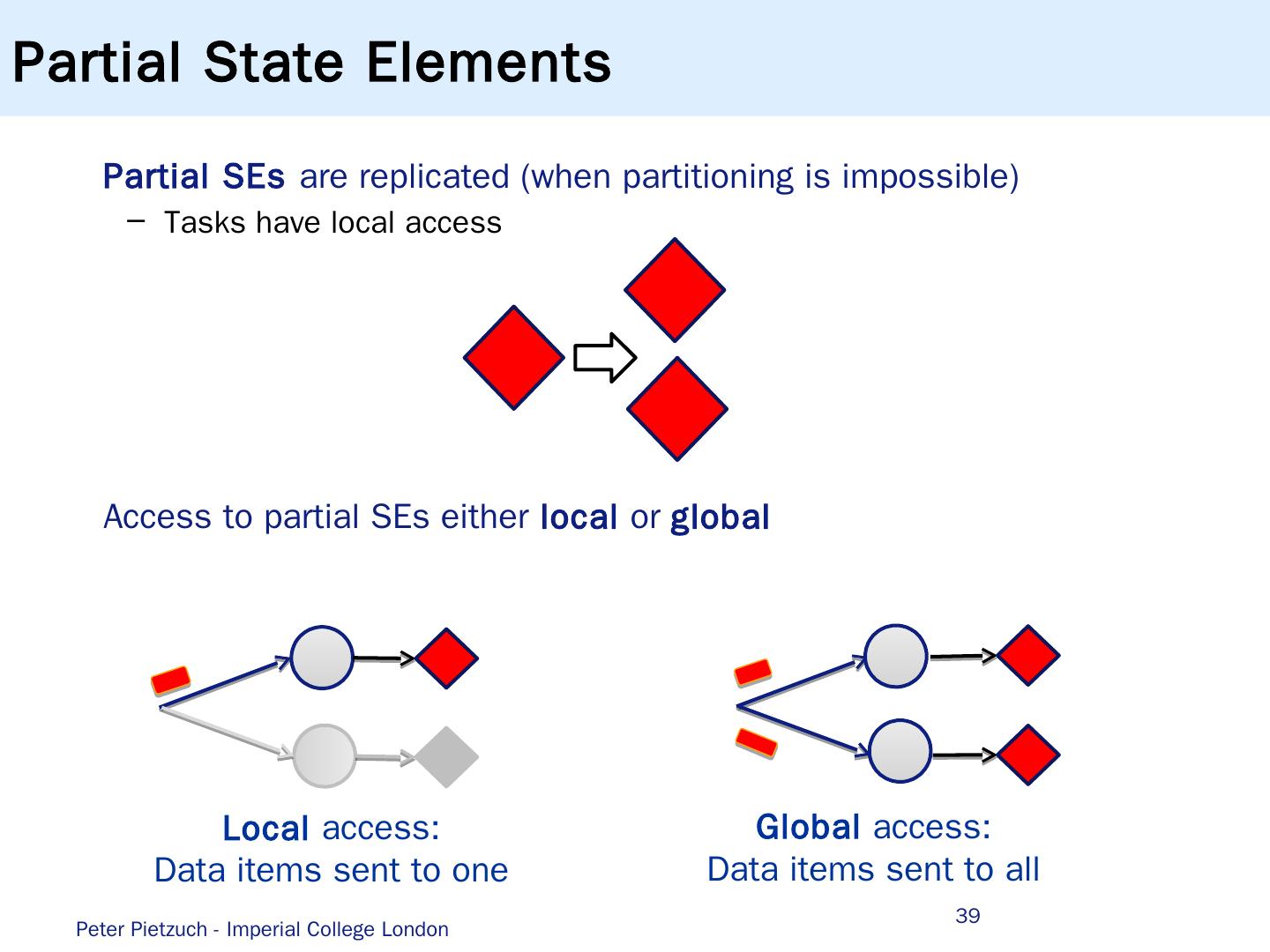
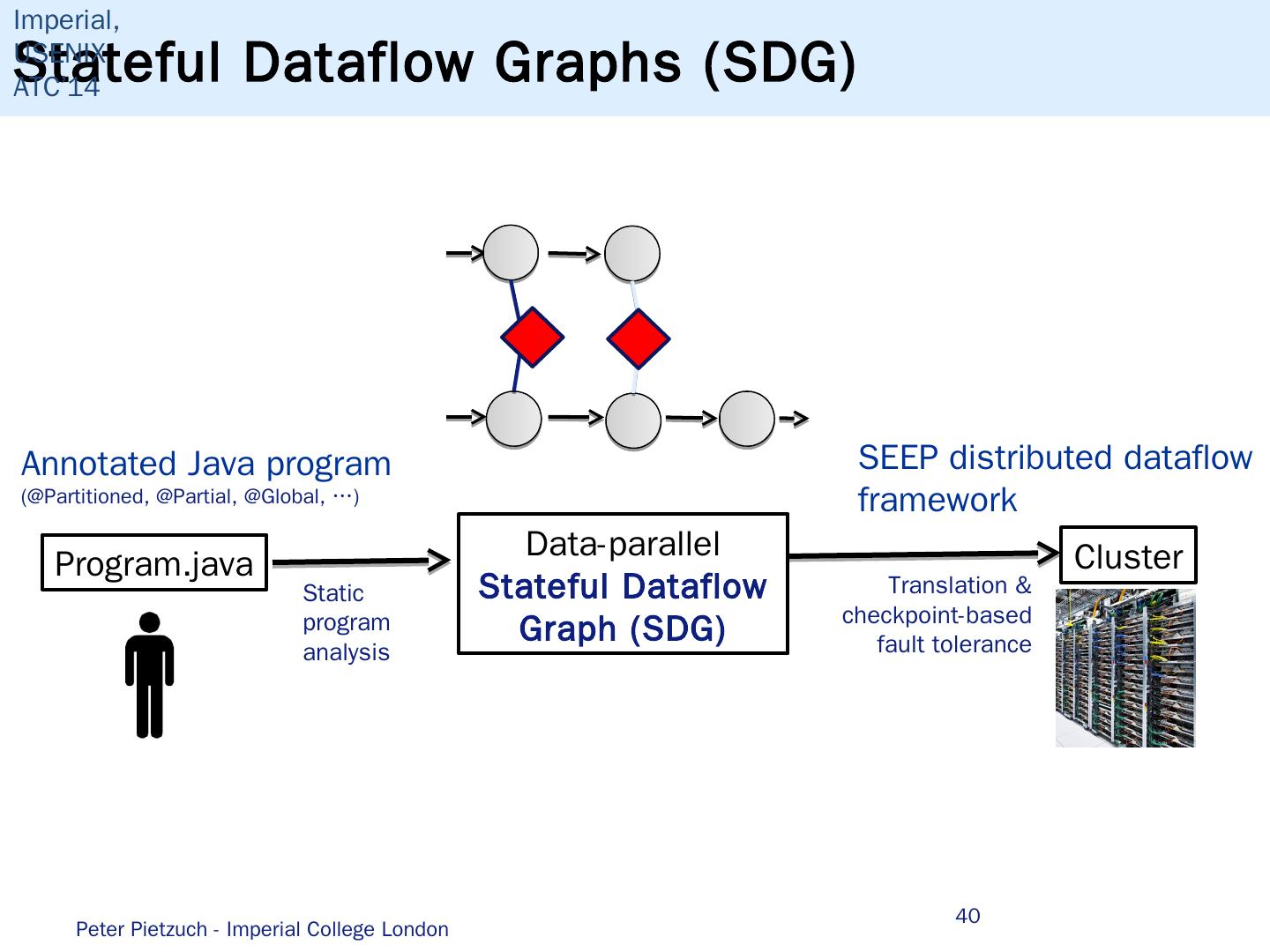
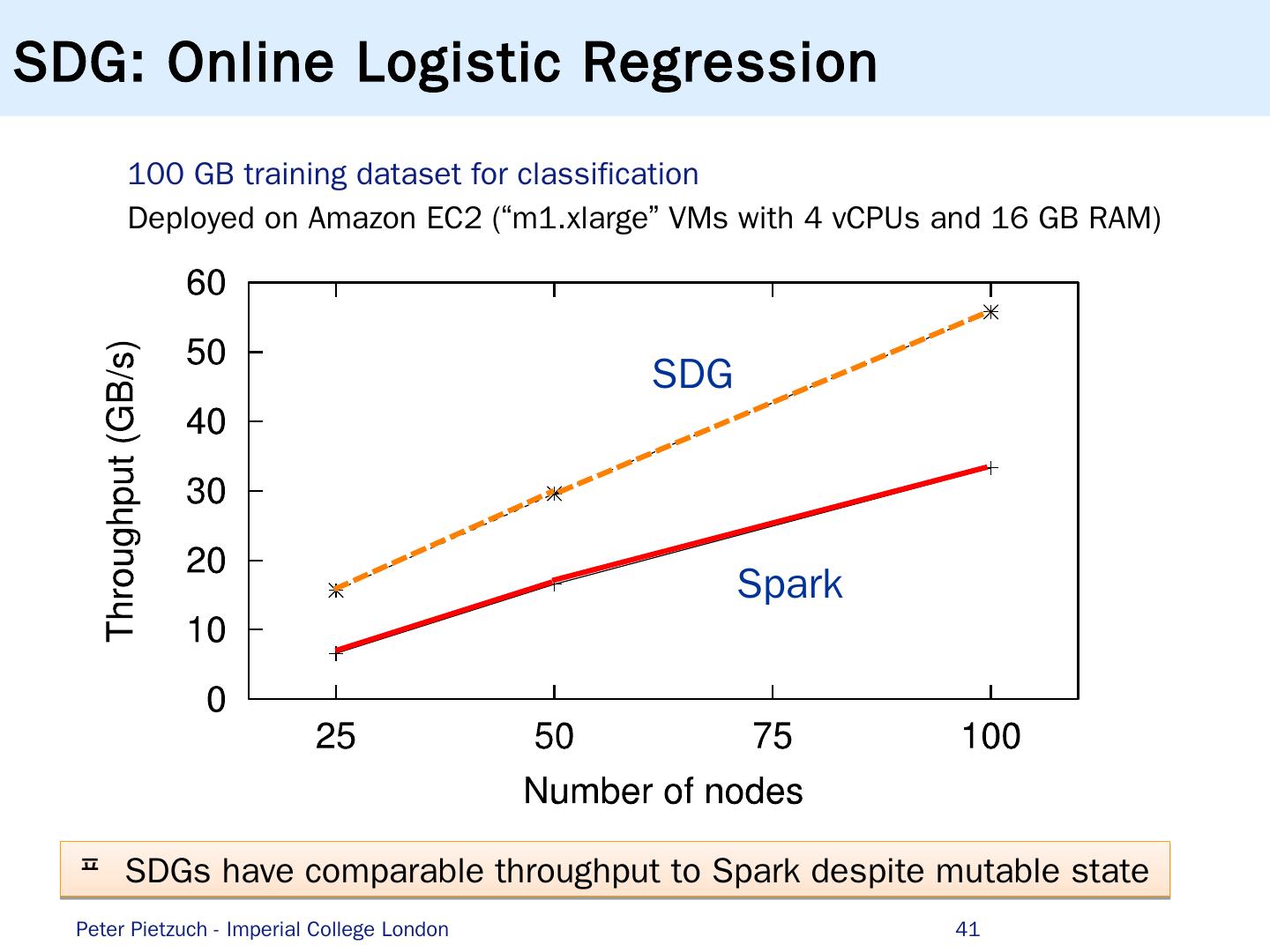


- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Apache Spark - DBOnto
Apache Spark: Micro-Batching. 19. UC Berkeley, SOSP'13. Idea: Reduce size of data partitons to produce up-to-date, incremental results; Micro-batching for ...
展开查看详情
1 .Trends in Scalable Stream Processing: Parallelism & Programmability Peter Pietzuch Large-Scale Distributed Systems Group Department of Computing, Imperial College London http://lsds.doc.ic.ac.uk ATI Oxford Meeting 2016 - London prp@doc.ic.ac.uk
2 .How to Make Sense of Big Data On-The-Fly? More data than ever is… c reated : 2.5 Exabytes (billion GBs) generate each day in 2015 s tored : hard drive cost per GB dropped from $8.93 (2000) to $0.03 (2014) Many new sources of data become available s ensors , mobile devices, cameras w eb feeds, social networking d atabases s cientific instruments 2 Peter Pietzuch - Imperial College London But data value decreases over time …
3 .Real-Time Analysis of Sensed Data 3 Supporting intelligent transportation services Many interested parties Road authorities, traffic planners, emergency services, commuters Analytics queries Intelligent route planning: “What is the best time/route for my commute through central London between 7am-8am?” Emergency response Informing urban planning Peter Pietzuch - Imperial College London
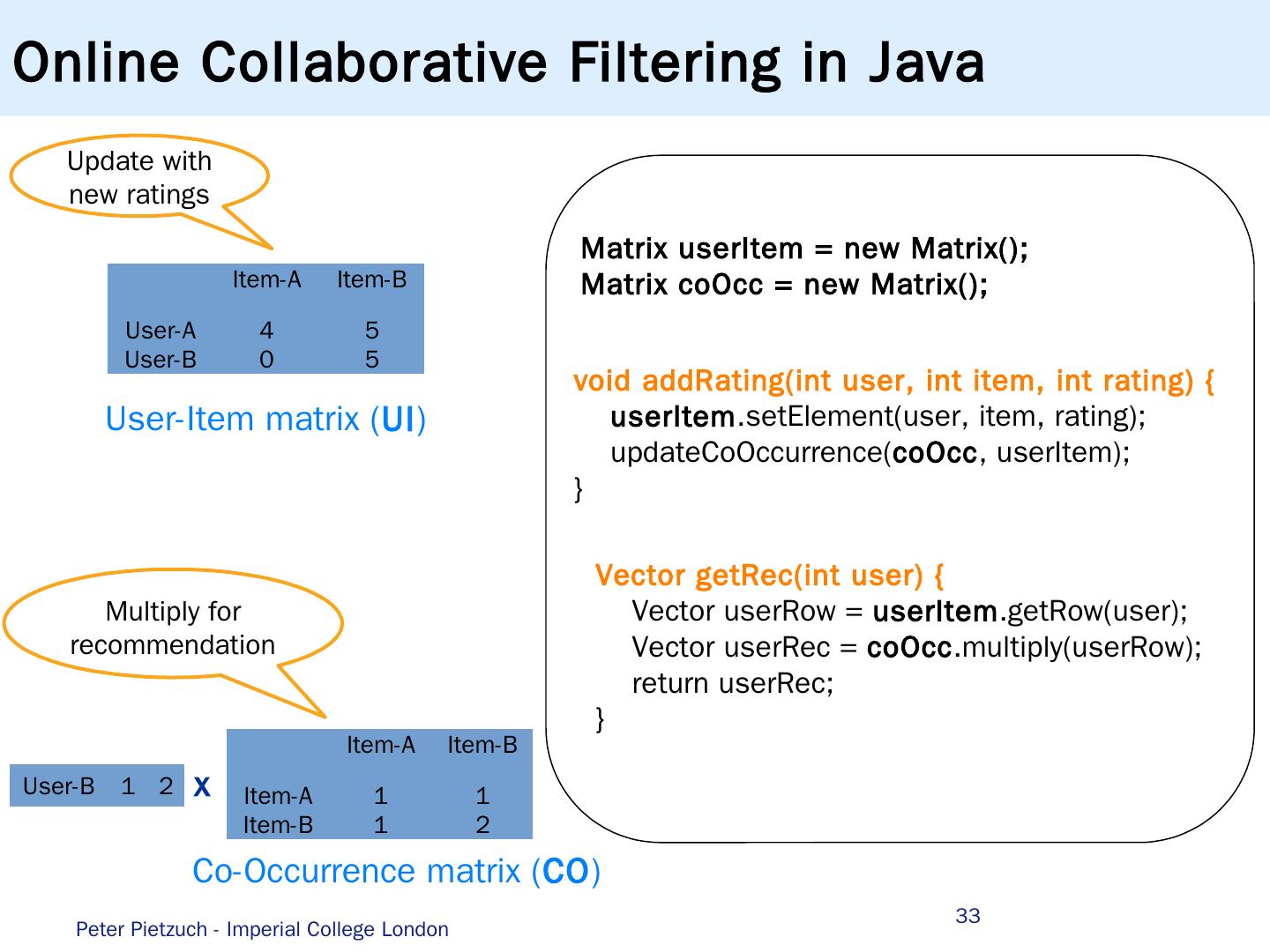
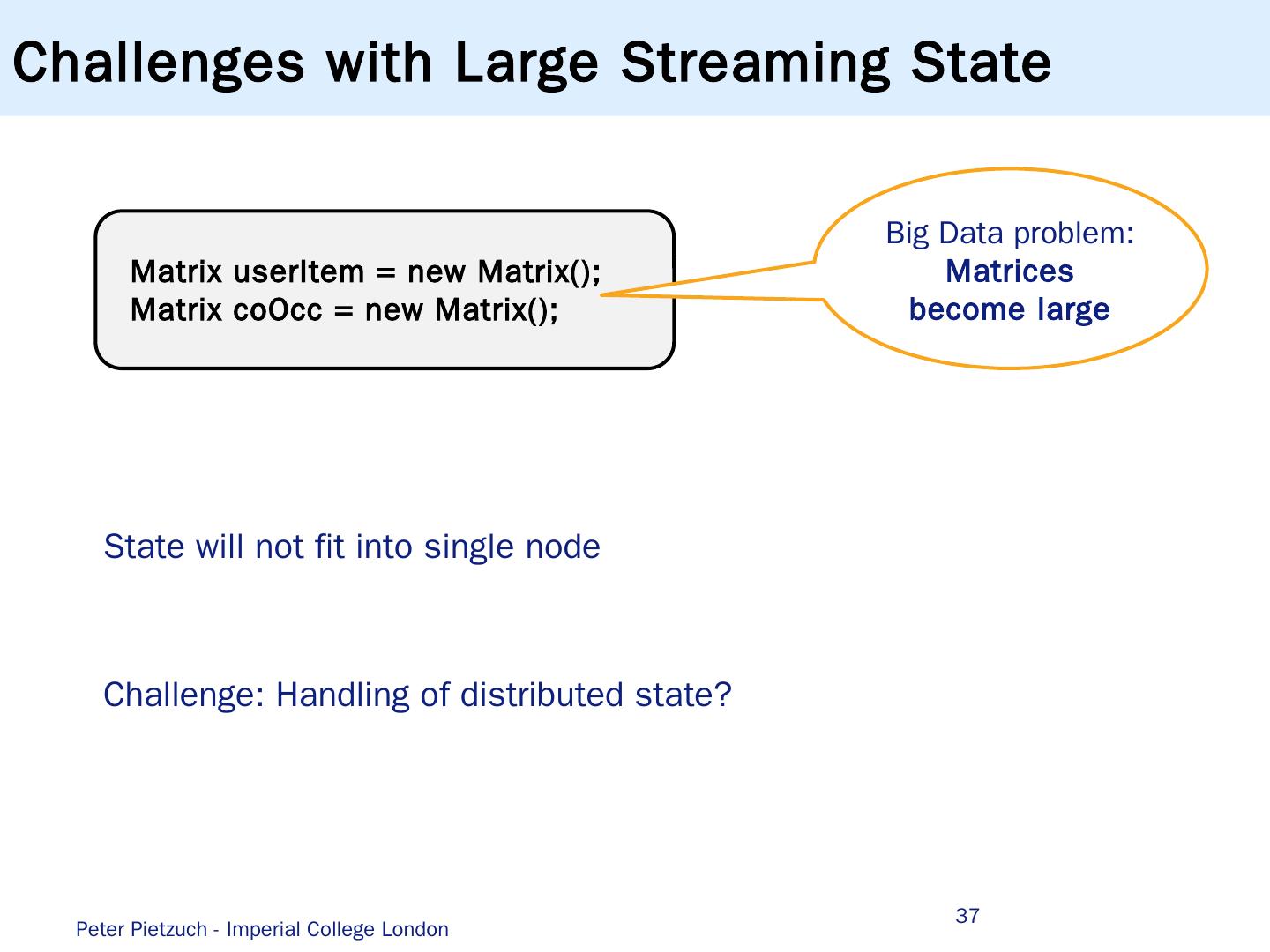
4 .Machine Learning for Web Analytics … f 1 f n y E {−1,1} p redict update Problem: Provide up-to-date predictions regarding which ads to serve Solution : AdPredictor Bayesian online learning algorithm ranks adverts according to click probabilities … Share state Aggregate Iterate … Pre-process Parallelize … Peter Pietzuch - Imperial College London 4
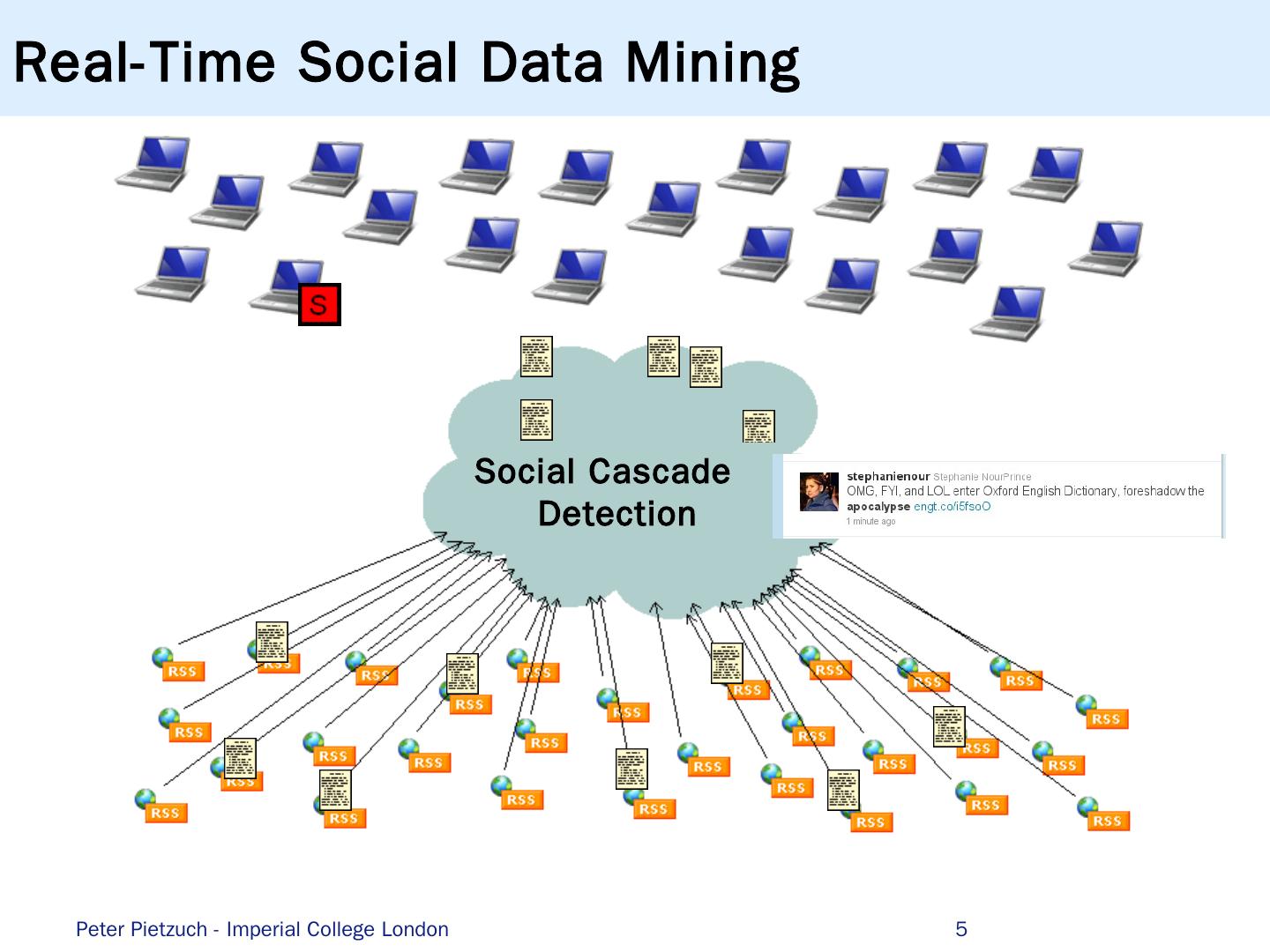
5 .Real-Time Social Data Mining 5 Social Cascade Detection Peter Pietzuch - Imperial College London
6 .Throughput and Latency Matter … High-throughput streams Facebook Insights : Aggregates 9 GB/s < 10 sec latency Google Zeitgeist : 40K user queries/s (1-sec windows) < 1 ms latency Feedzai : 40K credit card transactions/s < 25 ms latency NovaSparks : 150M trade options/s < 1 ms latency Low-latency results Peter Pietzuch - Imperial College London 6
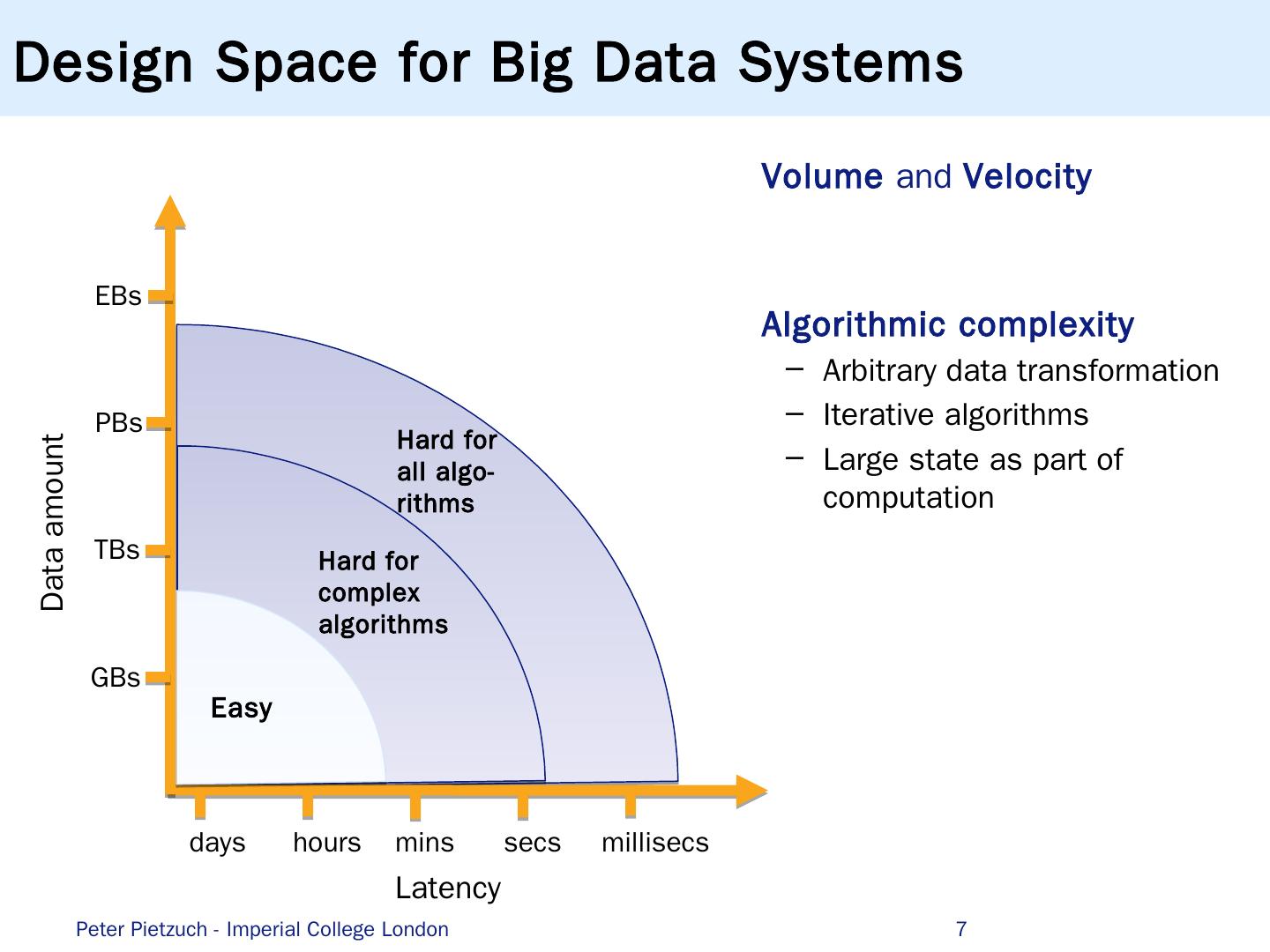
7 .Design Space for Big Data Systems 7 Easy Hard for complex algorithms Hard for all algo - rithms Volume and Velocity Algorithmic complexity Arbitrary data transformation Iterative algorithms Large state as part of computation Latency Data amount GBs T Bs PBs E Bs days hours mins secs millisecs Peter Pietzuch - Imperial College London
8 .Database Centric Processing Doesn’t Work Traditional Database Management System (DBMS) Data relatively static but queries dynamic 8 DBMS Data Queries Results Index Potentially high query latency Updates limited by disk I/O Indices of limited use for fast changing data Peter Pietzuch - Imperial College London
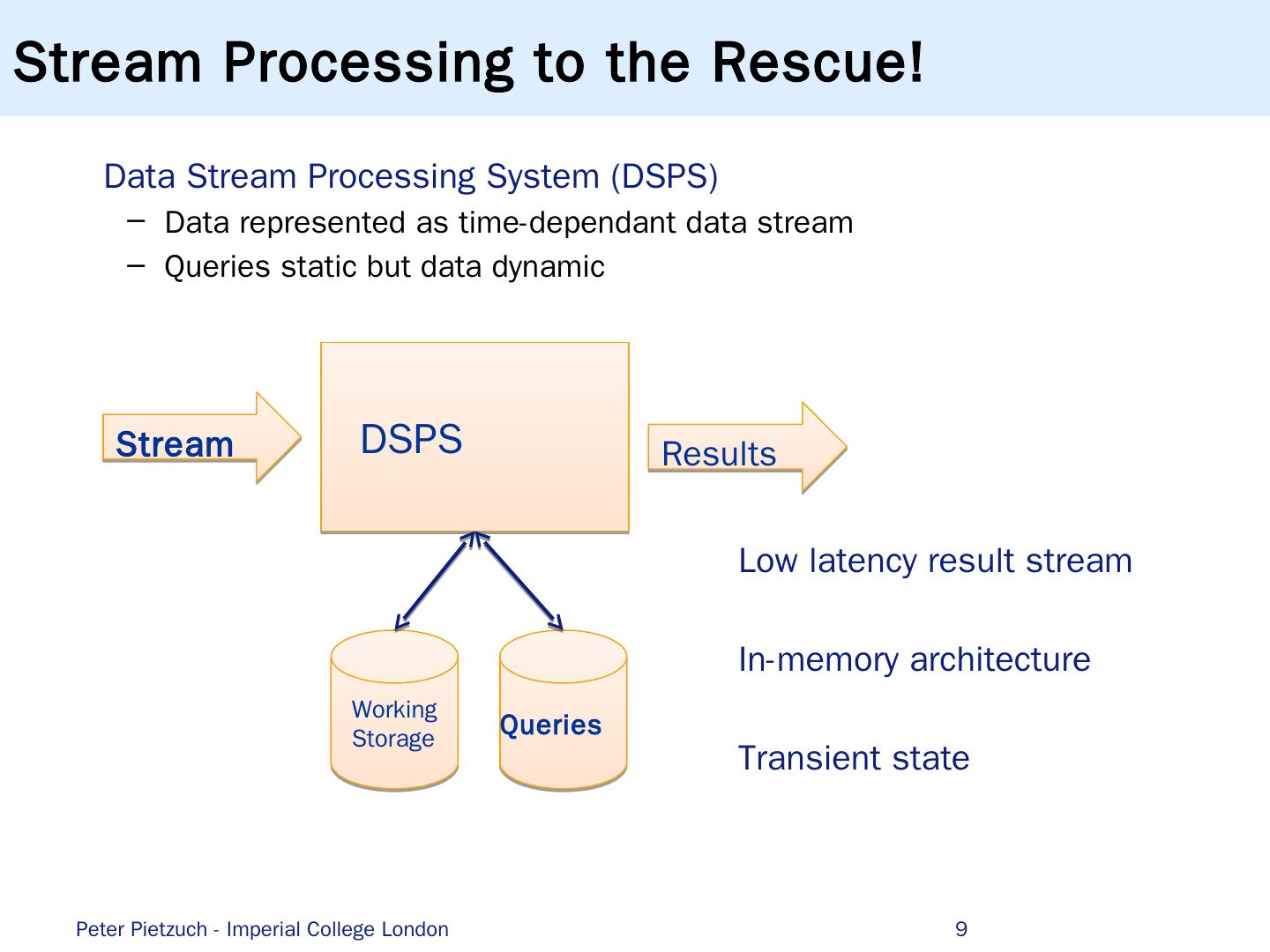
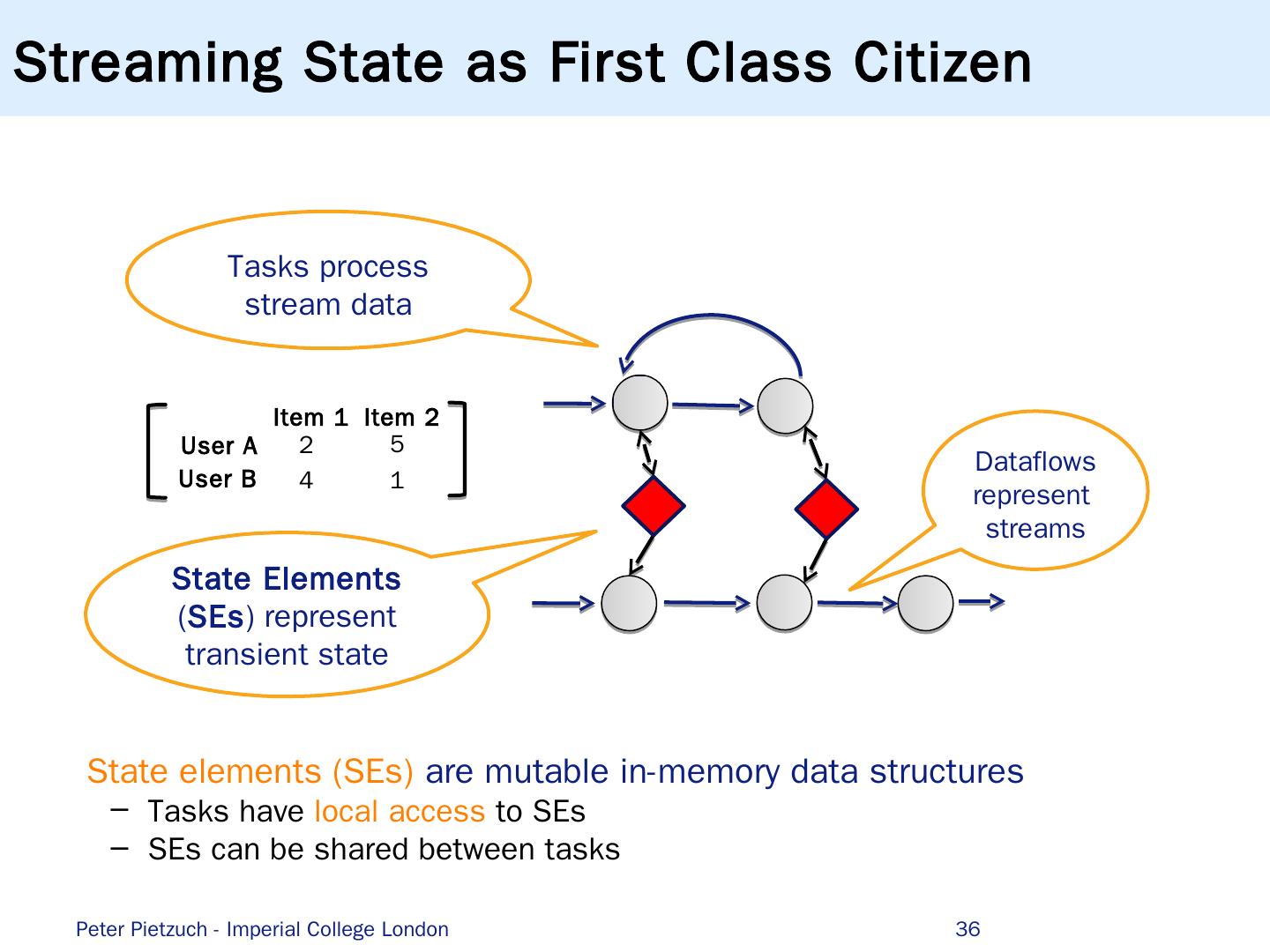
9 .Stream Processing to the Rescue! Data Stream Processing System (DSPS) Data represented as time-dependant data stream Queries static but data dynamic 9 DSPS Queries Stream Results Working Storage Low latency result stream In-memory architecture Transient state Peter Pietzuch - Imperial College London
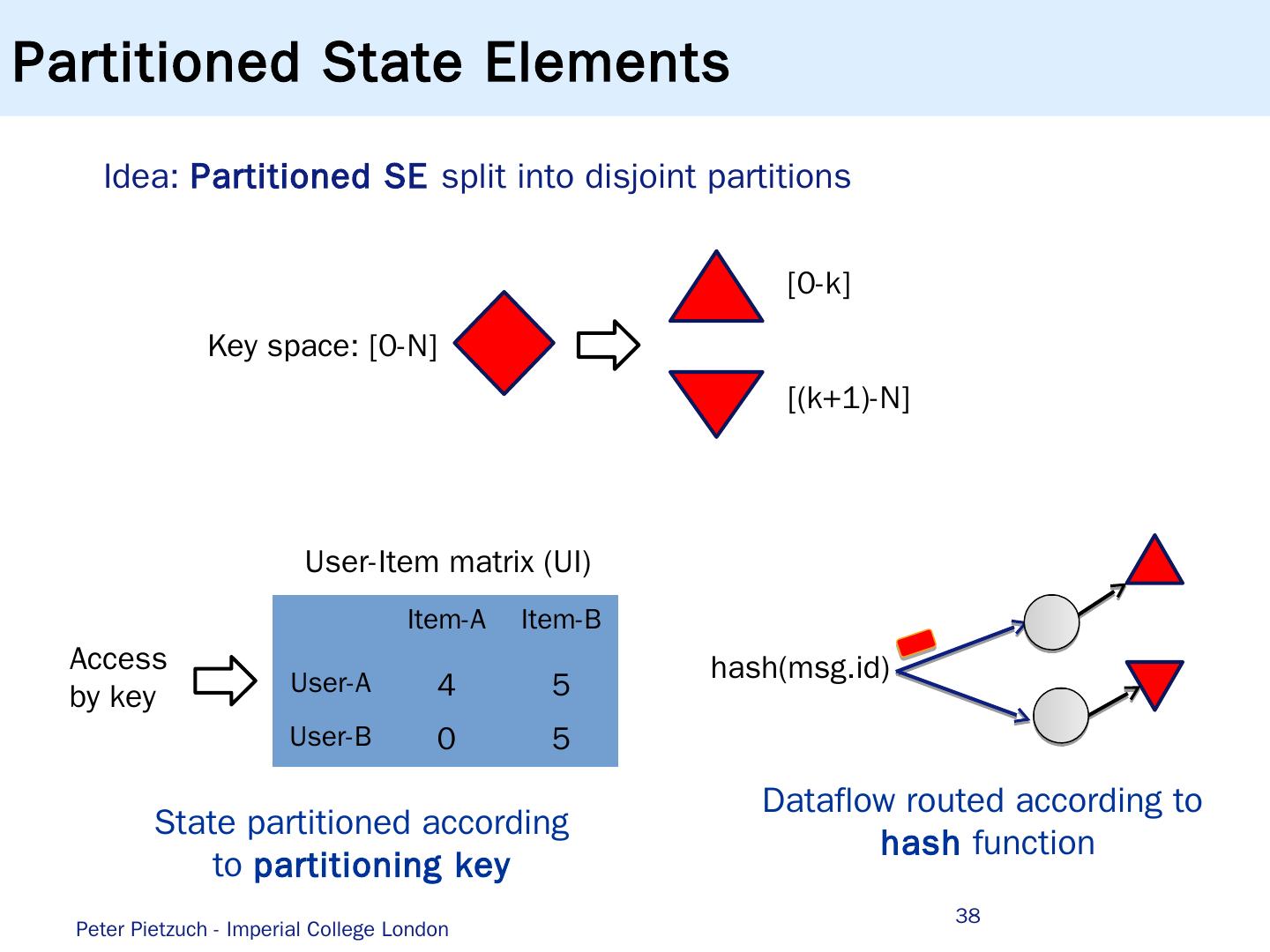
10 .Relational Data Stream Model Streams consist of infinite sequence of tuples Tuples typically associated with timestamp, e.g. arrival time, time of reading, ... Tuples can have fixed relational schema Set of attributes 10 highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed time highway = M25 segment = 42 direction = north speed = 85 Vehicle speed data Sensors data stream Vehicles(highway , segment, direction, speed) t 1 t 2 t 3 t 4 ... Peter Pietzuch - Imperial College London
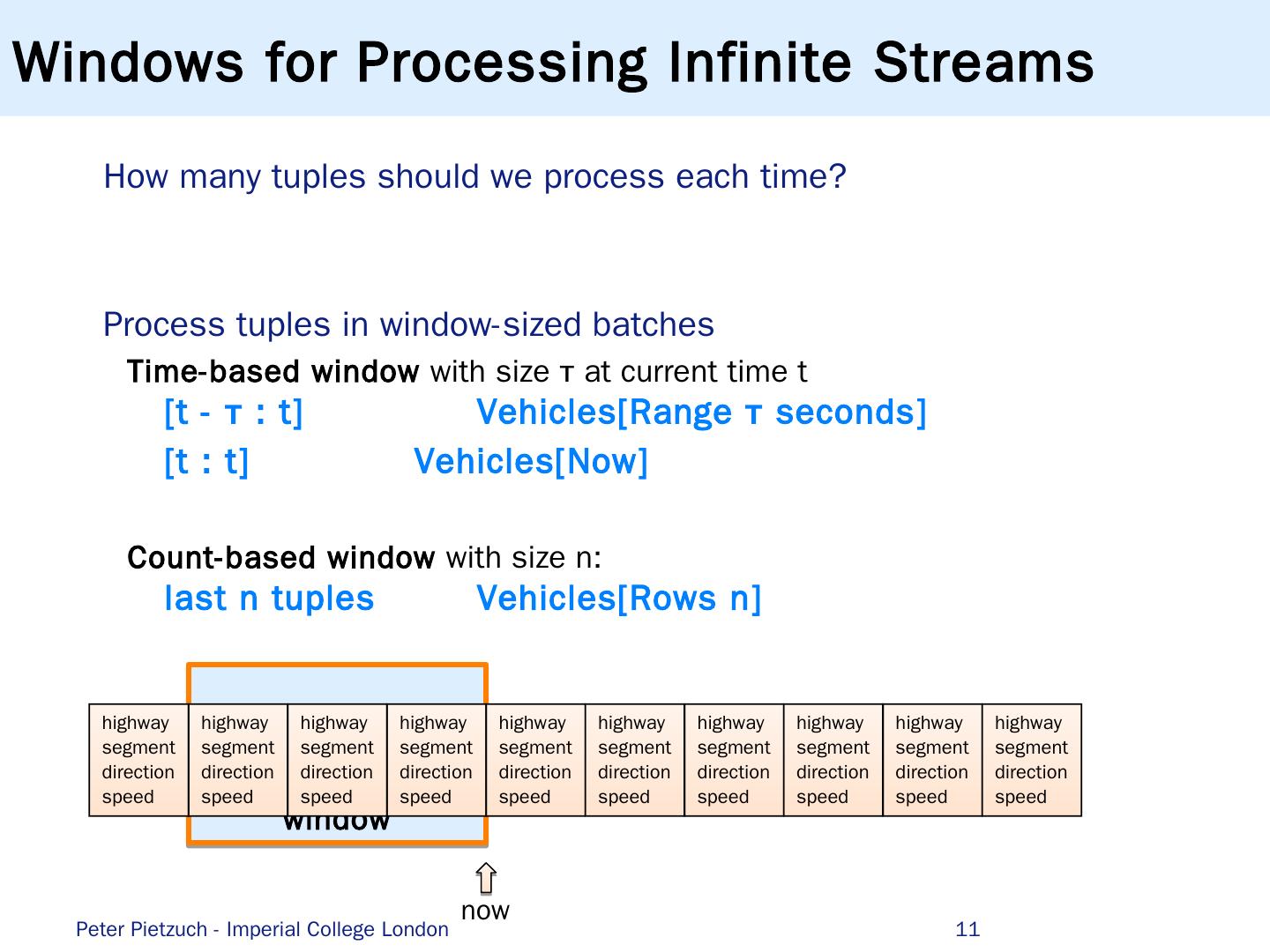
11 .window Windows for Processing Infinite Streams How many tuples should we process each time? Process tuples in window-sized batches Time-based window with size τ at current time t [t - τ : t] Vehicles[Range τ seconds] [t : t] Vehicles[Now] Count-based window with size n: last n tuples Vehicles[Rows n] 11 highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed highway segment direction speed now Peter Pietzuch - Imperial College London
12 .Providing Well-Defined Query Semantics CQL : SQL -based declarative language for continuous queries Based on well-defined relational algebra (select, project, join, …) Example: Identifying slow moving traffic on a highway: Find highway segments with average speed below 40 km/h 12 select highway , segment , direction , AVG ( speed ) as avg from Vehicles [ range 5 seconds slide 1 second ] group by highway , segment , direction having avg < 40 Peter Pietzuch - Imperial College London
13 .Introduction to S tream Processing (1) Scalable and Parallel Stream Processing … …b ut with Principled Query Semantics (2) Streaming Machine Learning Applications … ...but with a Natural Programming Model Conclusions Roadmap Peter Pietzuch - Imperial College London 13
14 .How to Scale Big Data Systems? Use s cale o ut and not s cale u p Commodity multi-core servers Fast network interconnect Data-parallelism is king Software designed for failure 14 Google : over 20 data centre locations over 1 million servers 260 Megawatts (0.01 % of global energy) 4.2 billion searches per day (2011) Exabytes (10 18 ) of storage Peter Pietzuch - Imperial College London
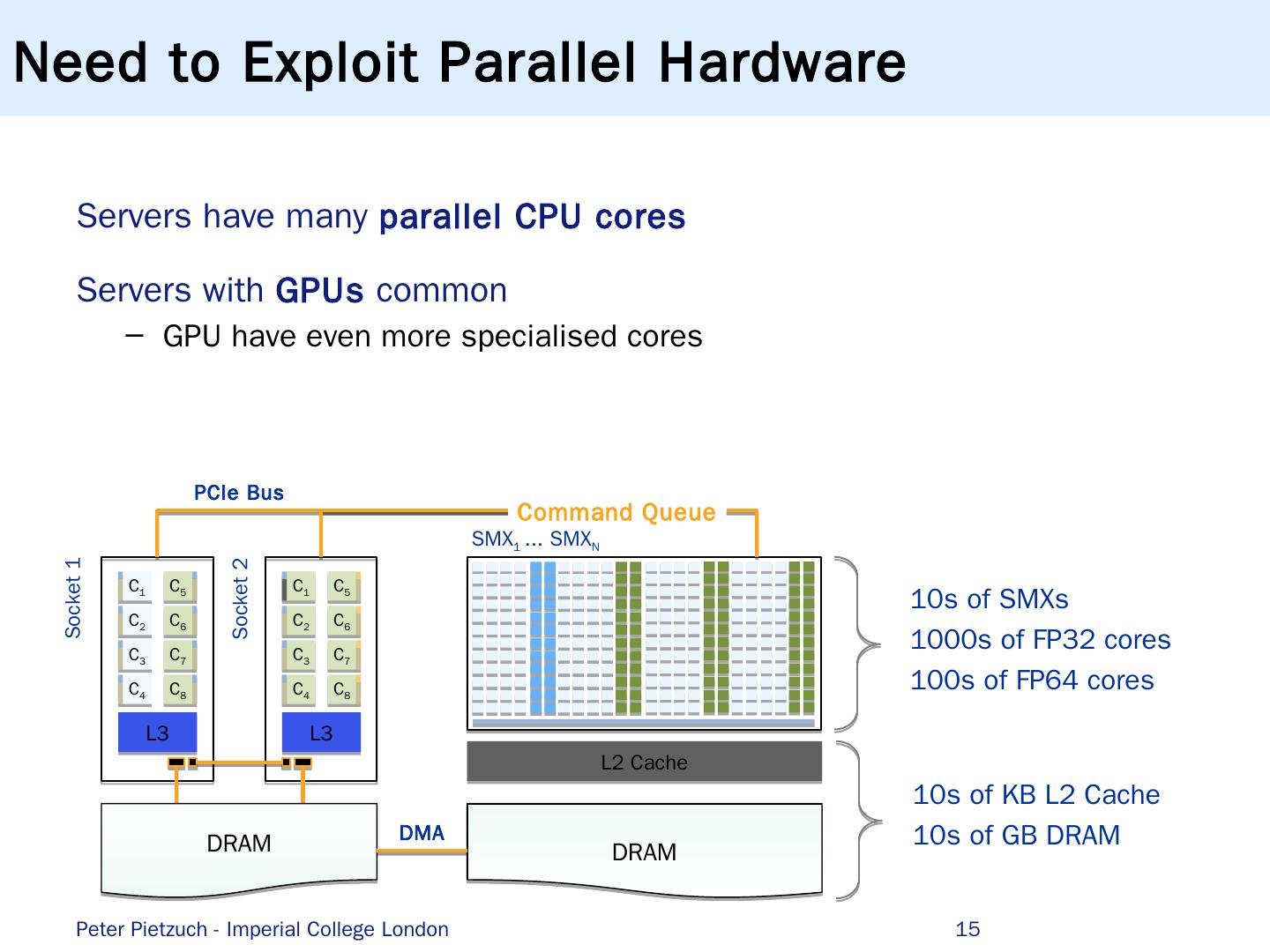
15 .Servers have many parallel CPU cores Servers with GPUs common GPU have even more specialised cores L3 C 1 C 2 C 3 C 4 C 5 C 6 C 7 C 8 L3 C 1 C 2 C 3 C 4 C 5 C 6 C 7 C 8 L2 Cache DRAM DRAM SMX 1 ... S MX N Socket 1 Socket 2 Command Queue PCIe Bus DMA 10s of SMXs 1000s of FP32 cores 100s of FP64 cores 10s of KB L2 Cache 10s of GB DRAM Need to Exploit Parallel Hardware Peter Pietzuch - Imperial College London 15
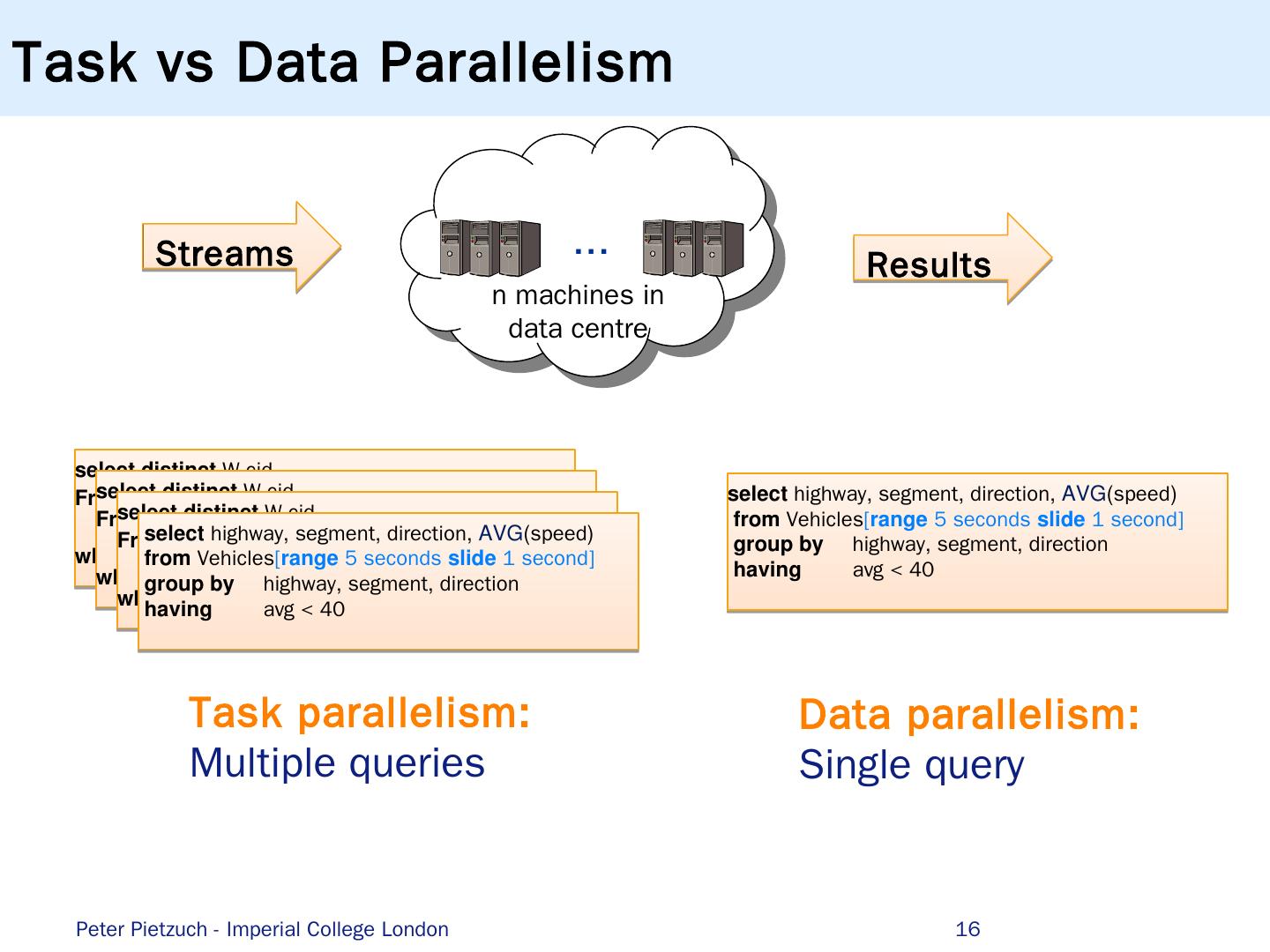
16 .Task vs Data Parallelism 16 Streams ... n machines in data centre Results Peter Pietzuch - Imperial College London select highway , segment , direction , AVG ( speed ) from Vehicles [ range 5 seconds slide 1 second ] group by highway , segment , direction having avg < 40 Task parallelism: Multiple queries Data parallelism: Single query select distinct W . c id From Payments [ range 300 seconds ] as W, Payments [ partition-by 1 row ] as L where W.cid = L.cid and W.region != L .region select distinct W . c id From Payments [ range 300 seconds ] as W, Payments [ partition-by 1 row ] as L where W.cid = L.cid and W.region != L .region select distinct W . c id From Payments [ range 300 seconds ] as W, Payments [ partition-by 1 row ] as L where W.cid = L.cid and W.region != L .region select highway , segment , direction , AVG ( speed ) from Vehicles [ range 5 seconds slide 1 second ] group by highway , segment , direction having avg < 40
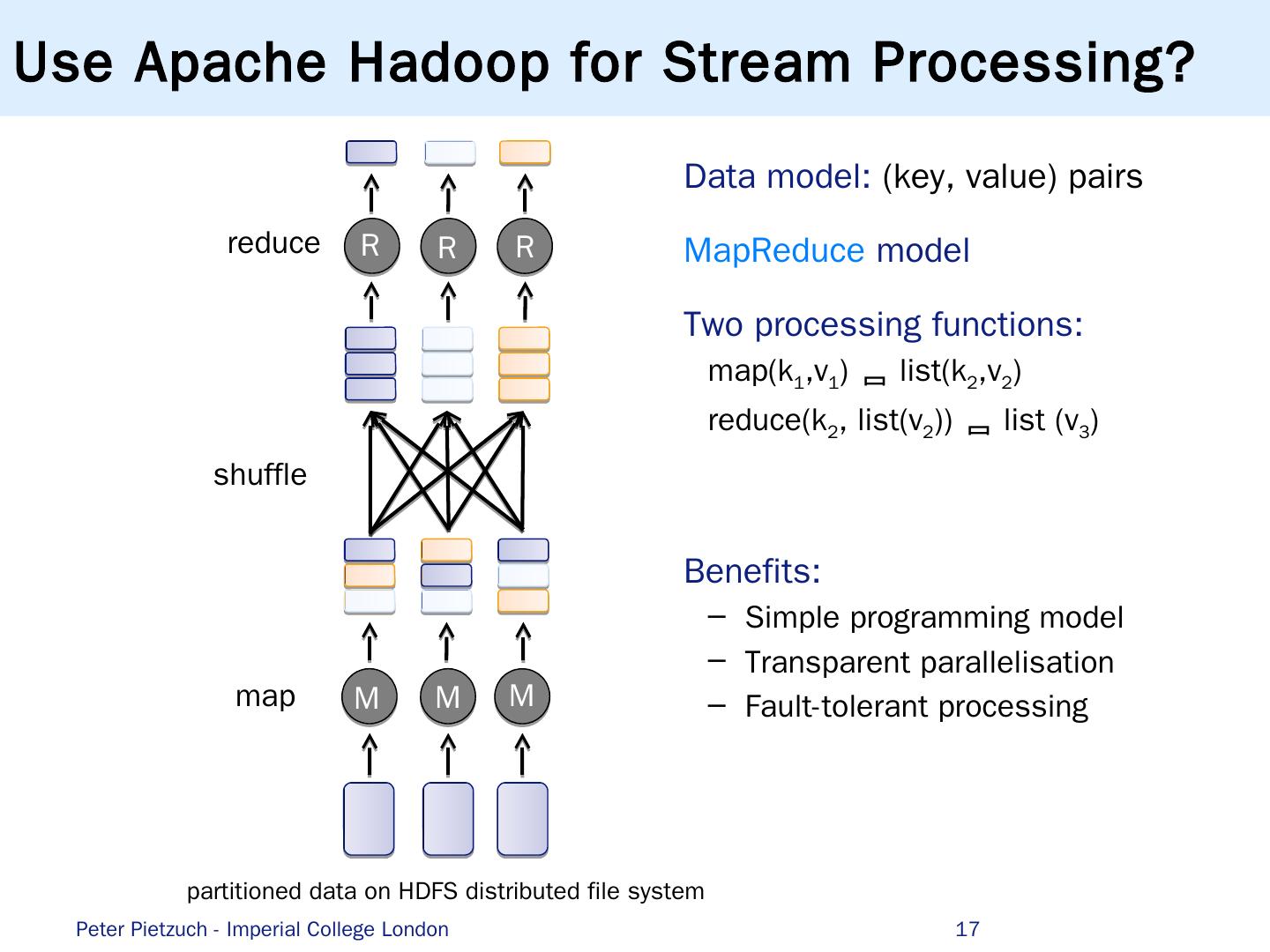
17 .Use Apache Hadoop for Stream Processing? 17 Data model: (key, value) pairs MapReduce model Two processing functions: map(k 1 ,v 1 ) list(k 2 ,v 2 ) reduce(k 2 , list(v 2 )) list (v 3 ) Benefits: Simple programming model Transparent parallelisation Fault-tolerant processing map reduce shuffle partitioned data on HDFS distributed file system M M M R R R Peter Pietzuch - Imperial College London
18 .Executing Hadoop Jobs on Cluster 18 Map/reduce tasks scheduled across cluster nodes Shuffle phase (repartitioning) introduces synchronisation barrier M M M R R R MapReduce is a batch processing model … Peter Pietzuch - Imperial College London
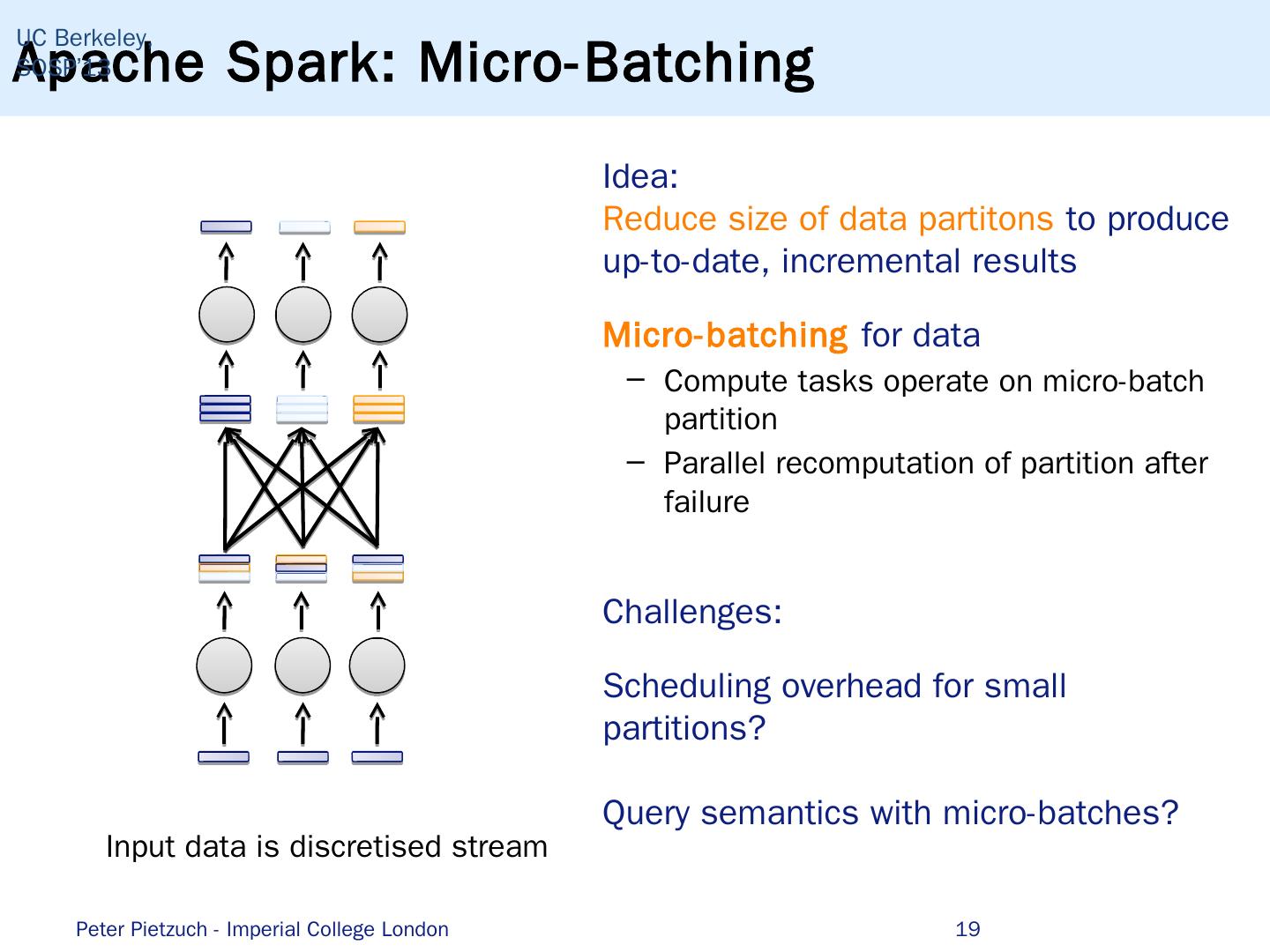
19 .Apache Spark: Micro-Batching 19 UC Berkeley, SOSP’13 Idea: Reduce size of data partitons to produce up-to-date, incremental results Micro-batching for data Compute tasks operate on micro-batch partition P arallel recomputation of partition after failure Challenges: Scheduling overhead for small partitions? Query semantics with micro-batches? Input data is discretised stream Peter Pietzuch - Imperial College London
20 .Apache Storm: Pipelined Dataflows 20 Idea: Materialise tasks in dataflow graph to avoid scheduling overhead Many systems do this, e.g. Apache Storm, Apache Flink , SEEP, Google Dataflow, … Challenges: Allocation of tasks to nodes? Failure recovery? Peter Pietzuch - Imperial College London
21 .Latency Impact of Micro-Batches Streaming word count of text data Deployed on 4 nodes (4-core 3.4 Ghz Intel Xeon with 8 GB RAM) 21 SEEP Peter Pietzuch - Imperial College London
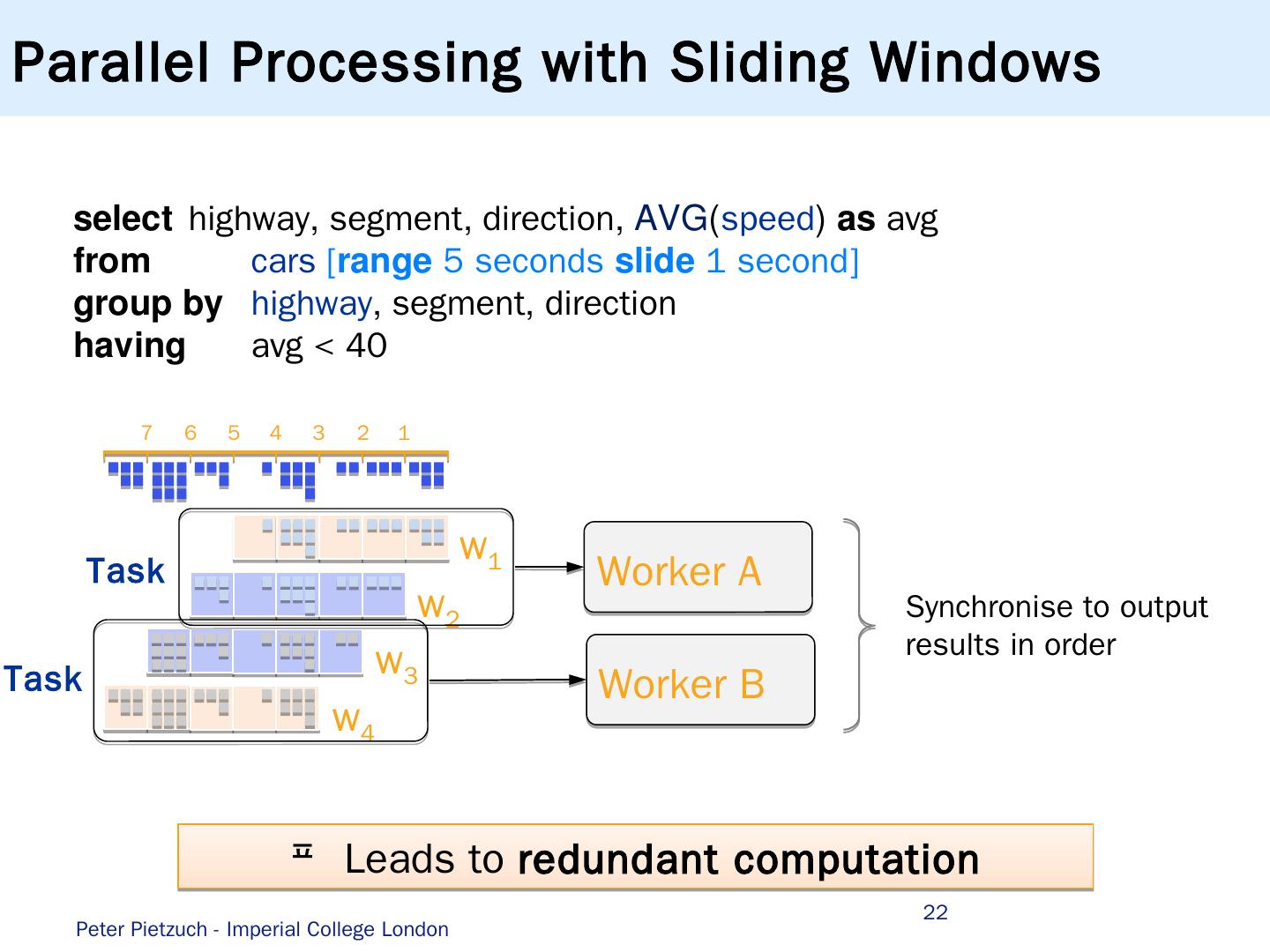
22 .22 select highway , segment , direction , AVG ( speed ) as avg from cars [ range 5 seconds slide 1 second ] group by highway , segment , direction having avg < 40 1 2 3 4 5 6 7 w 1 w 2 w 3 w 4 Worker B Worker A Synchronise to output results in order Task Task Parallel Processing with Sliding Windows Leads to redundant computation Peter Pietzuch - Imperial College London
23 .No Redundant Computation with Panes Pane: smallest unit of parallelism without data dependencies based on window semantics Pane size = gcd (window size, slide) 1 2 3 4 5 6 7 p 1 p 2 p 3 p 4 p 5 p 6 p 7 p 8 Panes can be processed in parallel Window results assembled by panes results Peter Pietzuch - Imperial College London 23
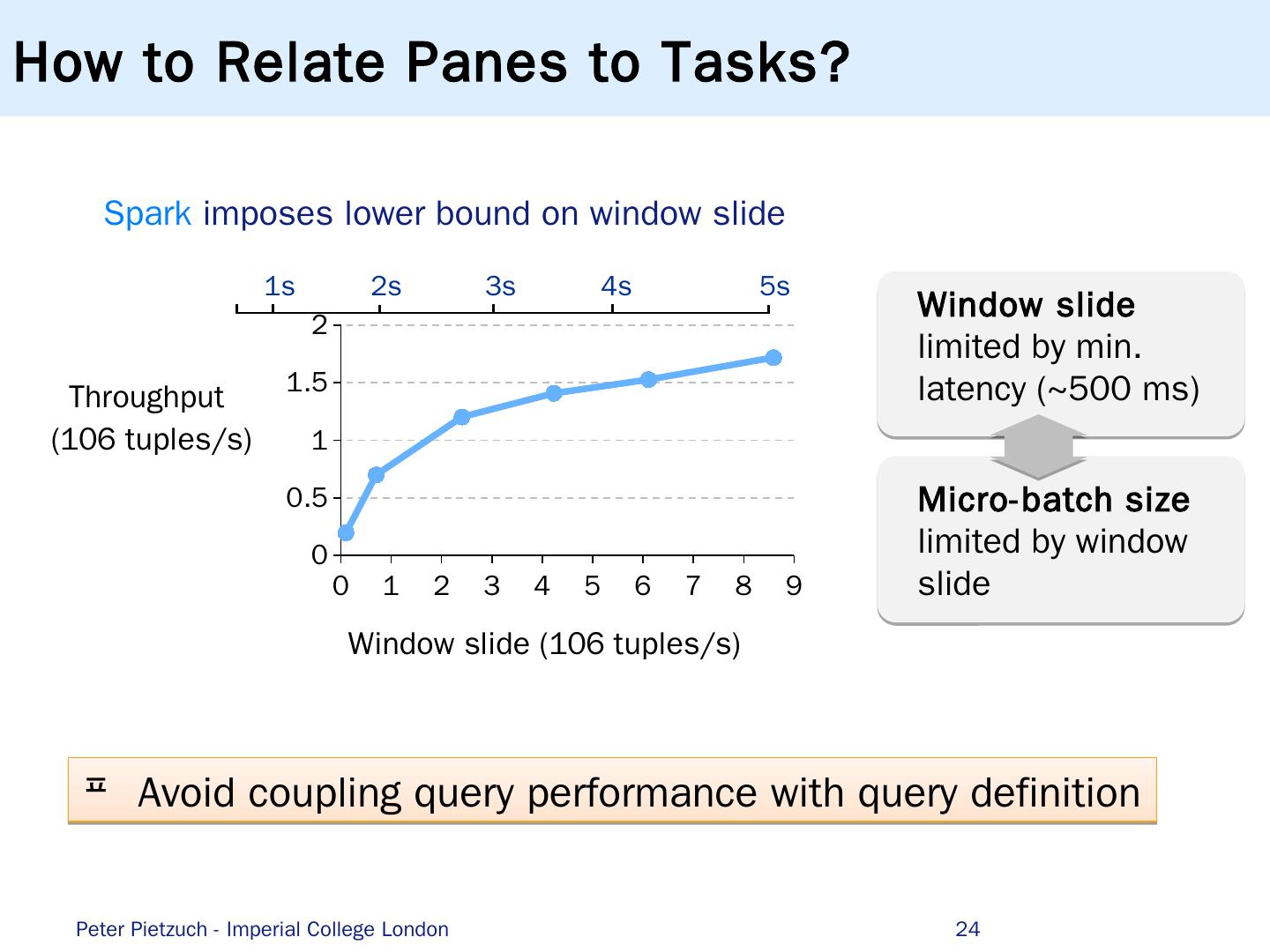
24 .How to Relate Panes to Tasks? Spark imposes lower bound on window slide 24 1s 2 s 3 s 4 s 5 s Window slide limited by min. latency (~500 ms ) Micro- batch size limited by window slide Peter Pietzuch - Imperial College London Avoid coupling query performance with query definition
25 .SABER: Window Fragment Model Idea: Decouple task size from window size/slide e .g. 5 tuples/task, window size 7 rows, slide 2 rows 25 10 9 8 7 6 5 4 3 2 1 15 14 13 12 11 w 1 w 2 w 3 w 4 w 5 T 1 T 2 T 3 w 1 w 2 w 3 w 4 w 5 Task contains one or more window fragments Closing/pending/opening windows in T 2 Workers can process fragments incrementally Imperial, SIGMOD’16 Peter Pietzuch - Imperial College London
26 .Merge Window Fragment Results Idea: Decouple task size from window size/slide Assemble window fragment results O utput them in correct order 26 Worker B : T 2 w 1 w 2 w 3 w 4 w 5 Worker A: T 1 w 1 w 2 w 3 w 1 result w 2 result Result Stage Slot 2 Slot 1 Empty Empty Output result circular buffer Worker B stores T 2 results and exits (nothing to forward) Worker A stores T 1 results, merges window fragment results and forwards complete windows downstream Peter Pietzuch - Imperial College London
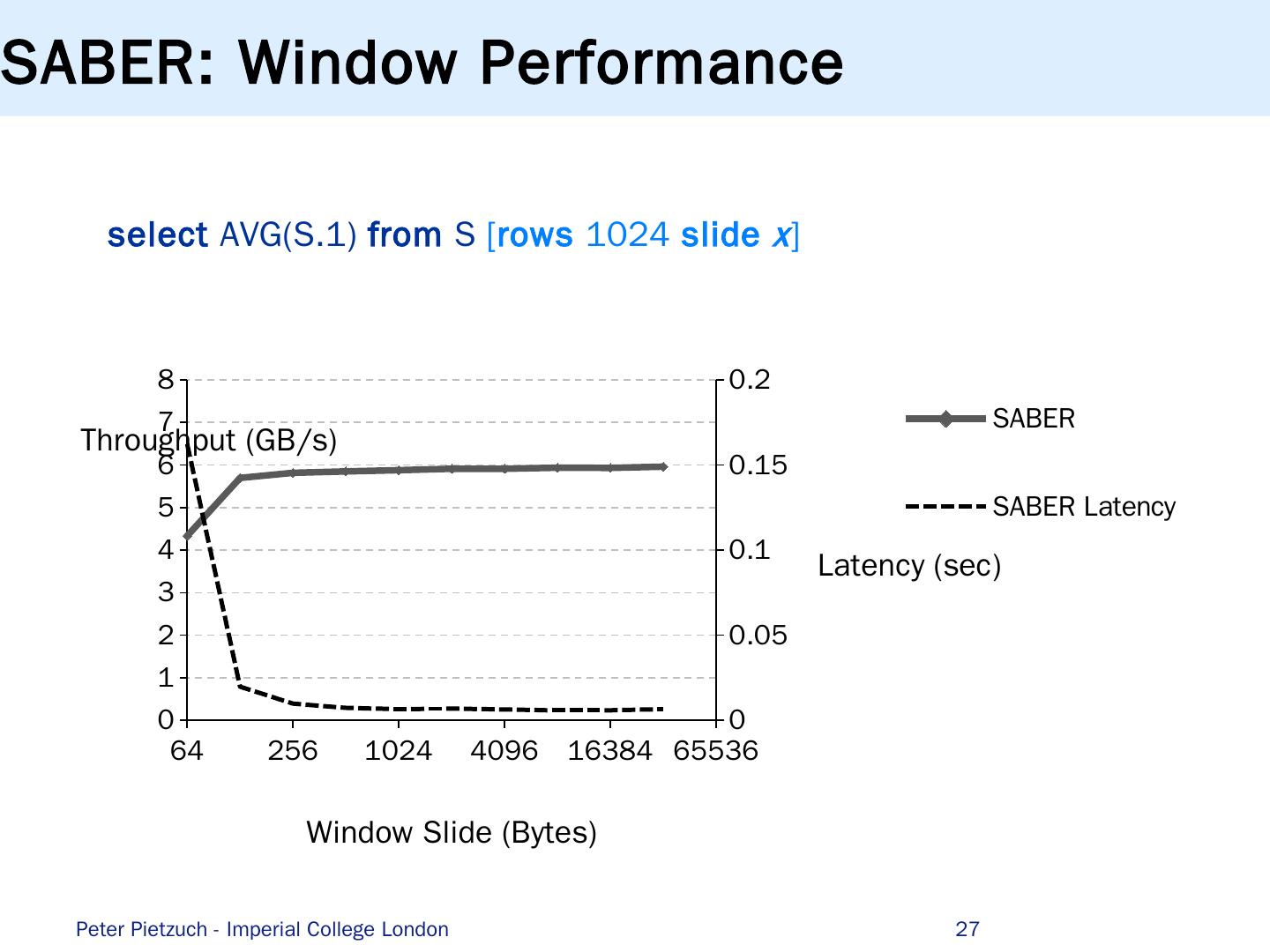
27 .SABER: Window Performance s elect AVG(S.1) from S [ rows 1024 slide x ] Peter Pietzuch - Imperial College London 27
28 .Introduction to S tream Processing (1) Scalable and Parallel Stream Processing … …b ut with Principled Query Semantics (2) Streaming Machine Learning Applications … ...but with a Natural Programming Model Conclusions Roadmap Peter Pietzuch - Imperial College London 28
29 .Democratising Big Data Analytics 29 Need to enable more users to do (streaming) analytics … Peter Pietzuch - Imperial College London
3秒后跳转登录页面
去登陆

