






































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
自动化大数据平台报告调研“Reserch for Automation big data platform”_Infoworks
基于Infoworks 的自动化大数据调研报告
展开查看详情
1 .Automated Data Engine Prepared by: Kaniel 2019/4/4
2 .研究报告合作请联系
3 .Agenda • Technical Scope • Industry Application • Implement Plan • Reference • Q&A
4 . Data Engineering Plataform For End-to-End Big Data Automation
5 .Chapter ONE 壹. The Autonomous Data Engine 贰. Automated Data Ingestion 叁. Automated Data Transformation and Preparation 肆. Automated Data Modeling and OLAP Cubes for Big Data 伍. DataOps and Data Governance
6 . Autonomous Data Engine -Any Source, Any Big Data Platform, Any Analytics- Any Source Autonomous Data Engine Any Analytics Metadata Register,Platform&Data ApI Business Relational Orchestration and Production Data Ops Management Intelligence Data Ingestion Data Models,Cubes &Synch Data Prep: &In-Memory Models Transformation HDFS/Hive &Pipeline Design Advanced Analytics Workload Migration Integration DataScience AI&Machine Cloud Compute - Storage Independence & Optimization Learning Row Data - Current&Historical Data - Data Model - In Memory Models - Cubes Streaming Any Big Data Data Infrastructure
7 .⾃自动化数据提取 -For batch and streaming- ⾃自动化元数据同步 ⾃自动化数据同步 ⾃自动抓取数据源 持续同步 ⽂文件、XML、JSON、RDB log & queue based 元数据可查询 ⽀支持Schema 变更更 数据摄取⾃自动化 ⾃自动判别数据源 根据元数据信息 ⽀支持同步和导出 批量量 & 增量量 ⽆无码环境 多种数据源 批量量、流式、更更改数据捕获⽅方式 本机连接器器 - - ⾼高性能并⾏行行提取 保持数据精度
8 . ⾃自动化数据提取 -For batch and streaming- ⽆无代码提取配置 可扩展的并⾏行行化数据提取 增量量数据的同步与合并 数据类型转换 Schema 更更改监测与传递 流数据
9 . ⾃自动化数据仓库卸载 & 迁移 - Migrate from legacy data warehouses like Teradata and Netezza to the cloud & big data in days - 避免在数据仓库迁移中的错综复杂 • ⾃自动将数据从Teradata和Netezza等DW及其上游源复制到 适⽤用于所有⼯工作负载的⾃自动化,可重复且⼀一致的 ⼤大数据和云 流程. • ⾃自动将传统转换逻辑和ETL过程迁移到易易于维护的可视化 ⼯工作流程中 • ⾃自动将旧DW查询的翻译和优化⾃自动化到⼤大数据和云 • 将数据仓库⽤用例例迁移到⼤大数据和云环境的完整解决⽅方案 ⼯工作负载迁移到易易于维护的优化数据⼯工作流程. 消除了了对稀缺和专业资源的需求。
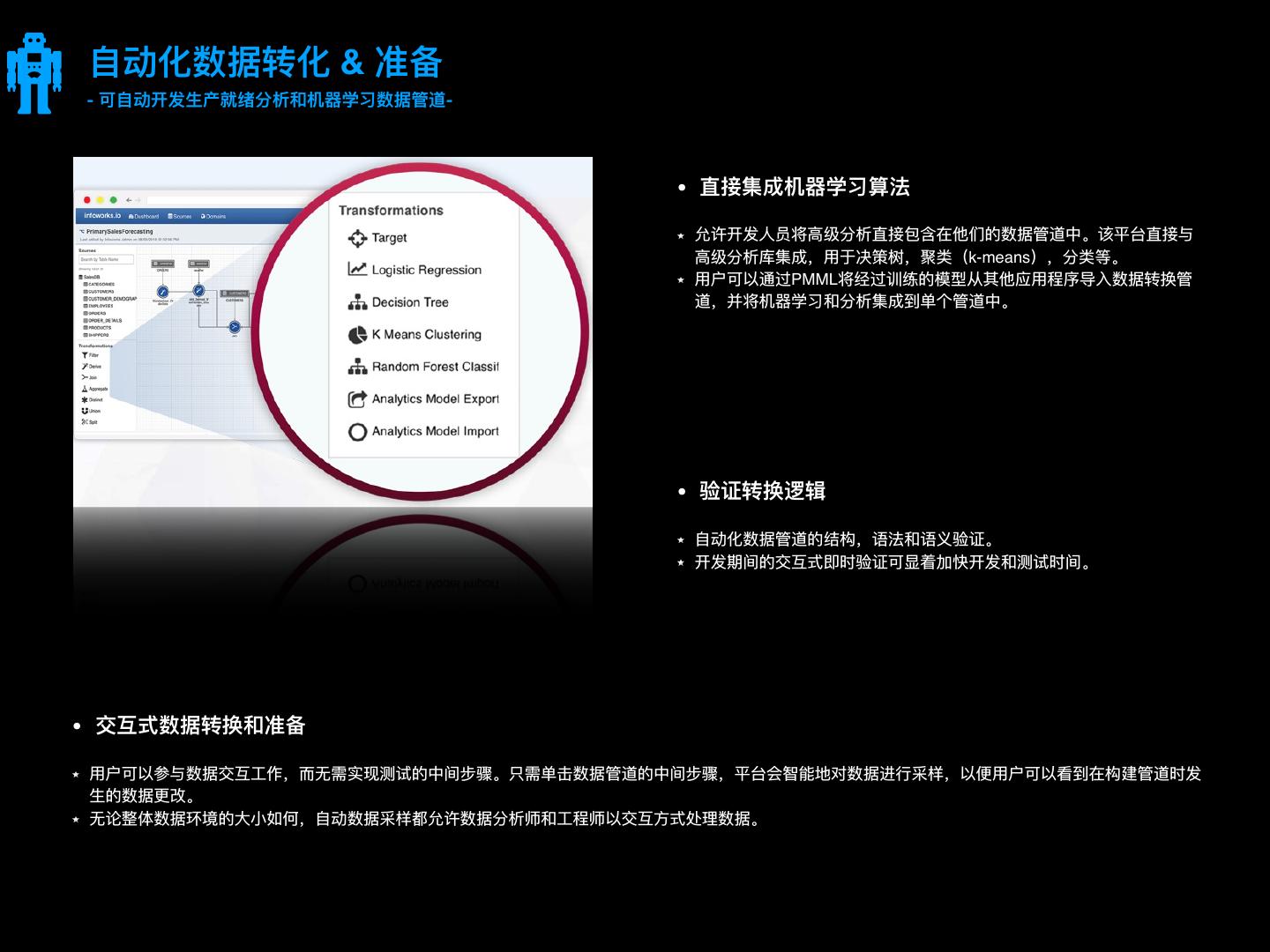
10 .⾃自动化数据转化 & 准备 -For Infoworks automates the development of production -ready analytics and machine leaning data pipelines- ⽤用于分析的⾃自助数据准备 • ⾃自助数据准备界⾯面提供交互式拖放数据转换功能, ⽀支持基于SQL和其他转换。 • ⽤用户通过基于建议的协作界⾯面以交互⽅方式处理理数 据,从⽽而减少或消除对IT技能的依赖。 • 使⽤用敏敏捷数据⼯工程平台创建的机器器学习和分析数据 管道可以在所有流⾏行行的⼤大数据环境中⼤大规模运⾏行行, ⽆无需重新编码 ⾃自动转换SQL⼯工作负载 集成机器器学习算法 通过将SQL⾃自动转换为易易于维护,优化,可移植,可视 • 开发⼈人员可以将⾼高级分析直接包含在他们的数据管道中。平台直接 • 与⾼高级分析库集成,例例如决策树,聚类(k-means),分类等。 化的数据转换管道,可以显着加速迁移旧数据仓库作 • ⽤用户还可以通过PMML将经过训练的模型从其他应⽤用程序直接导⼊入 业。 到他们的数据转换管道中。
11 . ⾃自动化数据转化 & 准备 - 可⾃自动开发⽣生产就绪分析和机器器学习数据管道- ⽤用于开发数据管道的⽆无码 环境 • Infoworks为开发分析和机器器学 习数据管道提供了了拖放环境。 • ⽆无需Hadoop或Spark知识即可 创建可扩展且⾼高度调整的数据 ⾃自动⽣生成增量量数据管道 管道。 将SQL⾃自动转换为⼤大数据管道 促成从开发到⽣生产的数据管道 经典ETL⼯工具要求⽤用户单独编码数据管道以进 • ⾏行行完整和增量量数据加载。 • Infoworks使添加增量量管道的过程就像点击按钮 • 通过将SQL⾃自动转换为易易于维护,优化,可 • Infoworks内置的数据管道可以⽴立即集成到端到 ⼀一样简单。在后台⾃自动⽣生成增量量数据管道。 端⼯工作流程中,并在⽣生产环境中运⾏行行,⽆无论是 移植,可视化的数据转换管道。 在本地还是在云中,⽆无需更更改任何代码。 • 显着加速迁移旧数据仓库作业。 • 管道构建为作为⼯工作流程的⼀一部分完全控制, 启动,停⽌止或暂停,并根据执⾏行行环境的⼤大⼩小⾃自 动扩展。 • Infoworks业务流程层还会⾃自动监控数据管道的 性能。 依赖管理理 • Infoworks管理理端到端数据依赖性,从数 据源的数据摄取开始,⼀一直到⾼高性能数 据模型的⽣生成。 跨执⾏行行引擎的⽆无缝可以治性 • 从源加载表后,依赖管道将开始构建。 管道将⾃自动等待依赖表加载和⾃自动恢 复。 • Infoworks数据管道提供了了内部和云端所有 主要分布式数据执⾏行行环境的可移植。 • Infoworks抽象底层执⾏行行引擎并⾃自动优化不不 同的后端(Hive,Spark等)。因此, Infoworks的可视化数据流⽔水线既便便携⼜又⾼高 性能,⽆无需重新编码。 数据管道优化 • Infoworks视觉设计师⼤大⼤大简化了了数据管 道的开发。但是,还必须调整数据管道 以执⾏行行,扩展并随后满⾜足服务级别协议 (SLA)。 • Infoworks⾃自动优化管道构建以满⾜足 SLA,⽽而⽆无需⼤大数据调整专家。因此, 使⽤用Infoworks创建的数据管道⽐比⼿手动编 写的SQL或HQL快25-40%
12 . ⾃自动化数据转化 & 准备 - 可⾃自动开发⽣生产就绪分析和机器器学习数据管道- • 直接集成机器器学习算法 允许开发⼈人员将⾼高级分析直接包含在他们的数据管道中。该平台直接与 ⾼高级分析库集成,⽤用于决策树,聚类(k-means),分类等。 ⽤用户可以通过PMML将经过训练的模型从其他应⽤用程序导⼊入数据转换管 道,并将机器器学习和分析集成到单个管道中。 • 验证转换逻辑 ⾃自动化数据管道的结构,语法和语义验证。 开发期间的交互式即时验证可显着加快开发和测试时间。 • 交互式数据转换和准备 ⽤用户可以参与数据交互⼯工作,⽽而⽆无需实现测试的中间步骤。只需单击数据管道的中间步骤,平台会智能地对数据进⾏行行采样,以便便⽤用户可以看到在构建管道时发 ⽣生的数据更更改。 ⽆无论整体数据环境的⼤大⼩小如何,⾃自动数据采样都允许数据分析师和⼯工程师以交互⽅方式处理理数据。
13 . ⾃自动数据建模&OLAP多维数据集 - Infoworks通过创建内存数据模型和OLAP多维数据集⼤大⼤大加快了了查询性能 - 拖放OLAP多维数据集创建 查询优化 ⾃自动更更新数据模型和多维数据集 • ⽤用户可以直观地设计star/snowflake • 数据湖Schema会因上游变化⽽而⾃自动更更新。 • 通过查询接⼝口⼤大⼤大加速了了⼤大数据查询,这些 schemas,并构建⾼高性能的OLAP多维数 • ⽆无论更更改是添加新源列列,更更改数据捕获内容 接⼝口⽀支持商业智能,数据科学,临时和批量量 据集。 更更新还是修改转换逻辑,更更改都可以⾃自动传 的各种分析⽤用例例。 • 数据分析师可以拖放事件、维度和度量量。 播到下游数据Schema。 • 对于BI分析,报告和仪表板样式⽤用例例,多维 在⼤大数据平台上⾃自动构建完全预聚合和优 数据集提供亚秒级和交互式响应时间。 化的多维数据集,为⼤大多数⽤用户查询提供 • 对于即席查询,内存加速模型可以快速访问 亚秒响应时间。 各种⽤用例例的粒度数据,⽽而批处理理⽤用例例可以从 优化的数据模型中受益。 • Infoworks提供这些多层查询加速,为每个⽤用 例例提供正确的性能和可伸缩性特征。
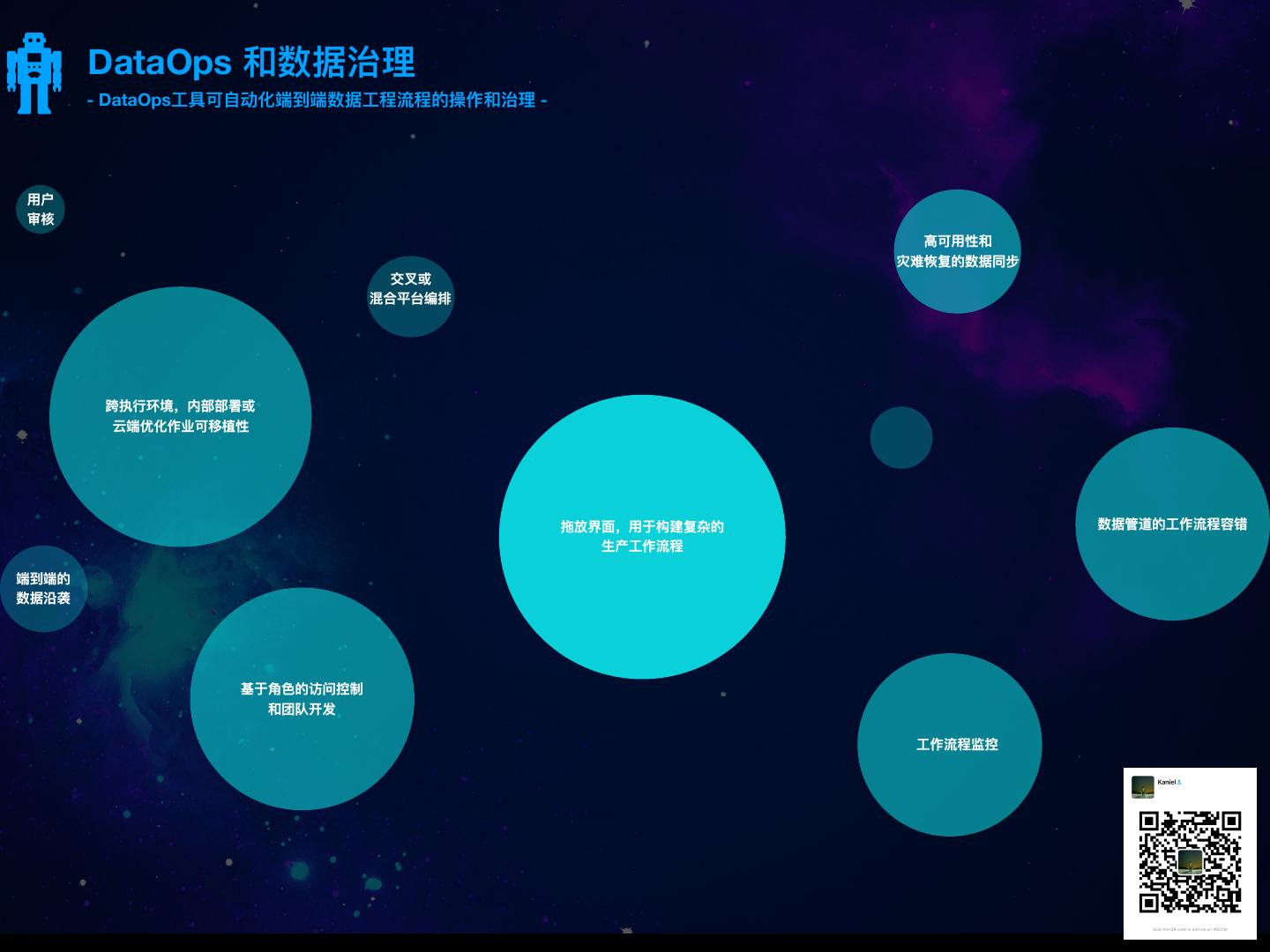
14 .DataOps 和数据治理理 - DataOps⼯工具可⾃自动化端到端数据⼯工程流程的操作和治理理 - • 数据编排和⽣生产操作 企业级安全集成 • 分布式协调器器监视⽣生产⼯工作负载并使其具有容错能⼒力力,从⽽而减轻系统 • 平台为⽤用户身份验证和数据安全策略略提供 和⽣生产管理理员的负担。 安全集成。 • 从开发迁移到⽣生产是⼀一个简单的单击操作。此外,在从摄取到消费的 • 它⽀支持单点登录/ LDAP集成,基于 端到端⼯工作流程中跟踪数据沿袭。 Kerberos的授权,还⽀支持对运动和静态数 据进⾏行行加密。 • 计算存储独⽴立性 • 设计⼈人员内置的数据提取,转换,多维数据集⽣生成 和⼯工作流可以在任何⽀支持的执⾏行行环境中运⾏行行, ⽆无需重新编码。 • 管道不不仅可移植,⽽而且还可以跨执⾏行行环境,内部部 署和云端进⾏行行性能优化
15 . DataOps 和数据治理理 - DataOps⼯工具可⾃自动化端到端数据⼯工程流程的操作和治理理 - ⽤用户 审核 ⾼高可⽤用性和 灾难恢复的数据同步 交叉或 混合平台编排 跨执⾏行行环境,内部部署或 云端优化作业可移植性 拖放界⾯面,⽤用于构建复杂的 数据管道的⼯工作流程容错 ⽣生产⼯工作流程 端到端的 数据沿袭 基于⻆角⾊色的访问控制 和团队开发 ⼯工作流程监控
16 .Chapter TWO 壹. Develiverable 贰. Change & Solution 叁. Customer Case Study 肆. Improvement of Capacity & Efficiency
17 . 简化Data Engineering 和 DataOps - 敏敏捷数据⼯工程平台 , 借助⾃自动化避免错综复杂- Automated Data Lake Creation Automated Data Warehouse Automated BI & Advanced Creation & Management Offload & Migration Analytics
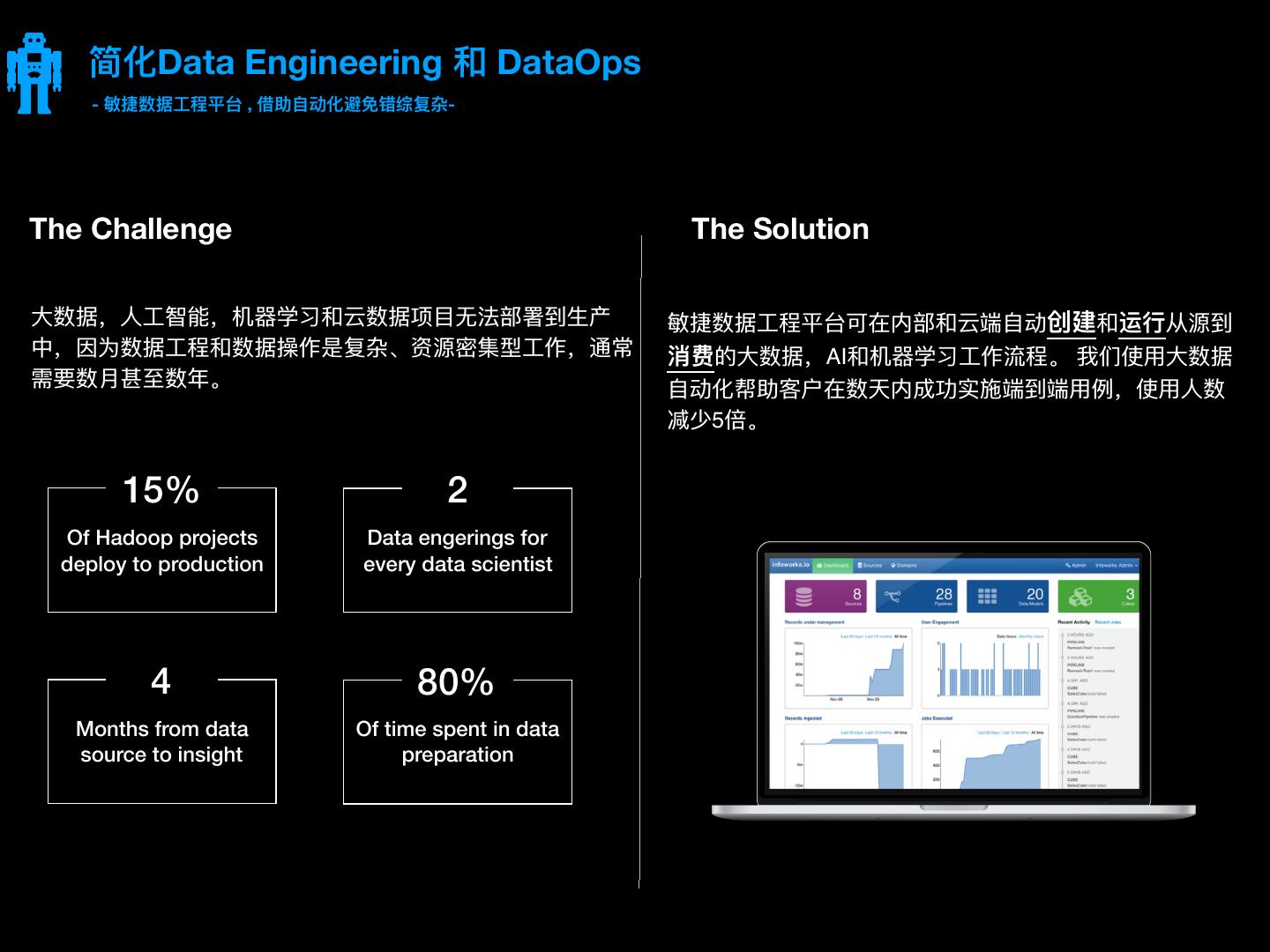
18 . 简化Data Engineering 和 DataOps - 敏敏捷数据⼯工程平台 , 借助⾃自动化避免错综复杂- The Challenge The Solution ⼤大数据,⼈人⼯工智能,机器器学习和云数据项⽬目⽆无法部署到⽣生产 敏敏捷数据⼯工程平台可在内部和云端⾃自动创建和运⾏行行从源到 中,因为数据⼯工程和数据操作是复杂、资源密集型⼯工作,通常 消费的⼤大数据,AI和机器器学习⼯工作流程。 我们使⽤用⼤大数据 需要数⽉月甚⾄至数年年。 ⾃自动化帮助客户在数天内成功实施端到端⽤用例例,使⽤用⼈人数 减少5倍。 15% 2 Of Hadoop projects Data engerings for deploy to production every data scientist 4 80% Months from data Of time spent in data source to insight preparation
19 . Simplify Data Engineering and DataOps - Aglie Data Engineering Platform , Eliminate Complexity Through Automation - Customer Case Studies
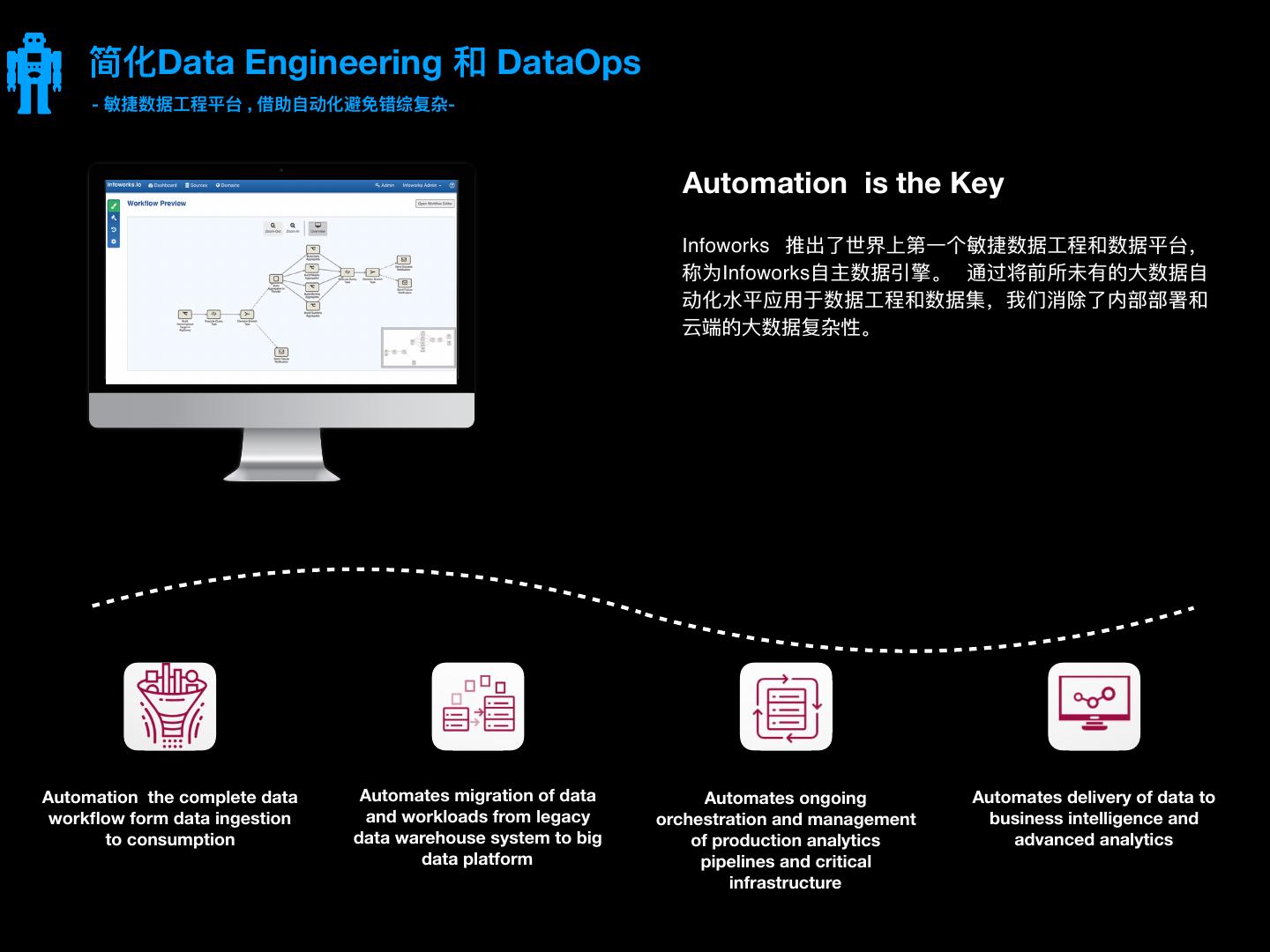
20 . 简化Data Engineering 和 DataOps - 敏敏捷数据⼯工程平台 , 借助⾃自动化避免错综复杂- Automation is the Key Infoworks 推出了了世界上第⼀一个敏敏捷数据⼯工程和数据平台, 称为Infoworks⾃自主数据引擎。 通过将前所未有的⼤大数据⾃自 动化⽔水平应⽤用于数据⼯工程和数据集,我们消除了了内部部署和 云端的⼤大数据复杂性。 Automation the complete data Automates migration of data Automates ongoing Automates delivery of data to workflow form data ingestion and workloads from legacy orchestration and management business intelligence and to consumption data warehouse system to big of production analytics advanced analytics data platform pipelines and critical infrastructure
21 . 简化Data Engineering 和 DataOps - 敏敏捷数据⼯工程平台 , 借助⾃自动化避免错综复杂- Bid Data Automation Delivers Tremendous Value to Your Business 敏敏捷 灵活 • Deploys new cases in days …..not in months • Choose any analytics tools, methods, or algorithms • Add new data sources with a single click • Choose any big data platform, on premise or cloud • Enable self-service for faster data pipeline creation • Integrate custom or 3rd part applications 经济 ⾼高效 • Reduce time to build and maintain analytics use cases • Focus resources on generating business value • Reliably operationalize projects into production • Decrease demand on IT through self-service • Monitor the status of end to-end data pipelines • Spend less time maintaining existing data workflows
22 .Chapter Three 壹. Support big data platform 贰. Support data Source
23 .Infrastructure Support - Any platform ,Any Data Source - Support Big data Platform
24 .Infrastructure Support - Any platform ,Any Data Source - Support Data Sources
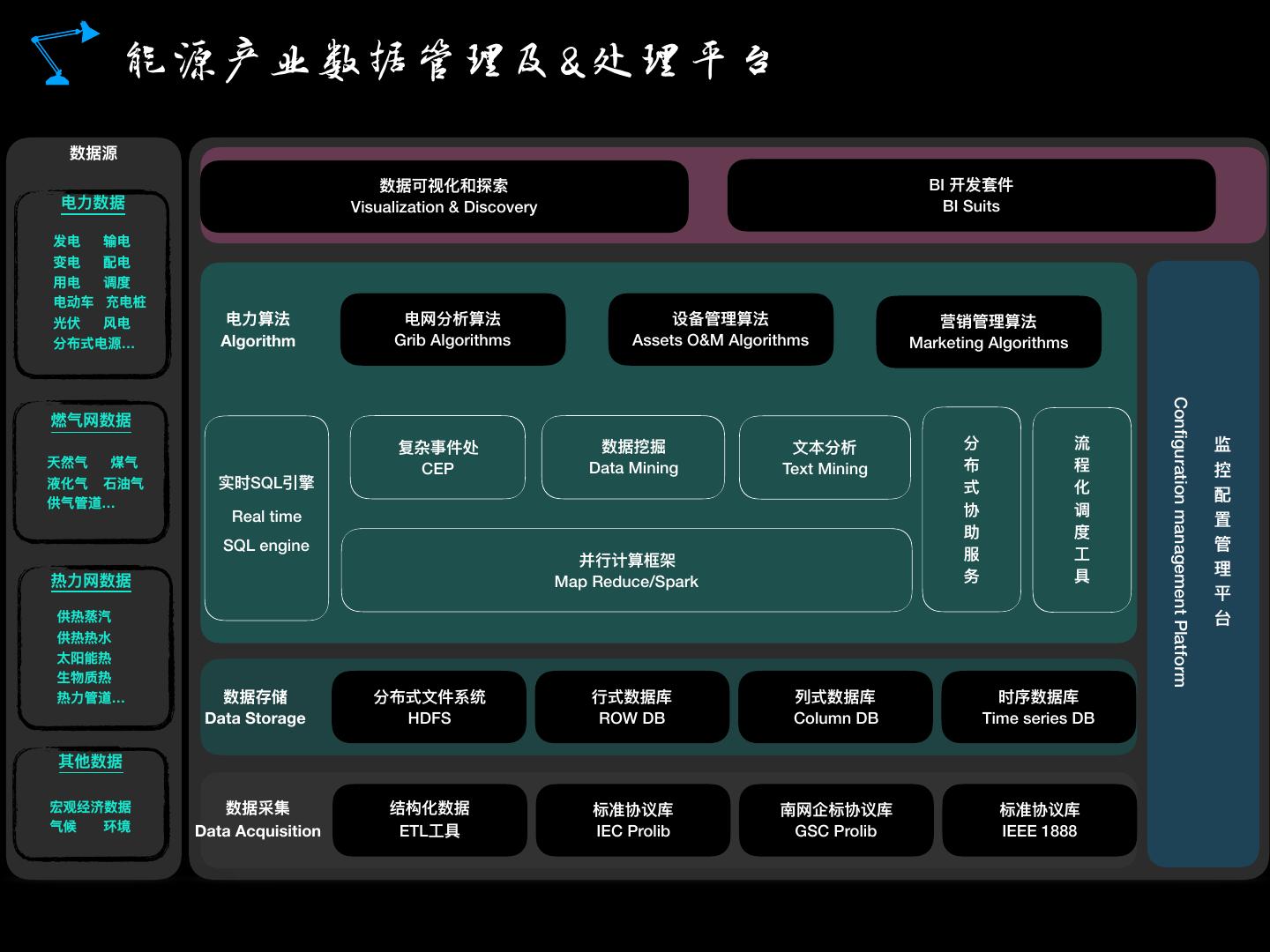
25 .Industry Application
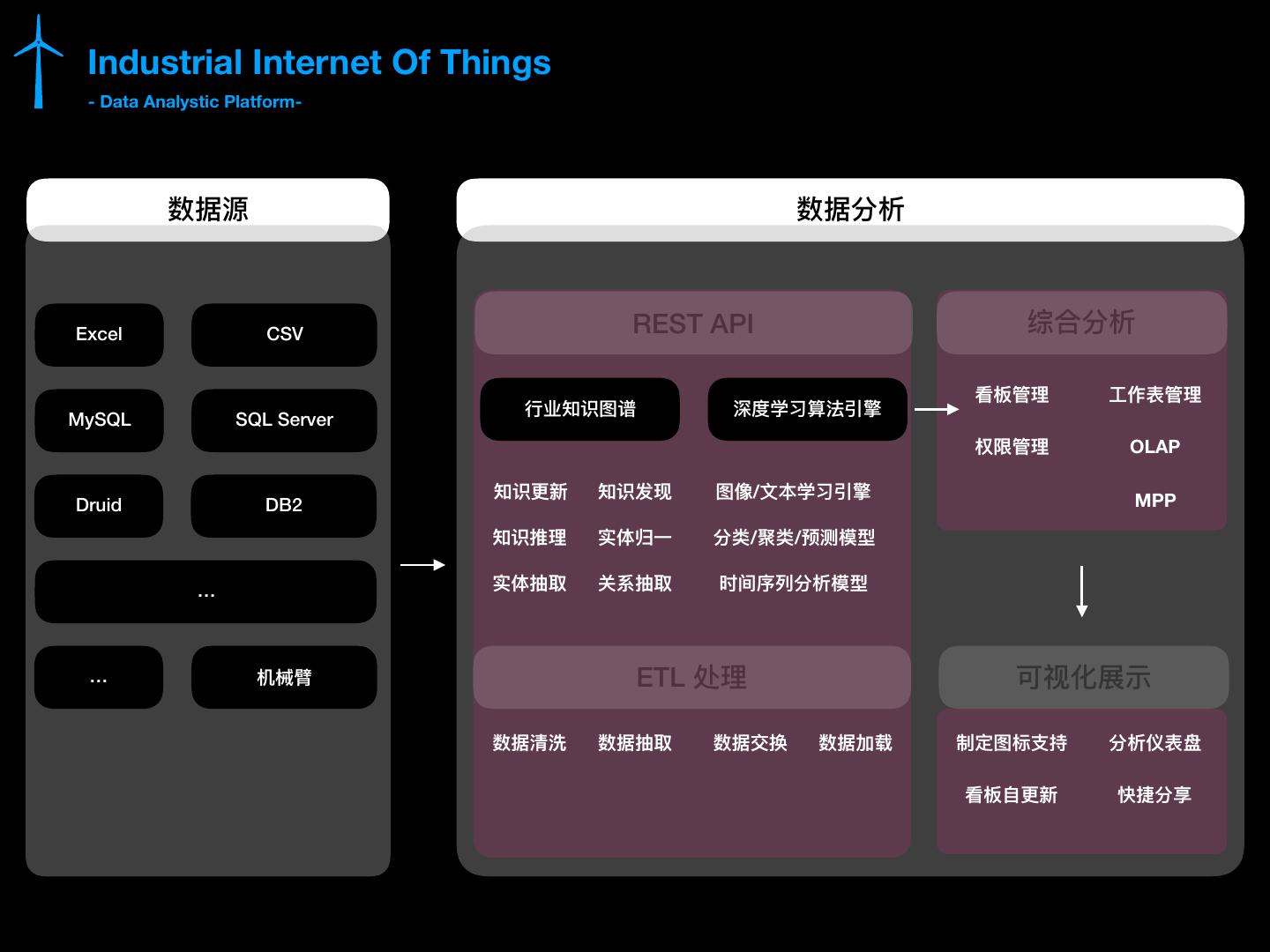
26 .Chapter ONE 壹. IOT 贰. IIOT(Digital twin) 叁. Education 肆. Energy 伍. Intelligent manufacturing
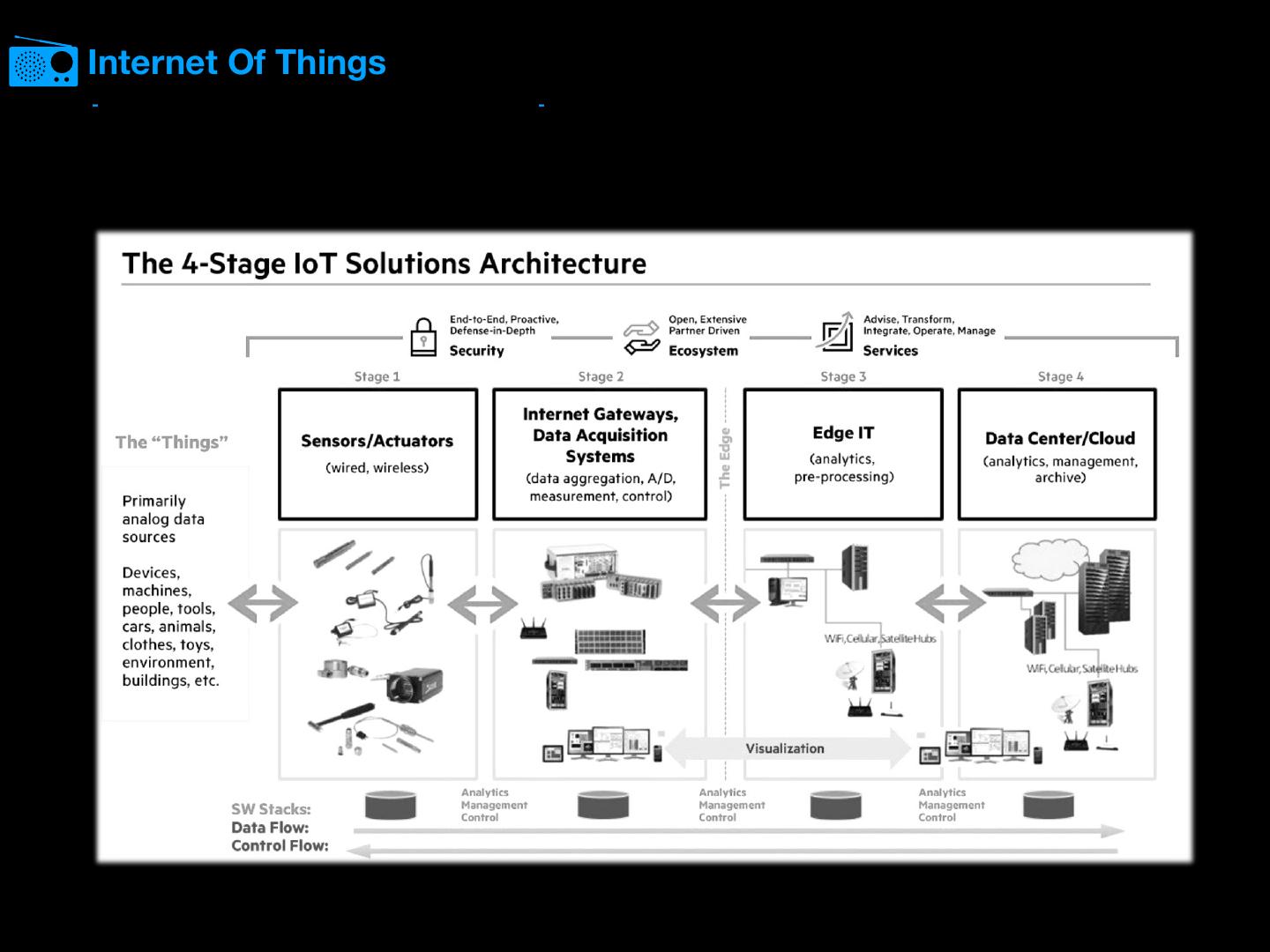
27 .Internet Of Things - -
28 .Internet Of Things - - Application IOT Integration Middleware (IoTIM) Gateway Device Device Device Device Device
29 .Internet Of Things - - IOT Fog Computing Edge Computing … IIOT
3秒后跳转登录页面
去登陆

