





















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
数据挖掘
大数据”是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力来适应海量、高增长率和 .... 继承了其他分布式系统的优良基因,并且加以改良和扩充。
展开查看详情
1 .大数据关键技术介绍
2 .董锐 rdong@ctrip.com 基础业务研发 - 大数据部门 大数据产品研发 Team 技术栈 :搜索, 高 可用系统服务, 大数据平台,推荐系统 自我介绍
3 .目录
4 .大 数据 Volume 数据规模大 Variety 数据种类多 Velocity 数据要求处理速度快 Value 数据价值密度低 4V 大数据概念 “大数据”是需要新处理模式才能具有更强的 决策力 、 洞察 发现力和流程优化能力来适应海量、高增长率和多样化的信息 资产 。 [1]
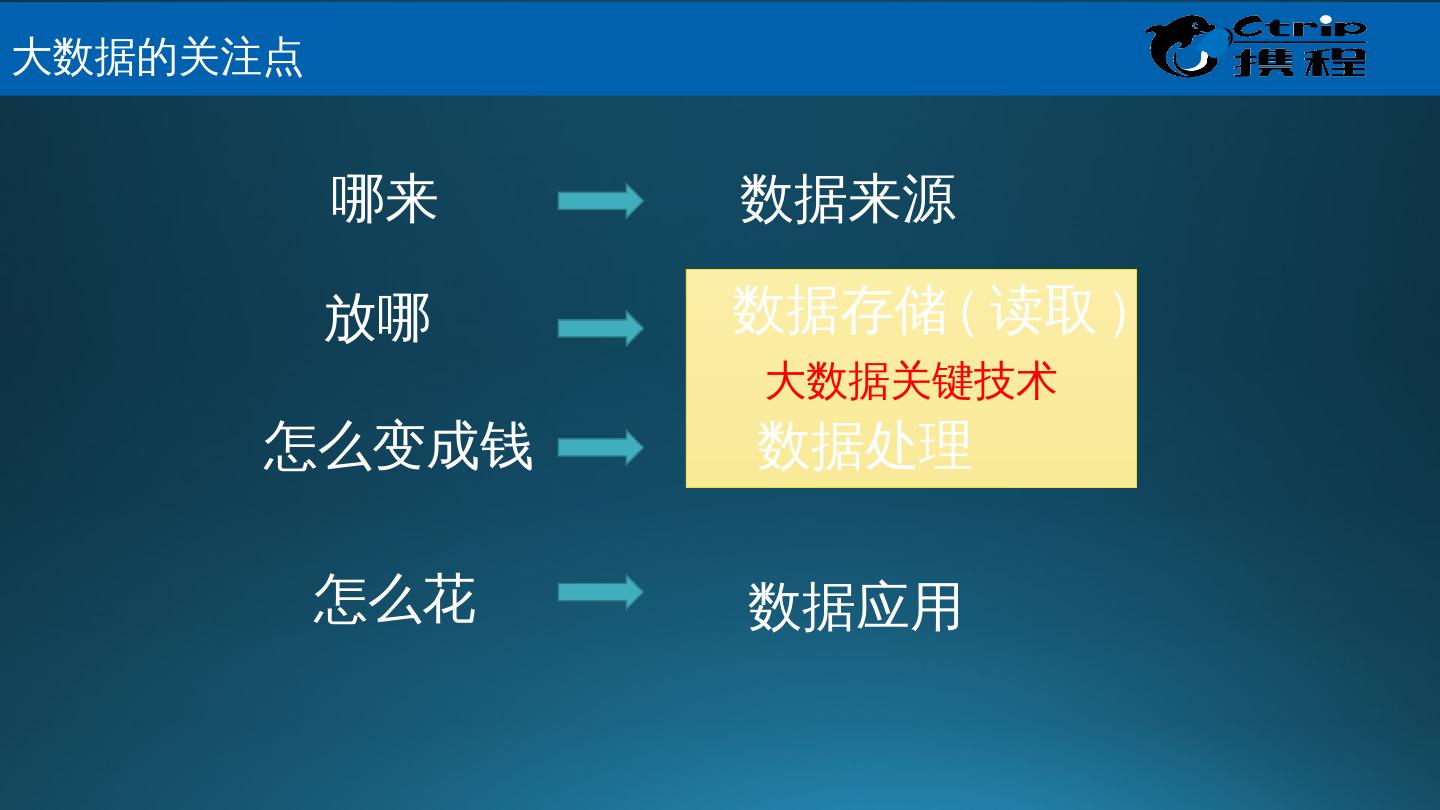
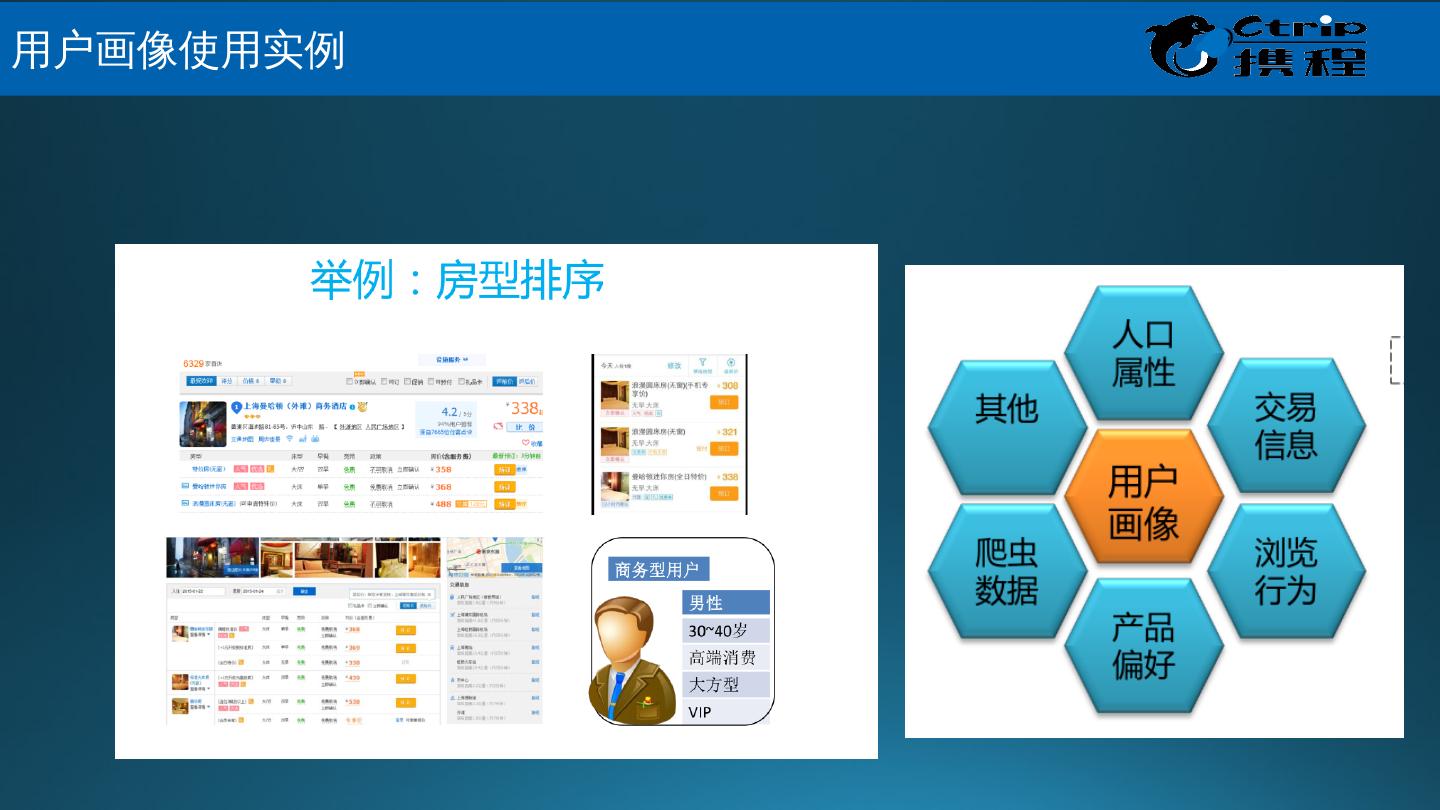
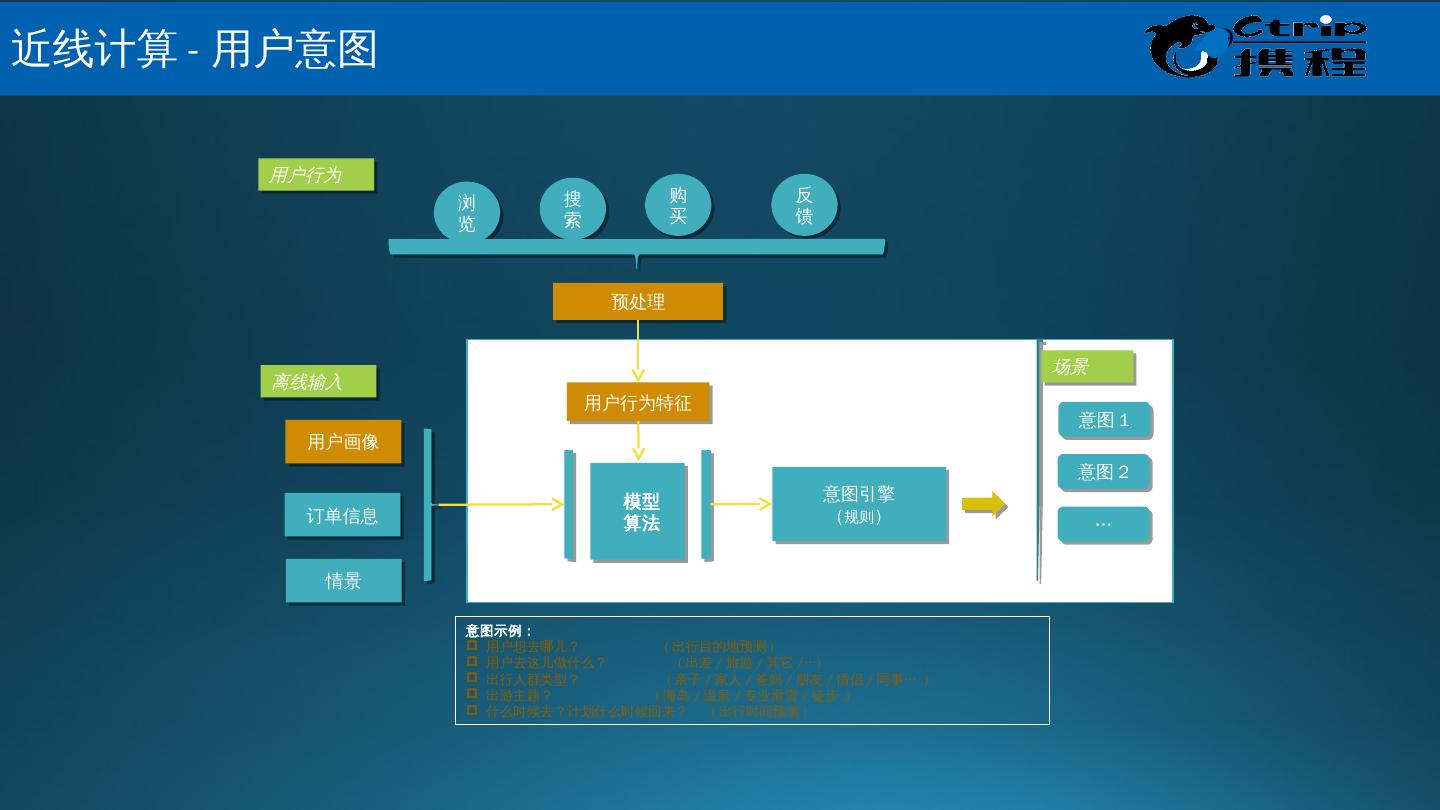
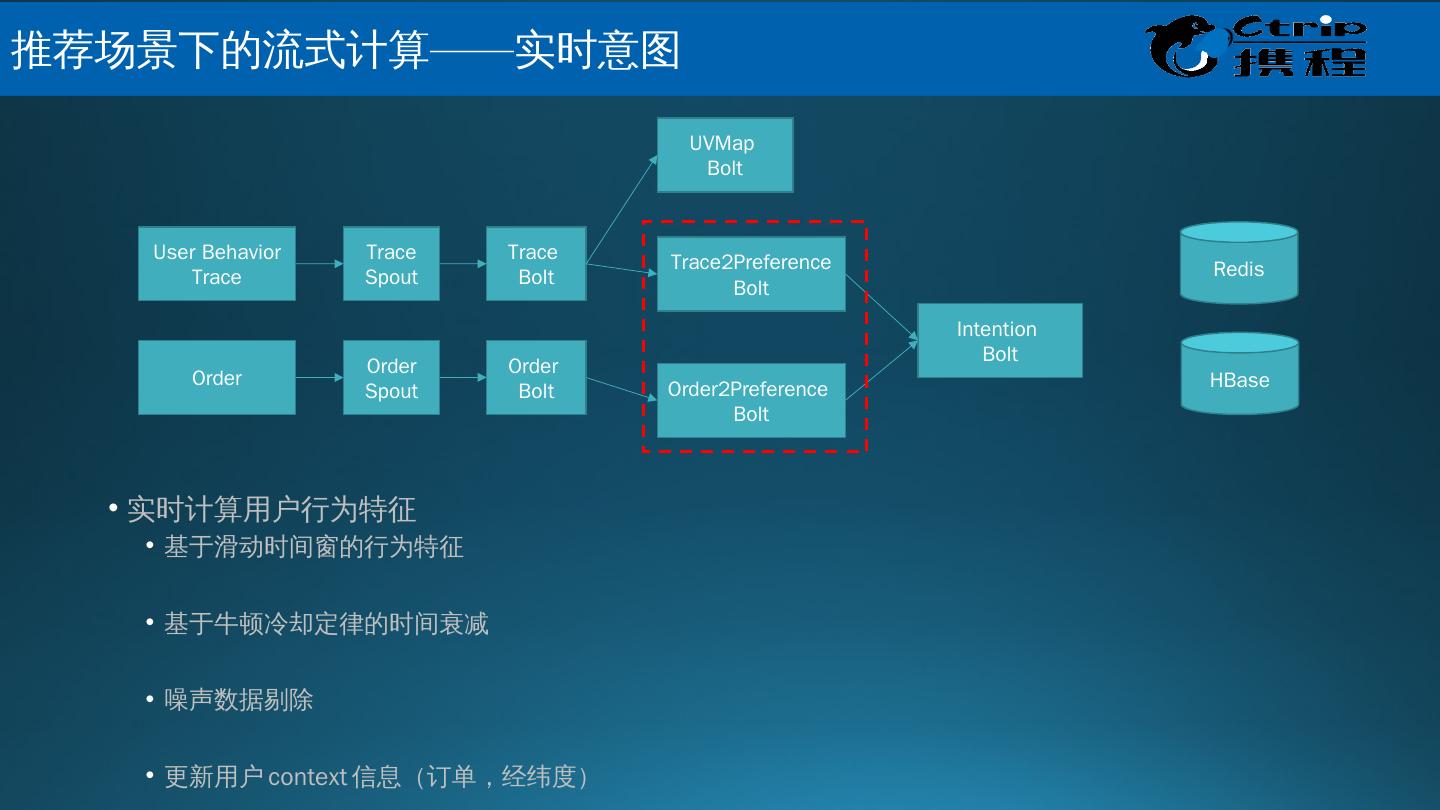
5 .大数据关键技术 数据来源 数据存储 ( 读取 ) 数据处理 数据应用 哪来 放哪 怎么变成钱 怎么花 大数据的关注点
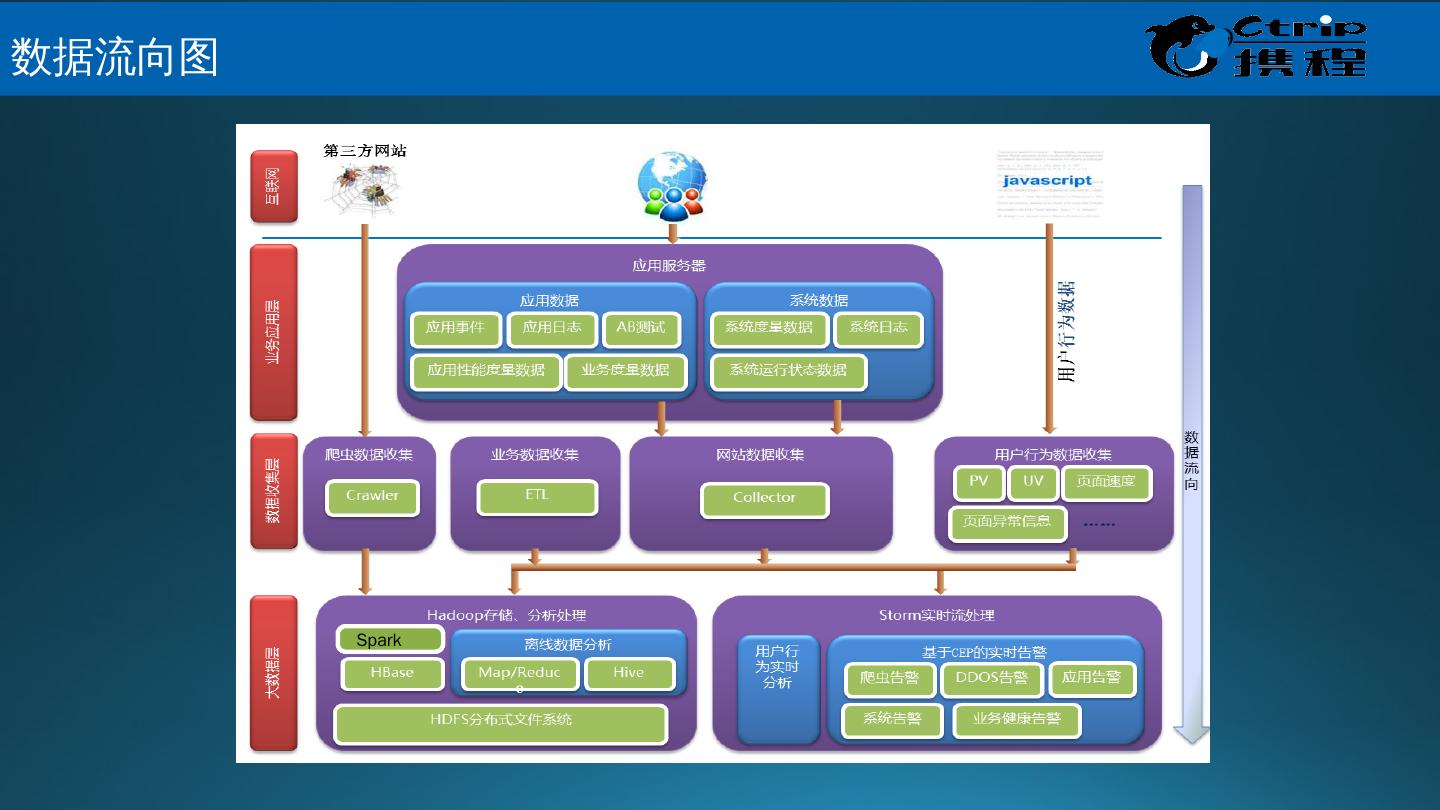
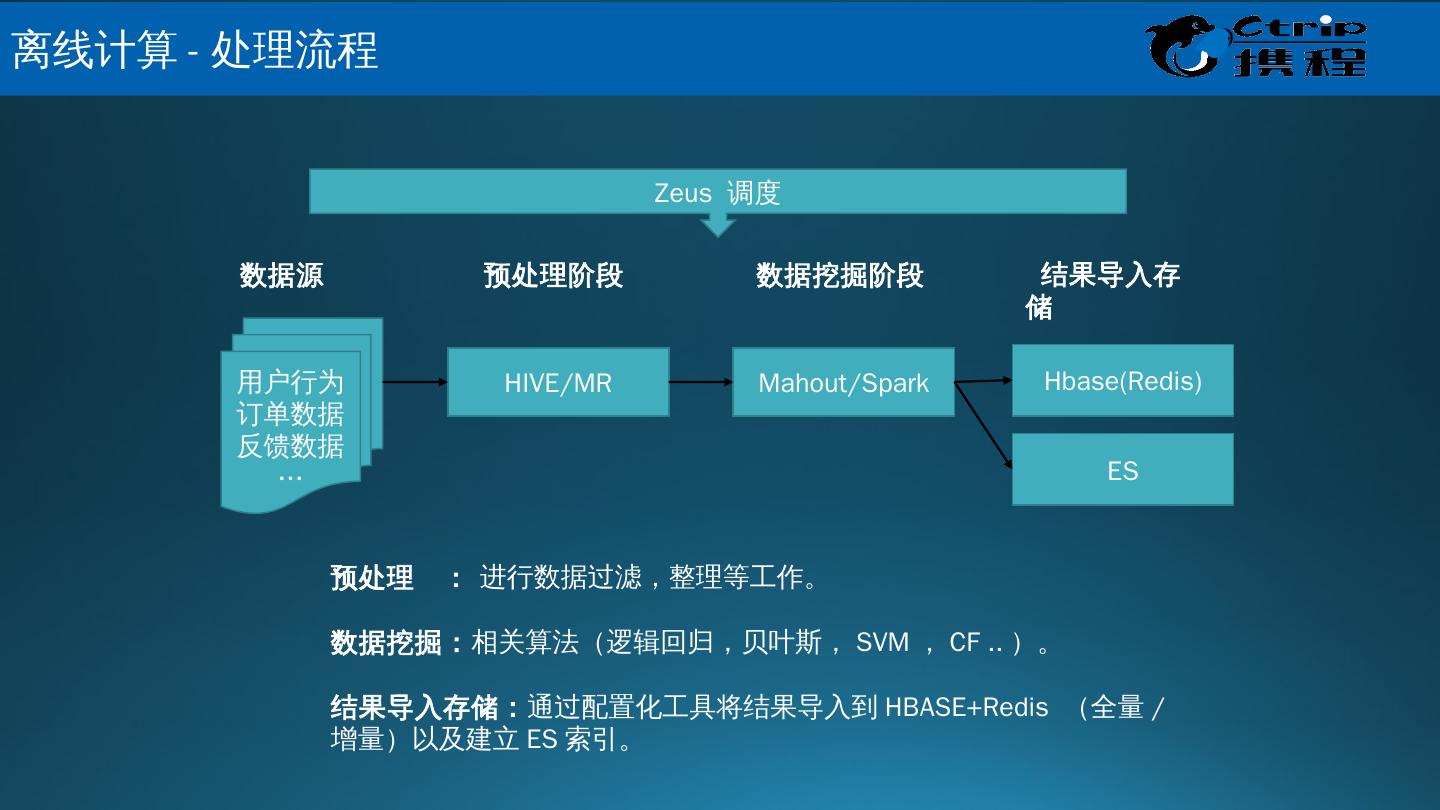
6 .数据采集: ETL 抽取,应用埋点,数据同步等。 数据存取: 关系数据库、 DFS 、 NOSQL 等 。 基础架构: 调度系统,数据血缘,数据安全等。 数据处理: 批量,流式,实时, Hadoop,Spark,Strom 统计分析: 回归分析、多元对应分析(最优尺度分析)、 bootstrap 技术 等等。 数据挖掘: 分类 ( Classification )、估计( Estimation )、预测 ( Prediction )、相关性分组或关联规则( Affinity grouping or association rules )、聚类( Clustering )、描述和可视化、 Description and Visualization )、复杂数据类型挖掘 (Text, Web , 图形图像,视频,音频等 ) 模型预测: 预测模型、机器学习、建模仿真。 结果呈现: 云计算、标签云、关系图等。 大数据处理流程
7 .Spark Streaming & Spark 数据流向图
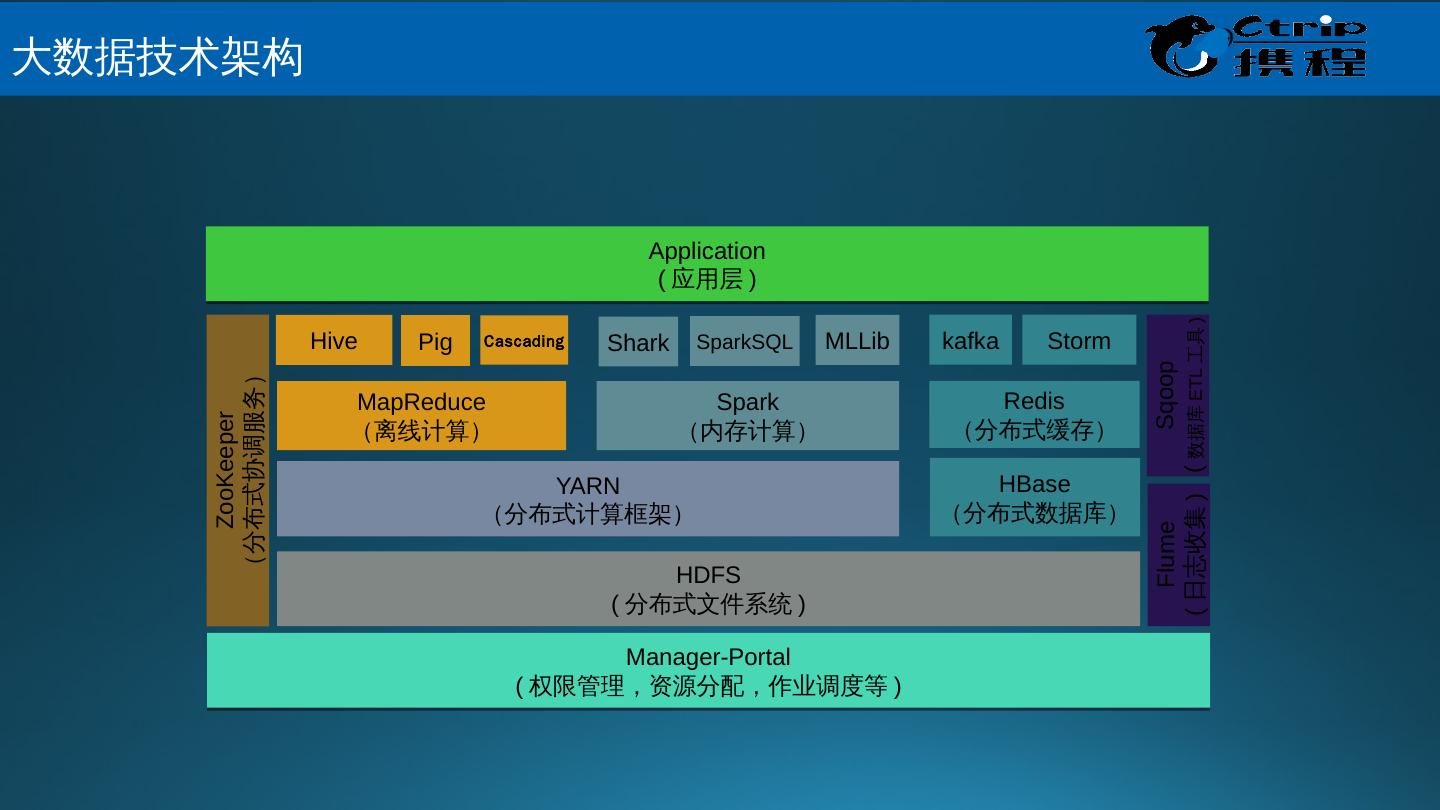
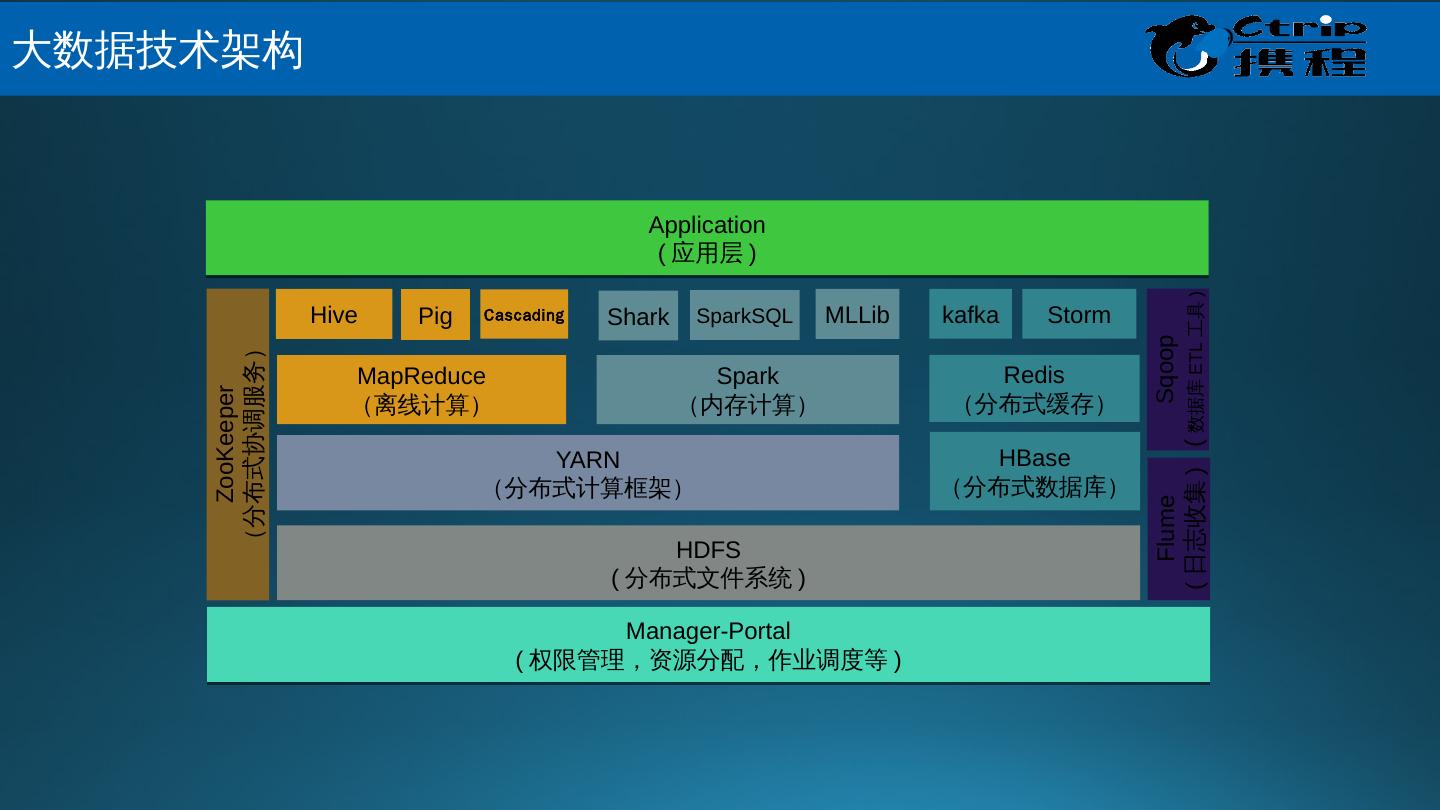
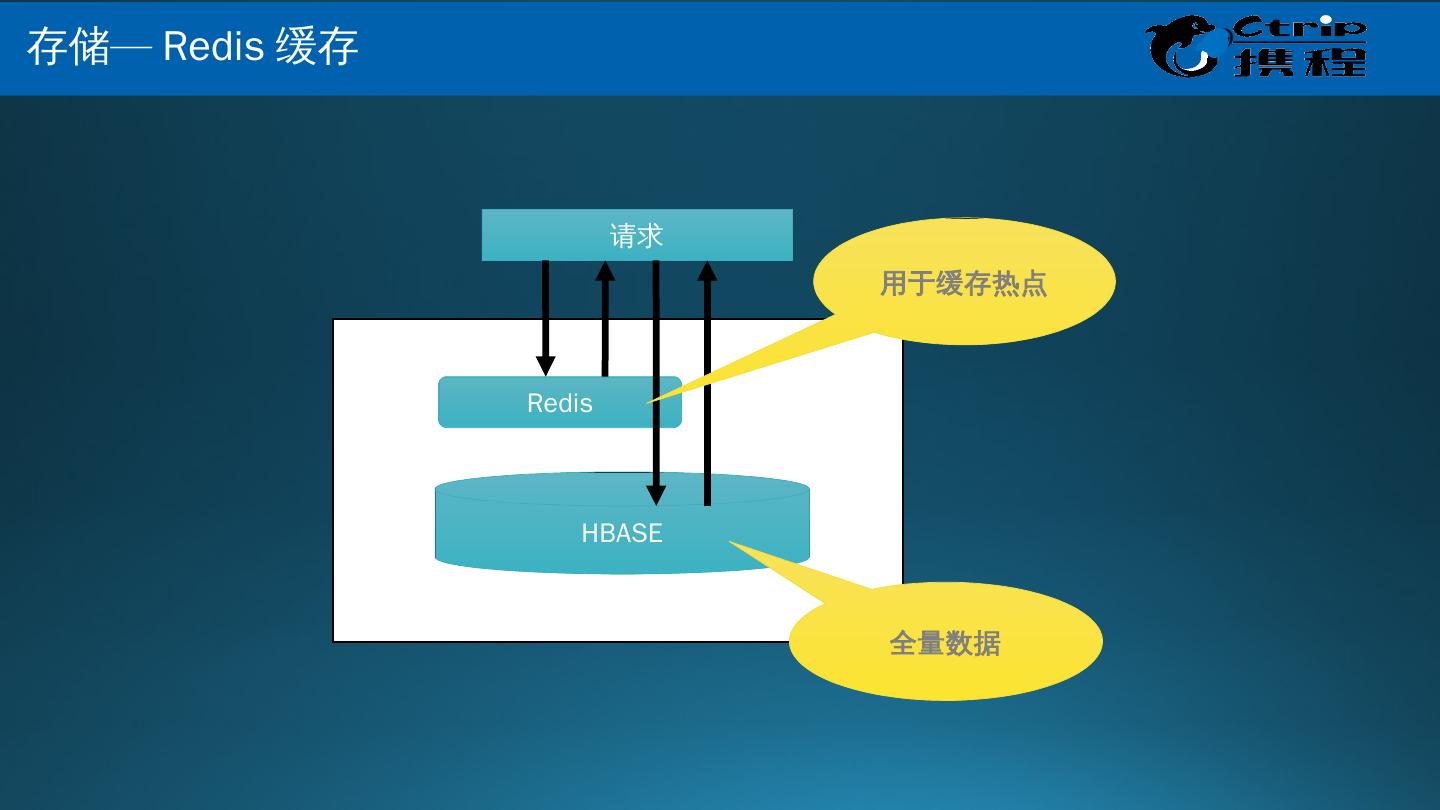
8 .HDFS ( 分布式文件系统 ) HBase (分布式数据库) YARN (分布式计算框架) MapReduce (离线计算) Spark (内存计算) Spark SQL MLLib kafka Hive Cascading Pig Storm Sqoop ( 数据库 ETL 工具 ) ZooKeeper (分布式协调服务) Manager -Portal ( 权限管理,资源分配,作业调度等 ) Flume ( 日志收集 ) Shark Application ( 应用层 ) Redis (分布式缓存) 大 数据技术架构
9 .HDFS ( 分布式文件系统 ) HDFS 源自于 Google 发表于 2003 年 10 月的 GFS 论文,是 GFS 的克隆版。 良好的扩展性 高容错性 适合 PB 级以上海量数据的存储 Yarn ( 资源管理系统 ) 负责集群的资源管理和调度 支持多种计算框架 多租户共享资源 MapReduce ( 资源管理系统 ) MapReduce 源自于 Google 发表于 2004 年 12 月的 MapReduce 论文 , 是 Google MapReduce 克隆版 高容错性 适合 PB 级以上海量数据的处理 大 数据关键技术 -Hadoop
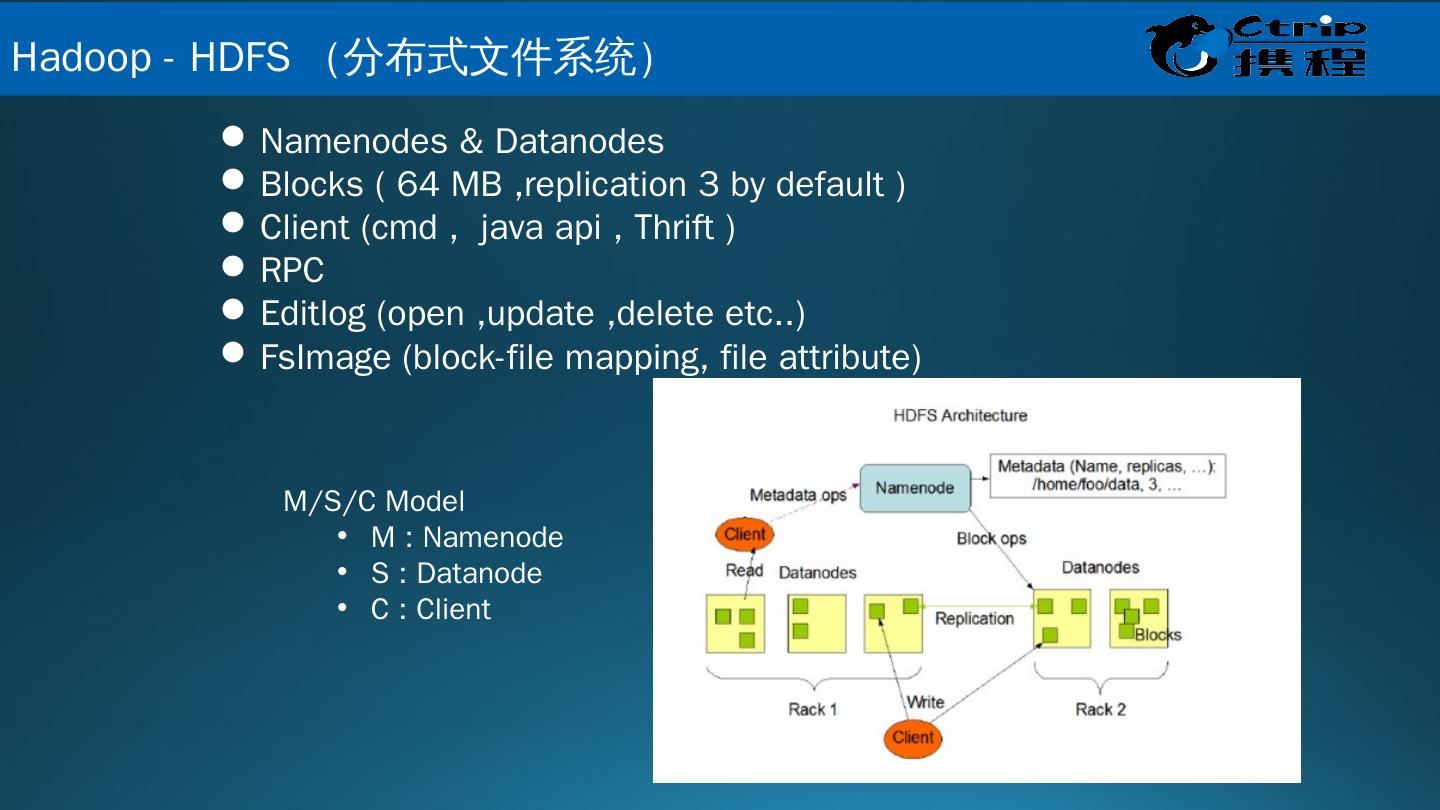
10 .Namenodes & Datanodes Blocks ( 64 MB ,replication 3 by default ) Client ( cmd , java api , Thrift ) RPC Editlog (open ,update ,delete etc..) FsImage (block-file mapping, file attribute) M/S/C Model M : Namenode S : Datanode C : Client Hadoop - HDFS (分布式文件系统 )
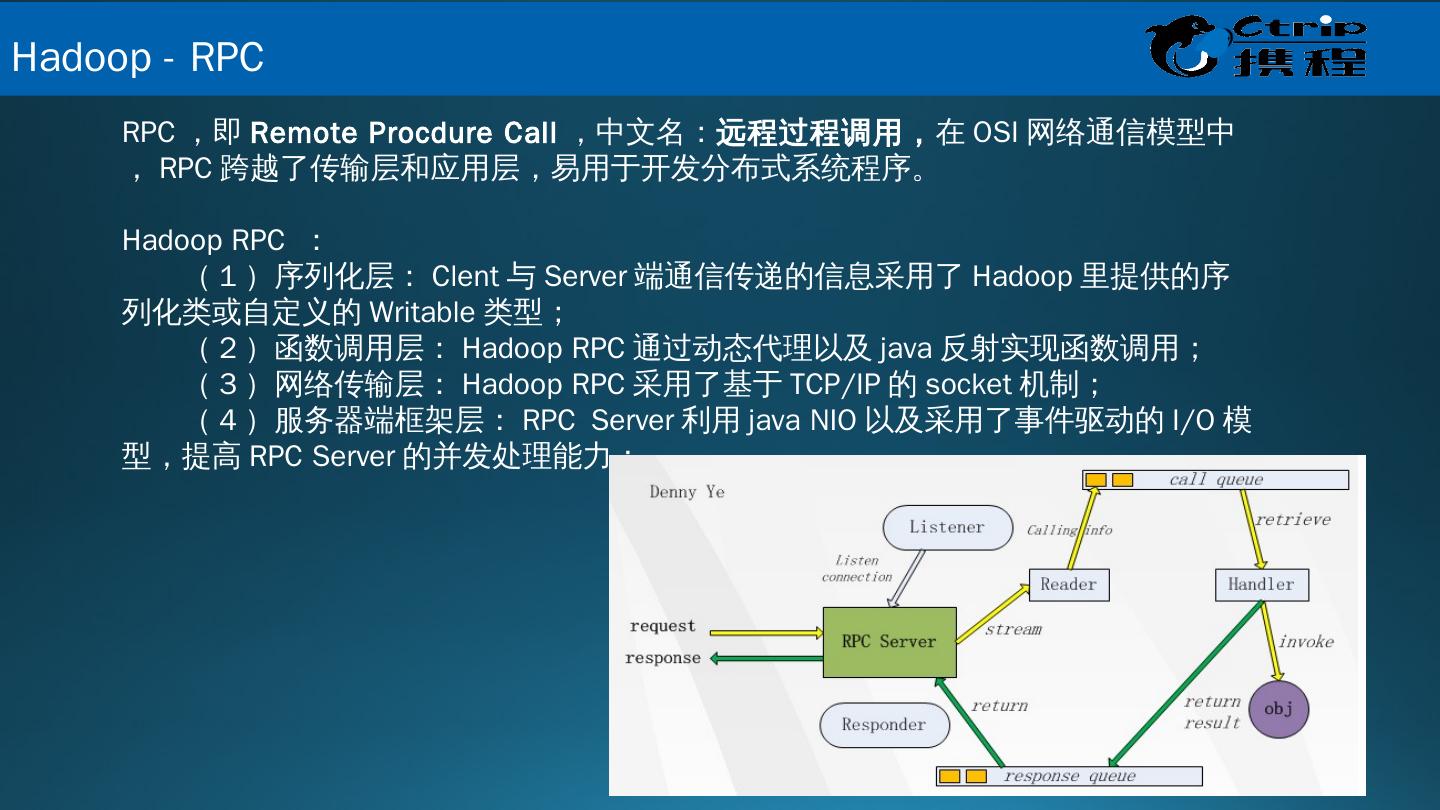
11 .RPC ,即 Remote Procdure Call ,中文名: 远程过程调用, 在 OSI 网络通信模型中, RPC 跨越了传输层和应用层,易用于开发分布式系统程序。 Hadoop RPC : ( 1 )序列化层: Clent 与 Server 端通信传递的信息采用了 Hadoop 里提供的序列化类或自定义的 Writable 类型; ( 2 )函数调用层: Hadoop RPC 通过动态代理以及 java 反射实现函数调用; ( 3 )网络传输层: Hadoop RPC 采用了基于 TCP/IP 的 socket 机制; ( 4 )服务器端框架层: RPC Server 利用 java NIO 以及采用了事件驱动的 I/O 模型,提高 RPC Server 的并发处理能力; Hadoop - RPC
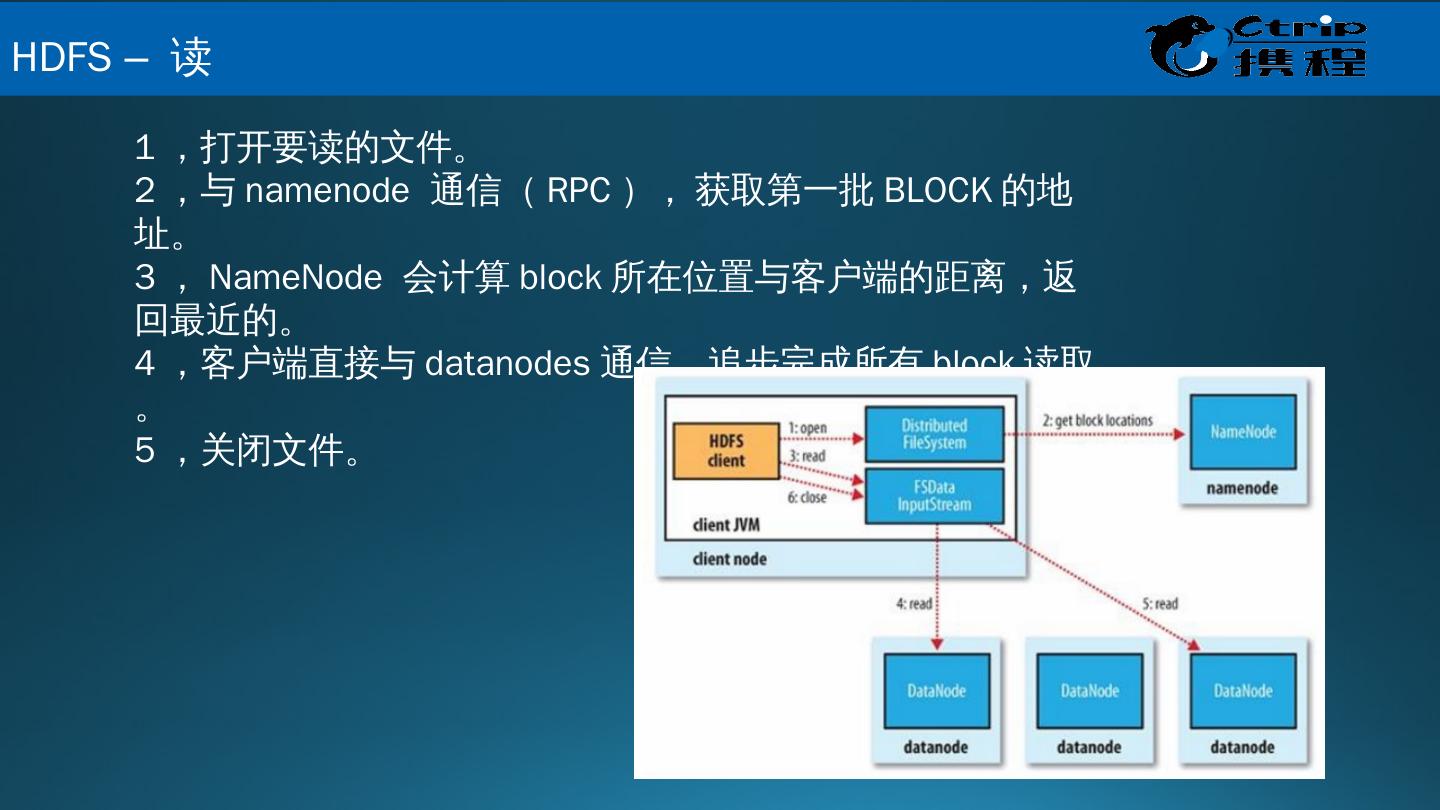
12 .1 ,打开要读的文件。 2 ,与 namenode 通信( RPC ) , 获取第一批 BLOCK 的地址。 3 , NameNode 会计算 block 所在位置与客户端的距离,返回最近的。 4 ,客户端直接与 datanodes 通信,追步完成所有 block 读取。 5 ,关闭文件。 HDFS – 读
13 .1 ,创建一个新文件或追加已存在文件。 2 ,与 namenode 通信( RPC ) , 由 namenode 按照一定的策略来分配具体写入的 datanodes 。 3 ,如果设置有多个副本,会循序写入。 4 ,关闭文件。 HDFS – 写
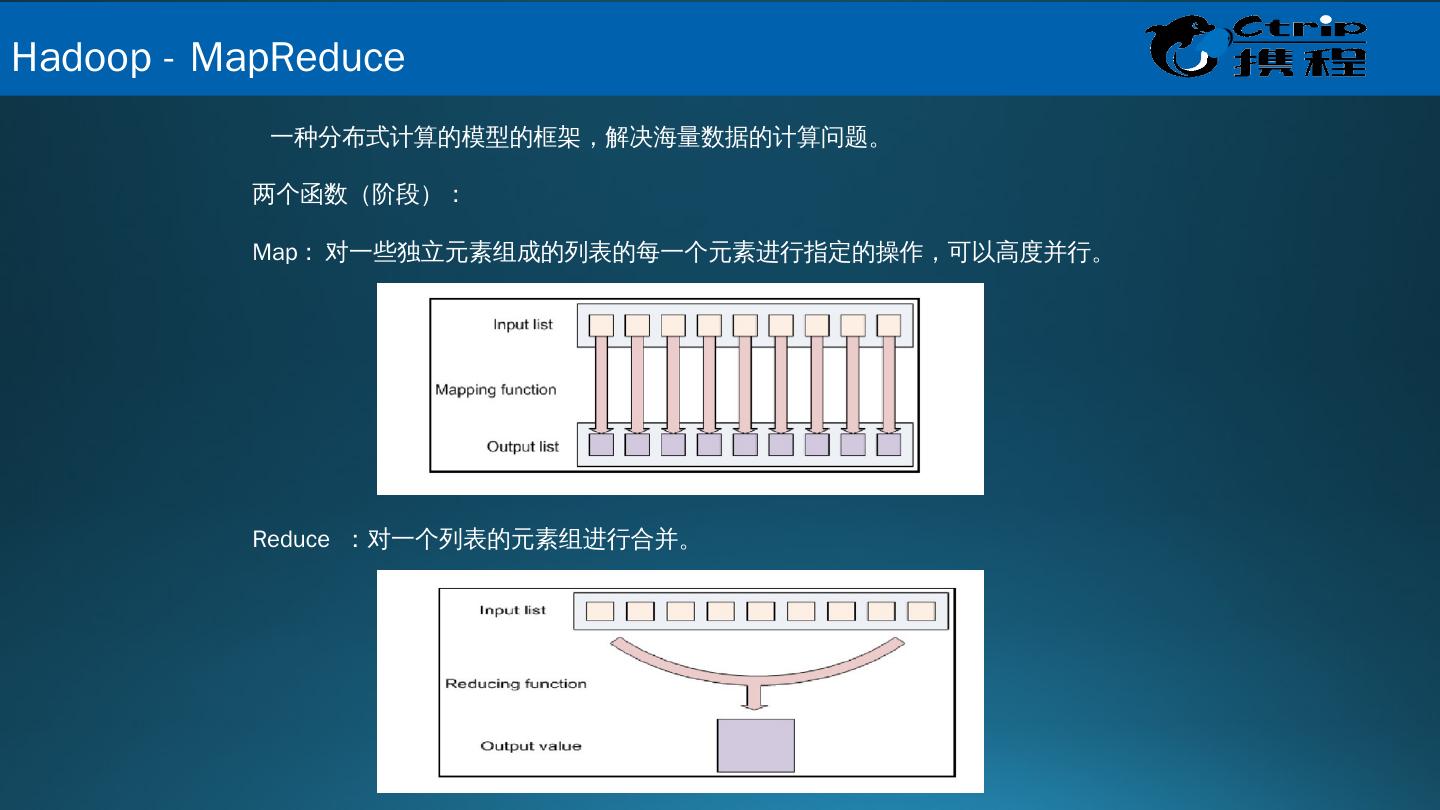
14 . 一种分布式计算的模型的框架,解决海量数据的计算问题。 两个函数(阶段): Map : 对一些独立元素组成的列表的每一个元素进行指定的操作,可以高度并行。 Reduce :对一个列表的元素组进行合并。 Hadoop - MapReduce
15 .Hbase 是建立的 hdfs 之上,提供高可靠性、高性能、列存储、可伸缩、实时读写的数据库系统 (参考 google bigtable )。 大 数据关键技术 - HBase
16 . 一个表可以有上亿行,上百万列 可以只对一行上“锁” 对行的写操作是始终是“原子”的 面向列 : 面向列 ( 族 ) 的存储和权限控制,列 ( 族 ) 独立检索。 稀疏 : 对于为空 (null) 的列,并不占用存储空间,因此,表可以设计的非常稀疏。 HBase - HTable
17 .region 按大小分割的,每个表一开始只有一个 region ,随着数据不断插入表, region 不断增大,当增大到一个阀值的时候, Hregion 就会等分会两个新的 Hregion 。当 table 中的行不断增多,就会有越来越多的 Hregion 。 Table 在行的方向上分割为多个 Hregion HBase - HTable
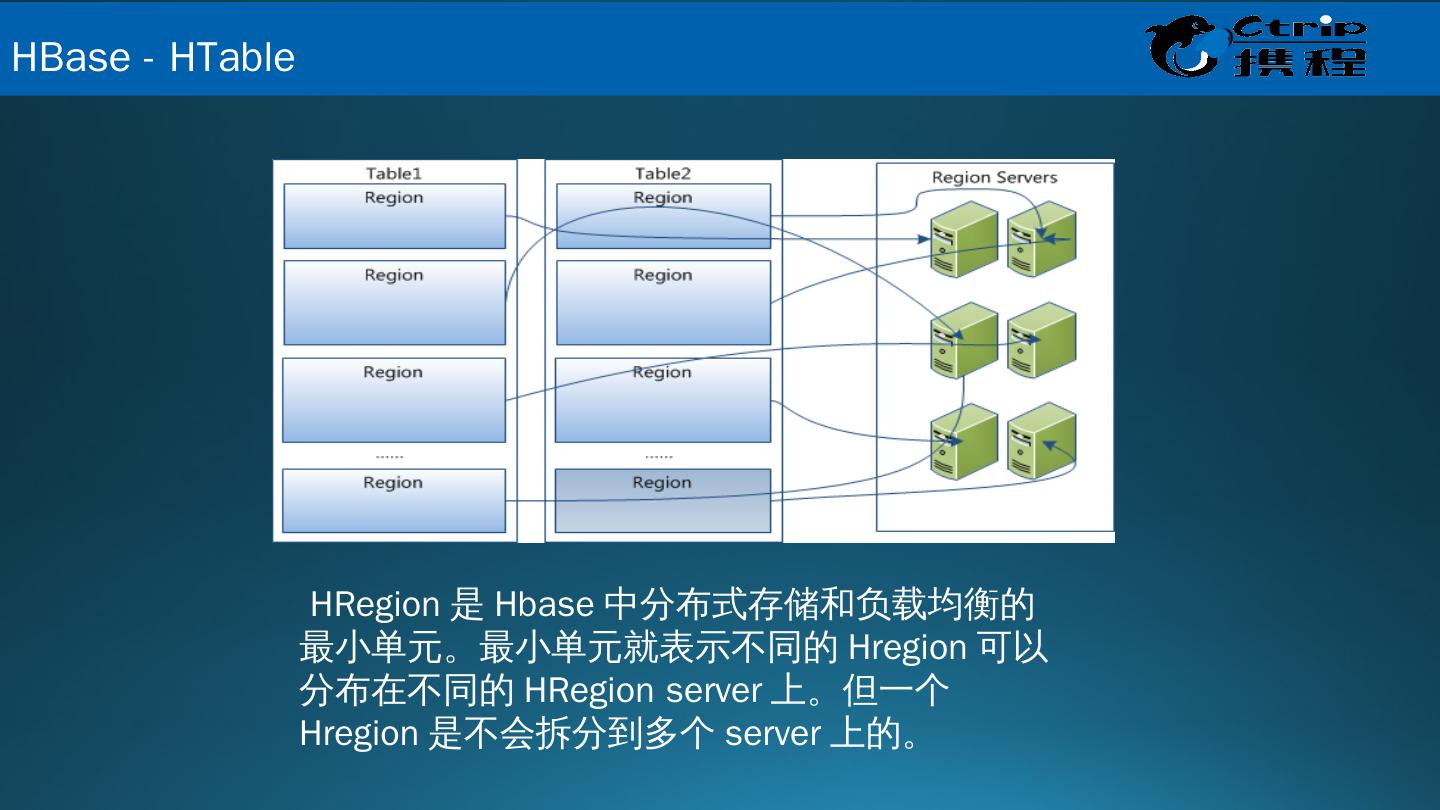
18 . HRegion 是 Hbase 中分布式存储和负载均衡的最小单元。最小单元就表示不同的 Hregion 可以分布在不同的 HRegion server 上。但一个 Hregion 是不会拆分到多个 server 上的。 HBase - HTable
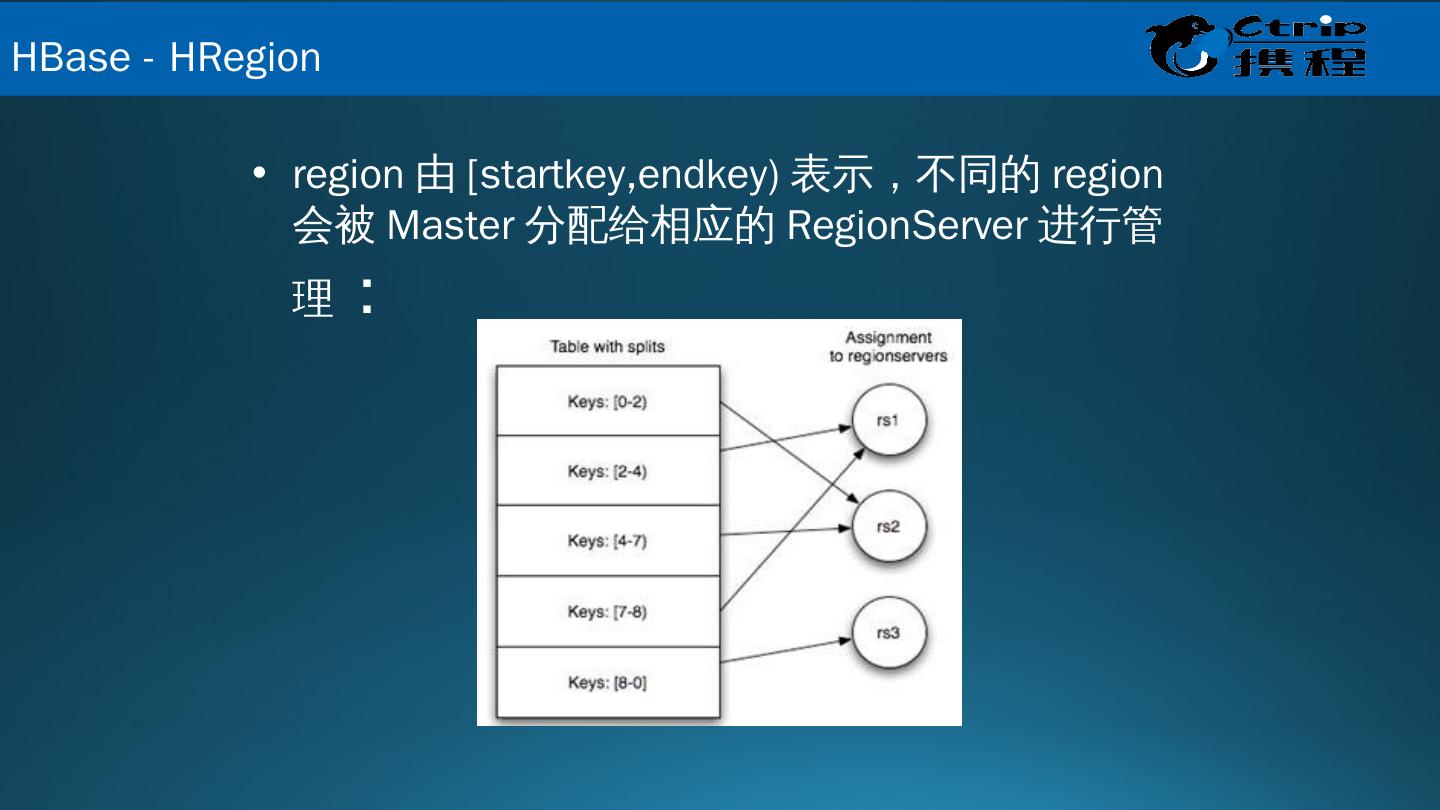
19 .region 由 [ startkey,endkey ) 表示,不同的 region 会被 Master 分配给相应的 RegionServer 进行管理 : HBase - HRegion
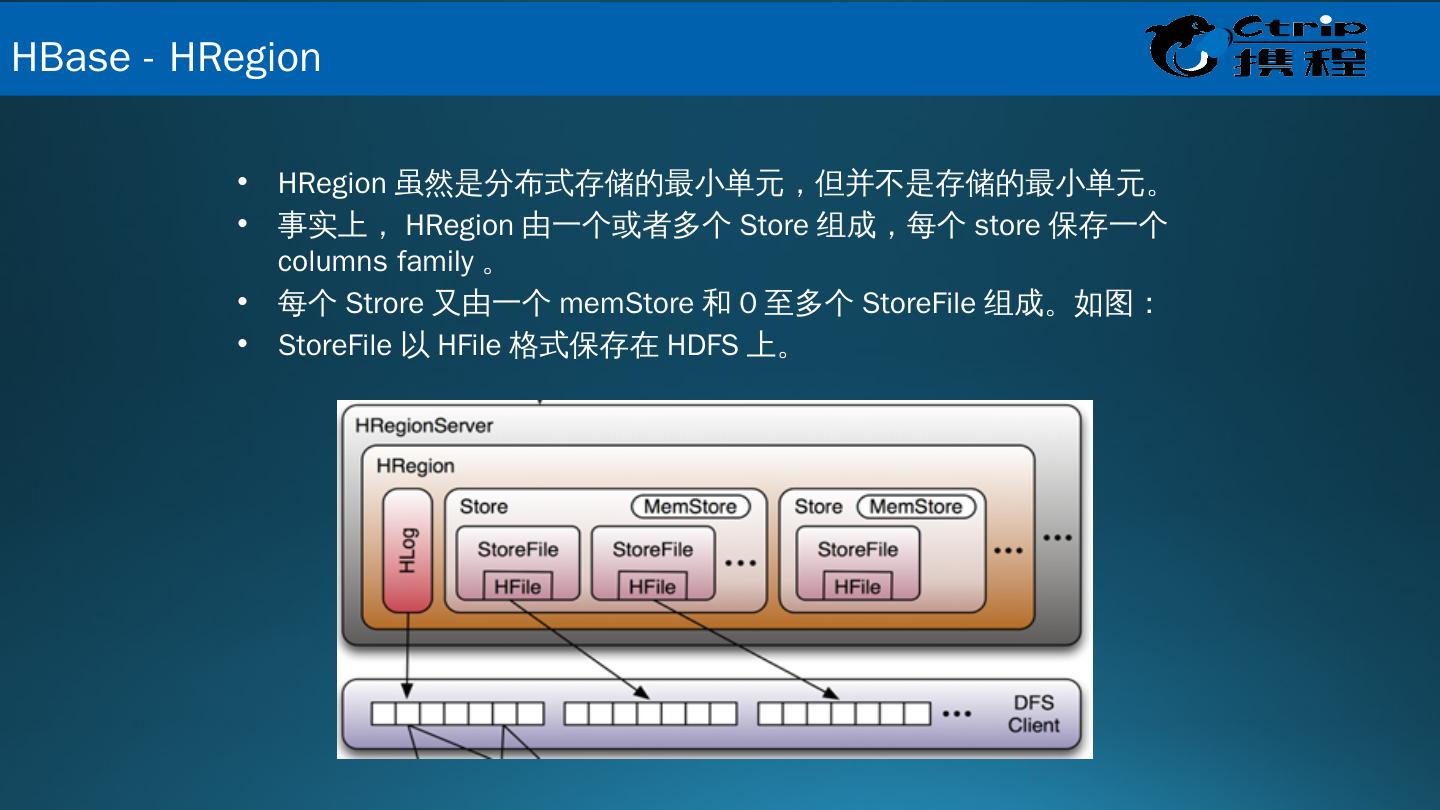
20 .HRegion 虽然是分布式存储的最小单元,但并不是存储的最小单元。 事实上, HRegion 由一个或者多个 Store 组成,每个 store 保存一个 columns family 。 每个 Strore 又由一个 memStore 和 0 至多个 StoreFile 组成。如图: StoreFile 以 HFile 格式保存在 HDFS 上。 HBase - HRegion
21 .HRegionServer 主要负责响应用户 I/O 请求,向 HDFS 文件系统中读写数据,是 HBase 中最核心的模块 。 HBase - HRegionServer
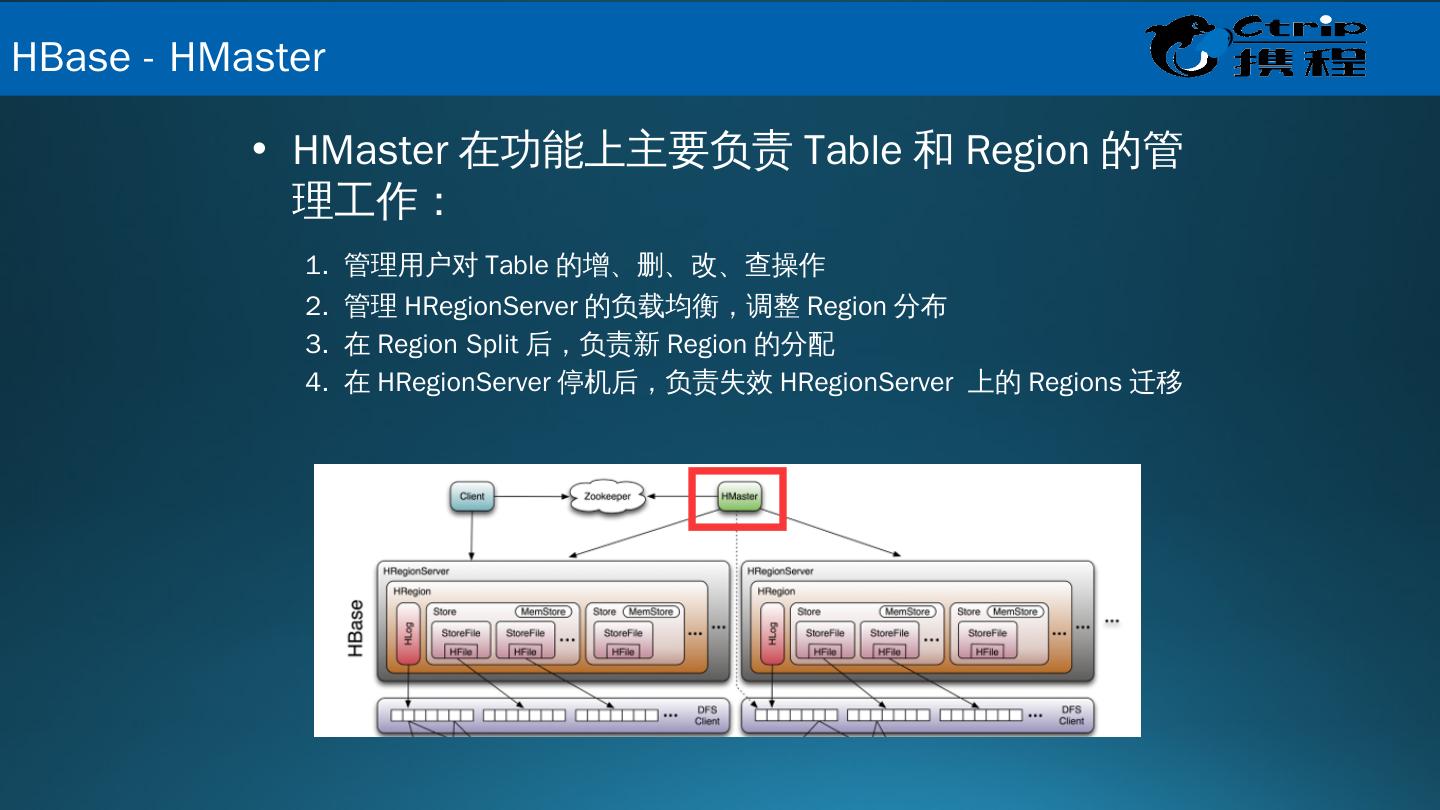
22 .HMaster 在功能上主要负责 Table 和 Region 的管理工作: 1. 管理用户对 Table 的增、删、改、查操作 2. 管理 HRegionServer 的负载均衡,调整 Region 分布 3. 在 Region Split 后,负责新 Region 的分配 4. 在 HRegionServer 停机后,负责失效 HRegionServer 上的 Regions 迁移 HBase - HMaster
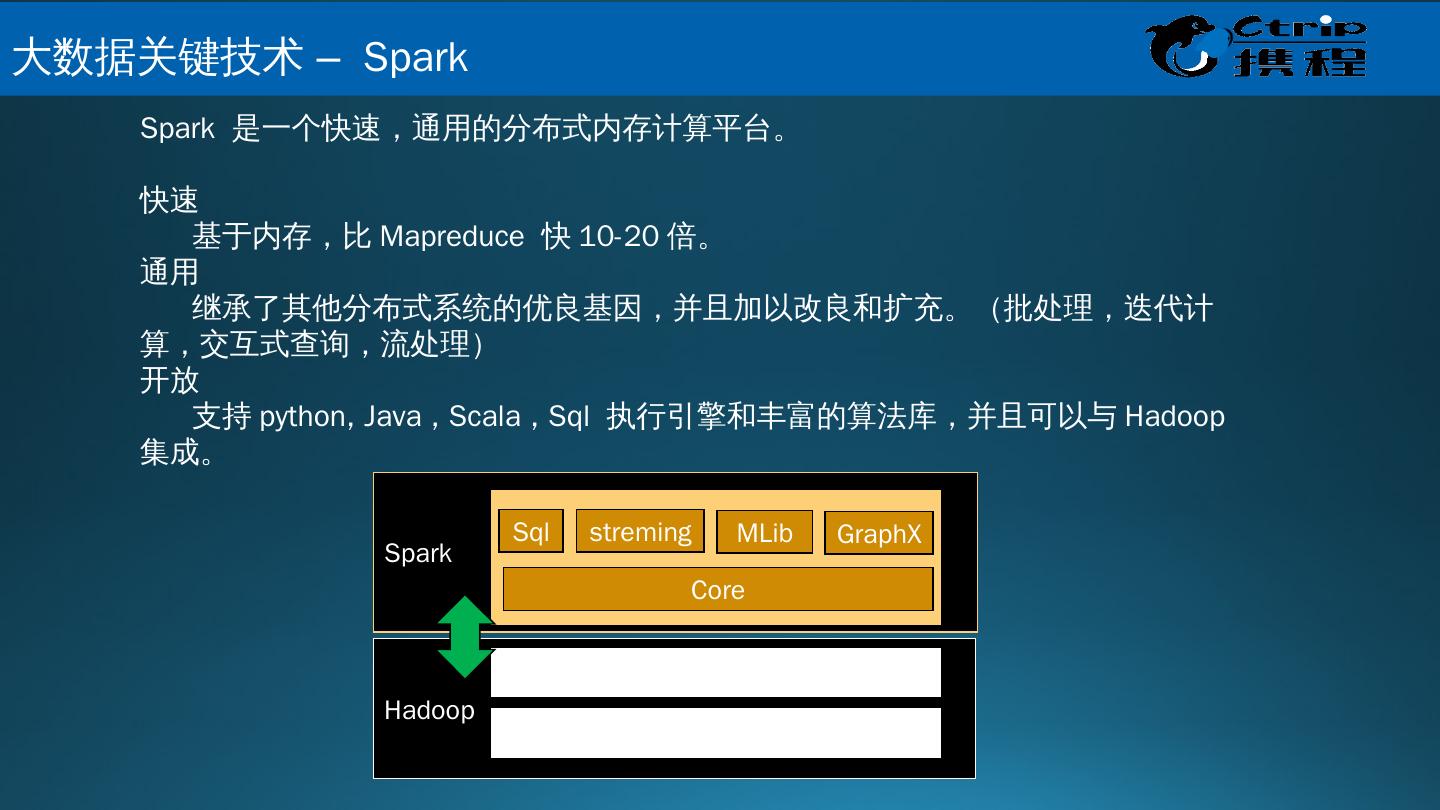
23 .Spark Hadoop Spark 是一个快速,通用的分布式内存计算平台。 快速 基于内存,比 Mapreduce 快 10-20 倍。 通用 继承了其他分布式系统的优良基因,并且 加以改良和扩充。 (批处理,迭代计算,交互式查询,流处理) 开放 支持 python, Java , Scala , Sql 执行引擎和丰富的算法库,并且可以与 Hadoop 集成。 Yarn HDFS Core Sql streming MLib GraphX 大 数据关键技术 – Spark
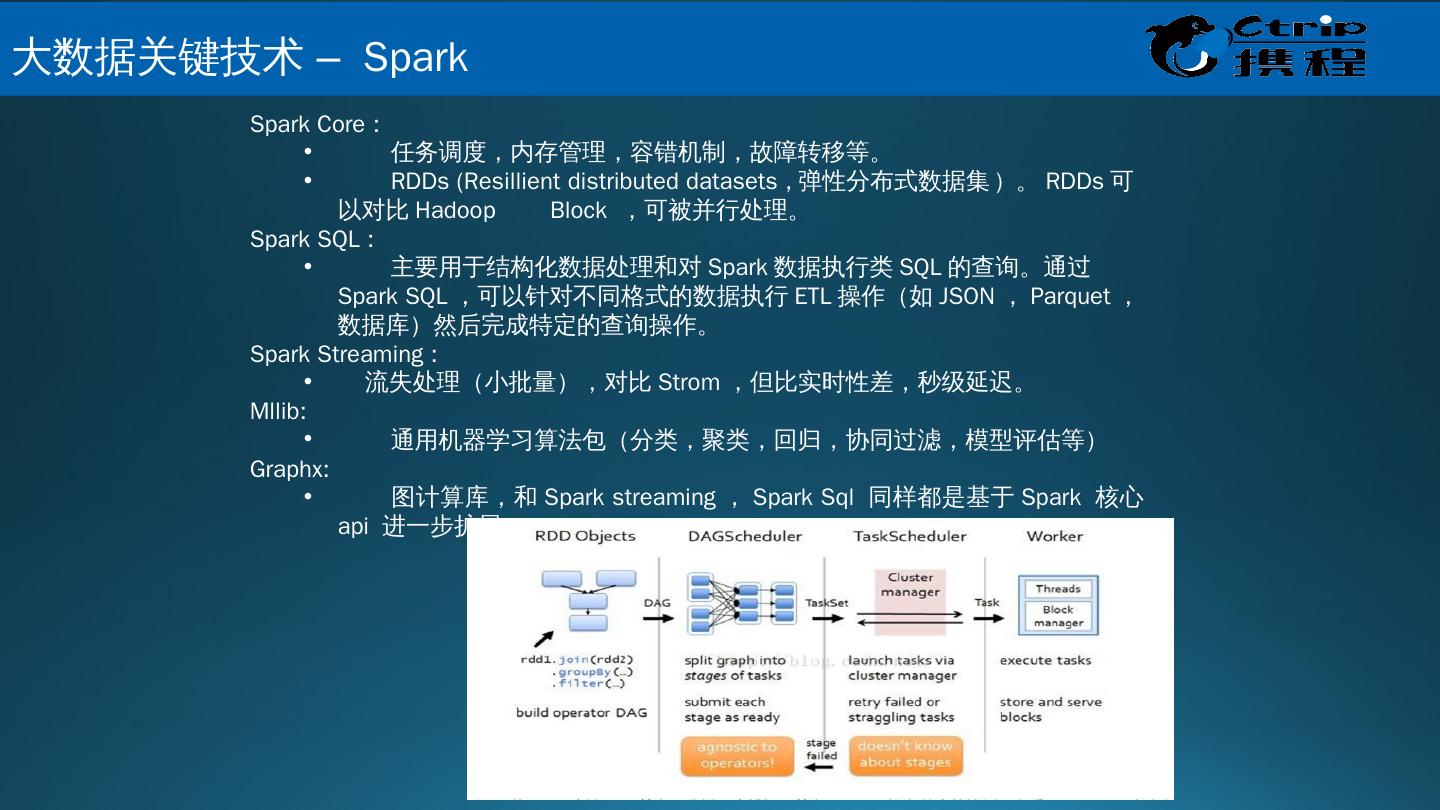
24 .Spark Core : 任务调度,内存管理,容错机制,故障转移等。 RDDs ( Resillient distributed datasets , 弹性分布式数据集 ) 。 RDDs 可以对比 Hadoop Block ,可被并行处理。 Spark SQL : 主要用于结构化数据处理和对 Spark 数据执行类 SQL 的查询。通过 Spark SQL ,可以针对不同格式的数据执行 ETL 操作(如 JSON , Parquet ,数据库)然后完成特定的查询操作。 Spark Streaming : 流失处理(小批量),对比 Strom ,但比实时性差,秒级延迟。 Mllib : 通用机器学习算法包(分类,聚类,回归,协同过滤,模型评估等) Graphx : 图计算库,和 Spark streaming , Spark Sql 同样都是基于 Spark 核心 api 进一步扩展。 大 数据关键技术 – Spark
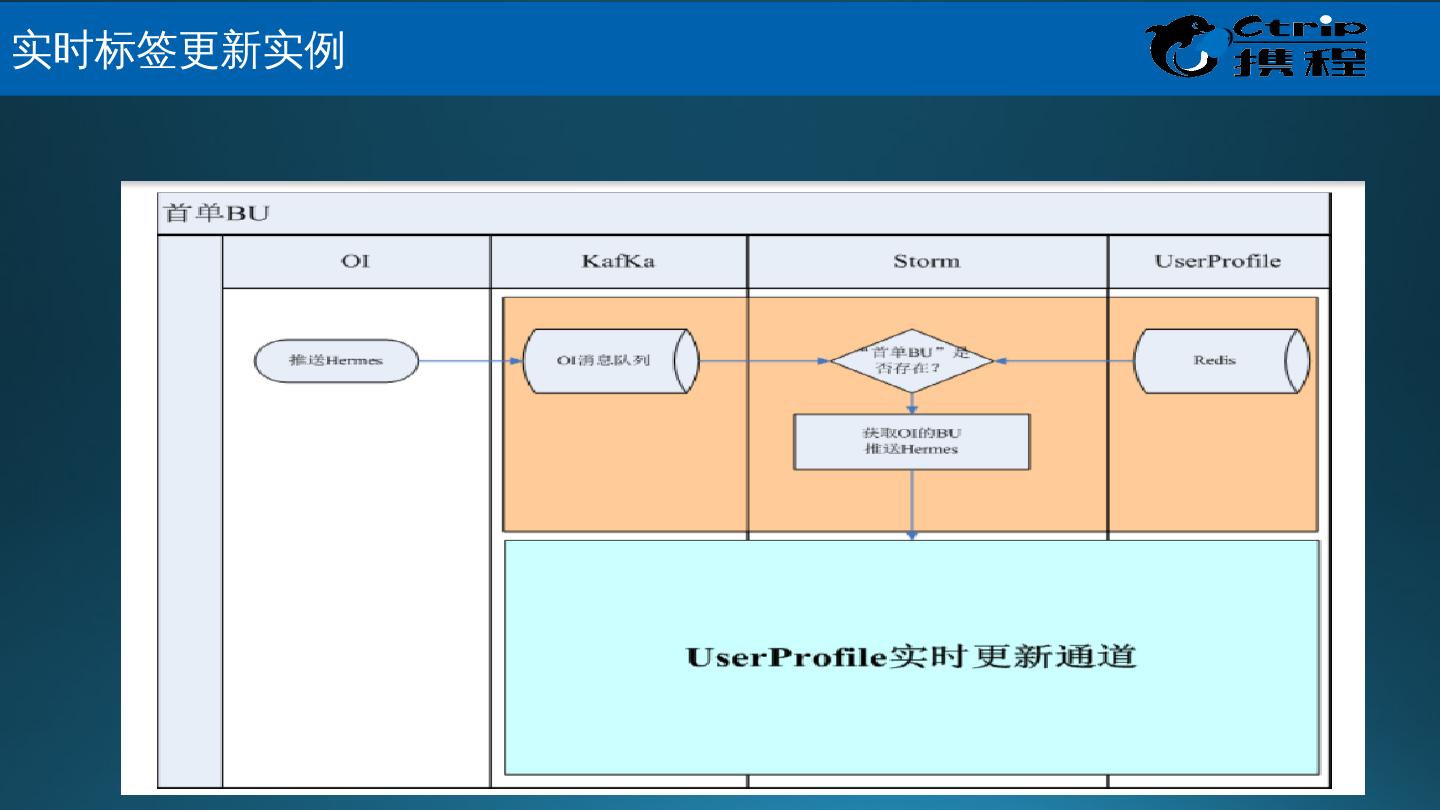
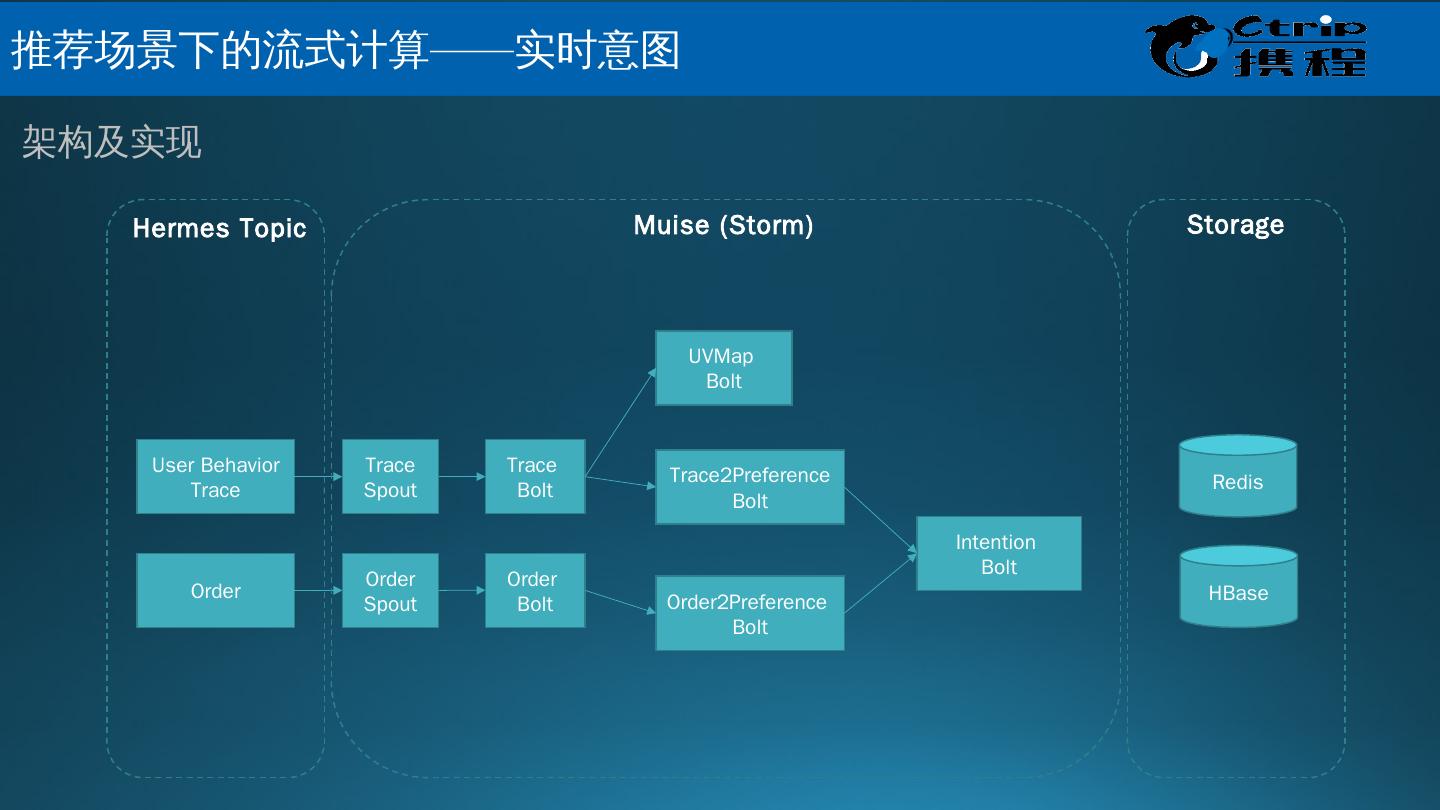
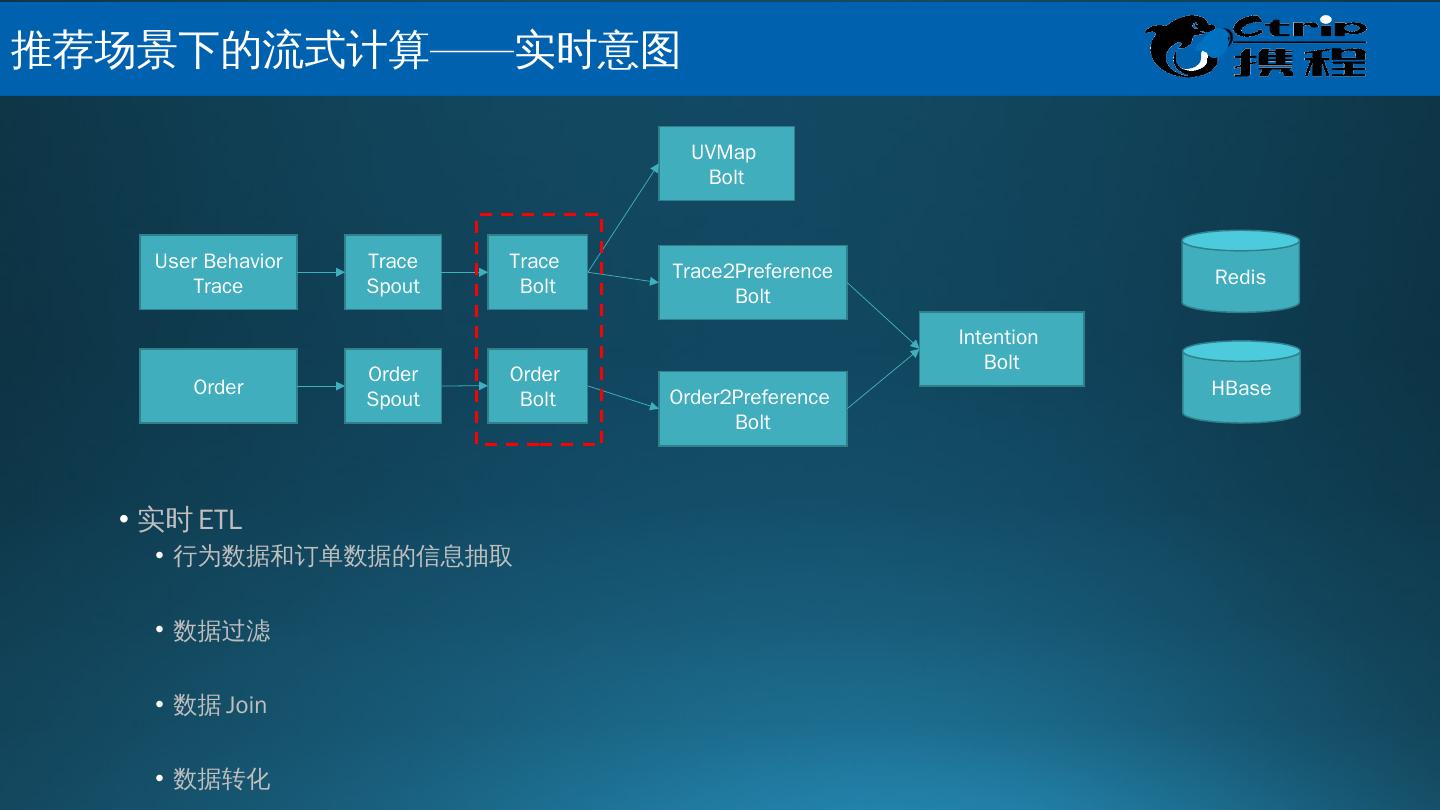
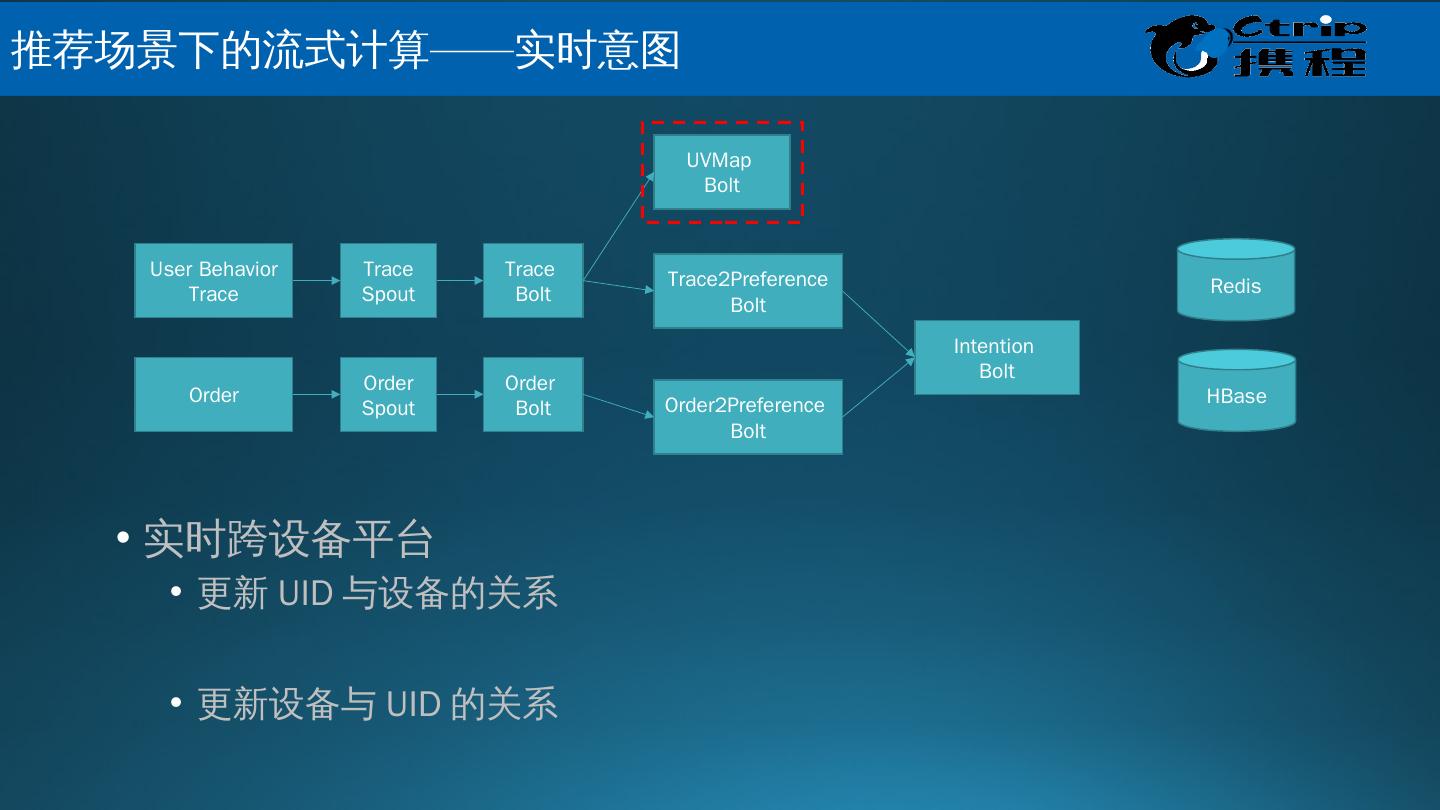
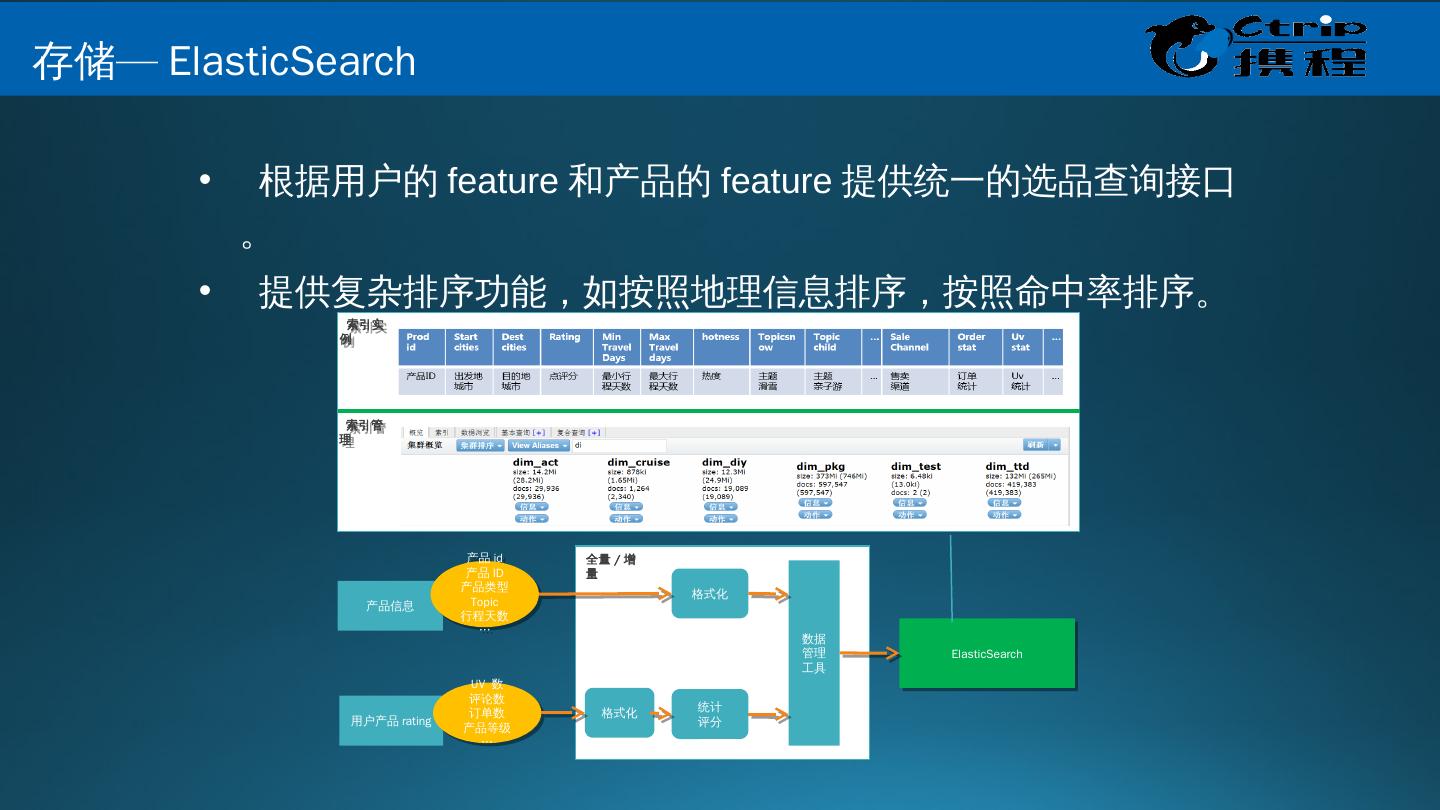
25 .Muise 是什么? Muise ,取自希腊神话的文艺女神缪斯之名,是携程的实时数据分析和处理的平台; 它底层基于开源的消息队列 Kafka 和开源的实时处理系统 Storm ,能够支持 秒级,甚至是毫秒级延迟的流式数据处理 。 数据接入 :使用 Hermes Producer API 将数据写入 Kafka 的 Topic 中 数据处理 :使用 Muise Storm API 从 Kafka 的 Topic 实时读取数据,使用 Storm 提供的实时数据处理的方式处理数据 数据管理 : Portal 提供对于 Kafka Topic 和 Storm 作业的管理 监控和告警 :使用 Storm 提供的 Metrics 框架,支持自定义的 metrics ; metrics 信息中心化管理,接入 Ops 的监控和告警系统,提供全面的监控和告警支持 Muise 的功能 大 数据关键技术 – 携程 Muise
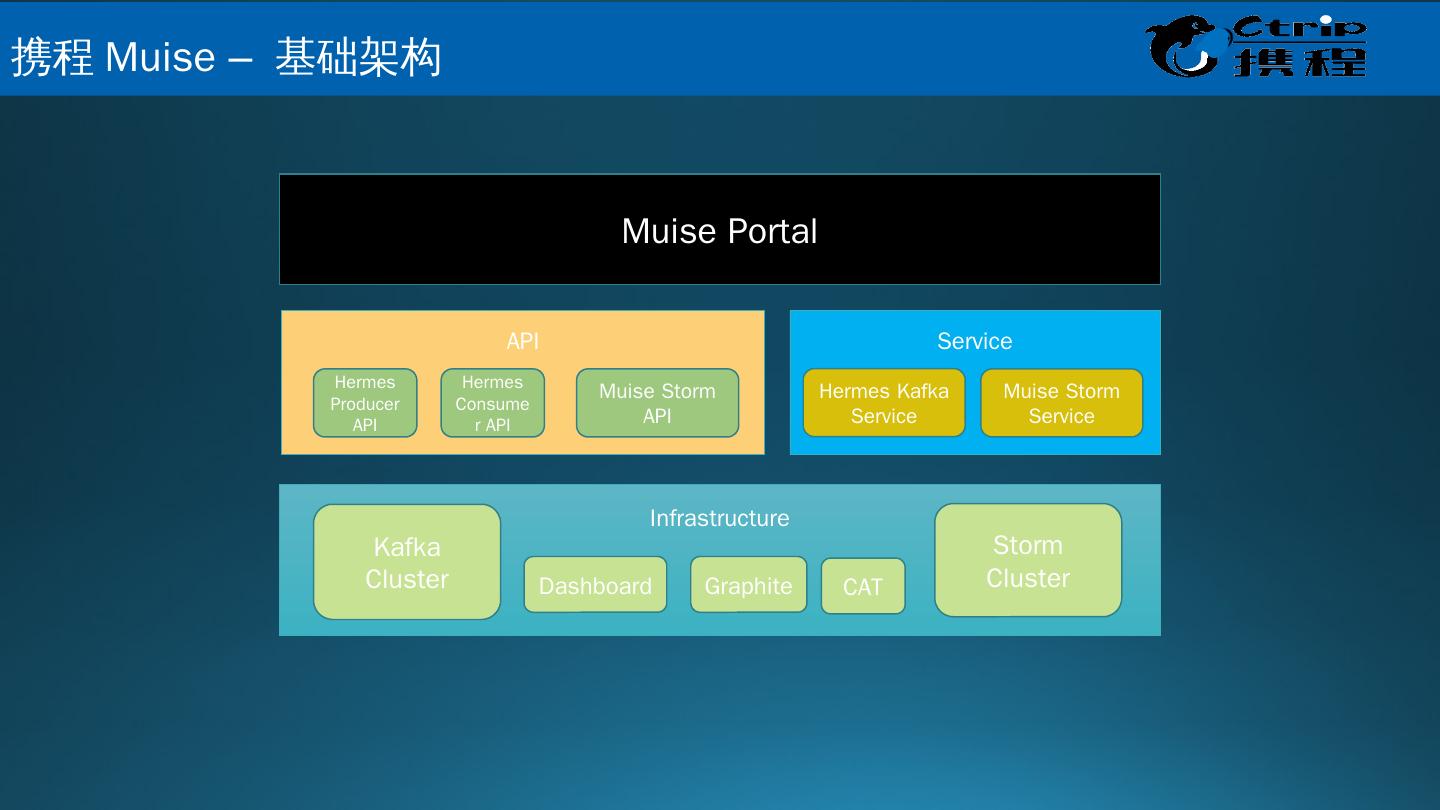
26 .Infrastructure API Service Storm Cluster Kafka Cluster Dashboard Graphite CAT Hermes Producer API Hermes Consumer API Muise Storm API Hermes Kafka Service Muise Storm Service Muise Portal 携 程 Muise – 基础架构
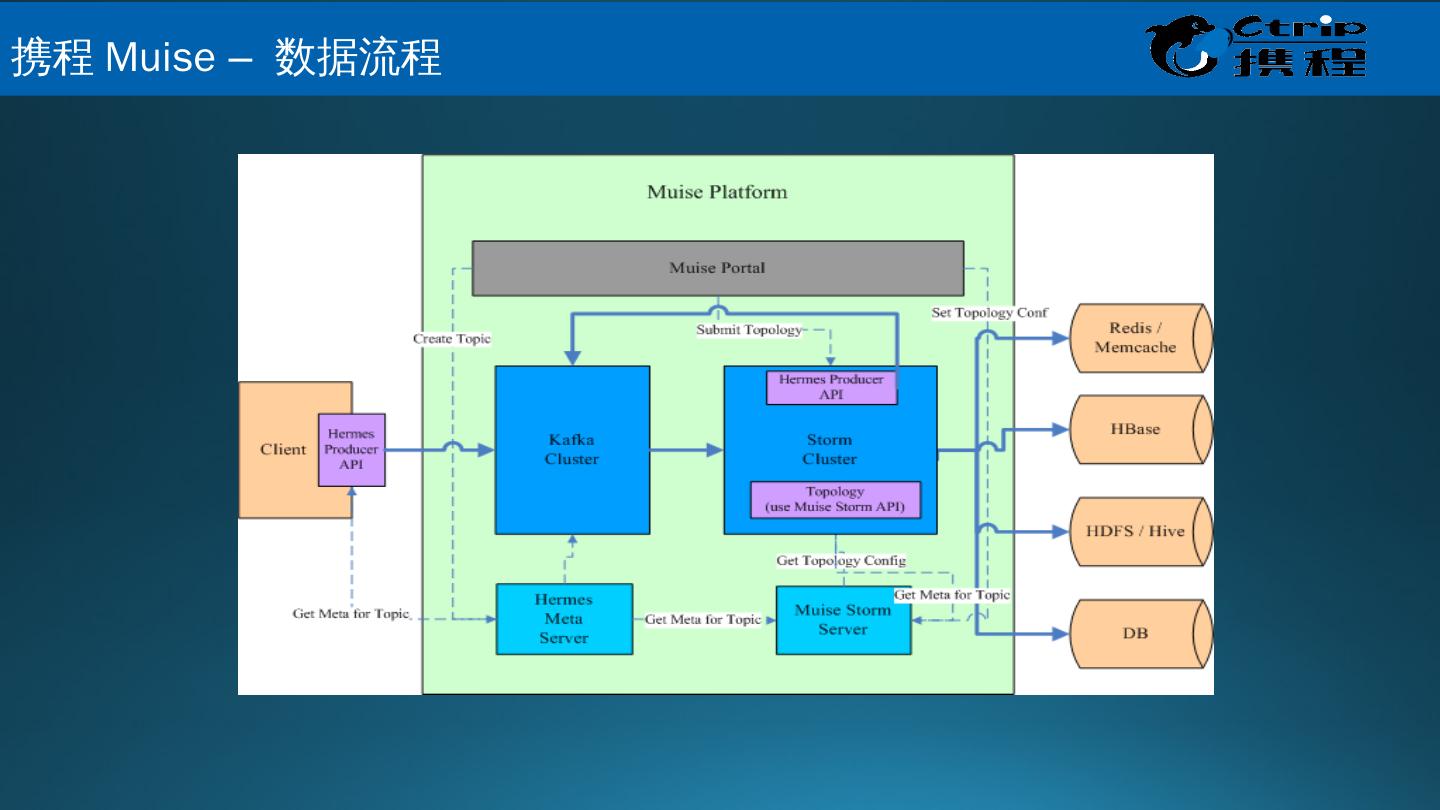
27 .携 程 Muise – 数据流程
28 .携 程 Muise – 作业管理
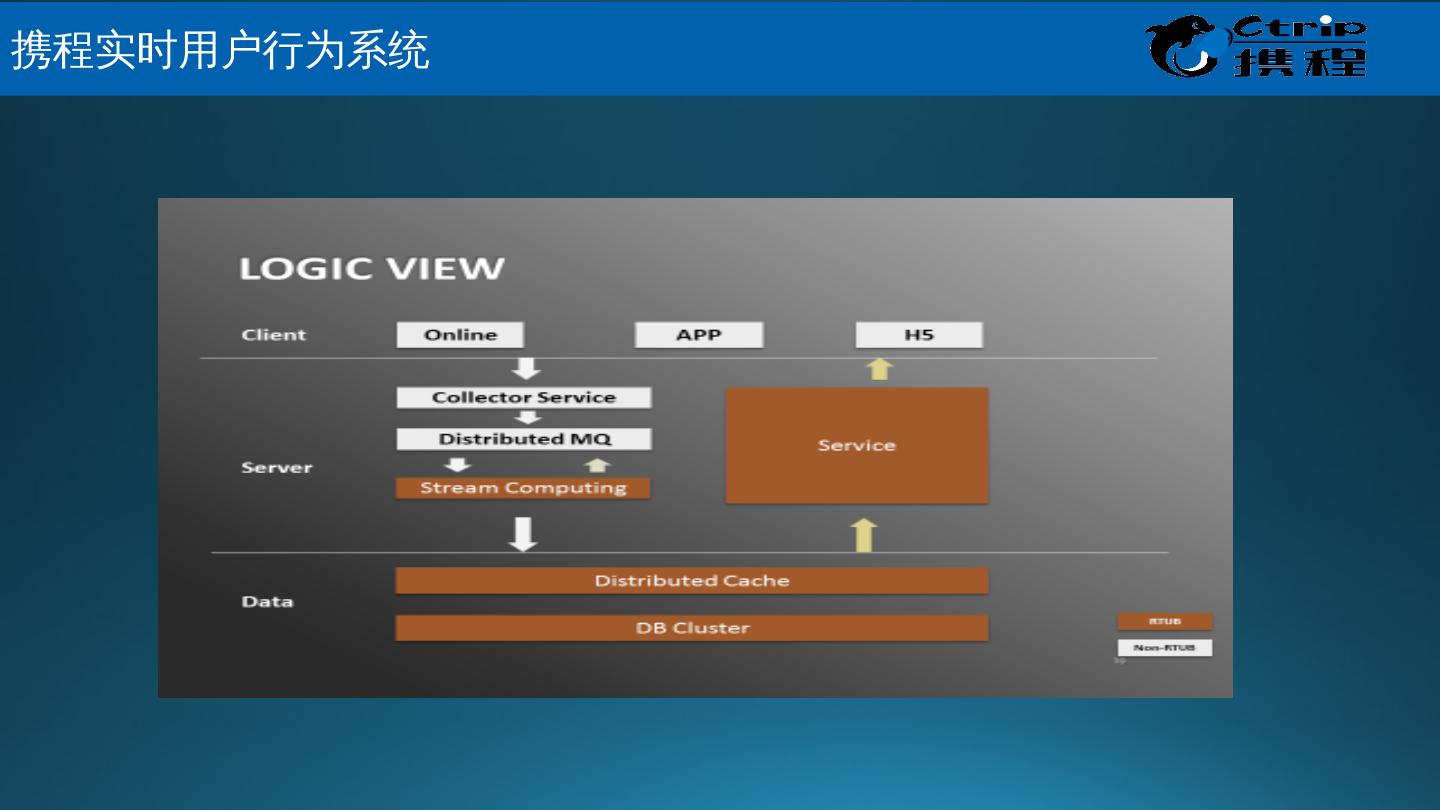
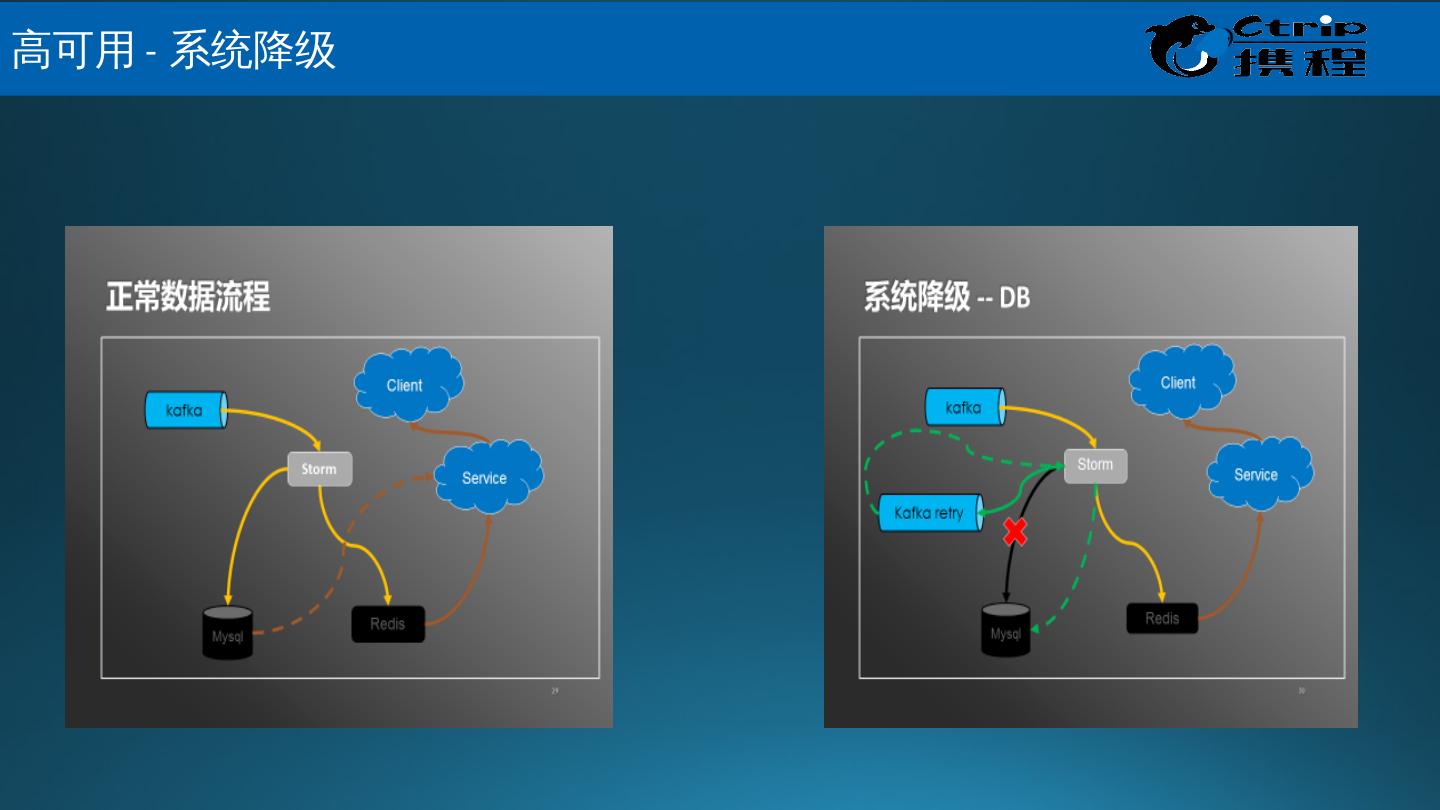
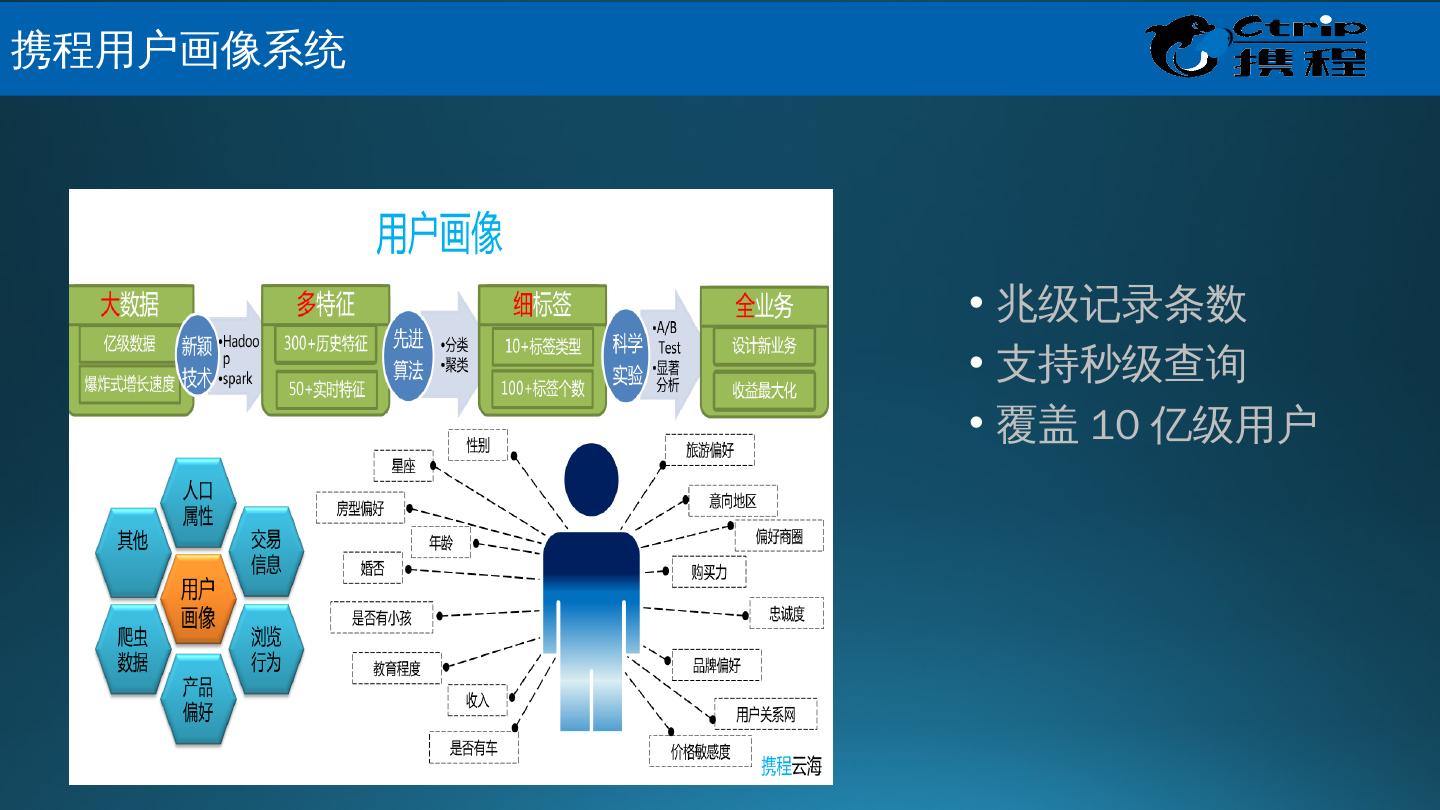
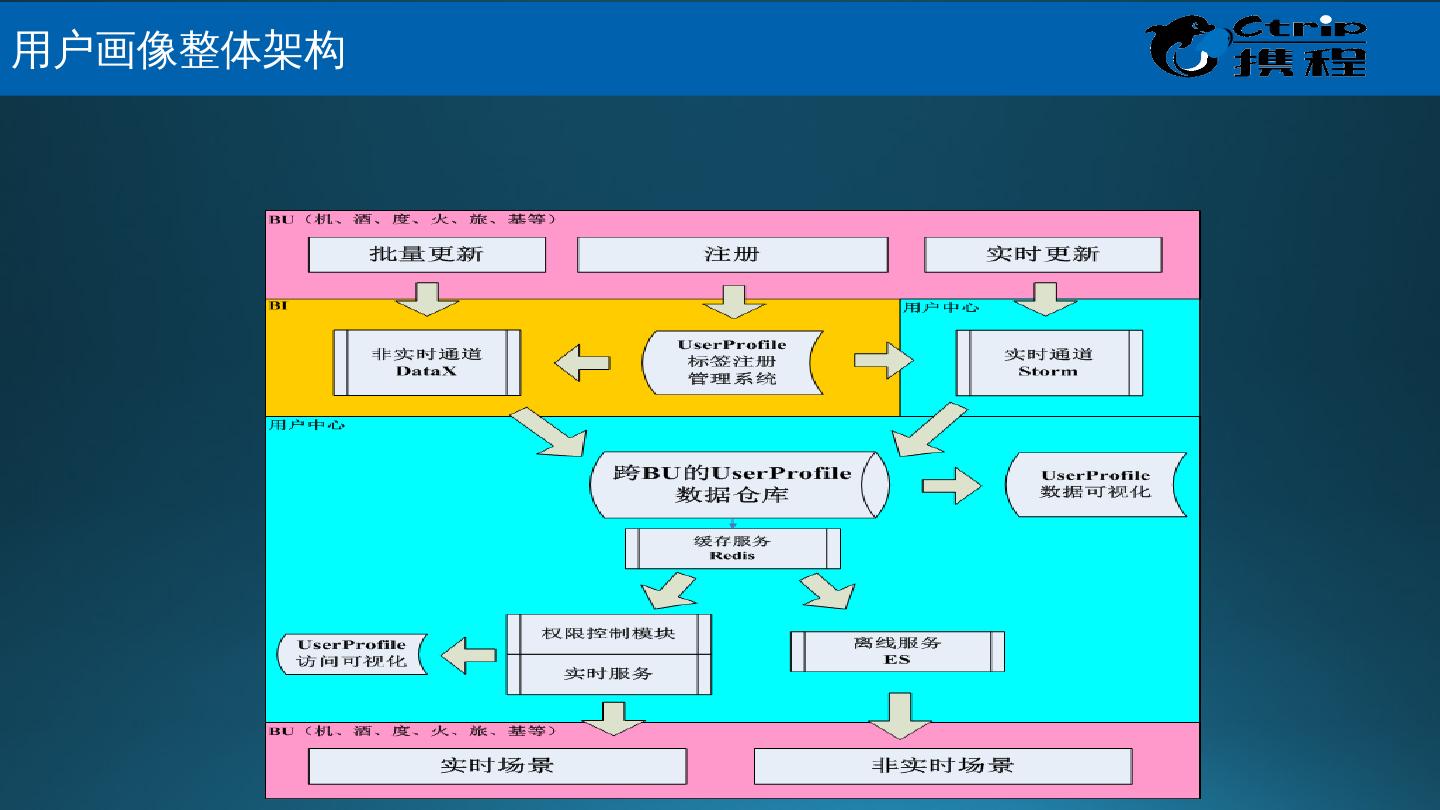
29 .携 程 Muise – 应用
3秒后跳转登录页面
去登陆

