Kafka - 51CTO.com
分享
点赞
1
收藏
0
下载 3
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
传统的日志分析系统提供了一种离线处理日志信息的可扩展方案,但若要进行实时 ... (3)显式分布式,即所有的producer、broker和consumer都会有多个,均为分布式的。 ... (5)kafka对事务处理比较弱,但是message分发上还是做了一定的策略来保证 ...
展开查看详情
2 .Kafka 基础知识 产生背景 设计理念 部署架构 基本概念 关键技术
3 .Kafka 基础知识 产生背景 传统的日志分析系统提供了一种离线处理日志信息的可扩展方案,但若要进行实时处理,通常会有较大延迟。而现有的消(队列)系统能够很好的处理实时或者近似 实时的应用,但未处理的数据通常不会写到磁盘上,这对于 Hadoop 之类(一小时或者一天只处理一部分数据)的离线应用而言,可能存在问题。 Kafka 正 是为了解决以上问题而设计的,它能够很好地离线和在线应用。
4 .Kafka 基础知识 设计理念 ( 1 )数据在磁盘上存取代价为 O(1) 。一般数据在磁盘上是使用 BTree 存储的,存取代价为 O ( lgn )。 ( 2 )高吞吐率。即使在普通的节点上每秒钟也能处理成百上千的 message 。 ( 3 )显式分布式,即所有的 producer 、 broker 和 consumer 都会有多个,均为分布式的。 ( 4 )支持数据并行加载到 Hadoop 中。
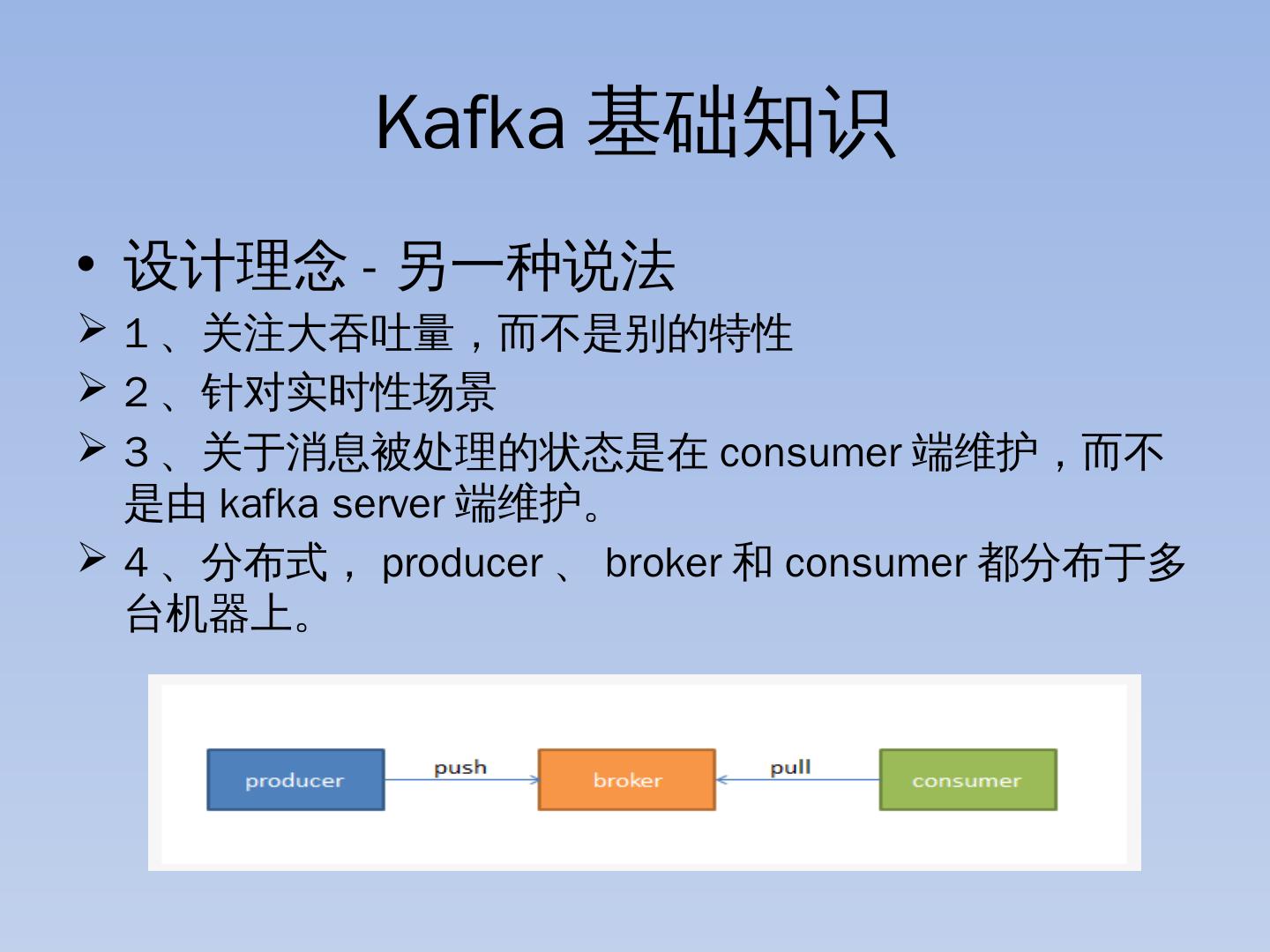
5 .Kafka 基础知识 设计理念 - 另一种说法 1 、关注大吞吐量,而不是别的特性 2 、针对实时性场景 3 、关于消息被处理的状态是在 consumer 端维护,而不是由 kafka server 端维护。 4 、分布式, producer 、 broker 和 consumer 都分布于多台机器上。
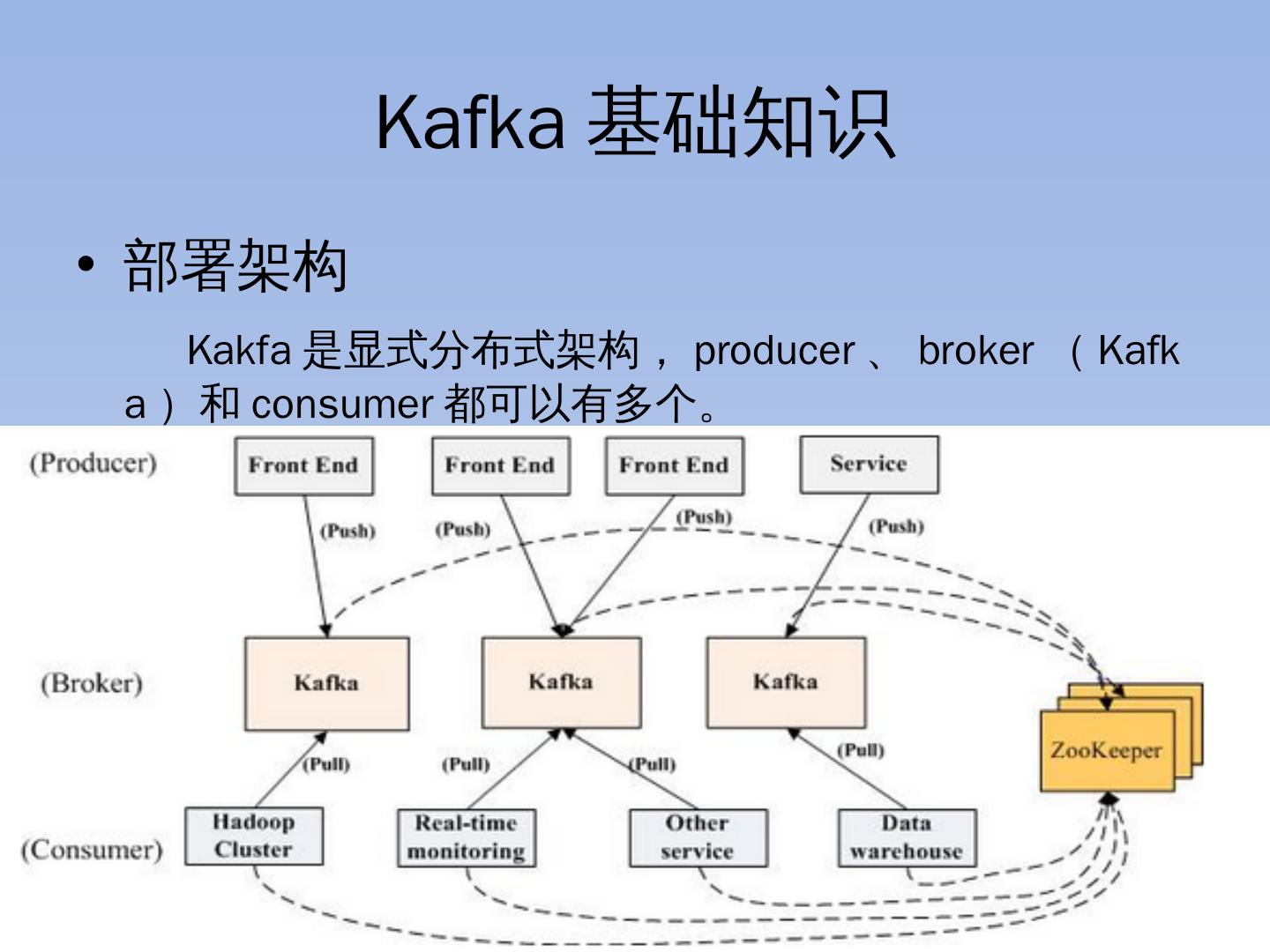
6 .Kafka 基础知识 部署架构 Kakfa 是显式分布式架构, producer、broker(Kafka ) 和 consumer 都可以有多个。
7 .Kafka 基础知识 基本概念 几个术语 ( 1 ) message (消息)是通信的基本单位,每个 producer 可以向一个 topic (主题)发布一些消息。如果 consumer 订阅了这个主题,那么新发布的消息就会广播给这些 consumer 。 ( 2 ) Kafka 是显式分布式的,多个 producer 、 consumer 和 broker 可以运行在一个大的集群上,作为一个逻辑整体对外提供服务。对于 consumer ,多个 consumer 可以组成一个 group ,这个 message 只能传输给某个 group 中的某一个 consumer. ( 3 ) topic: 在 kafka 中,不同的数据可以按照不同的 topic 存储。
8 .Kafka 基础知识 基本概念 依赖技术 ( 1 )硬件上, kafka 利用线性存储来进行硬盘直接读写。 ( 2 ) kafka 没有使用内存作为缓存。 ( 3 )用 zero-copy 。 ( 4 ) Gzip 和 Snappy 压缩 ( 5 ) kafka 对事务处理比较弱,但是 message 分发上还是做了一定的策略来保证数据递送的准确性的。
9 .Kafka 基础知识 基本概念 关于存储的几个概念 ( 1 ) Partition: 同一个 topic 下可以设置多个 partition, 目的是为了提高并行处理的能力。可以将同一个 topic 下的 message 存储到不同的 paritition 下。 ( 2 ) Offset:kafka 的存储文件都是按照 offset.kafka 来命名,用 offset 做名字的好处是方便查找。
10 .Kafka 基础知识 基本概念 分布式方面 ( 1 ) broker 的部署是没有主从结构的,每个节点都是同等的,节点的增减和减少都不需要改变任何配置。 ( 2 ) producer 和 consumer 通过 zookeeper 去发现 topic, 并通过 zookeeper 来协调生产和消费的过程。 ( 3 ) producer、consumer 和 broker 均采用 TCP 连接,通信基于 NIO 实现。并且 Producer 和 consumer 能自动检测 broker 的增加和减少。
11 .Kafka 基础知识 关键技术 zero-copy 在 Kafka 上,有两个原因可能导致低效: 1 )太多的网络请求 2 )过多的字节拷贝。为了提高效率, Kafka 把 message 分成一组一组的,每次请求会把一组 message 发给相应的 consumer 。 此外, 为了减少字节拷贝,采用了 sendfile 系统调用。 http://www.ibm.com/developerworks/cn/linux/l-cn-zerocopy2/
12 .Kafka 基础知识 关键技术 Exactly once message transfer 怎样记录每个 consumer 处理的信息的状态?在 Kafka 中仅保存了每个 consumer 已经处理数据的 offset 。这样有两个好处: 1 )保存的数据量少 2 )当 consumer 出错时,重新启动 consumer 处理数据时,只需从最近的 offset 开始处理数据即可。
13 .Kafka 基础知识 关键技术 Push/pull Producer 向 Kafka(push ) 推数据, consumer 从 kafka 拉( pull) 数据。
14 .Kafka 基础知识 关键技术 负载均衡和容错 Producer 和 broker 之间没有负载均衡机制。 broker 和 consumer 之间利用 zookeeper 进行负载均衡。所有 broker 和 consumer 都会在 zookeeper 中进行注册,且 zookeeper 会保存他们的一些元数据信息。如果某个 broker 和 consumer 发生了变化,所有其他的 broker 和 consumer 都会得到 通知。