


















- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
statistical learning and data mining introduction
Introduction statistical learning and data mining course, including its definition, prerequisite, research fields, application range, terminology, etc. Some examples and graphics to explain statistical learning and data mining.
展开查看详情
1 .Statistical Learning and Data Mining Stat557 Statistical Learning and Data Mining Stat557 Jia Li Department of Statistics The Pennsylvania State University Email: jiali@stat.psu.edu http://www.stat.psu.edu/∼jiali Jia Li http://www.stat.psu.edu/∼jiali
2 .Statistical Learning and Data Mining Stat557 General Information Course homepage: http://www.stat.psu.edu/˜jiali/stat557 Prerequisite: Elementary probability theory Conditional distribution, expectation C, Matlab, or S-plus programming Jia Li http://www.stat.psu.edu/∼jiali
3 .Statistical Learning and Data Mining Stat557 Text books: Required: The Elements of Statistical Learning, by T. Hastie, R. Tibshirani, and J. Friedman (ElemStatLearn). Optional: 1. Classification and Regression Trees by L. Breiman, J. H. Friedman, R. A. Olshen, and C. J. Stone 2. Pattern Recognition and Neural Networks by B. Ripley 3. Principles of Data Mining by H. Mannila, P. Smyth and D. J. Hand 4. Data Mining: Concepts and Techniques by J. Han and M. Kamber Jia Li http://www.stat.psu.edu/∼jiali
4 .Statistical Learning and Data Mining Stat557 What Is Data Mining? Data mining: tools, methodologies, and theories for revealing patterns in data—a critical step in knowledge discovery. Driving forces: Big data: Enormous volume High complexity: dimension, structure Dynamic Explosive growth of data in a great variety of fields Cheaper storage devices with higher capacity Faster communication Better database manage systems Rapidly increasing computing power: distributed and parallel platforms Make data to work for us Jia Li http://www.stat.psu.edu/∼jiali
5 .Statistical Learning and Data Mining Stat557 Research fields Statistics Machine learning Pattern recognition Signal processing Database Jia Li http://www.stat.psu.edu/∼jiali
6 .Statistical Learning and Data Mining Stat557 Applications Business Wal-Mart data warehouse Credit card companies Genomics Human genome project: DNA sequences Microarray data Information retrieval Terrabytes of data on the internet Multimedia information Communication systems Speech recognition Image analysis Many other scientific fields Jia Li http://www.stat.psu.edu/∼jiali
7 .Statistical Learning and Data Mining Stat557 Problems Focused: Prediction Jia Li http://www.stat.psu.edu/∼jiali
8 .Statistical Learning and Data Mining Stat557 Terminology Notation Input X : X is often multidimensional. Each dimension of X is denoted by Xj and is referred to as a feature, predictor, or independent variable/variable. Output Y : response, dependent variable. Categorization Supervised learning vs. unsupervised learning Is Y available in the training data? Regression vs. Classification Is Y quantitative or qualitative? For qualitative Y , it is also denoted by G ∈ G = {1, 2, ..., K }. Jia Li http://www.stat.psu.edu/∼jiali
9 .Statistical Learning and Data Mining Stat557 Examples Email spam: (ElemStatLearn) Goal: predict whether an email is a junk email, i.e., “spam”. Raw data: text email messages. Input X : relative frequencies of 57 of the most commonly occurring words and punctuation marks in the email message. Training data set: 4601 email messages with email type known (supervised learning). Jia Li http://www.stat.psu.edu/∼jiali
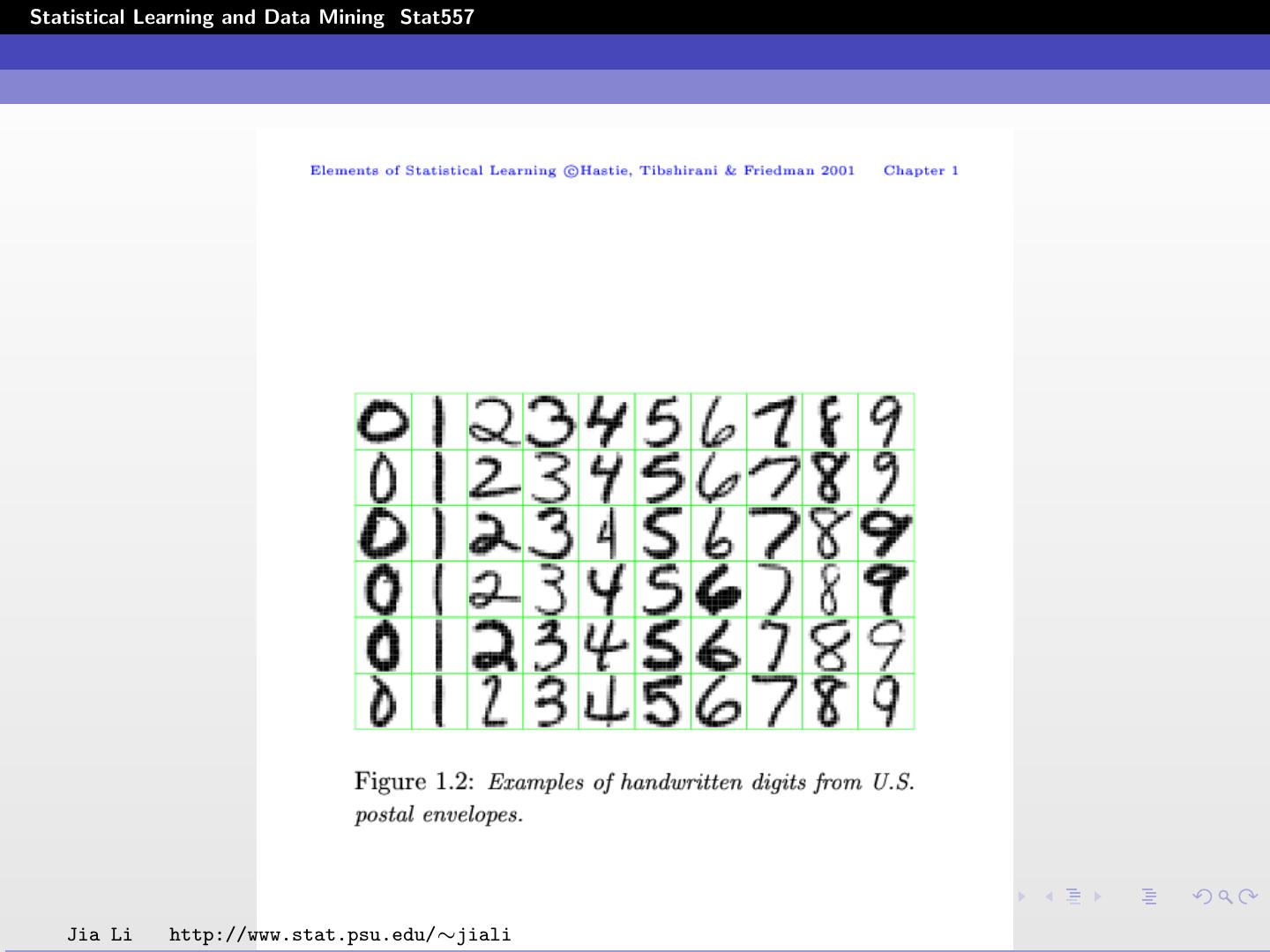
10 .Statistical Learning and Data Mining Stat557 Examples Handwritten digit recognition:(ElemStatLearn) Goal: identify single digits 0 ∼ 9 based on images. Raw data: images that are scaled segments from five digit ZIP codes. 16 × 16 eight-bit grayscale maps Pixel intensities range from 0 (black) to 255 (white). Input data: a 256 dimension vector, or feature vectors with lower dimensions. Jia Li http://www.stat.psu.edu/∼jiali
11 .Statistical Learning and Data Mining Stat557 Jia Li http://www.stat.psu.edu/∼jiali
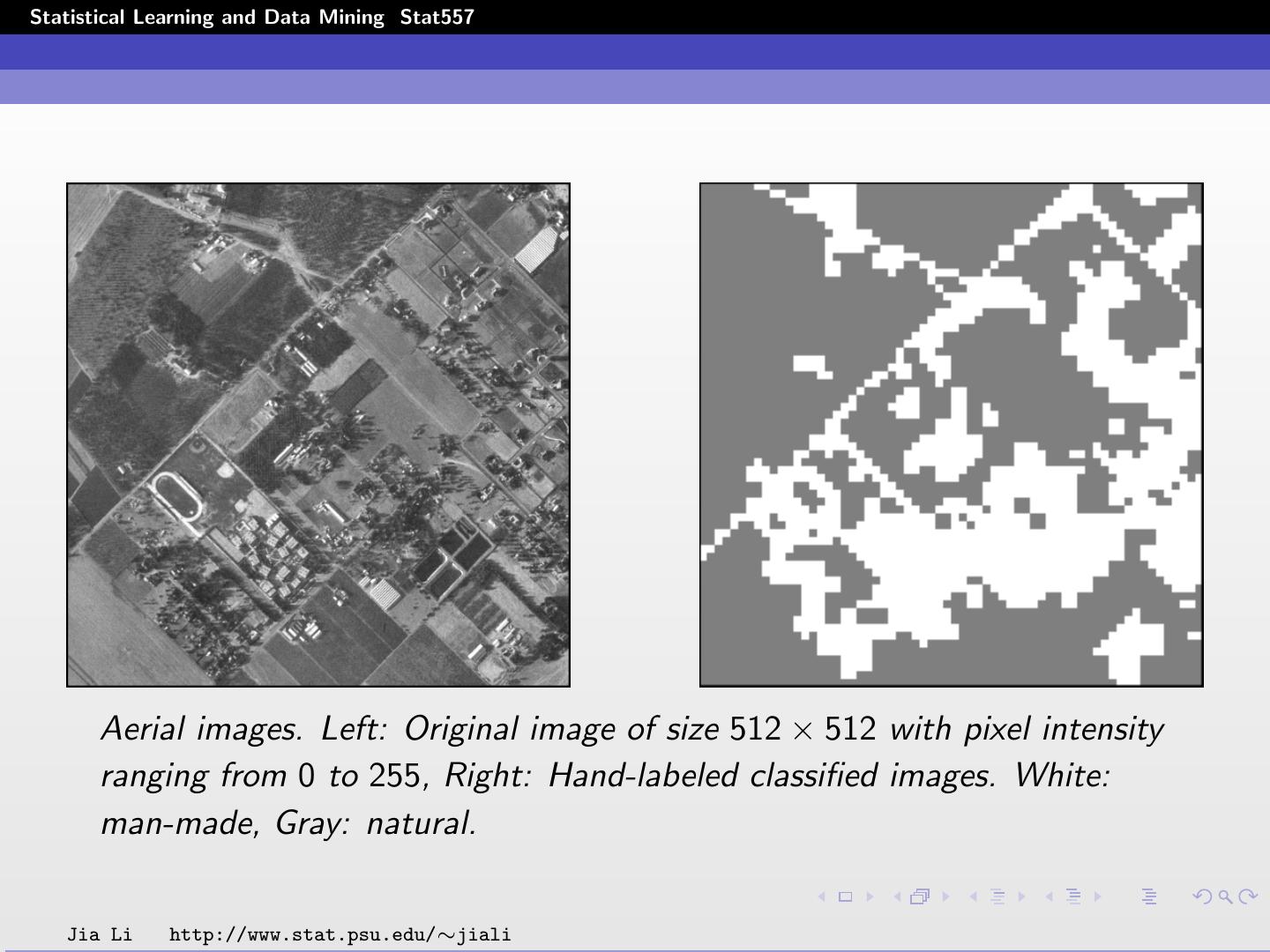
12 .Statistical Learning and Data Mining Stat557 Examples Image segmentation: Goal: segment images into regions of different types, e.g., man-made vs. natural in aerial images, graph and picture vs. text in document images. Raw data: grayscale images represented by matrices of size m × n, or color images represented by 3 such matrices. Jia Li http://www.stat.psu.edu/∼jiali
13 .Statistical Learning and Data Mining Stat557 Aerial images. Left: Original image of size 512 × 512 with pixel intensity ranging from 0 to 255, Right: Hand-labeled classified images. White: man-made, Gray: natural. Jia Li http://www.stat.psu.edu/∼jiali
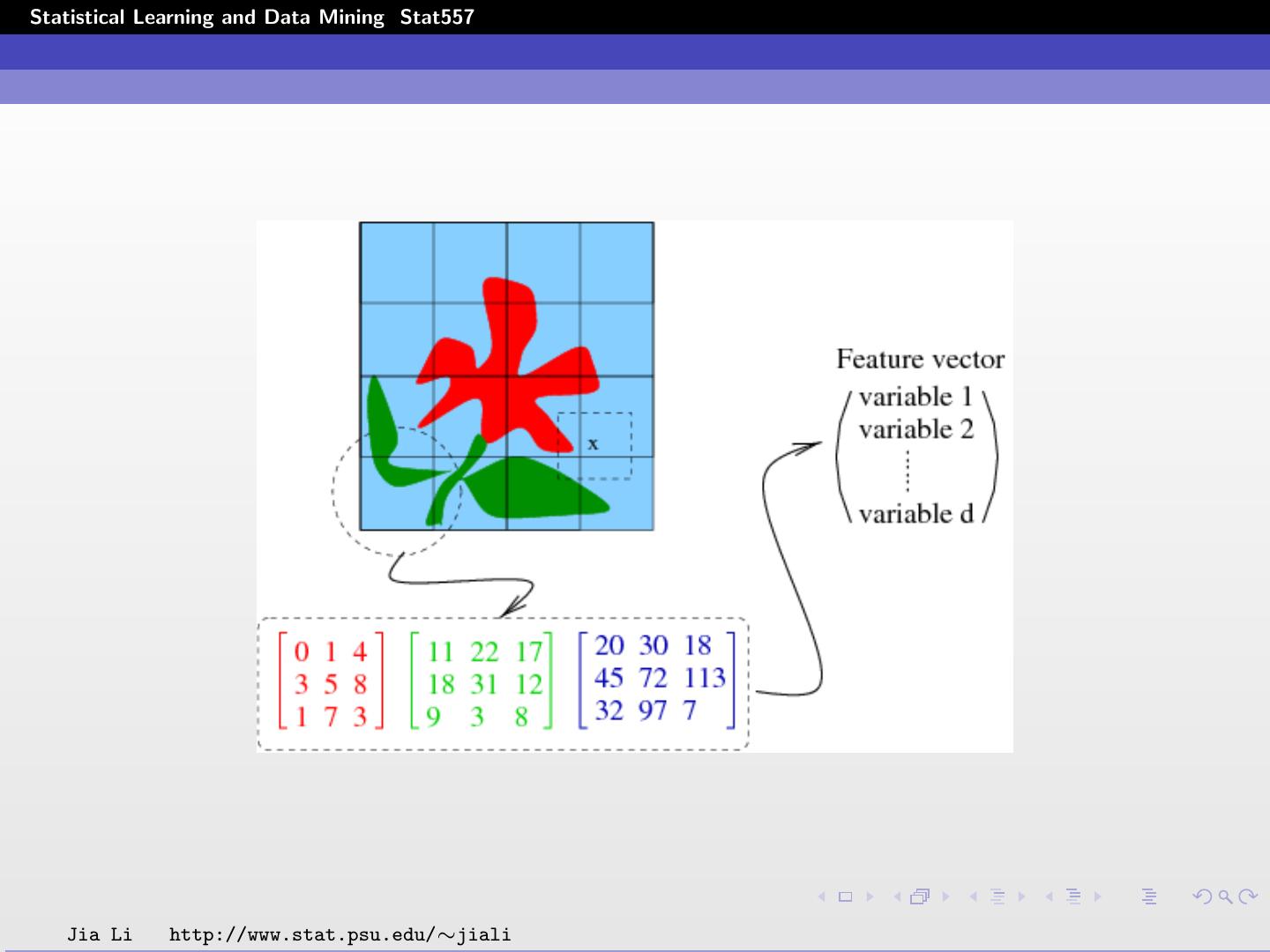
14 .Statistical Learning and Data Mining Stat557 Input data: Divide images into blocks of pixels or form a neighborhood around each pixel. Compute statistics using pixel intensities in each block. An image is converted to an array of input vectors. Methodologies: Assume the feature vectors are independent. Employ spatial models to capture dependence among the vectors. Jia Li http://www.stat.psu.edu/∼jiali
15 .Statistical Learning and Data Mining Stat557 Jia Li http://www.stat.psu.edu/∼jiali
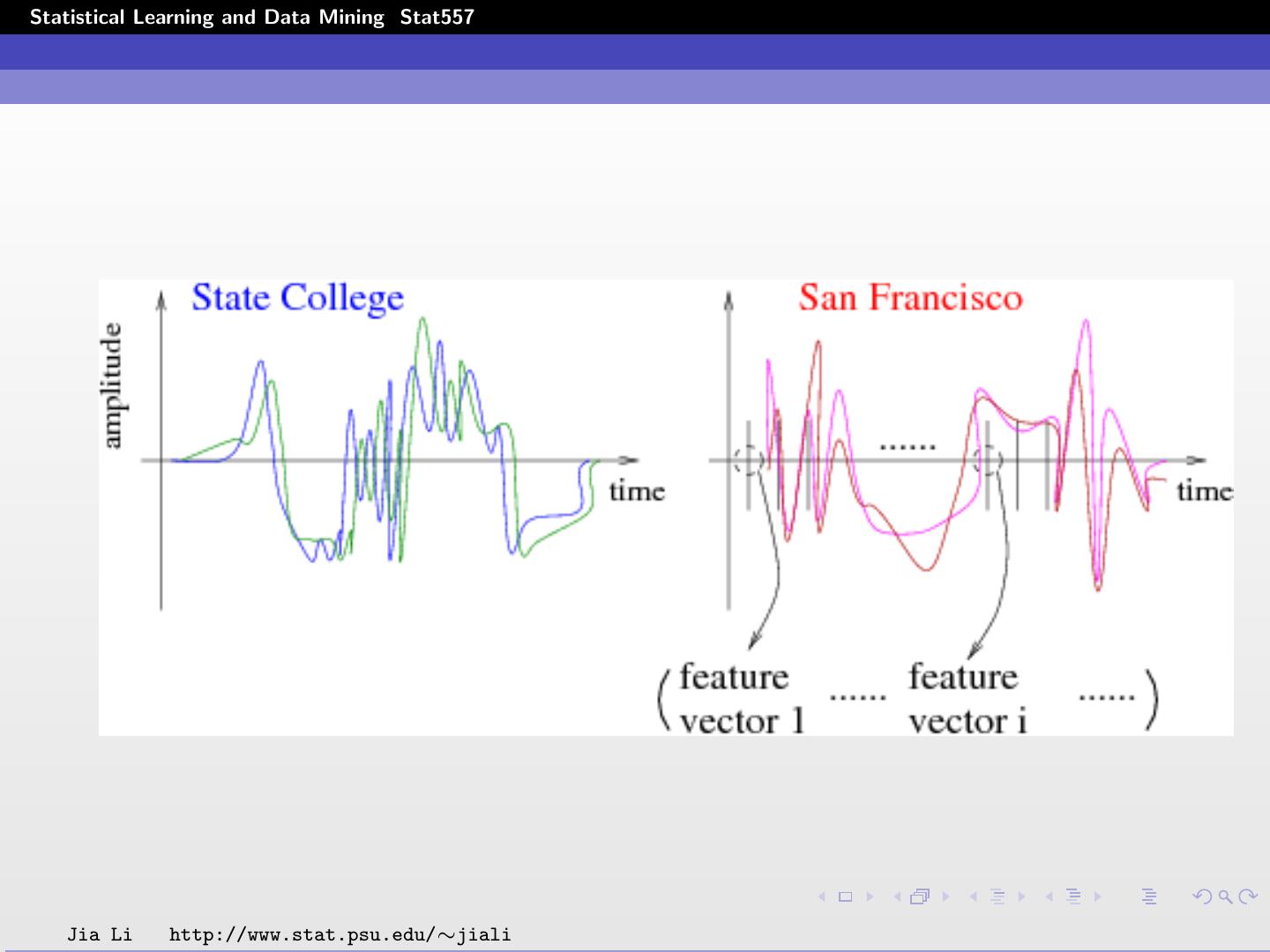
16 .Statistical Learning and Data Mining Stat557 Examples Speech recognition: Goal: identify words spoken according to speech signals Automatic voice recognition systems used by airline companies Automatic stock price reporting Raw data: voice amplitude sampled at discrete time spots (a time sequence). Jia Li http://www.stat.psu.edu/∼jiali
17 .Statistical Learning and Data Mining Stat557 Jia Li http://www.stat.psu.edu/∼jiali
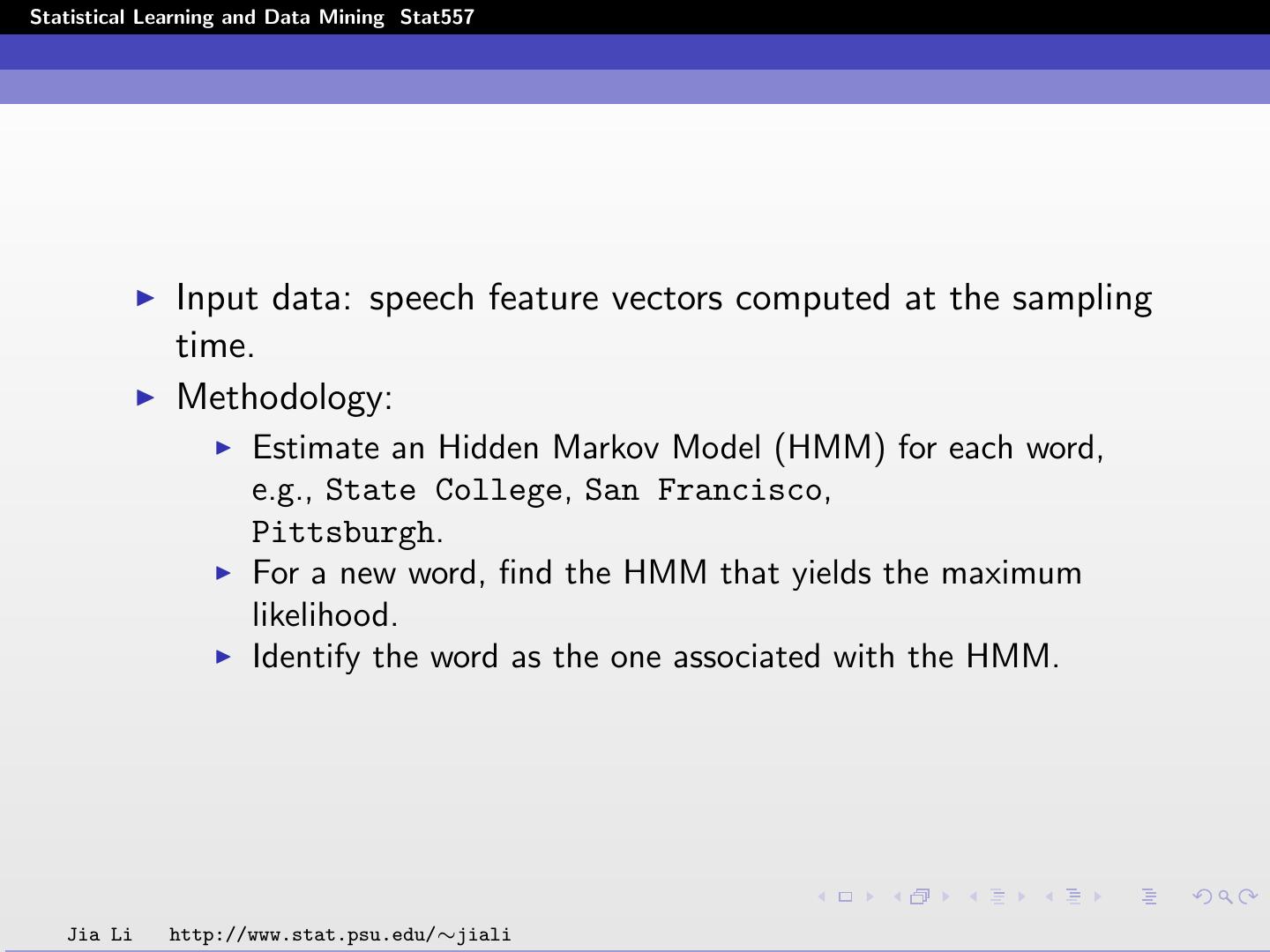
18 .Statistical Learning and Data Mining Stat557 Input data: speech feature vectors computed at the sampling time. Methodology: Estimate an Hidden Markov Model (HMM) for each word, e.g., State College, San Francisco, Pittsburgh. For a new word, find the HMM that yields the maximum likelihood. Identify the word as the one associated with the HMM. Jia Li http://www.stat.psu.edu/∼jiali
19 .Statistical Learning and Data Mining Stat557 Examples DNA Expression Microarray: Goal: identify disease or tissue types Raw data: for each sample taken from a tissue of a particular disease type, the expression levels of a large collection of genes are measured. Input data: cleaned-up gene expression data Normalization Denoising. Ample literature on the topic of cleaning microarray data Example data set: 4026 genes, 96 samples taken from 9 classes of tissues. Challenges: very high dimensional data very limited number of samples Jia Li http://www.stat.psu.edu/∼jiali
20 .Statistical Learning and Data Mining Stat557 Examples DNA sequence classification: Goal: distinguish “junk” segments from coding segments. Raw data: sequences of letters, e.g., A,C,G,T for DNA sequences. Input data: likelihood ratio statistics computed from stochastic models. Supervised learning: estimate stochastic models, select models. Jia Li http://www.stat.psu.edu/∼jiali
21 .Statistical Learning and Data Mining Stat557 Supervised Learning Two types of learning: Regression: the response Y is quantitative. Classification: the response Y is qualitative, or categorical. Two aspects in learning: Fit the data well. Robust Equivalent concepts: Training error vs. testing error Bias vs. variance Fitting vs. overfitting Empirical risk vs. model complexity (capacity) Jia Li http://www.stat.psu.edu/∼jiali
22 .Statistical Learning and Data Mining Stat557 Jia Li http://www.stat.psu.edu/∼jiali
23 .Statistical Learning and Data Mining Stat557 Learning Spectrum Jia Li http://www.stat.psu.edu/∼jiali
24 .Statistical Learning and Data Mining Stat557 Regression Overview: Linear models: The mean response is a linear function of the independent variables. Generalized linear models Expand basis: Splines (polynomials) Reproducing Kernel Hilbert Spaces Wavelet smoothing Kernel methods Jia Li http://www.stat.psu.edu/∼jiali
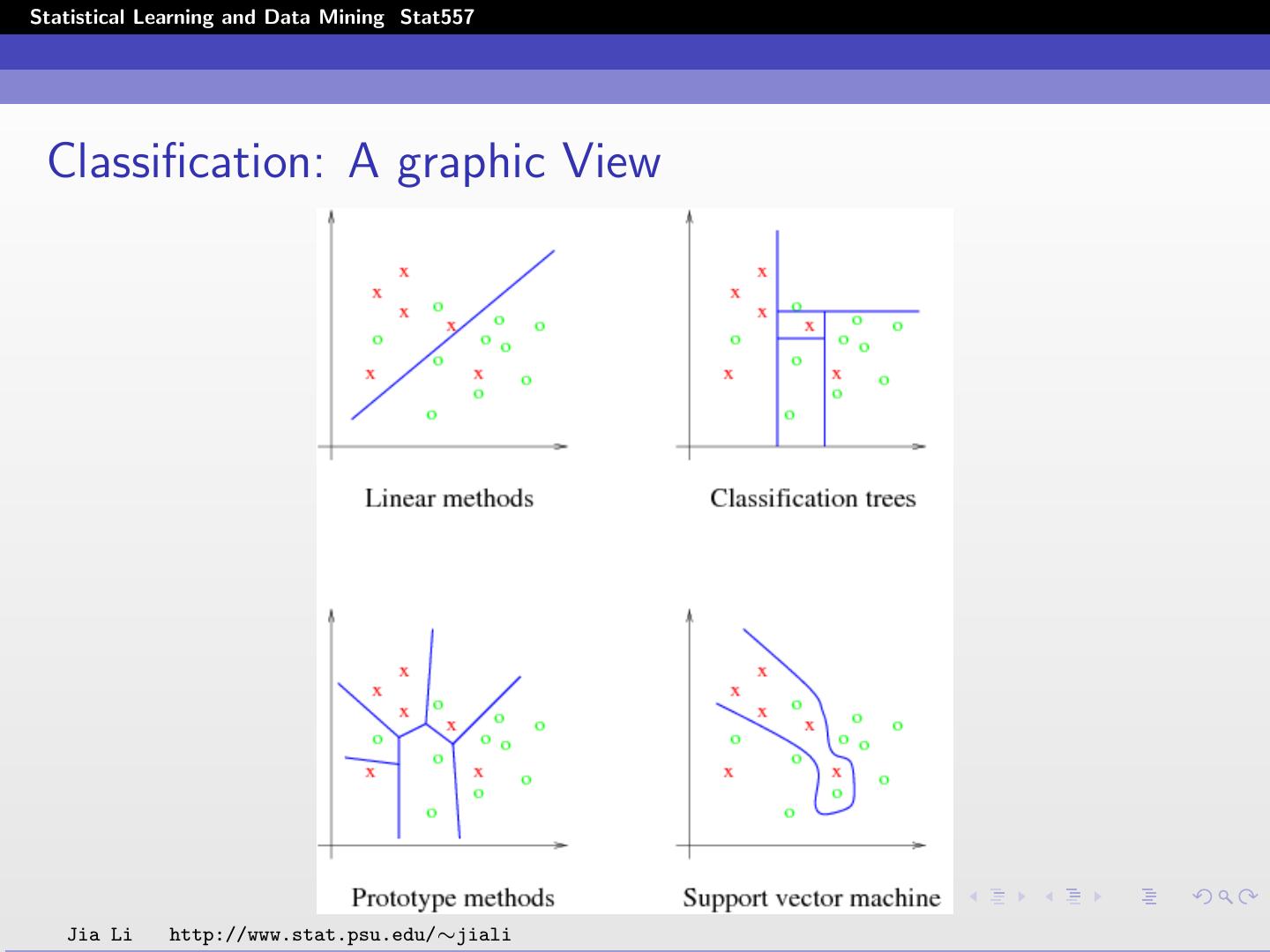
25 .Statistical Learning and Data Mining Stat557 Classification: A graphic View Jia Li http://www.stat.psu.edu/∼jiali
26 .Statistical Learning and Data Mining Stat557 Outlines Linear regression Linear methods for classification Prototype methods Classification and regression tree (CART) Mixture discriminant analysis Hidden Markov models and its applications Jia Li http://www.stat.psu.edu/∼jiali
3秒后跳转登录页面
去登陆

