







































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
experience-of-optimizing-spark-s
从17年开始,eBay将它的数据仓库系统向Spark做迁移,我们分享了迁移过程中为Spark做的两个主要优化:Adaptive Execution和Indexed Bucket。
展开查看详情
1 .Experience of optimizing SparkSQL when migrating from MPP DBMS Yucai Yu, Yuming Wang, Chenxiao Mao eBay, Data Services and Solutions #SAISExp11
2 .About Us • Spark / Hadoop Contributors • eBay Data Services and Solutions team • Responsible for enterprise data warehouse / data lake development and optimization #SAISExp11 2
3 .Migrating from MPP DBMS Spark as Core ETL Engine #SAISExp11 3
4 .Spark as DW Processing Engine DS Model (Data Science) RT Data Service Batch Service Metadata Service DW Knowledge Metadata Integrated Data Layer Graph (Data Warehouse) ODS Layer DI ZETA (Data Infrastructure) Compute/Storage #SAISExp11 4
5 .Memory Capacity Challenge • 5K Target tables • 20K Intermediate/Working tables • 30PB Compressed data • 60PB Relational data processing every day #SAISExp11 5
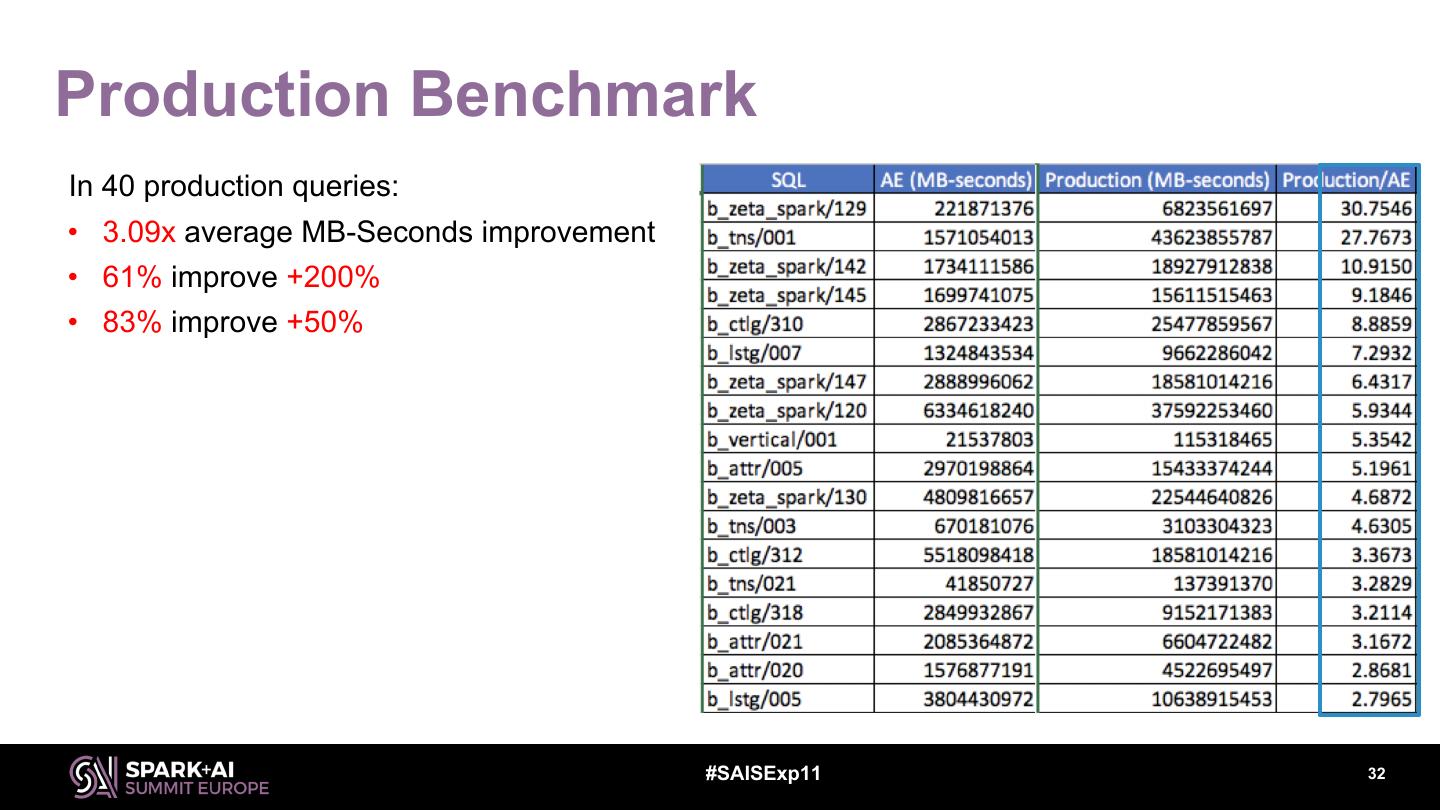
6 .Optimization Objectives • Increase overall throughput: MB-Seconds (Memory x Duration) • Reduce response time for critical jobs: Duration #SAISExp11 6
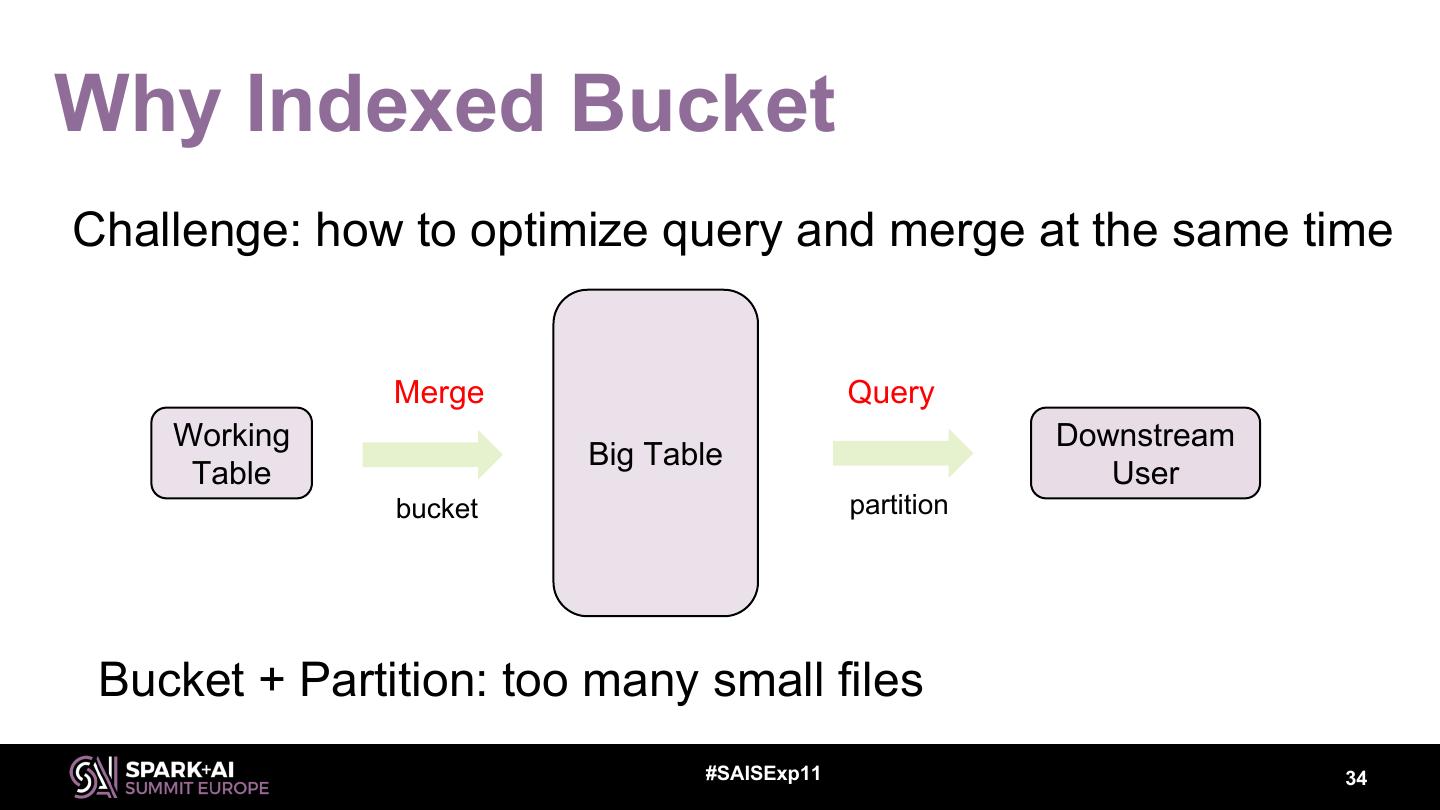
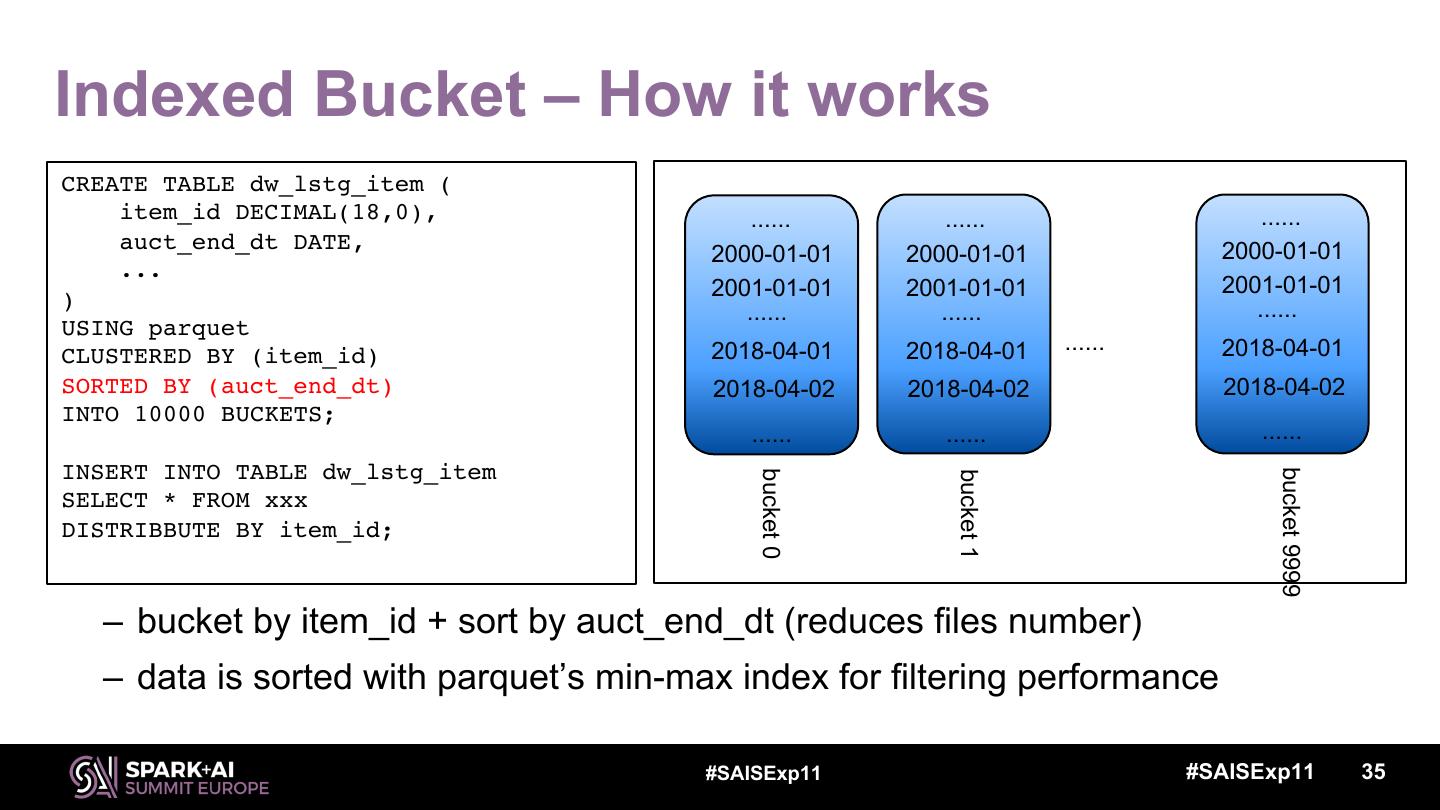
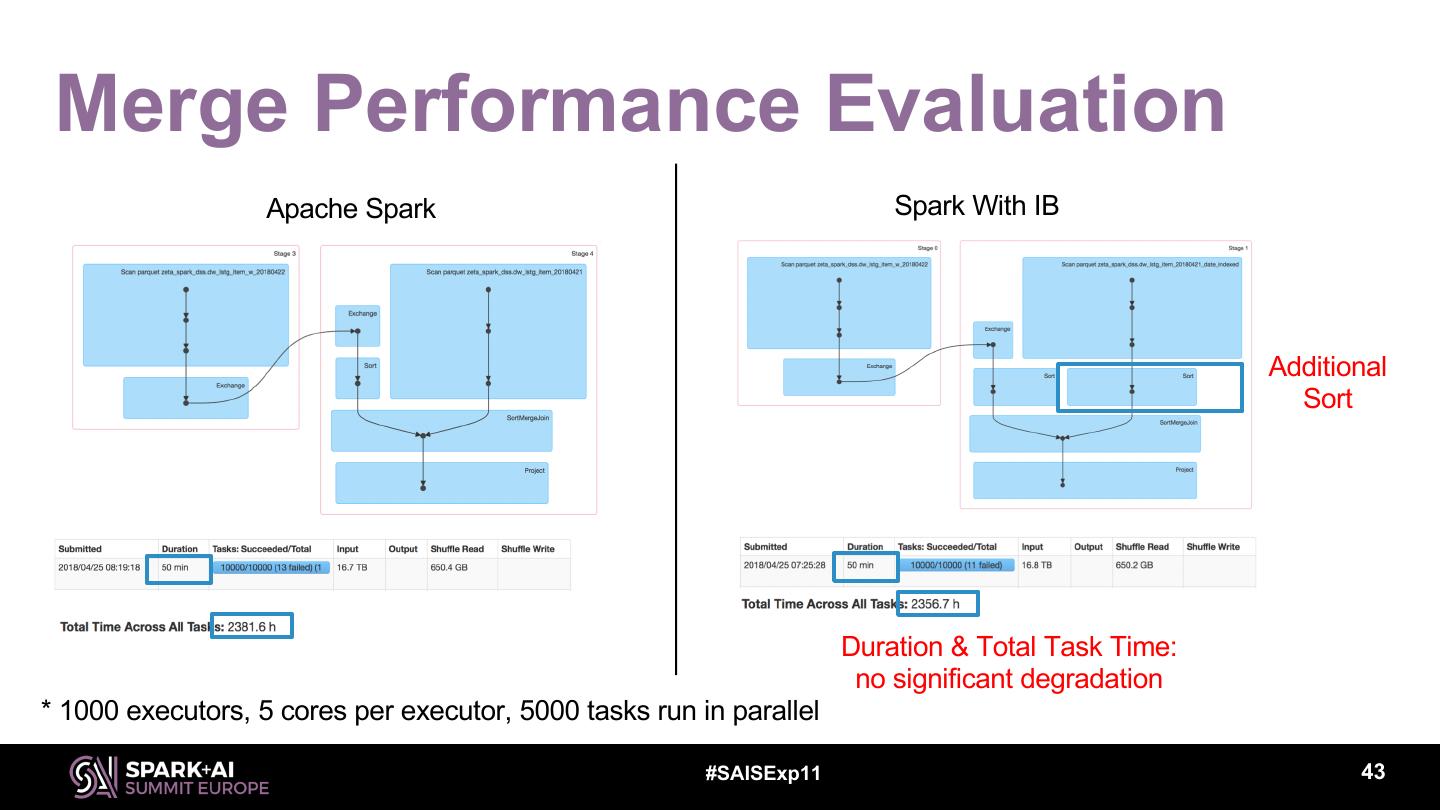
7 .Spark Core Optimization Adaptive Execution – Dynamically optimize execution plan Indexed Bucket – Optimize data layout #SAISExp11 7
8 .Adaptive Execution Background • Initial by Databricks since 2015 @SPARK-9850 • At 2017, new design & implementation @SPARK-23128 • Main contributors from Intel and eBay. – Carson Wang – Yuming Wang – Yucai Yu – JkSelf – Chenzhao Guo – Windpiger – Cheng Hao – Chenxiao Mao – Yuanjian Li #SAISExp11 8
9 .What’s Adaptive Execution? Original Spark Even with CBO, hard to get optimal execution plans Catalyst Execution Execution SQL Results Plan Spark With Adaptive Execution Oracle has already supported AE in their latest products Execute stage Execute stage Catalyst and planning and planning SQL Execution Plan AE Optimized AE Optimized … Results Plan 1 Plan 2 #SAISExp11 9
10 .Major Cases • Simplify and Optimize configuration • Optimize join strategy • Handle skewed join #SAISExp11 10
11 .Dive Into Top Memory Intensive Queries Improper user configuration actually lead to many memory issue • Migration timeline is very tight • Tuning is very time consuming #SAISExp11 11
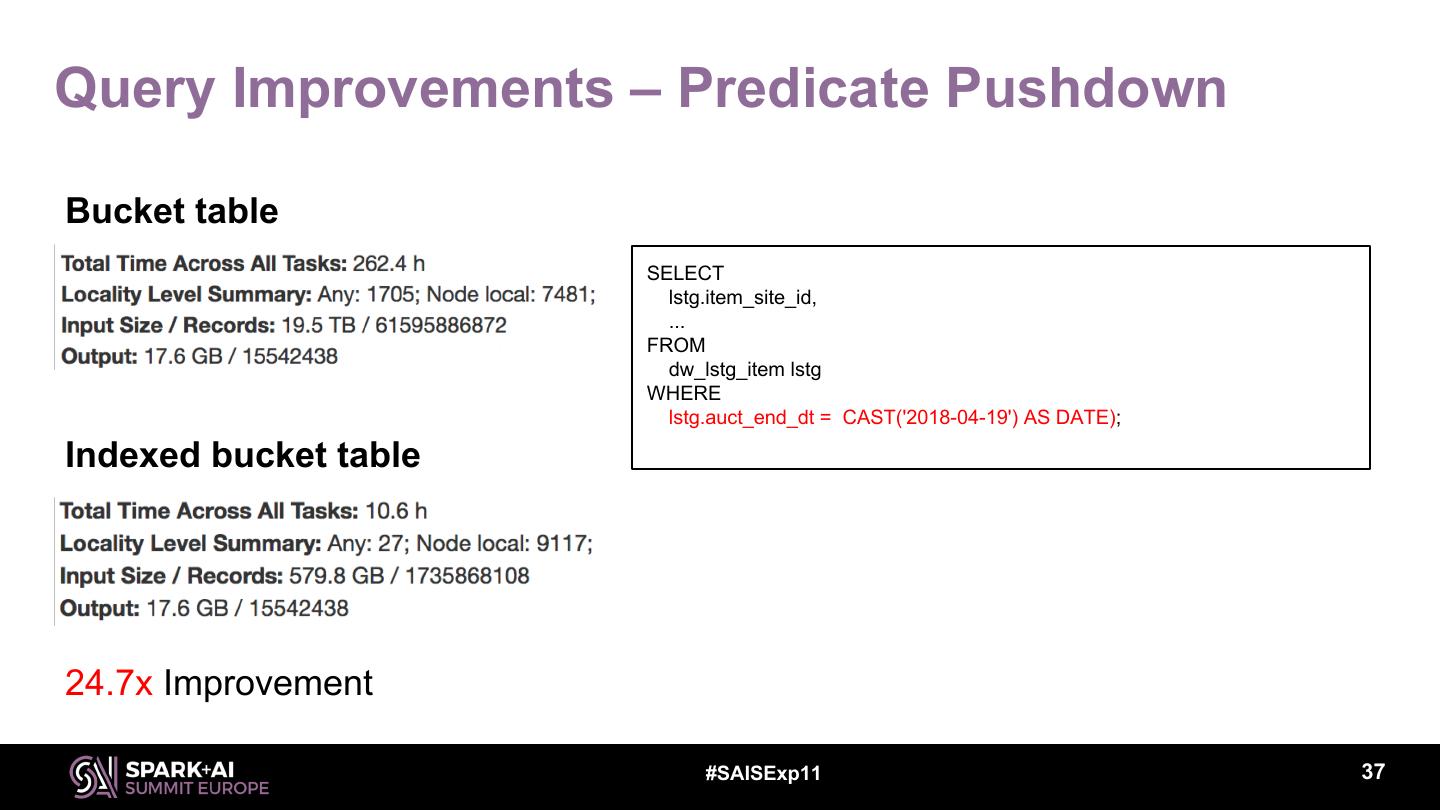
12 .Query 1: shuffle.partition is too big • shuffle.partition = 5000, each task processes only 20MB data. • Many schedule overhead, IO overhead etc. 113.5 GB / 5000 = 23.2 MB 85.6 GB / 5000 = 17.5 MB #SAISExp11 12
13 .Query 2: shuffle.partition is too small • shuffle.partition = 600 • Lots of GC overhead, the tasks run slow Duration: 7.0 min GC: 43s #SAISExp11 13
14 .Query 2: memory per core is too big • CPU usage is low: each core has 20GB memory spark.executor.memory 40g spark.executor.cores 2 40 GB / 2 = 20 GB spark.sql.shuffle.partitions 600 #SAISExp11 14
15 .Cluster-wide Configuration • Best memory per core is 5GB q eBay has separate storage nodes and computer nodes q Each computer node has 384GB memory and 64 cores q CPU is the most expensive, max the CPU utilization: 384 / 64 = 5GB #SAISExp11 15
16 .Cluster-wide Configuration • Roughly estimated data size per core (shuffle stage) is 100MB q Spark UMM 5 GB * 60% = 3GB = 3072 MB q Shuffle data’s compression rate is 5x – 30x, suppose 15x q Temporary space for algorithm (e.g. radix sort), suppose 2x q 5GB * 60% / 15 / 2 ~ 102.4 MB: less spill, GC etc. #SAISExp11 16
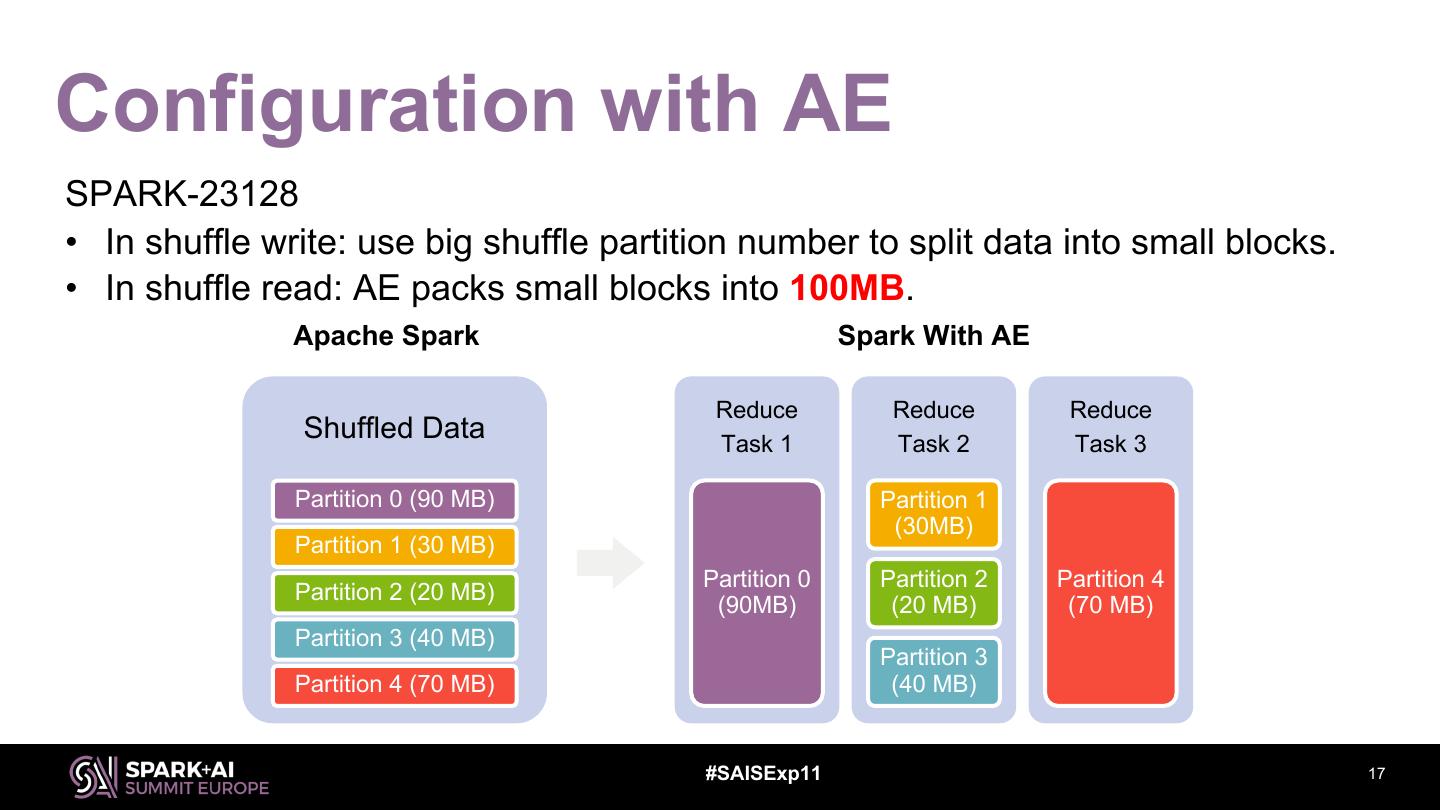
17 .Configuration with AE SPARK-23128 • In shuffle write: use big shuffle partition number to split data into small blocks. • In shuffle read: AE packs small blocks into 100MB. Apache Spark Spark With AE Reduce Reduce Reduce Shuffled Data Task 1 Task 2 Task 3 Partition 0 (90 MB) Partition 1 (30MB) Partition 1 (30 MB) Partition 0 Partition 2 Partition 4 Partition 2 (20 MB) (90MB) (20 MB) (70 MB) Partition 3 (40 MB) Partition 3 Partition 4 (70 MB) (40 MB) #SAISExp11 17
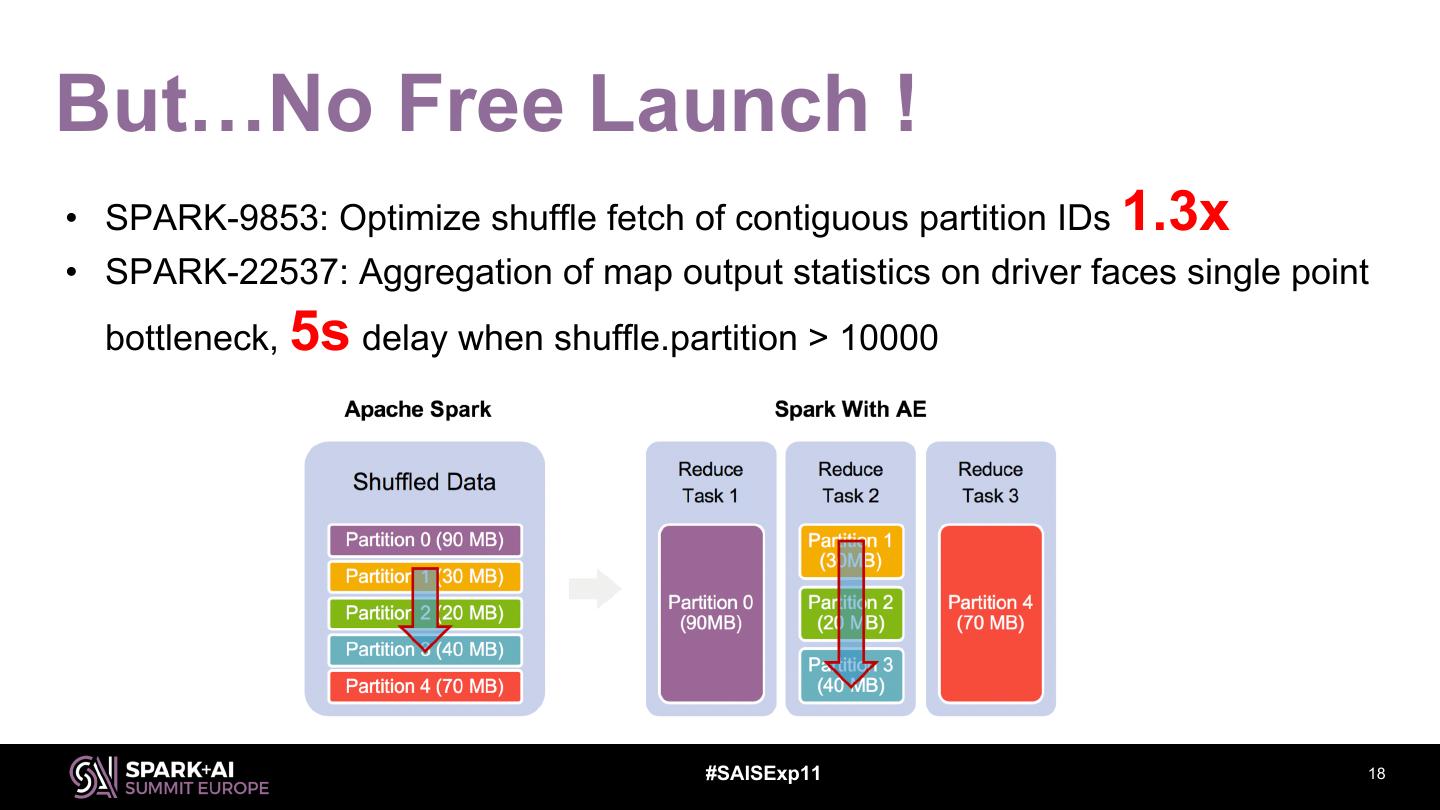
18 .But…No Free Launch ! • SPARK-9853: Optimize shuffle fetch of contiguous partition IDs 1.3x • SPARK-22537: Aggregation of map output statistics on driver faces single point bottleneck, 5s delay when shuffle.partition > 10000 #SAISExp11 18
19 .Unified Configuration with AE • spark.executor.memory=20GB • spark.executor.cores=4 // memory per core 5GB • spark.sql.adaptive.maxNumPostShufflePartitions=10000 • spark.sql.adaptive.shuffle.targetPostShuffleInputSize=100MB less spill, less GC, less schedule overhead less human configuration #SAISExp11 19
20 .Query 1: 1.7x MB-Seconds improvement Apache Spark Spark With AE MB-Seconds: 7,661,564,130 MB-Seconds: 4,540,665,342 5000 2500 1112 #SAISExp11 20
21 .Query 2: 6x MB-Seconds improvement • Enable AE: no GC issue, 1.4x MB-Seconds improvement • Less memory in new configuration solution Duration: 17s GC: 0.2s #SAISExp11 21
22 .Major Cases • Simplify and Optimize configuration • Optimize join strategy • Handle skewed join #SAISExp11 22
23 .Optimize Join Strategy – Overview • Based on runtime intermediate table size, AE builds best join plan. Apache Spark Spark With AE Sort Merge Broadcast Join Hash Join Shuffle Shuffle Broadcast Intermediate Intermediate Intermediate Intermediate Table A Table B Table A Table B Big Table Small Table #SAISExp11 23
24 .Optimize Join Strategy – How it works • Enable stats estimation for physical plan • Allow shuffle readers to request data from just one mapper • Optimize SortMergeJoin to BroadcastHashJoin at runtime #SAISExp11 24
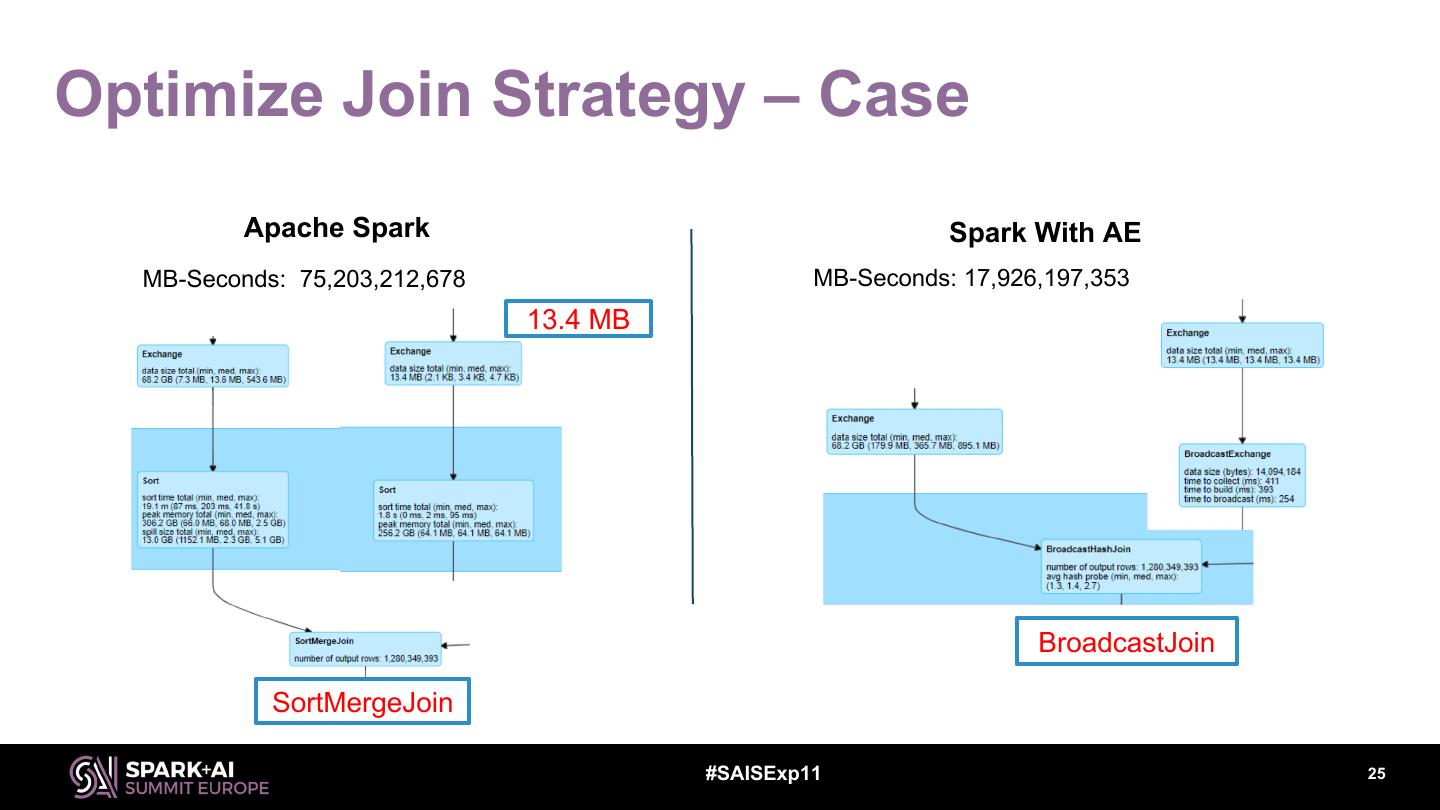
25 .Optimize Join Strategy – Case Apache Spark Spark With AE MB-Seconds: 75,203,212,678 MB-Seconds: 17,926,197,353 13.4 MB BroadcastJoin SortMergeJoin #SAISExp11 25
26 .Optimize Join Strategy – Case Apache Spark 4.2x MB-Seconds improvement Spark With AE 26 Data Services and Solutions
27 .Major Cases • Simplify and Optimize shuffle partitions • Optimize join strategy • Handle skewed join #SAISExp11 27
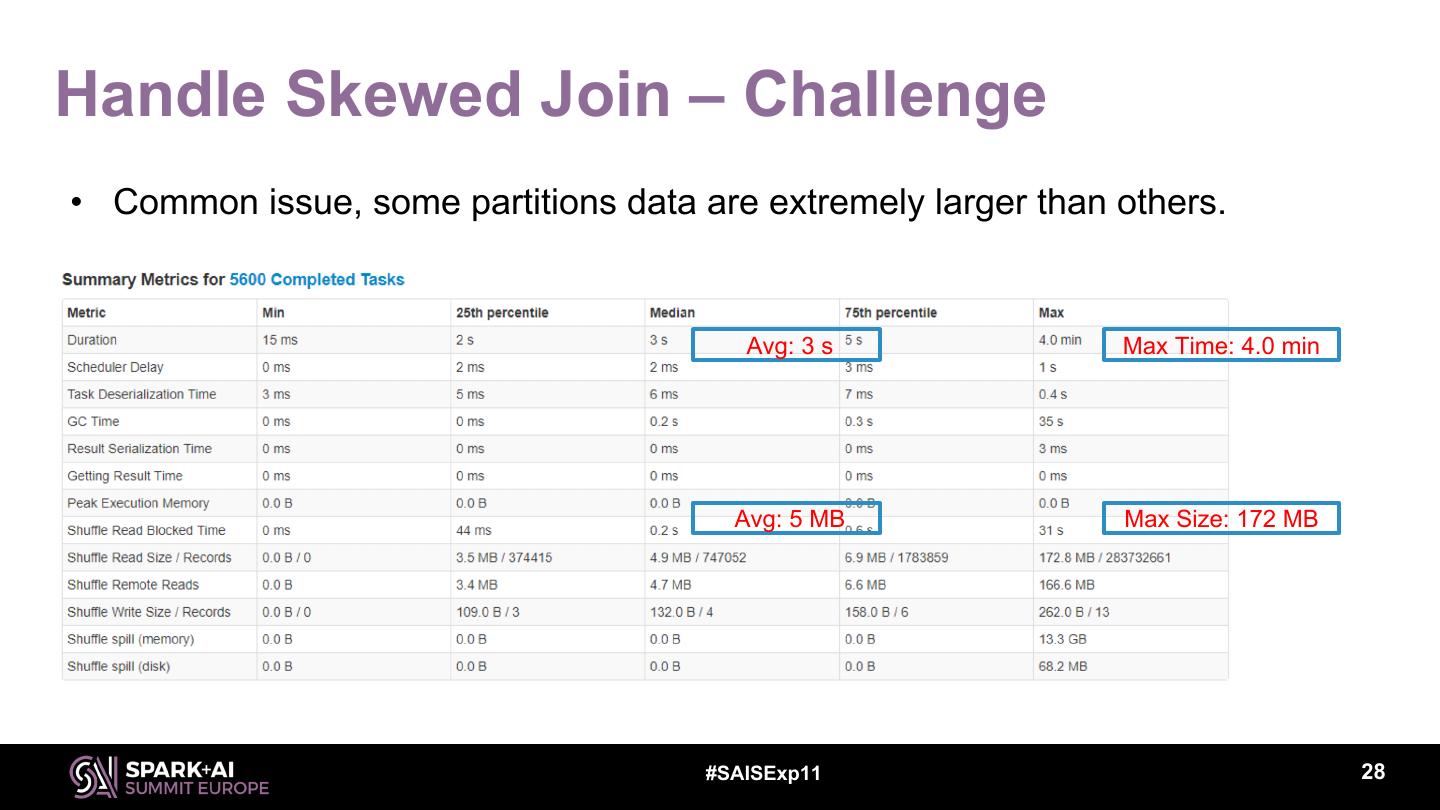
28 .Handle Skewed Join – Challenge • Common issue, some partitions data are extremely larger than others. Avg: 3 s Max Time: 4.0 min Avg: 5 MB Max Size: 172 MB #SAISExp11 28
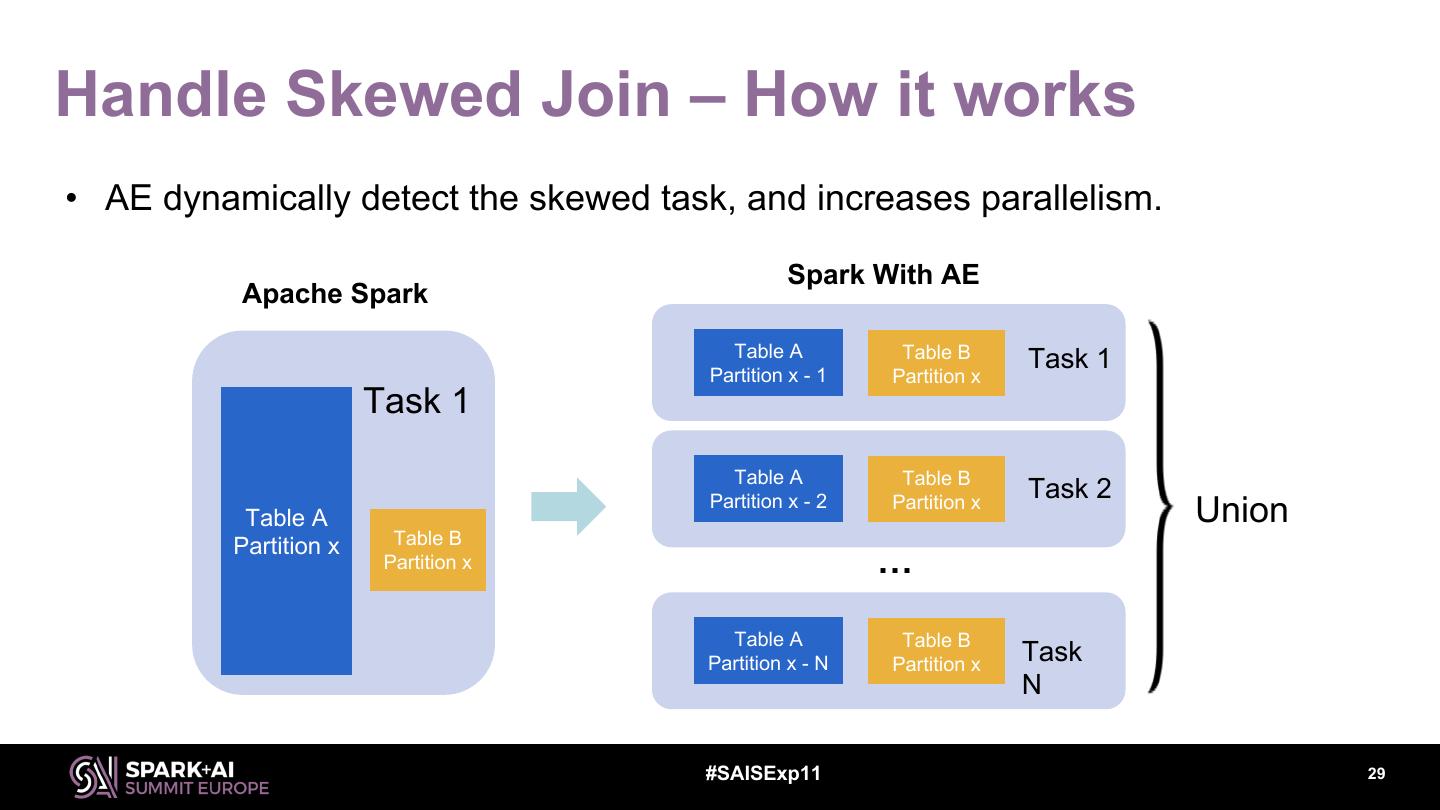
29 .Handle Skewed Join – How it works • AE dynamically detect the skewed task, and increases parallelism. Spark With AE Apache Spark Table A Table B Task 1 Partition x - 1 Partition x Task 1 Table A Table B Task 2 Table A Partition x - 2 Partition x Union Partition x Table B Partition x … Table A Table B Partition x - N Partition x Task N #SAISExp11 29
3秒后跳转登录页面
去登陆

