































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
149.165.228.101 - Digital Science Center
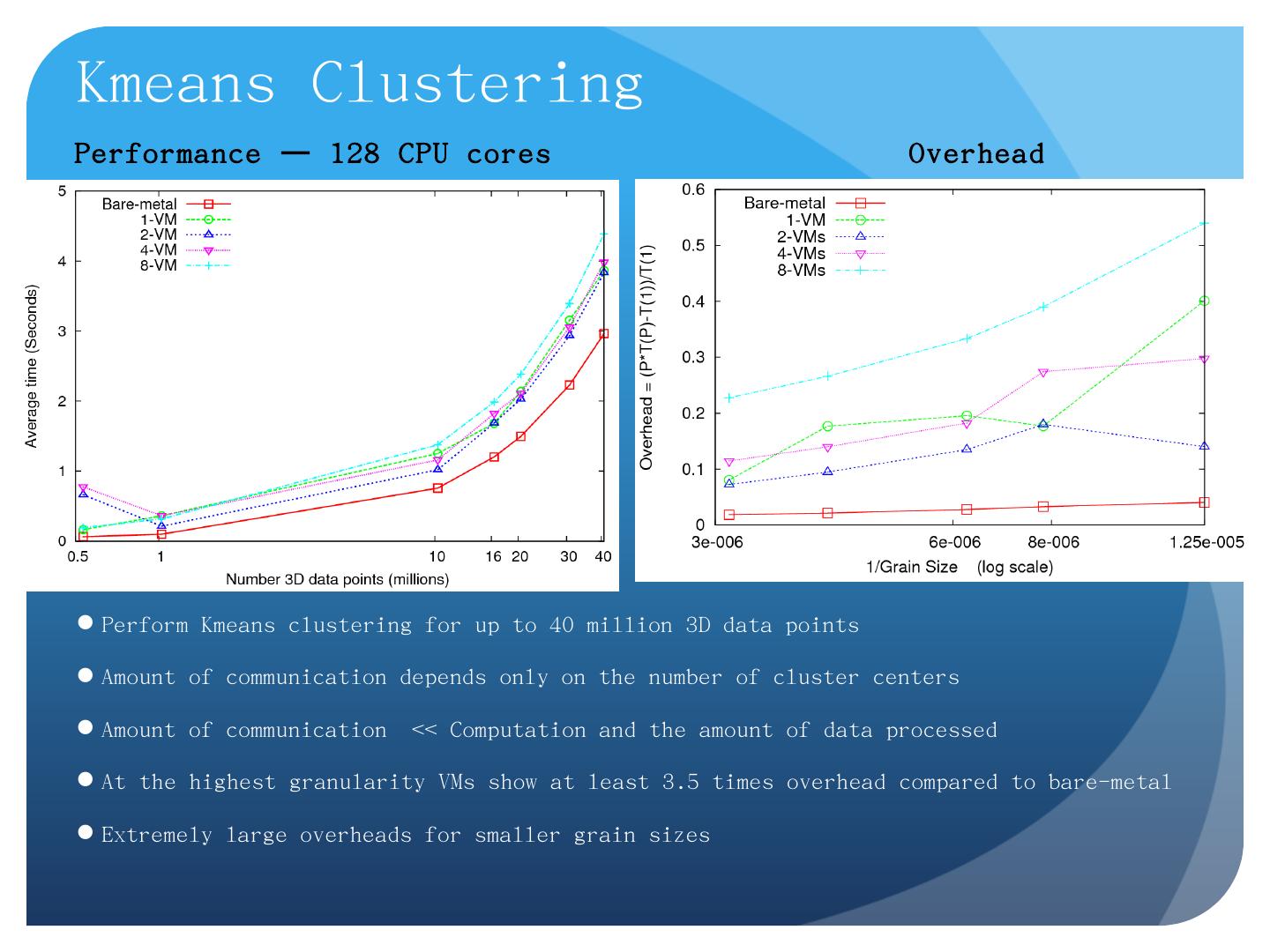
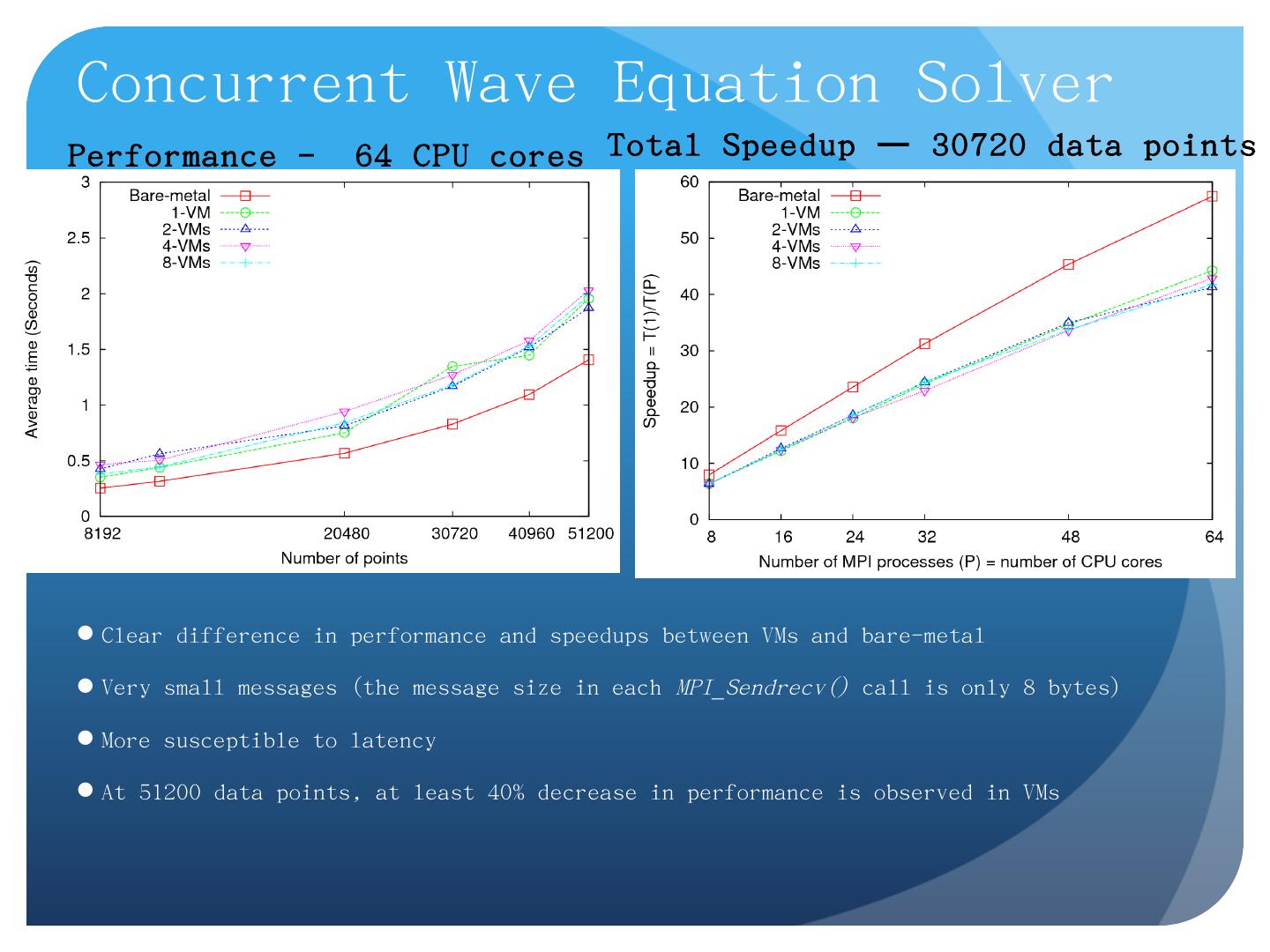
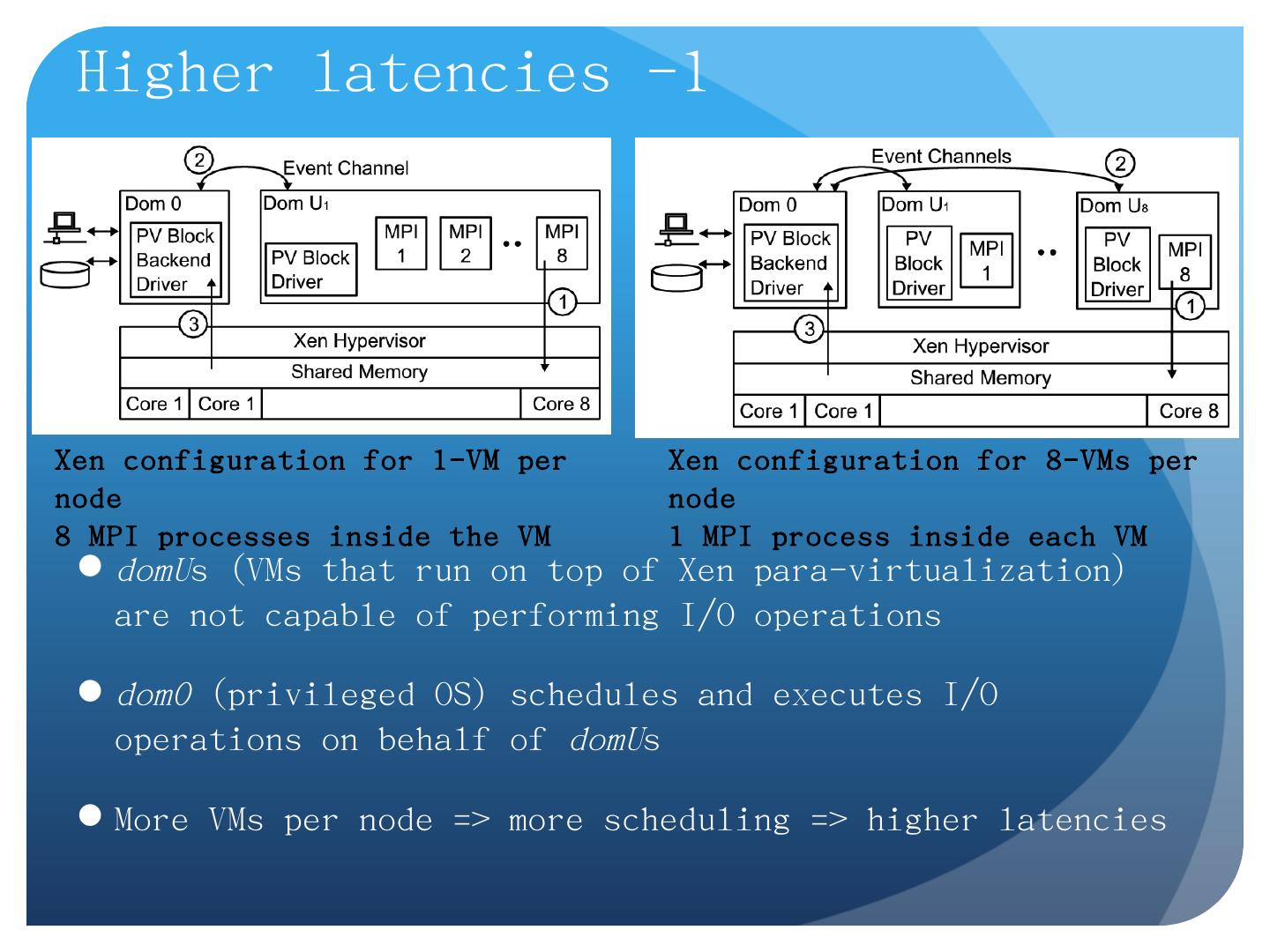
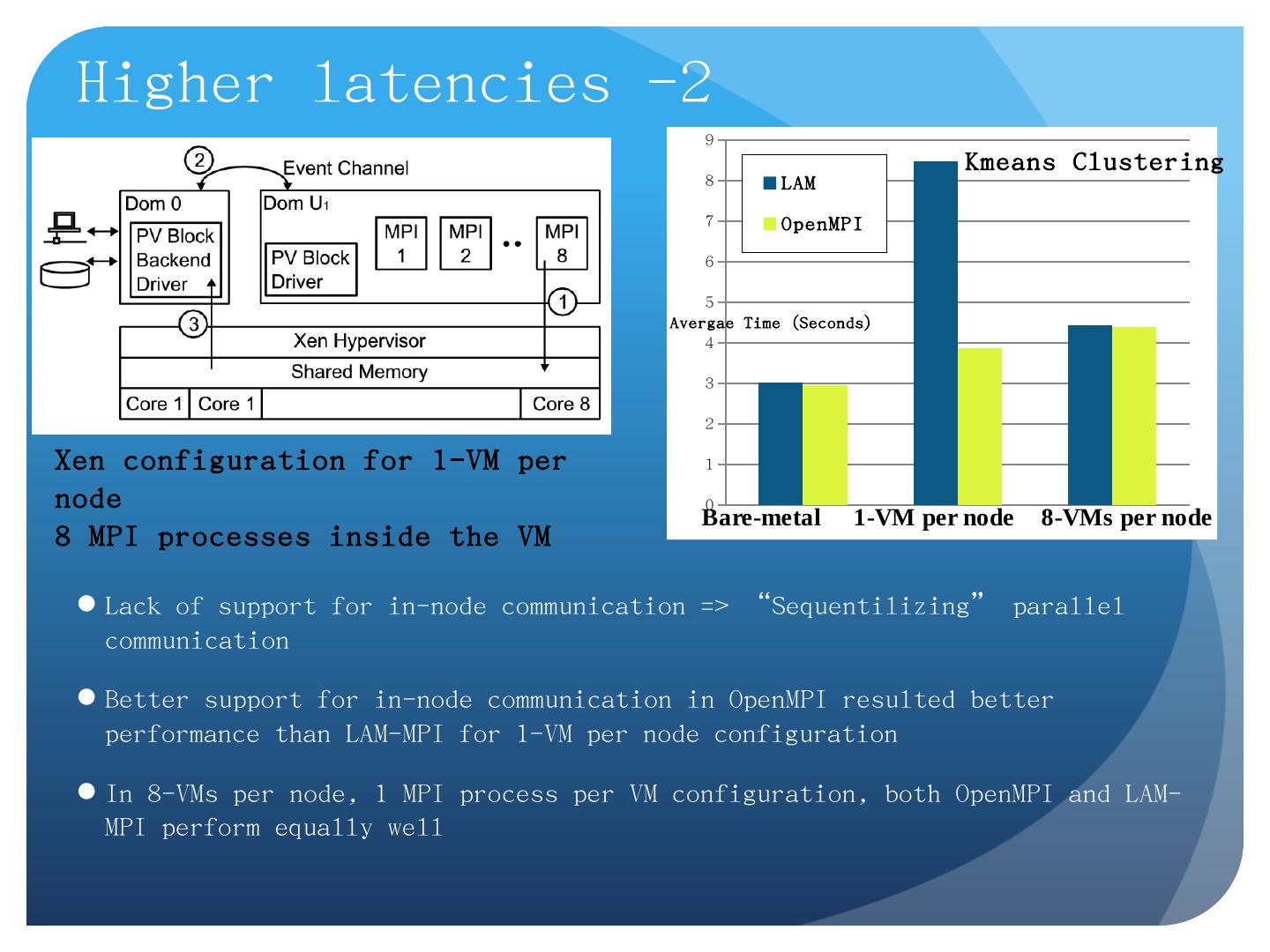
Apache Hadoop, Google MapReduce, Microsoft Dryad, and others; Designed for information retrieval but are excellent for a wide range of machine learning and ...
展开查看详情
1 .Cloud activities at Indiana University: Case studies in service hosting, storage, and computing Marlon Pierce, Joe Rinkovsky , Geoffrey Fox, Jaliya Ekanayake , Xiaoming Gao , Mike Lowe, Craig Stewart, Neil Devadasan mpierce@cs.indiana.edu
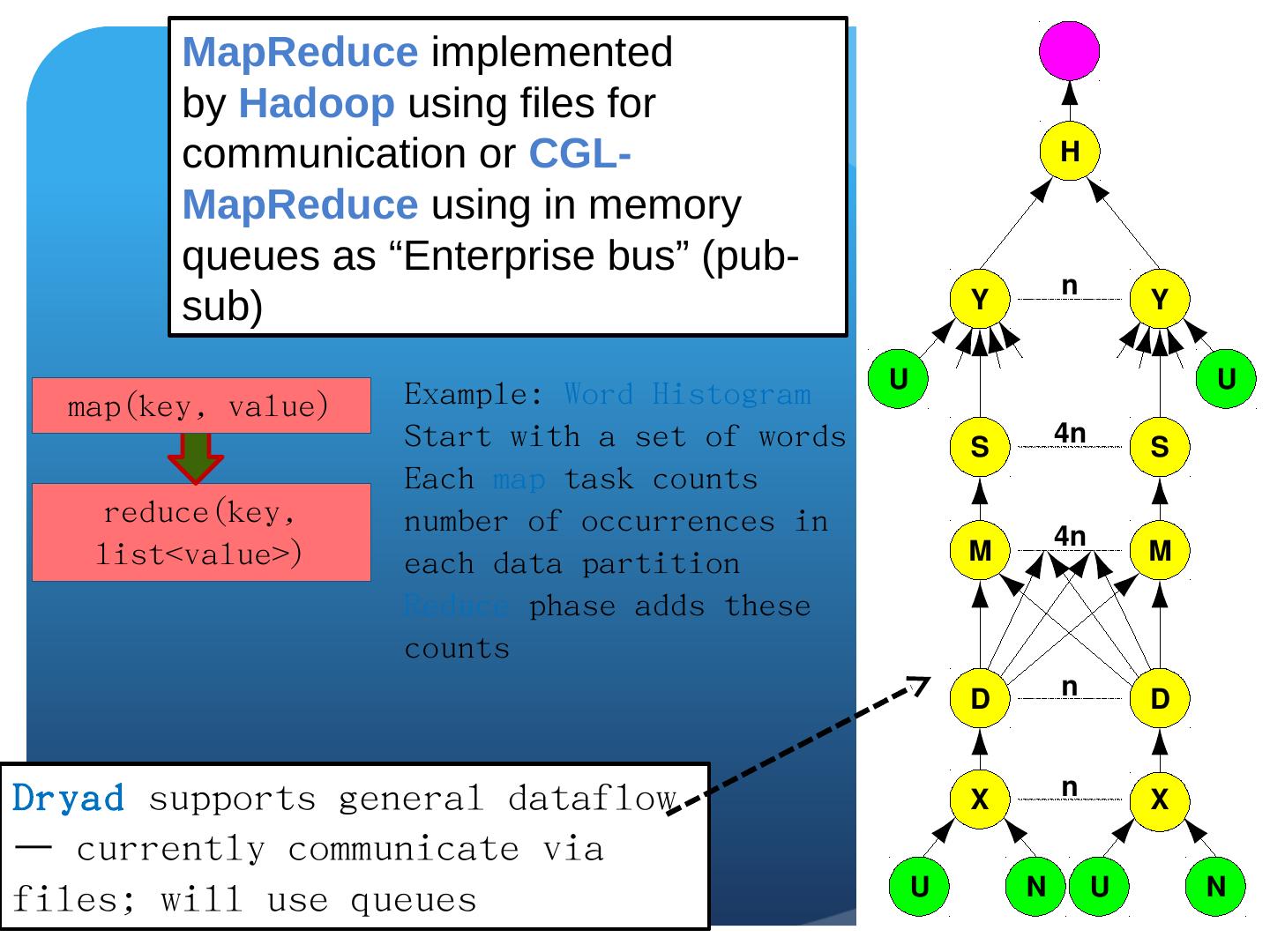
2 .Cloud Computing: Infrastructure and Runtimes Cloud infrastructure: outsourcing of servers, computing, data, file space, etc. Handled through Web services that control virtual machine lifecycles. Cloud runtimes: tools for using clouds to do data-parallel computations. Apache Hadoop , Google MapReduce , Microsoft Dryad, and others Designed for information retrieval but are excellent for a wide range of machine learning and science applications. Apache Mahout Also may be a good match for 32-128 core computers available in the next 5 years.
3 .Commercial Clouds Cloud/ Service Amazon Microsoft Azure Google (and Apache) Data S3, EBS, SimpleDB Blob , Table, SQL Services GFS, BigTable Computing EC2 , Elastic Map Reduce (runs Hadoop ) Compute Service MapReduce (not public, but Hadoop ) Service Hosting None ? Web Hosting Service AppEngine/ AppDrop
4 .Open Architecture Clouds Amazon, Google, Microsoft, et al., don’t tell you how to build a cloud. Proprietary knowledge Indiana University and others want to document this publically . What is the right way to build a cloud? It is more than just running software. What is the minimum-sized organization to run a cloud? Department? University? University Consortium? Outsource it all? Analogous issues in government, industry, and enterprise. Example issues: What hardware setups work best? What are you getting into? What is the best virtualization technology for different problems? What is the right way to implement S3- and EBS-like data services? Content Distribution Systems? Persistent, reliable SaaS hosting?
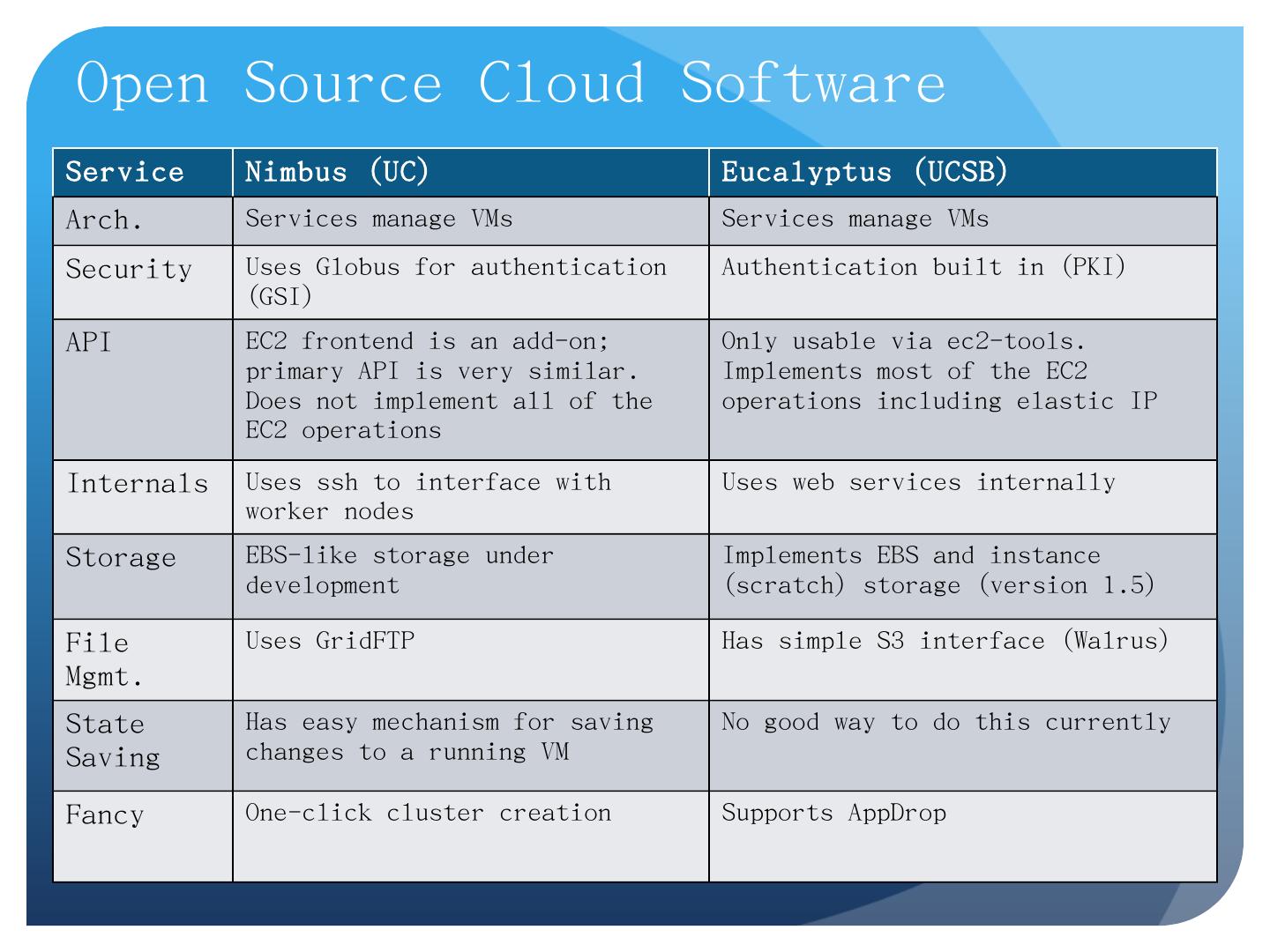
5 .Service Nimbus (UC) Eucalyptus (UCSB) Arch. Services manage VMs Services manage VMs Security Uses G lobus for authentication (GSI) Authentication built in (PKI) API EC2 frontend is an add-on; primary API is very similar. Does not implement all of the EC2 operations Only usable via ec2-tools. Implements most of the EC2 operations including elastic IP Internals Uses ssh to interface with worker nodes Uses web services internally Storage EBS-like storage under development Implements EBS and instance (scratch) storage (version 1.5) File Mgmt. Uses GridFTP Has simple S3 interface (Walrus) State Saving Has easy mechanism for saving changes to a running VM No good way to do this currently Fancy One-click cluster creation Supports AppDrop Open Source Cloud Software
6 .IU’s Cloud Testbed Host Hardware: IBM iDataplex = 84 nodes 32 nodes for Eucalyptus 32 nodes for nimbus 20 nodes for test and/or reserve capacity 2 dedicated head nodes Nodes specs: 2 x Intel L5420 Xeon 2.50 (4 cores/ cpu ) 32 gigabytes memory 160 gigabytes local hard drive Gigabit network No support in Xen for Infiniband or Myrinet (10 Gbps )
7 .IU’s Cloud Testbed Host Hardware: IBM iDataplex = 84 nodes 32 nodes for Eucalyptus 32 nodes for nimbus 20 nodes for test and/or reserve capacity 2 dedicated head nodes Nodes specs: 2 x Intel L5420 Xeon 2.50 (4 cores/ cpu ) 32 gigabytes memory 160 gigabytes local hard drive Gigabit network No support in Xen for Infiniband or Myrinet (10 Gbps )
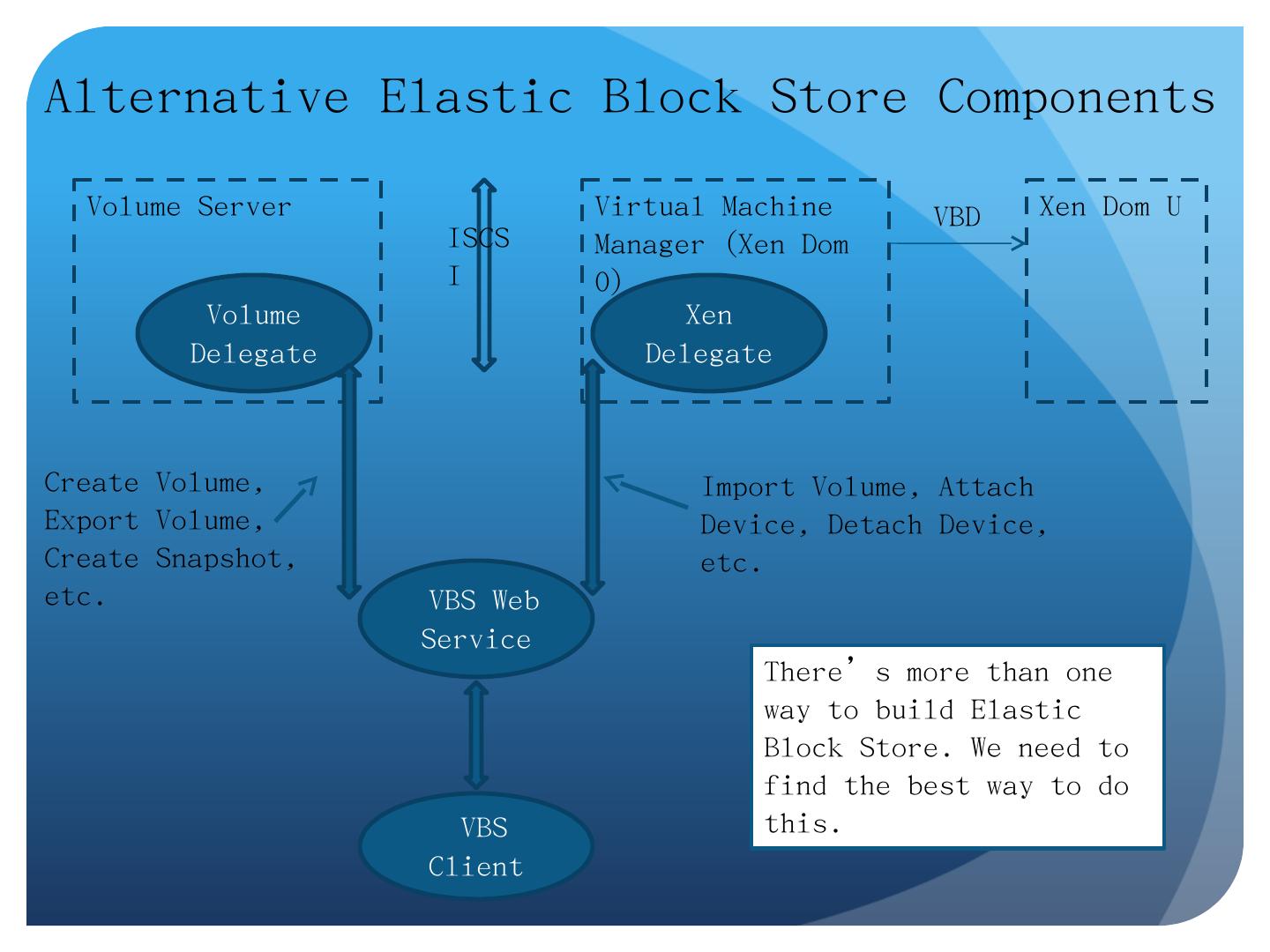
8 .Alternative Elastic Block Store Components Volume Server Volume Delegate Virtual Machine Manager ( Xen Dom 0) Xen Delegate Xen Dom U VBS Web Service VBS Client VBD ISCSI Create Volume, Export Volume, Create Snapshot, etc. Import Volume, Attach Device, Detach Device, etc. There’s more than one way to build Elastic Block Store. We need to find the best way to do this.
9 .Case Study: Eucalyptus, GeoServer , and Wetlands Data
10 .Running GeoServer on Eucalyptus We’ll walk through the steps to create an image with GeoServer . Not amenable to a live demo Command line tools. Some steps take several minutes. If everything works, it looks like any other GeoServer . But we can do this offline if you are interested.
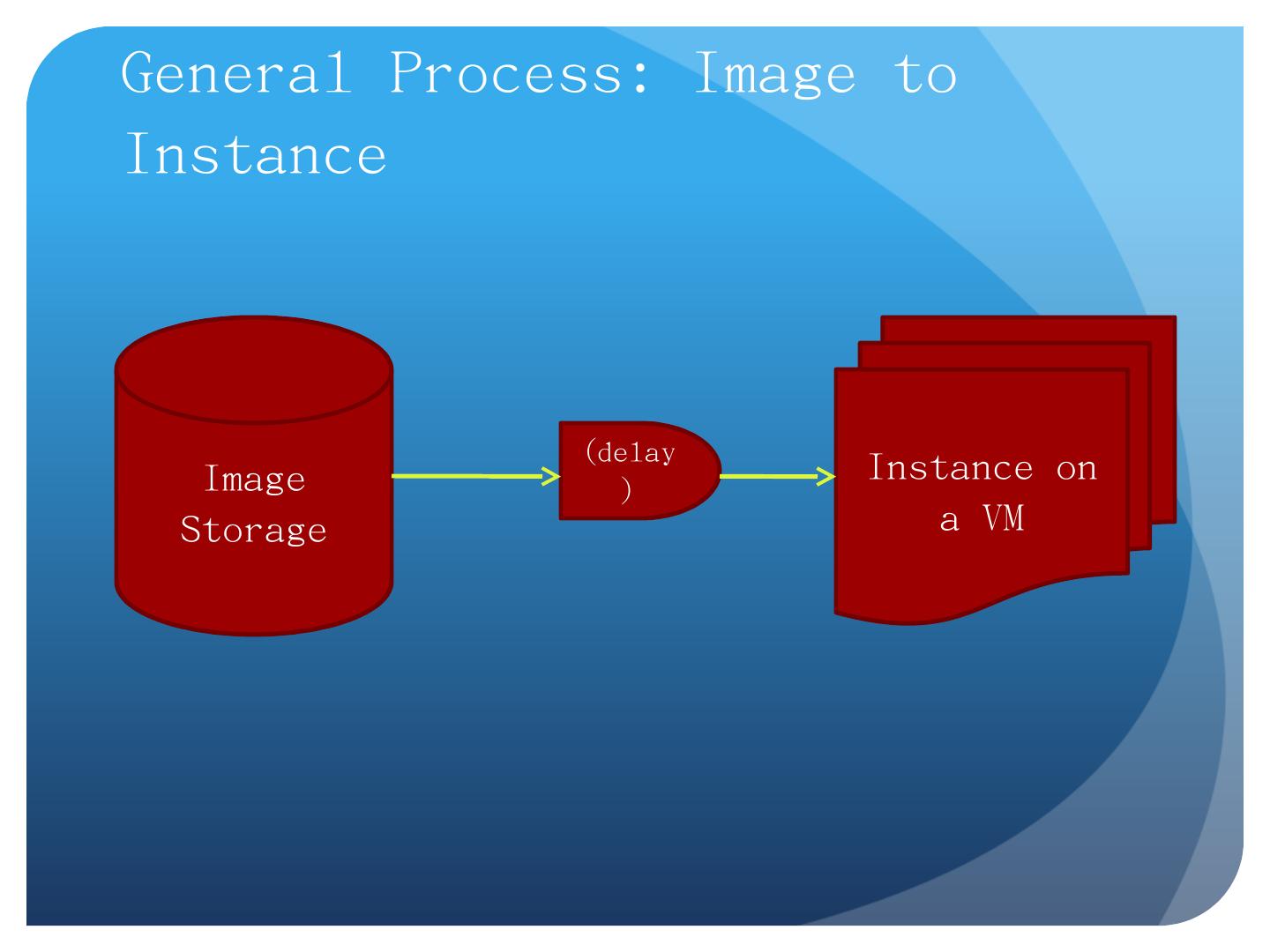
11 .Image Storage (delay) Instance on a VM General Process: Image to Instance
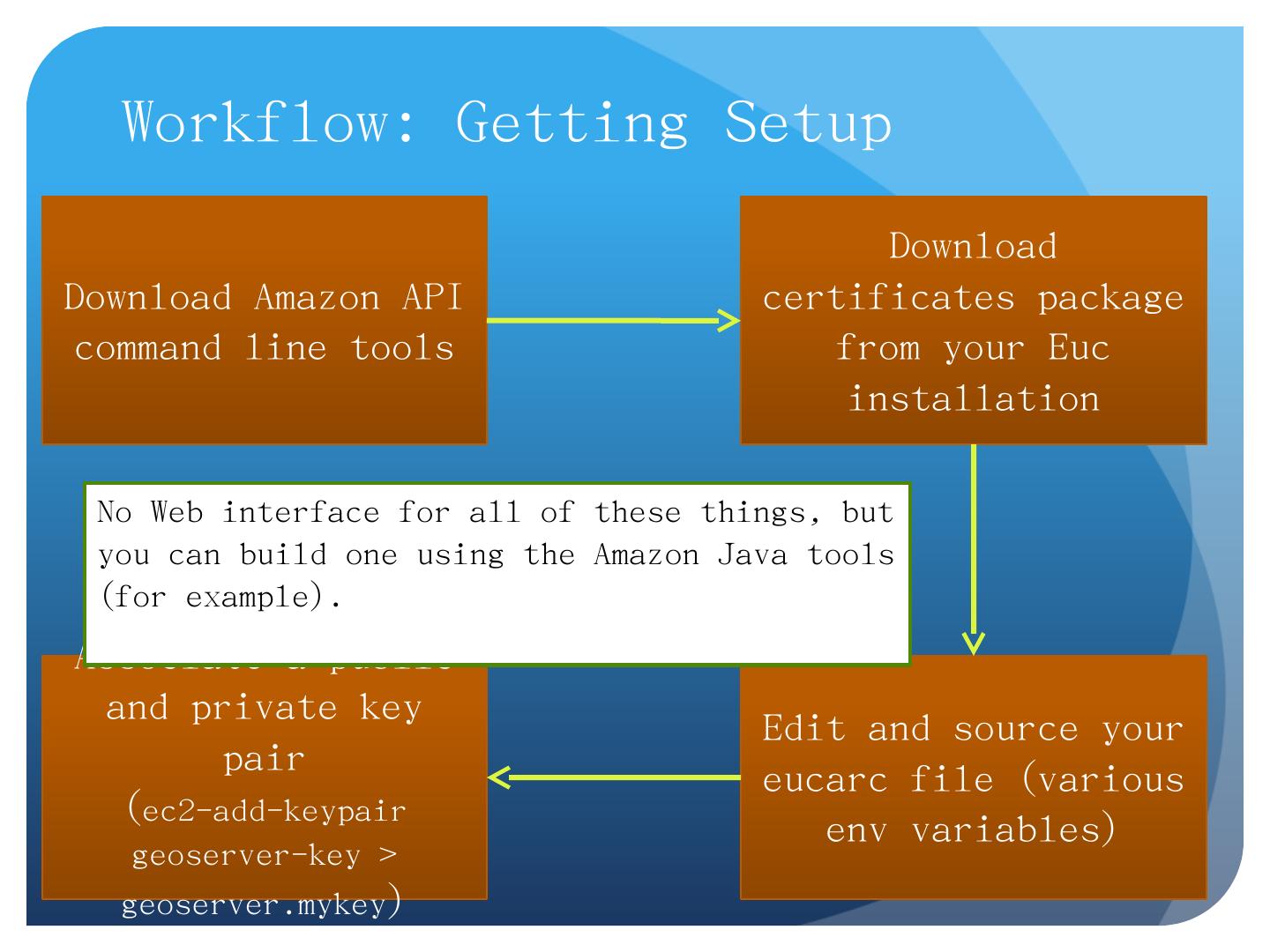
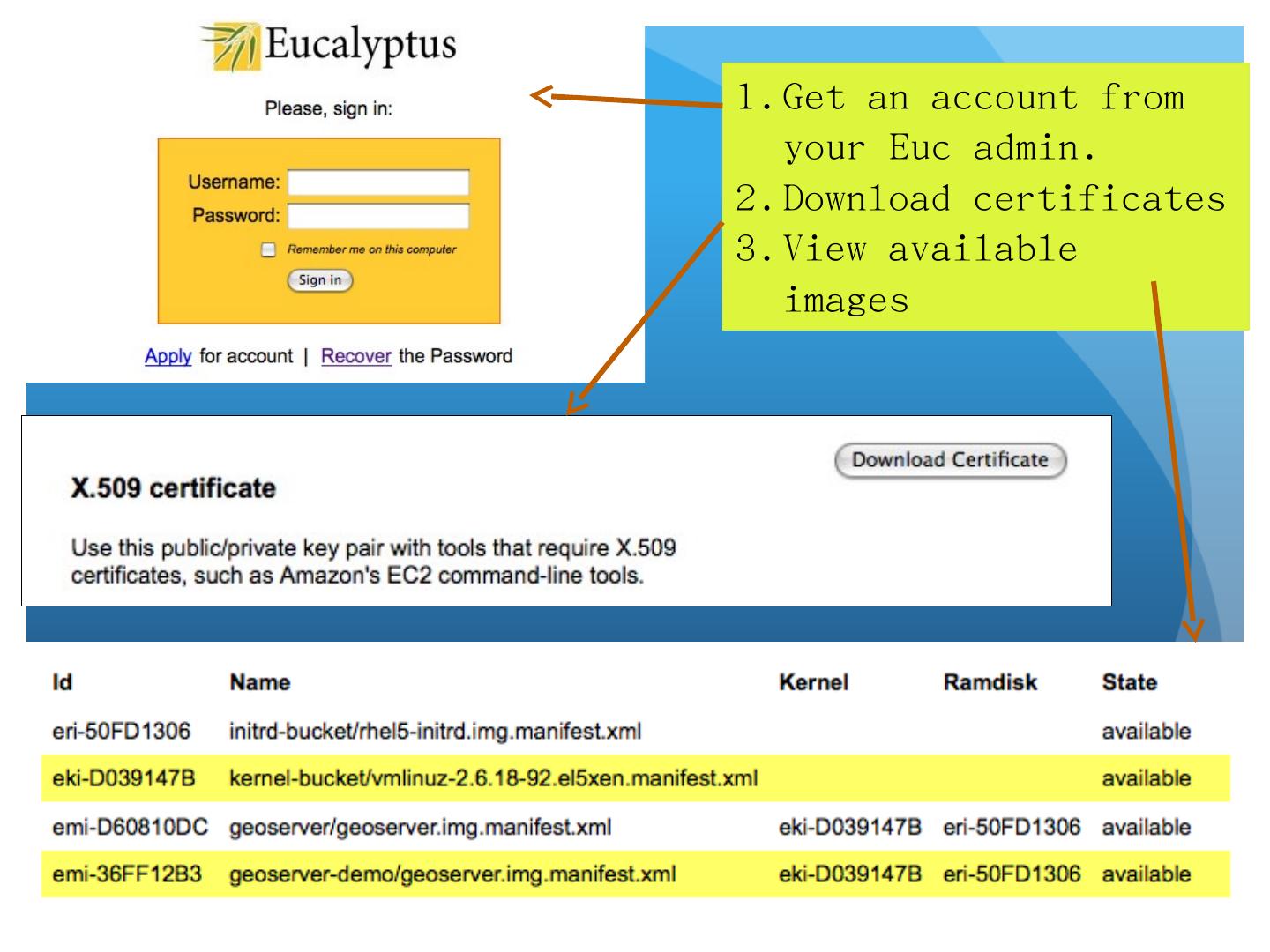
12 .Workflow: Getting Setup Download Amazon API command line tools Download certificates package from your Euc installation Edit and source your eucarc file (various env variables) Associate a public and private key pair ( ec2-add-keypair geoserver -key > geoserver.mykey ) No Web interface for all of these things, but you can build one using the Amazon Java tools (for example).
13 .Get an account from your Euc admin. Download certificates View available images
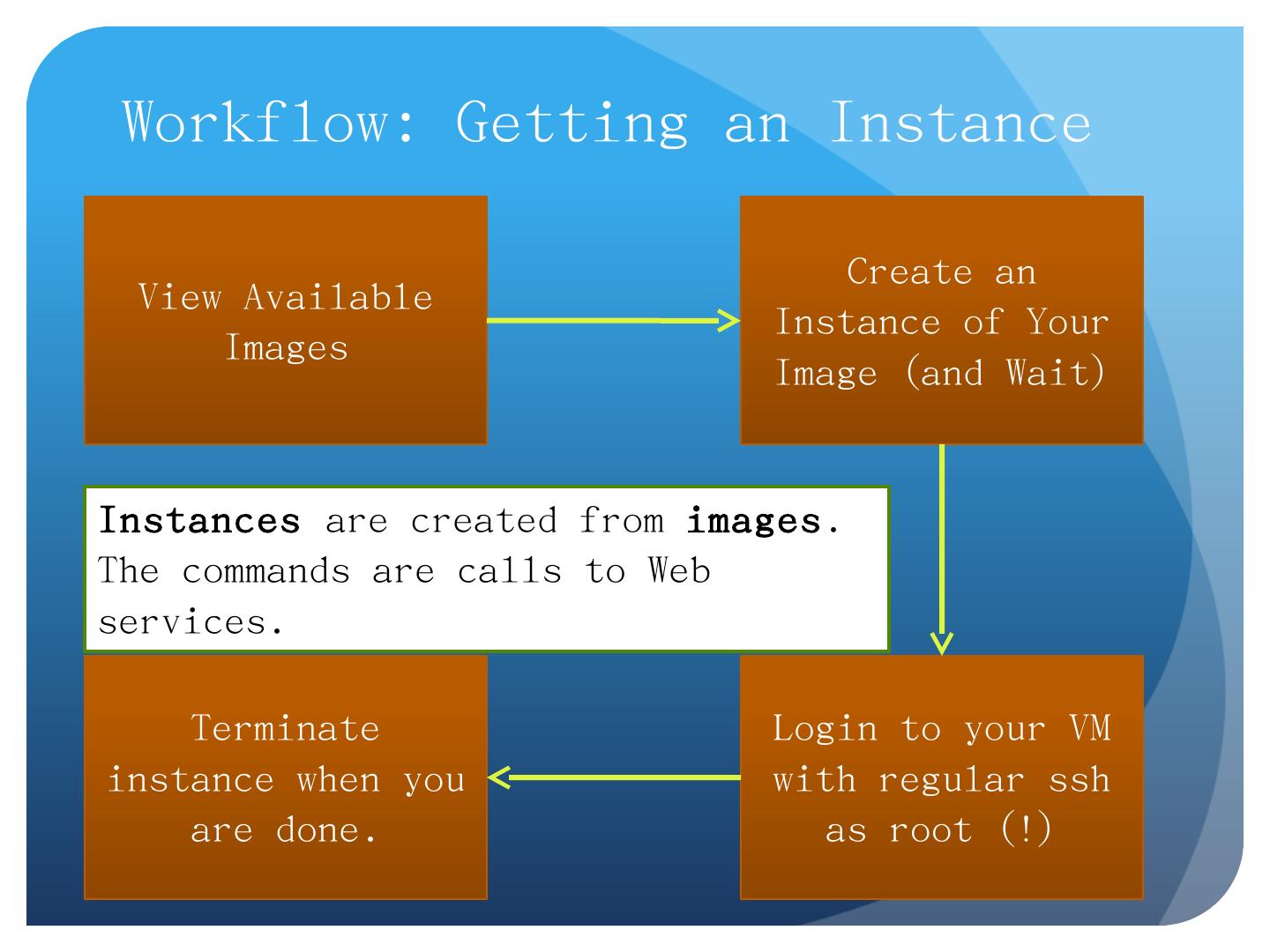
14 .Workflow: Getting an Instance View Available Images Create an Instance of Your Image (and Wait) Login to your VM with regular ssh as root (!) Terminate instance when you are done. Instances are created from images . The commands are calls to W eb services.
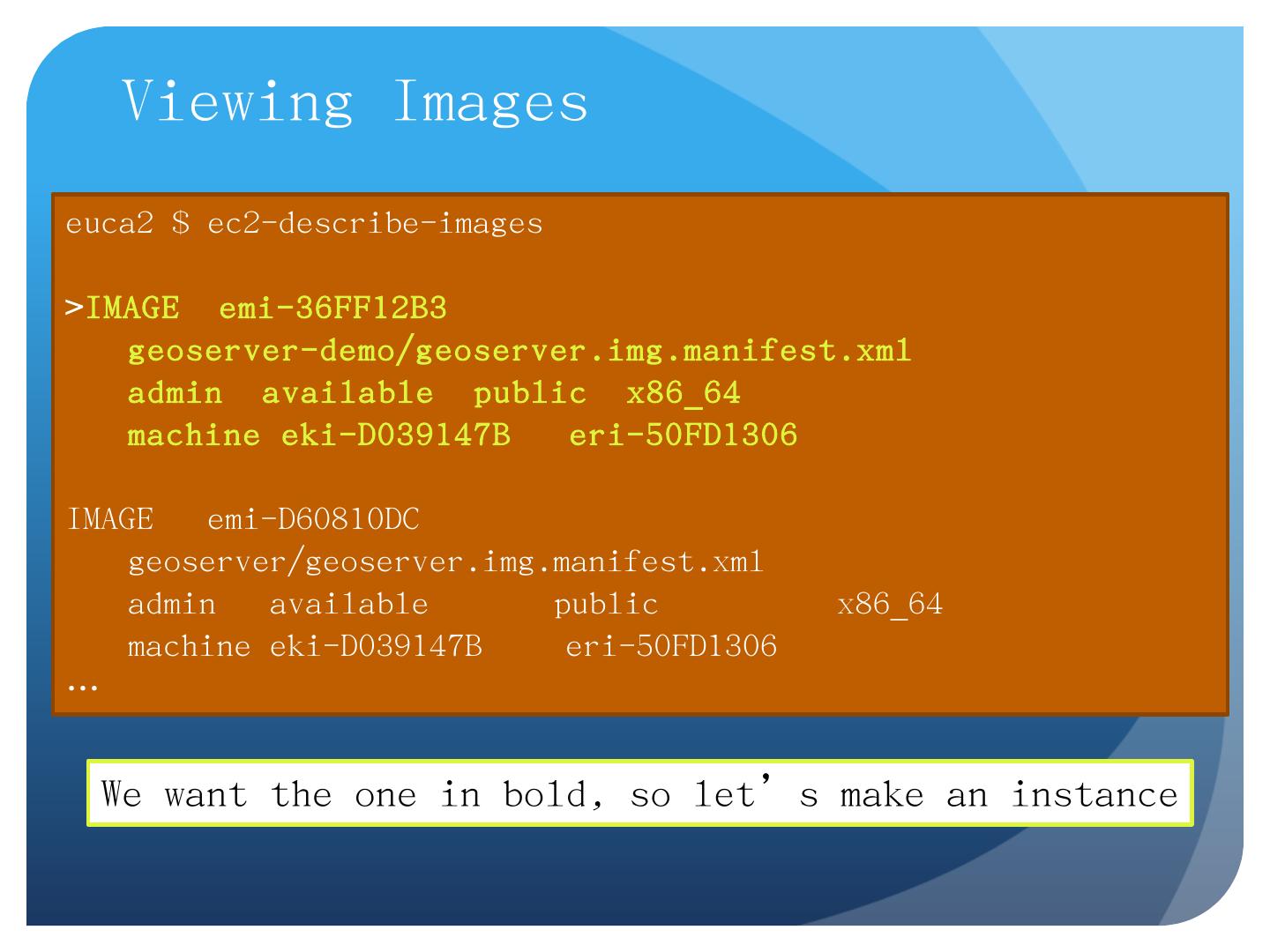
15 .Viewing Images euca2 $ ec2-describe-images > IMAGE emi-36FF12B3 geoserver-demo/geoserver.img.manifest.xml admin available public x86_64 machine eki-D039147B eri-50FD1306 IMAGE emi-D60810DC geoserver/geoserver.img.manifest.xml admin available public x86_64 machine eki-D039147B eri-50FD1306 … We want the one in bold, so let’s make an instance
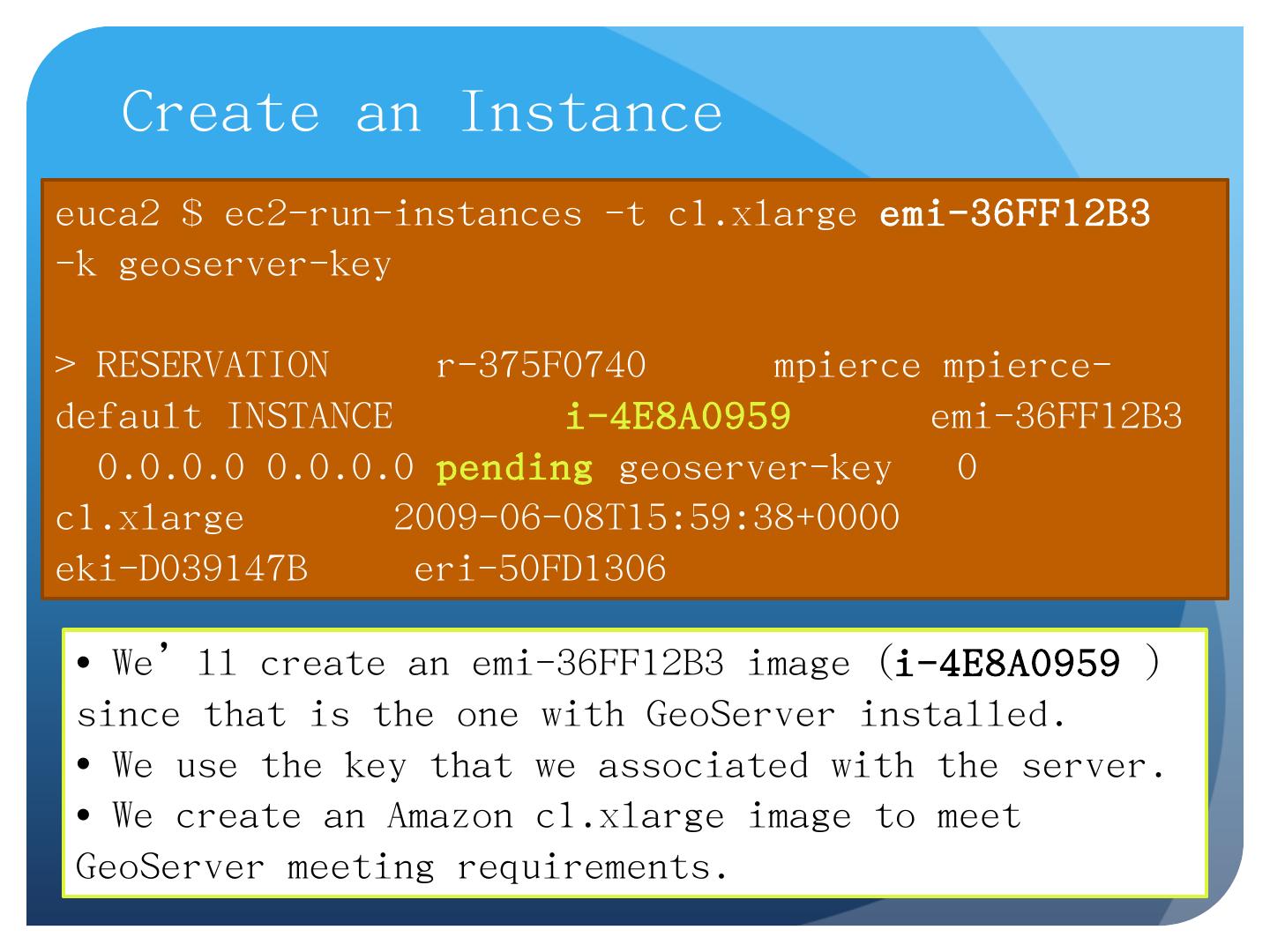
16 .Create an Instance euca2 $ ec2-run-instances - t c1.xlarge emi-36FF12B3 - k geoserver -key > RESERVATION r-375F0740 mpierce mpierce -default INSTANCE i-4E8A0959 emi-36FF12B3 0.0.0.0 0.0.0.0 pending geoserver -key 0 c1.xlarge 2009-06-08T15:59:38+0000 eki-D039147B eri-50FD1306 We’ll create an emi-36FF12B3 image ( i-4E8A0959 ) since that is the one with GeoServer installed. We use the key that we associated with the server. We create an Amazon c1.xlarge image to meet GeoServer meeting requirements.
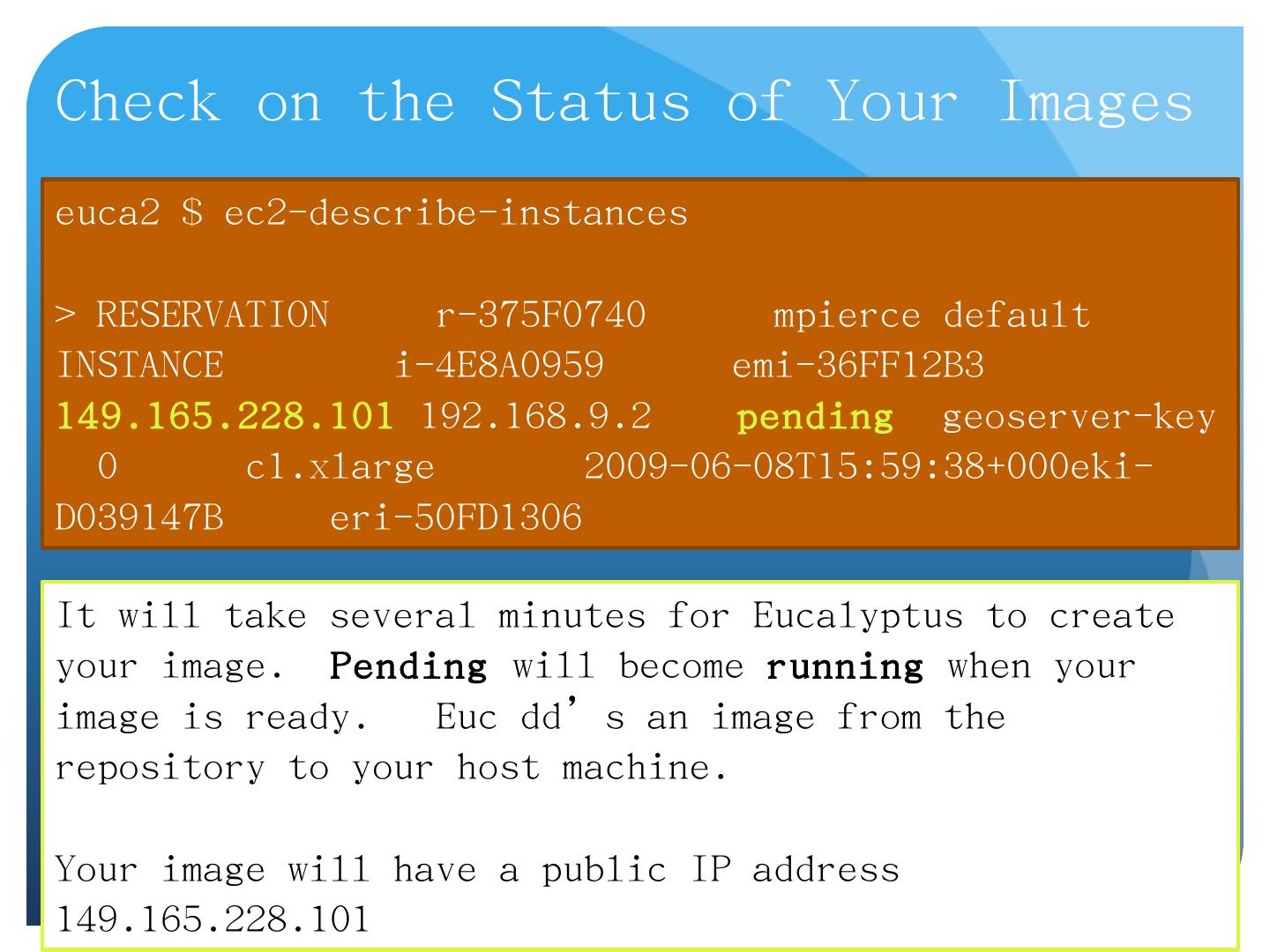
17 .Check on the Status of Your Images euca2 $ ec2-describe-instances > RESERVATION r-375F0740 mpierce default INSTANCE i-4E8A0959 emi-36FF12B3 149.165.228.101 192.168.9.2 pending geoserver -key 0 c1.xlarge 2009-06-08T15:59:38+000eki-D039147B eri-50FD1306 It will take several minutes for Eucalyptus to create your image. Pending will become running when your image is ready. Euc dd’s an image from the repository to your host machine. Your image will have a public IP address 149.165.228.101
18 .Now Run GeoServer We’ve created an instance with GeoServer pre-configured. We’ve also injected our public key. Login: ssh – i mykey.pem root@149.165.228.101 Startup the server on your VM: /root/ start.sh Point your browser to http ://149.165.228.101:8080/geoserver Actual GeoServer public demo is 149.165.228.100
19 .As advertised, it has the VM’s URL.
20 .Now Attach Wetlands Data Attach the Wetlands data volume. ec2-attach-volume vol-4E9E0612 - i i-546C0AAA - d /dev/sda5 Mount the disk image from your virtual machine. /root/mount- ebs.sh is a convenience script. Fire up PostgreSQL on your virtual machine. /etc/ init.d/postgres start Note our image updates the basic RHEL version that comes with the image. Unlike Xen images, we only have one instance of the Wetlands EBS. Takes too much space. Only one Xen image can mount this at a time.
21 .Experiences with the Installation The Tomcat and G eoServer installations are identical to how they would be on a physical system. The main challenge was handling persistent storage for PostGIS . We use an EBS volume for the data directory of Postgres . It adds two steps to the startup/tear down process but you gain the ability to retain database changes. This also allows you to overcome the 10 gigabyte root file system limit that both Eucalyptus and EC2 proper have. Currently the database and GeoServer are running on the same instance. In the future it would probably be good to separate them.
22 .IU Gateway Hosting Service Users get OpenVZ virtual machines. All VMs run in same kernel, unlike Xen . Images replicated between IU (Bloomington) and IUPUI (Indianapolis) Uses DRBD Mounts Data Capacitor (~500 TB Lustre File System) OpenVZ has no support yet for libvirt Would make it easy to integrate with Xen -based clouds Maybe some day from Enomaly
23 .Summary: Clouds + GeoServer Best Practices: We chose Eucalyptus open source software in part because it mimics faithfully Amazon. Better interoperability compared to Nimbus Eucalyptus.edu Eucalyptus.com Maturity Level: very early for Eucalyptus No fail-over, redundancy, load-balancing, etc. Not specifically designed for Web server hosting. Impediments to adoption: not production software yet. Security issues: do you like Euc’s PKI? Do you mind handing out root? Hardware, networking requirements and configuration are not known No good support for high performance file systems. What level of government should run a cloud?
24 .Science Clouds
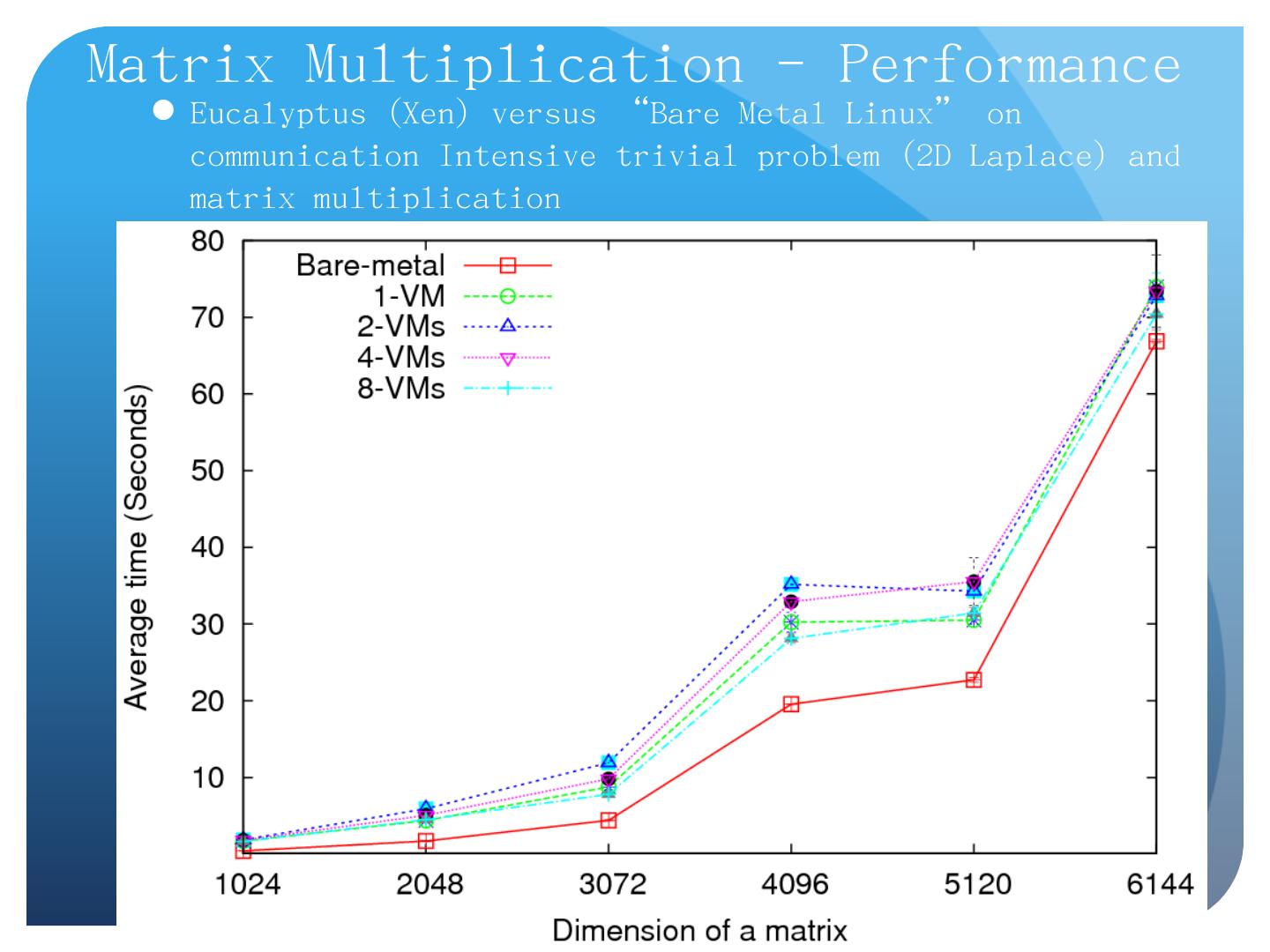
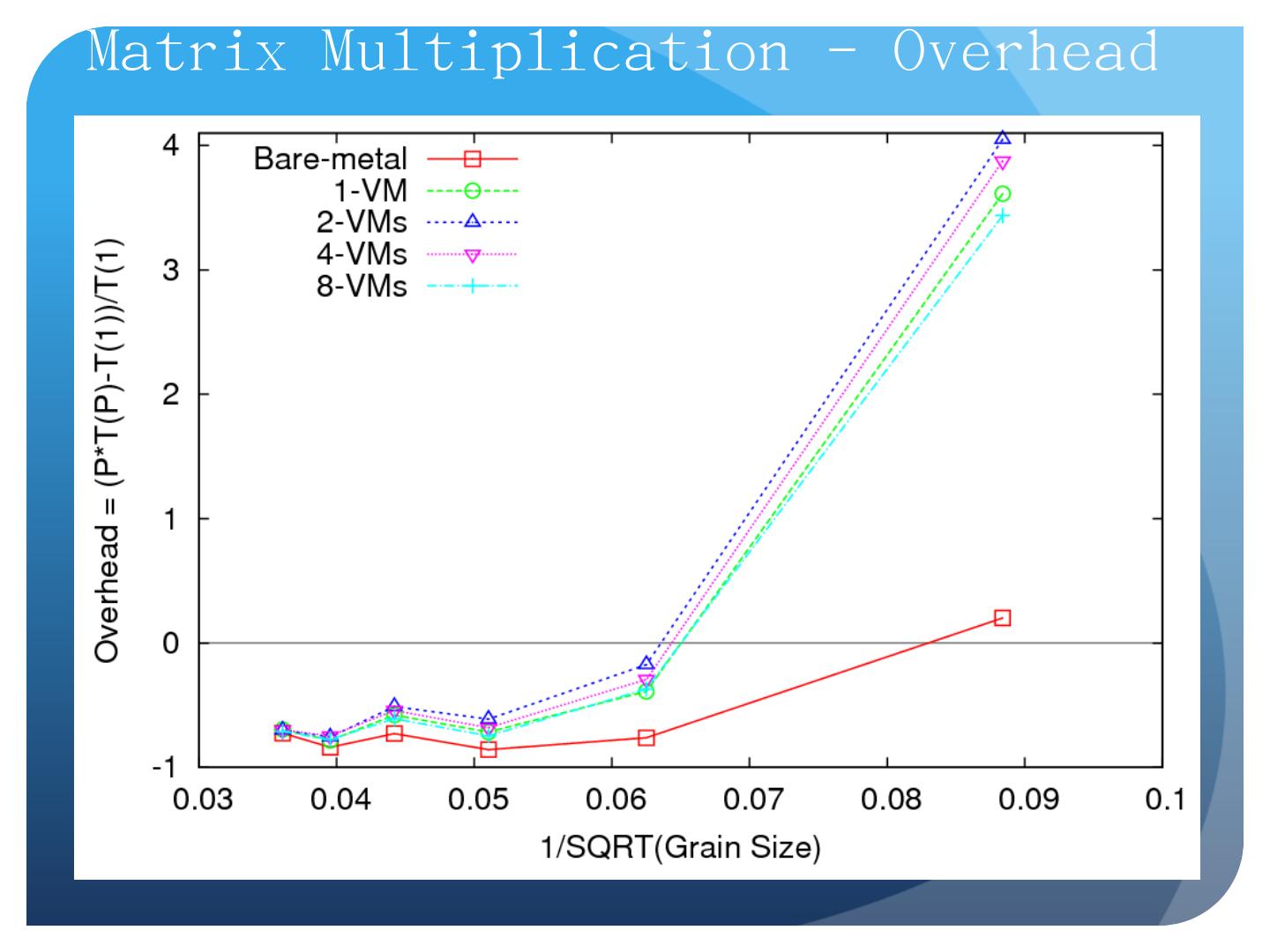
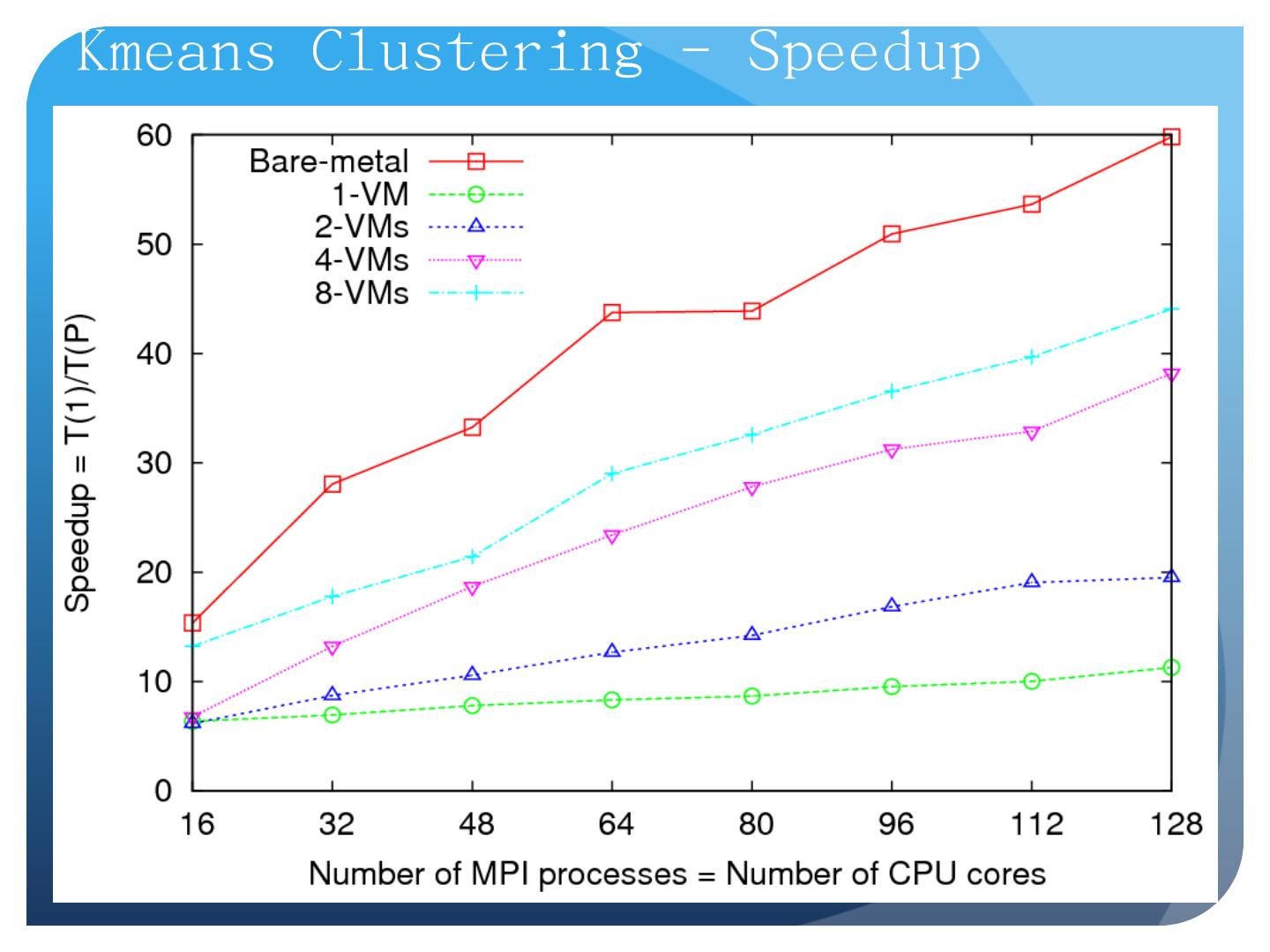
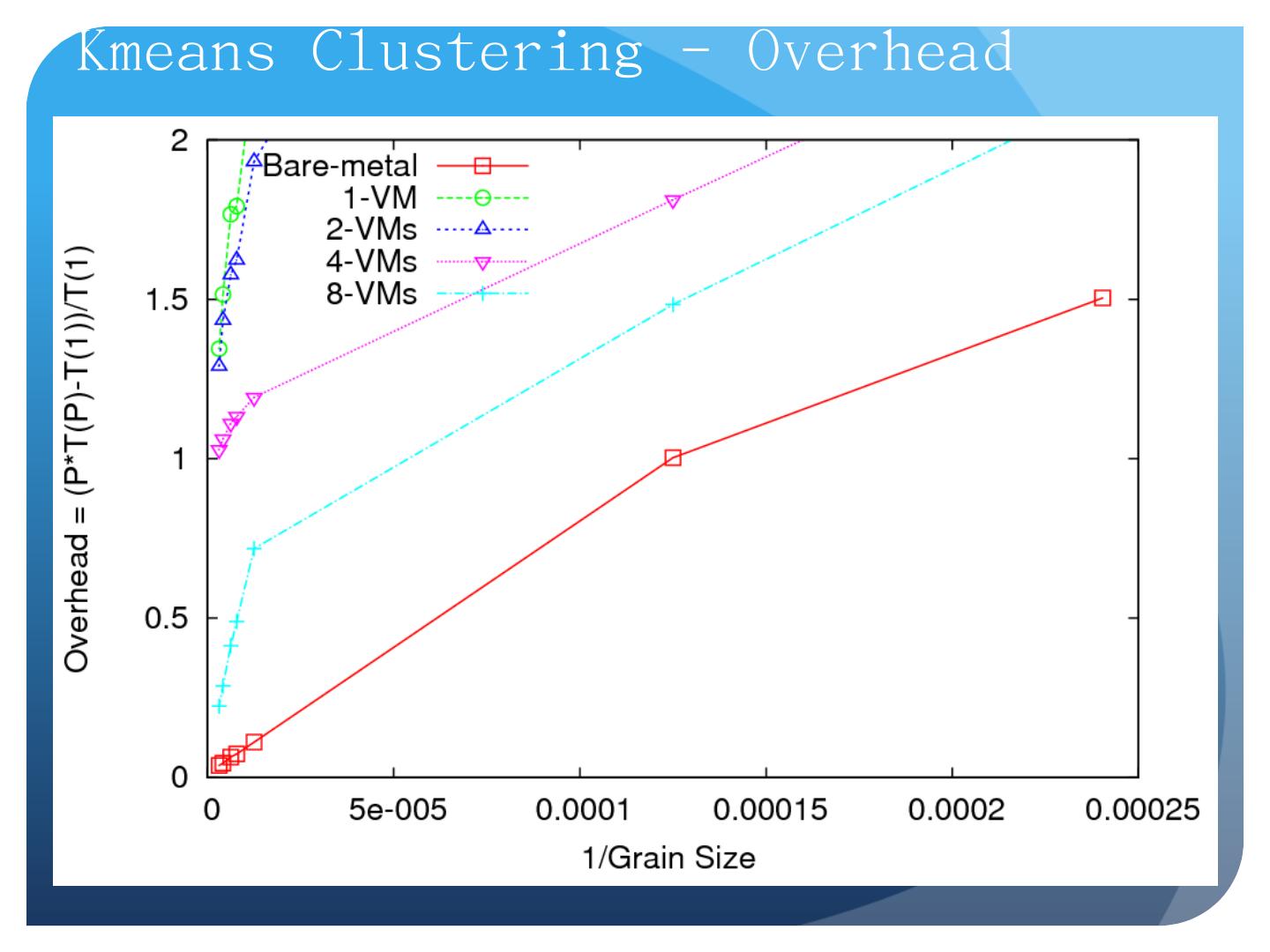
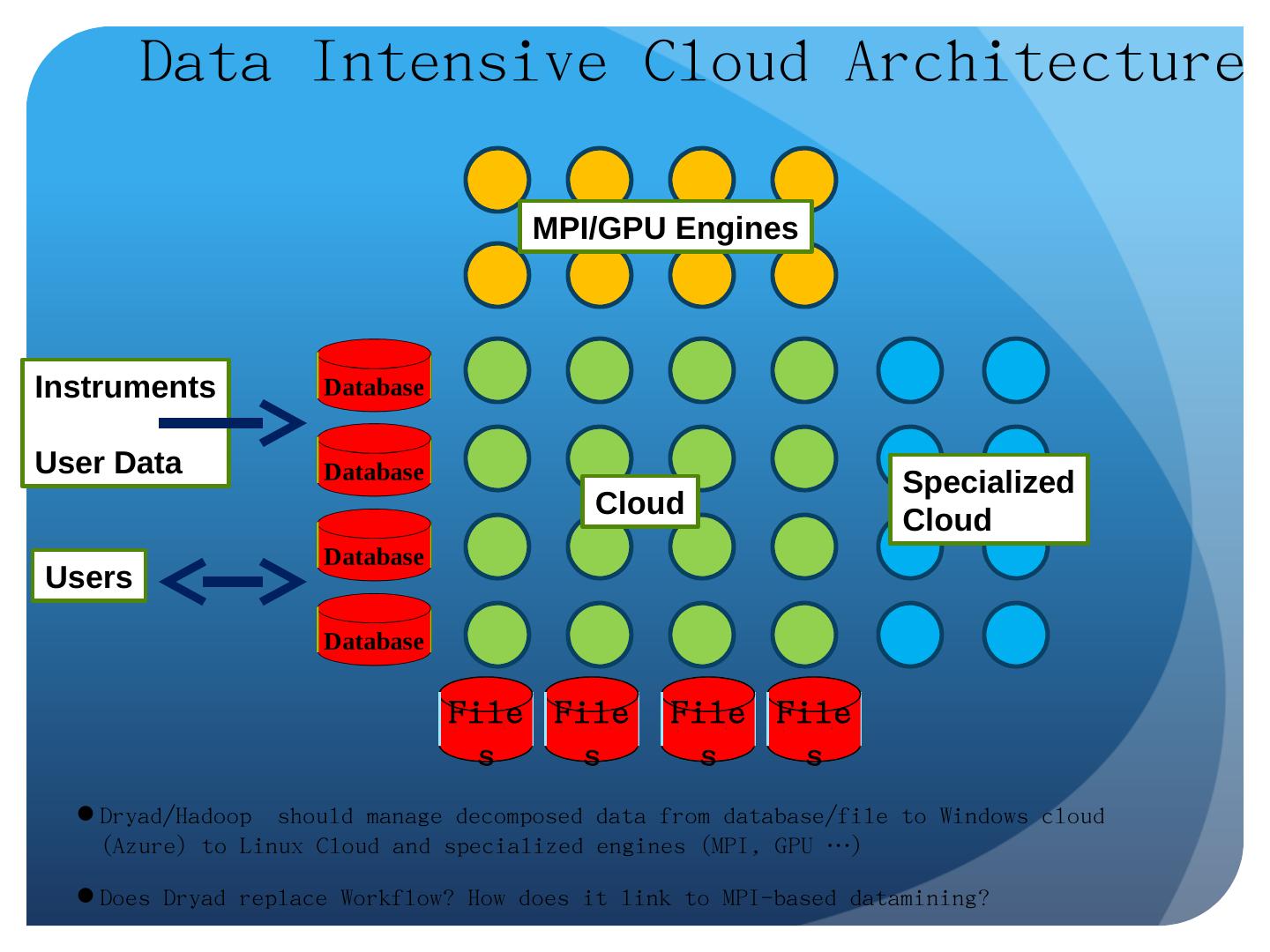
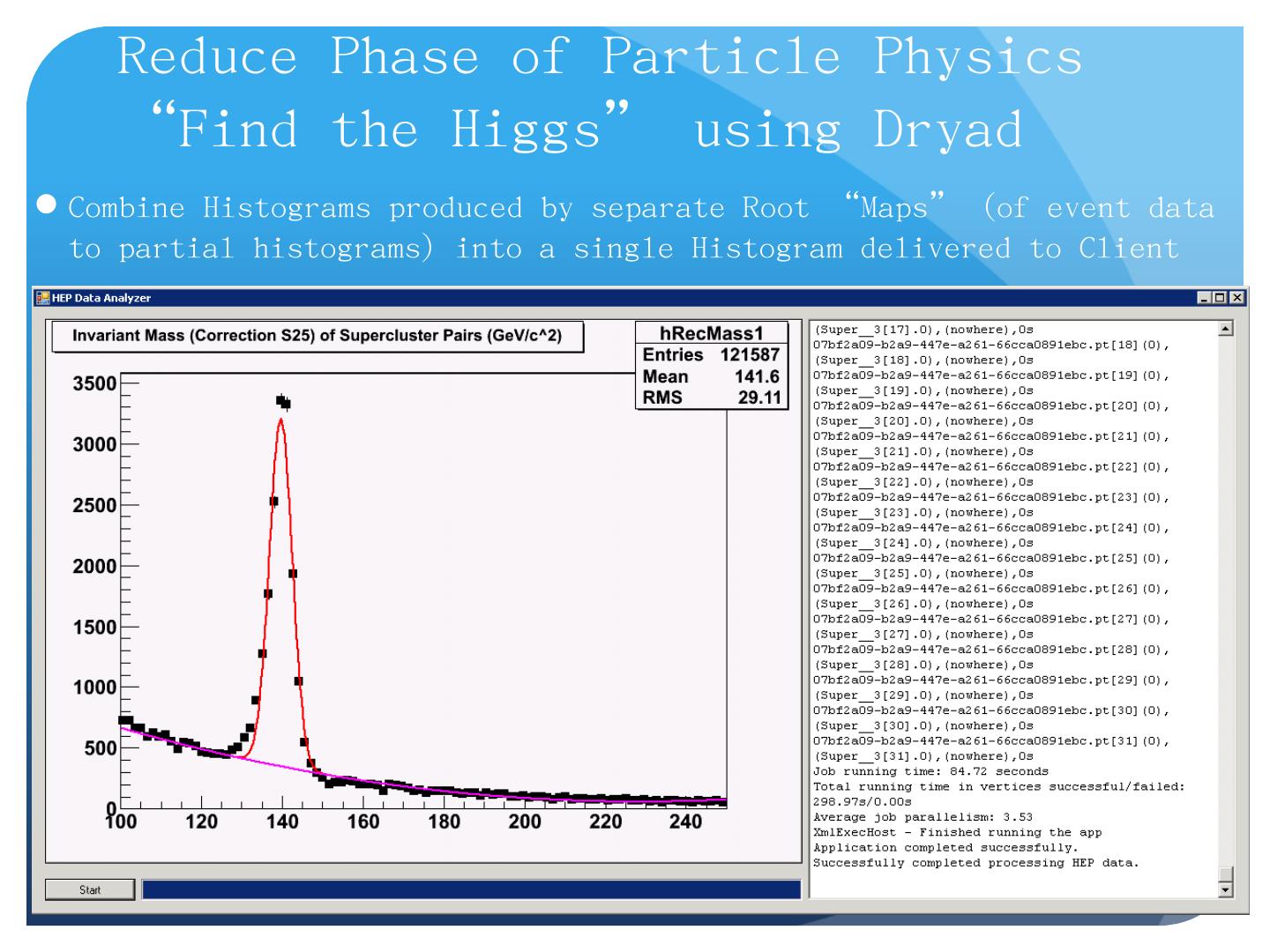
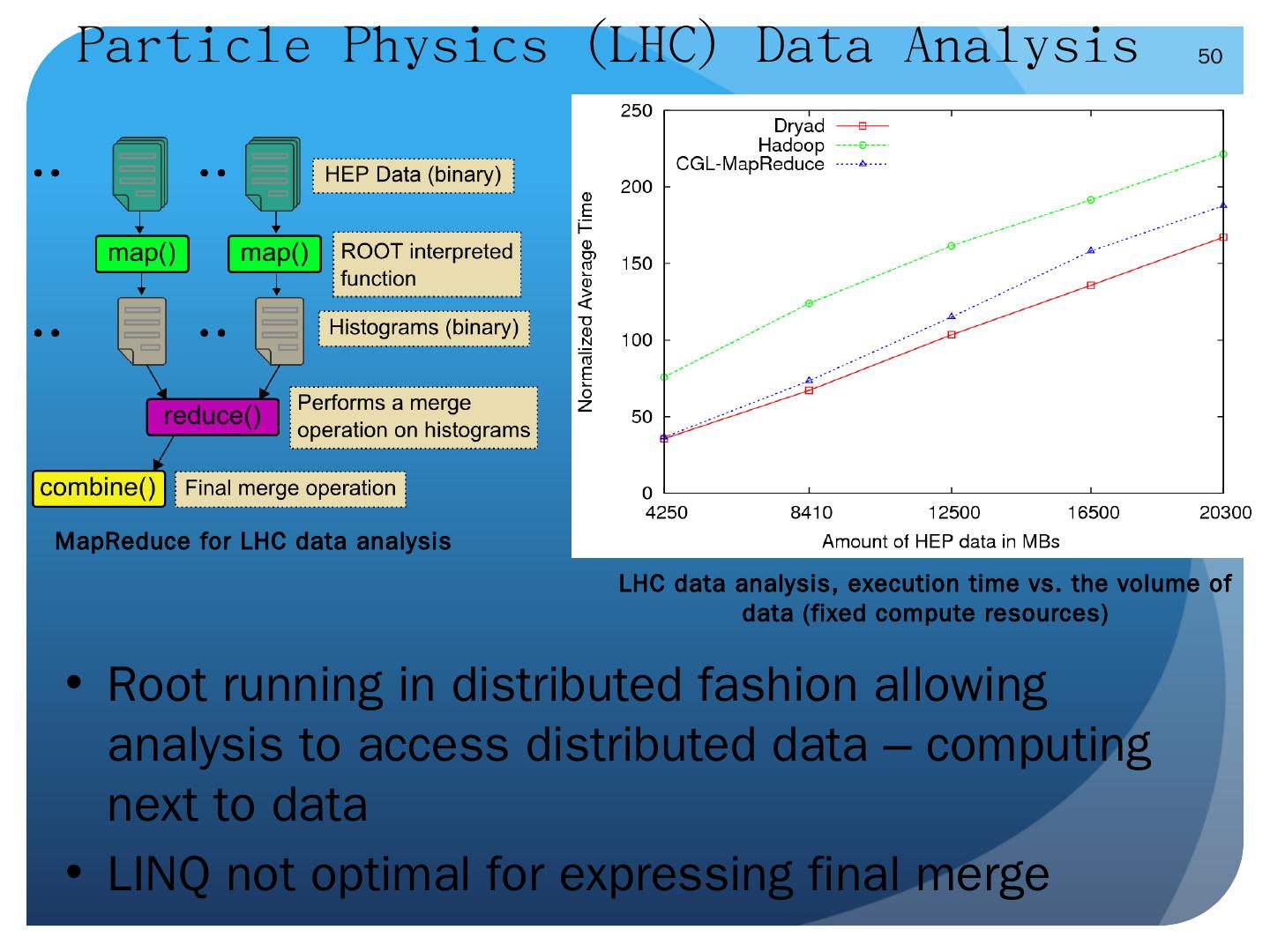
25 .Data-File Parallelism and Clouds Now that you have a cloud, you may want to do large scale processing with it. Classic problems are to perform the same (sequential) algorithm on fragments of extremely large data sets. Cloud runtime engines manage these replicated algorithms in the cloud. Can be chained together in pipelines ( Hadoop ) or DAGs (Dryad). Runtimes manage problems like failure control. We are exploring both scientific applications and classic parallel algorithms (clustering, matrix multiplication) using Clouds and cloud runtimes.
26 .Clouds, Data and Data Pipelines Data products are produced by pipelines. Can’t separate data from the way they are produced. NASA CODMAC levels for data products Clouds and virtualization give us a way to potentially serialize and preserve both data and their pipelines.
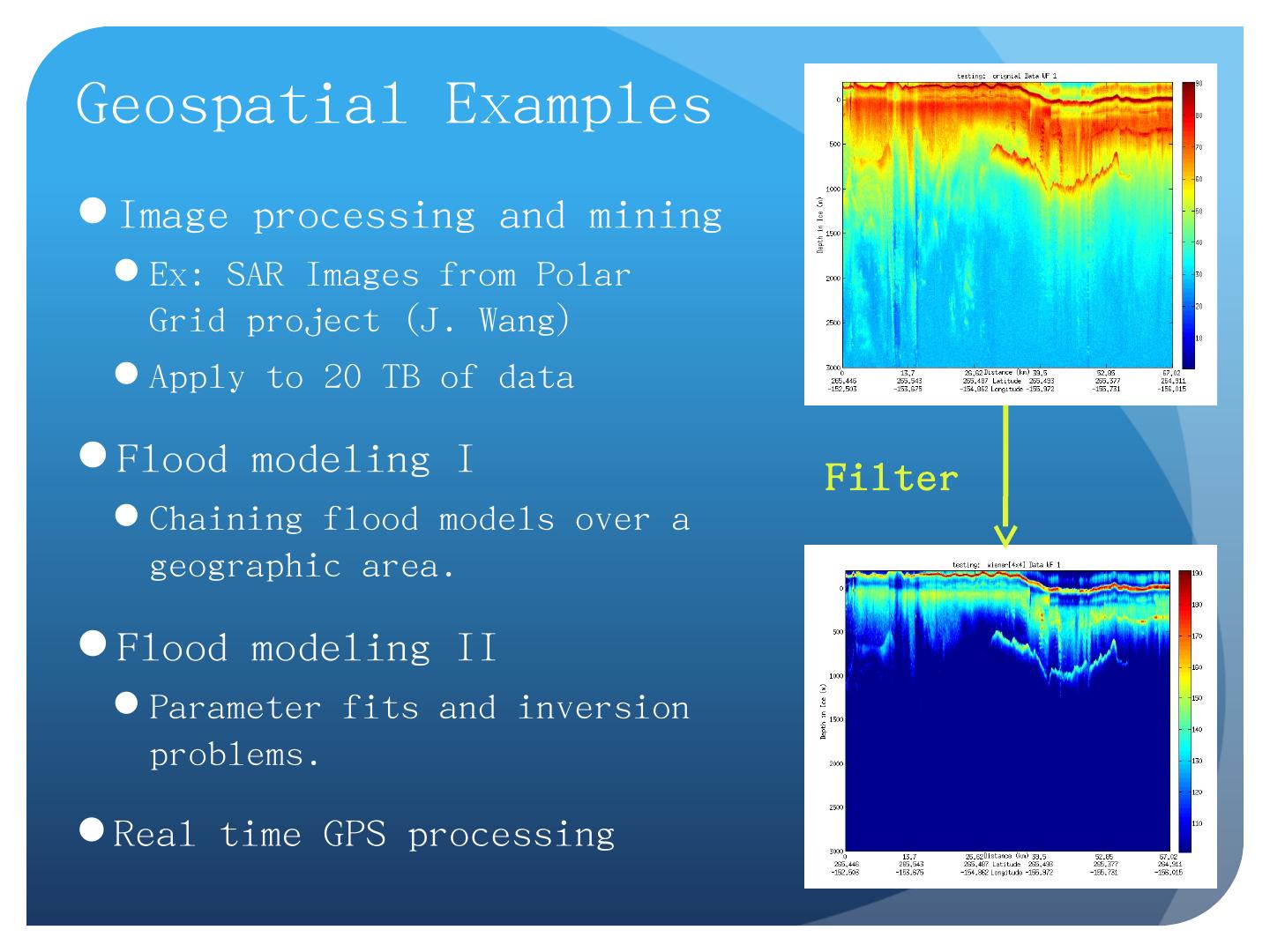
27 .Geospatial Examples Image processing and mining Ex: SAR Images from Polar Grid project (J. Wang) Apply to 20 TB of data Flood modeling I Chaining flood models over a geographic area. Flood modeling II Parameter fits and inversion problems . Real time GPS processing Filter
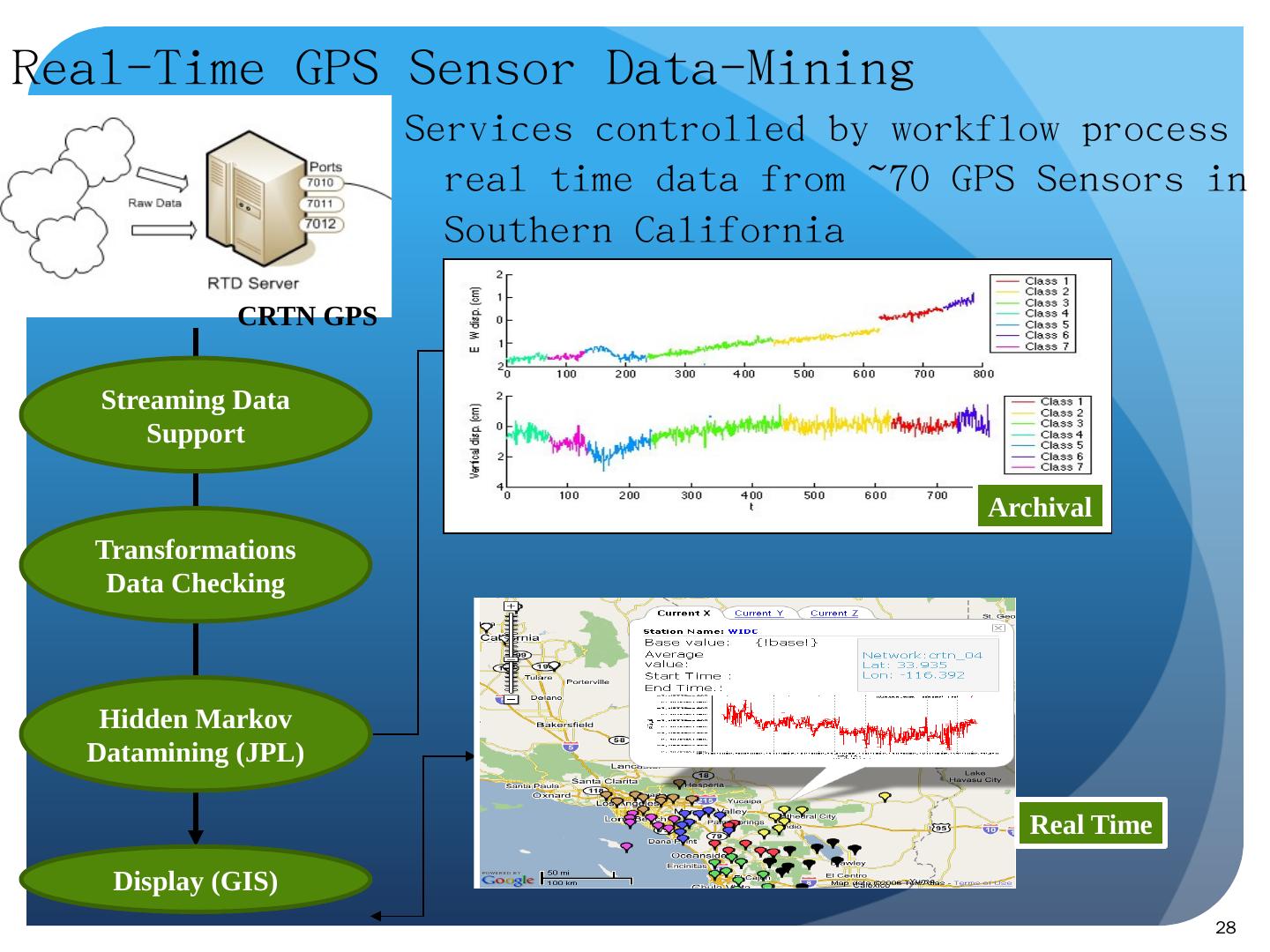
28 .Real-Time GPS Sensor Data-Mining S ervices controlled by workflow process real time data from ~70 GPS Sensors in Southern California 28 Streaming Data Support Transformations Data Checking Hidden Markov Datamining (JPL) Display (GIS) CRTN GPS Earthquake Real Time Archival
29 .Some Other File/Data Parallel Examples from Indiana University Biology Dept EST (Expressed Sequence Tag) Assembly: (Dong) 2 million mRNA sequences generates 540000 files taking 15 hours on 400 TeraGrid nodes (CAP3 run dominates) MultiParanoid/InParanoid gene sequence clustering: (Dong) 476 core years just for Prokaryotes Population Genomics: (Lynch) Looking at all pairs separated by up to 1000 nucleotides Sequence-based transcriptome profiling: ( Cherbas , Innes) MAQ, SOAP Systems Microbiology: ( Brun ) BLAST, InterProScan Metagenomics ( Fortenberry , Nelson) Pairwise alignment of 7243 16s sequence data took 12 hours on TeraGrid All can use Dryad or Hadoop 29
3秒后跳转登录页面
去登陆

