基于Hadoop和Spark构建可扩展的网络安全分析平台
分享
点赞
1
收藏
2
下载 0
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
基于Hadoop与Spark构建安全数据分析检测平台 ... 高于Map-Reduce模型;; Spark-Streaming - 流数据实时/半实时处理; MLlib 机器学习模块; GraphX 图计算模块.
展开查看详情
1 .基于 Hadoop 和 Spark 构建
可扩展的网络安全分析平台
山东大学 赵科军 葛连升 刘洋 秦丰林
L/O/G/O
�
2 .挑战
• 网络安全检测数据量迅速增长
– 流量信息数据
– 系统日志
– 应用服务日志
–…
• 机器学习技术广泛应用于安全分析检测
– 大量迭代计算
• 支持实时/半实时安全分析检测
�
3 .现状
• 单机处理受限
• 自建集群
– 并行计算开发难度大,开发量
– 工程质量
– 业务可扩展性
– 集群可扩展性
�
4 .现状 -Hadoop
• Hadoop 集群
– Hadoop 是 Apache 基金会管理的一个分布式
系统基础架构;
– 用户在不了解分布式底层实现细节的情况下,
可以充分利用廉价的硬件平台开发分布式程
序;
– Hadoop 拥有高可扩展性,高可用性,低廉应
用成本等优点;
– 缺点:计算模型 MapReduce 需要多次的读写
磁盘,计算速度慢。
– 适合线下数据分析
�
5 .基于 Hadoop 与 Spark 构建安
全数据分析检测平台
• Spark 是 UC Berkeley AMP lab 开源的并
行计算框架;
• 基于内存的计算,计算速度明显高于 Map-
Reduce 模型;
• Spark-Streaming - 流数据实时/半实时处
理
• MLlib 机器学习模块
• GraphX 图计算模块
�
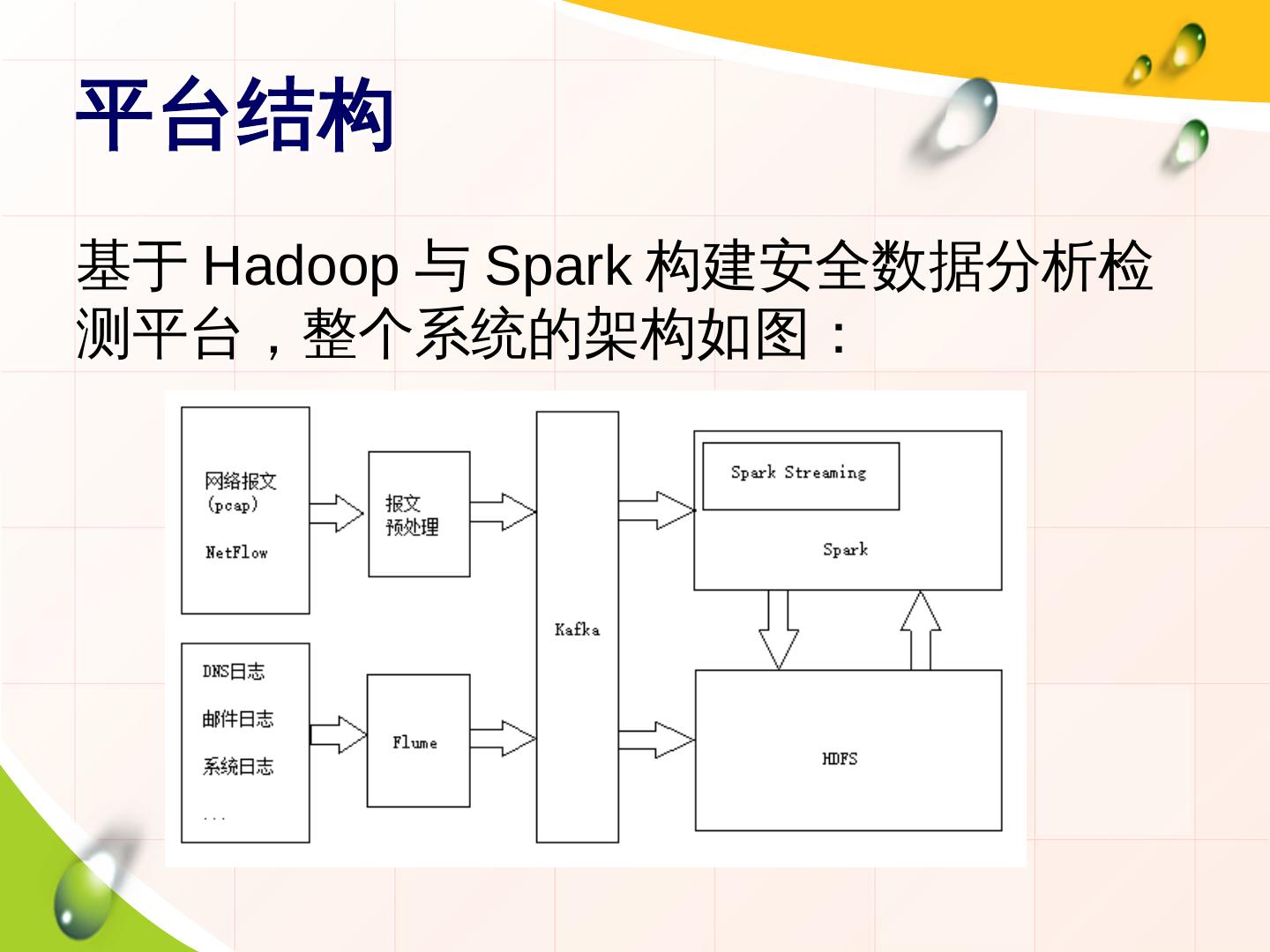
6 .平台结构
基于 Hadoop 与 Spark 构建安全数据分析检
测平台,整个系统的架构如图:
�
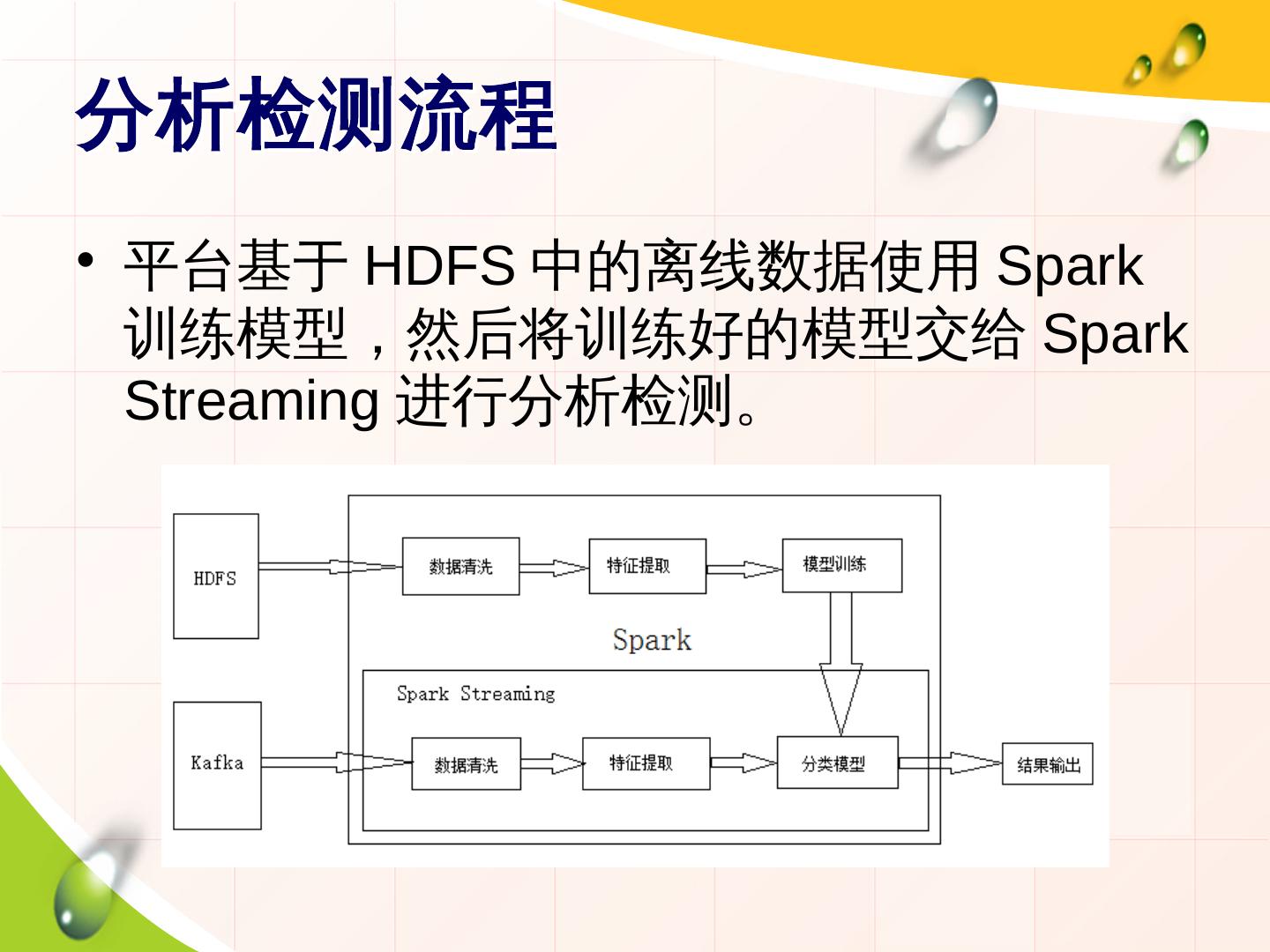
7 .分析检测流程
• 平台基于 HDFS 中的离线数据使用 Spark
训练模型,然后将训练好的模型交给 Spark
Streaming 进行分析检测。
�
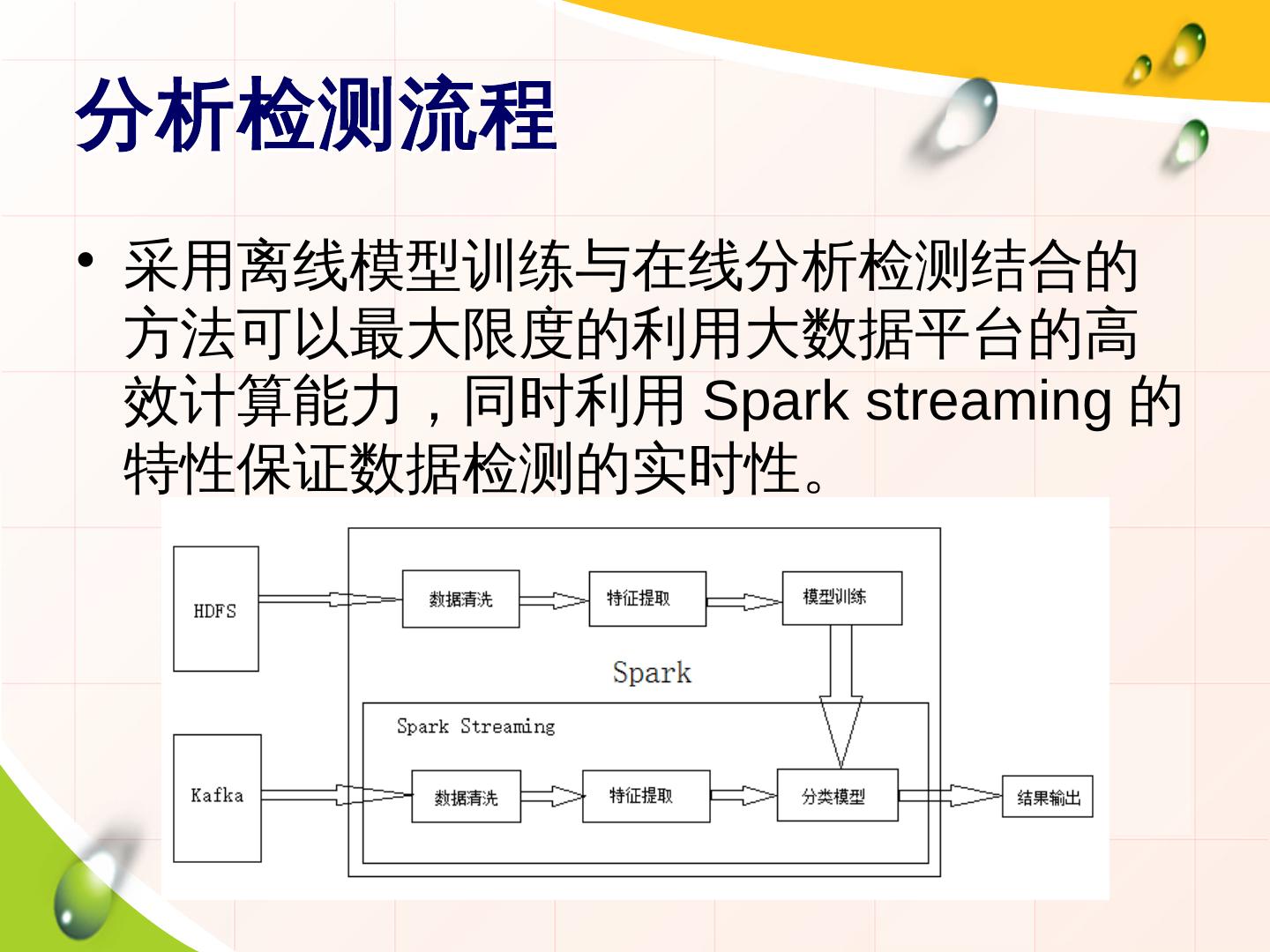
8 .分析检测流程
• 采用离线模型训练与在线分析检测结合的
方法可以最大限度的利用大数据平台的高
效计算能力,同时利用 Spark streaming 的
特性保证数据检测的实时性。
�
9 .实验结果与分析
• 实验环境
– 6 台服务器: 2 颗 Xeon(R) E5-2407 V2
@2.4GHz CPU(4 核 ) , 32GB 内存
– HDFS 本身提供了可靠的冗余备份机制,所有
服务器均不使用 RAID 配置,硬盘采用直接挂
载的方式,提高 I/O 吞吐能力;
– 6 台服务器安装在同一个机架中,服务器使用
单块千兆网卡通过一台千兆交换机互联。
�
10 .实验数据
• 采用山东大学济南六校区 DNS 查询日志作
为本实验的测试数据。
• 使用 Flume 将 2016 年 6 月 20 日 -2016 年
6 月 26 日总共一周的 DNS 查询日志数据
写入了安全平台的文件系统。该数据样本
大小为 486GB ,总共包含 33 亿
(3,357,813,618) 条查询记录。
• 使用 DNS 查询频率特征提取作为主要的性
能测试对象。
�
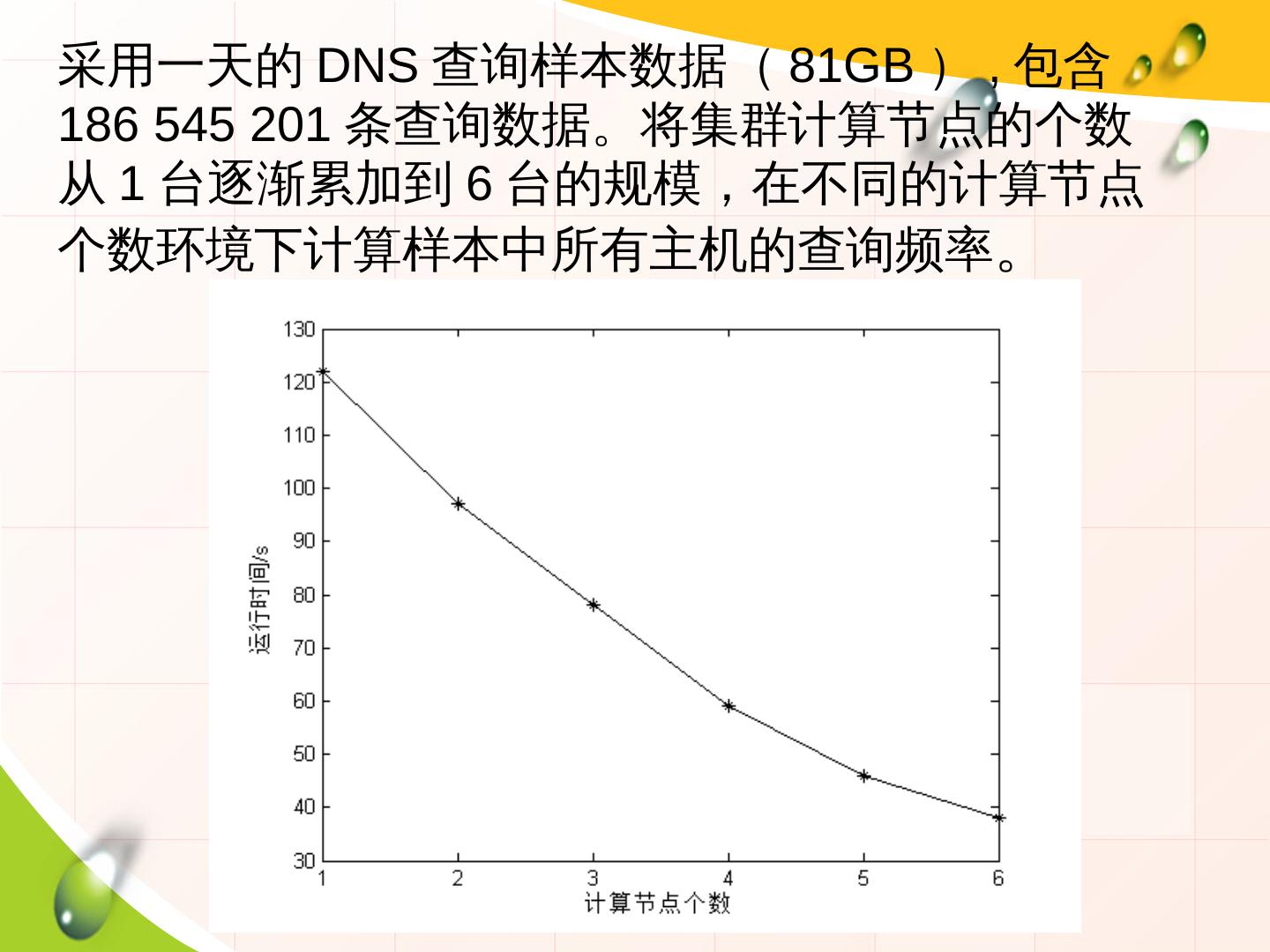
11 .采用一天的 DNS 查询样本数据( 81GB ) , 包含
186 545 201 条查询数据。将集群计算节点的个数
从 1 台逐渐累加到 6 台的规模,在不同的计算节点
个数环境下计算样本中所有主机的查询频率。
�
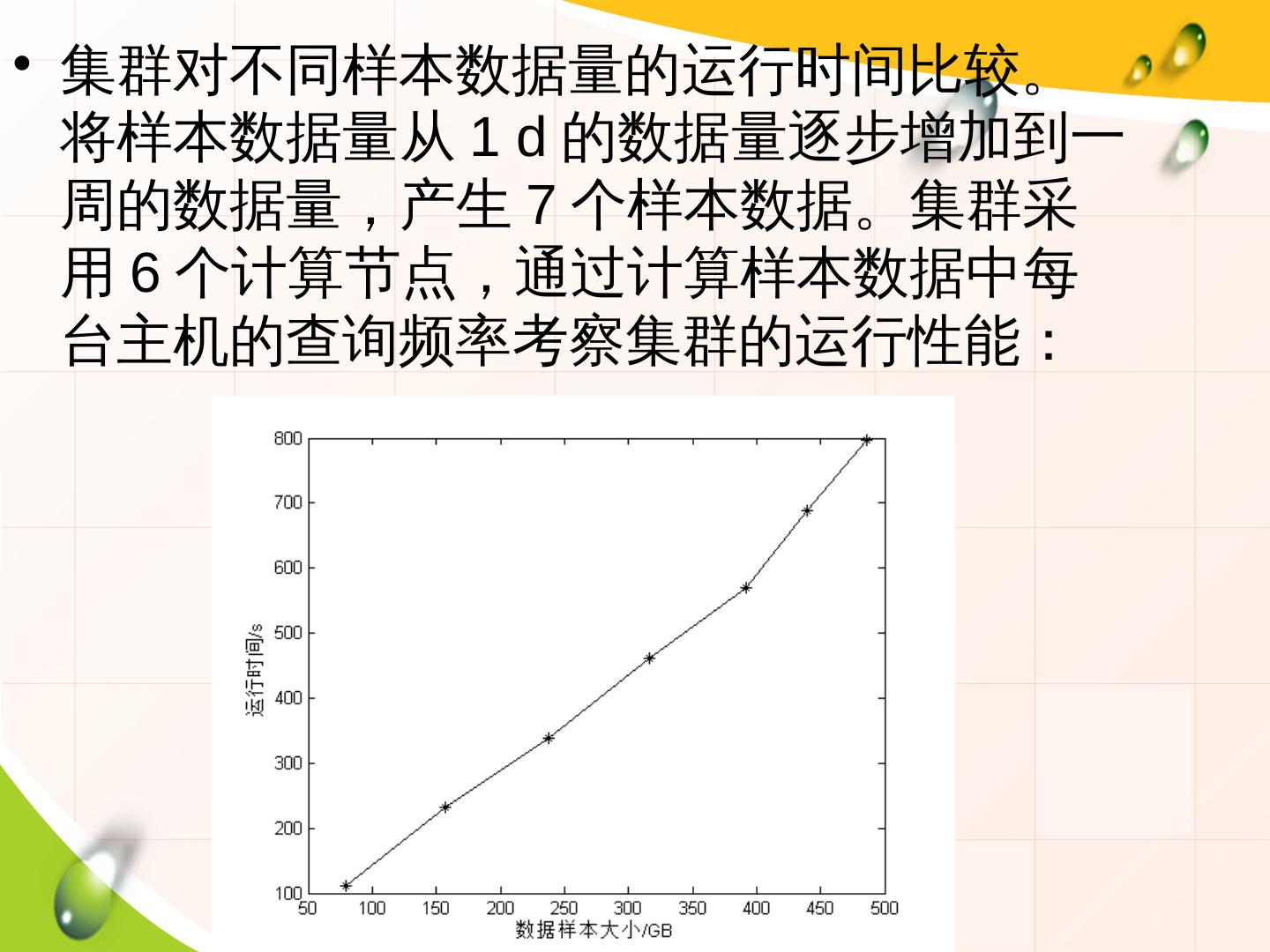
12 .• 集群对不同样本数据量的运行时间比较。
将样本数据量从 1 d 的数据量逐步增加到一
周的数据量,产生 7 个样本数据。集群采
用 6 个计算节点,通过计算样本数据中每
台主机的查询频率考察集群的运行性能:
�
13 .总结
• 本文提出基于 Hadoop 和 Spark 计算框架构建一
种低成本的可扩展性的大数据安全分析检测平
台。
• 使用离线模型生成与在线检测相结合的方式对大
规模网络数据进行分析,同时能够实现实时安全
分析检测。
• 通过实验证明:基于 Hadoop 和 Spark 的大数据
安全分析平台具有良好的可扩展性及高效处理能
力,能够满足安全大数据的分析与检测要求。
• 下一阶段,将在该大数据安全分析平台基础上充
分利用 DNS 日志和网络流量数据,在异构数据环
境中开展实时僵尸网络检测分析的工作。
�