展开查看详情
1 . Object Recognition by Parts
• Object recognition started with line segments.
- Roberts recognized objects from line segments
and junctions.
- This led to systems that extracted linear features.
.
- CAD-model-based vision works well for industrial.
• An “appearance-based approach” was first developed
for face recognition and later generalized up to a point.
• The new interest operators have led to a new kind of
recognition by “parts” that can handle a variety of
objects that were previously difficult or impossible.
1
�
2 . Object Class Recognition
by Unsupervised Scale-Invariant Learning
R. Fergus, P. Perona, and A. Zisserman
Oxford University and Caltech
CVPR 2003
won the best student paper award
CVPR 2013
won the best 10-year award
2
�
3 . Goal:
• Enable Computers to
Recognize Different
Categories of Objects
in Images.
3
�
5 . Approach
• An object is a constellation of parts (from Burl, Weber
and Perona, 1998).
• The parts are detected by an interest operator (Kadir’s).
• The parts can be recognized by appearance.
• Objects may vary greatly in scale.
• The constellation of parts for a given object is learned
from training images
5
�
6 . Components
• Model
– Generative Probabilistic Model including
Location, Scale, and Appearance of Parts
• Learning
– Estimate Parameters Via EM Algorithm
• Recognition
– Evaluate Image Using Model and Threshold
6
�
7 . Model: Constellation Of
Parts
Fischler & Elschlager,
1973
Yuille, ‘91
Brunelli & Poggio, ‘93
Lades, v.d. Malsburg et al. ‘93
Cootes, Lanitis, Taylor et al. ‘95
Amit & Geman, ‘95, ‘99
Perona et al. ‘95, ‘96, ’98, ‘00
7
�
8 . Parts Selected by
Interest Operator
Kadir and Brady's Interest Operator.
Finds Maxima in Entropy Over Scale and Location
8
�
9 . Representation of
Appearance
c1
Projection onto c2
11x11 patch Normalize PCA basis
121 dimensions was too big, so they used PCA to reduce to 10-15.
c915
�
10 . Learning a Model
• An object class is represented by a generative
model with P parts and a set of parameters .
• Once the model has been learned, a decision
procedure must determine if a new image
contains an instance of the object class or not.
• Suppose the new image has N interesting
features with locations X, scales S and
appearances A.
10
�
11 . Probabilistic Model
• X is a description of the shape of the object (in terms of locations of parts)
• S is a description of the scale of the object
• A is a description of the appearance of the object
• θ is the (maximum likelihood value of) the parameters of the object
• h is a hypothesis: a set of parts in the image that might be the parts of the object
• H is the set of all possible hypotheses for that object in that image.
• For N features in the image and P parts in the object, its size is O(NP)
11
�
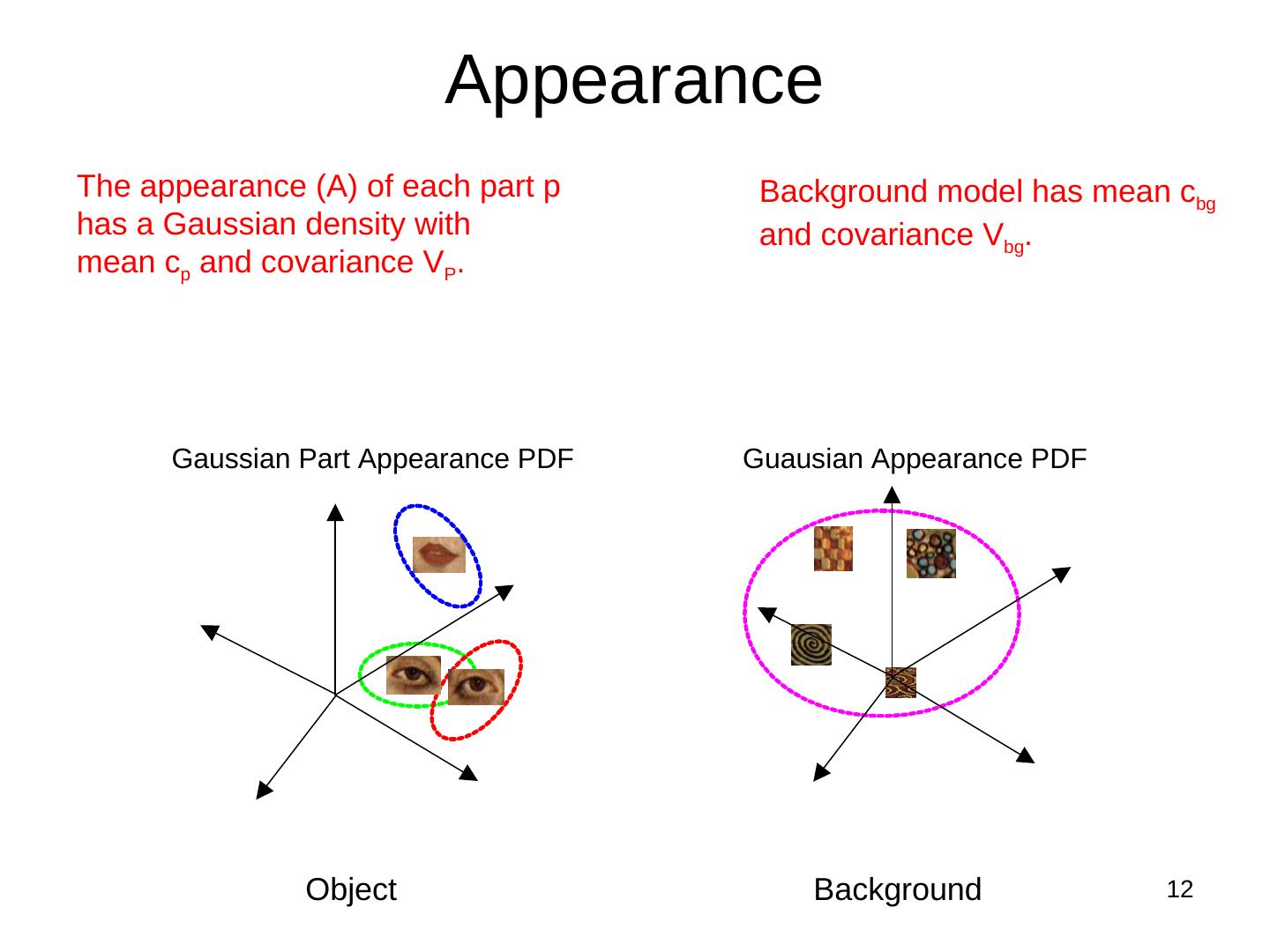
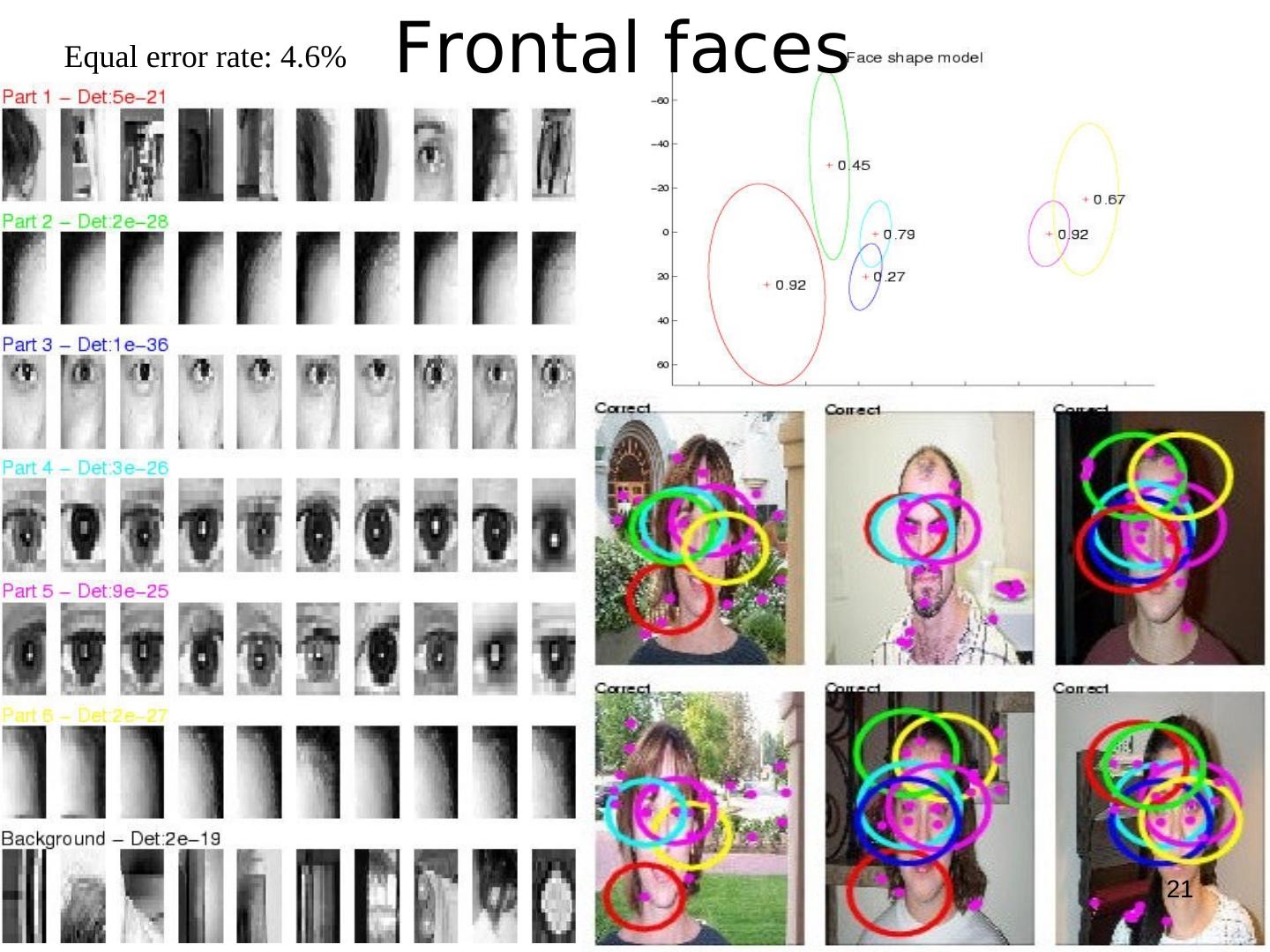
12 . Appearance
The appearance (A) of each part p Background model has mean cbg
has a Gaussian density with and covariance Vbg.
mean cp and covariance VP.
Gaussian Part Appearance PDF Guausian Appearance PDF
Object Background 12
�
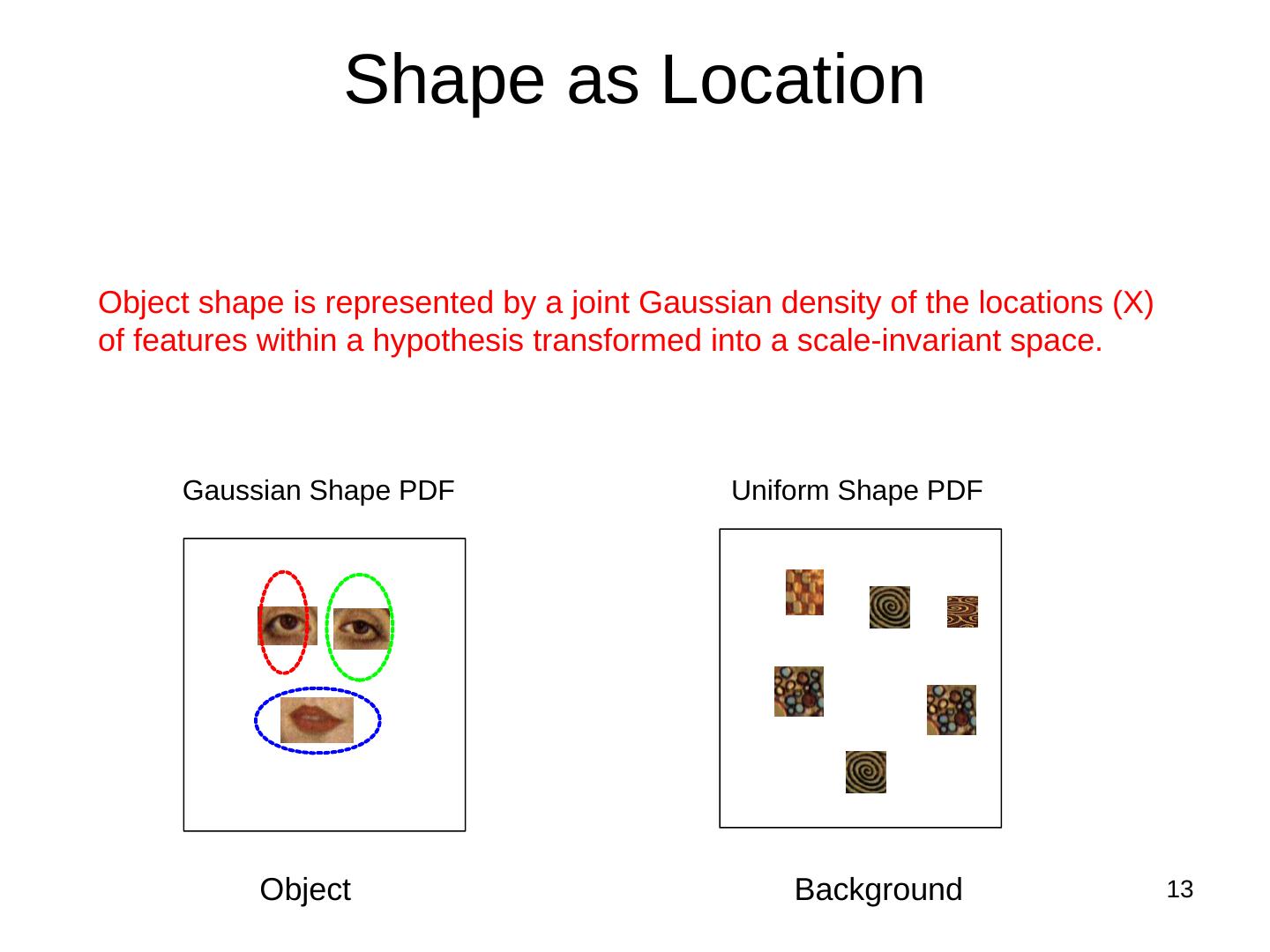
13 . Shape as Location
Object shape is represented by a joint Gaussian density of the locations (X)
of features within a hypothesis transformed into a scale-invariant space.
Gaussian Shape PDF Uniform Shape PDF
Object Background 13
�
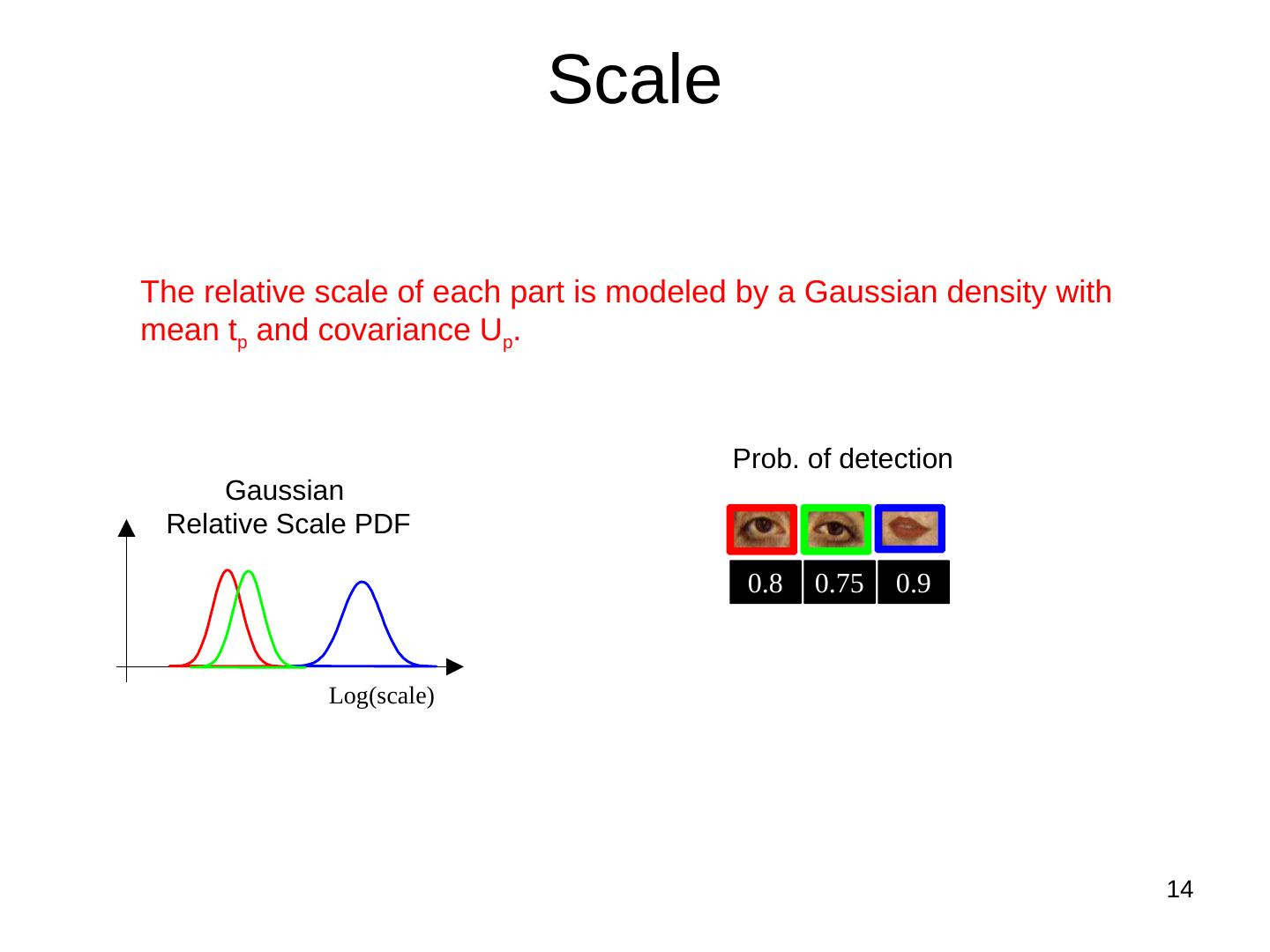
14 . Scale
The relative scale of each part is modeled by a Gaussian density with
mean tp and covariance Up.
Prob. of detection
Gaussian
Relative Scale PDF
0.8 0.75 0.9
Log(scale)
14
�
15 .Occlusion and Part Statistics
This was very complicated and turned out to not work
well and not be necessary, in both Fergus’s work and
other subsequent works.
15
�
16 . Learning
• Train Model Parameters
occlusion
Using EM: location
appearance scale
• Optimize Parameters
• Optimize Assignments
• Repeat Until Convergence
16
�
17 . Recognition
Make this likelihood ratio:
greater than a threshold.
17
�
18 . RESULTS
• Initially tested on the Caltech-4 data set
– motorbikes
– faces
– airplanes
– cars
• Now there is a much bigger data set: the
Caltech-101 http://
www.vision.caltech.edu/archive.html
18
�
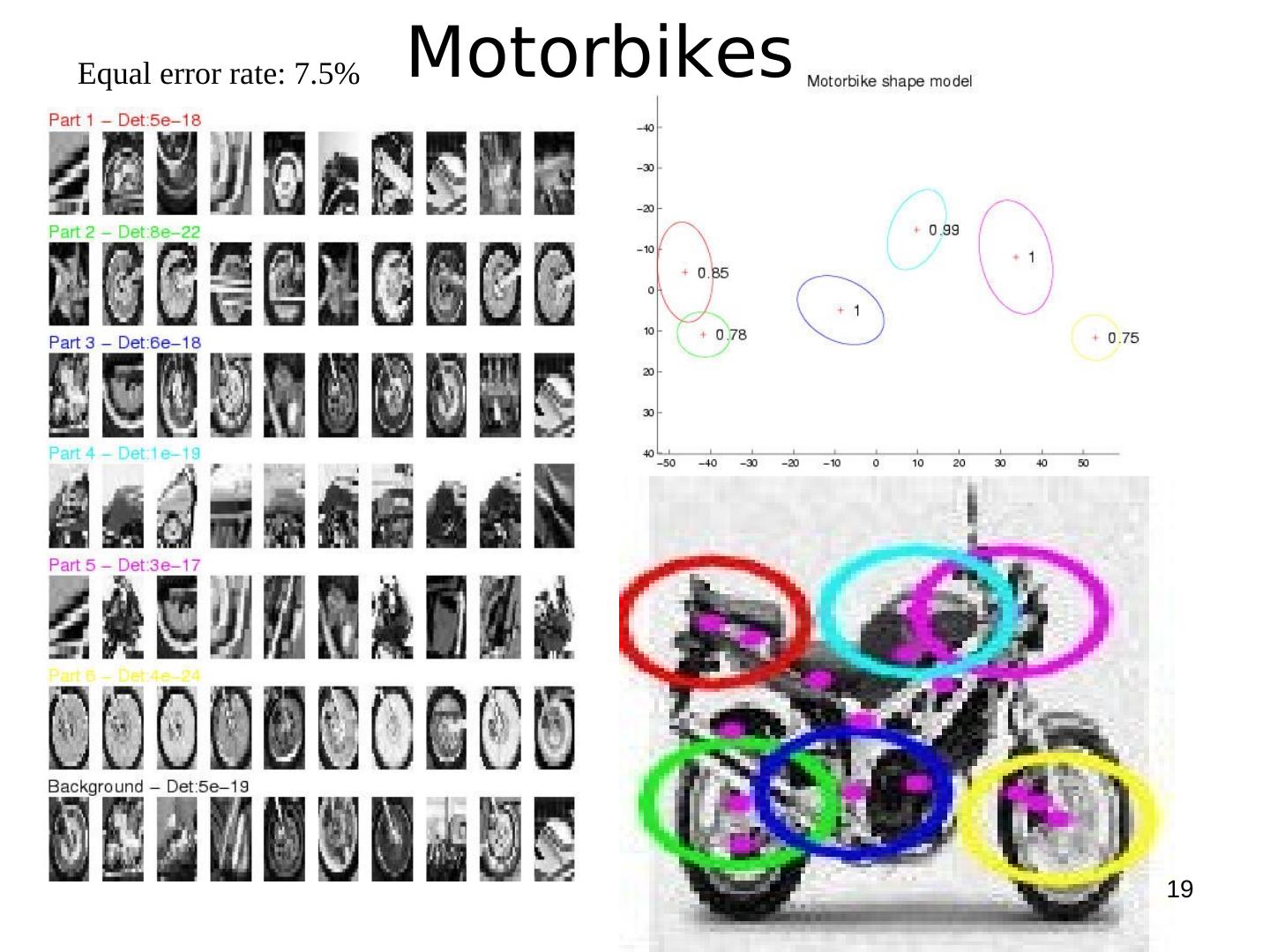
19 .Equal error rate: 7.5% Motorbikes
19
�
20 .Background Images
It learns that these are NOT motorbikes.
20
�
21 .Equal error rate: 4.6% Frontal faces
21
�
22 .Equal error rate: 9.8%
Airplanes
22
�
23 .Scale-Invariant Cats
Equal error rate: 10.0%
23
�
24 . Scale-Invariant Cars
Equal error rate: 9.7%
24
�
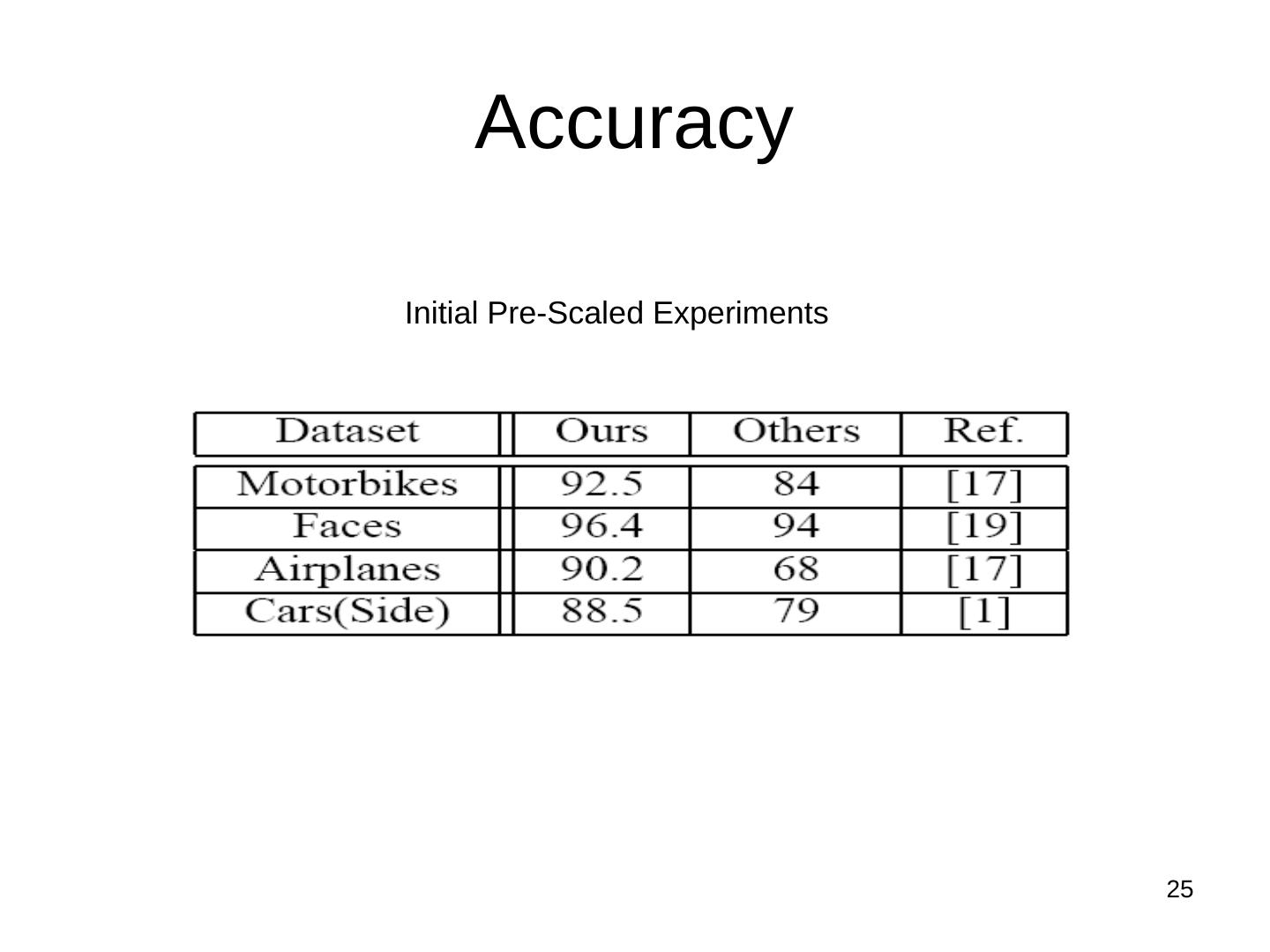
25 . Accuracy
Initial Pre-Scaled Experiments
25
�