












































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Spilling Your Data into Azure Data Lake: Patterns & How-Tos
With a WebHDFS endpoint Azure Data Lake Store is a Hadoop-compatible file system ... Apache Sqoop is a tool designed to transfer data between relational ...
展开查看详情
1 .Microsoft Machine Learning & Data Science Summit September 26 – 27 | Atlanta, GA
2 .‘Spilling’ Your Data into Azure Data Lake: Patterns & How-tos Jason Chen Principal Program Manager
3 .Content Big Data Pipeline and Workflow Azure Data Lake Overview Data Ingestion Tools & How-to Patterns, scenarios, considerations Data Workflow Patterns Demo Ingest data using Azure Data Factory
4 .Big Data Pipeline and Workflow
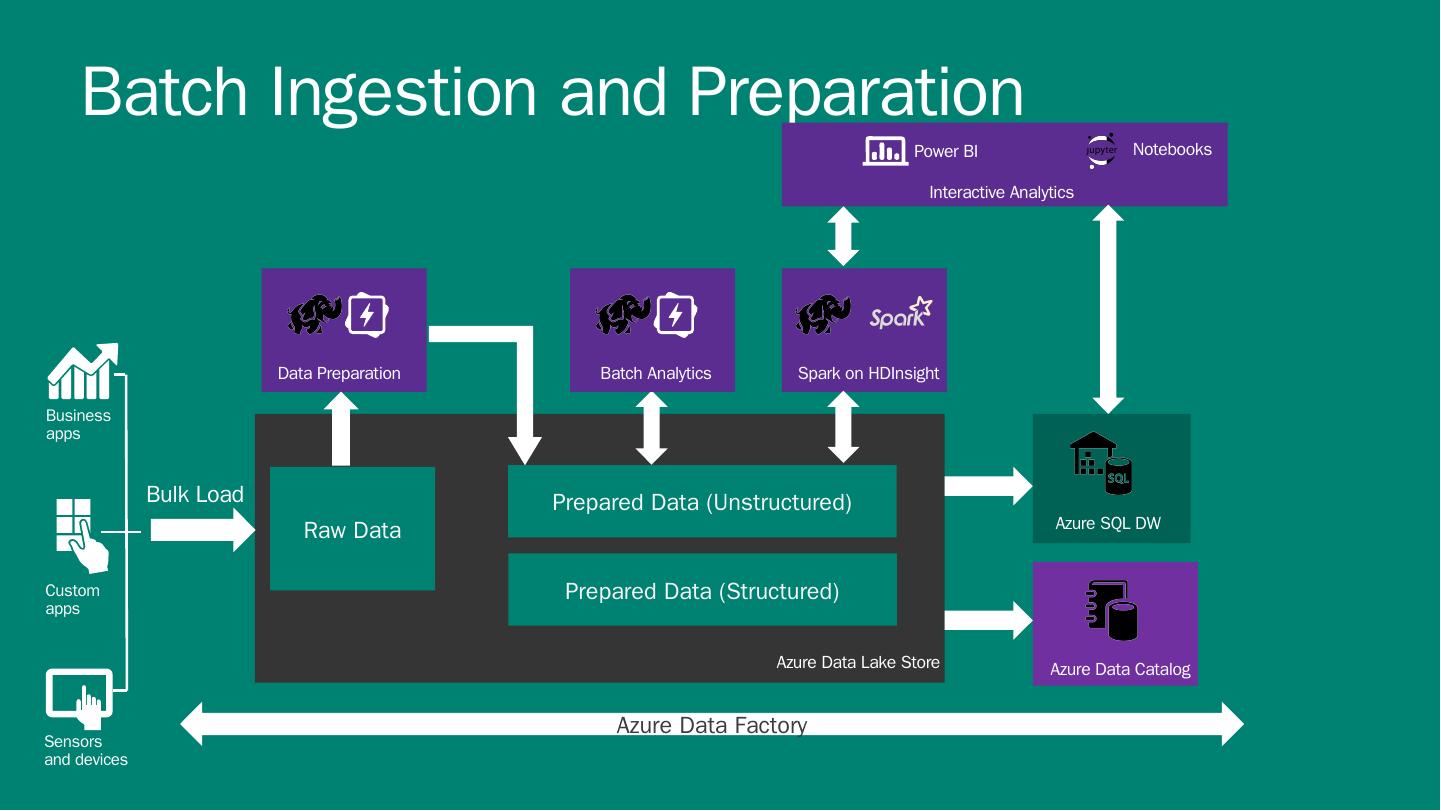
5 .DATA Business apps Custom apps Sensors and devices INTELLIGENCE ACTION People Preparation, Analytics and Machine Learning Big Data Store Ingestion Bulk Ingestion Event Ingestion Discovery Visualization Big Data Pipeline and Workflow
6 .DATA Business apps Custom apps Sensors and devices INTELLIGENCE ACTION People Preparation, Analytics and Machine Learning Azure Data Lake Store Ingestion Bulk Ingestion Event Ingestion Discovery Azure Data Catalog Visualization Power BI Big Data Pipeline and Data Flow in Azure HDInsight (Hadoop and Spark) Stream Analytics Data Lake Analytics Machine Learning
7 .Azure Data Lake: Overview
8 .No limits to SCALE Store ANY DATA in its native format HADOOP FILE SYSTEM (HDFS) for the cloud Optimized for analytic workload PERFORMANCE ENTERPRISE GRADE authentication, access control, audit, encryption at rest Azure Data Lake Store A hyper scale repository for big data analytics workloads Introducing ADLS
9 .No fixed limits on: Amount of data stored How long data can be stored Number of files Size of the individual files Ingestion/egress throughput Seamlessly scales from a few KBs to several PBs No limits to scale
10 .No limits to storage 10 Each file in ADL Store is sliced into blocks Blocks are distributed across multiple data nodes in the backend storage system With sufficient number of backend storage data nodes, files of any size can be stored Backend storage runs in the Azure cloud which has virtually unlimited resources Metadata is stored about each file No limit to metadata either. Azure Data Lake Store file … Block 1 Block 2 Block 2 Backend Storage Data node Data node Data node Data node Data node Data node Block Block Block Block Block Block
11 .Massive throughput 11 Through read parallelism ADL Store provides massive throughput Each read operation on a ADL Store file results in multiple read operations executed in parallel against the backend storage data nodes Read operation Azure Data Lake Store file … Block 1 Block 2 Block 2 Backend storage Data node Data node Data node Data node Data node Data node Block Block Block Block Block Block
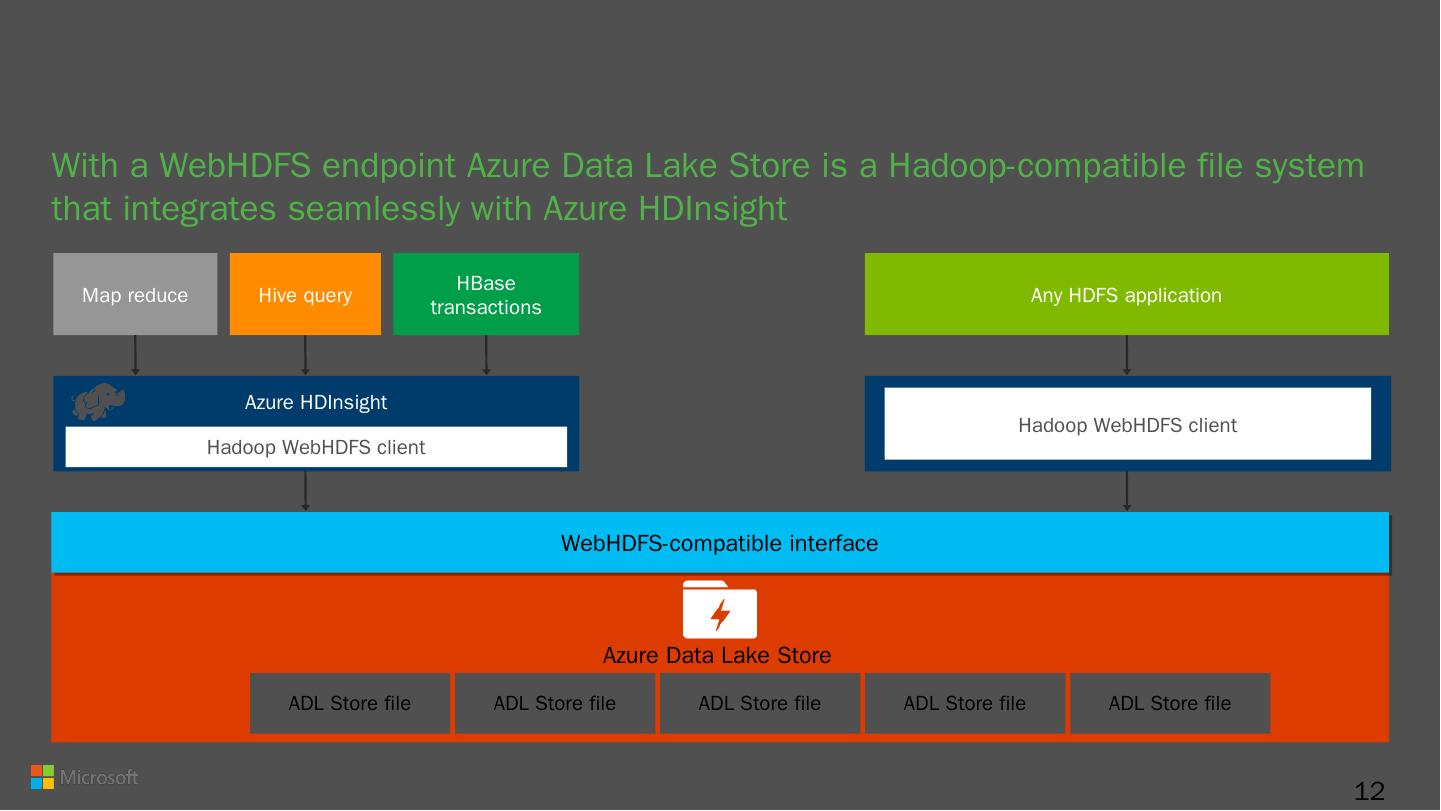
12 .HDFS-compatible With a WebHDFS endpoint Azure Data Lake Store is a Hadoop-compatible file system that integrates seamlessly with Azure HDInsight Map reduce HBase t ransactions Any HDFS application Hive query Azure HDInsight Hadoop WebHDFS client Hadoop WebHDFS client 12 ADL Store file ADL Store f ile ADL Store f ile ADL Store f ile ADL Store file Azure Data Lake Store WebHDFS -compatible interface
13 .A highly scalable, distributed, parallel file system in the cloud specifically designed to work with multiple analytic frameworks 13 Analytics on any data, any size LOB Applications Social Devices Clickstream Sensors Video Web Relational HDInsight ADL Analytics Machine Learning Spark R ADLS
14 .Enterprise grade security Enterprise-grade security permits even sensitive data to be stored securely Regulatory compliance can be enforced Integrates with Azure Active Directory for authentication Data is encrypted at rest and in flight POSIX-style permissions on files and directories Audit logs for all operations 14
15 .Enterprise grade availability and reliability 15 Azure maintains 3 replicas of each data object per region across three fault and upgrade domains Each create or append operation on a replica is replicated to other two Writes are committed to application only after all replicas are successfully updated Read operations can go against any replica Provides ‘read-after-write’ consisten cy Data is never lost or unavailable even under failures Replica 1 Replica 2 Replica 3 Fault/upgrade domains Write Replication Replication Commit
16 .Data Ingestion: how to
17 .ADLS: Tools for data ingestion Data on your desktop Data located in other stores Azure Portal PowerShell ADL Tools for Visual Studio AdlCopy Easy to use Good for small amount of data Analyzing data using Portal Upload file and folders Control parallelism Control format of upload Need to use other services Integrated experience Drag-and-drop Programmatic Analytics Copy data easily from Azure Storage at least cost CLI Linux, Mac Most features of PowerShell OSS tools on HDI Distcp , Sqoop on HDI cluster If analyzing data using HDInsight Azure Data Factory Copy Wizard for intuitive one-time copy from multiple sources
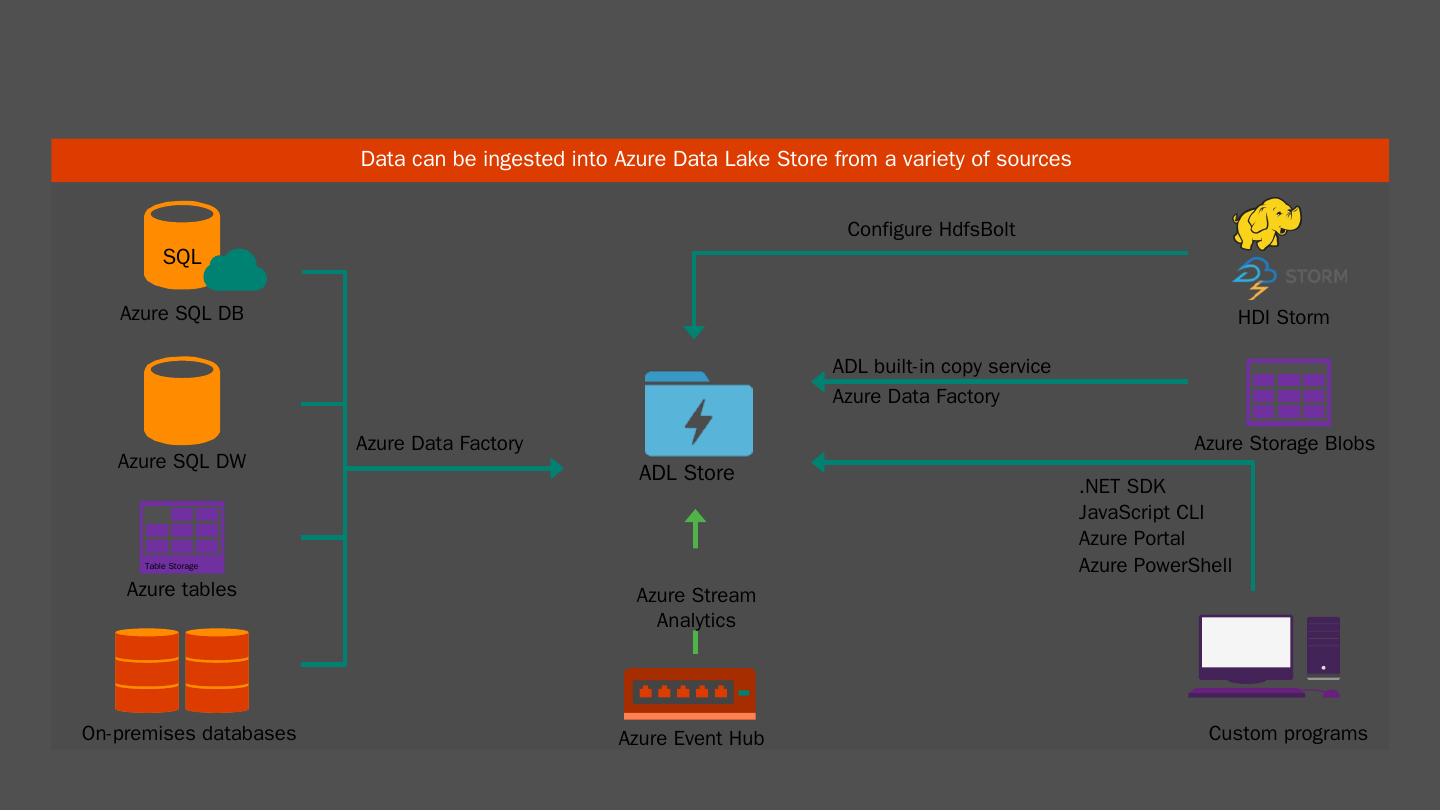
18 .ADLS: Ingress Data can be ingested into Azure Data Lake Store from a variety of sources Azure Event Hub Azure Storage Blobs Custom programs .NET SDK JavaScript CLI Azure Portal Azure PowerShell Azure Data Factory Azure SQL DB Azure SQL DW Azure tables Table Storage On-premises databases SQL ADL Store ADL built-in copy service Azure Stream Analytics Azure Data Factory HDI Storm Configure HdfsBolt
19 .ADLS: Move really large datasets Azure ExpressRoute Dedicated private connections Supported bandwidth up to 10Gbps "Offline“ Azure Import/Export service Data is first uploaded to Azure Storage Blobs Use Azure Data Factory or AdlCopy to copy data from Azure Storage Blobs to Data Lake Store
20 .A command line tool Copy data Azure Storage Blobs <==>Azure Data Lake Store Azure Data Lake Store <==>Azure Data Lake Store Run in two ways: Standalone Using a Data Lake Analytics account AdlCopy AdlCopy / Source <Blob source> / Dest <ADLS destination> / SourceKey <Key for Blob account> / Account <ADLA account> / Units <Number of Analytics units>
21 .Copy data M/R Hadoop job HDInsight cluster storage <==> Data Lake Store account distcp hadoop distcp wasb://<container_name>@<storage_account_name>.blob.core.windows.net/example/data/gutenberg adl://<data_lake_store_account>.azuredatalakestore.net:443/myfolder
22 .Apache Sqoop is a tool designed to transfer data between relational databases and a big data repository, such as Data Lake Store. You can use Sqoop to copy data to and from Azure SQL database into a Data Lake Store account, in addition to other other relational DBs. More details are here . sqoop sqoop -import -- connect " jdbc:sqlserver ://< sql -database-server-name>.database .windows.net:1433;username=<username>@< sql -database-server-name>;password= <password>;database=< sql -database-name>“ -- table Table1 -- target- dir adl:// <data-lake-store-name>.azuredatalakestore.net/Sqoop/SqoopImportTable1
23 .Relational and non-relational On-premises or cloud Azure Data Factory Cloud-based data integration service that orchestrates and automates the movement and transformation of data Linked Services Connect data factories to the resources and services you want to use Connect to data stores like Azure Storage and on premises SQL Server Connect to compute services like Azure ML, Azure HDI, and Azure Batch Data Sets A named reference/pointer to data you want to use as an input or output of an activity Activities Actions you perform on your data Takes inputs and produce outputs Pipelines Logical grouping of activities for group operations AZURE DATA FACTORY Relational and non-relational On-premises or cloud Hadoop (Hive, Pig, etc.) Data Lake Analytics Azure Machine Learning Stored Procedures Custom code Data Movement from Manage and monitor Data and operational lineage Coordination and scheduling Policy DATA PIPELINES Processing activity Information assets Raw data Compose services to transform data into actionable intelligence Orchestration and monitoring Processing activity LINKED SERVICES: Data processing Data Movement to
24 .ADF: Ingest / Data Movement On-Premises / Azure IaaS Sources SQL Server File System (NTFS) Oracle Database MySQL Database DB2 Database Teradata Database Sybase Database PostgreSQL Database ODBC data sources Hadoop Distributed File System (HDFS) On-Premises Sinks SQL Server File System (NTFS) Globally-deployed data movement as a service infrastructure with 11 locations Data Movement Gateway for hybrid, on premises to cloud data movement Cloud Sources Azure Blob Azure Table Azure SQL Database Azure SQL Data Warehouse Azure DocumentDB Azure Data Lake Store Cloud Sinks Azure Blob Azure Table Azure SQL Database Azure SQL Data Warehouse Azure DocumentDB Azure Data Lake Store
25 .Many tools available to ingest data to ADLS Use generic Azure tools e.g. PowerShell Use Open Source tools e.g. DistCP Use rich special purpose tools e.g. Azure Data Factory Create your own tools Pick the tool that meets your scenario requirements Data type, sources, and location Encoding / compression Security Performance Operations: ad hoc vs. operational (schedule, event driven etc.) Cost Ingestion - Summary
26 .Data Ingestion: Patterns
27 .Data Migration Scenarios : Move on-premise HDFS to ADLS Move on-premise RMDBS to ADLS Move S3 data to ADLS Solution : Compatibility check: can all the items in the source be represented in the target Move objects: files, tables, views, triggers, configurations, etc. 1-time bulk move data from source to destination Run a delta-flow from source to destination so the destination keeps up-to-date with the source Move apps, flows, etc. to target the destination system & stop the delta flows in lock step Decommission the source storage system Tools : Sqoop , Azcopy , ADF
28 .Global retailer moving decision support system to the Cloud Ingestion Requirement Data is streamed from enterprise data sources into an On Prem HDFS setup; 100s of TB in size Data is then uploaded to ADLS Don’t install software on-premise Solution Uploading data in bulk in two steps. First to WAS using AzCopy and then to ADLS using ADF Consideration Not creating new tools Ease of use
29 .ON PREMISES CLOUD Relational DB On Prem HDFS Active Incoming Data Azure DW CONSUMPTION Web Portals Power BI Data cleansing Data analysis Data Migration: for a global retailer Azure Data Factory
3秒后跳转登录页面
去登陆

