什么是业务逻辑
分享
点赞
1
收藏
0
下载 6
-
快召唤伙伴们来围观吧
-
微博
QQ
QQ空间
贴吧
-
文档嵌入链接
- 复制
-
-
微信扫一扫分享
-
已成功复制到剪贴板
关注开发人员和架构师在完成不同系统中的问题解决和经验实战, ... 本质:DRDS的后端不是真正意义上的分布式数据库,而是关系型数据的分布式处理,它是介于 ... 分布式事务:单机→多机,网络延迟不可避免. 分布式锁. 分布式join:基于内存→ 基于网络 ... 我们没法同时获取分布式系统中所有节点的状态信息,这其中的罪魁祸首就是 ...
展开查看详情
1 .阿里技术嘉年华 - aDev 内容 感悟 占进冬 2013 年 7 月
3 .这 次杭州之行,干货确实 有,但很多时候自己没有切身体会或者 没有相同规 模 的应用场景可能很难产生共鸣。 对于我个人 来说启发的 价值大于实际应用的价值,有些抽象的东西不管 大系统还是小系统都是很有指导意义的。 这个分享内容主要是自己 在这次会议中感悟到 的一些东西并结合了大牛们的一些经验之谈,有不对的地方,欢迎批证。
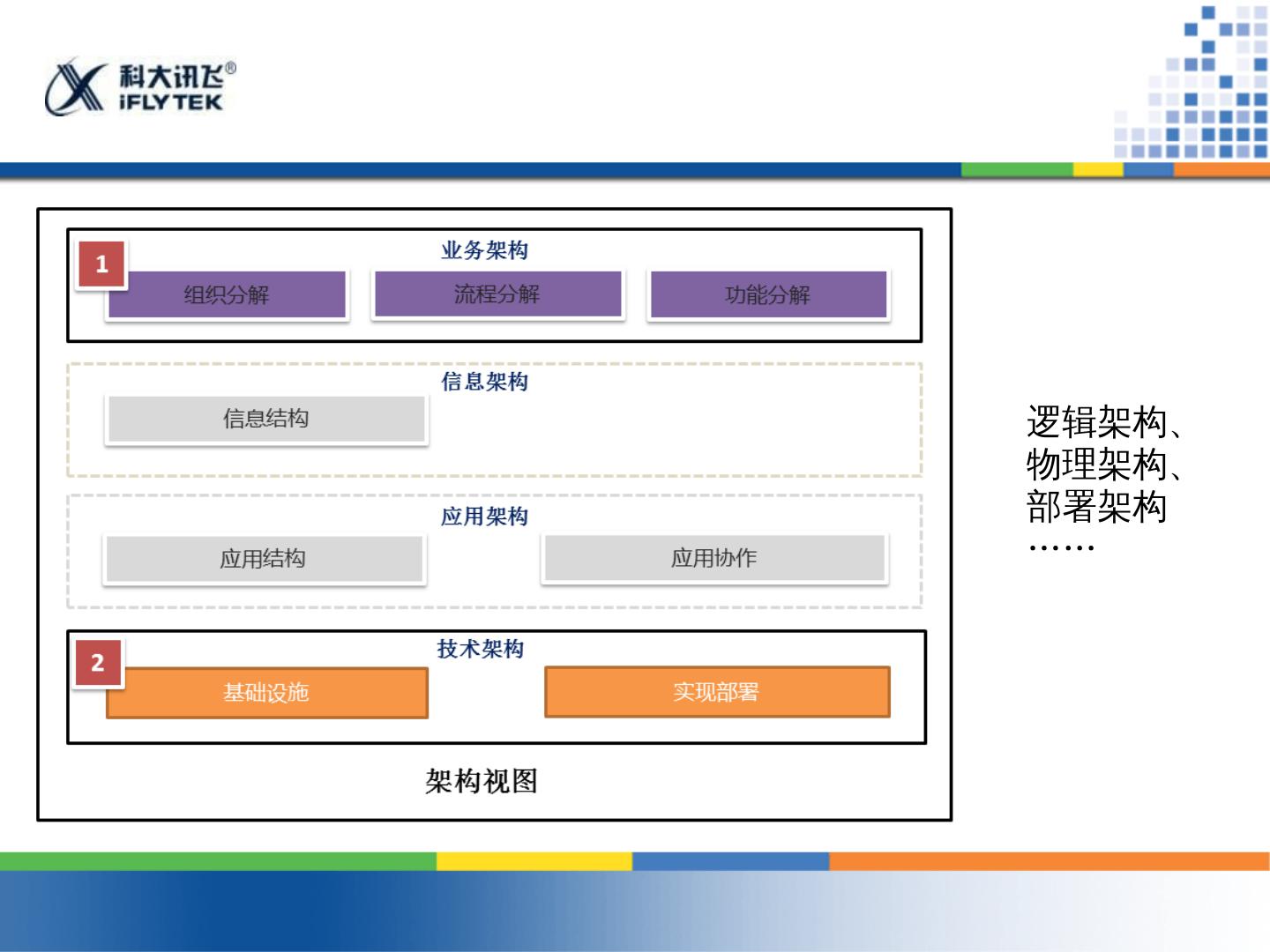
5 .“ aDev 由淘宝技术工程师自由发起的组织,主要关注 的后端 技术 。 关注开发人员和架构师在完成不同系统中的问题解决和经验实战, 以及 相关的技术趋势。 业务架构 & 后端技术 整个软件架构中,从不同的角度可以看到很多视图, aDev 主要关注的是 业务 架构 和 技术 架构, 之所以 说是后端技术,是因为在整个软件架构中,技术 架 构在 底层为上层业务架构所服务。
7 .淘宝业务和后端技术 宏观上 :整个淘宝的架构是业务 拆分,后端 技术共享。 微观 上 :具体到某个子业务上, 依然能得到业务拆分和技术架构 作为底层服务的类似的结构。 抽象 :某个技术架构依然可以 看成底层模块为上层模块服务 的结构。 再抽象 …… 什么是架构?
8 .架构 = 组件 + 交互 + 约束 架构 = 结构 + 结构 +…… 结构 = 组件 + 交互 + 约束
10 .对于业务逻辑的理解很多人仅 限于对 三 层架构中业务逻辑层的理解 => 仅仅 是对数据访问层的简单封装 。 原因是我们大多接触的三层架构都很简单,基本上都是对数据库的 CURD 操作,比如 OSSP 的 运营管理系统 业务逻辑 = 三层架构中的业务逻辑层
11 .分层的目的:为了 分离 和 复用 。 领域逻辑 :业务逻辑也叫领域逻辑,每个人站的领域不同,看到的业务逻辑的范围 自然 不相同。这既跟软件客体有关系,也和架构师主体有关系,因此同样一个软件不同的人分层也不同。 对于甲来说,从软件 1 和软件 2 中抽取公共部分之后,剩下的就是各个软件中的业务逻辑了。 而对于乙来说,从软件 1 和软件 2 中没有抽象出任何公共部分,那么设计出来的软件架构可想而知:必然将业务逻辑穿插于软件的各层。
12 .个人理解 : 以 某个领域的视角, 将 一个软件中所有可以复用的部分抽象出来,那么剩下的就是业务逻辑。大部分都能做到将数据访问和界面展示抽出来,所以有了三层架构。 具体例子 :比如 VAServer 和 VAClientServer 将请求信源也独立成一个 Source.jar 包可以复用,那么对于 VAServer 和 VAClientServer 来说剩下的 BLL 就是各自业务逻辑了。 如果站的更高一点来看 OSSP 接口和灵犀业务服务器,那么 Source.jar 其实也是属于业务逻辑了。 但是 OSSP 接口和灵犀业务服务器的数据访问层理论上依然是可以抽象出来的,再比如配置也是可以抽出来的。
13 .检验 : 一个 检验程序是否将业务逻辑分离出来的方法很简单:让别人复用你抽象出来的组件。
16 .DRDS 是阿里巴巴即将对外发布的云服务,阿里目前已经提供关系数据库服务 RDS ( http://www.aliyun.com/product/rds/ ) 好处: 通过阿里分布式数据库服务,可以将一张表中的数据映射到不同的物理数据库服务器上,从而给数据库带来弹性扩展能力。从大处讲,使用了阿里分布式数据库服务你就拥有了一个海量数据库,不用担心数据库物理服务器的计算能力跟不上;从小处讲,在开发中你不用再纠结于如何进行表拆分 。 同时可以在线数据迁移(全量复制 + 增量复制) 本质: DRDS 的后端不是真正意义上的分布式数据库,而是关系型数据的分布式处理,它是介于应用程序与关系型数据库之间的中间件。
17 .限制 : 分布式 事务:单机→多机,网络延迟不可避免 分布式 锁 分布式 join :基于内存 → 基于网络 分布式 索引:保证一致性、实时更新索引 分布式分页 ……
18 .这些限制很多都是相互依赖的,本质上都是一个问题。我们没法同时获取分布式系统中所有节点的状态信息,这其中的罪魁祸首就是 网络延迟 ,节点之间距离越远,延迟也就越大 。 分布式的一个原则:“ 不要分布式 ”,两层意思: 1 )当我们的规模单机就可以搞定的时候完全没必要拆分; 2 )当不得以需要拆分后,尽可能利用单机的资源: ①尽可能走内存; ②一次性查询需要的数据要放到一台机器上(如:文章和文章的评论列表) ③合理的冗余:减少网络开销
19 .一些理论和思路 : 分布式事务 : 1 )两阶段提交协议:阻塞的 因为为了克服不可避免 的 网络 开销 保证在获取到所有节点的状态后再做出决策,这种 方式存在着很大的 代价: A 组织 B 、 C 和 D 三个人去爬长城:如果所有人都同意去爬长城,那么活动将举行;如果有一人不同意去爬长城,那么活动将取消 。 A 就是协调者( coordinator ), B 、 C 、 D 就是事务参与者( participants 、 workers ) → →参考备注
20 .二 阶段锁的改进和变种 : 协调者备份、超时机制→三阶段提交协议、 树形 2PC 协议(或称递归 2PC 协议)、动态 2 阶段提交协议( D2PC ) ……
21 .2 )基于消息通知的分布式事务:最终一致性的
22 .分布式锁 : ZooKeeper 分布式锁服务: http:// www.cnblogs.com/shanyou/archive/2012/09/22/2697818.html 分布式 join : 小表 广播 相同的切分条件:将同一个用户的数据放在一起 异构复制
23 .分布式 分页 : 写时有序(单机没问题),但多台机器一定会有热点 Map-Reduce :写时保证各个节点有序,上层做归并
27 .无处不在的缓存 c pu 中的 L1 Cache/L2 Cache 、 memmcahe 、 sqlserver 中的存储过程的预编译、 Aps.net 中页面输出缓存、浏览器中 css / js / img 资源的缓存 …… 从生活到技术、从 整体 到 局部 为什么需要缓存 因为从生活到技术的各个方面存在着不对等,不对等的计算能力,不对等的传输速率,不对等的成本 …… 缓存最关键 指标 命中率
28 .无处不在的队列 无处不在 的异步 无处不在的 超时 …… 所有这些,目的都是提高系统的鲁棒性和稳定性。