














- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
谷歌的全球分布式数据库
Spanner is Google’s scalable, multi-version, globallydistributed, and synchronously-replicated database. It is the first system to distribute data at global scale and support externally-consistent distributed transactions. This paper describes how Spanner is structured, its feature set, the rationale underlying various design decisions, and a novel time API that exposes clock uncertainty. This API and its implementation are critical to supporting external consistency and a variety of powerful features: nonblocking reads in the past, lock-free read-only transactions, and atomic schema changes, across all of Spanner.
展开查看详情
1 . Spanner: Google’s Globally-Distributed Database James C. Corbett, Jeffrey Dean, Michael Epstein, Andrew Fikes, Christopher Frost, JJ Furman, Sanjay Ghemawat, Andrey Gubarev, Christopher Heiser, Peter Hochschild, Wilson Hsieh, Sebastian Kanthak, Eugene Kogan, Hongyi Li, Alexander Lloyd, Sergey Melnik, David Mwaura, David Nagle, Sean Quinlan, Rajesh Rao, Lindsay Rolig, Yasushi Saito, Michal Szymaniak, Christopher Taylor, Ruth Wang, Dale Woodford Google, Inc. Abstract tency over higher availability, as long as they can survive 1 or 2 datacenter failures. Spanner is Google’s scalable, multi-version, globally- distributed, and synchronously-replicated database. It is Spanner’s main focus is managing cross-datacenter the first system to distribute data at global scale and sup- replicated data, but we have also spent a great deal of port externally-consistent distributed transactions. This time in designing and implementing important database paper describes how Spanner is structured, its feature set, features on top of our distributed-systems infrastructure. the rationale underlying various design decisions, and a Even though many projects happily use Bigtable [9], we novel time API that exposes clock uncertainty. This API have also consistently received complaints from users and its implementation are critical to supporting exter- that Bigtable can be difficult to use for some kinds of ap- nal consistency and a variety of powerful features: non- plications: those that have complex, evolving schemas, blocking reads in the past, lock-free read-only transac- or those that want strong consistency in the presence of tions, and atomic schema changes, across all of Spanner. wide-area replication. (Similar claims have been made by other authors [37].) Many applications at Google have chosen to use Megastore [5] because of its semi- 1 Introduction relational data model and support for synchronous repli- cation, despite its relatively poor write throughput. As a Spanner is a scalable, globally-distributed database de- consequence, Spanner has evolved from a Bigtable-like signed, built, and deployed at Google. At the high- versioned key-value store into a temporal multi-version est level of abstraction, it is a database that shards data database. Data is stored in schematized semi-relational across many sets of Paxos [21] state machines in data- tables; data is versioned, and each version is automati- centers spread all over the world. Replication is used for cally timestamped with its commit time; old versions of global availability and geographic locality; clients auto- data are subject to configurable garbage-collection poli- matically failover between replicas. Spanner automati- cies; and applications can read data at old timestamps. cally reshards data across machines as the amount of data Spanner supports general-purpose transactions, and pro- or the number of servers changes, and it automatically vides a SQL-based query language. migrates data across machines (even across datacenters) As a globally-distributed database, Spanner provides to balance load and in response to failures. Spanner is several interesting features. First, the replication con- designed to scale up to millions of machines across hun- figurations for data can be dynamically controlled at a dreds of datacenters and trillions of database rows. fine grain by applications. Applications can specify con- Applications can use Spanner for high availability, straints to control which datacenters contain which data, even in the face of wide-area natural disasters, by repli- how far data is from its users (to control read latency), cating their data within or even across continents. Our how far replicas are from each other (to control write la- initial customer was F1 [35], a rewrite of Google’s ad- tency), and how many replicas are maintained (to con- vertising backend. F1 uses five replicas spread across trol durability, availability, and read performance). Data the United States. Most other applications will probably can also be dynamically and transparently moved be- replicate their data across 3 to 5 datacenters in one ge- tween datacenters by the system to balance resource us- ographic region, but with relatively independent failure age across datacenters. Second, Spanner has two features modes. That is, most applications will choose lower la- that are difficult to implement in a distributed database: it Published in the Proceedings of OSDI 2012 1
2 .provides externally consistent [16] reads and writes, and globally-consistent reads across the database at a time- stamp. These features enable Spanner to support con- sistent backups, consistent MapReduce executions [12], and atomic schema updates, all at global scale, and even in the presence of ongoing transactions. These features are enabled by the fact that Spanner as- signs globally-meaningful commit timestamps to trans- actions, even though transactions may be distributed. The timestamps reflect serialization order. In addition, Figure 1: Spanner server organization. the serialization order satisfies external consistency (or equivalently, linearizability [20]): if a transaction T1 commits before another transaction T2 starts, then T1 ’s servers [9]. Zones are the unit of administrative deploy- commit timestamp is smaller than T2 ’s. Spanner is the ment. The set of zones is also the set of locations across first system to provide such guarantees at global scale. which data can be replicated. Zones can be added to or The key enabler of these properties is a new TrueTime removed from a running system as new datacenters are API and its implementation. The API directly exposes brought into service and old ones are turned off, respec- clock uncertainty, and the guarantees on Spanner’s times- tively. Zones are also the unit of physical isolation: there tamps depend on the bounds that the implementation pro- may be one or more zones in a datacenter, for example, vides. If the uncertainty is large, Spanner slows down to if different applications’ data must be partitioned across wait out that uncertainty. Google’s cluster-management different sets of servers in the same datacenter. software provides an implementation of the TrueTime Figure 1 illustrates the servers in a Spanner universe. API. This implementation keeps uncertainty small (gen- A zone has one zonemaster and between one hundred erally less than 10ms) by using multiple modern clock and several thousand spanservers. The former assigns references (GPS and atomic clocks). data to spanservers; the latter serve data to clients. The Section 2 describes the structure of Spanner’s imple- per-zone location proxies are used by clients to locate mentation, its feature set, and the engineering decisions the spanservers assigned to serve their data. The uni- that went into their design. Section 3 describes our new verse master and the placement driver are currently sin- TrueTime API and sketches its implementation. Sec- gletons. The universe master is primarily a console that tion 4 describes how Spanner uses TrueTime to imple- displays status information about all the zones for inter- ment externally-consistent distributed transactions, lock- active debugging. The placement driver handles auto- free read-only transactions, and atomic schema updates. mated movement of data across zones on the timescale Section 5 provides some benchmarks on Spanner’s per- of minutes. The placement driver periodically commu- formance and TrueTime behavior, and discusses the ex- nicates with the spanservers to find data that needs to be periences of F1. Sections 6, 7, and 8 describe related and moved, either to meet updated replication constraints or future work, and summarize our conclusions. to balance load. For space reasons, we will only describe the spanserver in any detail. 2 Implementation 2.1 Spanserver Software Stack This section describes the structure of and rationale un- This section focuses on the spanserver implementation derlying Spanner’s implementation. It then describes the to illustrate how replication and distributed transactions directory abstraction, which is used to manage replica- have been layered onto our Bigtable-based implementa- tion and locality, and is the unit of data movement. Fi- tion. The software stack is shown in Figure 2. At the nally, it describes our data model, why Spanner looks bottom, each spanserver is responsible for between 100 like a relational database instead of a key-value store, and and 1000 instances of a data structure called a tablet. A how applications can control data locality. tablet is similar to Bigtable’s tablet abstraction, in that it A Spanner deployment is called a universe. Given implements a bag of the following mappings: that Spanner manages data globally, there will be only a handful of running universes. We currently run a (key:string, timestamp:int64) → string test/playground universe, a development/production uni- verse, and a production-only universe. Unlike Bigtable, Spanner assigns timestamps to data, Spanner is organized as a set of zones, where each which is an important way in which Spanner is more zone is the rough analog of a deployment of Bigtable like a multi-version database than a key-value store. A Published in the Proceedings of OSDI 2012 2
3 . Figure 3: Directories are the unit of data movement between Paxos groups. that require synchronization, such as transactional reads, acquire locks in the lock table; other operations bypass the lock table. Figure 2: Spanserver software stack. At every replica that is a leader, each spanserver also implements a transaction manager to support distributed tablet’s state is stored in set of B-tree-like files and a transactions. The transaction manager is used to imple- write-ahead log, all on a distributed file system called ment a participant leader; the other replicas in the group Colossus (the successor to the Google File System [15]). will be referred to as participant slaves. If a transac- tion involves only one Paxos group (as is the case for To support replication, each spanserver implements a most transactions), it can bypass the transaction manager, single Paxos state machine on top of each tablet. (An since the lock table and Paxos together provide transac- early Spanner incarnation supported multiple Paxos state tionality. If a transaction involves more than one Paxos machines per tablet, which allowed for more flexible group, those groups’ leaders coordinate to perform two- replication configurations. The complexity of that de- phase commit. One of the participant groups is chosen as sign led us to abandon it.) Each state machine stores the coordinator: the participant leader of that group will its metadata and log in its corresponding tablet. Our be referred to as the coordinator leader, and the slaves of Paxos implementation supports long-lived leaders with that group as coordinator slaves. The state of each trans- time-based leader leases, whose length defaults to 10 action manager is stored in the underlying Paxos group seconds. The current Spanner implementation logs ev- (and therefore is replicated). ery Paxos write twice: once in the tablet’s log, and once in the Paxos log. This choice was made out of expedi- ency, and we are likely to remedy this eventually. Our 2.2 Directories and Placement implementation of Paxos is pipelined, so as to improve Spanner’s throughput in the presence of WAN latencies; On top of the bag of key-value mappings, the Spanner but writes are applied by Paxos in order (a fact on which implementation supports a bucketing abstraction called a we will depend in Section 4). directory, which is a set of contiguous keys that share a The Paxos state machines are used to implement a common prefix. (The choice of the term directory is a consistently replicated bag of mappings. The key-value historical accident; a better term might be bucket.) We mapping state of each replica is stored in its correspond- will explain the source of that prefix in Section 2.3. Sup- ing tablet. Writes must initiate the Paxos protocol at the porting directories allows applications to control the lo- leader; reads access state directly from the underlying cality of their data by choosing keys carefully. tablet at any replica that is sufficiently up-to-date. The A directory is the unit of data placement. All data in set of replicas is collectively a Paxos group. a directory has the same replication configuration. When At every replica that is a leader, each spanserver im- data is moved between Paxos groups, it is moved direc- plements a lock table to implement concurrency control. tory by directory, as shown in Figure 3. Spanner might The lock table contains the state for two-phase lock- move a directory to shed load from a Paxos group; to put ing: it maps ranges of keys to lock states. (Note that directories that are frequently accessed together into the having a long-lived Paxos leader is critical to efficiently same group; or to move a directory into a group that is managing the lock table.) In both Bigtable and Span- closer to its accessors. Directories can be moved while ner, we designed for long-lived transactions (for exam- client operations are ongoing. One could expect that a ple, for report generation, which might take on the order 50MB directory can be moved in a few seconds. of minutes), which perform poorly under optimistic con- The fact that a Paxos group may contain multiple di- currency control in the presence of conflicts. Operations rectories implies that a Spanner tablet is different from Published in the Proceedings of OSDI 2012 3
4 .a Bigtable tablet: the former is not necessarily a single age than Bigtable’s, and because of its support for syn- lexicographically contiguous partition of the row space. chronous replication across datacenters. (Bigtable only Instead, a Spanner tablet is a container that may encap- supports eventually-consistent replication across data- sulate multiple partitions of the row space. We made this centers.) Examples of well-known Google applications decision so that it would be possible to colocate multiple that use Megastore are Gmail, Picasa, Calendar, Android directories that are frequently accessed together. Market, and AppEngine. The need to support a SQL- Movedir is the background task used to move direc- like query language in Spanner was also clear, given tories between Paxos groups [14]. Movedir is also used the popularity of Dremel [28] as an interactive data- to add or remove replicas to Paxos groups [25], be- analysis tool. Finally, the lack of cross-row transactions cause Spanner does not yet support in-Paxos configura- in Bigtable led to frequent complaints; Percolator [32] tion changes. Movedir is not implemented as a single was in part built to address this failing. Some authors transaction, so as to avoid blocking ongoing reads and have claimed that general two-phase commit is too ex- writes on a bulky data move. Instead, movedir registers pensive to support, because of the performance or avail- the fact that it is starting to move data and moves the data ability problems that it brings [9, 10, 19]. We believe it in the background. When it has moved all but a nominal is better to have application programmers deal with per- amount of the data, it uses a transaction to atomically formance problems due to overuse of transactions as bot- move that nominal amount and update the metadata for tlenecks arise, rather than always coding around the lack the two Paxos groups. of transactions. Running two-phase commit over Paxos A directory is also the smallest unit whose geographic- mitigates the availability problems. replication properties (or placement, for short) can The application data model is layered on top of the be specified by an application. The design of our directory-bucketed key-value mappings supported by the placement-specification language separates responsibil- implementation. An application creates one or more ities for managing replication configurations. Adminis- databases in a universe. Each database can contain an trators control two dimensions: the number and types of unlimited number of schematized tables. Tables look replicas, and the geographic placement of those replicas. like relational-database tables, with rows, columns, and They create a menu of named options in these two di- versioned values. We will not go into detail about the mensions (e.g., North America, replicated 5 ways with query language for Spanner. It looks like SQL with some 1 witness). An application controls how data is repli- extensions to support protocol-buffer-valued fields. cated, by tagging each database and/or individual direc- Spanner’s data model is not purely relational, in that tories with a combination of those options. For example, rows must have names. More precisely, every table is re- an application might store each end-user’s data in its own quired to have an ordered set of one or more primary-key directory, which would enable user A’s data to have three columns. This requirement is where Spanner still looks replicas in Europe, and user B’s data to have five replicas like a key-value store: the primary keys form the name in North America. for a row, and each table defines a mapping from the For expository clarity we have over-simplified. In fact, primary-key columns to the non-primary-key columns. Spanner will shard a directory into multiple fragments A row has existence only if some value (even if it is if it grows too large. Fragments may be served from NULL) is defined for the row’s keys. Imposing this struc- different Paxos groups (and therefore different servers). ture is useful because it lets applications control data lo- Movedir actually moves fragments, and not whole direc- cality through their choices of keys. tories, between groups. Figure 4 contains an example Spanner schema for stor- ing photo metadata on a per-user, per-album basis. The 2.3 Data Model schema language is similar to Megastore’s, with the ad- ditional requirement that every Spanner database must Spanner exposes the following set of data features be partitioned by clients into one or more hierarchies to applications: a data model based on schematized of tables. Client applications declare the hierarchies in semi-relational tables, a query language, and general- database schemas via the INTERLEAVE IN declara- purpose transactions. The move towards support- tions. The table at the top of a hierarchy is a directory ing these features was driven by many factors. The table. Each row in a directory table with key K, together need to support schematized semi-relational tables and with all of the rows in descendant tables that start with K synchronous replication is supported by the popular- in lexicographic order, forms a directory. ON DELETE ity of Megastore [5]. At least 300 applications within CASCADE says that deleting a row in the directory table Google use Megastore (despite its relatively low per- deletes any associated child rows. The figure also illus- formance) because its data model is simpler to man- trates the interleaved layout for the example database: for Published in the Proceedings of OSDI 2012 4
5 .CREATE TABLE Users { uid INT64 NOT NULL, email STRING Denote the absolute time of an event e by the func- } PRIMARY KEY (uid), DIRECTORY; tion tabs (e). In more formal terms, TrueTime guaran- tees that for an invocation tt = TT.now(), tt.earliest ≤ CREATE TABLE Albums { tabs (enow ) ≤ tt.latest, where enow is the invocation event. uid INT64 NOT NULL, aid INT64 NOT NULL, name STRING The underlying time references used by TrueTime } PRIMARY KEY (uid, aid), are GPS and atomic clocks. TrueTime uses two forms INTERLEAVE IN PARENT Users ON DELETE CASCADE; of time reference because they have different failure modes. GPS reference-source vulnerabilities include an- tenna and receiver failures, local radio interference, cor- related failures (e.g., design faults such as incorrect leap- second handling and spoofing), and GPS system outages. Atomic clocks can fail in ways uncorrelated to GPS and each other, and over long periods of time can drift signif- icantly due to frequency error. Figure 4: Example Spanner schema for photo metadata, and TrueTime is implemented by a set of time master ma- the interleaving implied by INTERLEAVE IN. chines per datacenter and a timeslave daemon per ma- chine. The majority of masters have GPS receivers with dedicated antennas; these masters are separated physi- example, Albums(2,1) represents the row from the cally to reduce the effects of antenna failures, radio in- Albums table for user id 2, album id 1. This terference, and spoofing. The remaining masters (which interleaving of tables to form directories is significant we refer to as Armageddon masters) are equipped with because it allows clients to describe the locality relation- atomic clocks. An atomic clock is not that expensive: ships that exist between multiple tables, which is nec- the cost of an Armageddon master is of the same order essary for good performance in a sharded, distributed as that of a GPS master. All masters’ time references database. Without it, Spanner would not know the most are regularly compared against each other. Each mas- important locality relationships. ter also cross-checks the rate at which its reference ad- vances time against its own local clock, and evicts itself if there is substantial divergence. Between synchroniza- 3 TrueTime tions, Armageddon masters advertise a slowly increasing time uncertainty that is derived from conservatively ap- Method Returns plied worst-case clock drift. GPS masters advertise un- TT.now() TTinterval: [earliest, latest] certainty that is typically close to zero. TT.after(t) true if t has definitely passed Every daemon polls a variety of masters [29] to re- TT.before(t) true if t has definitely not arrived duce vulnerability to errors from any one master. Some are GPS masters chosen from nearby datacenters; the Table 1: TrueTime API. The argument t is of type TTstamp. rest are GPS masters from farther datacenters, as well as some Armageddon masters. Daemons apply a variant This section describes the TrueTime API and sketches of Marzullo’s algorithm [27] to detect and reject liars, its implementation. We leave most of the details for an- and synchronize the local machine clocks to the non- other paper: our goal is to demonstrate the power of liars. To protect against broken local clocks, machines having such an API. Table 1 lists the methods of the that exhibit frequency excursions larger than the worst- API. TrueTime explicitly represents time as a TTinterval, case bound derived from component specifications and which is an interval with bounded time uncertainty (un- operating environment are evicted. like standard time interfaces that give clients no notion Between synchronizations, a daemon advertises a of uncertainty). The endpoints of a TTinterval are of slowly increasing time uncertainty. is derived from type TTstamp. The TT.now() method returns a TTinterval conservatively applied worst-case local clock drift. also that is guaranteed to contain the absolute time during depends on time-master uncertainty and communication which TT.now() was invoked. The time epoch is anal- delay to the time masters. In our production environ- ogous to UNIX time with leap-second smearing. De- ment, is typically a sawtooth function of time, varying fine the instantaneous error bound as , which is half of from about 1 to 7 ms over each poll interval. is there- the interval’s width, and the average error bound as . fore 4 ms most of the time. The daemon’s poll interval is The TT.after() and TT.before() methods are convenience currently 30 seconds, and the current applied drift rate is wrappers around TT.now(). set at 200 microseconds/second, which together account Published in the Proceedings of OSDI 2012 5
6 . Timestamp Concurrency Operation Discussion Control Replica Required Read-Write Transaction § 4.1.2 pessimistic leader leader for timestamp; any for Read-Only Transaction § 4.1.4 lock-free read, subject to § 4.1.3 Snapshot Read, client-provided timestamp — lock-free any, subject to § 4.1.3 Snapshot Read, client-provided bound § 4.1.3 lock-free any, subject to § 4.1.3 Table 2: Types of reads and writes in Spanner, and how they compare. for the sawtooth bounds from 0 to 6 ms. The remain- the reads in a read-only transaction can proceed on any ing 1 ms comes from the communication delay to the replica that is sufficiently up-to-date (Section 4.1.3). time masters. Excursions from this sawtooth are possi- A snapshot read is a read in the past that executes with- ble in the presence of failures. For example, occasional out locking. A client can either specify a timestamp for a time-master unavailability can cause datacenter-wide in- snapshot read, or provide an upper bound on the desired creases in . Similarly, overloaded machines and network timestamp’s staleness and let Spanner choose a time- links can result in occasional localized spikes. stamp. In either case, the execution of a snapshot read proceeds at any replica that is sufficiently up-to-date. For both read-only transactions and snapshot reads, 4 Concurrency Control commit is inevitable once a timestamp has been cho- This section describes how TrueTime is used to guaran- sen, unless the data at that timestamp has been garbage- tee the correctness properties around concurrency con- collected. As a result, clients can avoid buffering results trol, and how those properties are used to implement inside a retry loop. When a server fails, clients can inter- features such as externally consistent transactions, lock- nally continue the query on a different server by repeat- free read-only transactions, and non-blocking reads in ing the timestamp and the current read position. the past. These features enable, for example, the guar- antee that a whole-database audit read at a timestamp t 4.1.1 Paxos Leader Leases will see exactly the effects of every transaction that has Spanner’s Paxos implementation uses timed leases to committed as of t. make leadership long-lived (10 seconds by default). A Going forward, it will be important to distinguish potential leader sends requests for timed lease votes; writes as seen by Paxos (which we will refer to as Paxos upon receiving a quorum of lease votes the leader knows writes unless the context is clear) from Spanner client it has a lease. A replica extends its lease vote implicitly writes. For example, two-phase commit generates a on a successful write, and the leader requests lease-vote Paxos write for the prepare phase that has no correspond- extensions if they are near expiration. Define a leader’s ing Spanner client write. lease interval as starting when it discovers it has a quo- rum of lease votes, and as ending when it no longer has 4.1 Timestamp Management a quorum of lease votes (because some have expired). Spanner depends on the following disjointness invariant: Table 2 lists the types of operations that Spanner sup- for each Paxos group, each Paxos leader’s lease interval ports. The Spanner implementation supports read- is disjoint from every other leader’s. Appendix A de- write transactions, read-only transactions (predeclared scribes how this invariant is enforced. snapshot-isolation transactions), and snapshot reads. The Spanner implementation permits a Paxos leader Standalone writes are implemented as read-write trans- to abdicate by releasing its slaves from their lease votes. actions; non-snapshot standalone reads are implemented To preserve the disjointness invariant, Spanner constrains as read-only transactions. Both are internally retried when abdication is permissible. Define smax to be the (clients need not write their own retry loops). maximum timestamp used by a leader. Subsequent sec- A read-only transaction is a kind of transaction that tions will describe when smax is advanced. Before abdi- has the performance benefits of snapshot isolation [6]. cating, a leader must wait until TT.after(smax ) is true. A read-only transaction must be predeclared as not hav- ing any writes; it is not simply a read-write transaction 4.1.2 Assigning Timestamps to RW Transactions without any writes. Reads in a read-only transaction ex- ecute at a system-chosen timestamp without locking, so Transactional reads and writes use two-phase locking. that incoming writes are not blocked. The execution of As a result, they can be assigned timestamps at any time Published in the Proceedings of OSDI 2012 6
7 .when all locks have been acquired, but before any locks maximum timestamp at which a replica is up-to-date. A have been released. For a given transaction, Spanner as- replica can satisfy a read at a timestamp t if t <= tsafe . signs it the timestamp that Paxos assigns to the Paxos Define tsafe = min(tPaxos TM safe , tsafe ), where each Paxos write that represents the transaction commit. state machine has a safe time tPaxos safe and each transac- Spanner depends on the following monotonicity in- tion manager has a safe time tsafe . tPaxos TM safe is simpler: it variant: within each Paxos group, Spanner assigns times- is the timestamp of the highest-applied Paxos write. Be- tamps to Paxos writes in monotonically increasing or- cause timestamps increase monotonically and writes are der, even across leaders. A single leader replica can triv- applied in order, writes will no longer occur at or below ially assign timestamps in monotonically increasing or- tPaxos safe with respect to Paxos. der. This invariant is enforced across leaders by making tTM safe is ∞ at a replica if there are zero prepared (but use of the disjointness invariant: a leader must only as- not committed) transactions—that is, transactions in be- sign timestamps within the interval of its leader lease. tween the two phases of two-phase commit. (For a par- Note that whenever a timestamp s is assigned, smax is ticipant slave, tTM safe actually refers to the replica’s leader’s advanced to s to preserve disjointness. transaction manager, whose state the slave can infer Spanner also enforces the following external- through metadata passed on Paxos writes.) If there are consistency invariant: if the start of a transaction T2 any such transactions, then the state affected by those occurs after the commit of a transaction T1 , then the transactions is indeterminate: a participant replica does commit timestamp of T2 must be greater than the not know yet whether such transactions will commit. As commit timestamp of T1 . Define the start and commit we discuss in Section 4.2.1, the commit protocol ensures events for a transaction Ti by estarti and ecommit i ; and that every participant knows a lower bound on a pre- the commit timestamp of a transaction Ti by si . The pared transaction’s timestamp. Every participant leader invariant becomes tabs (ecommit 1 ) < tabs (estart 2 ) ⇒ s1 < s2 . (for a group g) for a transaction Ti assigns a prepare The protocol for executing transactions and assigning timestamp sprepare i,g to its prepare record. The coordinator timestamps obeys two rules, which together guarantee leader ensures that the transaction’s commit timestamp this invariant, as shown below. Define the arrival event si >= sprepare i,g over all participant groups g. Therefore, of the commit request at the coordinator leader for a for every replica in a group g, over all transactions Ti pre- write Ti to be eserver . prepare i pared at g, tTM safe = mini (si,g ) − 1 over all transactions Start The coordinator leader for a write Ti assigns prepared at g. a commit timestamp si no less than the value of TT.now().latest, computed after eserver i . Note that the participant leaders do not matter here; Section 4.2.1 de- 4.1.4 Assigning Timestamps to RO Transactions scribes how they are involved in the implementation of A read-only transaction executes in two phases: assign the next rule. a timestamp sread [8], and then execute the transaction’s Commit Wait The coordinator leader ensures that reads as snapshot reads at sread . The snapshot reads can clients cannot see any data committed by Ti until execute at any replicas that are sufficiently up-to-date. TT.after(si ) is true. Commit wait ensures that si is The simple assignment of sread = TT.now().latest, at less than the absolute commit time of Ti , or si < any time after a transaction starts, preserves external con- tabs (ecommit i ). The implementation of commit wait is de- sistency by an argument analogous to that presented for scribed in Section 4.2.1. Proof: writes in Section 4.1.2. However, such a timestamp may s1 < tabs (ecommit 1 ) (commit wait) require the execution of the data reads at sread to block tabs (ecommit ) < tabs (estart if tsafe has not advanced sufficiently. (In addition, note 1 2 ) (assumption) start that choosing a value of sread may also advance smax to tabs (e2 ) ≤ tabs (eserver 2 ) (causality) preserve disjointness.) To reduce the chances of block- tabs (eserver 2 ) ≤ s2 (start) ing, Spanner should assign the oldest timestamp that pre- s1 < s2 (transitivity) serves external consistency. Section 4.2.2 explains how such a timestamp can be chosen. 4.1.3 Serving Reads at a Timestamp 4.2 Details The monotonicity invariant described in Section 4.1.2 al- This section explains some of the practical details of lows Spanner to correctly determine whether a replica’s read-write transactions and read-only transactions elided state is sufficiently up-to-date to satisfy a read. Every earlier, as well as the implementation of a special trans- replica tracks a value called safe time tsafe which is the action type used to implement atomic schema changes. Published in the Proceedings of OSDI 2012 7
8 .It then describes some refinements of the basic schemes 4.2.2 Read-Only Transactions as described. Assigning a timestamp requires a negotiation phase be- 4.2.1 Read-Write Transactions tween all of the Paxos groups that are involved in the reads. As a result, Spanner requires a scope expression Like Bigtable, writes that occur in a transaction are for every read-only transaction, which is an expression buffered at the client until commit. As a result, reads that summarizes the keys that will be read by the entire in a transaction do not see the effects of the transaction’s transaction. Spanner automatically infers the scope for writes. This design works well in Spanner because a read standalone queries. returns the timestamps of any data read, and uncommit- If the scope’s values are served by a single Paxos ted writes have not yet been assigned timestamps. group, then the client issues the read-only transaction to Reads within read-write transactions use wound- that group’s leader. (The current Spanner implementa- wait [33] to avoid deadlocks. The client issues reads tion only chooses a timestamp for a read-only transac- to the leader replica of the appropriate group, which tion at a Paxos leader.) That leader assigns sread and ex- acquires read locks and then reads the most recent ecutes the read. For a single-site read, Spanner gener- data. While a client transaction remains open, it sends ally does better than TT.now().latest. Define LastTS() to keepalive messages to prevent participant leaders from be the timestamp of the last committed write at a Paxos timing out its transaction. When a client has completed group. If there are no prepared transactions, the assign- all reads and buffered all writes, it begins two-phase ment sread = LastTS() trivially satisfies external consis- commit. The client chooses a coordinator group and tency: the transaction will see the result of the last write, sends a commit message to each participant’s leader with and therefore be ordered after it. the identity of the coordinator and any buffered writes. If the scope’s values are served by multiple Paxos Having the client drive two-phase commit avoids send- groups, there are several options. The most complicated ing data twice across wide-area links. option is to do a round of communication with all of A non-coordinator-participant leader first acquires the groups’s leaders to negotiate sread based on LastTS(). write locks. It then chooses a prepare timestamp that Spanner currently implements a simpler choice. The must be larger than any timestamps it has assigned to pre- client avoids a negotiation round, and just has its reads vious transactions (to preserve monotonicity), and logs a execute at sread = TT.now().latest (which may wait for prepare record through Paxos. Each participant then no- safe time to advance). All reads in the transaction can be tifies the coordinator of its prepare timestamp. sent to replicas that are sufficiently up-to-date. The coordinator leader also first acquires write locks, but skips the prepare phase. It chooses a timestamp for the entire transaction after hearing from all other partici- pant leaders. The commit timestamp s must be greater or 4.2.3 Schema-Change Transactions equal to all prepare timestamps (to satisfy the constraints discussed in Section 4.1.3), greater than TT.now().latest TrueTime enables Spanner to support atomic schema at the time the coordinator received its commit message, changes. It would be infeasible to use a standard transac- and greater than any timestamps the leader has assigned tion, because the number of participants (the number of to previous transactions (again, to preserve monotonic- groups in a database) could be in the millions. Bigtable ity). The coordinator leader then logs a commit record supports atomic schema changes in one datacenter, but through Paxos (or an abort if it timed out while waiting its schema changes block all operations. on the other participants). A Spanner schema-change transaction is a generally Before allowing any coordinator replica to apply non-blocking variant of a standard transaction. First, it the commit record, the coordinator leader waits until is explicitly assigned a timestamp in the future, which TT.after(s), so as to obey the commit-wait rule described is registered in the prepare phase. As a result, schema in Section 4.1.2. Because the coordinator leader chose s changes across thousands of servers can complete with based on TT.now().latest, and now waits until that time- minimal disruption to other concurrent activity. Sec- stamp is guaranteed to be in the past, the expected wait ond, reads and writes, which implicitly depend on the is at least 2 ∗ . This wait is typically overlapped with schema, synchronize with any registered schema-change Paxos communication. After commit wait, the coordi- timestamp at time t: they may proceed if their times- nator sends the commit timestamp to the client and all tamps precede t, but they must block behind the schema- other participant leaders. Each participant leader logs the change transaction if their timestamps are after t. With- transaction’s outcome through Paxos. All participants out TrueTime, defining the schema change to happen at t apply at the same timestamp and then release locks. would be meaningless. Published in the Proceedings of OSDI 2012 8
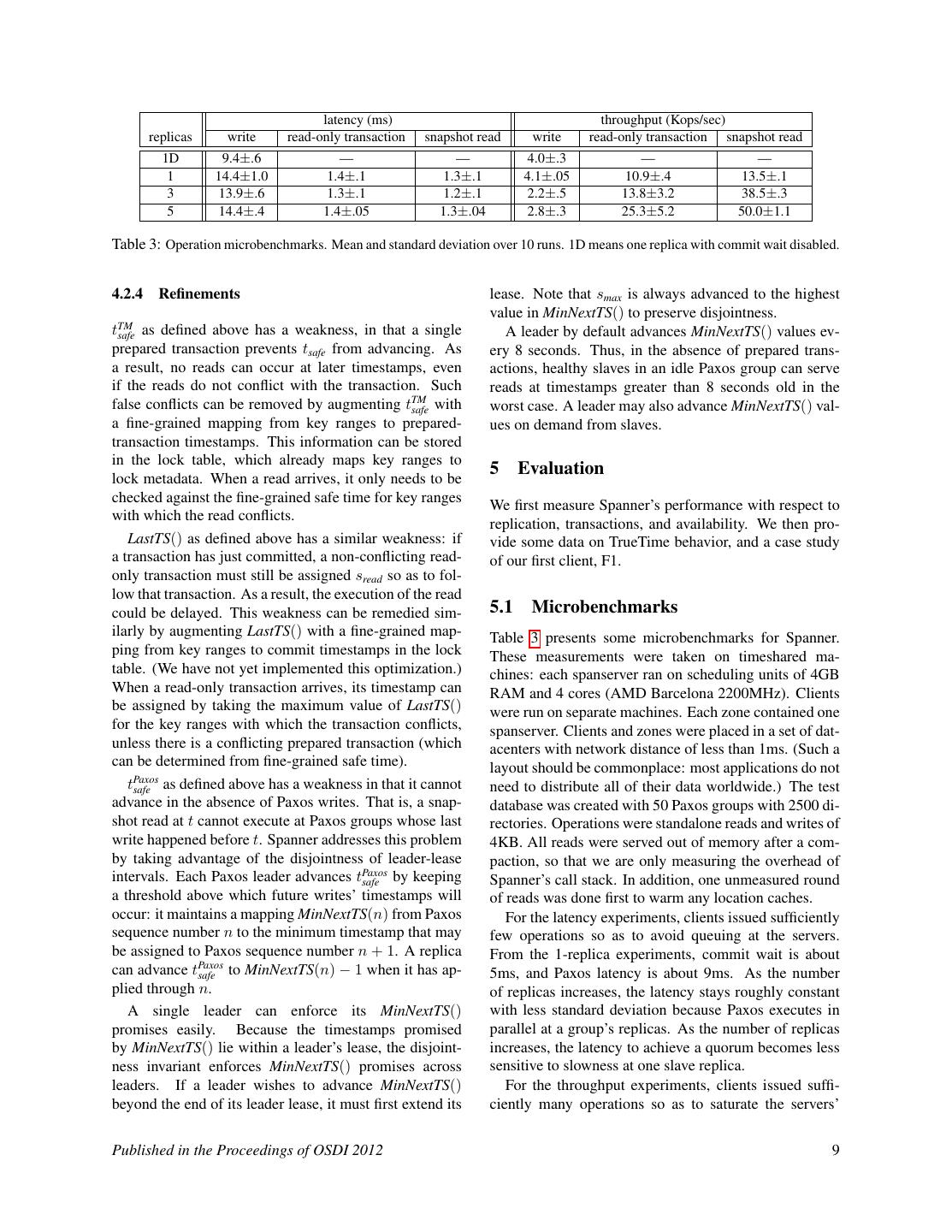
9 . latency (ms) throughput (Kops/sec) replicas write read-only transaction snapshot read write read-only transaction snapshot read 1D 9.4±.6 — — 4.0±.3 — — 1 14.4±1.0 1.4±.1 1.3±.1 4.1±.05 10.9±.4 13.5±.1 3 13.9±.6 1.3±.1 1.2±.1 2.2±.5 13.8±3.2 38.5±.3 5 14.4±.4 1.4±.05 1.3±.04 2.8±.3 25.3±5.2 50.0±1.1 Table 3: Operation microbenchmarks. Mean and standard deviation over 10 runs. 1D means one replica with commit wait disabled. 4.2.4 Refinements lease. Note that smax is always advanced to the highest value in MinNextTS() to preserve disjointness. tTM safe as defined above has a weakness, in that a single A leader by default advances MinNextTS() values ev- prepared transaction prevents tsafe from advancing. As ery 8 seconds. Thus, in the absence of prepared trans- a result, no reads can occur at later timestamps, even actions, healthy slaves in an idle Paxos group can serve if the reads do not conflict with the transaction. Such reads at timestamps greater than 8 seconds old in the false conflicts can be removed by augmenting tTM safe with worst case. A leader may also advance MinNextTS() val- a fine-grained mapping from key ranges to prepared- ues on demand from slaves. transaction timestamps. This information can be stored in the lock table, which already maps key ranges to lock metadata. When a read arrives, it only needs to be 5 Evaluation checked against the fine-grained safe time for key ranges We first measure Spanner’s performance with respect to with which the read conflicts. replication, transactions, and availability. We then pro- LastTS() as defined above has a similar weakness: if vide some data on TrueTime behavior, and a case study a transaction has just committed, a non-conflicting read- of our first client, F1. only transaction must still be assigned sread so as to fol- low that transaction. As a result, the execution of the read could be delayed. This weakness can be remedied sim- 5.1 Microbenchmarks ilarly by augmenting LastTS() with a fine-grained map- Table 3 presents some microbenchmarks for Spanner. ping from key ranges to commit timestamps in the lock These measurements were taken on timeshared ma- table. (We have not yet implemented this optimization.) chines: each spanserver ran on scheduling units of 4GB When a read-only transaction arrives, its timestamp can RAM and 4 cores (AMD Barcelona 2200MHz). Clients be assigned by taking the maximum value of LastTS() were run on separate machines. Each zone contained one for the key ranges with which the transaction conflicts, spanserver. Clients and zones were placed in a set of dat- unless there is a conflicting prepared transaction (which acenters with network distance of less than 1ms. (Such a can be determined from fine-grained safe time). layout should be commonplace: most applications do not tPaxos safe as defined above has a weakness in that it cannot need to distribute all of their data worldwide.) The test advance in the absence of Paxos writes. That is, a snap- database was created with 50 Paxos groups with 2500 di- shot read at t cannot execute at Paxos groups whose last rectories. Operations were standalone reads and writes of write happened before t. Spanner addresses this problem 4KB. All reads were served out of memory after a com- by taking advantage of the disjointness of leader-lease paction, so that we are only measuring the overhead of intervals. Each Paxos leader advances tPaxos safe by keeping Spanner’s call stack. In addition, one unmeasured round a threshold above which future writes’ timestamps will of reads was done first to warm any location caches. occur: it maintains a mapping MinNextTS(n) from Paxos For the latency experiments, clients issued sufficiently sequence number n to the minimum timestamp that may few operations so as to avoid queuing at the servers. be assigned to Paxos sequence number n + 1. A replica From the 1-replica experiments, commit wait is about can advance tPaxos safe to MinNextTS(n) − 1 when it has ap- 5ms, and Paxos latency is about 9ms. As the number plied through n. of replicas increases, the latency stays roughly constant A single leader can enforce its MinNextTS() with less standard deviation because Paxos executes in promises easily. Because the timestamps promised parallel at a group’s replicas. As the number of replicas by MinNextTS() lie within a leader’s lease, the disjoint- increases, the latency to achieve a quorum becomes less ness invariant enforces MinNextTS() promises across sensitive to slowness at one slave replica. leaders. If a leader wishes to advance MinNextTS() For the throughput experiments, clients issued suffi- beyond the end of its leader lease, it must first extend its ciently many operations so as to saturate the servers’ Published in the Proceedings of OSDI 2012 9
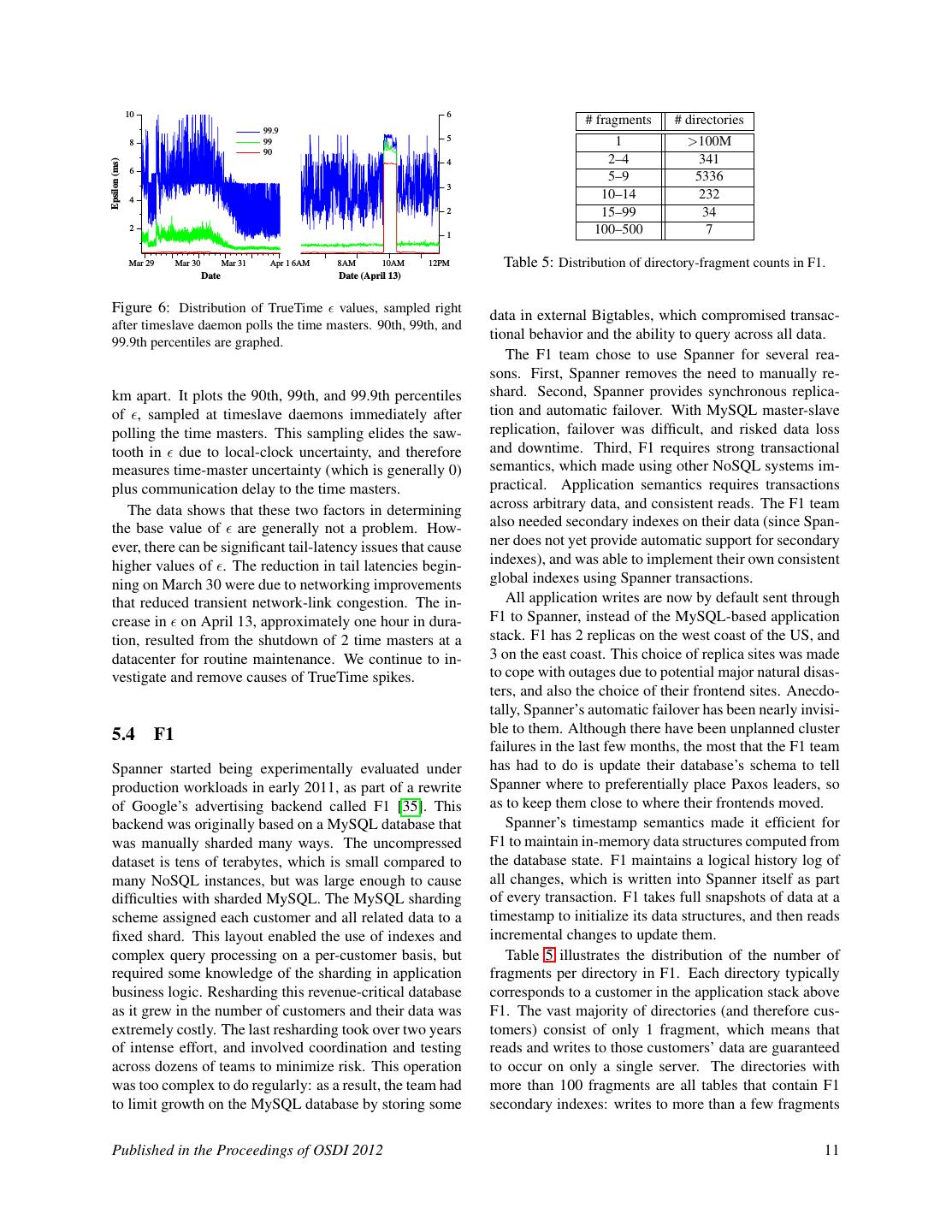
10 . latency (ms) Cumulative reads completed 1.4M participants mean 99th percentile non-leader 1.2M 1 17.0 ±1.4 75.0 ±34.9 leader-soft 2 24.5 ±2.5 87.6 ±35.9 1M leader-hard 5 31.5 ±6.2 104.5 ±52.2 800K 10 30.0 ±3.7 95.6 ±25.4 25 35.5 ±5.6 100.4 ±42.7 600K 50 42.7 ±4.1 93.7 ±22.9 400K 100 71.4 ±7.6 131.2 ±17.6 200 150.5 ±11.0 320.3 ±35.1 200K Table 4: Two-phase commit scalability. Mean and standard 0 5 10 15 20 deviations over 10 runs. Time in seconds Figure 5: Effect of killing servers on throughput. CPUs. Snapshot reads can execute at any up-to-date replicas, so their throughput increases almost linearly with the number of replicas. Single-read read-only trans- a different zone has a minor effect: the throughput drop actions only execute at leaders because timestamp as- is not visible in the graph, but is around 3-4%. On the signment must happen at leaders. Read-only-transaction other hand, killing Z1 with no warning has a severe ef- throughput increases with the number of replicas because fect: the rate of completion drops almost to 0. As leaders the number of effective spanservers increases: in the get re-elected, though, the throughput of the system rises experimental setup, the number of spanservers equaled to approximately 100K reads/second because of two ar- the number of replicas, and leaders were randomly dis- tifacts of our experiment: there is extra capacity in the tributed among the zones. Write throughput benefits system, and operations are queued while the leader is un- from the same experimental artifact (which explains the available. As a result, the throughput of the system rises increase in throughput from 3 to 5 replicas), but that ben- before leveling off again at its steady-state rate. efit is outweighed by the linear increase in the amount of We can also see the effect of the fact that Paxos leader work performed per write, as the number of replicas in- leases are set to 10 seconds. When we kill the zone, creases. the leader-lease expiration times for the groups should Table 4 demonstrates that two-phase commit can scale be evenly distributed over the next 10 seconds. Soon af- to a reasonable number of participants: it summarizes ter each lease from a dead leader expires, a new leader is a set of experiments run across 3 zones, each with 25 elected. Approximately 10 seconds after the kill time, all spanservers. Scaling up to 50 participants is reasonable of the groups have leaders and throughput has recovered. in both mean and 99th-percentile, and latencies start to Shorter lease times would reduce the effect of server rise noticeably at 100 participants. deaths on availability, but would require greater amounts of lease-renewal network traffic. We are in the process of 5.2 Availability designing and implementing a mechanism that will cause slaves to release Paxos leader leases upon leader failure. Figure 5 illustrates the availability benefits of running Spanner in multiple datacenters. It shows the results of 5.3 TrueTime three experiments on throughput in the presence of dat- acenter failure, all of which are overlaid onto the same Two questions must be answered with respect to True- time scale. The test universe consisted of 5 zones Zi , Time: is truly a bound on clock uncertainty, and how each of which had 25 spanservers. The test database was bad does get? For the former, the most serious prob- sharded into 1250 Paxos groups, and 100 test clients con- lem would be if a local clock’s drift were greater than stantly issued non-snapshot reads at an aggregrate rate 200us/sec: that would break assumptions made by True- of 50K reads/second. All of the leaders were explic- Time. Our machine statistics show that bad CPUs are 6 itly placed in Z1 . Five seconds into each test, all of times more likely than bad clocks. That is, clock issues the servers in one zone were killed: non-leader kills Z2 ; are extremely infrequent, relative to much more serious leader-hard kills Z1 ; leader-soft kills Z1 , but it gives no- hardware problems. As a result, we believe that True- tifications to all of the servers that they should handoff Time’s implementation is as trustworthy as any other leadership first. piece of software upon which Spanner depends. Killing Z2 has no effect on read throughput. Killing Figure 6 presents TrueTime data taken at several thou- Z1 while giving the leaders time to handoff leadership to sand spanserver machines across datacenters up to 2200 Published in the Proceedings of OSDI 2012 10
11 . 10 6 # fragments # directories 99.9 8 99 5 1 >100M 90 2–4 341 Epsilon (ms) 4 6 5–9 5336 3 4 10–14 232 2 15–99 34 2 1 100–500 7 Mar 29 Mar 30 Mar 31 Apr 1 6AM 8AM 10AM 12PM Table 5: Distribution of directory-fragment counts in F1. Date Date (April 13) Figure 6: Distribution of TrueTime values, sampled right data in external Bigtables, which compromised transac- after timeslave daemon polls the time masters. 90th, 99th, and 99.9th percentiles are graphed. tional behavior and the ability to query across all data. The F1 team chose to use Spanner for several rea- sons. First, Spanner removes the need to manually re- km apart. It plots the 90th, 99th, and 99.9th percentiles shard. Second, Spanner provides synchronous replica- of , sampled at timeslave daemons immediately after tion and automatic failover. With MySQL master-slave polling the time masters. This sampling elides the saw- replication, failover was difficult, and risked data loss tooth in due to local-clock uncertainty, and therefore and downtime. Third, F1 requires strong transactional measures time-master uncertainty (which is generally 0) semantics, which made using other NoSQL systems im- plus communication delay to the time masters. practical. Application semantics requires transactions The data shows that these two factors in determining across arbitrary data, and consistent reads. The F1 team the base value of are generally not a problem. How- also needed secondary indexes on their data (since Span- ever, there can be significant tail-latency issues that cause ner does not yet provide automatic support for secondary higher values of . The reduction in tail latencies begin- indexes), and was able to implement their own consistent ning on March 30 were due to networking improvements global indexes using Spanner transactions. that reduced transient network-link congestion. The in- All application writes are now by default sent through crease in on April 13, approximately one hour in dura- F1 to Spanner, instead of the MySQL-based application tion, resulted from the shutdown of 2 time masters at a stack. F1 has 2 replicas on the west coast of the US, and datacenter for routine maintenance. We continue to in- 3 on the east coast. This choice of replica sites was made vestigate and remove causes of TrueTime spikes. to cope with outages due to potential major natural disas- ters, and also the choice of their frontend sites. Anecdo- tally, Spanner’s automatic failover has been nearly invisi- 5.4 F1 ble to them. Although there have been unplanned cluster failures in the last few months, the most that the F1 team Spanner started being experimentally evaluated under has had to do is update their database’s schema to tell production workloads in early 2011, as part of a rewrite Spanner where to preferentially place Paxos leaders, so of Google’s advertising backend called F1 [35]. This as to keep them close to where their frontends moved. backend was originally based on a MySQL database that Spanner’s timestamp semantics made it efficient for was manually sharded many ways. The uncompressed F1 to maintain in-memory data structures computed from dataset is tens of terabytes, which is small compared to the database state. F1 maintains a logical history log of many NoSQL instances, but was large enough to cause all changes, which is written into Spanner itself as part difficulties with sharded MySQL. The MySQL sharding of every transaction. F1 takes full snapshots of data at a scheme assigned each customer and all related data to a timestamp to initialize its data structures, and then reads fixed shard. This layout enabled the use of indexes and incremental changes to update them. complex query processing on a per-customer basis, but Table 5 illustrates the distribution of the number of required some knowledge of the sharding in application fragments per directory in F1. Each directory typically business logic. Resharding this revenue-critical database corresponds to a customer in the application stack above as it grew in the number of customers and their data was F1. The vast majority of directories (and therefore cus- extremely costly. The last resharding took over two years tomers) consist of only 1 fragment, which means that of intense effort, and involved coordination and testing reads and writes to those customers’ data are guaranteed across dozens of teams to minimize risk. This operation to occur on only a single server. The directories with was too complex to do regularly: as a result, the team had more than 100 fragments are all tables that contain F1 to limit growth on the MySQL database by storing some secondary indexes: writes to more than a few fragments Published in the Proceedings of OSDI 2012 11
12 . latency (ms) The notion of layering transactions on top of a repli- operation mean std dev count cated store dates at least as far back as Gifford’s disser- all reads 8.7 376.4 21.5B tation [16]. Scatter [17] is a recent DHT-based key-value single-site commit 72.3 112.8 31.2M store that layers transactions on top of consistent repli- multi-site commit 103.0 52.2 32.1M cation. Spanner focuses on providing a higher-level in- terface than Scatter does. Gray and Lamport [18] de- Table 6: F1-perceived operation latencies measured over the scribe a non-blocking commit protocol based on Paxos. course of 24 hours. Their protocol incurs more messaging costs than two- phase commit, which would aggravate the cost of com- of such tables are extremely uncommon. The F1 team mit over widely distributed groups. Walter [36] provides has only seen such behavior when they do untuned bulk a variant of snapshot isolation that works within, but not data loads as transactions. across datacenters. In contrast, our read-only transac- tions provide a more natural semantics, because we sup- Table 6 presents Spanner operation latencies as mea- port external consistency over all operations. sured from F1 servers. Replicas in the east-coast data centers are given higher priority in choosing Paxos lead- There has been a spate of recent work on reducing ers. The data in the table is measured from F1 servers or eliminating locking overheads. Calvin [40] elimi- in those data centers. The large standard deviation in nates concurrency control: it pre-assigns timestamps and write latencies is caused by a pretty fat tail due to lock then executes the transactions in timestamp order. H- conflicts. The even larger standard deviation in read la- Store [39] and Granola [11] each supported their own tencies is partially due to the fact that Paxos leaders are classification of transaction types, some of which could spread across two data centers, only one of which has avoid locking. None of these systems provides external machines with SSDs. In addition, the measurement in- consistency. Spanner addresses the contention issue by cludes every read in the system from two datacenters: providing support for snapshot isolation. the mean and standard deviation of the bytes read were VoltDB [42] is a sharded in-memory database that roughly 1.6KB and 119KB, respectively. supports master-slave replication over the wide area for disaster recovery, but not more general replication con- figurations. It is an example of what has been called 6 Related Work NewSQL, which is a marketplace push to support scal- able SQL [38]. A number of commercial databases im- plement reads in the past, such as MarkLogic [26] and Consistent replication across datacenters as a storage Oracle’s Total Recall [30]. Lomet and Li [24] describe an service has been provided by Megastore [5] and Dy- implementation strategy for such a temporal database. namoDB [3]. DynamoDB presents a key-value interface, Farsite derived bounds on clock uncertainty (much and only replicates within a region. Spanner follows looser than TrueTime’s) relative to a trusted clock refer- Megastore in providing a semi-relational data model, ence [13]: server leases in Farsite were maintained in the and even a similar schema language. Megastore does same way that Spanner maintains Paxos leases. Loosely not achieve high performance. It is layered on top of synchronized clocks have been used for concurrency- Bigtable, which imposes high communication costs. It control purposes in prior work [2, 23]. We have shown also does not support long-lived leaders: multiple repli- that TrueTime lets one reason about global time across cas may initiate writes. All writes from different repli- sets of Paxos state machines. cas necessarily conflict in the Paxos protocol, even if they do not logically conflict: throughput collapses on a Paxos group at several writes per second. Spanner pro- 7 Future Work vides higher performance, general-purpose transactions, and external consistency. We have spent most of the last year working with the Pavlo et al. [31] have compared the performance of F1 team to transition Google’s advertising backend from databases and MapReduce [12]. They point to several MySQL to Spanner. We are actively improving its mon- other efforts that have been made to explore database itoring and support tools, as well as tuning its perfor- functionality layered on distributed key-value stores [1, mance. In addition, we have been working on improving 4, 7, 41] as evidence that the two worlds are converging. the functionality and performance of our backup/restore We agree with the conclusion, but demonstrate that in- system. We are currently implementing the Spanner tegrating multiple layers has its advantages: integrating schema language, automatic maintenance of secondary concurrency control with replication reduces the cost of indices, and automatic load-based resharding. Longer commit wait in Spanner, for example. term, there are a couple of features that we plan to in- Published in the Proceedings of OSDI 2012 12
13 .vestigate. Optimistically doing reads in parallel may be Acknowledgements a valuable strategy to pursue, but initial experiments have indicated that the right implementation is non-trivial. In Many people have helped to improve this paper: our addition, we plan to eventually support direct changes of shepherd Jon Howell, who went above and beyond Paxos configurations [22, 34]. his responsibilities; the anonymous referees; and many Given that we expect many applications to replicate Googlers: Atul Adya, Fay Chang, Frank Dabek, Sean their data across datacenters that are relatively close to Dorward, Bob Gruber, David Held, Nick Kline, Alex each other, TrueTime may noticeably affect perfor- Thomson, and Joel Wein. Our management has been mance. We see no insurmountable obstacle to reduc- very supportive of both our work and of publishing this ing below 1ms. Time-master-query intervals can be paper: Aristotle Balogh, Bill Coughran, Urs H¨olzle, reduced, and better clock crystals are relatively cheap. Doron Meyer, Cos Nicolaou, Kathy Polizzi, Sridhar Ra- Time-master query latency could be reduced with im- maswany, and Shivakumar Venkataraman. proved networking technology, or possibly even avoided We have built upon the work of the Bigtable and through alternate time-distribution technology. Megastore teams. The F1 team, and Jeff Shute in particu- Finally, there are obvious areas for improvement. Al- lar, worked closely with us in developing our data model though Spanner is scalable in the number of nodes, the and helped immensely in tracking down performance and node-local data structures have relatively poor perfor- correctness bugs. The Platforms team, and Luiz Barroso mance on complex SQL queries, because they were de- and Bob Felderman in particular, helped to make True- signed for simple key-value accesses. Algorithms and Time happen. Finally, a lot of Googlers used to be on our data structures from DB literature could improve single- team: Ken Ashcraft, Paul Cychosz, Krzysztof Ostrowski, node performance a great deal. Second, moving data au- Amir Voskoboynik, Matthew Weaver, Theo Vassilakis, tomatically between datacenters in response to changes and Eric Veach; or have joined our team recently: Nathan in client load has long been a goal of ours, but to make Bales, Adam Beberg, Vadim Borisov, Ken Chen, Brian that goal effective, we would also need the ability to Cooper, Cian Cullinan, Robert-Jan Huijsman, Milind move client-application processes between datacenters in Joshi, Andrey Khorlin, Dawid Kuroczko, Laramie Leav- an automated, coordinated fashion. Moving processes itt, Eric Li, Mike Mammarella, Sunil Mushran, Simon raises the even more difficult problem of managing re- Nielsen, Ovidiu Platon, Ananth Shrinivas, Vadim Su- source acquisition and allocation between datacenters. vorov, and Marcel van der Holst. References 8 Conclusions [1] Azza Abouzeid et al. “HadoopDB: an architectural hybrid of To summarize, Spanner combines and extends on ideas MapReduce and DBMS technologies for analytical workloads”. Proc. of VLDB. 2009, pp. 922–933. from two research communities: from the database com- munity, a familiar, easy-to-use, semi-relational interface, [2] A. Adya et al. “Efficient optimistic concurrency control using loosely synchronized clocks”. Proc. of SIGMOD. 1995, pp. 23– transactions, and an SQL-based query language; from 34. the systems community, scalability, automatic sharding, [3] Amazon. Amazon DynamoDB. 2012. fault tolerance, consistent replication, external consis- [4] Michael Armbrust et al. “PIQL: Success-Tolerant Query Pro- tency, and wide-area distribution. Since Spanner’s in- cessing in the Cloud”. Proc. of VLDB. 2011, pp. 181–192. ception, we have taken more than 5 years to iterate to the [5] Jason Baker et al. “Megastore: Providing Scalable, Highly current design and implementation. Part of this long it- Available Storage for Interactive Services”. Proc. of CIDR. eration phase was due to a slow realization that Spanner 2011, pp. 223–234. should do more than tackle the problem of a globally- [6] Hal Berenson et al. “A critique of ANSI SQL isolation levels”. replicated namespace, and should also focus on database Proc. of SIGMOD. 1995, pp. 1–10. features that Bigtable was missing. [7] Matthias Brantner et al. “Building a database on S3”. Proc. of One aspect of our design stands out: the linchpin of SIGMOD. 2008, pp. 251–264. Spanner’s feature set is TrueTime. We have shown that [8] A. Chan and R. Gray. “Implementing Distributed Read-Only Transactions”. IEEE TOSE SE-11.2 (Feb. 1985), pp. 205–212. reifying clock uncertainty in the time API makes it possi- [9] Fay Chang et al. “Bigtable: A Distributed Storage System for ble to build distributed systems with much stronger time Structured Data”. ACM TOCS 26.2 (June 2008), 4:1–4:26. semantics. In addition, as the underlying system en- [10] Brian F. Cooper et al. “PNUTS: Yahoo!’s hosted data serving forces tighter bounds on clock uncertainty, the overhead platform”. Proc. of VLDB. 2008, pp. 1277–1288. of the stronger semantics decreases. As a community, we [11] James Cowling and Barbara Liskov. “Granola: Low-Overhead should no longer depend on loosely synchronized clocks Distributed Transaction Coordination”. Proc. of USENIX ATC. and weak time APIs in designing distributed algorithms. 2012, pp. 223–236. Published in the Proceedings of OSDI 2012 13
14 .[12] Jeffrey Dean and Sanjay Ghemawat. “MapReduce: a flexible [37] Michael Stonebraker. Why Enterprises Are Uninterested in data processing tool”. CACM 53.1 (Jan. 2010), pp. 72–77. NoSQL. 2010. [13] John Douceur and Jon Howell. Scalable Byzantine-Fault- [38] Michael Stonebraker. Six SQL Urban Myths. 2010. Quantifying Clock Synchronization. Tech. rep. MSR-TR-2003- [39] Michael Stonebraker et al. “The end of an architectural era: (it’s 67. MS Research, 2003. time for a complete rewrite)”. Proc. of VLDB. 2007, pp. 1150– [14] John R. Douceur and Jon Howell. “Distributed directory service 1160. in the Farsite file system”. Proc. of OSDI. 2006, pp. 321–334. [40] Alexander Thomson et al. “Calvin: Fast Distributed Transac- [15] Sanjay Ghemawat, Howard Gobioff, and Shun-Tak Leung. “The tions for Partitioned Database Systems”. Proc. of SIGMOD. Google file system”. Proc. of SOSP. Dec. 2003, pp. 29–43. 2012, pp. 1–12. [16] David K. Gifford. Information Storage in a Decentralized Com- [41] Ashish Thusoo et al. “Hive — A Petabyte Scale Data Ware- puter System. Tech. rep. CSL-81-8. PhD dissertation. Xerox house Using Hadoop”. Proc. of ICDE. 2010, pp. 996–1005. PARC, July 1982. [42] VoltDB. VoltDB Resources. 2012. [17] Lisa Glendenning et al. “Scalable consistency in Scatter”. Proc. of SOSP. 2011. [18] Jim Gray and Leslie Lamport. “Consensus on transaction com- A Paxos Leader-Lease Management mit”. ACM TODS 31.1 (Mar. 2006), pp. 133–160. [19] Pat Helland. “Life beyond Distributed Transactions: an Apos- The simplest means to ensure the disjointness of Paxos- tate’s Opinion”. Proc. of CIDR. 2007, pp. 132–141. leader-lease intervals would be for a leader to issue a syn- [20] Maurice P. Herlihy and Jeannette M. Wing. “Linearizability: a chronous Paxos write of the lease interval, whenever it correctness condition for concurrent objects”. ACM TOPLAS would be extended. A subsequent leader would read the 12.3 (July 1990), pp. 463–492. interval and wait until that interval has passed. [21] Leslie Lamport. “The part-time parliament”. ACM TOCS 16.2 TrueTime can be used to ensure disjointness without (May 1998), pp. 133–169. these extra log writes. The potential ith leader keeps a [22] Leslie Lamport, Dahlia Malkhi, and Lidong Zhou. “Reconfigur- lower bound on the start of a lease vote from replica r as ing a state machine”. SIGACT News 41.1 (Mar. 2010), pp. 63– leader vi,r = TT.now().earliest, computed before esend i,r (de- 73. fined as when the lease request is sent by the leader). [23] Barbara Liskov. “Practical uses of synchronized clocks in dis- tributed systems”. Distrib. Comput. 6.4 (July 1993), pp. 211– Each replica r grants a lease at lease egrant i,r , which hap- receive 219. pens after ei,r (when the replica receives a lease re- [24] David B. Lomet and Feifei Li. “Improving Transaction-Time quest); the lease ends at tend i,r = TT.now().latest + 10, DBMS Performance and Functionality”. Proc. of ICDE (2009), computed after ereceive . A replica r obeys the single- pp. 581–591. i,r vote rule: it will not grant another lease vote until [25] Jacob R. Lorch et al. “The SMART way to migrate replicated stateful services”. Proc. of EuroSys. 2006, pp. 103–115. TT.after(tend i,r ) is true. To enforce this rule across different incarnations of r, Spanner logs a lease vote at the grant- [26] MarkLogic. MarkLogic 5 Product Documentation. 2012. ing replica before granting the lease; this log write can [27] Keith Marzullo and Susan Owicki. “Maintaining the time in a distributed system”. Proc. of PODC. 1983, pp. 295–305. be piggybacked upon existing Paxos-protocol log writes. When the ith leader receives a quorum of votes [28] Sergey Melnik et al. “Dremel: Interactive Analysis of Web- (event equorum i ), it computes its lease interval as Scale Datasets”. Proc. of VLDB. 2010, pp. 330–339. leader leasei = [TT.now().latest, minr (vi,r ) + 10]. The [29] D.L. Mills. Time synchronization in DCNET hosts. Internet lease is deemed to have expired at the leader when Project Report IEN–173. COMSAT Laboratories, Feb. 1981. leader TT.before(minr (vi,r ) + 10) is false. To prove disjoint- [30] Oracle. Oracle Total Recall. 2012. ness, we make use of the fact that the ith and (i + 1)th [31] Andrew Pavlo et al. “A comparison of approaches to large-scale leaders must have one replica in common in their quo- data analysis”. Proc. of SIGMOD. 2009, pp. 165–178. rums. Call that replica r0. Proof: [32] Daniel Peng and Frank Dabek. “Large-scale incremental pro- cessing using distributed transactions and notifications”. Proc. leader leasei .end = minr (vi,r ) + 10 (by definition) of OSDI. 2010, pp. 1–15. leader leader minr (vi,r ) + 10 ≤ vi,r0 + 10 (min) [33] Daniel J. Rosenkrantz, Richard E. Stearns, and Philip M. Lewis leader II. “System level concurrency control for distributed database vi,r0 + 10 ≤ tabs (esend i,r0 ) + 10 (by definition) systems”. ACM TODS 3.2 (June 1978), pp. 178–198. tabs (esend receive i,r0 ) + 10 ≤ tabs (ei,r0 ) + 10 (causality) [34] Alexander Shraer et al. “Dynamic Reconfiguration of Pri- mary/Backup Clusters”. Proc. of USENIX ATC. 2012, pp. 425– tabs (ereceive i,r0 ) + 10 ≤ tend i,r0 (by definition) 438. tend i,r0 < tabs (egrant i+1,r0 ) (single-vote) [35] Jeff Shute et al. “F1 — The Fault-Tolerant Distributed RDBMS tabs (egrant i+1,r0 ) ≤ tabs (equorum i+1 ) (causality) Supporting Google’s Ad Business”. Proc. of SIGMOD. May 2012, pp. 777–778. tabs (equorum i+1 ) ≤ leasei+1 .start (by definition) [36] Yair Sovran et al. “Transactional storage for geo-replicated sys- tems”. Proc. of SOSP. 2011, pp. 385–400. Published in the Proceedings of OSDI 2012 14
3秒后跳转登录页面
去登陆

