

























































































































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
Relational DB Design
Defining Relations - Deciding which Attributes belong Together in Each Relation Choosing Appropriate Names for the Relations and Their Attributes (with Domains and Data Types) Identifying the Candidate Keys and Choosing a PK for Each Relation, and Specifying All Foreign Keys Two Techniques for Relational Schema Design
展开查看详情
1 .Chap 15 & 16 6e - 14 5e: Relational DB Design, Functional Dependencies and Normalization Prof. Steven A. Demurjian, Sr. Computer Science & Engineering Department The University of Connecticut 191 Auditorium Road, Box U-155 Storrs, CT 06269-3155 steve@engr.uconn.edu http://www.engr.uconn.edu/~steve (860) 486 - 4818 A portion of these slides are being used with the permission of Dr. Ling Lui, Associate Professor, College of Computing, Georgia Tech. Other slides and figures have been adapted from the AWL web site for the textbook.
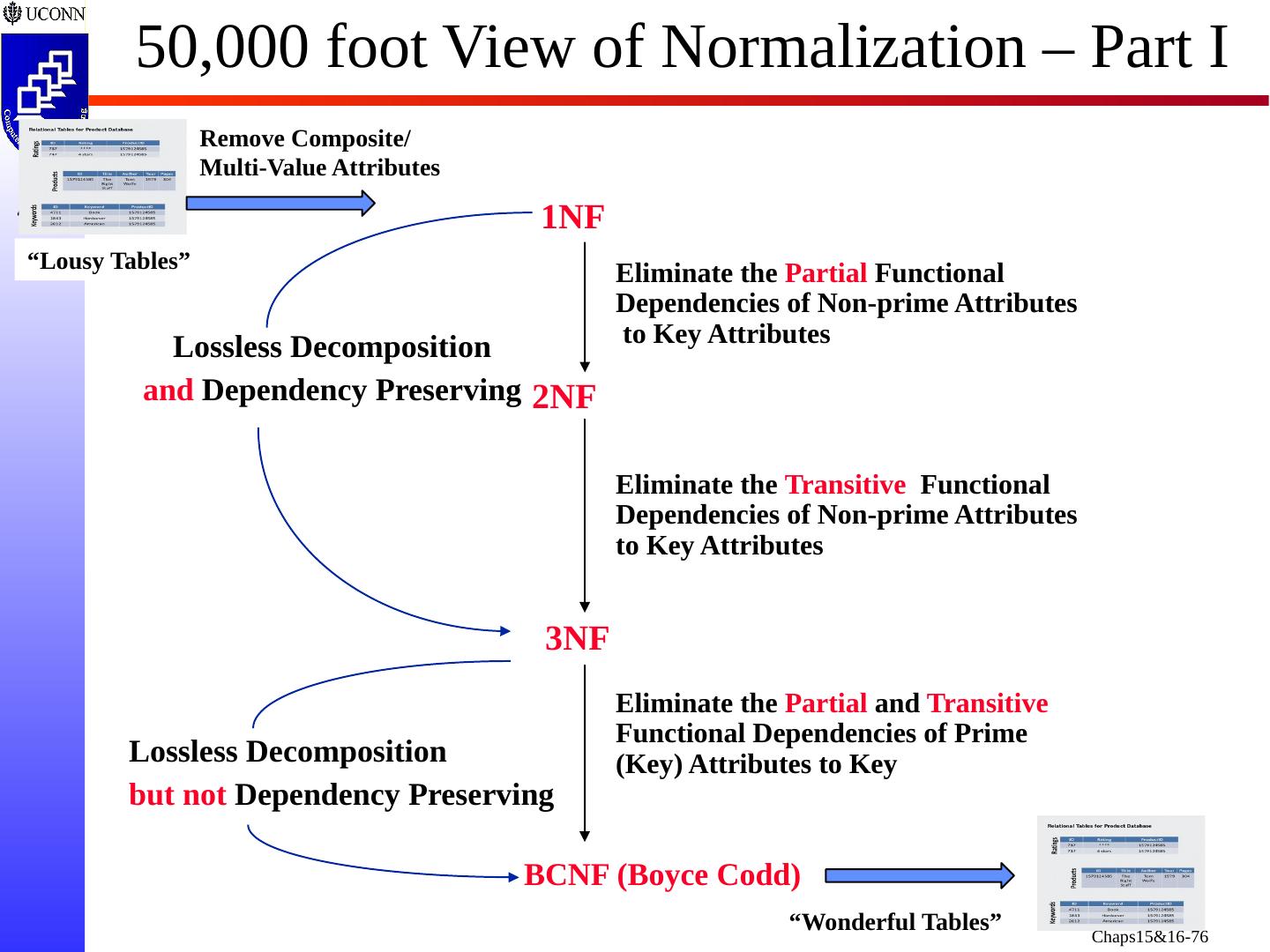
2 .Normalizing a Relational DB Schema Recall: Defining Relations - Deciding which Attributes belong Together in Each Relation Choosing Appropriate Names for the Relations and Their Attributes (with Domains and Data Types) Identifying the Candidate Keys and Choosing a PK for Each Relation, and Specifying All Foreign Keys Two Techniques for Relational Schema Design Using ER-to-Relational Mapping (Chapter 9) Relational Normalization Theory ( Chaps 15/16) In Normalization, we Strive for an “Optimal” Design in Terms of Redundancy - Improve Performance Anomalies - Eliminate “Problems”
3 .Design Process - Where are we? Conceptual Design Conceptual Schema (ER Model) Logical Design Logical Schema (Relational Model) Analysis of Schema Step 2: Normalization Analyzing the Schema from Performance/Efficiency Perspectives to arrive at “Optimal” Schema Normalized Schema
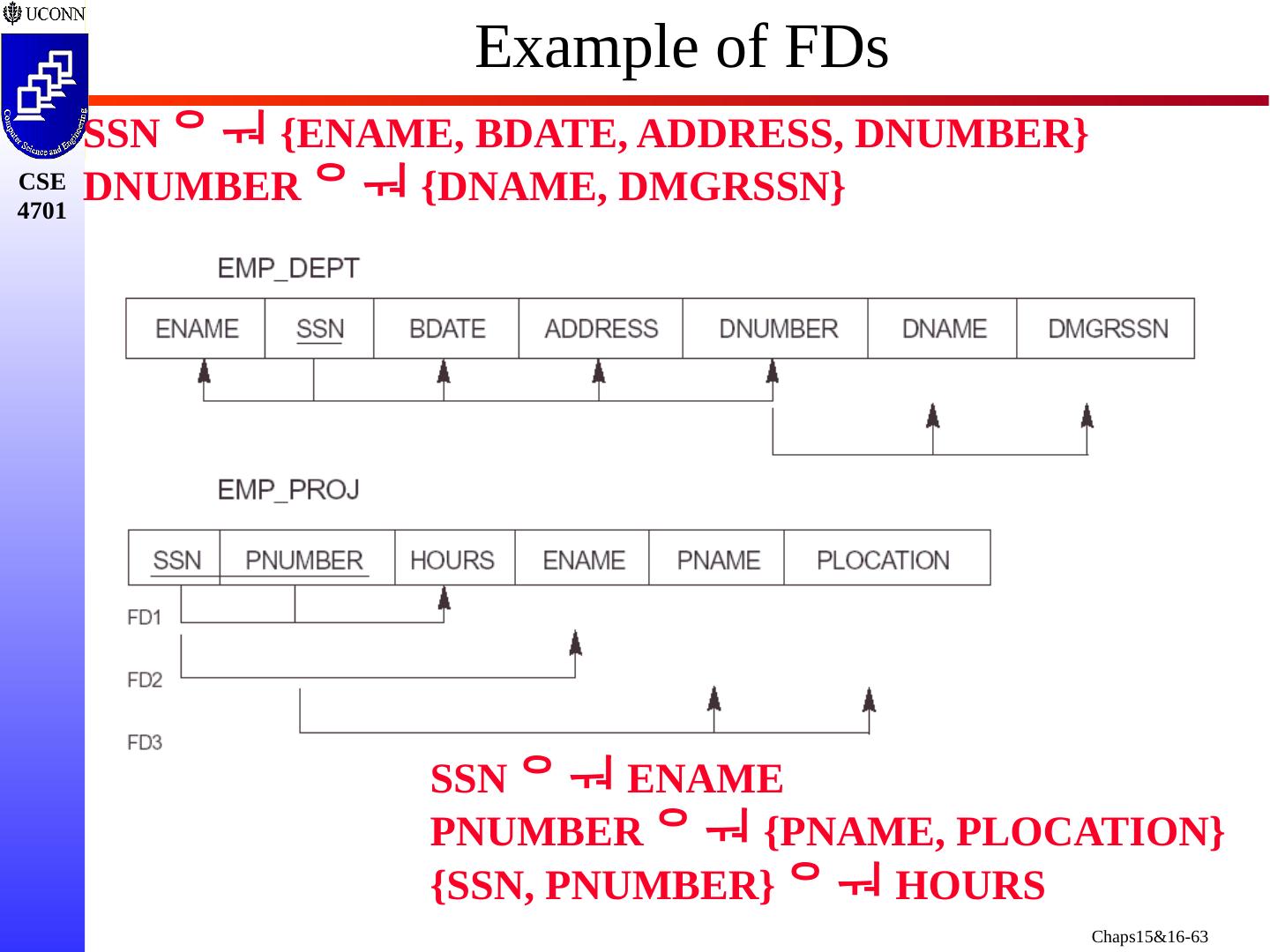
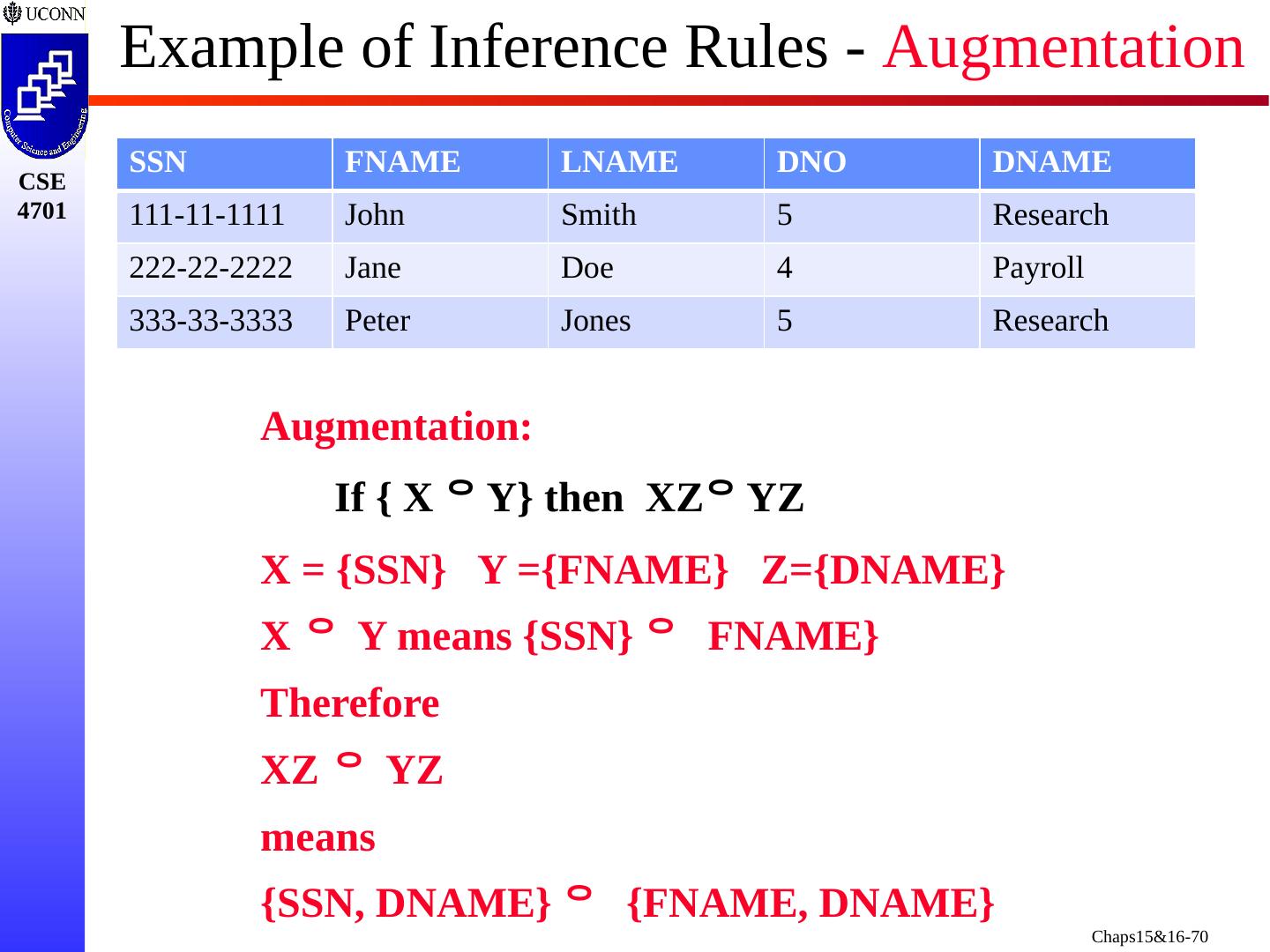
4 .Focus of this Chapter Informal Design Guidelines for Relational Databases Semantics of the Relation Attributes Redundant Information in Tuples/Update Anomalies Null Values in Tuples Spurious Tuples Functional Dependencies (FDs) Recall Key Concepts from Chapter 7 Inference Rules for FDs Normal Form and Normalization First, Second, and Third Normal Forms Boyce- Codd Normal Form
5 .Informal DB Design Guidelines What is Relational Database Design? The Grouping of Attributes to Form "Good" Relation Schemas Two Levels of Relation Schemas: The Logical "User View" Level The Storage "Base Relation" Level Design is Concerned Mainly with Base Relations What are the Criteria for "Good" Base Relations? We’ll Start with Informal Guidelines for Good Relational Design
6 .The Four Commandments : Thou Shalt Commit No Redundancy of Fact Thou Shalt Clutter No Facts Thou Shalt Preserve Information Thou Shalt Preserve Functional Dependencies What are Commandments for DB Design? © Leo Mark, Database Group, Georgia Tech
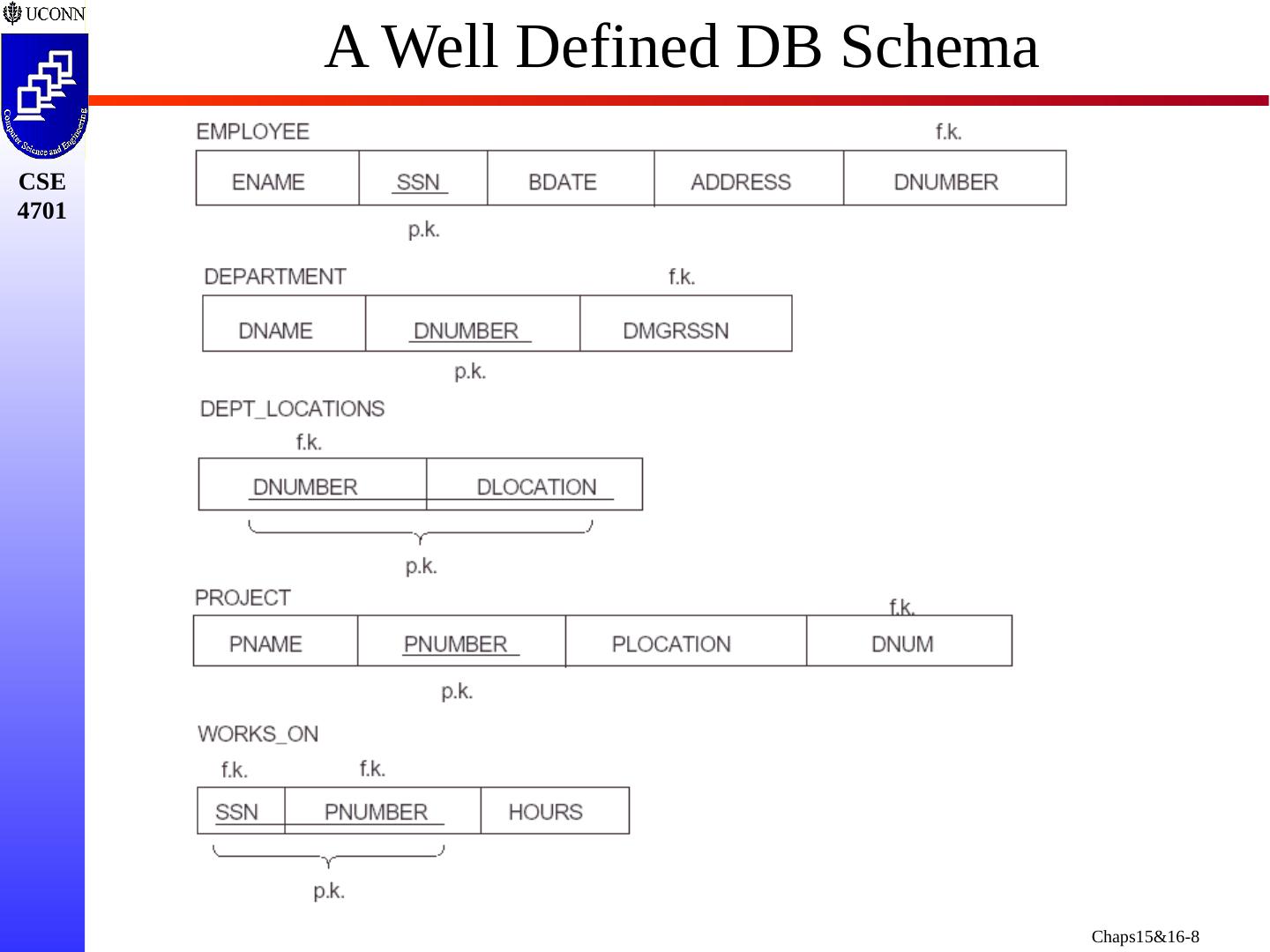
7 .What is a “Good” DB Schema? Focus on the “Semantics” of the Relations What Does Each Relation Mean? Do the “Semantics” of Each Relation Make Sense? Each Relation has a Consistent Meaning Dependencies Between Relations are Clear What about Keys? Are Primary Keys Well Defined? Do Links to Foreign Keys Make Sense? How Does Relational Schema Relate to ER or EER Predecessor? What is an Example of a “Good” Schema? Why?
8 .A Well Defined DB Schema
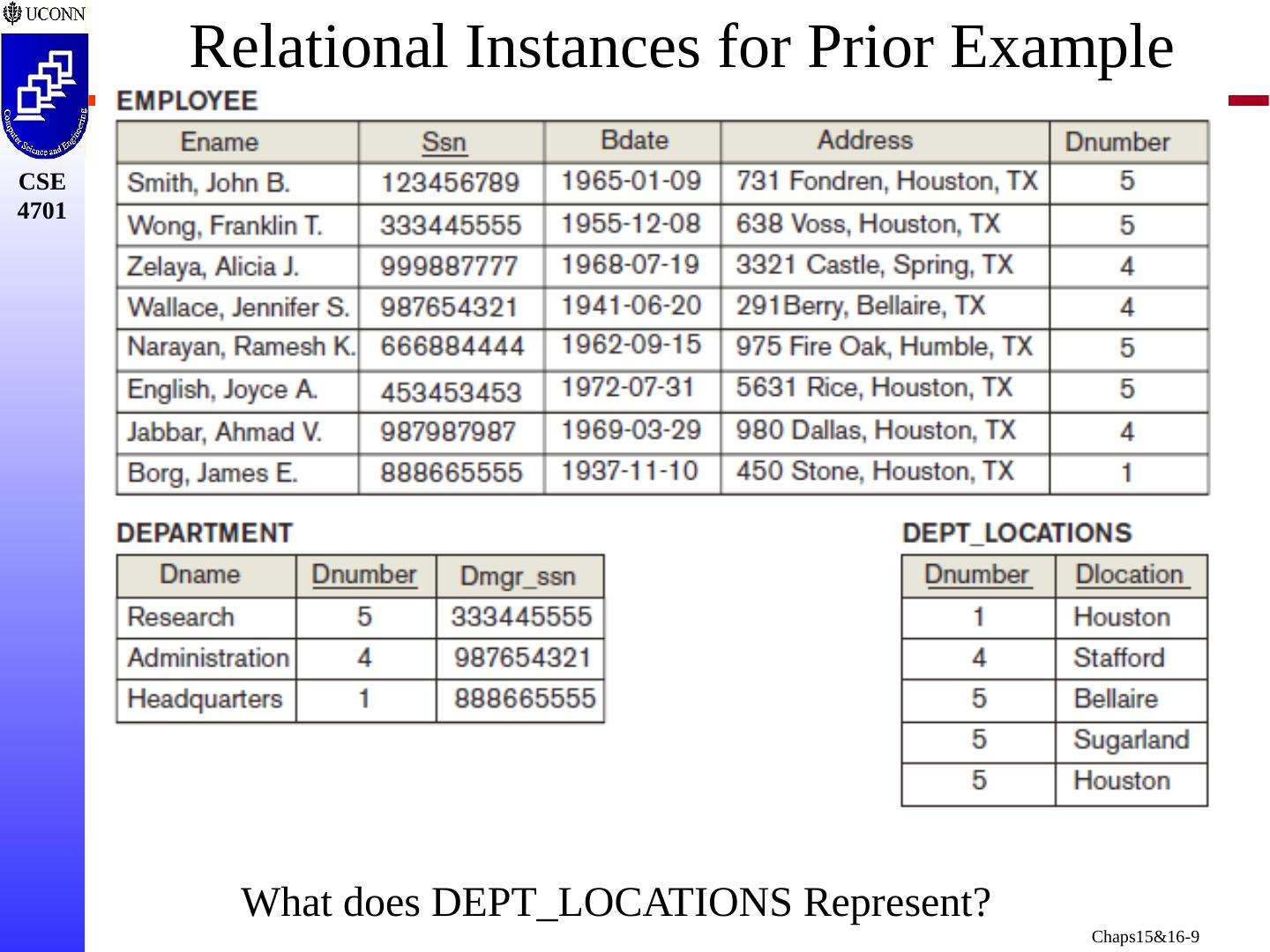
9 .Relational Instances for Prior Example What does DEPT_LOCATIONS Represent?
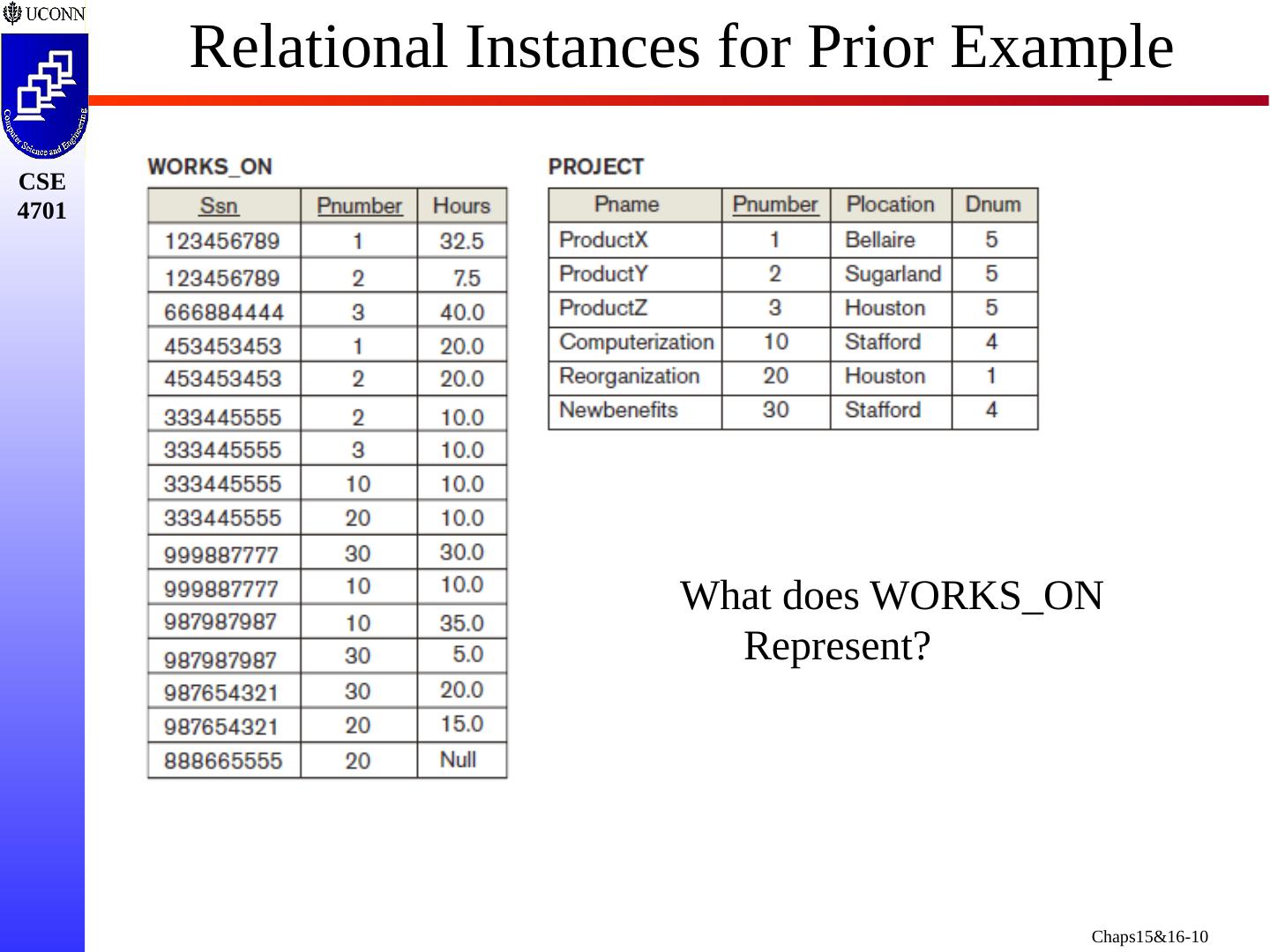
10 .Relational Instances for Prior Example What does WORKS_ON Represent?
11 .Guideline 1: Represent a Single Entity GUIDELINE 1 : Informally, Each Tuple in a Relation Should Represent One Entity or Relationship Instance (Applies to Individual Relations and their Attributes) Attributes of Different Entities should not be Mixed in the Same Relation Only FKs should be used to Refer to Other Entities Entity and Relationship Attributes should be Kept Apart as Much as Possible Bottom Line : Design a Schema that can be Explained Easily Relation by Relation The Semantics of Attributes should be Easy to Interpret
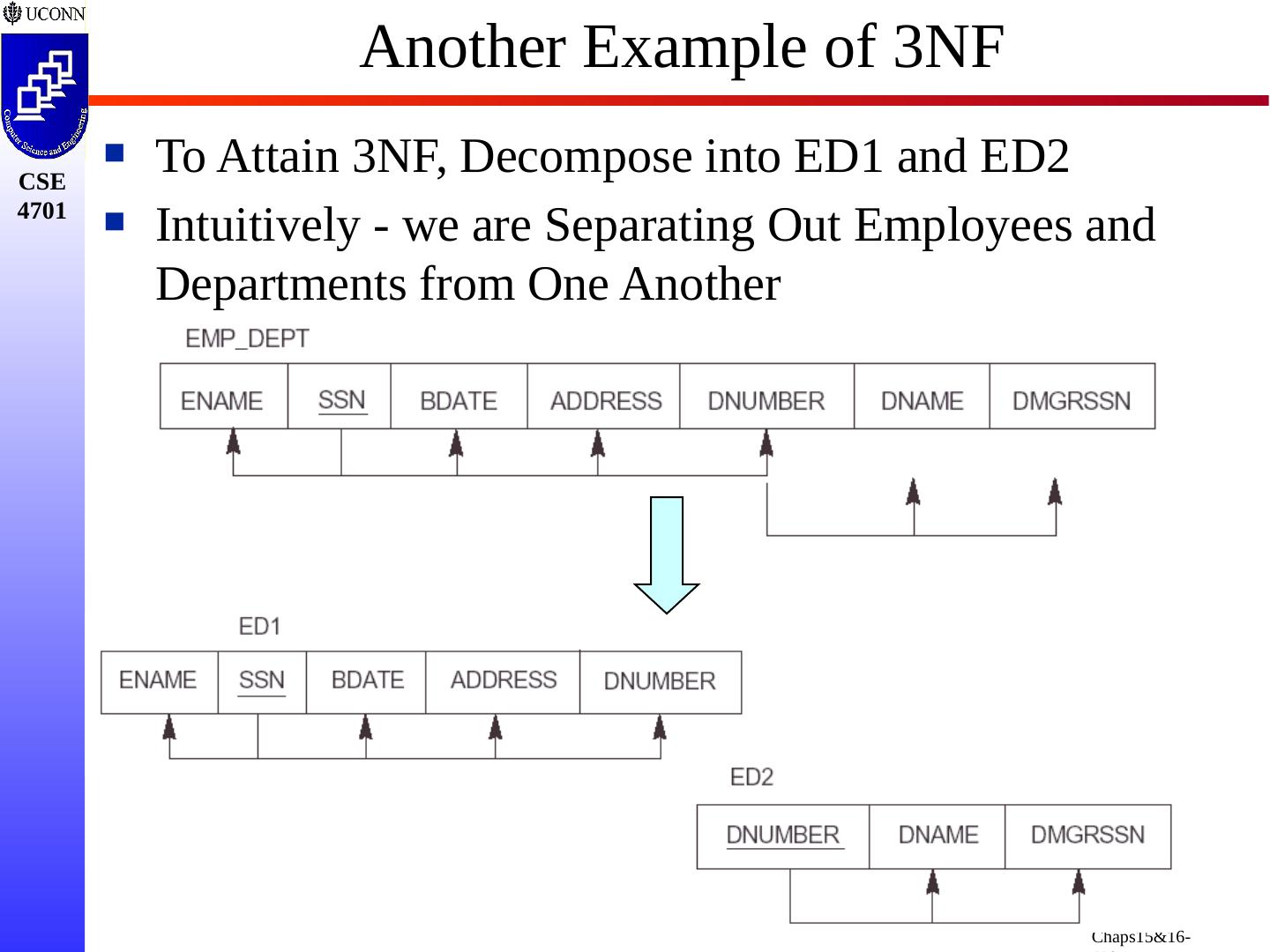
12 .What is a “Lousy” Relation? Why? Represents a “Single” Employee in Each Line as Identified via SSN What is it Trying to Represent? Each Employee Works in a Department Identified by DNUMBER, DNAME, and DMGRSSN What is the Problem with this Design? What Happens When you Update? Delete?
13 .What is a “Lousy” Relation? Why? What Happens When you Update? Delete ? Update “Research” to “R&D” What are the Problems? Research misspelled in Table Query Needs to Final All Rows Department Name no longer in 1 Location
14 .What is a “Lousy” Relation? Why? What is the Problem with this Design? Mixing Attributes from EMPLOYEE and PROJECT Relations! Significant Amounts of Redundant Data More Critically - Anomalies in Update, Delete, Insert
15 .What is a “Lousy” Relation? Why? Where are the Redundancies? ENAMEs, PNAMs, PLOCATIONs Are SSNs Redundant?
16 . Guideline 2: Redundant Information and Update Anomalies Mixing Attributes of Multiple Entities (see Prior Two Slides) May Cause Problems Key Problem: Information is Stored Redundantly There are Two Consequences: Wasting Storage Problems with Update Anomalies Insertion Anomalies - Inserting New Tuples Deletion Anomalies - Removing Existing Tuples Modification Anomalies - Changing Existing Tuples
17 .Insertion Anomalies What Happens When Insert a new Employee Who Works in Department 5? Must Enter DNUMBER, DNAME, and DMGRSSN Must Be Exact w.r.t. Other Dept. 5 Employees! What Happens if you Enter: “ Res aer ch ” or “ 33344 5565 ”? What are Implications?
18 .Insertion Anomalies What are Some Specific Problems with Table? Can’t Add New Department without Employee Redundant Project Names Can you Delete a Department ?
19 .Insertion Anomalies What Happens When you Want to Insert a New Department? (3, “Education”, 123123123) Can you do the Insert? If so, How? If Not, Why Not?
20 .Deletion Anomalies What Happens When you Delete “Borg, James” from the EMP_DEPT Table? Is the Resulting Table OK? Why or Why Not?
21 .Modification Anomalies What Happens When you Want to Change “Research” to “R and D”? What is Required in this Case ? Change Multiple Tuples What is the Responsibility of the DB Application Programmer or Anyone Doing an Update ? Know the DB Content to Write a Correct Query
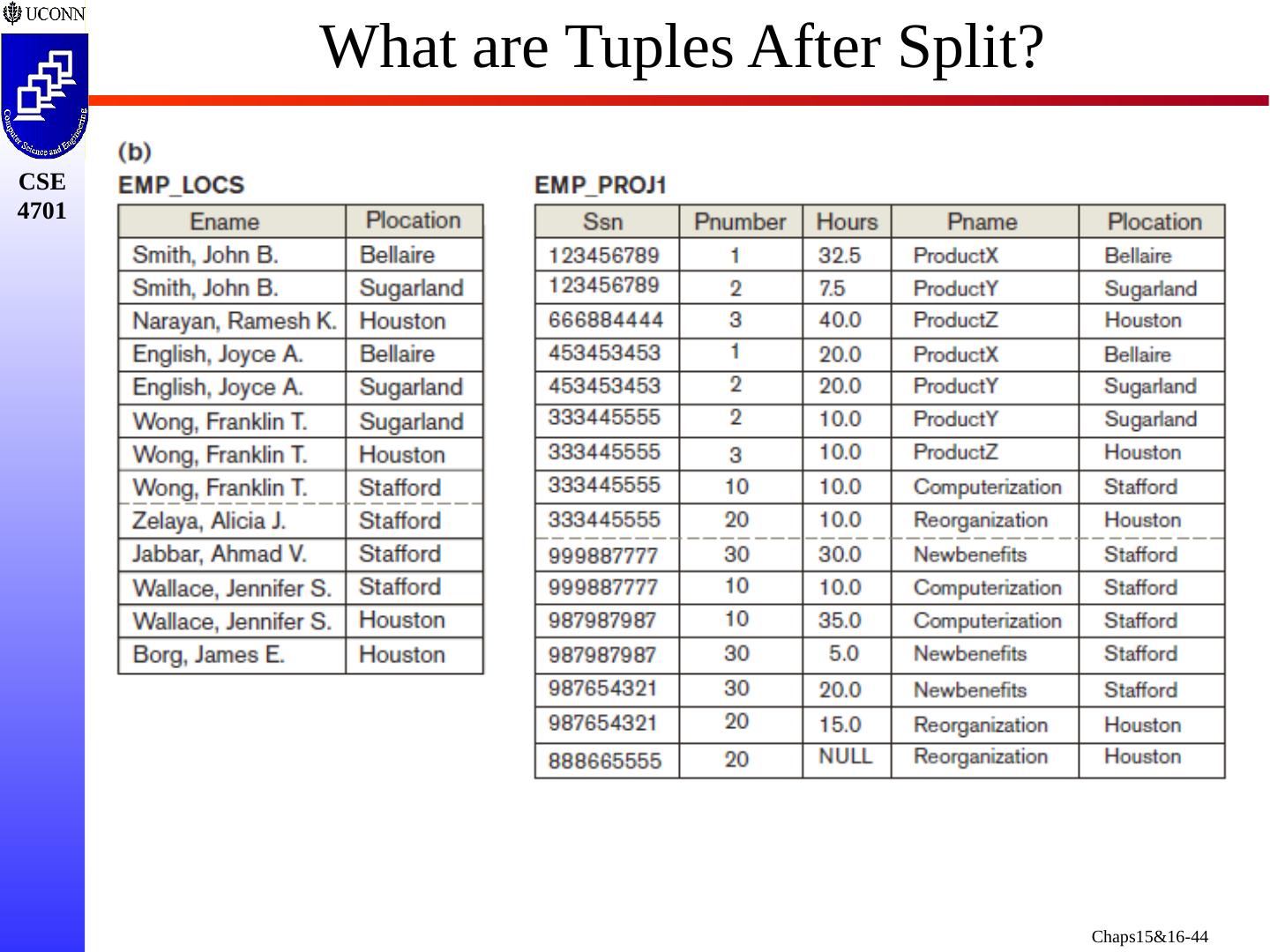
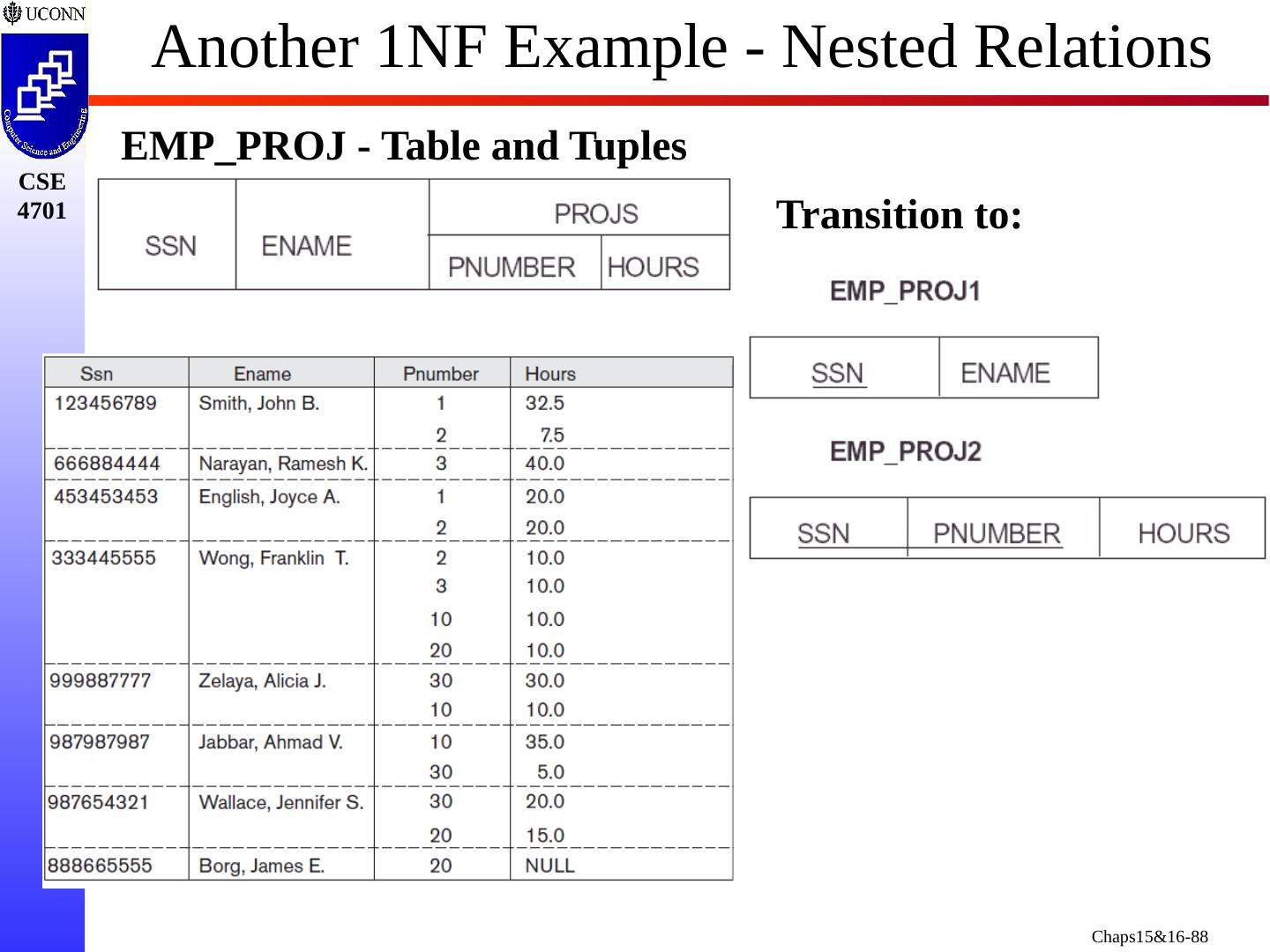
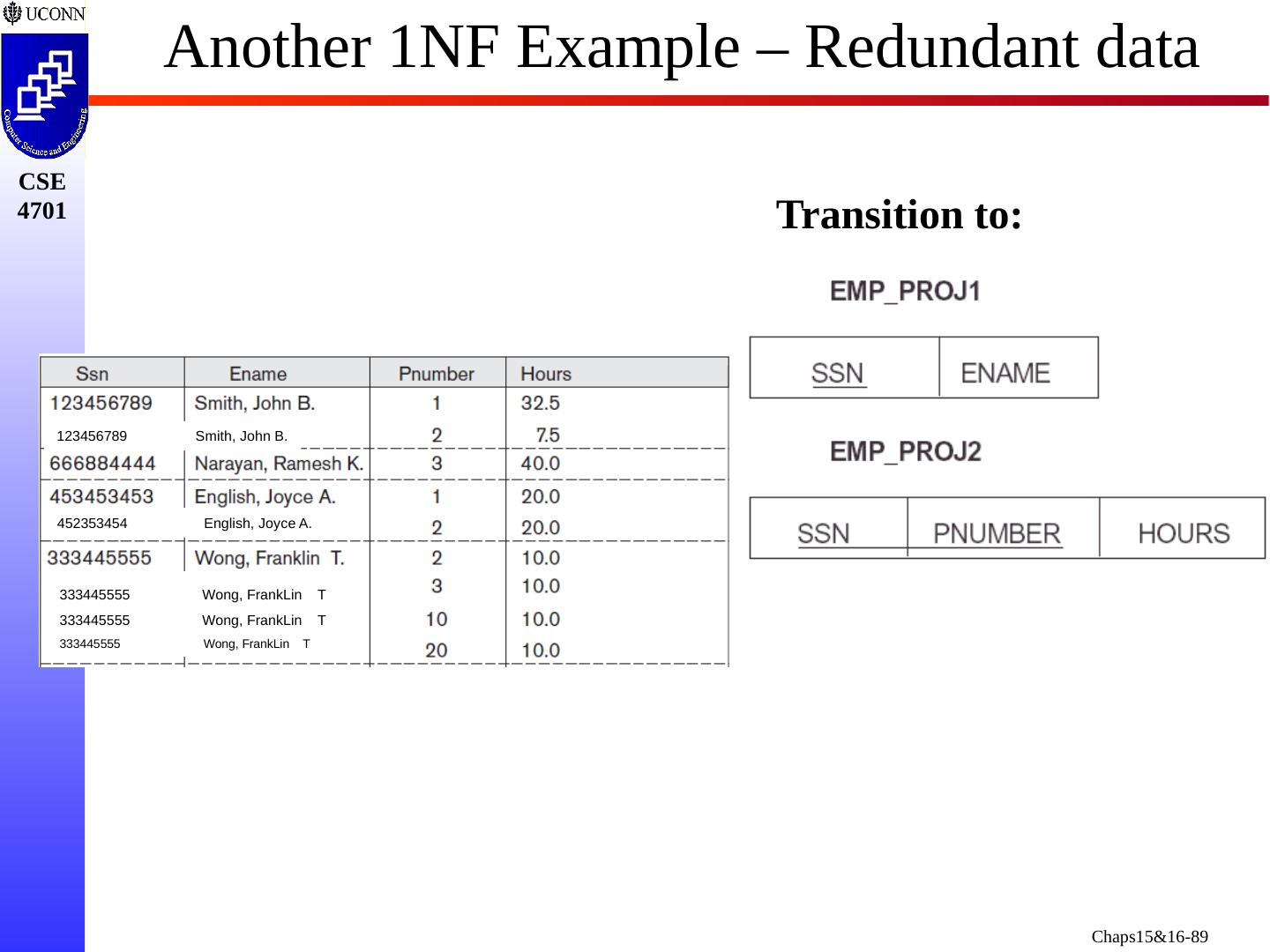
22 .Another Schema with Problems Two relation schemas suffering from update anomalies (a) Dname and Dmgr_ssn Replicated for Each Employee (b) Ename , Pname , Ploc Replicated each SSN/ Pnumber combo
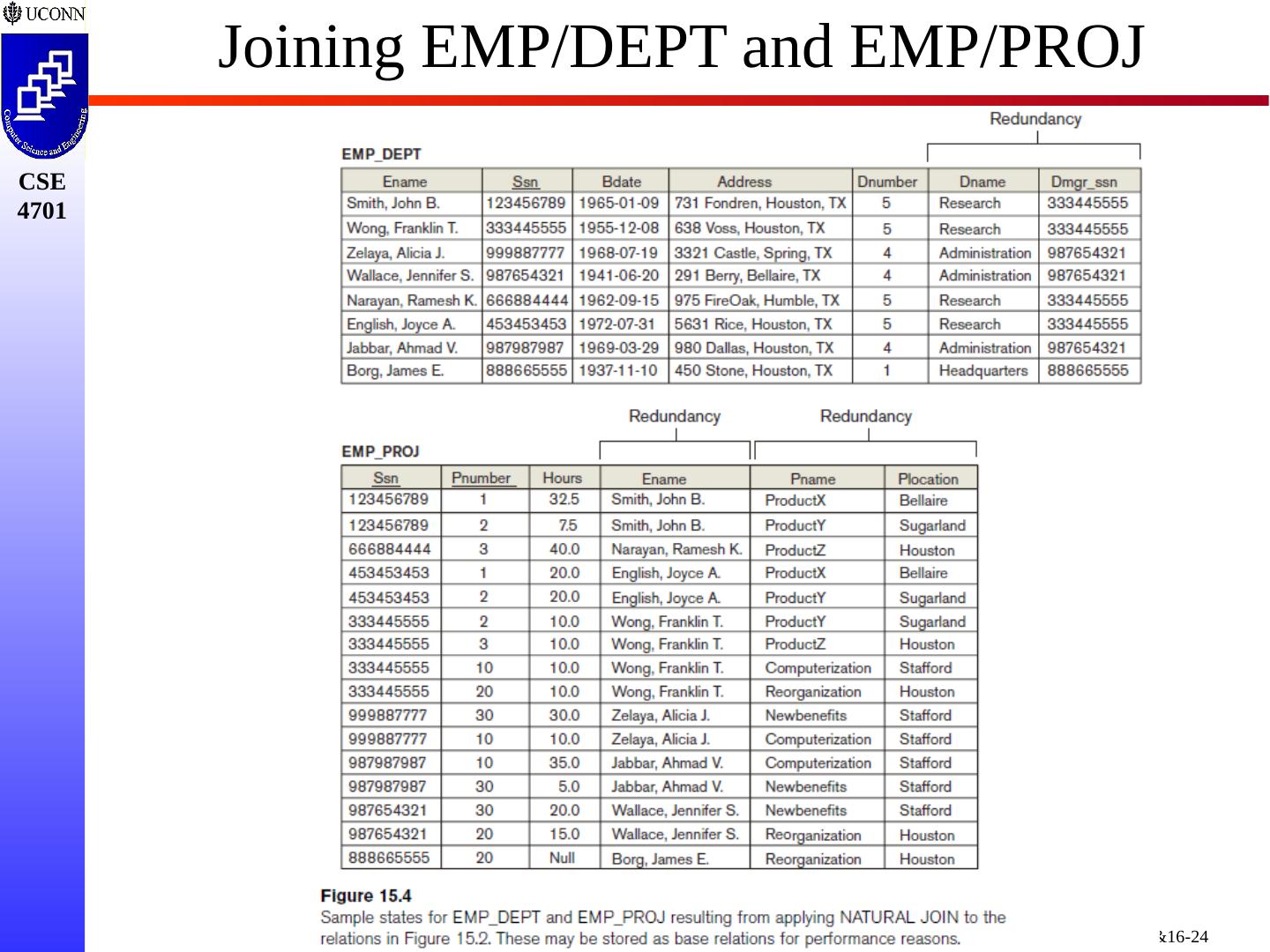
23 .Consider Three Tables What Happens Join EMP/DEPT and EMP/PROJ?
24 .Joining EMP/DEPT and EMP/PROJ
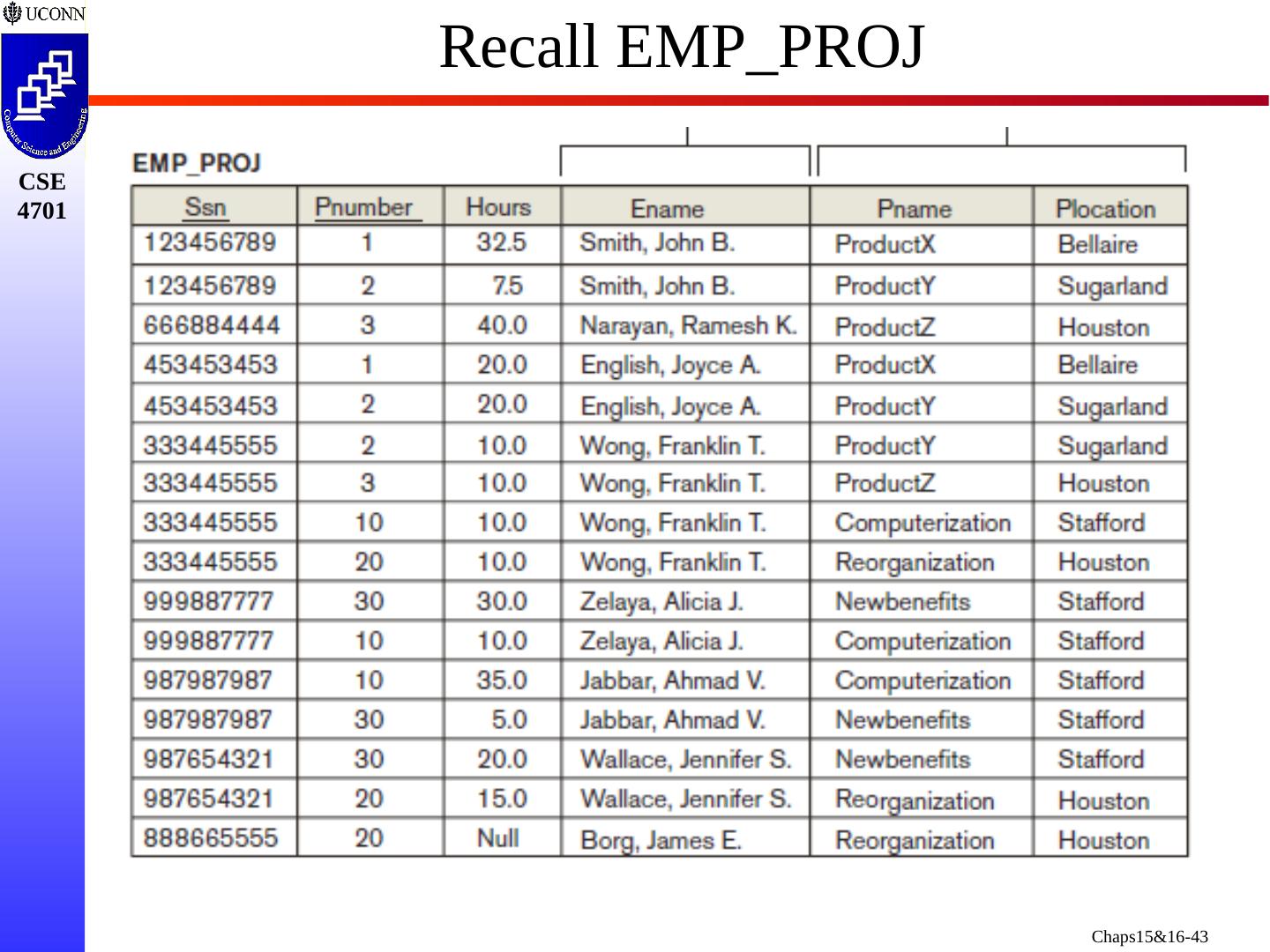
25 .Example of an Update Anomaly Consider the relation: EMP_PROJ( Emp #, Proj #, Ename , Pname , No_hours ) Update Anomaly: Changing the name of project number P1 from “Billing” to “Customer-Accounting” requires update to be made for all 100 employees working on project P1.
26 .Example of an Insert Anomaly Consider the relation: EMP_PROJ( Emp #, Proj #, Ename , Pname , No_hours ) Insert Anomaly: Cannot insert a project unless an employee is assigned to it. Conversely Cannot insert an employee unless a he/she is assigned to a project.
27 .Example of an Delete Anomaly Consider the relation: EMP_PROJ( Emp #, Proj #, Ename , Pname , No_hours ) Delete Anomaly: When a project is deleted, it will result in deleting all the employees who work on that project. Alternately, if an employee is the sole employee on a project, deleting that employee would result in deleting the corresponding project.
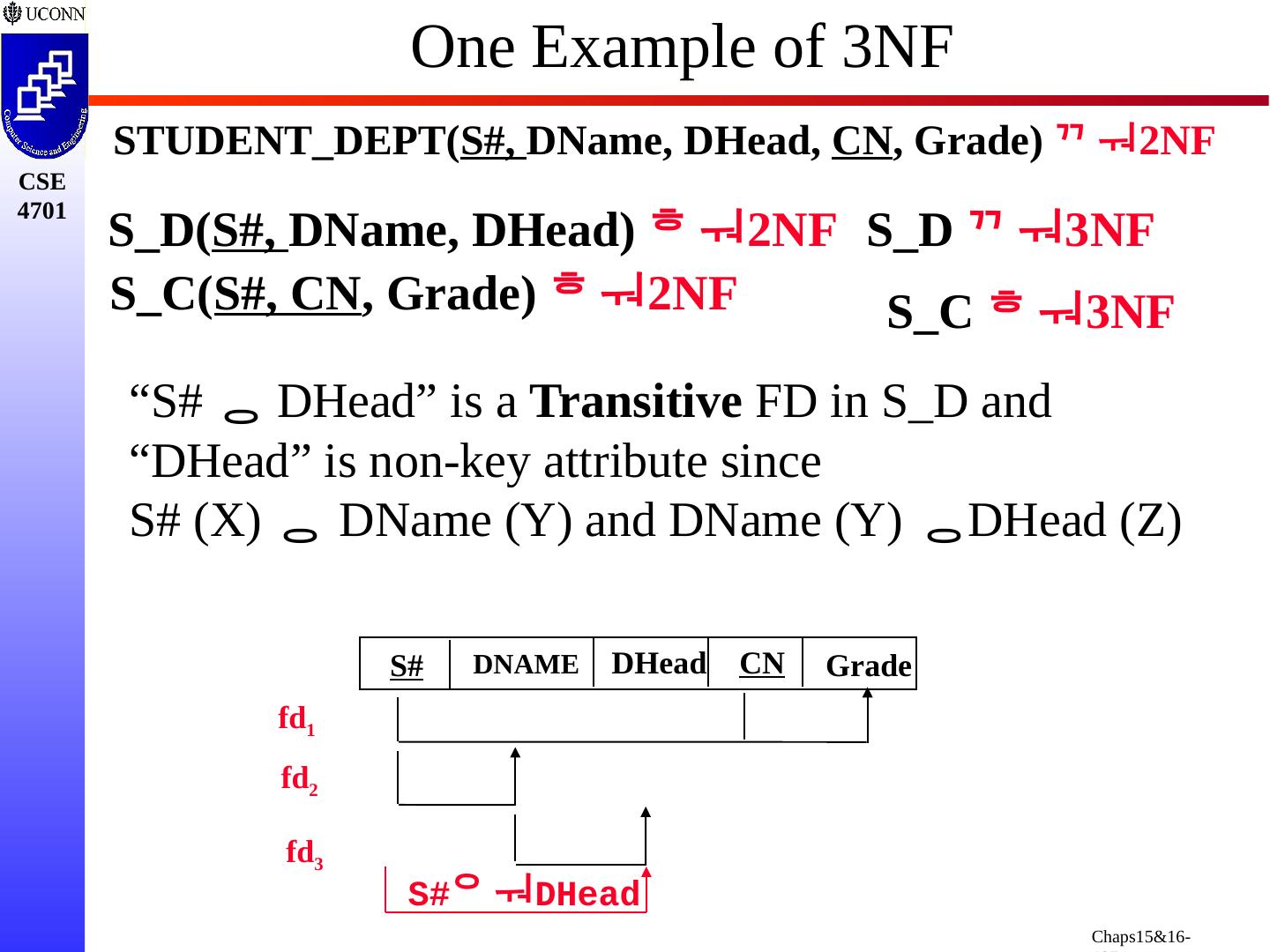
28 .Yet Another Example 1. Each Dept. has several students, and a student may enroll in one Dept. for his/her major 3. A student may register more than one course, and each course may have many students. 4. Each student registered for a course must have a corresponding grade 2. A Dept. has only one head , i.e., the Dept. chair STUDENT_DEPT(S#, DName , DHead , CN, Grade)
29 .Yet Another Example STUDENT_DEPT(S#, DName , DHead , CN, Grade ) s1, CSE, Smith, 1010, B s1, CSE, Smith, 2102, C s1, CSE, Smith, 4701, F s2, CSE, Smith, 1010, A- s2, CSE, Smith 4100, D
3秒后跳转登录页面
去登陆

