展开查看详情
1 .Chapters 17 & 18 6e, 13 & 14 5e: Design/Storage/Index Prof. Steven A. Demurjian, Sr. Computer Science & Engineering Department The University of Connecticut 191 Auditorium Road, Box U-155 Storrs, CT 06269-3155 steve@engr.uconn.edu http://www.engr.uconn.edu/~steve (860) 486 - 4818 A portion of these slides are being used with the permission of Dr. Ling Lui , Associate Professor, College of Computing, Georgia Tech. Other slides have been adapted from the AWL web site for the textbook. Remaining slides represent new material.
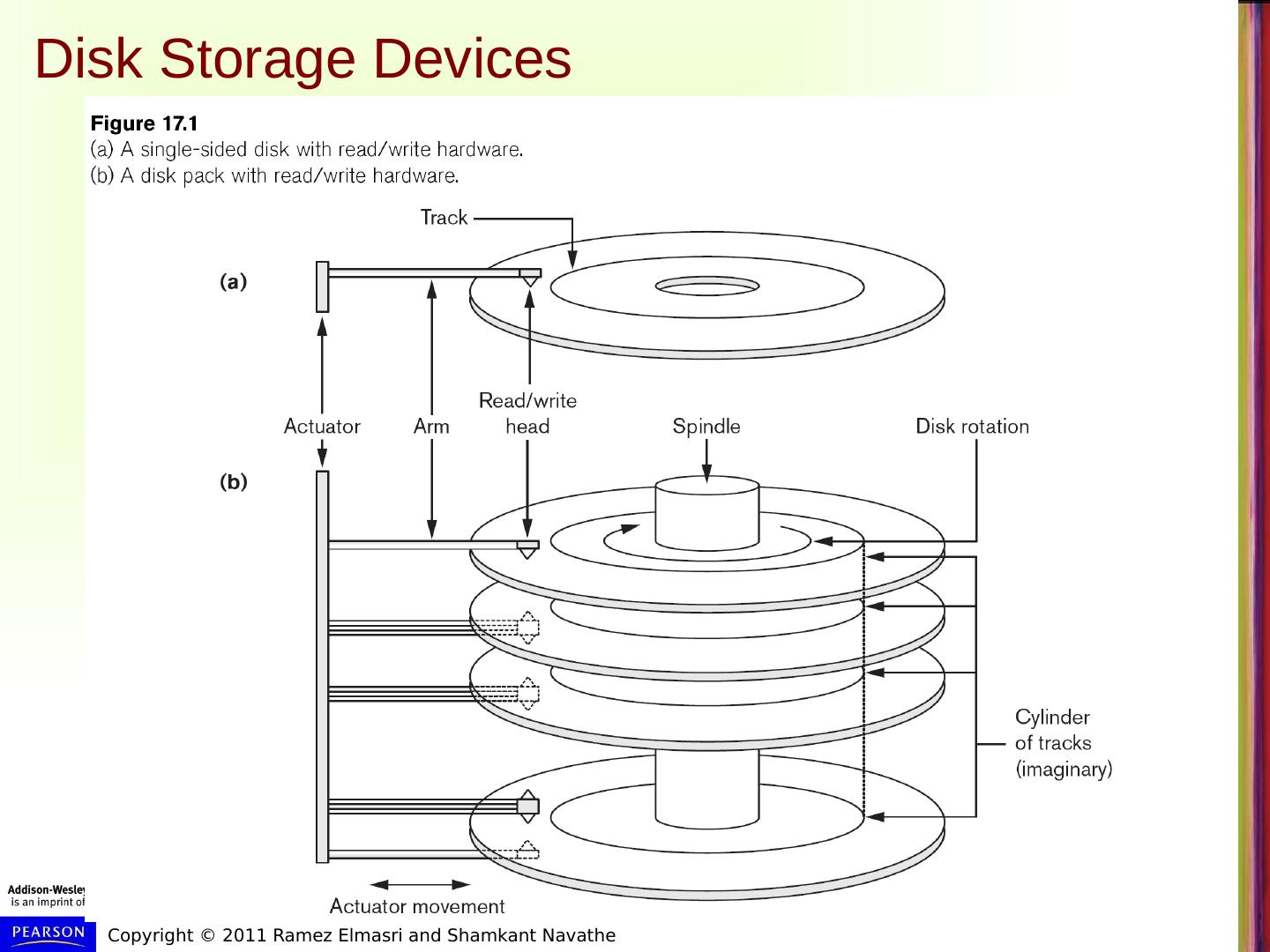
2 .Disk Storage Devices Preferred secondary storage device for high storage capacity and low cost. Data stored as magnetized areas on magnetic disk surfaces. A disk pack contains several magnetic disks connected to a rotating spindle. Disks are divided into concentric circular tracks on each disk surface . Track capacities vary typically from 4 to 50 Kbytes or more
3 .Disk Storage Devices A track is divided into smaller blocks or sectors because it usually contains a large amount of information The division of a track into sectors is hard-coded on the disk surface and cannot be changed. One type of sector organization calls a portion of a track that subtends a fixed angle at the center as a sector. A track is divided into blocks . The block size B is fixed for each system. Typical block sizes range from B=512 bytes to B=4096 bytes. Whole blocks are transferred between disk and main memory for processing.
4 .Disk Storage Devices A read-write head moves to the track that contains the block to be transferred. Disk rotation moves the block under the read-write head for reading or writing. A physical disk block (hardware) address consists of: a cylinder number (imaginary collection of tracks of same radius from all recorded surfaces) the track number or surface number (within the cylinder) and block number (within track). Reading or writing a disk block is time consuming because of the seek time s and rotational delay (latency) rd . Double buffering can be used to speed up the transfer of contiguous disk blocks.
6 .Typical Disk Parameters
7 .Records Fixed and variable length records Records contain fields which have values of a particular type E.g., amount, date, time, age Fields themselves may be fixed length or variable length Variable length fields can be mixed into one record: Separator characters or length fields are needed so that the record can be “parsed.”
8 .Blocking Blocking : Refers to storing a number of records in one block on the disk. Blocking factor ( bfr ) refers to the number of records per block. There may be empty space in a block if an integral number of records do not fit in one block. Spanned Records : Refers to records that exceed the size of one or more blocks and hence span a number of blocks.
9 .Average Access Times The following table shows the average access time to access a specific record for a given type of file
10 .Types of Single-Level Indexes Primary Index Defined on an ordered data file The data file is ordered on a key field Includes one index entry for each block in the data file; the index entry has the key field value for the first record in the block, which is called the block anchor A similar scheme can use the last record in a block. A primary index is a nondense (sparse) index, since it includes an entry for each disk block of the data file and the keys of its anchor record rather than for every search value.
11 .Primary Index on the Ordering Key Field
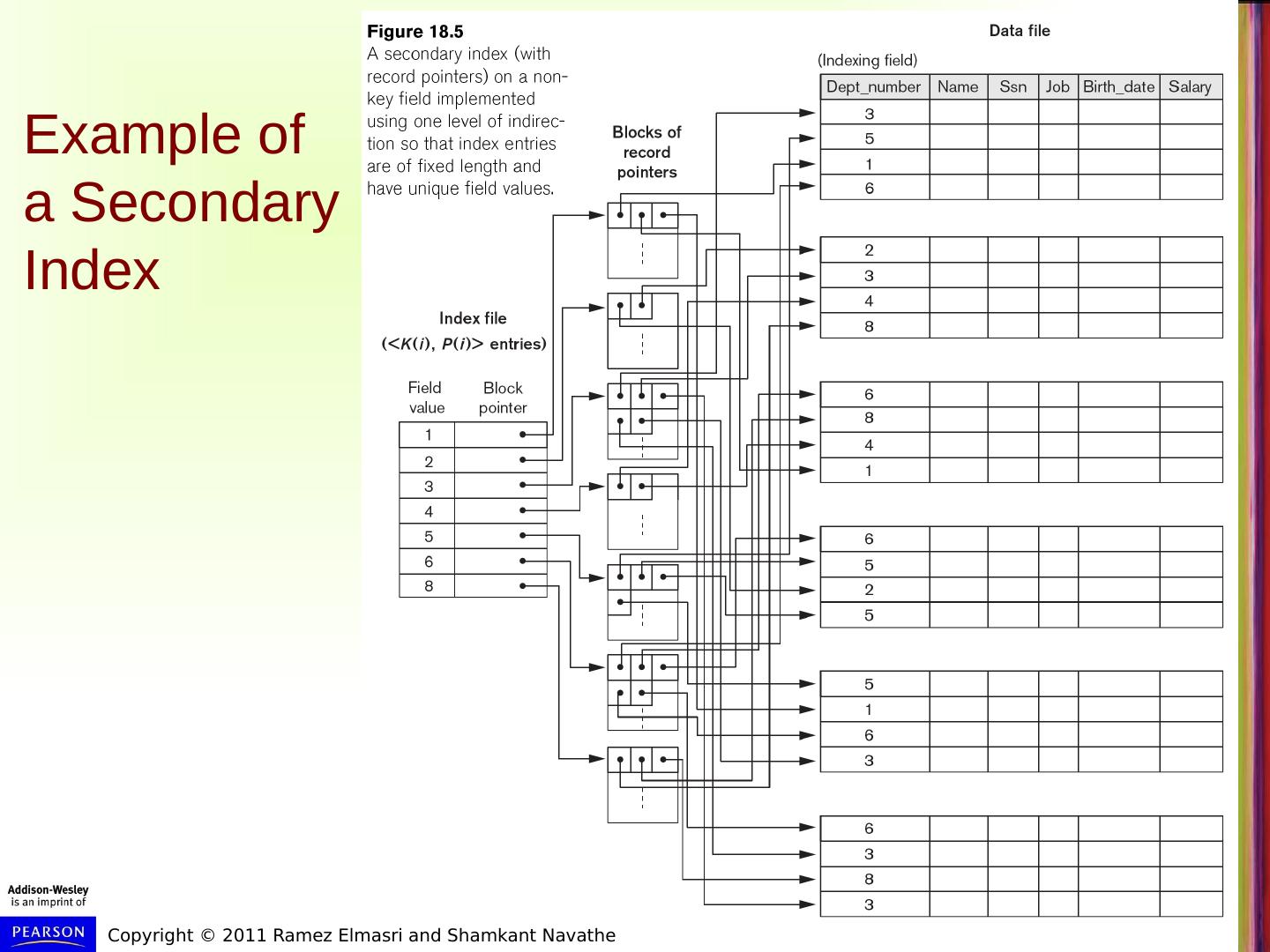
12 .Types of Single-Level Indexes Secondary Index A secondary index provides a secondary means of accessing a file for which some primary access already exists. The secondary index may be on a field which is a candidate key and has a unique value in every record, or a non-key with duplicate values. The index is an ordered file with two fields. The first field is of the same data type as some non-ordering field of the data file that is an indexing field. The second field is either a block pointer or a record pointer. There can be many secondary indexes (and hence, indexing fields) for the same file. Includes one entry for each record in the data file; hence, it is a dense index
13 .Example of a Dense Secondary Index
14 .Example of a Secondary Index
15 .Dynamic Multilevel Indexes Using B-Trees and B+-Trees Most multi-level indexes use B-tree or B+-tree data structures because of the insertion and deletion problem This leaves space in each tree node (disk block) to allow for new index entries These data structures are variations of search trees that allow efficient insertion and deletion of new search values. In B-Tree and B+-Tree data structures, each node corresponds to a disk block Each node is kept between half-full and completely full
16 .Dynamic Multilevel Indexes Using B-Trees and B+-Trees An insertion into a node that is not full is quite efficient If a node is full the insertion causes a split into two nodes Splitting may propagate to other tree levels A deletion is quite efficient if a node does not become less than half full If a deletion causes a node to become less than half full, it must be merged with neighboring nodes
17 .Difference between B-tree and B+-tree In a B-tree, pointers to data records exist at all levels of the tree In a B+-tree, all pointers to data records exists at the leaf-level nodes A B+-tree can have less levels (or higher capacity of search values) than the corresponding B-tree
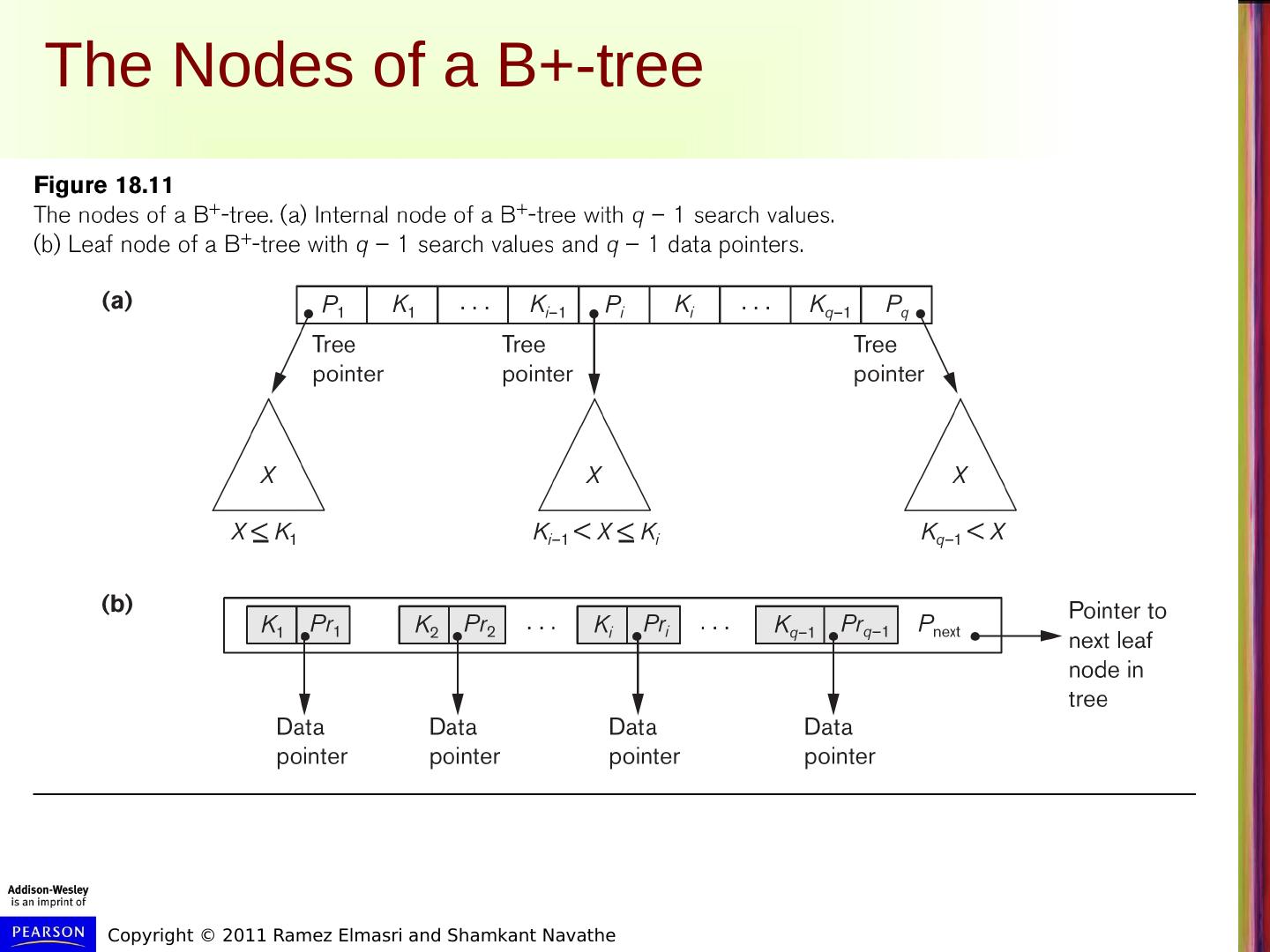
19 .The Nodes of a B+-tree
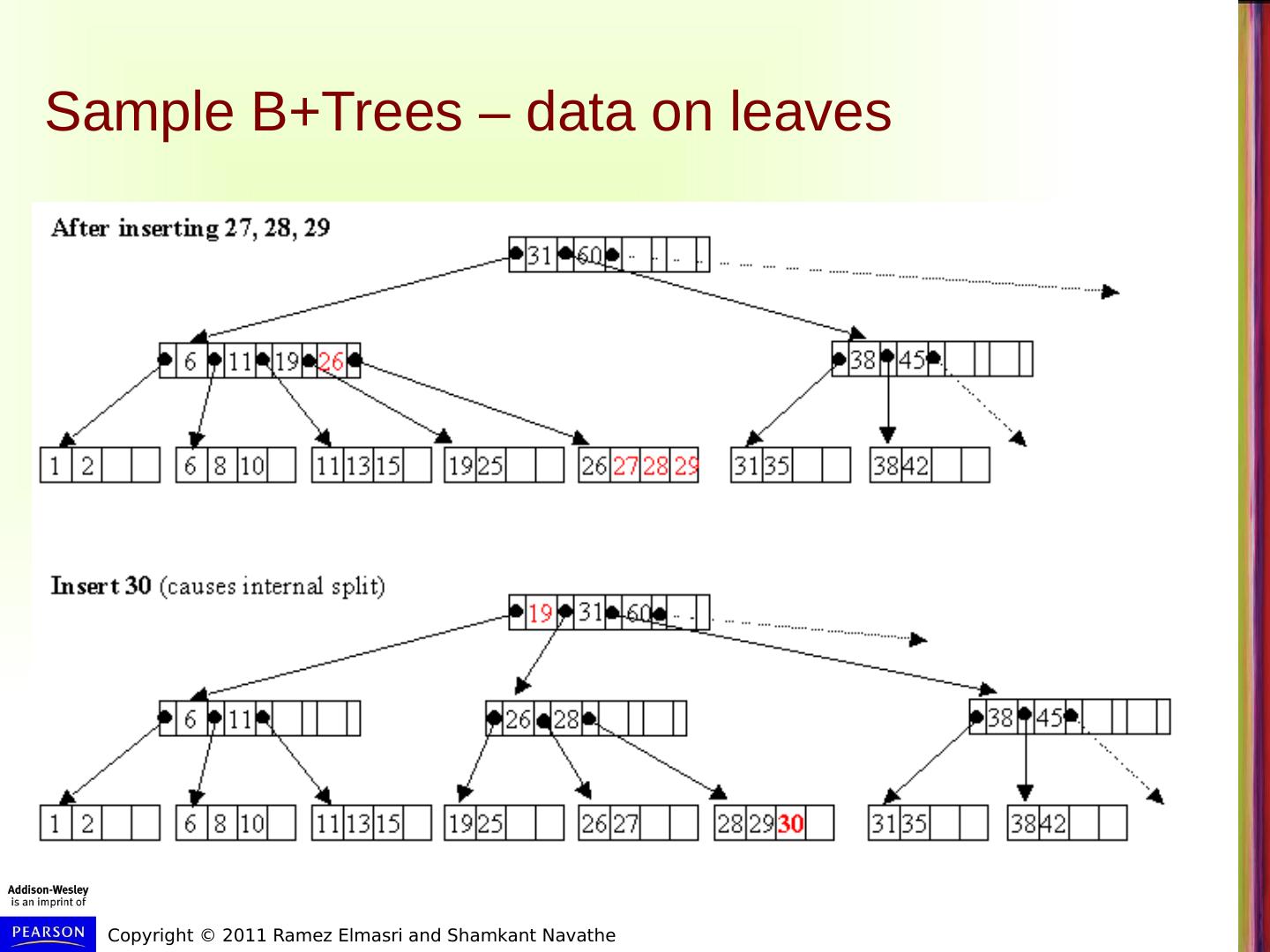
20 .Sample B+Trees – data on leaves
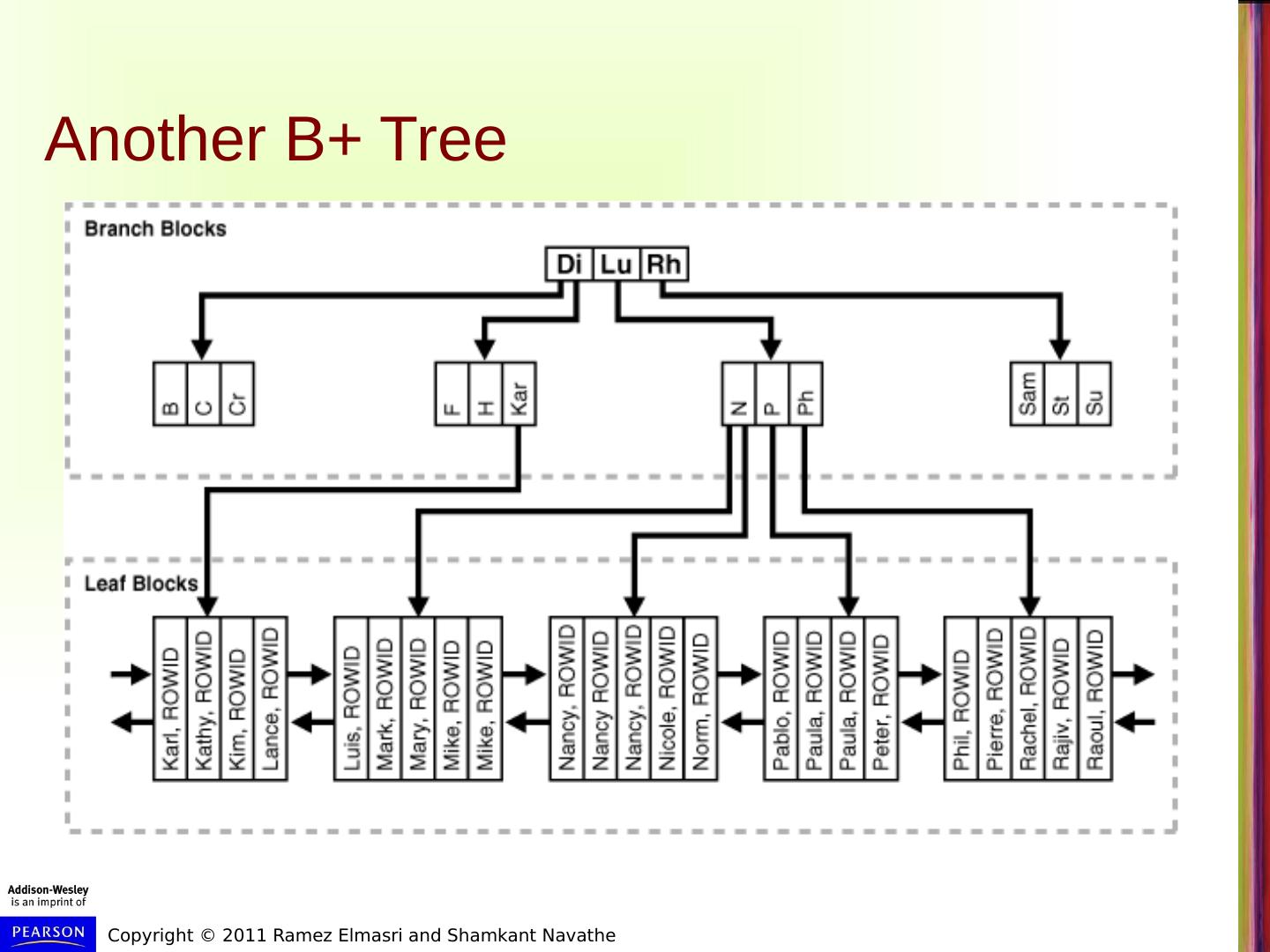
22 .Another Example – Nodes Linked
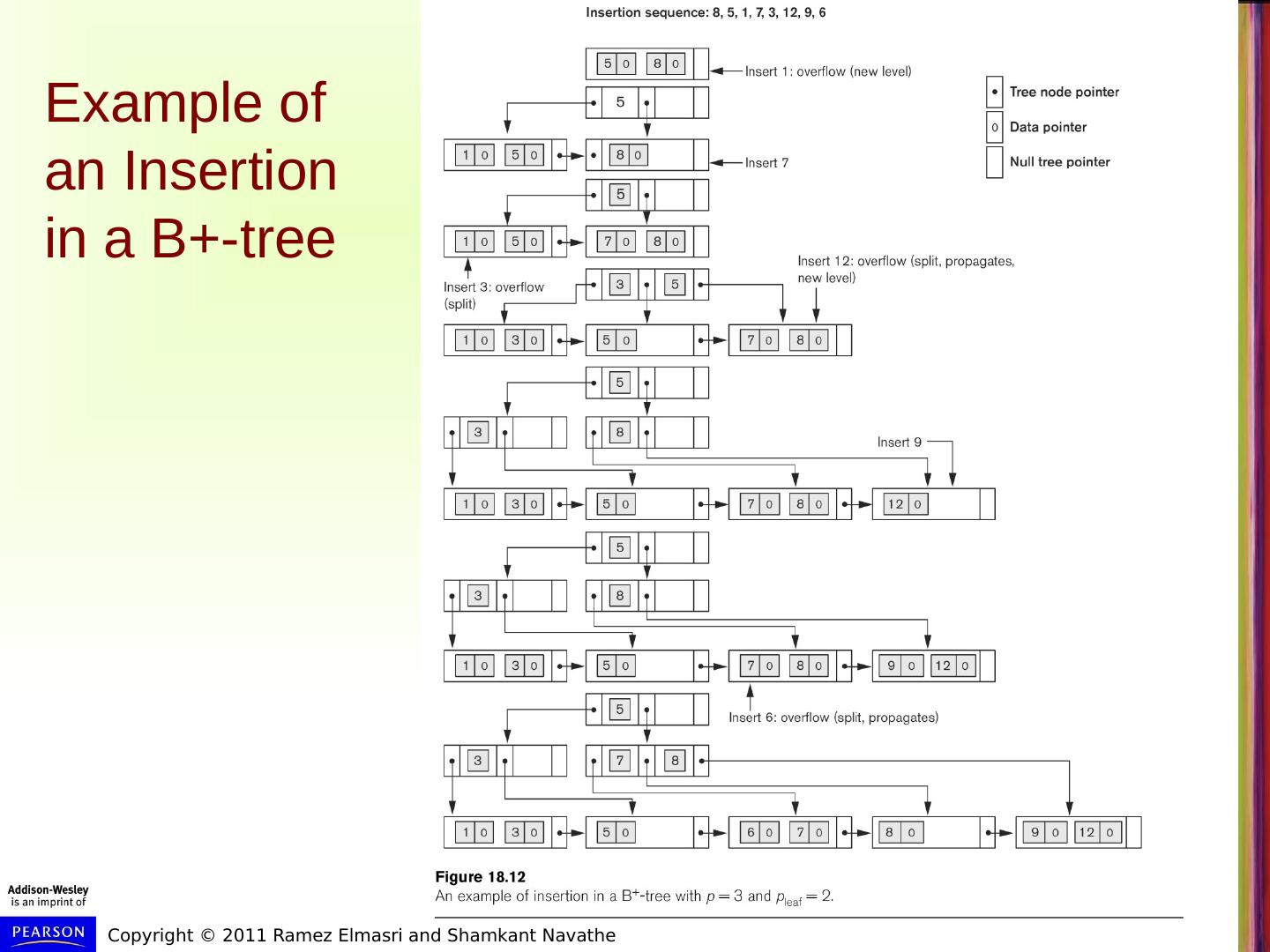
23 .Example of an Insertion in a B+-tree
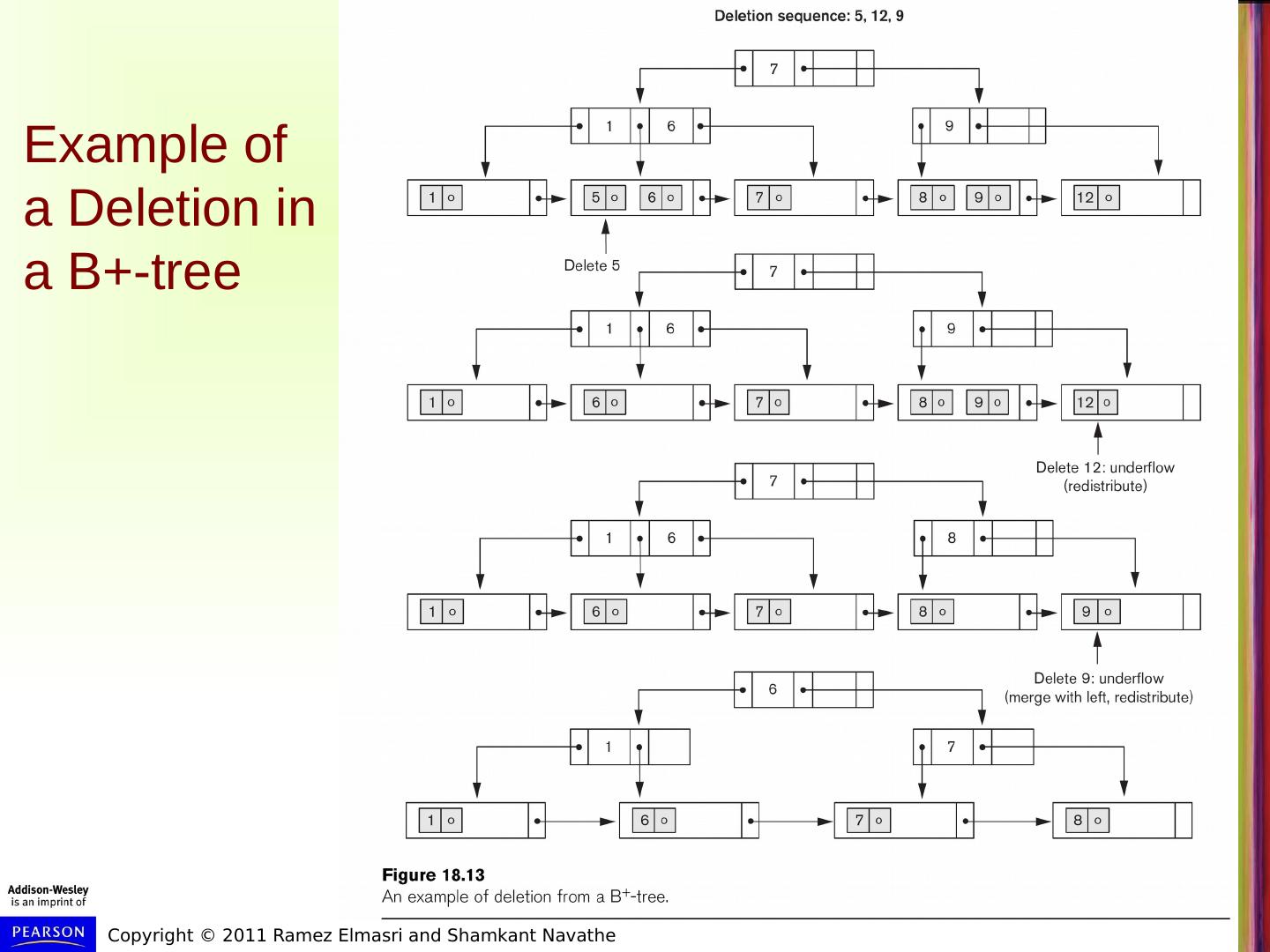
24 .Example of a Deletion in a B+-tree