展开查看详情
2 .目 录 CONTENTS 一、数据仓库的定义 三、数据仓库架构 四、数据仓库设计 二、操作型系统与分析型系统 五、数据分层
3 .数据仓库是一个面向主题的、集成的、随时间变化的、非易失的数据集合,用于支持管理者的决策过程。 集成:将多个分散的数据源统一成一致的、无歧义的数据格式后放置到数据仓库中,解决命名冲突、计量单位不一致等问题; 随时间变化:数据仓库中的数据反映了某一历史时间点的数据快照; 非易失:一旦进入数据仓库中,数据就不应该再有改变。 数据仓库中的粒度是指数据的细节或汇总程度,细节程度越高,粒度级别越低。 数据仓库中的数据来自各个业务应用系统。 很多因素导致直接访问业务系统无法进行全局数据分析的工作,这也是需要一个数据仓库的原因所在。 数据仓库的基本需求是安全性、可访问性、自动化,对数据的要求是准确性、时效性、历史可追溯性。 数据仓库的定义
4 .数据仓库是一个面向主题的、集成的、随时间变化的、非易失的数据集合,用于支持管理者的决策过程。 集成:将多个分散的数据源统一成一致的、无歧义的数据格式后放置到数据仓库中,解决命名冲突、计量单位不一致等问题; 随时间变化:数据仓库中的数据反映了某一历史时间点的数据快照; 非易失:一旦进入数据仓库中,数据就不应该再有改变。 数据仓库中的粒度是指数据的细节或汇总程度,细节程度越高,粒度级别越低。 数据仓库中的数据来自各个业务应用系统。 很多因素导致直接访问业务系统无法进行全局数据分析的工作,这也是需要一个数据仓库的原因所在。 数据仓库的基本需求是安全性、可访问性、自动化,对数据的要求是准确性、时效性、历史可追溯性。 数据仓库的定义
5 .操作型系统与分析型系统 操作性系统 操作性系统是一类专门用于管理面向事务的应用的信息系统。 几乎所有的互联网线上系统、 OA 等都属于这类系统的应用。 第一范式( 1NF ) 表中的列只能含有原子性(不可在分割)。 第二范式( 2NF ) 满足第一范式;没有部分依赖。 第三范式( 3NF ) 满足第二范式;没有传递依赖。 分析型系统 分析型系统是一种快速回答多维分析查询的实现方式。 分析型系统的典型应用包括市场管理报告、预算和预测、金融分析报告及其类似的应用。 数据库物理设计: 并行化操作、 表分区 成本考虑
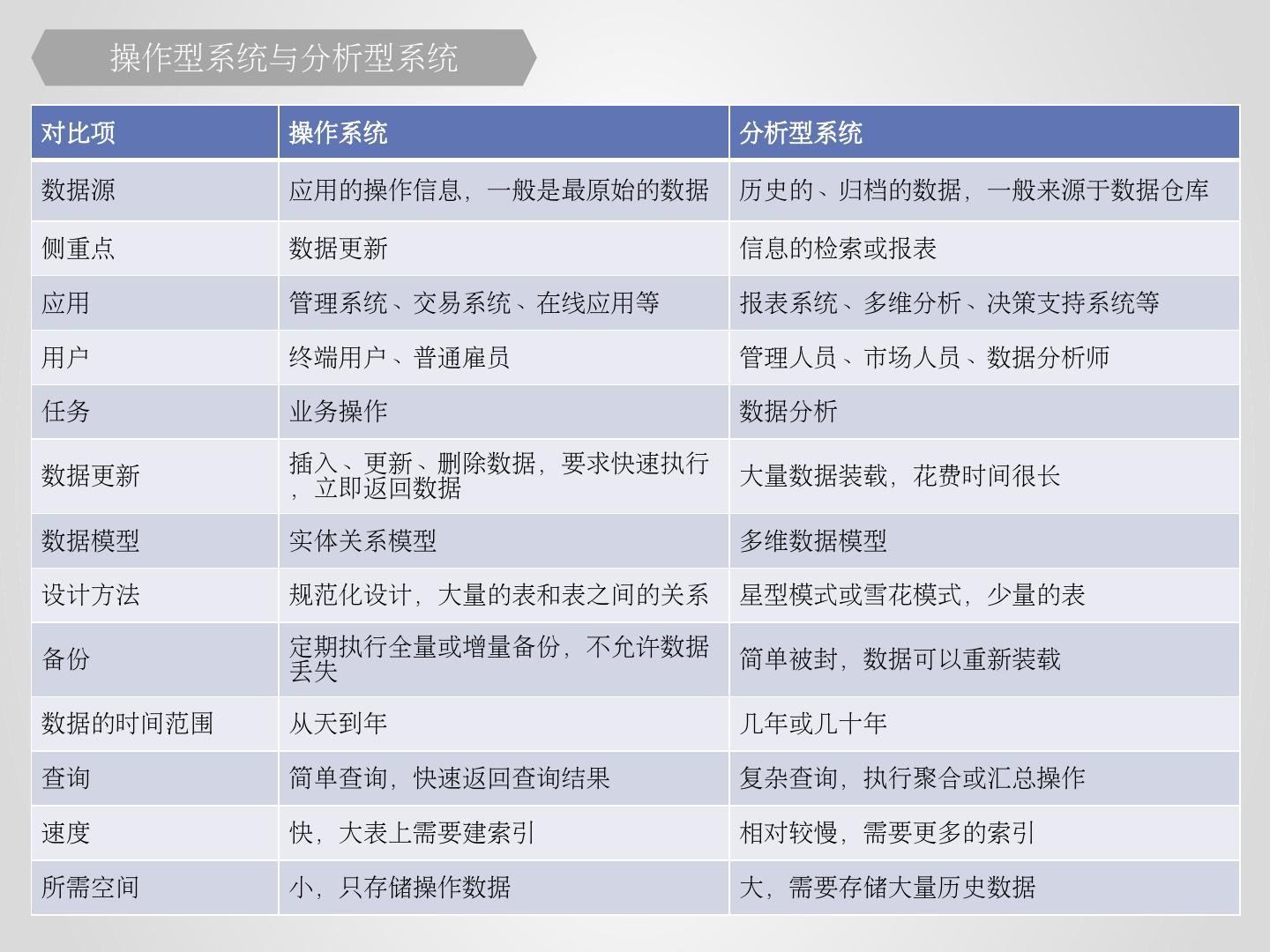
6 .对比项 操作系统 分析型系统 数据源 应用的操作信息,一般是最原始的数据 历史的、归档的数据,一般来源于数据仓库 侧重点 数据更新 信息的检索或报表 应用 管理系统、交易系统、在线应用等 报表系统、多维分析、决策支持系统等 用户 终端用户、普通雇员 管理人员、市场人员、数据分析师 任务 业务操作 数据分析 数据更新 插入、更新、删除数据,要求快速执行,立即返回数据 大量数据装载,花费时间很长 数据模型 实体关系模型 多维数据模型 设计方法 规范化设计,大量的表和表之间的关系 星型模式或雪花模式,少量的表 备份 定期执行全量或增量备份,不允许数据丢失 简单被封,数据可以重新装载 数据的时间范围 从天到年 几年或几十年 查询 简单查询,快速返回查询结果 复杂查询,执行聚合或汇总操作 速度 快,大表上需要建索引 相对较慢,需要更多的索引 所需空间 小,只存储操作数据 大,需要存储大量历史数据 操作型系统与分析型系统
7 .对比项 操作系统 分析型系统 数据源 应用的操作信息,一般是最原始的数据 历史的、归档的数据,一般来源于数据仓库 侧重点 数据更新 信息的检索或报表 应用 管理系统、交易系统、在线应用等 报表系统、多维分析、决策支持系统等 用户 终端用户、普通雇员 管理人员、市场人员、数据分析师 任务 业务操作 数据分析 数据更新 插入、更新、删除数据,要求快速执行,立即返回数据 大量数据装载,花费时间很长 数据模型 实体关系模型 多维数据模型 设计方法 规范化设计,大量的表和表之间的关系 星型模式或雪花模式,少量的表 备份 定期执行全量或增量备份,不允许数据丢失 简单被封,数据可以重新装载 数据的时间范围 从天到年 几年或几十年 查询 简单查询,快速返回查询结果 复杂查询,执行聚合或汇总操作 速度 快,大表上需要建索引 相对较慢,需要更多的索引 所需空间 小,只存储操作数据 大,需要存储大量历史数据 操作型系统与分析型系统
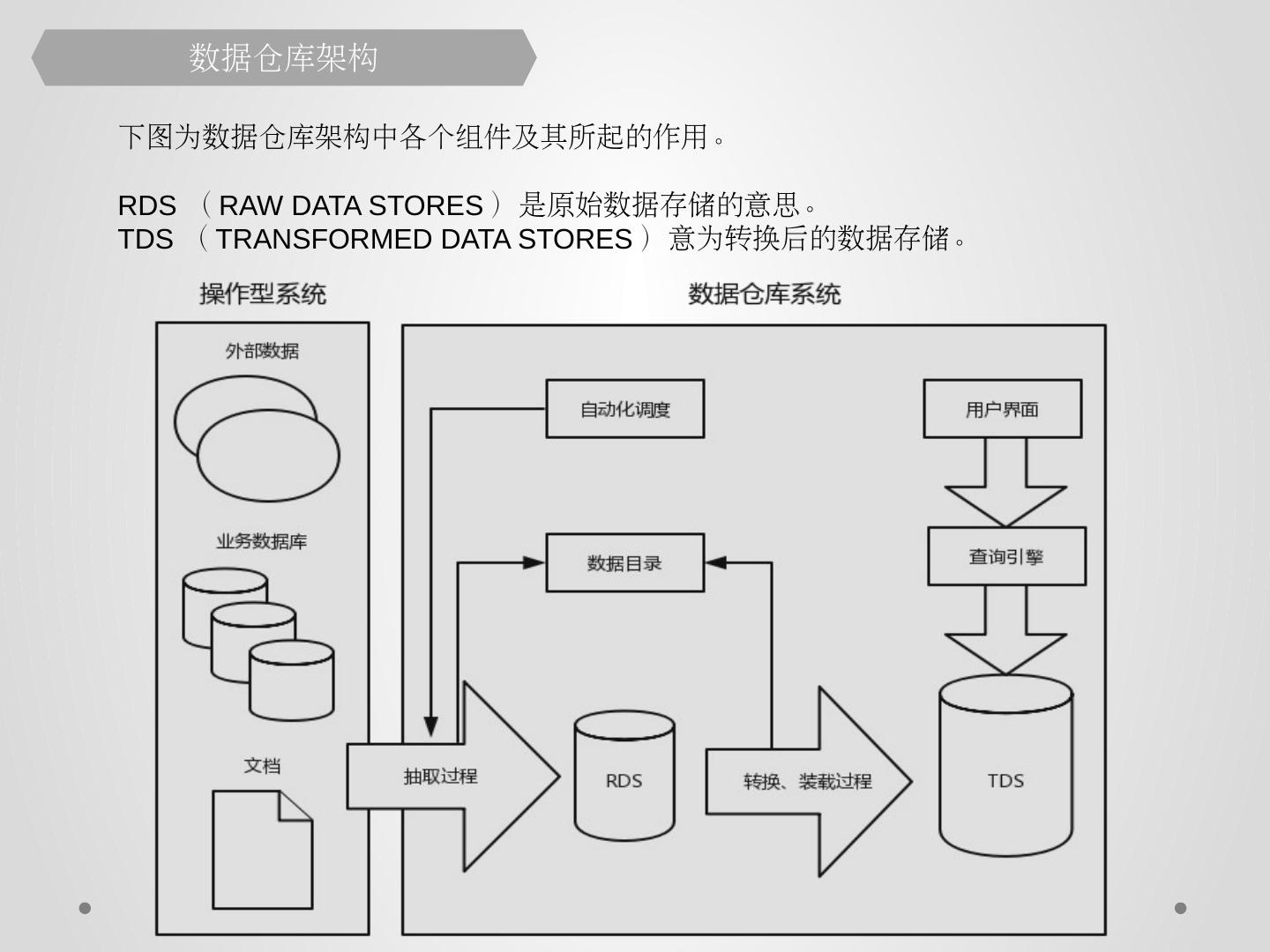
8 .数据仓库架构 下图为数据仓库架构中各个组件及其所起的作用。 RDS ( RAW DATA STORES )是原始数据存储的意思。 TDS ( TRANSFORMED DATA STORES )意为转换后的数据存储。
9 .数据仓库架构 Inmon 企业信息工厂架构 应用系统 -> ETL 过程 -> 企业级数据仓库 -> 部门级数据集市
10 .数据仓库架构 Inmon 企业信息工厂架构 应用系统 -> ETL 过程 -> 企业级数据仓库 -> 部门级数据集市
11 .数据仓库设计 维度数据模型 维度数据模型简称维度模型( Dimensional modeling , DM )是一套技术和概念的集合,用于数据仓库设计。 构建维度模型步骤: 选择业务流程 确认哪些业务处理流程是数据仓库应该覆盖的,是维度方法的基础。 声明粒度 确认了业务流程后,下一步是声明维度模型的粒度。 确认维度 设计过程的第三步是确认模型的维度。维度的粒度必须和第二步所声明的粒度一致。 确认事实 确认维度后,下一步也是维度模型四步设计法的最后一步,就是确认事实。这一步识别数字化的度量,构成事实表的记录。
12 .数据仓库设计 维度数据模型 事实和维度是两个维度模型中的核心概念。事实表示对业务数据的度量,而维度是观察数据的角度。 维度表 维度表的记录数通常比事实表少,但每条记录包含有大量用于描述事实数据的属性字段。 例如:时间、地理、产品、人员等 事实表 事实表记录了特定事件的数字化的考量,一般由数字值和指向维度表的外键组成。 例如:销售、月底账户余额、当月的总的销售金额等
13 .数据分层 属性 描述 主键 系统生成的代理键,供内部使用 业务主键 唯一标识的业务单元,用于已知业务的源系统 属性 {1...N} 属性自身 版本 数据的更新标识 生效时间 数据第一次装载到数据仓库时系统生成的时间戳 失效时间 数据失效时的时间戳 维度表 属性 描述 主键 系统生成的代理键,供内部使用 外键{1...N} 引用维度表的代理键 度量值 发生在业务系统中的操作性事务所产生的可度量数值 分区字段 由该字段做物理分区 事实表
15 .数据分层 DV ( Data Vault ) 模型 介绍 DV 是一种数据仓库建模方法,用来存储来自多个操作型系统的完整的历史数据。 特点 所有数据都基于时间来存储,即使数据是低质量的,也不能在 ETL 过程中处理掉。 依赖越少越好。 和源系统越独立越好。 设计上适合变化。 源系统中数据后的变化。 在不改变模型的情况下可扩展。 ETL 工作可重复执行。 数据完全可追踪。
16 .数据分层 属性 描述 主键 系统生成的代理键,供内部使用 业务主键 唯一标识的业务单元,用于已知业务的源系统 装载时间 数据第一次装载到数据仓库时系统生成的时间戳 数据来源 定义了数据来源(例如源系统或表) 中心表 属性 描述 主键 系统生成的代理键,供内部使用 外键{1...N} 引用中心表的代理键 装载时间 数据第一次装载到数据仓库时系统生成的时间戳 数据来源 定义了数据来源(例如源系统或表) 链接表 属性 描述 主键 系统生成的代理键,供内部使用 外键 引用中心表或链接表的代理键 装载时间 数据第一次装载到数据仓库时系统生成的时间戳 失效时间 数据失效时的时间戳 数据来源 定义了数据来源(例如源系统或表) 属性 {1...N} 属性自身 附属表 Data Vault 模型
17 .数据分层 属性 描述 主键 系统生成的代理键,供内部使用 业务主键 唯一标识的业务单元,用于已知业务的源系统 装载时间 数据第一次装载到数据仓库时系统生成的时间戳 数据来源 定义了数据来源(例如源系统或表) 中心表 属性 描述 主键 系统生成的代理键,供内部使用 外键{1...N} 引用中心表的代理键 装载时间 数据第一次装载到数据仓库时系统生成的时间戳 数据来源 定义了数据来源(例如源系统或表) 链接表 属性 描述 主键 系统生成的代理键,供内部使用 外键 引用中心表或链接表的代理键 装载时间 数据第一次装载到数据仓库时系统生成的时间戳 失效时间 数据失效时的时间戳 数据来源 定义了数据来源(例如源系统或表) 属性 {1...N} 属性自身 附属表 Data Vault 模型
18 .数据分层 为什么要分层 我们对数据进行分层的一个主要原因就是希望在管理数据的时候,能对数据有一个更加清晰的掌控,详细来讲,主要有下面几个原因: 清晰数据结构:每一个数据分层都有它的作用域,这样我们在使用表的时候能更方便地定位和理解。 数据血缘追踪:简单来讲可以这样理解,我们最终给业务诚信的是一能直接使用的张业务表,但是它的来源有很多,如果有一张来源表出问题了,我们希望能够快速准确地定位到问题,并清楚它的危害范围。 减少重复开发:规范数据分层,开发一些通用的中间层数据,能够减少极大的重复计算。 把复杂问题简单化。将一个复杂的任务分解成多个步骤来完成,每一层只处理单一的步骤,比较简单和容易理解。而且便于维护数据的准确性,当数据出现问题之后,可以不用修复所有的数据,只需要从有问题的步骤开始修复。 屏蔽原始数据的异常。 屏蔽业务的影响,不必改一次业务就需要重新接入数据。
19 .数据分层 怎样分层 我们从理论上,可以把数据仓库分为下面三个层: RDS ( Raw Data Store ),原始数据层 DW( Data Warehouse ),数据仓库层 DM ( Data Market ),数据集市层 实例 原始数据层( RDS [23]) 数据仓库层 明细层( DWD : Data Warehouse Detail [21] ), 历史操作数据层( DWO : Data Warehouse Operational [49] ), 轻度汇总层( DWS : Data Warehouse Service ) 数据集市层( DM ) RDS 关系型; DWO 层遵循 DV ( Data Vault ) 模型构建; DWD 层使用星型模式; DWS 层使用雪花模式; DM 层使用雪花模式。