

































































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
TLP和缓存一致性
什么是TLP?什么是ILP?在本章中对这个做了介绍,以及将他们做了对比,另外介绍了OpenMP作为C的简单并行扩展,OpenMP的作用以及使用规律,在过程中线程级编程与并行的实用程序,私有变量,缩减等。
展开查看详情
1 .CS 61C: Great Ideas in Computer Architecture TLP and Cache Coherency Instructors: Krste Asanović and Randy H. Katz http://inst.eecs.Berkeley.edu/~cs61c/fa17 1 Fall 2017 -- Lecture #20 11/8/17
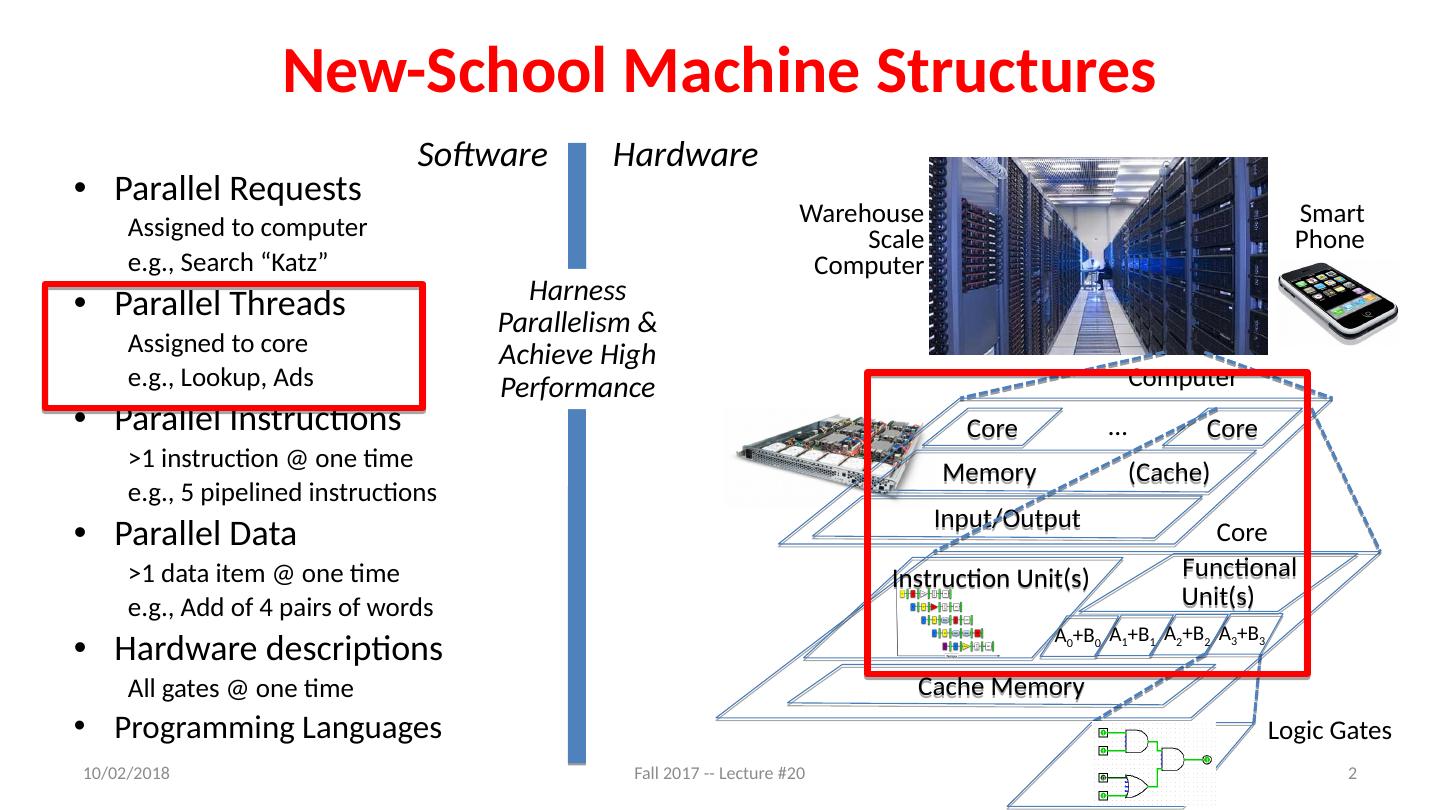
2 .New-School Machine Structures Parallel Requests Assigned to computer e.g., Search “Katz” Parallel Threads Assigned to core e.g., Lookup, Ads Parallel Instructions >1 instruction @ one time e.g., 5 pipelined instructions Parallel Data >1 data item @ one time e.g., Add of 4 pairs of words Hardware descriptions All gates @ one time Programming Languages 11/8/17 Fall 2017 -- Lecture #20 2 Smart Phone Warehouse Scale Computer Software Hardware Harness Parallelism & Achieve High Performance Logic Gates Core Core … Memory (Cache) Input/Output Computer Cache Memory Core Instruction Unit(s ) Functional Unit(s ) A 3 +B 3 A 2 +B 2 A 1 +B 1 A 0 +B 0
3 .Agenda Thread Level Parallelism Revisited Open MP Part II Multiprocessor Cache Coherency False Sharing (if time) And, in Conclusion, … 11/8/17 Fall 2017 -- Lecture #20 3
4 .Agenda Thread Level Parallelism Revisited Open MP Part II Multiprocessor Cache Coherency False Sharing (if time) And, in Conclusion, … 11/8/17 Fall 2017 -- Lecture #20 4
5 .ILP vs. TLP Instruction Level Parallelism Multiple instructions in execution at the same time, e.g., instruction pipelining Superscalar : launch more than one instruction at a time, typically from one instruction stream ILP limited because of pipeline hazards 11/8/17 Fall 2017 -- Lecture #20 5
6 .ILP vs. TLP Thread Level Parallelism Thread : sequence of instructions, with own program counter and processor state (e.g., register file) Multicore : Physical CPU : One thread (at a time) per CPU, in software OS switches threads typically in response to I/O events like disk read/write Logical CPU : Fine-grain thread switching, in hardware, when thread blocks due to cache miss/memory access Hyperthreading (aka Simultaneous Multithreading --SMT): Exploit superscalar architecture to launch instructions from different threads at the same time! 11/8/17 Fall 2017 -- Lecture #20 6
7 .SMT (HT): Logical CPUs > Physical CPUs Run multiple threads at the same time per core Each thread has own architectural state (PC, Registers, etc.) Share resources (cache, instruction unit, execution units) Improves Core CPI (clock ticks per instruction) May degrade Thread CPI (Utilization/Bandwidth v. Latency) See http://dada.cs.washington.edu/smt / 11/8/17 Fall 2017 -- Lecture #20 7
8 .11/8/17 Fall 2017 -- Lecture #20 8
9 .Review: Randy’s (Rather Old) Mac Air / usr/sbin/sysctl -a | grep hw\. hw.model = Core i7, 4650U … hw.physicalcpu : 2 hw.logicalcpu : 4 … hw.cpufrequency = 1,700,000,000 hw.physmem = 8,589,934,592 (8 Gbytes ) ... hw.cachelinesize = 64 hw.l1icachesize: 32,768 hw.l1dcachesize: 32,768 hw.l2cachesize: 262,144 hw.l3cachesize: 4,194,304 Every machine is multicore, Even your phone! 11/8/17 Fall 2017 -- Lecture #20 9
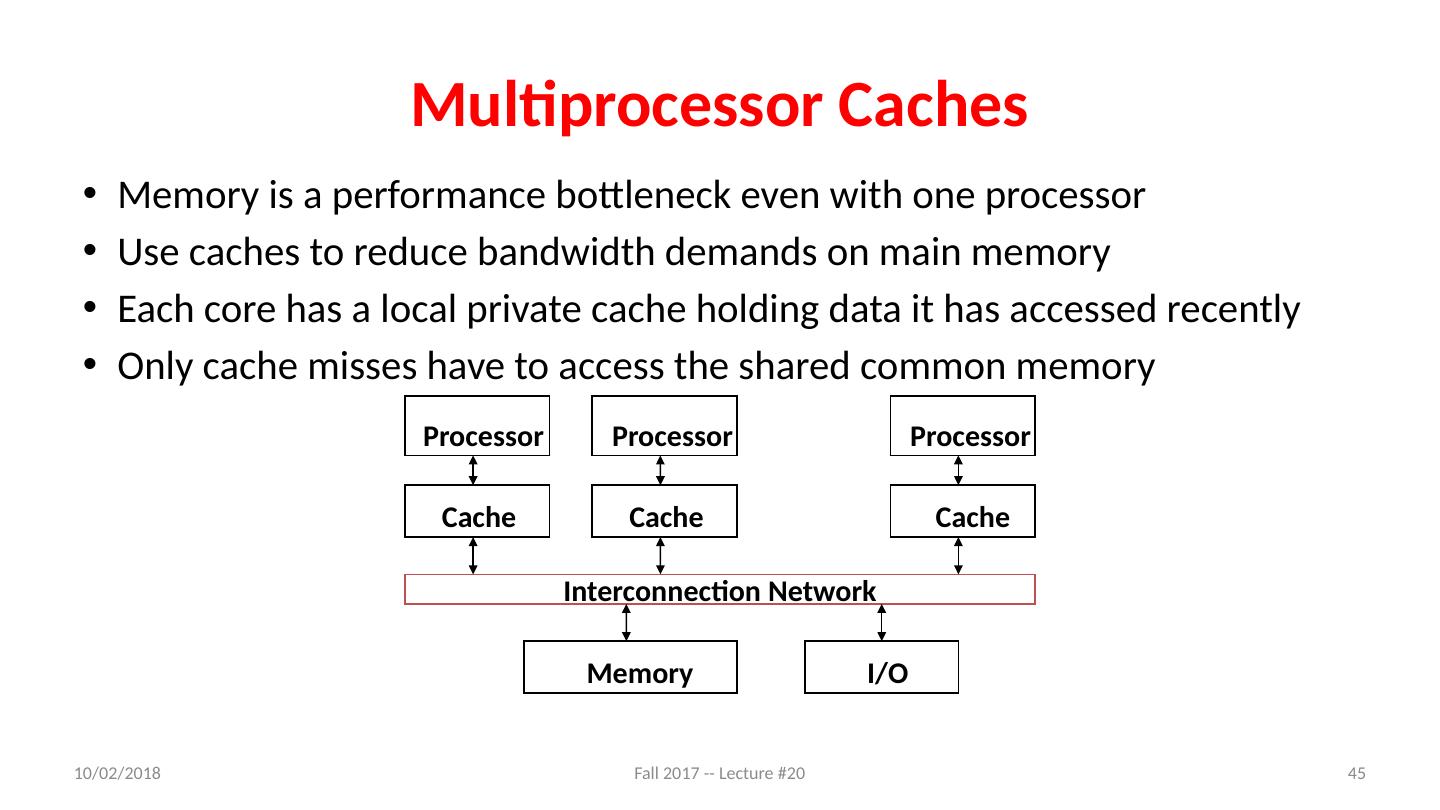
10 .Review: Hive Machines hw.model = Core i7 4770K hw.physicalcpu : 4 hw.logicalcpu : 8 … hw.cpufrequency = 3,900,000,000 hw.physmem = 34,359,738,368 hw.cachelinesize = 64 hw.l1icachesize: 32,768 hw.l1dcachesize: 32,768 hw.l2cachesize: 262,144 hw.l3cachesize: 8,388,608 Therefore, should try up to 8 threads to see if performance gain even though only 4 cores 11/8/17 Fall 2017 -- Lecture #20 10
11 .Review: Why Parallelism? Only path to performance is parallelism Clock rates flat or declining SIMD: 2X width every 3-4 years AVX-512 2015, 1024b in 2018? 2019? MIMD: Add 2 cores every 2 years (2, 4, 6, 8, 10, …) Intel Broadwell -Extreme (2Q16): 10 Physical CPUs, 20 Logical CPUs K ey challenge: craft parallel programs with high performance on multiprocessors as # of processors increase – i.e., that scale Scheduling, load balancing, time for synchronization, overhead for communication Project #3: fastest code on 8 processor computer 2 logical CPUs/core, 8 cores/computer 11/8/17 Fall 2017 -- Lecture #20 11
12 .Agenda Thread Level Parallelism Revisited Open MP Part II Multiprocessor Cache Coherency False Sharing (if time) And, in Conclusion, … 11/8/17 Fall 2017 -- Lecture #20 12
13 .Review: OpenMP Building Block: for loop for (i=0; i<max; i++) zero[i] = 0; Breaks for loop into chunks, and allocate each to a separate thread e.g. if max = 100 with 2 threads: assign 0-49 to thread 0, and 50-99 to thread 1 Must have relatively simple “shape” for an OpenMP -aware compiler to be able to parallelize it Necessary for the run-time system to be able to determine how many of the loop iterations to assign to each thread No premature exits from the loop allowed i.e. No break , return , exit , goto statements In general, don’t jump outside of any pragma block 11/8/17 Fall 2017 -- Lecture #20 13
14 .#pragma omp parallel for for (i=0; i<max; i++) zero[i] = 0; Master thread creates additional threads, each with a separate execution context All variables declared outside for loop are shared by default, except for loop index which is implicitly private per thread Implicit “barrier” synchronization at end of for loop Divide index regions sequentially per thread Thread 0 gets 0, 1, …, (max/n)-1; Thread 1 gets max/n, max/n+1, …, 2*(max/n)-1 Why? Review: OpenMP Parallel for pragma 14 11/8/17 Fall 2017 -- Lecture #20
15 .Example 2: Computing p http://openmp.org/mp-documents/omp-hands-on-SC08.pdf 15 11/8/17 Fall 2017 - Lecture # 19
16 .Review: Working Parallel p 16 11/8/17 Fall 2017 - Lecture #20
17 .Trial Run i = 1, id = 1 i = 0, id = 0 i = 2, id = 2 i = 3, id = 3 i = 5, id = 1 i = 4, id = 0 i = 6, id = 2 i = 7, id = 3 i = 9, id = 1 i = 8, id = 0 pi = 3.142425985001 17 11/8/17 Fall 2017 - Lecture #20
18 .Scale up: num_steps = 10 6 pi = 3.141592653590 Y ou verify how many digits are correct … 18 11/8/17 Fall 2017 - Lecture #20
19 .Can We Parallelize C omputing sum ? Summation inside parallel section Insignificant speedup in this example, but … pi = 3.138450662641 Wrong ! And value changes between runs ?! What’s going on? Always looking for ways to beat Amdahl’s Law … 19 11/8/17 Fall 2017 - Lecture #20
20 .Operation is really pi = pi + sum[id] What if >1 threads reads current (same) value of pi , computes the sum, stores the result back to pi ? Each processor reads same intermediate value of pi ! Result depends on who gets there when A “race” result is not deterministic What’s Going On? 20 11/8/17 Fall 2017 - Lecture #20
21 .OpenMP Reduction double avg , sum=0.0, A[MAX]; int i ; #pragma omp parallel for private ( sum ) for ( i = 0; i <= MAX ; i ++) sum += A[ i ]; avg = sum/MAX; // bug Problem is that we really want sum over all threads! Reduction : specifies that 1 or more variables that are private to each thread are subject of reduction operation at end of parallel region: reduction( operation:var ) where Operation : operator to perform on the variables ( var ) at the end of the parallel region Var : One or more variables on which to perform scalar reduction. double avg , sum=0.0, A[MAX]; int i ; #pragma omp for reduction(+ : sum) for ( i = 0; i <= MAX ; i ++) sum += A[ i ]; avg = sum/MAX; 11/8/17 Fall 2017 -- Lecture #20 21
22 .Calculating π Original Version #include < omp.h > #define NUM_THREADS 4 static long num_steps = 100000; double step; void main () { int i ; double x, pi, sum[NUM_THREADS]; step = 1.0/(double) num_steps ; #pragma omp parallel private ( i , x ) { int id = omp_get_thread_num (); for ( i =id, sum[id]=0.0; i < num_steps ; i = i+NUM_THREADS ) { x = (i+0.5)*step; sum[id] += 4.0/(1.0+x*x); } } for( i =1; i <NUM_THREADS; i ++) sum[0] += sum[ i ]; pi = sum[0]; printf ("pi = %6.12f
23 .Version 2: p arallel for, reduction #include < omp.h > #include < stdio.h > /static long num_steps = 100000; double step; void main () { int i ; double x , pi, sum = 0.0; step = 1.0/(double) num_steps ; #pragma omp parallel for private(x) reduction(+:sum) for ( i =1; i <= num_steps ; i ++){ x = (i-0.5)*step; sum = sum + 4.0/(1.0+x*x); } pi = sum; printf ("pi = %6.8f
24 .Data Races and Synchronization Two memory accesses form a data race if from different threads access same location, at least one is a write, and they occur one after another If there is a data race, result of program varies depending on chance (which thread first?) Avoid data races by synchronizing writing and reading to get deterministic behavior Synchronization done by user-level routines that rely on hardware synchronization instructions 11/8/17 Fall 2017 -- Lecture #20 24
25 .Locks Computers use locks to control access to shared resources Serves purpose of microphone in example Also referred to as “semaphore” Usually implemented with a variable int lock; 0 for unlocked 1 for locked 25 11/8/17 Fall 2017 - Lecture #20
26 .Synchronization with Locks // wait for lock released while (lock != 0) ; // lock == 0 now (unlocked) // set lock lock = 1; // access shared resource ... // e.g. pi // sequential execution! (Amdahl ...) // release lock lock = 0; 26 11/8/17 Fall 2017 - Lecture #20
27 .Lock Synchronization Thread 1 while (lock != 0) ; lock = 1; // critical section lock = 0; Thread 2 while (lock != 0) ; lock = 1; // critical section lock = 0; Thread 2 finds lock not set, before thread 1 sets it Both threads believe they got and set the lock! Try as you like, this problem has no solution, not even at the assembly level. Unless we introduce new instructions, that is! 27 11/8/17 Fall 2017 - Lecture #20
28 .Hardware Synchronization Solution: Atomic read/write Read & write in single instruction No other access permitted between read and write Note: Must use shared memory ( multi processing) Common implementations: Atomic swap of register ↔ memory Pair of instructions for “linked” read and write write fails if memory location has been “tampered” with after linked read RISC-V has variations of both, but for simplicity we will focus on the former 28 11/8/17 Fall 2017 - Lecture #20
29 .RISC-V Atomic Memory Operations (AMOs) AMOs atomically perform an operation on an operand in memory and set the destination register to the original memory value R-Type Instruction Format: Add , And , Or , Swap , Xor , Max , Max Unsigned , Min , Min Unsigned 29 11/8/17 Fall 2017 - Lecture #20 Load from address in rs1 to “t” rd = ”t”, i.e., the value in memory Store at address in rs1 the calculation “t” <operation> rs2 aq and rl insure in order execution amoadd.w rd,rs2,(rs1): t = M[x[rs1]]; x[ rd ] = t; M[x[rs1]] = t + x[rs2]
3秒后跳转登录页面
去登陆

