













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
ColumnStores VS rowstores
最近有很多令人兴奋的工作 在面向列的数据库系统上(“列存储”)。这些 数据库系统执行的命令不止一个 比传统的面向行的数据库系统要好 (“行存储”)在分析工作负载上,如那些在 数据仓库、决策支持和业务智能应用程序。 这种性能差异背后的电梯间距是简单明了。
展开查看详情
1 . Column-Stores vs. Row-Stores: How Different Are They Really? Daniel J. Abadi Samuel R. Madden Nabil Hachem Yale University MIT AvantGarde Consulting, LLC New Haven, CT, USA Cambridge, MA, USA Shrewsbury, MA, USA dna@cs.yale.edu madden@csail.mit.edu nhachem@agdba.com ABSTRACT General Terms There has been a significant amount of excitement and recent work Experimentation, Performance, Measurement on column-oriented database systems (“column-stores”). These database systems have been shown to perform more than an or- der of magnitude better than traditional row-oriented database sys- Keywords tems (“row-stores”) on analytical workloads such as those found in C-Store, column-store, column-oriented DBMS, invisible join, com- data warehouses, decision support, and business intelligence appli- pression, tuple reconstruction, tuple materialization. cations. The elevator pitch behind this performance difference is straightforward: column-stores are more I/O efficient for read-only 1. INTRODUCTION queries since they only have to read from disk (or from memory) Recent years have seen the introduction of a number of column- those attributes accessed by a query. oriented database systems, including MonetDB [9, 10] and C-Store [22]. This simplistic view leads to the assumption that one can ob- The authors of these systems claim that their approach offers order- tain the performance benefits of a column-store using a row-store: of-magnitude gains on certain workloads, particularly on read-intensive either by vertically partitioning the schema, or by indexing every analytical processing workloads, such as those encountered in data column so that columns can be accessed independently. In this pa- warehouses. per, we demonstrate that this assumption is false. We compare the Indeed, papers describing column-oriented database systems usu- performance of a commercial row-store under a variety of differ- ally include performance results showing such gains against tradi- ent configurations with a column-store and show that the row-store tional, row-oriented databases (either commercial or open source). performance is significantly slower on a recently proposed data These evaluations, however, typically benchmark against row-orient- warehouse benchmark. We then analyze the performance differ- ed systems that use a “conventional” physical design consisting of ence and show that there are some important differences between a collection of row-oriented tables with a more-or-less one-to-one the two systems at the query executor level (in addition to the obvi- mapping to the tables in the logical schema. Though such results ous differences at the storage layer level). Using the column-store, clearly demonstrate the potential of a column-oriented approach, we then tease apart these differences, demonstrating the impact on they leave open a key question: Are these performance gains due performance of a variety of column-oriented query execution tech- to something fundamental about the way column-oriented DBMSs niques, including vectorized query processing, compression, and a are internally architected, or would such gains also be possible in new join algorithm we introduce in this paper. We conclude that a conventional system that used a more column-oriented physical while it is not impossible for a row-store to achieve some of the design? performance advantages of a column-store, changes must be made Often, designers of column-based systems claim there is a funda- to both the storage layer and the query executor to fully obtain the mental difference between a from-scratch column-store and a row- benefits of a column-oriented approach. store using column-oriented physical design without actually ex- ploring alternate physical designs for the row-store system. Hence, one goal of this paper is to answer this question in a systematic way. One of the authors of this paper is a professional DBA spe- Categories and Subject Descriptors cializing in a popular commercial row-oriented database. He has H.2.4 [Database Management]: Systems—Query processing, Re- carefully implemented a number of different physical database de- lational databases signs for a recently proposed data warehousing benchmark, the Star Schema Benchmark (SSBM) [18, 19], exploring designs that are as “column-oriented” as possible (in addition to more traditional de- signs), including: Permission to make digital or hard copies of all or part of this work for • Vertically partitioning the tables in the system into a collec- personal or classroom use is granted without fee provided that copies are tion of two-column tables consisting of (table key, attribute) not made or distributed for profit or commercial advantage and that copies pairs, so that only the necessary columns need to be read to bear this notice and the full citation on the first page. To copy otherwise, to answer a query. republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. SIGMOD’08, June 9–12, 2008, Vancouver, BC, Canada. • Using index-only plans; by creating a collection of indices Copyright 2008 ACM 978-1-60558-102-6/08/06 ...$5.00. that cover all of the columns used in a query, it is possible 1
2 . for the database system to answer a query without ever going 1. We show that trying to emulate a column-store in a row-store to the underlying (row-oriented) tables. does not yield good performance results, and that a variety of techniques typically seen as ”good” for warehouse perfor- • Using a collection of materialized views such that there is a mance (index-only plans, bitmap indices, etc.) do little to view with exactly the columns needed to answer every query improve the situation. in the benchmark. Though this approach uses a lot of space, it is the ‘best case’ for a row-store, and provides a useful 2. We propose a new technique for improving join performance point of comparison to a column-store implementation. in column stores called invisible joins. We demonstrate ex- perimentally that, in many cases, the execution of a join us- We compare the performance of these various techniques to the ing this technique can perform as well as or better than se- baseline performance of the open-source C-Store database [22] on lecting and extracting data from a single denormalized ta- the SSBM, showing that, despite the ability of the above methods ble where the join has already been materialized. We thus to emulate the physical structure of a column-store inside a row- conclude that denormalization, an important but expensive store, their query processing performance is quite poor. Hence, one (in space requirements) and complicated (in deciding in ad- contribution of this work is showing that there is in fact something vance what tables to denormalize) performance enhancing fundamental about the design of column-store systems that makes technique used in row-stores (especially data warehouses) is them better suited to data-warehousing workloads. This is impor- not necessary in column-stores (or can be used with greatly tant because it puts to rest a common claim that it would be easy reduced cost and complexity). for existing row-oriented vendors to adopt a column-oriented phys- 3. We break-down the sources of column-database performance ical database design. We emphasize that our goal is not to find the on warehouse workloads, exploring the contribution of late- fastest performing implementation of SSBM in our row-oriented materialization, compression, block iteration, and invisible database, but to evaluate the performance of specific, “columnar” joins on overall system performance. Our results validate physical implementations, which leads us to a second question: previous claims of column-store performance on a new data Which of the many column-database specific optimizations pro- warehousing benchmark (the SSBM), and demonstrate that posed in the literature are most responsible for the significant per- simple column-oriented operation – without compression and formance advantage of column-stores over row-stores on warehouse late materialization – does not dramatically outperform well- workloads? optimized row-store designs. Prior research has suggested that important optimizations spe- cific to column-oriented DBMSs include: The rest of this paper is organized as follows: we begin by de- scribing prior work on column-oriented databases, including sur- • Late materialization (when combined with the block iteration veying past performance comparisons and describing some of the optimization below, this technique is also known as vector- architectural innovations that have been proposed for column-oriented ized query processing [9, 25]), where columns read off disk DBMSs (Section 2); then, we review the SSBM (Section 3). We are joined together into rows as late as possible in a query then describe the physical database design techniques used in our plan [5]. row-oriented system (Section 4), and the physical layout and query execution techniques used by the C-Store system (Section 5). We • Block iteration [25], where multiple values from a column then present performance comparisons between the two systems, are passed as a block from one operator to the next, rather first contrasting our row-oriented designs to the baseline C-Store than using Volcano-style per-tuple iterators [11]. If the val- performance and then decomposing the performance of C-Store to ues are fixed-width, they are iterated through as an array. measure which of the techniques it employs for efficient query ex- ecution are most effective on the SSBM (Section 6). • Column-specific compression techniques, such as run-length encoding, with direct operation on compressed data when us- ing late-materialization plans [4]. 2. BACKGROUND AND PRIOR WORK In this section, we briefly present related efforts to characterize • We also propose a new optimization, called invisible joins, column-store performance relative to traditional row-stores. which substantially improves join performance in late-mat- Although the idea of vertically partitioning database tables to erialization column stores, especially on the types of schemas improve performance has been around a long time [1, 7, 16], the found in data warehouses. MonetDB [10] and the MonetDB/X100 [9] systems pioneered the design of modern column-oriented database systems and vector- However, because each of these techniques was described in a ized query execution. They show that column-oriented designs – separate research paper, no work has analyzed exactly which of due to superior CPU and cache performance (in addition to re- these gains are most significant. Hence, a third contribution of duced I/O) – can dramatically outperform commercial and open this work is to carefully measure different variants of the C-Store source databases on benchmarks like TPC-H. The MonetDB work database by removing these column-specific optimizations one-by- does not, however, attempt to evaluate what kind of performance one (in effect, making the C-Store query executor behave more like is possible from row-stores using column-oriented techniques, and a row-store), breaking down the factors responsible for its good per- to the best of our knowledge, their optimizations have never been formance. We find that compression can offer order-of-magnitude evaluated in the same context as the C-Store optimization of direct gains when it is possible, but that the benefits are less substantial in operation on compressed data. other cases, whereas late materialization offers about a factor of 3 The fractured mirrors approach [21] is another recent column- performance gain across the board. Other optimizations – includ- store system, in which a hybrid row/column approach is proposed. ing block iteration and our new invisible join technique, offer about Here, the row-store primarily processes updates and the column- a factor 1.5 performance gain on average. store primarily processes reads, with a background process mi- In summary, we make three contributions in this paper: grating data from the row-store to the column-store. This work 2
3 .also explores several different representations for a fully vertically tion about their respective entities in the expected way. Figure 1 partitioned strategy in a row-store (Shore), concluding that tuple (adapted from Figure 2 of [19]) shows the schema of the tables. overheads in a naive scheme are a significant problem, and that As with TPC-H, there is a base “scale factor” which can be used prefetching of large blocks of tuples from disk is essential to im- to scale the size of the benchmark. The sizes of each of the tables prove tuple reconstruction times. are defined relative to this scale factor. In this paper, we use a scale C-Store [22] is a more recent column-oriented DBMS. It in- factor of 10 (yielding a LINEORDER table with 60,000,000 tuples). cludes many of the same features as MonetDB/X100, as well as optimizations for direct operation on compressed data [4]. Like CUSTOMER LINEORDER PART the other two systems, it shows that a column-store can dramati- CUSTKEY ORDERKEY PARTKEY cally outperform a row-store on warehouse workloads, but doesn’t NAME LINENUMBER NAME ADDRESS CUSTKEY MFGR carefully explore the design space of feasible row-store physical CITY PARTKEY CATEGOTY designs. In this paper, we dissect the performance of C-Store, not- NATION SUPPKEY BRAND1 ing how the various optimizations proposed in the literature (e.g., REGION ORDERDATE COLOR [4, 5]) contribute to its overall performance relative to a row-store PHONE ORDPRIORITY TYPE on a complete data warehousing benchmark, something that prior MKTSEGMENT SHIPPRIORITY SIZE Size=scalefactor x QUANTITY CONTAINER work from the C-Store group has not done. 30,0000 EXTENDEDPRICE Size=200,000 x Harizopoulos et al. [14] compare the performance of a row and ORDTOTALPRICE (1 + log2 scalefactor) SUPPLIER column store built from scratch, studying simple plans that scan SUPPKEY DISCOUNT REVENUE DATE data from disk only and immediately construct tuples (“early ma- NAME DATEKEY SUPPLYCOST terialization”). This work demonstrates that in a carefully con- ADDRESS DATE TAX trolled environment with simple plans, column stores outperform CITY COMMITDATE DAYOFWEEK NATION MONTH row stores in proportion to the fraction of columns they read from SHIPMODE REGION YEAR disk, but doesn’t look specifically at optimizations for improving PHONE Size=scalefactor x YEARMONTHNUM row-store performance, nor at some of the advanced techniques for 6,000,000 Size=scalefactor x YEARMONTH improving column-store performance. 2,000 DAYNUMWEEK Halverson et al. [13] built a column-store implementation in Shore …. (9 add!l attributes) and compared an unmodified (row-based) version of Shore to a ver- Size= 365 x 7 tically partitioned variant of Shore. Their work proposes an opti- mization, called “super tuples”, that avoids duplicating header in- Figure 1: Schema of the SSBM Benchmark formation and batches many tuples together in a block, which can reduce the overheads of the fully vertically partitioned scheme and Queries: The SSBM consists of thirteen queries divided into which, for the benchmarks included in the paper, make a vertically four categories, or “flights”: partitioned database competitive with a column-store. The paper does not, however, explore the performance benefits of many re- 1. Flight 1 contains 3 queries. Queries have a restriction on 1 di- cent column-oriented optimizations, including a variety of differ- mension attribute, as well as the DISCOUNT and QUANTITY ent compression methods or late-materialization. Nonetheless, the columns of the LINEORDER table. Queries measure the gain “super tuple” is the type of higher-level optimization that this pa- in revenue (the product of EXTENDEDPRICE and DISCOUNT) per concludes will be needed to be added to row-stores in order to that would be achieved if various levels of discount were simulate column-store performance. eliminated for various order quantities in a given year. The LINEORDER selectivities for the three queries are 1.9×10−2 , 6.5 × 10−4 , and 7.5 × 10−5 , respectively. 3. STAR SCHEMA BENCHMARK In this paper, we use the Star Schema Benchmark (SSBM) [18, 2. Flight 2 contains 3 queries. Queries have a restriction on 19] to compare the performance of C-Store and the commercial 2 dimension attributes and compute the revenue for particu- row-store. lar product classes in particular regions, grouped by product The SSBM is a data warehousing benchmark derived from TPC- class and year. The LINEORDER selectivities for the three H 1 . Unlike TPC-H, it uses a pure textbook star-schema (the “best queries are 8.0 × 10−3 , 1.6 × 10−3 , and 2.0 × 10−4 , respec- practices” data organization for data warehouses). It also consists tively. of fewer queries than TPC-H and has less stringent requirements on 3. Flight 3 consists of 4 queries, with a restriction on 3 di- what forms of tuning are and are not allowed. We chose it because mensions. Queries compute the revenue in a particular re- it is easier to implement than TPC-H and we did not have to modify gion over a time period, grouped by customer nation, sup- C-Store to get it to run (which we would have had to do to get the plier nation, and year. The LINEORDER selectivities for the entire TPC-H benchmark running). four queries are 3.4 × 10−2 , 1.4 × 10−3 , 5.5 × 10−5 , and Schema: The benchmark consists of a single fact table, the LINE- 7.6 × 10−7 respectively. ORDER table, that combines the LINEITEM and ORDERS table of TPC-H. This is a 17 column table with information about individual 4. Flight 4 consists of three queries. Queries restrict on three di- orders, with a composite primary key consisting of the ORDERKEY mension columns, and compute profit (REVENUE - SUPPLY- and LINENUMBER attributes. Other attributes in the LINEORDER COST) grouped by year, nation, and category for query 1; table include foreign key references to the CUSTOMER, PART, SUPP- and for queries 2 and 3, region and category. The LINEORDER LIER, and DATE tables (for both the order date and commit date), selectivities for the three queries are 1.6 × 10−2 , 4.5 × 10−3 , as well as attributes of each order, including its priority, quan- and 9.1 × 10−5 , respectively. tity, price, and discount. The dimension tables contain informa- 1 http://www.tpc.org/tpch/. 3
4 .4. ROW-ORIENTED EXECUTION the (salary) index, which will be much slower. We use this opti- In this section, we discuss several different techniques that can mization in our implementation by storing the primary key of each be used to implement a column-database design in a commercial dimension table as a secondary sort attribute on the indices over the row-oriented DBMS (hereafter, System X). We look at three differ- attributes of that dimension table. In this way, we can efficiently ac- ent classes of physical design: a fully vertically partitioned design, cess the primary key values of the dimension that need to be joined an “index only” design, and a materialized view design. In our with the fact table. evaluation, we also compare against a “standard” row-store design Materialized Views: The third approach we consider uses mate- with one physical table per relation. rialized views. In this approach, we create an optimal set of materi- Vertical Partitioning: The most straightforward way to emulate alized views for every query flight in the workload, where the opti- a column-store approach in a row-store is to fully vertically parti- mal view for a given flight has only the columns needed to answer tion each relation [16]. In a fully vertically partitioned approach, queries in that flight. We do not pre-join columns from different some mechanism is needed to connect fields from the same row tables in these views. Our objective with this strategy is to allow together (column stores typically match up records implicitly by System X to access just the data it needs from disk, avoiding the storing columns in the same order, but such optimizations are not overheads of explicitly storing record-id or positions, and storing available in a row store). To accomplish this, the simplest approach tuple headers just once per tuple. Hence, we expect it to perform is to add an integer “position” column to every table – this is of- better than the other two approaches, although it does require the ten preferable to using the primary key because primary keys can query workload to be known in advance, making it practical only be large and are sometimes composite (as in the case of the line- in limited situations. order table in SSBM). This approach creates one physical table for each column in the logical schema, where the ith table has two 5. COLUMN-ORIENTED EXECUTION columns, one with values from column i of the logical schema and Now that we’ve presented our row-oriented designs, in this sec- one with the corresponding value in the position column. Queries tion, we review three common optimizations used to improve per- are then rewritten to perform joins on the position attribute when formance in column-oriented database systems, and introduce the fetching multiple columns from the same relation. In our imple- invisible join. mentation, by default, System X chose to use hash joins for this purpose, which proved to be expensive. For that reason, we exper- 5.1 Compression imented with adding clustered indices on the position column of Compressing data using column-oriented compression algorithms every table, and forced System X to use index joins, but this did and keeping data in this compressed format as it is operated upon not improve performance – the additional I/Os incurred by index has been shown to improve query performance by up to an or- accesses made them slower than hash joins. der of magnitude [4]. Intuitively, data stored in columns is more Index-only plans: The vertical partitioning approach has two compressible than data stored in rows. Compression algorithms problems. First, it requires the position attribute to be stored in ev- perform better on data with low information entropy (high data ery column, which wastes space and disk bandwidth. Second, most value locality). Take, for example, a database table containing in- row-stores store a relatively large header on every tuple, which formation about customers (name, phone number, e-mail address, further wastes space (column stores typically – or perhaps even snail-mail address, etc.). Storing data in columns allows all of the by definition – store headers in separate columns to avoid these names to be stored together, all of the phone numbers together, overheads). To ameliorate these concerns, the second approach we etc. Certainly phone numbers are more similar to each other than consider uses index-only plans, where base relations are stored us- surrounding text fields like e-mail addresses or names. Further, ing a standard, row-oriented design, but an additional unclustered if the data is sorted by one of the columns, that column will be B+Tree index is added on every column of every table. Index-only super-compressible (for example, runs of the same value can be plans – which require special support from the database, but are run-length encoded). implemented by System X – work by building lists of (record- But of course, the above observation only immediately affects id,value) pairs that satisfy predicates on each table, and merging compression ratio. Disk space is cheap, and is getting cheaper these rid-lists in memory when there are multiple predicates on the rapidly (of course, reducing the number of needed disks will re- same table. When required fields have no predicates, a list of all duce power consumption, a cost-factor that is becoming increas- (record-id,value) pairs from the column can be produced. Such ingly important). However, compression improves performance (in plans never access the actual tuples on disk. Though indices still addition to reducing disk space) since if data is compressed, then explicitly store rids, they do not store duplicate column values, and less time must be spent in I/O as data is read from disk into mem- they typically have a lower per-tuple overhead than the vertical par- ory (or from memory to CPU). Consequently, some of the “heavier- titioning approach since tuple headers are not stored in the index. weight” compression schemes that optimize for compression ratio One problem with the index-only approach is that if a column (such as Lempel-Ziv, Huffman, or arithmetic encoding), might be has no predicate on it, the index-only approach requires the index less suitable than “lighter-weight” schemes that sacrifice compres- to be scanned to extract the needed values, which can be slower sion ratio for decompression performance [4, 26]. In fact, com- than scanning a heap file (as would occur in the vertical partition- pression can improve query performance beyond simply saving on ing approach.) Hence, an optimization to the index-only approach I/O. If a column-oriented query executor can operate directly on is to create indices with composite keys, where the secondary keys compressed data, decompression can be avoided completely and are from predicate-less columns. For example, consider the query performance can be further improved. For example, for schemes SELECT AVG(salary) FROM emp WHERE age>40 – if we like run-length encoding – where a sequence of repeated values is have a composite index with an (age,salary) key, then we can an- replaced by a count and the value (e.g., 1, 1, 1, 2, 2 → 1 × 3, 2 × 2) swer this query directly from this index. If we have separate indices – operating directly on compressed data results in the ability of a on (age) and (salary), an index only plan will have to find record-ids query executor to perform the same operation on multiple column corresponding to records with satisfying ages and then merge this values at once, further reducing CPU costs. with the complete list of (record-id, salary) pairs extracted from Prior work [4] concludes that the biggest difference between 4
5 .compression in a row-store and compression in a column-store are the advantages of operating directly on compressed data described the cases where a column is sorted (or secondarily sorted) and there above. Third, cache performance is improved when operating di- are consecutive repeats of the same value in a column. In a column- rectly on column data, since a given cache line is not polluted with store, it is extremely easy to summarize these value repeats and op- surrounding irrelevant attributes for a given operation (as shown erate directly on this summary. In a row-store, the surrounding data in PAX [6]). Fourth, the block iteration optimization described in from other attributes significantly complicates this process. Thus, the next subsection has a higher impact on performance for fixed- in general, compression will have a larger impact on query perfor- length attributes. In a row-store, if any attribute in a tuple is variable- mance if a high percentage of the columns accessed by that query width, then the entire tuple is variable width. In a late materialized have some level of order. For the benchmark we use in this paper, column-store, fixed-width columns can be operated on separately. we do not store multiple copies of the fact table in different sort or- ders, and so only one of the seventeen columns in the fact table can 5.3 Block Iteration be sorted (and two others secondarily sorted) so we expect com- In order to process a series of tuples, row-stores first iterate through pression to have a somewhat smaller (and more variable per query) each tuple, and then need to extract the needed attributes from these effect on performance than it could if more aggressive redundancy tuples through a tuple representation interface [11]. In many cases, was used. such as in MySQL, this leads to tuple-at-a-time processing, where there are 1-2 function calls to extract needed data from a tuple for 5.2 Late Materialization each operation (which if it is a small expression or predicate evalu- ation is low cost compared with the function calls) [25]. In a column-store, information about a logical entity (e.g., a per- Recent work has shown that some of the per-tuple overhead of son) is stored in multiple locations on disk (e.g. name, e-mail tuple processing can be reduced in row-stores if blocks of tuples are address, phone number, etc. are all stored in separate columns), available at once and operated on in a single operator call [24, 15], whereas in a row store such information is usually co-located in and this is implemented in IBM DB2 [20]. In contrast to the case- a single row of a table. However, most queries access more than by-case implementation in row-stores, in all column-stores (that we one attribute from a particular entity. Further, most database output are aware of), blocks of values from the same column are sent to standards (e.g., ODBC and JDBC) access database results entity-at- an operator in a single function call. Further, no attribute extraction a-time (not column-at-a-time). Thus, at some point in most query is needed, and if the column is fixed-width, these values can be plans, data from multiple columns must be combined together into iterated through directly as an array. Operating on data as an array ‘rows’ of information about an entity. Consequently, this join-like not only minimizes per-tuple overhead, but it also exploits potential materialization of tuples (also called “tuple construction”) is an ex- for parallelism on modern CPUs, as loop-pipelining techniques can tremely common operation in a column store. be used [9]. Naive column-stores [13, 14] store data on disk (or in memory) column-by-column, read in (to CPU from disk or memory) only 5.4 Invisible Join those columns relevant for a particular query, construct tuples from Queries over data warehouses, particularly over data warehouses their component attributes, and execute normal row-store operators modeled with a star schema, often have the following structure: Re- on these rows to process (e.g., select, aggregate, and join) data. Al- strict the set of tuples in the fact table using selection predicates on though likely to still outperform the row-stores on data warehouse one (or many) dimension tables. Then, perform some aggregation workloads, this method of constructing tuples early in a query plan on the restricted fact table, often grouping by other dimension table (“early materialization”) leaves much of the performance potential attributes. Thus, joins between the fact table and dimension tables of column-oriented databases unrealized. need to be performed for each selection predicate and for each ag- More recent column-stores such as X100, C-Store, and to a lesser gregate grouping. A good example of this is Query 3.1 from the extent, Sybase IQ, choose to keep data in columns until much later Star Schema Benchmark. into the query plan, operating directly on these columns. In order to do so, intermediate “position” lists often need to be constructed SELECT c.nation, s.nation, d.year, in order to match up operations that have been performed on differ- sum(lo.revenue) as revenue ent columns. Take, for example, a query that applies a predicate on FROM customer AS c, lineorder AS lo, two columns and projects a third attribute from all tuples that pass supplier AS s, dwdate AS d the predicates. In a column-store that uses late materialization, the WHERE lo.custkey = c.custkey predicates are applied to the column for each attribute separately AND lo.suppkey = s.suppkey and a list of positions (ordinal offsets within a column) of values AND lo.orderdate = d.datekey that passed the predicates are produced. Depending on the predi- AND c.region = ’ASIA’ cate selectivity, this list of positions can be represented as a simple AND s.region = ’ASIA’ array, a bit string (where a 1 in the ith bit indicates that the ith AND d.year >= 1992 and d.year <= 1997 value passed the predicate) or as a set of ranges of positions. These GROUP BY c.nation, s.nation, d.year position representations are then intersected (if they are bit-strings, ORDER BY d.year asc, revenue desc; bit-wise AND operations can be used) to create a single position list. This list is then sent to the third column to extract values at the This query finds the total revenue from customers who live in desired positions. Asia and who purchase a product supplied by an Asian supplier The advantages of late materialization are four-fold. First, se- between the years 1992 and 1997 grouped by each unique combi- lection and aggregation operators tend to render the construction nation of the nation of the customer, the nation of the supplier, and of some tuples unnecessary (if the executor waits long enough be- the year of the transaction. fore constructing a tuple, it might be able to avoid constructing it The traditional plan for executing these types of queries is to altogether). Second, if data is compressed using a column-oriented pipeline joins in order of predicate selectivity. For example, if compression method, it must be decompressed before the combi- c.region = ’ASIA’ is the most selective predicate, the join nation of values with values from other columns. This removes on custkey between the lineorder and customer tables is 5
6 .performed first, filtering the lineorder table so that only or- are used to build a hash table that can be used to test whether a ders from customers who live in Asia remain. As this join is per- particular key value satisfies the predicate (the hash table should formed, the nation of these customers are added to the joined easily fit in memory since dimension tables are typically small and customer-order table. These results are pipelined into a join the table contains only keys). An example of the execution of this with the supplier table where the s.region = ’ASIA’ pred- first phase for the above query on some sample data is displayed in icate is applied and s.nation extracted, followed by a join with Figure 2. the data table and the year predicate applied. The results of these joins are then grouped and aggregated and the results sorted ac- Apply region = 'Asia' on Customer table cording to the ORDER BY clause. custkey region nation ... 1 Asia China ... Hash table An alternative to the traditional plan is the late materialized join with keys 2 Europe France ... 1 and 3 technique [5]. In this case, a predicate is applied on the c.region 3 Asia India ... column (c.region = ’ASIA’), and the customer key of the Apply region = 'Asia' on Supplier table customer table is extracted at the positions that matched this pred- suppkey region nation ... icate. These keys are then joined with the customer key column 1 Asia Russia ... Hash table with key 1 from the fact table. The results of this join are two sets of posi- 2 Europe Spain ... tions, one for the fact table and one for the dimension table, indi- Apply year in [1992,1997] on Date table cating which pairs of tuples from the respective tables passed the dateid year ... join predicate and are joined. In general, at most one of these two 01011997 1997 ... Hash table with keys 01011997, position lists are produced in sorted order (the outer table in the 01021997 1997 ... 01021997, and 01031997 1997 ... 01031997 join, typically the fact table). Values from the c.nation column at this (out-of-order) set of positions are then extracted, along with values (using the ordered set of positions) from the other fact table Figure 2: The first phase of the joins needed to execute Query columns (supplier key, order date, and revenue). Similar joins are 3.1 from the Star Schema benchmark on some sample data then performed with the supplier and date tables. Each of these plans have a set of disadvantages. In the first (tra- In the next phase, each hash table is used to extract the positions ditional) case, constructing tuples before the join precludes all of of records in the fact table that satisfy the corresponding predicate. the late materialization benefits described in Section 5.2. In the This is done by probing into the hash table with each value in the second case, values from dimension table group-by columns need foreign key column of the fact table, creating a list of all the posi- to be extracted in out-of-position order, which can have significant tions in the foreign key column that satisfy the predicate. Then, the cost [5]. position lists from all of the predicates are intersected to generate As an alternative to these query plans, we introduce a technique a list of satisfying positions P in the fact table. An example of the we call the invisible join that can be used in column-oriented databases execution of this second phase is displayed in Figure 3. Note that for foreign-key/primary-key joins on star schema style tables. It is a position list may be an explicit list of positions, or a bitmap as a late materialized join, but minimizes the values that need to be shown in the example. extracted out-of-order, thus alleviating both sets of disadvantages described above. It works by rewriting joins into predicates on Fact Table the foreign key columns in the fact table. These predicates can orderkey custkey suppkey orderdate revenue be evaluated either by using a hash lookup (in which case a hash 1 3 1 01011997 43256 2 3 2 01011997 33333 join is simulated), or by using more advanced methods, such as a 3 2 1 01021997 12121 technique we call between-predicate rewriting, discussed in Sec- 4 1 1 01021997 23233 tion 5.4.2 below. 5 2 2 01021997 45456 6 1 2 01031997 43251 By rewriting the joins as selection predicates on fact table columns, 7 3 2 01031997 34235 they can be executed at the same time as other selection predi- cates that are being applied to the fact table, and any of the predi- probe probe probe cate application algorithms described in previous work [5] can be Hash table 1 Hash table 1 1 used. For example, each predicate can be applied in parallel and Hash table with with keys = 1 with key 1 = 0 keys 01011997, 1 the results merged together using fast bitmap operations. Alterna- 1 and 3 0 1 = 1 01021997, and tively, the results of a predicate application can be pipelined into 1 1 01031997 1 matching fact 0 0 1 another predicate application to reduce the number of times the table bitmap 1 0 1 second predicate must be applied. Only after all predicates have for cust. dim. 1 0 1 join 1 been applied are the appropriate tuples extracted from the relevant 0 dimensions (this can also be done in parallel). By waiting until 0 fact table all predicates have been applied before doing this extraction, the Bitwise = 1 tuples that number of out-of-order extractions is minimized. And 0 satisfy all join 0 predicates The invisible join extends previous work on improving perfor- 0 mance for star schema joins [17, 23] that are reminiscent of semi- joins [8] by taking advantage of the column-oriented layout, and rewriting predicates to avoid hash-lookups, as described below. Figure 3: The second phase of the joins needed to execute Query 3.1 from the Star Schema benchmark on some sample data 5.4.1 Join Details The invisible join performs joins in three phases. First, each The third phase of the join uses the list of satisfying positions P predicate is applied to the appropriate dimension table to extract a in the fact table. For each column C in the fact table containing a list of dimension table keys that satisfy the predicate. These keys foreign key reference to a dimension table that is needed to answer 6
7 . 1 0 fact table dimension table of expressing the join as a predicate comes into play in the surpris- 0 1 tuples that nation ingly common case (for star schema joins) where the set of keys in satisfy all join 0 predicates China dimension table that remain after a predicate has been applied are 0 France custkey 0 India contiguous. When this is the case, a technique we call “between- 3 predicate rewriting” can be used, where the predicate can be rewrit- 3 2 bitmap 3 position India ten from a hash-lookup predicate on the fact table to a “between” 1 value = = 2 extraction 1 Positions lookup China predicate where the foreign key falls between two ends of the key 1 range. For example, if the contiguous set of keys that are valid af- Fact Table Columns 3 nation Russia ter a predicate has been applied are keys 1000-2000, then instead suppkey Spain of inserting each of these keys into a hash table and probing the Join Results 1 2 bitmap hash table for each foreign key value in the fact table, we can sim- 1 1 position Russia value = = 1 extraction 1 Positions lookup Russia ply check to see if the foreign key is in between 1000 and 2000. If 2 2 so, then the tuple joins; otherwise it does not. Between-predicates dateid year 2 01011997 1997 are faster to execute for obvious reasons as they can be evaluated orderdate 01021997 1997 directly without looking anything up. 01011997 01011997 01031997 1997 The ability to apply this optimization hinges on the set of these bitmap 1997 01021997 value 01011997 = 01021997 join = valid dimension table keys being contiguous. In many instances, 01021997 extraction Values 1997 01021997 this property does not hold. For example, a range predicate on 01031997 01031997 a non-sorted field results in non-contiguous result positions. And even for predicates on sorted fields, the process of sorting the di- mension table by that attribute likely reordered the primary keys so Figure 4: The third phase of the joins needed to execute Query they are no longer an ordered, contiguous set of identifiers. How- 3.1 from the Star Schema benchmark on some sample data ever, the latter concern can be easily alleviated through the use of dictionary encoding for the purpose of key reassignment (rather than compression). Since the keys are unique, dictionary encoding the query (e.g., where the dimension column is referenced in the the column results in the dictionary keys being an ordered, con- select list, group by, or aggregate clauses), foreign key values from tiguous list starting from 0. As long as the fact table foreign key C are extracted using P and are looked up in the corresponding column is encoded using the same dictionary table, the hash-table dimension table. Note that if the dimension table key is a sorted, to between-predicate rewriting can be performed. contiguous list of identifiers starting from 1 (which is the common Further, the assertion that the optimization works only on predi- case), then the foreign key actually represents the position of the cates on the sorted column of a dimension table is not entirely true. desired tuple in dimension table. This means that the needed di- In fact, dimension tables in data warehouses often contain sets of mension table columns can be extracted directly using this position attributes of increasingly finer granularity. For example, the date list (and this is simply a fast array look-up). table in SSBM has a year column, a yearmonth column, and This direct array extraction is the reason (along with the fact that the complete date column. If the table is sorted by year, sec- dimension tables are typically small so the column being looked ondarily sorted by yearmonth, and tertiarily sorted by the com- up can often fit inside the L2 cache) why this join does not suffer plete date, then equality predicates on any of those three columns from the above described pitfalls of previously published late mate- will result in a contiguous set of results (or a range predicate on rialized join approaches [5] where this final position list extraction the sorted column). As another example, the supplier table is very expensive due to the out-of-order nature of the dimension has a region column, a nation column, and a city column table value extraction. Further, the number values that need to be (a region has many nations and a nation has many cities). Again, extracted is minimized since the number of positions in P is depen- sorting from left-to-right will result in predicates on any of those dent on the selectivity of the entire query, instead of the selectivity three columns producing a contiguous range output. Data ware- of just the part of the query that has been executed so far. house queries often access these columns, due to the OLAP practice An example of the execution of this third phase is displayed in of rolling-up data in successive queries (tell me profit by region, Figure 4. Note that for the date table, the key column is not a tell me profit by nation, tell me profit by city). Thus, “between- sorted, contiguous list of identifiers starting from 1, so a full join predicate rewriting” can be used more often than one might ini- must be performed (rather than just a position extraction). Further, tially expect, and (as we show in the next section), often yields a note that since this is a foreign-key primary-key join, and since all significant performance gain. predicates have already been applied, there is guaranteed to be one Note that predicate rewriting does not require changes to the and only one result in each dimension table for each position in the query optimizer to detect when this optimization can be used. The intersected position list from the fact table. This means that there code that evaluates predicates against the dimension table is capa- are the same number of results for each dimension table join from ble of detecting whether the result set is contiguous. If so, the fact this third phase, so each join can be done separately and the results table predicate is rewritten at run-time. combined (stitched together) at a later point in the query plan. 5.4.2 Between-Predicate Rewriting 6. EXPERIMENTS As described thus far, this algorithm is not much more than an- In this section, we compare the row-oriented approaches to the other way of thinking about a column-oriented semijoin or a late performance of C-Store on the SSBM, with the goal of answering materialized hash join. Even though the hash part of the join is ex- four key questions: pressed as a predicate on a fact table column, practically there is little difference between the way the predicate is applied and the 1. How do the different attempts to emulate a column store in a way a (late materialization) hash join is executed. The advantage row-store compare to the baseline performance of C-Store? 7
8 . 2. Is it possible for an unmodified row-store to obtain the bene- In contrast with this expectation, the System X numbers are sig- fits of column-oriented design? nificantly faster (more than a factor of two) than the C-Store num- bers. In retrospect, this is not all that surprising — System X has 3. Of the specific optimizations proposed for column-stores (com- teams of people dedicated to seeking and removing performance pression, late materialization, and block processing), which bottlenecks in the code, while C-Store has multiple known perfor- are the most significant? mance bottlenecks that have yet to be resolved [3]. Moreover, C- 4. How does the cost of performing star schema joins in column- Store, as a simple prototype, has not implemented advanced perfor- stores using the invisible join technique compare with exe- mance features that are available in System X. Two of these features cuting queries on a denormalized fact table where the join are partitioning and multi-threading. System X is able to partition has been pre-executed? each materialized view optimally for the query flight that it is de- signed for. Partitioning improves performance when running on a By answering these questions, we provide database implementers single machine by reducing the data that needs to be scanned in or- who are interested in adopting a column-oriented approach with der to answer a query. For example, the materialized view used for guidelines for which performance optimizations will be most fruit- query flight 1 is partitioned on orderdate year, which is useful since ful. Further, the answers will help us understand what changes need each query in this flight has a predicate on orderdate. To determine to be made at the storage-manager and query executor levels to row- the performance advantage System X receives from partitioning, stores if row-stores are to successfully simulate column-stores. we ran the same benchmark on the same materialized views with- All of our experiments were run on a 2.8 GHz single processor, out partitioning them. We found that the average query time in this dual core Pentium(R) D workstation with 3 GB of RAM running case was 20.25 seconds. Thus, partitioning gives System X a fac- RedHat Enterprise Linux 5. The machine has a 4-disk array, man- tor of two advantage (though this varied by query, which will be aged as a single logical volume with files striped across it. Typical discussed further in Section 6.2). C-Store is also at a disadvan- I/O throughput is 40 - 50 MB/sec/disk, or 160 - 200 MB/sec in ag- tage since it not multi-threaded, and consequently is unable to take gregate for striped files. The numbers we report are the average of advantage of the extra core. several runs, and are based on a “warm” buffer pool (in practice, we Thus, there are many differences between the two systems we ex- found that this yielded about a 30% performance increase for both periment with in this paper. Some are fundamental differences be- systems; the gain is not particularly dramatic because the amount tween column-stores and row-stores, and some are implementation of data read by each query exceeds the size of the buffer pool). artifacts. Since it is difficult to come to useful conclusions when 6.1 Motivation for Experimental Setup comparing numbers across different systems, we choose a different tactic in our experimental setup, exploring benchmark performance Figure 5 compares the performance of C-Store and System X on from two angles. In Section 6.2 we attempt to simulate a column- the Star Schema Benchmark. We caution the reader to not read store inside of a row-store. The experiments in this section are only too much into absolute performance differences between the two on System X, and thus we do not run into cross-system comparison systems — as we discuss in this section, there are substantial dif- problems. In Section 6.3, we remove performance optimizations ferences in the implementations of these systems beyond the basic from C-Store until row-store performance is achieved. Again, all difference of rows vs. columns that affect these performance num- experiments are on only a single system (C-Store). bers. By performing our experiments in this way, we are able to come In this figure, “RS” refers to numbers for the base System X case, to some conclusions about the performance advantage of column- “CS” refers to numbers for the base C-Store case, and “RS (MV)” stores without relying on cross-system comparisons. For example, refers to numbers on System X using an optimal collection of ma- it is interesting to note in Figure 5 that there is more than a factor terialized views containing minimal projections of tables needed to of six difference between “CS” and “CS (Row MV)” despite the answer each query (see Section 4). As shown, C-Store outperforms fact that they are run on the same system and both read the minimal System X by a factor of six in the base case, and a factor of three set of columns off disk needed to answer each query. Clearly the when System X is using materialized views. This is consistent with performance advantage of a column-store is more than just the I/O previous work that shows that column-stores can significantly out- advantage of reading in less data from disk. We will explain the perform row-stores on data warehouse workloads [2, 9, 22]. reason for this performance difference in Section 6.3. However, the fourth set of numbers presented in Figure 5, “CS (Row-MV)” illustrate the caution that needs to be taken when com- paring numbers across systems. For these numbers, we stored the 6.2 Column-Store Simulation in a Row-Store identical (row-oriented!) materialized view data inside C-Store. In this section, we describe the performance of the different con- One might expect the C-Store storage manager to be unable to store figurations of System X on the Star Schema Benchmark. We con- data in rows since, after all, it is a column-store. However, this can figured System X to partition the lineorder table on order- be done easily by using tables that have a single column of type date by year (this means that a different physical partition is cre- “string”. The values in this column are entire tuples. One might ated for tuples from each year in the database). As described in also expect that the C-Store query executer would be unable to op- Section 6.1, this partitioning substantially speeds up SSBM queries erate on rows, since it expects individual columns as input. How- that involve a predicate on orderdate (queries 1.1, 1.2, 1.3, 3.4, ever, rows are a legal intermediate representation in C-Store — as 4.2, and 4.3 query just 1 year; queries 3.1, 3.2, and 3.3 include a explained in Section 5.2, at some point in a query plan, C-Store re- substantially less selective query over half of years). Unfortunately, constructs rows from component columns (since the user interface for the column-oriented representations, System X doesn’t allow us to a RDBMS is row-by-row). After it performs this tuple recon- to partition two-column vertical partitions on orderdate (since struction, it proceeds to execute the rest of the query plan using they do not contain the orderdate column, except, of course, standard row-store operators [5]. Thus, both the “CS (Row-MV)” for the orderdate vertical partition), which means that for those and the “RS (MV)” are executing the same queries on the same in- query flights that restrict on the orderdate column, the column- put data stored in the same way. Consequently, one might expect oriented approaches are at a disadvantage relative to the base case. these numbers to be identical. Nevertheless, we decided to use partitioning for the base case 8
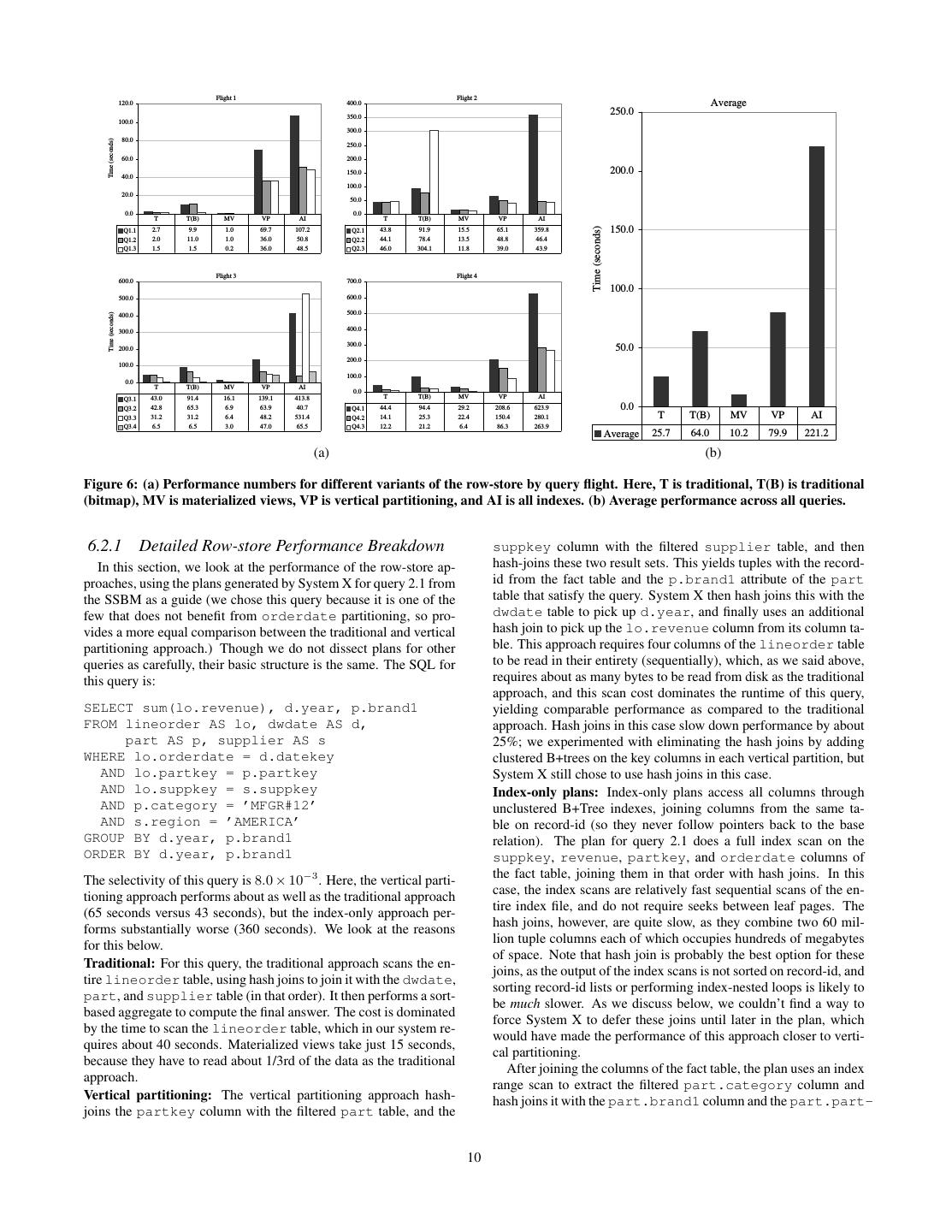
9 . 60 Time (seconds) 40 20 0 1.1 1.2 1.3 2.1 2.2 2.3 3.1 3.2 3.3 3.4 4.1 4.2 4.3 AVG RS 2.7 2.0 1.5 43.8 44.1 46.0 43.0 42.8 31.2 6.5 44.4 14.1 12.2 25.7 RS (MV) 1.0 1.0 0.2 15.5 13.5 11.8 16.1 6.9 6.4 3.0 29.2 22.4 6.4 10.2 CS 0.4 0.1 0.1 5.7 4.2 3.9 11.0 4.4 7.6 0.6 8.2 3.7 2.6 4.0 CS (Row-MV) 16.0 9.1 8.4 33.5 23.5 22.3 48.5 21.5 17.6 17.4 48.6 38.4 32.1 25.9 Figure 5: Baseline performance of C-Store “CS” and System X “RS”, compared with materialized view cases on the same systems. because it is in fact the strategy that a database administrator would ure 6(b). Materialized views perform best in all cases, because they use when trying to improve the performance of these queries on a read the minimal amount of data required to process a query. Af- row-store. When we ran the base case without partitioning, per- ter materialized views, the traditional approach or the traditional formance was reduced by a factor of two on average (though this approach with bitmap indexing, is usually the best choice. On varied per query depending on the selectivity of the predicate on average, the traditional approach is about three times better than the orderdate column). Thus, we would expect the vertical the best of our attempts to emulate a column-oriented approach. partitioning case to improve by a factor of two, on average, if it This is particularly true of queries that can exploit partitioning on were possible to partition tables based on two levels of indirec- orderdate, as discussed above. For query flight 2 (which does tion (from primary key, or record-id, we get orderdate, and not benefit from partitioning), the vertical partitioning approach is from orderdate we get year). competitive with the traditional approach; the index-only approach Other relevant configuration parameters for System X include: performs poorly for reasons we discuss below. Before looking at 32 KB disk pages, a 1.5 GB maximum memory for sorts, joins, the performance of individual queries in more detail, we summarize intermediate results, and a 500 MB buffer pool. We experimented the two high level issues that limit the approach of the columnar ap- with different buffer pool sizes and found that different sizes did proaches: tuple overheads, and inefficient tuple reconstruction: not yield large differences in query times (due to dominant use of Tuple overheads: As others have observed [16], one of the prob- large table scans in this benchmark), unless a very small buffer pool lems with a fully vertically partitioned approach in a row-store is was used. We enabled compression and sequential scan prefetch- that tuple overheads can be quite large. This is further aggravated ing, and we noticed that both of these techniques improved per- by the requirement that record-ids or primary keys be stored with formance, again due to the large amount of I/O needed to process each column to allow tuples to be reconstructed. We compared these queries. System X also implements a star join and the opti- the sizes of column-tables in our vertical partitioning approach to mizer will use bloom filters when it expects this will improve query the sizes of the traditional row store tables, and found that a single performance. column-table from our SSBM scale 10 lineorder table (with 60 Recall from Section 4 that we experimented with six configura- million tuples) requires between 0.7 and 1.1 GBytes of data after tions of System X on SSBM: compression to store – this represents about 8 bytes of overhead per row, plus about 4 bytes each for the record-id and the column 1. A “traditional” row-oriented representation; here, we allow attribute, depending on the column and the extent to which com- System X to use bitmaps and bloom filters if they are benefi- pression is effective (16 bytes × 6 × 107 tuples = 960 M B). In cial. contrast, the entire 17 column lineorder table in the traditional 2. A “traditional (bitmap)” approach, similar to traditional, but approach occupies about 6 GBytes decompressed, or 4 GBytes with plans biased to use bitmaps, sometimes causing them to compressed, meaning that scanning just four of the columns in the produce inferior plans to the pure traditional approach. vertical partitioning approach will take as long as scanning the en- tire fact table in the traditional approach. As a point of compar- 3. A “vertical partitioning” approach, with each column in its ison, in C-Store, a single column of integers takes just 240 MB own relation with the record-id from the original relation. (4 bytes × 6 × 107 tuples = 240 M B), and the entire table com- 4. An “index-only” representation, using an unclustered B+tree pressed takes 2.3 Gbytes. on each column in the row-oriented approach, and then an- Column Joins: As we mentioned above, merging two columns swering queries by reading values directly from the indexes. from the same table together requires a join operation. System X favors using hash-joins for these operations. We experimented 5. A “materialized views” approach with the optimal collection with forcing System X to use index nested loops and merge joins, of materialized views for every query (no joins were per- but found that this did not improve performance because index ac- formed in advance in these views). cesses had high overhead and System X was unable to skip the sort preceding the merge join. The detailed results broken down by query flight are shown in Figure 6(a), with average results across all queries shown in Fig- 9
10 . Flight 1 Flight 2 120.0 400.0 Average 350.0 250.0 100.0 300.0 80.0 Time (seconds) 250.0 60.0 200.0 40.0 150.0 200.0 100.0 20.0 50.0 0.0 0.0 T T(B) MV VP AI T T(B) MV VP AI Q1.1 2.7 9.9 1.0 69.7 107.2 Q2.1 43.8 91.9 15.5 65.1 359.8 150.0 Time (seconds) Q1.2 2.0 11.0 1.0 36.0 50.8 Q2.2 44.1 78.4 13.5 48.8 46.4 Q1.3 1.5 1.5 0.2 36.0 48.5 Q2.3 46.0 304.1 11.8 39.0 43.9 Flight 3 Flight 4 600.0 700.0 100.0 500.0 600.0 400.0 500.0 Time (seconds) 300.0 400.0 200.0 300.0 50.0 200.0 100.0 100.0 0.0 T T(B) MV VP AI 0.0 Q3.1 43.0 91.4 16.1 139.1 413.8 T T(B) MV VP AI Q3.2 42.8 65.3 6.9 63.9 40.7 Q4.1 44.4 94.4 29.2 208.6 623.9 0.0 Q3.3 31.2 31.2 6.4 48.2 531.4 Q4.2 14.1 25.3 22.4 150.4 280.1 T T(B) MV VP AI Q3.4 6.5 6.5 3.0 47.0 65.5 Q4.3 12.2 21.2 6.4 86.3 263.9 Average 25.7 64.0 10.2 79.9 221.2 (a) (b) Figure 6: (a) Performance numbers for different variants of the row-store by query flight. Here, T is traditional, T(B) is traditional (bitmap), MV is materialized views, VP is vertical partitioning, and AI is all indexes. (b) Average performance across all queries. 6.2.1 Detailed Row-store Performance Breakdown suppkey column with the filtered supplier table, and then In this section, we look at the performance of the row-store ap- hash-joins these two result sets. This yields tuples with the record- proaches, using the plans generated by System X for query 2.1 from id from the fact table and the p.brand1 attribute of the part the SSBM as a guide (we chose this query because it is one of the table that satisfy the query. System X then hash joins this with the few that does not benefit from orderdate partitioning, so pro- dwdate table to pick up d.year, and finally uses an additional vides a more equal comparison between the traditional and vertical hash join to pick up the lo.revenue column from its column ta- partitioning approach.) Though we do not dissect plans for other ble. This approach requires four columns of the lineorder table queries as carefully, their basic structure is the same. The SQL for to be read in their entirety (sequentially), which, as we said above, this query is: requires about as many bytes to be read from disk as the traditional approach, and this scan cost dominates the runtime of this query, SELECT sum(lo.revenue), d.year, p.brand1 yielding comparable performance as compared to the traditional FROM lineorder AS lo, dwdate AS d, approach. Hash joins in this case slow down performance by about part AS p, supplier AS s 25%; we experimented with eliminating the hash joins by adding WHERE lo.orderdate = d.datekey clustered B+trees on the key columns in each vertical partition, but AND lo.partkey = p.partkey System X still chose to use hash joins in this case. AND lo.suppkey = s.suppkey Index-only plans: Index-only plans access all columns through AND p.category = ’MFGR#12’ unclustered B+Tree indexes, joining columns from the same ta- AND s.region = ’AMERICA’ ble on record-id (so they never follow pointers back to the base GROUP BY d.year, p.brand1 relation). The plan for query 2.1 does a full index scan on the ORDER BY d.year, p.brand1 suppkey, revenue, partkey, and orderdate columns of The selectivity of this query is 8.0 × 10−3 . Here, the vertical parti- the fact table, joining them in that order with hash joins. In this tioning approach performs about as well as the traditional approach case, the index scans are relatively fast sequential scans of the en- (65 seconds versus 43 seconds), but the index-only approach per- tire index file, and do not require seeks between leaf pages. The forms substantially worse (360 seconds). We look at the reasons hash joins, however, are quite slow, as they combine two 60 mil- for this below. lion tuple columns each of which occupies hundreds of megabytes of space. Note that hash join is probably the best option for these Traditional: For this query, the traditional approach scans the en- joins, as the output of the index scans is not sorted on record-id, and tire lineorder table, using hash joins to join it with the dwdate, sorting record-id lists or performing index-nested loops is likely to part, and supplier table (in that order). It then performs a sort- be much slower. As we discuss below, we couldn’t find a way to based aggregate to compute the final answer. The cost is dominated force System X to defer these joins until later in the plan, which by the time to scan the lineorder table, which in our system re- would have made the performance of this approach closer to verti- quires about 40 seconds. Materialized views take just 15 seconds, cal partitioning. because they have to read about 1/3rd of the data as the traditional After joining the columns of the fact table, the plan uses an index approach. range scan to extract the filtered part.category column and Vertical partitioning: The vertical partitioning approach hash- hash joins it with the part.brand1 column and the part.part- joins the partkey column with the filtered part table, and the 10
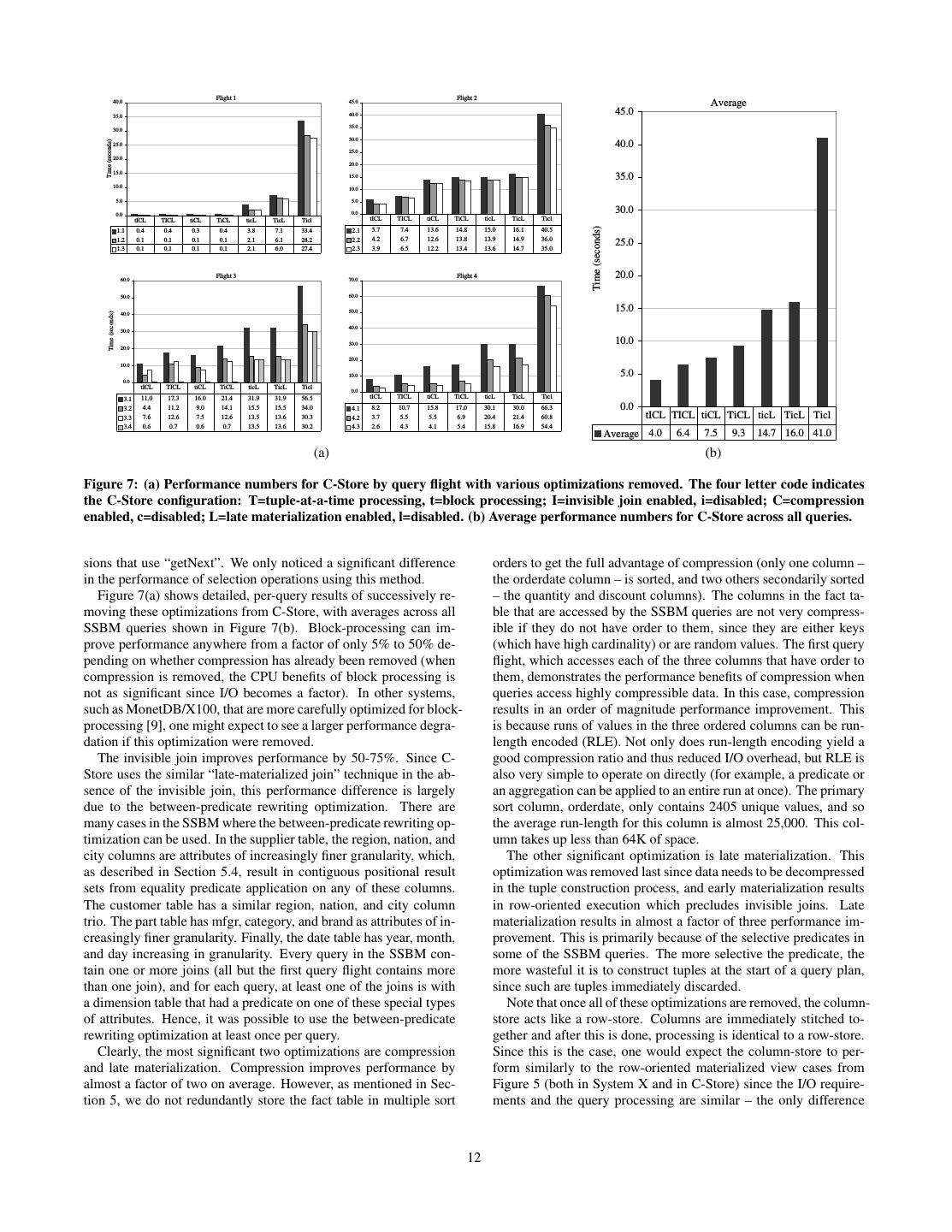
11 .key column (both accessed via full index scans). It then hash the “CS Row-MV” case from Section 6.1, where the amount of joins this result with the already joined columns of the fact table. I/O across systems is similar, and the other systems does not need Next, it hash joins supplier.region (filtered through an in- join together columns from the same table. In order to understand dex range scan) and the supplier.suppkey columns (accessed this latter performance difference, we perform additional experi- via full index scan), and hash joins that with the fact table. Fi- ments in the column-store where we successively remove column- nally, it uses full index scans to access the dwdate.datekey oriented optimizations until the column-store begins to simulate a and dwdate.year columns, joins them using hash join, and hash row-store. In so doing, we learn the impact of these various op- joins the result with the fact table. timizations on query performance. These results are presented in Section 6.3.2. 6.2.2 Discussion The previous results show that none of our attempts to emulate a 6.3.1 Tuple Overhead and Join Costs column-store in a row-store are particularly effective. The vertical Modern column-stores do not explicitly store the record-id (or partitioning approach can provide performance that is competitive primary key) needed to join together columns from the same table. with or slightly better than a row-store when selecting just a few Rather, they use implicit column positions to reconstruct columns columns. When selecting more than about 1/4 of the columns, how- (the ith value from each column belongs to the ith tuple in the ta- ever, the wasted space due to tuple headers and redundant copies of ble). Further, tuple headers are stored in their own separate columns the record-id yield inferior performance to the traditional approach. and so they can be accessed separately from the actual column val- This approach also requires relatively expensive hash joins to com- ues. Consequently, a column in a column-store contains just data bine columns from the fact table together. It is possible that System from that column, rather than a tuple header, a record-id, and col- X could be tricked into storing the columns on disk in sorted order umn data in a vertically partitioned row-store. and then using a merge join (without a sort) to combine columns In a column-store, heap files are stored in position order (the from the fact table but our DBA was unable to coax this behavior ith value is always after the i − 1st value), whereas the order of from the system. heap files in many row-stores, even on a clustered attribute, is only Index-only plans have a lower per-record overhead, but introduce guaranteed through an index. This makes a merge join (without another problem – namely, the system is forced to join columns of a sort) the obvious choice for tuple reconstruction in a column- the fact table together using expensive hash joins before filtering store. In a row-store, since iterating through a sorted file must be the fact table using dimension columns. It appears that System X is done indirectly through the index, which can result in extra seeks unable to defer these joins until later in the plan (as the vertical par- between index leaves, an index-based merge join is a slow way to titioning approach does) because it cannot retain record-ids from reconstruct tuples. the fact table after it has joined with another table. These giant It should be noted that neither of the above differences between hash joins lead to extremely slow performance. column-store performance and row-store performance are funda- With respect to the traditional plans, materialized views are an mental. There is no reason why a row-store cannot store tuple obvious win as they allow System X to read just the subset of headers separately, use virtual record-ids to join data, and main- the fact table that is relevant, without merging columns together. tain heap files in guaranteed position order. The above observation Bitmap indices sometimes help – especially when the selectivity simply highlights some important design considerations that would of queries is low – because they allow the system to skip over be relevant if one wanted to build a row-store that can successfully some pages of the fact table when scanning it. In other cases, they simulate a column-store. slow the system down as merging bitmaps adds some overhead to plan execution and bitmap scans can be slower than pure sequential 6.3.2 Breakdown of Column-Store Advantages scans. As described in Section 5, three column-oriented optimizations, As a final note, we observe that implementing these plans in Sys- presented separately in the literature, all claim to significantly im- tem X was quite painful. We were required to rewrite all of our prove the performance of column-oriented databases. These opti- queries to use the vertical partitioning approaches, and had to make mizations are compression, late materialization, and block-iteration. extensive use of optimizer hints and other trickery to coax the sys- Further, we extended C-Store with the invisible join technique which tem into doing what we desired. we also expect will improve performance. Presumably, these op- In the next section we study how a column-store system designed timizations are the reason for the performance difference between from the ground up is able to circumvent these limitations, and the column-store and the row-oriented materialized view cases from break down the performance advantages of the different features Figure 5 (both in System X and in C-Store) that have similar I/O of the C-Store system on the SSBM benchmark. patterns as the column-store. In order to verify this presumption, we successively removed these optimizations from C-Store and 6.3 Column-Store Performance measured performance after each step. It is immediately apparent upon the inspection of the average Removing compression from C-Store was simple since C-Store query time in C-Store on the SSBM (around 4 seconds) that it is includes a runtime flag for doing so. Removing the invisible join faster than not only the simulated column-oriented stores in the was also simple since it was a new operator we added ourselves. row-store (80 seconds to 220 seconds), but even faster than the In order to remove late materialization, we had to hand code query best-case scenario for the row-store where the queries are known in plans to construct tuples at the beginning of the query plan. Remov- advance and the row-store has created materialized views tailored ing block-iteration was somewhat more difficult than the other three for the query plans (10.2 seconds). Part of this performance dif- optimizations. C-Store “blocks” of data can be accessed through ference can be immediately explained without further experiments two interfaces: “getNext” and “asArray”. The former method re- – column-stores do not suffer from the tuple overhead and high quires one function call per value iterated through, while the latter column join costs that row-stores do (this will be explained in Sec- method returns a pointer to an array than can be iterated through di- tion 6.3.1). However, this observation does not explain the reason rectly. For the operators used in the SSBM query plans that access why the column-store is faster than the materialized view case or blocks through the “asArray” interface, we wrote alternative ver- 11
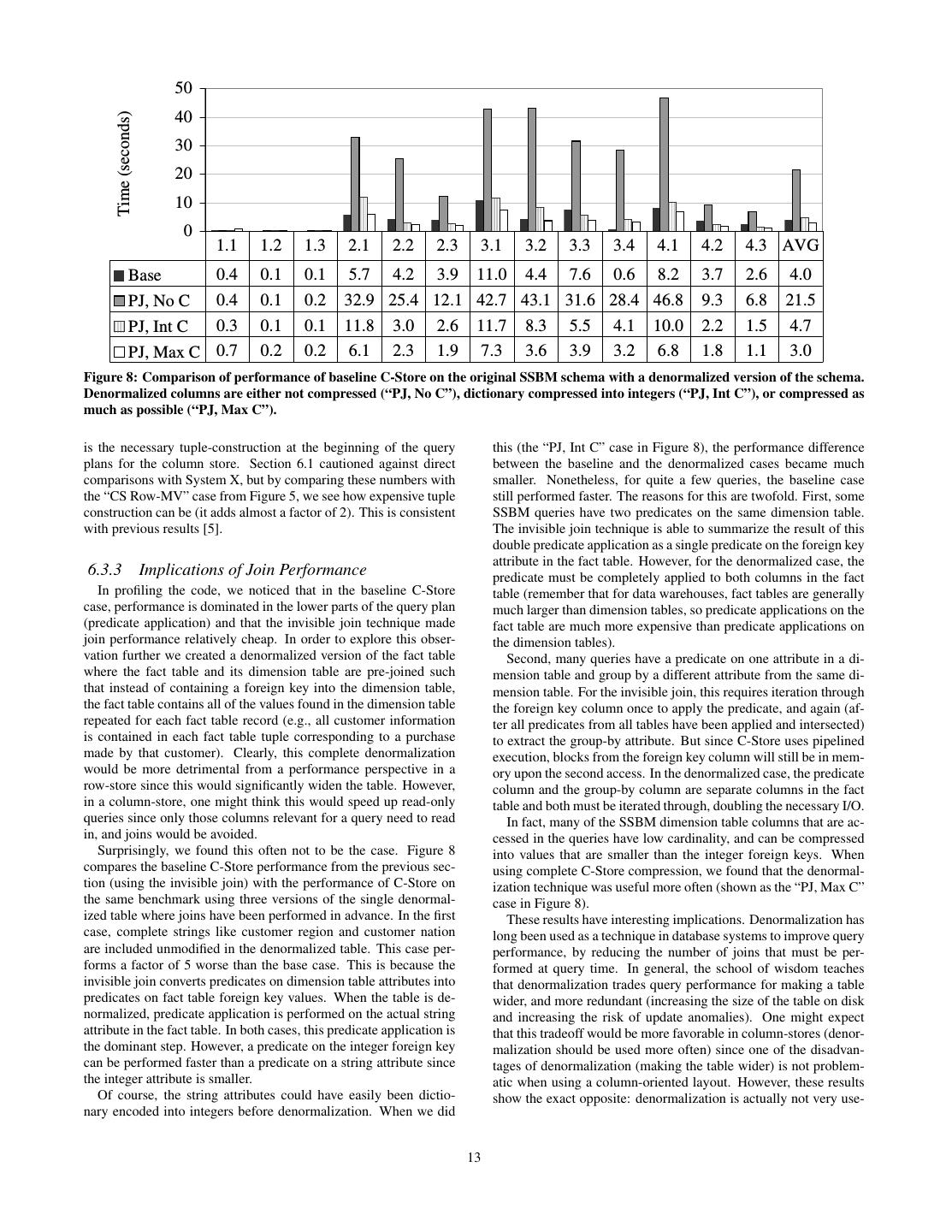
12 . Flight 1 Flight 2 40.0 45.0 Average 35.0 40.0 45.0 35.0 30.0 30.0 40.0 Time (seconds) 25.0 25.0 20.0 20.0 35.0 15.0 15.0 10.0 10.0 5.0 5.0 0.0 0.0 30.0 tICL TICL tiCL TiCL ticL TicL Ticl tICL TICL tiCL TiCL ticL TicL Ticl 2.1 5.7 7.4 13.6 14.8 15.0 16.1 40.5 Time (seconds) 1.1 0.4 0.4 0.3 0.4 3.8 7.1 33.4 1.2 0.1 0.1 0.1 0.1 2.1 6.1 28.2 2.2 4.2 3.9 6.7 6.5 12.6 12.2 13.8 13.4 13.9 13.6 14.9 14.7 36.0 35.0 25.0 1.3 0.1 0.1 0.1 0.1 2.1 6.0 27.4 2.3 60.0 Flight 3 70.0 Flight 4 20.0 50.0 60.0 40.0 50.0 15.0 Time (seconds) 40.0 30.0 30.0 10.0 20.0 20.0 10.0 10.0 5.0 0.0 tICL TICL tiCL TiCL ticL TicL Ticl 0.0 3.1 11.0 17.3 16.0 21.4 31.9 31.9 56.5 tICL TICL tiCL TiCL ticL TicL Ticl 3.2 4.4 11.2 9.0 14.1 15.5 15.5 34.0 4.1 8.2 10.7 15.8 17.0 30.1 30.0 66.3 0.0 3.3 7.6 12.6 7.5 12.6 13.5 13.6 30.3 4.2 3.7 5.5 5.5 6.9 20.4 21.4 60.8 tICL TICL tiCL TiCL ticL TicL Ticl 3.4 0.6 0.7 0.6 0.7 13.5 13.6 30.2 4.3 2.6 4.3 4.1 5.4 15.8 16.9 54.4 Average 4.0 6.4 7.5 9.3 14.7 16.0 41.0 (a) (b) Figure 7: (a) Performance numbers for C-Store by query flight with various optimizations removed. The four letter code indicates the C-Store configuration: T=tuple-at-a-time processing, t=block processing; I=invisible join enabled, i=disabled; C=compression enabled, c=disabled; L=late materialization enabled, l=disabled. (b) Average performance numbers for C-Store across all queries. sions that use “getNext”. We only noticed a significant difference orders to get the full advantage of compression (only one column – in the performance of selection operations using this method. the orderdate column – is sorted, and two others secondarily sorted Figure 7(a) shows detailed, per-query results of successively re- – the quantity and discount columns). The columns in the fact ta- moving these optimizations from C-Store, with averages across all ble that are accessed by the SSBM queries are not very compress- SSBM queries shown in Figure 7(b). Block-processing can im- ible if they do not have order to them, since they are either keys prove performance anywhere from a factor of only 5% to 50% de- (which have high cardinality) or are random values. The first query pending on whether compression has already been removed (when flight, which accesses each of the three columns that have order to compression is removed, the CPU benefits of block processing is them, demonstrates the performance benefits of compression when not as significant since I/O becomes a factor). In other systems, queries access highly compressible data. In this case, compression such as MonetDB/X100, that are more carefully optimized for block- results in an order of magnitude performance improvement. This processing [9], one might expect to see a larger performance degra- is because runs of values in the three ordered columns can be run- dation if this optimization were removed. length encoded (RLE). Not only does run-length encoding yield a The invisible join improves performance by 50-75%. Since C- good compression ratio and thus reduced I/O overhead, but RLE is Store uses the similar “late-materialized join” technique in the ab- also very simple to operate on directly (for example, a predicate or sence of the invisible join, this performance difference is largely an aggregation can be applied to an entire run at once). The primary due to the between-predicate rewriting optimization. There are sort column, orderdate, only contains 2405 unique values, and so many cases in the SSBM where the between-predicate rewriting op- the average run-length for this column is almost 25,000. This col- timization can be used. In the supplier table, the region, nation, and umn takes up less than 64K of space. city columns are attributes of increasingly finer granularity, which, The other significant optimization is late materialization. This as described in Section 5.4, result in contiguous positional result optimization was removed last since data needs to be decompressed sets from equality predicate application on any of these columns. in the tuple construction process, and early materialization results The customer table has a similar region, nation, and city column in row-oriented execution which precludes invisible joins. Late trio. The part table has mfgr, category, and brand as attributes of in- materialization results in almost a factor of three performance im- creasingly finer granularity. Finally, the date table has year, month, provement. This is primarily because of the selective predicates in and day increasing in granularity. Every query in the SSBM con- some of the SSBM queries. The more selective the predicate, the tain one or more joins (all but the first query flight contains more more wasteful it is to construct tuples at the start of a query plan, than one join), and for each query, at least one of the joins is with since such are tuples immediately discarded. a dimension table that had a predicate on one of these special types Note that once all of these optimizations are removed, the column- of attributes. Hence, it was possible to use the between-predicate store acts like a row-store. Columns are immediately stitched to- rewriting optimization at least once per query. gether and after this is done, processing is identical to a row-store. Clearly, the most significant two optimizations are compression Since this is the case, one would expect the column-store to per- and late materialization. Compression improves performance by form similarly to the row-oriented materialized view cases from almost a factor of two on average. However, as mentioned in Sec- Figure 5 (both in System X and in C-Store) since the I/O require- tion 5, we do not redundantly store the fact table in multiple sort ments and the query processing are similar – the only difference 12
13 . 50 Time (seconds) 40 30 20 10 0 1.1 1.2 1.3 2.1 2.2 2.3 3.1 3.2 3.3 3.4 4.1 4.2 4.3 AVG Base 0.4 0.1 0.1 5.7 4.2 3.9 11.0 4.4 7.6 0.6 8.2 3.7 2.6 4.0 PJ, No C 0.4 0.1 0.2 32.9 25.4 12.1 42.7 43.1 31.6 28.4 46.8 9.3 6.8 21.5 PJ, Int C 0.3 0.1 0.1 11.8 3.0 2.6 11.7 8.3 5.5 4.1 10.0 2.2 1.5 4.7 PJ, Max C 0.7 0.2 0.2 6.1 2.3 1.9 7.3 3.6 3.9 3.2 6.8 1.8 1.1 3.0 Figure 8: Comparison of performance of baseline C-Store on the original SSBM schema with a denormalized version of the schema. Denormalized columns are either not compressed (“PJ, No C”), dictionary compressed into integers (“PJ, Int C”), or compressed as much as possible (“PJ, Max C”). is the necessary tuple-construction at the beginning of the query this (the “PJ, Int C” case in Figure 8), the performance difference plans for the column store. Section 6.1 cautioned against direct between the baseline and the denormalized cases became much comparisons with System X, but by comparing these numbers with smaller. Nonetheless, for quite a few queries, the baseline case the “CS Row-MV” case from Figure 5, we see how expensive tuple still performed faster. The reasons for this are twofold. First, some construction can be (it adds almost a factor of 2). This is consistent SSBM queries have two predicates on the same dimension table. with previous results [5]. The invisible join technique is able to summarize the result of this double predicate application as a single predicate on the foreign key attribute in the fact table. However, for the denormalized case, the 6.3.3 Implications of Join Performance predicate must be completely applied to both columns in the fact In profiling the code, we noticed that in the baseline C-Store table (remember that for data warehouses, fact tables are generally case, performance is dominated in the lower parts of the query plan much larger than dimension tables, so predicate applications on the (predicate application) and that the invisible join technique made fact table are much more expensive than predicate applications on join performance relatively cheap. In order to explore this obser- the dimension tables). vation further we created a denormalized version of the fact table Second, many queries have a predicate on one attribute in a di- where the fact table and its dimension table are pre-joined such mension table and group by a different attribute from the same di- that instead of containing a foreign key into the dimension table, mension table. For the invisible join, this requires iteration through the fact table contains all of the values found in the dimension table the foreign key column once to apply the predicate, and again (af- repeated for each fact table record (e.g., all customer information ter all predicates from all tables have been applied and intersected) is contained in each fact table tuple corresponding to a purchase to extract the group-by attribute. But since C-Store uses pipelined made by that customer). Clearly, this complete denormalization execution, blocks from the foreign key column will still be in mem- would be more detrimental from a performance perspective in a ory upon the second access. In the denormalized case, the predicate row-store since this would significantly widen the table. However, column and the group-by column are separate columns in the fact in a column-store, one might think this would speed up read-only table and both must be iterated through, doubling the necessary I/O. queries since only those columns relevant for a query need to read In fact, many of the SSBM dimension table columns that are ac- in, and joins would be avoided. cessed in the queries have low cardinality, and can be compressed Surprisingly, we found this often not to be the case. Figure 8 into values that are smaller than the integer foreign keys. When compares the baseline C-Store performance from the previous sec- using complete C-Store compression, we found that the denormal- tion (using the invisible join) with the performance of C-Store on ization technique was useful more often (shown as the “PJ, Max C” the same benchmark using three versions of the single denormal- case in Figure 8). ized table where joins have been performed in advance. In the first These results have interesting implications. Denormalization has case, complete strings like customer region and customer nation long been used as a technique in database systems to improve query are included unmodified in the denormalized table. This case per- performance, by reducing the number of joins that must be per- forms a factor of 5 worse than the base case. This is because the formed at query time. In general, the school of wisdom teaches invisible join converts predicates on dimension table attributes into that denormalization trades query performance for making a table predicates on fact table foreign key values. When the table is de- wider, and more redundant (increasing the size of the table on disk normalized, predicate application is performed on the actual string and increasing the risk of update anomalies). One might expect attribute in the fact table. In both cases, this predicate application is that this tradeoff would be more favorable in column-stores (denor- the dominant step. However, a predicate on the integer foreign key malization should be used more often) since one of the disadvan- can be performed faster than a predicate on a string attribute since tages of denormalization (making the table wider) is not problem- the integer attribute is smaller. atic when using a column-oriented layout. However, these results Of course, the string attributes could have easily been dictio- show the exact opposite: denormalization is actually not very use- nary encoded into integers before denormalization. When we did 13
14 .ful in column-stores (at least for star schemas). This is because the [5] D. J. Abadi, D. S. Myers, D. J. DeWitt, and S. R. Madden. invisible join performs so well that reducing the number of joins Materialization strategies in a column-oriented DBMS. In via denormalization provides an insignificant benefit. In fact, de- ICDE, pages 466–475, 2007. normalization only appears to be useful when the dimension ta- [6] A. Ailamaki, D. J. DeWitt, M. D. Hill, and M. Skounakis. ble attributes included in the fact table are sorted (or secondarily Weaving relations for cache performance. In VLDB, pages sorted) or are otherwise highly compressible. 169–180, 2001. [7] D. S. Batory. On searching transposed files. ACM Trans. 7. CONCLUSION Database Syst., 4(4):531–544, 1979. [8] P. A. Bernstein and D.-M. W. Chiu. Using semi-joins to In this paper, we compared the performance of C-Store to several solve relational queries. J. ACM, 28(1):25–40, 1981. variants of a commercial row-store system on the data warehous- ing benchmark, SSBM. We showed that attempts to emulate the [9] P. Boncz, M. Zukowski, and N. Nes. MonetDB/X100: physical layout of a column-store in a row-store via techniques like Hyper-pipelining query execution. In CIDR, 2005. vertical partitioning and index-only plans do not yield good per- [10] P. A. Boncz and M. L. Kersten. MIL primitives for querying formance. We attribute this slowness to high tuple reconstruction a fragmented world. VLDB Journal, 8(2):101–119, 1999. costs, as well as the high per-tuple overheads in narrow, vertically [11] G. Graefe. Volcano - an extensible and parallel query partitioned tables. We broke down the reasons why a column-store evaluation system. 6:120–135, 1994. is able to process column-oriented data so effectively, finding that [12] G. Graefe. Efficient columnar storage in b-trees. SIGMOD late materialization improves performance by a factor of three, and Rec., 36(1):3–6, 2007. that compression provides about a factor of two on average, or an [13] A. Halverson, J. L. Beckmann, J. F. Naughton, and D. J. order-of-magnitude on queries that access sorted data. We also pro- Dewitt. A Comparison of C-Store and Row-Store in a posed a new join technique, called invisible joins, that further im- Common Framework. Technical Report TR1570, University proves performance by about 50%. of Wisconsin-Madison, 2006. The conclusion of this work is not that simulating a column- [14] S. Harizopoulos, V. Liang, D. J. Abadi, and S. R. Madden. store in a row-store is impossible. Rather, it is that this simu- Performance tradeoffs in read-optimized databases. In lation performs poorly on today’s row-store systems (our experi- VLDB, pages 487–498, 2006. ments were performed on a very recent product release of System [15] S. Harizopoulos, V. Shkapenyuk, and A. Ailamaki. QPipe: a X). A successful column-oriented simulation will require some im- simultaneously pipelined relational query engine. In portant system improvements, such as virtual record-ids, reduced SIGMOD, pages 383–394, 2005. tuple overhead, fast merge joins of sorted data, run-length encoding [16] S. Khoshafian, G. Copeland, T. Jagodis, H. Boral, and across multiple tuples, and some column-oriented query execution P. Valduriez. A query processing strategy for the techniques like operating directly on compressed data, block pro- decomposed storage model. In ICDE, pages 636–643, 1987. cessing, invisible joins, and late materialization. Some of these im- [17] P. O’Neil and G. Graefe. Multi-table joins through provements have been implemented or proposed to be implemented bitmapped join indices. SIGMOD Rec., 24(3):8–11, 1995. in various different row-stores [12, 13, 20, 24]; however, building a [18] P. E. O’Neil, X. Chen, and E. J. O’Neil. Adjoined Dimension complete row-store that can transform into a column-store on work- Column Index (ADC Index) to Improve Star Schema Query loads where column-stores perform well is an interesting research Performance. In ICDE, 2008. problem to pursue. [19] P. E. O’Neil, E. J. O’Neil, and X. Chen. The Star Schema Benchmark (SSB). http: 8. ACKNOWLEDGMENTS //www.cs.umb.edu/∼poneil/StarSchemaB.PDF. We thank Stavros Harizopoulos for his comments on this paper, [20] S. Padmanabhan, T. Malkemus, R. Agarwal, and and the NSF for funding this research, under grants 0704424 and A. Jhingran. Block oriented processing of relational database 0325525. operations in modern computer architectures. In ICDE, 2001. [21] R. Ramamurthy, D. Dewitt, and Q. Su. A case for fractured mirrors. In VLDB, pages 89 – 101, 2002. 9. REPEATABILITY ASSESSMENT [22] M. Stonebraker, D. J. Abadi, A. Batkin, X. Chen, All figures containing numbers derived from experiments on the M. Cherniack, M. Ferreira, E. Lau, A. Lin, S. R. Madden, C-Store prototype (Figure 7a, Figure 7b, and Figure 8) have been E. J. O’Neil, P. E. O’Neil, A. Rasin, N. Tran, and S. B. verified by the SIGMOD repeatability committee. We thank Ioana Zdonik. C-Store: A Column-Oriented DBMS. In VLDB, Manolescu and the repeatability committee for their feedback. pages 553–564, 2005. [23] A. Weininger. Efficient execution of joins in a star schema. 10. REFERENCES In SIGMOD, pages 542–545, 2002. [1] http://www.sybase.com/products/ [24] J. Zhou and K. A. Ross. Buffering databse operations for informationmanagement/sybaseiq. enhanced instruction cache performance. In SIGMOD, pages 191–202, 2004. [2] TPC-H Result Highlights Scale 1000GB. http://www.tpc.org/tpch/results/ [25] M. Zukowski, P. A. Boncz, N. Nes, and S. Heman. tpch result detail.asp?id=107102903. MonetDB/X100 - A DBMS In The CPU Cache. IEEE Data Engineering Bulletin, 28(2):17–22, June 2005. [3] D. J. Abadi. Query execution in column-oriented database systems. MIT PhD Dissertation, 2008. PhD Thesis. [26] M. Zukowski, S. Heman, N. Nes, and P. Boncz. Super-Scalar RAM-CPU Cache Compression. In ICDE, 2006. [4] D. J. Abadi, S. R. Madden, and M. Ferreira. Integrating compression and execution in column-oriented database systems. In SIGMOD, pages 671–682, 2006. 14
3秒后跳转登录页面
去登陆

