































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
传统的文件系统--FFS和LFS
本章介绍了传统的文件系统,包括快速文件系统以及日志结构文件系统,就目前关于LFS-FFS比较有很多的争议,这两个系统都是很有影响力的,IBM日志文件系统Ext3文件系统在Linux软更新中在FreeBSD中启用。
展开查看详情
1 .Classic File Systems: FFS and LFS Hakim Weatherspoon CS6410 1
2 .A Fast File System for UNIX Marshall K. McKusick , William N. Joy, Samuel J Leffler , and Robert S Fabry Bob Fabry Professor at Berkeley. Started CSRG (Computer Science Research Group) developed the Berkeley SW Dist (BSD) Bill Joy Key developer of BSD, sent 1BSD in 1977 Co-Founded Sun in 1982 Marshall (Kirk) McKusick (Cornell Alum) Key developer of the BSD FFS (magic number based on his birthday, soft updates, snapshot and fsck . USENIX Sam Leffler Key developer of BSD, author of Design and Implementation
3 .3 Background: Unix Fast File Sys Original UNIX File System (UFS) Simple, elegant, but slow 20 KB/sec/arm; ~2% of 1982 disk bandwidth Problems blocks too small consecutive blocks of files not close together (random placement for mature file system) i -nodes far from data (all i -nodes at the beginning of the disk, all data afterward) i -nodes of directory not close together no read-ahead
4 .4 Inodes and directories Inode doesnt contain a file name Directories map files to inodes Multiple directory entries can point to same Inode Low-level file system doesnt distinguish files and directories Separate system calls for directory operations
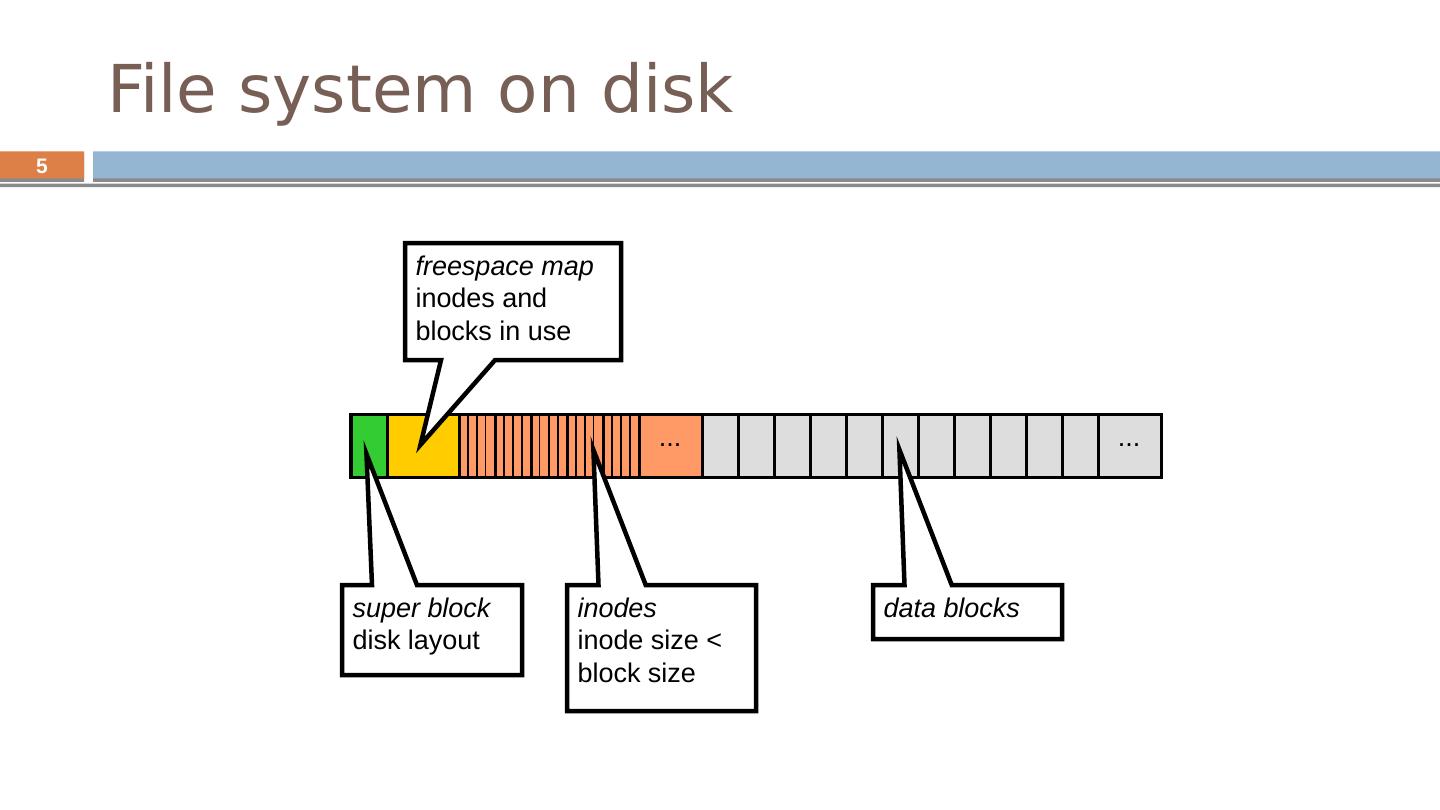
5 .5 File system on disk ... ... super block disk layout freespace map inodes and blocks in use inodes inode size < block size data blocks
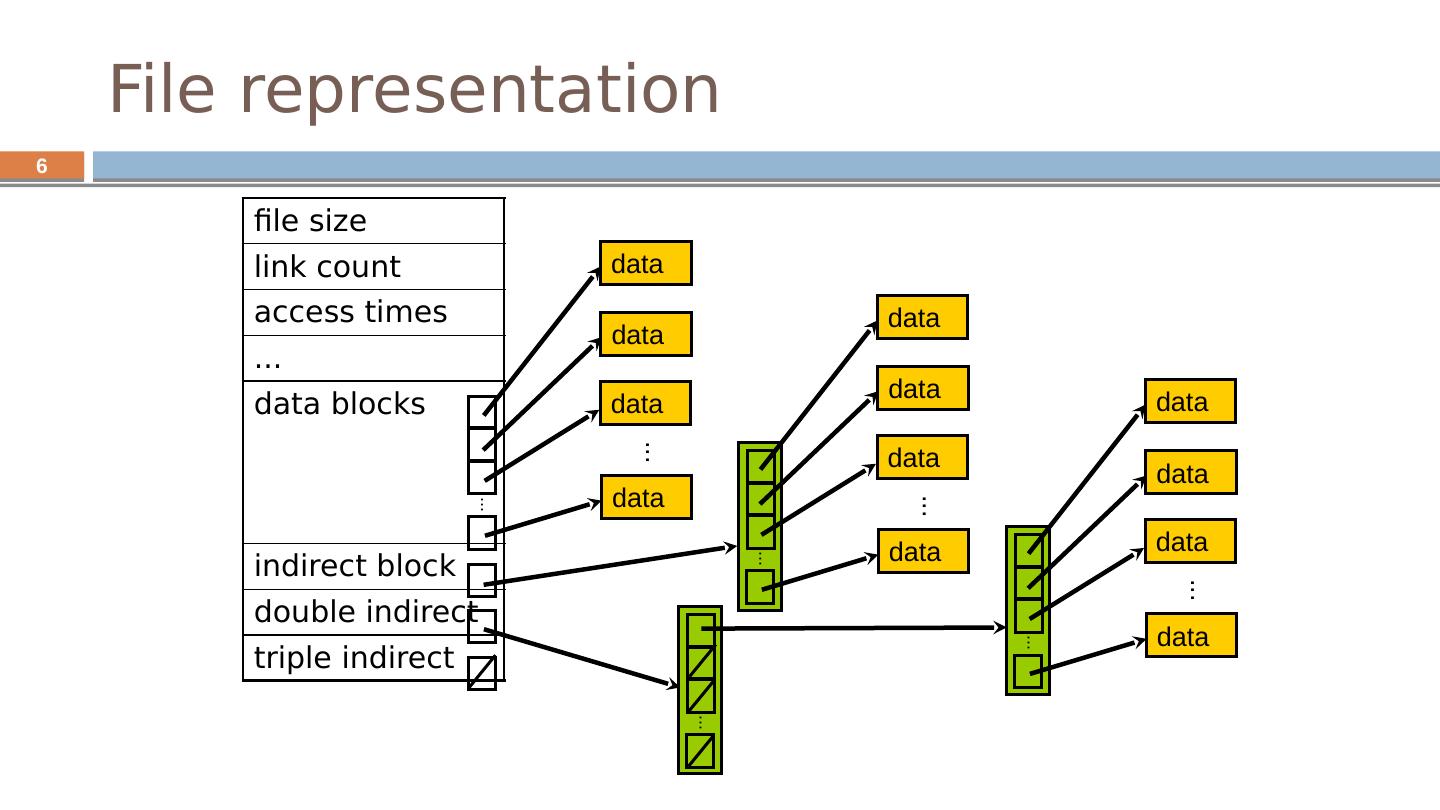
6 .6 File representation file size link count access times ... data blocks indirect block double indirect triple indirect data data data data ... ... ... data data data data ... ... data data data data ... ...
7 .7 The Unix Berkeley Fast File System Berkeley Unix (4.2BSD ) 4kB and 8kB blocks (why not larger?) Large blocks and small fragments Reduces seek times by better placement of file blocks i -nodes correspond to files Disk divided into cylinders contains superblock, i -nodes, bitmap of free blocks, summary info Inodes and data blocks grouped together Fragmentation can still affect performance
8 .8 FFS implementation Most operations do multiple disk writes File write: update block, inode modify time Create: write freespace map, write inode, write directory entry Write-back cache improves performance Benefits due to high write locality Disk writes must be a whole block Syncer process flushes writes every 30s
9 .9 FFS Goals keep dir in cylinder group, spread out different dir’s Allocate runs of blocks within a cylinder group, every once in a while switch to a new cylinder group (jump at 1MB). layout policy: global and local global policy allocates files & directories to cylinder groups. Picks “optimal” next block for block allocation. local allocation routines handle specific block requests. Select from a sequence of alternative if need to.
10 .10 FFS locality don’t let disk fill up in any one area paradox: for locality, spread unrelated things far apart note: FFS got 175KB/sec because free list contained sequential blocks (it did generate locality), but an old UFS had randomly ordered blocks and only got 30 KB/sec
11 .11 FFS Results 20-40% of disk bandwidth for large reads/writes 10-20x original UNIX speeds Size: 3800 lines of code vs. 2700 in old system 10% of total disk space unusable
12 .12 FFS Enhancements long file names (14 -> 255) advisory file locks (shared or exclusive) process id of holder stored with lock => can reclaim the lock if process is no longer around symbolic links (contrast to hard links) atomic rename capability (the only atomic read-modify-write operation, before this there was none) Disk Quotas Overallocation More likely to get sequential blocks; use later if not
13 .13 FFS crash recovery Asynchronous writes are lost in a crash Fsync system call flushes dirty data Incomplete metadata operations can cause disk corruption (order is important) FFS metadata writes are synchronous Large potential decrease in performance Some OSes cut corners
14 .14 After the crash Fsck file system consistency check Reconstructs freespace maps Checks inode link counts, file sizes Very time consuming Has to scan all directories and inodes
15 .15 Perspective Features parameterize FS implementation for the HW in use measurement-driven design decisions locality “wins” Flaws measuremenets derived from a single installation. ignored technology trends Lessons Do not ignore underlying HW characteristics Contrasting research approach Improve status quo vs design something new
16 .The Design and Impl of a Log-structured File System Mendel Rosenblum and John K. Ousterhout Mendel Rosenblum Designed LFS, PhD from Berkeley Professor at Stanford, designed SimOS Founder of VM Ware John Ousterhout Professor at Berkeley 1980-1994 Created Tcl scripting language and TK platform Research group designed Sprite OS and LFS Now professor at Stanford after 14 years in industry
17 .17 The Log-Structured File System Technology Trends I/O becoming more and more of a bottleneck CPU speed increases faster than disk speed Big Memories: Caching improves read performance Most disk traffic are writes Little improvement in write performance Synchronous writes to metadata Metadata access dominates for small files e.g. Five seeks and I/Os to create a file file i -node (create), file data, directory entry, file i -node (finalize), directory i -node (modification time).
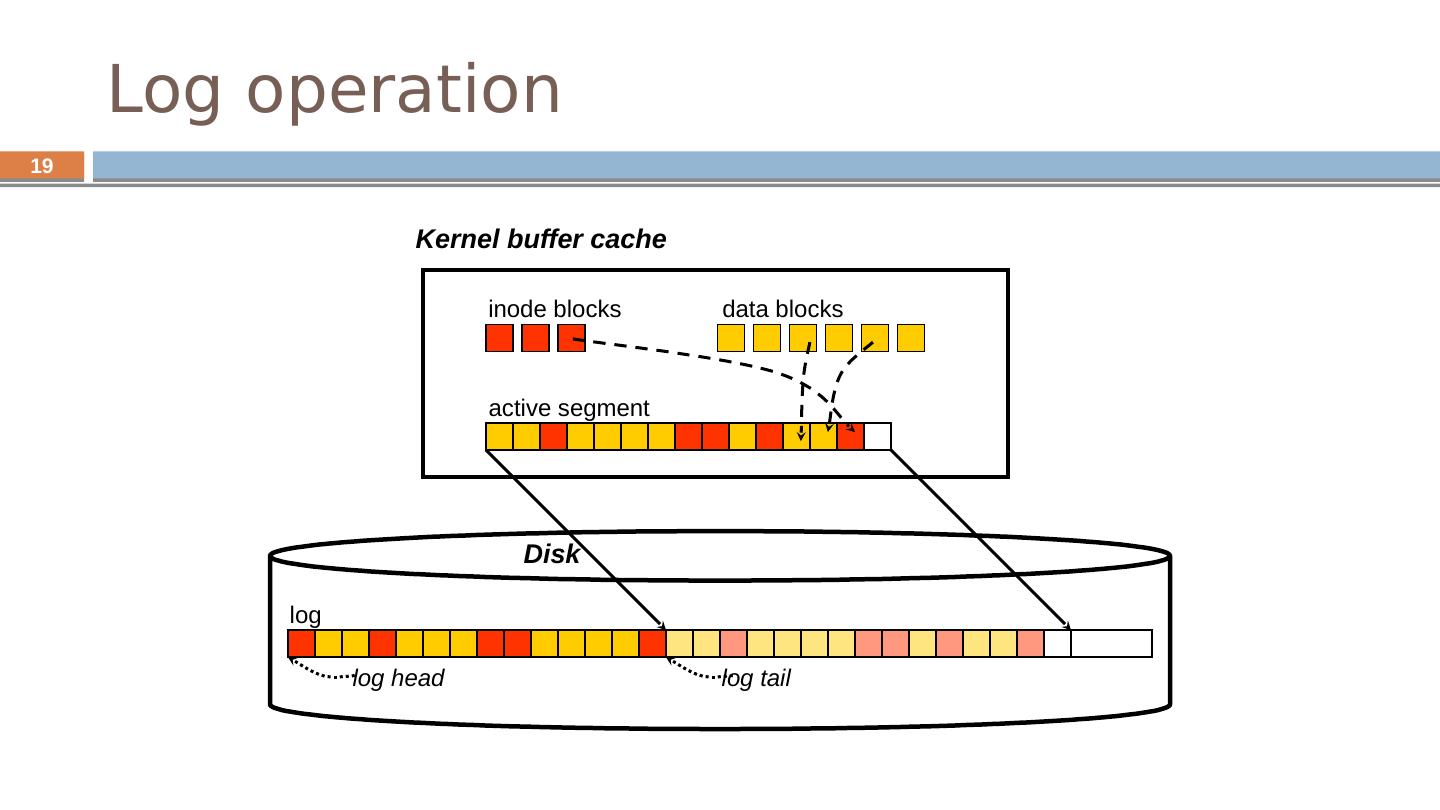
18 .18 LFS in a nutshell Boost write throughput by writing all changes to disk contiguously Disk as an array of blocks, append at end Write data, indirect blocks, inodes together No need for a free block map Writes are written in segments ~1MB of continuous disk blocks Accumulated in cache and flushed at once Data layout on disk “temporal locality” (good for writing) rather than “logical locality” (good for reading). Why is this a better? Because caching helps reads but not writes!
19 .19 Log operation inode blocks data blocks active segment log Kernel buffer cache log head log tail Disk
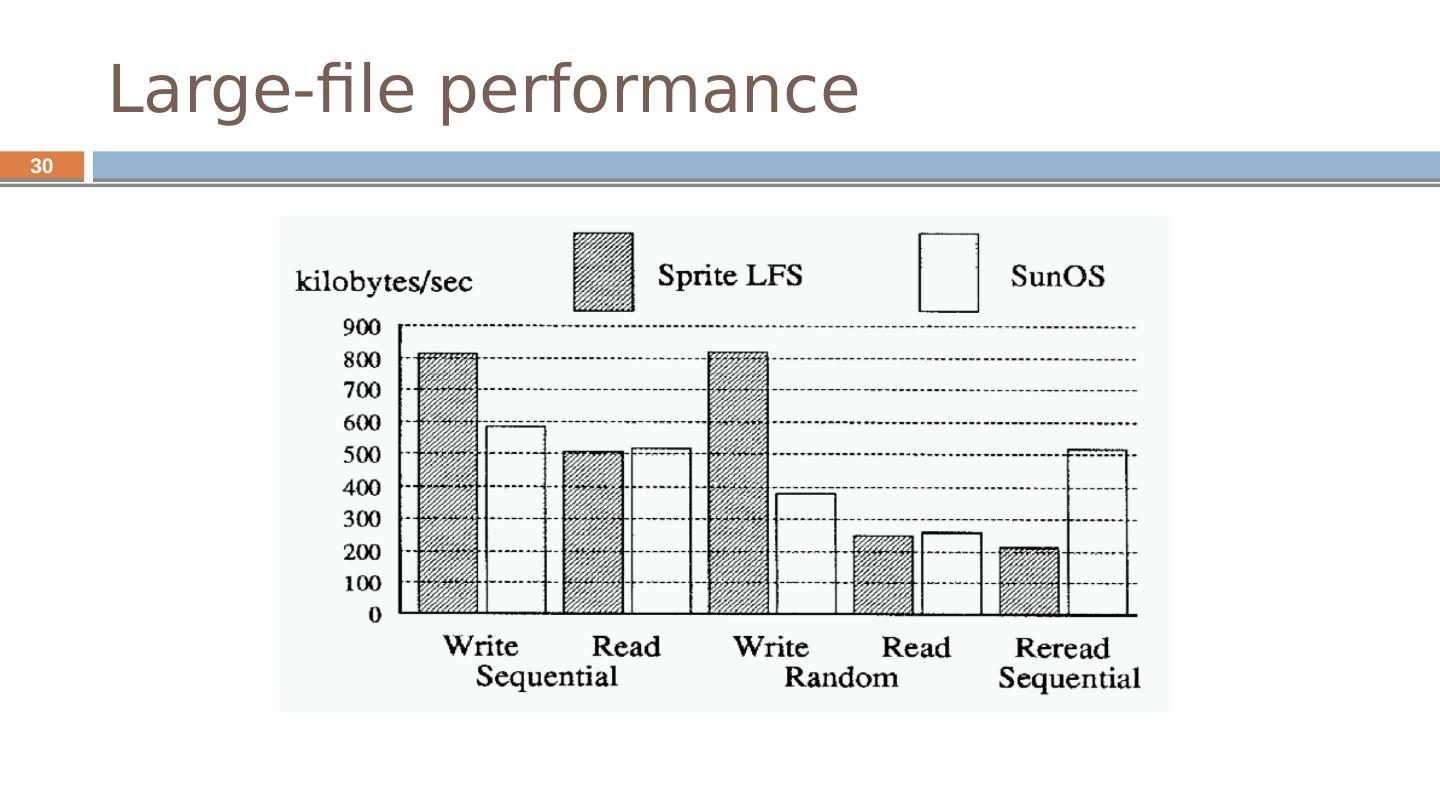
20 .20 LFS design Increases write throughput from 5-10% of disk to 70% Removes synchronous writes Reduces long seeks Improves over FFS "Not more complicated" Outperforms FFS except for one case
21 .21 LFS challenges Log retrieval on cache misses Locating inodes What happens when end of disk is reached?
22 .22 Locating inodes Positions of data blocks and inodes change on each write Write out inode , indirect blocks too! Maintain an inode map Compact enough to fit in main memory Written to disk periodically at checkpoints Checkpoints (map of inode map) have special location on disk Used during crash recovery
23 .23 Cleaning the log: “ Achilles Heel ” Log is infinite, but disk is finite Reuse the old parts of the log Clean old segments to recover space Writes to disk create holes Segments ranked by "liveness", age Segment cleaner "runs in background" Group slowly-changing blocks together Copy to new segment or "thread" into old
24 .Cleaning policies Simulations to determine best policy Greedy: clean based on low utilization Cost-benefit: use age (time of last write) Measure write cost Time disk is busy for each byte written Write cost 1.0 = no cleaning Cost-benefit: Greedy: smallest µ
25 .25 Greedy versus Cost-benefit
26 .26 Cost-benefit segment utilization
27 .27 LFS crash recovery Log and checkpointing Limited crash vulnerability At checkpoint flush active segment, inode map No fsck required
28 .28 LFS performance Cleaning behaviour better than simulated predictions Performance compared to SunOS FFS Create-read-delete 10000 1k files Write 100-MB file sequentially, read back sequentially and randomly
29 .29 Small-file performance
3秒后跳转登录页面
去登陆

