













- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
现代处理器上的合并和排序
大量基于日志的数据出现在数据中心中 ,产生了对排序几乎已排序数据集的兴趣。我们重新审视 主内存中数据的排序和合并问题,并显示 这是一种被遗忘已久的技巧,叫做耐心排序 关键的修改,要与当今最好的竞争 基于比较的随机和几乎排序技术 .排序的数据排序再现,实际上也是对排序算法在实践中的应用和权衡的一个很好的综述.
展开查看详情
1 . Patience is a Virtue: Revisiting Merge and Sort on Modern Processors Badrish Chandramouli and Jonathan Goldstein Microsoft Research {badrishc, jongold}@microsoft.com ABSTRACT In particular, the vast quantities of almost sorted log-based data The vast quantities of log-based data appearing in data centers has appearing in data centers has generated this interest. In these generated an interest in sorting almost-sorted datasets. We revisit scenarios, data is collected from many servers, and brought the problem of sorting and merging data in main memory, and show together either immediately, or periodically (e.g. every minute), that a long-forgotten technique called Patience Sort can, with some and stored in a log. The log is then typically sorted, sometimes in key modifications, be made competitive with today’s best multiple ways, according to the types of questions being asked. If comparison-based sorting techniques for both random and almost those questions are temporal in nature [7][17][18], it is required that sorted data. Patience sort consists of two phases: the creation of the log be sorted on time. A widely-used technique for sorting sorted runs, and the merging of these runs. Through a combination almost sorted data is Timsort [8], which works by finding of algorithmic and architectural innovations, we dramatically contiguous runs of increasing or decreasing value in the dataset. improve Patience sort for both random and almost-ordered data. Of Our investigation has resulted in some surprising discoveries about particular interest is a new technique called ping-pong merge for a mostly-ignored 50-year-old sorting technique called Patience merging sorted runs in main memory. Together, these innovations Sort [3]. Patience sort has an interesting history that we cover in produce an extremely fast sorting technique that we call P3 Sort (for Section 6. Briefly, Patience sort consists of two phases: the creation Ping-Pong Patience+ Sort), which is competitive with or better of natural sorted runs, and the merging of these runs. Patience sort than the popular implementations of the fastest comparison-based can leverage the almost-sortedness of data, but the classical sort techniques of today. For example, our implementation of P 3 algorithm is not competitive with either Quicksort or Timsort. In sort is around 20% faster than GNU Quicksort on random data, and this paper, through a combination of algorithmic innovations and 20% to 4x faster than Timsort for almost sorted data. Finally, we architecture-sensitive, but not architecture-specific, investigate replacement selection sort in the context of single-pass implementation, we dramatically improve both phases of Patience sorting of logs with bounded disorder, and leverage P3 sort to sort for both random and almost-ordered data. Of particular interest improve replacement selection. Experiments show that our is a novel technique for efficiently merging sorted runs in memory, proposal, P3 replacement selection, significantly improves called Ping-Pong merge. Together, these innovations produce an performance, with speedups of 3x to 20x over classical replacement extremely fast sorting technique that we call P3 Sort (for Ping-Pong selection. Patience+ Sort), which is competitive with or better than the Categories and Subject Descriptors popular implementations of the fastest comparison-based sort E.0 [Data]: General; E.5 [Data]: Files – Sorting/searching. techniques on modern CPUs and main memory. For instance, our implementation of P3 sort is approximately 20% faster than GNU Keywords Quicksort on random data, and 20% to 4x faster than the popular Sorting; Patience; Merging; Replacement Selection; Performance. Timsort implementation for almost-sorted data. 1. INTRODUCTION We then investigate methods for sorting almost-sorted datasets in a In this paper, we investigate new and forgotten comparison based single pass, when the datasets are stored in external memory, and sorting techniques suitable for sorting both nearly sorted, and disorder is bounded by the amount of data which can fit in memory. random data. While sorting randomly ordered data is a well-studied We show how P3 sort may be combined with replacement selection problem which has produced a plethora of useful results over the sort to minimize the CPU cost associated with single pass sorting. last five decades such as Quicksort, Merge Sort, and Heap Sort (see We propose flat replacement selection, where a periodically sorted [9] for a summary), the importance of sorting almost sorted data buffer is used instead of a heap, and P3 replacement selection, where quickly has just emerged over the last decade. the P3 sorting algorithm is deeply integrated into replacement. P3 Permission to make digital or hard copies of all or part of this work for personal replacement selection, in particular, is a dramatic practical or classroom use is granted without fee provided that copies are not made or improvement over classical replacement selection, achieving CPU distributed for profit or commercial advantage and that copies bear this notice speedups of between 3x and 20x. and the full citation on the first page. Copyrights for components of this work owned by others than ACM must be honored. Abstracting with credit is We believe that these techniques form a foundation for the kind of permitted. To copy otherwise, or republish, to post on servers or to redistribute tuning process that their brethren have already undergone, and to lists, requires prior specific permission and/or a fee. Request permissions given their current level of competitiveness, could become from Permissions@acm.org. commonly used sorting techniques similar to Quicksort and SIGMOD/PODS'14, June 22 - 27 2014, Salt Lake City, UT, USA Copyright 2014 ACM 978-1-4503-2376-5/14/06…$15.00. Timsort. For instance, we do not, in this paper, explore methods of http://dx.doi.org/10.1145/2588555.2593662 parallelizing or exploiting architecture-specific features (such as
2 .SIMD [20]) for further performance improvement. Rather, we element. Since the 2 cannot be added to either the first or second intend to establish a solid foundation for such future investigation. sorted run, a third sorted run is created and 2 added. Similarly, a We also expect this work to revive interest in replacement selection, fourth sorted run is created with 1. At this point, we have the 4 which was once used to bring the number of external memory sorted runs shown in Figure 2. passes down to two, and which can now, for many logs, be used to run 1 3 5 bring the number of external memory passes down to one. run 2 4 The paper is organized as outlined in Table 1. Sections 6 and 7 run 3 2 cover related work and conclude with directions for future work. run 4 1 Basic Sort and Patience sort Sec. 2.1 Prior work Improvements Patience+ Sec. 2.2 Re-architecture to make Figure 2: Sorted Runs After 5 Inputs (Section 2) sort Patience sort competitive Next, we read the 7. Since the first run is the run with the earliest Ping-Pong Merge Balanced Sec. 3.1 Basic merge approach creation time which 7 can be added to, we add the 7 to the first run. (Section 3) Unbalanced Sec. 3.2 Handles almost sorted data Next, we read the 6. In this case, the second run is the run with Naïve P3 sort Sec. 4.1 First sorting version that earliest creation time which 6 can be added to, so we add 6 to the P3 Sort combines our prior ideas (Section 4) CS P3 sort Sec. 4.2 Cache-sensitive version second run. Similarly, we add the rest of the input to the first run, P3 sort Sec. 4.3 Final sorting version with all resulting in the sorted runs after phase 1 shown in Figure 3. optimizations added 3 5 7 8 9 10 Flat RS Sec. 5.2 Replace heap with a sort Replacement 4 6 buffer in RS Selection (RS) P3 RS Sec. 5.3 Integrates P3 into the sort 2 (Section 5) buffer in RS Table 1: Paper Outline and Contributions 1 Figure 3: Sorted Runs After Phase 1 2. PATIENCE AND PATIENCE+ SORT The usual priority queue based remove and replace strategy is then 2.1 Background on Patience Sort used on the 4 final runs, resulting in the final sorted list. Patience Sort [3] derives its name from the British card game of Runtime Complexity For uniform random data, on average, the Patience (called Solitaire in America), as a technique for sorting a number of sorted runs created by the run generation phase of deck of cards. The patience game (slightly modified for clarity) works as follows: Consider a shuffled deck of cards. We deal one Patience sort is 𝑂(√𝑛) [2]. Since each element needs to perform a card at a time from the deck into a sequence of piles on a table, binary search across the runs, the expected runtime is 𝑂(𝑛 ⋅ log 𝑛). according to the following rules: The merge phase has to merge 𝑂(√𝑛) sorted runs using a priority queue, which also takes 𝑂(𝑛 ⋅ log 𝑛) time, for a total expected 1. We start with 0 piles. The first card forms a new pile by itself. running time of 𝑂(𝑛 ⋅ log 𝑛). It is easy to see that if the data is 2. Each new card may be placed on either an existing pile whose already sorted, only 1 run will be generated, and the algorithm time top card has a value no greater than the new card, or, if no such is 𝑂(𝑛). As the data becomes more disordered, the number of runs pile exists, on a new pile below all existing piles. increases, and performance gracefully degrades into 𝑂(𝑛 ⋅ log 𝑛). The game ends when all cards have been dealt, and the goal of the Observe that even if the number of lists is 𝑛, the execution time is game is to finish with as few piles as possible. still 𝑂(𝑛 ⋅ log 𝑛), and the technique essentially becomes merge sort. Patience sort is a comparison-based sorting technique based on the patience game, and sorts an array of elements as follows. Given an 2.2 Patience+ Sort n-element array, we simulate the patience game played with the To understand the historic lack of interest in Patience sort, we greedy strategy where we place each new card (or element) on the measured the time it takes to sort an array of uniform random 8- oldest (by pile creation time) legally allowed pile (or sorted run). byte integers. We use Quicksort (GNU implementation [11]) and a This strategy guarantees that the top cards across all the piles are standard implementation of Patience sort (from [12]). The Patience always in increasing order from the newest to oldest pile, which sort implementation is written using the C++ standard template allows us to use binary search to quickly determine the sorted run library, and uses their priority queue and vector data structures. The that the next element needs to be added to. GNU Quicksort implementation includes the well-known After the run generation phase is over, we have a set of sorted runs Sedgewick optimizations for efficiency [10]: there is no recursion, that we merge into a single sorted array using an n-way merge the split key is chosen from first, middle, and last, the smaller sub- (usually with a priority queue), during the merge phase [1]. partition is always processed first, and insertion sort is used on Example 1 (Patience sort) Figure 1 shows a 10-element array that small lists. All versions of all sort techniques in this paper are we use to create sorted runs. written in C++ and compiled in Visual Studio 2012 with maximum time optimizations enabled. All the sorting techniques in this paper 3 5 4 2 1 7 6 8 9 10 use the same key comparison API as the system qsort. All experiments in this paper were conducted on a Windows 2008 R2 Figure 1: Patience Sort Input 64-bit machine with a 2.67GHz Intel Xeon W3520 CPU with 12GB Patience sort scans the data from left to right. At the beginning, of RAM. The array size is varied from 100000(~ 1MB) to around there are no sorted runs, so when the 3 is read, a new sorted run is 50 million (~ 400MB). All experiments were performed 3 times on created and 3 inserted at the end. Since 5 comes after three, it is identical datasets, and the minimum of the times taken. added to the end of the first run. Since the 4 cannot be added to the end of the first sorted run, a new run is created with 4 as the only Figure 4 demonstrates the dismal performance of existing Patience sort implementations, which are 10x to 20x slower than Quicksort.
3 .To some degree, these dismal results are a reflection of the lack of entire dataset exactly once. In order to improve performance, our attention Patience sort has received. We first, therefore, re- implementation carefully packs all the destination runs for a implemented Patience sort using a collection of optimizations particular level into a single array as large as the original dataset, designed to eliminate most memory allocations, and mostly and reuses unneeded memory from lower levels of the merge tree. sequentialize memory access patterns, making better use of As a result, there is no actual memory allocation during this phase. memory prefetching. We call our Patience sort implementation Figure 5 shows how both versions of Patience+ sort fare against with this collection of optimizations Patience+ Sort. Quicksort. Note that Patience+ sort is already a dramatic improvement over Patience sort, bringing the execution time difference w.r.t. Quicksort down from 10x-20x to 1.5x-2x. Somewhat reassuring is that the tree-Q Patience+ sort seems to mostly eliminate the deterioration compared to Quicksort as dataset sizes increase. It is interesting to note, though, that re-designing Patience sort and merging around memory subsystem performance did significantly improve Patience sort. Figure 4: Patience Sort vs. Quicksort More specifically, we pass in a pre-allocated buffer which is usually sufficient for storing data from sorted runs. In the event that this buffer is fully consumed, more large buffers are allocated and freed as necessary. All memory used in the algorithm comes from these large blocks, minimizing the number of memory allocations. Figure 5: Patience+ Sort vs. Figure 6: Patience+ Sort In order to best utilize memory bandwidth during the first phase, Quicksort Merge Cost each sorted run is represented using a linked list of fixed size The remaining bottleneck in Patience+ sort becomes clear from memory blocks. The final memory block of each linked list is Figure 6, which shows the fraction of time spent in the merge phase pointed to in an array of memory block pointers (one for each run) of Patience+ sort. In both cases, the Patience+ sort cost is to facilitate fast appends to the sorted runs. Copies of the individual dominated by merging, reaching almost 90% for the single queue tail elements of the sorted runs are stored and maintained separately approach, and almost 75% for the tree-based merge. This led us to in a dynamic array for fast binary searching. search for a faster merge technique, which we cover next. The initial runs array and tails array sizes are set to the square root of the input size, and double when the number of runs exceeds this 3. PING-PONG MERGE size. Since, for random data, the expected number of runs is the The previous section showed some of the benefits of sorting in a square root of input size, and since the number of runs decreases as manner sensitive to memory subsystem performance, in particular the data becomes more sorted, array expansions are fairly rare. by eliminating fine grained memory allocations, sequentializing memory access, and improving caching behavior. Recent work While, for reverse ordered data, the number of runs is equal to the [20][22][23][24] has shown that using binary merges instead of a number of elements, this can be significantly mitigated by adding heap is effective when combined with architecture-specific features the capability of appending to either side of a sorted run. In this (such as SIMD) and parallelism. This section describes an case, we would maintain both an array of tail elements and an array algorithm for merging sorted runs, called ping-pong merge, which of head elements. After searching the tail elements, before adding leverages binary merging in a single-core architecture-agnostic another run, we would first binary search the head elements, which setting. Ping-pong merge is cache friendly, takes greater advantage would naturally be in order, for a place to put the element. Sorting of modern compilers and CPU prefetching to maximize memory reverse ordered lists would then take linear time. The case where bandwidth, and also significantly reduces the code path per merged the number of runs is linear in the input is then quite obscure. element. Ping-pong merge demonstrates the superiority of binary- For the priority queue based merging in the second phase, we tried merge-based techniques over heap-based merging schemes, even in two approaches. The first is the classic n-way merge of n sorted architecture independent settings. In this section, we introduce two runs using our own highly optimized heap implementation (e.g. no variants, balanced and unbalanced. As we will see, the unbalanced recursion). Note that there are no memory allocations since the version is important for sorting nearly ordered input. result can be merged into the destination. The second approach, which we call a tree-Q merge, is a less well 3.1 Balanced Ping-Pong Merge Ping-pong merge assumes the existence of two arrays, each of known, more performant approach [4], which performs a balanced which is the size of the number of elements to be merged. Let r be tree of k-way merges. Each k-way merge uses the same highly the number of sorted runs. We begin by packing the r sorted runs performant priority queue implementation as the classical into one of the arrays. For instance, Figure 7 shows a valid packing approach. The idea of this approach is to choose k such that the of the runs from Figure 3 packed into an array of 10 elements. priority queue fits into the processor’s L2 cache. On our experimental machine, we tuned k to its optimal value of 1000. This 3 5 7 8 9 10 4 6 2 1 approach is the best performing priority queue based merge technique known today. Note that each tree level processes the Figure 7: Packed Runs
4 .Note the need for ancillary information storing the locations of the 3.2 Unbalanced Ping-Pong Merge beginnings of each run, which are shown in bold. Adjacent runs are Of course, one of the prime motivations for using Patience sort is then combined, pairwise, into the target array. For instance, we can its linear complexity on mostly sorted data. Perhaps the most initially combine the first and second runs, and then combine the prevalent real source of such data is event logs, where some data third and fourth runs, into the target array, resulting in the array arrives late (for example, due to network delays), leading to a with two runs shown in Figure 8. tardiness distribution. Therefore, we built a synthetic data generator 3 4 5 6 7 8 9 10 1 2 to produce datasets that closely model such distributions. The generator takes two parameters: percentage of disorder (𝑝) and Figure 8: Packed Runs After One Round of Merging amount of disorder (𝑑). It starts with an in-order dataset with We now have just two runs. The first run begins at the first array increasing timestamps, and makes 𝑝% of elements tardy by moving position, while the second run begins at the ninth array position. their timestamps backward, based on the absolute value of a sample We now merge these two runs back into the original array, resulting from a normal distribution with mean 0 and standard deviation 𝑑. in the final sorted list. In general, one can go back and forth (i.e., ping-pong) in this manner between the two arrays until all runs have For such a disorder model, the first phase of Patience sort typically been merged. This style of merging has several benefits: produces a few very large runs. Figure 10 and Figure 11 illustrate The complexity of this algorithm is O(𝑛 ⋅ log 𝑟), the same as this effect. Figure 10 shows the distribution of run size after the first the priority queue based approach, which is optimal. phase of Patience sort on 100000 elements of random data. The There are no memory allocations. distribution is shown in order of creation. Note that the total number The algorithm is cache friendly: we only need three cache of runs, and the maximum run size is roughly √𝑛, which is expected lines for the data, one for each input and one for the output. given the theoretical properties of Patience sort over random data These lines are fully read/written before they are invalidated. [1]. Figure 11 shows the run size distribution for a 100000 element The number of instructions executed per merged element is disordered dataset with 𝑝 and 𝑑 set to 10. First, note that there are (potentially) very small, consisting of one if-then block, one only 5 runs. In addition, the run size distribution is highly skewed, comparison, one index increment, and one element copy. with the first run containing over 90% of the data. Modern compilers and CPUs, due to the algorithm’s simple, sequential nature, make excellent use of prefetching and memory bandwidth. At a high level, ping-pong merge, as described so far, is similar to merging using a tree-Q with a tree fanout of 2. The main difference is that instead of copying out the heads to a priority queue, and performing high instruction count heap adjustments, we hardcode the comparison between the two heads (without unnecessary copying), before writing out the result to the destination. In addition, we took care to minimize the codepath in the critical loop. Figure 10: Run Size – Figure 11: Run Size - Almost For instance, we repeatedly merge l total elements, where l is the Random Data Ordered Data minimum of the unmerged number of elements from the two runs We know that when merging sorted runs two-at-a-time, it is more being merged. This allows us to avoid checking if one run has been efficient to merge small runs together before merging the results fully merged in the inner loop. Finally, we manually unroll 4 loop with larger runs [13]. Put another way, rather than perform a iterations in the innermost loop. This much more explicit code path balanced tree of merges, it is more efficient to merge larger runs should be more easily understood by the compiler and CPU, and higher in the tree. For instance, consider the packed sorted runs in result in improved prefetching and memory throughput. Figure 7. Using the balanced approach described so far, we merge We now compare the performance of the binary tree-Q merge the first two runs, which involves copying 8 elements, and merge approach (we call it B-TreeQ), the k-way tree-Q approach (with k the last two elements into the second sorted run. We then do the set to 1000) used in Section 2.2, and ping-pong merge. The sorted final merge. Therefore, in total, we merge 8+2+10=20 elements. runs were generated by the first phase of Patience sort over uniform Suppose, instead, we merge the last two runs into the second array, random data (i.e., identical to the random workload used in Section producing the state shown in Figure 12. 2.2). The runs were packed into the array in order of creation. The results are shown in Figure 9. Note that ping-pong merge is 3 5 7 8 9 10 4 6 consistently 3-4 times faster than the k-way tree-Q merge. 1 2 Figure 12: Unbalanced Merge (first merge) We next merge the last run in the first array, and the last run in the second array. This is an interesting choice, because we are merging adjacent runs in different arrays. If we merge into the bottom array, we can actually blindly merge without worrying about overrunning the second run. The result is shown in Figure 13. 3 5 7 8 9 10 1 2 4 6 Figure 13: Unbalanced Merge (second merge) Figure 9: Merge Comparison (Random Data)
5 .Since we are down to two sorted runs, we can now do another blind 3.3 Evaluating Unbalanced Ping-Pong Merge merge into the bottom array. The result is shown in Figure 14. In order to better understand the potential impact of this optimization, we begin by examining the best and worst cases. 1 2 3 4 5 6 7 8 9 10 Clearly, the best case occurs when we have one very large run, and Figure 14: Unbalanced Merge (third merge) many small runs. We therefore conducted an experiment where we have a single large run of 60 million 8 byte integers (about 500 The total number of merges performed in the unbalanced merge is MB), and a variable number of single element runs. We measured 2+4+10=16, compared to 20 for the balanced approach. As the the time to merge using both the balanced and the optimized distribution of run lengths becomes more skewed, the difference unbalanced approach. Figure 15 shows the results. The cost of the between the balanced and unbalanced approaches widens. unoptimized approach increases exponentially with the number of We now propose an improvement to ping-pong merge, which runs (the x-axis is log scale). This is expected since every time we differs from the previous ping-pong merge algorithm in two ways: double the number of runs, the number of levels of the merge tree increases by one. Since the large run gets merged once at each level, 1. Runs are initially packed into the first array in run size order, the overall cost increases linearly. starting with the smallest run at the beginning. 2. Rather than merge all runs once before merging the result, merge in pairs, from smallest to largest. Reset the merge position back to the first two runs when either: we have merged the last two runs, or the next merge result will be larger than the result of merging the first two runs. Together, the two changes above efficiently approximate always merging the two smallest runs. Algorithm A1: Unbalanced Ping-Pong Merge 1 UPingPongMerge(Runs: Array of sorted runs, Sizes: Array of sorted run sizes) 2 RunSizeRefs : Array of (RunIndex, RunSize) pairs Figure 15: Unbalanced Merge - Best Case 3 Elems1 : Array of sort elements 4 Elems2 : Array of sort elements On the other hand, the optimized approach is pretty insensitive to 5 ElemsRuns : List of (ElemArr, ElemIndex, RunSize) the number of runs, since the cost is dominated by the single merge Triples that the large run participates in. These results generally hold in the situation where there are a few runs that contain almost all the data. 6 For each element i of Runs 7 RunSizeRefs[i] = (i, Sizes[i]) In contrast, we now consider the worst case for unbalanced 8 Sort RunSizeRefs by RunSize ascending merging. This occurs when there is little to no benefit of merging 9 NextEmptyArrayLoc = 0; the small runs early, but where the cost of sorting the run sizes is 10 for each element i of RunSizeRefs significant compared to merging. Initially, we tried a large number 11 copy Runs[i.RunIndex] into Elems1 starting at of single element lists. The sorting overhead turned out to be position NextEmptyArrayLoc negligible since sorting already sorted data is quite fast. We then 12 ElemsRuns.Insert (1, NextEmptyArrayLoc, i.RunSize) tried, with more success, a run size pattern of 1-2-1-2-1-2… This 13 NextEmpotyArrayLoc += i.RunSize run pattern ensured that the sort had to push half the ones into the first half, and half the twos into the second half. The sorting 14 curRun = ElemsRuns.IterateFromFirst 15 while ElemsRuns has at least two runs overhead in this case was significant enough to be noticeable. We 16 if (curRun has no next) or then tried 1-2-3-1-2-3…, which was even worse. We continued to (size of merging curRun and its next > increase the maximum run size up to 40, and varied the total size of merging the first and second runs) number of runs between 800k and 3.2M. Figure 16 shows the CurRun = ElemsRuns.IterateFromFirst results. 17 if (curRun.ElemsArr == 1) 18 Blindly merge curRun and curRun’s next into Elems2 starting at element position curRun.ElemIndex 19 curRun.ElemArr = 2 20 else 21 Blindly merge curRun and curRun’s next into Elems1 starting at element position curRun.ElemIndex 22 curRun.ElemArr = 1 23 curRun.RunSize += curRun.Next.RunSize 24 remove curRun’s next 25 curRun.MoveForward 26 if (ElemsRuns.First.RunIndex == 1) return Elems1 27 else return Elems2 Figure 16: Unbalanced Merge - Worst Case Algorithm A1 shows unbalanced ping-pong merge. Lines 8-13 sort the runs and pack them in the array. Lines 14-25 perform the The worst case peaks at ~30% overall penalty, with a maximum run unbalanced merge. We finally return the array of sorted elements. size of about 9. As the maximum run size increases, so does the average run size. As a result, more time is spent merging instead of sorting run sizes, and the overhead of sorting eventually decreases.
6 .Given the data dependent effect of unbalanced merging, we now investigate the effect of unbalanced merging on sorted runs generated by the first phase of Patience sort. In particular, consider our disordered data generator from Section 3.2. In Figure 11, we fixed both the percentage and the standard deviation of disorder. Figure 17 shows the results of an experiment where we varied both the disorder percentage, and the amount of disorder, and measured the effect of the unbalanced merge improvement on merge time. Figure 18: Quicksort vs Naïve P3 Sort 4.2 Cache-Sensitive P3 Sort Note that naïve P3 sort’s improvement over Quicksort diminishes as the dataset size increases. To understand this phenomenon more clearly, we first examine the percentage of time spent in the first phase of naïve P3 sort as dataset size increases. The results are shown in Figure 19. Figure 17: Effect of Unbalanced Merging on Ping-Pong Merge First, notice that when there is no disorder (0%) unbalanced merging has no effect. This makes sense when one considers that there is only one sorted run. Looking at the other extreme, where 100% of the data is disordered, as the disorder amount grows, the optimization becomes less effective. This makes sense when one considers that for purely disordered data, the run sizes are more uniform than for disordered data, as is illustrated in Figure 10 and Figure 11. When disorder is rare, increasing the amount of disorder actually causes the optimization to become more effective, because the likelihood that each disordered element causes a new run to form is much higher, than if there is a small amount of disorder. Figure 19: Phase 1 Time for Naïve P3 Sort There are two important takeaways from this experiment: First, unbalanced tree merging is never detrimental to performance for Note that as dataset size increases, so does the percentage of time the types of Patience sort workloads we are targeting. Second, we spent in the first phase. Suspecting this might be a caching effect, saw improvements by as much as a factor of 5, with possibly even we decided to limit the binary search of tail values in phase 1 to a higher levels of improvement for other Patience sort cases. For the fixed number of the most recently created runs. This idea is to fit best case measured here, unbalanced ping-pong merge was more all the searched tail values in the cache. We tried a size of 1000, than a factor of 10 faster than state-of-the-art heap based merge which is the optimal size for the array in tree-Q merge (see Section techniques such as cache-aware k-way tree-Q merge. 2.2). The results are shown in Figure 20. Limiting the number of runs which can be actively appended to, achieves the intended 4. PING-PONG PATIENCE SORT effect. Cache-Sensitive (CS) P3 sort on random data takes 73% to 75% of the time it takes Quicksort to sort the same data, with no 4.1 Naïve P3 Sort observable change in relative performance as dataset size increases. We now combine our efficient implementation of the first phase of Patience+ Sort, with our optimized ping-pong merge. We call the result naïve Ping-Pong Patience+ Sort (i.e., naïve P3 Sort). We call this version “naïve” because we introduce further important optimizations later in this section. In particular, we introduce a cache-sensitive version, called Cache Sensitive Ping-Pong Patience Sort, which includes optimizations in the first phase to improve cache related performance. In the final variant, simply called Ping- Pong Patience Sort, additional optimizations are made in the first phase to improve performance for almost ordered input. To begin, we re-run our experiment comparing Quicksort with Patience sort, but this time use naïve P3 sort. The result is shown in Figure 18. First, note that naïve P3 sort is faster than Quicksort in all measured cases, ranging between 73% and 83% of the time taken by Quicksort. Figure 20: Effect of Cache Sensitivity So far, our focus for P3 sort has been on random data, where Quicksort excels, and P3 sort is unable to leverage order. We now examine the performance of cache sensitive P 3 sort for the synthetic
7 .workloads described in Section 3.2. In these workloads we Learning from this approach, we optimize our CS P3 sort effectively “push forward” a fixed percentage of in-order data by a implementation to handle this case as follows. After we add a new number of positions which follows the absolute value of a normal element to the tail of a sorted run during phase 1, we introduce a distribution with mean 0. We vary the percentage of data which is small loop where we try to insert as many subsequent elements pushed, and also vary the standard deviation of amount of push. We from the input as possible to the same sorted run. This is achieved compare, for these workloads, the time taken to sort using cache by comparing each new element in the input with the current tail as sensitive P3 sort and Quicksort. The results are shown in Figure 21. well as the tail of the previous sorted run (if one exists, i.e., this is not the first sorted run). If the new element lies between the current tail and previous tail, we can add it to the current sorted run and resume the loop. This allows us to quickly process a sequence of increasing elements in the input, which lie between the current and previous tail. This loop is terminated when we encounter an element that does not belong to the current sorted run. In our current implementation, we apply this optimization only to the first sorted run – this is usually the largest run for data such as logs, where elements are tardy. This allows us to avoid the second comparison with the tail of the previous run. Incorporating these optimizations produces our final P3 sort variant, which we simply call P 3 sort. Algorithm A2 shows P3 sort. Line 8 shows the optimization that makes the algorithm cache-sensitive. Lines 14-17 depict (at a high Figure 21: CS P3 Sort vs. Quicksort (partially ordered) level) the optimization to continue adding elements to the chosen First, note that when the data is already sorted, CS P3 sort is tail. Finally, Line 18 invokes unbalanced ping-pong merge to approximately 3x faster than Quicksort. It is worth noting that while complete the second phase of the algorithm. For clarity, we have Quicksort benefits significantly from the data being sorted, excluded from this algorithm the optimization described in Section performance falls off faster for Quicksort than CS P3 sort as the data 2.2 for efficiently handling reverse sorted lists. becomes mildly disordered. This explains the up to 5x improvement of CS P3 sort over Quicksort with mild disorder. Algorithm A2: P3 Sort 1 P3Sort(ElemsToSort: Array of comparable elements) 4.3 Final P3 Sort 2 Runs: Array of sorted runs While this is an excellent showing for CS P 3 sort, it is worth noting 3 Tails: Array of sorted run tails 4 Sizes: Array of sorted run sizes that the total cost of CS P3 sort is still significantly higher (about 7 times) than performing two memory copies of the dataset for 5 CurElemIndex: Index of the element being processed perfectly ordered data. In fact, when considering the cost this way, 6 CurElemIndex = 0 the overall costs of mildly disordered data seems too high. To better 7 while CurElemIndex < ElemsToSort.Size understand this, we measured the ratio of time spent in phase 1 for 8 Binary search the k highest indexed tails for the the above experiment. The results are shown in Figure 22. earliest which is <= ElemsToSort[CurElemIndex] 9 If there isn’t such a tail 10 Add a new sorted run, with highest index, containing just ElemsToSort[CurElemIndex] 11 Update Tails and Sizes 12 Increment CurElemIndex 13 else 14 do 15 Add ElemsToSort[CurElemIndex] to found run 16 Increment CurElemIndex 17 while ElemsToSort[CurElemIndex] should be added to the chosen tail 18 UPingPongMerge(Runs, Sizes) Figure 22: Phase 1 Time for CS P3 Sort (Partially Ordered) 4.4 Evaluating P3 Sort Note that while the time is about evenly split between phase 1 and Figure 23 shows the results of re-running our comparison with phase 2 for mostly random data, as the data becomes more ordered, Quicksort, using P3 sort instead of the cache-sensitive CS P3 sort. more of the time is spent in the first phase. At the most extreme, First, note the dramatic overall improvement. P 3 sort is more than 80% of the time is spent in the first phase. Looking to approximately 10 times faster than Quicksort when 5% or less of the literature on sorting almost-sorted data, the best-known current the data is disordered, regardless of the degree of disorder. As the technique is Timsort, which is the system sort in Python, and is used dataset size increases, P3 sort improves further against Quicksort to sort arrays of non-primitive type in Java SE 7, on the Android due to its linear complexity for ordered data. In addition, observe platform, and in GNU Octave [8]. Timsort has a heavily optimized that the random case has not degraded as a result of these in-order Java implementation (which we translated to C++). While we defer data optimizations. Finally, the total time taken to sort sorted data a comparison until Section 4.4, we note that this implementation is now approximately the cost of 2 memory copies of the entire has many optimizations around trying to, as quickly as possible, dataset. This indicates that there are no further opportunities to copy consecutive sorted elements in the input into sorted runs. improve this case.
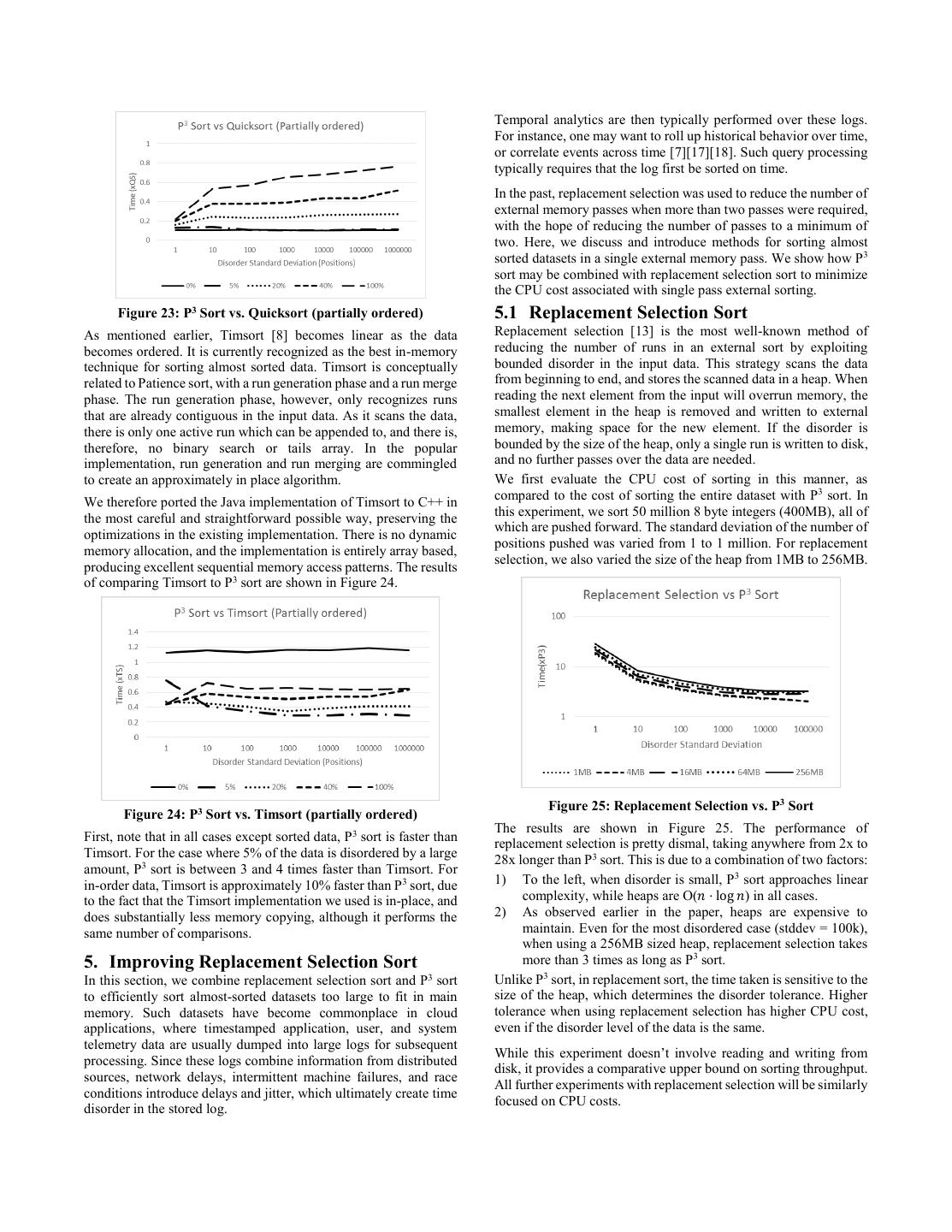
8 . Temporal analytics are then typically performed over these logs. For instance, one may want to roll up historical behavior over time, or correlate events across time [7][17][18]. Such query processing typically requires that the log first be sorted on time. In the past, replacement selection was used to reduce the number of external memory passes when more than two passes were required, with the hope of reducing the number of passes to a minimum of two. Here, we discuss and introduce methods for sorting almost sorted datasets in a single external memory pass. We show how P3 sort may be combined with replacement selection sort to minimize the CPU cost associated with single pass external sorting. Figure 23: P3 Sort vs. Quicksort (partially ordered) 5.1 Replacement Selection Sort As mentioned earlier, Timsort [8] becomes linear as the data Replacement selection [13] is the most well-known method of becomes ordered. It is currently recognized as the best in-memory reducing the number of runs in an external sort by exploiting technique for sorting almost sorted data. Timsort is conceptually bounded disorder in the input data. This strategy scans the data related to Patience sort, with a run generation phase and a run merge from beginning to end, and stores the scanned data in a heap. When phase. The run generation phase, however, only recognizes runs reading the next element from the input will overrun memory, the that are already contiguous in the input data. As it scans the data, smallest element in the heap is removed and written to external there is only one active run which can be appended to, and there is, memory, making space for the new element. If the disorder is therefore, no binary search or tails array. In the popular bounded by the size of the heap, only a single run is written to disk, implementation, run generation and run merging are commingled and no further passes over the data are needed. to create an approximately in place algorithm. We first evaluate the CPU cost of sorting in this manner, as compared to the cost of sorting the entire dataset with P3 sort. In We therefore ported the Java implementation of Timsort to C++ in this experiment, we sort 50 million 8 byte integers (400MB), all of the most careful and straightforward possible way, preserving the which are pushed forward. The standard deviation of the number of optimizations in the existing implementation. There is no dynamic positions pushed was varied from 1 to 1 million. For replacement memory allocation, and the implementation is entirely array based, selection, we also varied the size of the heap from 1MB to 256MB. producing excellent sequential memory access patterns. The results of comparing Timsort to P3 sort are shown in Figure 24. Figure 25: Replacement Selection vs. P3 Sort Figure 24: P3 Sort vs. Timsort (partially ordered) The results are shown in Figure 25. The performance of First, note that in all cases except sorted data, P3 sort is faster than replacement selection is pretty dismal, taking anywhere from 2x to Timsort. For the case where 5% of the data is disordered by a large 28x longer than P3 sort. This is due to a combination of two factors: amount, P3 sort is between 3 and 4 times faster than Timsort. For in-order data, Timsort is approximately 10% faster than P3 sort, due 1) To the left, when disorder is small, P 3 sort approaches linear to the fact that the Timsort implementation we used is in-place, and complexity, while heaps are O(𝑛 ⋅ log 𝑛) in all cases. does substantially less memory copying, although it performs the 2) As observed earlier in the paper, heaps are expensive to same number of comparisons. maintain. Even for the most disordered case (stddev = 100k), when using a 256MB sized heap, replacement selection takes 5. Improving Replacement Selection Sort more than 3 times as long as P3 sort. In this section, we combine replacement selection sort and P3 sort Unlike P3 sort, in replacement sort, the time taken is sensitive to the to efficiently sort almost-sorted datasets too large to fit in main size of the heap, which determines the disorder tolerance. Higher memory. Such datasets have become commonplace in cloud tolerance when using replacement selection has higher CPU cost, applications, where timestamped application, user, and system even if the disorder level of the data is the same. telemetry data are usually dumped into large logs for subsequent While this experiment doesn’t involve reading and writing from processing. Since these logs combine information from distributed disk, it provides a comparative upper bound on sorting throughput. sources, network delays, intermittent machine failures, and race All further experiments with replacement selection will be similarly conditions introduce delays and jitter, which ultimately create time focused on CPU costs. disorder in the stored log.
9 .5.2 Flat Replacement Selection (FRS) Sort This is a significant improvement over classical replacement When replacement selection is used for run formation in external selection, particularly on modern hardware. Modern caches and memory sorting, data is typically flushed, read, and enqueued in memory hierarchies have been far kinder to Quicksort than batches. This is done to optimize the bandwidth of external replacement selection, which is based on heaps. Two decades ago, memory, which is generally block oriented. The resulting tolerance when there was far more interest in replacement selection, flat to disorder is the memory footprint minus the batch size. For replacement selection was probably not an improvement over instance, if the batch size is one quarter the memory footprint, the standard replacement selection. The fact that the two techniques are disorder tolerance is three quarters of the memory footprint. quite close for small buffer sizes is evidence of this. We now introduce a variant of batched replacement selection, If, on the other hand, we use a sorting technique which is linear on called flat replacement selection, which overcomes the two sorted data, like P3 sort, when we re-sort, the already sorted portion replacement selection deficiencies identified in the previous of the data is simply copied into the correct final location. This section. In particular, instead of maintaining a heap, we maintain a should significantly improve upon standard replacement selection. sorted list in a buffer. Initially, we fill the buffer with the first Note that both replacement selection deficiencies identified in the portion of the dataset, and sort it. We then flush the initial portion previous section are addressed: Because we are using P 3 sort, the (determined by the batch size) of the sorted list, fill the empty cost of sorting is now nearly linear for nearly sorted data. Also, portion of the list with the next portion of the input data, re-sort, since there is no heap, the constant time inefficiencies associated and repeat until the entire dataset is processed. Algorithm A3 with maintaining heaps are no longer relevant. We reran the depicts this technique. Line 7 sorts the elements in the buffer, while previous experiment, using replacement selection as the baseline, Lines 8-12 write out BatchSize elements to the output. Lines 13-14 with a batch size of half the buffer. The results are in Figure 27. read more data in, and the process is repeated until the end of input. Algorithm A3: Flat Replacement Selection Sort 1 FlatRSSort(InputElems: Input sequence, 2 OutputElems: Sorted output sequence, BatchSize: The # of elems in a batch) 3 Buffer: Array of k elements 4 ElemsToRead = min(InputElems.#Unread, k) 5 Read the first ElemsToRead elements of InputElems into Buffer 6 do 7 sort the elements in Buffer 8 if there are no more input elements 9 write the elements in Buffer to OutputElems 10 else Figure 27: Flat (P3) vs. Standard Replacement Selection Sort 11 write the first Batchsize elements in Buffer to OutputElems The improvement in performance is now far more dramatic, 12 delete the first Batchsize elements in Buffer ranging between a 3x and 10x speedup. Additionally, the 13 ElemsToRead = min(InputElems.#Unread, k-Batchsize) performance gap narrows as disorder increased, and widens as 14 append the next ElemsToRead elements of InputElems disorder tolerance (buffer size) increases. As disorder increases, flat into Buffer selection sort, which ultimately relies on P 3 sort, loses its linear 15 while OutputElems hasn’t had all elements written advantage over heap sort on mostly sorted data. This seems like a very straightforward idea, and we were surprised On the other hand, as the buffer size increases, the extra memory we didn’t find any reference to something like it in the literature. In copying associated with moving data around in the buffer for order to better understand this gap, we first tried this technique piecewise sorting decreases. using Quicksort when we re-sort. We then reran the previous experiment, using replacement selection as the baseline, with a 5.3 P3 Replacement Selection Sort batch size of half the buffer. The results are shown in Figure 26. We now introduce the final variant of replacement selection, which we call P3 replacement selection. This sorting variant deeply integrates the batch replacement strategy into the P3 sorting algorithm itself. Algorithm A4 shows P3 replacement selection. In particular, we begin by performing phase 1 of P 3 sort, until our memory budget is half used. By building a histogram over a sample of the data as we process it in phase 1, we determine the approximate median of all the data stored in the sorted runs (Lines 11-14). We then perform phase 2 of the P3 sort on the smallest half of the data, as determined by the median, and output the result (Lines 15-19). Furthermore, we remove the outputted data from the sorted runs held in memory. Note that this might result in the removal of some runs. We then continue phase 1, processing new input until the memory taken by the sorted runs is once again half the memory footprint. Figure 26: Flat (QS) vs. Standard Replacement Selection Sort We then repeat merging and flushing the smallest half of the data.
10 . Algorithm A4: P3 Replacement Selection Sort Note that while not as dramatic as the introduction of flat 1 P3RSSort(InputElems: Input sequence, replacement sort, there are, nevertheless, significant gains, 2 OutputElems: Sorted output sequence, especially when the level of disorder is low. BatchSize: The # of elems in a batch) 3 RunSizeRefs : Array of (RunIndex, MergeSize) pairs There are two trends worth discussing. The first trend is the closing 4 Runs: Array of sorted runs of the performance gap as the memory footprint increases. As the 5 Tails: Array of sorted run tails memory footprint approaches the size of the dataset, the two 6 Sizes: Array of sorted run sizes algorithms behave very similarly, although there is some extra 7 k: The target maximum memory footprint in elements overhead in the P3 replacement selection version. The second trend 8 SampleFreq: The number of elements between samples is that as disorder increases, the gap again closes. As disorder 9 Samples: Array of k/SampleFreq elements increases, both algorithms become O(𝑛 ⋅ log 𝑛), and the linear time extra work associated with both techniques becomes irrelevant. 10 While not all output has been written 11 perform phase 1 of P3 sort, correctly sampling, In our final comparison over synthetic data, we compare P 3 and stopping when either all input is consumed, selection sort with P3 sort over the entire dataset. The results are or Samples is full shown in Figure 29. 12 Sort Samples using P3 Sort 13 MergeVal = Samples[BatchSize/SampleFreq] 14 delete the first BatchSize/SampleFreq values from Samples 15 For each sorted run index i RunSizeRefs[i] = (i, # of elements <= MergeVal) 16 Sort ElemsToMerge by MergeSize 17 Pack the first ElemsToMerge.MergeSize elements of each run, in ElemsToMerge order, into the first ping pong array 18 Delete the first ElemsToMerge.MergeSize elements of each run, maintaining Tails, and Sizes 19 Use unbalanced ping pong merge to merge, writing the result to OutputElems We continue alternating between phases 1 and 2 in this manner until all the data is processed. Figure 29: P3 Replacement Sort vs. P3 Sort P3 replacement selection sort introduces the following additional First, note that smaller memory footprints improve the performance work over P3 sort: of P3 replacement sort. This is due to improved caching behavior. Maintains a sample of the input which resides in a sorted run In addition, as disorder increases, the two techniques converge to Must sort the sample once per batch identical performance for the same reason as in the previous After phase 1, before we ping-pong merge, we don’t know experiment: The two algorithms become identically dominated by how much of each run is smaller than the median across the their O(𝑛 ⋅ log 𝑛) components. The additional constant time work sample, we must therefore make an extra pass over the blocks performed by P3 replacement sort therefore becomes insignificant. of memory which hold the run, so that we can pack the partial runs into the merge buffer by size before ping-pong merge. It is interesting to note that these two effects combine, in some cases, making P3 replacement sort faster than P3 sort, despite the Because some runs may become empty, we must compact the extra work. Even though both algorithms, in these cases, produce run pointer arrays after phase 2. the same output, P3 replacement sort is fundamentally not able to Observe, however, that compared to flat selection sort, we are sort random datasets using a buffer smaller than the dataset size. significantly reducing sorted data movement (i.e. re-sorting sorted data). Also, we eliminate the overhead of repeatedly initializing and 5.4 Replacement Selection, Batch Size, cleaning up the resources associated with calls to P3 sort. We reran Memory, and Disorder Tolerance the previous experiment, using flat replacement selection sort as a For classical replacement selection, the disorder tolerance is the baseline. The results are shown in Figure 28. size of memory, the maximum of any technique presented here. On the other hand, there is an extreme sacrifice in efficiency which is made to achieve this robustness to disorder. On the other hand, our flat replacement selection and P3 replacement selection experiments chose a batch size of one half the buffer size. For flat replacement selection, this resulted in a disorder tolerance of half the buffer size, or half of available memory. By choosing a smaller batch size, for instance ¼ the buffer size, we could have increased the disorder tolerance to ¾ of main memory, but we would also have doubled the number of re-sorts, where each re-sort would move ¾ the buffer size of already sorted data instead of ½. This is clearly an unfortunate situation for flat replacement selection, where the cost of improving the disorder tolerance is very high. Figure 28: P3 vs. Flat Replacement Selection Sort
11 .P3 replacement selection, in contrast, needs twice the batch size The basic idea of Timsort is to recognize and merge existing sorted extra memory in order to perform ping-pong merge, and also needs runs in the input. Unlike Patience sort, only one run can be added to sort the sample every batch. If the memory buffer is large, say 1 to at any point in the algorithm. When a data element is processed, GB, and 50 MB batches are merged at a time, the total memory it either extends the current run, or starts a new one. The run needed is only 1.1 GB, and the disorder tolerance is ~95% of the recognition and merge phases are commingled cleverly in order to buffer size. Note that the number of samples needed is dependent sort the data efficiently, and approximately in-place. Where on the batch size as a percentage of the buffer size. appropriate, we compare our proposed sorting techniques in this In order to better understand the effect of smaller batch sizes on P 3 paper to our careful port of Timsort’s Java implementation to C++. replacement selection, we re-ran the previous experiment with a Bitonic sorting [19] has emerged as a popular sorting technique, but buffer size of 128MB, and varied the batch size. We used a its benefits are mostly limited to massively parallel GPU sampling frequency of 1024. This resulted in 16K samples, which architectures. Chhugani et al. [20] show how to exploit SIMD and is more than enough for our smallest batch size of 1%. The results modern processor architectures to speed up merge in the context of are shown in Figure 30. merge sort and bitonic sorting. Efficient merging techniques have also been investigated in the context of merge joins with modern hardware [24][23][22]. For instance, Balkesen et al. [22] argue that merging more than two runs at once is beneficial, while using a tree of binary merges to perform the merge. Like ping-pong merge, all these techniques use binary merges instead of heaps, but focus on taking advantage of multiple cores and processor-specific features such as SIMD. Further, they do not target or optimize for almost- sorted datasets. We focus on general single-core processor-agnostic techniques in this paper, and believe that multiple cores and processor-specific techniques can be adapted to make P3 sort even faster; this is a rich area for future work (see Section 7). The most related previous work is Patience sort itself [3]. The name Patience sorting (Patience is the British name for solitaire) comes Figure 30: Decreasing Batch Size for P3 Replacement from Mallows [15], who in [3] credits A.S.C. Ross for its discovery. Selection Mallows' analysis was done in 1960, but was not published until much later. Aldous et al. also point out in [1] that Patience sorting For batch sizes of 12MB and 6MB, there is no measureable impact was discovered independently by Bob Floyd in 1964 and developed of using a smaller batch size (compared to 50MB). At a batch size briefly in letters between Floyd and Knuth, but their work has of 1.2 MB, we are just beginning to see the effect of reducing batch apparently not been published. Hammersley [16] independently size. As a result, one can use P3 replacement selection as a much recognized its use as an algorithm for computing the length of the more performant alternative to classical replacement selection, longest increasing subsequence. More recently, Gopalan et al. [5] without significant adverse effects on either memory footprint or showed how Patience sort can be used to estimate the sortedness of disorder tolerance. a sequence of elements. 6. RELATED WORK P3 sort uses ping-pong merge for merging sorted runs in memory. Sorting has a long history, even predating computer science Ping-pong merge and its run ordering for the unbalanced case draw [9][13]. Over the years, there have been many algorithms, each with motivation from the early tape-based merging techniques described their own unique requirements and characteristics. In this paper, we by Knuth [13]. A key difference is that main memory buffers allow focus on two cases of high practical value: (1) In-memory, single simultaneous reads and writes, which allows us to perform the node comparison based sorting of randomly ordered data; and (2) merge with just two ping-pong buffers and execute “blind merges” Single node comparison based sorting of almost ordered data (in- when merging runs. Moreover, our run-ordering targets a different memory and external). need – that of making merge extremely lightweight for highly skewed runs generated from almost sorted data by phase 1 of For in-memory single node comparison based sorting of randomly Patience sort. Other merging approaches proposed in the past ordered data, Quicksort [14] remains the most commonly include the classic heap-based approach such as the selection tree implemented technique, due to both its high efficiency and ease of algorithms from Knuth [13]. Wickremesinghe et al. [4] introduced implementation. Quicksort also has excellent cache performance, a variant of these algorithms, which uses a tree of priority-queue focusing for long periods of time on small subsets of the data. based merges, limiting the size of the heap in order to improve Where appropriate, we compare our proposed sorting techniques to cache behavior. An extensive comparison to this technique is the GNU C++ implementation of Quicksort [11], which includes presented in Section 3. the four popular Sedgewick optimizations [10] described earlier. For in-memory single-node comparison-based sorting of almost Further contributions of this paper include two new variants of ordered data, Timsort [8] has emerged as the clear winner in prior replacement selection [13][21], a technique for reducing the work. Like Patience sort, Timsort is O(𝑛 ⋅ log 𝑛) in the worst case, number of sorted runs when performing external-memory-based and is linear on sorted data. Timsort is the system sort in Python sort-merge. The potential importance of replacement selection and and is used to sort arrays of non-primitive type in Java SE 7, on the its variants has become especially acute due to the plethora of Android platform, and in GNU Octave [8]. Timsort has a very almost sorted telemetry logs generated by Big Data and Cloud popular and heavily optimized implementation in Java. applications, where network delivery of data introduces jitter and delay [7][17][18]. In many of these cases, the number of runs can
12 .be reduced to 1, eliminating the second pass of sort-merge entirely. ACKNOWLEDGEMENTS Unfortunately, the CPU costs associated with such techniques, We would like to thank Isaac Kunen, Paul Larson, Yinan Li, Burton which are heap, or tree based [13][4], are an order of magnitude Smith, and the anonymous reviewers for their comments, advice, higher than conventional high performance sorting techniques, and support. significantly limiting the achievable throughput. 8. REFERENCES 7. CONCLUSIONS AND FUTURE WORK [1] David Aldous and Persi Diaconis. Longest increasing In this paper, we have reexamined and significantly improved upon subsequences: from Patience sorting to the Baik-Deift- Patience sort, a 50+ year old sorting technique mostly overlooked Johansson theorem. Bull. of the Amer. Math. Society, Vol. 36, by the sorting literature. In particular, we have introduced both No. 4, pages 413–432. algorithmic, and architecture-sensitive, but not architecture- specific, improvements to both the run generation phase and the run [2] Sergei Bespamyatnikh and Michael Segal. Enumerating merging phase. For the run merging phase, we have introduced a Longest Increasing Subsequences and Patience Sorting. new technique for merging sorted runs called Ping-Pong merge. Pacific Inst. for the Math. Sci. Preprints, PIMS-99-3., pp.7–8. The result is a new sorting technique, called Ping-Pong Patience [3] C. L. Mallows. “Problem 62-2, Patience Sorting”. SIAM Sort (P3 Sort), which is ~20% faster than GNU Quicksort on Review 4 (1962), 148–149. random data, and 20%-4x faster than our careful C++ port of the [4] Rajiv Wickremesinghe, Lars Arge, Jeffrey S. Chase, Jeffrey popular Java implementation of Timsort on almost ordered data. Scott Vitter: Efficient Sorting Using Registers and Caches. This paper also investigates new opportunities for replacement ACM Journal of Experimental Algorithmics 7: 9 (2002). selection sort, which can be used to sort many external memory [5] P. Gopalan et al. Estimating the Sortedness of a Data Stream. resident datasets in a single pass. In particular, we introduce two In SODA 2007. new variants of replacement selection sort, which integrate P 3 sort [6] A. LaMarca and R.E. Ladner. The influence of caches on the into replacement selection sort in two different ways. The faster performance of sorting. Volume 7 (1997), pp. 370-379. approach, which more deeply integrates P3 sort into selection sort, [7] B. Chandramouli, J. Goldstein, and S. Duan. Temporal improves CPU performance/throughput by 3x-20x over classical Analytics on Big Data for Web Advertising. In ICDE 2012. replacement selection sort, with little effect on either memory [8] TimSort. http://en.wikipedia.org/wiki/Timsort. footprint or disorder tolerance. [9] Sorting Algorithms. http://en.wikipedia.org/wiki/ This work is the beginning of several research threads. The Sort_algorithms. observation that Patience sort, a mostly overlooked sorting technique, can be the basis of a highly competitive sort algorithm [10] R. Sedgewick. Implementing Quicksort programs. Comm. (P3 sort) is new. Undoubtedly there will be other interesting ACM 21 (10): 847–857. innovations to come, further improving on the bar for Patience sort [11] GNU Quicksort Implementation. http://aka.ms/X5ho47. variants established in this paper. For instance, a related sort [12] Patience Sorting. http://en.wikipedia.org/wiki/ technique, Timsort, was able to be algorithmically restructured in a Patience_sorting. way which made it almost in place. A similar optimization may be [13] Donald Knuth. The Art of Computer Programming, Sorting possible with P3 sort, improving P3 sort’s utility when main and Searching, Volume 3, 1998. memory is limited. [14] C.A.R. Hoare. Quicksort. Computer J. 5, 4, April 1962. Inside a DBMS, P3 sort is also applicable as a sorting technique that [15] C.L. Mallows. Patience sorting. Bull. Inst. Math. Appl., 9:216- can automatically exploit the potential of efficiently sorting a 224, 1973. dataset by a new sort order that is closely related to an existing sort [16] J.M. Hammersley. A few seedlings of research. In Proc. Sixth order (for example, when a dataset sorted on columns {A, B} needs Berkeley Symp. Math. Statist. and Probability, Volume 1, to be sorted on column {B}, and A has low cardinality). pages 345-394. University of California Press, 1972. Also, Patience sort’s explicit decomposition of sorting into run [17] M. Kaufmann et al. Timeline Index: A Unified Data Structure generation and run merging forms an intriguing basis for an for Processing Queries on Temporal Data in SAP HANA. In investigation into multicore, SIMD, and distributed parallel SIGMOD, 2013. execution with Patience sort. In fact, it is immediately clear that [18] Splunk. http://www.splunk.com/. some of the architecture specific innovations, like the use of SSE instructions, described in [20] could be applied to ping-pong merge. [19] K. E. Batcher. Sorting networks and their applications. In Spring Joint Computer Conference, pages 307–314, 1968. Finally, there has been very little interest in replacement selection sort and its variants over the last 15 years. This is easy to understand [20] J. Chhugani et al. Efficient Implementation of Sorting on when one considers that the previous goal of replacement selection MultiCore SIMD CPU Architecture. In VLDB, 2008. sort was to reduce the number of external memory passes to 2. [21] P. Larson. External Sorting: Run Formation Revisited. IEEE Since, the size of 2 pass sortable (without replacement selection Trans. Knowl. Data Eng. 15(4): 961-972 (2003). sort) datasets increases quadratically with the size of main memory, [22] C. Balkesen et al. Multi-Core, Main-Memory Joins: Sort vs. as main memories have grown, the value of replacement selection Hash Revisited. In VLDB, 2014. sort has drastically diminished. [23] M.-C. Albutiu et al. Massively parallel sort-merge joins in Replacement selection sort, however, now has the opportunity, for main memory multi-core database systems. In VLDB, 2012. many logs, which typically have bounded disorder, to reduce the [24] C. Kim et al. Sort vs. hash revisited: Fast join implementation number of passes from 2 to 1. This paper represents the first work on modern multi-core CPUs. In VLDB, 2009. in that direction, which again, is likely to be improved upon.
3秒后跳转登录页面
去登陆

