

































- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
计算机语言的流水线
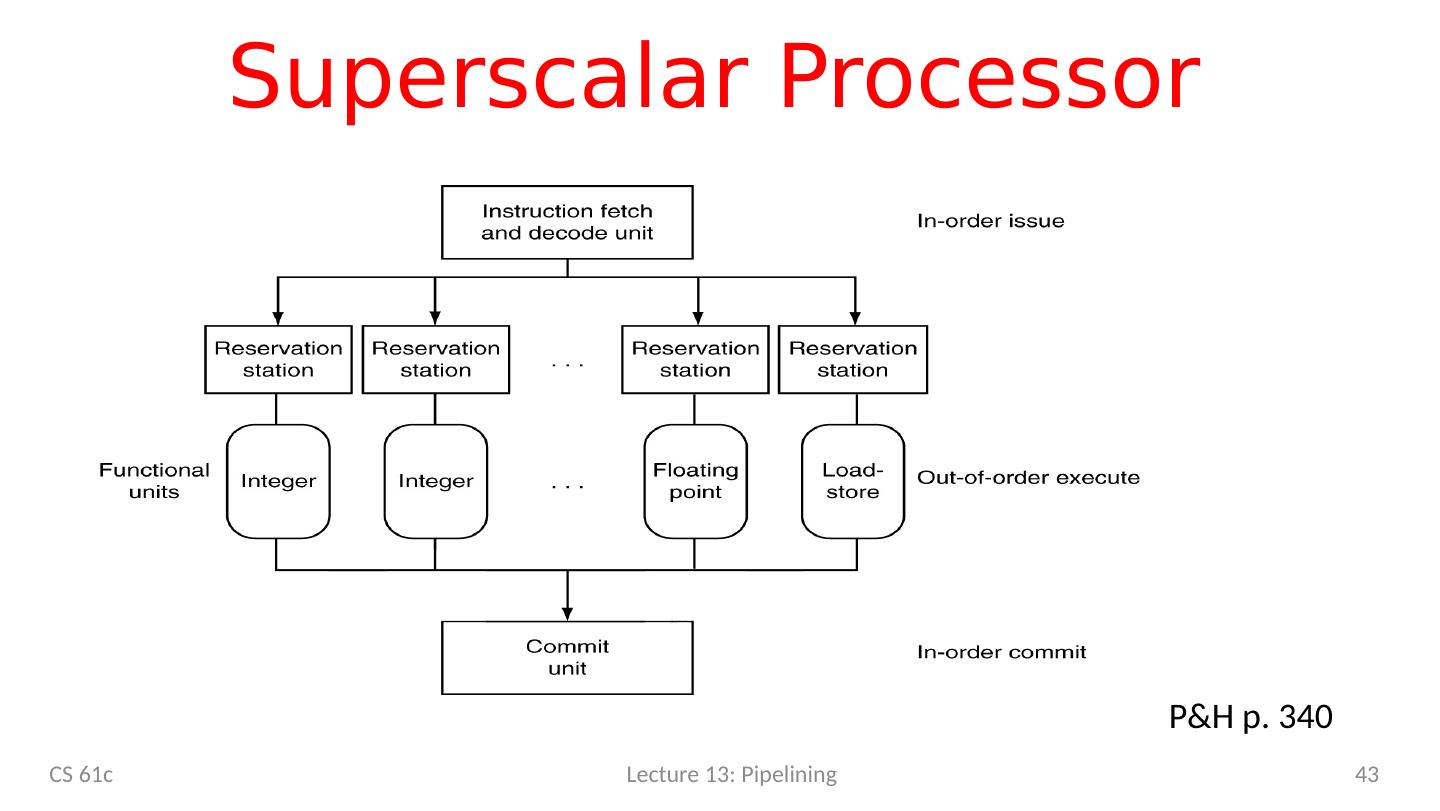
本章节重点介绍了流水线,概括来讲流水线通过交叉执行多条指令来提高吞吐量,介绍了管道阶段以及所有管道阶段都有相同的持续时间,以及什么是超标量处理器,超标量处理器使用多个执行单元来实现额外的指令级并行,其性能性能得益于高度依赖代码。
展开查看详情
1 .CS 61C: Great Ideas in Computer Architecture Lecture 13: Pipelining Krste Asanović & Randy Katz http:// inst.eecs.berkeley.edu /~ cs61c/fa17
2 .Agenda RISC-V Pipeline Pipeline Control Hazards Structural Data R-type instructions Load Control Superscalar processors CS 61c Lecture 13: Pipelining 2
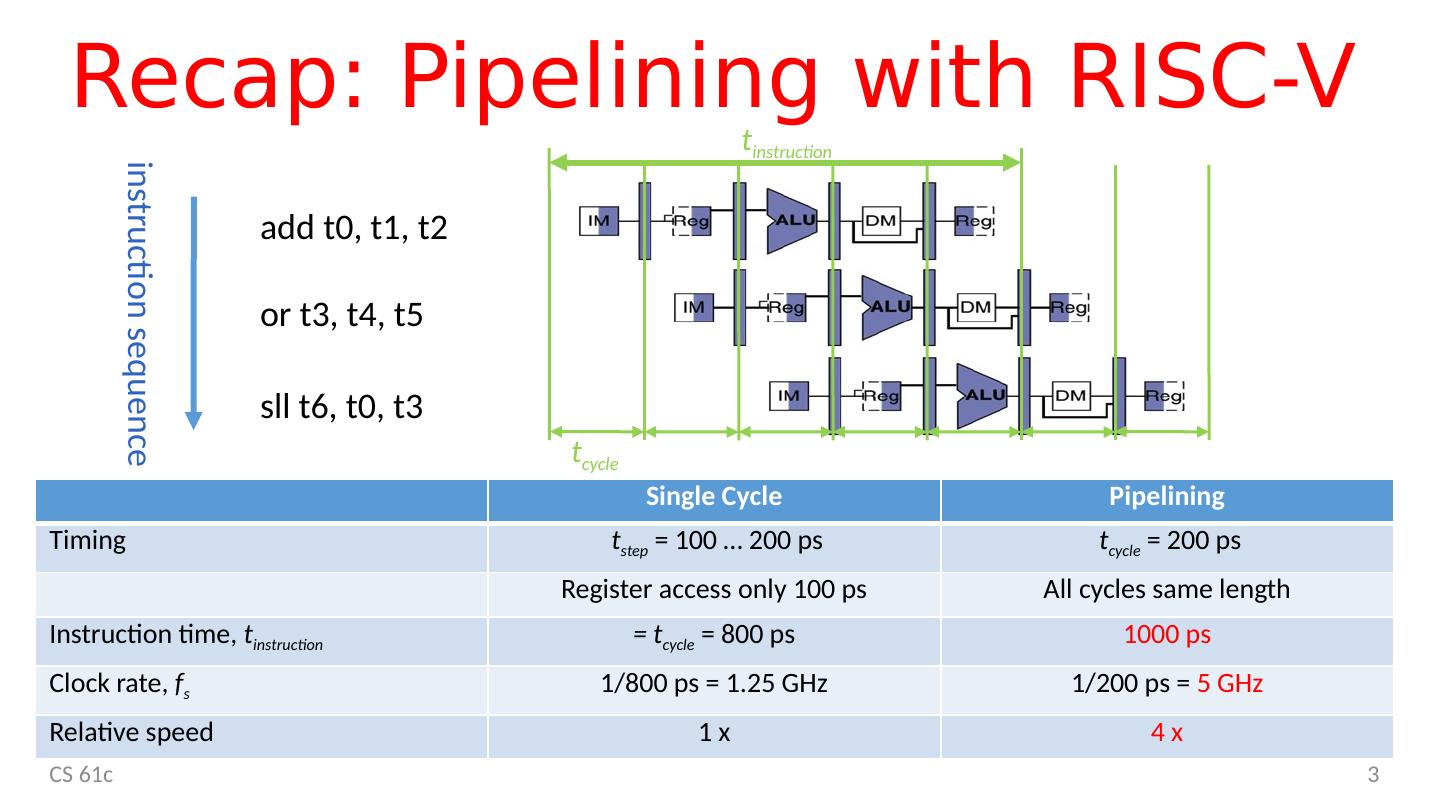
3 .Recap: Pipelining with RISC-V CS 61c 3 add t0, t1, t2 or t3, t4, t5 sll t6, t0, t3 t cycle instruction sequence t instruction Single Cycle Pipelining Timing t step = 100 … 200 ps t cycle = 200 ps Register access only 100 ps All cycles same length Instruction time, t instruction = t cycle = 800 ps 1000 ps Clock rate, f s 1/800 ps = 1.25 GHz 1/200 ps = 5 GHz Relative speed 1 x 4 x
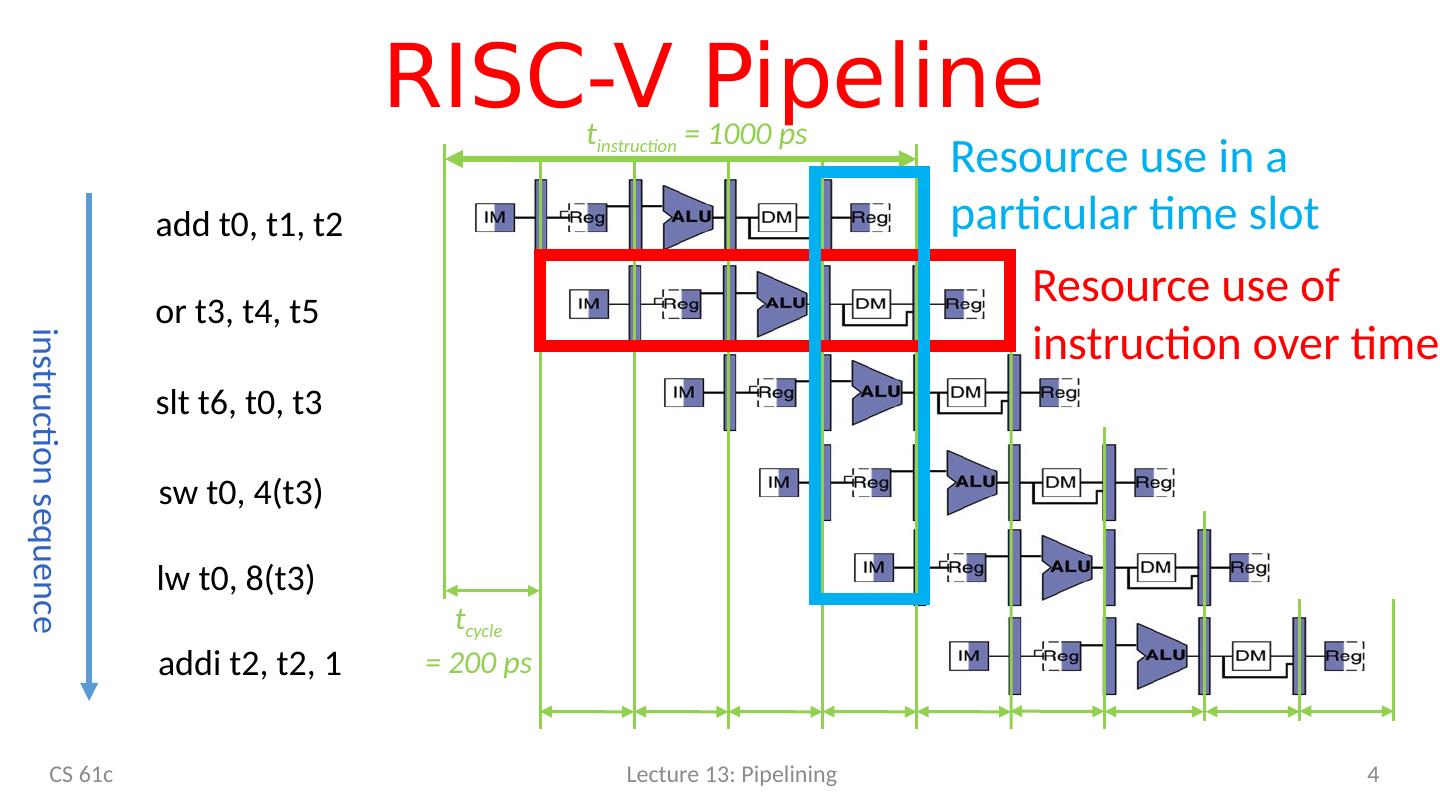
4 .RISC-V Pipeline add t0, t1, t2 or t3, t4, t5 slt t6, t0, t3 t cycle = 200 ps instruction sequence t instruction = 1000 ps s w t0, 4(t3) lw t0, 8(t3) addi t2, t2, 1 Resource use of instruction over time Resource use in a particular time slot CS 61c Lecture 13: Pipelining 4
5 .Single-Cycle RISC-V RV32I Datapath CS 61c 5 IMEM ALU Imm . Gen +4 D MEM Branch Comp. Reg [] AddrA AddrB DataA AddrD DataB DataD Addr DataW DataR 1 0 0 1 2 1 0 pc 0 1 inst [11:7] inst [19:15] inst [24:20] inst [31:7] pc+4 alu mem wb alu pc+4 Reg [rs1] pc imm [31:0] Reg [rs2] inst [31:0] ImmSel RegWEn BrUn BrEq BrLT ASel BSel ALUSel MemRW WBSel PCSel wb
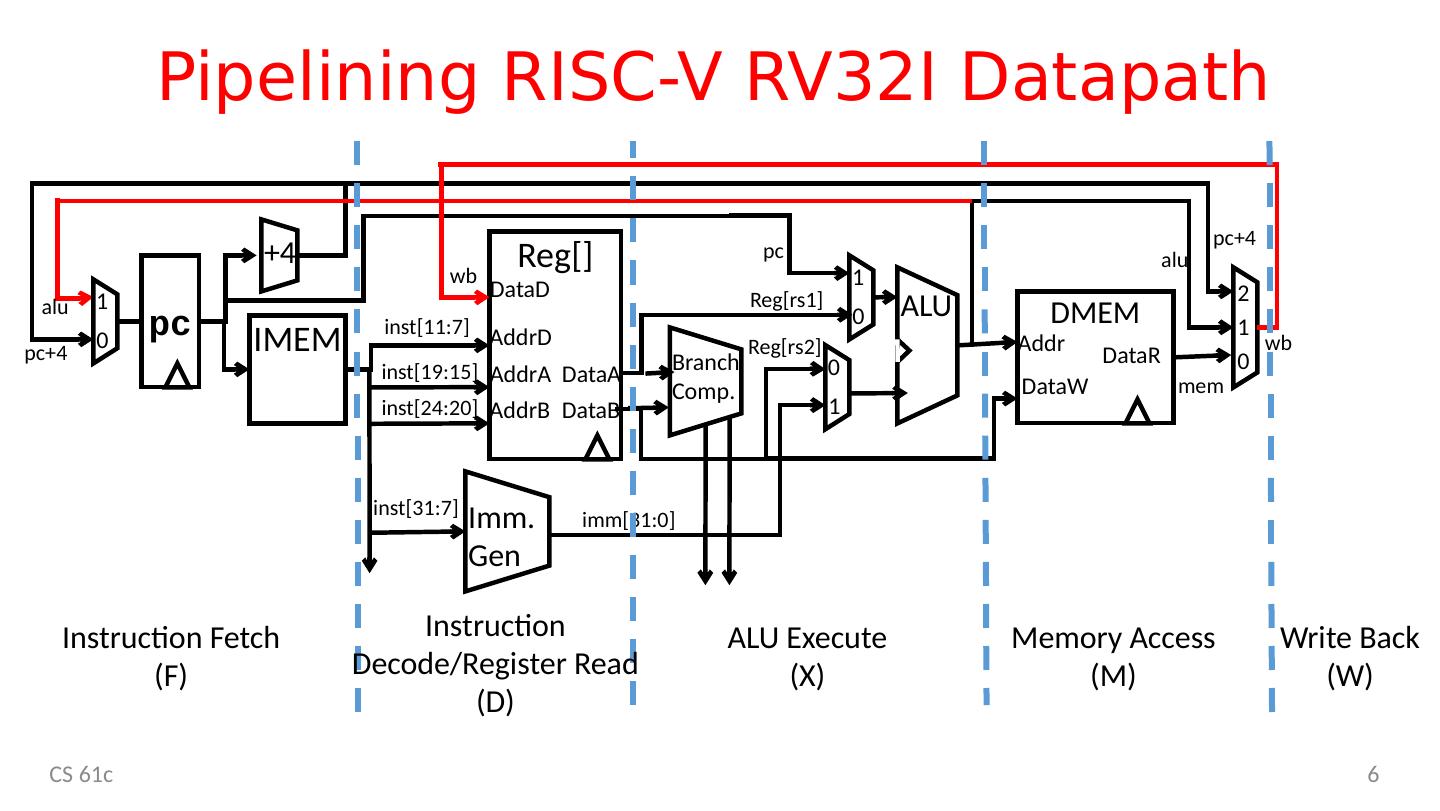
6 .Pipelining RISC-V RV32I Datapath CS 61c 6 IMEM ALU Imm . Gen +4 D MEM Branch Comp. Reg [] AddrA AddrB DataA AddrD DataB DataD Addr DataW DataR 1 0 0 1 2 1 0 pc 0 1 inst [11:7] inst [19:15] inst [24:20] inst [31:7] pc+4 alu mem wb alu pc+4 Reg [rs1] pc imm [31:0] Reg [rs2] wb Instruction Fetch (F) Instruction Decode/Register Read (D) ALU Execute (X) Memory Access (M) Write Back (W)
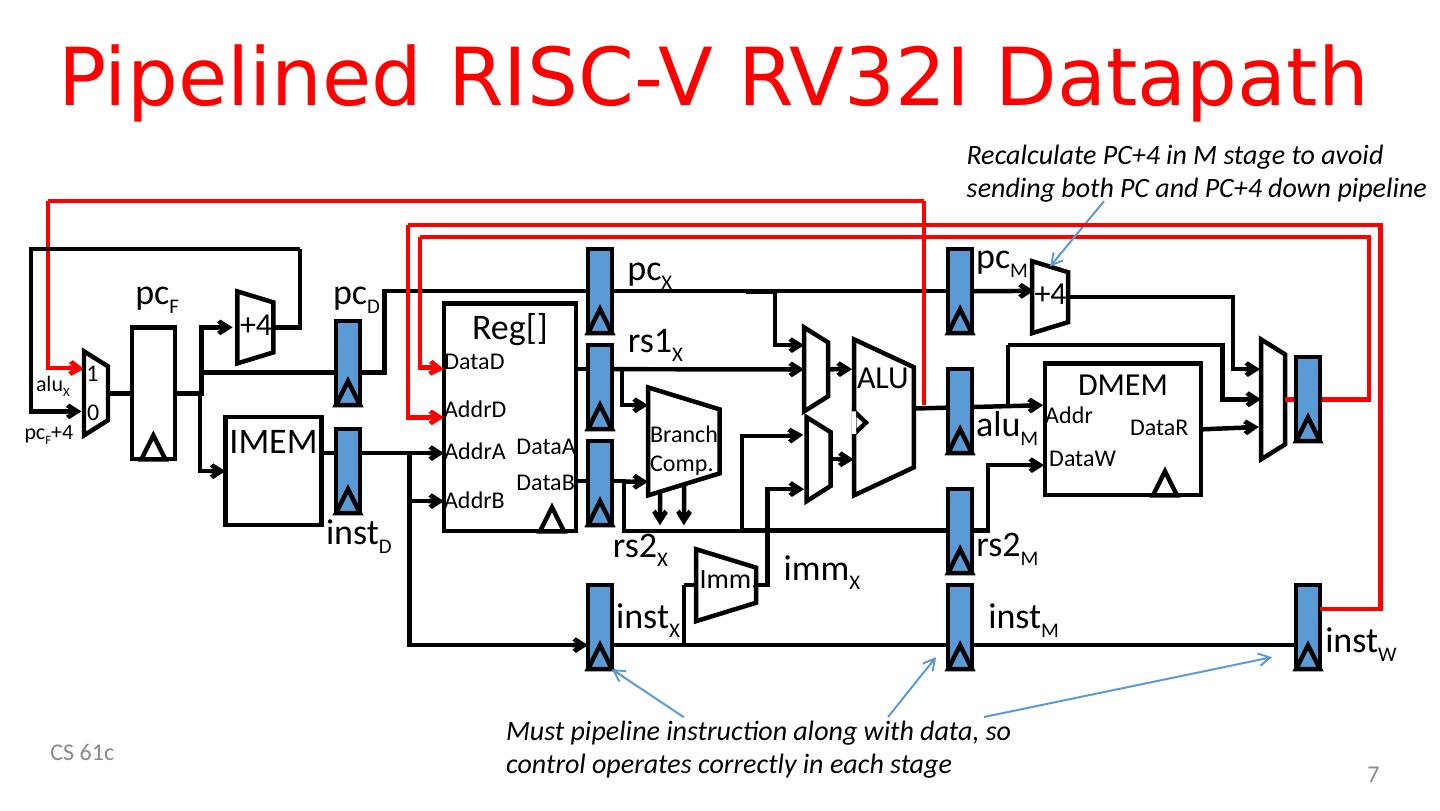
7 .Pipelined RISC-V RV32I Datapath CS 61c 7 IMEM ALU +4 D MEM Branch Comp. Reg [] AddrA AddrB DataA AddrD DataB DataD Addr DataW DataR 1 0 alu X pc F +4 +4 pc D pc F pc X pc M inst D inst X rs1 X rs2 X alu M rs2 M imm X Imm . R ecalculate PC+4 in M stage to avoid sending both PC and PC+4 down pipeline inst M inst W Must pipeline instruction along with data, so control operates correctly in each stage
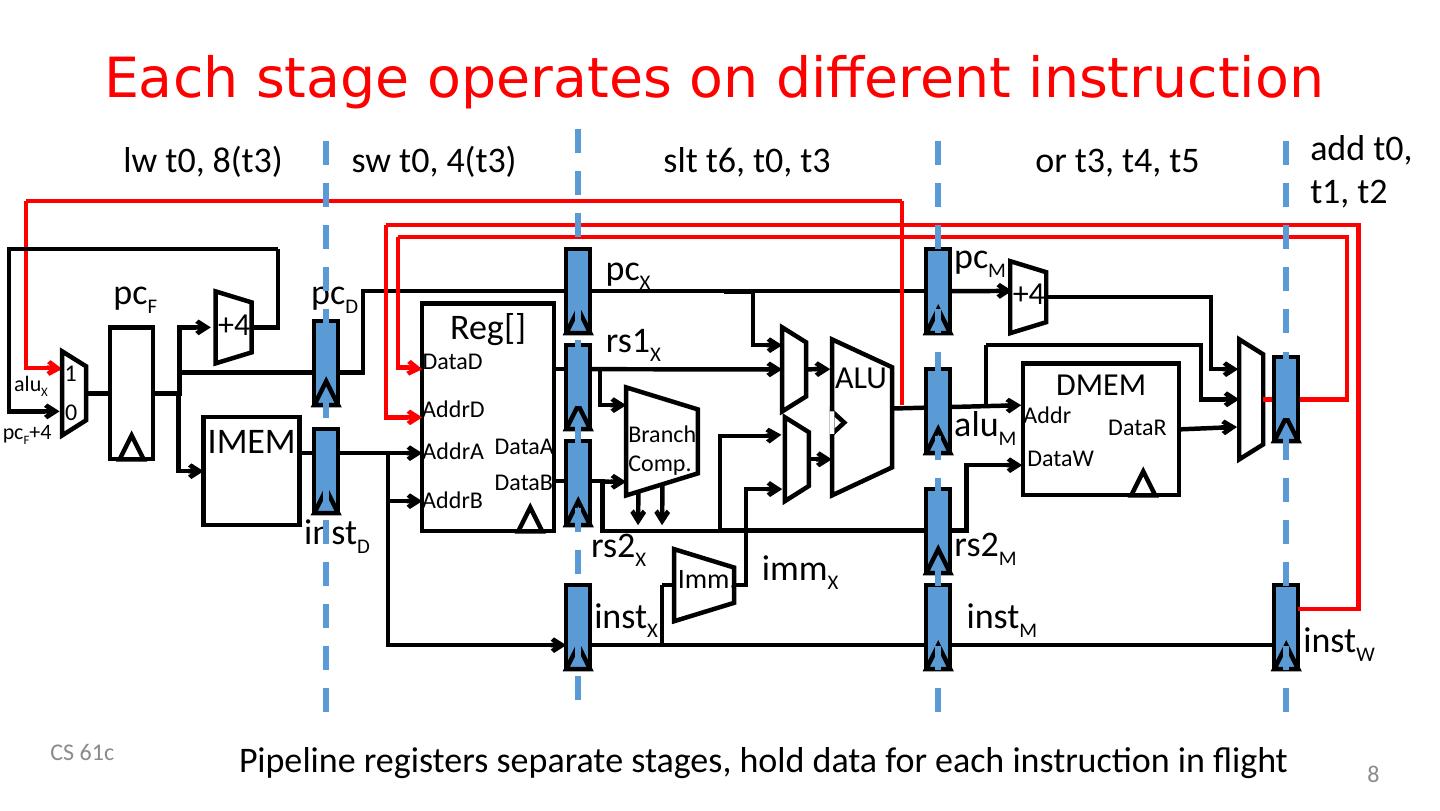
8 .Each stage operates on different instruction CS 61c 8 IMEM ALU +4 D MEM Branch Comp. Reg [] AddrA AddrB DataA AddrD DataB DataD Addr DataW DataR 1 0 alu X pc F +4 +4 pc D pc F pc X pc M inst D inst X rs1 X rs2 X alu M rs2 M imm X Imm . inst M inst W add t0, t1, t2 or t3, t4, t5 slt t6, t0, t3 s w t0, 4(t3) lw t0, 8(t3) Pipeline registers separate stages, hold data for each instruction in flight
9 .Agenda RISC-V Pipeline Pipeline Control Hazards Structural Data R-type instructions Load Control Superscalar processors CS 61c Lecture 13: Pipelining 9
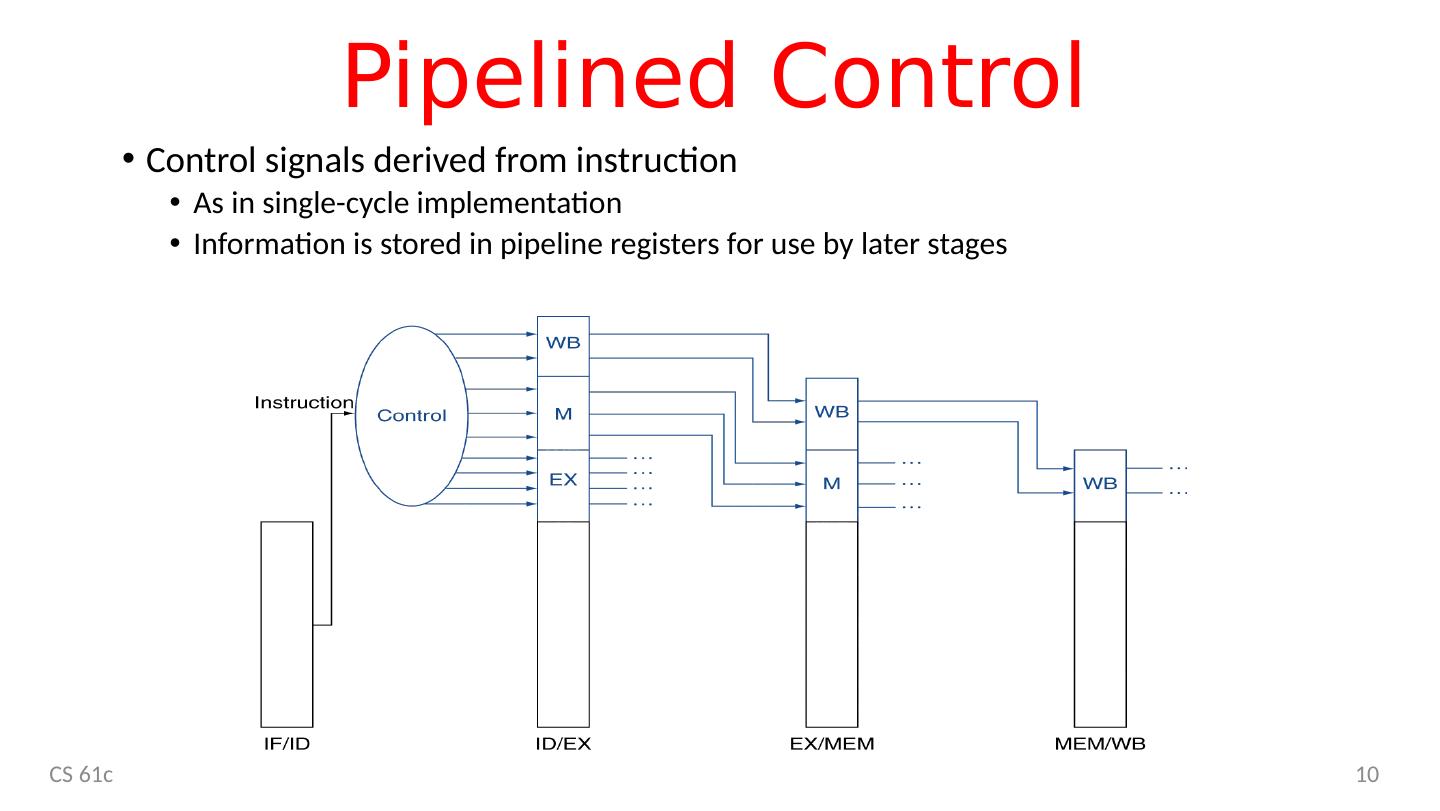
10 .Pipelined Control Control signals derived from instruction As in single-cycle implementation Information is stored in pipeline registers for use by later stages CS 61c 10
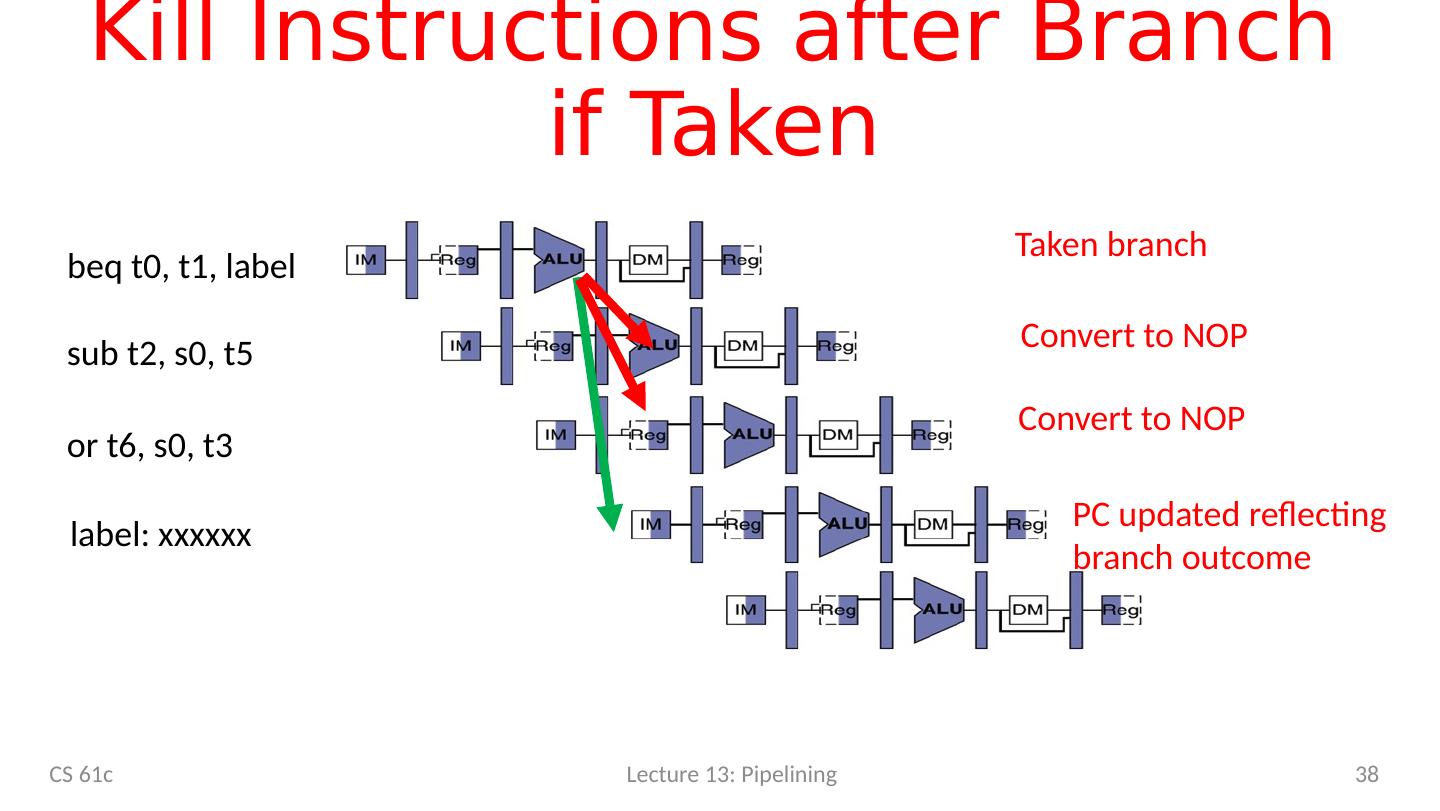
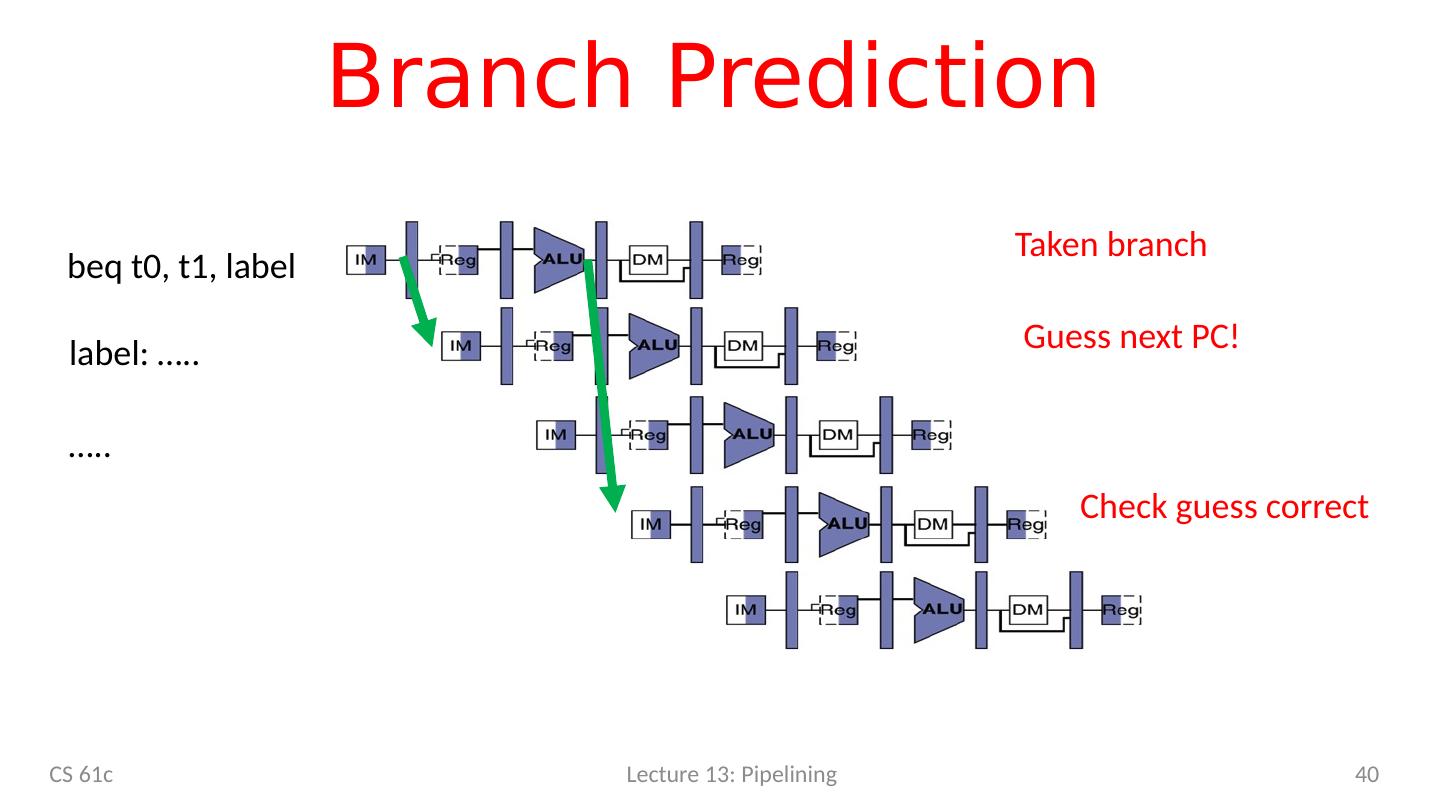
11 .Hazards Ahead CS 61c Lecture 13: Pipelining 11
12 .Agenda RISC-V Pipeline Pipeline Control Hazards Structural Data R-type instructions Load Control Superscalar processors CS 61c Lecture 13: Pipelining 12
13 .Structural Hazard Problem: Two or more instructions in the pipeline compete for access to a single physical resource Solution 1: Instructions take it in turns to use resource, some instructions have to stall Solution 2: Add more hardware to machine Can always solve a structural hazard by adding more hardware CS 61c Lecture 13: Pipelining 13
14 .Regfile Structural Hazards Each instruction: can read up to two operands in decode stage can write one value in writeback stage Avoid structural hazard by having separate “ports” two independent read ports and one independent write port Three accesses per cycle can happen simultaneously CS 61c Lecture 13: Pipelining 14
15 .Structural Hazard: Memory Access add t0, t1, t2 or t3, t4, t5 slt t6, t0, t3 instruction sequence s w t0, 4(t3) lw t0, 8(t3) Instruction and data memory used simultaneously Use two separate memories CS 61c Lecture 13: Pipelining 15
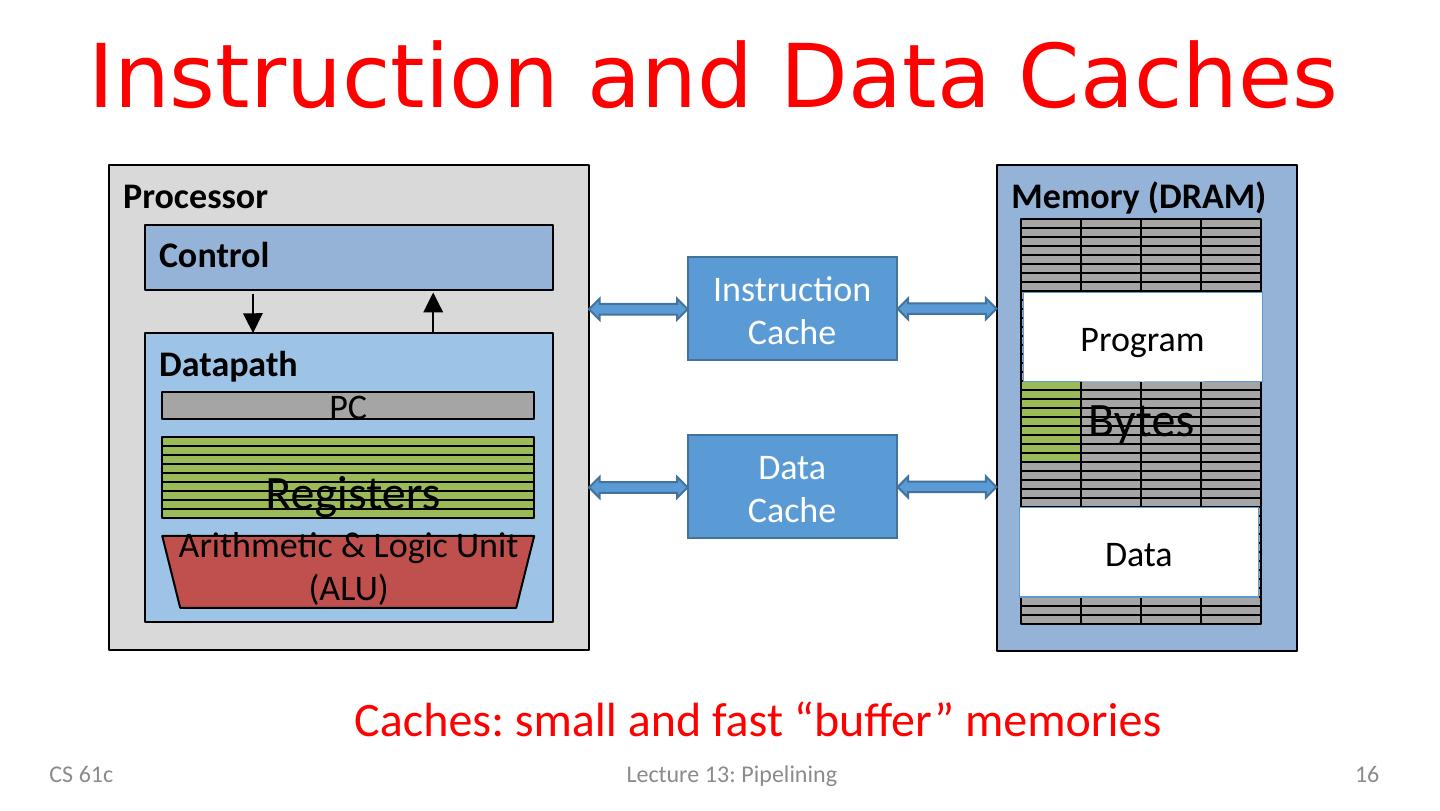
16 .Instruction and Data Caches 16 CS 61c Lecture 13: Pipelining Processor Control Datapath PC Registers Arithmetic & Logic Unit (ALU) Memory (DRAM) Bytes Program Data Instruction Cache Data Cache Caches: small and fast “buffer” memories
17 .Lecture 13: Pipelining Structural Hazards – Summary Conflict for use of a resource In RISC-V pipeline with a single memory Load/store requires data access Without separate memories, instruction fetch would have to stall for that cycle All other operations in pipeline would have to wait Pipelined datapaths require separate instruction/data memories Or separate instruction/data caches RISC ISAs (including RISC-V) designed to avoid structural hazards e.g. at most one memory access/instruction 17
18 .Agenda RISC-V Pipeline Pipeline Control Hazards Structural Data R-type instructions Load Control Superscalar processors CS 61c Lecture 13: Pipelining 18
19 .Data Hazard: Register Access add t0, t1, t2 or t3, t4, t5 slt t6, t0, t3 instruction sequence s w t0, 4(t3) lw t0, 8(t3) Separate ports, but what if write to same value as read? Does sw in the example fetch the old or new value? CS 61c Lecture 13: Pipelining 19
20 .Register Access Policy add t0, t1, t2 or t3, t4, t5 slt t6, t0, t3 instruction sequence s w t0, 4(t3) lw t0, 8(t3) Exploit high speed of register file (100 ps ) WB updates value ID reads new value Indicated in diagram by shading CS 61c Lecture 13: Pipelining 20 Might not always be possible to write then read in same cycle, especially in high-frequency designs. Check assumptions in any question.
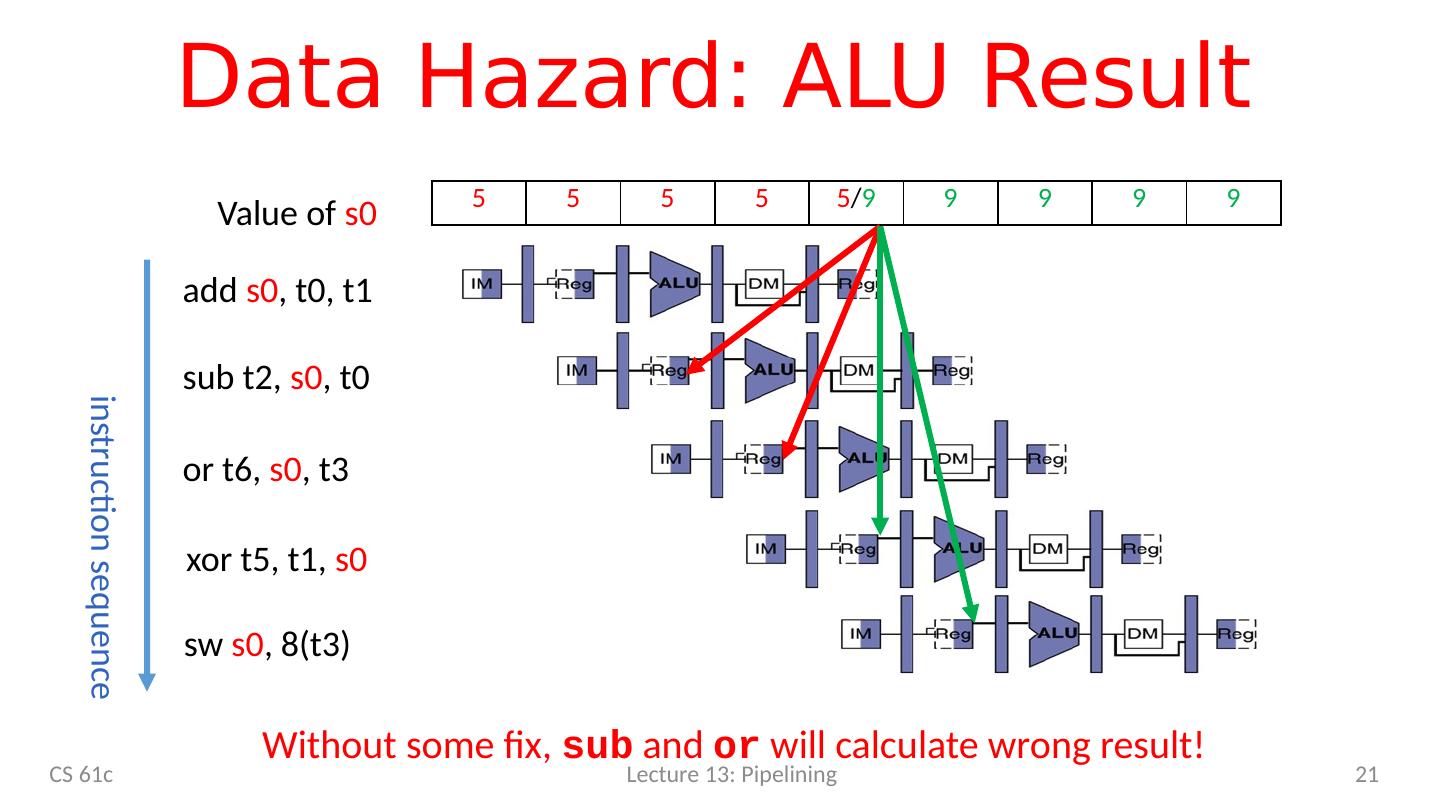
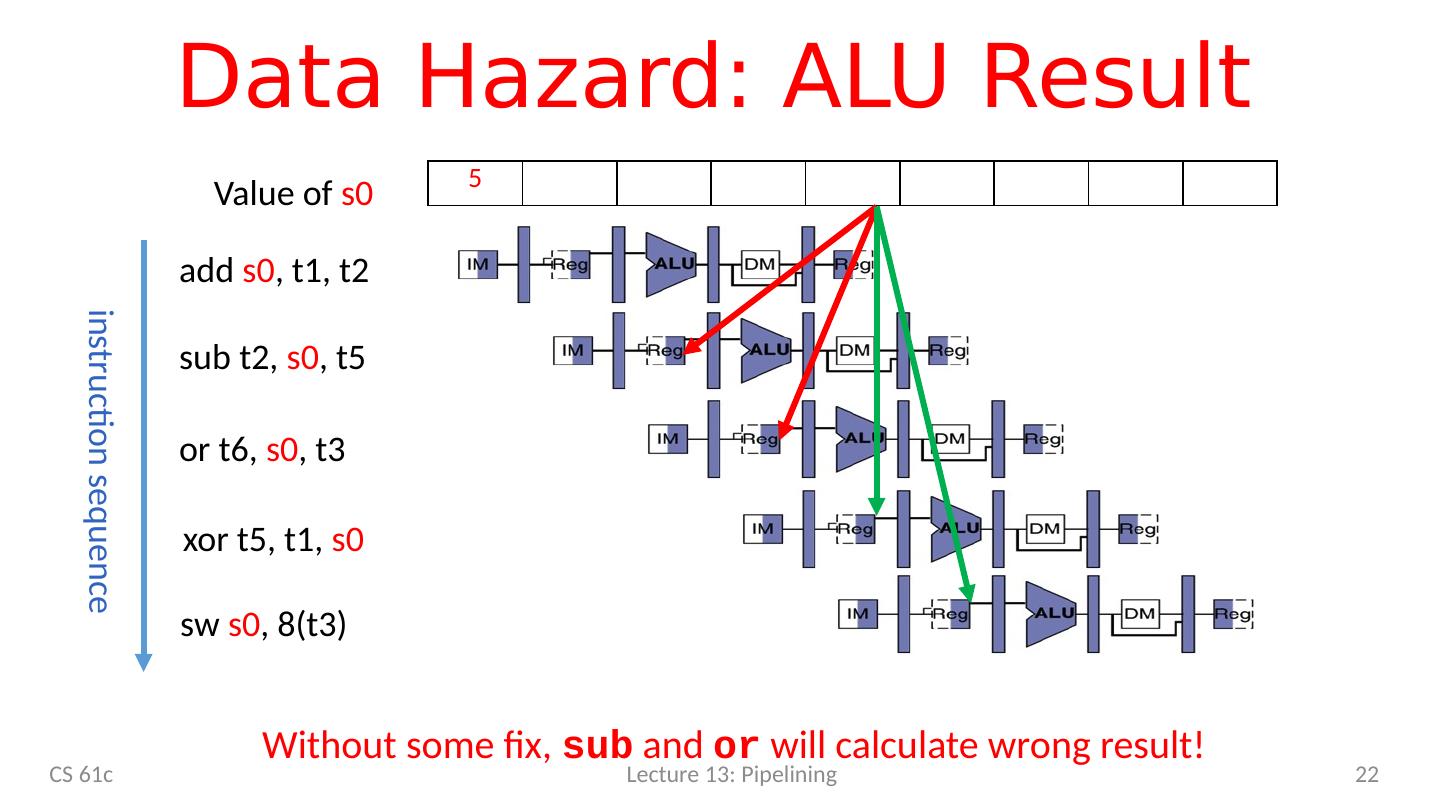
21 .Data Hazard: ALU Result add s0 , t0, t1 s ub t2, s0 , t0 o r t6, s0 , t3 instruction sequence xor t5, t1, s0 s w s0 , 8(t3) 5 5 5 5 5 / 9 9 9 9 9 Value of s0 Without some fix, sub and or will calculate wrong result! CS 61c Lecture 13: Pipelining 21
22 .Data Hazard: ALU Result add s0 , t1, t2 s ub t2, s0 , t5 o r t6, s0 , t3 instruction sequence xor t5, t1, s0 s w s0 , 8(t3) 5 Value of s0 Without some fix, sub and or will calculate wrong result! CS 61c Lecture 13: Pipelining 22
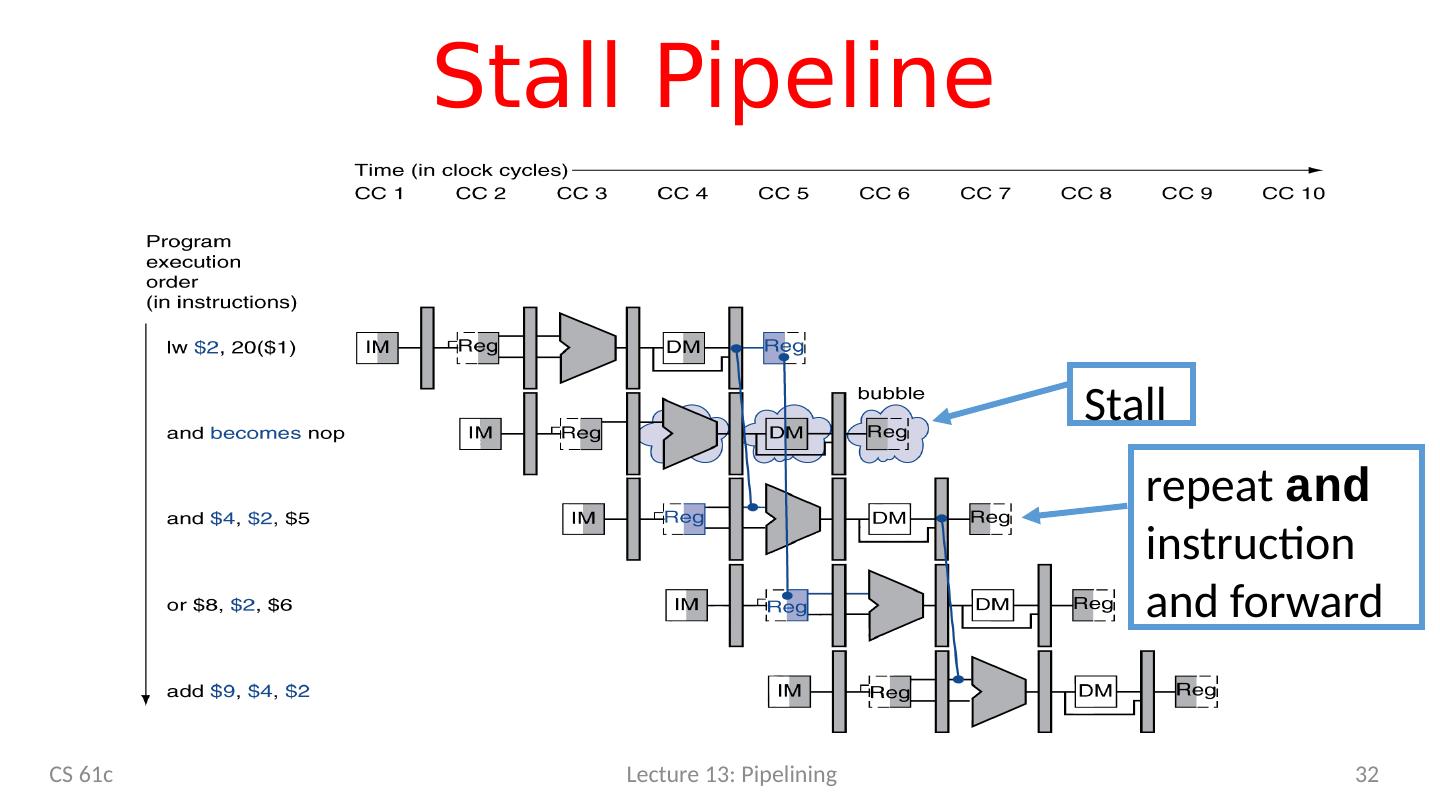
23 .Solution 1 : Stalling Problem: Instruction depends on result from previous instruction add s0 , t0 , t1 sub t2 , s0 , t3 Bubble: effectively NOP: affected pipeline stages do “nothing”
24 .Stalls and Performance Stalls reduce performance But stalls are required to get correct results Compiler can arrange code to avoid hazards and stalls Requires knowledge of the pipeline structure CS 61c 24
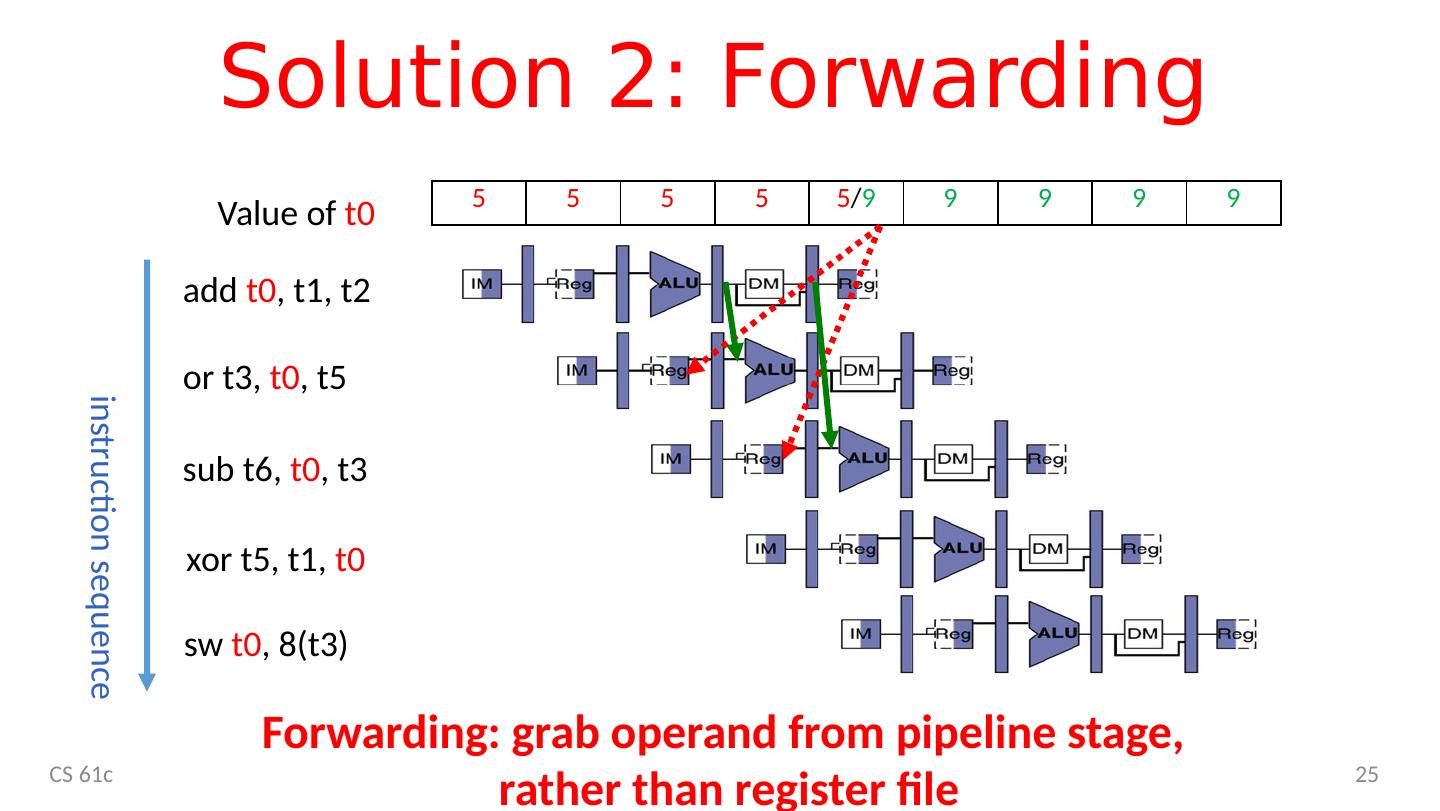
25 .Solution 2: Forwarding add t0 , t1, t2 or t3, t0 , t5 s ub t6, t0 , t3 instruction sequence xor t5, t1, t0 s w t0 , 8(t3) 5 5 5 5 5 / 9 9 9 9 9 Value of t0 Forwarding: grab operand from pipeline stage, rather than register file CS 61c 25
26 .Forwarding (aka Bypassing) Use result when it is computed Don’t wait for it to be stored in a register Requires extra connections in the datapath CS 61c 26 Lecture 13: Pipelining
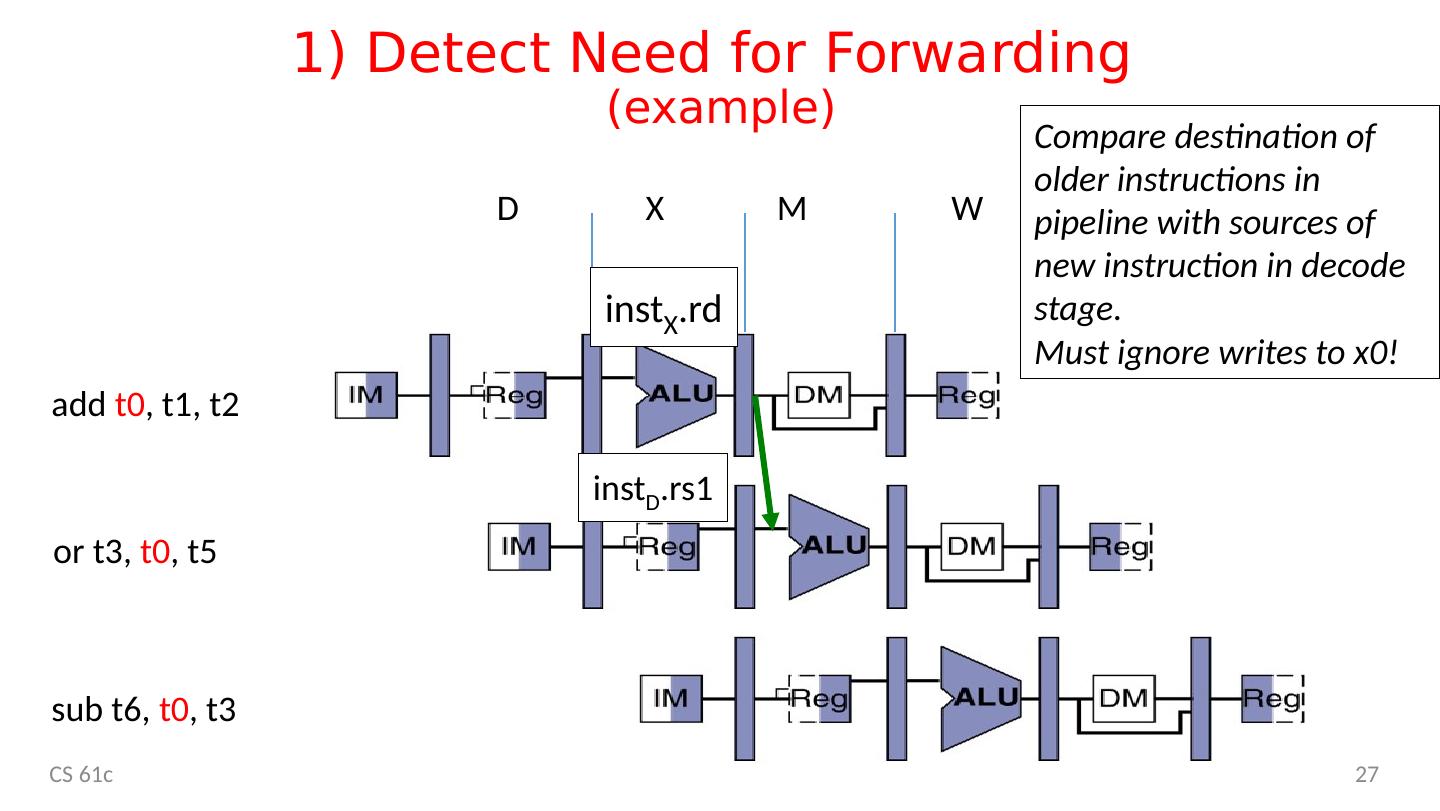
27 .1) Detect Need for Forwarding (example) add t0 , t1, t2 or t3, t0 , t5 s ub t6, t0 , t3 X M W D inst X .rd inst D .rs1 CS 61c 27 Compare destination of older instructions in pipeline with sources of new instruction in decode stage. Must ignore writes to x0!
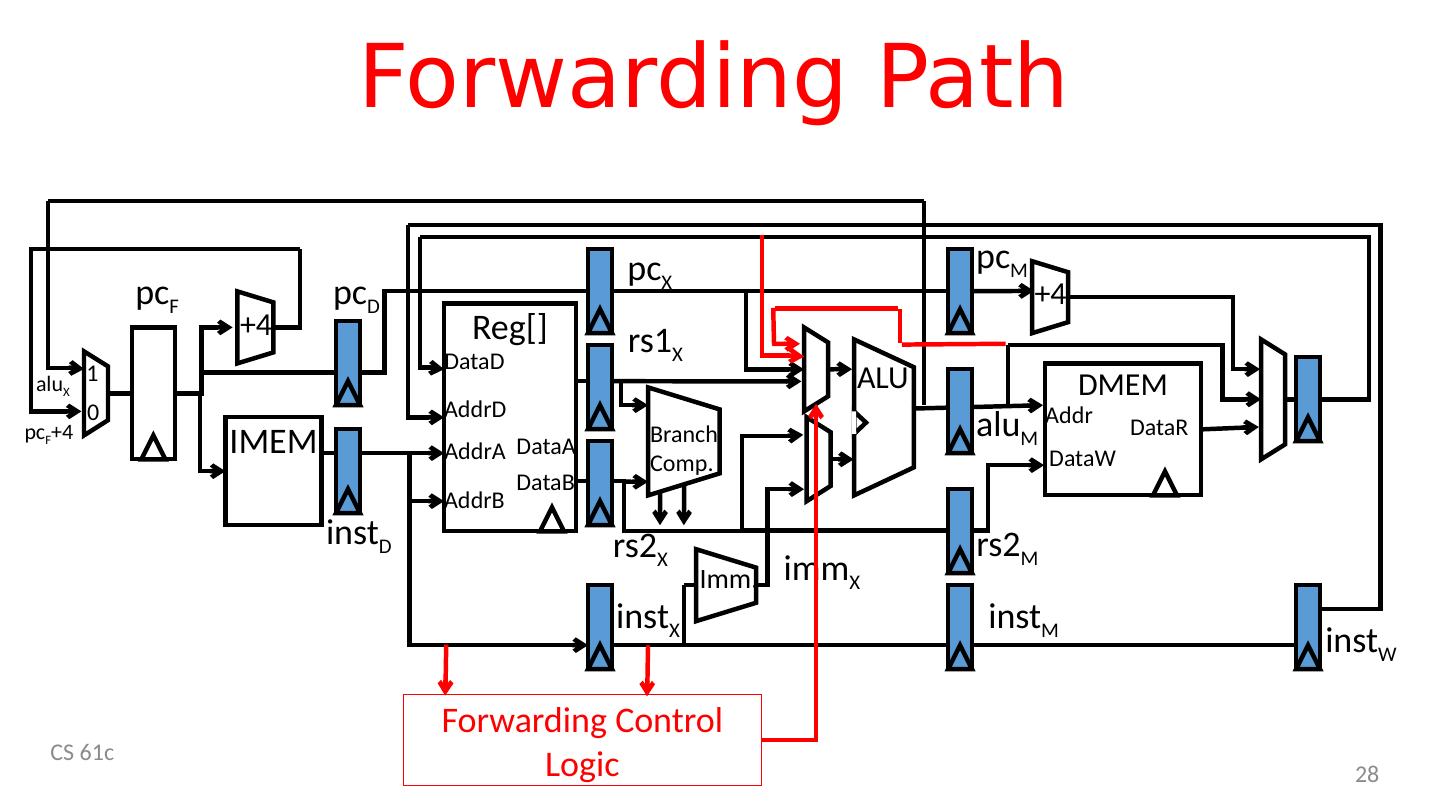
28 .Forwarding Path CS 61c 28 IMEM ALU +4 D MEM Branch Comp. Reg [] AddrA AddrB DataA AddrD DataB DataD Addr DataW DataR 1 0 alu X pc F +4 +4 pc D pc F pc X pc M inst D inst X rs1 X rs2 X alu M rs2 M imm X Imm . inst M inst W Forwarding Control Logic
29 .Administrivia CS 61c Lecture 13: Pipelining 29 Project 1 Part 2 due next Monday Project Party this Wednesday 7-9pm in Cory 293 HW3 will be released by Friday Midterm 1 regrades due tonight Guerrilla Session tonight 7-9pm in Cory 293
3秒后跳转登录页面
去登陆

