





























- 快召唤伙伴们来围观吧
- 微博 QQ QQ空间 贴吧
- 文档嵌入链接
- 复制
- 微信扫一扫分享
- 已成功复制到剪贴板
MPI
本章节主要介绍了MPI的相关知识,目前许多超级计算机的硬件实现需要依靠它,但是很难将MPI移植到所有的应用程序中并使用所有的专用硬件;解决方面,可移植性与性能权衡,MPICH通过仔细地设计内核API来实现这两项目标,另外介绍了许多使用硬件的ADI实现。
展开查看详情
1 .MPI and comparison of models Lecture 23, cs262a Ion Stoica & Ali Ghodsi UC Berkeley April 16, 2018
2 .MPI MPI - Message Passing Interface Library standard defined by a committee of vendors, implementers, and parallel programmers Used to create parallel programs based on message passing Portable : one standard, many implementations Available on almost all parallel machines in C and Fortran De facto standard platform for the HPC community
3 .Groups, Communicators, Contexts Group : a fixed ordered set of k processes, with ranks , i.e., 0, 1, … , k-1 Communicator : specify scope of communication Between processes in a group (intra) Between two disjoint groups (inter) Context : partition of comm. space A message sent in one context cannot be received in another context This image is captured from: “Writing Message Passing Parallel Programs with MPI”, Course Notes , Edinburgh Parallel Computing Centre The University of Edinburgh
4 .Synchronous vs. Asynchronous Message Passing A synchronous communication is not complete until the message has been received An asynchronous communication completes before the message is received
5 .Communication Modes Synchronous : completes once ack is received by sender Asynchronous : 3 modes Standard send : completes once the message has been sent, which may or may not imply that the message has arrived at its destination Buffered send : completes immediately, if receiver not ready, MPI buffers the message locally Ready send : completes immediately, if the receiver is ready for the message it will get it, otherwise the message is dropped silently
6 .Blocking vs. Non-Blocking Blocking , means the program will not continue until the communication is completed Synchronous communication Barriers: wait for every process in the group to reach a point in execution Non-Blocking , means the program will continue, without waiting for the communication to be completed
7 .MPI library Huge (125 functions) Basic (6 functions)
8 .MPI Basic Many parallel programs can be written using just these six functions, only two of which are non-trivial; MPI_INIT MPI_FINALIZE MPI_COMM_SIZE MPI_COMM_RANK MPI_SEND MPI_RECV
9 .Skeleton MPI Program (C) # include < mpi.h > m ain( int argc , char** argv ) { MPI_Init (& argc , & argv ); /* main part of the program */ / * Use MPI function call depend on your data * partitioning and the parallelization architecture */ MPI_Finalize (); }
10 .A minimal MPI program (C) # include “ mpi.h ” #include < stdio.h > int main( int argc , char * argv []) { MPI_Init (& argc , & argv ); printf ( “ Hello, world!
11 .A minimal MPI program (C) #include “ mpi.h ” provides basic MPI definitions and types. MPI_Init starts MPI MPI_Finalize exits MPI Notes: Non-MPI routines are local; this “ printf ” run on each process MPI functions return error codes or MPI_SUCCESS
12 .Improved Hello (C) # include < mpi.h > #include < stdio.h > int main( int argc , char * argv []) { int rank, size; MPI_Init (& argc , & argv ); /* rank of this process in the communicator */ MPI_Comm_rank (MPI_COMM_WORLD, &rank); /* get the size of the group associates to the communicator */ MPI_Comm_size ( MPI_COMM_WORLD, &size); printf ("I am %d of %d
13 .Improved Hello (C) /* Find out rank, size */ int world_rank , size; MPI_Comm_rank (MPI_COMM_WORLD, & world_rank ); MPI_Comm_size (MPI_COMM_WORLD, & world_size ); int number; if ( world_rank == 0) { number = -1; MPI_Send (&number, 1, MPI_INT, 1, 0, MPI_COMM_WORLD); } else if ( world_rank == 1) { MPI_Recv (&number, 1, MPI_INT, 0, 0, MPI_COMM_WORLD, MPI_STATUS_IGNORE) ; printf ("Process 1 received number %d from process 0
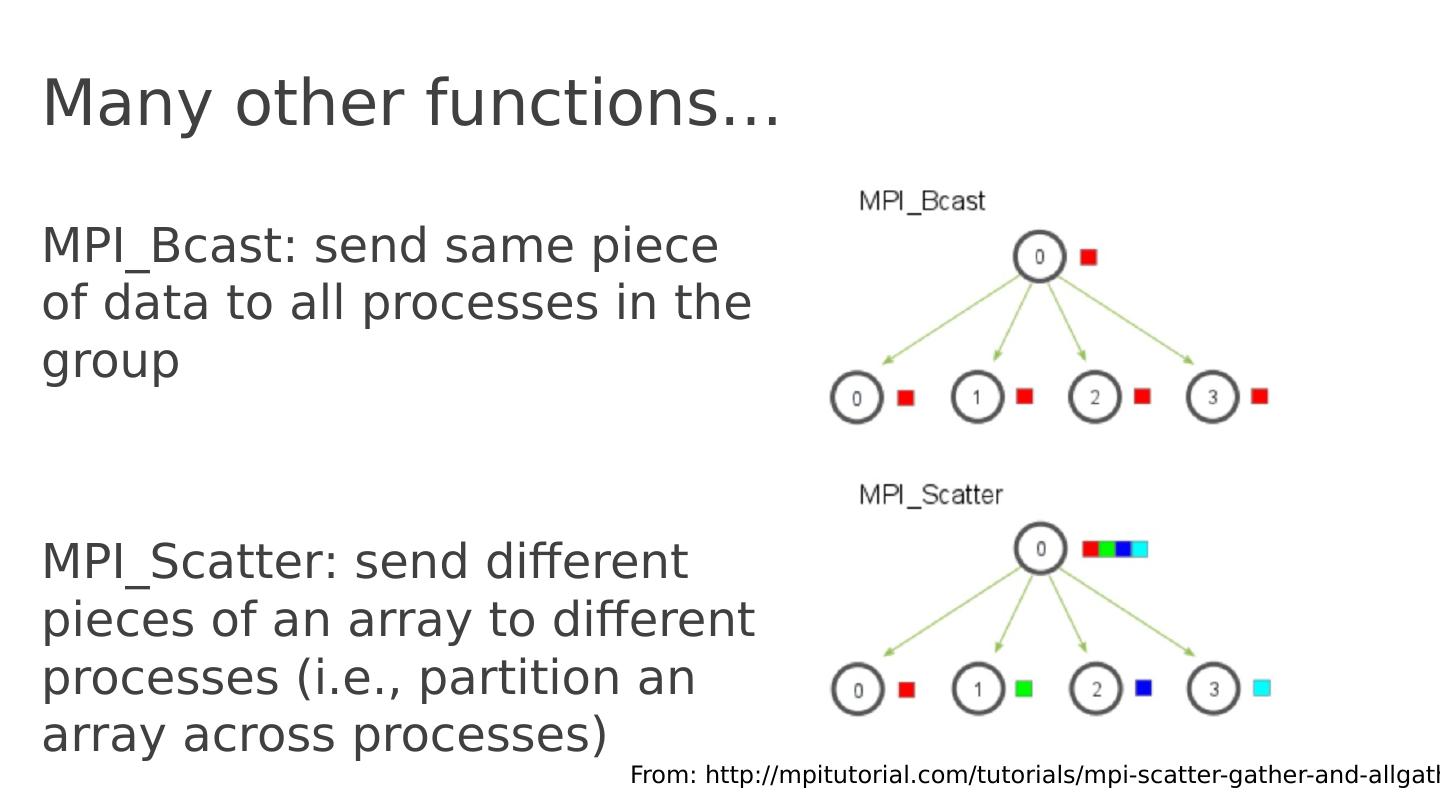
14 .Many other functions … MPI_Bcast : send same piece of data to all processes in the group MPI_Scatter : send different pieces of an array to different processes (i.e., partition an array across processes) From: http :// mpitutorial.com /tutorials/ mpi -scatter-gather-and- allgather /
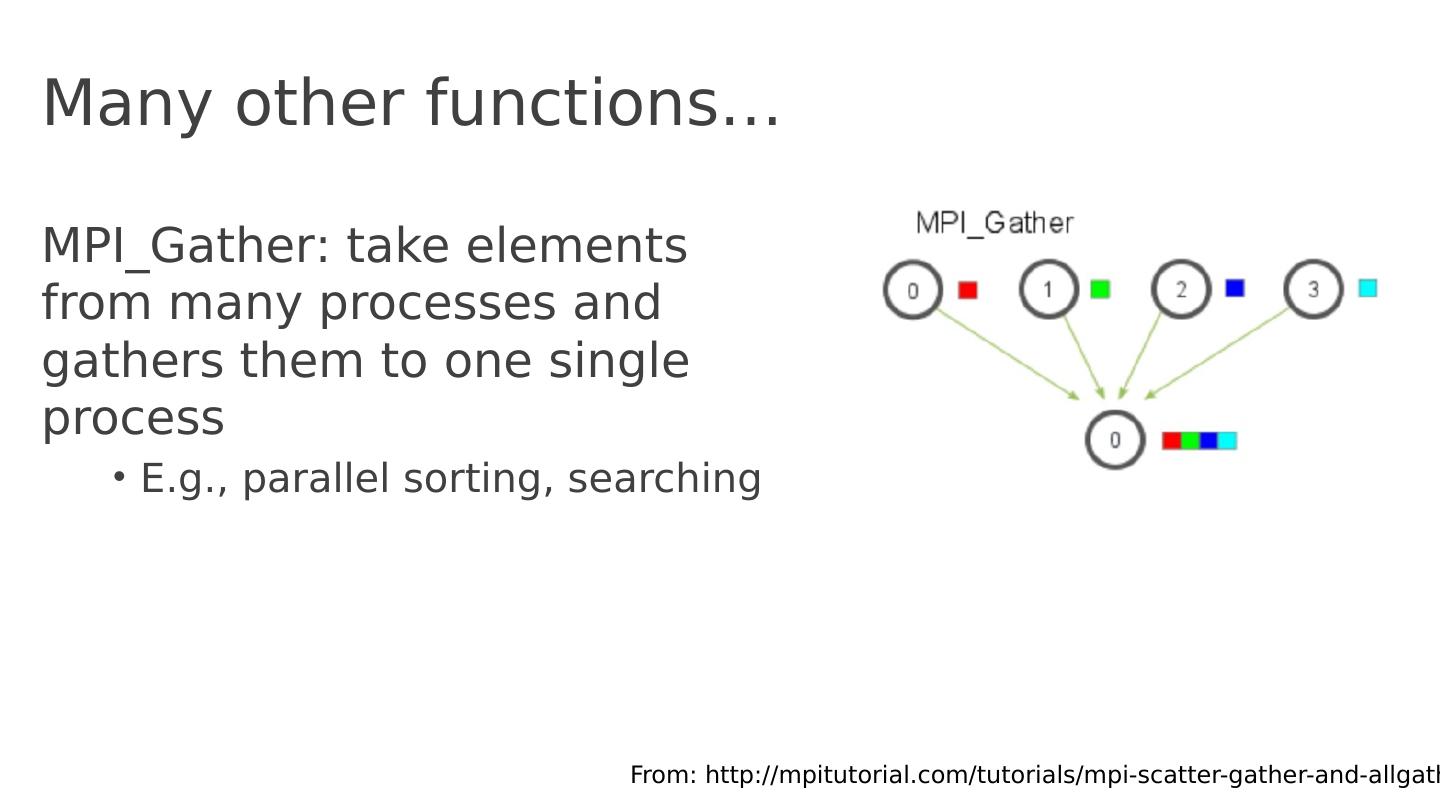
15 .Many other functions … MPI_Gather : take elements from many processes and gathers them to one single process E.g., parallel sorting, searching From: http :// mpitutorial.com /tutorials/ mpi -scatter-gather-and- allgather /
16 .Many other functions … MPI_Reduce : takes an array of input elements on each process and returns an array of output elements to the root process given a specified operation MPI_Allreduce : Like MPI_Reduce but distribute results to all processes From: http :// mpitutorial.com /tutorials/ mpi -scatter-gather-and- allgather /
17 .MPI Discussion Gives full control to programmer Exposes number of processes Communication is explicit, driven by the program Assume Long running processes Homogeneous (same performance) processors Little support for failures ( checkpointing ), no straggler mitigation Summary : achieve high performance by hand-optimizing jobs but requires experts to do so, and little support for fault tolerance
18 .Today’s Paper A High-Performance, Portable Implementation of the MPI Message Passing Interface Standard , William Gropp , Ewing Lusk, Nathan Doss, Anthony Skjellum , Journal of Parallel Computing, Vol 22, Issue 6, Sep 1996 https ://ucbrise.github.io/cs262a-spring2018/notes/ MPI.pdf
19 .MPI Chameleon Many MPI implementations existed. MPICH’s goal was to create an implementation that was both Portable (hence the name CHameleon ) Performant
20 .Portability MPICH is portable and leverages: High performance switches Supercomputers where different node communicate over switches (Paragon, SP2, CM-5) Shared memory architectures Implement efficient message passing on these machines (SGI Onyx) Networks of workstations Ethernet connected distributed systems communicating using TCP/IP
21 .Performance MPI standard already allowed to optimizations where usability wasn’t restricted. MPICH comes with performance test suite ( mpptest ), it works both on MPICH but also on top of other MPI implementations!
22 .Performance & Portability tradeoff Why is there a tradeoff? Custom implementation for each hardware (+performance) Shared re-usable code across all hardware (+quick portability) Keep in mind that this was the era of super computers IBM SP2, Meiko CS-2, CM-5, NCube-2 (fast switching) Cray T3D, SGI Onyx, Challenge, Power Challenge, IBM SMP ( shared memory) How do you use all the advanced hardware features ASAP? This paper shows you how to have your cake and eat it too!
23 .How to eat your cake and have it too? Small narrow Abstract Device Interface (ADI) Implemented on lots of different hardwares Highly tuned and performant Uses an even smaller (5 function) Channel Interface . Implement all of MPI on top of ADI and the Channel interface Porting to a new hardware requires porting ADI/Channel implementations. All of the rest of the code is re-used (+portability) Super fast message passing for various hardwares (+performance)
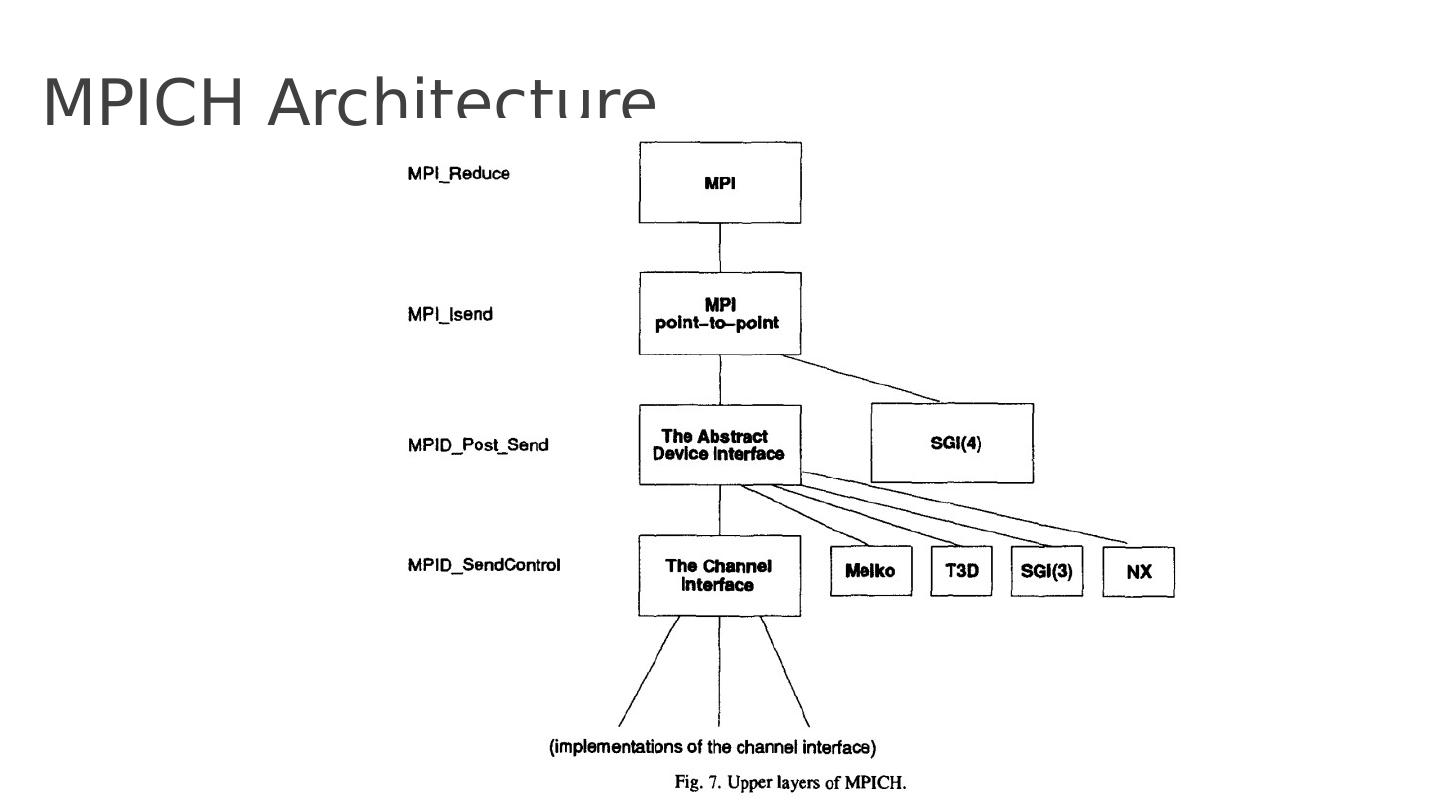
24 .MPICH Architecture
25 .ADI functions Message abstraction Moving messages from MPICH to actual hardware Managing mailboxes (messages received/sent) Providing information about the environment If some hardware doesn’t support the above, then emulate it.
26 .Channel Interface Implements transferring data or envelope (e.g. communicator, length, tag) from one process to another MPID_SendChannel to send a message MPID_RecvFromChannel to receive a message MPID_SendControl to send control (envelope) information MPID_ControlMsgAvail checks if new ctrl msgs available MPID_RecvAnyControl to receive any control message Assuming that the hardware implements buffering. Tradeoff!
27 .Eager vs Rendezvous Eager mode immediately sends data to receiver Deliver envelope and data immediately without checking with recv Rendezvous Deliver envelope, but check that receiver is ready to recv before sending data Pros/Cons? Why needed? Buffer overflow, asynchrony! Speed vs robustness
28 .How to use Channel Interface? Shared memory Complete channel implementation with malloc , locks, mutex:es Specialized Bypass shard memory portability, use hardware directly available in SGI and HPI shared memory systems Scalable Coherent Interface (SCI) Special implementation that uses the SCI standard
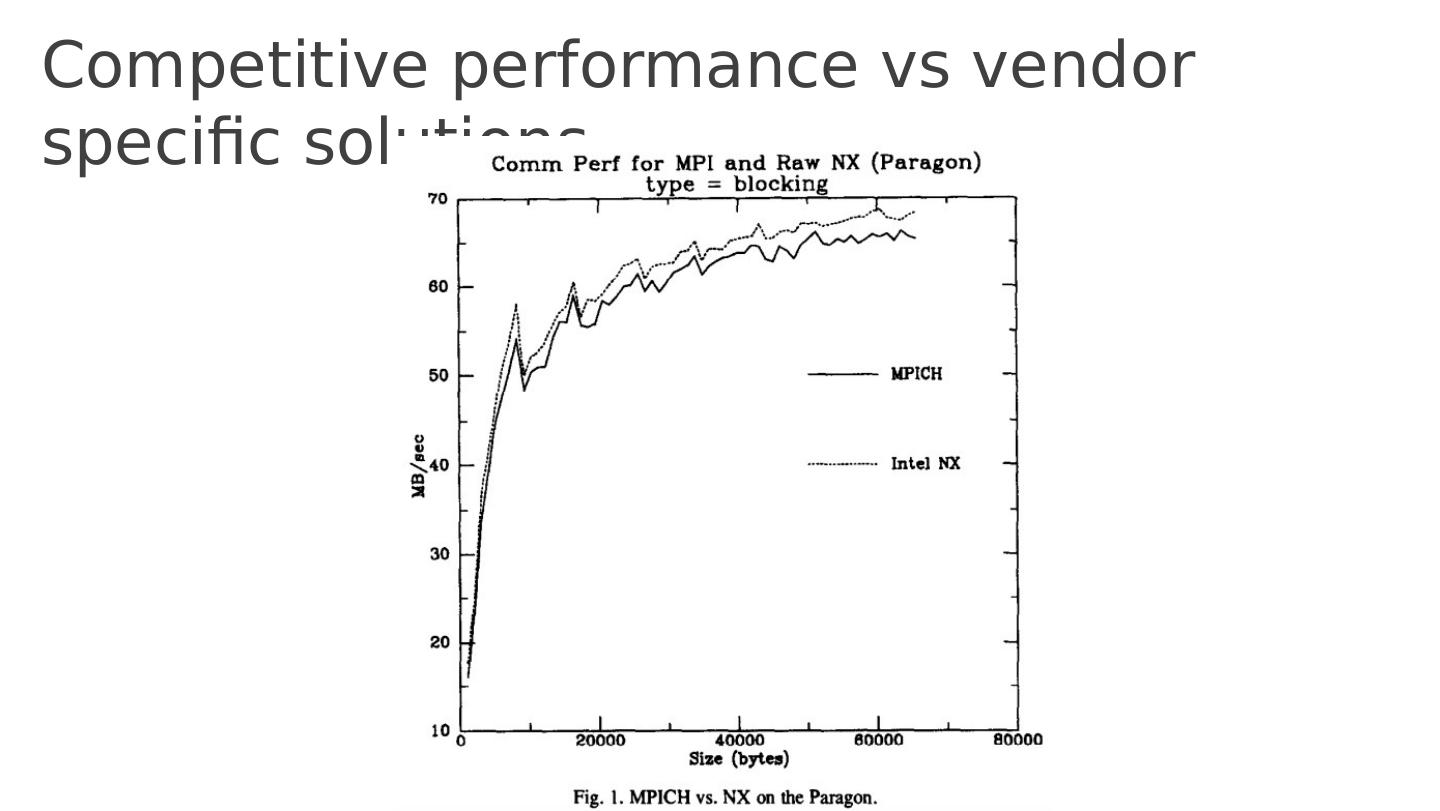
29 .Competitive performance vs vendor specific solutions
3秒后跳转登录页面
去登陆

